Abstract
Automobile license plate image generation represents a pivotal technology for the development of intelligent transportation systems. However, existing methods are constrained by their inability to simultaneously preserve geometric structure and radiometric properties of both license plates and characters. To overcome this limitation, we propose a novel framework for generating geometrically and radiometrically consistent license plate images. The proposed radiometric enhancement framework integrates two specialized modules, which are precise geometric rectification and radiometric property learning. The precise geometric rectification module exploits the perspective transformation consistency between character regions and license plate boundaries. By employing a feature matching algorithm based on character endpoint correspondence, this module achieves precise plate rectification, thereby establishing a geometric foundation for maintaining character structural integrity in generated images. The radiometric property learning module implements a precise character inpainting strategy with fluctuation compensation inpainting to reconstruct background regions, followed by a character-wise style transfer approach to ensure both geometric and radiometric consistency with realistic automobile license plates. Furthermore, we introduce a physical validation and evaluation method to quantitatively assess image quality. Comprehensive evaluation on real-world datasets demonstrate that our method achieves superior performance, with a peak signal-to-noise ratio (PSNR) of 13.83 dB and a structural similarity index measure (SSIM) of 0.57, representing significant improvements over comparative methods in preserving both structural integrity and radiometric properties. This framework effectively enhances the visual fidelity and reliability of generated automobile license plate images, thereby providing high-quality data for intelligent transportation recognition systems while advancing license plate image generation technology.
1. Introduction
With the development of autonomous driving technology, automobile license plate generation technology has demonstrated significant value in scenarios such as training data augmentation and intelligent system evaluation. As a beneficial supplement to real-world automobile license plate images, it significantly alleviates critical challenges faced with license plate detection and recognition models during training, such as insufficient real-world data and limited sample diversity [,]. The quality of data significantly impacts the robustness and generalization of intelligent systems [,]. Therefore, the development of techniques for generating high-quality license plate images is critically important for advancing autonomous systems.
The development of the automobile license plate generation technologies has experienced significant evolution []. Conventional approaches predominantly employed image processing techniques, which involved pasting standardized characters onto predefined background templates in compliance with regulatory specifications. To enhance dataset diversity, OpenCV is used to randomly add noise, geometric transformations, and color changes to generate new automobile license plate image datasets. This method has been widely applied in generating automobile license plates from countries such as China, the United States, Brazil, and Italy [,,]. However, while these methods adequately preserve character-level geometric properties, they still exhibit limitations in accurately reproducing precise radiometric properties, e.g., the luminance and contrast of both the background and characters on a license plate image [].
To further enhance the realism of the generated automobile license plates, researchers have increasingly explored deep learning-based techniques. Predominant approaches employ Generative Adversarial Networks (GANs) and their variants such as pix2pix, CycleGAN and Diffusion methods [,,,,]. These techniques generate new images by extracting and learning feature representations from sample license plates, thereby increasing both the quantity and diversity of generated plates. Nevertheless, current methods still struggle to precisely reproduce critical radiometric properties, particularly in preserving the radiometric properties and maintaining character structural integrity, leading to perceptible artifacts in the generated images.
Current research on automobile license plate generation faces two major challenges: first, the low precision in generating characters and license plate geometric properties, particularly under oblique views or partial cover conditions, and second, the insufficient adaptability to varying lighting conditions, such as complex illumination in real-world scenarios, resulting in differentiated radiometric properties on automobile license plates.
To address these issues, we propose a novel automobile license plate generation framework for generating high-quality automobile license plate images that simultaneously achieve realistic geometric and radiometric properties. Our framework adopts a two-stage processing pipeline to achieve high-quality automobile license plate generation. In the first stage, we perform geometric rectification by adopting a hybrid approach combining the YOLOv5-based license plate detection and recognition method with the character endpoint feature matching method, optimizing vertex coordinates to ensure strict compliance with regulatory specifications for character glyph and spatial distribution. The second stage focuses on radiometric property learning, where we first apply a region-specific and channel-wise strategy to precisely extract character and shadow region masks of characters from the geometrically rectified plates and then employ a method based on Texture Effects Transfer GAN (TET-GAN) to learn radiometric properties at the character level, thereby preserving both structural integrity and visual realism []. This framework not only enables content control through customizable text input and visual style control via real-world image guidance but generates automobile license plate images that are visually indistinguishable from real-world images.
The main contributions can be summarized as follows:
- (1)
- This paper introduces a novel high-quality automobile license plate image generation framework by integrating rule-based constraints with deep learning. This framework ensures both geometric and radiometric properties of generated images, demonstrating robust performance under challenging conditions such as extreme viewing angles and partial covers.
- (2)
- To address the issue of inaccurate vertices of the license plate, we propose a module that combines the YOLO-v5 detector with the character endpoint feature matching strategy. This method leverages filtered character contours and their endpoints to rectify the license plate vertices in the expanded license plate region detected by YOLO-v5.
- (3)
- To enhance radiometric properties of the generated license plate, a two-stage radiometric property learning module is proposed. It employs a region-specific and channel-wise strategy for character mask extraction and background inpainting, followed by a pre-trained TET-GAN model to maintain consistency with original character styles.
- (4)
- A comprehensive evaluation methodology, combining novel physical validation and evaluation with standard image quality metrics, is adopted to evaluate the quality of generated images. Experimental results indicate the superiority of the proposed framework in both geometric accuracy and radiometric fidelity, demonstrating its value for intelligent transportation systems.
2. Related Work
2.1. Automobile License Plate Detection Methods
Automobile license plate detection methods aim to precisely localize the region of plates within complex backgrounds by leveraging various feature extraction techniques. Current approaches can be mainly categorized into two categories: rule-based heuristic methods and training-based methods [].
Rule-based heuristic methods typically employ image processing technologies such as edge detection and color texture analysis for localization. Among these, edge detection based on geometric specifications of automobile license plate is widely adopted. Silvano utilized OpenCV with adaptive thresholding and probabilistic Hough transform to detect straight lines and estimate tilt angles for accurate positioning []. Kim introduced a perspective distortion correction algorithm using the Random Sample Consensus, leveraging morphological filtering and intersection points of license plate edges as features to enhance recognition rates []. However, such methods are performance-degraded when the boundary lines of the automobile license plate are partially covered, thereby decreasing boundary detection and localization precision. Asif calculated a heuristic energy map of vertical edges within the region of interest and applied a specialized histogram method to identify edge-dense regions as license plates in a complex background, exploiting prior knowledge of rear light positions and the vehicle body []. This method is independent of license plate color, size, or content, enabling detection across multiple countries.
Training-based automobile license plate detection methods are primarily divided into two categories: machine learning and deep learning methods. Machine learning methods often employ classifiers cascading multiple support vector machines or an adaptive boosting algorithm based on Haar-like features [,,]. Deep learning-based detection methods, on the other hand, widely adopt architectures such as CNN, U-Net, and YOLO [,,,]. For instance, Wang proposed the VSNet network, in which the VertexNet subnetwork utilizes an Integration Block as the backbone network to extract the spatial features of automobile license plates. In the head networks, they introduced a vertex evaluation branch to predict the four vertices of an automobile license plate. The architecture significantly enhances automobile license plate detection performance and recognition accuracy []. Nevertheless, under challenging conditions such as oblique views and partial covers, the effectiveness of vertex evaluation still needs improvement.
While current automobile license plate detection methods achieve satisfactory performance, they still exhibit two major limitations. First, detection results are typically bounded by rectangular regions rather than precise four-vertex coordinates, leading to insufficient localization accuracy. Second, achieving high-precision detection of automobile license plate vertices remains challenging when employing heuristic rules or deep learning methods independently. Therefore, the development of novel algorithms that integrate heuristic rules with deep learning presents a promising direction for improving the accuracy of license plate vertex localization. Such a hybrid method is expected to leverage the prior knowledge embedded in heuristic rules along with the robust feature representation capabilities of deep learning, thereby significantly improving localization accuracy.
2.2. Automobile License Plate Image Generation Methods
In early research, license plate image generation primarily relied on traditional image processing techniques. These methods often employ OpenCV to combine fixed font templates with background images, thereby generating new license plates. To enhance the diversity of the generated samples, augmentations such as 3D rotation, translation, noise injection, and displacement were commonly applied.
Bala proposed an artificial set of license plate images for accelerated training and optimization of ALPR algorithms, generating synthetic license plate images tailored to jurisdictional designs and simulating realistic image capture distortions []. Tomas Björklund modeled the key variables responsible for significant intra-class variation in real-world license plate images. The high variance inherent in real image datasets allowed the trained classifier to generalize across natural variations, thereby generating a sufficiently challenging image dataset []. Silvano proposed a new automobile license plate generation method compliant with the Brazilian Mercosur standard form, which incorporated multi-directional shadow before reintegrating the generated license plates into real-world scenes to produce realistic images. A convolutional neural network trained using this dataset was effectively validated on real-world data collected from parking lots and traffic cameras [].
Bulan proposed an end-to-end license plate simulation framework, consisting of graphically rendering characters onto blank license plate images and mimicking imaging distortions. It considers the geometric properties of standard automobile license plates (e.g., font, spacing) and radiometric properties (e.g., contrast, brightness, noise) []. However, a fundamental limitation of these methods lies in their inability to authentically learn the radiometric characteristics of real-world license plates. Consequently, the generated images often exhibit perceptible discrepancies from real-world images, leading to suboptimal performance of license plate recognition systems in practical applications [].
Deep learning-based generative methods have demonstrated a superior capacity for learning the style of real-world images, leading to their widespread adoption in automobile license plate generation. Wang proposed a GAN framework capable of generating diverse license plate images []. This diversity enhances the feature learning capability of license plate recognition models, considerably improving both accuracy and robustness []. Zhang proposed a CycleGAN-based approach that generates license plates with more balanced character distributions and varied conditions, which substantially boosts recognition performance []. Han proposed GAN-based image-to-image translation (LP-GAN), a method leveraging three advanced image-to-image translation models, including pix2pix, CycleGAN, and StarGAN, to generate Korean license plates. The generated images exhibit high visual realism and have proven effective for training character recognition modules [].
Since methods based on CycleGAN learns a general style representation from the training data, the generated images often lack stylistic specificity. To address this limitation, Anton Maltsev employed neural style transfer to generate Russian license plate images, achieving specific image styles []. More recently, Li proposed the Disentangled Generation Network (DGNet), an end-to-end framework that decouples the generation process into text-image generation and background generation. This disentanglement facilitates style transfer for enlarged license plates, ensuring improved diversity and structural completeness, which in turn significantly enhances recognition accuracy []. However, the generated enlarged license plates still exhibit noticeable regional inconsistencies when compared to real-world automobile license plates.
However, most existing generating license plate methods struggle to effectively balance the precision of geometric and radiometric properties. In contrast, our work introduces a robust generation framework specifically designed to enhance photometric realism, which remains effective even under challenging conditions such as extreme angles or partial covers. The advantages of the proposed framework are threefold: Methodologically, the framework decouples geometric rectified and radiometric learning under explicit rule-based constraints, creating a more stable and interpretable optimization compared to existing methods. Geometrically, the geometric rectification module based on character endpoint feature matching enables more precise license plate localization than conventional bounding box detectors, providing superior geometric priors for subsequent processing. Radiometrically, the generation module disentangles background inpainting and character stylization, coupled with character-level and shadow-aware features, significantly enhancing the visual fidelity of the generated license plates.
3. Method
3.1. Problem Description
The license plate image generation task aims to generate a realistic image based on an original real-world image and a new target automobile license plate number, where W and H denote the image width and height, respectively. The input comprises a real-world scene and a local license plate region . The can be processed into a rectified license plate image through a perspective transformation, which is crucial for preserving the geometric and radiometric properties of the generated images more effectively. Thus, the input can be mathematically expressed as:
where denotes the perspective transformation matrix mapping the standard automobile license plate to its real-world counterpart, and are the background image and character image of the transformed license plate, respectively. Similarly, the generated real-world image can be formulated as:
where denotes the generated automobile license plate image after perspective transformation, represents the perspective transformation matrix between the standard and the generated automobile license plate. The term corresponds to the generated local automobile license plate image, with and denoting the width and height, respectively. Additionally, and represent the inpainted background and generated character image of the transformed license plate image, respectively.
Given that remains unchanged, the generated output image simplifies to a generated precise local license plate image . To enhance the fidelity of the generated license plates, the process of constructing is decomposed into three dedicated subtasks: geometric rectification of the license plate, background inpainting, and character style transfer. Accordingly, the formulation can be re-expressed mathematically as follows:
where denotes the optimization transformation for vertex coordinates of license plate, represents the transformation for background image inpainting, and corresponds to the style transfer transformation. The generation of precise license plate images is achieved by minimizing errors in both geometric rectification and radiometric property learning. The optimal expression for generating local license plate images is as follows:
However, existing methods still fall short in simultaneously satisfying the geometric and radiometric properties of generated images. To further enhance the precision of the generated images, the following three constraint rules are introduced to regulate the generation process:
Rule 1: Both real-world and standard automobile license plates, along with their constituent characters, follow the identical perspective transformation. The core idea of this rule is to achieve precise rectification of the license plate region by leveraging the vertex pairs of character regions. Given the vertices coordinates of each character’s bounding box in the standard license plate, the corresponding four vertices of individual real-world characters can be derived via the perspective transformation matrix , as illustrated in Figure 1.
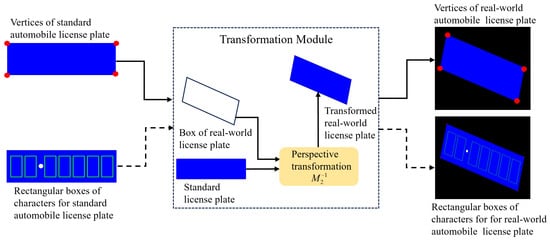
Figure 1.
Identical perspective transformation rules between standard automobile license plates and real-world automobile license plates.
Rule 2: Geometric knowledge of the standard form of automobile license plate. Chinese automobile license plates must comply with the specifications of the GA36-2018 standard, which regulates license dimensions, character font, spacing, and proportions []. A standard blue license plate size is mm, with each character measuring mm. These constraints play a critical role in both precise geometric rectification and radiometric property learning modules.
Rule 3: Character glyph and shadow constraints. The inpainting of automobile license plate background images is guided by the detected character region mask, as well as the radiometric properties of non-character regions. The learning of character glyphs is further constrained by geometric properties and valley features of shadows arising from interactions between backgrounds and characters. The enforcement of this rule enables precise background inpainting and ensures radiometric property consistency between the generated characters and their real-world counterparts.
Subject to these three rules, we further express the problem as a mathematical formula:
where , , and denote Rule 1, Rule 2, and Rule 3, respectively. The expression indicates the transformation subject to the joint constraints of and , while refers to the transformation under the combined constraints of and .
3.2. Radiometric Enhancement Generation Framework
We propose a radiometric enhancement generation framework, which utilizes a real-world license plate image and target character text to generate realistic images that preserve accurate geometric structure and radiometric properties of the characters.
The proposed framework consists of two stages: precise geometric rectification of automobile license plates and automobile license plate radiometric property learning, as illustrated in Figure 2. In the first stage, the automobile license plate is detected, and its vertices are coarsely estimated by YOLOv5. These estimates are then refined using a character endpoints matching method to achieve plate geometric rectification, providing a stable foundation for radiometric property learning. The second stage decouples radiometric learning into two complementary components: background inpainting and style transfer learning. This dual-path approach ensures high precision of both geometric and radiometric properties in the generated license plate images.
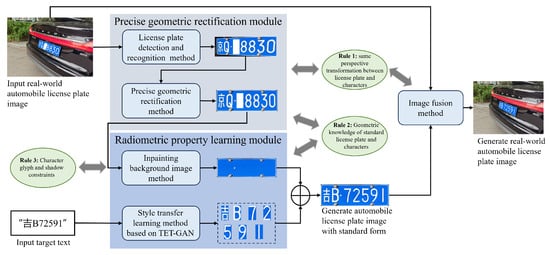
Figure 2.
The precise radiometric enhancement generation for automobile license plate images.
A detailed description of each component within the proposed framework is provided in the subsequent sections.
3.2.1. Precise Geometric Rectification Module
The precise geometric rectification module aims to obtain the precise vertex coordinates by using the geometric rectification process. Leveraging prior knowledge of standard license plate specifications and utilizing the shared perspective transformation properties between the plate and character regions of standard and real-world automobile license plates. We introduce a vertex computation rule that integrates character contour filtering and feature extraction. The geometric rectification process is implemented through three sequential steps: license plate detection and number recognition, character localization, and plate vertex calculation.
First, the YOLOv5 model, an enhanced version of the original YOLO architecture introduced by Redmon, is utilized to detect the license plate region within the input image, providing coarse vertex predictions and facilitating license plate number recognition [,]. Next, the initially detected region is adaptively expanded, and character contours are localized through contour filtering rules to determine precise character positions in the real-world license plate. Finally, a character endpoint matching algorithm, derived from standard character glyph properties, is applied to compute optimal vertex coordinates, enabling high-precision localization of character-level vertices in the generated plate image.
Automobile License Plate Detection and Recognition
The initial phase of radiometric enhancement framework consists of localizing the license plate region in a real-world image and recognizing its number. This process is implemented through a two-stage detection and recognition architecture.
In the first stage, the YOLOv5 object detection algorithm is employed to localize the license plate region and estimate four approximate vertex coordinates. Through a series of convolutional and pooling operations, YOLOv5 gradually extracts multi-scale features, ranging from low-level edges and textures to high-level semantic representations, and predicts bounding boxes along with confidence scores at the grid level, ultimately providing coarse plate localization and initial vertex estimates. In the second stage, a convolutional recurrent neural network is utilized for license plate number recognition. The architecture integrates a CNN component, which extracts discriminative features capturing character shape, case, and style, and an RNN component, which processes the sequential feature representations to predict character sequences. This stage provides critical information for subsequent character endpoint feature extraction within the geometric refinement pipeline.
Precise Geometric Rectification Method Based on Character Endpoint Feature Matching
To address the geometric distortion in generated license plates resulting from vertex localization deviations during rectification, this study introduces a novel precise geometric rectification method based on character endpoint feature matching. The method is implemented in two stages: character contour filtering and localization, followed by endpoint feature matching. Through a collaborative optimization strategy integrating both components, the method achieves high-precision geometric rectification of license plate images.
In the first stage, based on an analysis of the spatial distribution properties of automobile license plate, an adaptive contour filtering and localization algorithm was adopted to localize the 2nd to 7th character contours, as illustrated in Figure 3. Character contour localization aims to provide geometric position information for subsequent endpoint feature extraction.
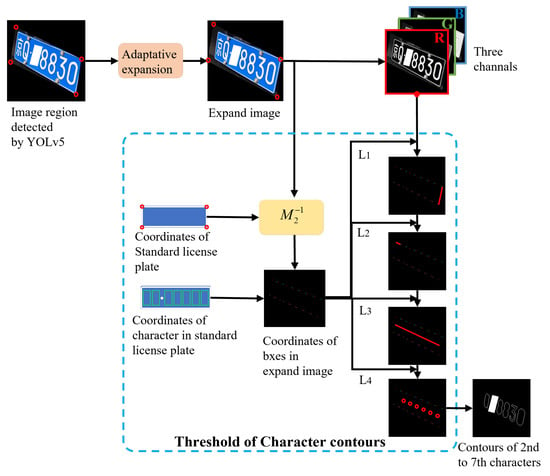
Figure 3.
The workflow of character contour filtering process.
The procedure initiates with an adaptive expansion of the coarsely detected vertices obtained from YOLOv5 to preserve character completeness. To avoid incomplete characters caused by imprecise initial coarse vertices, the vertex nearest to the license plate center is selected as a reference for determining the expansion ratio. This ratio is then proportionally applied to the remaining vertices. The mathematical formulation is defined as follows:
where denotes the scaling factor for outward expansion from the four vertices, is the i-th vertex, is the intersection point between the extension line of segment and the license plate boundary, refers to the centroid of the four vertices, indicates the length of the segment connecting and , and denotes the distance from to the centroid .
Subsequently, by leveraging the shared perspective transformation properties between the character region and the license plate region, a contour filtering threshold is computed to robustly identify and localize character contours. A four-level contour filtering criterion is designed to filter character contours based on the distinctive features of the R channel image, effectively eliminating non-character contours. Notably, due to the structural complexity of first Chinese characters and their susceptibility to interference from rivets and borders, the algorithm utilizes the contours of the 2nd to the 7th characters as references to ensure robust positioning.
The bounding boxes of seven standard characters are projected onto real-world images to estimate the vertex coordinates of each character’s bounding box. The distance between adjacent points within each bounding box serves as a key parameter for contour filtering. The corresponding formula is defined as follows:
where and are the coordinates of two adjacent vertices in the k-th character rectangle box.
Contours are evaluated as valid character candidates using a four-level filtering criterion with threshold set . Specifically, contours are first discarded if they contain any adjacent point distance exceeding the maximum length or falling below the minimum length , followed by the removal of those failing to intersect the reference line . The remaining contours are then sorted by horizontal position, and the six with the largest horizontal coordinates (under criterion ) are retained as the precise contours for characters 2 through 7. The threshold T is described as follows:
where represent the horizontal and vertical coordinates of the center point of the bounding box for the k-th character, lsq represents the straight line fitted to the seven center points via the least squares method, and indicates sorting the contours in descending order according to .
Building upon the contour filtering method that effectively addresses the challenge of character localization, this paper further introduces character endpoint feature analysis to improve localization accuracy and robustness. An optimized method for character region calculation based on endpoint feature matching is proposed. The recognized license plate characters are combined with prior knowledge of endpoint features in standard fonts to compute the endpoint coordinates of characters in the real-world license plate. Furthermore, by integrating standard license plate dimensions and the transformation matrix mapping the standard character region to the real-world character region, the four precise vertices of the real-world license plate are accurately derived.
Based on the corner counts at the top and bottom endpoints of characters in standard automobile license plates, we systematically classify these features and construct a standard feature template library, as illustrated in Figure 4. The library comprises 7 distinct categories of top features and 6 types of bottom features. Within these templates, these yellow arrows indicate discardable feature points, whereas the red arrows denote selected feature points. Leveraging these pre-defined features, we compute the endpoints of characters in real-world license plate images. The top vertices and are precisely matched to the top endpoint corresponding to the 2nd and 7th characters within the license plate sequence. Concurrently, the bottom vertices and are matched to their corresponding bottom endpoint features.

Figure 4.
Standard character feature template library. The left and right columns represent the top and bottom endpoint features of the characters, respectively. Each row represents the endpoint features of the character on one side. These yellow arrows indicate discardable feature points, while the red arrows represent selected feature points.
The vertex localization for characters on real-world license plates is determined by the geometric properties of their endpoints, which are categorized into three distinct cases for computational processing:
- (1)
- Dual-Arc Endpoints: When both top endpoints exhibit arc-like geometric properties, a spatial convex optimization approach is employed. The minimal-area tangent method is applied, wherein the line connecting the highest points of the two characters serves as the initial tangent. The slope and intercept parameters of this tangent are iteratively optimized to minimize the enclosed area between the tangent and the character contours. The optimization objective function F is formulated as:The intersection points of the optimized tangent with the character contours are output as the refined vertex coordinates.
- (2)
- Dual-Corner Endpoints: When both top endpoints are identified as corners, the Shi-Tomasi algorithm is directly employed for corner detection. To enhance location precision, a sub-pixel level method is applied, optimizing the precise corner coordinates to achieve higher spatial precision [].
- (3)
- Hybrid Endpoints (Arc-Corner Combination): For cases involving one arc endpoint and one corner, a hybrid approach is used. The arc endpoint is processed using the minimal-area tangent optimization, while the corner endpoint is computed via the Shi-Tomasi method with sub-pixel refinement. The resulting coordinates are integrated to form the final vertex pair, ensuring consistency and accuracy across disparate geometric types.
Following the analogous computational paradigm, the two bottom vertices of the character region within the real-world license plate can be obtained. Upon recognition of the plate number via license plate recognition methods, the corresponding four endpoint coordinates of the standard characters in the reference template are retrieved. A mapping relationship, denoted as , is rigorously established between the standard character endpoints from the standard template and their corresponding coordinates in the real-world license plate image. Utilizing the vertex coordinates of the standard license plate and the transformation matrix , the four precise vertex coordinates of the real-world license plate are calculated. This procedure yields a precisely rectified, upright license plate image, effectively eliminating perspective distortions and significantly enhancing the precision of subsequent automated license plate recognition systems.
3.2.2. Radiometric Property Learning Module
Building upon the geometric rectification module, which effectively addresses the challenge of precise license plate vertices localization, this paper proposes a radiometric property learning module to enhance the realism of the generated license plate images. The process initiates with the license plate background image inpainting and radiometrically consistent character generation. To minimize the influence of character geometric structure on radiometric property learning and reduce the impact of non-license plate area information on background inpainting, this module uses the rectified image output from the geometric calibration module as its critical prerequisite. Building upon this foundation, it first performs background inpainting on the image, then focuses on learning the radiation characteristics of the rectified characters. This workflow ensures that the radiometric property learning and the preservation of character glyph structures are optimized. Consequently, it enhances image quality while ensuring the integrity of character geometric features.
This is accomplished through a two-stage approach for radiometric property learning. In the first stage, characters and their associated shadows are removed using a partition-based and multi-channel strategy, followed by inpainting the background based on the radiometric properties of the remaining non-character regions. In the second stage, the radiometric properties of the characters are learned based on the TET-GAN method, and the newly generated characters are composited into the inpainted background to produce a radiometrically consistent license plate image.
Automobile License Plate Background Image Inpainting
The objective of automobile license plate background inpainting is to obtain a complete character-free background image. This process consists of two steps: precise character removal and background inpainting. Precise character masking is essential to ensure the complete elimination of character regions. Due to the embossed properties of license plate characters, complex shadow effects are produced under natural illumination. Nevertheless, adopting direct application of morphological dilation operations presents two major challenges: ineffective extraction of both the character glyphs and shadow regions, and excessive loss of background pixels.
To address the challenge of precise character region extraction, we propose a region-specific and channel-aware removal strategy designed to completely eliminate both character glyphs and their associated shadows. This approach employs a dual mechanism combining region-specific and channel-aware analysis processing.
For region-specific operations, we differentiate between the first Chinese character, which undergoes complete region removal, and characters 2 to 7, which are processed via precise extraction. The image is decomposed into two distinct regions: the Chinese character region and the non-Chinese character region .
Channel-aware processing overcomes optical limitations through multi-channel analysis. While the blue channel proves ineffective due to similarity between the background and shadow intensities, the red channel exhibits distinctive intensity valleys that facilitate shadow localization. Leveraging this property, we develop a novel pixel-difference dynamic threshold (PDDT) algorithm for precise shadow extraction, generating a final segmentation mask . The complete PDDT algorithm is formally detailed in Algorithm 1.
| Algorithm 1 Pixel-Difference Dynamic Threshold (PDDT) algorithm |
| Require: The rectified image , the pixel values of the three-channel images are . The perturbation cutoff ratio for the entire image and each row are and , respectively. Ensure: the image with characters removed .
|
For background inpainting, we introduce a baseline fitting and fluctuation compensation inpainting algorithm, leveraging radiometric properties from non-character regions. This approach preserves the continuity of background texture while closely approximating the radiometric properties of the original license plate background, ensuring seamless visual and radiometric integration between the inpainted areas and the unmodified background. The detailed procedure for license plate background inpainting is outlined in Algorithm 2.
| Algorithm 2 Baseline fitting and fluctuation compensation inpainting algorithm |
| Require: Character mask , background of removed character . Ensure: Inpainted background image .
|
Style Transfer Learning Method Based on TET-GAN
This paper conceptualizes the radiometric properties of license plate characters as stylized features that represent plate realism. By establishing a style mapping between real-world and generated license plates, we formulate radiometric property learning as a structured style transfer task. To address this, we introduce a style transfer learning method based on TET-GAN, which explicitly leverages the spatial distribution of texture within character properties []. The TET-GAN network learns individual character stylistic representations from real license plates and generates new plate images that maintain both stylistic consistency and geometric integrity.
To enhance the efficiency of radiometric property learning, we utilize a pre-trained TET-GAN network. However, since this model was originally trained on an artistic character dataset, its font and style properties are different from those of license plate characters, making it suboptimal for direct application. To address this discrepancy, we design a three-stage style learning pipeline, as depicted in Figure 5. First, character image pairs are constructed by converting standard character images into target feature images x based on distance transforms, while real-world character images are processed into stylized feature images y, with both resized to a unified resolution of . Second, the model is fine-tuned using TET-GAN’s self-stylization strategy. Image pairs sharing identical character shapes with y are input into the pre-trained model for a single learning cycle. The de-stylization subnetwork learns the structural content of text from geometrically rectified inputs, while a set of stylized effect images but varying pixel domains is generated via random cropping for model training. Finally, x and y are fed into the fine-tuned TET-GAN, where textual features are extracted from x and style features from y. These features are concatenated and fused to the generator to generate stylized character images .
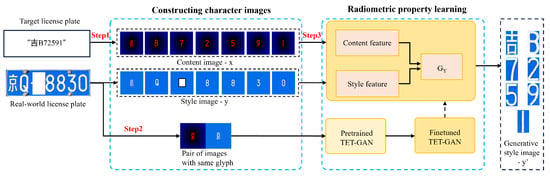
Figure 5.
The workflow of radiometric property learning.
To achieve seamless fusion of the generated license plate with the real-world background, character and plate replacement is performed using Poisson fusion [,], as shown in Figure 6. The composite license plate integrates perfectly with the real-world background in terms of geometric structure and environmental lighting, resulting in a highly realistic generated license plate image that preserves both the geometric and radiometric properties of the original images. The method ensures high precision and visual perception.
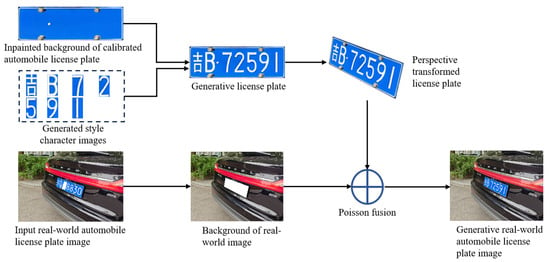
Figure 6.
The workflow of real-world automobile license plate generation by fusion method.
4. Experiments and Results
4.1. Dataset
For the automobile license plate detection and recognition module, the Chinese City Parking Dataset (CCPD) dataset and a small number of collected real-world automobile license plate images are utilized as the training data []. The CCPD dataset, primarily collected from the car parks in Anhui Province, comprises over 340,000 images under diverse illumination environments. As illustrated in Figure 7, the dataset includes samples with different lighting, views, and complex backgrounds, providing a comprehensive benchmark for training robust detection and recognition models.

Figure 7.
Example of CCPD samples.
To evaluate and validate the entire framework, we collected some images under diverse views and lighting conditions. Figure 8a illustrates the standard automobile license plate in the People’s Republic of China. One blue license plate consists of seven characters: the first is a Chinese character abbreviating one of the 31 provinces, autonomous regions, or municipalities; the second is an English letter indicating the Registration number; and the third to seventh characters are, with at most two letters allowed in this segment []. A representative sample image from our collected images is shown in Figure 8b. To ensure privacy protection, the license plate number has been partially covered.
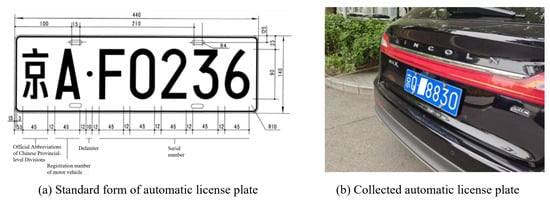
Figure 8.
Standard automobile license plate in China and a sample of collected automobile license plates.
4.2. Evaluation Metrics
To quantitatively evaluate the proposed automobile license plate geometric rectification method, we adopt the relative Root Mean Square Error (RMSE) as the primary metric to assess the accuracy of geometric property matching. This metric specifically quantifies the overall deviation between the four predicted vertices and their corresponding manually annotated ground-truth coordinates. The RMSE is calculated as follows:
where denote the coordinates of the vertices predicted by the radiometric enhancement framework, represent the corresponding manually annotated reference coordinates. A lower RMSE value indicates higher precision of the predicted vertices.
To validate the effectiveness of the generated images in terms of radiometric properties, we employ the following three evaluation metrics:
- (1)
- Peak Signal-to-Noise Ratio (PSNR): This metric quantifies the quality of a generated image by measuring the ratio between the maximum possible signal power and the power of corrupting noise. A higher PSNR value indicates a smaller difference between the generated image and the real-world image, reflecting better image quality.where is the maximum value of image pixel and is the mean square error.
- (2)
- Structural Similarity Index Measurement (SSIM): The SSIM metric assesses the perceptual similarity between the generated and real-world images through three aspects: luminance, contrast, and structural similarity, which are estimated from the mean intensity, standard deviation, and covariance, respectively []. The SSIM value ranges from 0 to 1. Higher SSIM values correspond to better perceptual quality of the generated image [].where and represent the mean intensities of image x and y respectively, and denote their variances, and is the covariance between the two images. The terms and are constants included to stabilize the division when the denominators are close to zero.
- (3)
- Physical Validation and Evaluation Method: Two customized automobile license plate images are captured as the first spatio-temporal image and the second spatio-temporal image . Here, consists of the background and the target region , while consists of the background and target region . To evaluate the radiometric enhancement method, two matching rules are employed to calculate sub-scores, respectively, which are then weighted and fused into a composite score. This comprehensive scoring mechanism provides an objective assessment of the method’s performance. By leveraging collected data and multi-rule integration, this method effectively addresses the limitation of lacking ground truth in conventional evaluation metrics.
Matching Rule I: Based on the proposed method, is used to generate , which is then combined with the background to compose the third spatio-temporal image . Simultaneously, the target region is combined with to compose the fourth spatio-temporal image . The structural similarity between and is computed to obtain the sub-score .
Matching Rule II: Symmetrically, is used to generate , which is combined with the background to compose ; the target region is also combined with to compose . The sub-score is derived by calculating the structural similarity between and .
The comprehensive score is then defined as:
4.3. Comparative Results for Generated Automobile License Plate Images
To validate the effectiveness of the radiometric enhancement framework, comparative experiments were conducted focusing on both geometric and radiometric properties. Conventional metrics as well as physical validation methods were employed to assess the performance of the radiometric enhancement framework.
4.3.1. Comparative Results of Geometric Rectification
The geometric rectification performance is compared against three license plate vertex acquisition methods, namely manual annotation (serving as ground truth), Unet [], and YOLOv5. All methods are evaluated on the same test set to ensure a fair comparison of vertex localization accuracy.
The comparative results of geometrically rectified automobile license plates are shown in Figure 9. The first row displays four real-world automobile license plate images, while the second to the fifth rows present the perspective transformed results using the four comparative methods. It shows that license plate regions detected by Unet and YOLOv5 exhibit incomplete plates with distorted borders and characters. In contrast, the license plate regions rectified using the radiometric enhancement algorithm exhibit well-defined characters and borders, presenting license plates free from complex background information. The results demonstrate that the automobile license plates obtained by the radiometric enhancement framework are closer to the results of the manual annotation.

Figure 9.
Automobile license plate visualization results of four vertex detection methods.
Quantitative results of vertex rectification accuracy are summarized in Table 1. The comparison confirms that the precise geometric rectification module significantly enhances the positioning precision of vertices for automobile license plate.

Table 1.
RMSE values of comparative automobile license plate vertex detection methods.
4.3.2. Comparative Results of Radiometric Property Learning
To assess the radiometric quality of the images generated by the proposed method, we compare it with five existing methods. The generated automobile license plate images obtained by comparative methods are shown in Figure 10, where subfigures (a) to (h) correspond to the rectified real-world image, along with results generated by OpenCV [], CycleGAN [], Neural style transfer [], StarGAN [], NICEGAN [], DRIT [], and radiometric enhancement method, respectively. Since no public implementation is available for the DGNet method [], the comparative methods NICEGAN [] and DRIT [] are adopted for comparison.

Figure 10.
Results of generated automobile license plate images obtained from comparative methods. (a) rectified automobile license plate of original images, new automobile license plates generated by (b) OpenCV [], (c) CycleGAN [], (d) Neural style transfer [], (e) StarGAN [], (f) NICEGAN [], (g) DRIT [], (h) Radiometric enhancement framework.
Figure 10b shows that when generated by the OpenCV-based method, it maintains the geometric structure of the text but exhibits significant differences in radiometric properties compared to real-world license plates. Figure 10c–h, produced by deep learning-based methods, reveal distinct limitations: CycleGAN fails to generate diverse radiometric styles and exhibits character distortion; Neural Style Transfer achieves relatively better performance in both glyph structure and radiometric properties but still suffers from local structural inaccuracies and imperfect background restoration; StarGAN and NICEGAN produce blurred characters with limited style variation; while DRIT severely compromises text structural integrity, significantly impairing recognition performance. In contrast, the radiometric enhancement method demonstrates superior performance in preserving both geometric and radiometric properties, as clearly evidenced by the comparative results.
The quantitative results of image quality, based on PSNR and SSIM metrics, is summarized in Table 2. In terms of radiometric properties, the deep learning-based methods consistently achieve higher PSNR values compared to the OpenCV-based method, indicating their superior capability in preserving pixel-level intensity precision. Conversely, the OpenCV method obtains higher SSIM scores than several other comparative methods, suggesting better performance in maintaining structural, geometric, and textural consistency between the generated and original images. The radiometric enhancement method outperforms all other methods across both metrics, demonstrating its effectiveness in generating license plate images with high realism in both geometric structure and radiometric properties.
Table 2.
PSNR and SSIM values of comparative methods.
To validate the effectiveness of generated real-world automobile license plates, the generated plate images were accurately pasted into their corresponding locations within the original background images, as shown in Figure 11. Visual inspection confirms that the generative automobile license plates maintain radiometric property consistency with original plate images.

Figure 11.
Original real-world and generative automobile license plate images. The first and second rows show original images and generated images, respectively.
4.4. Results of Physical Validation and Evaluation Method
The customized different number plates with the same size and font as the standard images were placed under consistent illumination conditions from a fixed viewpoint, producing two spatio-temporal images and . The physical validation and evaluation results are presented in Figure 12. Figure 12a shows the original plate images vs. , while Figure 12b–f illustrates the background image of removing the licence plate, the isolated license plate region, the generated plate with new characters, and a comparative view of the third and the fourth spatio-temporal images. With the fourth spatio-temporal image serving as ground truth, comparative analysis between vs. and vs. demonstrates high consistency in both radiometric properties and geometric properties between the third and fourth spatio-temporal images.

Figure 12.
Results of physical validation and evaluation method. (a) and represents the first and second spatio-temporal images, respectively; (b) and (c) show the background images and license plate region images extracted from and ; (d) the generated license plate region image transformed into the real-world scene; (e) the third spatio-temporal image; (f) the fourth spatio-temporal image.
To quantitatively assess the radiometric enhancement method, a multi-scale evaluation strategy was employed. This method computes the SSIM between the third and fourth spatio-temporal at both global and local levels. The global evaluation examines overall perceptual consistency, while the local assessment focuses on properties in the license plate region.
As summarized in Table 3, the SSIM values for the global image pairs vs. and vs. both reach 0.98, indicating excellent overall similarity. At the local level, the corresponding SSIM values are 0.77 and 0.76, respectively. These results consistently surpass those of all comparative methods, confirming that the radiometric enhancement method effectively preserves luminance, contrast, and geometric structure, thereby producing license plate images of high visual realism.
Table 3.
SSIM values of licence plate images obtained using physical inspection methods.
5. Conclusions
In this study, we propose an automobile license plate image generation framework with enhanced geometric and radiometric details, based on the integrated rule-based and deep learning method. By utilizing prior knowledge of automobile license plate structures within a dual-module framework, high-precision automobile license plate images can be generated. Under rule-based constraints, the collaborative optimization of the geometric rectification module and the radiometric property learning module ensures both the geometric accuracy of generated automobile license plates and their visual realism with real-world images. To improve the geometric rectification precision, we introduce a character endpoint feature matching strategy to enhance license plate vertex accuracy. For radiometric properties, we decompose the process into background inpainting and character style transfer learning, thereby optimizing radiometric representation. Furthermore, we propose a novel physical evaluation method to validate the reliability of the generated data and the superiority of our framework. Experimental results show that the radiometric enhancement framework outperforms existing baselines in terms of both geometric and radiometric quality, with a peak signal-to-noise ratio (PSNR) of 13.83 dB and a structural similarity index measure (SSIM) of 0.57, generating highly realistic automobile license plate images.
In future work, we plan to introduce adaptive rules to enhance the diversity and generalizability of the generated automobile license plates. For instance, subsequent research could explore dynamically integrating the three constraints into adaptive algorithms to improve adaptability and universality across different automobile license plate types and lighting conditions. Further research may investigate the intrinsic relationships between individual characters and the automobile license plate, beyond the strict perspective transformation, to handle challenging scenarios involving curved plates or damaged characters. In addition, by incorporating end-to-end networks with more effective parameter tuning strategies, such networks can achieve superior accuracy and significantly enhanced model efficiency.
Author Contributions
Conceptualization, Y.D. and H.G.; methodology, Y.D. and H.G.; software, Y.D. and Z.P.; validation, Y.D. and Z.P.; formal analysis, W.L.; investigation, Z.P.; resources, H.G.; data curation, Y.D. and Z.P.; writing—original draft preparation, Y.D.; writing—review and editing, Y.D.; visualization, W.L.; supervision, Y.D., W.L. and H.G.; project administration, W.L. and H.G.; funding acquisition, W.L. and H.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program (Grant No. 2021YFF0600201).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wu, C.; Xu, S.; Song, G.; Zhang, S. How many labeled license plates are needed? In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; pp. 334–346. [Google Scholar]
- Liu, Q.; Chen, S.L.; Chen, Y.X.; Yin, X.C. Improving license plate recognition via diverse stylistic plate generation. Pattern Recognit. Lett. 2024, 183, 117–124. [Google Scholar] [CrossRef]
- Whang, S.E.; Roh, Y.; Song, H.; Lee, J.G. Data collection and quality challenges in deep learning: A data-centric ai perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
- Zha, D.; Bhat, Z.P.; Lai, K.H.; Yang, F.; Jiang, Z.; Zhong, S.; Hu, X. Data-centric artificial intelligence: A survey. ACM Comput. Surv. 2025, 57, 1–42. [Google Scholar] [CrossRef]
- Habeeb, D.; Alhassani, A.; Abdullah, L.N.; Der, C.S.; Alasadi, L.K.Q. Advancements and Challenges: A Comprehensive Review of GAN-based Models for the Mitigation of Small Dataset and Texture Sticking Issues in Fake License Plate Recognition. Eng. Technol. Appl. Sci. Res. 2024, 14, 18401–18408. [Google Scholar] [CrossRef]
- Izidio, D.M.; Ferreira, A.P.; Medeiros, H.R.; Barros, E.N.d.S. An embedded automatic license plate recognition system using deep learning. Des. Autom. Embed. Syst. 2020, 24, 23–43. [Google Scholar] [CrossRef]
- Björklund, T.; Fiandrotti, A.; Annarumma, M.; Francini, G.; Magli, E. Robust license plate recognition using neural networks trained on synthetic images. Pattern Recognit. 2019, 93, 134–146. [Google Scholar] [CrossRef]
- Silva, S.M.; Jung, C.R. License plate detection and recognition in unconstrained scenarios. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 580–596. [Google Scholar]
- Wang, X.; Man, Z.; You, M.; Shen, C. Adversarial generation of training examples: Applications to moving vehicle license plate recognition. arXiv 2017, arXiv:1707.03124. [Google Scholar] [CrossRef]
- Wu, S.; Zhai, W.; Cao, Y. PixTextGAN: Structure aware text image synthesis for license plate recognition. IET Image Process. 2019, 13, 2744–2752. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, P.; Li, H.; Li, Z.; Shen, C.; Zhang, Y. A robust attentional framework for license plate recognition in the wild. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6967–6976. [Google Scholar] [CrossRef]
- Shvai, N.; Hasnat, A.; Nakib, A. Multiple auxiliary classifiers GAN for controllable image generation: Application to license plate recognition. IET Intell. Transp. Syst. 2023, 17, 243–254. [Google Scholar] [CrossRef]
- Shpir, M.; Shvai, N.; Nakib, A. License Plate Images Generation with Diffusion Models. In Proceedings of the European Conference on Artificial Intelligence ECAI, Santiago de Compostela, Spain, 19–24 October 2024. [Google Scholar]
- Yang, S.; Liu, J.; Wang, W.; Guo, Z. TET-GAN: Text effects transfer via stylization and destylization. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1238–1245. [Google Scholar]
- Peng, Y.; Xu, M.; Jin, J.S.; Luo, S.; Zhao, G. Cascade-based license plate localization with line segment features and haar-like features. In Proceedings of the 2011 Sixth International Conference on Image and Graphics, Hefei, China, 12–15 August 2011; pp. 1023–1028. [Google Scholar]
- Silvano, G.; Ribeiro, V.; Greati, V.; Bezerra, A.; Silva, I.; Endo, P.T.; Lynn, T. Synthetic image generation for training deep learning-based automated license plate recognition systems on the Brazilian Mercosur standard. Des. Autom. Embed. Syst. 2021, 25, 113–133. [Google Scholar] [CrossRef]
- Kim, T.G.; Yun, B.J.; Kim, T.H.; Lee, J.Y.; Park, K.H.; Jeong, Y.; Kim, H.D. Recognition of vehicle license plates based on image processing. Appl. Sci. 2021, 11, 6292. [Google Scholar] [CrossRef]
- Asif, M.R.; Chun, Q.; Hussain, S.; Fareed, M.S.; Khan, S. Multinational vehicle license plate detection in complex backgrounds. J. Vis. Commun. Image Represent. 2017, 46, 176–186. [Google Scholar] [CrossRef]
- Yuan, Y.; Zou, W.; Zhao, Y.; Wang, X.; Hu, X.; Komodakis, N. A Robust and Efficient Approach to License Plate Detection. IEEE Trans. Image Process. 2017, 26, 1102–1114. [Google Scholar] [CrossRef]
- Zhao, Y.; Gu, J.; Liu, C.; Han, S.; Gao, Y.; Hu, Q. License Plate Location Based on Haar-Like Cascade Classifiers and Edges. In Proceedings of the 2010 Second WRI Global Congress on Intelligent Systems, Wuhan, China, 16–17 December 2010; Volume 3, pp. 102–105. [Google Scholar]
- Dlagnekov, L. License Plate Detection Using Adaboost; Computer Science and Engineering Department, UC San Diego: San Diego, CA, USA, 2004. [Google Scholar]
- Selmi, Z.; Ben Halima, M.; Alimi, A.M. Deep Learning System for Automatic License Plate Detection and Recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1132–1138. [Google Scholar]
- Laroca, R.; Severo, E.; Zanlorensi, L.A.; Oliveira, L.S.; Goncalves, G.R.; Schwartz, W.R.; Menotti, D. A Robust Real-Time Automatic License Plate Recognition Based on the YOLO Detector. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–10. [Google Scholar]
- Zou, Y.; Zhang, Y.; Yan, J.; Jiang, X.; Huang, T.; Fan, H.; Cui, Z. License plate detection and recognition based on YOLOv3 and ILPRNET. Signal Image Video Process. 2022, 16, 473–480. [Google Scholar] [CrossRef]
- Wang, Y.; Bian, Z.P.; Zhou, Y.; Chau, L.P. Rethinking and designing a high-performing automatic license plate recognition approach. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8868–8880. [Google Scholar] [CrossRef]
- Bala, R.; Zhao, Y.; Burry, A.; Kozitsky, V.; Fillion, C.; Saunders, C.; Rodríguez-Serrano, J. Image simulation for automatic license plate recognition. In Proceedings of the Visual Information Processing and Communication III, Burlingame, CA, USA, 24–26 January 2012; Volume 8305, pp. 294–302. [Google Scholar]
- Bulan, O.; Kozitsky, V.; Ramesh, P.; Shreve, M. Segmentation-and annotation-free license plate recognition with deep localization and failure identification. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2351–2363. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Han, B.G.; Lee, J.T.; Lim, K.T.; Choi, D.H. License plate image generation using generative adversarial networks for end-to-end license plate character recognition from a small set of real images. Appl. Sci. 2020, 10, 2780. [Google Scholar] [CrossRef]
- Maltsev, A.; Lebedev, R.; Khanzhina, N. On realistic generation of new format license plate on vehicle images. Procedia Comput. Sci. 2021, 193, 190–199. [Google Scholar] [CrossRef]
- Li, C.; Yang, X.; Wang, G.; Zheng, A.; Tan, C.; Tang, J. Disentangled generation network for enlarged license plate recognition and a unified dataset. Comput. Vis. Image Underst. 2024, 238, 103880. [Google Scholar] [CrossRef]
- Ministry of Public Security of the People’s Republic of China. License Plates of Motor Vehicles of the People’s Republic of China; Ministry of Public Security of the People’s Republic of China: Beijing, China, 2018.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Poznanski, J.; Yu, L.; Rai, P.; Ferriday, R.; et al. YOLOv5; Zenodo: Geneva, Switzerland, 2020. [Google Scholar]
- Shi, J. Good features to track. In Proceedings of the 1994 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Pérez, P.; Gangnet, M.; Blake, A. Poisson image editing. ACM Trans. Graph. (TOG) 2003, 22, 313–318. [Google Scholar] [CrossRef]
- Pérez, P.; Gangnet, M.; Blake, A. Poisson image editing. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 577–582. [Google Scholar]
- Xu, Z.; Yang, W.; Meng, A.; Lu, N.; Huang, H.; Ying, C.; Huang, L. Towards end-to-end license plate detection and recognition: A large dataset and baseline. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 255–271. [Google Scholar]
- Wang, Z. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. pp. 234–241. [Google Scholar]
- Zheng, Y. License Plate Generator. 2019. Available online: https://github.com/zheng-yuwei/license-plate-generator (accessed on 18 April 2019).
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Chen, R.; Huang, W.; Huang, B.; Sun, F.; Fang, B. Reusing discriminators for encoding: Towards unsupervised image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8168–8177. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).