

Mach. Learn. Knowl. Extr. 2026, 8(6), 152; https://doi.org/10.3390/make8060152 - 1 Jun 2026
Abstract
Conventional CNN architectures often struggle with information loss during feature extraction, particularly in pooling and flattening layers, where spatial coherence and high-frequency details critical for tasks such as medical diagnostics are compromised. To address this, we introduce a novel integration of Hilbert curve
[...] Read more.
Conventional CNN architectures often struggle with information loss during feature extraction, particularly in pooling and flattening layers, where spatial coherence and high-frequency details critical for tasks such as medical diagnostics are compromised. To address this, we introduce a novel integration of Hilbert curve flattening and multiscale frequency-selective wavelet pooling, which preserves diagnostically relevant features while optimizing computational efficiency. Multifrequency selective wavelet pooling improves the performance and adaptability of convolutional neural networks by preserving spatial adjacency structures and eliminating duplicate information. Here, raster flattening was replaced with a conventional Hilbert curve that organized data more efficiently, and wavelet pooling performed feature selection across frequency bands better than average pooling or max-pooling. On standard architectures (Inception, VGG16, ResNet, EfficientNet), our approach consistently produced an improved precision of 1.42% over earlier methods across all datasets and classes, including diagnosis of autism via structural MRI in a proof-of-concept dataset (38 subjects, 4 in the test set), with high precision, at 99%. Hence, validation on larger independent cohorts will be part of the future work. The synergy of Hilbert curve flattening and multiscale frequency-selective wavelet pooling mitigates signal decomposition losses and maintains spatial frequency relationships, advancing CNNs for high-stakes applications like medical imaging and remote sensing. These new strategies enhance spatial coherence and global efficiency, ensuring robustness in applications ranging from medical imaging to time-series forecasting.
Full article
(This article belongs to the Special Issue Artificial Intelligence for Signal, Image, and Multimodal Data Processing: Algorithms, Models, and Knowledge Extraction)
►
Show Figures
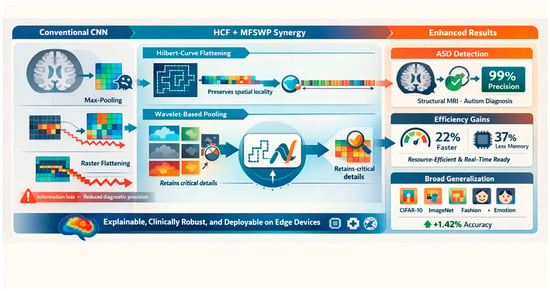
Graphical abstract












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}