
PruneEnergyAnalyzer: An Open-Source Toolkit for Evaluating Energy Consumption in Pruned Deep Learning Models




Abstract
1. Introduction
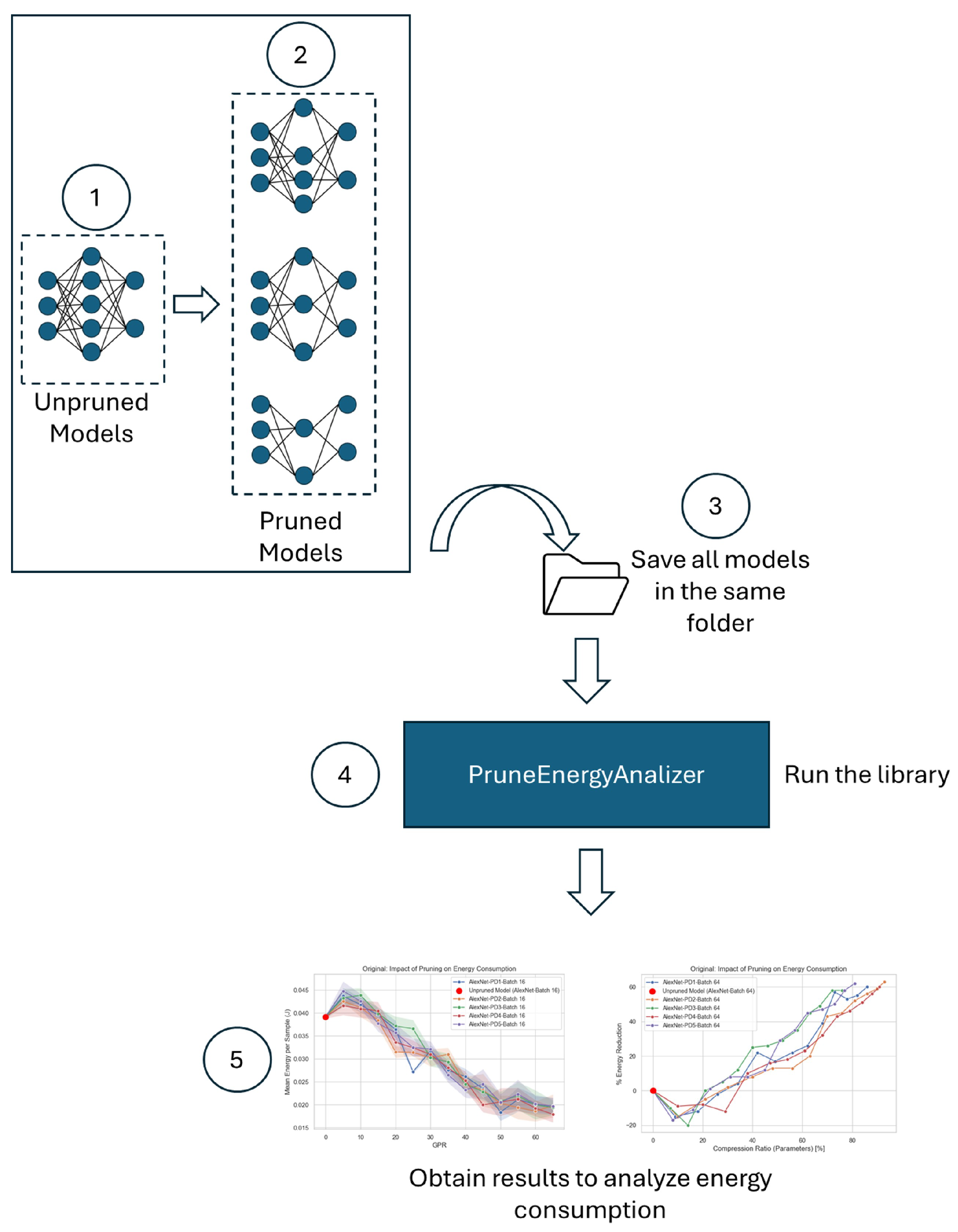
- We present a tool, called PruneEnergyAnalyzer, which computes energy consumption and its reduction, FLOPs and their reduction, and the number of parameters and their reduction across multiple pruned models compared to the unpruned model. Additionally, it estimates the number of images the model can infer per second (FPS) by performing 10,000 inferences using a user-defined batch size.
- The tool automatically generates performance graphs that simultaneously analyze multiple variables, including Compression Ratio (%) vs. Energy Reduction (%), Pruning Distribution vs. Energy Reduction (%), Network Architecture vs. Energy Consumption, Batch Size vs. Energy Consumption, and Batch Size vs. FPS Values. To enable automated plotting, users must name their models following a specific naming convention.
- The tool supports decision-making regarding the most suitable model based not only on pruned model performance (e.g., accuracy or other similar metrics), FLOPs or parameter savings, but also on actual energy consumption and inference throughput values.
2. Background
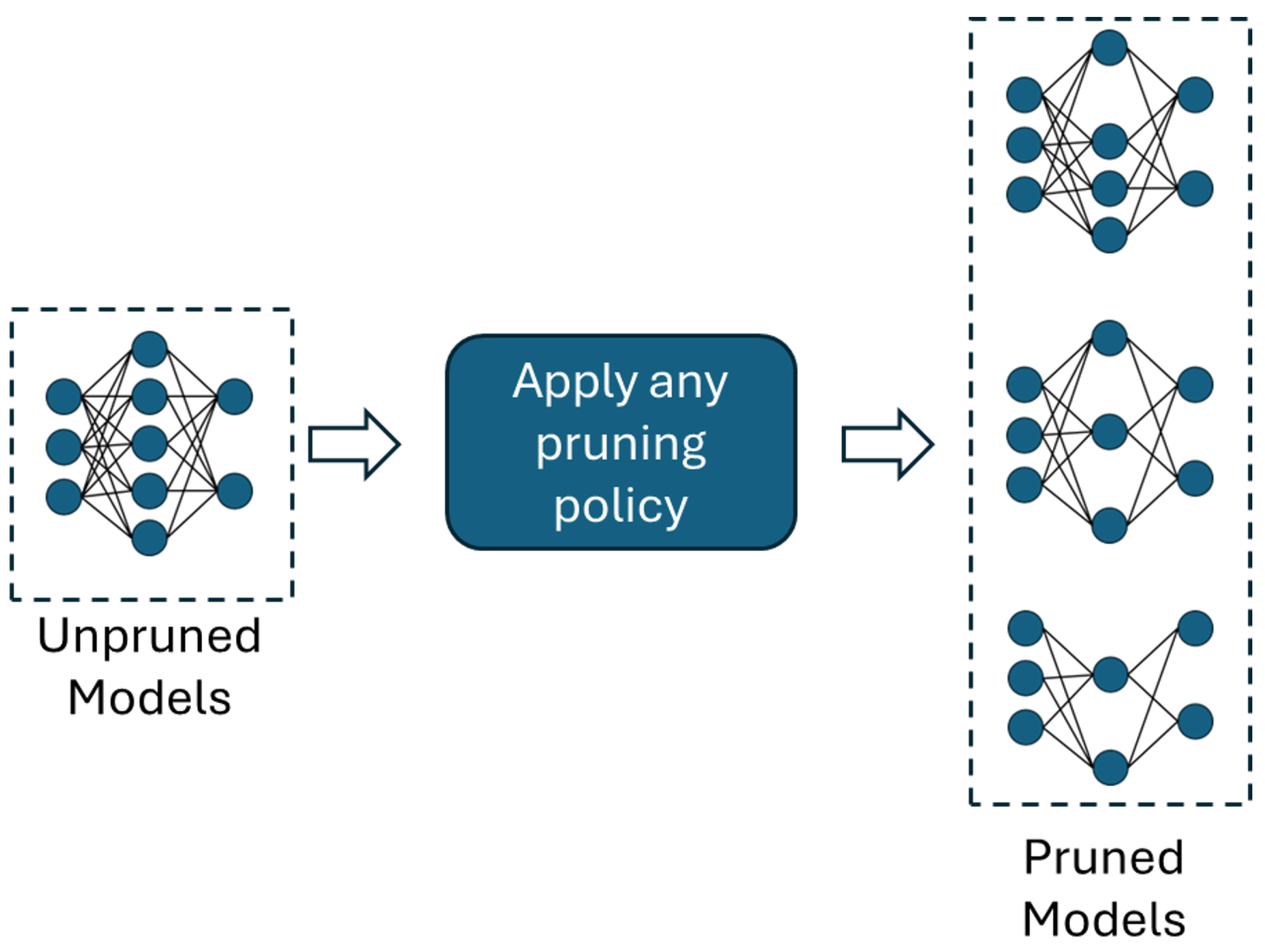
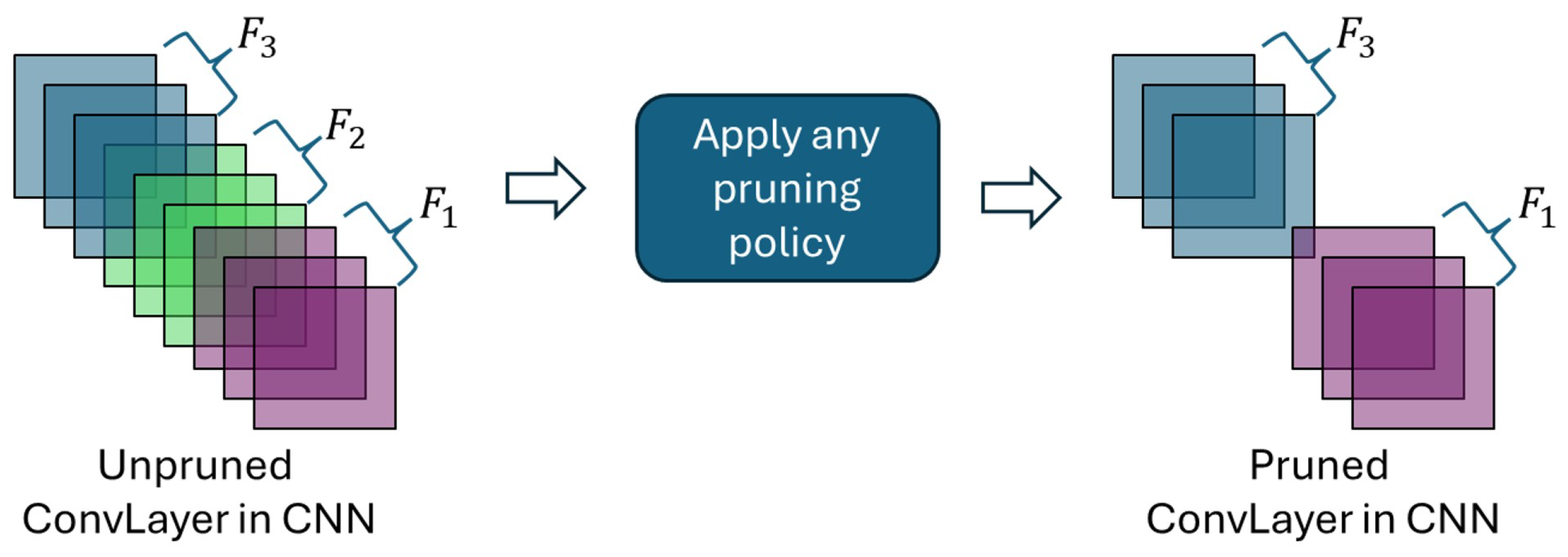
2.1. Pruning
Pruning Distributions
- Uniform distribution (): The same percentage of parameters is removed from each layer.
- Bottom-up (): Pruning starts lightly in the early layers and gradually increases in the deeper ones.
- Top-down (): A more aggressive pruning method is applied to the early layers and is gradually reduced in the deeper ones.
- Bottom-up/top-down (): Less pruning is applied to the first and last layers, while intermediate layers are pruned more heavily.
- Top-down/bottom-up (): More pruning is applied to the first and last layers, and less to the intermediate ones.

2.2. Parameters
2.3. FLOPs
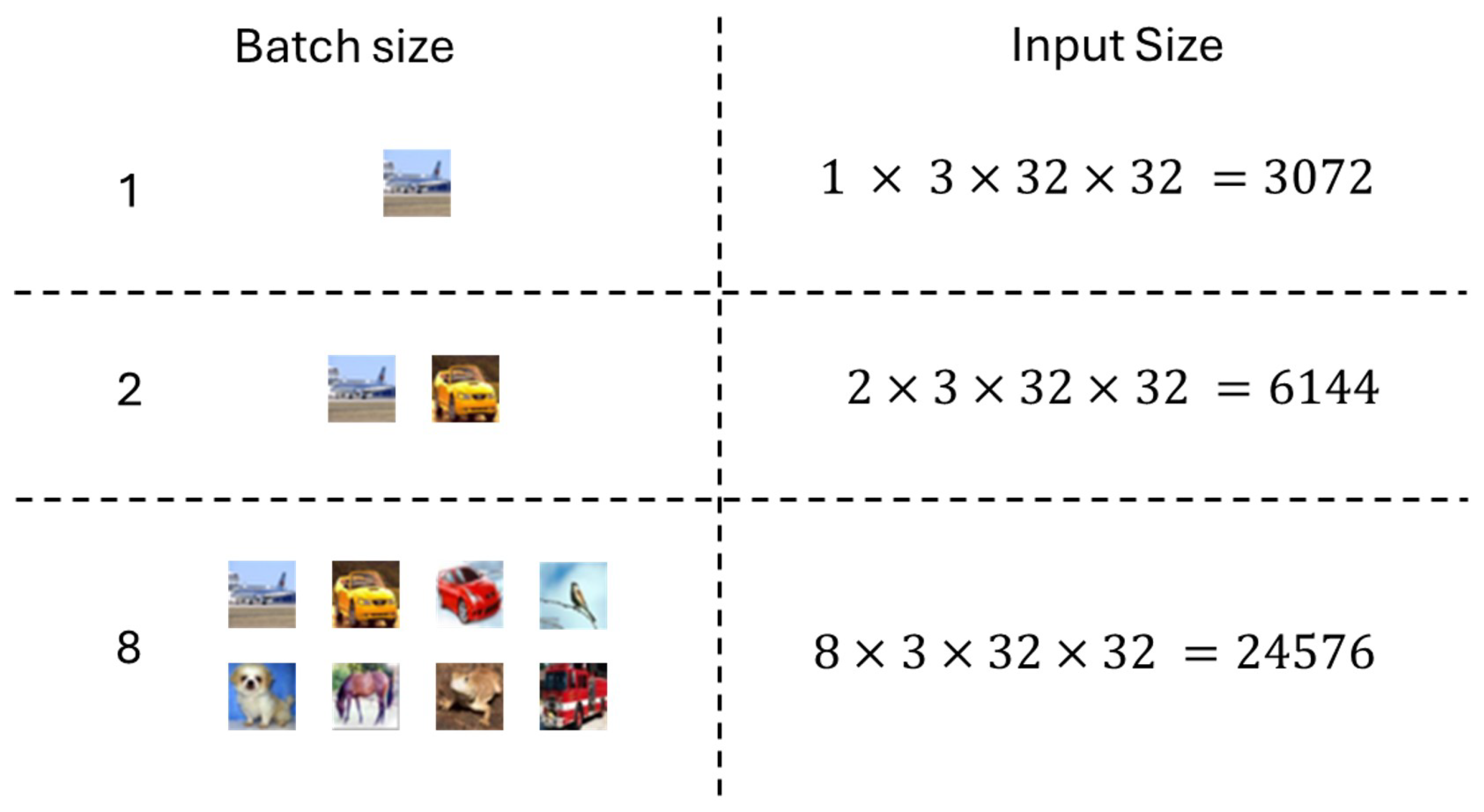
2.4. Batch Size
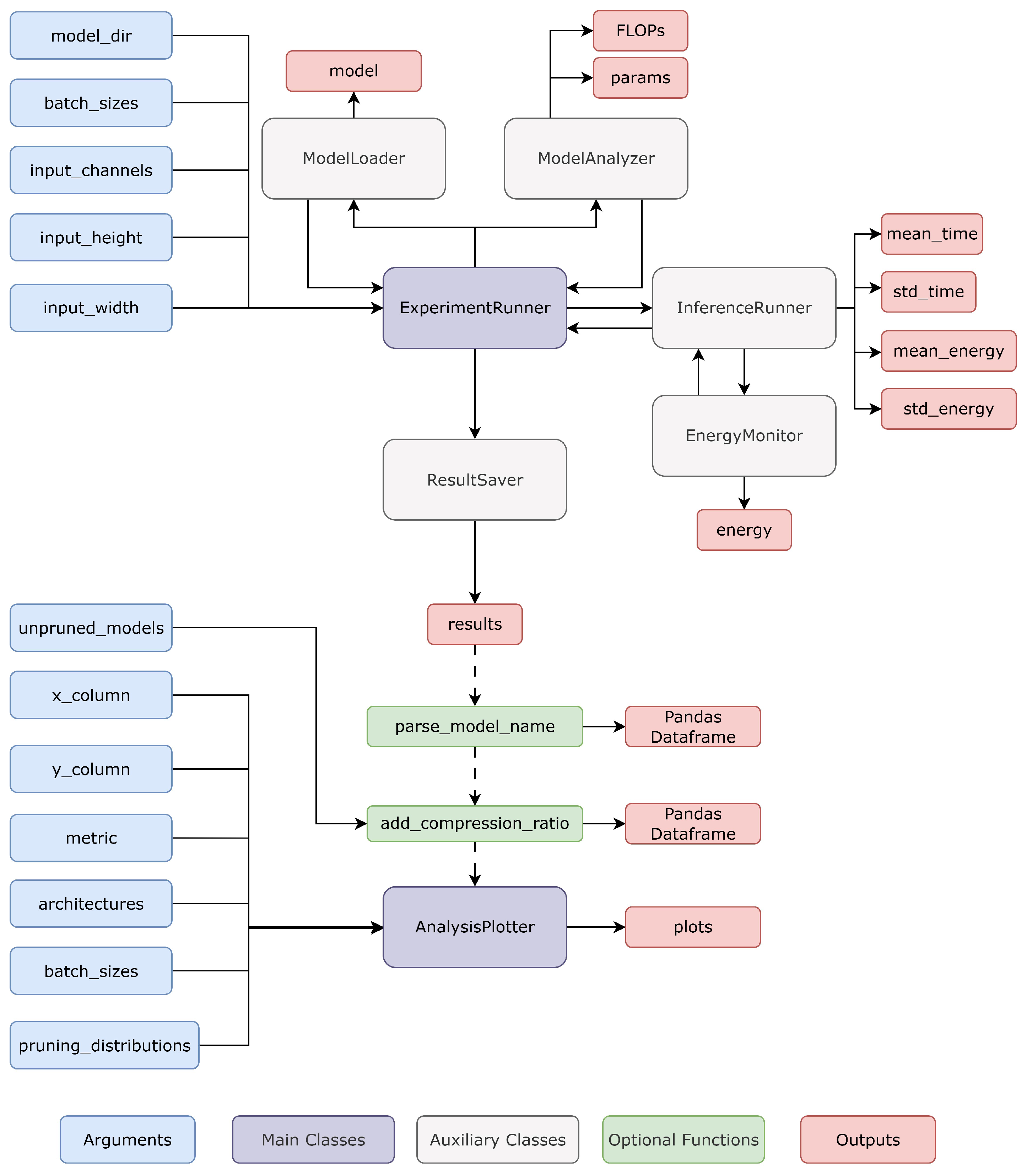
3. The Proposed PruneEnergyAnalyzer Toolkit
3.1. PruneEnergyAnalyzer: Architecture
- ARCHITECTURE refers to the model architecture (e.g., AlexNet, VGG16);
- DATASET indicates the dataset used for training (e.g., CIFAR10);
- METHOD specifies the pruning method applied (e.g., random, LRP, SeNPIS);
- PD denotes the pruning distribution used, if applicable (e.g., PD3, PD2);
- GPR-PR indicates the pruning ratio value (e.g., 10, 20, 30);
- UNPRUNED refers to the baseline model prior to pruning.
3.2. Using PruneEnergyAnalyzer
| Algorithm 1: Energy evaluation of pruned models. |
 |
| Algorithm 2: Energy analysis and visualization. |
 |
4. Results: Illustrative Example of Use
- Impact of Compression Ratio (%) on Energy Reduction (%).
- Impact of Pruning Distribution on Energy Reduction (%).
- Impact of Network Architecture on Energy Consumption.
- Impact of Batch Size on Energy Consumption.
- Impact of Batch Size on FPS Values.
- Network architecture: We used AlexNet, VGG11, and VGG16.
- Compression ratio (CR): Twelve different CR values were selected.
- Pruning distribution (PD): Five distributions, labeled PD1 through PD5 (see Section Pruning Distributions for details).
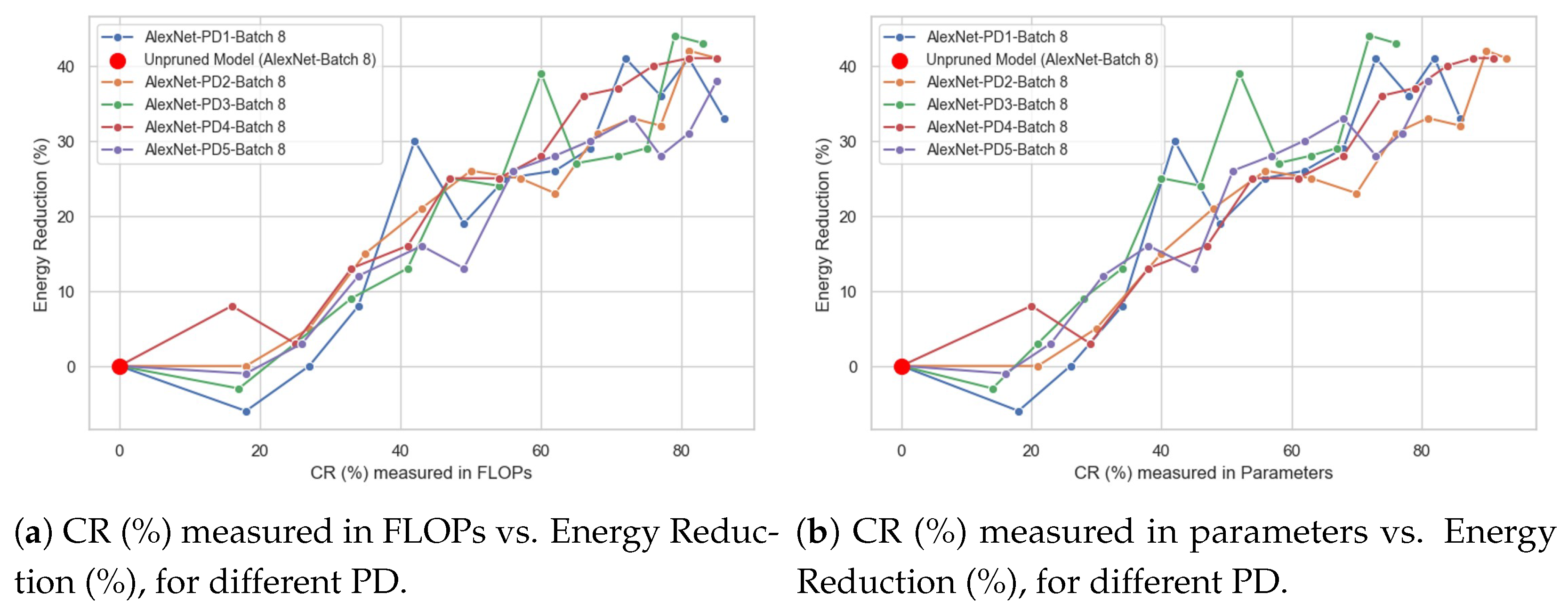
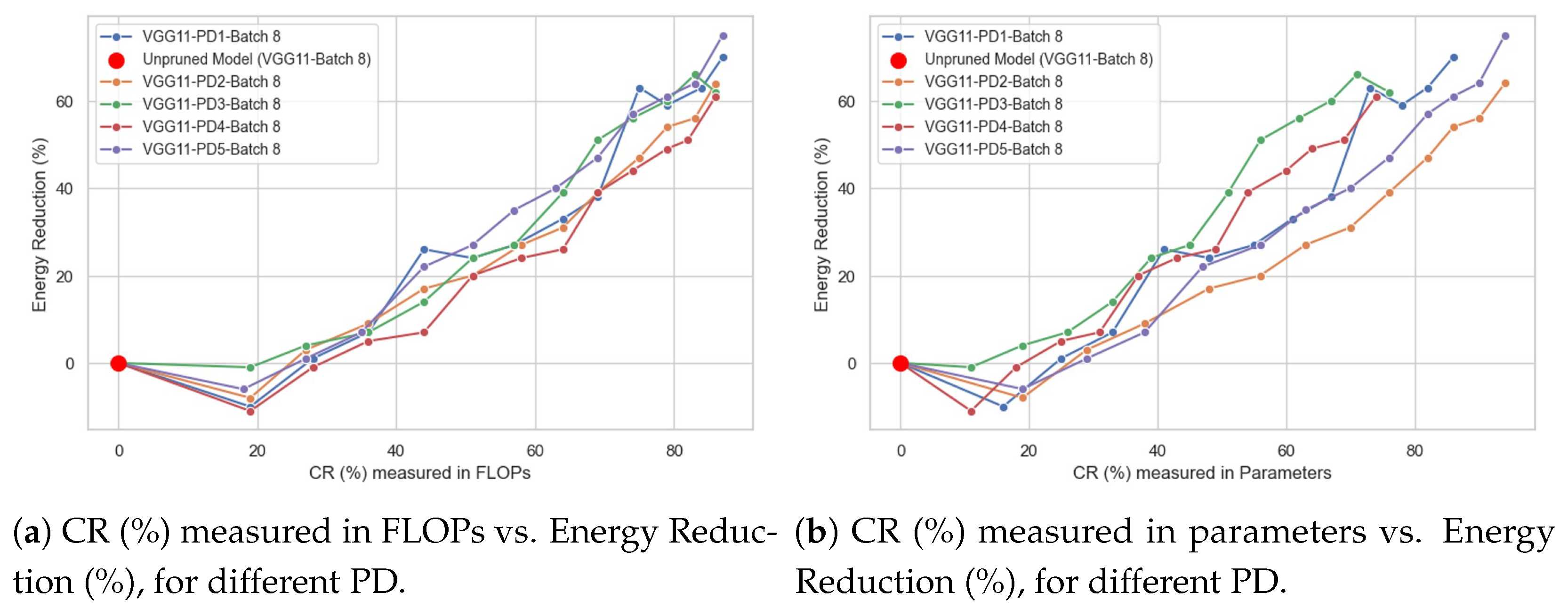
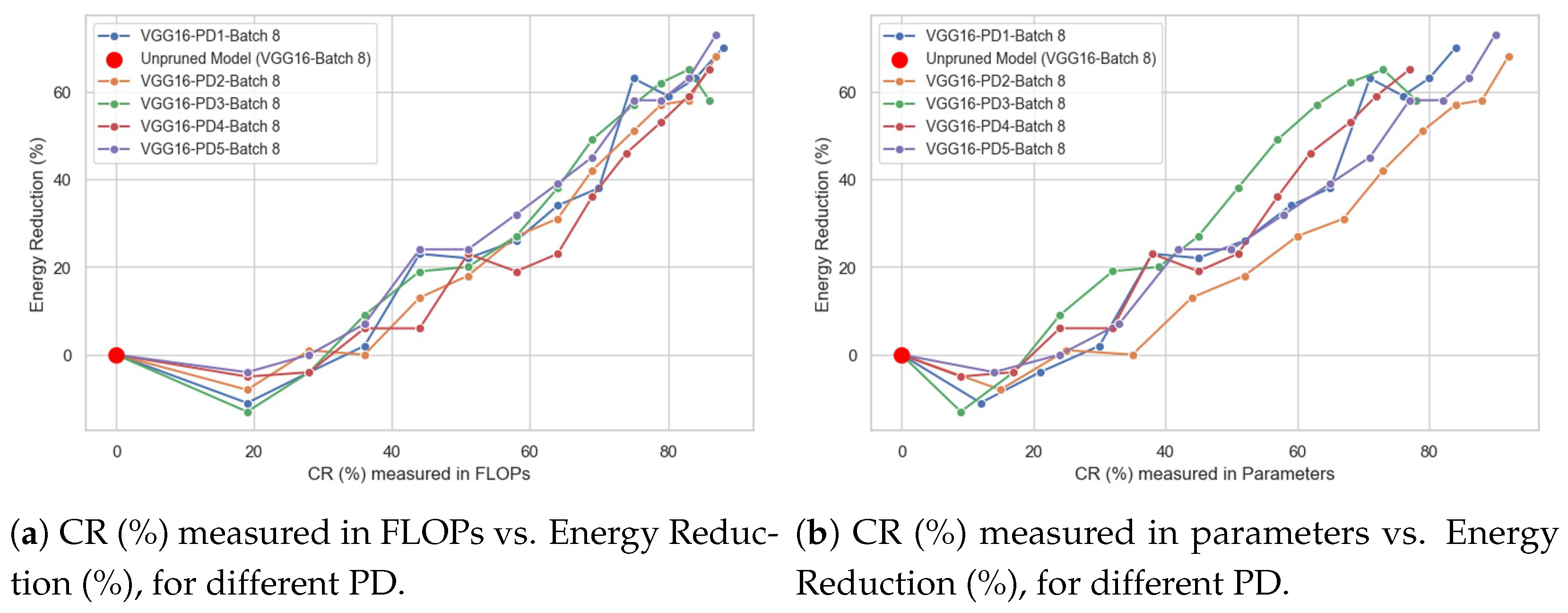
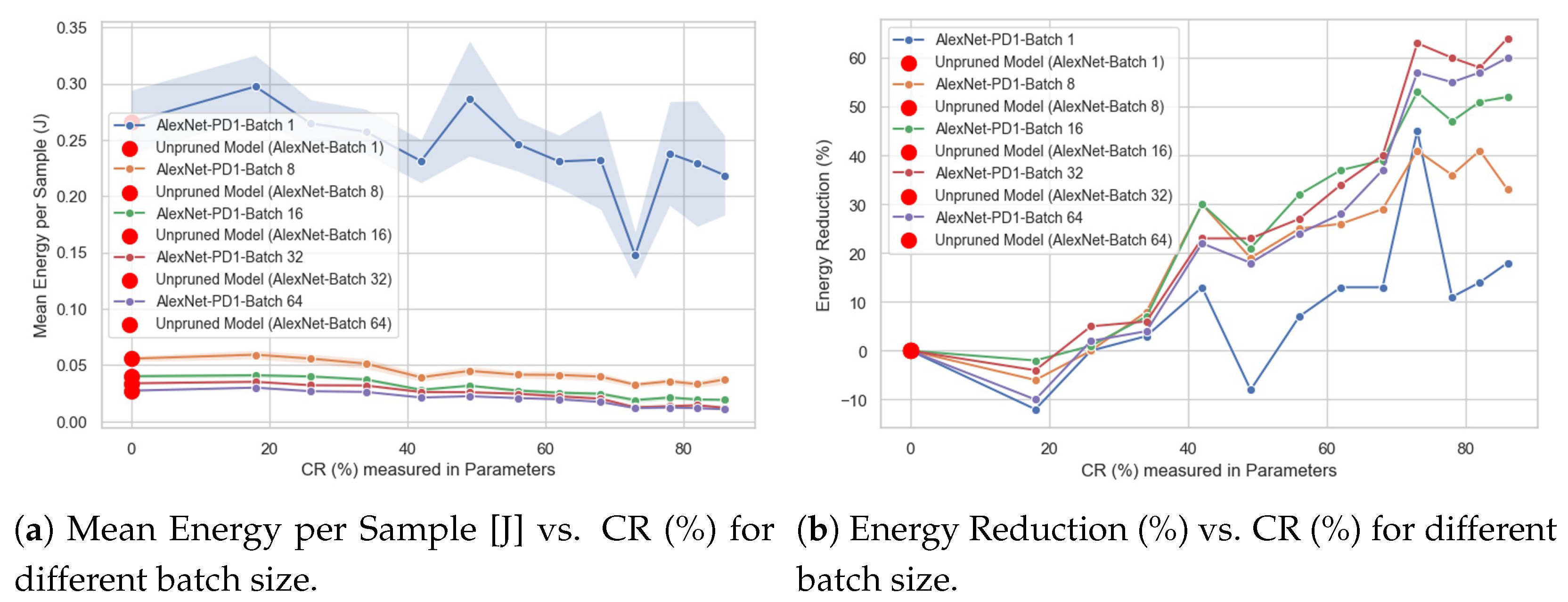
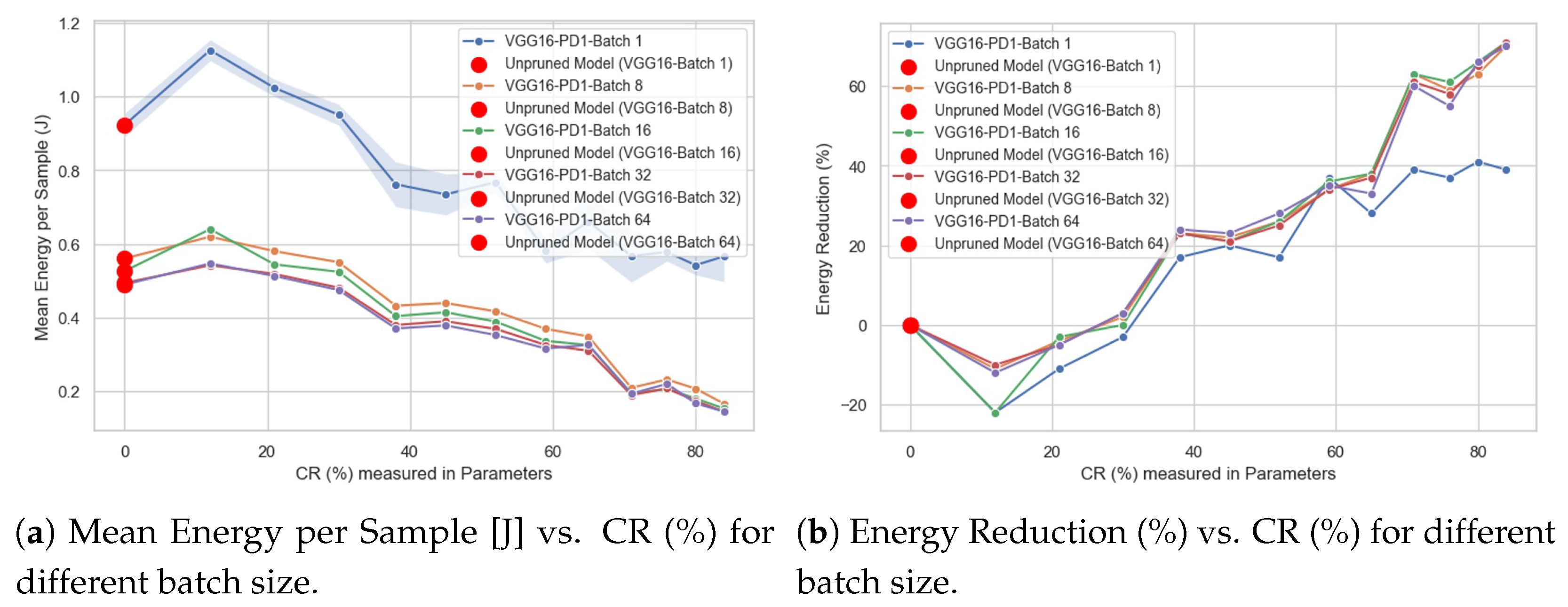
4.1. Impact of Compression Ratio (%) on Energy Reduction (%)
- Compression Ratio (%) vs. Mean Energy per Sample, expressed in units of joules [J].
- Compression Ratio (%) vs. Energy Reduction (%).
- The type of behavior of the CR (%) vs. Energy Reduction (%) curve, identifying whether it is linear or not. For example, one could answer the following question: does doubling the CR (%) value lead to a doubling of the Energy Reduction (%) value?
- Whether there is a “breaking point”; that is, a specific CR (%) value, measured in either FLOPs or parameters at which the direction of the curve changes. For example, in the Energy Reduction (%) curve, there could be a CR (%) value where the curve shifts from increasing to decreasing.
4.2. Impact of Pruning Distribution on Energy Reduction (%)
- For a specific CR (%), either in terms of FLOPs or parameters, it helps determine which type of pruning distribution (PD) most effectively reduces energy consumption, and which one is the least energy-efficient.
- For a specific pruning distribution (PD), it allows identifying its energy-saving behavior as the compression rate (CR%) increases, whether in terms of FLOPs or parameters, and determining which CR(%) value is most suitable for the particular characteristics of the problem being addressed.
4.3. Impact of Network Architecture on Energy Consumption
- Compare the initial energy consumption values of the unpruned models in different architectures.
- Analyze how increasing CR (%) impacts the Mean Energy per Sample [J] or Energy Reduction (%).
- Identify which type of network meets the energy consumption requirements for a given CR (%), allowing the selection of not only the model with the lowest consumption, but also the one with the best performance (based on tests carried out outside the tool), as long as it remains below a defined threshold.
4.4. Impact of Batch Size on Energy Consumption
- Compare the energy consumption for the same CR (%) and network across five different batch sizes (i.e., 1, 8, 16, 32, and 64).
- Analyze how energy consumption decreases for a fixed batch size as the CR (%) increases.
- Determine which batch size is most appropriate based on the energy consumption per sample requirement.
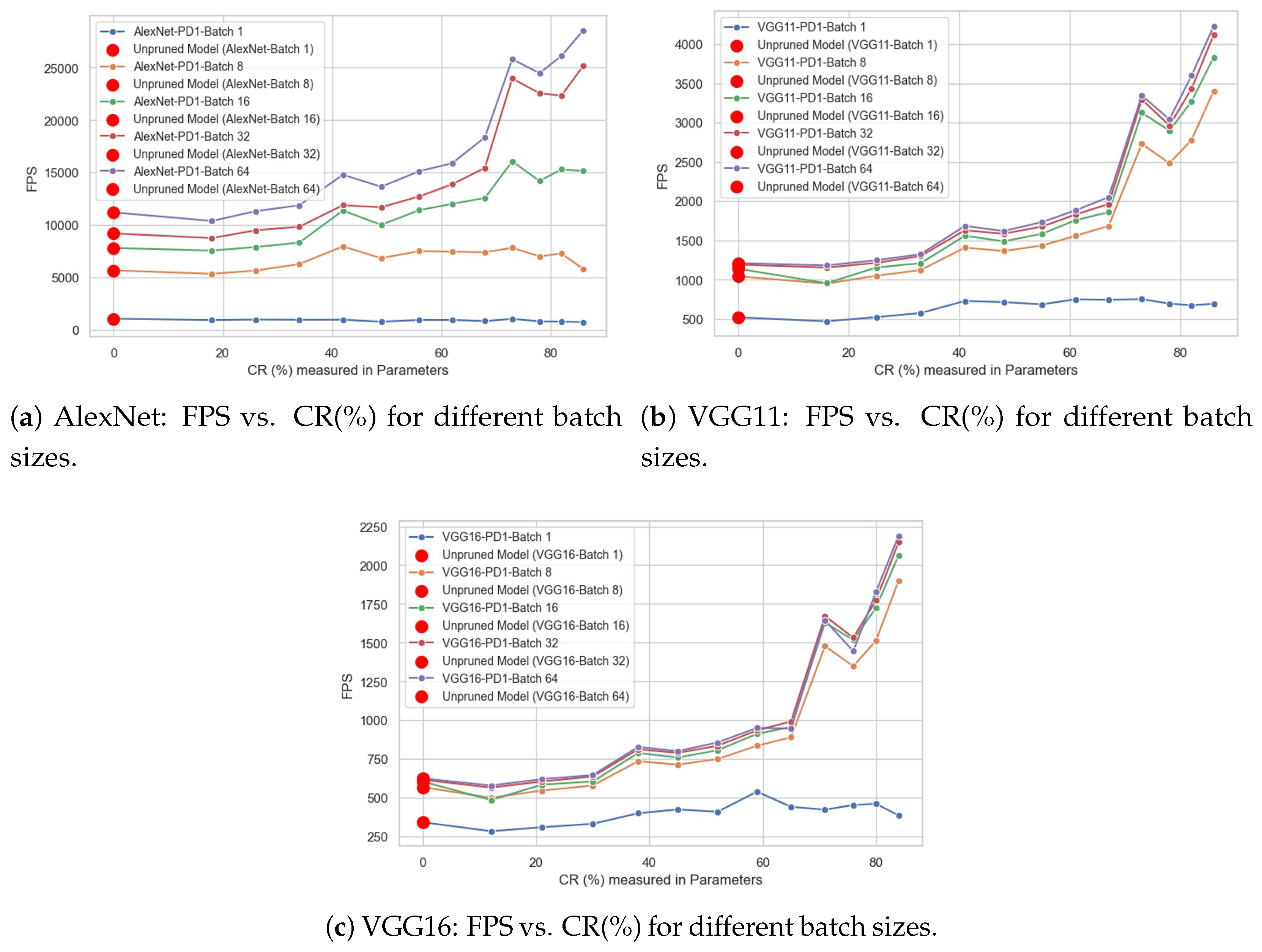
4.5. Impact of Batch Size on FPS Values
- Compare FPS values for the same CR (%) and network across five different batch size values (i.e., 1, 8, 16, 32, and 64).
- Understand how FPS changes for a fixed batch size as the CR (%) increases.
- Identify which batch size is most suitable based on the FPS values.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| CNN | Convolutional neural network |
| CR | Compression ratio |
| DL | Deep learning |
| FLOPs | Floating-point operations |
| PD | Pruning distribution |
| PP | Percentage points |
References
- Rawas, S. AI: The Future of Humanity. Discov. Artif. Intell. 2024, 4, 25. [Google Scholar] [CrossRef]
- Rashid, A.B.; Kausik, M.A.K. AI revolutionizing industries worldwide: A comprehensive overview of its diverse applications. Hybrid Adv. 2024, 7, 100277. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G. A Comprehensive Review of Deep Learning: Architectures, Recent Advances, and Applications. Information 2024, 15, 755. [Google Scholar] [CrossRef]
- Islam, S.; Elmekki, H.; Elsebai, A.; Bentahar, J.; Drawel, N.; Rjoub, G.; Pedrycz, W. A comprehensive survey on applications of transformers for deep learning tasks. Expert Syst. Appl. 2024, 241, 122666. [Google Scholar] [CrossRef]
- Ersavas, T.; Smith, M.A.; Mattick, J.S. Novel applications of Convolutional Neural Networks in the age of Transformers. Sci. Rep. 2024, 14, 10000. [Google Scholar] [CrossRef]
- Alwakid, G.; Gouda, W.; Humayun, M.; Sama, N.U. Melanoma Detection Using Deep Learning-Based Classifications. Healthcare 2022, 10, 2481. [Google Scholar] [CrossRef]
- Bachute, M.R.; Subhedar, J.M. Autonomous Driving Architectures: Insights of Machine Learning and Deep Learning Algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Lazzaroni, L.; Bellotti, F.; Berta, R. An embedded end-to-end voice assistant. Eng. Appl. Artif. Intell. 2024, 136, 108998. [Google Scholar] [CrossRef]
- Gaba, S.; Budhiraja, I.; Kumar, V.; Martha, S.; Khurmi, J.; Singh, A.; Singh, K.K.; Askar, S.S.; Abouhawwash, M. A Systematic Analysis of Enhancing Cyber Security Using Deep Learning for Cyber Physical Systems. IEEE Access 2024, 12, 6017–6035. [Google Scholar] [CrossRef]
- Wermelinger, M. Using GitHub Copilot to Solve Simple Programming Problems. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1, New York, NY, USA, 15–18 March 2023; SIGCSE 2023. pp. 172–178. [Google Scholar] [CrossRef]
- PyTorch Team. Deep Learning Energy Measurement and Optimization | PyTorch. 2025. Available online: https://pytorch.org/blog/zeus/ (accessed on 6 February 2025).
- Hamilton, J. Data Center and Cloud Innovation. Keynote at CIDR 2024. 2024. Available online: https://mvdirona.com/jrh/talksandpapers/JamesHamiltonCIDR2024.pdf (accessed on 27 July 2025).
- Alizadeh, N.; Castor, F. Green AI: A Preliminary Empirical Study on Energy Consumption in DL Models Across Different Runtime Infrastructures. In Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering–Software Engineering for AI, New York, NY, USA, 14–15 April 2024; CAIN ’24. pp. 134–139. [Google Scholar] [CrossRef]
- Martinez, M. The Impact of Hyperparameters on Large Language Model Inference Performance: An Evaluation of vLLM and HuggingFace Pipelines. arXiv 2024, arXiv:2408.01050. [Google Scholar]
- Qi, Q.; Lu, Y.; Li, J.; Wang, J.; Sun, H.; Liao, J. Learning Low Resource Consumption CNN Through Pruning and Quantization. IEEE Trans. Emerg. Top. Comput. 2022, 10, 886–903. [Google Scholar] [CrossRef]
- Li, J.; Louri, A. AdaPrune: An Accelerator-Aware Pruning Technique for Sustainable CNN Accelerators. IEEE Trans. Sustain. Comput. 2022, 7, 47–60. [Google Scholar] [CrossRef]
- Just, F.; Ghinami, C.; Zbinden, J.; Ortiz-Catalan, M. Deployment of Machine Learning Algorithms on Resource-Constrained Hardware Platforms for Prosthetics. IEEE Access 2024, 12, 40439–40449. [Google Scholar] [CrossRef]
- Park, S.; Kim, H.; Kim, H.; Choi, J. Pruning with Scaled Policy Constraints for Light-Weight Reinforcement Learning. IEEE Access 2024, 12, 36055–36065. [Google Scholar] [CrossRef]
- Pachón, C.G.; Ballesteros, D.M.; Renza, D. SeNPIS: Sequential Network Pruning by class-wise Importance Score. Appl. Soft Comput. 2022, 129, 109558. [Google Scholar] [CrossRef]
- Rajaraman, S.; Siegelman, J.; Alderson, P.O.; Folio, L.S.; Folio, L.R.; Antani, S.K. Iteratively Pruned Deep Learning Ensembles for COVID-19 Detection in Chest X-Rays. IEEE Access 2020, 8, 115041–115050. [Google Scholar] [CrossRef]
- Fontana, F.; Lanzino, R.; Marini, M.R.; Avola, D.; Cinque, L.; Scarcello, F.; Foresti, G.L. Distilled Gradual Pruning with Pruned Fine-Tuning. IEEE Trans. Artif. Intell. 2024, 5, 4269–4279. [Google Scholar] [CrossRef]
- Yang, T.J.; Chen, Y.H.; Emer, J.; Sze, V. A method to estimate the energy consumption of deep neural networks. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October 2017–1 November 2017; pp. 1916–1920. [Google Scholar] [CrossRef]
- Yang, T.J.; Chen, Y.H.; Sze, V. Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kinnas, M.; Violos, J.; Kompatsiaris, I.; Papadopoulos, S. Reducing inference energy consumption using dual complementary CNNs. Future Gener. Comput. Syst. 2025, 165, 107606. [Google Scholar] [CrossRef]
- Huang, D.; Xiong, Y.; Xing, Z.; Zhang, Q. Implementation of energy-efficient convolutional neural networks based on kernel-pruned silicon photonics. Opt. Express 2023, 31, 25865–25880. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, R.; Sun, J.; Liu, Y. How Sparse Can We Prune A Deep Network: A Fundamental Limit Viewpoint. arXiv 2023, arXiv:2306.05857. [Google Scholar]
- Pachon, C.G.; Pinzon-Arenas, J.O.; Ballesteros, D. Pruning Policy for Image Classification Problems Based on Deep Learning. Informatics 2024, 11, 67. [Google Scholar] [CrossRef]
- Beckers, J.; Van Erp, B.; Zhao, Z.; Kondrashov, K.; De Vries, B. Principled Pruning of Bayesian Neural Networks Through Variational Free Energy Minimization. IEEE Open J. Signal Process. 2024, 5, 195–203. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. 2020, 33, 1877–1901. [Google Scholar]
- Goel, A.; Tung, C.; Lu, Y.H.; Thiruvathukal, G.K. A Survey of Methods for Low-Power Deep Learning and Computer Vision. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 2021, 461, 370–403. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Pachon, C.G.; Pinzon-Arenas, J.O.; Ballesteros, D. FlexiPrune: A Pytorch tool for flexible CNN pruning policy selection. SoftwareX 2024, 27, 101858. [Google Scholar] [CrossRef]
- Pachon Suescun, C.G.; Ballesteros L, D.M.; Pedraza, C. PruneEnergyAnalizer. 2025. Available online: https://data.mendeley.com/datasets/cc2cd723hb/1 (accessed on 27 July 2025).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Details |
|---|---|
| Hardware | NVIDIA RTX 3080 GPU |
| Framework | PyTorch 2.6.0+cu118 |
| Python version | 3.11 |
| Input shape | |
| Architectures | AlexNet, VGG11, VGG16 |
| Pruning distributions | , , , , |
| Compression levels | 13 (including unpruned model) |
| Batch sizes | 1, 8, 16, 32, 64 |
| Number of pruned models | 180 |
| Number of unpruned models | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pachon, C.; Pedraza, C.; Ballesteros, D. PruneEnergyAnalyzer: An Open-Source Toolkit for Evaluating Energy Consumption in Pruned Deep Learning Models. Big Data Cogn. Comput. 2025, 9, 200. https://doi.org/10.3390/bdcc9080200
Pachon C, Pedraza C, Ballesteros D. PruneEnergyAnalyzer: An Open-Source Toolkit for Evaluating Energy Consumption in Pruned Deep Learning Models. Big Data and Cognitive Computing. 2025; 9(8):200. https://doi.org/10.3390/bdcc9080200
Chicago/Turabian StylePachon, Cesar, Cesar Pedraza, and Dora Ballesteros. 2025. "PruneEnergyAnalyzer: An Open-Source Toolkit for Evaluating Energy Consumption in Pruned Deep Learning Models" Big Data and Cognitive Computing 9, no. 8: 200. https://doi.org/10.3390/bdcc9080200
APA StylePachon, C., Pedraza, C., & Ballesteros, D. (2025). PruneEnergyAnalyzer: An Open-Source Toolkit for Evaluating Energy Consumption in Pruned Deep Learning Models. Big Data and Cognitive Computing, 9(8), 200. https://doi.org/10.3390/bdcc9080200