Abstract
In complex urban traffic scenes, reliable pedestrian trajectory prediction is essential for Automated and Connected Electric Vehicles (ACEVs) and active safety systems. Despite recent progress, many existing approaches still suffer from limited long-term prediction accuracy, redundant temporal features, and high computational cost, which restricts their deployment on vehicles with constrained onboard resources. To address these issues, this paper presents a lightweight trajectory prediction framework named BiTraP-DGF. The model adopts parallel Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM) temporal encoders to extract motion information at different time scales, allowing both short-term motion changes and longer-term movement tendencies to be captured from observed trajectories. A conditional variational autoencoder (CVAE) with a bidirectional GRU decoder is further employed to model multimodal uncertainty, where forward prediction is combined with backward goal estimation to guide trajectory generation. In addition, a gated sparse attention mechanism is introduced to suppress irrelevant temporal responses and focus on informative time segments, thereby reducing unnecessary computation. Experimental results on the JAAD dataset show that BiTraP-DGF consistently outperforms the BiTraP-NP baseline. For a prediction horizon of 1.5 s, CADE is reduced by 20.9% and CFDE by 22.8%. These results indicate that the proposed framework achieves a practical balance between prediction accuracy and computational efficiency for autonomous driving applications.
1. Introduction
Automated and Connected Electric Vehicle (ACEV) technology is an integral component of the new technological revolution and has become a strategic high ground for major industrial nations [1]. In the context of autonomous driving, predicting the trajectories of dynamic targets such as pedestrians is crucial for the environmental perception system. It is a key element for achieving a high level of situational awareness. The vehicle must be able to accurately predict the trajectories of surrounding pedestrians. This capability is essential to alleviate traffic congestion, decrease the dangers of accidents and establish a safeguard line for the human–vehicle interaction [2,3]. Reliable pedestrian trajectory prediction enables intelligent vehicles to plan safe and efficient paths and make appropriate control decisions. This capability directly affects driving safety and passenger comfort [4]. However, pedestrian motion is not singular or deterministic; it is affected by both internal intentions and external surroundings (complex social interactions, road edges, traffic lights), making it inherently nonlinear and multimodal. Therefore, achieving accurate and reliable long-term trajectory forecasting based on a short period of observation history is an urgent challenge that needs to be addressed in the areas of computer vision and artificial intelligence.
Deep learning trajectory prediction algorithms have developed rapidly in recent years, from early simple path regression to the generative models focusing on interaction and goals. Alahi et al. [5] were the first to introduce Social-LSTM, which utilizes LSTM networks and “social pooling” layers to tackle the interaction modeling issue in crowded scenes. Conversely, to quantify prediction uncertainty, Bhattacharyya et al. [6] proposed B-LSTM, treating the uncertainty of model parameters as a Bayesian neural network. These approaches succeeded in capturing some temporal dependencies, but a single trajectory output cannot fully account for the randomness of pedestrian movement. To address this limitation, Gupta et al. [7] combined Generative Adversarial Networks (GANs) and created Social-GAN by adding different kinds of loss functions to generate multimodal trajectories compliant with social norms. After the attention mechanism was introduced into the sequence modeling field, researchers began employing it to capture the complicated spatiotemporal relations dynamically. Vemula et al. [8] introduced the Social Attention model, employing spatiotemporal graphs to dynamically allocate significance weights to nearby pedestrians; Sadeghian et al. [9] introduced SoPhie, which fuses physical scene constraints with attention mechanisms.
To facilitate the processing of non-Euclidean information, researchers utilize Graph Neural Networks (GNNs). Huang et al. [10] utilized STGAT and Kosaraju et al. [11] utilized Social-BiGAT, both applied GAT for improving pedestrian interaction modeling, while Mohamed et al. [12] proposed Social-STGCNN that directly treats trajectories as spatiotemporal graphs for convolution operations. Yu et al. [13] proposed the STAR framework based on the transformer architecture. It employs a self-attention mechanism to capture long-range spatiotemporal interactions. For the problem of redundant interactions in dense scenes, Shi et al. [14] proposed SGCN, introducing sparse graph convolutional networks to filter out irrelevant interaction noise. In the particular case of the egocentric vehicle view, Rasouli et al. [15] introduced the PIEtraj model, proving the relevance of merging vehicle speed and pedestrian intention features to improve the prediction precision; Yao et al. [16] presented FOL-X, improving trajectory generation under ego motion by forecasting future positions according to the present frame residuals. Recently, Wang et al. [17] with SGNet and Wu et al. [18] with MGNet have further developed single goals into stepwise or multistage goals, improving the rationality of trajectory generation by means of detailed goal guidance strategies.
Even though the aforementioned approaches greatly improve the prediction quality, some problems remain. Firstly, the traditional recursive decoding framework tends to accumulate error over a period of time, causing trajectory deviation. Secondly, most current methods rely on a single temporal encoding structure, which fails to simultaneously capture both abrupt changes and long-term behavioral intentions. Lastly, the mainstream dense attention mechanism assigns equal weight to all time steps, and no sparse strategy is applied. Since electric vehicle onboard devices have limited resources, the high computational cost of those models makes it challenging to deploy them in real-time. Therefore, improving both long-term forecast accuracy and computational speed at the same time remains an open problem for ACEV onboard deployment.
In order to solve these problems, we base our work on BiTraP, a bidirectional framework based on CVAE that leverages multimodal goal estimation and bidirectional decoding to reduce long-horizon uncertainty [19]. In this work, we adopt its non-parametric implementation as the backbone framework and add lightweight yet effective architectural improvements tailored for ACEV deployment. Based on this, we propose a Bi-Directional Trajectory Prediction model with Dual-branch Gated-sparse Fusion (BiTraP-DGF) to enhance prediction accuracy while maintaining the lightweight property required by ACEVs.
The proposed model uses a dual-branch temporal encoder composed of parallel GRU and LSTM networks to capture both short-term motion changes and longer-term movement patterns. To limit unnecessary temporal information, a gated sparse attention mechanism is introduced to suppress redundant temporal responses while preserving the most informative features, thereby helping control computational cost. The method is evaluated on the JAAD dataset, and the results indicate improved long-horizon trajectory prediction with stable behavior under typical driving conditions.
Compared with the original BiTraP-NP framework, the proposed BiTraP-DGF retains the CVAE-based bidirectional decoding strategy, while introducing three key modifications:
- a dual-branch GRU–LSTM temporal encoder to capture heterogeneous motion dynamics;
- an adaptive gated fusion mechanism to balance short-term and long-term features;
- a gated sparse attention module that replaces dense attention to reduce redundant temporal computation.
These changes are specifically designed to improve long-horizon accuracy under onboard computational constraints.
2. Methodology
For Automated and Connected Electric Vehicles (ACEVs), perception-related tasks are often constrained by limited onboard computing resources and power availability. In this work, we consider these practical limitations and adopt a lightweight trajectory prediction approach, referred to as BiTraP-DGF. BiTraP-DGF adopts BiTraP as the backbone framework, where the CVAE-based latent variable modeling, goal decoder, and bidirectional GRU trajectory decoder are retained without structural modification. The proposed extensions focus on the historical trajectory encoding stage.
The overall structure of the model is shown in Figure 1. The observed trajectory information is processed using recurrent networks operating in parallel, and different temporal characteristics are handled at different stages of the model. Short-term motion changes, such as sudden braking or turning, are taken into account, while information related to earlier movement is retained. To avoid unnecessary temporal redundancy, a gating mechanism is applied during feature processing. Trajectory prediction is then carried out in both forward and backward directions, which helps keep the predicted paths stable when the prediction horizon becomes longer.
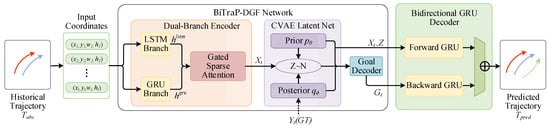
Figure 1.
Overall architecture of the proposed BiTraP-DGF model. The observed trajectories are represented by dark blue solid arrows, the ground truth future trajectories by red solid arrows, and the predicted trajectories by green dashed arrows.
The mathematical details and the main parts of the method are described in the next sections.
2.1. Trajectory Input and Encoded Representation
Pedestrian trajectory prediction from an egocentric driving perspective can be formulated as a sequence generation problem. This approach requires only the bounding box sequences of pedestrians in the image plane as input, eliminating the need for the heavy computation of dense optical flow or 3D point clouds.
For the i-th pedestrian in the scene, let the observed state vector at time step be defined as:
where denotes the center coordinates of the bounding box, and represents the width and height. It is noteworthy that the variation in implicitly encodes the depth changes relative to the ego vehicle, which is critical for understanding approaching or receding motions.
Let and denote the lengths of the historical observation window and the future prediction horizon, respectively. The historical observed trajectory sequence and the ground truth future trajectory sequence can be expressed as:
In real driving data, the observed trajectories are influenced by vehicle motion and different starting positions. Using absolute pixel coordinates makes the input sensitive to the camera view and the initial location of pedestrians. To avoid this issue, we represent each frame by its change relative to the previous frame instead of using absolute values. Thus, the network input becomes relative displacements and scales. Then these differences are mapped to a high-dimensional latent space through FC layers to generate the trajectory embedding. The embedding process keeps the pedestrian’s natural movement trends intact and suppresses global disturbances, such as background motion. This yields a robust and compact feature set for subsequent modules designed to capture temporal dynamic evolution.
Moreover, inside the created CVAE framework, it is necessary to encode both the past observation and the ground truth future trajectory at the time of training. This allows the network to effectively learn how the model’s hidden variables relate to the real randomness that occurs. For clarity in the subsequent mathematical derivation, the encoded feature representation of the observed trajectory sequence is uniformly denoted as , and the encoded representation of the ground truth future trajectory is denoted as .
2.2. Dual-Branch Temporal Encoder
The standard BiTraP-NP model employs one branch GRU to encode past trajectories [19]. While computationally efficient, it struggles to simultaneously capture rapid movements such as abrupt stops and retain long-term motion patterns for a long time, which limits its efficacy in complex driving scenarios. Such a unified temporal encoding approach is computationally efficient, but it implicitly assumes that pedestrian motions can be adequately captured by a single recurrent dynamic. However, previous studies on sequence modeling show that pedestrian trajectories exhibit heterogeneous temporal characteristics, such as abrupt stopping or rapid avoidance behaviors, as well as continuous walking or crossing motions. Using a single recurrent structure to encode all these different dynamics might thus produce poor feature representations in complicated driving situations.
A dual-branch temporal encoder is used, with GRU and LSTM running in parallel. The GRU branch focuses on short-term motion changes. The LSTM branch keeps longer-term information through its memory. Both branches are trained at the same time, and their outputs are combined for trajectory prediction. As shown in Figure 2, the dual-branch temporal encoder takes the same trajectory embedding sequence and passes it through two parallel GRU and LSTM branches to capture diverse temporal dynamics.
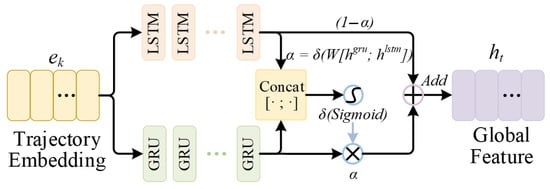
Figure 2.
Schematic Diagram of Dual-Branch Temporal Encoder Structure.
2.2.1. GRU Branch for Local Dynamics
The GRU branch takes the sequence of differential trajectory embedding as input, emphasizing the rapid change of local dynamics, such as sudden acceleration, deceleration or evading maneuver. Due to its simpler gate structure, GRU allows for faster state updates and fewer parameters than LSTM, which has been proven to enhance responsiveness to short-term temporal fluctuations in sequence modeling tasks [20]. This structural characteristic introduces an inductive bias that favors the encoding of high-frequency kinematic changes without excessive temporal smoothing.
Formally, the hidden state sequence encoded from the observation sequence is denoted as:
At the final time step, describes the information about the trajectory encoded mainly by short-term dynamics.
2.2.2. LSTM Branch for Global Trends
In contrast, the LSTM introduces an explicit memory cell that is specifically designed to alleviate the vanishing gradient problem over extended time horizons. This architectural property makes LSTM networks particularly suitable for modeling smooth, long-term movement trends and preserving consistent motion intentions over time. To explicitly capture such long-horizon dependencies, we augment the temporal encoder with a parallel LSTM branch that processes the same sequence of trajectory embeddings.
The LSTM branch is defined as:
Here, and denote the hidden state and the memory cell at time step . After the observation window, the final hidden state is used as the encoded representation of the past trajectory.
It is worth pointing out that the difference between “local” and “global” dynamics is not enforced, but arises from the architectural bias of the two recurrent branches and is learned implicitly during end-to-end training. This design enables the model to adaptively utilize the supplementary temporal representations given by GRU and LSTM encoders under different motion circumstances.
2.2.3. Adaptive Gated Fusion Mechanism
Pedestrian movement is dynamic, with certain situations dominated by impulsive movements (GRU features needed) and others following predictable patterns (LSTM features required). Simple concatenation strategies fail to adaptively capture these shifting modalities. Therefore, we incorporate a learnable gated fusion mechanism at the bottleneck of the encoder to adjust the contribution of each branch.
Specifically, the hidden states at the termination points of both branches are concatenated and projected through a fully connected layer. A Sigmoid activation function is then applied to generate a scalar fusion weight :
Here, denotes the final unified trajectory encoding. The network automatically learns to assign a larger for samples dominated by short-term bursts (increasing the GRU contribution) and a lower for those exhibiting stable long-term trends (relying more on the LSTM branch). This mechanism allows the downstream modules to use a feature representation that is better aligned with the pedestrian’s current motion characteristics.
2.3. Gated Sparse Attention Module
The dual-branch encoder provides multiscale temporal features, but using only the final hidden state does not sufficiently describe the evolution of the observation sequence. In practice, important information may be distributed across different time steps, particularly for trajectories that include abrupt speed changes or avoidance actions. In addition, past frames do not contribute equally to future prediction. Therefore, straightforward fusion operations, such as global averaging, tend to introduce redundant information and may weaken the representation of critical temporal cues. This computational inefficiency makes them unsuitable for deployment on EV platforms with limited resources. To address these problems, we design a Gated Sparse Attention Module. This module leverages the outputs of the dual-branch encoder for selective feature recalibration.
It is critical to clarify that the term “sparse” in this work does not refer to strict sparsity enforced by binary masking or explicit top- selection. Instead, sparsity is implicitly induced through a combination of convolutional gating and L1 regularization, which encourages the attention distribution to concentrate its mass on a limited subset of temporally critical frames while suppressing weak or noisy correlations. Therefore, the learned attention weights have a highly concentrated, approximately sparse structure in practice, instead of being exactly zero. As shown in Figure 3, an overview of the proposed Gated Sparse Attention Fusion module is provided. It recalibrates temporal features through convolutional gating and attention fusion, so that informative time steps receive greater emphasis while weak responses are suppressed.
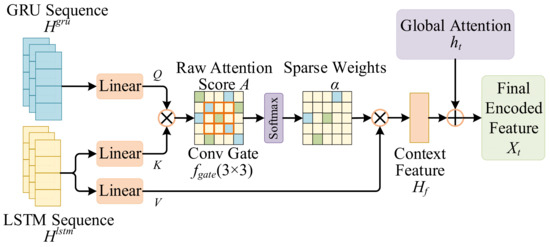
Figure 3.
Schematic Diagram of the Gated Sparse Attention Module Structure. Blue and green cells illustrate attention values with different intensities, where darker shades indicate relatively higher attention weights and lighter shades represent lower values. After convolutional gating and normalization, the attention distribution becomes more concentrated, resulting in an approximately sparse pattern while preserving informative temporal regions.
Formally, let the hidden state sequences of the GRU branch and the LSTM branch be denoted as:
We construct a cross-attention paradigm where the GRU branch (encoding local dynamics) serves as the Query, while the LSTM branch (encoding global trends) serves as the Key and Value. We apply linear transformations to obtain the Query matrix , Key matrix , and Value matrix :
where are learnable parameter matrices [21]. First, compute the scaled dot product attention score matrix:
This matrix measures the correlation between different time steps. Unlike conventional dense attention, we apply a convolutional gating step to the temporal score matrix to encourage local consistency and reduce noise in the correlation map. Let the gating function be denoted as . The gated score is obtained by:
where the convolution operates on the time–time score matrix.
In practice, the kernel aggregates information from neighboring entries and suppresses isolated high responses that are not supported by surrounding correlations. Noisy or unstable peaks caused by detection jitter are therefore weakened, while temporally consistent responses are preserved. As a result, only a small number of coherent temporal regions maintain high attention weights after normalization, leading to a concentrated and approximately sparse distribution.
The normalized attention weights are then computed by applying Softmax to the gated scores:
As the convolution gate suppresses weak correlations and keeps locally consistent responses, the resulting weights are usually highly concentrated on a limited number of time steps. This produces an approximately sparse pattern. In addition, the L1 regularization term used during training further encourages the attention weights to remain compact, without introducing hard masking or explicit top- selection.
With available, the temporal context feature is computed as a weighted sum over the value matrix:
This context feature highlights time steps that contribute most to prediction. Finally, we combine the global encoding vector with through a residual connection to form the final trajectory representation , which is then passed to the CVAE module and the bidirectional decoder.
Compared with BiTraP-NP, which uses a single-branch encoder with dense attention, the proposed gated sparse attention strategy works with the dual-branch temporal features and places more emphasis on informative motion segments while reducing redundant temporal responses.
2.4. Latent Variable Modeling and Bidirectional Trajectory Prediction
After trajectory encoding and gated fusion, pedestrian motion should be treated as stochastic. Modeling this uncertainty is important for safe decision-making in autonomous driving, especially when multiple plausible future paths may exist under the same observation. After the BiTraP formulation [19], we employ a CVAE framework to capture the multimodal distribution of future behaviors. This probabilistic module is connected with a bidirectional GRU decoder to create diverse and reasonable trajectory candidates.
2.4.1. Conditional Variational Autoencoder
The generative module is based on the conditional variational framework [22], which consists of a prior network and a posterior network . Here, refers to the fused trajectory features obtained by the dual-branch encoder, indicates the encoded features of the ground truth future trajectory, and represents the latent random variable capturing motion uncertainty.
The prior network estimates the parameters of the latent distribution using only the observed feature . In training, the posterior network is conditioned on both and the encoded future feature , so that it can provide a more informative latent distribution:
To allow gradients to pass through the sampling step, we apply the reparameterization trick and draw samples from the posterior as:
The sampled latent variable is then provided to the subsequent decoders to support multimodal trajectory generation. The optimization objective aims to maximize the Evidence Lower Bound (ELBO) of the conditional log likelihood, formulated as:
The first term minimizes the discrepancy between the generated trajectory and the ground truth path given the latent variable. It therefore enforces accurate reconstruction under the sampled hidden information. The second term, the Kullback–Leibler (KL) divergence, ensures that the posterior distribution after observing the future trajectory does not deviate excessively from the prior conditioned on the past observations. This constraint guarantees that the training distribution matches the inference distribution. Thus, the model can generate reliable predictions by utilizing only the prior network during testing.
2.4.2. Bidirectional Trajectory Prediction Network
As shown in the decoder module of Figure 1, our prediction architecture consists of a Goal Decoder and a Bidirectional Trajectory Decoder. The Goal Decoder maps the concatenated features to the target coordinate space through an MLP. It estimates the multimodal future target positions . The Bidirectional Trajectory Decoder generates sequential positions by synergizing two complementary streams.
Forward GRU: Propagates kinematic inertia from the current observation termination state, predicting stepwise from the present into the future:
where denotes the input feature derived from the prediction at the previous step.
Backward GRU: Backtraces from the predicted target point , propagating hidden states from the prediction horizon endpoint back to the current time:
At each prediction step, the hidden states from both directions are concatenated and projected to the coordinate space via a linear layer to yield the final position:
The forward branch captures kinematic continuity from the current state. The backward branch adds geometric constraints related to the predicted target. The bidirectional decoder uses information from both forward and backward directions. This setting is used for trajectory prediction over longer time horizons.
2.5. Loss Function
To ensure prediction accuracy, diversity, and model sparsity, the total loss function includes four components. These are target loss, trajectory loss, the KL divergence term, and a sparse regularization term. The model sparsity is critical for deployment under the constraints of ACEVs.
Let and denote the ground truth target point and future trajectory, respectively. Let and represent the i-th candidate predicted target and its corresponding trajectory, and denote the current pedestrian position. The overall objective function is defined as:
The first two terms adopt the “Best of Many” strategy to minimize the reconstruction error of the best matching hypothesis for targets and trajectories. represents the difference between the prior distribution and the posterior distribution, weighted by .
Crucially, we introduce a sparse regularization term to enforce sparsity within the attention weights, defined as:
where is the weighting coefficient. By jointly optimizing these components, the model can employ the L1 regularizer () to reduce attention responses on redundant time steps without affecting its capability to capture various types of trajectory distributions. Related sparsity regularization has been used in attention sequence modeling to reduce redundant temporal dependencies and to improve computational efficiency [21,22]. In our setting, this design helps maintain long-horizon prediction accuracy while keeping the inference cost low enough for efficient processing.
3. Experiments and Results Analysis
3.1. Datasets and Evaluation Metrics
To evaluate the proposed framework under an egocentric driving setting, we carry out experiments on the JAAD dataset, a widely used benchmark for pedestrian trajectory prediction. JAAD provides urban traffic videos recorded by vehicle-mounted cameras at a resolution of and 30 fps.
Following common practice [23], trajectory preprocessing techniques such as removing very short segments are employed to improve data reliability. We employ a sliding window strategy to construct samples: a sequence of consecutive frames is utilized as the historical observation to forecast the trajectory over the subsequent frames. In this study, the observation horizon is configured as = 15 frames (0.5 s), while the prediction horizons are set to 15, 30, and 45 frames, corresponding to short-term (0.5 s) and long-term (1.0 s, 1.5 s) prediction tasks, respectively.
Let the observed bounding box of the i-th pedestrian at time be denoted as:
where denote the center coordinates, and represent the dimensions. The ground truth future trajectory is defined as . For an observed sequence , the CVAE decoder samples candidate futures . Following standard practice, we use the Best of Many setting with ; for each sample, the candidate that is closest to the ground truth is selected for metric computation.
To provide an overall evaluation of prediction accuracy, we use four quantitative metrics: Average Displacement Error (ADE), Final Displacement Error (FDE), Center Average Displacement Error (CADE), and Center Final Displacement Error (CFDE).
- ADE and FDE are computed on the full bounding boxes, reflecting both location and scale consistency.
- CADE and CFDE are computed on the center coordinates only, providing a direct measure of trajectory alignment and final position accuracy.
Let the ground truth bounding box be and the predicted bounding box be . Similarly, let the corresponding center points be and . The metrics are formulated as follows:
ADE and CADE measure the average deviation over the full horizon, while FDE and CFDE focus on the endpoint error, which is particularly relevant for risk assessment in autonomous driving.
3.2. Implementation Details
The model is implemented using PyTorch (version 2.3.1, CUDA 12.1). The hidden state size is set to 256, and the latent dimension is set to 32. Both GRU and LSTM branches use two layers, and their outputs are combined during temporal processing.
The model is trained with Adam. The learning rate is 0.001, and the batch size is 128. Training runs for 50 epochs, with a learning rate decay applied during training.
All experiments are conducted on a machine with an NVIDIA A100 GPU running Ubuntu 20.04. All baseline models and the proposed BiTraP-DGF are trained and evaluated under the same hardware environment and identical training configurations. During inference, we sample 20 candidate trajectories from the learned latent distribution to compute the metrics reported in the following sections. This ensures a fair and consistent comparison across all evaluated methods.
3.3. Quantitative Analysis
3.3.1. Comparative Benchmarking
To examine the performance of BiTraP-DGF for egocentric pedestrian trajectory prediction, we compare it with several representative baselines and recent methods under the same data split and evaluation protocol. The comparison set includes:
- Deterministic baselines: Linear, LSTM, and B-LSTM;
- Generative models driven by goals: FOL-X, PIEtraj, BiTraP-D, and MGNet;
- Recent high-performance variants: BiTraP-NP (20) and SGNet-ED (20).
All models were trained and evaluated under identical data partitioning protocols. The prediction horizons were stratified into short-term (0.5 s), medium-term (1.0 s), and long-term (1.5 s) intervals. As shown in Table 1, the quantitative results of different methods on the JAAD dataset are summarized in terms of ADE, CADE, and CFDE.

Table 1.
Comparison of BiTraP-DGF with Baseline Model Results. The error metrics are reported in pixel units.
Analysis of Results: As presented in Table 1, traditional recurrent neural networks (e.g., Linear, LSTM, and B-LSTM) achieve acceptable accuracy for short-term prediction (0.5 s). However, their performance degrades sharply for long-term forecasting (1.5 s), indicating that standard recurrent architectures cannot effectively mitigate error accumulation or model long-term motion trends.
In contrast, the proposed BiTraP-DGF achieves the best overall performance among the compared methods on the JAAD dataset.
- Short-term Performance: For the 0.5 s horizon, BiTraP-DGF achieves competitive accuracy comparable to the best-performing baselines.
- Long-term Robustness: The advantages of our model become pronounced in long-term forecasting. Compared to the strong baseline BiTraP-NP (20), BiTraP-DGF (20) achieves substantial error reductions: ADE (1.5 s) is reduced by 14.9%, CADE (1.5 s) by 20.9%, and CFDE (1.5 s) by 22.8%. This significant improvement in endpoint metrics (CFDE) underscores the model’s superior ability to maintain geometric consistency over extended timeframes.
- Comparison with Methods Driven by Goals: SGNet-ED (20) uses explicit goal modeling. In short-term prediction, its error is slightly lower. At the 1.5 s prediction horizon, BiTraP-DGF (20) achieves a lower CFDE, with a reduction of 1.58%. At the 1.5 s prediction horizon, BiTraP-DGF (20) achieves a lower CFDE than SGNet-ED. This result suggests that the proposed dual-branch fusion strategy provides stronger long-term predictive capability than approaches relying solely on explicit goal guidance. In particular, it shows improved robustness in modeling the stochastic nature of pedestrian motion in egocentric driving scenarios.
Efficiency Analysis: The computational cost of the proposed model is further examined under typical onboard resource conditions. This slight rise in overall test set inference time occurred on an NVIDIA A100 GPU. This result indicates that BiTraP-DGF achieves a favorable tradeoff between accuracy and latency on high-performance platforms. Although the A100 is not representative of embedded onboard hardware, it is used here to evaluate the relative computational overhead introduced by the proposed modules. Though the A100 platform is not embedded into the hardware, it is meant to compare the relative computational overhead added by the proposed architectural elements apart from speedups specific to the platform. Total test set inference time refers to the wall clock time needed for processing all images in the JAAD test set, indicating throughput instead of per sample latency. As shown in Table 2, a quantitative comparison is given.
Table 2.
Parameters and Inference Time for Different Models.
Although BiTraP-DGF introduces extra parameters due to the dual-branch encoder and the gated sparse attention module, its overall runtime remains close to that of BiTraP-NP under the same evaluation setting. On an NVIDIA A100 GPU, it takes 3.38 s for BiTraP-DGF to process the whole JAAD test set, whereas BiTraP-NP finishes the same test set in 3.29 s. This marginal difference shows that the proposed model improves prediction accuracy with only a slight increase in computational cost.
3.3.2. Ablation Study
To verify the contribution of each individual component within the proposed framework, we designed four architectural variants (A0 to A4) and evaluated them on the JAAD dataset. The definitions of these variants are as follows:
- A0 (Baseline): The original BiTraP-NP model.
- A1 (Dual-Branch): Adds the parallel GRU-LSTM encoder to A0 but employs simple concatenation without attention.
- A2 (Dense Attention): Incorporates standard multihead attention on top of A1.
- A3 (Dense BiTraP-DGF) represents the proposed model with the full gated architecture. However, it employs standard (dense) attention weights.
- A4 (BiTraP-DGF): The final proposed model incorporating the Gated Sparse Attention mechanism.
As shown in Table 3, the ablation results are detailed.
Table 3.
Ablation Experiment Results. The error metrics are reported in pixel units.
Impact of Dual-Branch Encoding (A0 vs. A1):
Comparing A0 and A1, introducing the dual-branch structure alone brings only limited improvement. This indicates that simply widening the network is insufficient. An effective method is required to introduce feature fusion between the GRU and LSTM branches. This integration allows their different characteristics to be properly combined.
Impact of Attention Modeling (A1 vs. A2 vs. A3):
The attention mechanism introduced into A2 shows clear improvements in ADE and CADE. Based on this, A3 introduces a gated fusion method and achieves the lowest errors on long-term metrics. Compared with the baseline A0, A3 reduces ADE (1.5 s) from 222 to 187 and CFDE (1.5 s) from 565 to 432. These results show that explicitly modeling temporal dependencies through gating helps improve the stability of long-term predictions.
Impact of Sparsification (A3 vs. A4):
Compared with A3 (Dense), A4 (Sparse) shows only a minor change in ADE, which increases from 187 to 189. Although there is such a slight degradation, the sparsification method greatly decreases the amount of computation needed, as shown in Table 4. This shows that the sparsification method achieves an optimal balance between prediction performance and computational speed.
Table 4.
Parameter Count and Inference Time Before and After Attention Module Sparsification.
Replacing the standard multihead attention with the proposed Gated Sparse Attention reduces the number of parameters of the attention submodule from 263,204 to 197,412, which is a reduction of 25.0%. Using the same testing protocol on an NVIDIA A100 GPU, the total inference time for the test set decreases from 3.49 s to 3.38 s. These results show that the sparsification strategy reduces redundant computation without affecting prediction ability, making the model more computationally efficient for deployment.
3.4. Qualitative Visualization and Analysis
To further examine the prediction behavior of the proposed BiTraP-DGF model, we present qualitative visualization results on representative samples from the JAAD dataset. The predicted trajectories are compared with those produced by the baseline BiTraP-NP model to analyze stability under different pedestrian motion patterns.
- As shown in Figure 4, a comparison of the prediction results under different motion conditions is presented: Long-term Stability (Column a): In cases with approximately linear movement or fast street crossing, the BiTraP-NP baseline produces reasonable predictions over short time horizons. When the prediction horizon becomes longer, the predicted trajectories tend to extend further than the ground truth, and deviations at the final position can be observed. In comparison, the trajectories generated by BiTraP-DGF stay closer to the ground truth and show smoother changes over time.
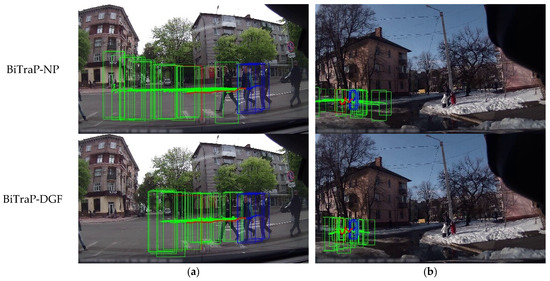 Figure 4. Qualitative comparison of trajectory prediction results on the JAAD dataset. The observed trajectories are shown in dark blue, the ground truth future trajectories in red, and the predicted trajectories in green. Final bounding box positions are also indicated. Panel (a) shows a case with approximately linear motion. Panel (b) shows a case with nonlinear motion.
Figure 4. Qualitative comparison of trajectory prediction results on the JAAD dataset. The observed trajectories are shown in dark blue, the ground truth future trajectories in red, and the predicted trajectories in green. Final bounding box positions are also indicated. Panel (a) shows a case with approximately linear motion. Panel (b) shows a case with nonlinear motion. - Dynamic Maneuvering (Column b): For cases involving sharp turns or sudden changes in movement direction, the baseline model often produces trajectories that do not follow the observed motion well. The predicted paths show inertia effects. The trajectories produced by BiTraP-DGF follow the observed direction changes.
4. Conclusions
In this study, we address two major issues in long-term pedestrian trajectory prediction for ACEVs: error accumulation over extended prediction horizons and redundant feature representation. To this end, we develop a lightweight yet accurate framework, termed BiTraP-DGF, which integrates a dual-branch temporal encoder with a gated sparse attention mechanism.
The main contributions and findings of this work are summarized as follows:
- Multiscale Temporal Modeling: A hybrid GRU–LSTM encoder is added to the BiTraP-NP backbone to model trajectory information at different time scales. Short-term motion changes and longer-term movement patterns are handled through parallel temporal encoding.
- Efficient Feature Fusion: A gated sparse attention mechanism is used to adjust the contribution of temporal features. Less informative responses are suppressed during feature processing, while relevant temporal information is retained.
- Performance Superiority: The JAAD dataset is used for evaluation. It reaches 20.9% reduction on CADE and 22.8% reduction on CFDE for the 1.5 s prediction horizon, which verifies its robustness in long-term prediction.
- Deployment Feasibility: BiTraP-DGF shows improved accuracy with only marginal additional cost. Its design is oriented toward efficiency under onboard constraints, and future work will assess per-sample latency on embedded platforms.
Future work will explore incorporating scene-specific semantic priors (e.g., crosswalks, traffic lights) and social interaction cues to further refine uncertainty modeling. Additionally, we plan to validate the algorithm on heterogeneous hardware platforms to assess its energy consumption profiles in real-world EV deployment scenarios.
Author Contributions
Conceptualization, Y.Z. and G.L.; methodology, Y.Z.; software, Y.Z., H.Q. and W.C.; validation, Y.Z., G.L., H.Q. and Z.Z.; formal analysis, Y.Z.; investigation, Y.Z. and Z.Z.; resources, G.L.; data curation, W.C.; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z., G.L. and Z.Z.; visualization, Y.Z.; supervision, G.L.; project administration, G.L.; funding acquisition, G.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the International Industrial Technology R&D Project of Liaoning Province (2025JH2/101900027).
Data Availability Statement
The data used in this study is publicly available. The JAAD (Joint Attention in Autonomous Driving) dataset was downloaded from the official dataset page at https://data.nvision2.eecs.yorku.ca/JAAD_dataset/ (accessed on 12 January 2026).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Xu, M.; Liu, Z.; Wang, B.; Li, S. A Survey of Autonomous Driving Trajectory Prediction: Methodologies, Challenges, and Future Prospects. Machines 2025, 13, 818. [Google Scholar] [CrossRef]
- Zaier, M.; Wannous, H.; Drira, H.; Boonaert, J. Pedestrian Trajectory Prediction: A Literature Review and Current Trends. Neural Comput. Appl. 2025, 37, 28869–28906. [Google Scholar] [CrossRef]
- Ge, M.; Ohtani, K.; Ding, M.; Niu, Y.; Zhang, Y.; Takeda, K. Multimodal Trajectory Prediction for Diverse Vehicle Types in Autonomous Driving with Heterogeneous Data and Physical Constraints. Sensors 2024, 24, 7323. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Li, Y.; Li, D.; Mu, Y.; Qin, H.; Zheng, N. Post-Interactive Multimodal Trajectory Prediction for Autonomous Driving. arXiv 2025, arXiv:2503.09366. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Li, F.-F.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar] [CrossRef]
- Bhattacharyya, A.; Fritz, M.; Schiele, B. Long-Term On-Board Prediction of People in Traffic Scenes under Uncertainty. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4194–4202. [Google Scholar] [CrossRef]
- Gupta, A.; Johnson, J.; Li, F.-F.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2255–2264. [Google Scholar] [CrossRef]
- Vemula, A.; Muelling, K.; Oh, J. Social Attention: Modeling Attention in Human Crowds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4601–4607. [Google Scholar] [CrossRef]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, H.; Savarese, S. SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar] [CrossRef]
- Huang, Y.; Bi, H.; Li, Z.; Mao, T.; Wang, Z. STGAT: Modeling Spatial-Temporal Interactions for Human Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6272–6281. [Google Scholar] [CrossRef]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, H.; Savarese, S. Social-BiGAT: Multimodal Trajectory Forecasting Using Bicycle-GAN and Graph Attention Networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: South Lake Tahoe, NV, USA, 2019. [Google Scholar]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 14424–14432. [Google Scholar] [CrossRef]
- Yu, C.; Ma, X.; Ren, J.; Zhao, H.; Yi, S. Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction. In Computer Vision–ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 507–523. [Google Scholar] [CrossRef]
- Shi, L.; Wang, L.; Long, C.; Zhou, S.; Zhou, M.; Niu, Z.; Hua, G. SGCN: Sparse Graph Convolution Network for Pedestrian Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8994–9003. [Google Scholar] [CrossRef]
- Rasouli, A.; Kotseruba, I.; Kunic, T.; Tsotsos, J.K. PIE: A Large-Scale Dataset and Models for Pedestrian Intention Estimation and Trajectory Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6262–6271. [Google Scholar] [CrossRef]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric Vision-Based Future Vehicle Localization for Intelligent Driving Assistance Systems. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9711–9717. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Xu, M.; Crandall, D.J. Stepwise Goal-Driven Networks for Trajectory Prediction. IEEE Robot. Autom. Lett. 2022, 7, 2716–2723. [Google Scholar] [CrossRef]
- Wu, X.; Wang, T.; Cai, Y.; Liang, L.; Papageorgiou, G. A Multi-Stage Goal-Driven Network for Pedestrian Trajectory Prediction. In Proceedings of the 5th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 19–21 April 2024; pp. 1039–1046. [Google Scholar] [CrossRef]
- Yao, Y.; Atkins, E.; Johnson-Roberson, M.; Vasudevan, R.; Du, X. BiTraP: Bi-Directional Pedestrian Trajectory Prediction with Multi-Modal Goal Estimation. IEEE Robot. Autom. Lett. 2021, 6, 1463–1470. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: South Lake Tahoe, NV, USA, 2017. [Google Scholar]
- Sohn, K.; Lee, H.; Yan, X. Learning Structured Output Representation Using Deep Conditional Generative Models. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: South Lake Tahoe, NV, USA, 2015. [Google Scholar]
- Halawa, M.; Hellwich, O.; Bideau, P. Action-Based Contrastive Learning for Trajectory Prediction. In Computer Vision–ECCV 2022; Springer: Cham, Switzerland, 2022; pp. 143–159. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Published by MDPI on behalf of the World Electric Vehicle Association. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.