1. Introduction
In the study and modeling of systems, differential equations can be obtained with parameters that depend on observations. That is, they are parameters that can vary throughout the domain of definition and for which experimental data are known. Differential equations can be either ordinary differential equations or partial differential equations. Problems modeled by this type of differential equations are, for example, (see [
1,
2,
3,
4,
5]): (a) the heat equation with unknown specific heat and heat sources; (b) the diffusion equation of products with non-constant and unknown innovation and imitation coefficients; (c) the study of hydraulic transients; and (d) water flows such as groundwater seepage in anisotropic media. In this sense, it is important to obtain hybrid-modeling methodologies that allow combining parameter estimation methods with algorithms of numerical resolution of differential equations.
When the dynamics of the processes underlying the system under study are known, differential equations can model their behavior, especially in the case of complex dynamic processes. In many cases, these differential equations contain constant parameters or functional dependencies with the independent variable that determine the characteristics of the corresponding solutions. The exact knowledge of its parameters is crucial for predicting the behavior of the solutions. Some concrete examples of the study of the problem considered in specific fields could be, for example, in biology and ecology [
6,
7,
8], chemistry [
9,
10], electronics [
11] and engineering [
12,
13].
The problem of determining the constant coefficients present in a differential equation from the study of the solutions of the system has been the subject of different studies, presenting a variety of methods of resolution. First approaches were based on least squares techniques. However, due to the absence of an analytical solution, the need to solve the ODEs numerically makes this approach computationally expensive. An alternative is the generalized profiling estimation method, where the solution is approximated using a linear combination of basis functions and adjusting the coefficients of the corresponding expansion equation by comparing them with the differential equation (see [
14,
15]). This method is applied even in the case in which the model is stochastic [
16]. A study on the properties of this type of algorithm can be found in [
17]. Other investigations are based on the use of non-deterministic methods (for example genetic algorithms [
18], particle swarm optimization [
10]) or Machine Learning (ML) techniques. Some studies focus on methods applicable to specific types of equations. For example [
19], where the problem corresponds to a differential equation associated with the time evolution of a system, and is solved by making a large number of observations of the evolution of the system over short intervals.
However, the application of the techniques discussed in real problems presents a series of difficulties due to the characteristics of the numerical data available in such cases, as discussed in [
20]. In addition, the presence of outliers makes it necessary to design and use robust algorithms, see, for example, [
21]. There are also some considerations that complicate the efficient use of some of the methods. For example, in stiff problems, the presence of nonlinearity in the solution space [
10] or high dimensionality of the parameters space, in partial differential equations (PDE) [
12].
The approach taken in the present investigation is in a certain way the inverse of that of the cases previously considered. It is proposed to obtain a solution of the differential equations by previously determining the values of the parameters that best fit the observations made. However, the approach used in [
10] has a certain similarity in its first stages to the one presented in this paper.
When the function to model corresponds to a spatial-distributed variable, kriging is usually used as the best linear estimator of the function from a set of random measurements. This can be found in the work of [
22,
23] for the calculation of unknown coefficients in linear PDE [
24,
25].
The proposal presented in this research work performs a modeling of the parameters of the differential equation in the case of functional dependence, by means of a local regression method based on the finite element method. Therefore, a brief introduction to the modeling methods will be given below.
The number of techniques available to model a relationship between variables is large. Selecting one or another depends on a variety of factors, from the data itself to the knowledge of the underlying equation involving the variables. The toolbox goes from classical statistical methods as linear or multilinear regression to machine-learning oriented methods as neural networks and related techniques, random trees, support vector regression and others.
The problem under consideration consists of obtaining a model of the relationship between a set of variables that is assumed to be determined by a function
All the considered methods start from an experimental dataset
of
P tuples sampled from the relation (1):
where, for every
is verified
.
The literature developing the different methods can be easily accessed and they are widely applied to a variety of problems. From these data, each methodology allows us to obtain estimates of the values of
at each point of
using an algorithm:
where
represents a set of parameters specific to each methodology and which determines the output value of the model. These estimated values will be denoted by:
The methods for numeric model estimation are usually stated as a minimization problem over some kind of global error
obtained as a function
of individual errors
defined over the sampled and estimated values:
with
.
Thus considered, the function H allows the approach of an optimization problem (see Equation (6)). Then, the optimal values
that minimize the value of H for the available dataset are sought.
These optimum parameters define the final model
as:
The present work follows the previous line of research developed by the authors with methodologies based on the finite elements method (FEM), a method for finding numerical solutions to differential equations with boundary conditions, developed initially to be applied in civil and aeronautical engineering [
26,
27,
28,
29,
30,
31].
In the following, in order to simplify notation, the criterion of writing the d-dimension points as a single variable will be used. Let us consider a given differential equation defined by a differential operator
, acting on a domain
:
where
,
being a function space defined over
.
The finite element method replaces the domain
of
by a collection of
closed sets
called elements, that verify:
where
is the frontier of the closed
.
This process is called meshing and it is usually done using sets of specific geometries, for example, in two dimensional triangles or rectangles. The generated mesh has an associated number that is related to the size of the elements. This parameter is usually denoted by
and relates to the order of the error in the interpolations that will be defined in the next paragraph:
where
is the open ball centred in
with radius
.
Meshing on a domain also defines a set of
Q points called nodes
that are used as support for the interpolation of any function defined on
through a related set of functions called shape functions
verifying the following conditions at the nodes:
for every
.
The linear span defined from the set of functions
forms a finite dimensional subspace which is composed by continuous piecewise polynomial functions of degree K (Sobolev space). This vector space is associated with a given division of the domain where the problem is set in and it will be denoted by
. That is:
On the space , a derivative operator that generalizes the usual derivative to the functions of that are not derivable at all points of can be defined.
The original problem can now be posed by searching the function
:
that best approximates the equation:
where
is the function of
that corresponds with the interpolation of
defined in Equation (8).
The application of the FEM to the modelling of systems developed by the authors is based on the principle of projection through interpolation of any function
in the space
as:
where
.
The numerical regression model for the relation Equation (1) will consist of the determination of the values that minimize an error function defined in a similar way to that in Equation (5).
The authors have been developing regression techniques based on Equation (15) as a method of approximation [
32,
33,
34,
35]. The last proposal is given by the octahedric regression methodology that will be presented in the next section.
The rest of the paper is organized as follows:
Section 2 presents the basics of the modelling technique used in the proposed methodology, the octahedric regression and a study on the overfitting control and the computational algorithm.
Section 3 presents four application examples. The first three correspond to the static heat equation and the last one to the Bass equation. Finally,
Section 4 presents an analysis of the results obtained and a description of the computational characteristics of the methodology, together with a reflection on future lines of research.
2. Materials and Methods
The problem under consideration can be divided into two different phases: first, a model for the coefficients of the equation is determined. After this model has been obtained, it can be used to solve the differential equation using a typical numerical method, as those based on Runge–Kutta or multistep approaches.
In this section, we will proceed to the explanation of the modeling method to be used to estimate the coefficient functions at the nodes where the approximate numerical function is calculated. The following section presents the proposed solution to deal with the problem of overfitting, which is common to the techniques of modeling from experimental data. The last subsection develops the algorithm in the form of pseudocode, commenting on its main features.
2.1. Octahedric Regression
The problem of obtaining a model for the functional coefficients will be solved using the technique developed by the authors, called octahedric regression, and is presented in the research paper [
36]. This algorithm presents good properties with respect to the following points: easy detection and control of the overfitting problem, efficient parallelization based on its embarrassing parallelism and fast numerical estimation for out of sample points.
Octahedral regression is an evolution of the previous numerical methodologies developed by the authors and corresponds to the fastest and most efficient of them. The next paragraphs provide a brief presentation of the basis of this methodology.
The basis is the use of parameterized radial functions, defined in the following point.
Definition 1. A radial function is a functionthat accomplishes the conditions The next definition introduces the averaged value estimator for a function at any point. In the following points, it is assumed that a radial function is selected and that the conditions on the functions for the existence of the corresponding integrals are satisfied.
Definition 2. Given a function, the weighted average regressionofatis defined using the implicit definition:whereandare a function as presented in Definition 1.
In order to reduce the bias that may exist when calculating the previous weighted average, a set of points is introduced that will be used in the final estimation of the model.
Definition 3. Given a pointand a parameter(in the model is called pseudocomplexity), the octahedric support of sizearoundis the set ofpoints:whereare the vectors of the canonical basis of.
Definition 4. The octahedric regression model ofatis defined as the average of the weighted average regressionscalculated at the points of the octahedric support introduced in Definition 3. This estimated value will be denoted byand is given by: The following proposition shows the nature of the proposed estimator.
Proposition 1. The octahedric estimationofatis a correction of order two with respect to the weighted average regressionat the same point.
Demonstration. Developing the
functions in Equation (19) and
through the implicit definition given in Equation (17) in powers of
h, the first order term cancels and the following expression holds:
Equation (20) shows that octahedric regression is a correction of order to the weigthed average for central objective points. Consequently, when , both values tend to coincide , causing overfitting on the points of the sample with respect to the points nearest to . The way to study the existence and importance of this effect is through a second estimation called restricted model, where in the calculation of the model at a point, the corresponding values are removed from the sample in the case of being part of it. The results will be discussed in the next subsection.
When the problem is modelling a function from a discrete sample of size
P (see Equation (2)) of points and values of
, the integrals must be calculated using finite sums, so:
Then, the discrete version of Equation (17) is:
2.2. Control of Model Overfitting
From the result of Proposition 1, the trend to overfitting has been discussed. In this point, the question will be considered further.
Let us study the problem of estimating the value of an objective function
at the first point of the sample
, and suppose that the rest of the points on the sample are ordered depending on the distance to
. Taking Equation (21) at the support points
,
The term on brackets represents the relative weight of each sample point in the weighted average. Summing up the contributions on each support point, the result can be written as:
where
The value of
represents the weight of all the points in the estimation of the model calculated at
. At zero order in
h, Equation (27) is approximately:
By Equation (16), the fractions converge very fast to zero as the distance to grows, and the only contribution depends on the points that are at a distance similar to the nearest point, that is, when . The number of points involved is determined by the value of the parameter , and is a weighted mean of the q-nearest points. Therefore, the octahedric regression presented in the present paper corresponds to a mean of a simpler estimator calculated on the support of size h defined around . These simple estimators correspond to the weighted average of the -nearest neighbors. In the limit , are obtained from the nearest point. In the case of considering all the experimental points, the model is called full. In that case, when , the nearest to the support points will very frequently be , and then: , and according to Equation (20), , confirming the trend to overfitting.
The overfitting is caused by the incorporation of noise to the model. If the point that is being calculated is not included in the estimation, the points that are used to obtain the values of have a greater probability of presenting independent noise influence, diminishing the overfitting in that form. The new model calculated in this form is called restricted and corresponds to having a cross-validation for each experimental point where the test set is formed by itself.
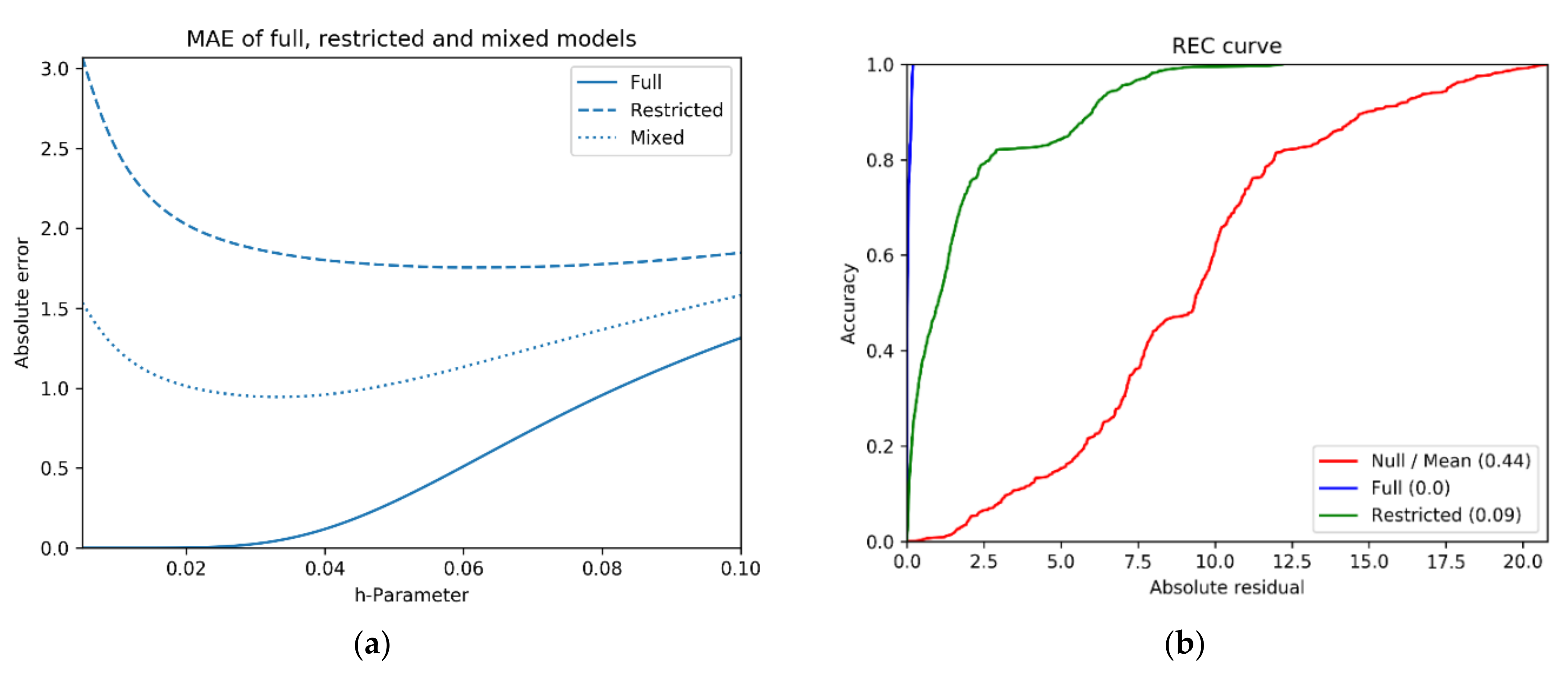
It has been commented previously that the methodology trends to overfitting when the size of the parameter h is small. Now, a real case of the application of octahedric regression will be shown in order to illustrate how this problem can be treated. Different statistical coefficients can be used to quantify the goodness of fit of a model. For example, the mean absolute error or REC curves. The example is a resume of the results presented in [
36]. The first step is to calculate the so-called full and restricted models for different values of the parameter
h.
As
Figure 1a shows, the mixed model, calculated as the average of the errors of the restricted and full models, presents a minimum that can be used to fix the best value of the parameter
h in the estimation process.
2.3. Computational Algorithm
The second step of the global algorithm corresponds with the numeric integration of the ordinary differential equation. As is well known, there is a variety of general algorithms and methods and, depending on the concrete ODE under study, some specific methodologies can be considered.
In the present research, the numerical method of integration used in the calculations corresponds to the predictor-corrector method based on the fourth-order multi-step Adams–Bashforth and Adams–Moulton algorithms. In these methods, it is necessary to calculate the unknown functional parameters at the nodes, so the regression model is used to estimate these values.
The exact form for the algorithm depends on the ODE under study. Algorithm 1 corresponds to the differential equation solved presented in
Section 3.1:
Following Equations (21)–(23), the algorithm can be condensed in the next schema (Algorithm 1), where Euler’s method has been used in the numerical solution of the equation:
| Algorithm 1. Sampled factors ODE numerical integrator |
| Input: |
: Number of intervals,
: Left interval extreme,
: Right interval extreme,
: Parameter of radial function,
: Sample of independent variable,
: Sample of alpha function,
: Sample of f function, |
| Output: |
: Coordinates of nodes,
: Estimated numerical function,
: Estimated numerical derivative |
| Procedure IntegratingODE |
|
|
| /* Modeling unknown functions at nodes*/ |
| for do |
|
|
| See Equation (21) |
| See Equation (22) |
| See Equation (22) |
| for do |
|
|
|
|
|
|
|
|
| See Equation (23) |
| See Equation (23) |
| /* Initial conditions */ |
|
|
|
|
| /* Calculating numerical solution (Euler’s method)*/ |
| for do |
|
|
|
|
|
return |
3. Results
To test the behavior of the proposed methodology, several examples are solved. First, two cases of the one-dimensional static inhomogeneous heat equation will be studied. Later, the Bass equation is analyzed to consider a different example.
Let us denote the solution to the differential equations on an interval by u(x).
For a given selection of standard deviation (
) and sample size (
P), the functional parameters are sampled and generate the corresponding numerical solutions for the equations. Denoting the set of samples by
and each individual sample by
, the solution can be represented as
. In the examples, 200 iterations with different samples of the characteristic functions of the equation are run. From this set of solutions, the following statistical indexes are considered:
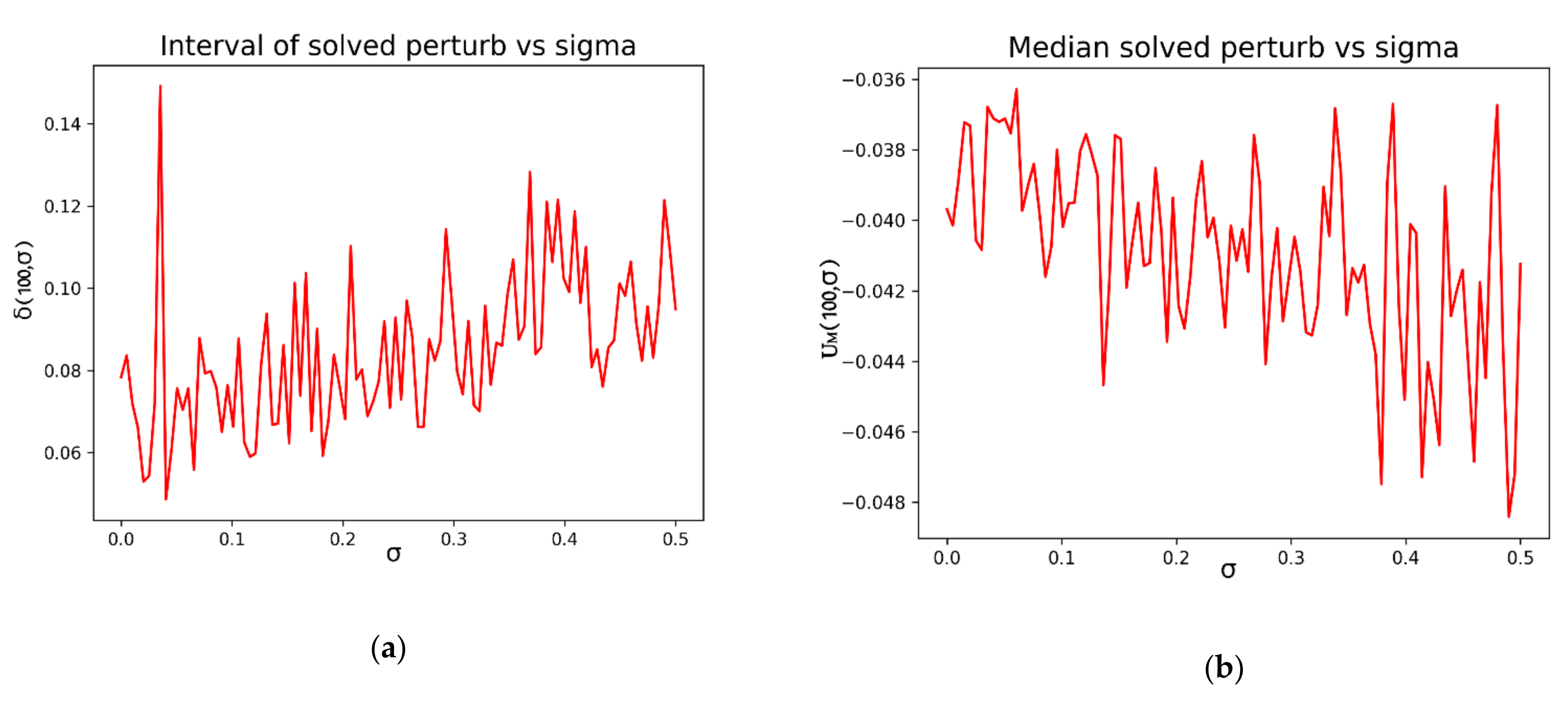
and represent the extreme values of the solutions at each point for a given sample size n and standard deviation . The amplitude of the difference shows the size of variations in the solutions related to a given value of P and .
These indexes can be greatly influenced by low frequent extreme values, so additional parameters must be considered. For example, in the case that the exact solution is known, something frequent when studying the behavior of the algorithm, the average (Equation (32)) and median (Equation (33)) of the error calculated over the samples can be a more convenient approach when studying the behavior of the solutions and their dependence on the magnitude of the perturbation.
The testing process followed these steps:
Selection of the different standard deviation values
for the perturbation (see next point) with which the study is to be carried out. The following steps should be performed once for each value of
in the above set and as many times as indicated by the number of iterations (see
Table 1,
Table 2,
Table 3 and
Table 4);
Generation of function samples from the uniform distribution
for the points coordinates and a random normal distribution for the perturbation
as follows:
where
represents the i-th functional parameter of the ODE under study and
is the corresponding sample. The size of each sample is specified in
Table 1,
Table 2,
Table 3 and
Table 4;
Once the number of intervals has been selected, the model is obtained at the +1 nodes obtained by dividing the interval into sub-intervals;
Numerical resolution of the equation using the values of the functional parameters at the nodes obtained in the previous step, by means of an ordinary ODE resolution method, in the present case predictor-corrector;
Calculation of statistical values , , and from the results obtained in each iteration and their use (in the form of tables or graphs).
3.1. Static Heat Equation for Inhomogeneous Media
The application is based on the one-dimensional case of the second order heat equation, given by:
In steady state, the dependence with time vanishes, obtaining the static heat equation in the form:
3.1.1. Example 1
The first example corresponds to the equation:
with
defined over the interval
and constrained by the initial conditions
and
.
The functions and are perturbed using a random variable following a normal distribution with average zero and standard deviation ranging from zero to 0.5. Different samples of these perturbed functions are considered with sizes between 5 and 100.
The equation is solved numerically using a predictor–corrector method (fourth order Adams–Bashforth and Adams–Moulton) in the interval using a step size of .
The analytical solution for the Equation (37) is , and is used to compare with the numerical solution .
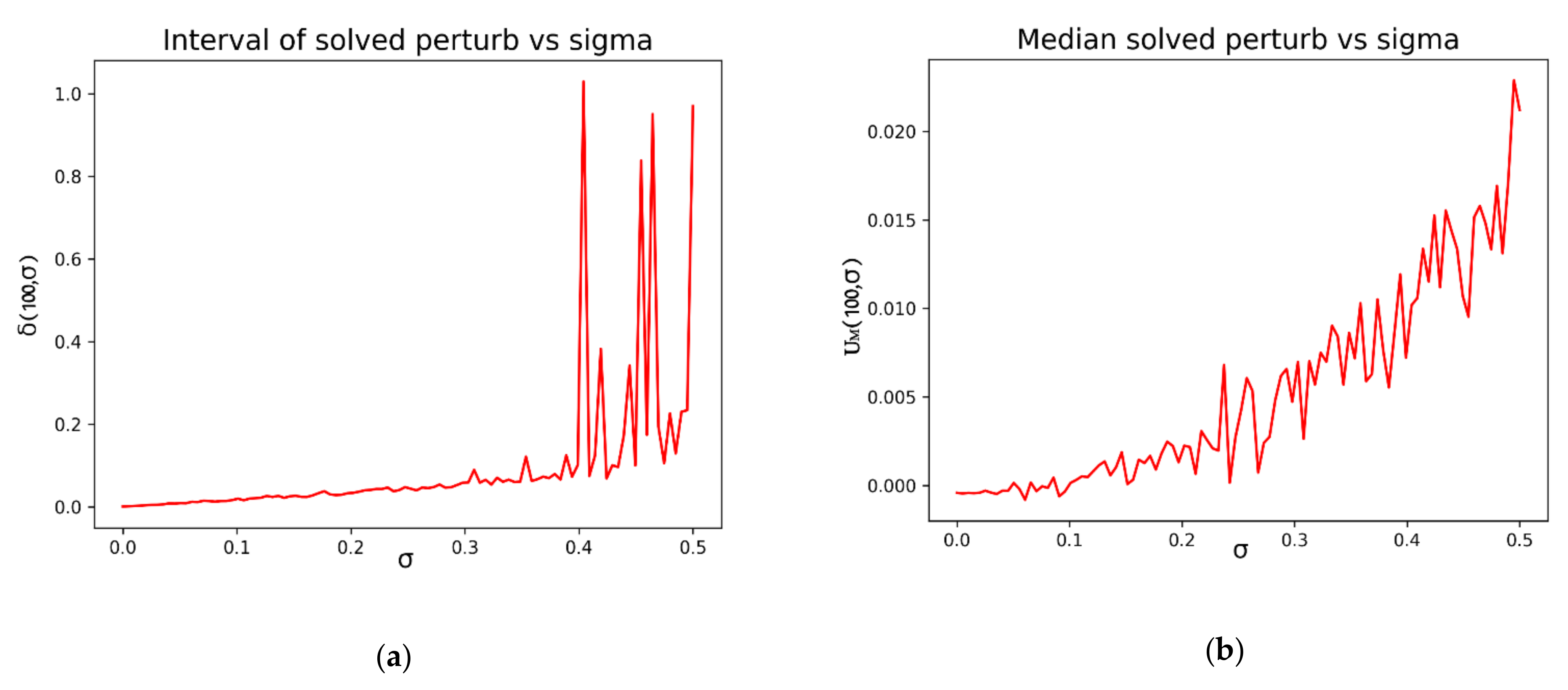
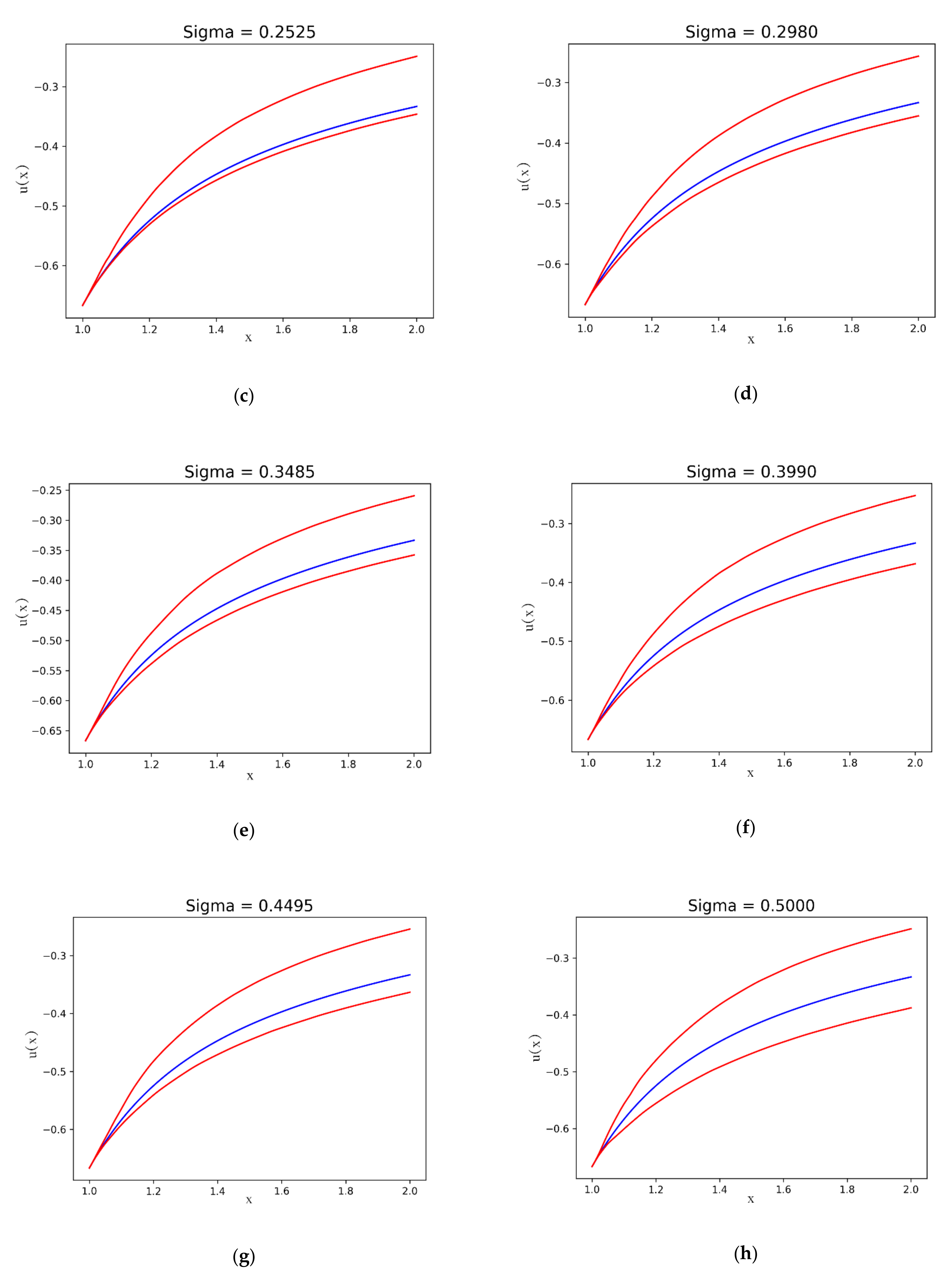
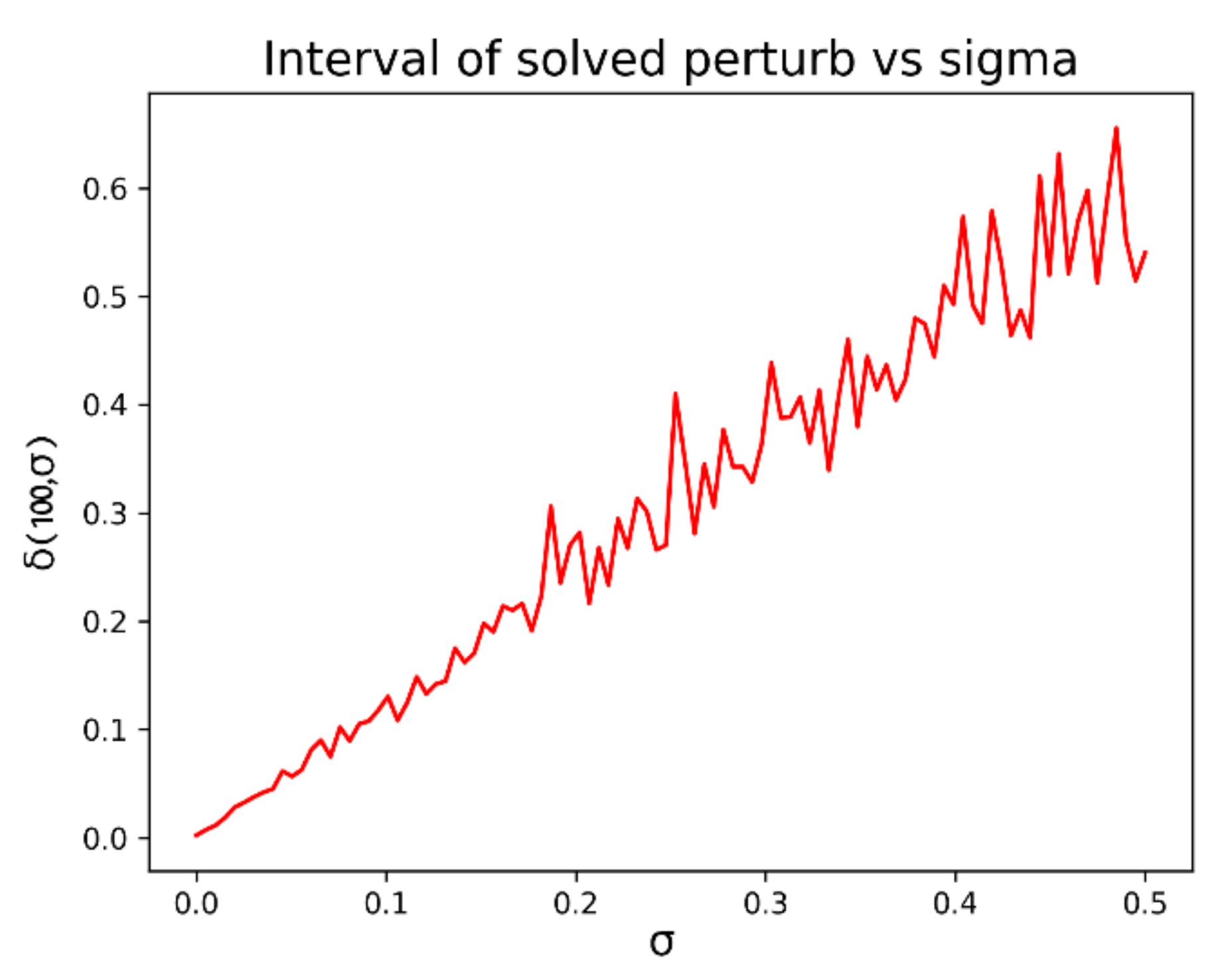
First, we can study the influence of the standard deviation parameter of the perturbation with respect to the differences between the extreme values
. It is also interesting to compare the evolution of
with respect to the standard deviation. Those results can be seen in
Figure 2a,b:
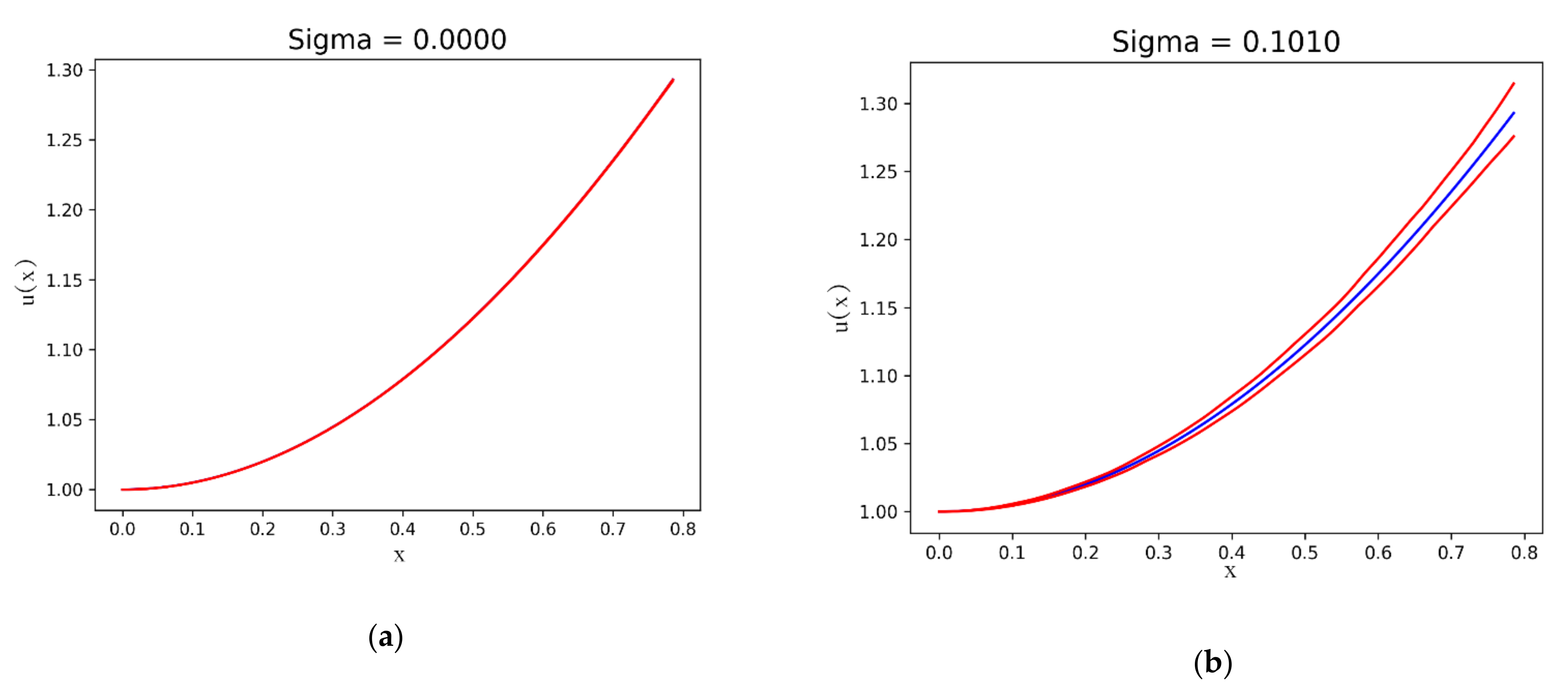
Figure 3 shows the exact
and the maximum
and minimum
of the numerical solutions at each point on for the iterations corresponding to different values of the standard deviation on the normal perturbation term:
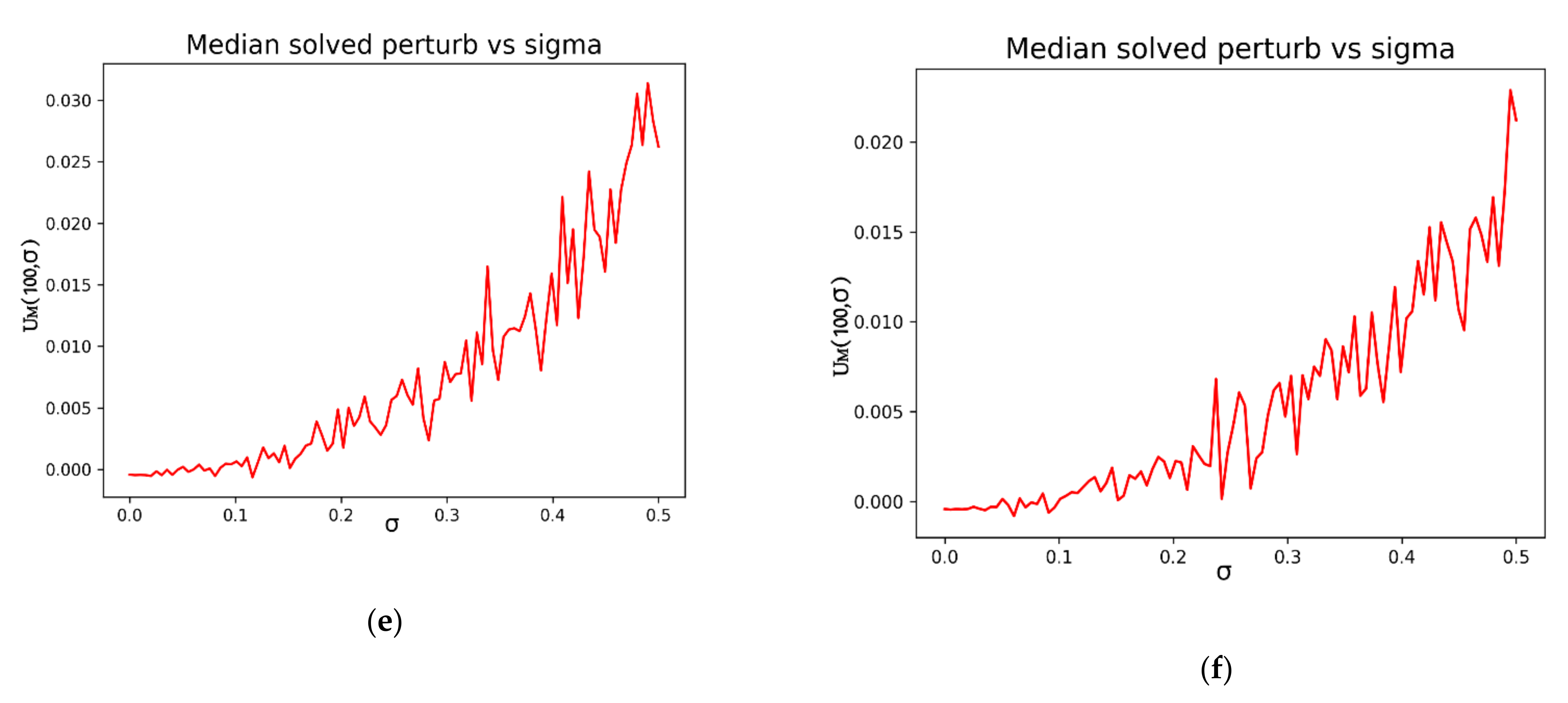
The dependence of the numerical solutions on the sample size can also be considered in order to study the algorithm efficiency.
Figure 4 shows the same information that has been presented in
Figure 2b for different sample sizes, from 5 to 100.
Table 1.
Model parameters for the Example 1.
Table 1.
Model parameters for the Example 1.
| Sample Size | Std. Dev. | Iterations |
|---|
| 100 | 0–0.5 | 200 |
| 5–100 1 | 0–0.5 | 200 |
In general, the behavior is as expected, obtaining better accuracies as the number of points in the sample increases. However, it can be seen in
Figure 4 how, for very small values of
P, the result does not present a completely determinate behavior.
3.1.2. Example 2a
Another case of Equation (36) is:
where:
The exact solution of this ODE can be obtained as:
where:
The next two examples will allow comparing the results corresponding to the solutions of the different members of the family of parametric functions .
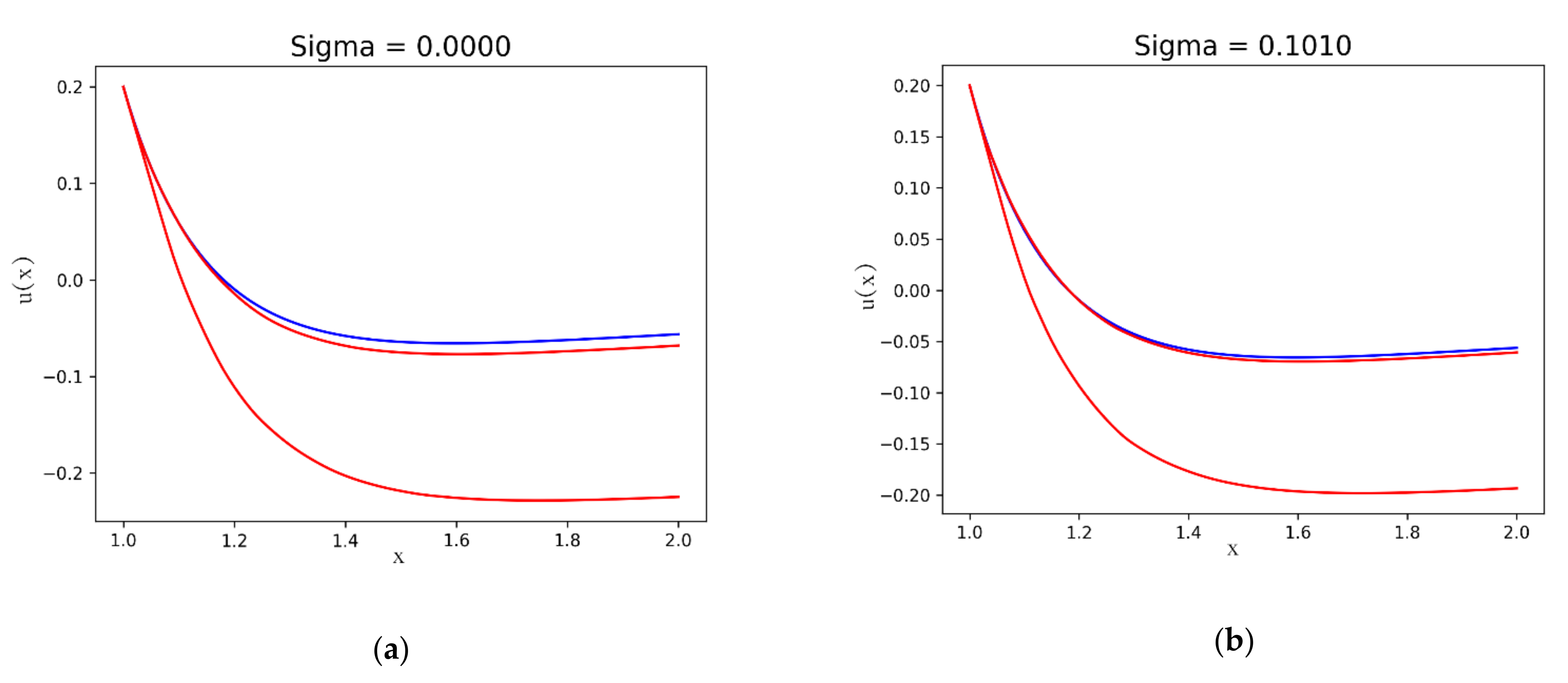
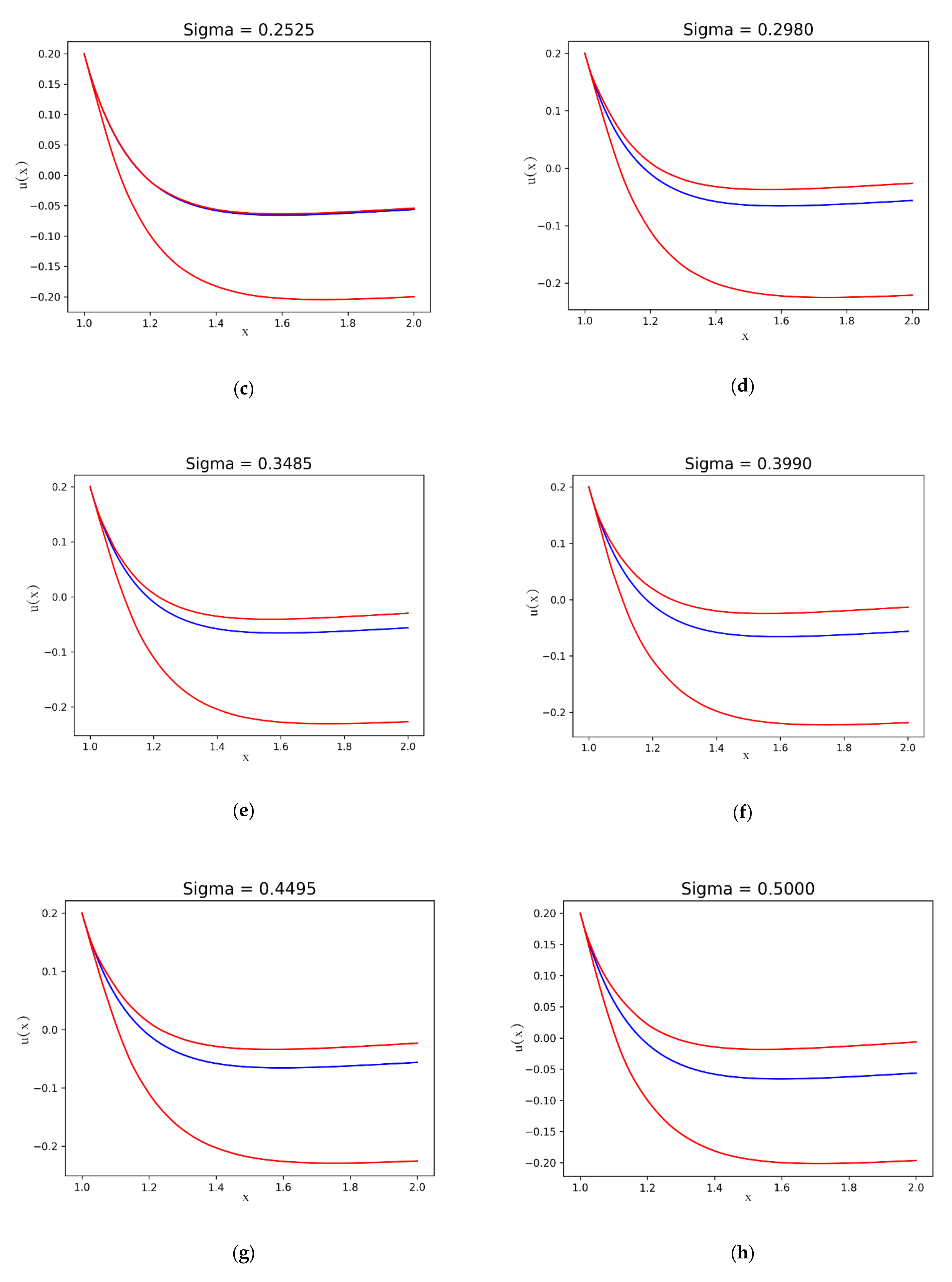
The first case corresponds with the values of the parameters given by and . Let us study the solution on the interval for the initial conditions and . The exact solution for the last equation is .
Table 2.
Model parameters for the Example 2a.
Table 2.
Model parameters for the Example 2a.
| Sample Size | Std. Dev. | Iterations |
|---|
| 100 | 0–0.5 | 200 |
Figure 5 shows the result for the equation given by
and
.
In
Figure 6 ,
and
are shown.
3.1.3. Example 2b
Example 2b corresponds to
and
on the interval
, with initial conditions
and
. In this case, the exact solution is given by the function
.
Figure 7 shows the difference
and the median
.
Figure 8 shows the exact and the maximum and minimum numerical solutions for the iterations corresponding to different values of the standard deviation on the normal perturbation term.
Figure 9 presents the effect of sample size on the solution error for sample sizes between 5 and 100 points.
Table 3.
Model parameters for theExample 2b.
Table 3.
Model parameters for theExample 2b.
| Sample Size | Std. Dev. | Iterations |
|---|
| 100 | 0–0.5 | 200 |
| 5–100 1 | 0–0.5 | 200 |
3.2. Bass Equation. Example 3
The third example is a variation of a normalized Bass equation [
37] with non-constant coefficients of innovation and imitation:
defined over an interval
with the initial condition given by
. Typical values for the constants in Equation (42), are
and
[
38]. In the studied example, two expressions are proposed. For the innovation coefficient:
and for the imitation coefficient:
Table 4.
Model parameters for the Example 3.
Table 4.
Model parameters for the Example 3.
| Sample Size | Std. Dev. | Iterations |
|---|
| 100 | 0–0.5 | 200 |
Figure 10 represents the parameters
calculated with 200 different samples of the normal perturbation depending on the values of
.
Figure 11 shows the difference between the exact and the maximum and minimum numerical solutions for the iterations corresponding to different values of the standard deviation on the normal perturbation term.
In order to facilitate the comparison between the different results,
Figure 12 shows together some of the curves represented in
Figure 11 for a different execution and function samples.
4. Discussion
In this research, the authors present a methodology for the modeling of differential equations and their resolution in systems where the functional expression of the functional parameters present in these equations is unknown and only an experimental sample of data is available. In the scientific literature, there are references to the determination of parameters of the differential equations governing a system by means of nonlinear regression on experimental data of the solution of the equation under study. Likewise, the field of study of differential equations for which the parameters follow a given distribution constitutes a fertile field of research.
The proposal developed focuses on considering equations whose parameters are unknown functions and whose values are deterministically determined, although affected by some type of error or perturbation. The algorithm allows obtaining numerical solutions for these equations by performing a previous numerical model of the functions involved from the experimental data.
Three different examples have been considered, two of them with known analytical solutions and another one considering only the numerical solution. From the study of the results obtained, it can be verified that the result of the algorithm shows behavior in accordance with what is expected with respect to the magnitude of the perturbation and the size of the experimental sample used to perform the modeling. On the other hand, the results show how the proposed methodology obtains solutions with a stable response to the corresponding perturbations.
From the present work, the main lines of future research would be two. On the one hand, the modification of the algorithm for the treatment of partial differential equations (PDE). On the other hand, it is worth investigating how to modify the design of the resolution algorithm to make it more computationally efficient. The way to do this would be to study how to combine the modeling algorithm with the resolution algorithm, minimizing the number of operations and the need for storage of the total program.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}