
LAI: Label Annotation Interaction-Based Representation Enhancement for End to End Relation Extraction


Abstract
1. Introduction
- We explore a novel two-round semantic interaction approach for enhancing span representations, wherein the first-round interaction reorganizes the PLM input with annotated information in what we term an annotation & enumeration-based method, and the second-round interaction employs a graph convolutional network (GCN) built atop Gaussian graph generator modules to facilitate label semantic fusion.
- We conduct a coarse screening with a entity candidate filter to eliminate out spans that are clearly not real entities, which also promotes the saving of computing resources.
- Experiments demonstrate that our method, while slightly lagging behind current SOTA in NER performance, takes the lead in the downstream RE task, surpassing the current SOTA performance.
2. Related Work
3. Datasets and Preprocessing
4. Methodology
4.1. Task Definition
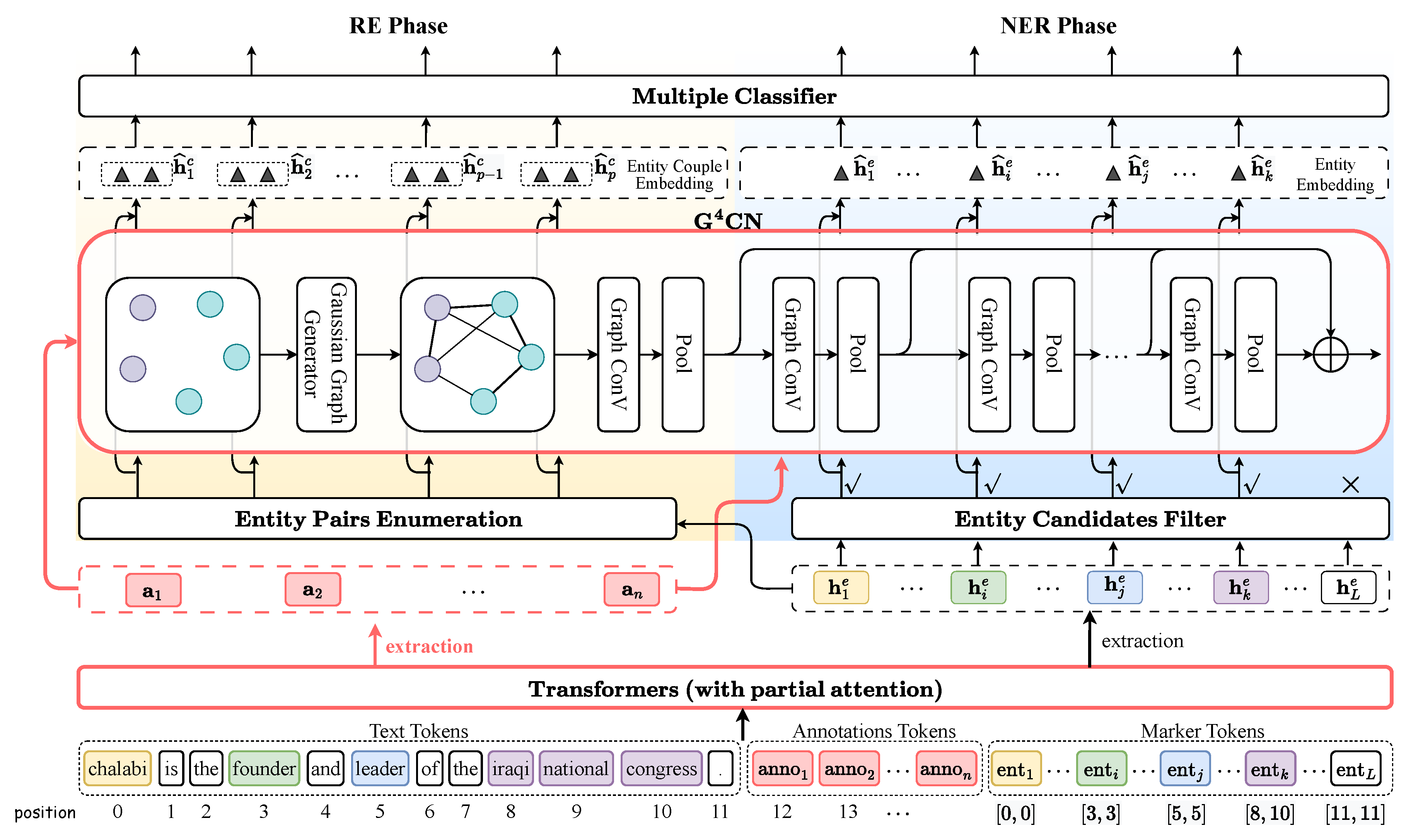
4.2. First-Round Semantic Interaction
- Text Tokens. Our approach breaks down the words from raw text into text token sequences as part of the model input.
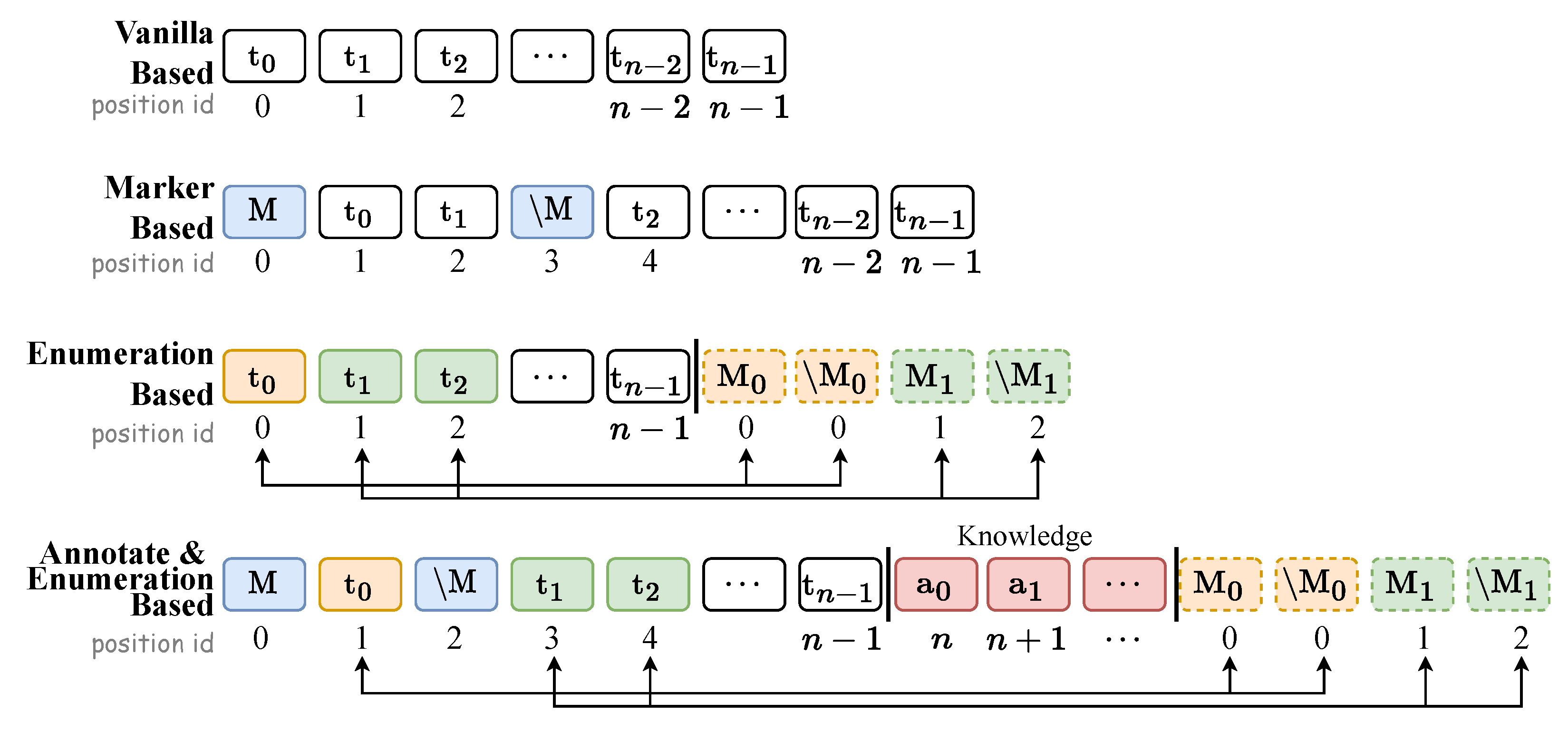
- Annotation Tokens. Inspired by [3,60], we augment semantic information by manually annotating the entity (or relation) abbreviated label both in the NER and the RE phase. For example, the abbreviated entity type GPE can be annotated as “geography political entity”, a fully-semantic unbroken phrase. Correspondingly, the abbreviated relation type ORG-AFF can be annotated as “organization affiliation”. Each label is manually expanded to enrich semantic content and then tokenized into annotation tokens (highlighted by red rectangle in bottom of Figure 2), which are appended to the text tokens sequentially.
- Marker Tokens. We enumerate all potential consecutive token sequences (i.e., entity candidates) not exceeding a predefined limitation of length c (with ) within a sentence, labeling each with an entity type. If , as shown in Figure 2, the set of all the possible spans from sentence “chalabi is the founder and leader of the iraqi national congress.” can be written as “chalabi”, “chalabi is”, “is”, “is the”, “the founder”, “founder”, “founder and”, “and”, “and leader”. The i-th span can be written as , where and are indicative of start and end position IDs of entity span, respectively. Therefore, the entity candidate series can also be written as given position ID perspective. Thus, the number of candidates for a sentence with m words: .
- Partial Attention. Although special tokens such as [CLS] and [SEP] serve to isolate different types of tokens, there still exists semantic interference among them. The straightforward blend of annotation tokens and marker tokens with text tokens may disrupt semantic consistency of the raw text. To mitigate this, we devise a partial attention mechanism, allowing selective semantic influence among the different types of token. This mechanism can effectively control the information flow (could be regarded as a kind of visibility) between different tokens, by adjusting the value of elements of the attention mechanism mask matrix. It suppresses the information interaction among tokens that are mutually invisible while enhancing the information interaction among tokens that are mutually visible. Experimental results show that partial attention effectively improves model performance. See Appendix B for more detailed information about partial attention.
4.3. Second-Round Semantic Interaction
4.4. Name Entity Recognition
4.5. Relation Extraction
- Entity pairs representation. We match subject and object representations up pairwise to obtain a series of entity pairs (). The label semantic confused pair representation formulas can be written as in Equation (13), where are matrixes formed by concatenating entity pair or relation label annotation representations.
5. Experiments
5.1. Main Results
5.1.1. Results Against Horizontal Comparison
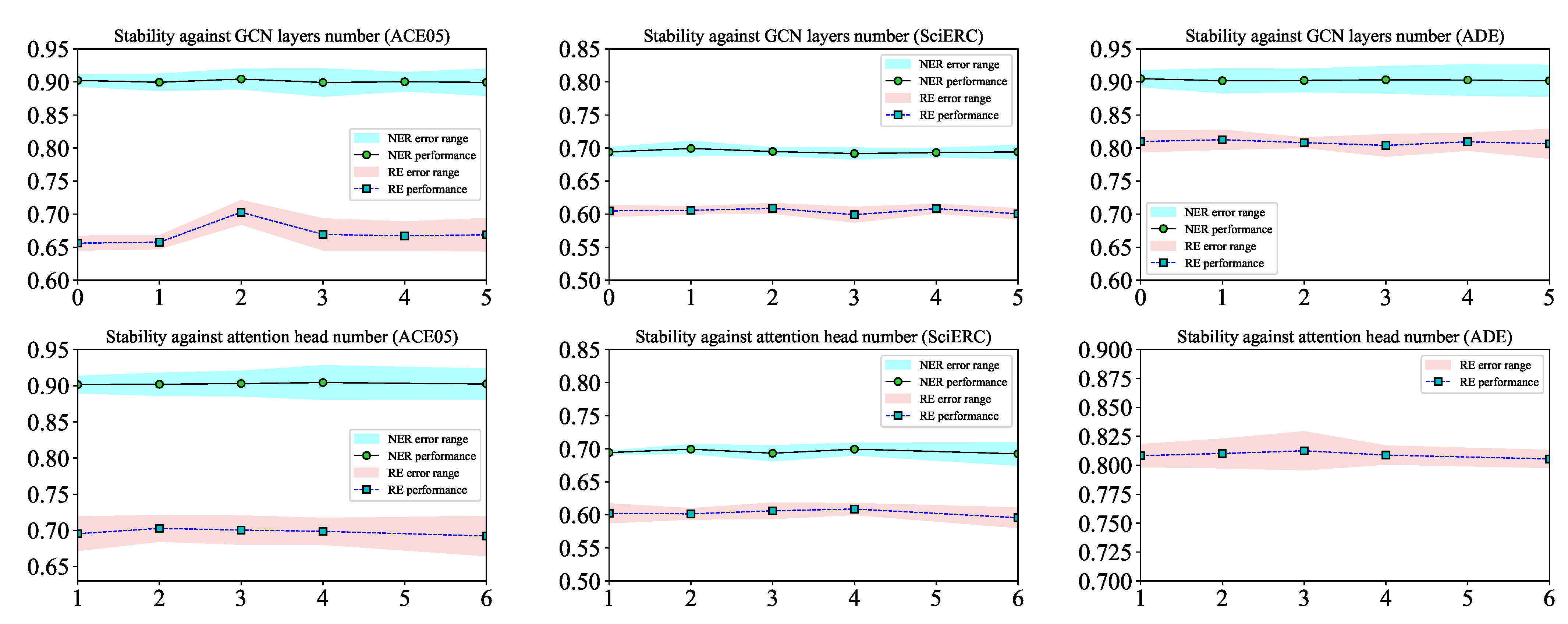
5.1.2. Results Against Significant Hyperparameters
5.2. Inference Speed
5.3. Ablation Study
5.3.1. Ablations Against Entity Filter
5.3.2. Ablation Against Two Rounds of Interaction
5.3.3. Ablations Against Attention Mask Matrix
5.4. Case Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Vanilla Graph Convolutional Network
Appendix B. Implement Details
Appendix B.1. Chosen of Baselines
Appendix B.2. PLMs and Hardware Devices
Appendix B.3. Optimizer and Learning Rate Settings
Appendix B.4. Maximum Length Settings
Appendix B.5. Batch Size and Epoch Settings
Appendix B.6. Avoidance the Negative Influence of Annotation
Appendix B.7. Cold Start Settings for NER
Appendix B.8. Symmetry of Relation for RE
Appendix B.9. Stability of Training
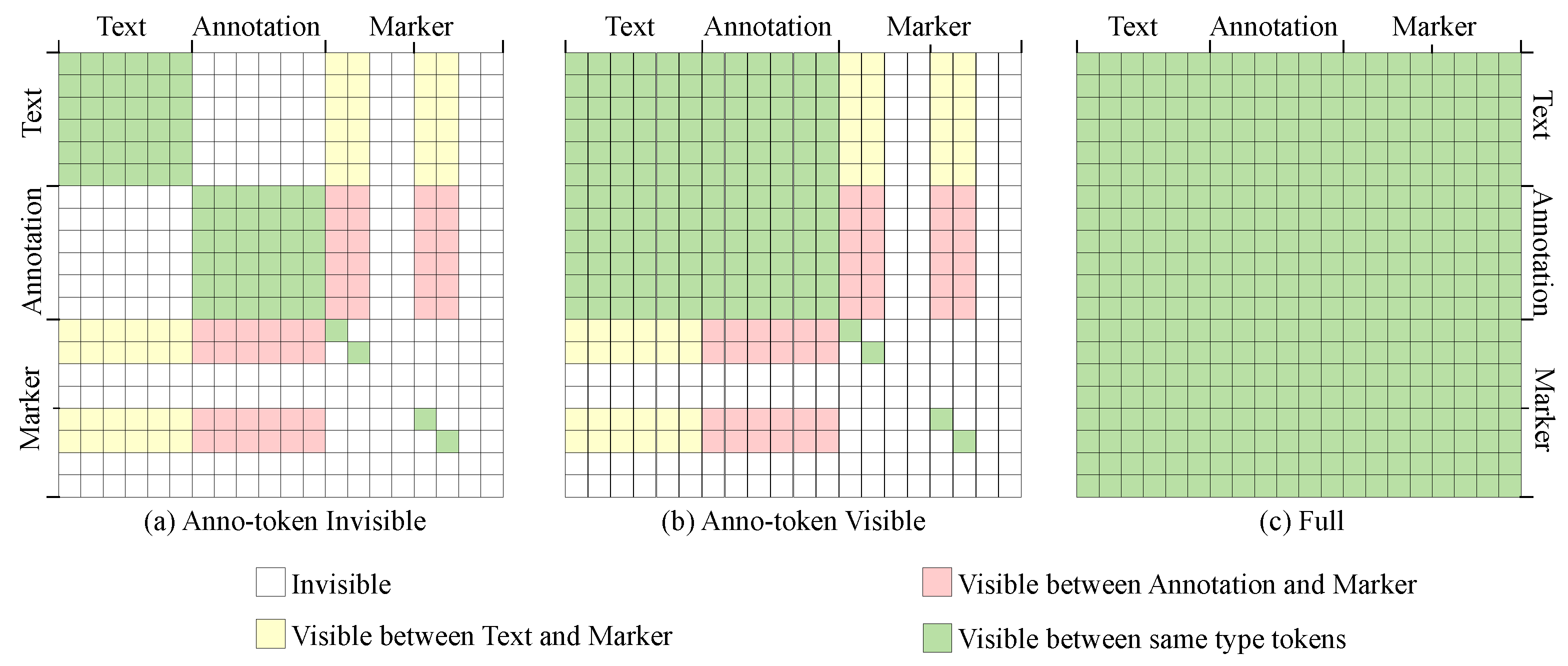
Appendix B.10. Parital Attention Mask
References
- Tang, W.; Xu, B.; Zhao, Y.; Mao, Z.; Liu, Y.; Liao, Y.; Xie, H. UniRel: Unified Representation and Interaction for Joint Relational Triple Extraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 7087–7099. [Google Scholar] [CrossRef]
- Sun, C.; Gong, Y.; Wu, Y.; Gong, M.; Jiang, D.; Lan, M.; Sun, S.; Duan, N. Joint Type Inference on Entities and Relations via Graph Convolutional Networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1361–1370. [Google Scholar] [CrossRef]
- Yang, P.; Cong, X.; Sun, Z.; Liu, X. Enhanced Language Representation with Label Knowledge for Span Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Moens, M.F., Huang, X., Specia, L., Yih, S.W.T., Eds.; Online; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 4623–4635. [Google Scholar] [CrossRef]
- Ji, B.; Li, S.; Xu, H.; Yu, J.; Ma, J.; Liu, H.; Yang, J. Span-based joint entity and relation extraction augmented with sequence tagging mechanism. arXiv 2022, arXiv:2210.12720. [Google Scholar] [CrossRef]
- Shang, Y.M.; Huang, H.; Sun, X.; Wei, W.; Mao, X.L. Relational Triple Extraction: One Step is Enough. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22; Raedt, L.D., Ed.; International Joint Conferences on Artificial Intelligence Organization; Main Track: Forest Lake, QLD, Australia; Volume 7, pp. 4360–4366. [CrossRef]
- Dai, Z.; Wang, X.; Ni, P.; Li, Y.; Li, G.; Bai, X. Named entity recognition using BERT BiLSTM CRF for Chinese electronic health records. In Proceedings of the 2019 12th iNternational Congress on Image and Signal Processing, Biomedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; pp. 1–5. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 50–61. [Google Scholar] [CrossRef]
- Ye, D.; Lin, Y.; Li, P.; Sun, M. Packed Levitated Marker for Entity and Relation Extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 4904–4917. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1441–1451. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8968–8975. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 2790–2799. [Google Scholar]
- Liu, W.; Fu, X.; Zhang, Y.; Xiao, W. Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 5847–5858. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 1554–1564. [Google Scholar] [CrossRef]
- Sui, D.; Chen, Y.; Liu, K.; Zhao, J.; Liu, S. Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3830–3840. [Google Scholar] [CrossRef]
- Li, X.; Yan, H.; Qiu, X.; Huang, X. FLAT: Chinese NER Using Flat-Lattice Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6836–6842. [Google Scholar] [CrossRef]
- Qian, Y.; Santus, E.; Jin, Z.; Guo, J.; Barzilay, R. GraphIE: A Graph-Based Framework for Information Extraction. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 751–761. [Google Scholar] [CrossRef]
- Daigavane, A.; Ravindran, B.; Aggarwal, G. Understanding Convolutions on Graphs, Understanding the Building Blocks and Design Choices of Graph Neural Networks. 2021. Available online: https://distill.pub/2021/understanding-gnns/ (accessed on 2 September 2021).
- Wu, L.; Chen, Y.; Shen, K.; Guo, X.; Gao, H.; Li, S.; Pei, J.; Long, B. Graph neural networks for natural language processing: A survey. Found. Trends® Mach. Learn. 2023, 16, 119–328. [Google Scholar] [CrossRef]
- Quirk, C.; Poon, H. Distant Supervision for Relation Extraction beyond the Sentence Boundary. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers; Lapata, M., Blunsom, P., Koller, A., Eds.; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 1171–1182. [Google Scholar]
- Luo, Y.; Zhao, H. Bipartite Flat-Graph Network for Nested Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6408–6418. [Google Scholar] [CrossRef]
- Sun, K.; Zhang, R.; Mao, Y.; Mensah, S.; Liu, X. Relation extraction with convolutional network over learnable syntax-transport graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8928–8935. [Google Scholar]
- Xue, F.; Sun, A.; Zhang, H.; Chng, E.S. Gdpnet: Refining latent multi-view graph for relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Electr Network, 2–9 February 2021; Volume 35, pp. 14194–14202. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 2205–2215. [Google Scholar] [CrossRef]
- Fu, T.J.; Li, P.H.; Ma, W.Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1409–1418. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 241–251. [Google Scholar] [CrossRef]
- Sahu, S.K.; Christopoulou, F.; Miwa, M.; Ananiadou, S. Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4309–4316. [Google Scholar] [CrossRef]
- Christopoulou, F.; Miwa, M.; Ananiadou, S. Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 4925–4936. [Google Scholar] [CrossRef]
- Zeng, S.; Xu, R.; Chang, B.; Li, L. Double Graph Based Reasoning for Document-level Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1630–1640. [Google Scholar] [CrossRef]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Ostendorf, M.; Hajishirzi, H. A general framework for information extraction using dynamic span graphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 3036–3046. [Google Scholar] [CrossRef]
- McDonald, R.; Pereira, F.; Kulick, S.; Winters, S.; Jin, Y.; White, P. Simple algorithms for complex relation extraction with applications to biomedical IE. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Stroudsburg, PA, USA, 25–30 June 2005; pp. 491–498. [Google Scholar]
- Iria, J. T-rex: A flexible relation extraction framework. In Proceedings of the 8th Annual Colloquium for the UK Special Interest Group for Computational Linguistics (CLUK’05), Manchester, UK, 2005; Volume 6, p. 9. [Google Scholar]
- Culotta, A.; Sorensen, J. Dependency tree kernels for relation extraction. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), Barcelona, Spain, 21–26 July 2004; pp. 423–429. [Google Scholar]
- Jiang, J.; Zhai, C. A systematic exploration of the feature space for relation extraction. In Proceedings of the Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics, Rochester, NY, USA, 22–27 April 2007; Proceedings of the Main Conference. pp. 113–120. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar] [CrossRef]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. arXiv 2019, arXiv:1909.03227. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. arXiv 2017, arXiv:1706.05075. [Google Scholar] [CrossRef]
- Ji, B.; Yu, J.; Li, S.; Ma, J.; Wu, Q.; Tan, Y.; Liu, H. Span-based Joint Entity and Relation Extraction with Attention-based Span-specific and Contextual Semantic Representations. In Proceedings of the 28th International Conference on Computational Linguistics; Scott, D., Bel, N., Zong, C., Eds.; Online; Association for Computational Linguistics: Barcelona, Spain, 2020; pp. 88–99. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, C.; Wu, Y.; Zhou, H.; Li, L.; Yan, J. UniRE: A Unified Label Space for Entity Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 220–231. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, C.; Wu, Y.; Li, L.; Yan, J.; Zhou, H. HIORE: Leveraging High-order Interactions for Unified Entity Relation Extraction. arXiv 2023, arXiv:2305.04297. [Google Scholar] [CrossRef]
- Yan, Z.; Yang, S.; Liu, W.; Tu, K. Joint Entity and Relation Extraction with Span Pruning and Hypergraph Neural Networks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 7512–7526. [Google Scholar] [CrossRef]
- Zhu, T.; Ren, J.; Yu, Z.; Wu, M.; Zhang, G.; Qu, X.; Chen, W.; Wang, Z.; Huai, B.; Zhang, M. Mirror: A Universal Framework for Various Information Extraction Tasks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 8861–8876. [Google Scholar] [CrossRef]
- Li, J.; Zhang, Y.; Liang, B.; Wong, K.F.; Xu, R. Set Learning for Generative Information Extraction. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 13043–13052. [Google Scholar] [CrossRef]
- Tang, R.; Chen, Y.; Qin, Y.; Huang, R.; Zheng, Q. Boundary regression model for joint entity and relation extraction. Expert Syst. Appl. 2023, 229, 120441. [Google Scholar] [CrossRef]
- Zaratiana, U.; Tomeh, N.; Holat, P.; Charnois, T. An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 19477–19487. [Google Scholar]
- Wang, Y.; Liu, X.; Kong, W.; Yu, H.T.; Racharak, T.; Kim, K.S.; Le Nguyen, M. A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations. IEEE Access 2024, 12, 103313–103328. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, W.; Zu, C.; Xia, H.; Chen, T.; Zhang, Y.; Zheng, R.; Ye, J.; Zhang, Q.; Gui, T.; et al. InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction. arXiv 2023, arXiv:2304.08085. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Han, J.; Zhao, S.; Cheng, B.; Ma, S.; Lu, W. Generative prompt tuning for relation classification. arXiv 2022, arXiv:2210.12435. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Xie, X.; Deng, S.; Yao, Y.; Tan, C.; Huang, F.; Si, L.; Chen, H. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In Proceedings of the ACM Web Conference 2022, Online, 25–29 April 2022; pp. 2778–2788. [Google Scholar]
- Wei, X.; Cui, X.; Cheng, N.; Wang, X.; Zhang, X.; Huang, S.; Xie, P.; Xu, J.; Chen, Y.; Zhang, M.; et al. Zero-shot information extraction via chatting with chatgpt. arXiv 2023, arXiv:2302.10205. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, Y.; Chen, B. A prompt tuning method based on relation graphs for few-shot relation extraction. Neural Netw. 2025, 185, 107214. [Google Scholar] [CrossRef] [PubMed]
- Cui, X.; Yang, Y.; Li, D.; Cui, J.; Qu, X.; Song, C.; Liu, H.; Ke, S. PURE: A Prompt-based framework with dynamic Update mechanism for educational Relation Extraction. Complex Intell. Syst. 2025, 11, 1–14. [Google Scholar] [CrossRef]
- Han, P.; Liang, G.; Wang, Y. A Zero-Shot Framework for Low-Resource Relation Extraction via Distant Supervision and Large Language Models. Electronics 2025, 14, 593. [Google Scholar] [CrossRef]
- Duan, J.; Lu, F.; Liu, J. CPTuning: Contrastive Prompt Tuning for Generative Relation Extraction. arXiv 2025, arXiv:2501.02196. [Google Scholar] [CrossRef]
- Li, Q.; Ji, H. Incremental Joint Extraction of Entity Mentions and Relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Toutanova, K., Wu, H., Eds.; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 402–412. [Google Scholar] [CrossRef]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1105–1116. [Google Scholar]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 3219–3232. [Google Scholar] [CrossRef]
- Gurulingappa, H.; Rajput, A.M.; Roberts, A.; Fluck, J.; Hofmann-Apitius, M.; Toldo, L. Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports. J. Biomed. Inform. 2012, 45, 885–892. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Ballesteros, M.; Doss, S.; Anubhai, R.; Mallya, S.; Al-Onaizan, Y.; Roth, D. Label Semantics for Few Shot Named Entity Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 1956–1971. [Google Scholar] [CrossRef]
- He, S.; Liu, K.; Ji, G.; Zhao, J. Learning to Represent Knowledge Graphs with Gaussian Embedding. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (CIKM ’15), New York, NY, USA, 18–23 October 2015; pp. 623–632. [Google Scholar] [CrossRef]
- Liu, T.; Jiang, Y.E.; Monath, N.; Cotterell, R.; Sachan, M. Autoregressive Structured Prediction with Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 993–1005. [Google Scholar] [CrossRef]
- Wang, S.; Sun, X.; Li, X.; Ouyang, R.; Wu, F.; Zhang, T.; Li, J.; Wang, G. GPT-NER: Named Entity Recognition via Large Language Models. arXiv 2023, arXiv:2304.10428. [Google Scholar] [CrossRef]
- Wan, Z.; Cheng, F.; Mao, Z.; Liu, Q.; Song, H.; Li, J.; Kurohashi, S. GPT-RE: In-context Learning for Relation Extraction using Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 3534–3547. [Google Scholar] [CrossRef]
- Li, B.; Fang, G.; Yang, Y.; Wang, Q.; Ye, W.; Zhao, W.; Zhang, S. Evaluating ChatGPT’s Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness. arXiv 2023, arXiv:2304.11633. [Google Scholar]
- Wadden, D.; Wennberg, U.; Luan, Y.; Hajishirzi, H. Entity, Relation, and Event Extraction with Contextualized Span Representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 5784–5789. [Google Scholar] [CrossRef]
- Eberts, M.; Ulges, A. Span-based Joint Entity and Relation Extraction with Transformer Pre-training. arXiv 2019, arXiv:1909.07755. [Google Scholar]
- Wang, J.; Lu, W. Two are Better than One: Joint Entity and Relation Extraction with Table-Sequence Encoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Online; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1706–1721. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3615–3620. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Backbone | NER | RE | RE+ | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |||||
| ACE05 | SPAN (2020) [38] | • Bert-base | 89.32 | 89.86 | 89.59 | - | - | - | 71.22 | 60.19 | 65.24 | ||
| UniRE (2021) [39] | • Bert-base | 88.80 | 88.90 | 88.80 | - | - | - | 67.10 | 61.80 | 64.30 | |||
| PURE (2021) [7] | • Bert-base | - | - | 90.20 | - | - | 67.70 | - | - | 64.60 | |||
| PL-Marker (2022) [8] | • Bert-base | - | - | 89.70 | - | - | 68.80 | - | - | 66.30 | |||
| ASP (2022) [62] | ∘ T5-base | - | - | 90.70 | - | - | 71.10 | - | - | 68.60 | |||
| HIORE (2023) [40] | • Bert-base | - | - | 89.60 | - | - | - | - | - | 65.80 | |||
| HGERE (2023) [41] | • Bert-base | - | - | 89.60 | - | - | - | - | - | 65.80 | |||
| Mirror (2023) [42] | ∘ DeBERTa-v3 | - | - | 86.72 | - | - | - | - | - | 64.88 | |||
| GPT-NER (2023) [63] | ⋆ GPT3 | 72.77 | 75.51 | 73.59 | - | - | - | - | - | - | |||
| GPT-RE (2023) [64] | ⋆ GPT3 | - | - | - | - | - | - | - | - | 68.73 | |||
| ChatGPT (2023) [65] | ⋆ ChatGPT | - | - | - | - | - | - | - | - | 40.50 | |||
| SET (2023) [43] | ∘ T5-large | - | - | - | - | - | - | - | - | 65.90 | |||
| BR (2023) [44] | • Albert | - | - | 90.80 | - | - | - | - | - | 66.00 | |||
| ATG (2024) [45] | ∘ DeBERTa-v3 | - | - | 90.10 | - | - | 68.70 | - | - | 66.20 | |||
| BiDArtER (2024) [46] | • Albert | - | - | 89.80 | - | - | - | - | - | 68.40 | |||
| LAI-Net (Ours) | • Bert-base | 90.28 | 90.60 | 90.44 | 73.80 | 70.42 | 72.06 | 71.96 | 68.67 | 70.27 | |||
| SciERC | DyGIE++ (2019) [66] | • SciBert | - | - | 67.50 | - | - | - | - | - | 48.40 | ||
| Spert (2019) [67] | • SciBert | 70.87 | 69.79 | 70.33 | - | - | - | 53.40 | 48.54 | 50.84 | |||
| UniRE (2021) [39] | • SciBert | 65.80 | 71.10 | 68.40 | 37.30 | 36.60 | 36.90 | ||||||
| PURE (2021) [7] | • SciBert | - | - | 68.20 | - | - | 50.10 | - | - | 36.70 | |||
| PL-Marker (2022) [8] | • SciBert | - | - | 69.90 | - | - | 52.00 | - | - | 40.60 | |||
| HIORE (2023) [40] | • SciBert | - | - | 68.20 | - | - | - | - | - | 38.30 | |||
| Mirror (2023) [42] | ∘ DeBERTa-v3 | - | - | - | - | - | - | - | - | 36.66 | |||
| ChatGPT (2023) [65] | ⋆ ChatGPT | - | - | - | - | - | - | - | - | 25.90 | |||
| InstructUIE (2023) [47] | ⋆ FlanT5-11B | - | - | - | - | - | - | - | - | 45.15 | |||
| GPT-RE (2023) [64] | ⋆ GPT3 | - | - | - | - | - | - | - | - | 69.00 | |||
| SET (2023) [43] | ∘ T5-large | - | - | - | - | - | - | - | - | 35.90 | |||
| ATG (2024) [45] | • SciBert | - | - | 69.70 | - | - | 51.10 | - | - | 38.60 | |||
| BiDArtER (2024) [46] | • SciBert | - | - | 69.40 | - | - | - | - | - | 39.90 | |||
| LAI-Net (Ours) | • SciBert | 70.04 | 69.89 | 69.94 | 65.56 | 68.48 | 66.99 | 59.84 | 62.01 | 60.88 | |||
| ADE | Spert (2019) [67] | • Bert-base | 89.02 | 88.87 | 88.94 | - | - | - | 78.09 | 80.43 | 79.24 | ||
| Table-Sequence (2020) [68] | • Bert-base | - | - | 89.70 | - | - | 80.10 | ||||||
| SPAN (2020) [38] | • Bert-base | 89.88 | 91.32 | 90.59 | - | - | - | 79.56 | 81.93 | 80.73 | |||
| LAI-Net (Ours) | • Bert-base | 89.78 | 91.24 | 90.49 | 80.48 | 83.79 | 82.09 | 79.37 | 83.28 | 81.25 | |||
| Task | Number of GCN Layer | Number of Attention Head | Entity Filter | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 6 | w | w/o | ||||
| ACE05 | NER | 90.23 | 89.95 | 90.44 | 89.92 | 90.03 | 89.94 | 90.16 | 90.21 | 90.30 | 90.44 | 90.24 | 90.44 | 88.70 | ||
| RE | 68.05 | 68.38 | 72.06 | 69.37 | 69.26 | 69.53 | 71.75 | 72.06 | 72.16 | 71.84 | 71.37 | - | - | |||
| RE+ | 65.61 | 65.75 | 70.27 | 66.93 | 66.70 | 66.88 | 69.54 | 70.27 | 70.03 | 69.86 | 69.21 | - | - | |||
| ADE | NER | 90.49 | 90.18 | 90.23 | 90.32 | 90.28 | 90.17 | - | - | - | - | - | 90.49 | 89.92 | ||
| RE | 80.99 | 82.09 | 81.64 | 80.71 | 81.25 | 81.04 | 81.42 | 81.79 | 82.09 | 81.21 | 80.94 | - | - | |||
| RE+ | 80.99 | 81.25 | 80.81 | 80.39 | 80.95 | 80.63 | 80.83 | 81.02 | 81.25 | 80.88 | 80.55 | - | - | |||
| SciERC | NER | 69.40 | 69.94 | 69.47 | 69.17 | 69.31 | 69.40 | 69.42 | 69.76 | 69.32 | 69.94 | 69.23 | 69.94 | 69.76 | ||
| RE | 66.08 | 66.27 | 66.99 | 66.43 | 66.35 | 66.28 | 65.80 | 65.66 | 65.62 | 66.99 | 64.48 | - | - | |||
| RE+ | 60.49 | 60.57 | 60.88 | 59.91 | 60.82 | 60.06 | 60.24 | 60.15 | 60.61 | 60.88 | 59.56 | - | - | |||
| Task | Metric | PL-Marker | LAI-Net | |
|---|---|---|---|---|
| ACE05 | NER | F1 | 89.70 | 90.44 |
| Speed (sent/s) | 62.94 | 35.10 (−44.23%) | ||
| RE | F1 | 66.30 | 70.27 | |
| Speed (sent/s) | 93.14 | 43.00 (−53.83%) | ||
| SciERC | NER | F1 | 69.90 | 69.94 |
| Speed (sent/s) | 54.13 | 52.17 (−3.62%) | ||
| RE | F1 | 40.60 | 60.88 | |
| Speed (sent/s) | 93.29 | 39.57 (−57.58%) | ||
| Task | Method | P | R | F1 | |
|---|---|---|---|---|---|
| ACE05 | NER | LAI-Net | 90.28 | 90.60 | 90.44 |
| w/o 2nd | 89.97 (−0.31) | 90.50 (−0.10) | 90.23 (−0.21) | ||
| w/o 1st | 89.72 (−0.55) | 90.68 (0.08) | 90.20 (−0.24) | ||
| RE | LAI-Net | 73.80 | 70.42 | 72.06 | |
| w/o 2nd | 69.70 (−4.09) | 66.49 (−3.94) | 68.05 (−4.01) | ||
| w/o 1st | 68.64 (−5.16) | 67.16 (−3.26) | 67.89 (−4.17) | ||
| RE+ | LAI-Net | 71.96 | 68.67 | 70.27 | |
| w/o 2nd | 67.20 (−4.77) | 64.10 (−4.58) | 65.61 (−4.67) | ||
| w/o 1st | 66.47 (−5.49) | 64.35 (−4.32) | 65.39 (−4.89) | ||
| ADE | NER | LAI-Net | 89.78 | 91.24 | 90.49 |
| w/o 2nd | - | - | - | ||
| w/o 1st | 88.94 (−0.84) | 91.07 (−0.17) | 89.99 (−0.51) | ||
| RE | LAI-Net | 79.38 | 83.29 | 81.26 | |
| w/o 2nd | 79.01 (−0.37) | 83.17 (−0.12) | 81.04 (−0.22) | ||
| w/o 1st | 79.08 (−0.30) | 82.99 (−0.30) | 80.99 (−0.27) | ||
| RE+ | LAI-Net | 79.37 | 83.28 | 81.25 | |
| w/o 2nd | 78.73 (−0.64) | 82.64 (−0.64) | 80.63 (−0.62) | ||
| w/o 1st | 78.47 (−0.91) | 82.44 (−0.84) | 80.41 (−0.85) | ||
| SciERC | NER | LAI-Net | 70.04 | 69.89 | 69.94 |
| w/o 2nd | 69.82 (−0.22) | 68.98 (−0.91) | 69.40 (−0.54) | ||
| w/o 1st | 69.58 (−0.46) | 69.12 (−0.77) | 69.35 (−0.59) | ||
| RE | LAI-Net | 65.56 | 68.48 | 66.99 | |
| w/o 2nd | 64.21 (−1.35) | 68.07 (−0.41) | 66.08 (−0.91) | ||
| w/o 1st | 63.96 (−1.60) | 67.82 (−0.66) | 65.83 (−1.16) | ||
| RE+ | LAI-Net | 59.84 | 62.01 | 60.88 | |
| w/o 2nd | 59.79 (−0.05) | 61.22 (−0.80) | 60.49 (−0.39) | ||
| w/o 1st | 59.81 (−0.03) | 60.47 (−1.54) | 60.14 (−0.74) | ||
| Task | NER | RE | RE+ | |
|---|---|---|---|---|
| ACE05 | Inv. | 90.44 | 72.06 | 70.27 |
| Vis. | 90.36 (−0.08) | 68.01 (−4.05) | 65.57 (−4.70) | |
| Full | 88.29 (−2.14) | 65.79 (−6.28) | 64.28 (−5.99) | |
| ADE | Inv. | 90.49 | 82.09 | 81.25 |
| Vis. | 90.09 (−0.40) | 81.26 (−0.83) | 80.09 (−1.16) | |
| Full | 89.40 (−1.10) | 79.99 (−2.10) | 78.92 (−2.33) | |
| SciERC | Inv. | 69.94 | 66.99 | 60.88 |
| Vis. | 69.13 (−0.81) | 66.44 (−0.55) | 60.61 (−0.27) | |
| Full | 66.21 (−3.73) | 66.06 (−0.93) | 60.30 (−0.59) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, R.; Wu, W.; Zou, L.; Liao, F.; Wang, Z.; Mi, H. LAI: Label Annotation Interaction-Based Representation Enhancement for End to End Relation Extraction. Big Data Cogn. Comput. 2025, 9, 198. https://doi.org/10.3390/bdcc9080198
Lai R, Wu W, Zou L, Liao F, Wang Z, Mi H. LAI: Label Annotation Interaction-Based Representation Enhancement for End to End Relation Extraction. Big Data and Cognitive Computing. 2025; 9(8):198. https://doi.org/10.3390/bdcc9080198
Chicago/Turabian StyleLai, Rongxuan, Wenhui Wu, Li Zou, Feifan Liao, Zhenyi Wang, and Haibo Mi. 2025. "LAI: Label Annotation Interaction-Based Representation Enhancement for End to End Relation Extraction" Big Data and Cognitive Computing 9, no. 8: 198. https://doi.org/10.3390/bdcc9080198
APA StyleLai, R., Wu, W., Zou, L., Liao, F., Wang, Z., & Mi, H. (2025). LAI: Label Annotation Interaction-Based Representation Enhancement for End to End Relation Extraction. Big Data and Cognitive Computing, 9(8), 198. https://doi.org/10.3390/bdcc9080198