To comprehensively examine the impact of AI on the development of students’ critical and independent thinking, a complex methodology was employed, combining both quantitative and qualitative analytical approaches. The use of a mixed-methods design provided interpretive depth, enabling analysis of both objective indicators (such as cognitive skill levels) and subjective perceptions of AI technologies among students and instructors. This design facilitated verification of the results from multiple research perspectives, including pedagogical, psychological, and technological.
2.2. Participants
The study involved 28 instructors and 28 undergraduate and graduate students from three universities with pedagogical, technical, and humanities profiles.
Inclusion and exclusion criteria were applied equally to both the experimental and control groups to ensure comparability. The specific criteria used for group selection are summarized in
Table 3. All participants, regardless of group assignment, were required to have at least one semester of systematic experience in higher education (either as instructors or as students), and to provide informed consent for participation in surveys and interviews.
All participants were invited to both the survey and interview components; interviewees were purposively selected from the survey sample to ensure balanced representation.
For the experimental group, both instructors and students were selected based on their direct involvement in AI-integrated coursework or teaching during the semester under study, as described in Section “Formation of Experimental and Control Groups”.
For the control group, participants were drawn from parallel courses of similar academic level and discipline in which AI was not systematically used, but which met the same general inclusion criteria.
This approach ensured that both groups were balanced in terms of academic discipline, level, and educational experience, isolating the use of AI as the principal differentiating variable.
Inclusion Criteria:
Systematic experience using AI in education for at least one academic semester;
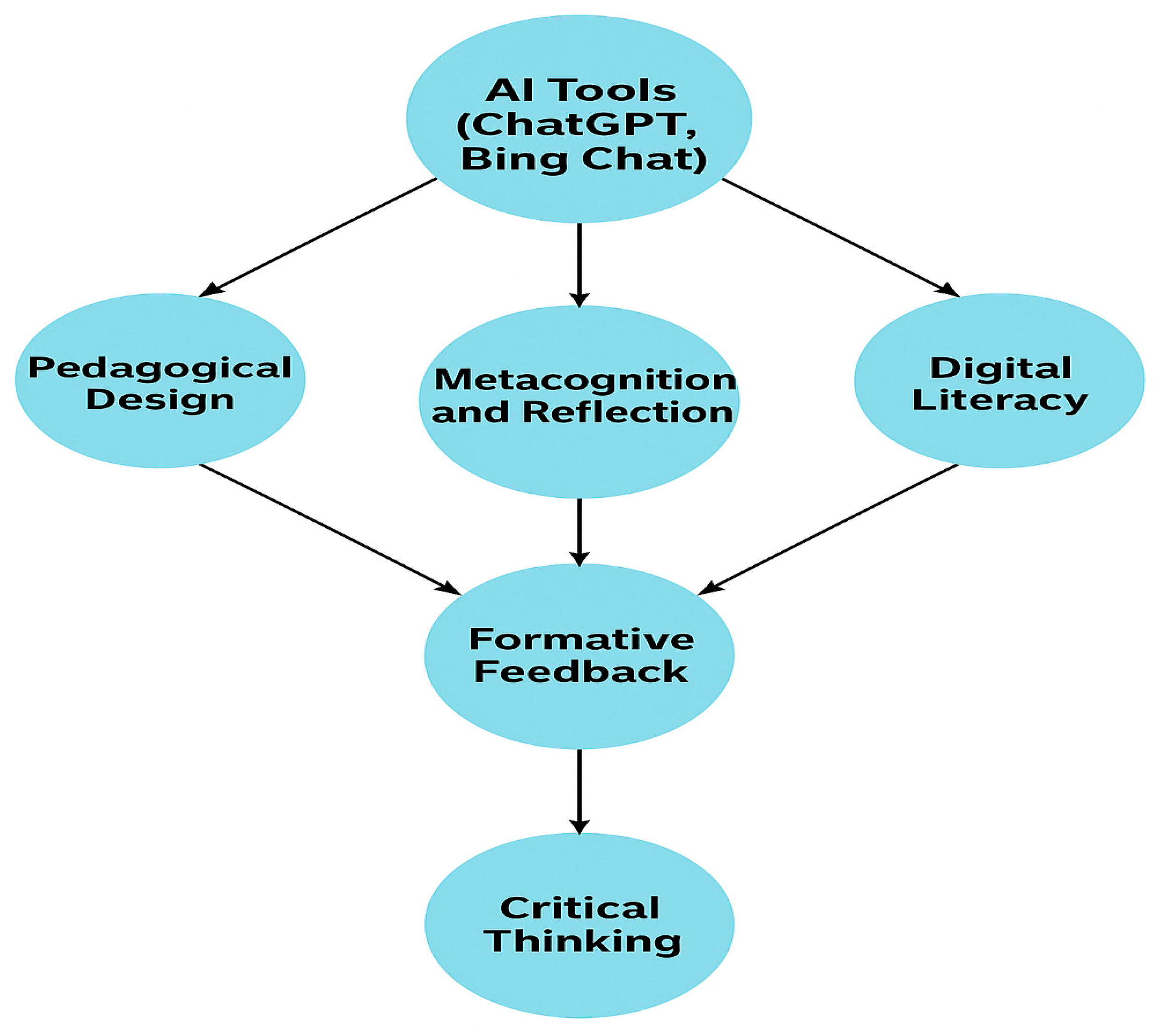
For instructors: integration of AI tools (e.g., ChatGPT, Bing Chat, Copilot, digital tutors, and adaptive platforms) into teaching, assessment, or student advising;
For students: participation in courses where AI was part of learning activities (e.g., text generation, data analysis, problem-solving, and project work);
Consent to participate in surveys, interviews, and anonymized data processing.
Exclusion Criteria:
AI use experience of less than one semester;
Passive use (e.g., incidental use of generative models not integrated into coursework);
Inability to complete interviews or surveys for technical, linguistic, or other reasons;
Refusal to provide evidence of AI engagement in courses (students) or integration in teaching (instructors).
Verification Procedure:
Initial screening: participants completed a pre-survey about AI tools used, purposes, frequency, assignment types, and integration methods;
Document verification: instructors submitted course syllabi with AI elements; students identified specific courses and instructors (verified independently);
Qualitative filtering: interview data were analyzed to verify context; inconsistent responses led to exclusion.
Rationale for Methodological Approach:
Purposive sampling was chosen to focus on participants with practical experience in educational AI use. Despite a small sample size, the rigorous inclusion criteria and multi-level verification ensured internal validity and data reliability.
2.4. Data Analysis Methods
The interview analysis was conducted in NVivo, encompassing initial coding, categorization, the creation of thematic matrices, and semantic visualization. Contextual variables such as academic discipline, teaching experience, and digital literacy were also considered.
The quantitative analysis was performed in SPSS, (Version 29.0) utilizing the following statistical procedures: Descriptive statistics (mean and standard deviation) were used to summarize the central tendency and variability of key variables (e.g., critical thinking scores;
Field, 2017). Independent samples t-tests were applied to determine whether there were statistically significant differences in mean scores between the experimental and control groups (
Field, 2017;
Cohen et al., 2018). One-way ANOVA was employed to verify group differences and assess variance among more than two groups or variables where applicable (
Field, 2017). Correlation analysis measured the strength and direction of relationships between variables such as AI use, metacognitive activity, and critical thinking levels (
Bryman, 2016). Factor analysis was applied to identify underlying constructs and validate the structure of survey instruments (
Tabachnick & Fidell, 2019). Levene’s test assessed the homogeneity of variances to confirm that parametric tests were appropriate (
Field, 2017). The Shapiro–Wilk test checked for normality of data distributions (
Field, 2017). Cronbach’s Alpha evaluated the internal consistency and reliability of multi-item scales (e.g., survey questionnaires;
Bryman & Bell, 2015). These methods were selected to ensure the robustness and validity of the statistical findings (
Field, 2017;
Cohen et al., 2018).
Operationalization of Composite Hypotheses
In accordance with best practices for methodological transparency and in response to reviewer feedback, each element of composite (multi-component) hypotheses—specifically those containing more than one conceptual construct (e.g., “instructor involvement and formative feedback”)—was operationalized, measured, and analyzed independently.
For Hypothesis 2 (“Instructor involvement and formative feedback when using AI positively correlate with students’ cognitive independence”), the following procedures were employed.
Instructor involvement was assessed through distinct qualitative interview prompts (e.g., descriptions of direct instructor engagement and individualized guidance in the context of AI-supported coursework) and dedicated items on the quantitative survey (e.g., “My instructor provided guidance on AI-related assignments”, rated on a Likert scale).
Formative feedback was evaluated separately using both qualitative questions about the perceived frequency and usefulness of feedback, and quantitative survey items (e.g., “I received timely formative feedback during AI-supported tasks”).
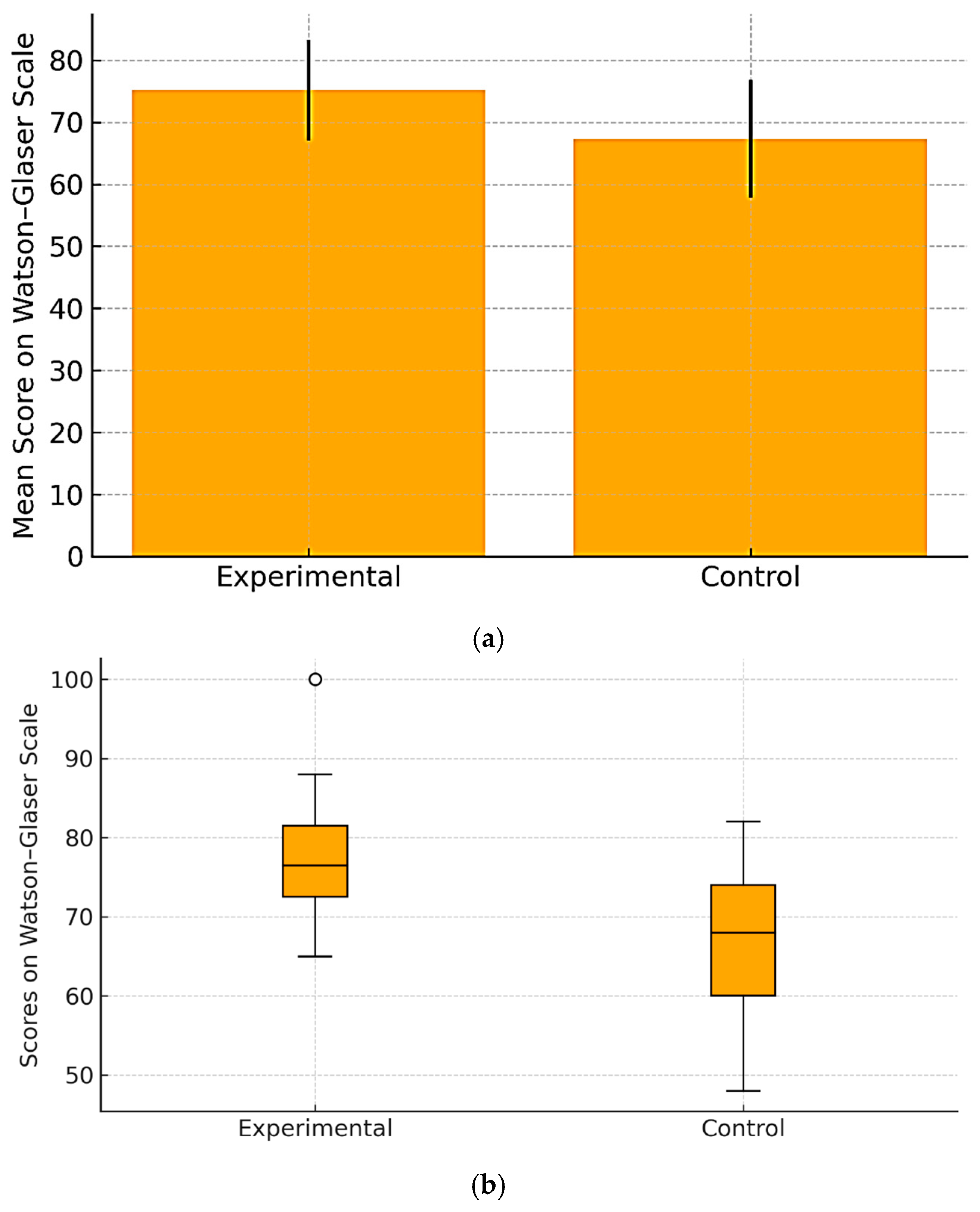
Cognitive independence was measured using the standardized Watson–Glaser Critical Thinking Appraisal and supplementary items assessing independent problem-solving, critique of AI outputs, and self-regulated learning behaviors.
Statistical analyses were conducted separately for each independent variable using correlation and regression models, with the combined effects of these components also explored through multivariate analysis.
Table 4 presents the measurement items and operational definitions, while
Table 5 summarizes the disaggregated statistical results for each component.
This approach was similarly applied to other composite hypotheses, ensuring analytical clarity and construct validity throughout this study.
Operationalization and Analysis for H3
For Hypothesis 3 (“Pedagogically meaningful integration of AI—including metacognitive tasks, reflective analysis, and instructor support—results in lower levels of algorithmic dependence among students”), each component was operationalized and measured independently.
Metacognitive tasks were examined through interviews (e.g., student examples of engaging in self-reflection assignments and reflective journaling) and survey items (e.g., “I regularly completed metacognitive/reflection tasks”).
The reflective analysis was assessed via qualitative questions regarding the depth of error analysis and learning reviews, and through quantitative items (e.g., “I analyzed my learning mistakes and adapted strategies accordingly”).
Instructor support was measured separately, similarly to H2, using both interviews and survey statements (e.g., “The instructor encouraged reflection on AI use”).
Algorithmic dependence was assessed using dedicated scales and custom items reflecting passive reliance on AI-generated answers, decreased autonomy, and tendencies toward intellectual inertia.
Separate and combined statistical analyses were performed using correlation and regression.
Table 6 details the operationalization, while
Table 7 summarizes the results.
Operationalization and Analysis for H4
For Hypothesis 4 (“Students’ digital literacy and ability to critically evaluate information moderate the effectiveness of AI in supporting cognitive skill development”), the following variables were separately measured.
Digital literacy was assessed using standardized digital competence scales (e.g., self-assessment, digital skills tests, and cybersecurity questions).
Critical evaluation skills were analyzed through interviews (examples of verifying, analyzing, and critiquing information obtained via AI) and survey items (e.g., “I critically assess information from AI sources”).
Cognitive skill development was measured using pre- and post-intervention scores on the Watson–Glaser scale and other cognitive development indicators.
The analysis included correlations, moderation analysis, and hierarchical regression, with the moderating role of digital and critical competencies examined in detail.
Table 8 and
Table 9 provide operational definitions and statistical results.
2.8. Study Limitations
Despite the rigorous design and use of mixed methods, this study possesses several substantial limitations that must be acknowledged.
First, the relatively small sample size (n = 56) substantially limits the generalizability and external validity of the results (
Cohen et al., 2018;
Field, 2017;
Creswell & Creswell, 2017;
Mertens, 2020;
Punch, 2014). Even with purposive sampling and strict participant verification, the final sample size cannot be considered fully representative of broader educational populations (
Bryman, 2016;
Kelley et al., 2003). The scholarly literature emphasizes that small samples are particularly susceptible to statistical errors, random variation, and the influence of hidden variables (
Maxwell, 2004;
Tabachnick & Fidell, 2019).
Additionally, although the study sample included both undergraduate and graduate students, the subgroup sizes were insufficient to permit robust statistical analysis of differences by academic level. As a result, we were unable to systematically assess whether the impact of AI-driven interventions varies between undergraduate and graduate cohorts. Future studies should address this limitation by ensuring adequate subgroup sizes and employing stratified or multifactorial statistical analysis.
Second, the institutional scope of this study (only three universities) may lead to a contextual specificity in the findings, complicating transferability to other educational contexts (
Shadish et al., 2002;
Hammersley, 2013;
Bortnikova, 2016;
Schwandt, 2015). Such organizational and geographic constraints increase the risk of contextual and cultural biases.
Fourth, the time frame (one semester) does not permit an assessment of the long-term sustainability of the observed effects or their impact on cognitive development (
Vinogradova, 2021;
Sharma, 2017;
Ruspini, 2016;
Menard, 2002). Only longitudinal studies spanning multiple academic years and diverse age cohorts can reveal the true dynamics of intellectual autonomy development (
McMillan & Schumacher, 2014).
Finally, it is important to note the possible impact of uncontrolled variables such as individual learning styles, varying levels of digital literacy, prior AI experience, and pedagogical strategies (
Luckin et al., 2016;
Holmes et al., 2021).
International research underscores that small and institutionally limited samples remain a typical but acknowledged barrier to producing universally generalizable results in educational research (
Bakker, 2018;
Henrich et al., 2010;
Blatchford & Edmonds, 2019). Thus, future research should prioritize large-scale, multi-site, and longitudinal projects employing randomization and representative sampling (
Floridi & Cowls, 2019).
To increase the reliability and external validity of results, researchers are encouraged to do the following:
Standardize inclusion criteria and ensure transparent participant verification (
Levitt et al., 2018);
The limitations of sample size, institutional specificity, research duration, and methodological choices warrant caution in the interpretation and extrapolation of results. Further studies with larger and more heterogeneous samples will be needed to confirm the stability and universality of the observed trends.





{kind=link}
{kind=link}
{kind=link}