Abstract
The analysis of multivariate data is a central issue in biomedical research, where the accurate classification of patients and the extraction of reliable conclusions are of critical importance. Linear Discriminant Analysis (LDA) remains one of the most established methods for both dimensionality reduction and classification of data. In this paper, we examine in detail the theoretical foundations, assumptions, and statistical properties of LDA, and apply the method step by step to real data from the Breast Cancer Wisconsin (Diagnostic) database, which includes cellular features from breast biopsy samples with the aim of distinguishing benign from malignant tumors. Emphasis is placed on the importance of the method’s assumptions, such as multivariate normality, equality of covariance matrices, and absence of multicollinearity, demonstrating that their fulfillment leads to significant improvements in model performance. Specifically, careful preprocessing and strict adherence to these assumptions increase classification accuracy from ( cross-validated) to ( cross-validated). To our knowledge, this study is the first to demonstrate the dual use of LDA as both a dimensionality-reduction tool and a predictive classification model for this medical database within the same biomedical analysis framework. Moreover, we provide, for the first time, a systematic comparison between our assumption-aware LDA model and related studies employing the most accurate machine-learning classifiers reported in the literature for this dataset, showing that classical LDA achieves accuracy comparable to these more complex methods. The resulting discriminant model, which uses 13 variables out of the original 30, can be applied easily by clinical researchers to classify new cases as benign or malignant, while simultaneously providing interpretable coefficients that reveal the underlying relationships among variables. The implementation is carried out in the SPSS environment, following the theoretical steps described in the paper, thus offering a user-friendly and reproducible framework for reliable application. In addition, the study establishes a structured and transparent workflow for the proper application of LDA in biomedical research by explicitly linking assumption verification, preprocessing, dimensionality reduction, and classification.
1. Introduction
In many problems of medical research, as well as in everyday activities, the complexity of the phenomena under study and the widespread use of modern technology necessitate the simultaneous processing of large volumes of multivariate data. In Statistics and Machine Learning, a variety of methods have been developed for analyzing such data, depending on whether class labels are available. Supervised approaches, which rely on labeled data to build predictive models, include Multiple Linear Regression for modeling linear relationships with continuous outcomes [1,2], Logistic Regression for modeling class membership probabilities in binary response settings [3], and Linear Discriminant Analysis (LDA) for classification into known groups through linear combinations of explanatory variables that enhance group separability [4,5]. In addition, widely used machine learning algorithms include Support Vector Machines (SVM), which determine optimal separating hyperplanes with maximum margin [6], Random Forests and Decision Trees, which construct flexible, nonparametric decision rules via recursive partitioning and ensemble learning [7,8], and k-Nearest Neighbors (k-NN), which assigns class labels based on proximity in the feature space [9]. By contrast, unsupervised approaches are designed to uncover latent structure in the data without prior class labels and include clustering methods such as k-means, which partitions observations by minimizing within-cluster variance [10], and hierarchical clustering, which builds nested groupings based on pairwise similarity measures [11].
A third important category is formed by dimensionality reduction techniques, which aim to represent multivariate data in fewer dimensions while retaining the most relevant information. These methods can be unsupervised, such as Principal Component Analysis (PCA), which projects the data onto orthogonal directions of maximal variance [12,13], and Factor Analysis (FA), which explains observed correlations through a smaller number of latent factors [14,15], or supervised, such as LDA, which simultaneously reduces dimensionality and constructs a classification rule. Within this landscape, an especially important method for classifying multivariate data into existing groups, while at the same time reducing dimensionality, is Linear Discriminant Analysis.
Linear Discriminant Analysis constitutes a family of statistical methods for transforming an initial set of observations belonging to known groups with the dual aim of (i) interpreting the differences between these groups and (ii) classifying the observations as accurately as possible into the existing categories using selected discriminant variables. From a statistical perspective, LDA addresses the problem of assigning observations to the categories of a categorical, typically nominal, response variable on the basis of continuous independent variables measured on interval or ratio scales [16]. From a mathematical perspective, given a set of points in a multidimensional space, LDA constructs a lower-dimensional space spanned by a minimal number of new directions, referred to as discriminant functions, such that the projection of the original data facilitates group separation. This construction is obtained by solving a generalized eigenvalue problem involving the between-class and within-class covariance operators.
Its creator is Fisher (1936) [4], who used it to predict the national origin of individuals based on measurements on their skeleton. Applications of LDA exist in (a) Medicine: Disease diagnosis based on (i) certain symptoms, (ii) medical test results [17,18,19]; (b) Economics: Studying socio-economic differences between regions of a country [20]; (c) Archeology: Determining the sex of a human skeleton from measurements of the skull [21,22]; (d) Political Economy: Classification into parties of undecided individuals [23], etc.
Several recent works have sought to clarify LDA’s theoretical underpinnings and practical implementation. Tharwat et al. [24] presented a comprehensive tutorial on LDA, providing detailed mathematical derivations, visualizations, and numerical examples that build intuition and highlight common issues such as the small-sample-size problem and linear separability. In contrast, Qu and Pei [25] published a broad review focusing on recent methodological developments in LDA, including robust and kernel-based variants, adaptations for high-dimensional data, and strategies for handling multimodal distributions. While both contributions are valuable, they differ in scope: the former strengthens fundamental understanding, while the latter surveys modern methodological innovations. By contrast, the present work remains firmly within the framework of classical LDA, but distinguishes itself by offering a rigorous, assumption-driven application guide tailored to biomedical data, implemented step by step in Statistical Package for the Social Sciences (SPSS) for accessibility to clinical researchers. Moreover, the transparent structure and interpretable outputs of LDA make it particularly suitable for integration into decision–support and knowledge-based systems [26] for medical classification, while related data-driven frameworks addressing interpretability have been explored in oncological applications [27]. Recent developments in applied statistics continue to underline the versatility of classical LDA across a broad range of modeling scenarios. Notable methodological developments include functional LDA for high-dimensional curve data [28] and multiblock extensions for structured predictor sets [29], among several others. These extensions, while methodologically valuable, fall outside the scope of the present work, which focuses exclusively on classical LDA.
The present work contributes to this literature by offering a rigorous, step-by-step application of classical LDA to the Wisconsin Breast Cancer Diagnostic dataset. Our approach is distinctive in several respects:
- A theoretical foundation: We provide a complete guide to LDA, with a detailed account of its theoretical basis, assumptions, and statistical properties, including conditions of multivariate normality, equality of covariance matrices, and the absence of multicollinearity, and we show how these assumptions can be tested and satisfied in practice.
- A practical guide: Following the theory, we present a transparent step-by-step application of LDA in SPSS, enabling clinical researchers to apply the method reliably to real-world biomedical data.
- Dual use of LDA: To our knowledge, this is the first study to demonstrate LDA as both a dimensionality reduction tool and a classification model within the same biomedical framework.
- Improved predictive accuracy: We demonstrate how carefully satisfying the assumptions of LDA leads to measurable improvements in prediction, thereby emphasizing the critical importance of diagnostic checks prior to model use.
- Comparison with machine learning methods: Finally, we show that LDA, despite its conceptual simplicity and interpretability, can achieve classification accuracy comparable to more complex machine learning models while retaining the advantages of transparency and immediate applicability for the binary distinction between malignant and benign tumors.
2. Theoretical Framework of LDA
This section presents the purpose, objectives, and underlying assumptions of Linear Discriminant Analysis (LDA) in a detailed and rigorous manner. The implementation of Simple and Multiple Linear Discriminant Analysis is described. The discriminant functions (especially Fisher’s rule [4]), their number, characteristics, construction method, statistical tests for their significance, and their interpretation are described. In addition, methods for examining the significance of the (initial) variables are provided. Methods for classifying observations and evaluating the accuracy of such classifications are discussed. Any potential application problems of the method are described, and alternative forms of the method are presented (e.g., nonlinear D.A. [30,31]).
2.1. The Main Points of LDA
The purpose of Linear Discriminant Analysis can be summarized as follows:
- (a)
- Exploring the differences between (pre-existing) groups/classes;
- (b)
- Determining the most “economical” way of separating these groups;
- (c)
- Eliminating variables/characteristics that contribute minimally to group separation;
- (d)
- Testing the significance of each discriminant function;
- (e)
- Classifying new data/observations into the groups;
- (f)
- Evaluating the effectiveness of the classification rule constructed each time.
2.2. Comparison of LDA with Classification and Prediction Methods
LDA shares similarities and differences with other classification/prediction methods:
- (a)
- Cluster Analysis (C.A.)In C.A., the data groups (and their number) are not known (in advance) and are created based on the similarities ("closeness") between observations (minimizing within-group dispersion) [16].
- (b)
- Logistic Regression (L.R.)In L.R., the independent variables can be of any measurement type and are typically used when the dependent variable is binary. The coefficients in L.R. are easily interpretable, while in the discriminant functions only show the contribution of each variable to the discriminant function’s significance. L.R. calculates the probability of classifying an observation into a specific group and uses a cutoff rule to assign the observation to a particular group [3].
- (c)
- Multiple Linear Regression (M.L.R.)Both methods can be considered prediction methods. M.L.R. is applied when the dependent variable is continuous (interval type) and provides predictions using a single function (regression line) involving weighted combinations of independent variables [32].
- (d)
- Analysis of Variance (ANOVA)In one-way ANOVA, the independent variable is categorical, while the dependent variable is continuous (interval or ratio), whereas in LDA, the roles are reversed. In ANOVA, the focus is on the differences between groups in terms of their means, and it does not allow the classification of new observations [16].
- (e)
- Principal Component Analysis (P.C.A.)Both methods aim to reduce the dimensionality of the data. P.C.A. does not consider group differences and cannot be used for classification. Additionally, the first principal component in P.C.A. captures the maximum variance in the data, and we use as many dimensions as deemed necessary [33].
2.3. Assumptions for Applying LDA
To apply LDA, the following assumptions should be met [16]:
- (i)
- The data can be classified into at least two known and mutually exclusive groups with similar sizes.
- (ii)
- The independent variables (features) used for group separation (discriminant variables) are measured on a scale of interval or ratio.
- (iii)
- Multicollinearity should be avoided. The independent variables should not be strongly correlated, as the predictive ability of the constructed model decreases with increasing correlation between these variables. In the case of strong correlations, an alternative analysis method such as logistic regression can be used (with fewer assumptions).
- (iv)
- The observations should constitute a random sample, with at least two observations per group. The sample size of the smallest group should, according to some authors, be larger than the number of independent variables (at least by two), while others suggest having a minimum of five cases for each independent variable.
- (v)
- The number of outliers should be minimized, or they have to be eliminated.
- (vi)
- Homoscedasticity should be ensured. The covariance matrices of the independent variables should be equal for each group. LDA is robust when this assumption is not satisfied and can be corrected through appropriate data transformations. The assumption can be examined using the Box-M test [5,16], which is sensitive to deviations from normality. An alternative way to test the assumption is to check the equality of determinants of the individual covariance matrices.
- (vii)
- Normality should be observed within each group, meaning that each group should follow a multivariate normal distribution with respect to the characteristics. LDA is robust when this assumption is not satisfied, if the non-normality is not due to the presence of outliers. An alternative approach to address non-normality is to transform the data (e.g., square root, inverse values, etc.).
2.4. Discriminant Functions
The idea behind constructing group-separating functions, called discriminant functions, is as follows: these functions (new axes) are obtained as linear combinations of the independent variables in a way that maximizes the distinctiveness between the specified groups. Thus, the first axis is chosen in such a way that the dispersion (variance) between the groups is maximized, while the dispersion within each group is minimized. It is the axis that optimally distinguishes the groups. Then, the second axis is chosen to be orthogonal to the first (uncorrelated new variables) and possesses the same property regarding variances [34].
The process continues until a (minimum) “suitable” number of separating functions is constructed. A (normal) separating function has the following form:
where is the value (score) of the observation m in the l group; are the coefficients of the function; and is the value of for the observation m in the l group.
Regarding the number g of separating functions, we have the following proposition.
Proposition 1
(Dimension of the LDA Discriminant Space [5,32]). In an LDA problem with k groups of the dependent variable, the maximum number g of discriminant functions is provided by
- (i)
- , i.e., one less than the number of groups, when ;
- (ii)
- , where p is the number of variables, when the sample size is smaller than the number of variables .
Remark 1
(Two-Group Case). In the case of two groups, optimal separation is achieved using a single discriminant function, regardless of the dimensionality of the data. Consequently, the data can be projected onto a single straight line, yielding a reduction to the minimum possible dimensionality.
2.5. The Construction and Interpretation of Discriminant Functions
To construct discriminant functions, we need a measure of the degree of the existing differences between the groups. The matrix of means and variances of the values of the variables is not sufficient. Therefore, we consider the variance–covariance matrix of the following variables:
where denotes the size of group l and k is the number of groups. Moreover,
denotes the overall sample mean of variable (with ). Throughout this section, dot notation is used exclusively for sample means, whereas population means are denoted by . Using this matrix, we obtain a picture of how scattered the data points are in the space of variables (variance between the groups). The variance of the points within the groups can be measured using the within-groups covariance matrix . Its elements are provided by
where
denotes the corresponding sample mean of within group l [5].
When there are no differences between the centroids of the groups, the elements of the matrix W will be (almost) equal to the corresponding elements of the matrix T. However, if there are significant differences, the elements of W will be smaller than the elements of T. The difference between the two matrices is measured using the between-groups covariance matrix, denoted as . By calculating these matrices and solving the generalized eigenvalue problem,
we obtain the p eigenvalues and the corresponding eigenvectors , which define the directions of the new axes.
Remark 2
(Standardized Discriminant Coefficients). The eigenvectors obtained earlier serve as the coefficients for the separating functions. Therefore, by calculating the values (discriminant scores) of each observation with respect to these functions, we determine its location in the new space. However, because the raw coefficients lack direct interpretive meaning (and the associated scores are not inherently meaningful), the coefficients are typically standardized to produce the normalized coefficients u of the separating functions.
The resulting scores can be used to assess the position of each observation in the new space. The discriminant scores are linear combinations of the original variables and are typically centered for interpretability; however, their variances depend on group dispersion and are not constrained to unity within each group. Thus, the score of an observation (with respect to a separating function) indicates its position on the axis defined by that function.
Normalization leaves the relative positions of the groups and their degree of separability unchanged. Its purpose is to shift the new axes so that they are centered on the overall centroid, making interpretation easier. In this normalized space, the location of any point can be assessed relative to the new coordinate system. Moreover, normalization removes the influence of the original measurement units, as distances are expressed in standard deviation units. Without this adjustment, classification would be biased toward groups with the largest dispersions. Consequently, a point’s distance reflects how many standard deviations it lies from the overall centroid.
The coefficients produced through this normalization procedure are referred to as unstandardized coefficients. If, however, the original data has already been standardized, then applying the same procedure yields the standardized coefficients. Discriminant scores are computed using the unstandardized coefficients. In this context, an unstandardized coefficient for a given separating function and variable indicates the change in an observation’s position along that separating function (axis) resulting from a one-unit increase in that variable, assuming all other variables remain constant [34].
2.6. Significance of Separating Variables
The contribution of a separating variable to the creation of a separating function can be estimated in two main ways [32,34]:
- (I)
- Standardized Coefficients: Although the unstandardized coefficients of the discriminant functions provide the absolute contribution of a separating variable in calculating a discriminant score, the information they provide can be “misleading” when a one-unit change in one measurement (variable) is not equivalent to a one-unit change in another (unequal/different units of measurement). To assess the relative importance of a variable, we consider the standardized coefficients . The magnitude of these coefficients helps us determine which variables contribute more to the calculation of discriminant scores.
- (II)
- Structure Coefficients/Discriminant Loadings: The similarity between a separating variable and a separating function is evaluated using their correlation coefficient. These correlations, known as structure coefficients or discriminant loadings, represent the cosine of the angle between the variable and the function in the data space, thus revealing the geometry of the space. A separating function is typically named according to the variables that show the strongest associations with it.
2.7. Number, Importance, and Significance of Separating Functions
The number of solutions in Equation (6) is equal to the number of (original) variables. Each solution (discriminant function) corresponds to an eigenvalue. However, it may happen that some of these solutions may be trivial () and others may be statistically insignificant. The value of is equal to the ratio of the sum of squares between groups (SSB) to the sum of squares within groups (SSW) (from the corresponding analysis of variance with groups as a factor and the discriminant scores as the dependent variable). Therefore, the separating function associated with the largest (SSB > SSW, indicating greater variance between groups) is the most important in terms of separability [32,34].
The importance of a discriminant function can be further examined using the following two methods: (I) dividing its corresponding eigenvalue by the sum of all eigenvalues: . The quotient reveals the (relative) magnitude of the discriminant power of the separating function. For example, if , the first discriminant function contains of the total separability of the groups, meaning that it explains of the data variance. (II) Using the canonical correlation coefficient, which measures the relationship (correlation) between the groups and the discriminant function, given by the equation: . Instead of the term , we typically use the term (coefficient of determination). The coefficient (ratio of between-group sum of squares (SSB) to total sum of squares (SST)) indicates the proportion of variance in the scores (relative to the standard deviation) accounted for by the groups; thus, a higher value reflects a more important discriminant function.
The primary measure of a discriminant function’s statistical significance—known as the U statistic or Wilks’s lambda [35]—does not assess the function’s significance directly. Instead, it evaluates the residual discrimination present prior to the function’s construction. The statistic is expressed by the following formula:
where c is the number of discriminant functions that have already been constructed. This statistic acts as an “inverse” measure: values closer to 1 indicate greater remaining discriminability, meaning that a substantial portion of the group separation has not yet been captured by the discriminant functions constructed so far and that additional discriminant functions may therefore be warranted. Conversely, values closer to 0 indicate that most of the discriminability has already been explained. Specifically, (a) if is small, high discriminability has been achieved, and the additional information provided by further discriminant functions is minimal; thus, these functions are typically not computed. Whereas (b) if is large, considerable remaining discriminability is present, and the construction of additional discriminant functions may be justified.
Because Wilks’ Lambda is not particularly user-friendly, it is commonly transformed into a chi-square statistic in order to perform a formal significance test. The test statistic
approximately follows a chi-square distribution with degrees of freedom under the null hypothesis. For example, if has a p-value , the differences between the groups are significant before constructing the discriminant functions (d.f.), and additionally, the first d.f. is statistically significant. After constructing it, we calculate and suppose the p-value . Most researchers consider this result non-significant and do not proceed with the construction of the second d.f. (if the p-value , we continue with the construction of the second d.f., and so on, the process continues until the remaining discriminability is not significant).
2.8. Classification of Observations
LDA is also useful for classifying known observations based on their characteristics and for classifying new observations of unknown group membership. The classification of observations can be performed as follows:
- (a)
- Using discriminant variables and a simple decision rule when the probability distributions of the populations/groups are known. The main rules are (i) the maximum likelihood rule, (ii) the Bayes rule, (iii) the cost-of-misclassification rule, and (iv) the separation of populations using the normal distribution [5,32,34,36].
- (b)
- Using a discriminant rule based on discriminant functions (latent variables). The main rule in this case is Fisher’s discriminant rule, described in the next paragraph [5,32,36].
The classifications obtained from methods (a) and (b) may not necessarily coincide. In most cases, classification using discriminant functions provides more accurate results.
2.8.1. Fisher’s Discriminant Rule—Fisher’s Linear Discriminant
LDA, as mentioned earlier, is a family of methods in Statistics aimed at calculating one or more linear combinations of characteristics that characterize or separate two or more groups of "objects" or events. The resulting combination(s) can be used as a future (linear) classification rule for new objects or for dimensionality reduction in data before classification. It is based on (linear) transformations of the data using matrix multiplications.
In the case of Fisher’s discriminant rule, the data transformation is based on maximizing the ratio of “between-groups variance” to “within-groups variance,” with the aim of reducing the data variance within the same group and increasing separability between groups, in order to increase the discriminability.
The logic of the construction of the rule is explained below in the case of two groups . Thus, let us assume that we have a set of m samples (observations), which are p-dimensional objects, of which they belong to group and to the group . The sample mean vector of the objects in each of the two groups is provided by
We try to find a (weighted) transformation of the following form:
The goal is to project the values of X (data) onto a single line (thus reducing their dimension from p to 1), and this projection in the “ideal” direction ensures maximum separability between the two groups.
One (initial) way/measure to quantify this separability is to examine the distance between the average values of the projected object values (“projected” means) of each group, that is, the difference between the quantities:
We would like to calculate the direction that solves the following problem:
However, this criterion does not always work, as shown in Figure 1a. In other words, the distance between the means of the groups does not (always) guarantee the maximum possible separability between the groups.
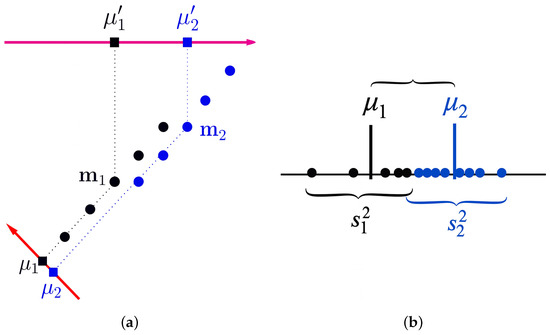
Figure 1.
Illustration of group separation criteria: (a) projection of group means along different axes; (b) between-group and within-group dispersion. Different colors correspond to different groups.
We need, in addition, to consider the variance within the groups, as shown in Figure 1b. We will calculate the value that maximizes the ratio of “between-groups variance” to “within-groups variance.” The difference between the means (in the new space) is yielded by the following equation:
Additionally, we define the within-groups variance using the following formulas:
Thus, the objective function that we want to maximize is
Maximizing this function aims to find a one-dimensional projection that clusters objects from the same group “tightly” together while simultaneously maximizing the distance between the group means of the projected values.
Let us analyze the quantity using the following formulas:
Theorem 1
(Fisher’s Linear Discriminant for Two Groups). Assume that the within-groups scatter matrix is invertible. Then the vector that maximizes
is given, up to a nonzero multiplicative constant (normalization), by
Proof.
The quantity:
Therefore, the denominator of , can be written as follows: and moreover . Furthermore, can take the following form: . To compute its maximum, we differentiate it with respect to and set it equal to zero, yielding the following:
If the matrix is invertible, we take
Thus, (after appropriate normalization). □
Remark 3.
An alternative way of determining , is based on the following:
- (I)
- The matrix is square, symmetric, and positive semi-definite, , i.e., it has only one positive eigenvalue.
- (II)
- The matrix is square, symmetric and positive semi-definite.
- (III)
- Theorem: Suppose the matrix is non-singular. The direction that maximizes our problem is given by the eigenvector corresponding to the largest eigenvalue of the (generalized) eigenvalue problem:
2.8.2. Classification Accuracy—Classification Table
Although researchers apply LDA for predicting the classification of new observations (whose group membership is unknown), we can also use it to assess the accuracy/correctness of the classification process. We are interested in the percentage of observations that are classified correctly (hit ratio), which is an indirect and intuitive measure of the degree of separability between groups (see Table 1). It is calculated using the confusion matrix (classification, confusion, or prediction table) and is equal to the sum of the diagonal elements of the matrix divided by the total size of the dataset [34,35].

Table 1.
Classification (confusion) table in LDA.
The percentage mentioned should be compared with the expected percentage of correct classification if the distribution of cases among groups was random (e.g., in the case of two groups, in the case of four groups). However, this percentage overestimates the power of the classification process because its evaluation is based on the same observations used to construct the discriminant functions.
When the sample size is large for classification evaluation, it is divided into two subsets: one for constructing the discriminant functions (training sample) and the other for validating the (correct) classifications (validation sample). Although there is disagreement about the size of these subsets, the one used for computing the discriminant functions should be sufficiently large to ensure the stability of the function coefficients. A special case of dividing the sample is cross-validation: one observation is withheld at each iteration, the discriminant functions are constructed, and then the group to which it belongs is estimated [5,32]. The process is repeated for each observation, and in the end, the percentage of correctly classified observations is calculated.
Alternatively, a second graphical way to assess the accuracy/validity of the classification process is as follows: at the end of applying the discriminant analysis, it is assumed that the discriminant scores (regarding each discriminant function) follow the normal distribution. The degree of overlap of these distributions can be used as a measure of the degree of correct classification of observations (Figure 2).
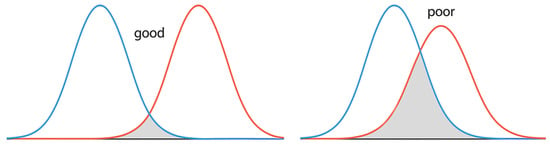
Figure 2.
Distributions of discriminant scores for assessing classification overlap between groups.
2.9. Problems with the Implementation of Discriminant Analysis—Violation of Assumptions
To apply LDA to a dataset, certain key assumptions need to be satisfied, including the multivariate normal distribution (MND) and equality of covariance matrices (within groups). Violating these assumptions has the following consequences:
- (I)
- Multivariate Normal Distribution
- (a)
- Significance test: In this approach, we compare the theoretical distribution of a statistic calculated under the assumption of a multivariate normal distribution (MND) of the population with its actual sampling distribution. If this assumption is violated, discrepancies will arise between the two distributions. Although Linear Discriminant Analysis (LDA) is robust to minor deviations from normality, the accuracy and validity of the results may still be affected.
- (b)
- Chi-square distribution: Normality is also essential when classifying observations based on their probabilities of group membership. These probabilities are derived under multivariate normality; under this assumption, the associated squared Mahalanobis distances follow a chi-square distribution. If this assumption is not satisfied, the resulting probabilities will be inaccurate, leading to suboptimal classification and an increased rate of misclassification.
- (II)
- Equality of Covariance MatricesWhen the within-group covariance matrices are unequal, distortions arise in both the discriminant and classification functions. The main source of error is the within-group covariance matrix W, which can no longer be used to simplify the discriminant functions when this assumption is violated. Consequently, the discriminant functions fail to maximize group separation, and the membership probabilities become biased to some extent. One way to address this issue is to incorporate the individual group covariance matrices into the probability calculations, as performed in quadratic discriminant analysis.
The difficulty with violating these assumptions lies in the uncertainty about the degree of violation that is acceptable for the analysis to remain valid. In such situations, indirect methods can be used to estimate the extent of violation by examining statistics that do not rely on these assumptions. Specifically:
- (i)
- When deciding the number and significance of discriminant functions, researchers commonly rely on Wilks’s lambda or its associated chi-square test, both of which depend heavily on the validity of underlying assumptions. Alternatively, canonical correlations or the percentage of relative significance can be used. If these values are low, the discriminant analysis may lack practical importance, even if statistically significant. Significance tests are especially crucial with small sample sizes, where assumption violations warrant careful consideration [23].
- (ii)
- In classification, difficulties occur when membership probabilities are close to each other. For instance, if an observation has a 0.51 probability of belonging to Group 1 and 0.49 to Group 2, minor errors from assumption violations can easily cause misclassification.
Additionally, several challenges arise when applying LDA:
- (i)
- The number of discriminant axes may be insufficient to accurately classify a substantial portion of the data.
- (ii)
- LDA may fail to capture complex data structures essential for accurate classification, particularly in cases where group means are similar but covariance structures differ.
- (iii)
- LDA can be ineffective when groups are not linearly separable; that is, when the discriminative information lies in differences in variance rather than in the means (see Figure 3). In such situations, Kernel Discriminant Analysis (K.D.A.) is used [37,38]. K.D.A. applies a nonlinear transformation that maps the data into a higher-dimensional space where they become linearly separable, allowing discriminant analysis to be performed effectively in this new space (see Figure 4).
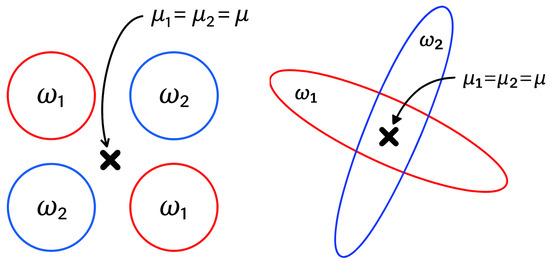 Figure 3. Example of groups that are not linearly separable in the original feature space.
Figure 3. Example of groups that are not linearly separable in the original feature space.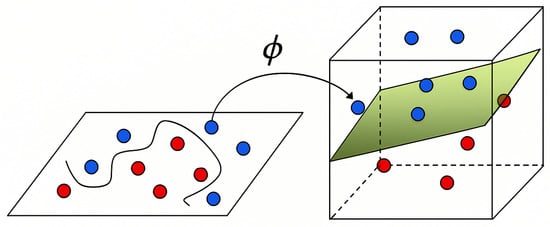 Figure 4. Visualization of nonlinearly separable groups in higher-dimensional space.
Figure 4. Visualization of nonlinearly separable groups in higher-dimensional space.
3. Case Study: Implementation of LDA in a Medical Context
In this study, we examine the implementation of LDA in the context of clinical diagnostics, using the “Breast Cancer Wisconsin (Diagnostic)” dataset, originally compiled by Dr. William H. Wolberg et al. at the University of Wisconsin–Madison and publicly available via the UCI Machine Learning Repository [39]. It consists of digitized images derived from fine needle aspirates (FNA) of breast masses (see Figure 5), processed to extract numerical features that characterize the morphology of cell nuclei present in the samples. Each case corresponds to one patient and includes a label indicating whether the tumor is benign (labeled 0) or malignant (labeled 1), stored in the column diagnosis.
Figure 5.
Representative breast mass image from which morphological features were extracted.
For each nucleus, ten real-valued features were calculated:
- Radius (mean distance from the center to points on the perimeter);
- Texture (standard deviation of gray-scale values);
- Perimeter;
- Area;
- Smoothness (local variation in radius lengths);
- Compactness (perimeter2/area );
- Concavity (severity of concave portions of the contour);
- Concave points (number of concave portions of the contour);
- Symmetry;
- Fractal dimension (“coastline approximation”).
For each of the above features, three statistical summaries were computed: the mean, the standard error, and the “worst” value (defined as the mean of the three largest values for that feature) named radius mean, radius_se, radius_worst, respectively. This results in a total of 30 features per sample. The dataset consists of 569 observations in total, with 357 labeled as benign and 212 as malignant. Although in our dataset all diagnostic labels are known, in cases where the disease status is partially missing (verification bias), estimation techniques such as the semiparametric and shrinkage-based approaches of Ahmed et al. [40] can be applied to recover diagnostic information reliably.
Given the binary classification nature of the problem (benign vs. malignant), LDA is a suitable method for modeling the class separability based on these quantitative features.
3.1. Data Preprocessing
Before applying LDA, a thorough preprocessing phase is essential, particularly due to the assumption that LDA performs optimally when input variables follow a normal distribution. The majority of the 30 features failed the Kolmogorov–Smirnov (K-S) test, suggesting that the assumption of normality does not hold for most variables in their original form. To further examine distributional properties, skewness and kurtosis values are assessed [41,42]. Ideally, skewness values should fall between −1 and +1, and kurtosis near 3. While some variables (e.g., radius mean, smoothness_mean) are within acceptable limits, others exhibited significant skewness or peakedness, confirming the need for transformation. To address these issues and enhance normality, a Box–Cox transformation is applied to all variables [2], yielding the following:
The Box–Cox transformation requires strictly positive data . The parameter is estimated from the data by maximizing the log-likelihood function, with the optimal corresponding to the value that provides the best model fit.
Effect of the Box–Cox Transformation on Feature Skewness
In the present dataset, the sample skewness of the original features ranges from moderate values (approximately ) up to strongly skewed cases exceeding 5, indicating substantial departures from symmetry for several variables. For a real-valued feature X with mean and standard deviation , the (Fisher–Pearson) skewness coefficient is defined as
For right-skewed features (), the application of a monotone transformation , such as the logarithmic or Box–Cox transformation, compresses the right tail of the distribution relative to the left tail. This reduces the contribution of extreme values to the third central moment and, consequently, decreases the magnitude of the skewness coefficient. After transformation, the skewness of all features is substantially reduced and concentrated within a narrow interval close to zero, with all values lying in the range , confirming improved distributional symmetry across the entire feature set. The effect of the Box–Cox transformation on feature skewness is summarized in Figure 6.
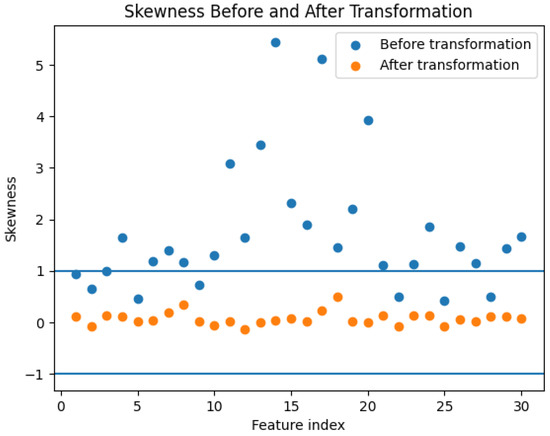
Figure 6.
Feature-wise skewness before and after the Box–Cox transformation. Horizontal reference lines at indicate the commonly accepted bounds for approximately symmetric distributions. After transformation, the skewness of all features lies within this interval.
In practice, statistical software packages (R 4.x, Python 3.x, SPSS 27, and SAS 9.4) perform this procedure automatically and report along with a confidence interval. The transformation is particularly useful in stabilizing variance and making the data more closely resemble a normal distribution. The transformed variables are then re-evaluated, confirming improved distributional properties suitable for LDA modeling. Next, we standardize all features to ensure comparability of scales and to aid in outlier detection. To identify and potentially exclude outliers, we apply the rule , which retains values within three standard deviations of the mean. After removing the outliers, the remaining dataset consists of 538 observations: 338 labeled as benign and 200 as malignant. This dataset is used for all subsequent modeling. Then, we run discriminant analysis, using SPSS software, v27 [43]. For reproducibility purposes, all tables and figures reported in this study are generated directly from SPSS output.
Although the analyses in this paper are conducted using SPSS, the same Linear Discriminant Analysis (LDA) methodology is readily available in other commonly used statistical platforms, including open-source environments. In Minitab, LDA can be performed via the Discriminant Analysis procedure (Stat → Multivariate → Discriminant Analysis), which provides classification functions, posterior probabilities, and misclassification summaries in a structured, menu-driven environment. In R, LDA is implemented through the lda function of the MASS package, following the classical Fisher framework and allowing direct access to group means, pooled covariance matrices, and discriminant coefficients [44]. In Python, the LinearDiscriminantAnalysis class in the scikit-learn library offers an efficient implementation with options for different solvers and covariance regularization, and integrates naturally with preprocessing and validation tools [45]. These observations indicate that the SPSS-based workflow adopted in this study is fully consistent with, and transferable to, other established statistical software platforms.
3.2. Tests of Equality of Group Means
Table 2, “Tests of Equality of Group Means”, presents the results of a series of univariate ANOVAs conducted on each of the standardized and transformed predictor variables, using the diagnostic outcome (benign vs. malignant) as the grouping factor. This step serves as an initial assessment of whether significant differences exist between the two groups for each independent variable and, consequently, whether the variables have discriminatory values. Similar insights into group separation can also be obtained from the descriptive ”Group Statistics” table provided by SPSS, based on group means and standard deviations.
Table 2.
Univariate ANOVA results assessing group differences between benign and malignant cases for each predictor.
Accordingly, Table 2 includes Wilks’ Lambda values, F-statistics, degrees of freedom, and significance levels. A lower Wilks’ Lambda and higher F-value, alongside a significance value (Sig.) below 0.05, indicate that a variable contributes meaningfully to the differentiation between groups. Here, most of the variables are statistically significant (Sig. ), suggesting they are strong candidates for inclusion in the LDA model. Specifically, variables such as concavepoints_mean, perimeter_worst, radius_worst, and concavepoints_worst show particularly low Wilks’ Lambda values (around 0.37–0.39) and extremely high F-values (above 850), indicating strong group separation. On the other hand, a small subset of variables—including fractal_dimension_mean (Sig. = 0.172), texture_se (Sig. = 0.363), smoothness_se (Sig. = 0.242), and symmetry_se (Sig. )—did not show statistically significant differences between groups (and may therefore be excluded from the final discriminant model). In summary, the significant group differences observed across most variables confirm their value as discriminators between benign and malignant cases, validating the application of LDA in this study.
3.3. Assessment of Homogeneity of Covariance Matrices (Box’s M Test)
The Box’s M test is used (Figure 7A) to evaluate the assumption of homogeneity of covariance matrices across groups (benign vs. malignant). The test examines the null hypothesis that the population covariance matrices are equal [3]. In the current analysis, it yielded Box’s and a significance level of ; thus, the null hypothesis is rejected, indicating that the assumption of equal covariance matrices is not satisfied. However, Box’s M test is known to be extremely sensitive to deviations from multivariate normality and large sample sizes, often resulting in significant outcomes even when the practical violation is minimal [16]. Therefore, a significant Box’s M test does not necessarily invalidate the use of LDA.
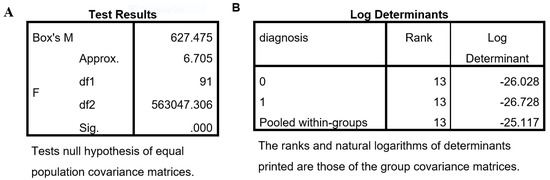
Figure 7.
Results of (A) Box’s M test and (B) logarithms of the determinants of the group covariance matrices for assessing the equality of population covariance matrices.
An alternative approach is to examine the logarithms of the determinants of the group covariance matrices (Figure 7B). The log determinant for group 0 is , for group 1, and for the pooled within-groups matrix . The small difference 0.7) between the determinants suggests that the covariance structures do not differ substantially, a fact that supports the argument that the assumption of homogeneity is not severely violated in practice [34].
3.4. Assessment of Multicollinearity (Tolerance Test)
Table 3, “Variables Failing Tolerance Test”, reports the within-groups variance and corresponding tolerance values for each predictor variable used in the discriminant analysis. The tolerance statistic is a measure of multicollinearity and reflects the degree to which a given independent variable is linearly related to the other predictors. A tolerance value close to zero indicates high multicollinearity, which may distort the estimation of discriminant functions and reduce the reliability of the model [16]. In this analysis, several variables exhibited low tolerance values, as shown in Table 3, raising concerns, for example, radius_worst (0.045), texture_worst (0.042), area_worst (0.040), and perimeter_worst (0.049). It is common practice to remove these variables from subsequent analyses. Accordingly, SPSS automatically excluded 17 variables from the discriminant model.
Table 3.
Multicollinearity diagnostics for predictor variables based on tolerance statistics.
3.5. Model Interpretation
- (A)
- Eigenvalues
Table 4, “Eigenvalues”, provides information about the discriminant function(s) derived from LDA. Since the dataset includes only two groups (benign and malignant), only one discriminant function is produced; therefore, the table reports a single eigenvalue. To this end, the eigenvalue indicates a strong discriminating power of the function, explaining 100% of the discriminant variance in the model (since only one discriminant function is used). The canonical correlation coefficient of 0.867 shows a strong relationship between the discriminant scores and the diagnostic groups. The square of the canonical correlation shows that approximately of the variance in the dependent variable is explained by the model. This result reflects a strong discriminative ability between benign and malignant tumors.
Table 4.
Eigenvalue and canonical correlation associated with the extracted discriminant function.
- (B)
- Wilks’ Lambda—Significance of the Discriminant Function
The Wilks’ Lambda test is used to evaluate the overall statistical significance of the discriminant function derived from the analysis. It measures the proportion of total variance that is not accounted for by differences among groups. A lower Wilks’ Lambda value indicates that a greater proportion of the variance is explained by group differences, suggesting a stronger discriminative ability of the function.
In this analysis, Wilks’ Lambda is 0.249, with an associated chi-square value of 737.012, 13 degrees of freedom, and a significance level (Sig.) of (see Table 5). These values confirm that the discriminant function is highly significant and effectively differentiates between the two diagnostic categories (benign and malignant). Specifically, a Lambda of 0.249 suggests a strong separation between groups, consistent with approximately of the discriminant variance explained by group membership, indicating a strong model fit. This result is consistent with the high canonical correlation reported earlier (), further validating the effectiveness of the model in capturing the variance related to the classification task.
Table 5.
Overall significance test of the discriminant function based on Wilks’ Lambda.
- (C)
- Canonical Discriminant Function Coefficients—Construction of the Discriminant Function
Table 6, “Canonical Discriminant Function Coefficients”, presents the unstandardized coefficients used to construct the linear discriminant function. These coefficients function similarly to those in a regression model, forming a linear equation that best separates the two groups based on the predictor variables included. The sign and magnitude of the coefficients indicate the direction and the relative strength of each predictor’s role in distinguishing between the groups. Based on Table 6, the estimated discriminant function includes 13 variables and can be written as:
Table 6.
Estimated coefficients of the linear discriminant function used for group separation.
The variables with the highest absolute values of coefficients, such as area_mean (14.061), radius_mean (−10.812), and perimeter_mean (−2.663), appear to make the strongest contribution to group separation, highlighting their importance in the model. This equation is used to compute discriminant scores for each case, which are then used for group classification.
- (D)
- Functions at Group Centroids - Interpretation
Table 7, “Functions at Group Centroids”, presents the average discriminant scores for each of the two diagnostic groups: 0 (benign) and 1 (malignant). The scores are calculated by inserting the mean values of the independent variables for each group into the discriminant function equation. In our case, the centroid for the benign group (0) is , while for the malignant group (1), it is .
Table 7.
Mean discriminant scores (centroids) for benign and malignant diagnostic groups.
As illustrated by Figure 8, these scores lie on opposite sides of the discriminant axis and are far apart, which suggests a strong separation between the two groups. As can be seen, the clear distance between these two centroids supports the model’s high classification ability and confirms that the discriminant function effectively distinguishes between the two categories of the dependent variable. Cases with discriminant scores closer to −1.335 are predicted to belong to the benign group, whereas cases closer to 2.256 are classified as malignant.
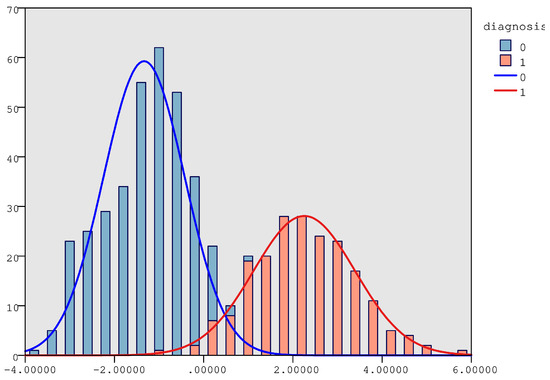
Figure 8.
Distribution of discriminant scores along the extracted discriminant function. Diagnosis: 0: the tumor is benign; 1: the tumor is malignant.
- (E)
- Classification Results—Accuracy
Table 8, “Classification Results”, summarizes the performance of the discriminant function in predicting group membership for the dependent variable (diagnosis: benign vs. malignant).
Table 8.
Classification performance of the linear discriminant model for original and cross-validated samples.
Original Classification
The analysis correctly classified of the original grouped cases. Specifically, 336 out of 338 benign cases () and 190 out of 200 malignant cases () were correctly classified, indicating high predictive accuracy. The diagonal values in the table represent correct classifications, while off-diagonal values indicate misclassifications. This high classification accuracy reflects the strong discriminating power of the model.
Cross-Validation (Leave-One-Out Method)
To assess the model’s generalizability, cross-validation was performed using the leave-one-out technique. In this method, each case is classified by the discriminant function derived from all other cases except the one being classified. The cross-validated accuracy remained high, with of the grouped cases correctly classified ( for benign and for malignant cases). This slight decrease from the original classification accuracy suggests a robust model with minimal overfitting.
- (F)
- Prior Probabilities—Interpretation and Model Accuracy
Table 9, “Prior Probabilities for Groups”, presents the assumed likelihood of each group membership before the discriminant analysis is conducted. These priors are based on the observed proportions in the sample: of cases belong to group 0 (benign), while belong to group 1 (malignant). These proportions are used in the classification process to reflect the unequal group sizes and to avoid bias in favor of the larger group.
Table 9.
Prior group membership probabilities used in the discriminant classification procedure.
An important aspect of interpreting discriminant analysis is assessing the hit ratio, which reflects the model’s classification accuracy [16,34,40]. To determine whether the hit ratio is acceptable, it must be compared against a baseline—the level of accuracy that would be expected by chance alone. In the case of two groups with equal sizes, a random assignment would yield an accuracy of . However, when group sizes are unequal, the chance hit ratio corresponds to the proportion of the largest group, in this case, . As a rule of thumb, most researchers consider the model acceptable if its hit ratio exceeds the chance level by at least . Thus, in this case, a hit ratio above would be considered acceptable. The predictor model developed in this study clearly surpasses this threshold.
- (G)
- Model Dimensionality Reduction and Classification Accuracy
As an additional approach, the stepwise discriminant analysis method was applied and reduced the initial set of 30 predictor variables to 10 statistically significant ones, effectively addressing the dimensionality of the problem and improving model interpretability. As observed in Table 10 (Wilks’ Lambda), each additional variable entered into the model led to a successive decrease in the Lambda value, with the last step 14 yielding a Wilks’ Lambda of . This consistent reduction, along with the highly significant F-statistics ( at each step), confirms that the selected variables contribute meaningfully to group discrimination.
Table 10.
Stepwise evolution of Wilks’ Lambda as predictor variables are sequentially entered into the discriminant model.
The effectiveness of the resulting discriminant function is reflected in the classification performance. According to the classification results table, of the original grouped cases were correctly classified. More importantly, the cross-validated accuracy—considered a more robust and unbiased estimate—remained high at . These high hit ratios indicate a strong discriminatory power of the model, with especially high sensitivity for classifying both benign and malignant cases during cross-validation.
Remark 4.
To underscore the importance of the fundamental assumptions of LDA, we initially applied the method without verifying whether these assumptions were satisfied. Notably, the inclusion of a data preprocessing step prior to applying LDA resulted in a marked improvement in classification accuracy, increasing from 95.6% (94.7% cross-validated) to 97.8% (97.4% cross-validated), corresponding to a relative gain of 2.2% (2.7% cross-validation). This finding demonstrates the critical role of preprocessing in enhancing model performance.
Table 11 compares the findings of this study with those reported in earlier works using the Wisconsin Diagnostic Breast Cancer dataset. In [46], LDA was employed as a dimensionality reduction step before applying Random Forest and SVM classifiers, which achieved accuracies of 95.6% and 96.4%, respectively. Naji et al. [47] performed a systematic evaluation of five classical machine learning algorithms—SVM, Random Forest, Logistic Regression, Decision Tree (C4.5), and k-NN—and found that SVM achieved the highest accuracy (97.2%), followed by Random Forest (96.5%) and Logistic Regression (95.8%), while k-NN was the weakest at 93.7%.
Table 11.
Comparison of classification accuracy with previously published studies on the Wisconsin Diagnostic Breast Cancer dataset.
In our study, classical LDA applied directly as both a dimensionality reduction tool and a classification model reached an accuracy of 97.4%, comparable to the best-performing SVM models. Notably, when a stepwise variable selection procedure was employed, the LDA model retained only 10 of the original 30 predictors while still maintaining a high accuracy of 96.8%. This underscores the efficiency of LDA in achieving strong predictive performance with a substantially reduced set of variables. Such parsimony not only enhances interpretability for clinicians but also improves computational efficiency, making the model more robust and practical for routine diagnostic use.
4. Conclusions
This study demonstrated that a rigorously specified classical LDA model, supported by appropriate preprocessing, validation, and assumption checks, can offer high interpretability and competitive predictive performance in biomedical classification tasks. The analysis highlights the powerful classification capabilities of LDA when applied appropriately and systematically.
The preprocessing steps, including Box–Cox transformations, standardization, and outlier removal, proved essential in improving model assumptions and enhancing performance, leading to an improvement in classification accuracy exceeding 2%. Specifically, the model achieved a high overall classification accuracy, correctly identifying 97.8% of the original grouped cases (99.4% of benign cases and 95.0% of malignant cases). These results demonstrate strong predictive performance across both groups.
The high hit ratio and balanced classification performance further support the validity and reliability of the discriminant function in distinguishing between benign and malignant diagnoses. Consequently, LDA constitutes a valuable tool for the targeted classification of new patients, underscoring its potential application in clinical decision-making.
Moreover, the dimensionality reduction achieved through stepwise discriminant analysis reduced the number of predictors from 30 to 10. This substantial reduction is particularly desirable in statistical classification methods, as it lowers the risk of overfitting, simplifies the model, and enhances interpretability. These findings support the conclusion that LDA can efficiently capture the underlying structure of complex biomedical data using a compact and informative set of predictors. Taken together with the comparative analysis against benchmark machine learning algorithms, the results demonstrate that, for the Wisconsin Diagnostic Breast Cancer dataset, a rigorously validated classical LDA model achieves predictive performance on par with state-of-the-art classifiers, offering a robust and reliable statistical alternative for routine diagnostic applications.
Author Contributions
Conceptualization, V.P. and T.D.; methodology, V.P.; software, V.P.; validation, V.P., V.M. and T.D.; formal analysis, V.P.; investigation, V.P., V.M. and T.D.; resources, V.P., V.M. and T.D.; data curation, V.P.; writing—original draft preparation, V.P.; writing—review and editing, V.P., V.M. and T.D.; visualization, V.P.; supervision, V.M. and T.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in this study are openly available in the UCI Machine Learning Repository at https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic) accessed on 1 December 2025, reference number WDBC (Wisconsin Breast Cancer Diagnostic Dataset).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Draper, N.R.; Smith, H. Applied Regression Analysis, 3rd ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis, 6th ed.; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Rencher, A.C.; Christensen, W.F. Methods of Multivariate Analysis, 3rd ed.; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 1993. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; Regents of the University of California: Oakland, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Ward, J.H. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a Complex of Statistical Variables into Principal Components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Devaraj, V.; Palanisamy, T.; Somasundaram, K. A Study on Geometrical Consistency of Surfaces Using Partition-Based PCA and Wavelet Transform in Classification. AppliedMath 2025, 5, 134. [Google Scholar] [CrossRef]
- Spearman, C. General Intelligence, Objectively Determined and Measured. Am. J. Psychol. 1904, 15, 201–293. [Google Scholar] [CrossRef]
- Gorsuch, R.L. Factor Analysis; Routledge: New York, NY, USA, 2015. [Google Scholar]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis, 8th ed.; Cengage Learning: Andover, UK, 2019. [Google Scholar]
- Dogantekin, E.; Dogantekin, A.; Avci, D.; Avci, L. An Intelligent Diagnosis System for Diabetes Based on Linear Discriminant Analysis and Adaptive Network Based Fuzzy Inference System. Digit. Signal Process. 2010, 20, 1248–1255. [Google Scholar] [CrossRef]
- Zhao, M.; Chan, R.H.; Tang, P.; Chow, T.W.; Wong, S.W. Trace Ratio Linear Discriminant Analysis for Medical Diagnosis: A Case Study of Dementia. IEEE Signal Process. Lett. 2013, 20, 431–434. [Google Scholar] [CrossRef]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Application of Breast Cancer Diagnosis Based on a Combination of Convolutional Neural Networks, Ridge Regression and Linear Discriminant Analysis Using Invasive Breast Cancer Images Processed with Autoencoders. Med. Hypotheses 2020, 135, 109503. [Google Scholar] [CrossRef]
- Hand, D.J.; Henley, W.E. Statistical Classification Methods in Consumer Credit Scoring: A Review. J. R. Stat. Soc. Ser. A 1997, 160, 523–541. [Google Scholar] [CrossRef]
- Baxter, M.J. Statistics in Archaeology; Wiley: Chichester, UK, 2003. [Google Scholar]
- Shennan, S. Quantifying Archaeology, 2nd ed.; Edinburgh University Press: Edinburgh, UK, 1997. [Google Scholar]
- Bidmos, M.A.; Mazengenya, P. Accuracies of Discriminant Function Equations for Sex Estimation Using Long Bones of Upper Extremities. Int. J. Leg. Med. 2021, 135, 1095–1102. [Google Scholar] [CrossRef] [PubMed]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear Discriminant Analysis: A Detailed Tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef]
- Qu, Y.; Pei, Y. Linear Discriminant Analysis: A Comprehensive Review of Theory and Applications. Processes 2024, 12, 1382. [Google Scholar]
- Mandikas, V.G.; Spanoudakis, N.I. An Effective Root-Finding Toolbox Using Computational Argumentation. In Proceedings of the 2025 6th International Conference in Electronic Engineering & Information Technology (EEITE), Chania, Greece, 4–6 June 2025; pp. 1–6. [Google Scholar] [CrossRef]
- Hasan, M.E.; Mostafa, F.; Hossain, M.S.; Loftin, J. Machine-Learning Classification Models to Predict Liver Cancer with Explainable AI to Discover Associated Genes. AppliedMath 2023, 3, 417–445. [Google Scholar] [CrossRef]
- Gardner-Lubbe, S. Linear Discriminant Analysis for Multiple Functional Data Analysis. J. Appl. Stat. 2021, 48, 1917–1933. [Google Scholar] [CrossRef]
- Casin, P. Categorical Multiblock Linear Discriminant Analysis. J. Appl. Stat. 2018, 45, 1396–1409. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Discriminant Analysis by Gaussian Mixtures. J. R. Stat. Soc. Ser. B 1996, 58, 155–176. [Google Scholar] [CrossRef]
- Baudat, G.; Anouar, F. Generalized Discriminant Analysis Using a Kernel Approach. Neural Comput. 2000, 12, 2385–2404. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Klecka, W.R. Discriminant Analysis; Sage: Beverly Hills, CA, USA, 1980. [Google Scholar]
- Huberty, C.J.; Olejnik, S. Applied MANOVA and Discriminant Analysis, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Anderson, T.W. An Introduction to Multivariate Statistical Analysis, 3rd ed.; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Mika, S.; Rätsch, G.; Weston, J.; Schölkopf, B.; Müller, K.R. Fisher Discriminant Analysis with Kernels. In Proceedings of the IEEE Workshop on Neural Networks for Signal Processing, Madison, WI, USA, 25–25 August 1999; pp. 41–48. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Wolberg, W.; Mangasarian, O.; Street, N.; Street, W. Breast Cancer Wisconsin (Diagnostic) Dataset; UCI Machine Learning Repository: Irvine, CA, USA, 1993. [Google Scholar] [CrossRef]
- Adimari, G.; Chiogna, M. Nearest-Neighbor Estimation for ROC Analysis under Verification Bias. Int. J. Biostat. 2015, 11, 109–124. [Google Scholar] [CrossRef] [PubMed]
- Daniel, W.W.; Cross, C.L. Biostatistics: A Foundation for Analysis in the Health Sciences, 11th ed.; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Tabachnick, B.G.; Fidell, L.S. Using Multivariate Statistics, 7th ed.; Pearson: Boston, MA, USA, 2019. [Google Scholar]
- IBM Corp. IBM SPSS Statistics, Version 27.0; IBM Corporation: Armonk, NY, USA, 2020.
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Adebiyi, M.O.; Arowolo, M.O.; Mshelia, M.D.; Olugbara, O.O. A Linear Discriminant Analysis and Classification Model for Breast Cancer Diagnosis. Appl. Sci. 2022, 12, 11455. [Google Scholar] [CrossRef]
- Naji, M.A.; Filali, S.E.; Aarika, K.; Benlahmar, E.H.; Abdelouhahid, R.A.; Debauche, O. Machine Learning Algorithms for Breast Cancer Prediction and Diagnosis. Procedia Comput. Sci. 2021, 191, 487–492. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.