Computer Vision, Deep Learning and Machine Learning with Applications
Share This Topical Collection
Editors
 Prof. Dr. Remus Brad
Prof. Dr. Remus Brad
Prof. Dr. Remus Brad
E-Mail
Website
Collection Editor
Computer Science and Electrical Engineering Department, Lucian Blaga University of Sibiu Bulevardul Victoriei 10, 550024 Sibiu, Romania
Interests: image processing; pattern recognition; computer vision; textile engineering; medical imaging
Special Issues, Collections and Topics in MDPI journals
 Dr. Arpad Gellert
Dr. Arpad Gellert
Dr. Arpad Gellert
E-Mail
Website
Co-Collection Editor
Computer Science and Electrical Engineering Department, Lucian Blaga University of Sibiu, Emil Cioran 4, 550025 Sibiu, Romania
Interests: image processing; smart buildings; smart factories; web mining; computer architecture
Topical Collection Information
Dear Colleagues,
In recent years, interest toward automation, both in industrial or domestic applications, has increased with the development of new methods and with the growth of computer processing capabilities. One of the major pillars of today’s research goes beyond image processing, in the more generous concept of computer vision. Nevertheless, the latest evolutions in neural networks and machine learning have added more valences and applications to the domain, starting from industrial process control to the challenging self-driving in automotive, passing from medical imaging, information retrieval and digital forensics.
The scope of this Topical Collection is to collect the latest works in the fields of computer vision, machine learning, and deep learning and gather researchers from different areas who are struggling to solve the provoking and demanding topics proposed by the industry and an ever-changing world. Potential topics include but are not limited to:
- Image processing and applications;
- Medical imaging;
- Autonomous vehicles;
- Convolutional neural networks;
- Digital forensics;
- Smart home;
- Smart city;
- Industrial quality control.
Prof. Dr. Remus Brad
Dr. Arpad Gellert
Collection Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Future Internet is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1800 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- image processing
- computer vision
- deep learning
- artificial intelligence
- machine learning
- convolutional neural networks
- automation
- smart home
- smart city
- medical imaging
Published Papers (24 papers)
Open AccessArticle
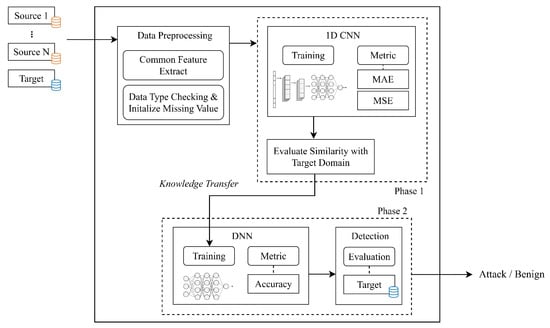
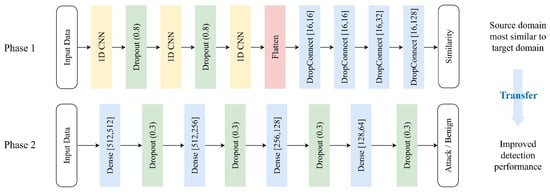
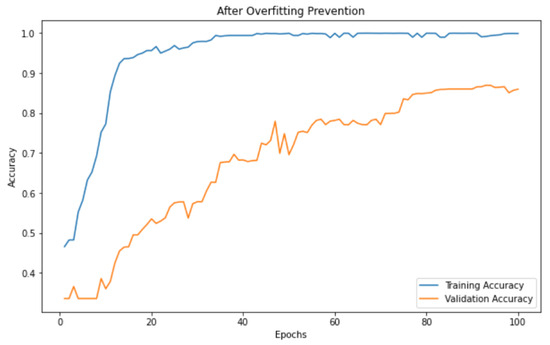
A Transferable Deep Learning Framework for Improving the Accuracy of Internet of Things Intrusion Detection
by
Haedam Kim, Suhyun Park, Hyemin Hong, Jieun Park and Seongmin Kim
Cited by 13 | Viewed by 4085
Abstract
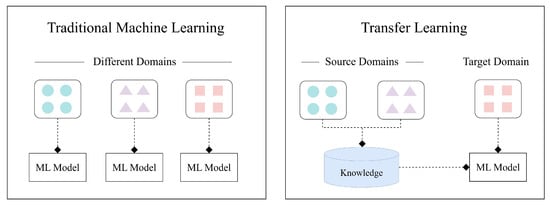
As the size of the IoT solutions and services market proliferates, industrial fields utilizing IoT devices are also diversifying. However, the proliferation of IoT devices, often intertwined with users’ personal information and privacy, has led to a continuous surge in attacks targeting these
[...] Read more.
As the size of the IoT solutions and services market proliferates, industrial fields utilizing IoT devices are also diversifying. However, the proliferation of IoT devices, often intertwined with users’ personal information and privacy, has led to a continuous surge in attacks targeting these devices. However, conventional network-level intrusion detection systems with pre-defined rulesets are gradually losing their efficacy due to the heterogeneous environments of IoT ecosystems. To address such security concerns, researchers have utilized ML-based network-level intrusion detection techniques. Specifically, transfer learning has been dedicated to identifying unforeseen malicious traffic in IoT environments based on knowledge distillation from the rich source domain data sets. Nevertheless, since most IoT devices operate in heterogeneous but small-scale environments, such as home networks, selecting adequate source domains for learning proves challenging. This paper introduces a framework designed to tackle this issue. In instances where assessing an adequate data set through pre-learning using transfer learning is non-trivial, our proposed framework advocates the selection of a data set as the source domain for transfer learning. This selection process aims to determine the appropriateness of implementing transfer learning, offering the best practice in such scenarios. Our evaluation demonstrates that the proposed framework successfully chooses a fitting source domain data set, delivering the highest accuracy.
Full article
►▼
Show Figures
Open AccessArticle
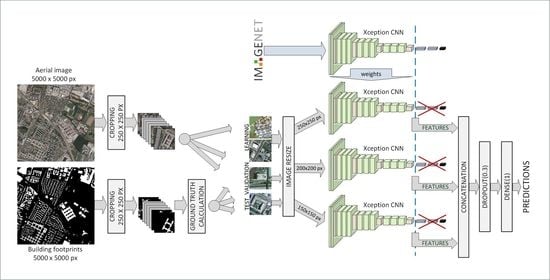
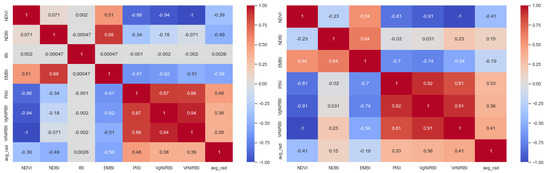
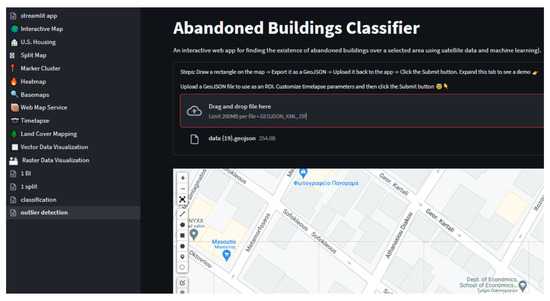
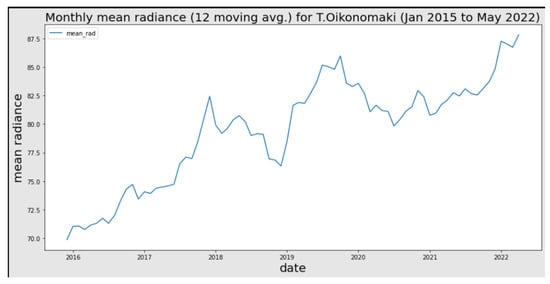
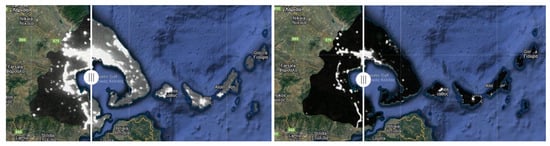
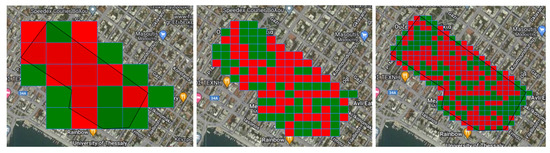
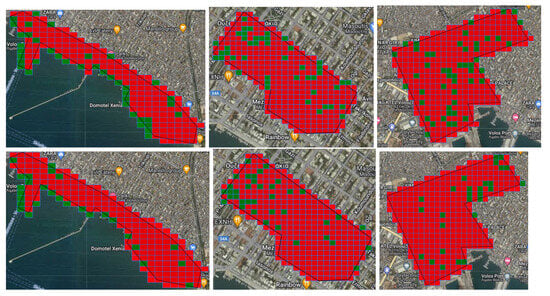
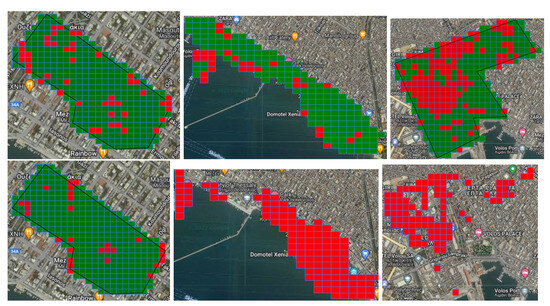
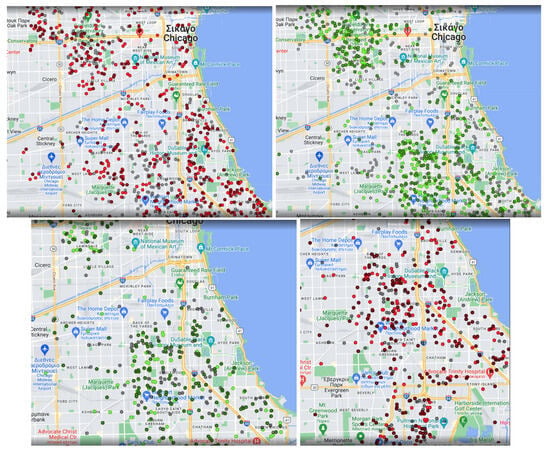
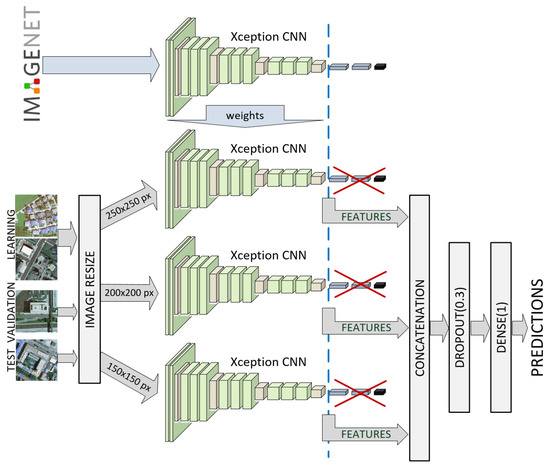
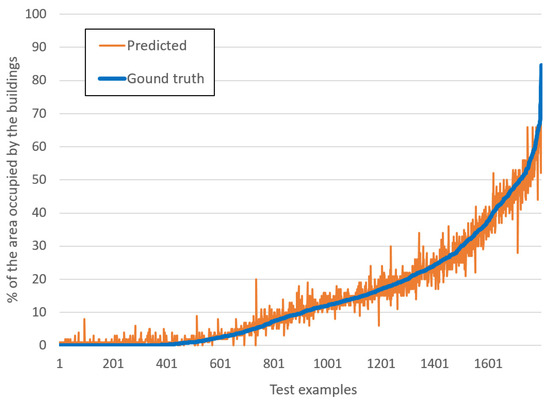
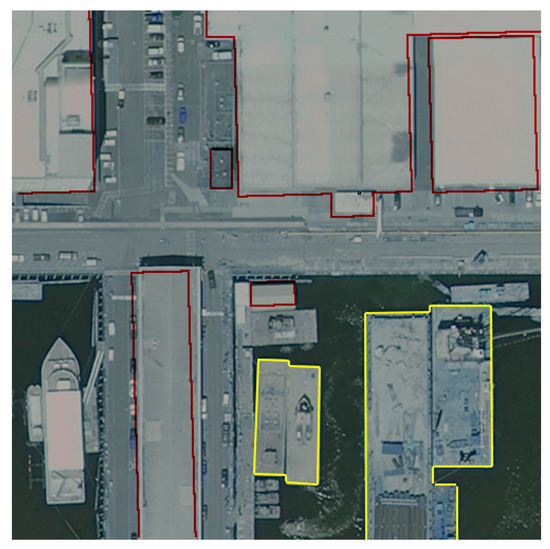
Business Intelligence through Machine Learning from Satellite Remote Sensing Data
by
Christos Kyriakos and Manolis Vavalis
Cited by 2 | Viewed by 4207
Abstract
Several cities have been greatly affected by economic crisis, unregulated gentrification, and the pandemic, resulting in increased vacancy rates. Abandoned buildings have various negative implications on their neighborhoods, including an increased chance of fire and crime and a drastic reduction in their monetary
[...] Read more.
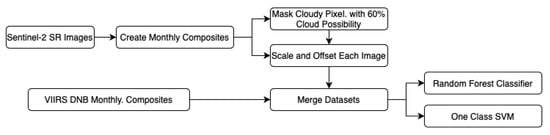
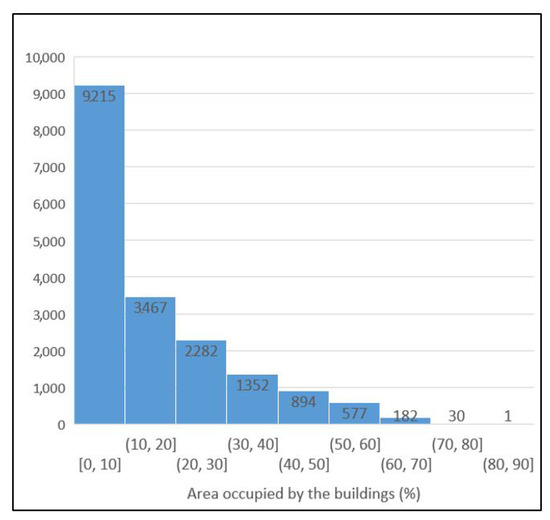
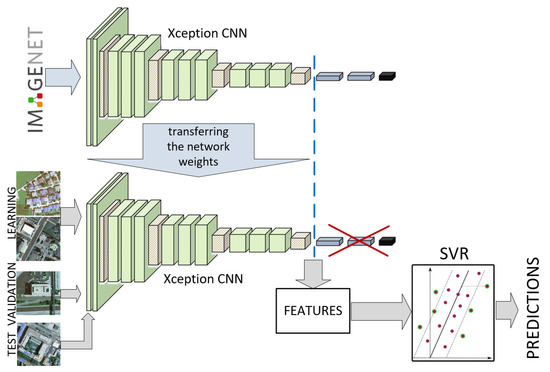
Several cities have been greatly affected by economic crisis, unregulated gentrification, and the pandemic, resulting in increased vacancy rates. Abandoned buildings have various negative implications on their neighborhoods, including an increased chance of fire and crime and a drastic reduction in their monetary value. This paper focuses on the use of satellite data and machine learning to provide insights for businesses and policymakers within Greece and beyond. Our objective is two-fold: to provide a comprehensive literature review on recent results concerning the opportunities offered by satellite images for business intelligence and to design and implement an open-source software system for the detection of abandoned or disused buildings based on nighttime lights and built-up area indices. Our preliminary experimentation provides promising results that can be used for location intelligence and beyond.
Full article
►▼
Show Figures
Open AccessArticle
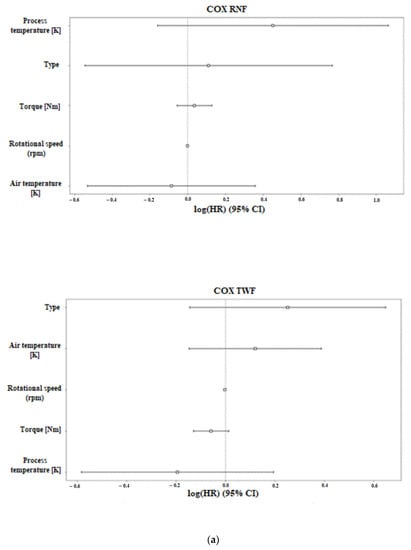
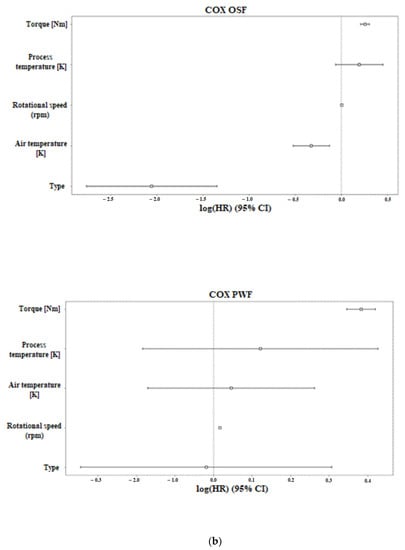
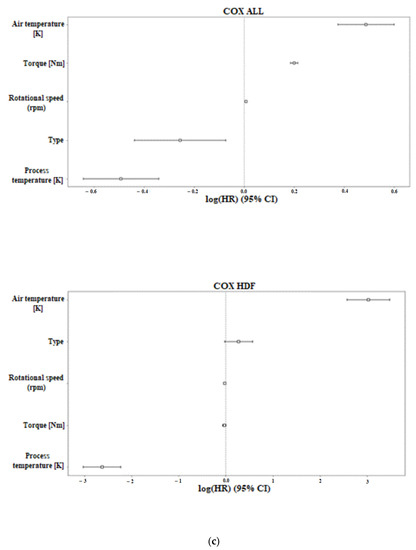
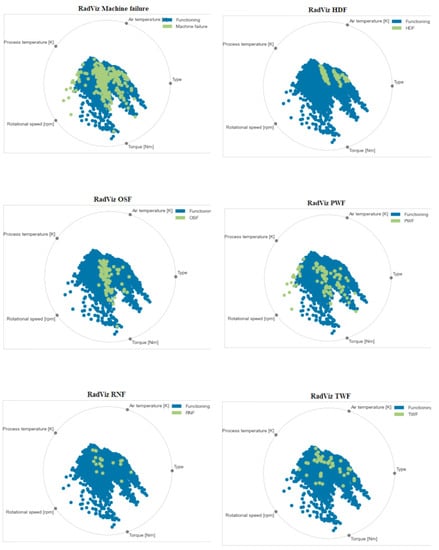
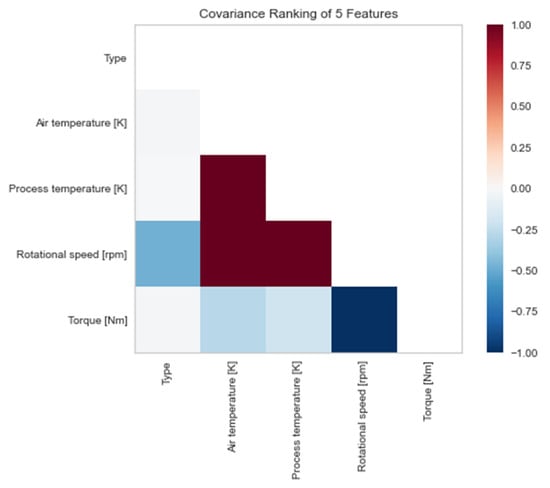
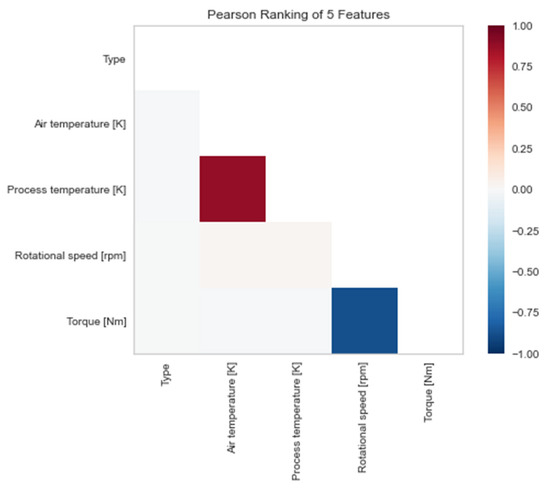
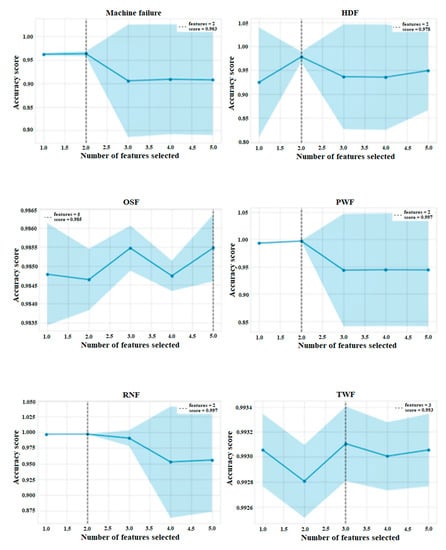
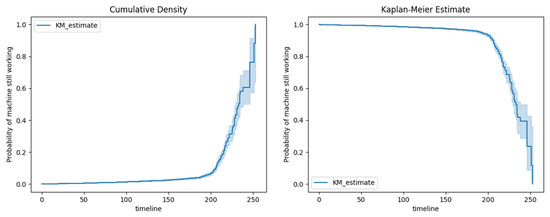
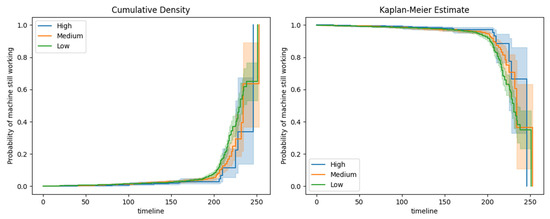
Machine Failure Prediction Using Survival Analysis
by
Dimitris Papathanasiou, Konstantinos Demertzis and Nikos Tziritas
Cited by 22 | Viewed by 8542
Abstract
With the rapid growth of cloud computing and the creation of large-scale systems such as IoT environments, the failure of machines/devices and, by extension, the systems that rely on them is a major risk to their performance, usability, and the security systems that
[...] Read more.
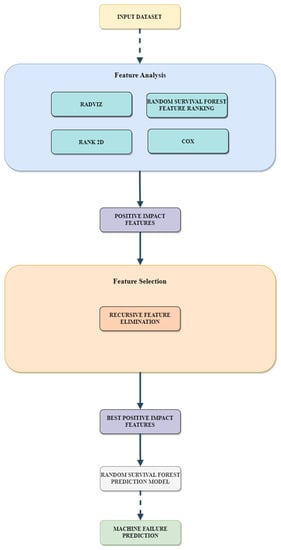
With the rapid growth of cloud computing and the creation of large-scale systems such as IoT environments, the failure of machines/devices and, by extension, the systems that rely on them is a major risk to their performance, usability, and the security systems that support them. The need to predict such anomalies in combination with the creation of fault-tolerant systems to manage them is a key factor for the development of safer and more stable systems. In this work, a model consisting of survival analysis, feature analysis/selection, and machine learning was created, in order to predict machine failure. The approach is based on the random survival forest model and an architecture that aims to filter the features that are of major importance to the cause of machine failure. The objectives of this paper are to (1) Create an efficient feature filtering mechanism, by combining different methods of feature importance ranking, that can remove the “noise” from the data and leave only the relevant information. The filtering mechanism uses the RadViz, COX, Rank2D, random survival forest feature ranking, and recursive feature elimination, with each of the methods used to achieve a different understanding of the data. (2) Predict the machine failure with a high degree of accuracy using the RSF model, which is trained with optimal features. The proposed method yields superior performance compared to other similar models, with an impressive C-index accuracy rate of approximately 97%. The consistency of the model’s predictions makes it viable in large-scale systems, where it can be used to improve the performance and security of these systems while also lowering their overall cost and longevity.
Full article
►▼
Show Figures
Open AccessArticle
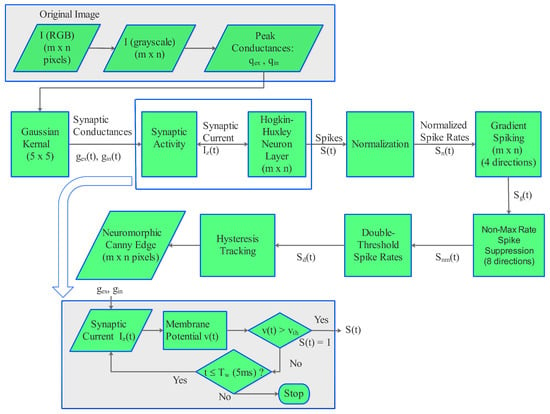
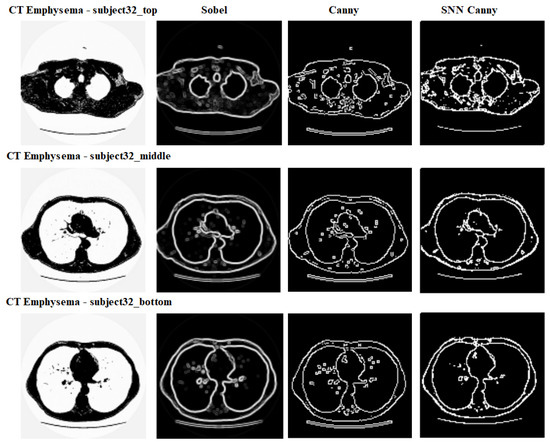
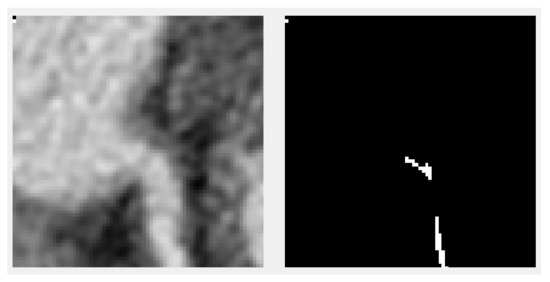
Implementation of the Canny Edge Detector Using a Spiking Neural Network
by
Krishnamurthy V. Vemuru
Cited by 8 | Viewed by 6502
Abstract
Edge detectors are widely used in computer vision applications to locate sharp intensity changes and find object boundaries in an image. The Canny edge detector is the most popular edge detector, and it uses a multi-step process, including the first step of noise
[...] Read more.
Edge detectors are widely used in computer vision applications to locate sharp intensity changes and find object boundaries in an image. The Canny edge detector is the most popular edge detector, and it uses a multi-step process, including the first step of noise reduction using a Gaussian kernel and a final step to remove the weak edges by the hysteresis threshold. In this work, a spike-based computing algorithm is presented as a neuromorphic analogue of the Canny edge detector, where the five steps of the conventional algorithm are processed using spikes. A spiking neural network layer consisting of a simplified version of a conductance-based Hodgkin–Huxley neuron as a building block is used to calculate the gradients. The effectiveness of the spiking neural-network-based algorithm is demonstrated on a variety of images, showing its successful adaptation of the principle of the Canny edge detector. These results demonstrate that the proposed algorithm performs as a complete spike domain implementation of the Canny edge detector.
Full article
►▼
Show Figures
Open AccessArticle
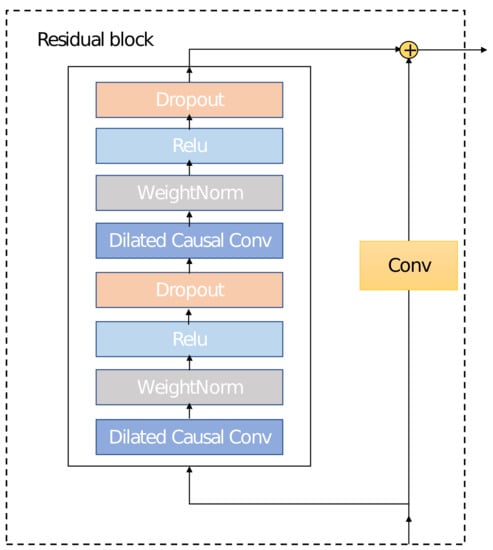
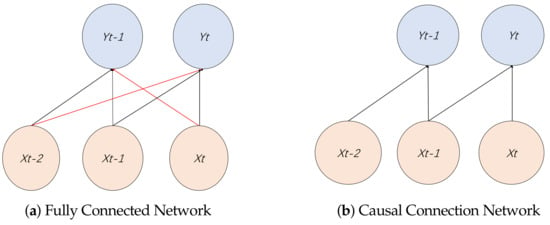
Financial Market Correlation Analysis and Stock Selection Application Based on TCN-Deep Clustering
by
Yuefeng Cen, Mingxing Luo, Gang Cen, Cheng Zhao and Zhigang Cheng
Cited by 6 | Viewed by 4399
Abstract
It is meaningful to analyze the market correlations for stock selection in the field of financial investment. Since it is difficult for existing deep clustering methods to mine the complex and nonlinear features contained in financial time series, in order to deeply mine
[...] Read more.
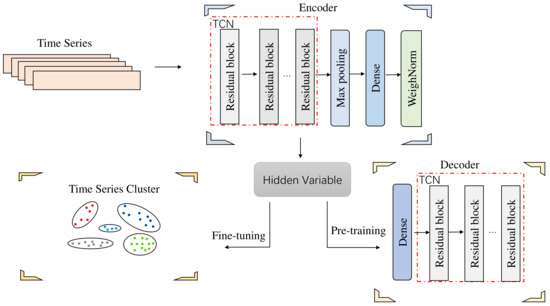
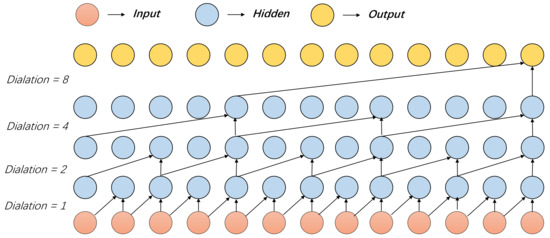
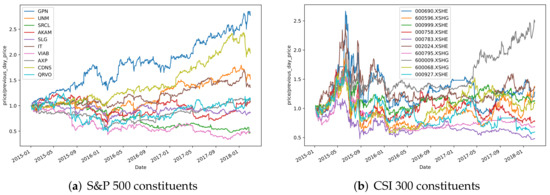
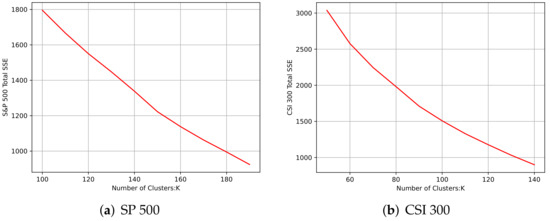
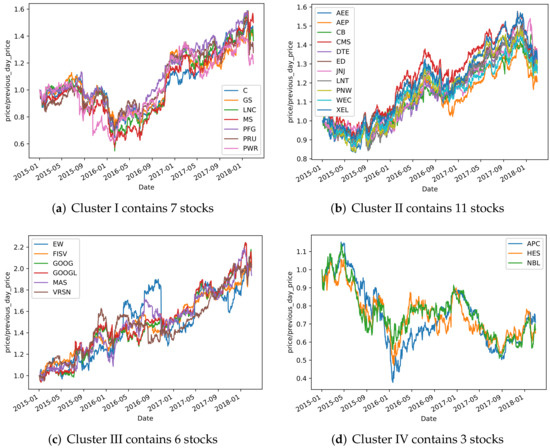
It is meaningful to analyze the market correlations for stock selection in the field of financial investment. Since it is difficult for existing deep clustering methods to mine the complex and nonlinear features contained in financial time series, in order to deeply mine the features of financial time series and achieve clustering, a new end-to-end deep clustering method for financial time series is proposed. It contains two modules: an autoencoder feature extraction network based on TCN (temporal convolutional neural) networks and a temporal clustering optimization algorithm with a KL (Kullback–Leibler) divergence. The features of financial time series are represented by the causal convolution and the dilated convolution of TCN networks. Then, the pre-training results based on the KL divergence are fine-tuned to make the clustering results discriminative. The experimental results show that the proposed method outperforms existing deep clustering and general clustering algorithms in the CSI 300 and S&P 500 index markets. In addition, the clustering results combined with an inference strategy can be used to select stocks that perform well or poorly, thus guiding actual stock market trades.
Full article
►▼
Show Figures
Open AccessArticle
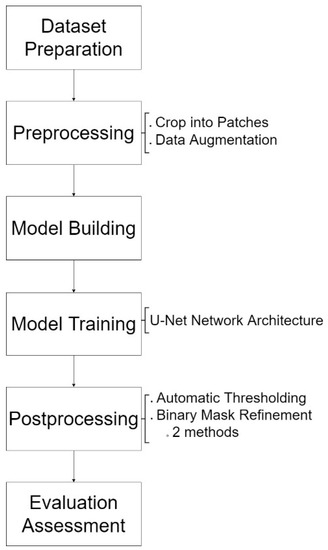
Post-Processing for Shadow Detection in Drone-Acquired Images Using U-NET
by
Siti-Aisyah Zali, Shahbe Mat-Desa, Zarina Che-Embi and Wan-Noorshahida Mohd-Isa
Cited by 9 | Viewed by 3841
Abstract
Shadows in drone images commonly appear in various shapes, sizes, and brightness levels, as the images capture a wide view of scenery under many conditions, such as varied flying height and weather. This property of drone images leads to a major problem when
[...] Read more.
Shadows in drone images commonly appear in various shapes, sizes, and brightness levels, as the images capture a wide view of scenery under many conditions, such as varied flying height and weather. This property of drone images leads to a major problem when it comes to detecting shadow and causes the presence of noise in the predicted shadow mask. The purpose of this study is to improve shadow detection results by implementing post-processing methods related to automatic thresholding and binary mask refinement. The aim is to discuss how the selected automatic thresholding and two methods of binary mask refinement perform to increase the efficiency and accuracy of shadow detection. The selected automatic thresholding method is Otsu’s thresholding, and methods for binary mask refinement are morphological operation and dense CRF. The study shows that the proposed methods achieve an acceptable accuracy of 96.43%.
Full article
►▼
Show Figures
Open AccessArticle
Deep Regression Neural Networks for Proportion Judgment
by
Mario Milicevic, Vedran Batos, Adriana Lipovac and Zeljka Car
Cited by 3 | Viewed by 4440
Abstract
Deep regression models are widely employed to solve computer vision tasks, such as human age or pose estimation, crowd counting, object detection, etc. Another possible area of application, which to our knowledge has not been systematically explored so far, is proportion judgment. As
[...] Read more.
Deep regression models are widely employed to solve computer vision tasks, such as human age or pose estimation, crowd counting, object detection, etc. Another possible area of application, which to our knowledge has not been systematically explored so far, is proportion judgment. As a prerequisite for successful decision making, individuals often have to use proportion judgment strategies, with which they estimate the magnitude of one stimulus relative to another (larger) stimulus. This makes this estimation problem interesting for the application of machine learning techniques. In regard to this, we proposed various deep regression architectures, which we tested on three original datasets of very different origin and composition. This is a novel approach, as the assumption is that the model can learn the concept of proportion without explicitly counting individual objects. With comprehensive experiments, we have demonstrated the effectiveness of the proposed models which can predict proportions on real-life datasets more reliably than human experts, considering the coefficient of determination (>0.95) and the amount of errors (
MAE < 2,
RMSE < 3). If there is no significant number of errors in determining the ground truth, with an appropriate size of the learning dataset, an additional reduction of
MAE to 0.14 can be achieved. The used datasets will be publicly available to serve as reference data sources in similar projects.
Full article
►▼
Show Figures
Open AccessArticle
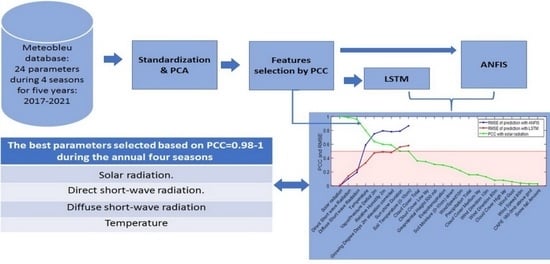
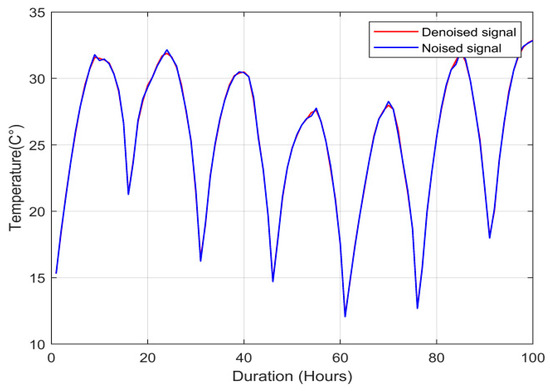
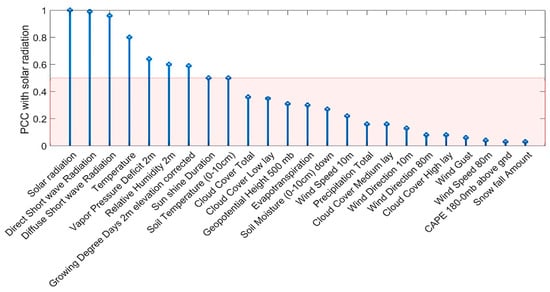
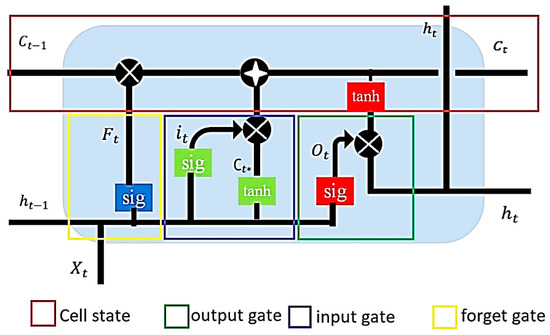
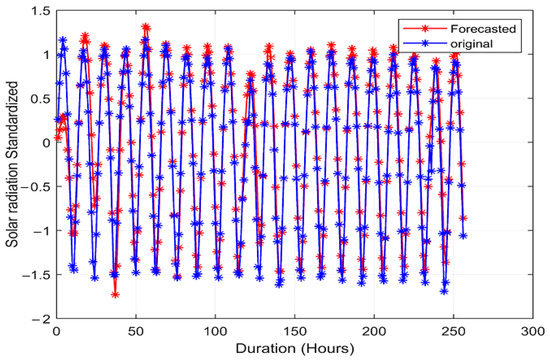
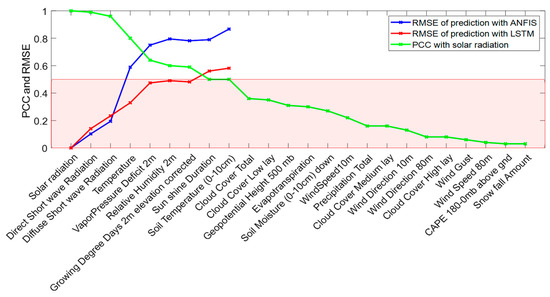
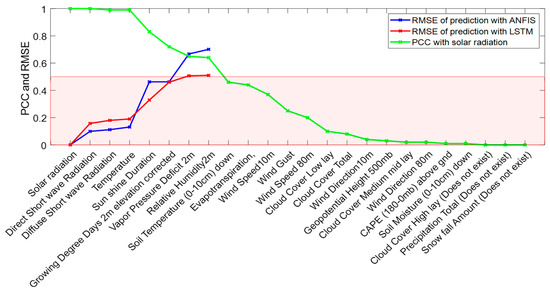
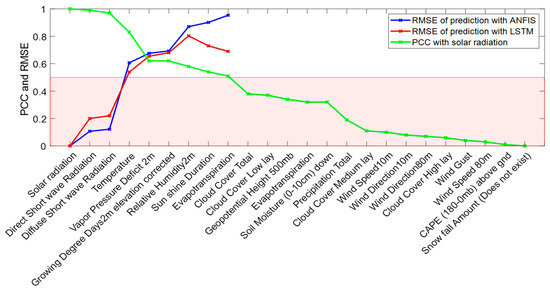
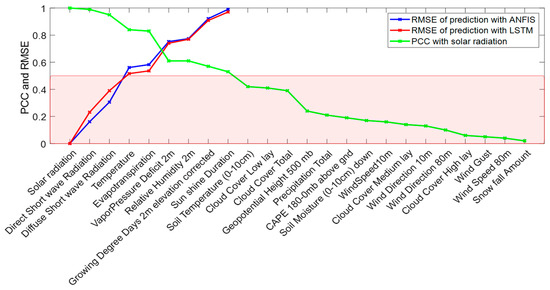
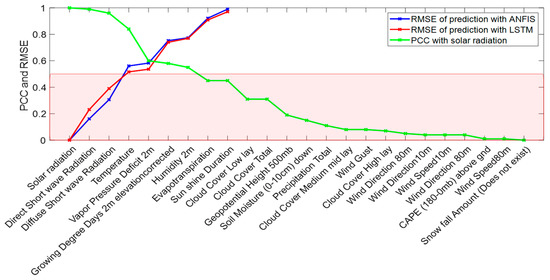
Solar Radiation Forecasting by Pearson Correlation Using LSTM Neural Network and ANFIS Method: Application in the West-Central Jordan
by
Hossam Fraihat, Amneh A. Almbaideen, Abdullah Al-Odienat, Bassam Al-Naami, Roberto De Fazio and Paolo Visconti
Cited by 43 | Viewed by 7534
Abstract
Solar energy is one of the most important renewable energies, with many advantages over other sources. Many parameters affect the electricity generation from solar plants. This paper aims to study the influence of these parameters on predicting solar radiation and electric energy produced
[...] Read more.
Solar energy is one of the most important renewable energies, with many advantages over other sources. Many parameters affect the electricity generation from solar plants. This paper aims to study the influence of these parameters on predicting solar radiation and electric energy produced in the Salt-Jordan region (Middle East) using long short-term memory (LSTM) and Adaptive Network-based Fuzzy Inference System (ANFIS) models. The data relating to 24 meteorological parameters for nearly the past five years were downloaded from the MeteoBleu database. The results show that the influence of parameters on solar radiation varies according to the season. The forecasting using ANFIS provides better results when the parameter correlation with solar radiation is high (i.e., Pearson Correlation Coefficient PCC between 0.95 and 1). In comparison, the LSTM neural network shows better results when correlation is low (PCC in the range 0.5–0.8). The obtained RMSE varies from 0.04 to 0.8 depending on the season and used parameters; new meteorological parameters influencing solar radiation are also investigated.
Full article
►▼
Show Figures
Open AccessArticle
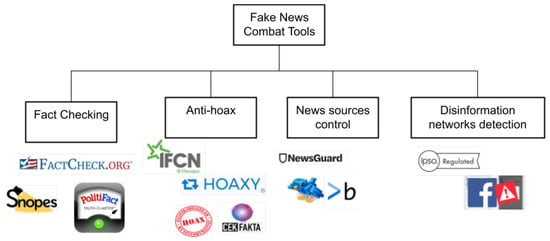
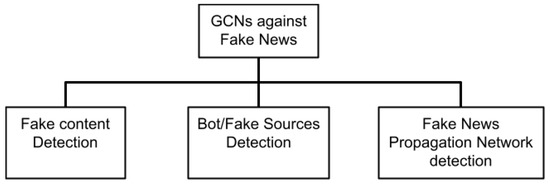
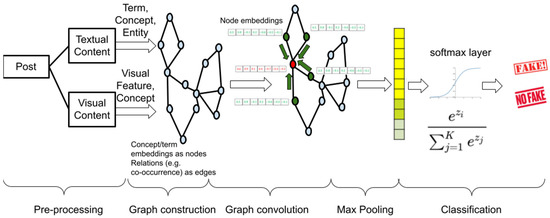
A Survey on the Use of Graph Convolutional Networks for Combating Fake News
by
Iraklis Varlamis, Dimitrios Michail, Foteini Glykou and Panagiotis Tsantilas
Cited by 32 | Viewed by 7669
Abstract
The combat against fake news and disinformation is an ongoing, multi-faceted task for researchers in social media and social networks domains, which comprises not only the detection of false facts in published content but also the detection of accountability mechanisms that keep a
[...] Read more.
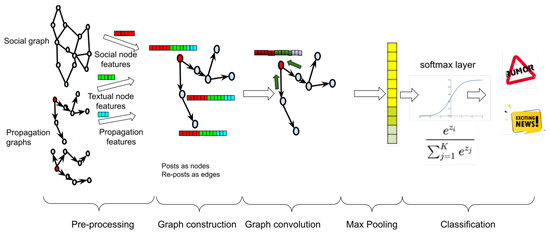
The combat against fake news and disinformation is an ongoing, multi-faceted task for researchers in social media and social networks domains, which comprises not only the detection of false facts in published content but also the detection of accountability mechanisms that keep a record of the trustfulness of sources that generate news and, lately, of the networks that deliberately distribute fake information. In the direction of detecting and handling organized disinformation networks, major social media and social networking sites are currently developing strategies and mechanisms to block such attempts. The role of machine learning techniques, especially neural networks, is crucial in this task. The current work focuses on the popular and promising graph representation techniques and performs a survey of the works that employ Graph Convolutional Networks (GCNs) to the task of detecting fake news, fake accounts and rumors that spread in social networks. It also highlights the available benchmark datasets employed in current research for validating the performance of the proposed methods. This work is a comprehensive survey of the use of GCNs in the combat against fake news and aims to be an ideal starting point for future researchers in the field.
Full article
►▼
Show Figures
Open AccessArticle
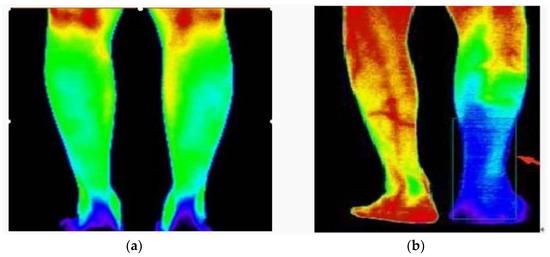
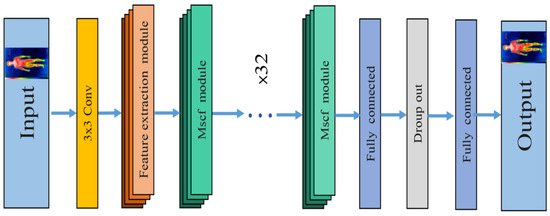
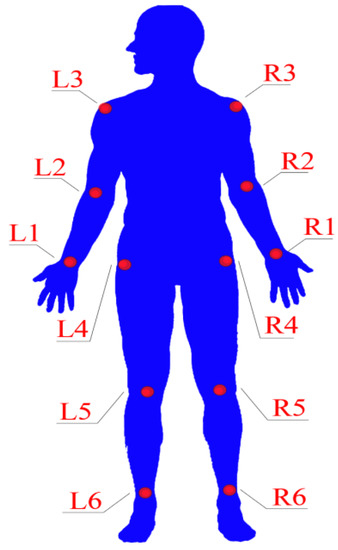
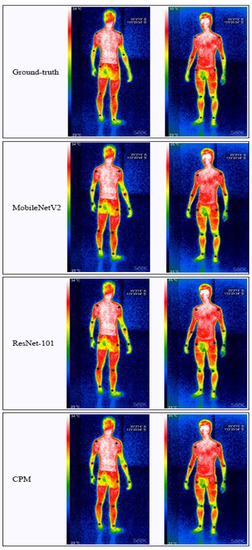
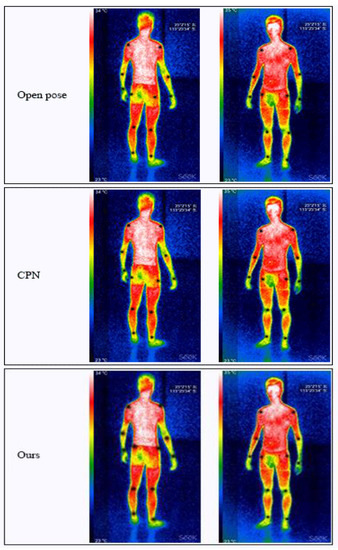
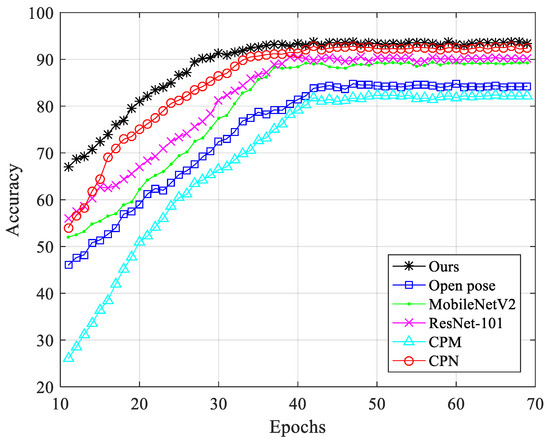
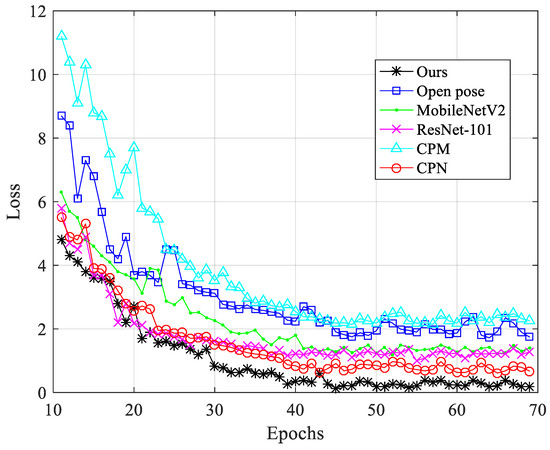
Key Points’ Location in Infrared Images of the Human Body Based on Mscf-ResNet
by
Shengguo Ge and Siti Nurulain Mohd Rum
Cited by 4 | Viewed by 5675
Abstract
The human body generates infrared radiation through the thermal movement of molecules. Based on this phenomenon, infrared images of the human body are often used for monitoring and tracking. Among them, key point location on infrared images of the human body is an
[...] Read more.
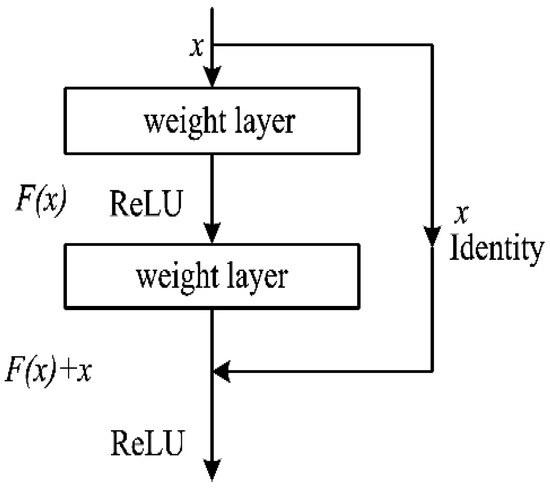
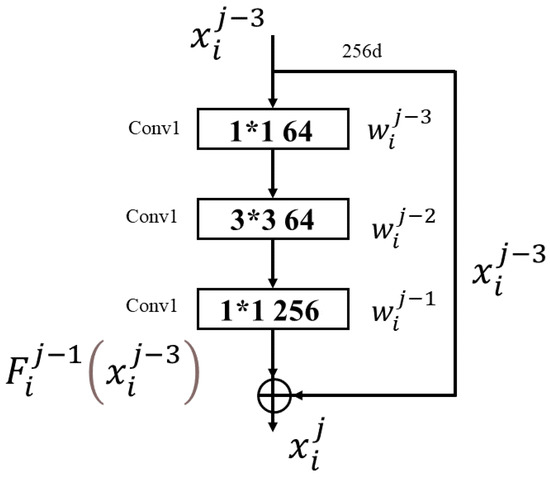
The human body generates infrared radiation through the thermal movement of molecules. Based on this phenomenon, infrared images of the human body are often used for monitoring and tracking. Among them, key point location on infrared images of the human body is an important technology in medical infrared image processing. However, the fuzzy edges, poor detail resolution, and uneven brightness distribution of the infrared image of the human body cause great difficulties in positioning. Therefore, how to improve the positioning accuracy of key points in human infrared images has become the main research direction. In this study, a multi-scale convolution fusion deep residual network (Mscf-ResNet) model is proposed for human body infrared image positioning. This model is based on the traditional ResNet, changing the single-scale convolution to multi-scale and fusing the information of different receptive fields, so that the extracted features are more abundant and the degradation problem, caused by the excessively deep network, is avoided. The experiments show that our proposed method has higher key point positioning accuracy than other methods. At the same time, because the network structure of this paper is too deep, there are too many parameters and a large volume of calculations. Therefore, a more lightweight network model is the direction of future research.
Full article
►▼
Show Figures
Open AccessArticle
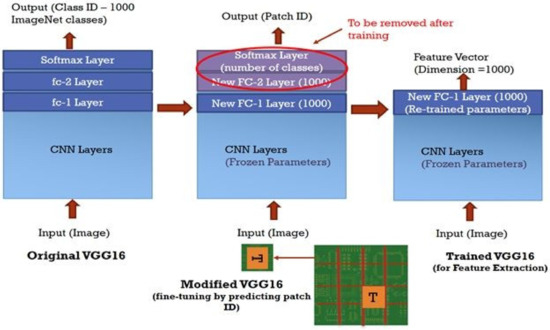
The Impact of a Number of Samples on Unsupervised Feature Extraction, Based on Deep Learning for Detection Defects in Printed Circuit Boards
by
Ihar Volkau, Abdul Mujeeb, Wenting Dai, Marius Erdt and Alexei Sourin
Cited by 11 | Viewed by 4381
Abstract
Deep learning provides new ways for defect detection in automatic optical inspections (AOI). However, the existing deep learning methods require thousands of images of defects to be used for training the algorithms. It limits the usability of these approaches in manufacturing, due to
[...] Read more.
Deep learning provides new ways for defect detection in automatic optical inspections (AOI). However, the existing deep learning methods require thousands of images of defects to be used for training the algorithms. It limits the usability of these approaches in manufacturing, due to lack of images of defects before the actual manufacturing starts. In contrast, we propose to train a defect detection unsupervised deep learning model, using a much smaller number of images without defects. We propose an unsupervised deep learning model, based on transfer learning, that extracts typical semantic patterns from defect-free samples (one-class training). The model is built upon a pre-trained VGG16 model. It is further trained on custom datasets with different sizes of possible defects (printed circuit boards and soldered joints) using only small number of normal samples. We have found that the defect detection can be performed very well on a smooth background; however, in cases where the defect manifests as a change of texture, the detection can be less accurate. The proposed study uses deep learning self-supervised approach to identify if the sample under analysis contains any deviations (with types not defined in advance) from normal design. The method would improve the robustness of the AOI process to detect defects.
Full article
►▼
Show Figures
Open AccessArticle
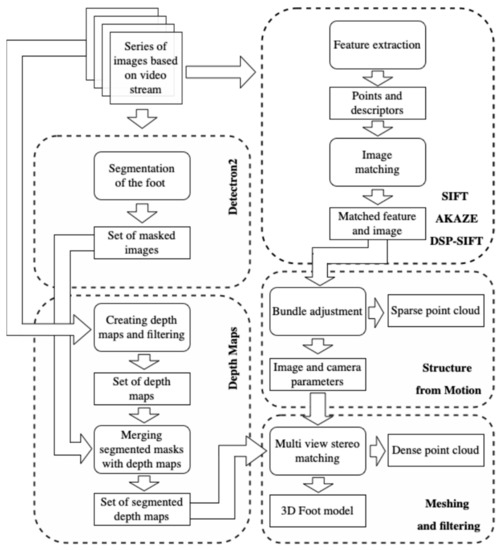
Reconstruction of a 3D Human Foot Shape Model Based on a Video Stream Using Photogrammetry and Deep Neural Networks
by
Lev Shilov, Semen Shanshin, Aleksandr Romanov, Anastasia Fedotova, Anna Kurtukova, Evgeny Kostyuchenko and Ivan Sidorov
Cited by 10 | Viewed by 8275
Abstract
Reconstructed 3D foot models can be used for 3D printing and further manufacturing of individual orthopedic shoes, as well as in medical research and for online shoe shopping. This study presents a technique based on the approach and algorithms of photogrammetry. The presented
[...] Read more.
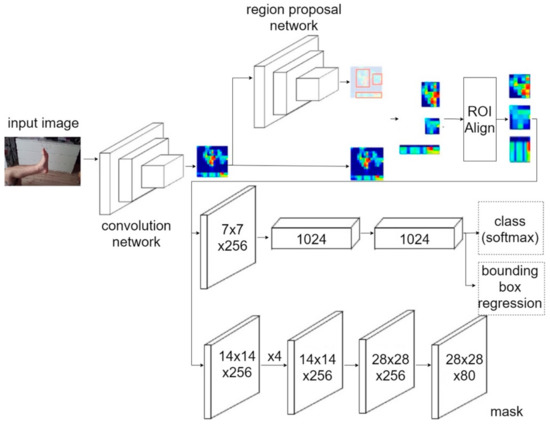
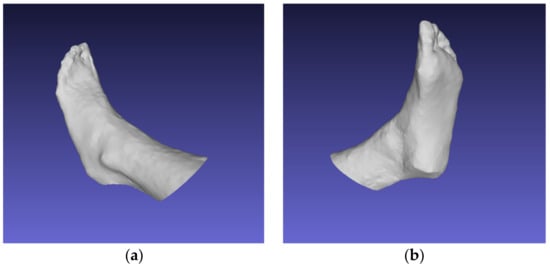
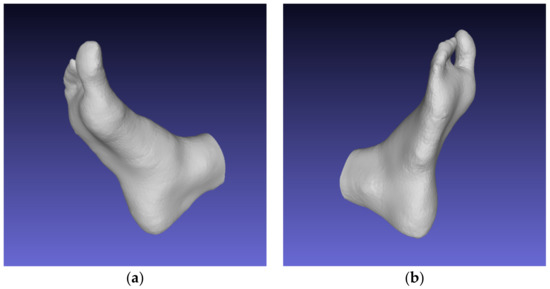
Reconstructed 3D foot models can be used for 3D printing and further manufacturing of individual orthopedic shoes, as well as in medical research and for online shoe shopping. This study presents a technique based on the approach and algorithms of photogrammetry. The presented technique was used to reconstruct a 3D model of the foot shape, including the lower arch, using smartphone images. The technique is based on modern computer vision and artificial intelligence algorithms designed for image processing, obtaining sparse and dense point clouds, depth maps, and a final 3D model. For the segmentation of foot images, the Mask R-CNN neural network was used, which was trained on foot data from a set of 40 people. The obtained accuracy was 97.88%. The result of the study was a high-quality reconstructed 3D model. The standard deviation of linear indicators in length and width was 0.95 mm, with an average creation time of 1 min 35 s recorded. Integration of this technique into the business models of orthopedic enterprises, Internet stores, and medical organizations will allow basic manufacturing and shoe-fitting services to be carried out and will help medical research to be performed via the Internet.
Full article
►▼
Show Figures
Open AccessArticle
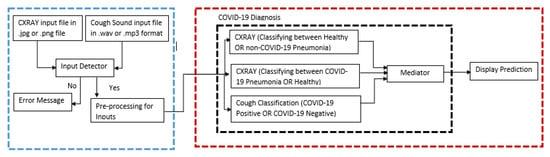
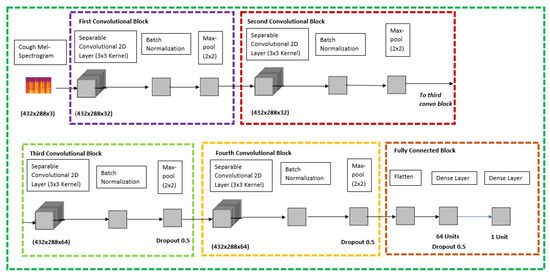
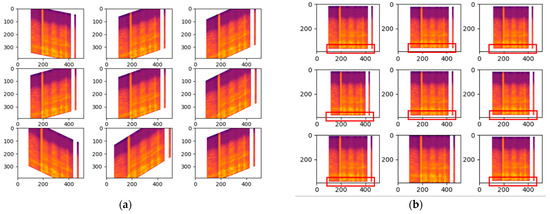
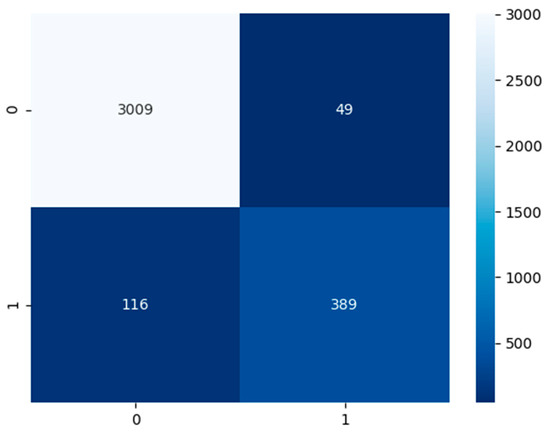
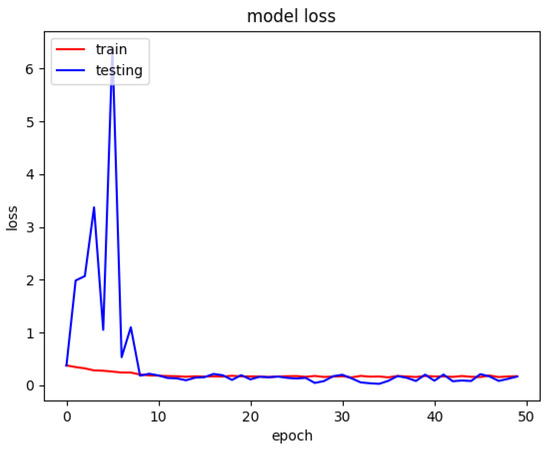
COVIDNet: Implementing Parallel Architecture on Sound and Image for High Efficacy
by
Manickam Murugappan, John Victor Joshua Thomas, Ugo Fiore, Yesudas Bevish Jinila and Subhashini Radhakrishnan
Cited by 4 | Viewed by 3143
Abstract
The present work relates to the implementation of core parallel architecture in a deep learning algorithm. At present, deep learning technology forms the main interdisciplinary basis of healthcare, hospital hygiene, biological and medicine. This work establishes a baseline range by training hyperparameter space,
[...] Read more.
The present work relates to the implementation of core parallel architecture in a deep learning algorithm. At present, deep learning technology forms the main interdisciplinary basis of healthcare, hospital hygiene, biological and medicine. This work establishes a baseline range by training hyperparameter space, which could be support images, and sound with further develop a parallel architectural model using multiple inputs with and without the patient’s involvement. The chest X-ray images input could form the model architecture include variables for the number of nodes in each layer and dropout rate. Fourier transformation Mel-spectrogram images with the correct pixel range use to covert sound acceptance at the convolutional neural network in embarrassingly parallel sequences. COVIDNet the end user tool has to input a chest X-ray image and a cough audio file which could be a natural cough or a forced cough. Three binary classification models (COVID-19 CXR, non-COVID-19 CXR, COVID-19 cough) were trained. The COVID-19 CXR model classifies between healthy lungs and the COVID-19 model meanwhile the non-COVID-19 CXR model classifies between non-COVID-19 pneumonia and healthy lungs. The COVID-19 CXR model has an accuracy of 95% which was trained using 1681 COVID-19 positive images and 10,895 healthy lungs images, meanwhile, the non-COVID-19 CXR model has an accuracy of 91% which was trained using 7478 non-COVID-19 pneumonia positive images and 10,895 healthy lungs. The reason why all the models are binary classification is due to the lack of available data since medical image datasets are usually highly imbalanced and the cost of obtaining them are very pricey and time-consuming. Therefore, data augmentation was performed on the medical images datasets that were used. Effects of parallel architecture and optimization to improve on design were investigated.
Full article
►▼
Show Figures
Open AccessArticle
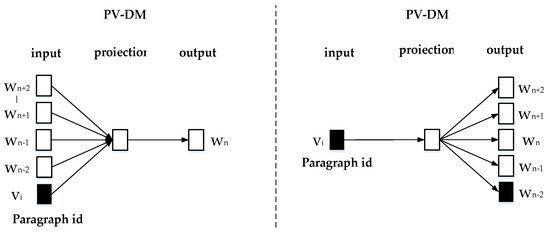
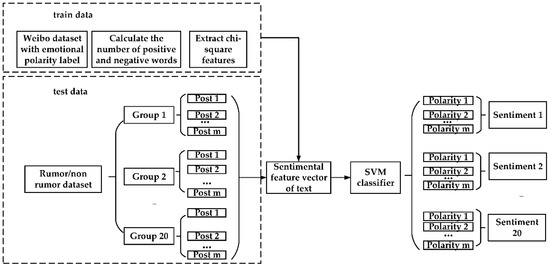
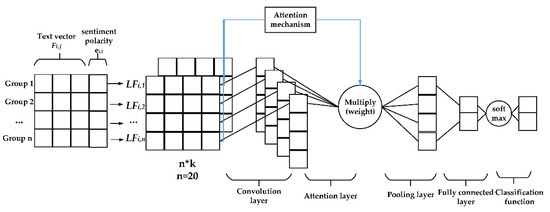
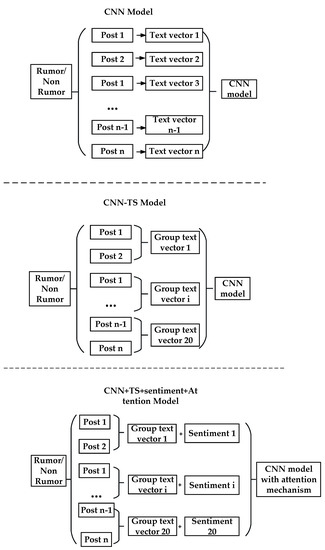
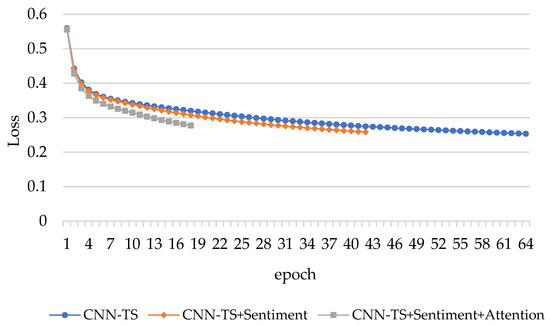
Rumor Detection Based on Attention CNN and Time Series of Context Information
by
Yun Peng and Jianmei Wang
Cited by 7 | Viewed by 4505
Abstract
This study aims to explore the time series context and sentiment polarity features of rumors’ life cycles, and how to use them to optimize the CNN model parameters and improve the classification effect. The proposed model is a convolutional neural network embedded with
[...] Read more.
This study aims to explore the time series context and sentiment polarity features of rumors’ life cycles, and how to use them to optimize the CNN model parameters and improve the classification effect. The proposed model is a convolutional neural network embedded with an attention mechanism of sentiment polarity and time series information. Firstly, the whole life cycle of rumors is divided into 20 groups by the time series algorithm and each group of texts is trained by Doc2Vec to obtain the text vector. Secondly, the SVM algorithm is used to obtain the sentiment polarity features of each group. Lastly, the CNN model with the spatial attention mechanism is used to obtain the rumors’ classification. The experiment results show that the proposed model introduced with features of time series and sentiment polarity is very effective for rumor detection, and can greatly reduce the number of iterations for model training as well. The accuracy, precision, recall and F1 of the attention CNN are better than the latest benchmark model.
Full article
►▼
Show Figures
Open AccessReview
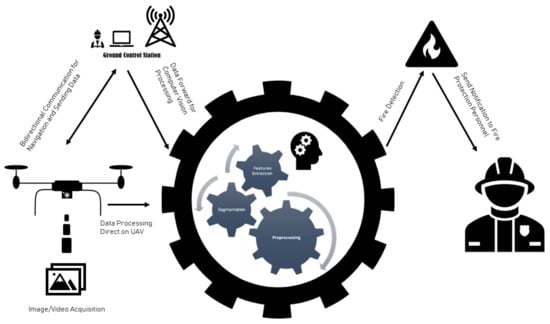
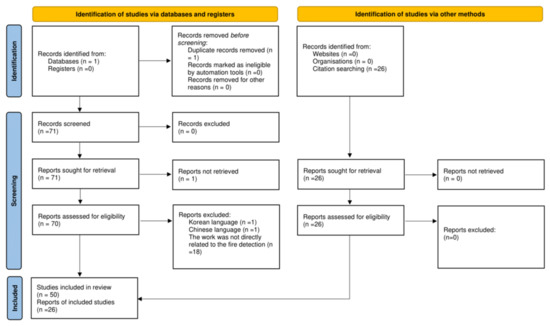
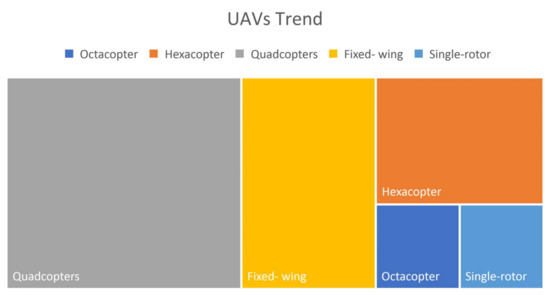
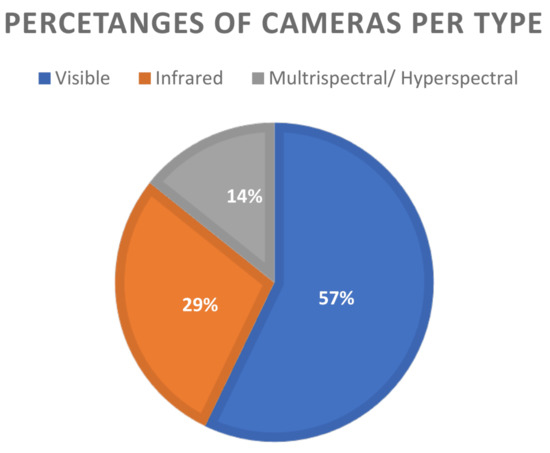
Computer Vision for Fire Detection on UAVs—From Software to Hardware
by
Seraphim S. Moumgiakmas, Gerasimos G. Samatas and George A. Papakostas
Cited by 35 | Viewed by 8708
Abstract
Fire hazard is a condition that has potentially catastrophic consequences. Artificial intelligence, through Computer Vision, in combination with UAVs has assisted dramatically to identify this risk and avoid it in a timely manner. This work is a literature review on UAVs using Computer
[...] Read more.
Fire hazard is a condition that has potentially catastrophic consequences. Artificial intelligence, through Computer Vision, in combination with UAVs has assisted dramatically to identify this risk and avoid it in a timely manner. This work is a literature review on UAVs using Computer Vision in order to detect fire. The research was conducted for the last decade in order to record the types of UAVs, the hardware and software used and the proposed datasets. The scientific research was executed through the Scopus database. The research showed that multi-copters were the most common type of vehicle and that the combination of RGB with a thermal camera was part of most applications. In addition, the trend in the use of Convolutional Neural Networks (CNNs) is increasing. In the last decade, many applications and a wide variety of hardware and methods have been implemented and studied. Many efforts have been made to effectively avoid the risk of fire. The fact that state-of-the-art methodologies continue to be researched, leads to the conclusion that the need for a more effective solution continues to arouse interest.
Full article
►▼
Show Figures
Open AccessArticle
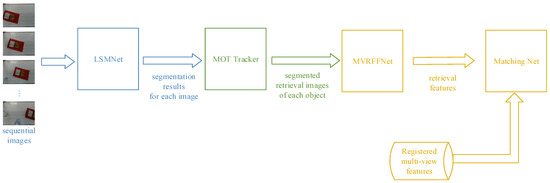
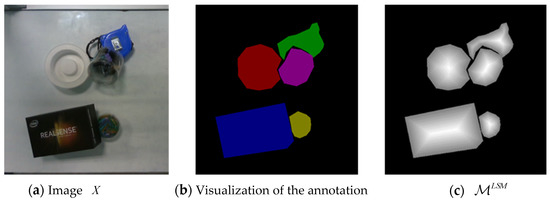
Dynamic Detection and Recognition of Objects Based on Sequential RGB Images
by
Shuai Dong, Zhihua Yang, Wensheng Li and Kun Zou
Cited by 3 | Viewed by 3334
Abstract
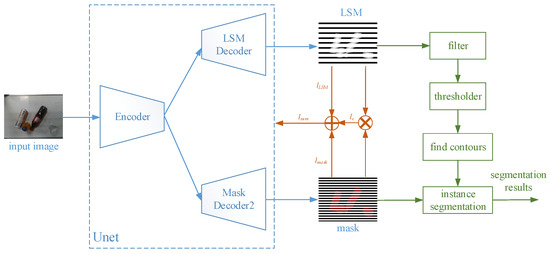
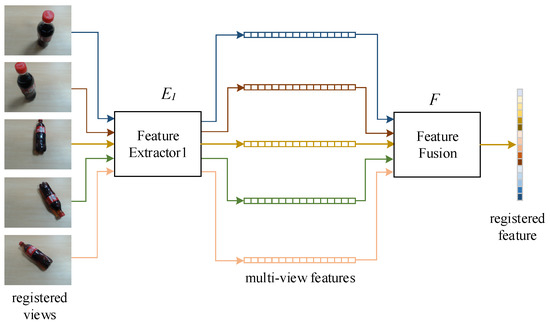
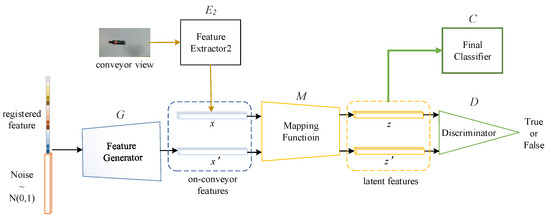
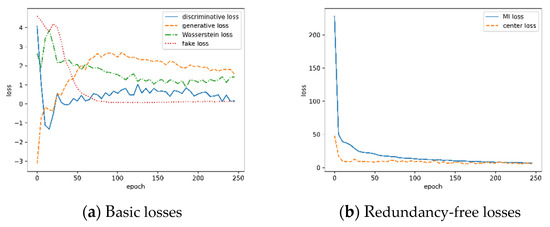
Conveyors are used commonly in industrial production lines and automated sorting systems. Many applications require fast, reliable, and dynamic detection and recognition for the objects on conveyors. Aiming at this goal, we design a framework that involves three subtasks: one-class instance segmentation (OCIS),
[...] Read more.
Conveyors are used commonly in industrial production lines and automated sorting systems. Many applications require fast, reliable, and dynamic detection and recognition for the objects on conveyors. Aiming at this goal, we design a framework that involves three subtasks: one-class instance segmentation (OCIS), multiobject tracking (MOT), and zero-shot fine-grained recognition of 3D objects (ZSFGR3D). A new level set map network (LSMNet) and a multiview redundancy-free feature network (MVRFFNet) are proposed for the first and third subtasks, respectively. The level set map (LSM) is used to annotate instances instead of the traditional multichannel binary mask, and each peak of the LSM represents one instance. Based on the LSM, LSMNet can adopt a pix2pix architecture to segment instances. MVRFFNet is a generalized zero-shot learning (GZSL) framework based on the Wasserstein generative adversarial network for 3D object recognition. Multi-view features of an object are combined into a compact registered feature. By treating the registered features as the category attribution in the GZSL setting, MVRFFNet learns a mapping function that maps original retrieve features into a new redundancy-free feature space. To validate the performance of the proposed methods, a segmentation dataset and a fine-grained classification dataset about objects on a conveyor are established. Experimental results on these datasets show that LSMNet can achieve a recalling accuracy close to the light instance segmentation framework You Only Look At CoefficienTs (YOLACT), while its computing speed on an NVIDIA GTX1660TI GPU is 80 fps, which is much faster than YOLACT’s 25 fps. Redundancy-free features generated by MVRFFNet perform much better than original features in the retrieval task.
Full article
►▼
Show Figures
Open AccessArticle
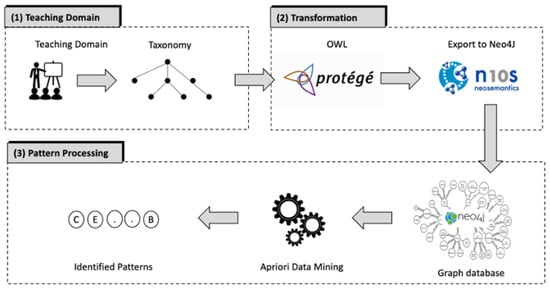
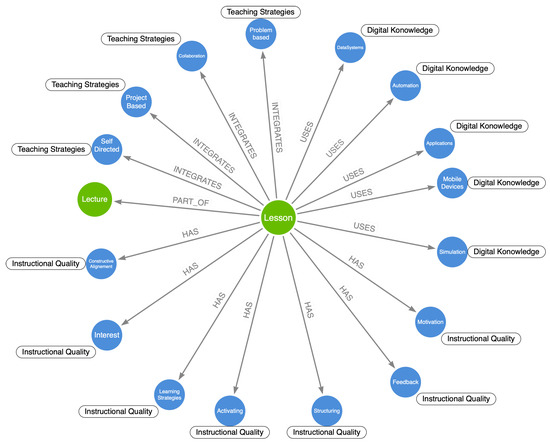
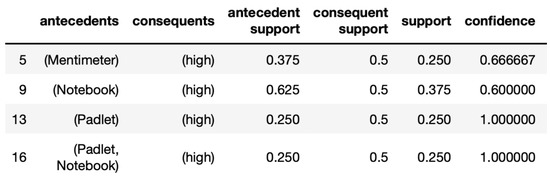
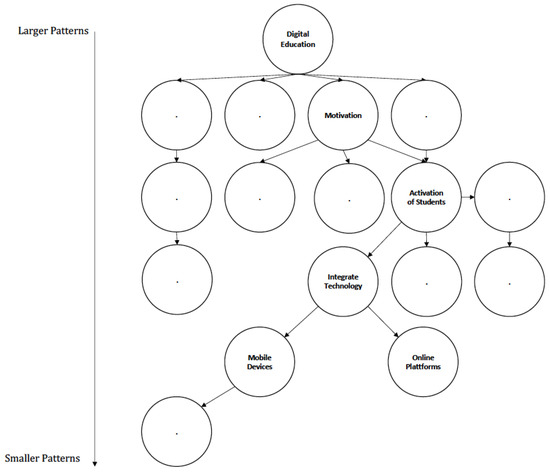
A Pattern Mining Method for Teaching Practices
by
Bernhard Standl and Nadine Schlomske-Bodenstein
Cited by 5 | Viewed by 3587
Abstract
When integrating digital technology into teaching, many teachers experience similar challenges. Nevertheless, sharing experiences is difficult as it is usually not possible to transfer teaching scenarios directly from one subject to another because subject-specific characteristics make it difficult to reuse them. To address
[...] Read more.
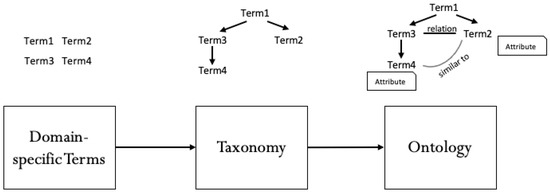
When integrating digital technology into teaching, many teachers experience similar challenges. Nevertheless, sharing experiences is difficult as it is usually not possible to transfer teaching scenarios directly from one subject to another because subject-specific characteristics make it difficult to reuse them. To address this problem, instructional scenarios can be described as patterns, which has already been applied in educational contexts. Patterns capture proven teaching strategies and describe teaching scenarios in a unified structure that can be reused. Since priorities for content, methods, and tools are different in each subject, we show an approach to develop a domain-independent graph database to collect digital teaching practices from a taxonomic structure via the intermediate step of an ontology. Furthermore, we outline a method to identify effective teaching practices from interdisciplinary data as patterns from the graph database using an association rule algorithm. The results show that an association-based analysis approach can derive initial indications of effective teaching scenarios.
Full article
►▼
Show Figures
Open AccessArticle
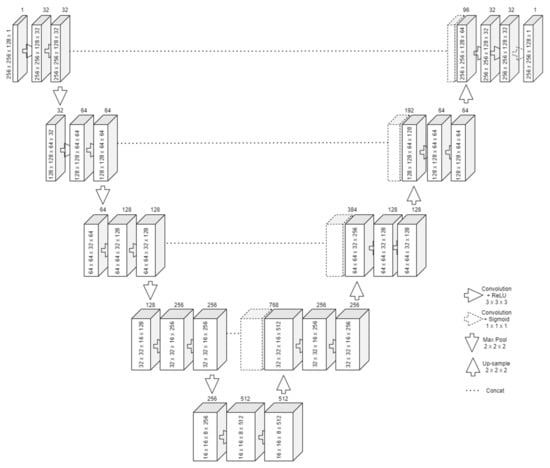
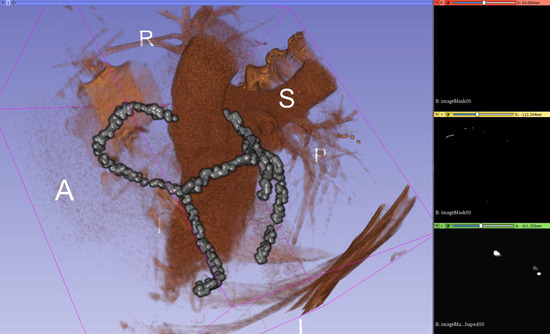
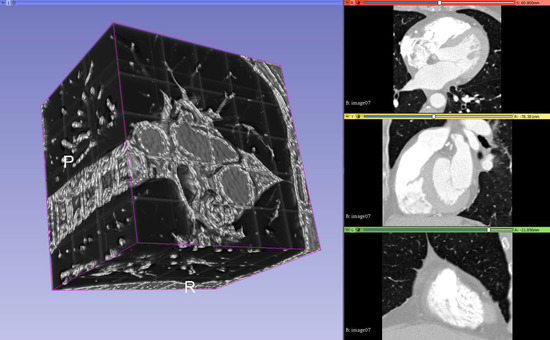
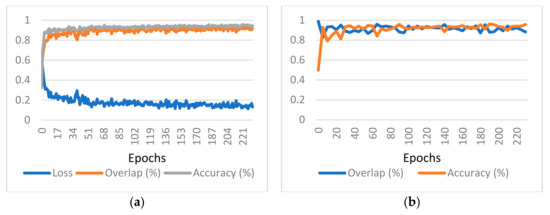
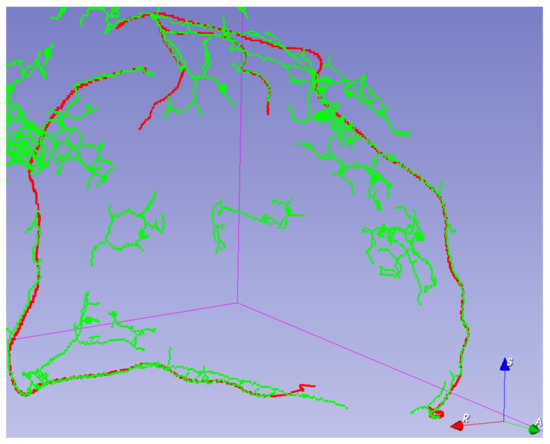
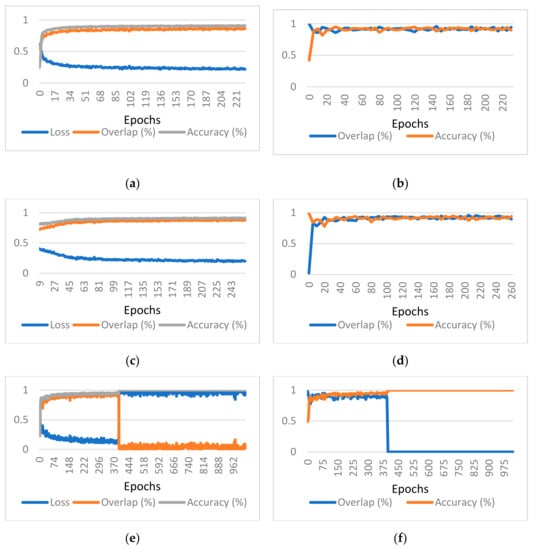
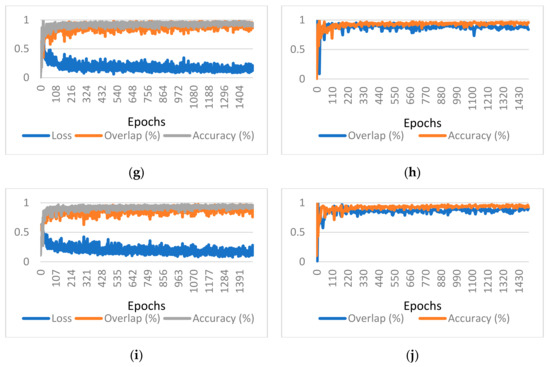
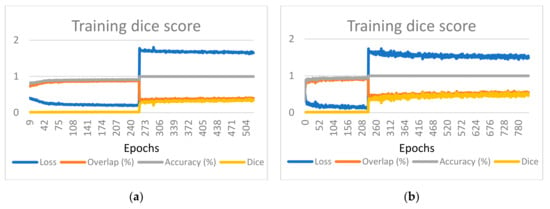
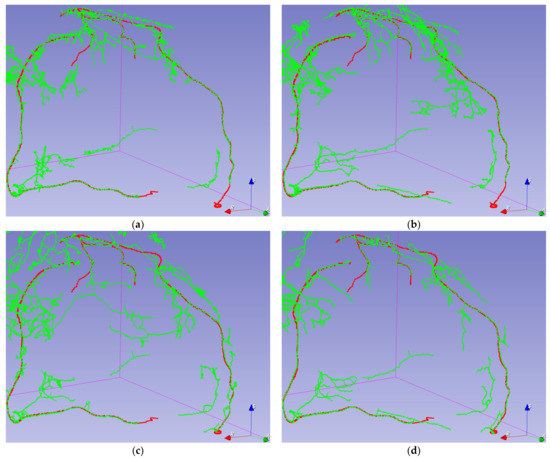
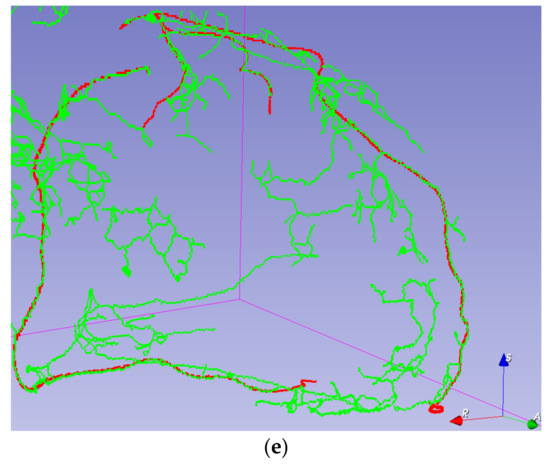
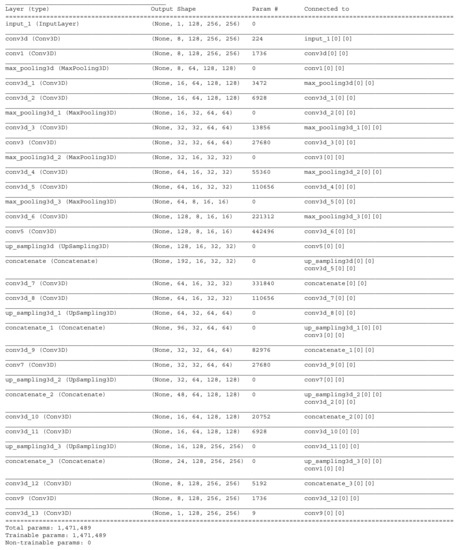
Coronary Centerline Extraction from CCTA Using 3D-UNet
by
Alexandru Dorobanțiu, Valentin Ogrean and Remus Brad
Cited by 10 | Viewed by 6562
Abstract
The mesh-type coronary model, obtained from three-dimensional reconstruction using the sequence of images produced by computed tomography (CT), can be used to obtain useful diagnostic information, such as extracting the projection of the lumen (planar development along an artery). In this paper, we
[...] Read more.
The mesh-type coronary model, obtained from three-dimensional reconstruction using the sequence of images produced by computed tomography (CT), can be used to obtain useful diagnostic information, such as extracting the projection of the lumen (planar development along an artery). In this paper, we have focused on automated coronary centerline extraction from cardiac computed tomography angiography (CCTA) proposing a 3D version of U-Net architecture, trained with a novel loss function and with augmented patches. We have obtained promising results for accuracy (between 90–95%) and overlap (between 90–94%) with various network training configurations on the data from the Rotterdam Coronary Artery Centerline Extraction benchmark. We have also demonstrated the ability of the proposed network to learn despite the huge class imbalance and sparse annotation present in the training data.
Full article
►▼
Show Figures
Open AccessArticle
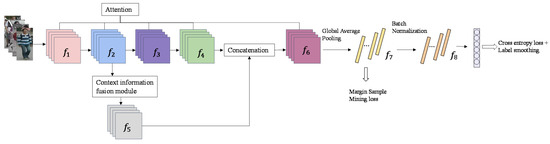
Person Re-Identification Based on Attention Mechanism and Context Information Fusion
by
Shengbo Chen, Hongchang Zhang and Zhou Lei
Cited by 5 | Viewed by 5125
Abstract
Person re-identification (ReID) plays a significant role in video surveillance analysis. In the real world, due to illumination, occlusion, and deformation, pedestrian features extraction is the key to person ReID. Considering the shortcomings of existing methods in pedestrian features extraction, a method based
[...] Read more.
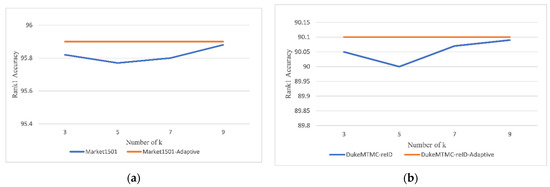
Person re-identification (ReID) plays a significant role in video surveillance analysis. In the real world, due to illumination, occlusion, and deformation, pedestrian features extraction is the key to person ReID. Considering the shortcomings of existing methods in pedestrian features extraction, a method based on attention mechanism and context information fusion is proposed. A lightweight attention module is introduced into ResNet50 backbone network equipped with a small number of network parameters, which enhance the significant characteristics of person and suppress irrelevant information. Aiming at the problem of person context information loss due to the over depth of the network, a context information fusion module is designed to sample the shallow feature map of pedestrians and cascade with the high-level feature map. In order to improve the robustness, the model is trained by combining the loss of margin sample mining with the loss function of cross entropy. Experiments are carried out on datasets Market1501 and DukeMTMC-reID, our method achieves rank-1 accuracy of 95.9% on the Market1501 dataset, and 90.1% on the DukeMTMC-reID dataset, outperforming the current mainstream method in case of only using global feature.
Full article
►▼
Show Figures
Open AccessArticle
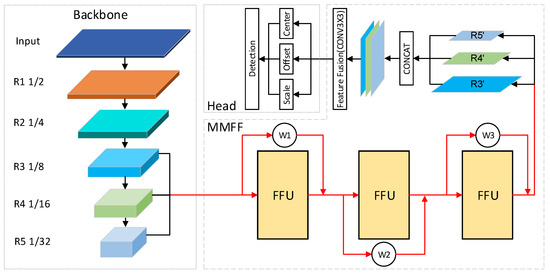
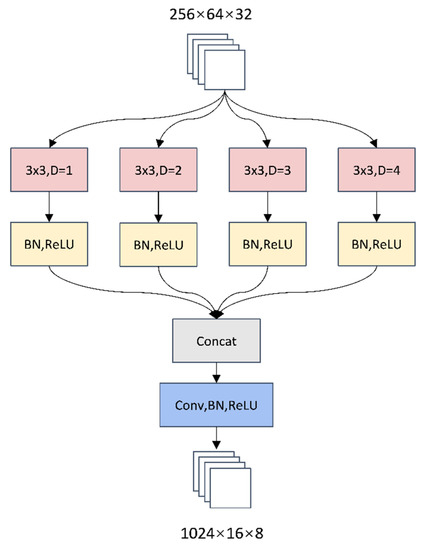
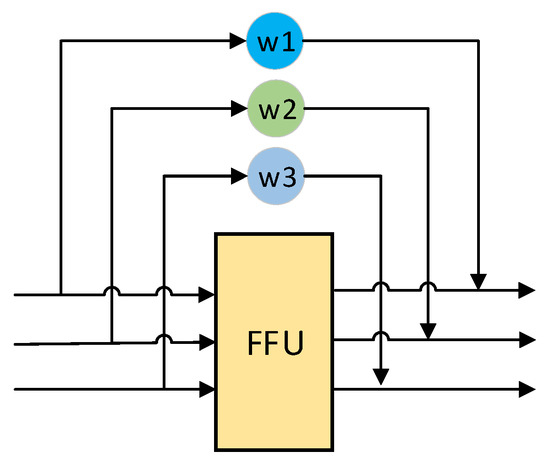
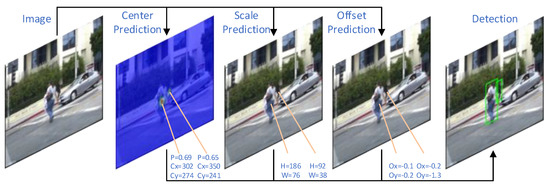
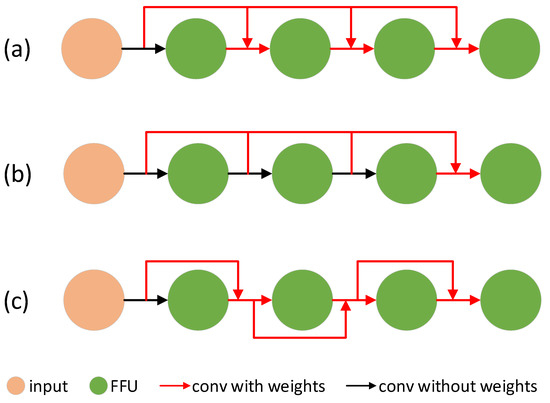
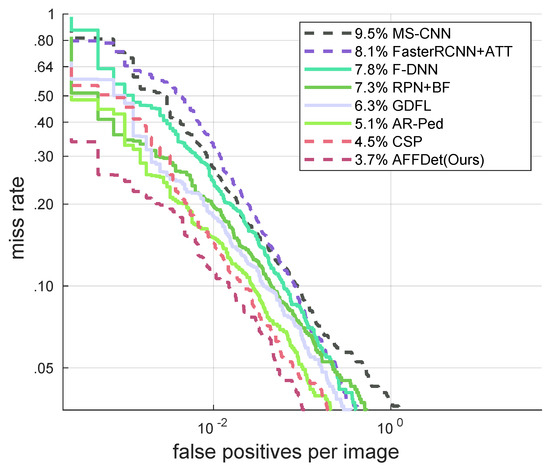
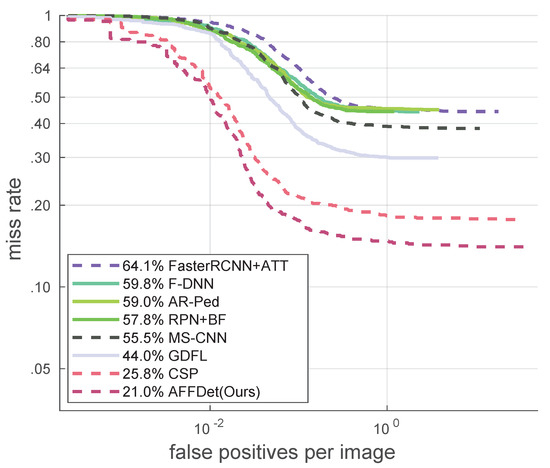
Adaptive Weighted Multi-Level Fusion of Multi-Scale Features: A New Approach to Pedestrian Detection
by
Yao Xu and Qin Yu
Cited by 5 | Viewed by 3907
Abstract
Great achievements have been made in pedestrian detection through deep learning. For detectors based on deep learning, making better use of features has become the key to their detection effect. While current pedestrian detectors have made efforts in feature utilization to improve their
[...] Read more.
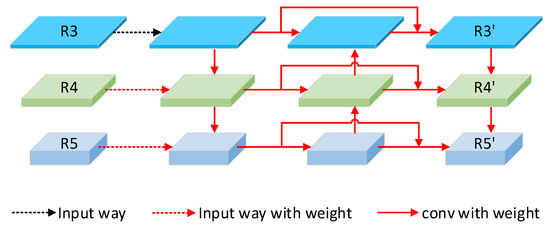
Great achievements have been made in pedestrian detection through deep learning. For detectors based on deep learning, making better use of features has become the key to their detection effect. While current pedestrian detectors have made efforts in feature utilization to improve their detection performance, the feature utilization is still inadequate. To solve the problem of inadequate feature utilization, we proposed the Multi-Level Feature Fusion Module (MFFM) and its Multi-Scale Feature Fusion Unit (MFFU) sub-module, which connect feature maps of the same scale and different scales by using horizontal and vertical connections and shortcut structures. All of these connections are accompanied by weights that can be learned; thus, they can be used as adaptive multi-level and multi-scale feature fusion modules to fuse the best features. Then, we built a complete pedestrian detector, the Adaptive Feature Fusion Detector (AFFDet), which is an anchor-free one-stage pedestrian detector that can make full use of features for detection. As a result, compared with other methods, our method has better performance on the challenging Caltech Pedestrian Detection Benchmark (Caltech) and has quite competitive speed. It is the current state-of-the-art one-stage pedestrian detection method.
Full article
►▼
Show Figures
Open AccessArticle
Collaborative Filtering Based on a Variational Gaussian Mixture Model
by
FengLei Yang, Fei Liu and ShanShan Liu
Cited by 5 | Viewed by 4261
Abstract
Collaborative filtering (CF) is a widely used method in recommendation systems. Linear models are still the mainstream of collaborative filtering research methods, but non-linear probabilistic models are beyond the limit of linear model capacity. For example, variational autoencoders (VAEs) have been extensively used
[...] Read more.
Collaborative filtering (CF) is a widely used method in recommendation systems. Linear models are still the mainstream of collaborative filtering research methods, but non-linear probabilistic models are beyond the limit of linear model capacity. For example, variational autoencoders (VAEs) have been extensively used in CF, and have achieved excellent results. Aiming at the problem of the prior distribution for the latent codes of VAEs in traditional CF is too simple, which makes the implicit variable representations of users and items too poor. This paper proposes a variational autoencoder that uses a Gaussian mixture model for latent factors distribution for CF, GVAE-CF. On this basis, an optimization function suitable for GVAE-CF is proposed. In our experimental evaluation, we show that the recommendation performance of GVAE-CF outperforms the previously proposed VAE-based models on several popular benchmark datasets in terms of recall and normalized discounted cumulative gain (NDCG), thus proving the effectiveness of the algorithm.
Full article
►▼
Show Figures
Open AccessArticle
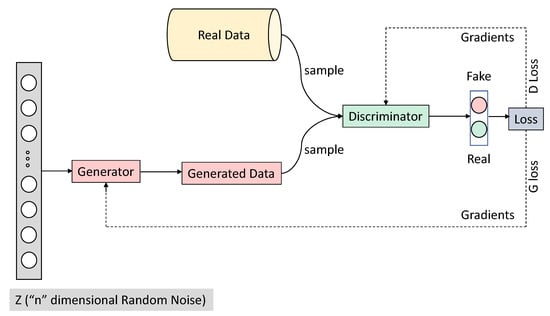
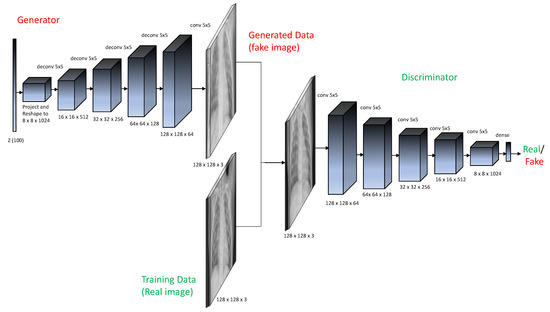
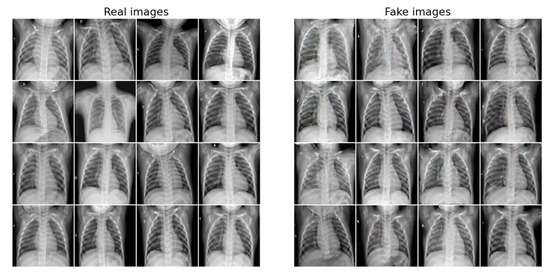
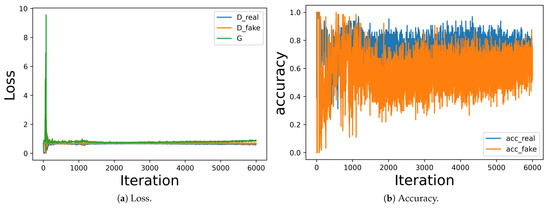
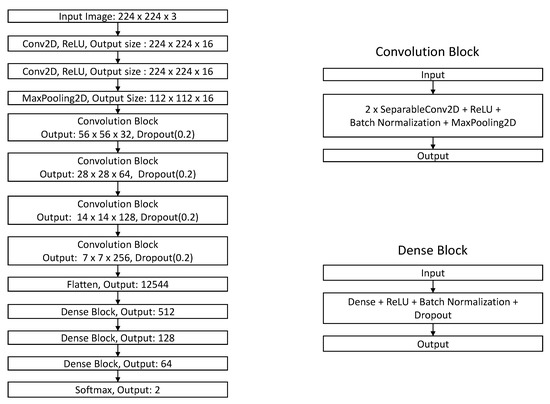
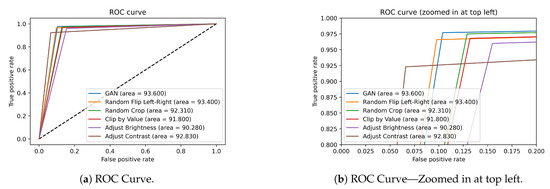
Evaluation of Deep Convolutional Generative Adversarial Networks for Data Augmentation of Chest X-ray Images
by
Sagar Kora Venu and Sridhar Ravula
Cited by 63 | Viewed by 10100
Abstract
Medical image datasets are usually imbalanced due to the high costs of obtaining the data and time-consuming annotations. Training a deep neural network model on such datasets to accurately classify the medical condition does not yield the desired results as they often over-fit
[...] Read more.
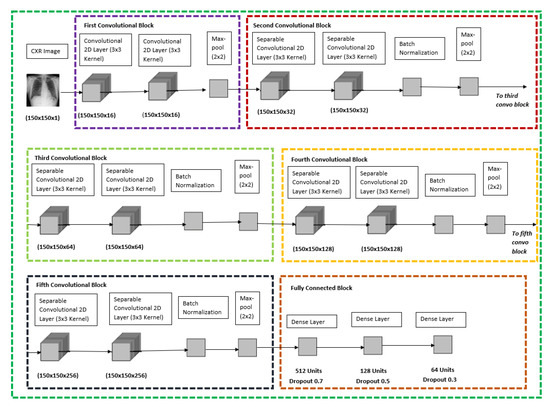
Medical image datasets are usually imbalanced due to the high costs of obtaining the data and time-consuming annotations. Training a deep neural network model on such datasets to accurately classify the medical condition does not yield the desired results as they often over-fit the majority class samples’ data. Data augmentation is often performed on the training data to address the issue by position augmentation techniques such as scaling, cropping, flipping, padding, rotation, translation, affine transformation, and color augmentation techniques such as brightness, contrast, saturation, and hue to increase the dataset sizes. Radiologists generally use chest X-rays for the diagnosis of pneumonia. Due to patient privacy concerns, access to such data is often protected. In this study, we performed data augmentation on the Chest X-ray dataset to generate artificial chest X-ray images of the under-represented class through generative modeling techniques such as the Deep Convolutional Generative Adversarial Network (DCGAN). With just 1341 chest X-ray images labeled as Normal, artificial samples were created by retaining similar characteristics to the original data with this technique. Evaluating the model resulted in a Fréchet Distance of Inception (FID) score of 1.289. We further show the superior performance of a CNN classifier trained on the DCGAN augmented dataset.
Full article
►▼
Show Figures
Open AccessArticle
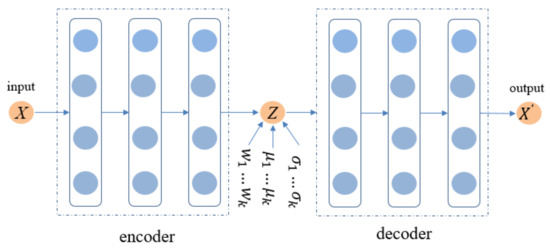
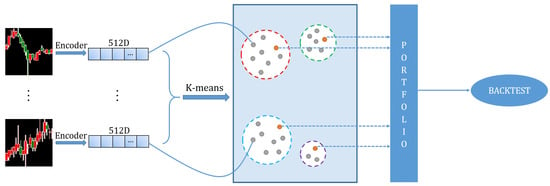
Portfolio Learning Based on Deep Learning
by
Wei Pan, Jide Li and Xiaoqiang Li
Cited by 7 | Viewed by 4209
Abstract
Traditional portfolio theory divides stocks into different categories using indicators such as industry, market value, and liquidity, and then selects representative stocks according to them. In this paper, we propose a novel portfolio learning approach based on deep learning and apply it to
[...] Read more.
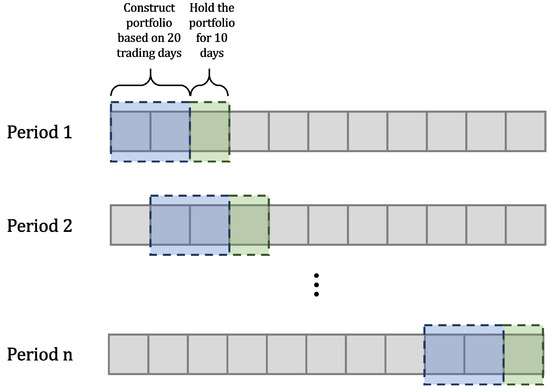
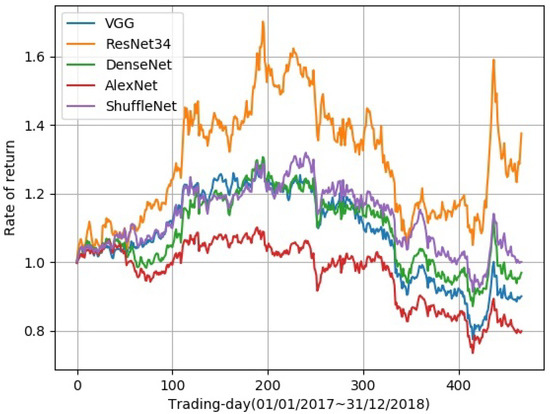
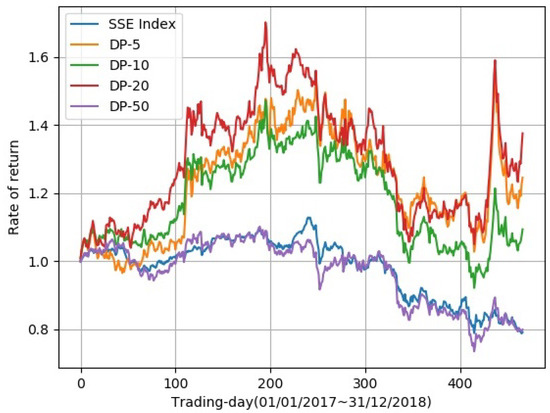
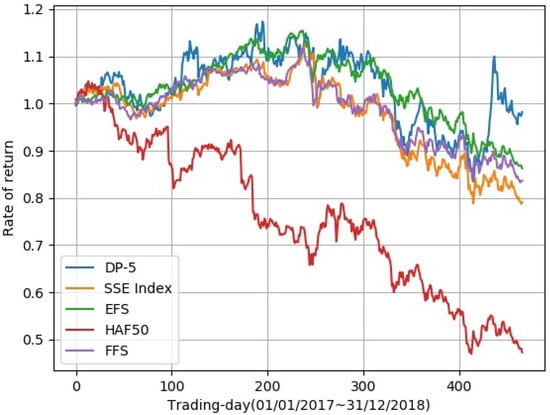
Traditional portfolio theory divides stocks into different categories using indicators such as industry, market value, and liquidity, and then selects representative stocks according to them. In this paper, we propose a novel portfolio learning approach based on deep learning and apply it to China’s stock market. Specifically, this method is based on the similarity of deep features extracted from candlestick charts. First, we obtained whole stock information from Tushare, a professional financial data interface. These raw time series data are then plotted into candlestick charts to make an image dataset for studying the stock market. Next, the method extracts high-dimensional features from candlestick charts through an autoencoder. After that, K-means is used to cluster these high-dimensional features. Finally, we choose one stock from each category according to the Sharpe ratio and a low-risk, high-return portfolio is obtained. Extensive experiments are conducted on stocks in the Chinese stock market for evaluation. The results demonstrate that the proposed portfolio outperforms the market’s leading funds and the Shanghai Stock Exchange Composite Index (SSE Index) in a number of metrics.
Full article
►▼
Show Figures
Open AccessArticle
Comparison of Machine Learning and Deep Learning Models for Network Intrusion Detection Systems
by
Niraj Thapa, Zhipeng Liu, Dukka B. KC, Balakrishna Gokaraju and Kaushik Roy
Cited by 100 | Viewed by 13070
Abstract
The development of robust anomaly-based network detection systems, which are preferred over static signal-based network intrusion, is vital for cybersecurity. The development of a flexible and dynamic security system is required to tackle the new attacks. Current intrusion detection systems (IDSs) suffer to
[...] Read more.
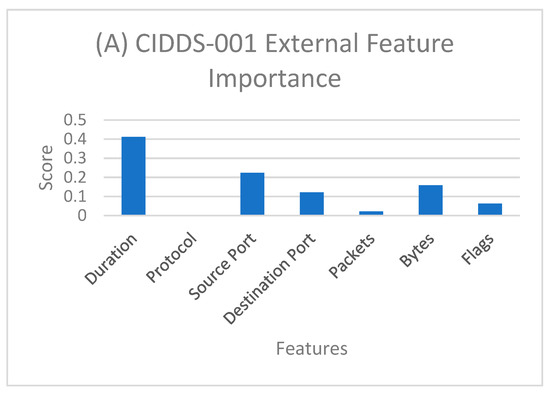
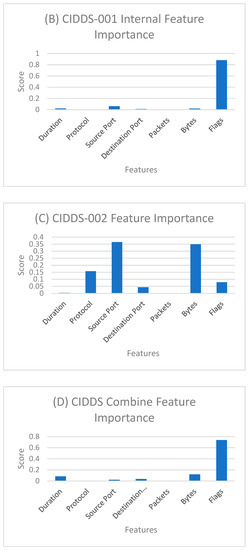
The development of robust anomaly-based network detection systems, which are preferred over static signal-based network intrusion, is vital for cybersecurity. The development of a flexible and dynamic security system is required to tackle the new attacks. Current intrusion detection systems (IDSs) suffer to attain both the high detection rate and low false alarm rate. To address this issue, in this paper, we propose an IDS using different machine learning (ML) and deep learning (DL) models. This paper presents a comparative analysis of different ML models and DL models on Coburg intrusion detection datasets (CIDDSs). First, we compare different ML- and DL-based models on the CIDDS dataset. Second, we propose an ensemble model that combines the best ML and DL models to achieve high-performance metrics. Finally, we benchmarked our best models with the CIC-IDS2017 dataset and compared them with state-of-the-art models. While the popular IDS datasets like KDD99 and NSL-KDD fail to represent the recent attacks and suffer from network biases, CIDDS, used in this research, encompasses labeled flow-based data in a simulated office environment with both updated attacks and normal usage. Furthermore, both accuracy and interpretability must be considered while implementing AI models. Both ML and DL models achieved an accuracy of 99% on the CIDDS dataset with a high detection rate, low false alarm rate, and relatively low training costs. Feature importance was also studied using the Classification and regression tree (CART) model. Our models performed well in 10-fold cross-validation and independent testing. CART and convolutional neural network (CNN) with embedding achieved slightly better performance on the CIC-IDS2017 dataset compared to previous models. Together, these results suggest that both ML and DL methods are robust and complementary techniques as an effective network intrusion detection system.
Full article
►▼
Show Figures






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}