

Forecasting 2026, 8(3), 50; https://doi.org/10.3390/forecast8030050 (registering DOI) - 12 Jun 2026
Abstract
This study proposes a hybrid forecasting framework that integrates Kalman Filtering (KF), Markov Switching (MS), and nonlinear recurrent learning for stock-index prediction. The KF component smooths short-term price noise, the MS model identifies latent return–volatility regimes, and the LSTM/GRU components learn nonlinear temporal
[...] Read more.
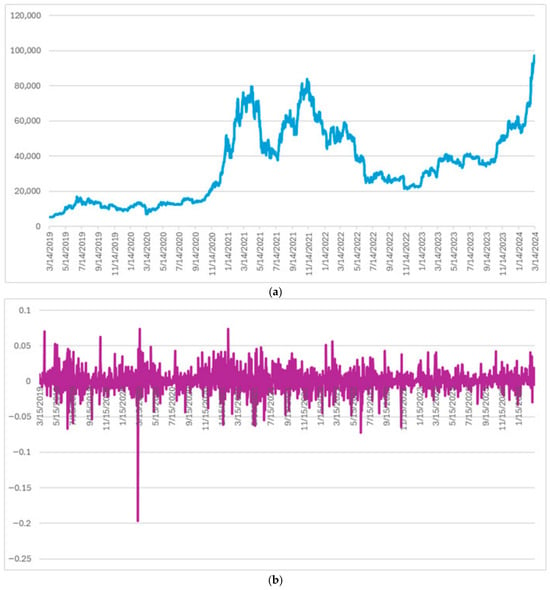
This study proposes a hybrid forecasting framework that integrates Kalman Filtering (KF), Markov Switching (MS), and nonlinear recurrent learning for stock-index prediction. The KF component smooths short-term price noise, the MS model identifies latent return–volatility regimes, and the LSTM/GRU components learn nonlinear temporal patterns from regime-conditioned information. The framework is evaluated using the CSI 300, S&P 500, and Nikkei 225 indices through forecasting-accuracy measures, Bootstrap Diebold–Mariano tests with Modified Bayes Factor evidence, out-of-sample trading simulations, and robustness checks. The empirical results show that regime conditioning is the primary source of forecasting and economic improvement. KF–MS–LSTM performs best for the CSI 300 and Standard MS performs strongest for the S&P 500, while KF–MS–LSTM and KF–MS–GRU are more competitive for the Nikkei 225. In contrast, models without regime information, including pure LSTM/GRU and the standalone Transformer, generally exhibit weaker forecasting and trading performance. The findings suggest that latent market-state information is more important than neural-network complexity alone for robust financial forecasting, while the incremental value of Kalman filtering and recurrent learning remains market dependent. Overall, the results support regime-aware forecasting as an interpretable and economically meaningful approach for stock-index prediction under heterogeneous market environments.
Full article




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}