Abstract
The semantic segmentation model usually provides pixel-wise category prediction for images. However, a massive amount of pixel-wise annotation images is required for model training, which is time-consuming and labor-intensive. An image-level categorical annotation is recently popular and attempted to overcome the above issue in this work. This is also termed weakly supervised semantic segmentation, and the general framework aims to generate pseudo masks with class activation mapping. This can be learned through classification tasks that focus on explicit features. Some major issues in these approaches are as follows: (1) Excessive attention on the specific area; (2) for some objects, the detected range is beyond the boundary, and (3) the smooth areas or minor color gradients along the object are difficult to categorize. All these problems are comprehensively addressed in this work, mainly to overcome the importance of overly focusing on significant features. The suppression expansion module is used to diminish the centralized features and to expand the attention view. Moreover, to tackle the misclassification problem, the saliency-guided module is adopted to assist in learning regional information. It limits the object area effectively while simultaneously resolving the challenge of internal color smoothing. Experimental results show that the pseudo masks generated by the proposed network can achieve 76.0%, 73.3%, and 73.5% in mIoU with the PASCAL VOC 2012 train, validation, and test set, respectively, and outperform the state-of-the-art methods.
1. Introduction
Supervised semantic segmentation [1,2] comprises deep neural networks that perform intensive regional feature learning. The network provides point-by-point category prediction for all image pixels. The data preparation for such training tasks is tedious, and requires enormous labor. For instance, let us consider a street scene image [3], containing many elements such as vehicles, people, houses, street lights, roads, and other trivial objects. The manual annotations need to be performed to a fine-grain level for such images, and it is heavily time-consuming and expensive to develop a large-scale dataset. This limits the generalization capabilities of the semantic segmentation models. To address the above issue, weakly supervised approaches have been investigated, and the motivation is to use annotations that are weaker than that of the pixel-level labels.
Among the various types of weak annotations, image-level class labels have been widely used for their promising results, and many large-scale image datasets in relevance are already available. In general, the weakly supervised semantic segmentation tasks [4,5,6,7] use the class activation map (CAM) [8] as the base object location. The classifier can effectively determine the object’s existence in the image and localize well to the object of interest. The resultant attention features are mapped to the image, producing a pixel-level pseudo-label. The generation of such pseudo masks may cause several problems:
- (1)
- Finding the location of objects by classification model focuses on features that are well-defined and frequently appear on the same object. Mostly, the predictions are based on the well-localized and fine-grain regions, and hence the complete object may not be properly localized and segmented.
- (2)
- When the focus is on the scenes, such as the image of a boat on the water, an airplane in the air, etc., the background is sometimes misjudged as a single object in the mapping. This results in pseudo masks generated even beyond the object areas.
- (3)
- Smooth color regions in the object are hard to label using the general classifiers.
To overcome the above limitations, a new architecture is proposed to generate pixel-wise pseudo labels based on a classification scheme. The main contributions of this study are as follows.
- The ideal Suppression Module (SUPM) is proposed and integrated to enlarge the object’s attention.
- Saliency Map Guided Module (SMGM) is developed to resolve the issues in smooth color regions.
- Multi-Task Learning framework is adopted to jointly train the model for classification and segmentation task.
The overall manuscript is organized as follows. Section 2 provides a brief review of weakly supervised semantic segmentation models. Section 3 provides a detailed description of the proposed method. Section 4 focuses on detailed experiments to validate the performance of the proposed method compared to the state-of-the-art works. Finally, Section 5 draws a conclusion.
2. Related Works
The weakly supervision uses the more easily available annotation data, and the pseudo-labels are generated for subsequent training. The basic annotation methods that are commonly seen in weakly supervised semantic analysis tasks are bounding boxes [9,10,11], scribbles [12,13], and image-level annotation [5,6,14,15,16,17,18,19,20,21,22,23,24,25,26]. Some important works in the weakly supervised semantic segmentation is presented in Table 1.

Table 1.
Literature Review.
The most common approach to generate pseudo masks uses image-level annotations, which perform object identification through classification networks. The distinctive features are generally visualized using Class Activation Maps (CAM) tools. The classification prediction results can backward search the attention features of its objects with global average pooling layers for visualization. The original CAMs [8] method has a drawback that tends to focus on a small object area. The Puzzle-CAM [7] is proposed to enhance the category mapping using the image slice. This method improves the consistency of the object’s area of interest by merging and making the range of class features in more comprehensive. Among the existing work, the current work is built on the base model of the Puzzle-CAM method, and many novel techniques are built on its top to arrive at state-of-the-art performance.
Firstly, the suppression control mechanism is developed to improvise the object recognition area. Highly discriminative features are critical for classification tasks, yet these features are often a part of the object, and the entire object may not be covered. Suppression controls are used to expand the field of view of the feature attention to spread the attention from the high-recognition area to the surrounding neighborhood.
Secondly, a saliency guidance module is developed for improvised category mapping classification networks. It is often possible for objects to co-occur with the corresponding backgrounds, and this leads to an erroneous dispersion of attention to the external range of the objects from the region where the features are distinctive. To obtain more precise object localization, saliency assistance is used to provide coarse foreground object inspection. This prevents the spread of attention to unexpected background regions.
Finally, the Multi-Task Learning (MTL) framework is adopted to improve the model generalization through shared representations among related tasks. The proposed approach uses MTL to enhance semantic segmentation by jointly training the model for classification and segmentation tasks. The overall architechture of the proposed method is shown in Figure 1 and a detailed description is provided in the next section.
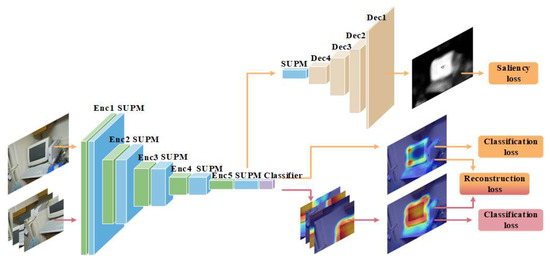
Figure 1.
Proposed suppression module and saliency map guided module.
3. Proposed Method
In this study, a novel architecture is proposed for pseudo masks generation. The proposed method contains three main components: (1) Classification, (2) Suppression Module (SUPM), and (3) Saliency Map Guided Module (SMGM). Figure 1 shows the overall framework of the proposed architecture. The first phase of the proposed architecture comprises of a classification module, generating class activation as the first step to obtain pseudo masks. The second part is the saliency map guidance, which is used to assist the classification mapping with global object information.
The foremost process of classification to obtain the category mapping consists of two steps: To start with, the full-image version is initially passed through the classification network to predict the object in the image. Simultaneously, the image is cropped into four equal parts and also fed into the classification module. The classification activation map of the complete path and the split path are compared, and the result shows that the difference is reduced. It can be seen from Figure 1 that the field of attention is expanded in the cropped version in comparison to the full image. Consequently, the classification map has the complete coverage over the object of interest
Figure 2 shows the backbone of the classification architecture. The standard ResNet backbone [18] is used, which consists of five levels of feature extraction stages from Enc1 to Enc5, and the high-dimensional features are extracted in the image. The SUPM is connected after each extraction layer to suppress the most concerned feature area on the feature map. Moreover, the suppression control also expands the attention to the surrounding objects of concern, and helps to learn more subtle features. After the feature extraction and suppression in the convolution layer, the extracted feature map is optimized using the classification and reconstruction loss function. As in [25], the global average pooling is used as it can make the network more stable, and achieve better results than that using a fully connected layer. Global average pooling effectively reflects the classification results on the class feature map, and finally obtains the activation map and image category type for the object of interest.
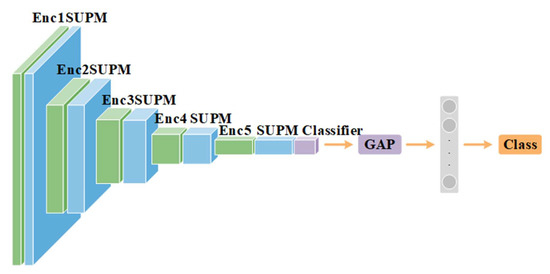
Figure 2.
Backbone model of the proposed method.
The purpose of the SUPM is to restrain the high recognition features and make recognition more difficult. This helps to learn more subtle and distinctive feature regions, and also facilitates mask diffusion. In addition, it can improve the attention from a small localized area to the neighboring areas in the target object. The overall procedure to obtain suppression value is as follows. Let us assume, intermediate and suppressed feature maps are and . The maximum and minimum feature values of each channel are computed as in Equations (1) and (2).
Further, the controller and suppressor module are applied, and then final value is computed as in Equations (3)–(5).
In the target extraction stage, the corresponds to the maximum feature value of each channel in the feature map. As shown in Figure 3, the second stage is the output of the suppression control base, indicated as It is the average value of each channel’s feature points, which is used as the reference baseline of the controller. The of each channel is passed through the fully connected layer and also sigmoid function to learn the suppression weight of each channel, and the normalization is performed. Subsequently, the final suppression is performed to obtain the suppression target , and is multiplied by the controller. When a feature value in this layer is larger than the inhibition value, it is constrained to the inhibition value size to achieve the inhibition effect.
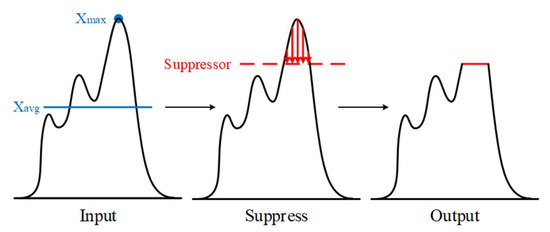
Figure 3.
Suppression control operation.
In the Saliency Map Guided Module (SMGM), the saliency map is used to guide and assist the classification network in a multi-task learning approach. Based on the autoencoder method, the encoder is responsible for feature extraction, and the decoder is responsible for decoding the extracted features. The classification network performs feature extraction as the encoder operation, and guides the extracted features into the SMGM decoder. The module assists the classification activation map to keep the objects within their boundaries. The region learning works simultaneously in the foreground, providing more feature information on the parts of the objects.
In the classification task, as the dataset image contains multiple objects, the multi-label approach is used to learn the prediction result. The main network contains the full-image path and the cropped-merged image path, and respectively provide the classification loss, and , to predict objects in images as in Equations (6) and (7).
In reconstruction learning, is the predicted area for each category of the full-image, and is the predicted area for each category after merging the cropped images. Due to the necessity of reducing the difference between the two predictions, the Mean Absolute Error (MAE) loss function is used to reduce the absolute difference between the two predicted images for each pixel as shown in Equation (8).
For saliency loss, the learning target of the saliency map is , and the feature decoding reduction result is . To accelerate the training process, The Mean Square Error (MSE) loss is used as in Equation (9) to learn the pixel difference between each other.
In the total loss as provided in Equation (10), the is weight for the restoration loss of weight, and is the weight for saliency loss.
4. Experiment Result
In this section, the public dataset PASCAL VOC 2012 is utilized for comprehensive experimentation and analysis. The results are compared against the former state-of-the-art weakly supervised segmentation algorithms [7,17,23,24,25,26]. In this study, the mean Intersection over Union (mIoU) is adopted for the evaluation of the overall performance.
4.1. Datasets
4.1.1. PASCAL VOC 2012
PASCAL VOC dataset [27] is also known as the PASCAL Visual Objected Classes which includes many machine vision tasks such as classification, object detection, segmentation, action classification, etc. In the weakly supervised semantic segmentation task, we use image-level labels for pseudo mask generation and pixel-level labels for validating semantic segmentation results.
4.1.2. Augmented Dataset
The augmented dataset used in this paper is derived from the SBD dataset [28]. The images in SBD dataset are from PASCAL VOC 2011. It is used in the classification task to increase object diversity in the training phase.
4.1.3. Saliency Map
The salient images are used as a guide for salient feature learning in the classification tasks. Subsequently, the PASCAL VOC 2012 training dataset and augmented dataset are applied to PoolNet [29] to obtain the salient maps.
4.2. Training
For training, the computational hardware platform consists of the following components. CPU: Intel(R) Xeon(R) Gold 5218 CPU 2.30 GHz; GPU: 1 × NVIDIA A100 (80 GB); RAM: 8 × DDR4 2666 (64 GB), and operating system: Ubuntu 18.04 LTS. The images are randomly re-scaled in the range of [320, 640] and then cropped to 512 × 512. Thus, we adopted multi-scale and horizontal flips to generate pseudo masks.
4.3. Ablation Test
4.3.1. Module Ablation Experiment
To verify the proposed class-activated classification network, the SUPM and SMGM are analyzed using the ResNet50 backbone. Table 2 shows that the combination of SUPM and SMGM yields the best results. Figure 4 shows the visualization results of class activation with the two modules, and it is found that when the SUPM and SMGM are used together, there is an object diffusion in the area of interest along the dining table and the local restriction in the area of interest of the airplane. Thus, using SUPM and SMGM together can generate the best-quality pseudo-labels for subsequent semantic segmentation task training.
Table 2.
Testing with SUPM AND SMGM on PASCAL VOC2012 Training Dataset of Pseudo Masks in MIOU (%).
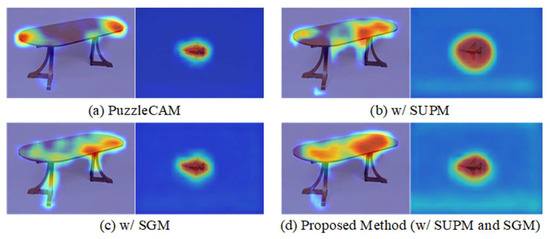
Figure 4.
Ablation test with ResNet50 as the backbone along with SUPM and SMGM on PASCAL VOC2012 training dataset in CAM.
4.3.2. Loss Function
In the proposed class mapping network, the total loss is The is the difference between the complete image region of interest and the restored segmented image, and is the region loss assisted by the saliency map. The pseudo labels generated on the PASCAL VOC 2012 training set are evaluated by mIoU using different loss functions in the same case. Table 3 shows that with mean absolute error loss and with mean square is best suited for pseudo mask generation. The reason is that learns the difference between the area of concern of the complete image and the segmented images. The sensitivity of the mean square error loss to the deviation value is too strong, and thus the predicted changes between the two are harmful to each other, making it more difficult to stabilize. In contrast, the sensitivity of mean absolute error is lower, and the two predicted results can learn better from each other.
Table 3.
Testing loss function weights for generating pseudo masks in PASCAL VOC 2012 training set in MIOU (%).
4.3.3. Backbone Selection
In this study, the same backbone networks as that of the baseline PuzzleCAM [7] such as ResNet [30], and ResNeSt [18] are used for fair comparison. Table 4 shows the experimental results, in which Random Walk (RW) is adopted from affininty-net [5] and dense conditional random field (dCRF) is adopted from [19]. The proposed method in this paper uses ResNeSt101 as the backbone and further enhancement through the random walk and dense conditional random field to generate pseudo masks.
Table 4.
Testing different backbones for generating pseudo masks in PASCAL VOC 2012 testing set in MIOU (%).
4.3.4. Comparison
The experimental results yielded the best-performing architecture for the generation of pixel-level pseudo labels, which were compared with previous techniques with the PASCAL VOC 2012 dataset. In Table 5, Sup. represents the supervised approach, in which I is the training image with image-level labels and S is the training image with saliency maps. According to the comparison results in Table 5, the proposed method achieved the best results on the pseudo masks generated from the public dataset of 76.0% in terms of the mIoU. Figure 5 shows the pseudo masks generated from the proposed method, and the locality of the objects in the pseudo masks are well represented.
Table 5.
Comparison of pseudo masks generation results with other existing method in MIOU (%).

Figure 5.
Pseudo masks on PASCAL VOC 2012 training dataset. Top: original images; Middle: ground truth; Bottom: prediction results.
The generated pseudo masks are on PASCAL VOC 2012 training dataset and the augmented dataset for semantic segmentation training with deeplabv3+ [31], the final results were compared with other methods in PASCAL VOC 2012 validation and test datasets and evaluated with mIoU. The results are shown in Table 6. As it can be seen that the proposed weakly supervised semantic segmentation achieve the best performance with improvement 0.9% over the existing state-of-the-art RSCM [23] for the validation dataset, and 0.3% for the testing dataset, respectively. Figure 6 shows the practical segmentation results compared with ground truth.
Table 6.
Comparison of semantic segmentation results against the state-of-the-art methods with MIOU (%).

Figure 6.
Segmentation results on PASCAL VOC 2012 validation dataset. Top: original images; Middle: ground truth, and Bottom: prediction results.
5. Conclusions
In weakly supervised semantic segmentation tasks, classification networks are often used to learn the regions of interest for each category, and generate pixel-level pseudo masks. In this paper, the Suppression Module (SUPM) is adopted to suppress strong points of interest and to diffuse concern to the surrounding area. To resolve the problem of misclassifying scenes as objects, the Saliency Map Guidance Module (SMGM) is designed and integrated, which uses a multi-task learning mechanism to help the classification network obtain the background area of objects. Compared with the state-of-the-art methods, the classification network framework designed in this study generates 76.0% pseudo masks on the PASCAL VOC 2012 training set and 73.3% and 73.5% on the PASCAL VOC 2012 validation and testing sets for training semantic segmentation networks with pseudo masks, and these are examined with superior performance compared to the state-of-the-art methods.
Author Contributions
Conceptualization, J.-M.G.; methodology, R.-H.C.; software, R.-H.C.; validation, S.S.; formal analysis, S.S.; investigation, J.-M.G.; resources, S.S.; data curation, R.-H.C.; writing—original draft preparation, S.S.; writing—review and editing, S.S.; visualization, R.-H.C.; supervision, J.-M.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 3213–3223. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2016; pp. 695–711. [Google Scholar]
- Ahn, J.; Kwak, S. Learning Pixel-Level Semantic Affinity with Image-Level Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4981–4990. [Google Scholar]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7014–7023. [Google Scholar]
- Jo, S.; Yu, I.-J. Puzzle-Cam: Improved Localization via Matching Partial and Full Features. In Proceedings of the International Conference on Image Processing (ICIP), Alaska, WA, USA, 19–22 September 2021; pp. 639–643. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 2921–2929. [Google Scholar]
- Papandreou, G.; Chen, L.-C.; Murphy, K.P.; Yuille, A.L. Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1742–1750. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple Does It: Weakly Supervised Instance and Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 876–885. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning Random-Walk Label Propagation for Weakly-Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 7158–7166. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 3159–3167. [Google Scholar]
- Hou, Q.; Jiang, P.; Wei, Y.; Cheng, M.-M. Self-Erasing Network for Integral Object Attention. arXiv 2018, arXiv:1810.09821v1. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad Is Not a Train: Saliency as Pseudo-Pixel Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5495–5505. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and Semi-Supervised Semantic Image Segmentation Using Stochastic Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5267–5276. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected Crfs with Gaussian Edge Potentials. arXiv 2017, arXiv:1210.5644. [Google Scholar] [CrossRef]
- Sutton, C.; McCallum, A. An Introduction to Conditional Random Fields. Found. Trends® Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Kim, B.; Han, S.; Kim, J. Discriminative Region Suppression for Weakly-Supervised Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 1754–1761. [Google Scholar]
- Jiang, P.-T.; Yang, Y.; Hou, Q.; Wei, Y. L2G: A Simple Local-to-Global Knowledge Transfer Framework for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16886–16896. [Google Scholar]
- Jo, S.H.; Yu, I.J.; Kim, K.-S. RecurSeed and CertainMix for Weakly Supervised Semantic Segmentation. arXiv 2022, arXiv:2204.06754. [Google Scholar]
- Yao, Q.; Gong, X. Saliency Guided Self-Attention Network for Weakly and Semi-Supervised Semantic Segmentation. IEEE Access 2020, 8, 14413–14423. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Ahn, J.; Cho, S.; Kwak, S. Weakly Supervised Learning of Instance Segmentation with Inter-Pixel Relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2209–2218. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (Voc) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic Contours from Inverse Detectors. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Feng, J.; Jiang, J. A Simple Pooling-Based Design for Real-Time Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).