Abstract
The development of robust and efficient computational methodologies is crucial for vision-based flame detection systems. While deep learning has shown promise, many existing models are direct applications of generic architectures, lacking principled methodologies to address the inherent physical characteristics of flame, such as heat diffusion and multi-scale radiative patterns. To bridge this gap, this paper proposes FlameDet, a novel flame detection framework grounded in physics-inspired computing and multi-resolution analysis. Unlike conventional approaches, FlameDet formulates visual feature propagation through the lens of heat conduction physics. The core contribution is the Heat Diffusion Module, a computationally efficient backbone that explicitly models feature spread by solving a parameterized heat equation via discrete cosine transform. This physics-aligned design achieves a global receptive field with complexity, processing high-resolution inputs 2× faster with 54% less memory than RT-DETR-ResNet50, while providing an interpretable computational process. Furthermore, a High–Low Frequency Analysis module is proposed, a multi-resolution computational strategy that decomposes features into low-frequency components for global context and high-frequency components for fine-grained details. To enhance contextual reasoning for small flames without computational penalty, a DSK_C3 module that employs dilated convolutions and structural re-parameterization is designed, expanding the receptive field and by 26.5%. Extensive experiments on FlameLife dataset demonstrate that FlameDet establishes a new state-of-the-art, improving the F1-score and AP50 by 3.5% and 4.0%, respectively, while maintaining superior efficiency.
1. Introduction
In computational science and engineering, developing effective computational models to simulate physical phenomena remains a research challenge. This is particularly true for the visual understanding of dynamic processes like flame propagation. Conventional Convolutional Neural Networks (CNNs) [1,2] and Vision Transformers (ViTs) [3,4] often rely on physics-agnostic operators, failing to leverage the inherent physical principles governing the underlying processes. This misalignment in modeling leads to issues both in computational efficiency and robustness. Models require extensive parameters to learn features that could be explicitly guided by physical laws, and they often demonstrate fragility when confronted with out-of-distribution interference, such as thermal imaging artifacts from high-temperature metals.
While object detection architectures like YOLO [5,6,7,8] and Faster R-CNN [9,10,11] have been successfully applied to flame recognition, they remain general-purpose recognition tools. Consequently, they suffer from fundamental bottlenecks including high false-positive rates, significant miss rates for small flames, and notable performance degradation in complex environments. Although recent studies have explored physics inspired models [12] and frequency domain analysis [13], the systematic integration of these ideas into an efficient and end-to-end visual detection framework remains an open problem. Specifically, current methods for enlarging the receptive field to detect small flames incur substantial computational overhead, lacking lightweight solutions.
To address these challenges, FlameLife is presented, a new dataset collected specifically for flame detection under diverse scenarios, as illustrated in Figure 1. Subsequently, FlameDet is proposed, a physics-inspired computational framework for real-time flame detection. The core contribution of this work lies in its computational methodology, rather than merely being another detector with improved performance. The process of feature extraction and propagation is rebuild to align with physical principles and efficient computational strategies.

Figure 1.
Demo of flame detection dataset. To enhance the generalization ability of the model, flame detection data from different scenarios is collected, including: varying lighting, weather, flames of small targets or interference from heat-based artifacts.
The computational methodology presented in this paper provides a generalizable paradigm for integrating physical principles and adaptive numerical analysis into visual models. Its value may extend to other visual recognition tasks governed by diffusion processes. The source code and the dataset will be made publicly available to facilitate further research.
The remainder of this paper is organized as follows. Section 2 reviews related work on vision-based and sensor-based flame detection. Section 3 describes the proposed FlameDet framework, including the Heat Diffusion Module, High–Low Frequency Analysis module, and DSK_C3 module. Section 4 presents experimental setups, results, ablation studies, and case analyses. Section 5 discusses the findings and outlines limitations and future research directions, while Section 6 concludes the paper.
2. Related Work
Flame detection techniques are primarily divided into two categories: vision-based methods [14] and sensor-based approaches [15]. Early vision-based methods often relied on handcrafted color and texture features [16], while recent advances leverage deep learning. With the advances in deep learning, vision-based flame detection has seen substantial improvement in performance and reliability [17]. Recent comprehensive reviews have surveyed the landscape of deep learning-based fire and smoke detection [18].
Numerous studies have contributed to this progress. For instance, Muhammad et al. developed an efficient CNN-based system using lightweight architectures without dense layers, reducing computational cost for detecting fire in videos under uncertain surveillance conditions [19]. Similarly, Li et al. proposed a method that better balances detection accuracy and processing speed in [20], achieving a 3.76% faster inference on GPU and a 63.64% reduction in model size compared to suboptimal methods, respectively. To enhance feature discrimination, Yar et al. proposed a Dual Fire Attention Network (DFAN) that integrates channel and spatial attention mechanisms to highlight critical features and spatial structures, improving the separation of fire and non-fire objects [21]. Incorporating traditional image processing with deep learning, Huang et al. designed a Wavelet-CNN model that employs a 2D Haar transform for multi-scale spectral feature extraction, integrated at different CNN stages [22]. Their model improves fire detection accuracy and reduces false alarms, especially for the light-weight MobileNet v2. To reduce false alarms, Zulfiqar et al. proposed a Stacked Encoded EfficientNet that improves recognition accuracy through cost-sensitive learning in [23]; they use dense connections to ensure effective fire scene recognition, where the weights are randomly initialized to solve the vanishing gradient problems and provide fast convergence speed. Addressing domain adaptation issues, Hikmat et al. utilized mono-depth and atmospheric models to generate synthetic training images under diverse conditions such as haze, fog, and nighttime [24], and to further enhance the detection of small fire-affected areas, a refined DenseNet backbone is employed. For better interpretability and performance under limited data, Yang et al. presented a pixel-precision detection algorithm named Preferred Vector Machine, and to guarantee high fire detection rate under precise control, they introduce a new L0 norm constraint to the fire class, thus offering high precision and controllable detection rates [25]. Yar et al. also modified YOLOv5 by incorporating a stem block, refining the SPP Neck with smaller kernels, and adding a P6 module, leading to improved detection of both small and large fire regions with reduced model complexity [26]. Further integrating classical and deep learning techniques, Zhao et al. proposed the Fire Segmentation-Detection Framework (FSDF), which combines color (HSV) and texture (CLBP) features to enhance flame region detection [27], they also use YOLOv8 and vector quantized variational autoencoders to facilitate image segmentation and carry out unsupervised fire detection. Kong et al. developed an attention-guided dual-encoding network for pixel-level fire segmentation, aggregating spatial and semantic features through a dedicated fusion module [28]. For model compression, Tao et al. introduced a knowledge distillation framework that transfers learning to a pruned network, significantly reducing parameters while maintaining performance [29,30]. Yar et al. further combined 3D convolutions with a modified soft attention mechanism within a MobileNet architecture to optimize feature extraction and control computational cost [31]. Feng et al. introduced a multi-scale fire detection method capable of handling varied image sizes [32], they first use dense connection to enhance the information flow between different layers, then use groups channel attention to recalibrate the features. To tackle the scarcity of high-quality datasets, Zheng et al. proposed a diffusion-based augmentation framework combined with a deformable DETR architecture for improved detection in complex environments [33]. Most recently, Khan et al. designed a Cross-Module Attention Network (CANet) to improve detection accuracy while maintaining manageable model complexity [34]. These efforts reflect a consistent trend toward integrating architectural innovation, multi-modal feature extraction, and efficiency-oriented designs to address key challenges in flame detection, including false alarms, limited data, model size, and real-time requirements.
Sensor-based flame detection has been explored through various technological approaches. And ensor-based approaches have been reviewed in [35]. Huang et al. employed a 4H-SiC phototransistor detector capable of sensing weak UV light, along with a dedicated circuit system that converts photogenerated analog current into digital voltage signals for transmission to a host computer [36]. Morchid et al. introduced an IoT-based framework for early fire detection that combines smoke and flame sensors with a Raspberry Pi for on-site processing and ThingSpeak for data visualization and storage [37]. In another study, bio-inspired event cameras were investigated for flame detection due to their advantages over conventional RGB cameras in handling issues such as static backgrounds, overexposure, and redundant data [38]. Additionally, to address the latency and reliability limitations of traditional wildfire detection methods like satellite and remote camera systems, Ramadan et al. proposed an unmanned aerial vehicle (UAV)-assisted IoT system aimed at wildfire sensing, detection, and suppression [39].
Despite these improvements, several challenges persist. Many vision-based models still struggle with generalization across diverse and complex environments (e.g., varying lighting, weather, or interference from heat-based artifacts). Sensor-based methods often require specialized hardware, are sensitive to calibration and environmental conditions, and may lack contextual understanding. Additionally, both categories frequently rely on large, high-quality datasets, which are often scarce or costly to acquire. Many proposed systems also face trade-offs between detection accuracy and computational efficiency, limiting their practical deployment in resource-constrained scenarios. Overall, while existing methods each offer distinct strengths, a robust and universally applicable flame detection system remains an open research challenge.
3. Methods
The flame detection framework follows the classic object detection architecture, comprising three main components—the backbone, the neck, and the head—as depicted in Figure 2. The backbone is built upon the heat diffusion module (HDM), which provides a computationally efficient and physically intuitive approach to visual modeling by emulating heat diffusion processes in images. Its key advantage lies in efficient global feature propagation through lightweight spectral operations rather than computationally expensive attention mechanisms. More importantly, the physics-inspired design aligns naturally with fire dynamics; similar to how real flames propagate thermal energy via conduction and radiation, the HDM treats image patches as heat sources that diffusively spread features across the scene. This inherent correspondence enables accurate modeling of fire characteristics—such as thermal gradients and smoke plumes—while maintaining real-time performance essential for emergency response applications. In the neck section, high–low frequency attention module (HLFA) is introducted, which enables the model to capture both global patterns and local details effectively [13]. HLFA decomposes visual features into two complementary pathways: one focuses on low-frequency information such as large-scale heat distribution via efficient low-resolution analysis, while the other extracts high-frequency details including flame edges and smoke textures using high-pass filtering and localized operations. The two streams are adaptively fused, allowing the model to represent fire signatures across scales with minimal computational overhead—making it well-suited for real-time detection. To further improve inference speed, the neck part is redesigned into a new module termed DSK_C3, which means using dilated small kernels by C3 structure [40]. DSK_C3 incorporates dilated convolutions to enlarge the receptive field without increasing parameters, improving the detection of small and distant flames by integrating contextual information such as smoke patterns. The module employs a multi-branch design during training that is streamlined into a simple and efficient structure during deployment. This enhancement strengthens recognition performance for challenging cases without compromising inference speed. The detection head adopts a detection transformer (DETR) structure, which further enhances end-to-end detection performance. These contributions allow FlameDet to achieve high accuracy in flame detection while operating at speeds suitable for real-world real-time applications.
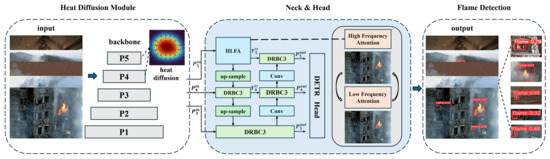
Figure 2.
Structure of the flame detection framework. The head and neck adopt classic feature pyramid network structure, the feature maps from different levels (P3, P4, and P5) are merged with lateral connections. Heat Diffusion Module is used at P4 and P5 levels of the backbone. For the neck section, the High–Low Frequency Analysis module is introduced to help the model fully understand both the broad patterns and fine details in the image. And the dilated convolutional layers are reconstructed using a C3-based approach to make the model more lightweight. The head adopts a detection transformer (DETR) head.
3.1. Heat Diffusion Module
The adoption of heat diffusion as the backbone for flame detection is motivated by its inherent physical alignment with thermal dynamics and its computational advantages [12]. Flame patterns naturally follow heat diffusion principles, such as spatial propagation of thermal energy, gradient transitions, and radiative characteristics, which align precisely with the HDM’s foundational analogy of image patches as heat sources governed by conduction laws. In contrast to attention-based models [41,42,43], which suffer from quadratic computational complexity, or convolutional networks constrained by local receptive fields, the HDM achieves global contextual modeling with only complexity. This efficiency enables high-resolution inputs, which is essential for detecting subtle flame signatures like smoke-thermal boundaries. And the HDM can minimize GPU memory by 75% and tripling inference throughput compared to Swin-Transformer. Moreover, the HDM’s physics-inspired design offers interpretable feature propagation, increasing its reliability in safety-critical fire monitoring applications.
As shown in Figure 3, the HDM employs a multi-scale hierarchical architecture consisting of four stages, with progressive downsampling of feature maps and increasing channel dimensions. At its core lies the Heat Conduction Operator (HCO), which replaces standard self-attention through a three-step process. The first step is Spectral Transformation. Patch-embedded input features are transformed via 2D Discrete Cosine Transform (DCT), converting spatial representations into spectral components:
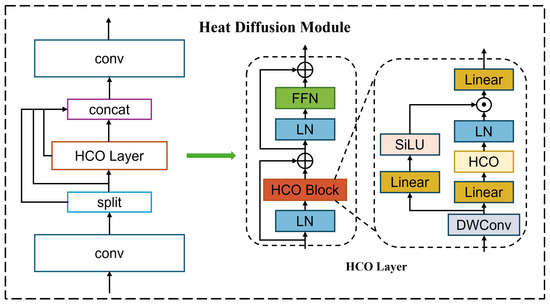
Figure 3.
Heat diffusion backbone of FlameDet. It mainly includes C2f structure and heat diffusion structure. The inspiration for the HDM mainly comes from the heat transfer in physics. The C2f structure is used to lightweight it to ensure the real-time performance of flame detection.
The second step is adaptive diffusion. Frequency-specific diffusion rates k are learned using frequency value embeddings that encode spectral coordinates . A conduction kernel modulates the frequency components F, with k adapting spatially to image content to enable content-aware feature propagation. The last step is inverse transformation. The modulated features are transformed back to the spatial domain via inverse DCT, where t denotes the virtual diffusion time step:
Both DCT and inverse DCT are implemented as block-wise 2D DCT over non-overlapping patches. A pre-computed DCT matrix is applied via matrix multiplication, which is fully differentiable and compatible with standard deep learning frameworks. The spatial frequency coordinate is computed directly on the same grid and passed through a frequency value embedding to obtain the diffusion rate k.
Each HCO layer is followed by a channel-wise multi-layer perceptron, forming a Heat Conduction Block (HCB). Between stages, patch merging is used to reduce spatial resolution. This design achieves a global receptive field comparable to vision transformers [44], while reducing floating point operations and accelerating inference on high-resolution inputs.
3.2. High–Low Frequency Analysis
Effective flame detection requires analyzing both large-scale thermal patterns, such as heat distribution, and fine-grained details like flickering edges or smoke textures. Conventional attention mechanisms process all image regions uniformly, which often leads to inefficient resource usage in low-frequency regions and insufficient capture of high-frequency features essential for accurate fire recognition. High–Low Frequency Analysis module solves this by splitting features into two parallel paths: one efficiently processes low-frequency big picture information like overall heat distribution, while the other focuses on high-frequency sharp details such as flame boundaries. This separation enables FlameDet to balance accuracy and speed, making it ideal for real-time fire monitoring systems.
As illustrated in Figure 4, HLFA adopts dual-branch structure for frequency-aware feature decomposition. The low-frequency path downsamples input features using average pooling:
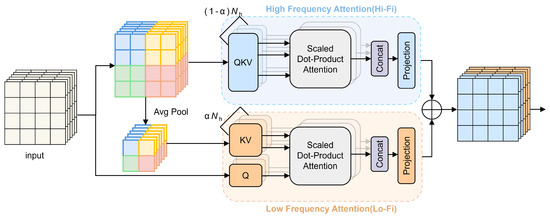
Figure 4.
Framework of High–Low Frequency Analysis module. It includes two parallel paths: one efficiently processes low-frequency big-picture information like overall heat distribution, while the other focuses on high-frequency sharp details such as flame boundaries.
A lightweight multi-head self-attention (MSA) mechanism is then applied to capture global thermal trends efficiently:
This captures broad thermal trends with minimal computation. The high-frequency path keeps the original resolution but extracts fine details using high-pass filtering to identify fine details like sparks or smoke trails, where the size of the Gaussian kernel is :
Crucially, it filters out simple low-frequency signals via high-pass operations, forcing it to focus solely on complex textures:
where DWConv is depthwise convolution, enhancing local texture representation. Finally, the outputs of both branches are merged through adaptive weighting, where a small neural network dynamically balances their contributions based on input content:
where is dynamically generated from input features. This design captures broad thermal patterns and microscopic textures simultaneously while optimizing compute resources. And it ensures comprehensive feature extraction without excessive computational cost.
3.3. DSK_C3
The C3 module serves as a core component for learning residual features. It consists of two branches: one incorporates multiple bottleneck layers along with a standard convolutional layer, while the other passes through only a single convolutional module. The outputs of both branches are subsequently concatenated. A key challenge in flame detection lies in recognizing small or distant flames, which often appear as tiny objects in images. Standard convolutions possess a limited receptive field, constraining their ability to capture broader contextual cues. To address this, the dilated small kernels are introduced, and they employ dilated convolutions to expand the receptive field without increasing computational cost—analogous to zooming out for a wider view. This enables the model to incorporate relevant context from surrounding regions, such as smoke patterns or thermal halos, thereby improving the detection of faint and small flames. Furthermore, a re-parameterization strategy is utilized—a multi-branch structure is used during training to enhance representational capacity, while branches are merged into a single efficient convolution during inference. This ensures high accuracy without compromising real-time performance.
As illustrated in Figure 5, the proposed DSK_C3 module operates in two distinct phases. In training phase, input features pass through three parallel branches: standard 3 × 3 convolution, dilated 3 × 3 convolution and an identity shortcut. Their outputs are added together:
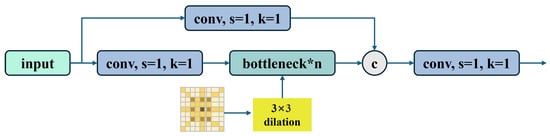
Figure 5.
Framework of dilated small kernels using the C3 structure. C3 is the main one for learning residual features. Its structure is divided into two branches. It contains three standard convolutional layers and multiple bottleneck modules. Dilated small kernels are used to make the model runs faster.
This allows for rich feature learning from both local details and wide contexts. After training, all branches are merged into one fast 3 × 3 convolution using re-parameterization:
where denotes the fused convolution operator that integrates the parameters of all three branches. This merged block is embedded within a cross-stage partial network replacing its original convolution operations to enhance contextual awareness and detection performance.
4. Experiments
4.1. Datasets
Although there are some public datasets for flame detection, they often lack diversity in scenarios such as indoor fires, wildfires at long range, or a need for high-quality annotations for small targets. To address these gaps and better evaluate the model’s performance in real-world applications, the FlameLife dataset is constructed. Data is collected from multiple sources, including controlled indoor laboratory fires, real outdoor wildfire scenarios, and video footage from online repositories of real fire incidents with careful filtering and annotation. All images are annotated by well-trained annotators, ensuring high inter-annotator agreement. The FlameLife dataset contains 5168 images, and is randomly split into 90% for training, 5% for validation, and 5% for testing. The FlameLife dataset presents significant challenges due to the high proportion of small and occluded flames, complex backgrounds, and varying illumination conditions. It will serve as a valuable benchmark for the research.
4.2. Settings
All of the experiments are conducted on 2 NVIDIA RTX-4090 GPUs, both with a generous memory capacity of 24 GB. The input size is 640 × 640. The batch sizes are both set to 16. During training, the IoU parameter for non-maximum suppression is set to 0.5. The confidence threshold for flame detection is set to 0.3. The optimization algorithm is AdamW. The initial learning rate is 0.0001 with a weight decay of 0.0001, while momentum is set to 0.9. Color jittering and random scale are used as data augmentation methods; the parameters are set to 0.4 and 0.5, respectively. In addition, random translate is set to 0.1 and horizontal flip to 0.5.
4.3. Evaluation Metrics
To evaluate the performance of the flame detection model, mean Average Precision (mAP) and Average Precision (AP) are used as the main metrics. AP is calculated based on the overlap between predicted bounding boxes and ground-truth annotations, measured by Intersection over Union (IoU). A detection is considered a true positive if its IoU with a ground-truth box exceeds a predefined threshold; otherwise, it is regarded as a false positive. Precision and recall are then derived as TP/(TP + FP) and TP/(TP + FN), respectively. After sorting all detections by confidence, the precision–recall curve is summarized into a single AP value by averaging the precision across recall levels. The mAP metric extends AP by evaluating performance at multiple IoU thresholds, from 0.5 to 0.95 in increments of 0.05. The final mAP is the average of the AP values across these thresholds, providing a comprehensive measure of detection accuracy under varying localization criteria.
4.4. Comparative Experiments
Table 1 provides a comprehensive comparison of multiple detection models on the FlameLife dataset, evaluating both accuracy and efficiency metrics. The proposed FlameDet model achieves state-of-the-art performance across nearly all evaluation criteria while maintaining competitive computational efficiency. In terms of detection accuracy, FlameDet achieves the highest scores in both precision and recall, with 0.89 and 0.748, separately. Thus resulting in an F1-score of 0.813, an improvement of 3.5% over the baseline model. All average precision (AP) metrics also show notable gains, with AP50 improving by 4.0% to 0.865, AP75 improving by 3.0% to 0.633, and mAP increasing by 2.6% to 0.601. Notably, FlameDet outperforms both two-stage detectors like Faster R-CNN and one-stage models such as YOLOv8x, demonstrating its strong ability to balance precise localization with comprehensive coverage of flame regions. In particular, the significant improvement in AP75 further indicates enhanced accuracy in precisely localized detections.

Table 1.
Detection Results on FlameLife Dataset.
Regarding model efficiency, FlameDet demonstrates high efficiency with only 19.4 M parameters, making it one of the lightest models evaluated. It is slightly lighter than RT-DETR using a ResNet18 backbone at 19.9 M parameters. And it is significantly smaller than other models such as Cascade R-CNN and YOLOv8x, which have 69.2 M and 68.2 M parameters, respectively. In terms of computational cost, FlameDet requires only 54.5 GFLOPs.This is considerably lower than the 258.1 GFLOPs needed by YOLOv8x. Compared to the strong baseline RT-DETR with ResNet50, FlameDet improves mAP by 2.1% while using only 46.2% of the parameters. It also reduces computational cost by 57.9%. These comparisons clearly highlight the effectiveness of the proposed HDM, HLFA and overall framework. In summary, FlameDet achieves an optimal balance between detection performance and operational efficiency. This makes it highly suitable for real-time flame detection applications.
4.5. Parameter Analysis
To further investigate the impact of key hyper-parameters, a detailed study is performed on the configurations of the HDM, HLFA, and DSK_C3 modules. The results are presented in Table 2. Experimental results show that different parameter settings significantly influence both model performance and efficiency. The optimal configuration—with HDM layers set to 384, HLFA layers to 1024, and DSK_C3 layers to 256—achieves the highest scores across all metrics. This includes a precision of 0.890, a recall of 0.748, an F1-score of 0.813, and an mAP of 0.601. Moreover, this configuration maintains a moderate parameter count of 19.4 M and a computational cost of 54.5 GFLOPs. These results demonstrate an effective balance between model capability and operational efficiency.
Table 2.
Detection Results of Different Settings on FlameLife Dataset.
Larger HDMs and HLFA modules, like increasing the HDM from 256 to 384 and HLFA from 512 to 1024, generally enhance the model’s representational capacity and detection accuracy, particularly improving precision and mAP. However, these improvements come at the cost of increased parameter size and computational overhead. The configuration of the DSK_C3 module also plays a critical role—employing the full module over a reduced version noticeably boosts overall performance, especially in detecting small or distant flames. These findings validate the critical importance of each module’s design and scaling within the overall framework. The optimal configuration not only delivers superior detection performance but also preserves computational efficiency, making it well-suited for real-world flame detection applications.
4.6. Ablation Experiments
To comprehensively evaluate the contribution of each component in FlameDet, extensive ablation studies are conducted on the FlameLife dataset. And RT-DETR with ResNet50 (RT-DETR-R50) is adopted as the baseline model. Results are shown in Table 3.
Table 3.
Ablation study results on FlameLife Dataset.
The baseline model without any proposed modules achieves an mAP of 0.580, with 42.0 M parameters and 129.5 G FLOPs. Adding only the HDM backbone significantly reduces computational costs, reducing parameters by 37.1% and FLOPs by 41.7%, while still improving mAP slightly to 0.583. This confirms that HDMs are important for enhancing efficiency and feature representation. Using only HLFA boosts improves recall to 0.726 and F1-score to 0.797; with no increases in computational overhead, this shows its ability to capture discriminative multi-scale features without compromising efficiency. Employing only DSK_C3 also improves recall to 0.733 and F1-score to 0.798, while cutting parameters by 16.9% and FLOPs by 27.0 percent. It proves effective at expanding receptive fields with little cost.
Combining two modules yields further gains. The paired HDM and HLFA raise mAP to 0.593. Meanwhile, the HDM with DSK_C3 attains a higher recall of 0.742 and the lowest computational cost before full integration, using only 19.4 M parameters and 54.3 G FLOPs. The complete model, integrating the HDM, HLFA, and DSK_C3, achieves top performance across all metrics. It reaches the highest precision of 0.890, recall of 0.748, F1-score of 0.813, and mAP of 0.601, while keeping computational cost low at 19.4 M parameters and 54.5 G FLOPs. These results affirm the synergistic effects of the three components. Each contributes distinctively to enhancing accuracy and efficiency. The ablation study confirms both the individual value and collective compatibility of the proposed modules, demonstrating a balanced step forward toward accurate real-time flame detection.
4.7. Case Study
To further evaluate the practical effectiveness of FlameDet, a qualitative case study is present with visual comparisons between FlameDet and the baseline model, as shown in Figure 6. The results demonstrate clear advantages of the FlameDet framework across diverse fire scenarios. Specifically, FlameDet shows major improvements in detecting small and distant flames—situations where the baseline often fails. It also significantly reduces false alarms in challenging conditions such as complex backgrounds, strong lighting, and reflective surfaces with flame-like appearances. Moreover, FlameDet consistently yields higher confidence scores for true positives, indicating more reliable and confident detection.

Figure 6.
Detection samples of FlameDet. The former is the detection result of FlameDet, and the latter is the detection result of the baseline. The FlameDet framework not only enhances the recall rate, but also reduces false alarms and improves the confidence score at the same time.
These visual findings align with the quantitative results presented earlier, confirming that FlameDet enhances both recall—especially for small and occluded fires—and precision through effective suppression of false positives. The combination of the HDM backbone, HLFA, and DSK_C3 module supports more robust and interpretable feature learning, contributing to superior performance in real-world flame detection.
5. Discussion
In this work, FlameDet—a novel and efficient framework for accurate real-time flame detection—is presented. The primary goal is to address key challenges in visual fire monitoring, including high false alarm rates, limited detection capability for small or obscured flames, and the computational constraints of real-world deployment. Experimental results demonstrate that FlameDet successfully balances these requirements, achieving superior accuracy while maintaining high inference speed.
The effectiveness of FlameDet stems from its co-designed components, each targeting specific aspects of flame detection. The HDM backbone plays a critical role by incorporating a physics-inspired heat conduction mechanism that inherently models thermal diffusion—a fundamental property of fire. This design not only improves feature representation but also ensures high computational efficiency, serving as a robust foundation for the entire system. Furthermore, the HLFA component addresses the multi-scale nature of flame phenomena. It separates feature processing into distinct pathways for low-frequency information, such as global context and thermal spread, and high-frequency details like fine edges and textures. This dual-branch architecture significantly reduces false alarms caused by flame-like objects and enhances the detection of small and early-stage fires. The DSK_C3 module augments the model’s ability to detect small objects through dilated convolutions, which expand the receptive field without adding computational overhead. This enables the model to incorporate broader contextual information, such as smoke patterns and thermal halos. Additionally, structural re-parameterization ensures that training time complexity does not impede deployment efficiency, preserving real-time performance.
Regarding false-positive analysis, we observed that the majority of false alarms occur at medium scales, with the object area approximately – pixels, primarily involving objects that share visual similarities with flames, such as traffic lights, red clothing, autumn leaves, and sunlit reflective surfaces. Small-scale false positives, below pixels, are relatively rare due to the model’s limited sensitivity to extremely tiny patterns, while large-scale false positives are uncommon as the global context captured by the HDM backbone helps disambiguate broad thermal-like regions.
To mitigate these false positives, we plan to pursue a two-stage strategy. First, temporal consistency will be leveraged by analyzing frame sequences; real flames exhibit characteristic flicker frequencies and dynamic shape deformation, whereas static flame-like objects remain temporally invariant. A lightweight temporal verification module, possibly based on frame differencing or optical flow, could be integrated to suppress such static false alarms. Second, a cascaded classification approach will be explored, where candidate regions first undergo appearance-based detection and then pass through a contextual reasoning module that incorporates scene semantics (e.g., presence of smoke, spatial location) to further reduce false positives. These strategies are part of our future research directions outlined above.
Despite promising results, certain limitations remain. While robust across many scenarios, FlameDet’s performance can be affected by extreme weather conditions, such as heavy fog or rain, which are underrepresented in current dataset. Additionally, the current framework operates on static images and does not yet exploit temporal dynamics that could help distinguish real flames from static false positives. As noted in recent work [52], many existing fire detection datasets are dominated by fully developed flames and lack intra-video diversity, which can lead to overestimated model performance in real-world deployment scenarios.
Future research will proceed along four main directions:
- First, we intend to incorporate temporal information by extending FlameDet to a video-based framework that processes short frame sequences. Temporal modeling techniques such as 3D convolutions or optical flow will be explored to capture dynamic flame characteristics including flicker frequency and growth patterns, which can effectively discriminate real fires from static false positives like red lanterns or autumn leaves.
- Second, we plan to expand the FlameLife dataset to include a wider range of challenging scenarios, such as nighttime fires, indoor conflagrations, heavy smoke, and adverse weather conditions. This diversification will enhance the model’s robustness and generalization across real-world environments.
- Third, to facilitate deployment on resource-constrained edge devices, we will investigate model compression techniques including network quantization, structured pruning, and knowledge distillation, targeting hardware platforms like NVIDIA Jetson or Raspberry Pi for IoT-based wildfire prevention.
- Finally, we aim to develop a cascaded verification module that combines temporal consistency checks with semantic context reasoning to further reduce false alarm rates, particularly for flame-like objects observed in complex backgrounds.
In conclusion, FlameDet establishes a new strong baseline for real-time flame detection. By combining physics-aware modeling, multi-scale feature learning, and lightweight design, FlameDet offers a practical and effective solution for improving safety in numerous fire monitoring contexts.
6. Conclusions
The primary contributions of this work can be summarized as follows:
- A Heat Diffusion Module (HDM) is introduced, which simulates heat conduction in the spectral domain via discrete cosine transform, achieving global feature propagation with complexity and enabling efficient high-resolution processing.
- A High–Low Frequency Analysis (HLFA) module is designed to decompose features into low- and high-frequency pathways, enabling adaptive multi-scale representation with minimal computational overhead.
- A DSK_C3 module is constructed, combining dilated convolutions and structural re-parameterization to expand the receptive field for small flame detection while reducing the parameter count by 26.5%.
This paper presented FlameDet, a novel flame detection framework grounded in physics-inspired computation and multi-resolution analysis. Departing from generic architectures, a Heat Diffusion Module that reformulates feature propagation was introduced as a spectral-domain simulation of heat conduction; a High–Low Frequency Analysis module that enables resource-aware multi-scale feature extraction was also introduced; and the DSK_C3 module that synergizes dilated convolution with structural re-parameterization for efficient context modeling. These designs effectively address key challenges such as small-flame detection, low recall rate, and performance degradation in complex environments. Extensive experiments confirm the FlameDet framework achieves state-of-the-art performance, improving AP50 and F1-score by 4.0% and 3.5%, respectively, while maintaining real-time efficiency. The ablation studies validate each module’s necessity and their collective contributions. Case studies under challenging scenarios also verify the model’s robustness and strong generalization capability. The underlying computational principles in this paper, such as physics inspired modeling, multi-resolution frequency analysis, and training inference decoupling, establish a generalizable paradigm for future work. This work provides a significant step towards more principled and efficient computational models for engineering science, with potential applications extending to other physical process recognition tasks.
Author Contributions
Conceptualization, S.H. and H.C.; methodology, S.H. and F.R.; validation, C.L., Z.Z. and T.W.; formal analysis, S.H. and J.L.; investigation, S.H., F.R. and C.L.; resources, H.C.; data curation, Z.Z. and T.W.; writing—original draft preparation, S.H. and F.R.; writing—review and editing, C.L. and H.C.; visualization, J.L. and Z.Z.; supervision, H.C.; project administration, H.C.; funding acquisition, H.C. and S.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China under Grants 52304262, 52474254, and 52504177.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors would like to acknowledge the China Academy of Safety Science and Technology, the Key Laboratory of Urban Fire Monitoring and Warning under the Ministry of Emergency Management, and the Institute of Biomedical Research, Henan Academy of Sciences (Zhengzhou 450046, China), for providing the essential infrastructure and support to carry out this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Singh, S.K.; Khawale, R.P.; Hazarika, S.; Rai, R. Hybrid Physics-Infused One-Dimensional Convolutional Neural Network-Based Ensemble Learning Framework for Diesel Engine Fault Diagnostics. ASME J. Comput. Inf. Sci. Eng. 2025, 25, 041006. [Google Scholar] [CrossRef]
- Vatandoust, F.; Yan, X.; Rosen, D.; Melkote, S.N. Manufacturing Feature Recognition with a Sparse Voxel-Based Convolutional Neural Network. ASME J. Comput. Inf. Sci. Eng. 2025, 25, 031002. [Google Scholar] [CrossRef]
- Zhang, X.; Tian, S.; Liang, X.; Zheng, M.; Behdad, S. Early Prediction of Human Intention for Human–Robot Collaboration Using Transformer Network. ASME J. Comput. Inf. Sci. Eng. 2024, 24, 051003. [Google Scholar] [CrossRef]
- Deng, J.; Wei, H.; Lai, Z.; Gu, G.; Chen, Z.; Chen, L.; Ding, L. Spatial Transform Depthwise Over-Parameterized Convolution Recurrent Neural Network for License Plate Recognition in Complex Environment. ASME J. Comput. Inf. Sci. Eng. 2023, 23, 011010. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y. M. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2017; pp. 2961–2969. [Google Scholar]
- Wang, Z.; Liu, Y.; Tian, Y.; Liu, Y.; Wang, Y.; Ye, Q. Building Vision Models upon Heat Conduction. In Proceedings of the Computer Vision and Pattern Recognition Conference; IEEE: Piscataway, NJ, USA, 2025; pp. 9707–9717. [Google Scholar]
- Pan, Z.; Cai, J.; Zhuang, B. Fast vision transformers with hilo attention. Adv. Neural Inf. Process. Syst. 2022, 35, 14541–14554. [Google Scholar]
- Diaconu, B.M. Recent advances and emerging directions in fire detection systems based on machine learning algorithms. Fire 2023, 6, 441. [Google Scholar] [CrossRef]
- Khan, F.; Xu, Z.; Sun, J.; Khan, F.M.; Ahmed, A.; Zhao, Y. Recent advances in sensors for fire detection. Sensors 2022, 22, 3310. [Google Scholar] [CrossRef]
- Çelik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Cheng, G.; Chen, X.; Wang, C.; Li, X.; Xian, B.; Yu, H. Visual fire detection using deep learning: A survey. Neurocomputing 2024, 596, 127975. [Google Scholar] [CrossRef]
- Štula, M.; Krstinić, D.; Šerić, L.; Braović, M. Current trends in wildfire detection, monitoring and surveillance. Fire 2025, 8, 356. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Ahmed, S.H.; Baik, S.W. Efficient fire detection for uncertain surveillance environment. IEEE Trans. Ind. Inform. 2019, 15, 3113–3122. [Google Scholar] [CrossRef]
- Li, S.; Yan, Q.; Liu, P. An efficient fire detection method based on multiscale feature extraction, implicit deep supervision and channel attention mechanism. IEEE Trans. Image Process. 2020, 29, 8467–8475. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Agarwal, M.; Khan, Z.A.; Gupta, S.K.; Baik, S.W. Optimized dual fire attention network and medium-scale fire classification benchmark. IEEE Trans. Image Process. 2022, 31, 6331–6343. [Google Scholar] [CrossRef]
- Huang, L.; Liu, G.; Wang, Y.; Yuan, H.; Chen, T. Fire detection in video surveillances using convolutional neural networks and wavelet transform. Eng. Appl. Artif. Intell. 2022, 110, 104737. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Ullah, F.U.M.; Gupta, S.K.; Lee, M.Y.; Baik, S.W. Randomly initialized CNN with densely connected stacked autoencoder for efficient fire detection. Eng. Appl. Artif. Intell. 2022, 116, 105403. [Google Scholar] [CrossRef]
- Yar, H.; Ullah, W.; Khan, Z.A.; Baik, S.W. An effective attention-based CNN model for fire detection in adverse weather conditions. ISPRS J. Photogramm. Remote Sens. 2023, 206, 335–346. [Google Scholar] [CrossRef]
- Yang, X.; Hua, Z.; Zhang, L.; Fan, X.; Zhang, F.; Ye, Q.; Fu, L. Preferred vector machine for forest fire detection. Pattern Recognit. 2023, 143, 109722. [Google Scholar] [CrossRef]
- Yar, H.; Khan, Z.A.; Ullah, F.U.M.; Ullah, W.; Baik, S.W. A modified YOLOv5 architecture for efficient fire detection in smart cities. Expert Syst. Appl. 2023, 231, 120465. [Google Scholar] [CrossRef]
- Zhao, H.; Jin, J.; Liu, Y.; Guo, Y.; Shen, Y. FSDF: A high-performance fire detection framework. Expert Syst. Appl. 2024, 238, 121665. [Google Scholar] [CrossRef]
- Kong, S.; Deng, J.; Yang, L.; Liu, Y. An attention-based dual-encoding network for fire flame detection using optical remote sensing. Eng. Appl. Artif. Intell. 2024, 127, 107238. [Google Scholar] [CrossRef]
- Tao, H.; Liu, J.; Yang, Z.; Wang, G.; Shang, J.; Qiu, H.; Gao, L. Revolutionizing flame detection: Novelization in flame detection through transferring distillation for knowledge to pruned model. Expert Syst. Appl. 2024, 249, 123787. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Yar, H.; Khan, Z.A.; Rida, I.; Ullah, W.; Kim, M.J.; Baik, S.W. An efficient deep learning architecture for effective fire detection in smart surveillance. Image Vis. Comput. 2024, 145, 104989. [Google Scholar] [CrossRef]
- Feng, J.; Sun, Y. Multiscale network based on feature fusion for fire disaster detection in complex scenes. Expert Syst. Appl. 2024, 240, 122494. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, G.; Xiao, D.; Liu, H.; Hu, X. FTA-DETR: An efficient and precise fire detection framework based on an end-to-end architecture applicable to embedded platforms. Expert Syst. Appl. 2024, 248, 123394. [Google Scholar] [CrossRef]
- Khan, Z.A.; Ullah, F.U.M.; Yar, H.; Ullah, W.; Khan, N.; Kim, M.J.; Baik, S.W. Optimized cross-module attention network and medium-scale dataset for effective fire detection. Pattern Recognit. 2025, 161, 111273. [Google Scholar] [CrossRef]
- Gaur, A.; Singh, A.; Kumar, A.; Kulkarni, K.S.; Lala, S.; Kapoor, K.; Srivastava, V.; Kumar, A.; Mukhopadhyay, S.C. Fire sensing technologies: A review. IEEE Sens. J. 2019, 19, 3191–3202. [Google Scholar] [CrossRef]
- Huang, D.; Zhao, X.; Li, Q.; Liang, Z.; Guo, S.; He, Y. Real-time ultraviolet flame detection system based on 4H-SiC phototransistor. IEEE Trans. Electron Devices 2024, 71, 1580–1586. [Google Scholar] [CrossRef]
- Morchid, A.; Oughannou, Z.; El Alami, R.; Qjidaa, H.; Jamil, M.O.; Khalid, H.M. Integrated internet of things (IoT) solutions for early fire detection in smart agriculture. Results Eng. 2024, 24, 103392. [Google Scholar] [CrossRef]
- Ding, S.; Zhang, H.; Zhang, Y.; Huang, X.; Song, W. Hyper real-time flame detection: Dynamic insights from event cameras and FlaDE dataset. Expert Syst. Appl. 2025, 263, 125746. [Google Scholar] [CrossRef]
- Ramadan, M.N.A.; Basmaji, T.; Gad, A.; Hamdan, H.; Akgün, B.T.; Ali, M.A.H.; Alkhedher, M.; Ghazal, M. Towards early forest fire detection and prevention using AI-powered drones and the IoT. Internet Things 2024, 27, 101248. [Google Scholar] [CrossRef]
- Park, H.; Yoo, Y.; Seo, G.; Han, D.; Yun, S.; Kwak, N. C3: Concentrated-comprehensive convolution and its application to semantic segmentation. arXiv 2018, arXiv:1812.04920. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2021; pp. 10012–10022. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2022; pp. 13619–13627. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2018; pp. 6154–6162. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision; IEEE: Piscataway, NJ, USA, 2019; pp. 9627–9636. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Yuan, Z.; Luo, P. Sparse R-CNN: An End-to-End Framework for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15650–15664. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. Yolov8: A novel object detection algorithm with enhanced performance and robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS); IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: Piscataway, NJ, USA, 2024; pp. 16965–16974. [Google Scholar]
- Ali, M.M.E.H.; Ghodrat, M. Reliable indoor fire detection using attention-based 3D CNNs: A fire safety engineering perspective. Fire 2025, 8, 285. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.