1. Introduction
Nowadays, for stochastic systems research, e.g., functioning at essentially nonstationary disturbances of complex structures, we need analytical modeling technologies for accurate analysis and synthesis. Methods of analysis and synthesis based on canonical expansions are very suitable for quick analytical modeling realizations using the first two probabilistic moments. Wavelet canonical expansions essentially increase the flexibility and accuracy of corresponding technologies.
It is known [
1,
2,
3] that canonical expansion (CE) of stochastic processes (StP) is widely used to solve problems of analysis, modeling and synthesis of linear nonstationary stochastic systems (StS). For StS with high availability, corresponding software tools based on CE were worked out in [
4,
5,
6,
7,
8]. In [
4], we gave a brief review of the known algorithmic and software tools. In [
5,
6], the issues of instrumental software for analytical modeling of nonstationary scalar and vector random functions by means of wavelet CE (WLCE) are considered. The parameters of WLCE are expressed in terms of the coefficients of the expansion of the covariance matrix of random function over two-dimensional Dobshy wavelets. Article [
7] continues the thematic cycle dedicated to analytical modeling of linear nonstationary StS based on wavelet and wavelet canonical expansions. The article describes wavelet algorithms for analytical modeling of mathematical expectation, a covariance matrix and a matrix of covariance functions, as well as wavelet algorithms for spectral and correlation-analytical express modeling.
The article [
8] continues the thematic cycle devoted to software tools for analytical modeling of linear with parametric interference (Gaussian and non-Gaussian) StS based on nonlinear correlation theory (the method of normal approximation and the method of canonical expansions). Analytical methods are based on orthogonal decomposition of covariance matrix elements using a two–dimensional Dobshy wavelet with a compact carrier and Galerkin–Petrov wavelet methods.
In [
5], for an essentially nonstationary StP wavelet, CE (WLCE) was proposed. Nowadays, deterministic wavelet methods are intensively applied to the problems of numerical analysis and modeling. A broad class of numerical methods based on Haar wavelets achieved great success [
9]. These methods are simple in the sense of versatility and flexibility and possess less computational cost for accuracy analysis problems. The theory and practice of wavelets has attained its modern growth due to mathematical analysis of the wavelet in [
10,
11,
12]. The concept of multiresolution analysis was given in [
13]. In [
14,
15] method to construct wavelets with compact support and scaling function was developed. Among the wavelet families, which are described by an analytical expression, the Haar wavelets deserve special attention. Haar wavelets, in combination with the Galerkin method, are very effective and popular for solving different classes of deterministic equations [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. The application of a wavelet for CE of StP and stochastic differential and integrodifferential equations was given in [
7,
8,
26].
In [
27,
28], design problems for linear mean square (MS) optimal filters are considered on the basis of WLCE. Explicit formulae for calculating the MS optimal estimate of the signal and the MS optimal estimate of the quality of the constructed linear MS optimal operator are derived. Articles [
29,
30] are devoted to the synthesis of wavelets in accordance with complex statistical criteria (CsC). The basic definitions of CsC and approaches are given. Methodological support is based on Haar wavelets. The main wavelet equations, algorithms, software tools and examples are given. Some particular aspects of the StS wavelet synthesis under nonstationary (for example, shock) perturbations are presented in [
31].
The developed wavelet algorithms have a fairly high degree of versatility and can be used in various applied fields of science. Such complex StS describes organizations–technical–economical systems functioning in the presence of internal and external noises and stochastic factors. The developed wavelet algorithms are used for data analysis and information processing in high-availability stochastic systems, in complex data storage systems, model building and calibration.
Let us state the general problem of the Bayes synthesis of linear nonstationary normal observable StS (OStS) by WLCE means. Special attention will be paid to the synthesis of linear optimal system for criterion of the maximum probability that the signal will not exceed a particular value in absolute magnitude. For example, the results of computer experiments are presented and discussed.
2. Bayes Criteria
In practice [
1,
2], the choice of criterion for comparing alternative systems for the same purpose, like any question regarding the choice of criteria, is largely a matter of common sense, which can often be approached from consideration of operating conditions and purpose of any particular system.
The criterion of the maximum probability that the signal will not exceed a particular value in absolute magnitude can be represented as
If we take the function
as the characteristic function of the corresponding set of values of the error, the following formula is valid:
In applications connected with damage accumulation (1) needs to be employed with function
in the form:
Thus, we get the following general principle for estimating the quality of a system and selecting the criterion of optimality. The quality of the solution of the problem in each actual case is estimated by a function
, the value of which is determined by the actual realizations of the signal
and its estimator
. It is expedient to call this the loss function. The quality of the solution of the problem on average for a given realization of the signal
with all possible realizations of the estimator
corresponding to particular realization of the signal
is estimated by the conditional mathematical expectation of the loss function for the given realization of the signal:
This quantity is called conditional risk. The conditional risk depends on the operator
for the estimator
and on the realization of signal
. Finally, the average quality of the solution for all possible realization of
and its estimator
is characterized by the mathematical expectation of the conditional risk
This quantity is called the mean risk.
All criteria of minimum risk which correspond to the possible loss functions or functionals which may contain undetermined parameters are known as Bayes’ criteria.
3. Basic formulae for Optimal Bayes Synthesis of Linear Systems
Let us consider scalar linear OStS with real StP
, which is the sum of the useful signal and the additive normal noise
:
The useful signal is the linear combination of given random parameters
. We need to get StP
in the following form:
Here, are known structural functions; are given random variables (RV) which do not depend on noises .
We state to construct an optimal system with operator
in cases when output StP:
based on observation StP
at time interval
, reproducing given output signal
for criteria (1) with maximal accuracy.
It is known [
1,
2,
3] that the solution of this problem through CE is based on two-stage procedures based on Formulae (4) and (5).
Vector CE
presents the linear combination of uncorrelated RV with deterministic coordinate functions:
According to [
1,
2] for
we have
Then, coordinate functions are calculated by the following formulae:
Here,
is a given set of deterministic functions satisfying biorthogonality conditions:
Let us consider RV
and its presentation
where
The sum of RV
, multiplied by
gives the CE of StP
To find the conditional mathematical expectation of the loss function for StP
, it is necessary to find the conditional probability density of output StP relatively on input StP
. According to (4), StP
depends upon the given random parameters
and random noise
. So, we get
The last formula shows that StP depends upon random parameters and the set of .
Let us introduce the vector of RV
. Conditional distribution of
relative StP
coincides with the set of RV
. Conditional density
is defined by the known formula:
Here, is a given apriority density of RV ; is a density of RV , relatively .
Taking into account that vector random noise is normal,
is the linear transform of vector
. We conclude that RV are not only correlated, but also independent. Joint density of
with zero mathematical exactions and variances
is expressed by formula
In (7), let us replace RV
with their realizations
; then,
is the linear function of RV
with known joint density. Expressing
by
and using Formula (21), we get:
where
.
After substituting Formula (22) into (20), we get the formula for a posteriori density
of
for input StP
:
This formula may be used after observation when realization is available.
A posteriori mathematical expectation of loss function
is called conditional risk, and is denoted as
:
In order to solve the stated problem, it is necessary to calculate the optimal output StP for every from condition of minimum of integral (11).
Let us consider this integral as a function of
at fixed values of parameters
and time
:
The value of parameter
when integral (27) reaches the minimum value defines the Bayes optimal operator for criterion (1). Changing
and
variables
and
with the corresponding RV
and
, we get the required optimal operator:
where
The quality of the optimal operator is estimated by the mean risk [
1,
2]
So, we get the following basic Formulae (23)–(31) necessary for wavelet canonical expansion method.
4. Wavelet Canonical Expansions Method
Let us construct an operator for an optimal linear system using the Haar wavelet CE method WLCE [
5,
6]:
where
are wavelets of level for is maximal resolution level defined by required accuracy of approximation for any function by finite linear combination of Haar wavelets, equal to .
Then, let us present a one-dimensional wavelet basis (32) as:
For construction of the Haar WLCE for vector
at
, we pass to new time variable
and assume
Additionally, for presentation of given covariance functions in the form of two-dimensional wavelet expansion, it is necessary to define the two-dimensional orthogonal basis through tensor composition of one-dimensional bases (32) when scaling is performed simultaneously for two variables
where
.
So, the two-dimensional wavelet expansion of given covariance functions takes the form
where
where
here
After transition to time variable
at
, expression (3) takes the form
According to [
3,
5], functions
may be expressed by functions:
Using notations:
we get the following formulae:
Here, RV
have zero mathematical expectations, and variances coordinate functions
and
are successively defined by the following formulae:
where
Parameters
are expressed by coefficients of two-dimensional wavelet expressions of covariance functions
,
, and
The other .
Auxiliary functions
,
are expressed by basic wavelet functions (38) and coefficients of wavelet expansions of covariance functions
,
,
:
Considering (45), (46), we get
If functions
, then
and have wavelet expansions
Using notation (38) we get from (61), (62)
From (60), (62), (64), we have
Finally, using formulae
we get the required WLCE for StP
:
In basic Formulae (23)–(31), the parameters are expressed as follows:
Note that expression
depends on fixed values
of
.
So, the WLCE method is defined by Formulae (67)–(71) at conditions (61)–(65).
5. Synthesis of a Linear Optimal System for Criterion of the Maximum Probability That Signal Will Not Exceed a Particular Value in Absolute Magnitude
Conditional risk
in case (2) is equal from interval to probability of error exit
A priori density
of RV
is defined by formula
where
is the covariance matrix of
,
is
elements.
Let us find minimum of the integral
Integral (74) is propositional to the probability of the normal point
, and does not get into the subspace defined by inequality
. This probability has a minimum, if its mathematical expectation lies on line
. Normal density has maximum mathematical expectation. So, for definition of mathematical expectation, it is enough to equate partial derivatives in (74) to zero for
. The (74) minimization value
is equal to:
For solution of functions
it is necessary to solve the system of linear algebraic equations:
In matrix form, Equation (76) is as follows:
where
Using notations
we get the Bayes optimal operator in matrix form:
The Bayes optimal estimate of output StP is defined by
Equations (75)–(83) define the method of synthesis of a linear system for criterion of maximum probability that the signal will not exceed a particular value in absolute magnitude.
New results generalize the following particular results [
27,
28,
29,
30,
31] for different Bayes criteria in OStS:
- –
Mean square error;
- –
Complex statistical criteria;
- –
Criterion of maximum probability that the signal not exceed particular value in absolute magnitude.
6. Example
The designed software tools based on results of
Section 5 provide the possibility to compare mathematical models of different classes of linear OStS, its optimal instrumental potential accuracy in case of stochastic factors and noises.
Let us consider the extrapolator for a radar-location device described by the following equations:
Here, and are random calibration parameters for the calibration device, and X is the colored noise. For the criterion of the maximum probability that the signal will not exceed a particular value in absolute magnitude, we use algorithm (82).
Suppose that:
- –
The noise is normal ;
- –
Random parameters
are normal with joint density:
(
are elements of the inverse covariance matrix
);
- –
Input data:
,
, ,
,
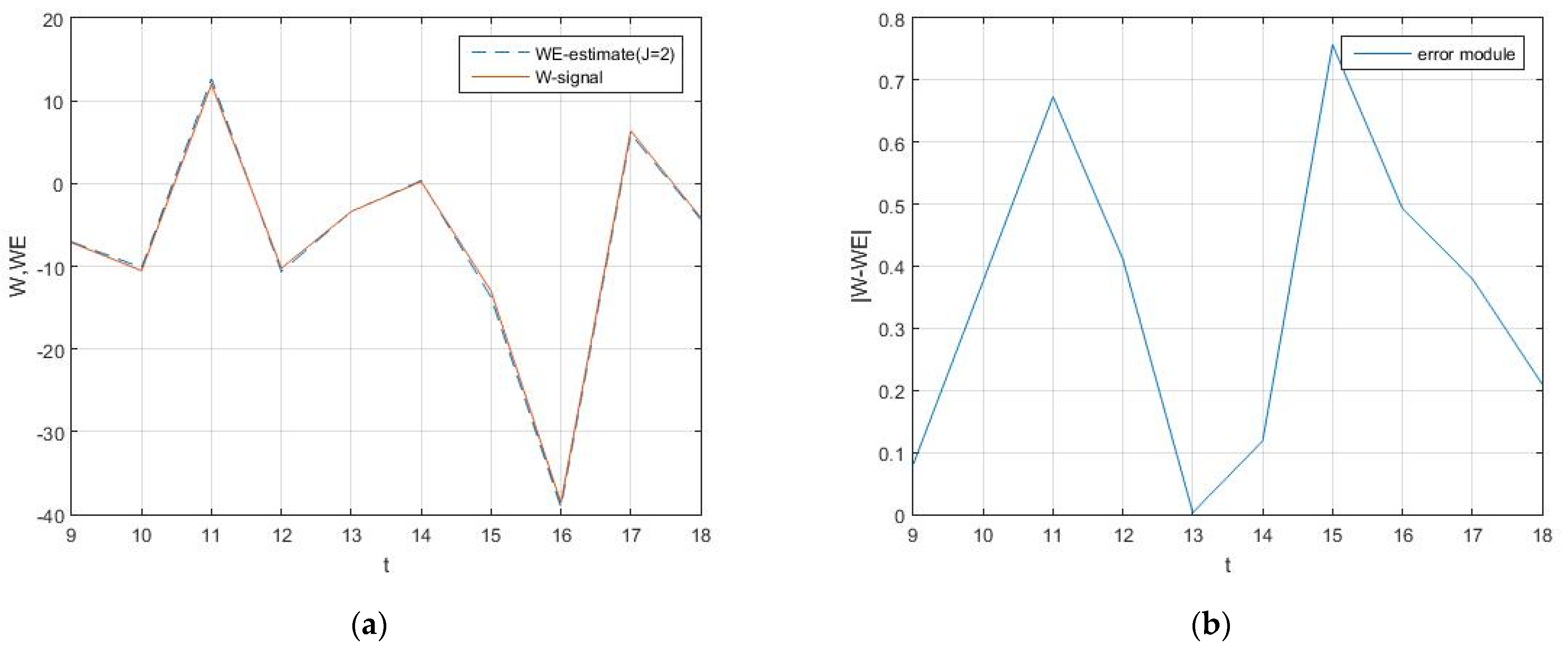
A typical realization method demonstrates high accuracy in
Figure 1. As practice for quick calibration of typical devices we use, algorithms more simple than (82) were developed, computed and compared. This information is necessary for passport documentation.
The extrapolator takes values from −38.6099 to 11.9854. At the same time, the extrapolator error modulus does not exceed 0.7568 (
Figure 1).
7. Conclusions
This article is devoted to problems with optimizing observable stochastic systems based on wavelet canonical expansions.
Section 2 is devoted to different Bayes criteria in terms of risk theory. Following [
1,
2], in
Section 3, basic formulae for optimal Bayes synthesis based on canonical expansions are given.
Section 4 is dedicated to the solution of a general optimization problem using wavelet canonical expansions in case of complex nonstationary linear systems. In
Section 5, a basic algorithm is given for the criterion of maximal probability that the signal will not exceed a particular value in absolute magnitude. An example of a radar-location extrapolator device is discussed.
The developed optimization methodology “quick probabilistic analytical numerical optimization” does not use statistical Monte Carlo methods.
Directions of future generalizations and implementations:
- –
New models of scalar and vector OStS (nonlinear, with parametric noises, etc.):
- –
New classes of the Bayes criteria.
The research was carried out using the infrastructure of the Shared Research Facilities “High Performance Computing and Big Data” (CKP “Informatics”) of FRC CSC RAS (Moscow).



{kind=link}