


Forecasting 2026, 8(2), 28; https://doi.org/10.3390/forecast8020028 (registering DOI) - 25 Mar 2026
Abstract
Medium-term 5G/NB-IoT planning is made difficult by simultaneous uncertainty in device adoption and per-device traffic behavior because deterministic point forecasts do not quantify overload risk or support reliability-based capacity decisions. A diffusion-to-dimensioning workflow is proposed in which S-curve adoption modeling, bounded usage priors,
[...] Read more.
Medium-term 5G/NB-IoT planning is made difficult by simultaneous uncertainty in device adoption and per-device traffic behavior because deterministic point forecasts do not quantify overload risk or support reliability-based capacity decisions. A diffusion-to-dimensioning workflow is proposed in which S-curve adoption modeling, bounded usage priors, scenario stress testing, and Monte Carlo uncertainty propagation are combined to generate predictive demand distributions, exceedance curves, and quantile-based capacity rules. The framework is applied to a Great Britain case study for 2025–2029 using smart meter deployment data and an M2M-based proxy for asset-tracking adoption. Analysis shows that planning-year upper-tail outcomes are driven primarily by asset-tracking usage uncertainty rather than by proxy scale alone. A ±30% perturbation of the AT adoption anchor changes
(This article belongs to the Special Issue Feature Papers of Forecasting 2026)
►
Show Figures

Figure 1



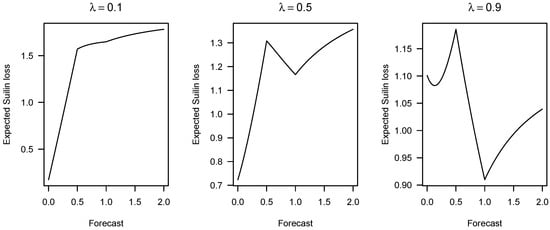
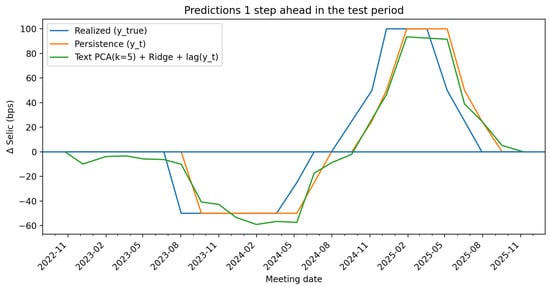



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}