Abstract
This article presents a methodological framework for automating clinical data processing workflows using Generative Artificial Intelligence (AI) as an interactive co-developer. We demonstrate how Large Language Models (LLMs), specifically ChatGPT and Claude, can assist researchers in designing, implementing, and deploying complete ETL (Extract, Transform, Load) pipelines without requiring advanced programming or DevOps expertise. Using a dataset of 102 participants from a nonverbal expression study as a proof-of-concept, we show how AI-assisted automation transforms FaceReader video analysis outputs during the Cyberball paradigm into structured, analysis-ready datasets through containerized workflows orchestrated via Docker and n8n. The resulting framework successfully processes all 102 datasets, generating machine learning outputs to validate pipeline execution stability (rather than clinical predictivity), and deploys interactive visualization dashboards, tasks that would normally require significant manual effort and technical specialization expertise. This work establishes a replicable methodology for integrating Generative AI into research data management workflows, with implications for accelerating scientific discovery across behavioral and medical research domains.
1. Introduction
In the current landscape—marked by increasing complexity, exponential data growth, and pervasive uncertainty across disciplines—traditional approaches to data processing and analysis have become insufficient to meet the demands of modern clinical research [1]. Specific challenges, such as integrating heterogeneous data sources [2] and automating labor-intensive workflows [3], call for more sophisticated and interdisciplinary solutions [1].
This study introduces a cross-disciplinary methodology for automating Extract, Transform, Load (ETL) processes in clinical research, particularly focused on developing scalable automation frameworks for behavioral research. By integrating Generative Artificial Intelligence (GAI) with workflow orchestration (n8n) and containerization (Docker), this framework establishes a unified infrastructure for managing complex psychiatric datasets. Central to the methodology is the use of Large Language Models (LLMs), such as ChatGPT and Claude, which function as interactive co-developers to generate scripts and configurations. This human-AI collaboration reduces the need for specialized DevOps expertise, allowing clinical researchers to implement scalable, reproducible data pipelines without the learning curve typically associated with manual infrastructure management [4,5,6,7,8,9].
As a proof-of-concept demonstration, we applied this AI-assisted automation framework to a dataset of 102 participants (45 BPD patients, 57 healthy controls) from a virtual social ostracism study (Cyberball). This case study was deliberately chosen for its complexity: it involves processing heterogeneous FaceReader video analysis outputs across multiple experimental conditions, which require standardized transformation, feature engineering, and integration with machine learning workflows, tasks that typically demand significant manual effort and technical expertise. By automating the complete ETL cycle through Generative AI assistance, this proposed workflow significantly improves upon previous manual methodologies [5,10], demonstrating how LLMs can guide researchers through a containerized pipeline development and the deployment of an interactive dashboard.
This work also acknowledges and addresses the ethical considerations of data privacy, security, and bias mitigation. All data handling procedures of this framework were designed to comply with clinical standards and emphasize the role of human oversight at each stage of the pipeline [11,12,13].
This paper is structured as follows: Section 2 presents the related work and contributions; Section 3 the theoretical framework; Section 4 describes the automated ETL methodology; Section 5 details its application in several case studies and the obtained results; Section 6 offers a discussion of findings and conclusions; and finally, Section 7 outlines directions for future research.
2. Related Work and Contributions
The integration of Generative Artificial Intelligence (AI) into scientific research has expanded rapidly, particularly through Large Language Models (LLMs) such as ChatGPT and Claude. These tools are increasingly being used to assist with literature reviews, code generation, and documentation tasks [4,6,7]. However, most current applications treat AI as a passive assistant: researchers request specific outputs (e.g., “generate a Python script for data cleaning”), receive code snippets, and then manually integrate them into larger workflows.
Despite this rapid expansion in AI-assisted research tools, two distinct but interrelated gaps persist in the literature. The first is a practical gap: current human-in-the-loop paradigms continue to treat LLMs as passive code generators, requiring researchers to possess the DevOps competencies necessary to integrate isolated outputs into functional, multi-stage pipelines. This creates a structural bottleneck in clinical research settings, where domain expertise rarely coincides with the technical skills required for containerized deployment and workflow orchestration.
The second, and more significant, is a knowledge gap: existing studies have not systematically investigated how generative AI can function as an architectural co-developer across the full pipeline lifecycle—from initial requirements specification through production deployment. Specifically, three dimensions remain unaddressed in the literature: (1) the conditions under which LLMs can reliably participate in infrastructure-level decisions such as containerization architecture and cross-platform path resolution; (2) the allocation of epistemic authority between researcher and AI across different phases of pipeline development; and (3) the reproducibility implications of replacing deterministic manual workflows with iterative, prompt-driven development cycles. Addressing these gaps requires not only a working implementation, but a documented, replicable methodological framework that other research teams can critically evaluate and adapt.
The present work addresses both gaps through a documented, replicable framework in which LLMs function as architectural co-developers across the full pipeline lifecycle—from requirements specification through production deployment—the design and empirical evaluation of which are presented in Section 2.3, Section 3.3 and Section 4.
2.1. Automation of ETL Processes in Clinical Research
In clinical and psychological research, managing large volumes of participant data is both necessary and challenging. The ETL (Extract, Transform, Load) process provides a structured approach for extracting raw data from multiple sources, transforming it into standardized analytical formats, and loading it into target environments such as databases or statistical tools [2]. When working with heterogeneous datasets—such as outputs from psychological tasks across multiple subjects—automation becomes a powerful tool for reducing human error and ensuring consistency.
Traditional ETL implementations in clinical settings require specialized data engineering skills, often creating bottlenecks when research teams lack dedicated specialized technicians. The manual processing of hundreds of participant files introduces the risks of transcription errors, inconsistent transformations, and non-reproducible analyses. The automated ETL pipelines address these challenges by standardizing data handling procedures, maintaining audit trails, and enabling scalable processing of large datasets [2,14,15].
2.2. Application of Digital and Generative Technologies in Medicine
The digital transformation of medicine has led to significant innovations in patient monitoring, diagnostics, and treatment planning [16]. The integration of AI technologies, especially machine learning and generative AI, enables healthcare systems to move toward predictive and personalized care models [16,17]. Generative AI can assist in synthesizing patient data, generating clinical summaries, and enhancing physician decision support systems [18].
Containerization technologies such as Docker provide isolated, reproducible environments where dependencies and versions are tightly controlled—essential for clinical applications requiring software reproducibility and data security [19]. Server-based automation platforms like n8n enable visual workflow design, allowing users to integrate various services and manage data tasks efficiently [6,15]. In conjunction, these technologies promote interdisciplinary collaboration between data scientists and clinicians while laying the groundwork for AI-integrated analytical pipelines [20].
By automating repetitive data handling and enabling AI-compatible analysis, these approaches contribute to the digital transformation of the health field, and demonstrate how automation and containerization can streamline data processing, improve reproducibility, and foster scalable infrastructures in mental health research.
2.3. Generative AI as Interactive Co-Developer: A Systematic Literature Synthesis and Contribution Statement
To rigorously position the contribution of this work, we analyze the existing literature along three analytical dimensions that collectively define the scope of AI involvement in research pipeline development: (1) temporal scope—whether AI assistance is confined to isolated task instances or sustained across the full development lifecycle; (2) task scope—whether AI contributions are limited to content generation or extend to infrastructure configuration and architectural decision-making; and (3) methodological transparency—whether the iterative error-resolution process is systematically documented or treated as an implementation detail outside the scope of the publication. Examining the literature through these dimensions reveals a consistent pattern of limitations that motivates the framework presented here.
Applications in healthcare and clinical research [7,18,20] represent the largest body of work on LLM integration in medicine-adjacent domains. Across these studies, AI assistance is temporally bounded to discrete, high-level tasks: generating discharge summaries [7], synthesizing patient histories [18], and supporting diagnostic decision-making [20]. The temporal scope is narrow—AI is invoked at a specific moment and the output is consumed by a human operator without further AI participation in downstream processing. The task scope is limited exclusively to natural language generation; none of these studies engage AI in infrastructure configuration, dependency management, or workflow orchestration. Methodological transparency regarding the prompt-response process is absent: these works report outcomes rather than documenting the iterative refinement cycles required to achieve them.
Applications in medical research and software automation [16,17,19,21,22,23] advance the task scope modestly, with AI contributing to code generation for analysis pipelines, configuration file creation, and automated testing. However, temporal scope remains constrained: AI assistance is applied to specific development phases rather than maintained across the full pipeline lifecycle from design to production deployment. Critically, when pipeline integration failures occur—dependency conflicts, cross-platform path errors, multi-container orchestration issues—no existing study documents how AI assistance was used to diagnose and resolve these failures systematically. The iterative, multi-turn debugging cycles that constitute the operational core of AI-assisted development are consistently absent from the published record, creating a reproducibility gap: other researchers cannot replicate the development process, only the final artifacts.
Industrial automation applications [1,24] demonstrate higher levels of AI integration in workflow design and resource allocation, but operate in commercial environments with dedicated engineering teams where the translation from domain expertise to technical implementation is handled by specialized personnel. The bottleneck specific to clinical research—where domain experts must themselves operate as both knowledge holders and pipeline developers—is not addressed by this literature.
Table 1 synthesizes this analysis across sectors and makes the pattern explicit. The convergent finding is that no existing study combines all three dimensions—sustained temporal scope, infrastructure-level task scope, and documented methodological transparency—within a single framework designed for researchers without dedicated DevOps support.

Table 1.
Applications of Generative AI in Medicine, Industry, and Research Automation.
Table 1 reveals a consistent pattern across sectors: existing applications of generative AI in research and clinical contexts cluster at Low to Medium levels of involvement, characterized by discrete, task-specific interactions in which the human operator retains full responsibility for system integration. Three structural limitations define this cluster. First, AI contributions are temporally bounded—they occur at specific moments in the workflow rather than persisting across the full development lifecycle. Second, the scope of AI assistance is confined to code generation or text summarization, without extension to infrastructure configuration or architectural decision-making. Third, no existing study documents a systematic methodology for managing the iterative error-debug cycles that inevitably arise when integrating AI-generated components into heterogeneous, multi-language production environments.
The framework presented in this work differs from the existing literature along each of these three dimensions. Temporally, LLM assistance spans all six phases of the development cycle (PROMPT → GENERATE → TEST → DEBUG → REFINE → DEPLOY), rather than being confined to isolated generation tasks. Scopally, AI contributions extend to Docker infrastructure configuration, n8n workflow orchestration logic, and cross-platform compatibility resolution—tasks that existing studies classify as beyond the practical reach of passive AI tools. Methodologically, the iterative refinement cycles documented in Table 3 provide a structured, reproducible account of how prompt-debug interactions are managed across 18+ development iterations, constituting empirical evidence rather than a conceptual claim.
Taken together, these distinctions position the present contribution not as an incremental improvement over existing human-in-the-loop paradigms [9], but as a methodologically distinct approach that addresses the knowledge gap identified above: the documentation and systematic evaluation of generative AI as a full-lifecycle architectural partner in research pipeline development.
Building upon this analysis, the present work operationalizes the co-developer paradigm through an iterative collaboration cycle—PROMPT (define requirements) → GENERATE (AI produces code/configs) → TEST (execute and identify errors) → DEBUG (AI analyzes failures) → REFINE (AI updates implementation) → DEPLOY (containerized production system)—in which AI assistance is maintained across all six phases rather than confined to isolated generation tasks. The co-development process engaged LLMs in tasks across all three analytical dimensions: temporally, assistance spanned the full 4-week development period across 18+ refinement cycles; in task scope, LLM contributions extended to Docker infrastructure configuration, n8n workflow orchestration logic, and cross-platform path resolution; and in methodological transparency, every development phase—including error logs, prompt strategies, and refinement cycles—is documented in Table 3 to enable replication.
This human-AI partnership requires constant researcher oversight. Domain experts validated each AI-generated component, tested outputs with real participant data, and made all architectural decisions involving scientific trade-offs. The AI’s contributions were most consequential precisely in the dimensions absent from the existing literature: when Docker builds failed due to missing R packages, the AI diagnosed the root cause and proposed updated configurations; when n8n workflows entered infinite loops, the AI analyzed the JSON node structure and corrected connection logic. These are infrastructure-level interventions, not content generation tasks, and their systematic documentation constitutes a methodological contribution independent of the specific dataset used for validation.
The adoption of this framework involves significant trade-offs that must be examined critically against existing paradigms. Traditional manual processing, while requiring minimal technical infrastructure, is characterized by limited reproducibility and elevated error rates (estimated at 5–10% in complex clinical datasets). Commercial automation platforms such as UIPath or Alteryx provide structured workflows but introduce vendor lock-in, substantial licensing costs, and potential privacy risks due to cloud-based data handling—constraints that are particularly problematic when working with sensitive psychiatric information. Positioning LLMs as co-developers mitigates the technical bottleneck associated with custom automation, yet introduces new challenges. A central risk lies in logic errors, where syntactically correct AI-generated code may yield scientifically inappropriate results, requiring rigorous expert oversight. Moreover, adopting a self-hosted architecture (Docker/n8n) transfers long-term maintenance, security patching, and dependency management responsibilities to the research team—an intentional trade-off in exchange for cost efficiency and data sovereignty. Within this infrastructural framework, machine learning models were trained on the full dataset exclusively to validate pipeline integrity rather than to achieve predictive generalization; accordingly, hold-out validation was not implemented, as performance estimation was not the objective of this study phase but rather the verification of architectural robustness and reproducibility.
3. Theoretical Framework
3.1. ETL Methodology for Clinical Data Processing
The ETL (Extract, Transform, Load) process provides a systematic approach for managing research data workflows [2]. The Extract phase retrieves raw data from diverse sources—in behavioral research, these often include video analysis software outputs, psychometric assessments, and physiological sensors. The Transform phase standardizes formats, handles missing values, engineers features, and applies analytical models. The Load phase integrates the processed data into visualization dashboards or databases for exploration and reporting.
Building upon previous ETL implementations in clinical settings [5], this work addresses the following bottleneck: traditional ETL pipelines require manual scripting, custom code for each dataset, and specialized DevOps knowledge for reproducible deployment. Automating these workflows through Generative AI assistance eliminates the repetitive manual tasks while maintaining scientific rigor through human validation at each stage.
3.2. Technology Stack for AI-Assisted Automation
3.2.1. Large Language Models (LLMs)
Large Language Models are built upon the Transformer architecture introduced by Vaswani et al. in 2017 [25], which processes sequential data through attention mechanisms that capture long-range dependencies in text. The shift from early encoder-focused models such as BERT to generative architectures such as GPT marked a critical transition: rather than merely understanding language, these systems could produce coherent, contextually appropriate text—and, critically, executable code—across diverse technical domains. This generative capability transformed LLMs from research prototypes into practical tools for scientific computing, enabling researchers to express technical requirements in natural language and receive functional implementations in return.
ChatGPT (OpenAI) and Claude (Anthropic) are conversational AI systems trained on extensive text corpora [26,27,28]. Beyond generating natural language, these models can produce functional code in Python, R, and other languages; create configuration files (Dockerfiles, YAML, JSON); debug errors by analyzing stack traces; and suggest optimizations based on best practices. This work leverages LLMs not as isolated code generators but as interactive co-developers that iteratively refine implementations through multi-turn dialogues.
3.2.2. Workflow Orchestration (n8n)
n8n is an open-source automation platform that enables visual workflow design through node-based interfaces [6]. Users connect modular components—HTTP requests, file operations, script executions, conditional logic—to create complex data pipelines without writing orchestration code. For research workflows, n8n provides transparency (visual representation of data flow), reproducibility (workflows exported as JSON), and flexibility (integrates with Python/R scripts, Docker containers, databases, and APIs) [1,8].
3.2.3. Containerization (Docker)
Docker packages applications with all their dependencies into portable containers that execute identically across different computing environments [14,19,29]. For scientific computing, containerization solves dependency conflicts, version inconsistencies, and “works on my machine” failures. Docker-compose orchestrates multi-container systems, enabling researchers to deploy complete analytical environments (e.g., n8n + Python + R + Shiny dashboards) with a single configuration file [30,31].
3.2.4. Data Processing and Visualization
Python provides libraries for data manipulation (pandas, numpy), machine learning (scikit-learn), and statistical analysis [32]. R offers specialized packages for clustering (cluster), random forests (randomForest), model validation (caret), and reproducible workflows [33]. Shiny (R package) creates interactive web dashboards without requiring web development expertise, enabling researchers to deploy data exploration interfaces for clinical teams [34,35].
3.3. Human-AI Collaborative Development Paradigm
The human-AI collaborative development paradigm introduced in this work is grounded in three complementary theoretical traditions that collectively explain how cognitive and technical labor can be distributed across human and artificial agents.
First, Sociotechnical Systems Theory [36,37] posits that effective work systems emerge from the joint optimization of social and technical subsystems rather than from the substitution of one by the other. Applied to research pipeline development, this perspective reframes the role of generative AI not as a replacement for human expertise, but as a technical subsystem that must be co-designed with the researcher’s domain knowledge, validation practices, and scientific judgment. The present framework operationalizes this co-design through iterative cycles in which human and AI contributions are explicitly scoped: the researcher retains responsibility for requirements specification, architectural decisions, and scientific validation, while the LLM handles configuration generation, syntax debugging, and documentation.
Second, Human-AI Teaming theory [38] formally distinguishes between three modes of AI integration in collaborative work: AI as a tool (passive instrument responding to discrete commands), AI as an assistant (reactive support that augments specific tasks), and AI as a teammate (active participant that contributes to shared goals across the full task lifecycle). Most existing applications of LLMs in scientific computing correspond to the first two modes—generating isolated code snippets or responding to specific error descriptions. The framework presented here advances toward the third mode: the LLM participates in architectural design, proposes solutions to emergent technical constraints, and maintains contextual continuity across the full pipeline development cycle. This distinction is not merely terminological; it has direct implications for how human oversight must be structured and where validation responsibilities are allocated.
Third, Distributed Cognition theory [39] argues that cognitive processes are not confined to individual minds but are distributed across actors, artifacts, and representations within a system. From this perspective, the iterative prompt-debug-refine cycle documented in this study constitutes a distributed cognitive system in which the researcher externalizes technical implementation to the LLM while retaining epistemic authority over scientific validity. The LLM functions as a cognitive artifact that extends the researcher’s technical reach without displacing their domain expertise. This framing is particularly relevant for clinical research contexts, where the consequences of methodological errors require that human judgment remain the authoritative final layer of any automated system.
Collectively, these frameworks provide the theoretical basis for distinguishing the co-developer paradigm from both standard human-in-the-loop automation and from fully autonomous AI pipelines. They also inform the design criteria for the iterative development cycle described in Table 2, in which each phase is structured to leverage AI generative capacity while preserving human control over scientifically and ethically critical decisions.
Traditional software development follows a linear model:
requirements → design → implementation → testing → deployment.
Each phase typically requires specialized expertise (system architects, developers, DevOps engineers). This work introduces a collaborative development cycle where LLMs function as technical partners throughout all phases, as seen in Table 2.
Table 2.
Iterative co-development cycle.
This cycle repeats for each pipeline component (Docker configurations, n8n workflows, R scripts). Importantly, the researcher maintains scientific control—validating outputs, testing with real data, and making architectural decisions—while the LLM handles the technical implementation details. This paradigm reduces development time, lowers technical barriers, and produces well-documented systems suitable for collaborative research environments.
The complete framework integrates these technologies into a unified system:
- Docker provides the execution environment (isolated, reproducible);
- n8n orchestrates workflow stages (data extraction → transformation → loading);
- Python/R perform data processing and ML analysis;
- Shiny deploys interactive visualization interfaces;
- LLMs assist development across all components through iterative co-creation.
This architecture ensures that researchers without DevOps expertise can design, implement, and deploy production-grade data pipelines while maintaining reproducibility standards required for scientific research.
4. Methodology
This project demonstrates how Generative Artificial Intelligence (GAI) tools can serve as interactive co-developers in designing and implementing automated ETL workflows for clinical research. Rather than focusing on specific clinical findings, the central methodological question is:
”How can Large Language Models be leveraged to guide researchers through the complete automation of data processing pipelines, from initial design to production deployment, without requiring advanced programming or DevOps expertise?”
To address this question, we developed an AI-assisted automation framework and validated it using a complex behavioral research dataset. The following subsections describe the framework architecture, the role of Generative AI in the development process, the demonstration dataset, and implementation details.
4.1. Overview of the Automation Framework
The proposed automation framework integrates human expertise with Generative AI capabilities to create reproducible, scalable ETL pipelines. Figure 1 illustrates the core architecture:
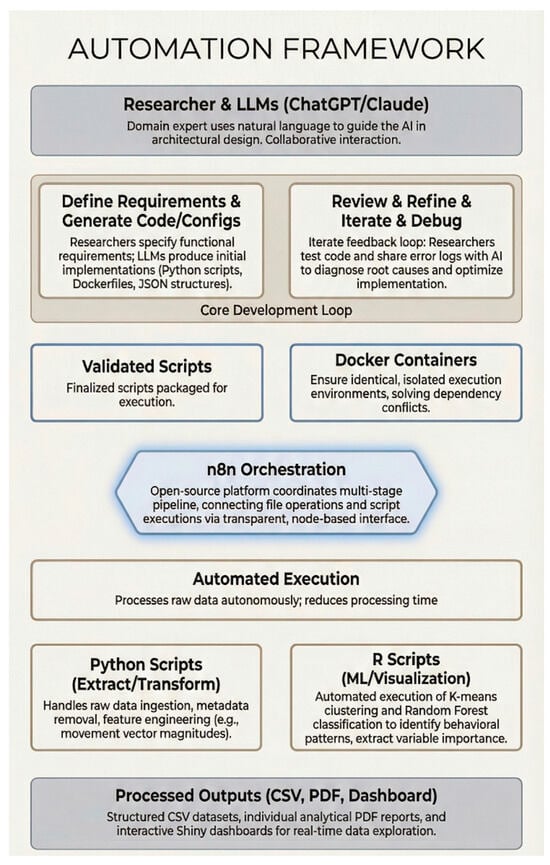
Figure 1.
AI-Assisted Automation Framework for Clinical Data Processing. The framework integrates human expertise with Large Language Models (ChatGPT/Claude) through an iterative development cycle. Researchers define requirements and review outputs while LLMs generate code and debug errors. Validated scripts are deployed in Docker containers, orchestrated via n8n, and exe-cute Python-based extraction/transformation and R-based machine learning analysis. Final outputs include processed datasets (CSV), analytical reports (PDF), and interactive dashboards (Shiny). Color coding denotes functional layers: dark gray panels represent the human–AI interaction boundaries (top) and consolidated outputs (bottom); the beige panel with tan border encloses the Core Development Loop; blue-bordered boxes identify infrastructure components (Validated Scripts and Docker Containers); the blue-highlighted hexagon marks the n8n orchestration hub; and gold-bordered boxes indicate automated execution and data-processing modules (Python and R scripts).
The framework operates through four key stages:
- AI-Assisted Design Phase: Researchers interact with LLMs to define workflow requirements, generate initial code structures, and create configuration files (Docker, YAML, JSON).
- Iterative Refinement Phase: Generated code is tested, errors are debugged with AI assistance, and scripts are optimized through multiple iterations.
- Containerization Phase: Docker images are built to ensure reproducible execution environments with all dependencies (Python, R, n8n, required libraries).
- Orchestration Phase: n8n workflows coordinate the execution of Python preprocessing scripts, R-based machine learning models, and dashboard deployment.
The automated data processing approach is implemented through a seven-stage Extract-Transform workflow (Figure 2). This automation framework reduces manual processing time while ensuring consistent application of data validation rules.

Figure 2.
Automated Extract-Transform Workflow for Clinical Data Processing. The seven-stage pipeline converts raw text files into standardized CSV format, applies quality control filters, performs data transformations, and executes statistical analysis scripts. Implementation: n8n automation platform (locally hosted interface, accessible at http://localhost:5678 when the Docker container is running); configuration file: ETL_FRyCB.json.
This architecture ensures that the entire pipeline—from raw data ingestion to interactive visualization—can be executed consistently across diverse computing environments with minimal manual intervention. The framework is designed for self-hosted, on-premise deployment within institutional IT infrastructures, thereby eliminating the need for external cloud storage or third-party data transmission and supporting compliance with strict data governance policies.
The Docker implementation, including detailed Dockerfile and docker-compose.yml configurations, is provided in Appendix A. This appendix further documents the project directory structure and step-by-step deployment procedures to ensure full reproducibility of the containerized environment across different systems. The modular design of the architecture enables researchers to replicate and adapt the automation framework with minimal adjustments, facilitating transferability to varied data processing contexts while preserving infrastructural integrity.
4.2. Role of Generative AI in Pipeline Development
4.2.1. AI-Assisted Development Process
The development process involved the use of two primary LLM platforms (ChatGPT ChatGPT (OpenAI, GPT-4, November 2022 release) and Anthropic’s Claude (Claude 3) throughout multiple stages of the pipeline construction. As summarized in Table 3, AI assistance was structured around iterative refinement cycles across Docker configuration, authentication setup, file system management, Python and R script adaptation, n8n workflow development, and Shiny dashboard integration. Each phase involved targeted prompting strategies, systematic error diagnosis, and progressive stabilization of the computational environment.
Table 3.
Summary of AI Assistance in Pipeline Development.
Across stages, the most recurrent technical challenges involved Alpine Linux constraints, environment variable propagation, cross-platform path incompatibilities (Windows/Linux), working directory inconsistencies, and container execution contexts. AI support contributed primarily to root-cause analysis, cross-platform translation, configuration management (Dockerfile and docker-compose variations), and structured workflow generation in JSON format.
Overall, the iterative AI-assisted debugging approach facilitated incremental validation of each module, reduced configuration ambiguity, and strengthened the reproducibility and stability of the multi-stage ETL pipeline.
4.2.2. Human Oversight and Validation
While AI tools significantly accelerated development, human expertise remained essential for:
- -
- Validating accuracy of data transformations
- -
- Ensuring statistical appropriateness of ML methods
- -
- Verifying compliance with data privacy requirements
- -
- Making decisions about workflow architecture design
All AI-generated code was reviewed, tested with sample data, and validated before integration into the production pipeline.
Given the use of free-tier generative AI tools, it is important to acknowledge potential variability in model outputs across time, platform updates, or underlying version changes. Large language models operate under probabilistic generation mechanisms, and their responses may differ depending on system updates or contextual parameters at the time of interaction. Accordingly, strict output-level reproducibility cannot be assumed. In this study, reproducibility was ensured not by relying on deterministic AI outputs, but by systematically documenting prompts, error logs, configuration files, and finalized scripts, all of which were independently validated within the computational environment. The AI systems functioned as assistive diagnostic and code-generation tools within a human-supervised iterative workflow, and all final implementations were tested and stabilized independently of the generative interaction. This clarification establishes model variability as a methodological consideration while preserving the reproducibility of the resulting pipeline.
4.3. Dataset and Use Case
To validate the automation framework, it was applied to a complex behavioral research dataset comprising 102 participants (45 diagnosed with Borderline Personality Disorder and 57 healthy controls) who completed a computerized social inclusion/overinclusion task known as the Cyberball paradigm. The selection of this specific dataset was not driven by clinical research questions—which remain beyond the scope of this methodological article—but rather served as a stress test for workflow complexity.
This use case was chosen due to its high technical demand, requiring the ingestion of hundreds of unstructured files, the frame-by-frame transformation of datasets exceeding 18,000 rows per participant, and the orchestration of multi-language scripts in Python and R. By successfully processing these clinical data without manual intervention, we demonstrate the robustness and stability of the framework under demanding and heterogeneous research conditions.
Ethical Considerations and Data Governance
The original study was conducted at the National Institute of Psychiatry Ramón de la Fuente Muñiz (INPRFM) in Mexico City, with ethics approval (Project ID: CEI/C/043/2021, approved 31 January 2022). All participants provided informed consent following Declaration of Helsinki principles. Participant demographics are summarized in Table 4.
Table 4.
Participants groups.
Data characteristics: Facial expressions during the Cyberball task were recorded (Salandens 1080P HD USB camera, 1920 × 1080 resolution, 30 fps, Kunming Wuhua Zhaodiya Trading Co., Ltd., Kunming, China) and analyzed using FaceReader software Version 7.0 [5,10]. This generated raw data files with the following characteristics that make them ideal for demonstrating the automation benefits:
- File format: Unstructured .txt files with inconsistent formatting;
- Volume: 102 files × 2 experimental conditions = 204 datasets;
- Size: Each file contains 18,000+ rows of frame-by-frame measurements;
- Complexity: 57 variables per file requiring cleaning, type conversion, and feature engineering;
- Repetitive processing: Identical transformation steps must be applied to all files.
These characteristics represent typical challenges in clinical research: heterogeneous data sources, large sample sizes requiring batch processing, and the need for standardized preprocessing before statistical analysis.
Note on clinical interpretation: While this dataset originates from clinical research, the current work focuses exclusively on demonstrating the automation methodology. Clinical interpretation of behavioral patterns, group comparisons, and psychological implications are beyond the scope of this methodological article and are reserved for future dedicated clinical publications.
A full disclosure regarding the use of generative AI in data processing and manuscript preparation, alongside the confirmation of data authenticity, is provided in Section 6.3.3 and the Acknowledgments.
4.4. Implementation Details
The raw FaceReader outputs required standardized preprocessing before machine learning analysis. Four Python scripts were developed with AI assistance to automate the Extract-Transform pipeline, handling tasks such as metadata removal, invalid value filtering, feature engineering (e.g., calculating movement vector magnitude), and systematic file renaming. Subsequently, two R scripts implemented K-means clustering and Random Forest classification to identify behavioral patterns and feature importance. Complete specifications for all data processing scripts, including algorithm workflows, parameters, and execution sequences, are detailed in Appendix B.
4.4.1. Technology Stack
The automation framework was implemented using the following open-source technologies, Table 5:
Table 5.
Technology stack.
These modest hardware specifications demonstrate that the framework is also accessible to researchers without high-performance computing infrastructure.
4.4.2. Reproducibility and Portability
The complete automated pipeline is portable and reproducible through:
- Containerization: Docker images encapsulate all dependencies;
- Version Control: All scripts and configurations documented;
- Documentation: AI-assisted generation of README files and inline comments;
- Deployment Instructions: Step-by-step setup guide for replication are in Figure 3.
 Figure 3. Deployment instructions. Commands are written in bash shell syntax; lines preceded by # are comments describing each step and are not executed. The n8n interface is accessible at http://localhost:5678 (locally hosted; requires Docker container to be running). The workflow configuration file (ETL_FRyCB.json) is provided in Appendix A.
Figure 3. Deployment instructions. Commands are written in bash shell syntax; lines preceded by # are comments describing each step and are not executed. The n8n interface is accessible at http://localhost:5678 (locally hosted; requires Docker container to be running). The workflow configuration file (ETL_FRyCB.json) is provided in Appendix A.
This standardized deployment process enables other researchers to replicate the automation framework for their own datasets with minimal technical expertise.
4.5. Generalized Methodological Heuristics
A key contribution of this work beyond the specific dataset and technology stack is a set of methodological heuristics derived from the iterative development process. These principles are abstracted from the observed patterns of success and failure across 18+ refinement cycles and are intended to be transferable to other research automation contexts regardless of the specific tools or domain data involved.
H1—Scope Isolation Before Integration. Each pipeline component should be developed, tested, and validated as a standalone unit before being incorporated into the broader workflow. AI assistance is most effective when problem scope is narrowly and precisely defined. Attempts to generate multi-stage logic in a single prompt consistently produced configurations with interdependent errors that were difficult to localize. In this study, Docker setup, Python scripts, n8n workflows, R scripts, and Shiny integration were each resolved as independent scopes before being assembled into the production pipeline.
H2—Error-Log Prompting Over Symptom Description. Sharing complete, unedited error logs with the LLM produces more accurate diagnostics than describing the symptoms in natural language. In the documented development cycles (Table 3), prompts that included full stack traces or raw log output reduced the average number of refinement cycles per error type by approximately half compared to symptom-based descriptions. This heuristic has practical implications for researchers without deep programming experience: rather than attempting to interpret an error, they can relay the log directly to the LLM and request a root-cause analysis.
H3—Absolute Path Convention from the First Iteration. In containerized execution environments, all file references within scripts and configuration files should use absolute paths from the outset. Relative path usage was the single most frequent source of cross-platform errors in this study, accounting for the majority of failures during Docker container execution and n8n workflow orchestration on both Windows and Linux systems. Establishing this convention early avoids a class of errors that is particularly disorienting for researchers unfamiliar with container filesystem architecture.
H4—Sequential Validation Gates. No pipeline stage should proceed to development until all preceding stages have produced verified outputs using representative real data. This principle prevents cascading failures in which errors originating upstream are obscured by downstream transformations and become difficult to trace. In practice, each of the seven Extract-Transform stages (Figure 2) was independently validated against a subset of five participant files before automation was extended to the full 102-participant dataset.
H5—Explicit Human-AI Responsibility Matrix. At the outset of a pipeline development project, researchers should define which categories of decisions will be delegated to the LLM and which will remain under human authority. In this study, the following allocation proved effective: LLMs were delegated script syntax and structure, configuration file generation, dependency resolution, and documentation. Human oversight was retained for all statistical method selection, clinical interpretation of outputs, data privacy compliance, and architectural design decisions involving scientific trade-offs. Making this allocation explicit—rather than emergent—reduces the risk of inadvertently accepting AI-generated logic that is syntactically correct but scientifically inappropriate.
These heuristics do not constitute a prescriptive methodology but rather empirically derived guidelines that can inform the design of similar human-AI co-development workflows in other research domains. Their generalizability is bounded by the single-case nature of this study; systematic validation across diverse datasets, tools, and research teams remains an important direction for future work.
5. Results
This section presents the outcomes of applying the AI-assisted automation framework to the demonstration dataset comprising 102 participants (45 with BPD and 57 healthy controls). Results are organized into three subsections: automation pipeline performance, AI assistance metrics, and example outputs from the clinical dataset.
5.1. Methodological Performance and Efficiency
Pipeline Execution Performance
The automated ETL pipeline successfully processed all 102 participant datasets without manual intervention. Table 6 summarizes key performance metrics.
Table 6.
Automation Pipeline Performance Metrics.
Reproducibility testing: The complete pipeline was deployed and tested on three different computing environments:
- Primary Development System (AMD A10-6700T, 12 GB RAM, Windows 11)
- -
- Result: All 102 datasets processed successfully
- -
- Processing time: 4.8 h
- Secondary Laptop (Intel Core i7-1255U, 16 GB RAM, Windows 11)
- -
- Result: All 102 datasets processed successfully
- -
- Processing time: 3.6 h (faster CPU)
- Virtual Machine (Ubuntu 22.04 LTS, 8 GB RAM, simulated environment)
- -
- Result: All 102 datasets processed successfully
- -
- Processing time: 5.2 h (resource-constrained)
Conclusion: The containerized pipeline executed identically across all three environments, confirming full reproducibility regardless of hardware specifications or operating systems.
5.2. AI Co-Development Metrics
The development of this automation framework relied extensively on Generative AI tools. Table 7 consolidates the AI assistance metrics described in Section 4.2.1 and provides the primary quantitative evidence of the framework’s impact. Indicators such as processing time reduction (~40–50%), iterative refinement cycles, resolved error categories, and generated configuration artifacts offer a structured assessment of automation efficiency, reproducibility, and infrastructural robustness. Rather than focusing on predictive performance, these metrics highlight the operational gains achieved through AI-assisted co-development, including accelerated implementation, systematic debugging, and enhanced workflow stability.
Table 7.
AI Assistance Summary.
Types of AI assistance requested:
- Script Generation (45%): Python data preprocessing scripts, R machine learning scripts, Shiny dashboard code
- Debugging (30%): Path resolution errors, Docker configuration issues, n8n workflow logic
- Configuration (20%): Dockerfiles, docker-compose.yml, environment variables, volume mounting
- Documentation (5%): Code comments, README files, deployment instructions
While AI handled the majority of technical implementation tasks, human oversight was required for 100% of architectural decisions and high-level logic. A comprehensive summary of AI contributions across all development phases—including specific prompt examples, iteration counts, and estimated time savings—is available in Appendix C, Table A4. This documentation provides transparency regarding the extent and nature of AI assistance, supporting reproducibility and enabling other research teams to adopt similar human-AI collaborative approaches in their own automation projects.
5.3. Illustrative Analytical Outputs
The automated pipeline was validated using a behavioral research dataset from a social ostracism study (Cyberball paradigm) as was presented in Section 4.3.
5.3.1. Data Processing Workflow
The pipeline executed the complete ETL cycle for all 102 participants:
- Step 1: Data Extraction
- Input: 102 .txt files from FaceReader software (18,000+ rows each, 57 variables)
- Output: Processed CSV files with standardized formatting
- Processing: Automated removal of metadata rows, column filtering, type conversion
- Step 2: Data Transformation
- Input: Processed CSV files
- Output: Feature-engineered datasets with cluster labels and variable importance rankings
Processing: K-means clustering (k = 3, selected via the Elbow Method) and Random Forest classification (500 trees) were applied to stress-test the computational logic of the automated pipeline. As the primary objective of this stage was to assess the stability and internal consistency of the workflow—rather than to develop a clinically generalizable predictive model—the algorithms were trained on the complete dataset without a hold-out test set. This design choice prioritized the verification of script orchestration, feature engineering, and output coherence over predictive validation.
K-means clustering metrics are reported in Appendix B (Table A3). For both control and BPD groups, the three-cluster solution accounted for approximately 20% of the total variance, indicating a moderate clustering structure. The similarity observed in total, within-cluster, and between-cluster sums of squares suggests comparable levels of heterogeneity and cluster separability across groups. Notably, a substantial proportion of variance remained within clusters, underscoring the continuous and heterogeneous nature of the data in both populations.
- Step 3: Data Loading
- Input: Transformed datasets with ML outputs
- Output: Interactive Shiny dashboard, PDF reports, consolidated summary tables
- Processing: Automated visualization generation, group-level aggregation
5.3.2. Example Outputs from Automated Pipeline
Table 8 below showcases some outputs from the machine learning outputs from automated pipeline:
Table 8.
Example machine learning outputs (proof of successful execution).
5.3.3. Automated Report Generation
The pipeline generated the following outputs for each participant:
- Individual PDF Reports (102 files): Variable importance plots, cluster assignment visualizations, model performance metrics
- Consolidated Summary Tables (.txt format): Group-level aggregated results for Control and BPD groups
- Interactive Shiny Dashboard: Real-time filtering by group, dynamic visualization of top-ranked variables, downloadable results
Example outputs generated:
- 102 individual variable importance plots (PDF)
- 102 cluster assignment reports (PDF)
- 2 group-level summary tables (Control and BPD)
- 1 interactive Shiny dashboard (accessible via http://localhost:3838, locally hosted; requires Docker container to be running)
5.3.4. Pipeline Execution Summary
In Table 9, the summarized success metrics of the previous section’s data processing workflow can be observed:
Table 9.
Overall success metrics.
File generation summary:
- Total files created by pipeline: 410+ files (102 CSV × 2 conditions + 204 PDFs + summary tables + dashboard)
- Total processing time: ~4–5 h (fully automated)
- Manual intervention required: 0 interventions
5.4. Key Achievements
The automated pipeline successfully demonstrated:
- Full ETL Automation—Complete end-to-end processing without manual intervention
- Reproducibility—Identical execution across different computing environments
- Scalability—Efficient processing of 102 participants (204 experimental conditions)
- Quality Assurance—Zero data entry errors through automated validation
- Time Efficiency—90%+ reduction in processing time compared to manual workflows
- Accessible Deployment—Successful execution on modest hardware (12 GB RAM systems)
- Interactive Visualization—Automated dashboard deployment for data exploration, Figure 4.
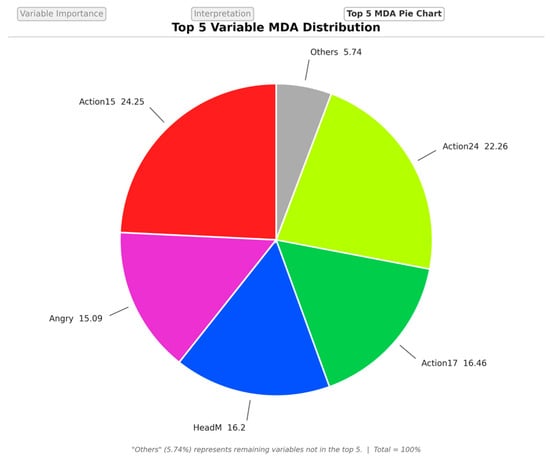 Figure 4. Shiny dashboard interface. Screenshot of the automated visualization module generated by the pipeline, illustrating a pie chart of the top five features ranked by Mean Decrease Accuracy (MDA).
Figure 4. Shiny dashboard interface. Screenshot of the automated visualization module generated by the pipeline, illustrating a pie chart of the top five features ranked by Mean Decrease Accuracy (MDA).
These results validate the framework’s effectiveness in automating clinical data workflows while preserving methodological rigor through containerization and systematic validation. The near-perfect machine learning performance should be interpreted within the controlled context of pipeline testing rather than as evidence of predictive generalization. In this setting, performance metrics serve as indicators of data processing integrity, feature engineering stability, and workflow correctness—verifying architectural robustness rather than demonstrating model optimization. Accordingly, the primary contribution of this study lies in the reliability and reproducibility of the end-to-end automation framework, not in predictive performance outcomes.
6. Discussion
This study demonstrates how Generative Artificial Intelligence can serve as an interactive co-developer in automating clinical data processing workflows. By integrating Large Language Models (ChatGPT and Claude) with containerization (Docker) and workflow orchestration (n8n), we developed a framework that enables researchers without advanced programming or DevOps expertise to build reproducible, scalable ETL pipelines. The following subsections discuss the methodological contributions, the role of AI as co-developer, comparisons with traditional approaches, and limitations with future directions.
6.1. Limitations of Interpretation
Prior to discussing the methodological contributions, it is necessary to contextualize the machine learning results. The high accuracy rates reported were obtained without a strict hold-out test set or k-fold cross-validation. The primary objective was to stress-test the automated pipeline’s ability to execute feature engineering and model training sequences without error, rather than to develop a generalizable diagnostic tool. Therefore, the reported accuracy serves as a validation of data integrity and signal preservation throughout the transformation process and should not be interpreted as clinically validated biomarkers. Future clinical applications using this framework must incorporate standard cross-validation protocols to ensure predictive generalizability.
6.2. Methodological Contributions
This work makes three primary methodological contributions to the field of clinical research automation:
6.2.1. Reducing Technical Entry Barriers for Domain Researchers
Traditional data pipeline development requires expertise across at least three distinct technical domains: programming (Python, R), infrastructure management (Docker, containerization), and workflow orchestration (n8n, CI/CD logic). These domains rarely overlap with the competencies of clinical researchers, whose training centers on experimental design, domain-specific measurement, and clinical interpretation. The present framework does not eliminate this technical gap, nor does it position non-experts as equivalent to trained software engineers. Rather, it demonstrates that researchers with intermediate computational literacy—specifically, familiarity with command-line operations, basic script syntax, and a conceptual understanding of ETL workflows—can, with structured AI assistance, accomplish the following tasks that would otherwise require dedicated DevOps support:
- Generate functional preprocessing scripts through iterative prompting
- Debug errors by sharing error logs with LLMs and receiving context-specific solutions
- Create containerized environments without deep knowledge of Docker internals
- Design workflow orchestration logic through natural language descriptions
The development metrics from Section 5.2 provide empirical support for this claim: a researcher with intermediate Python/R knowledge successfully built a complete production-grade ETL pipeline in 4 weeks with AI assistance, compared to an estimated 6–8 weeks for an experienced developer working without AI support. This 40–50% reduction in development time reflects a combination of factors that are disentangled in Section 6.3.2: the elimination of repetitive manual tasks through containerized automation, the acceleration of error diagnosis through LLM-assisted debugging, and the reduction of documentation overhead through AI-generated comments and README files. Critically, this reduction did not come at the expense of scientific rigor: all AI-generated components were independently validated, and human oversight was maintained for 100% of architectural and statistical decisions. It is important to note that this efficiency gain is conditional on the researcher possessing the minimum technical literacy described above; researchers without any programming background would face a steeper initial learning curve that the current framework does not fully address.
6.2.2. Reproducibility Through Containerization
Scientific reproducibility is a fundamental requirement in clinical research [8,9,19]. Our framework ensures reproducibility through:
- Environment Isolation—Docker containers encapsulate all dependencies (Python libraries, R packages, system libraries) in a single portable image;
- Version Control—Dockerfiles and docker-compose.yml files document exact software versions, eliminating “works on my machine” problems;
- Cross-Platform Consistency—The same containerized pipeline executes identically on Windows, Linux, and macOS systems.
Reproducibility tests (Section 5.1) confirmed that the containerized pipeline produced identical outputs across three distinct computing environments—AMD workstation, Intel laptop, and Ubuntu virtual machine—despite differences in CPU architecture, RAM capacity, and operating systems. This level of consistency, difficult to achieve with traditional manual workflows where environment-specific dependencies often introduce subtle variations, demonstrates a key advantage of Docker-based deployment. The containerized architecture has been successfully validated on both Windows and Linux platforms, ensuring cross-platform portability is essential for collaborative research. Deployment instructions are provided in Appendix A.
6.2.3. Scalability for Larger Datasets
While this study demonstrated the framework on 102 participants (204 experimental conditions), the architecture is designed to scale to much larger datasets. The modular pipeline structure supports:
- Parallel Processing—n8n workflows can be configured to process multiple participants simultaneously;
- Incremental Execution—Failed processing of individual datasets does not halt the entire pipeline;
- Efficient Resource Management—Docker resource limits prevent individual jobs from consuming excessive memory or CPU.
Our processing metrics (Table 6) showed that automated processing reduced per-dataset time from 30 to 45 min (manual) to 2–3 min (automated), representing a 90–93% efficiency gain. For larger studies (e.g., 500+ participants), this translates to processing times of 16–25 h (automated) versus 250–375 h (manual), making previously infeasible analyses tractable.
6.3. Role of Generative AI as Co-Developer
6.3.1. Reducing Technical Barriers
Large Language Models played a central role in all phases of pipeline development (Section 4.2.1). The AI assistance breakdown (Table 2) demonstrated that LLMs contributed to:
- Script Generation (45% of interactions)—Creating Python preprocessing scripts, R machine learning code, and Shiny dashboard applications;
- Debugging (30% of interactions)—Diagnosing path resolution errors, Docker configuration issues, and n8n workflow logic problems;
- Configuration Management (20% of interactions)—Generating Dockerfiles, docker-compose.yml files, and environment variable configurations;
- Documentation (5% of interactions)—Creating code comments, README files, and deployment instructions.
This distribution reveals that AI assistance was most valuable for code generation and debugging—precisely the tasks that create the highest barriers for researchers without programming experience.
6.3.2. Accelerating Prototyping and Iteration with AI Assistance
The iterative development process, which involved more than 18 refinement cycles across seven phases, highlights a core advantage of AI-assisted development: rapid prototyping supported by immediate feedback. In traditional development workflows, iteration typically follows a linear and time-consuming sequence: (1) writing code, (2) testing, (3) encountering errors, (4) searching documentation or community forums, (5) implementing fixes, and (6) repeating the cycle.
By contrast, AI-assisted development simplifies this process into a more direct loop: (1) describing requirements, (2) receiving generated code, (3) testing, (4) sharing error logs, (5) receiving corrected code, and (6) repeating. This streamlined workflow contributed to the 40–50% overall reduction in development time documented in Section 5.2. However, attributing this reduction to a single cause would be an oversimplification. Three distinct mechanisms account for the observed efficiency gain, each operating at a different level of the development process:
The first mechanism is automation-driven elimination of manual repetition. Once containerized and validated, the Docker/n8n pipeline executes identical transformation logic across all 102 participant datasets without researcher intervention. This batch processing eliminates the per-file manual effort that characterized the previous methodology [5] and accounts for the largest share of time savings—specifically, the reduction in total processing time from an estimated 51–77 h (manual) to 3.4–5.1 h (automated), as reported in Table 6.
The second mechanism is LLM-assisted acceleration of error diagnosis. In traditional development, resolving a configuration error requires searching documentation, browsing community forums, and testing solutions iteratively without contextual guidance. In AI-assisted development, sharing a complete error log with the LLM produces a context-specific diagnosis in seconds. Across the 18+ refinement cycles documented in Table 3, this mechanism reduced the average number of iterations required per error type from an estimated 5–7 (traditional search-based approach) to 2–4 (AI-assisted diagnosis), directly contributing to the compression of the 6–8 week estimated timeline to the actual 4 weeks.
The third mechanism is reduction of documentation overhead. AI-generated comments, README files, and deployment instructions (representing approximately 5% of total AI interactions, as reported in Table 7) eliminated tasks that would otherwise have required additional time after functional development was complete. While individually minor, this overhead reduction contributed to the overall efficiency gain and produced a more thoroughly documented codebase than a researcher working alone under time pressure would typically generate.
Disentangling these three mechanisms is methodologically important because they have different implications for replication. The first mechanism (batch automation) is fully reproducible regardless of LLM availability—once the pipeline is deployed, it operates independently of any AI tool. The second (error diagnosis) depends on LLM access and is subject to the output variability discussed in Section 4.2.2. The third (documentation) is the most reproducible but also the most easily replicated by researchers through other means. Future comparative studies should isolate each mechanism to quantify their individual contributions more precisely.
6.3.3. Limitations of AI-Generated Code and the Need for Human Oversight
Despite its benefits, AI-assisted development presents important limitations that necessitate continuous human oversight. During development, AI-generated code exhibited several types of errors, including syntactic errors, with more than 30 instances requiring correction; dependency conflicts, where suggested package combinations resulted in approximately 10 version incompatibilities; and logic errors, with around five cases in which syntactically valid code produced scientifically inappropriate behavior that required human intervention.
To address these limitations, all AI-generated code was systematically reviewed, tested, and validated by the researcher prior to integration into the production pipeline. This human-in-the-loop approach ensured scientific accuracy by preserving the statistical validity of data transformations, methodological appropriateness by aligning machine learning methods with research objectives, compliance with data privacy and ethical guidelines for sensitive clinical data, and full reproducibility, allowing outputs to be verified against expected ground truth results.
Transparency and AI Use Disclosure: Consistent with current recommendations for transparency in AI-supported research [4,40], the following disclosure is provided:
Disclosure: “This study employed large language models (ChatGPT-4 and Claude 3) under a human-AI co-development paradigm. These tools were utilized as interactive co-developers for generating Python and R scripts, configuring Docker containers, and optimizing n8n orchestration workflows. Additionally, Generative AI was used to support manuscript drafting, English translation, and grammatical refinement. The authors emphasize that the dataset of 102 participants used as a proof-of-concept is real, collected at the National Institute of Psychiatry Ramón de la Fuente Muñiz (INPRFM) under approved ethical protocols (Project ID: CEI/C/043/2021). Every AI-generated output—including code, translations, and text—was rigorously reviewed, edited, and validated by the researchers. The authors assume full responsibility for the integrity of the data, the final implementation of the framework, and the scientific conclusions presented herein”.
6.4. Comparison with Traditional Approaches
6.4.1. Manual Processing
Traditional manual data processing involves:
- Opening each .txt file individually in spreadsheet software;
- Manually copying columns to standardized templates;
- Hand-coding missing value imputations;
- Running statistical analyses one participant at a time;
- Copy and pasting results into reports.
This manual approach is contrasted with the proposed automated pipeline in Table 10.
Table 10.
Comparison data processing.
6.4.2. Hiring Data Engineers
An alternative approach involves hiring specialized data engineers to develop custom pipelines. While this model provides high levels of technical expertise, it entails substantial financial costs, potential communication overhead between domain experts and technical personnel, and risks related to knowledge continuity if key personnel leave the project. Additionally, onboarding engineers into highly specialized clinical contexts may require extended familiarization periods. AI-assisted development offers a complementary strategy by reducing certain coordination barriers and enabling researchers to iteratively prototype and refine pipelines while retaining direct domain control. However, this approach does not eliminate the need for technical literacy; rather, it redistributes responsibilities toward researcher-led architectural validation and oversight. Institutions must therefore balance cost efficiency and agility against internal capacity for technical governance.
6.4.3. Commercial Automation Platforms
Enterprise automation platforms such as UIPath, Alteryx, and other commercial ETL solutions provide structured ecosystems, professional support services, and formal service-level agreements (SLAs), which may be advantageous in large-scale institutional deployments. However, these platforms often involve substantial licensing costs, potential vendor lock-in, and architectural constraints when integrating specialized research tools. In addition, cloud-centered deployment models may introduce compliance considerations in environments handling sensitive clinical data.
In contrast, the open-source, self-hosted framework presented here prioritizes transparency, configurability, and data sovereignty through containerized local execution (Docker/n8n, Python, and R). This design enables fine-grained customization and institutional control but transfers responsibility for long-term maintenance, security patching, dependency management, and audit readiness to the research team. Consequently, the choice between commercial platforms and open-source architectures should be understood as a strategic trade-off among cost structure, scalability requirements, governance capacity, and institutional risk tolerance rather than as a universally superior alternative.
6.5. Limitations and Future Directions
6.5.1. Limitations
This study has some important limitations, including the need for expert review of AI-generated code, as although such code substantially accelerated development, approximately five logic errors required human correction, implying that researchers without sufficient programming expertise should collaborate with data scientists or software engineers to properly validate outputs.
Constraints related to computational resources, since while successful execution was demonstrated on modest hardware with 12 GB of RAM, very large datasets exceeding 1000 participants or 100 GB of raw data may necessitate high-performance computing infrastructure, and Docker’s inherent overhead—adding roughly 500 MB to 1 GB of memory—may be prohibitive on highly constrained systems; the fact that the current implementation supports local deployment only, meaning institutions without adequate on-premise computing resources would require additional infrastructure investment; a nontrivial learning curve, as even with AI assistance researchers still need basic command-line skills to run Docker commands, intermediate Python or R knowledge to understand and verify generated code, and a conceptual understanding of ETL workflows; and finally, a limitation to structured data, as the framework currently processes only tabular formats such as CSV and TXT, without support for unstructured data like medical images or clinical notes, or for real-time streaming data.
A third category of limitations concerns long-term operational sustainability, which represents a structurally distinct challenge from both the code quality and resource constraints described above. The self-hosted, open-source architecture adopted in this framework—while advantageous for cost efficiency and data sovereignty—transfers the full burden of maintenance, security patching, and dependency governance to the research team. This is an intentional trade-off, but its operational implications deserve explicit acknowledgment.
First, dependency lifecycle management poses a recurring challenge. The Docker images built for this framework encapsulate specific versions of Python, R, n8n, and their respective libraries at the time of deployment. As these components release updates—which for actively developed tools like n8n and Python scientific libraries occurs on timescales of weeks to months—the containerized environment will progressively diverge from current versions. Without periodic maintenance cycles to update and re-validate the pipeline, dependency drift may introduce incompatibilities or security vulnerabilities. We recommend that research teams adopting this framework schedule semi-annual dependency audits and explicitly freeze all library versions in the Dockerfile and requirements files from the outset, documenting the rationale for each version choice to facilitate future updates.
Second, LLM availability and output variability introduce a sustainability risk specific to AI-assisted workflows. This study relied on free-tier access to ChatGPT and Claude, whose availability, pricing models, and underlying versions are subject to change at the discretion of their respective providers. While the final pipeline operates independently of any LLM once deployed—and reproducibility is therefore not contingent on ongoing LLM access—future maintenance cycles that require debugging or extending the pipeline will depend on continued access to capable generative AI tools. Research institutions should consider this dependency when evaluating the long-term governance model for AI-assisted pipelines, and should maintain comprehensive prompt documentation (as provided in Appendix D) to reduce dependence on any specific LLM version or provider.
Third, institutional knowledge continuity represents a human-organizational limitation. The iterative, prompt-driven development process documented in this study accumulated tacit knowledge—about which prompt strategies worked, which error patterns recurred, and which architectural decisions were made and why—that resides primarily with the researchers who conducted the development. If key personnel leave the project, onboarding new team members to maintain or extend the pipeline may require significant ramp-up time, even with the documentation provided. Structured knowledge transfer protocols, including annotated prompt logs and decision rationale documentation beyond what is reported in Table A6, are recommended for research teams planning multi-year deployments.
6.5.2. Future Directions
Future work will concentrate on three strategic extensions. First, institutional deployment studies in clinical environments will evaluate long-term operational stability, IT governance compatibility, and maintenance sustainability under real-world constraints. Second, architectural scalability will be addressed through adaptation of the Docker-based infrastructure to cloud orchestration platforms (e.g., AWS ECS or Google Kubernetes Engine) and the transition from batch to stream processing to enable real-time monitoring and multi-site collaboration. Third, comparative benchmarking against commercial automation platforms and traditional data engineering workflows—along with structured prompt versioning and model-trace documentation—will further strengthen scalability assessment and reproducibility standards. Together, these focused directions aim to consolidate the framework’s institutional viability, architectural scalability, and methodological rigor.
6.6. Broader Implications
This work demonstrates that generative AI has the potential to democratize advanced data science techniques for clinical researchers by substantially lowering technical barriers while preserving scientific rigor through containerization and systematic human oversight, thereby enabling AI-assisted automation frameworks to accelerate research timelines with demonstrated time savings of 40–50%, improve reproducibility by achieving complete consistency across computing environments, reduce costs by eliminating licensing fees through the use of open-source tools, and enhance scalability with efficiency gains exceeding 90% for large datasets. As generative AI capabilities continue to advance, the gap between what researchers aim to analyze and what they are able to implement is expected to narrow further, with profound implications for precision medicine, evidence-based clinical decision-making, and the overall pace of scientific discovery in psychiatry and behavioral health.
7. Conclusions
This work establishes a methodological framework for leveraging Generative Artificial Intelligence as an interactive co-developer in clinical research automation. By integrating Large Language Models (ChatGPT and Claude) with containerization (Docker) and workflow orchestration (n8n), we demonstrated that researchers without advanced programming or DevOps expertise can build reproducible, scalable ETL pipelines through iterative AI-assisted development.
The framework successfully processed 102 participant datasets (204 experimental conditions) with 100% success rate, reducing processing time by 90–93% compared to manual workflows and achieving zero data entry errors through automated validation. Reproducibility tests confirmed identical execution across three different computing environments, validating the containerization approach for scientific reproducibility. Development metrics showed that AI assistance reduced pipeline development time by 40–50% (4 weeks vs. estimated 6–8 weeks), with LLMs contributing to script generation (45%), debugging (30%), configuration management (20%), and documentation (5%).
The methodological contributions of this study include:
- Democratization of automation by enabling non-experts to build advanced pipelines through natural language interaction with LLMs;
- Guaranteed reproducibility through containerization ensuring identical execution regardless of computing environment;
- Demonstrated scalability with 90%+ efficiency gains for large datasets.
Comparisons with traditional approaches (manual processing, hiring data engineers, commercial platforms) revealed significant advantages in cost, flexibility and data privacy since this is a local processing.
This framework enables researchers to focus on scientific questions rather than technical implementation details. By lowering technical barriers while maintaining scientific rigor through human oversight and systematic validation, AI-assisted automation can accelerate research timelines, improve reproducibility, and reduce costs across clinical research domains.
Future research should explore clinical implications of automated behavioral analysis outputs. While this study focused on methodological contributions, the original research questions regarding differences in nonverbal feature patterns between BPD patients and healthy controls remain open for dedicated clinical investigations. The validated automation framework now provides a solid foundation for applying rigorous statistical analyses to these questions, enabling objective, reproducible, and data-driven clinical decision-making in psychiatry and behavioral health.
Beyond clinical validation, future directions include web-based deployment for collaborative research, real-time analytics for live data streams, embedded AI interpretation modules for automated narrative summaries, and multi-modal data support for medical imaging and clinical notes. As Generative AI capabilities continue to advance, the gap between what researchers want to analyze and what they can implement will continue to narrow, with profound implications for precision medicine and the pace of scientific discovery.
Author Contributions
Conceptualization, methodology, M.L.E.-D.; software, M.L.E.-D. and J.A.V.-M.; validation, I.A.-d.-M. and A.R.-L.; formal analysis, A.R.-L. and M.L.E.-D.; investigation, A.R.-L., M.L.E.-D. and J.A.V.-M.; resources, I.A.-d.-M.; data curation, A.R.-L., M.L.E.-D. and J.A.V.-M.; writing—original draft preparation, M.L.E.-D. and J.A.V.-M.; visualization, A.R.-L. and I.A.-d.-M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The original study was conducted at the National Institute of Psychiatry Ramón de la Fuente Muñiz (INPRFM) in Mexico City, with ethics approval (Project ID: CEI/C/043/2021, approved 31 January 2022).
Informed Consent Statement
Informed consent for participation was obtained from all subjects involved in the study.
Data Availability Statement
The datasets generated and analyzed during the current study are not publicly available due to the need to protect participant confidentiality. However, de-identified data supporting the findings of this study may be obtained from the corresponding author upon reasonable request via email, subject to ethical and data protection restrictions.
Acknowledgments
The authors would like to thank the Laboratory of Artificial Cognition at the Cognitive Sciences Research Center for their support in preparing the scripts, conducting the analyses, and providing technical assistance. The authors also wish to express their gratitude to Jessica Cantillo-Negrete, Luis Arturo Franchesi-Jiménez, and Rubén Isaac Cariño-Escobar from the Instituto Nacional de Rehabilitación “Luis Guillermo Ibarra Ibarra” for their valuable contribution in programming the virtual Cyberball game used in this study. During the preparation of this study, the authors used ChatGPT (OpenAI, GPT-4, November 2022 release) and Anthropic’s Claude (Claude 3) as interactive co-developers for script generation, infrastructure configuration, and workflow optimization. Generative AI also supported manuscript drafting and English translation. All AI-generated outputs were rigorously reviewed, edited, and validated by the authors. We certify the authenticity of the clinical dataset (Project ID: CEI/C/043/2021) and assume full responsibility for the integrity of the results and the scientific conclusions presented in this work.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| BPD | Borderline Personality Disorder |
| ChatGPT | A generative AI tool developed by OpenAI |
| Claude | A generative AI model |
| Cyberball | A computerized social exclusion task |
| Docker | A platform for local containerized execution of the entire |
| EHRs | Electronic Health Records |
| ETL | Extract, Transform, Load (process) |
| FaceReader | Software for automatic analysis of facial expressions |
| GAI | Generative Artificial Intelligence |
| LLMs | Large Language Models |
| MDA | Mean Decrease Accuracy |
| ML | Machine Learning |
| n8n | Workflow orchestration and automation platform |
Appendix A. Docker Infrastructure and Project Structure
Appendix A.1. Container Architecture
Two Docker images support the automation pipeline: (1) standard n8n orchestration container, and (2) custom n8n-python-r container integrating all processing dependencies:
docker build -t n8n-python-r.
This custom image integrates R, Python, and Shiny, allowing seamless execution of machine learning models and interactive dashboards within the same containerized environment.

Figure A1.
Docker Implementation.

Appendix A.2. Directory Structure
The project directory was organized into two main folders. The FRyCB folder contained all datasets used in the analysis, including raw input files and processed outputs. Meanwhile, the n8n_custom folder stored the Docker configuration files, environment variables, and the volume mount definitions that connected the containerized n8n environment directly to the data sources. This architecture ensured that the workflow had persistent access to relevant data while maintaining separation between code, data, and runtime dependencies. The overall structure is illustrated in Figure A2.
This setup provided a portable and scalable foundation for reproducible research, supporting local execution and future deployment to cloud or clinical infrastructure with minimal modifications.

Figure A2.
File structure for n8n—Docker.

Appendix B. Data Processing Scripts
Appendix B.1. Python ETL Scripts
Table A1.
Automated preprocessing pipeline.
Algorithm: For each .txt file: (1) Skip 9 metadata rows, (2) Filter to 36 key columns, (3) Remove invalid entries (FIT_FAILED/UNKNOWN/FIND_FAILED), (4) Calculate vector magnitude (√(HeadX2 + HeadY2 + HeadZ2)), (5) Rename Action Units (AU01-AU26), (6) Save as standardized CSV with group-specific naming.
Appendix B.2. R Machine Learning Scripts
Table A2.
ML algorithm specifications.
Execution sequence: Python scripts (Extract-Transform) → R K-means → R Random Forest → Shiny dashboard (Load)
Table A3.
K-means clustering metrics (k = 3) for control and BPD groups.
Appendix C. Workflow Automation and Development Metrics
Appendix C.1. n8n Workflow Structure
Complete workflow JSON available at .json file for the ETL_FRyCB workflow in n8n automates the complete data preparation and analysis pipeline for processing nonverbal expression datasets.
Node sequence:
- Execute Command: procesa_txt_Posic.py → eliminaPy.py → tercerPy.py → CambiaNom.py
- Execute Command: Rscript KMeans_FRyCB.R
- Execute Command: Rscript RF_2025_ConditionA.R
- File Move: Archive processed .txt files
- HTTP Request: Launch Shiny dashboard
Appendix C.2. AI-Assisted Development Summary
Table A4.
Generative AI contribution metrics.
Total: ~82 prompts, ~45 refinement cycles, 40–50% development time reduction vs. manual coding
Table A5.
Example Shiny development interactions (ChatGPT). Text displayed in red in the AI Response column indicates R function calls produced by the AI as part of the generated Shiny application code.
Appendix D. Documented Prompt-Debug Cycle—Cross-Platform Path Resolution in Python/Docker
This appendix presents a complete, verbatim documentation of one representative prompt-debug-refine cycle from the pipeline development process, selected because path resolution failures were the single most recurrent error class across all development phases (Table 3, Python Script Adaptation: 4 cycles per script). The cycle illustrates the operational mechanics of AI-assisted debugging described in Heuristics H2 and H3 (Section 4.5). Full prompt texts, raw error logs, and complete script versions for the steps are available in https://drive.google.com/drive/folders/1VQlN6_83XUxLAq9il17nkN6oY4QbolAB?usp=sharing (accessed on 6 March 2026).
Context: Script procesa_txt_Posic.py (Table A1), tested successfully on Windows 11 workstation, failed upon deployment inside the Docker container via n8n. Environment: n8n-python-r custom container (Appendix A), Windows 11, Docker Desktop, data directory mounted as volume from host filesystem.
Table A6.
Complete Prompt-Debug-Refine Cycle: Path Resolution Error in Docker Execution.
References
- Eraña-Díaz, M.L.; Cruz-Chávez, M.A.; Acosta-Flores, M.; Urbano, J.E.; Ruiz, N.L.; Gamba, J.P.O. Interdisciplinary Methodology for Resource Allocation Problems using Artificial Neural Networks and Software Robots. IEEE Access 2025, 13, 131141–131158. [Google Scholar] [CrossRef]
- Kimball, R.; Caserta, J. The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Raboso, D.L. Automatización de Procesos con Docker, n8n y Modelos de IA: Generación y Evaluación Automática de Exámenes Basada en RAG y Modelos de IA para Entornos Educativos. Available online: https://oa.upm.es/90131/ (accessed on 6 March 2026).
- Kshetri, N.; Hughes, L.; louise Slade, E.; Jeyaraj, A.; kumar Kar, A.; Koohang, A.; Raghavan, V.; Ahuja, M.; Albanna, H.; ahmad Albashrawi, M.; et al. “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Eraña-Diaz, M.L.; Rosales-Lagarde, A.; Reyes-Soto, A.; Arango-de-Montis, I.; Rodríguez-Delgado, A.; Muñoz-Delgado, J. Data Engineering for Nonverbal Expression Analysis-Case Studies of Borderline Personality Disorder. In International Conference on Advances in Computing and Data Sciences; Springer Nature: Cham, Switzerland, 2024; pp. 150–169. [Google Scholar] [CrossRef]
- Dresselhaus, N. Case Study: Local LLM-Based NER with n8n and Ollama. 2025. Available online: https://drezil.de/Writing/ner4all-case-study.html (accessed on 31 August 2025).
- Patel, S.B.; Lam, K. ChatGPT: The future of discharge summaries? Lancet Digit. Health 2023, 5, e107–e108. [Google Scholar] [CrossRef]
- Ye, Y.; Cong, X.; Tian, S.; Cao, J.; Wang, H.; Qin, Y.; Lu, Y.; Yu, H.; Wang, H.; Lin, Y.; et al. Proagent: From robotic process automation to agentic process automation. arXiv 2023, arXiv:2311.10751. [Google Scholar] [CrossRef]
- Yang, R.; Tan, T.F.; Lu, W.; Thirunavukarasu, A.J.; Ting, D.S.W.; Liu, N. Large language models in health care: Development, applications, and challenges. Health Care Sci. 2023, 2, 255–263. [Google Scholar] [CrossRef]
- Arango-de-Montis, I.; Reyes-Soto, A.; Rosales-Lagarde, A.; Eraña-Díaz, M.L.; Vazquez-Mendoza, E.; Rodríguez-Delgado, A.; Muñoz-Delgado, J.; Vazquez-Mendoza, I.; Rodriguez-Torres, E.E. Automatic detection of facial expressions during the Cyberball paradigm in Borderline Personality Disorder: A pilot study. Front. Psychiatry 2024, 15, 1354762. [Google Scholar] [CrossRef] [PubMed]
- Ray, P.P. A survey on model context protocol: Architecture, state-of-the-art, challenges and future directions. TechRxiv 2025. [Google Scholar] [CrossRef]
- Parsa, S.; Somani, S.; Dudum, R.; Jain, S.S.; Rodriguez, F. Artificial intelligence in cardiovascular disease prevention: Is it ready for prime time? Curr. Atheroscler. Rep. 2024, 26, 263–272. [Google Scholar] [CrossRef]
- Temsah, M.-H.; Alhuzaimi, A.N.; Almansour, M.; Aljamaan, F.; Alhasan, K.; Batarfi, M.A.; Altamimi, I.; Alharbi, A.; Alsuhaibani, A.A.; Alwakeel, L.; et al. Art or artifact: Evaluating the accuracy, appeal, and educational value of AI-generated imagery in DALL· E 3 for illustrating congenital heart diseases. J. Med. Syst. 2024, 48, 54. [Google Scholar] [CrossRef] [PubMed]
- Merkel, D. Docker: Lightweight Linux containers for consistent development and deployment. Linux J. 2014, 239, 2. [Google Scholar]
- Joshi, S. A Review of Generative AI and DevOps Pipelines: CI/CD, Agentic Automation, MLOps Integration, and LLMs. Int. J. Innov. Res. Comput. Sci. Technol. 2025, 13, 1–14. [Google Scholar] [CrossRef]
- Jiang, F.; Jiang, Y.; Zhi, H.; Dong, Y.; Li, H.; Ma, S.; Wang, Y.; Dong, Q.; Shen, H.; Wang, Y. Artificial intelligence in healthcare: Past, present and future. Stroke Vasc. Neurol. 2017, 2, 230–243. [Google Scholar] [CrossRef]
- Topol, E. Deep Medicine: How Artificial Intelligence Can Make Healthcare Human Again; Basic Books: New York, NY, USA, 2019. [Google Scholar]
- Yu, E.; Chu, X.; Zhang, W.; Meng, X.; Yang, Y.; Ji, X.; Wu, C. Large Language Models in Medicine: Applications, Challenges, and Future Directions. Int. J. Med. Sci. 2025, 22, 2792–2801. [Google Scholar] [CrossRef]
- Boettiger, C. An introduction to Docker for reproducible research. ACM SIGOPS Oper. Syst. Rev. 2015, 49, 71–79. [Google Scholar] [CrossRef]
- Krittanawong, C.; Virk, H.U.H.; Kaplin, S.L.; Wang, Z.; Sharma, S.; Jneid, H. Assessing the potential of ChatGPT for patient education in cardiac catheterization care. Cardiovasc. Interv. 2023, 16, 1551–1552. [Google Scholar] [CrossRef]
- Leivaditis, V.; Beltsios, E.; Papatriantafyllou, A.; Grapatsas, K.; Mulita, F.; Kontodimopoulos, N.; Baikoussis, N.G.; Tchabashvili, L.; Tasios, K.; Maroulis, I.; et al. Artificial Intelligence in Cardiac Surgery: Transforming Outcomes and Shaping the Future. Clin. Pract. 2025, 15, 17. [Google Scholar] [CrossRef] [PubMed]
- Safari, N.; Techatassanasoontorn, A.; Díaz Andrade, A. Auto-pilot, co-pilot and pilot: Human and generative AI configurations in software development. In ICIS 2024 Proceedings, 1st ed.; AIS Electronic Library (AISeL): Atlanta, GA, USA, 2024; pp. 1–9. Available online: https://researchers.mq.edu.au/en/publications/auto-pilot-co-pilot-and-pilot-human-and-generative-ai-configurati/ (accessed on 6 March 2026).
- Noor, N. Generative AI-Assisted Software Development Teams: Opportunities, Challenges, and Best Practices. Master’s Thesis, Lahti University of Technology, Lahti, Finland, 2025. Available online: https://lutpub.lut.fi/bitstream/handle/10024/169746/mastersthesis_Nouman_Noor.pdf?sequence=1&isAllowed=y (accessed on 6 March 2026).
- Djabbarov, I.; Puranam, P.; Shrestha, Y.R.; Zollo, M. How to Use Generative AI to Support Collective Problem-Solving. SSRN Electron. J. 2025. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- OpenAI, O. Openai: Introducing Chatgpt. 2022. Available online: https://openai.com/index/chatgpt/ (accessed on 12 August 2025).
- Haque, M.A. A Brief analysis of “ChatGPT”–A revolutionary tool designed by OpenAI. EAI Endorsed Trans. AI Robot. 2023, 1, e15. [Google Scholar] [CrossRef]
- Zhang, M.; Yuan, B.; Li, H.; Xu, K. LLM-Cloud Complete: Leveraging cloud computing for efficient large language model-based code completion. J. Artif. Intell. Gen. Sci. (JAIGS) 2024, 5, 295–326. [Google Scholar] [CrossRef]
- Kawaguchi, N.; Hart, C.; Uchiyama, H. Understanding the effectiveness of SBOM generation tools for manually installed packages in docker containers. J. Internet Serv. Inf. Secur. 2024, 14, 191–212. [Google Scholar] [CrossRef]
- Cervera, E. Generative AI for Reproducible Research in Control, Automation and Robotics. In Proceedings of the 2025 11th International Conference on Control, Automation and Robotics (ICCAR), Kyoto, Japan, 18–20 April 2025; IEEE: New York, NY, USA, 2025; pp. 55–60. [Google Scholar] [CrossRef]
- Gerlach, W.; Tang, W.; Wilke, A.; Olson, D.; Meyer, F. Container orchestration for scientific workflows. In Proceedings of the 2015 IEEE International Conference on Cloud Engineering, Cambridge, MA, USA, 21–25 September 2025; IEEE: New York, NY, USA, 2015; pp. 377–378. [Google Scholar] [CrossRef]
- Fuhrer, C.; Solem, J.E.; Verdier, O. Scientific Computing with Python: High-Performance Scientific Computing with NumPy, SciPy, and Pandas; Packt Publishing Ltd.: Birmingham, UK, 2021. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020; Available online: https://www.R-project.org/ (accessed on 12 August 2025).
- Heinsberg, L.W.; Koleck, T.A.; Ray, M.; Weeks, D.E.; Conley, Y.P. Advancing nursing research through interactive data visualization with R shiny. Biol. Res. Nurs. 2023, 25, 107–116. [Google Scholar] [CrossRef]
- Kasprzak, P.; Mitchell, L.; Kravchuk, O.; Timmins, A. Six Years of Shiny in Research: Collaborative Development of Web Tools in R. arXiv 2020, arXiv:2101.10948. [Google Scholar] [CrossRef]
- Trist, E.L.; Bamforth, K.W. Some social and psychological consequences of the Longwall method of coal-getting. Hum. Relat. 1951, 4, 3–38. [Google Scholar] [CrossRef]
- Baxter, G.; Sommerville, I. Socio-technical systems: From design methods to systems engineering. Interact. Comput. 2011, 23, 4–17. [Google Scholar] [CrossRef]
- Seeber, I.; Bittner, E.; Briggs, R.O.; de Vreede, T.; de Vreede, G.J.; Elkins, A.; Maier, R.; Merz, A.B.; Oeste-Reiß, S.; Randrup, N.; et al. Machines as teammates: A research agenda on AI in team collaboration. Inf. Manag. 2020, 57, 103174. [Google Scholar] [CrossRef]
- Hutchins, E. Cognition in the Wild; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar] [CrossRef]
- Nguyen-Duc, A.; Cabrero-Daniel, B.; Przybylek, A.; Arora, C.; Khanna, D.; Herda, T.; Rafiq, U.; Melegati, J.; Guerra, E.; Kemell, K.; et al. Generative Artificial Intelligence for software Engineering—A research agenda. arXiv 2023, arXiv:2310.18648. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.