Abstract
The use of Large Language Models (LLMs) in organizational contexts has grown rapidly, particularly in project management activities. Despite this expansion, a relevant methodological gap can be observed in the literature: the absence of psychometrically validated instruments capable of measuring the acceptability of these technologies prior to their effective adoption, especially in project-oriented governance contexts. Traditional technology adoption models predominantly focus on a posteriori assessment of individual use, providing limited support for prospective analyses that inform strategic decision-making and organizational coordination mechanisms. In response to this gap, this study aims to develop and validate a psychometric scale to indirectly measure the acceptability, through outcome beliefs and with behavioral predispositions serving as structural proxies of the latent construct of LLM use by project management teams, with a focus on a priori judgments that precede the effective adoption of the technology. The initial scale, composed of 17 items, underwent content validation and was administered to a sample of 154 project management professionals. The latent structure was examined through Exploratory and Confirmatory Factor Analyses, resulting in the refinement of the instrument to 13 items distributed across two correlated factors. The results indicate that LLM acceptability is adequately represented by a bidimensional structure comprising the dimensions Intention/Predisposition and Trust/Perceived Benefit, both demonstrating high internal consistency and good statistical fit, and nomological validity evidenced by significant associations with respondents’ self-reported LLM usage frequency. These findings reinforce the conceptualization of acceptability as a prospective and multidimensional construct, relevant for supporting governance decisions and the adoption of artificial intelligence-based technologies in project-oriented organizational systems. The indirect measurement approach adopted here is theoretically grounded in the premise that a priori acceptability is not directly observable but is constituted by cognitive and dispositional beliefs formed prior to use.
1. Introduction
Information Technology (IT) project management has become a critical element in the contemporary landscape of technological development, reflecting the increasing complexity and dynamism of the sector [1]. The evolution of digital products and the widespread adoption of agile methodologies have introduced new challenges to project management, requiring more sophisticated and adaptive approaches [2]. This complexity is evidenced by the need to integrate multiple life cycles, coordinate multidisciplinary teams, and implement incremental improvements within rapidly changing technological environments [3]. Moreover, the growing interdependence among different aspects of IT projects has amplified the risks associated with simplistic interpretations of these endeavors, underscoring the importance of effective and informed management capable of sustaining evidence-based governance decisions in complex organizational contexts [4,5].
In this context, the emergence of tools based on artificial intelligence, particularly generative artificial intelligence (GenAI) and, more specifically, Large Language Models (LLMs), has positioned it as a transformative factor in project management, reshaping how decisions are made and how problems are addressed [6]. The recent literature highlights the positive impact of AI on the optimization of critical processes throughout the project lifecycle, from conception to final delivery [7]. The integration of AI-based tools into project management has demonstrated significant potential to enhance efficiency and accuracy in task execution [8]. For instance, AI applications have accelerated and improved budget preparation, the development of detailed reports, the collection and analysis of complex information, and strategic decision-making processes [9,10]. More specifically, the use of LLMs has been shown to support the preparation of project proposals, the construction of work plans, and the daily monitoring of development teams, offering levels of precision and agility that were previously unattainable [11].
Despite the significant advancement of the literature on the adoption of digital technology and, more recently, on the use of generative artificial intelligence in organizational contexts, a relevant methodological gap remains: the absence of psychometrically validated instruments capable of measuring the acceptability of Large Language Models (LLMs) prior to their effective adoption, particularly in project-oriented governance contexts. Traditional technology adoption models, such as the Technology Acceptance Model (TAM) and the Unified Theory of Acceptance and Use of Technology (UTAUT), predominantly focus on individual-level evaluations associated with usage intention and actual use, operating mainly in contexts that occur after the adoption decision [12,13]. Although widely applied, these models provide limited support for prospective analyses aimed at strategic decision-making, governance, and organizational coordination, especially in complex and collective contexts [14,15]. In this regard, the acceptability literature emphasizes the need for instruments that capture judgments formed prior to use, thereby informing organizational decisions before the effective implementation of new technologies [16,17]. This gap is particularly relevant given that the effective adoption of LLMs can represent a competitive differentiator for organizations [18].
However, despite the growing scholarly attention to AI applications in project management, it is important to recognize that the integration of these technologies into professional practice remains at an early and largely exploratory stage. Empirical investigations suggest that AI-based tools, including LLMs and generative chatbots, are still undergoing processes of organizational appropriation, in which project managers and their teams progressively adapt these technologies to their existing social practices and operational routines [19]. This appropriation is shaped not only by individual attitudes toward innovation but also by contextual factors such as peer influence, perceived Task–Technology Fit, and organizational readiness [19,20]. In a comparative study, Barcaui & Monat [18] demonstrated that generative AI can produce project planning outputs comparable to those of experienced project managers, yet their findings simultaneously reveal that such tools are primarily being evaluated against human performance rather than being seamlessly embedded in everyday practice. Similarly, the systematic mapping conducted by Khalil et al. [10] indicates that, while the volume of research on AI in project management has increased substantially in recent years, the field remains fragmented, with most contributions focusing on isolated applications rather than on comprehensive frameworks for integration and governance. Taken together, these observations suggest that AI in project management is best characterized as an emerging phenomenon, one that is gaining momentum in both academic discourse and professional experimentation, but that has not yet achieved widespread, institutionalized adoption across the discipline.
Furthermore, the current positioning of AI within the project management domain is not without tensions and contested perspectives. While proponents emphasize the potential of AI-driven tools to enhance decision-making speed, forecasting accuracy, and resource allocation efficiency [7,9], critical concerns have also been raised regarding the opacity of algorithmic processes, the variability of AI-generated outputs, and the consequent implications for trust and organizational accountability [21]. In project environments characterized by distributed decision-making and high systemic interdependence, the delegation of cognitive tasks to automated systems introduces uncertainties that are not fully addressed by existing adoption models [3,22]. The literature on AI and strategic management further underscores that, although four decades of research have explored the interplay between artificial intelligence and organizational decision-making, the practical integration of AI into managerial processes remains a subject of ongoing scholarly debate rather than a settled consensus [20]. In this regard, Zadeh, Khoulenjani & Safaei [23] explicitly positions AI as a “potential tool” for supporting project execution, a framing that reflects the prevailing view in the literature: AI is widely acknowledged as a promising resource for project management, yet its role is still being conceptualized and negotiated by both scholars and practitioners. This contested and evolving landscape reinforces the need for instruments capable of capturing organizational actors’ evaluative judgments prior to adoption, thereby informing governance decisions in a context where the technology’s place in professional practice is not yet fully established.
Considering this context, the following research question was formulated: How can a valid scale be constructed to indirectly measure the acceptability of LLM use in the daily activities of project management teams? The research question explicitly frames the measurement task as indirect, a design choice grounded in the theoretical nature of the acceptability construct itself. Acceptability, as an a priori mental phenomenon, is not directly observable: it exists as a latent cognitive state formed before actual technology use and, therefore, cannot be elicited through direct behavioral reports or usage records [17,24]. Consistent with the Theory of Planned Behavior [25] and the reasoned action approach [26], a priori acceptability is constituted by two classes of observable cognitive indicators: outcome beliefs, representations of what the technology is capable of producing and behavioral predispositions, the degree to which individuals and teams perceive alignment between the technology and their work practices. These indicators do not replace acceptability; they are its cognitive substrate, the observable manifestations from which the latent construct is inferred. A respondent who systematically attributes high performance outcomes to LLM use and perceives alignment between those capabilities and their project management tasks is, through that cognitive configuration, expressing a priori acceptability, even in the absence of explicit first-person willingness statements. This approach is analogous to established indirect measurement practices in constructs such as trust [27] and attitude [25], in which the latent state is inferred from its cognitive and dispositional manifestations rather than directly reported. The nomological validity of this indirect measurement strategy is examined in the results section through the association between scale scores and respondents’ self-reported LLM usage frequency.
To address this question, this study aims to develop and validate a psychometric scale designed to indirectly measure the acceptability of LLM use by project management teams. The measurement approach is grounded in outcome beliefs and behavioral predispositions the observable cognitive indicators that constitute the substrate of a priori acceptability judgments, formed prior to the effective adoption of these technologies. The proposed scale provides an analytical instrument applicable to organizational governance contexts and strategic decision-making processes
As the methodological framework for this study, the scale development protocols proposed by [28,29], which are widely adopted in psychometric research, were employed. The scale items were derived from the literature on the use of artificial intelligence in project management, consolidated into theoretically grounded factors, and subsequently subjected to evaluation by practitioners. The proposed structure was then validated through Exploratory and Confirmatory Factor Analyses, ensuring the robustness and validity of the instrument. Based on the results obtained with the proposed scale, it is expected that project managers will be able to assess the level of acceptability of LLM use within their teams, thereby informing and guiding decisions related to the adoption, training, and integration of these technologies into project management practices.
The remainder of this paper is organized as follows. Section 2 presents the theoretical background, covering the use of artificial intelligence tools in project management, the role of prompt engineering as a mediating factor in LLM effectiveness, and the construct of acceptability as conceptualized in the technology adoption literature. Section 3 describes the materials and methods, including the research design, instrument development and content validation, sample characteristics, and data analysis procedures. Section 4 reports the empirical results, encompassing descriptive statistics, the Exploratory and Confirmatory Factor Analyses, convergent and discriminant validity indicators, and the nomological validity assessment. Section 5 discusses the findings in light of the theoretical framework, addressing the factor structure and its coherence, the interpretation of each dimension, items with lower performance, and the contributions to the literature on governance and organizational systems. Section 6 presents the conclusions, practical implications, limitations, and directions for future research. The paper also includes two appendices: Appendix A provides an application and interpretation guide for the scale, and Appendix B reproduces the questionnaire administered to participants.
2. Theoretical Background
The relationship between project management methodologies and the adoption of emerging technologies constitutes a relevant analytical dimension for understanding the conditions under which AI-based tools may be integrated into professional practice. Traditional predictive approaches, such as the Waterfall model, are characterized by sequential phase progression, detailed upfront planning, and clearly defined scope boundaries, which tend to produce structured and stable work environments where the introduction of new technologies can be planned and controlled in advance [23].
However, the rigidity inherent in these methodologies may also constrain the iterative experimentation and rapid feedback cycles that are typically required for the effective appropriation of AI tools, particularly those based on generative models whose outputs are probabilistic and context-dependent [18]. In contrast, agile methodologies emphasize continuous adaptation, incremental delivery, and decentralized decision-making, creating environments in which technology adoption is often distributed across self-organizing teams rather than governed by centralized planning structures [2,30]. Hybrid approaches, which combine elements of both predictive and adaptive methodologies, have become increasingly prevalent and introduce additional complexity to the adoption process, as they require teams to navigate between different governance logics and coordination mechanisms within the same project or organizational context [2].
These methodological distinctions are not merely procedural; they shape the social and cognitive conditions under which technology appropriation occurs. As proposed by Adaptive Structuration Theory, the adoption of advanced technologies is mediated by the structures of the social system in which they are introduced, including the norms, roles, and interaction patterns that characterize the project team’s working environment [31].
In agile and hybrid settings, where decision-making authority is distributed and team members are expected to exercise autonomy in task execution, the acceptability of a new technology such as LLMs is unlikely to depend solely on individual perceptions of usefulness or ease of use; rather, it is shaped by collective judgments regarding the alignment between the technology’s capabilities and the team’s operational practices [19]. Furthermore, the complexity inherent in IT project environments, characterized by high systemic interdependence and multiple concurrent life cycles, amplifies the challenges associated with the introduction of AI-based tools, as the consequences of adoption decisions propagate across interconnected project subsystems [3]. In this context, the mere adoption of agile methodologies may be insufficient to address the full range of challenges associated with resource allocation, timeline estimation, and scope management, reinforcing the potential role of artificial intelligence as a complementary tool to support project execution and process improvement [23].
This analytical perspective underscores the importance of measuring technology acceptability at the team level and prior to adoption, rather than relying exclusively on individual-level assessments conducted after the technology has already been implemented.
2.1. Use of Artificial Intelligence Tools in Project Management
The application of artificial intelligence to project management has evolved from early rule-based decision support systems to more sophisticated approaches grounded in machine learning and, more recently, generative models. Lu [32] provides a broad historical account of this trajectory, highlighting that AI has progressively expanded from narrow, domain-specific automation tasks toward more general-purpose applications capable of operating across multiple organizational functions. In the specific context of project management, AI-based tools have emerged as alternatives to conventional approaches, with documented applications spanning resource allocation, estimation of task completion time, risk assessment, and support for managerial decision-making throughout the project lifecycle [7,9]. The systematic mapping conducted by [10] further indicates that the domains in which AI has been most intensively applied within project management include schedule and cost estimation, risk identification and mitigation, resource optimization, and quality assurance, with a growing number of studies exploring AI-driven support for stakeholder communication and strategic planning.
Within this broader landscape, the emergence of LLMs represents a qualitative shift in the type of AI-based support available to project teams. LLMs are computational models trained on extensive textual corpora, designed to generate contextually relevant and grammatically coherent outputs by predicting sequential tokens based on input text [33,34]. A distinguishing characteristic of these models is their capacity to process and generate natural language that closely resembles human-produced text, which enables their application not only to structured analytical tasks but also to inherently communicative and interpretive activities that pervade project management practice [33]. Unlike earlier AI tools that operated primarily on structured numerical data, LLMs can engage with the unstructured, language-intensive dimensions of project work, including the drafting of project proposals, the formulation of work breakdown structures, the generation of status reports, and the synthesis of stakeholder communications [11,18].
The concrete manifestations of LLM use in project management have been documented across several functional domains. In planning and estimation, Barcaui & Monat [18] demonstrated that generative AI can produce project plans comparable in quality to those developed by experienced project managers, suggesting that these tools can function as effective cognitive partners in early-phase project activities. In execution and monitoring, AI-based tools have been shown to accelerate budget preparation, enhance the accuracy of progress reports, and support the collection and analysis of complex project information [8,9].
In the domain of quality and compliance, the use of LLMs has been found to reduce the need for human analyst intervention in the validation of critical security controls, thereby streamlining governance-related verification processes [35]. Similarly, in the context of agile development practices, the automation of user story classification through LLM-based methods has been shown to significantly reduce manual effort and mitigate errors associated with subjective interpretation [36]. More broadly, AI tools have demonstrated the capacity to improve forecasting accuracy and optimize resource allocation in complex and agile project environments, contributing to enhanced team performance and more effective stakeholder management [37,38,39].
A further dimension that has received increasing scholarly attention concerns the adaptability of AI tools to diverse project contexts and task requirements. The literature suggests that the effectiveness of LLMs is not uniform across applications; rather, it depends on the degree to which the technology can be tailored to domain-specific demands through mechanisms such as prompt engineering, fine-tuning, and contextual configuration [40,41]. This adaptability has been conceptualized in terms of the alignment between the tool’s generative capabilities and the particular cognitive and operational requirements of the task at hand, a perspective that resonates with the Task–Technology Fit framework [42].
In project management, where tasks range from highly structured activities such as scheduling and budgeting to loosely defined challenges such as stakeholder negotiation and strategic prioritization, the capacity of LLMs to adapt to varying levels of task structure and ambiguity constitutes a critical factor in their organizational appropriation [7,19]. This observation reinforces the notion that the integration of AI into project management is not a monolithic phenomenon but rather a differentiated process, contingent upon the nature of the tasks, the methodological context, and the collective dispositions of the project team.
2.2. Prompt Engineering and Llm Effectiveness
While Section 2.1 examined the functional domains in which AI-based tools have been applied to project management, an major factor that mediates the actual value extracted from these technologies concerns the quality of the interaction between users and LLMs. Unlike traditional software tools that operate through structured interfaces and predefined input fields, LLMs require users to communicate their intent through natural language prompts, making the human–technology interaction fundamentally dependent on the user’s ability to articulate task requirements, contextual constraints, and expected output characteristics [43,44]. This dependency introduces prompt engineering as a key determinant of LLM effectiveness in organizational settings.
The literature has established that prompt quality and clarity are important factors in shaping the relevance and accuracy of LLM-generated outputs. Liu et al. [41] demonstrates that well-designed prompts substantially enhance the models’ capacity to interpret contextual information and infer appropriate responses, even when input data are incomplete. Similarly, Chen et al. [38] shows that semantic alignment between the examples provided within a prompt and the target task significantly improves model performance, suggesting that effective prompt construction requires not only linguistic skill but also domain-specific knowledge regarding the task to be supported. Zhao et al. [40] further argues that prompt engineering enables the efficient adaptation of LLMs to different domains and task-specific applications, functioning as a practical mechanism through which the general-purpose capabilities of these models are translated into context-sensitive outputs. The automation of prompt design has also been identified as a strategy to enhance accessibility and reduce the technical barriers associated with LLM use, thereby broadening the range of organizational actors who can benefit from these tools [18].
These findings carry direct implications for the acceptability of LLMs in project management contexts. If the effectiveness of LLM-based tools is contingent upon users’ prompting competence, then the perceived ease of use and perceived usefulness of these technologies are themselves mediated by the user’s technical familiarity and confidence in interacting with the tool. Marvin et al. [43] provides empirical support for this relationship, demonstrating that users with greater technical familiarity extract superior benefits from LLMs in software development tasks, which implies that heterogeneous levels of prompting skill within a project team may produce divergent acceptability judgments regarding the same technology. This observation is consistent with the broader literature on Task–Technology Fit, which posits that the perceived alignment between a tool’s capabilities and the user’s task requirements is a critical antecedent of adoption and continued use [42]. In the context of project teams, where members occupy diverse roles and possess varying levels of digital proficiency, prompt engineering competence may function as a differentiating factor that shapes not only individual evaluations of LLM utility but also the collective predisposition of the team toward technology integration.
2.3. The Construct of Acceptability
The acceptability construct is defined as a multifaceted concept that reflects the extent to which individuals who receive or deliver an intervention consider it appropriate, based on anticipated or experienced cognitive and emotional responses to the intervention [45]. Acceptability is a highly important criterion across multiple fields of study, as it constitutes a necessary precondition for the effectiveness of an intervention and influences adherence and practical outcomes [45].
It is necessary to distinguish between acceptability and acceptance, as they differ temporally. Acceptability is an a priori phenomenon along the temporal axis, representing the more or less positive mental representation that users hold before actually using a tool [17,24]. In contrast, acceptance constitutes an a posteriori pragmatic evaluation, which requires users to engage in real activity with a tool before forming a judgment [12]. This temporal distinction is important because representations of tool use are not fully defined in advance but are constructed and adapted through effective use, and users’ judgments about technology change significantly as they move from observation to actual experience [17].
The most influential model related to acceptability is grounded in the understanding that usage intention is primarily determined by two central cognitive factors: Perceived Usefulness and Perceived Ease of Use [12]. Perceived Usefulness refers to the degree to which an individual believes that using a system will enhance their job performance, focusing on the purpose and functional value of the tool. Perceived Ease of Use, in turn, expresses the degree to which an individual believes that using the system will be free of effort, representing the difficulty of manipulation as well as the associated cognitive or physical cost. Although perceived usefulness tends to be the strongest determinant of acceptance after prolonged use, perceived ease of use exerts a greater influence on acceptability judgments when users have little or no prior experience with the tool [17].
It should be noted that, although Perceived Ease of Use constitutes a relevant antecedent of acceptability in the broader technology adoption literature, the present scale does not include items directly measuring this dimension. This design choice reflects the specific operationalization adopted in this study, which focuses on outcome beliefs and behavioral predispositions as indirect indicators of the latent acceptability construct, rather than on the full set of antecedents described in the TAM framework [12]. The decision to prioritize outcome beliefs over ease-of-use perceptions was guided by two considerations: first, the items were derived from the literature on AI applications in project management, which predominantly emphasizes performance outcomes, task efficiency, and decision-making support rather than interface-level usability; and second, the rapid evolution of LLM interfaces and interaction modalities suggests that ease-of-use perceptions may be highly volatile and context-dependent, potentially reducing their stability as scale indicators in the medium term. Nevertheless, future iterations of the instrument should consider incorporating PEOU-related items, particularly for populations with limited prior experience, where ease-of-use perceptions may exert a stronger influence on a priori acceptability judgments [17].
In the context of project management, acceptability is closely related to appropriation, which refers to the process through which individuals or groups adopt and adapt technologies, such as generative AI chatbots, in order to integrate them into their social practices and operational needs [19,20,31]. This appropriation process is influenced by psychological factors, such as innovation attitude, as well as contextual and social considerations, including peer influence and Task–Technology Fit (TTF) [19,20]. TTF, in particular, plays a critical role in effective integration by indicating the perceived alignment between technological capabilities and task requirements [42].
Since acceptability constitutes an a priori mental state, its psychometric measurement is necessarily indirect. Consistent with the Theory of Planned Behavior [25] and the reasoned action approach [26], acceptability judgments are formed from outcome beliefs, defined as cognitive representations of the consequences of technology use, and from behavioral norms and predispositions. These elements function as indicators of the latent construct, not as conceptual substitutes for it. A respondent who attributes high performance to the technology and demonstrates collective predisposition to integrate it into project work reveals, through those observable signals, a high level of a priori acceptability even without being directly asked about their willingness to use it. This principle of indirect measurement is analogous to that employed in constructs such as attitude, purchase intention, and organizational trust, in which the latent construct is inferred from items capturing its cognitive and dispositional manifestations [25,27].
3. Materials & Methods
The development and confirmation of the Acceptability Scale for the Use of Large Language Models (LLMs) by Project Teams followed a quantitative research design of an exploratory–confirmatory nature, as recommended by Hair et al. [28] for studies aimed at identifying and validating latent structures associated with constructs that are still undergoing theoretical consolidation. The combined use of Exploratory and Confirmatory Factor Analyses was adopted to empirically examine the behavior of the indicators and to test the adequacy of the proposed theoretical model, thereby ensuring construct validity and statistical consistency. This approach is widely employed in organizational research and applied social sciences, particularly in contexts in which the phenomenon under investigation exhibits high complexity and strong dependence on cognitive and behavioral factors, as is the case with the acceptability of emerging technologies in project environments [28,46].
In alignment with the scale development protocol proposed by Hair et al. [28], the study methodology was structured into four main stages: (i) conceptual definition of the construct and its theoretical dimensions; (ii) initial item generation and content validation; (iii) empirical assessment of the factor structure through Exploratory Factor Analysis; and (iv) confirmation of the latent structure and evaluation of validity and reliability through Confirmatory Factor Analysis. The first stage focused on the conceptual delineation and theoretical grounding of the construct, drawing on the literature on technology adoption, governance, and the use of artificial intelligence, which enabled the definition of the initial dimensions of the scale. The second stage involved the construction of the measurement instrument and the content validation of the items, including expert evaluation and cognitive pretesting, in accordance with recommended practices to ensure semantic clarity and theoretical alignment [46,47]. The third stage consisted of empirical data collection and sample definition, followed by the application of multivariate statistical techniques to assess the factor structure, as well as the validity and reliability of the proposed scale. Finally, in the fourth stage, the validity and reliability of the scale were examined using Confirmatory Factor Analysis.
3.1. Research Design and Theoretical Foundations
The central construct of this research, Acceptability, was adopted because it represents an a priori phenomenon along the temporal axis, reflecting the mental representation or usage intention that individuals hold prior to their actual experience with a tool [45]. This concept differs from Acceptance, which constitutes an a posteriori pragmatic evaluation conducted after the effective use of the technology [12,16].
The conceptual model was grounded in technology adoption theories, such as the Technology Acceptance Model (TAM) and Adaptive Structuration Theory (AST) [17,19]. From a theoretical perspective, acceptability is determined by Perceived Usefulness (PU) and Perceived Ease of Use (PEOU) [12,17]. While perceived usefulness tends to be a stronger predictor of a posteriori acceptance, perceived ease of use is generally more influential in a priori acceptability judgments, particularly when user experience with the technology is limited.
Based on the literature, two initial dimensions were proposed for measuring the acceptability of LLMs:
- Technological Competence and Innovation: Reflecting technical proficiency (e.g., prompt engineering) and the organizational culture of adopting new technologies [38,41,43,44].
- Integration and Strategic Impact: Focusing on the alignment of AI solutions with management processes and the perceived operational benefits [37,38,39].
These dimensions were operationalized as belief domains, cognitive representations of technological outcomes and behavioral predispositions, which serve as indirect indicators of the underlying acceptability construct [17,25]. These initial theoretical dimensions were subsequently empirically reconfigured through factor analyses, resulting in the final factors labeled Intention/Predisposition and Trust/Perceived Benefit.
In addition to factor-analytic validity, the present study examines nomological validity by testing the association between scale scores and respondents’ self-reported LLM usage frequency, a behavioral criterion collected as part of the demographic questionnaire. This approach is consistent with the premise that a valid measure of a priori acceptability should correlate positively with observable behavioral engagement with the technology [25,48].
3.2. Instrument Development and Content Validation
The initial scale consisted of 17 statements (V1 to V17), formulated using a five-point Likert scale ranging from 1 (lowest value) to 5 (highest value). Item selection was grounded in a review of articles indexed in databases such as Scopus, Web of Science, and IEEE Xplore. Content validation was conducted in two stages:
- Expert Evaluation: The 17 statements were submitted to two industry experts in artificial intelligence to assess their theoretical and semantic coherence.
- Cognitive Pretest: The instrument was administered to three experienced project managers, selected by convenience sampling, in order to evaluate item clarity and response time. Minor semantic adjustments were made based on this feedback to ensure improved respondent experience.
Table 1 presents a summary of the 17 statements developed and consolidated in relation to the initial theoretical dimensions and the literature review conducted. The initial version of the scale comprised 17 items derived from the literature and organized according to the two proposed theoretical dimensions. This initial version was deliberately overinclusive, as recommended by [28], in order to allow for subsequent empirical refinement. Based on the results of the Exploratory and Confirmatory Factor Analyses, four items were excluded due to factor loadings below recommended thresholds or the presence of cross-loadings, resulting in the final version of the scale composed of 13 items distributed across two factors.

Table 1.
Proposed Statements for Measuring the Effectiveness of Prompt Use by Project Management Teams (Source: Authors’ elaboration).
An important clarification regarding the nature of the scale items is warranted. The items presented in Table 1 do not directly ask respondents whether they are willing to use LLMs or whether they find these tools personally acceptable. Instead, following the indirect measurement approach adopted in this study, the items capture two classes of cognitive indicators that constitute the observable substrate of the latent acceptability construct: outcome beliefs, which express the respondent’s evaluation of what LLMs are capable of producing in project management contexts (e.g., improved forecasting accuracy, more efficient resource allocation), and interaction efficacy beliefs, which express the respondent’s assessment of the conditions under which LLMs generate effective outputs (e.g., prompt quality, semantic alignment).
This operationalization is grounded in the Theory of Planned Behavior [25] and the reasoned action approach [26], which establish that behavioral attitudes and predispositions are constituted by beliefs about the expected consequences of performing a behavior. A respondent who systematically endorses positive outcome beliefs about LLM use in project management is, through that pattern of endorsement, expressing a favorable evaluative stance toward the technology—which is the cognitive core of a priori acceptability. This logic is analogous to established practices in attitude measurement, where the construct is inferred from beliefs about consequences rather than elicited through direct self-assessment [25,26]. The items are therefore performance-referencing by design, not by oversight: they reference AI performance as the stimulus through which the respondent’s evaluative disposition is indirectly assessed.
3.3. Participants and DATA Aquisition
Data were collected through an electronic survey conducted between March and May 2025. The target population comprised professionals engaged in project management activities, including project managers, coordinators, technical team members, and other roles directly involved in project-oriented work. Participants were recruited using a snowball sampling technique, initiated through the professional and academic networks of the research team, which is affiliated with a graduate program in project management at a Brazilian university (Universidade Nove de Julho, São Paulo, Brazil). The survey link was disseminated through professional contacts, LinkedIn groups focused on project management and technology, and academic networks in the field of business administration and information technology. No restrictions were imposed regarding industry sector, organizational size, or geographic location; however, given the recruitment channels employed, the sample is predominantly composed of professionals operating within the Brazilian context. No systematic data on participants’ geographic location or industry sector were collected as part of the demographic questionnaire, which constitutes a limitation that should be considered when assessing the generalizability of the findings. Eligibility required that respondents be currently or recently involved in project management activities, either in a managerial, coordination, or technical capacity. No minimum level of experience with LLMs was required, as the study aimed to capture acceptability judgments across the full spectrum of familiarity with the technology, including individuals with no prior use.
The final sample comprised 154 respondents. The sample size was considered adequate in accordance with the recommendations of Hair et al. [28], who suggest between 5 and 10 respondents per item in factor analysis studies, which, for an initial scale of 17 items, would indicate a minimum sample size ranging from 85 to 170 participants. Figure 1 presents a graphical representation of the distributions of the responses obtained during data collection. This visualization illustrates the response patterns for the 17 statements and allows for the observation of the frequency of each response option selected for the items.
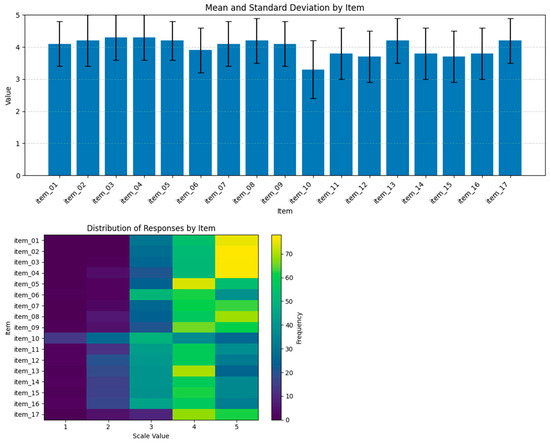
Figure 1.
Distribution of Participants’ Responses by Statements (Source: Author’s own elaboration).
It should be acknowledged that the snowball sampling technique, while widely used in organizational research targeting specialized professional populations, introduces the potential for self-selection bias, as initial respondents tend to recruit participants from their own professional networks, which may share similar attitudes, organizational contexts, and levels of familiarity with the technology under investigation [28]. The demographic profile of the sample is consistent with this concern: approximately 58% of respondents reported using LLMs daily or several times per week, which suggests a possible overrepresentation of AI-engaged professionals relative to the broader population of project management practitioners.
Furthermore, the sample was drawn predominantly from the Brazilian professional and academic context, as the survey was disseminated through networks associated with a graduate program in project management at a Brazilian university. No systematic data on geographic location, industry sector, or organizational size were collected, which limits the ability to assess the sectoral and cultural diversity of the sample. These characteristics should be taken into account when interpreting the generalizability of the findings, and future studies should employ probability-based or stratified sampling strategies, explicitly targeting diverse geographic regions, industry sectors, and organizational types, to establish the cross-contextual stability of the proposed scale.
3.4. Data Analysis
Data analysis followed an exploratory–confirmatory approach, as recommended for studies focused on the development and initial validation of psychometric scales in the applied social sciences. In accordance with the protocol proposed by Hair et al. [28], the adopted strategy combined Exploratory Factor Analysis (EFA) and Confirmatory Factor Analysis (CFA) with the objective of assessing the latent dimensionality of the construct, refining the item set, and examining the validity and reliability of the instrument.
Initially, Exploratory Factor Analysis was conducted to identify the underlying structure of the scale and to guide the empirical refinement of the items. Given the ordinal nature of the data, collected using a Likert-type scale, polychoric correlations were employed. The adequacy of the correlation matrix was assessed using the Kaiser–Meyer–Olkin (KMO) measure and Bartlett’s test of sphericity. Factor extraction was based on robust methods, and factor retention was determined through parallel analysis, which is recognized in the psychometric literature as a more accurate criterion than rules based solely on eigenvalues [28]. Items were evaluated in terms of their factor loadings and potential cross-loadings, with those presenting loadings below recommended thresholds or conceptual interpretation issues considered for exclusion.
Based on the results of the Exploratory Factor Analysis, the scale was refined, resulting in the exclusion of four items from the initial 17-item version. This procedure is consistent with the psychometric literature, which recommends the initial construction of instruments in a deliberately overinclusive manner, followed by empirical refinement based on statistical and theoretical criteria [29,46]. The refined version of the scale, composed of 13 items distributed across two factors, was then subjected to Confirmatory Factor Analysis.
The CFA aimed to confirm the factor structure identified in the exploratory stage and to evaluate the model’s fit to the empirical data. Model estimation was conducted using methods appropriate for the data distribution, and overall model fit was assessed using multiple indices, including the Comparative Fit Index (CFI), Tucker–Lewis Index (TLI), Root Mean Square Error of Approximation (RMSEA), and the Standardized Root Mean Square Residual (SRMR), following the reference criteria established by Hair et al. [28]. Internal consistency reliability was examined using appropriate coefficients, along with the assessment of convergent and discriminant validity of the construct.
Although the ideal scale validation procedure recommends the use of independent samples for exploratory and confirmatory analyses, methodological studies acknowledge that, in the early stages of instrument development, the use of the same sample is acceptable when the objective is internal validation and theoretical refinement of the construct [28,49,50]. Considering the exploratory nature of this study and its focus on scale construction, both the EFA and CFA were conducted using the same dataset. Accordingly, the results should be interpreted as preliminary evidence of construct validity, to be further examined in future studies employing independent samples.
To examine nomological validity, Spearman rank-order correlations were computed between the factor scores for Intention/Predisposition and Trust/Perceived Benefit and respondents’ self-reported LLM usage frequency (five-point ordinal scale: Daily; Several times per week; Several times per month; Rarely; Never used). Positive and statistically significant correlations were expected, consistent with the theoretical premise that higher a priori acceptability is associated with greater engagement with the technology.
4. Results
This section presents the empirical findings obtained through the application of the developed scale, focusing on the assessment of its factor structure, validity, and reliability.
4.1. Descriptive Statistics and Sample Adequacy
The measurement scale consisted of 17 items (V1 to V17), using a five-point Likert-type scale ranging from 1 (lowest value) to 5 (highest value). The sample comprised 154 respondents, recruited through snowball sampling between March and May 2025. Table 2 presents the demographic and professional characteristics of the participants.
Table 2.
Demographic and Professional Profile of the Sample.
Regarding the age profile, a concentration of professionals was observed in the 36–45 age group (34.42%), followed by those aged 26–35 (25.32%) and 46–55 (18.83%), characterizing a sample predominantly composed of professionally mature individuals. In terms of educational attainment, the sample demonstrated a high level of academic qualification, with 31.82% of respondents holding a specialization or MBA degree, 29.22% holding a bachelor’s degree, 22.73% holding a master’s degree, and 10.39% holding a doctoral degree. Only 1.95% of participants reported having secondary or technical education, while 3.89% reported postdoctoral training.
With respect to professional experience in project management, 44.81% of respondents reported more than 10 years of experience, indicating a group with high seniority in the field. Professionals with 4 to 6 years of experience accounted for 22.08% of the sample, while those with 1 to 3 years represented 20.78%. Only 5.84% reported less than 1 year of experience, and 6.49% reported between 7 and 10 years of professional experience.
Regarding job position or role, the sample was predominantly composed of project managers or project leaders (33.77%), followed by developers or technical team members (26.62%) and project coordinators or supervisors (14.94%). Project analysts or assistants represented 10.39% of the sample, while roles such as Product Owner and Scrum Master or Agile Coach showed lower representation (1.95% each). This distribution reflects a diverse sample in terms of hierarchical levels, with a predominance of professionals in leadership and coordination roles, which is appropriate given the study’s objective of assessing the acceptability of LLM use within project management teams.
Preliminary analysis indicated that the scale items exhibited skewness and kurtosis, which justified the use of polychoric correlations for factor modeling, as recommended for psychometric questionnaire data with ordinal variables. Mardia’s multivariate kurtosis analysis was statistically significant (401.247; p < 0.0001), further supporting the need for a robust factor analytic approach.
Sample adequacy for factor analysis was confirmed by two key indicators: the Kaiser–Meyer–Olkin (KMO) measure, which yielded a value of 0.791 (classified as “fair” or adequate), and Bartlett’s test of sphericity, which was highly significant (χ2 = 1686.6; df = 136; p < 0.001). The determinant of the correlation matrix was lower than 0.000001, indicating sufficient inter-item correlations for factor analysis.
4.2. Exploratory Factor Analysis (EFA)
Exploratory Factor Analysis (EFA) was conducted using the Factor software (version 12.06.07), employing a polychoric correlation matrix, the Robust Unweighted Least Squares (RULS) extraction method, and Direct Oblimin oblique rotation. Parallel Analysis (Horn), the recommended method for determining the number of factors, suggested the retention of two factors. Together, these two factors accounted for 54.4% of the total variance. Figure 2 presents a graphical representation of this analysis.
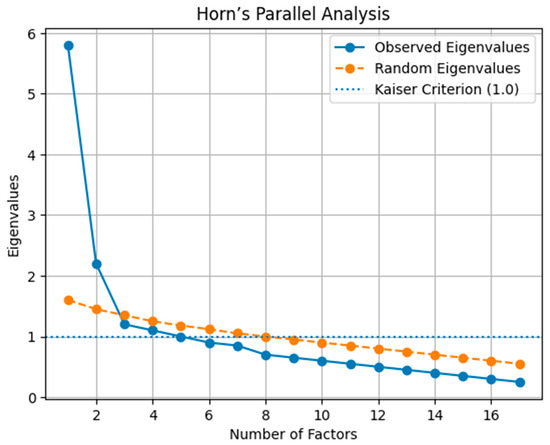
Figure 2.
Horn’s Parallel Analysis for determining the number of factors (Source: Author’s own elaboration).
The solution with two correlated factors (r = 0.373; 95% CI: 0.244–0.598) revealed a clear structure:
- Factor 1–Intention/Predisposition: Comprised items related to participants’ willingness to adopt and use the tool.
- Factor 2–Trust/Perceived Benefit: Included items associated with perceptions of the tool’s reliability and usefulness.
Assessment of Model Fit and Factor Loadings (EFA)
The global fit indices of the EFA indicated good model adequacy. The Comparative Fit Index (CFI) was 0.965, and the Non-Normed Fit Index (NNFI/TLI) was 0.954, indicating excellent fit (values > 0.95). The Goodness of Fit Index (GFI) and the Adjusted Goodness of Fit Index (AGFI) were also very high (0.979 and 0.972, respectively). The Root Mean Square Error of Approximation (RMSEA) was 0.082 (95% CI: 0.072–0.083), which is considered moderate and acceptable. In addition, the Root Mean Square of Residuals (RMSR) was 0.0679, remaining below the expected threshold (0.0808), thereby confirming the good overall fit of the two-factor model.
Table 3 presents the rotated factor loadings, confirming that most items loaded strongly (loadings ≥ 0.50) on their respective factors, which supports the construct validity of the scale.
Table 3.
Rotated Factor Loadings from the Exploratory Factor Analysis.
Some items were identified as warranting attention in future studies. Item V6 exhibited low cross-loading, and item V8 loaded on both factors, indicating that they may be candidates for revision or exclusion. Item V17 also showed a lower loading on Factor 1 (0.475). The reliability of the factor scores, measured using the ORION index, was excellent for both factors: Factor 1 = 0.933 and Factor 2 = 0.859.
4.3. Confirmatory Factor Analysis (CFA)
Confirmatory Factor Analysis (CFA) was conducted using the Factor software (version 12.06.07), employing a polychoric correlation matrix and the robust Mild-Restricted CFA approach. The tested model specified a structure of two correlated factors with all 17 original items, as determined by the EFA. This initial CFA served to confirm the factor structure and to provide an additional empirical basis for item exclusion decisions, complementing the EFA results. The bidimensional model demonstrated very good global fit, confirming the structure identified in the exploratory stage:
- RMSEA = 0.060 (95% CI: 0.050–0.061), meeting the criterion for good fit (≤0.06).
- CFI = 0.979 (95% CI: 0.971–0.988) and TLI/NNFI = 0.976, both classified as excellent fit (>0.95).
- The χ2/df ratio was 1.54 (95% CI: 1.38–1.56), below the threshold of 2.
- The Weighted Root Mean Square Residual (WRMR) was 0.135 (below 1.0).
- The GFI (0.953) and AGFI (0.946) indices also presented values close to or above the 0.95 cutoff.
The CFA confirmed the distinction between the dimensions, with a moderate and statistically significant correlation between Factor 1 and Factor 2 (r = 0.504; 95% CI: 0.376–0.690), indicating that although related, the factors represent distinct dimensions of the construct. Standardized factor loadings supported the coherence of the items with the two-factor structure:
- Factor 1 (Intention/Predisposition) demonstrated high consistency, with most items (V9–V16) loading strongly (loadings > 0.60).
- Factor 2 (Trust/Perceived Benefit) also showed consistency, with robust loadings for items V2–V5, V7, and V8 (ranging from 0.510 to 0.839). Items V1 (0.367) and V6 (0.286), however, exhibited loadings below recommended thresholds.
The CFA results reinforced the EFA evidence regarding the fragility of four items: V1 (0.367) and V6 (0.286) in Factor 2, and V17 (0.429) and V8 (cross-loading in the EFA) in Factor 1. On the basis of both the EFA and CFA evidence, these four items were excluded from the final version of the instrument, resulting in the 13-item scale. The reliability of the factor scores for the 17-item CFA model remained high: the ORION index yielded values of 0.920 for Factor 1 and 0.883 for Factor 2, which, together with high factor determinacy indices, confirms the precision of the measure. The complete CFA results for all 17 items are presented in Table 4, and the validity and reliability indicators recalculated specifically for the 13-item final scale are reported in Section 4.3.1. The CFA results are presented in Table 4.
Table 4.
Confirmatory Factor Analysis (CFA).
4.3.1. Convergent Validity, Reliability, and Discriminant Validity
To complement the assessment of the factor structure and address standard psychometric requirements for scale validation, convergent validity, internal consistency reliability, and discriminant validity were examined based on the CFA standardized factor loadings and the polychoric correlation matrix.
Convergent validity was assessed through the Average Variance Extracted (AVE) and Composite Reliability (CR) for each factor [28,51]. Because the CFA was estimated with all 17 original items whereas the final instrument comprises 13 items, the validity indicators are reported for both configurations to ensure transparency. For the full 17-item CFA model, Factor 1 yielded CR = 0.898 and AVE = 0.503, while Factor 2 yielded CR = 0.818 and AVE = 0.383. The lower AVE for Factor 2 in the 17-item model is attributable to the inclusion of items V1 (0.367), V6 (0.286), and V8 (0.510), which were subsequently excluded from the final scale. When the AVE and CR are recalculated using only the CFA standardized loadings of the 13 retained items, both factors exceed all conventional thresholds: Factor 1 (8 items: V9–V16) yields CR = 0.904 and AVE = 0.543, and Factor 2 (5 items: V2, V3, V4, V5, V7) yields CR = 0.840 and AVE = 0.518. These recalculated values confirm that the final 13-item instrument meets the convergent validity requirements established in the psychometric literature [28,51].
Discriminant validity was evaluated using both the Fornell–Larcker criterion and the Heterotrait–Monotrait (HTMT) ratio of correlations [52]. The Fornell–Larcker criterion requires that the square root of the AVE for each factor exceeds the inter-factor correlation. For the 17-item CFA model, the square root of the AVE for Factor 1 (√AVE = 0.709) and Factor 2 (√AVE = 0.619) both exceeded the inter-factor correlation (r = 0.504), satisfying this criterion. For the 13-item final scale, these margins improve further: √AVE = 0.737 for Factor 1 and √AVE = 0.720 for Factor 2, both comfortably exceeding the inter-factor correlation. Additionally, the HTMT ratio, computed from the polychoric correlation matrix of the 17-item model, yielded a value of 0.587, well below the conservative threshold of 0.85 recommended for establishing discriminant validity [52]. Together, these results provide robust evidence that the two dimensions, while correlated, represent empirically distinct facets of the LLM acceptability construct.
Internal consistency reliability was further assessed through McDonald’s omega coefficient. For the 17-item CFA model, omega yielded values of 0.898 for Factor 1 and 0.818 for Factor 2, consistent with the CR estimates and the ORION indices previously reported (0.920 and 0.883, respectively). Recalculated for the 13-item final scale, omega improves to 0.904 for Factor 1 and 0.840 for Factor 2. The convergence of these reliability indicators across different estimation approaches strengthens confidence in the precision and internal coherence of the scale. Table 5 summarizes the convergent validity, reliability, and discriminant validity indicators for both factors.
Table 5.
Convergent Validity, Internal Consistency Reliability, and Discriminant Validity Indicators.
4.4. Synthesis of Validation Results
The findings from the EFA and CFA analyses support the validity of the proposed bidimensional scale structure. The final two-factor model, Intention/Predisposition and Trust/Perceived Benefit, demonstrated robust statistical fit, high internal consistency, and preliminary construct validity. The moderate correlation between the factors is consistent with the expectation that they represent distinct yet related dimensions of the construct underlying the adoption of generative AI tools in project management.
The scale achieved a stable bidimensional solution, with high internal consistency (ORION > 0.85) and satisfactory factor loadings (>0.50 for all retained items). The four items exhibiting lower performance in both the EFA and CFA (V1, V6, V8, and V17) were excluded, resulting in a final 13-item instrument with improved convergent validity indicators (AVE > 0.50 for both factors). Figure 3 presents the confirmatory measurement model identified in this study, displaying the CFA standardized factor loadings and the inter-factor correlation, while the statements are reported in Table 6. These results reflect the empirical refinement process of the scale, as anticipated by the adopted methodological protocol.
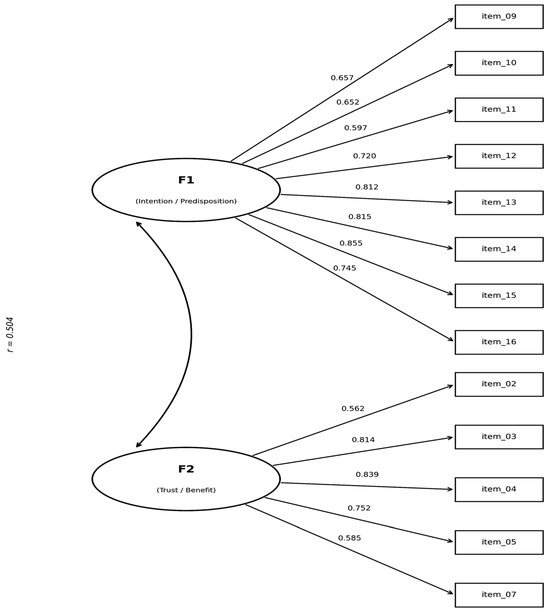
Figure 3.
Confirmatory Measurement Model of the Proposed Scale (CFA Standardized Loadings). (Source: Author’s own elaboration).
Table 6.
Scale Statements.
It should be noted that the model represented in Figure 3 is a first-order measurement model with two correlated latent factors, not a structural model in the predictive or causal sense, nor a formally estimated second-order model. The two factors, Intention/Predisposition and Trust/Perceived Benefit, are conceptualized as correlated dimensions that together compose the latent acceptability construct, and the double-headed arrow between them represents the estimated inter-factor correlation (r = 0.504). The standardized factor loadings displayed in the figure correspond to the CFA results reported in Table 4.
Within this framework, two implicit measurement hypotheses underlie the proposed structure: (H1) that the items V9–V16 are valid indicators of the Intention/Predisposition dimension, and (H2) that the items V2–V7 are valid indicators of the Trust/Perceived Benefit dimension. Both hypotheses are supported by the factor-analytic evidence presented in Section 4.2 and Section 4.3, as well as by the convergent and discriminant validity indicators reported in Section 4.3.1.
Additionally, the moderate and statistically significant inter-factor correlation (r = 0.504) supports the expectation that the two dimensions are related yet empirically distinct facets of the same higher-order construct. Future studies may extend this measurement model into a full structural model by incorporating antecedent variables (e.g., digital self-efficacy, organizational culture, Task–Technology Fit) and outcome variables (e.g., actual LLM adoption, usage frequency) to test predictive hypotheses regarding the role of acceptability in the technology adoption process.
Based on the validated factor structure and the observed psychometric properties, it is possible to synthesize a diagnostic logic for applying the LLM acceptability scale in project management contexts. Figure 4 presents an application flow derived directly from the empirical results, in which the dimensions Intention/Predisposition and Trust/Perceived Benefit support a cyclical process of diagnosis, segmentation, resource prioritization, and monitoring over time. This representation is not prescriptive in nature, but rather illustrates how the identified bidimensional structure can inform organizational analyses both prior to and during the introduction of LLMs.
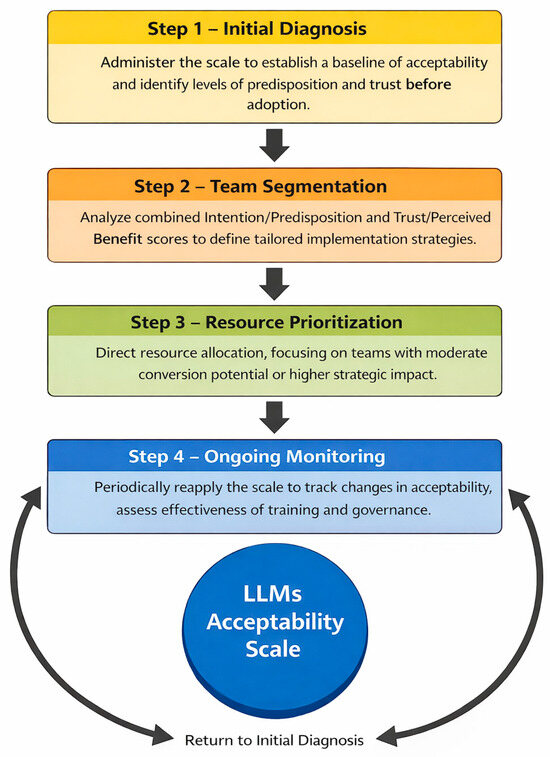
Figure 4.
Diagnostic application of the LLM acceptability scale in project management teams (Source: Author’s own elaboration).
Figure 4 illustrates a cyclical flow for applying the scale, derived from the validated factor structure, in which the dimensions Intention/Predisposition and Trust/Perceived Benefit inform stages of initial diagnosis, team segmentation, resource prioritization, and longitudinal monitoring of acceptability. These results provide the empirical basis for discussing, in the following section, the theoretical, methodological, and governance implications associated with the use of the scale in project-oriented organizational contexts.
4.5. Nomological Validity
To examine nomological validity, Spearman rank-order correlations were computed between the factor scores for Intention/Predisposition and Trust/Perceived Benefit and respondents’ self-reported LLM usage frequency. The usage frequency variable was operationalized on a five-point ordinal scale (1 = Never used; 2 = Rarely; 3 = Several times per month; 4 = Several times per week; 5 = Daily), as collected in the demographic questionnaire. Factor scores were calculated as the simple mean of the items composing each factor, as described in Appendix A.
The results indicate a positive association between both factor scores and LLM usage frequency. The Trust/Perceived Benefit factor yielded a statistically significant positive correlation with usage frequency (rs = 0.197, p = 0.015). The Intention/Predisposition factor also showed a positive correlation in the expected direction (rs = 0.153, p = 0.058), approaching but not reaching conventional significance thresholds. Descriptive inspection of mean factor scores across frequency groups is consistent with the expected monotonic pattern: respondents who reported daily use obtained higher mean scores on both dimensions (F1 = 3.94; F2 = 4.42) compared to those who reported never having used LLMs (F1 = 3.57; F2 = 4.13).
These findings provide partial support for the nomological validity of the scale. The significant association observed for Trust/Perceived Benefit is consistent with the theoretical premise that individuals who hold stronger outcome beliefs about a technology are more likely to engage with it behaviorally [25,48]. The weaker association for Intention/Predisposition, while directionally consistent, may reflect the a priori nature of that dimension: predispositional judgments formed prior to use are conceptually more distal from current behavioral engagement than trust-based outcome evaluations, and their predictive validity may be better assessed in longitudinal designs that capture the transition from pre-adoption attitudes to actual use behavior.
5. Discussion
The results of this study provide empirical evidence that the acceptability of Large Language Model (LLM) use by project management teams constitutes a multidimensional construct, structured around correlated yet conceptually distinct dimensions. This evidence is consistent with the literature that conceptualizes acceptability as a phenomenon composed of cognitive and motivational judgments, which can be assessed prospectively, prior to the effective adoption of a technological intervention [45].
The bidimensional structure contributes to theoretical advancement by clarifying how performance expectations, perceived benefits, and behavioral predispositions are organized at the a priori stage of adopting generative artificial intelligence technologies in complex organizational contexts. From a systems perspective, these judgments cannot be understood in isolation, but rather as outcomes of interactions among individuals, technological artifacts, and organizational structures, as proposed by sociotechnical approaches to technology adoption [31].
5.1. Factor Structure and Theoretical Coherence of the Construct
The two-factor solution identified through the exploratory and confirmatory analyses provides empirical support for the conception that the acceptability of LLM-based technologies constitutes an a priori judgment that precedes and conditions acceptance itself. This distinction is consistent with the literature that treats acceptability as a construct conceptually distinct from adoption or actual use, operating as a necessary condition for the implementation and appropriation of technologies in complex organizational contexts [45].
While most traditional technology adoption models primarily focus on a posteriori acceptance, assessed after concrete experience with use, prior studies have emphasized the analytical relevance of the pre-use phase, during which expectations, beliefs, and behavioral dispositions are formed and subsequently shape future behavior and the likelihood of effective adoption [16].
It is important to note that the items comprising the scale do not purport to directly elicit respondents’ personal willingness to adopt LLMs. Rather, following the logic of indirect construct measurement [25,26], the scale captures outcome beliefs and collective behavioral predispositions that constitute the cognitive substrate of a priori acceptability. The distinction is theoretically meaningful: a respondent who consistently attributes high performance outcomes to LLM use and who recognizes alignment between the technology and their project management tasks is, by that cognitive configuration, expressing a form of acceptability, even in the absence of explicit first-person willingness statements. This interpretation is further supported by the nomological validity evidence presented in Section 4.5, which shows that higher scale scores are associated with greater self-reported behavioral engagement with the technology.
The Intention/Predisposition factor reflects the acceptability dimension related to teams’ subjective willingness to incorporate LLMs into their everyday project management practices. This dimension directly engages with the concept of behavioral intention, extensively discussed in technology adoption models such as UTAUT, in which intention precedes and predicts actual technology use [13]. However, by situating this intention within a collective and organizational context, typical of project-oriented work systems, the construct also aligns with sociotechnical perspectives that emphasize the social formation of intention and technological appropriation [31].
In contrast, the Trust/Perceived Benefit factor represents the cognitive evaluation of the usefulness, reliability, and instrumental value of LLMs for project management activities. This dimension is conceptually close to perceived usefulness, as discussed in classical technology adoption models, in which perceptions of performance gains constitute the primary antecedent of usage intention [12]. In this study, the element of trust was also incorporated, which has been recognized as a distinct and complementary construct to usefulness in the evaluation of complex technologies [27]. This aspect becomes particularly relevant in generative artificial intelligence-based systems, in which algorithmic opacity and output variability may significantly affect perceived credibility and, consequently, technology acceptability in organizational contexts [21].
From Theoretical Dimensions to Empirical Factors: Reconfigurations and Factor Labeling
The initial theoretical framework proposed two dimensions: Technological Competence and Innovation, and Integration and Strategic Impact, both are derived from the literature on AI applications in project management. The first dimension was designed to capture items related to technical proficiency, including prompt engineering skills and the organizational culture of adopting new technologies, while the second was intended to capture the perceived alignment between AI tools and management processes, as well as the operational benefits attributed to their use. However, the empirical factor structure that emerged from the Exploratory Factor Analysis did not reproduce this theoretically proposed configuration, and the resulting two-factor solution required both reconceptualization and relabeling.
The divergence between the theoretical and empirical structures can be attributed to the way respondents cognitively organized the item content. Rather than distinguishing between technical competence and strategic impact, a distinction that is conceptually meaningful from a literature-based perspective, that respondents appeared to differentiate between two qualitatively different types of evaluative judgment. Items originally distributed across both theoretical dimensions clustered empirically according to whether they expressed beliefs about the concrete outcomes of AI use in project management tasks (Factor 1) or beliefs about the conditions that determine LLM effectiveness, particularly regarding prompt quality and user–technology interaction (Factor 2). This empirical reorganization is consistent with the psychometric literature on scale development, which recognizes that theoretically proposed dimensions frequently undergo reconfiguration when subjected to factor analysis, as respondents’ cognitive structures may not align with the analytical categories derived from the literature [28,29,46].
Regarding factor labeling, it is important to acknowledge that the labels assigned to the empirical factors, Intention/Predisposition and Trust/Perceived Benefit, both reflect an interpretive effort to connect the item clusters to the broader theoretical framework of technology acceptability, but they do not constitute a literal description of item content. Factor 1 (Intention/Predisposition) comprises items V9 through V16, which primarily describe perceived AI impacts on project management tasks, such as forecasting accuracy, resource allocation efficiency, decision-making speed, and stakeholder management. These items do not directly measure behavioral intention or personal willingness to adopt LLMs; rather, they capture outcome beliefs, cognitive representations of the expected consequences of technology use, which, within the Theory of Planned Behavior [25] and the reasoned action approach [26], function as antecedents and constitutive indicators of behavioral predisposition. The label “Intention/Predisposition” was therefore chosen to reflect the theoretical role of these outcome beliefs as proxies for the latent disposition toward technology adoption, rather than as a direct descriptor of item wording. A more precise alternative label, such as “Perceived Operational Impact,” could be considered in future iterations to improve the transparency of the factor’s content coverage.
Similarly, Factor 2 (Trust/Perceived Benefit) comprises items V2 through V7, which predominantly address the role of prompt engineering in shaping LLM output quality, contextual understanding, and domain adaptability. The label “Trust/Perceived Benefit” was intended to capture the evaluative dimension of these items, the degree to which respondents trust that well-structured interactions with LLMs produce reliable and beneficial outcomes. However, the label only partially reflects the specific content of the items, which centers more narrowly on the perceived efficacy of prompt-based interaction as a mediating condition for LLM performance. An alternative label such as “Perceived Interaction Efficacy” or “Confidence in Prompt-Mediated Outcomes” could more accurately represent the semantic scope of this factor in subsequent versions of the instrument.
This discussion underscores the iterative nature of scale development, in which the alignment between factor labels and item content is progressively refined across successive validation cycles [46,50]. The labels adopted in this study serve as working designations that facilitate theoretical interpretation and comparison with the existing literature, while their refinement remains an explicit objective for future research.
5.2. Intention/Predisposition as a Systemic Dimension of Acceptability
The predominance of high factor loadings on the Intention/Predisposition factor suggests that the acceptability of LLMs in project teams is strongly associated with perceptions of alignment between the technology and the operational and strategic objectives of the project management system. This evidence is consistent with the Task–Technology Fit perspective, according to which technology adoption depends on the extent to which its functionalities are perceived as appropriate to the demands and objectives of organizational tasks [42]. From a systemic standpoint, this dimension can be interpreted as an indicator of the organizational system’s adaptive readiness to incorporate new technological artifacts in contexts characterized by uncertainty and continuous change [53].
Unlike individualistic approaches to technology adoption, the results indicate that predisposition toward LLM use emerges from a set of interactions among organizational roles, work practices, and project governance structures. This interpretation aligns with sociotechnical approaches to technology adoption, which posit that usage intention and technological appropriation are collectively constructed within the context of organizational interactions [31]. In environments characterized by agile or hybrid methodologies, where continuous adaptation and decentralized decision-making are central, usage intention tends to reflect not only individual preferences but also social norms, collective performance expectations, and perceptions of the technology’s organizational legitimacy [13,30].
5.3. Trust/Perceived Benefit and the Cognitive Evaluation of Technology
The Trust/Perceived Benefit factor exhibited high internal consistency and robust factor loadings on items associated with the quality of LLM outputs, prompt clarity, and the perceived impact on the efficiency and accuracy of project management activities. These results reinforce the notion that the acceptability of LLM-based systems depends less on ease of use in a narrow sense and more on trust in the consequences of their use, particularly in contexts where users lack full visibility into the internal mechanisms of the technology [21,27].
From a sociotechnical systems perspective, trust in technology functions as a critical uncertainty-reducing element, especially in contexts involving the partial delegation of cognitive activities to automated artifacts [22]. In complex project environments, where decisions have significant and interdependent systemic effects, perceptions of benefit and reliability become fundamental prerequisites for organizational actors to be willing to integrate LLMs into their workflows and to share decision-making responsibilities with artificial intelligence-based systems [3].
5.4. Items with Lower Performance and Implications for Instrument Refinement
The empirical refinement process led to the exclusion of four items from the initial 17-item pool: V1, V6, V8, and V17. These items exhibited factor loadings below recommended thresholds in both the EFA and CFA, and were predominantly associated with more technical or abstract aspects of LLM functioning, such as the general adaptability of LLMs to real-time data (V6) and the broad positioning of LLMs as complementary decision-making tools (V17). This pattern suggests that, for a portion of respondents, technology acceptability is more strongly anchored in perceived outcomes, such as performance gains and efficiency improvements, than in detailed understandings of the underlying mechanisms. This finding is consistent with classical technology adoption models that emphasize evaluations based on perceived usefulness [12], as well as with approaches that characterize user interaction with complex technologies as primarily outcome-oriented rather than focused on the internal functioning of the system.
From a theoretical standpoint, this result reinforces the distinction between technical knowledge and acceptability judgments. In organizational systems, users may develop positive evaluations of a technology, even without an in-depth understanding of its operating principles, provided that they perceive clear performance gains and alignment with their tasks since attitudes and behavioral intentions are formed based on beliefs about perceived consequences rather than on detailed technical knowledge [25]. The exclusion of these items in the final 13-item scale is consistent with established practices in psychometric instrument development, which recommend iterative refinement based on both statistical and theoretical criteria [28,46]. Future iterations of the instrument may revisit the conceptual domains covered by the excluded items, particularly regarding the general adaptability and complementary role of LLMs, through reformulated statements designed to improve their psychometric performance.
5.5. Contributions to the Literature on Governance and Organizational Systems
This study contributes to the literature by providing a psychometrically validated instrument for measuring the acceptability of LLM use in the context of project management, addressing a relevant gap identified in recent studies on organizational governance and AI-assisted decision-making. By operationalizing acceptability as a multidimensional and a priori construct, the research extends the discussion on how emerging technologies are incorporated into complex organizational systems.
It is important, however, to specify the nature and boundaries of the practical information provided by the scale. Because the instrument is operationalized through outcome beliefs and behavioral predispositions rather than through direct measures of behavioral intention or personal willingness, the scores it produces should be interpreted as indicators of the cognitive conditions that precede and enable adoption, rather than as direct measures of adoption readiness. A project team that attributes high performance outcomes to AI use and demonstrates confidence in the efficacy of prompt-mediated interaction is exhibiting a favorable cognitive configuration for adoption, but this configuration does not guarantee that the team will effectively integrate LLMs into its workflow, as organizational barriers, resource constraints, leadership support, and institutional incentives also play determining roles [13,19]. In practical terms, a manager applying this scale would learn what teams believe about AI capabilities and how those beliefs are structured across the dimensions of perceived operational impact and interaction efficacy, information that is diagnostically valuable for identifying where cognitive resistance or skepticism may exist, but that should be complemented with assessments of organizational readiness, infrastructure availability, and change management capacity before adoption decisions are made. The diagnostic flowchart presented in Figure 4 and the application guide in Appendix A should therefore be understood as tools for mapping the belief landscape within project teams, which constitutes a necessary but not sufficient condition for informed adoption governance.
Furthermore, the empirical distinction between Intention/Predisposition and Trust/Perceived Benefit offers a useful analytical lens for understanding technology adoption dynamics in project-oriented systems, in which decisions are distributed, interdependent, and often made under conditions of uncertainty. In this regard, the proposed scale can support more refined analyses of how governance structures, management practices, and organizational contexts shape the interaction between project teams and LLM-based technologies.
6. Conclusions
This study aimed to develop and validate a psychometric scale designed to measure the acceptability of Large Language Model (LLM) use by project management teams, with a focus on a priori judgments that precede the effective adoption of these technologies. To achieve this objective, the research followed a rigorous methodological protocol for scale development and validation, combining theoretical grounding, content validation, and exploratory and confirmatory factor analyses.
The empirical results demonstrated that the acceptability of LLM use in the project management context is adequately represented by a bidimensional structure composed of the Intention/Predisposition and Trust/Perceived Benefit dimensions. Both dimensions exhibited high internal consistency, robust statistical fit, and a moderate correlation, indicating that they represent related yet conceptually distinct constructs. These findings confirm that the acceptability of generative artificial intelligence-based technologies is not limited to functional or technical evaluations but also involves behavioral dispositions and cognitive judgments formed prior to direct usage experience.
From a theoretical standpoint, this study contributes to the literature by operationalizing acceptability as a multidimensional and prospective construct, thereby extending traditional technology adoption models that tend to emphasize a posteriori evaluations. By integrating perspectives from technology adoption, sociotechnical systems, and governance in project-oriented contexts, the research provides a more appropriate analytical lens for understanding how emerging technologies are incorporated into complex organizational systems by operationalizing acceptability as a multidimensional and prospective construct measured indirectly through outcome beliefs and behavioral predispositions, thereby extending traditional technology adoption models that tend to emphasize a posteriori evaluations and direct self-report measures.
From a methodological perspective, the proposed scale represents a validated instrument that can be applied both in future research and in early organizational diagnostics related to LLM adoption. The iterative refinement process, in which four items exhibiting factor loadings below recommended thresholds were excluded on the basis of converging EFA and CFA evidence, resulted in a final 13-item instrument with adequate convergent validity (AVE > 0.50), discriminant validity, and internal consistency for both factors. Future studies may revisit the conceptual domains covered by the excluded items through reformulated statements.
Taken together, these findings allow the acceptability of LLM use in project management teams to be understood as a prospective and systemic construct, capturing judgments formed prior to the effective adoption of the technology. Unlike traditional approaches centered on individual use or a posteriori evaluation, acceptability as operationalized in this study reflects the combination of behavioral dispositions toward change and cognitive evaluations regarding trust and expected benefits. This definition broadens the understanding of the phenomenon by situating it at the level of teams and project-oriented organizational systems.
From a project governance perspective, the study’s results indicate that LLM acceptability constitutes critical information for organizational decision quality. By making visible different levels of Intention/Predisposition and Trust/Perceived Benefit, the scale enables managers, project leaders, and governance bodies to anticipate potential resistance, expectation asymmetries, and risks associated with the introduction of generative artificial intelligence-based systems. In this sense, the proposed instrument can be used as a governance mechanism, supporting decisions regarding the timing of adoption, the design of usage policies, the prioritization of investments in training, and the definition of organizational safeguards.
Despite its contributions, some limitations of this study should be acknowledged. First, the empirical validation was conducted using a single cross-sectional sample, with both the Exploratory and Confirmatory Factor Analyses performed on the same dataset of 154 respondents. While this approach is accepted in the psychometric literature as appropriate for early-stage scale development [49,50], it means that the CFA results represent a re-estimation of the structure identified in the EFA rather than an independent confirmation. Consequently, the validation evidence presented in this study should be regarded as preliminary, and the claims of construct validity are contingent upon future replication with independent samples. Cross-validation studies using separate datasets, preferably drawn from diverse organizational and cultural contexts, are essential to establish the stability and generalizability of the bidimensional factor structure.
Second, the scale measures acceptability indirectly, through cognitive outcome beliefs and behavioral predispositions that serve as structural indicators of the latent construct. This design choice reflects the theoretical premise that a priori acceptability is not directly observable [17,25] and is supported by the nomological validity evidence obtained in Section 4.5. Nevertheless, high acceptability scores do not necessarily imply effective or sustained use in the absence of favorable organizational conditions, such as leadership support, time availability, or institutional incentives. Future studies should complement the instrument with direct self-report items assessing personal willingness to adopt LLMs, allowing for triangulation between indirect and direct measurement approaches and further examination of their convergent validity.
Third, certain methodological characteristics inherent to the measurement approach adopted in this study should be acknowledged. As a broader limitation of Likert-type scales rather than a flaw specific to this instrument, such scales do not constitute equal-strength measures in practice: two respondents holding identical opinions may select different response options, such as “strongly agree” versus “agree,” introducing a degree of interpretative ambiguity in the captured responses [28]. Additionally, the formulation of the scale items predominantly presents the construct in a favorable context, which may subtly guide respondents toward more positive evaluations and, consequently, slightly inflate the measured levels of acceptability. While this positive framing is consistent with the outcome-belief operationalization adopted in this study, future iterations of the instrument could benefit from the inclusion of reverse-coded or neutrally framed items to mitigate potential acquiescence bias. Given the primarily exploratory nature of this research, these limitations are understandable and do not compromise the validity of the findings as preliminary evidence. Nevertheless, future research should complement these quantitative results with deeper qualitative investigations, such as semi-structured interviews or focus groups with project management practitioners, to capture the nuances, contextual contingencies, and interpretive processes that underlie acceptability judgments and that cannot be fully apprehended through closed-ended survey instruments alone.
Fourth, it should be acknowledged that the sample composition introduces a tension with the theoretical framing of acceptability as an a priori phenomenon. Approximately 58% of respondents reported using LLMs daily or several times per week, indicating that a substantial portion of the sample possesses accumulated experience with the technology. Since acceptability is conceptualized in this study as a set of judgments formed prior to effective adoption [16,17], the presence of experienced users raises the question of whether their responses reflect genuine a priori evaluations or are informed by a posteriori experience. Two considerations mitigate this concern. First, the sample also includes respondents with limited or no LLM experience (15.58% reported never having used LLMs and 17.54% reported only sporadic use), and the nomological validity analysis presented in Section 4.5 demonstrates that scale scores vary in the expected direction across the full frequency spectrum, which is consistent with the scale’s capacity to capture evaluative judgments at different stages of the adoption process. Second, the acceptability construct, while theoretically positioned as a priori, is not conceived as a static judgment formed exclusively before first contact with the technology; rather, it reflects ongoing cognitive representations and predispositions that are continuously updated as individuals accumulate information and experience [25,26]. In this sense, even experienced users maintain outcome beliefs and behavioral predispositions that can be meaningfully assessed and that may diverge from their actual usage patterns. Nevertheless, future studies should consider stratified sampling designs or the deliberate oversampling of non-users and novice users to enable a more precise assessment of the a priori dimension of the construct.
Fifth, given that all data were collected through a single self-reported questionnaire administered in one session using a uniform Likert-type response format, the results may be susceptible to common method bias (CMB), which can artificially inflate the correlations among the measured variables [54]. No procedural remedies, such as the inclusion of marker variables, nor post hoc statistical tests, such as Harman’s single-factor test, were implemented to assess or control for this potential source of bias. Although the emergence of a clearly defined two-factor structure rather than a single dominant factor in the EFA provides indirect evidence that common method variance does not fully account for the observed covariation among items, this evidence is not conclusive. Future studies should incorporate procedural strategies to mitigate CMB, such as introducing temporal separation between the measurement of different constructs, varying response formats, or including a theoretically unrelated marker variable to enable statistical detection and correction of common method effects.
Sixth, approximately 15.58% of respondents (n = 24) reported never having used LLMs. Given that these individuals are evaluating a technology with which they have no direct experience, their responses may reflect generalized attitudes toward artificial intelligence or expectations derived from indirect sources (e.g., media, peer reports) rather than informed evaluative judgments about LLM capabilities. This raises the question of whether their inclusion may introduce noise into the factor structure or attenuate the observed relationships. However, their inclusion is theoretically justified by the study’s conceptual framework: acceptability is defined as an a priori phenomenon that precedes actual use [16,17], and the scale is designed precisely to capture evaluative judgments formed in the absence of direct experience. Excluding non-users would restrict the measurement to individuals whose judgments are at least partially informed by a posteriori experience, thereby undermining the theoretical rationale for the instrument. Furthermore, the nomological validity analysis (Section 4.5) demonstrates that the scale scores vary monotonically across the full spectrum of usage frequency, with non-users exhibiting the lowest mean scores on both factors, which is consistent with the expected pattern and suggests that their responses contribute meaningful variance rather than random noise. Nevertheless, future studies with larger samples should conduct sensitivity analyses comparing the factor structure, loadings, and fit indices across subgroups defined by usage frequency (e.g., experienced users versus non-users) to assess the measurement invariance of the scale and to determine whether the instrument functions equivalently for populations with different levels of prior exposure to the technology.
These limitations also point to relevant avenues for future research. Longitudinal studies are particularly recommended to examine how acceptability evolves into acceptance and continued use of LLMs over time, enabling the assessment of the scale’s predictive validity with respect to actual usage behaviors. Future research may also explore the role of contextual antecedents and moderators, such as organizational culture, governance structures, project complexity, and digital maturity, in shaping the Intention/Predisposition and Trust/Perceived Benefit dimensions.
Additionally, constructs such as attitudes toward innovation, peer influence, Task–Technology Fit, digital self-efficacy, and prior experience with similar technologies may play relevant roles in explaining LLM acceptability. Incorporating these elements into more complex structural models, including mediation and moderation effects, may contribute to a deeper understanding of the psychological and contextual mechanisms governing the appropriation of generative artificial intelligence tools in project management contexts.
Author Contributions
Conceptualization: M.Z.d.C., R.P. and F.A.R.S.; Methodology, Formal analysis, Writing—original draft: M.Z.d.C. and R.P.; Writing—review and editing: M.Z.d.C., R.P., L.V. and F.S.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by FAP Uninove.
Institutional Review Board Statement
Ethical review and approval were waived for this study, as it involved anonymous survey data and posed no foreseeable risk to participants.
Informed Consent Statement
Informed consent was obtained from all participants involved in the study.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Application and Interpretation of the Scale
The Acceptability Scale for the Use of Large Language Models (LLMs) by Project Teams consists of 13 statements organized into two latent factors: Intention/Predisposition (8 items: V9, V10, V11, V12, V13, V14, V15, and V16) and Trust/Perceived Benefit (5 items: V2, V3, V4, V5, and V7). All items are answered using a five-point Likert scale ranging from 1 (“Strongly disagree”) to 5 (“Strongly agree”).
The bidimensional structure of the scale enables a differentiated assessment of both teams’ behavioral predisposition to integrate LLMs into project management practices and the cognitive judgments related to the perceived reliability and benefits of these technologies. For analytical and comparative purposes, it is recommended that factor scores be calculated using the simple mean of the items composing each factor, as follows:
Intention/Predisposition Score = (V9 + V10 + V11 + V12 + V13 + V14 + V15 + V16)/8
Trust/Perceived Benefit Score = (V2 + V3 + V4 + V5 + V7)/5
Based on the empirical distribution observed in the study sample (n = 154), scores may be interpreted across three general levels. Mean values below 3.0 indicate low levels of the evaluated factor; values between 3.0 and 4.0 reflect moderate levels; and values above 4.0 indicate high levels of acceptability in the respective dimension.
For the Intention/Predisposition factor, low scores suggest resistance or low willingness of teams to adopt LLMs in everyday project management activities, indicating the need for awareness initiatives, clarification efforts, and change management actions. Moderate scores reflect cautious openness, often associated with the absence of organizational incentives or consistent practical experience. High scores indicate strong behavioral predisposition toward integrating LLMs into work practices.
For the Trust/Perceived Benefit factor, low scores point to doubts regarding the effectiveness, reliability, and practical usefulness of LLMs, revealing skepticism toward the outcomes generated by the technology. Moderate scores indicate recognition of the tool’s potential, albeit accompanied by uncertainty or reservations. High scores reflect strong confidence in the benefits, output quality, and contribution of LLMs to the efficiency and accuracy of project management activities.
The joint analysis of both factors allows for the identification of typical acceptability profiles. Teams with low scores on both dimensions tend to exhibit generalized resistance to LLM use, requiring broad awareness-building and value demonstration interventions. Teams with high Intention/Predisposition but low Trust/Perceived Benefit appear open to adoption but require practical evidence, controlled pilot projects, and technical training to consolidate trust in the technology. Conversely, teams with high Trust/Perceived Benefit but low Intention/Predisposition recognize the value of LLMs but face organizational, cultural, or contextual barriers that inhibit effective adoption. Finally, teams with high scores on both dimensions are at an advanced stage of readiness and may act as agents for the dissemination of best practices and organizational learning.
From an applied perspective, the scale may be used as an initial diagnostic instrument in digital transformation initiatives involving artificial intelligence, as a tool for team segmentation to define differentiated implementation strategies, and as a mechanism for longitudinal monitoring of acceptability over time. In this way, the instrument provides support for both academic research and managerial practice, contributing to more informed decisions regarding the adoption, training, and governance of LLMs in project management contexts.
The proposed scale can also serve as a decision-support instrument in initiatives aimed at adopting Large Language Models (LLMs) in project management settings. In particular, its application enables project managers and organizational leaders to conduct an initial diagnosis, whereby administering the scale at the outset of AI-driven digital transformation initiatives allows the establishment of an acceptability baseline, facilitating the early identification of low levels of predisposition or trust that may represent barriers to effective technology adoption.
Subsequently, team segmentation can be performed based on the scores obtained for the Intention/Predisposition and Trust/Perceived Benefit dimensions, enabling the definition of differentiated implementation strategies. Teams with low Trust/Perceived Benefit scores tend to benefit from demonstration workshops, pilot projects, and the presentation of empirical evidence regarding efficiency and accuracy gains. Teams with low Intention/Predisposition, in turn, require strategies focused on change management, awareness of individual and collective benefits, and the creation of organizational incentives that foster adoption. Based on the resulting scores and team segmentation, resource prioritization can be undertaken, with the scale supporting investment decisions by directing efforts toward teams with greater conversion potential or higher strategic impact, such as those exhibiting moderate acceptability levels and openness to experimentation.
Finally, longitudinal monitoring can be conducted through the periodic reapplication of the scale—such as on a quarterly basis—allowing the evolution of LLM acceptability to be tracked over time. This approach makes it possible to assess the effectiveness of training, communication, and governance actions, as well as to identify stagnation or regression that may require adjustments to implementation strategies.
Appendix B. Questionnaire Administered to Participants
Use of Large Language Models (LLMs) in Project Management
Dear respondent,
Thank you for your contribution to this research.
This study is part of a Doctoral thesis in Business Administration–Project Management at Universidade Nove de Julho (PPGP-UNINOVE–São Paulo, Brazil).
This questionnaire is intended for individuals who work in project teams and will be used to support research on the effectiveness of the use of Large Language Models (LLMs) by project management teams in their daily activities. All data collected are confidential and will not be reported individually, only in aggregated form.
Large Language Models (LLMs) are artificial intelligence models trained on large volumes of data to understand and generate text in a way similar to human language.
Completing the questionnaire takes approximately 10 min. There are no right or wrong answers.
Thank you very much for your participation.
Murilo Zanini de Carvalho
Doutorando do Programa de Pós-graduação em Gestão de Projetos
PPGP-Univrsidade Nove de Julho
murilo.eletronica.mecatronica@gmail.com (e-mail primário)
Participant Profile
This section aims to collect information about your professional and demographic profile. This information will allow us to better understand the context in which you use (or may use) Large Language Models (LLMs) in activities related to project management.
We emphasize that the data provided are confidential and will be presented only in aggregated form, without individual identification.
Question—Age [Numeric response]
Question—Level of Education
- Secondary/Technical Education
- Bachelor’s Degree
- Specialization/MBA
- Master’s Degree
- Doctoral Degree (PhD)
- Postdoctoral Training
Questão-Project management experience
- Less than 1 year
- 1–3 years
- 4–6 years
- 7–10 years
- More than 10 years
Question—Please indicate below which project management approach you have used for the longest period in your professional activities
- Tradicional (predictive)–a structured approach with detailed planning from the outset and a clearly defined scope.
- Agile (adaptive)–a flexible, incremental approach with detailed planning from the outset and a clearly defined scope.
- Hybrid–experience with both methodologies, either within the same Project or across different projects and periods.
Question—Which role do you usually perform in project management teams? Please select the option that best represents your usual or predominant role.
- Project Manager or Team Leader
- Project Coordinator or Supervisor
- Project Analyst or Assistant
- Product Owner
- Scrum Master or Agile Coach
- Developer or Technical Team Member
- External Consultant
- Other role
Question—How often do you use Large Language Models (LLMs) in your activities related to project management? Please select the option that best represents your frequency of use:
- Daily
- Several times a week
- Several times a month
- Rarely (sporadic use)
- I have never used them
Technological Competence and Innovation
The following questions address both practical expertise (specific technical skills, such as prompt engineering) and the culture of innovation and willingness to adopt new technologies in projects. In project management terms, this reflects the individual’s ability to evolve through the use of technologies, learn, and innovate continuously.
Question—Users with greater technical familiarity are better positioned to leverage the benefits of Large Language Models (LLMs) in software development.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—The effectiveness of Large Language Models (LLMs) directly depends on users’ ability to create well-structured prompts.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Prompt engineering enhances the ability of Large Language Models (LLMs) to understand context and infer missing responses.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—The effectiveness of Large Language Models (LLMs) directly depends on the quality and clarity of the prompts used.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Semantic similarity between the examples provided and the target task improves the performance of Large Language Models (LLMs).
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Methods based on Large Language Models (LLMs) adapt well to the growth of real-time data.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Prompt engineering enables the efficient adaptation of Large Language Models (LLMs) to different domains and task-specific applications.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Automation in prompt design can enhance accessibility and efficiency in the use of Large Language Models (LLMs).
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Integration and Strategic Impact
These questions emphasize how Artificial Intelligence (AI) solutions (including Large Language Models–LLMs) fit into Project Management processes and how the use of these tools affects strategic and operational outcomes. This construct focuses on the practical application of AI (integration and automation) and the value generated (strategic and operational impact).
Question—Artificial Intelligence (AI) systems with prompt engineering contribute to faster and more effective decision-making in complex projects.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—The application of Large Language Models (LLMs) reduces the need for human analyst intervention in the validation of Critical Security Controls (CSCs). CSCs serve as practical guidelines for implementing essential protection measures, such as access control, vulnerability management, and continuous monitoring, ensuring that projects are aligned with security best practices and reducing exposure to threats.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—The automation of user story classification significantly reduces manual effort and errors associated with subjectivity.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—The use of Artificial Intelligence (AI) tools improves forecasting accuracy in project management.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—The use of Artificial Intelligence (AI) in project management tools significantly improves efficiency and accuracy in task execution.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Artificial Intelligence (AI) tools facilitate efficient resource allocation in complex projects.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Artificial Intelligence (AI) tools optimize resource allocation in agile projects, maximizing team efficiency.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Generative Artificial Intelligence (AI) assistants improve efficiency in stakeholder management within projects.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
Question—Large Language Models (LLMs) can be used as complementary tools to support project managers in decision-making processes.
- Strongly disagree
- Disagree
- Neither agree nor disagree
- Agree
- Strongly agree
References
- Iriarte, C.; Bayona, S. IT projects success factors: A literature review. Int. J. Inf. Syst. Proj. Manag. 2020, 8, 49–78. Available online: https://aisel.aisnet.org/ijispm/vol8/iss2/4 (accessed on 9 November 2025). [CrossRef]
- Gemino, A.; Reich, B.; Serrador, P. Agile, traditional, and hybrid approaches to project success: Is hybrid a poor second choice? Proj. Manag. J. 2021, 52, 87–100. [Google Scholar] [CrossRef]
- Morcov, S.; Pintelon, L.; Kusters, R. Definitions, characteristics and measures of IT project complexity: A systematic literature review. Int. J. Inf. Syst. Proj. Manag. 2021, 8, 5–21. [Google Scholar] [CrossRef]
- Mata, M.N.; Martins, J.M.; Inácio, P.L. Impact of absorptive capacity on project success through mediating role of strategic agility: Project complexity as a moderator. J. Innov. Knowl. 2023, 8, 100327. [Google Scholar] [CrossRef]
- Cruz, R.N.; Rosário, A.T. Data-driven decision-making in marketing: A systematic literature review of emerging themes and research gaps. Systems 2025, 13, 1114. [Google Scholar] [CrossRef]
- Carayannis, E.G.; Morawska-Jancelewicz, J. The futures of Europe: Society 5.0 and Industry 5.0 as driving forces of future universities. J. Knowl. Econ. 2022, 13, 3445–3471. [Google Scholar] [CrossRef]
- Hofmann, P.; Jöhnk, J.; Protschky, D.; Urbach, N. Developing purposeful AI use cases: A structured method and its application in project management. In Proceedings of the 15th International Conference on Wirtschaftsinformatik (WI), Potsdam, Germany, 9–11 March 2020; Available online: https://www.researchgate.net/publication/337482021_Developing_Purposeful_AI_Use_Cases_-_A_Structured_Method_and_Its_Application_in_Project_Management (accessed on 9 November 2025).
- Abbas, Q.; Younus, W.; Malik, S.; Hassan, M.H. ChatGPT: The next frontier in software project management. Int. Eur. Ext. Enablement Sci. Eng. Manag. 2023, 11. Available online: https://www.ieeesem.com/journal_volume11_issue9_September_2023_edition.html (accessed on 9 November 2025).
- Dukhiram, D.K.; Chitta, S.; Bonam, V.S.M.; Katari, P.; Thota, S. AI-assisted project management: Enhancing decision-making and forecasting. J. Artif. Intell. Res. 2023, 3, 146–169. Available online: https://thesciencebrigade.com/JAIR/article/view/333 (accessed on 9 November 2025).
- Khalil, M.; Bravo, A.; Vieira, D.; Carvalho, M.M. Mapping the AI landscape in project management context: A systematic literature review. Systems 2025, 13, 913. [Google Scholar] [CrossRef]
- Rane, N. Role of ChatGPT and similar generative artificial intelligence (AI) in construction industry. SSRN Electron. J. 2023. [Google Scholar] [CrossRef]
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef]
- Venkatesh, V.; Thong, J.Y.L.; Xu, X. Consumer acceptance and use of information technology: Extending the unified theory of acceptance and use of technology. MIS Q. 2012, 36, 157–178. [Google Scholar] [CrossRef]
- Jeyaraj, A.; Rottman, J.W.; Lacity, M.C. A review of the predictors, linkages, and biases in IT innovation adoption research. J. Inf. Technol. 2006, 21, 1–23. [Google Scholar] [CrossRef]
- Orlikowski, W.J.; Iacono, C.S. Desperately seeking the “IT” in IT research: A call to theorizing the IT artifact. Inf. Syst. Res. 2001, 12, 121–134. [Google Scholar] [CrossRef]
- Barcenilla, J.; Bastien, J.M.C. Acceptability of new technologies: Ergonomic and cognitive aspects. Int. J. Hum. Comput. Interact. 2009, 25, 124–153. [Google Scholar] [CrossRef]
- Alexandre, B.; Reynaud, E.; Osiurak, F.; Navarro, J. Acceptability and acceptance of new technologies: A conceptual distinction and future research agenda. Technol. Forecast. Soc. Change 2018, 133, 204–215. [Google Scholar] [CrossRef]
- Barcaui, A.; Monat, A. Who is better in project planning? Generative artificial intelligence or project managers? Proj. Leadersh. Soc. 2023, 4, 100101. [Google Scholar] [CrossRef]
- Felicetti, A.M.; Cimino, A.; Mazzoleni, A.; Ammirato, S. Artificial intelligence and project management: An empirical investigation on the appropriation of generative chatbots by project managers. J. Innov. Knowl. 2024, 9, 100545. [Google Scholar] [CrossRef]
- Keding, C. Understanding the interplay of artificial intelligence and strategic management: Four decades of research in review. Manag. Rev. Q. 2021, 71, 91–134. [Google Scholar] [CrossRef]
- Siau, K.; Wang, W. Building trust in artificial intelligence, machine learning, and robotics. Cutter Bus. Technol. J. 2018, 31, 47–53. Available online: https://www.researchgate.net/publication/324006061_Building_Trust_in_Artificial_Intelligence_Machine_Learning_and_Robotics (accessed on 3 November 2025).
- Parasuraman, R.; Sheridan, T.B.; Wickens, C.D. A model for types and levels of human interaction with automation. IEEE Trans. Syst. Man Cybern. Part A 2000, 30, 286–297. [Google Scholar] [CrossRef]
- Zadeh, E.K.; Khoulenjani, A.B.; Safaei, M. Integrating AI for agile project management: Innovations, challenges, and benefits. Int. J. Ind. Eng. Constr. Manag. 2024, 1, 1–10. Available online: https://www.ijiecm.com/index.php/ijiecm/article/view/1 (accessed on 10 February 2026).
- Tricot, A.; Plégat-Soutjis, F.; Camps, J.F.; Amiel, A.; Lutz, G.; Morcillo, A. Utilité, Utilisabilité, Acceptabilité: Interpréter les Relations Entre Trois Dimensions de l’Évaluation des EIAH. In Environnements Informatiques pour l’Apprentissage Humain (EIAH). 2003, pp. 391–402. Available online: https://edutice.hal.science/edutice-00000154v1 (accessed on 3 November 2025).
- Ajzen, I. The theory of planned behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Fishbein, M.; Ajzen, I. Predicting and Changing Behavior: The Reasoned Action Approach; Psychology Press: New York, NY, USA, 2010. [Google Scholar]
- Gefen, D.; Karahanna, E.; Straub, D.W. Trust and TAM in online shopping: An integrated model. MIS Q. 2003, 27, 51–90. [Google Scholar] [CrossRef]
- Hair, J.F.; Gabriel, M.L.D.S.; da Silva, D.; Braga Junior, S. Development and validation of attitudes measurement scales: Fundamental and practical aspects. RAUSP Manag. J. 2019, 54, 490–507. [Google Scholar] [CrossRef]
- Boateng, G.O.; Neilands, T.B.; Frongillo, E.A.; Melgar-Quiñonez, H.R.; Young, S.L. Best practices for developing and validating scales for health, social, and behavioral research: A primer. Front. Public Health 2018, 6, 149. [Google Scholar] [CrossRef] [PubMed]
- Hoda, R.; Noble, J.; Marshall, S. Self-organizing roles on agile software development teams. IEEE Trans. Softw. Eng. 2013, 39, 422–444. [Google Scholar] [CrossRef]
- De Sanctis, G.; Poole, M.S. Capturing the complexity in advanced technology use: Adaptive structuration theory. Organ. Sci. 1994, 5, 121–147. [Google Scholar] [CrossRef]
- Lu, Y. Artificial intelligence: A survey on evolution, models, applications and future trends. J. Manag. Anal. 2019, 6, 1–29. [Google Scholar] [CrossRef]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Topsakal, O.; Akinci, T.C. Creating large language model applications utilizing LangChain: A primer on developing LLM apps fast. In Proceedings of the 5th International Conference on Applied Engineering and Natural Sciences, Konya, Turkey, 10–12 July 2023. [Google Scholar] [CrossRef]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (LLM) security and privacy: The good, the bad, and the ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Camilleri, M.A. Artificial intelligence governance: Ethical considerations and opportunities. Expert Syst. 2024, 41, e13406. [Google Scholar] [CrossRef]
- Steyvers, M.; Tejeda, H.; Kumar, A.; Belem, C.; Hu, X.; Mayer, L.; Smyth, P. What large language models know and what people think they know. Nat. Mach. Intell. 2024, 7, 221–231. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, Z.; Langrené, N.; Zhu, S. Unleashing the potential of prompt engineering for large language models. Patterns 2025, 6, 101260. [Google Scholar] [CrossRef]
- Liao, Q.V.; Wortman Vaughan, J. AI transparency in the age of LLMs: A human-centered research roadmap. Harv. Data Sci. Rev. 2024. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, H.; Yang, F.; Liu, N.; Deng, H.; Cai, H.; Wang, S.; Yin, D.; Du, M. Explainability for large language models: A survey. ACM Trans. Intell. Syst. Technol. 2024, 15, 20. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 195. [Google Scholar] [CrossRef]
- Goodhue, D.; Thompson, R.L. Task-technology fit and individual performance. MIS Q. 1995, 19, 213–236. [Google Scholar] [CrossRef]
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D.C. A prompt pattern catalog to enhance prompt engineering with ChatGPT. In Proceedings of the 30th Conference on Pattern Languages of Programs (PLoP ’23); The Hillside Group: Rochester, NY, USA, 2023; pp. 1–31. Available online: https://dl.acm.org/doi/10.5555/3721041.3721046 (accessed on 3 November 2025).
- Marvin, G.; Raudha, N.H.; Jjingo, D.; Nakatumba-Nabende, J. Prompt engineering in large language models. In Data Intelligence and Cognitive Informatics. ICDICI 2023. Algorithms for Intelligent Systems; Springer: Singapore, 2024. [Google Scholar] [CrossRef]
- Sekhon, M.; Cartwright, M.; Francis, J.J. Acceptability of healthcare interventions: An overview of reviews and development of a theoretical framework. BMC Health Serv. Res. 2017, 17, 88. [Google Scholar] [CrossRef]
- Hinkin, T.R. A review of scale development practices in the study of organizations. J. Manag. 1995, 21, 967–988. [Google Scholar] [CrossRef]
- Bèrnie, J.P.; Fernandez, V. La validation sémantique dans la construction d’outils de mesure. Rev. Int. Psychol. Soc. 2012, 25, 5–36. [Google Scholar]
- Cronbach, L.J.; Meehl, P.E. Construct validity in psychological tests. Psychol. Bull. 1955, 52, 281–302. [Google Scholar] [CrossRef]
- Anderson, J.C.; Gerbing, D.W. Structural equation modeling in practice: A review and recommended two-step approach. Psychol. Bull. 1988, 103, 411–423. [Google Scholar] [CrossRef]
- Hinkin, T.R. A brief tutorial on the development of measures for use in survey questionnaires. Organ. Res. Methods 1998, 1, 104–121. [Google Scholar] [CrossRef]
- Fornell, C.; Larcker, D.F. Evaluating structural equation models with unobservable variables and measurement error. J. Mark. Res. 1981, 18, 39–50. [Google Scholar] [CrossRef]
- Henseler, J.; Ringle, C.M.; Sarstedt, M. A new criterion for assessing discriminant validity in variance-based structural equation modeling. J. Acad. Mark. Sci. 2015, 43, 115–135. [Google Scholar] [CrossRef]
- Weick, K.E.; Sutcliffe, K.M. Managing the Unexpected: Resilient Performance in an Age of Uncertainty, 2nd ed.; Jossey-Bass: San Francisco, CA, USA, 2007; Available online: https://www.researchgate.net/publication/265106124_Managing_the_Unexpected_Resilient_Performance_in_an_Age_of_Uncertainty (accessed on 14 November 2025).
- Podsakoff, P.M.; MacKenzie, S.B.; Lee, J.-Y.; Podsakoff, N.P. Common method biases in behavioral research: A critical review of the literature and recommended remedies. J. Appl. Psychol. 2003, 88, 879–903. [Google Scholar] [CrossRef] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.