Abstract
The paper shows an alternative perspective of the reduced chi-square as a measure of the goodness of fitting methods. The reduced chi-square is given by the ratio of the fitting over the propagation errors, that is, a universal relationship that holds for any linearity, but not for a nonlinearly parameterized fitting model. We begin by providing the proof for the traditional examples of one-parametric fitting of a constant and the bi-parametric fitting of a linear model, and then, for the general case of any linearly multi-parameterized model. We also show that this characterization is not generally true for nonlinearly parameterized fitting. Finally, we demonstrate these theoretical developments with an application in real data from the plasma protons in the heliosphere.
1. Introduction
The paper revisits a well-known concept—the reduced chi-square—and introduces and formalizes a novel interpretation of the ratio between fitting and propagation errors. This supports the usage of the reduced chi-square and the criterion of its deviation from one as a measure of the goodness of fitting.
The chi-square sums the squares of the residuals between a given dataset and a model, and is suitable for fitting this dataset [1]. Given the dataset of N observations, , the respective modeled values are determined as from the statistical model , which is expected to best describe the data. Often, the statistics of observational data are unknown, thus a general fitting method is employed to adjust the respective modeled values to data by minimizing their total deviations defined through a norm Φ. For the Euclidean norm, the sum of the square deviations is used, given by .
A mono-parametric fitting model, , depends on one single parameter p, e.g., the simple case of fitting a constant, . A bi-parametric fitting model depends on two independent parameters and , e.g., the famous least-square methods of a linear fit, . In general, we consider a multi-parametric fitting model that depends on M independent parameters, . In all of the cases, the fitting method involves finding the optimal values of the parameters that minimize the sum of the squares [2,3]. The chi-square is a similar sum expression to be minimized but also includes the data uncertainties.
Observational data are typically accompanied by the respective uncertainties, , which are used for normalizing the deviation of data with the fitted model, . These ratios are summed up to construct the chi-square, using the Euclidean norm L2, that is, by adding the squares,
There are four straightforward generalizations of the chi-square. These are described and formulated as follows:
- (1)
- When a non-Euclidean norm, Lq, is being used to sum the vector components , then, we minimized the chi-q (instead of the chi-square), defined by [4,5,6]
The optimization involves finding, aside from the optimal value of the fitting parameters, the optimal value of q that characterizes the non-Euclidean norm, Lq.
- (2)
- When the observations of the independent variable x have significant uncertainties , then, the optimization involves minimizing the chi-square defined by [7].
- (3)
- When the vector components are characterized by correlations, then, a non-diagonal covariance matrix exists, whose inverse matrix is involved in the construction of the chi-square [8], i.e.,
- (4)
- The relation between degrees of freedom and information is significant in statistics and information theory. Degrees of freedom represent the number of independent values in a dataset that can vary while satisfying statistical constraints. Therefore, this number indicates the amount of information available to estimate parameters. Furthermore, when a significant variability characterizes the uncertainties of observations, then, a potential statistical bias exists in their use as statistical weights (expressed as inverse variance). This bias is reduced through the effective statistical degrees of freedom Ne (replacing the number of data points, N), which is as follows [9]:
This is reduced to the number of observations, N, when all the uncertainties are equal, . Then, the effective independent degrees of freedom are given by , instead of , where is the number of the independent parameters to be optimized by the fitting. The notation of the effective independent degrees of freedom is used for formulating the reduced chi-square.
All the above four scenarios are well-studied and used in statistical analyses (e.g., see the cited references). In this paper, we focus on the standard form of (1), in order to demonstrate the statistical meaning of the chi-square in characterizing the goodness of fitting.
The statistical model is expressed by a function, f, of the independent variable x and of a number of independent parameters , in order to describe the observations of over , so that , where ei is the error term that follows a probability distribution (typically assumed to be a normal distribution). A linearly parametric model is referred to as a linear relationship of the model’s function with the involved parameter(s), and not with the variable x; e.g., the model function is linearly parameterized, while the function is nonlinear.
In general, the linearly parameterized model function can be written as
which involves arbitrary functions of the variable x, .
Minimization of the constructed chi-square,
involves finding the optimal values of the fitting parameters, , so that
The minimum value of the chi-square, , equals the sum of the residuals and can provide a measure of the goodness of the fitting. This is precisely given by the minimum reduced chi-square, that is, the chi-square over the independent degrees of freedom ,
How can a chi-square be used to characterize the goodness of a fitting method? The first thought is that the smaller the minimum chi-square value, the better the fitting. Ideally, the fitting is perfect when the sum of the residuals turns into zero for some value of the fitting parameters, ; when this occurs, all the vector components of the data-model deviation (fitting residuals) are zero, ; (note that we used the abbreviation ). Such a fitting would have been meaningful, if the observation uncertainties were negligible, . On the contrary, when these uncertainties are finite and not negligible, such an adaptation of a perfect fitting becomes meaningless; indeed, what is the point of having residuals between observations and the model tending to zero , if the uncertainties of these observations are significantly larger than these deviations, i.e., ?
The fit, once optimized, is considered good when the respective residuals are neither larger, (underfitting), nor smaller, (overfitting), than the observations uncertainties, but rather, when they have near values, . Ideally, the observation uncertainty would be equal to the minimum value of each data-model deviation, , instead of being equal to zero, in order for the fitting to be considered meaningful. In this case, the summation on all the points to derive the best chi-square value simply provides the number of points, , while the average of all the vector components provides unity, . The average chi-square approximates its reduced value, whose optimal value is ~1.
In a more detailed derivation, the reduced chi-square is exactly involved in this interpretation. In particular, let the observation’s uncertainties to be equal, ; then, the chi-square is and its reduced value is . The averaged squared residuals, that is, the variance between the data and model values, are determined by ; hence,
Therefore, the standard deviation is minimized to its smallest meaningful value, that is, the standard deviation of the observation values, , only when is equal to unity, i.e., . This observation is fundamental, interwoven with the definition, rather than a simple property, of the chi-square.
The concept and interpretation of the chi-square is interwoven with two types of errors characterizing the fitting parameters. The first, the fitting error, comes from the regression, caused by the nonzero deviation between the data and modeled values, . The second, the propagation error, comes from the existence of the observation data uncertainties, that is, the nonzero value of . Equation (10) provides insights that the chi-square expresses the ratio between the two types of errors, the fitting over the propagation error. We demonstrate this relation between the errors in Figure 1.
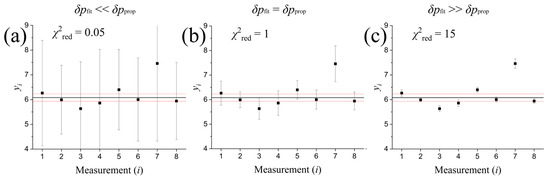
Figure 1.
A constant statistical model fits eight data points with different errors: (a) when the errors are too large (overestimation), the reduced chi-square is less than 1, the fitted line that represents the average of data points (black line) does pass through all the data points or their error lines, but the variation in the fitted model (red lines) is small compared to the size of errors, leading to a meaningless rate of good fitting. (c) When the errors are too small (underestimation), the calculated reduced chi-square is more than 1, and the fitted line does not pass through all the data points or their error lines, leading to an obvious bad fitting. (b) In the case where the errors are similar to the deviations of the data points from the model, the reduced chi-square is about 1, and the fitting is characterized as good.
In particular, Figure 1 shows the fitting of eight data values with a constant fitting model (a special case of a linear model is shown in detail in Section 2.1; see: [10,11,12]). This fitting is performed to test the statistical hypothesis that the data values are well represented by a constant. The characterization of the fitting depends on the accompanying observational uncertainties. Too large uncertainties (Figure 1a) lead to small value of the reduced chi-square (); if the fitting model is the right choice, then, this result indicates that there is an error overestimation characterizing the observational data. On the other hand, too small uncertainties (Figure 1c) lead to a large value of the reduced chi-square (); again, if the fitting model is the right choice, then, this outcome indicates that there is an error underestimation of the observational data. The optimal fitting goodness would be for observation uncertainties similar to the data variation (Figure 1b), meaning that the two types of errors are about the same, and the reduced chi-square is about one ().
The statistical behavior of chi-squared values derived from model residuals has been thoroughly understood for over a century, thanks to the foundational work of R.A. Fisher [13,14]. Fisher not only performed the necessary algebraic derivations but also rigorously established the associated probability distributions. Building on this classical framework, the current study introduces a fresh algebraic and intuitive perspective on reduced chi-squared statistics.
The purpose of this paper is to show an alternative perspective to the statistical meaning of the reduced chi-square as a measure of the goodness of fitting methods, and finally, to demonstrate it with several examples and applications. This expression is given by the ratio between the two types of errors, the fitting over the propagation error, which holds for any linearly parameterized fitting. We show this characterization of chi-square, as follows. We first work with the traditional examples of one-parametric fitting of a constant and the bi-parametric fitting of a linear model; then, we provide the proof for the general case of any linearly multi-parameterized model. Nevertheless, we present a counterexample of this characterization of chi-square, showing that it is not generally true for nonlinearly parameterized fitting. Furthermore, we focus on the nature of the two types of errors and show their independent origin. We also examine how the observation uncertainties affect the formulations of the fitting and propagation errors and the reduced chi-square. The developments of this paper in regard to the chi-square formulation and characterization are applied in the case of plasma protons of the heliosheath; we find that the acceptable characterization of the fitting goodness is given by one order of magnitude of the reduced chi-square around its optimal unity value, .
The paper is organized as follows: In Section 2, we show both the cases of linearly and nonlinearly parametric fitting models. We start with a linearly mono-parametric model, then work with bi-parametric model, and end up with the general case of a multi-parametric fitting model of an arbitrary number of independent parameters. In the same section, we show that the reduced chi-square cannot be used for nonlinear parametric fitting models. We show this separately for nonlinearly mono-parameterized and multi-parameterized models. In Section 3, we provide an example application from the plasma protons in the heliosphere. Finally, in Section 4, we summarize the conclusions and findings of this paper.
2. Methods
2.1. Linearly Parametrical Fitting
2.1.1. Linearly Mono-Parametric Fitting
The linearly mono-parametric model function can be generally written as
where the variable functions g0(x) and g1(x) may be linear or nonlinear. Here, we use the simplest case of a constant function, . Minimization of the chi-square,
involves finding the optimal values of the fitting parameters, , so that
In order to derive the fitting error, the chi-square is expanded near its minimum,
The square of the fitting error is proportional to the (reduced) chi-square and inversely proportional to the curvature coefficient A2 [5], i.e.,
where is the minimum chi-square and is the reduced chi-square. For more details, see [5]. In our case, the expansion of the chi-square, given by Equation (14), is
Hence, the curvature coefficient equals
thus, the fitting error equals
The origin of the fitting error comes from the residuals, i.e., the deviations between the data and model, . The role of the observational uncertainties of the data, , in the formulation of this deviation, is simply to express the statistical weights. They do not contribute to the measures of these deviations. For example, if all the observational uncertainties were equal, either big or small, then, they would have always zero impact on the value of the fitting error. Indeed, if , then,
that is, the fitting error becomes independent of the uncertainty σ.
The actual measure of the observational uncertainties comes with the propagation error. This is a type of error different from the fitting error; it generally differs in its nature, origin, and value. The propagation error originates from the function that expresses the optimal value in terms of the observation data, . The variation in this function leads to the propagation error,
In our case, where , the propagation error is specifically equal to
We note that the square of the propagation error equals the inverse curvature coefficient,
where we conclude that the chi-square is related to the ratio of the two errors, i.e.,
The fitting error is given by the formulation of the standard error, i.e.,
Thus, its connection to the reduced chi-square is
or
An example of this fitting is shown in Figure 1. Large deviations between propagation and fitting errors lead to a reduced chi-square significantly different than one, corresponding to low fitting goodness.
2.1.2. Linearly Bi-Parametric Fitting
The linearly bi-parametric model function can be written as
As an example, we use the simplest case of a linear function, , with the fitting parameters of intercept p1 and slope p2. Minimization of the chi-square,
leads to the optimal fitting parameters:
The minimum value of the chi-square equals
where we find
and
Next, we calculate the two types of errors. First, we find the propagation error of the optimal slope, which is,
We have
or
Hence, the propagation error of the optimal slope is
The propagation error of the optimal intercept is
where ; thus, we obtain
or
namely,
Hence, we find that the propagation error of the optimal intercept is
Next, we derive the respective fitting errors. For this, we expand the chi-square at its minimum value,
ignoring higher terms for . Then, the chi-square minimum is
while the curvature coefficient A2 is a matrix equal to half the Hessian matrix H [14],
defined by
The curvature coefficient matrix is
Thus,
Therefore, the fitting errors are given by
or
We observe that the respective propagation errors are
Finally, the ratio of the fitting over the propagation errors, for either the slope or the intercept, provides the chi-square,
which can be given more explicitly through the following formulation:
2.1.3. Linearly Multi-Parametric Fitting
Lastly, in this section, we examine the most general linearly multi-parametric model function, i.e.,
that involves the arbitrary nonlinear functions of x, . (Note that in this compact version of Equation (53), we have included the former function in the sum with p0 = 1.)
The chi-square is now formulated by
The expansion around its minimum is
where the minimum chi-square value is given by
while the curvature coefficient A2 is a matrix equal to half the Hessian matrix H,
The minimization of the chi-square, that is,
leads to the optimal values of the parameters, which are implicitly given by
Note that the argument is a matrix (two free indices, a and b), which is connected with Hessian matrix. Indeed, the Hessian or curvature matrix is derived from differentiating Equation (58) once more, that is,
Hence, we observe that Equation (59) can be written in terms of the curvature matrix, i.e.,
Some calculations lead to
and
thus,
leading to
Given the standard equation of fitting error,
with
we finally conclude that
Namely, the ratio of the fitting over the propagation errors is fixed for any of the M fitting parameters and provides (the square root of) the chi-square.
2.2. Nonlinearly Parametric Fitting
2.2.1. Nonlinearly Mono-Parameterized Fitting
We start with the mono-parametric model function , where the chi-square is given by
Minimization of the chi-square involves finding the optimal value that solves the equation
Applying the partial derivative to Equation (70), we have
Thus, we obtain
The respective curvature coefficient is given by
which can be included in the expression of propagation error, as follows:
or
Then, we find that the relationship of the two errors, propagation and fitting, involves the reduced chi-square of the nonlinearly parameterized fitting, ; however, the relationship is not universal:
Therefore, the chi-square cannot be expressed through the ratio of these errors; thus, there is no universal value of the best chi-square.
2.2.2. Nonlinearly Multi-Parameterized Fitting
The counterexample of the mono-parametric case is enough to show that the chi-square is a meaningless tool for characterizing the goodness of a nonlinearly parameterized fit. Nevertheless, we extend this example to the case of a multi-parametric model function .
Minimization of the chi-square,
involves finding the optimal parameter values, , that solve the m = 1, …, M, canonical equations:
Applying the derivative, , once more on the chi-square gives the curvature matrix
while the derivative on the optimal parameter values, as shown in Equation (78), gives
or
where the curvature matrix is given by Equation (79). Then, inversing Equation (81), we obtain
Then, we derive the propagation error, as follows:
After some calculations, we have
and
Hence,
or
Therefore,
or
Namely, in any of the general cases of a fitting with multi-parametric model, the chi-square is not given by the ratio of the respective errors (squares); neither has a universal value, because the difference differs from case to case depending on the particular fitting model.
3. Discussion: Application in the Outer Heliosphere
We use the reduced chi-square to characterize the goodness of the fitting involved in the method that determines the thermodynamic parameters of the inner heliosheath, that is, the distant outer shelf of our heliosphere. In addition, we use these datasets to compare the two measures related to the estimated chi-square, the reduced chi-square, and the respective p-value.
The Interstellar Boundary Explorer (IBEX) mission observes energetic neutral atom (ENA) emissions, constructing images of the whole sky every six months [15]. The persistence of these maps and its origins has been studied in detail [16,17]. Using these datasets, Livadiotis et al. [10] derived the sky maps of the temperature T, density n, and other thermodynamic quantities that characterize the plasma protons in the inner heliosheath (see also: [18,19,20]). These authors also showed the negative correlation between the values of temperature and density, which originates from the thermodynamic processes of the plasma.
The sky maps of temperature and density constitute 1800 pixels, each with angular dimensions of 60 × 60, while each map’s grid in longitude and latitude is separated in 60 × 30 pixels. The method used by [11] derives eight (statistically independent) measurements of the logarithms of the temperature and density of each pixel. This is based on fitting kappa distributions on the plasma protons, that is, the distribution function of particle velocities linked to the thermodynamics of space plasma particle populations [21,22,23,24,25,26,27,28,29,30]. Once these eight values (temperature and density) are well-fitted by a constant, then, the respective pixel is assigned by this thermodynamic parameter. Figure 2 shows two examples of these eight measurements of temperature and density values. As is shown in Section 2, the fitting parameter is a constant whose constant is the weighted mean. Both types of errors are plotted together with their weighted mean.
 The two errors were calculated as follows:
and
for some small value of ε (as this tends to zero, the value of the resultant errors becomes independent of ε).
The two errors were calculated as follows:
and
for some small value of ε (as this tends to zero, the value of the resultant errors becomes independent of ε).
Figure 2.
Two pixels’ examples of eight measurements of temperature and density values that characterize the sky map of the plasma protons in the inner heliosheath. The weighted average (black) is plotted together with the ± deviation caused by fitting errors (blue) and propagation errors (red). (Tables show statistical details for each fit.).
We repeat the above fitting procedure for eight neighboring pixels in the sky (taken from the annual maps of year 2010; see details in [10]). Figure 3a shows these neighboring pixels in the sky maps of temperature and density. Then, in Figure 3b we plot the derived temperature, density, and respective uncertainties (corresponding to the larger among the two error types). Finally, in Figure 3c we show their mutual relationship, by plotting the density against the temperature (logarithmic values). This is described by a negative correlation relationship, originated by a polytropic process with sub-isothermal polytropic index γ. A polytropic process is described by a power-law relation between temperature and density (i.e., ), or between thermal pressure and density (i.e., ), along a streamline of the flow. In particular, we find a slope (that is, the exponent in ) around ν ~ −2, but it is characterized with better statistics when outlining the last point, leading to ν ~ −1 (also, see: [10,30]).
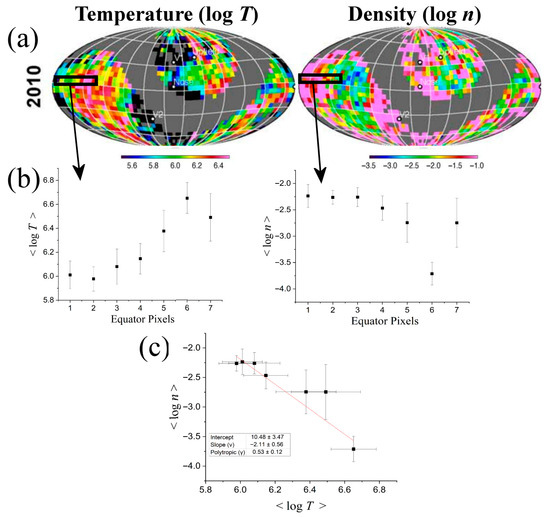
Figure 3.
(a) The eight examined neighboring pixels in the sky maps of temperature and density. (b) The results of weighted mean and the uncertainty (largest between fitting and propagation errors). (c) Co-plot of density vs. temperature shows its negative correlation. (Temperature and density are represented with logarithms).
Using the p-value method for evaluating the goodness of fitting [13], we compare the estimated chi-square value, , with any possible chi-square value larger than the estimated one, , by deriving this exact probability, ; this determined the p-value. This is determined by integrating the chi-square distribution, , that is the distribution of all the possible values (parameterized by the degrees of freedom D). Therefore, the likelihood of having a chi-square value, , larger than the estimated one, , is given in terms of the complementary cumulative chi-square distribution. The respective probability, the p-value, equals .
The larger the p-value, the better the goodness of the fitting. A p-value larger than 0.5 corresponds to < D or < 1. Larger p-values, up to p = 1, correspond to smaller chi-squares, down to ~ 0. Thus, an increasing p-value above the threshold of 0.5 cannot lead to a better fitting. Rather, it leads to a worse fit, similar to a decreasing < 1. On the other hand, a p-value smaller than the significance level of ~0.05 is typically rejected. Using these limits of the p-value, we find the respective limits of the reduced chi-square.
In Figure 4, we demonstrate the relationship between the reduced chi-square and the respective p-value Pv. We plot 16 pair values of ( and Pv), one pair for each of the 16 fitting measures performed (temperature and density fits, both for eight pixels). The deduced relationship between the two measures can be used to deduct the extreme acceptable values of the reduced chi-square; indeed, the best reduced chi-square value that characterizes the goodness of a fitting is one, but at what extreme should a lower goodness be accepted? The correspondence with the acceptable value of 0.05 of the p-value will provide an answer to this issue.
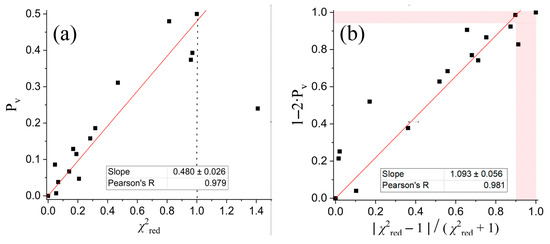
Figure 4.
(a) Co-plots of the p-values and the respective reduced chi-square values, showing their relationship. (b) Similar to (a) but with modified functions ranging in [0, 1]; (shaded area corresponds to rejected fits because of low goodness).
In Figure 4a we plot all ( and Pv) pair values and observe the linear behavior between the two measures. The plot shows the well-described linearity between the low chi-square values and the corresponding p-values. Nevertheless, in order to also catch the relationship for all the points, including those with , in Figure 4b we plot the values of 1–2∙Pv as a function of the modified chi-square values, that is, , which surely ranges in the interval [0, 1] (similarly for both axes). We find that the excluded p-values (Pv < 0.05) correspond to the reduced chi-square values and ; (of course, this is not a universal value, but corresponds to the examined datasets).
4. Conclusions
The paper showed the relationship between the two types of errors that characterize the optimal fitting parameters, the fitting and propagation errors. While the fitting error estimates the uncertainty originated from the variation in the observational data around the model, the propagation error comes from the raw uncertainties of the observational data. The (square) ratio of the two errors determines the value of the reduced chi-square.
Large deviations between propagation and fitting errors lead to a reduced chi-square significantly different than one, corresponding to low fitting goodness. In fact, large uncertainties lead to small values of the reduced chi-square (), indicating a possible error overestimation; small uncertainties lead to a large value of the reduced chi-square (), indicating that there is an error underestimation of the observation data. The optimal fitting goodness would be for observation uncertainties similar to the data variation, namely, the two types of errors are about the same, and the reduced chi-square is about one ().
The relationship between the two types of errors and the chi-square was shown for mono-parametric, bi-parametric, and in general, multi-parametric statistical models. In the multi-parametric case, it is interesting that the ratio is universal, namely, independent of the respective parameter; namely, , for any n: 1, …, M, as shown in Equation (68).
In addition to this theoretical development, we presented a counterexample of this characterization of chi-square, showing that it is not generally true for a nonlinearly parameterized fitting. Some alternative approaches for assessing nonlinear fits involve the bootstrap inference [31], the Bayesian frameworks [32,33], and the technique of averaging the parameter’s optimal values derived from solving by pairs [11].
Finally, the method of chi-square characterization as a measure of the fitting goodness is applied on the datasets of temperature and density of the plasma protons in the inner heliosheath, the outer shelf of our heliosphere. A previously applied method derived eight measurements of the logarithms of temperature and density for each pixel of the sky map [10]. Once these eight values (temperature and density) are well-fitted by a constant, then, the respective pixel is assigned by this thermodynamic parameter. We have determined the two types of errors of this analysis; the respective reduced chi-square values were compared with the respective p-values for completeness.
Funding
This research was funded by the interstellar Boundary Explorer (IBEX) mission (80NSSC20K0719), which is a part of NASA’s Explorer Program.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
No new data were created by this paper.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Cochran, W.G. The Chi-square Test of Goodness of Fit. Ann. Math. Stat. 1952, 23, 315–345. [Google Scholar] [CrossRef]
- McCullagh, P. What is statistical model? Ann. Stat. 2002, 30, 1225–1310. [Google Scholar] [CrossRef]
- Adèr, H.J. Modelling. In Advising on Research Methods: A Consultant’s Companion; Johannes van Kessel Publishing: Huizen, The Netherlands, 2008; Chapter 12; pp. 271–304. [Google Scholar]
- Burden, R.L.; Faires, J.D. Numerical Analysis; PWS Publishing Company: Boston, MA, USA, 1993; pp. 437–438. [Google Scholar]
- Livadiotis, G. Approach to general fitting methods and their sensitivity. Physica A 2007, 375, 518. [Google Scholar] [CrossRef]
- Livadiotis, G. Chi-p distribution: Characterization of the goodness of the fitting using L p norms. Physica A 2007, 1, 4. [Google Scholar] [CrossRef]
- Frisch, P.C.; Bzowski, M.; Livadiotis, G.; McComas, D.J.; Moebius, E.; Mueller, H.-R.; Pryor, W.R.; Schwadron, N.A.; Sokół, J.M.; Vallerga, J.V.; et al. Decades-long changes of the interstellar wind through our solar system. Science 2013, 341, 1080. [Google Scholar] [CrossRef] [PubMed]
- Shih, J.H.; Fay, M.P. Pearson’s Chi-square Test and Rank Correlation Inferences for Clustered Data. Biometrics 2017, 73, 822–834. [Google Scholar] [CrossRef] [PubMed]
- Bevington, P.R. Data Reduction and Error Analysis for the Physical Sciences; McGraw-Hill: New York, NY, USA, 1969; p. 336. [Google Scholar]
- Livadiotis, G.; McComas, D.J.; Funsten, H.O.; Schwadron, N.A.; Szalay, J.R.; Zirnstein, E. Thermodynamics of the Inner Heliosheath. Astrophys. J. Suppl. Ser. 2022, 262, 53. [Google Scholar] [CrossRef]
- Livadiotis, G.; Cummings, A.T.; Cuesta, M.E.; Bandyopadhyay, R.; Farooki, H.A.; Khoo, L.Y.; McComas, D.J.; Rankin, J.S.; Sharma, T.; Shen, M.M.; et al. Kappa-tail Technique: Modeling and Application to Solar Energetic Particles Observed by Parker Solar Probe. Astrophys. J. Suppl. Ser. 2024, 973, 6. [Google Scholar] [CrossRef]
- Cuesta, M.E.; Cummings, A.T.; Livadiotis, G.; McComas, D.J.; Cohen, C.M.S.; Khoo, L.Y.; Sharma, T.; Shen, M.M.; Bandyopadhyay, R.; Rankin, J.S.; et al. Observations of Kappa Distributions in Solar Energetic Protons and Derived Thermodynamic Properties. Astrophys. J. Suppl. Ser. 2024, 973, 76. [Google Scholar] [CrossRef]
- Fisher, R.A. On the Interpretation of χ2 from Contingency Tables and the Calculation of p. J. R. Stat. Soc. 1922, 85, 87–94. [Google Scholar] [CrossRef]
- Melissinos, A.C. Experiments in Modern Physics; Academic: London, UK, 1966; p. 438. [Google Scholar]
- McComas, D.J.; Allegrini, F.; Bochsler, P.; Bzowski, M.; Christian, E.R.; Crew, G.B.; DeMajistre, R.; Fahr, H.; Fichtner, H.; Frisch, P.C.; et al. Global Observations of the Interstellar Interaction from the Interstellar Boundary Explorer (IBEX). Science 2009, 326, 959. [Google Scholar] [CrossRef]
- Sarlis, N.V.; Livadiotis, G.; McComas, D.J.; Alimaganbetov, M.; Schwadron, N.A.; Fairchild, K. Persistent Behavior in Energetic Neutral Atom Time Series from IBEX. Astrophys. J. Suppl. Ser. 2024, 976, 45. [Google Scholar] [CrossRef]
- Sarlis, N.V.; Livadiotis, G.; McComas, D.J.; Alimaganbetov, M.; Schwadron, N.A. Origins of Persistence in Energetic Neutral Atom Time Series from IBEX. Astrophys. J. Suppl. Ser. 2025, 986, 131. [Google Scholar] [CrossRef]
- Livadiotis, G.; McComas, D.J.; Dayeh, M.A.; Funsten, H.O.; Schwadron, N.A. First Sky Map of the Inner Heliosheath Temperature Using IBEX Spectra. Astrophys. J. Suppl. Ser. 2011, 734, 1. [Google Scholar] [CrossRef]
- Livadiotis, G.; McComas, D.J.; Randol, B.M.; Funsten, H.O.; Möbius, E.S.; Schwadron, N.A.; Dayeh, M.A.; Zank, G.P.; Frisch, P.C. Pick-up Ion Distributions and Their Influence on Energetic Neutral Atom Spectral Curvature. Astrophys. J. Suppl. Ser. 2012, 751, 64. [Google Scholar] [CrossRef]
- Livadiotis, G.; McComas, D.J.; Schwadron, N.A.; Funsten, H.O.; Fuselier, S.A. Pressure of the Proton Plasma in the Inner Heliosheath. Astrophys. J. Suppl. Ser. 2013, 762, 134. [Google Scholar] [CrossRef]
- Livadiotis, G.; McComas, D.J. Beyond kappa distributions: Exploiting Tsallis statistical mechanics in space plasmas. J. Geophys. Res. 2009, 114, A11105. [Google Scholar] [CrossRef]
- Livadiotis, G. “Lagrangian Temperature”: Derivation and Physical Meaning for Systems Described by Kappa Distributions. Entropy 2014, 16, 4290–4308. [Google Scholar] [CrossRef]
- Livadiotis, G. Kappa Distributions: Theory and Applications in Plasmas; Elsevier: Amsterdam, The Netherlands, 2017; 738p. [Google Scholar]
- Nicolaou, G.; Livadiotis, G.; Owen, C.J.; Verscharen, D.; Wicks, R.T. Determining the kappa distributions of space plasmas from observations in a limited energy range. Astrophys. J. 2018, 864, 3. [Google Scholar] [CrossRef]
- Livadiotis, G. Thermodynamic origin of kappa distributions. Europhys. Lett. 2018, 122, 50001. [Google Scholar] [CrossRef]
- Nicolaou, G.; Livadiotis, G. Long-term correlations of polytropic indices with kappa distributions in solar wind plasma near 1 au. Astrophys. J. 2019, 884, 52. [Google Scholar] [CrossRef]
- Livadiotis, G.; McComas, D.J. Physical Correlations Lead to Kappa Distributions. Astrophys. J. 2022, 940, 83. [Google Scholar] [CrossRef]
- Livadiotis, G.; McComas, D.J. Entropy defect in thermodynamics. Sci. Rep. 2023, 13, 9033. [Google Scholar] [CrossRef] [PubMed]
- Livadiotis, G.; McComas, D.J. Thermodynamic Definitions of Temperature and Kappa and Introduction of the Entropy Defect. Entropy 2021, 23, 1683. [Google Scholar] [CrossRef]
- Livadiotis, G. Superposition of Polytropes in the Inner Heliosheath. Astrophys. J. Suppl. Ser. 2016, 223, 13. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap; Chapman & Hall/CRC: Boca Raton, FL, USA, 1993. [Google Scholar]
- Carlin, B.P.; Louis, T.A. Bayesian Methods for Data Analysis, 3rd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2008. [Google Scholar]
- McElreath, R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).