Abstract
This paper reviews Artificial Intelligence techniques for distributed energy management, focusing on integrating machine learning, reinforcement learning, and multi-agent systems within IoT-Edge-Cloud architectures. As energy infrastructures become increasingly decentralized and heterogeneous, AI must operate under strict latency, privacy, and resource constraints while remaining transparent and auditable. The study examines predictive models ranging from statistical time series approaches to machine learning regressors and deep neural architectures, assessing their suitability for embedded deployment and federated learning. Optimization methods—including heuristic strategies, metaheuristics, model predictive control, and reinforcement learning—are analyzed in terms of computational feasibility and real-time responsiveness. Explainability is treated as a fundamental requirement, supported by model-agnostic techniques that enable trust, regulatory compliance, and interpretable coordination in multi-agent environments. The review synthesizes advances in MARL for decentralized control, communication protocols enabling interoperability, and hardware-aware design for low-power edge devices. Benchmarking guidelines and key performance indicators are introduced to evaluate accuracy, latency, robustness, and transparency across distributed deployments. Key challenges remain in stabilizing explanations for RL policies, balancing model complexity with latency budgets, and ensuring scalable, privacy-preserving learning under non-stationary conditions. The paper concludes by outlining a conceptual framework for explainable, distributed energy intelligence and identifying research opportunities to build resilient, transparent smart energy ecosystems.
1. Introduction
Artificial Intelligence (AI) has become a central enabler of modern energy management systems, particularly within smart grids, intelligent buildings, and IoT-Edge-Cloud infrastructures. The increasing availability of sensor data, together with the deployment of heterogeneous IoT devices and embedded controllers, has accelerated the use of Machine Learning (ML), Deep Learning (DL), Reinforcement Learning (RL), and Multi-Agent Systems (MAS) for forecasting, optimization, and autonomous control [1]. Distributed computation across edge platforms enables low-latency inference and real-time adaptation to rapidly changing operating conditions, making such architectures attractive for applications where responsiveness and resource efficiency are critical.
AI-driven controllers are being incorporated into Building Energy Management Systems (BEMSs) and microgrid operations. RL algorithms—ranging from tabular methods to advanced deep RL architectures—have demonstrated the capacity to learn optimal strategies for HVAC control, demand response, and renewable integration [2,3]. In parallel, MAS frameworks enable distributed coordination, allowing autonomous agents to negotiate actions related to consumption, generation, and storage under uncertainty and heterogeneous objectives [4]. These decentralized approaches are particularly beneficial in bandwidth-limited IoT environments, where centralized control may hinder scalability.
However, the rapid scalability of these technologies faces a critical barrier: the increasing complexity and opacity of Artificial Intelligence models. While Deep Learning and Reinforcement Learning (RL) offer superior performance in handling non-linear energy patterns, they often function as “black boxes,” making their internal logic inaccessible to human operators [5]. This lack of transparency is a major bottleneck for deployment in critical energy infrastructure, where accountability, safety, and regulatory governance are paramount [6]. Stakeholders and grid operators are often reluctant to trust automated decisions—such as load shedding or battery dispatch—if the underlying reasoning cannot be audited or explained [7]. Consequently, Explainable AI (XAI) has transitioned from a theoretical preference to an operational necessity, essential for ensuring compliance and fostering trust in automated decision-making [8].
Furthermore, the centralization of these AI models creates significant technical inefficiencies. As the number of IoT devices increases, transmitting raw high-frequency telemetry to a central cloud induces latency bottlenecks and network congestion that jeopardize real-time stability [9]. Traditional centralized optimization methods struggle to handle the computational overhead and communication delays inherent in large-scale, geographically dispersed grids [10,11]. Therefore, shifting intelligence to the Edge is not merely an architectural choice but a requirement to maintain responsiveness and data privacy [12]. Despite this, existing surveys typically focus on individual aspects such as prediction models, optimization strategies, or explainability in isolation, without providing an integrated perspective on how XAI must operate within the resource constraints of distributed IoT-Edge-Cloud architectures.
In response to these open challenges, this paper provides a comprehensive state of the art review of AI and MAS methods for energy prediction and optimization across IoT-Edge-Cloud environments, together with an analysis of explainability techniques relevant to these domains. The contributions of this work are fourfold: (i) a structured synthesis of statistical, ML, DL, heuristic, and RL approaches for energy forecasting and optimization; (ii) an examination of MAS methodologies for distributed decision-making in buildings, microgrids, and smart energy networks; (iii) an analysis of explainability methods applicable to forecasting and real-time control; and (iv) the proposal of a conceptual framework integrating AI, MAS, XAI, and distributed architectures to support scalable, interpretable, and resource-efficient energy management. The review also identifies key research gaps and outlines future directions, including federated learning approaches, resilient RL policies, and techniques for achieving end-to-end explainability in distributed settings.
The remainder of this article is structured to guide the reader progressively from foundational concepts to advanced methodological considerations. Section 2 outlines the fundamental principles underlying distributed energy systems, multi-agent coordination mechanisms, explainable AI methods, and the enabling IoT-Edge-Cloud infrastructures that support modern energy analytics. Building on this foundation, Section 3 examines the state of the art in energy forecasting, optimization and control, MAS-based decision-making, and the datasets and evaluation metrics commonly employed in the literature. Section 4 then presents the proposed explainable and distributed framework, articulating its design objectives, architectural components, and integration strategy. Section 5 offers a broader discussion of the trade-offs, practical limitations, and open research challenges that emerge from current developments. Finally, Section 6 summarizes the key insights of the study and highlights promising directions for future research.
2. Fundamentals and Context
This section provides the theoretical background necessary to understand the architectural, computational and methodological foundations of modern energy management systems. It introduces the evolution from centralized to distributed paradigms, the role of multi-agent systems, communication technologies, and the increasing relevance of Edge AI infrastructures.
2.1. Evolution from Centralized to Distributed Architectures
The transition from traditional centralized EMS/BMS deployments toward distributed and hierarchical IoT-Edge-Cloud architectures is driven by the need for scalability, resilience, and reduced latency in modern energy systems. This subsection examines the characteristics, advantages, and limitations of each paradigm.
2.1.1. Centralized EMS/BMS Systems
Centralized Energy Management Systems (EMS) and Building Management Systems (BMS) have historically used a clear hierarchy. In these systems, one coordinator gathers data from many nodes, processes it, and sends out commands to optimize energy use. Access to network-wide information enables these systems to maintain an overview and coordinate actions, thereby improving efficiency [13]. Placing all computational resources in a central location also allows complex optimization without the limits of distributed hardware. While these traits shaped early energy management, new challenges have emerged as systems have grown more complex.
However, several technical and operational drawbacks have become evident as infrastructures scale. As the number of controlled devices or subsystems increases, processing demands at the central controller scale sharply, often creating bottlenecks that hinder real-time responsiveness [14]. Continuous transmission of large volumes of sensor readings and operational metrics to a single hub introduces significant communication overhead. Any delay in data transfer or command dissemination subsequently propagates throughout the entire network [13]. Centralization also creates a single point of failure: if the primary controller fails or is subject to cyberattacks, the entire infrastructure may be disrupted. Privacy and security concerns further intensify this issue, as a centralized data repository becomes an attractive target for malicious actors. Mitigation strategies—redundancy, cybersecurity hardening, and backup infrastructures—add complexity without eliminating fundamental vulnerabilities [11].
Centralized EMS/BMS architectures work well where coordination is needed or where local autonomy risks creating resource conflicts. For instance, pre-computed load-balancing or charging schedules can be applied to all participants, which is useful for predictable demand or strict industrial rules [15]. However, as infrastructure adds a range of assets—such as renewables with variable output, storage with different charge-discharge cycles, and diverse loads—scalability issues become more apparent. This shift opens the door to distributed and hybrid models.
From an algorithmic standpoint, centralized control enables the use of advanced methods such as Deep Q-Networks (DQN), Proximal Policy Optimization (PPO), or hybrid schemes combining reinforcement learning with model predictive control, all of which rely on continuous access to a global state representation. While manageable in simplified contexts, maintaining an accurate global view becomes challenging in distributed environments with intermittent connectivity or rapidly changing dynamics. These challenges motivate the development of architectures that better accommodate decentralized information.
Electric vehicle (EV) charging networks highlight these issues. Centralized scheduling optimizes system metrics but struggles with local demand spikes, such as many arrivals at a single station. Scalability is challenged in citywide smart grids powered by renewables that vary over time. External factors—such as weather-driven solar changes or unpredictable human activity—can quickly render preset schedules ineffective [11]. Relying on distant computation slows responses, while local decision-making architectures respond faster, showing the need for new control approaches.
Hybrid models address these issues by allowing local agents to handle low-level decisions while a central controller manages strategy [15]. This setup reduces communication and maintains coordination. But as infrastructures integrate more distributed energy resources (DERs), microgrids, and IoT devices, it becomes harder for a single controller to keep systems efficient and resilient. This diversity fuels interest in multi-agent reinforcement learning, since centralized models now struggle to meet modern demands.
Despite their drawbacks, centralized EMS/BMS systems remain common because organizations already have the necessary infrastructure and are accustomed to how these controls work. Many are slow to adopt new systems unless the short-term benefits are clear, even if they know about the issues with scaling and the risk of failure.
2.1.2. Distributed IoT, Edge, Cloud Paradigms
Distributed IoT-Edge-Cloud architectures represent a structural departure from traditional centralized EMS/BMS systems, redistributing computation and decision-making across multiple layers. This subsection outlines their operational principles, benefits, and challenges.
Transitioning from the centralized frameworks described previously to distributed IoT-Edge-Cloud architectures introduces structural changes that reshape energy management strategies. A defining feature of these paradigms is the relocation of computational tasks closer to the point of data generation, with edge devices performing inference and preliminary analytics before selectively forwarding information to cloud systems. This distribution mitigates latency by reducing dependency on distant processing resources [9]. Instead of saturating communication channels with raw sensor readings, preprocessing at the edge ensures that only relevant or aggregated data traverse network links, thereby decreasing uplink load and reducing bandwidth consumption [12].
At an operational level, this architectural shift supports responsiveness in applications where reaction time directly impacts system performance. For instance, in environmental monitoring systems integrated with IoT protocols such as LoRaWAN and MQTT, placing computation at the edge accelerates object detection and anomaly identification without waiting for round-trip delays to a remote server. These benefits become increasingly important in systems experiencing fluctuating loads or variable network conditions. By balancing task allocation among local devices, intermediary edge nodes, and cloud servers, energy optimization can adapt dynamically to both computational constraints and operational demands [16].
A key architectural element is the intermediate processing tier (edge nodes), which enables bidirectional data exchange between IoT devices and cloud infrastructure [12]. This configuration reduces transmission volumes while improving scalability through distributed control logic. Edge nodes can execute localized machine learning tasks independently; compressed neural networks and federated learning are notable strategies in this context. Federated learning, in particular, supports privacy preservation by keeping raw datasets local while still enabling global model improvement—highly relevant in residential energy optimization or industrial settings with strict data protection requirements.
From a scientific perspective, the edge–cloud continuum introduces flexibility in computational placement. Tasks with stringent real-time requirements (e.g., critical load shedding) remain at the edge layer, whereas computationally intensive but latency-insensitive operations (e.g., long-term demand forecasting) are offloaded to the cloud. This division leverages each layer’s strengths—immediate reaction capabilities at the edge combined with deep analytics in the cloud—resulting in hybrid workflows that outperform monolithic models under variable conditions.
Despite these advantages, engineering trade-offs persist. IoT nodes typically operate under tight energy and hardware constraints; prolonged computation can strain battery life or thermal budgets. Future iterations may benefit from model compression techniques that reduce computation time while preserving predictive accuracy [17]. Experimental results show that compressed architectures executed on low-power processors can sustain adequate inference performance while prolonging device uptime.
Another core advantage of distributed paradigms is their resilience to single points of failure. If one edge node fails, others may compensate locally, or tasks may be rerouted to neighboring devices until cloud resources can provide additional support. This redundancy contrasts with centralized EMS/BMS setups, where a single outage compromises global oversight. Furthermore, local autonomy enables continued operation under partial network loss, as decisions can still rely on cached data and learned policies.
The introduction of multi-agent frameworks further enhances coordination among decentralized units by embedding decision-making capabilities directly into agents situated at different network layers [18]. Integration into smart grids adds an additional dimension: distributed IoT-Edge-Cloud systems can correlate inputs from sensors monitoring temperature, humidity, luminosity, weather patterns, and occupancy metrics in near real-time. Edge nodes can then adjust loads based on immediate conditions while maintaining alignment with overarching grid strategies developed in the cloud. Predictive models trained on historical datasets refine scheduling efficiency over longer horizons but depend on rapid edge-level feedback to remain effective.
These layered architectures also support incremental scalability. New IoT devices can attach at appropriate layers without requiring significant reconstruction of central systems. Edge-based designs promote modular expansion because computational dependencies are not rigidly tied to a single physical location. This is exemplified by hybrid ensemble optimization systems that distribute multiple algorithms across processing sites [16]. While such systems require careful orchestration to prevent conflicting actions among nodes, they offer greater adaptability across diverse use cases.
However, persistent challenges remain. Synchronizing state representations between edge and cloud layers requires robust consistency protocols; asynchronous updates may cause divergences that degrade decision quality over time [17]. Variations in sampling rates among heterogeneous sensors—common in mixed-vendor deployments—require mechanisms to harmonize incoming streams before feeding them into distributed models. Failure to address such disparities can introduce bias or instability in predictions.
The interplay between local computation efficiency and global coordination mirrors emerging studies that blend reinforcement learning with offline optimization for scalable residential energy management. In these settings, agents learn contextually optimal strategies through localized experience while preserving system-wide alignment through periodic synchronization with centrally maintained global policies. Here, communication timing becomes as critical as algorithm selection.
Ultimately, deploying distributed IoT-Edge-Cloud infrastructures reshapes AI-driven energy management; responsiveness is enhanced by moving intelligence closer to action points; resources are conserved through layered processing; privacy is preserved thanks to federated learning; decentralized coordination is enabled by hybrid control loops; and overall resilience is improved through the decentralization of decision authority. The scientific challenge ahead lies in harmonizing these components so that explainability, accuracy, stability, and scalability remain balanced under fluctuating environmental and network dynamics.
To visualize these structural differences, Figure 1 contrasts the traditional centralized topology with the distributed IoT-Edge-Cloud framework, highlighting the redirection of data flows for local processing.
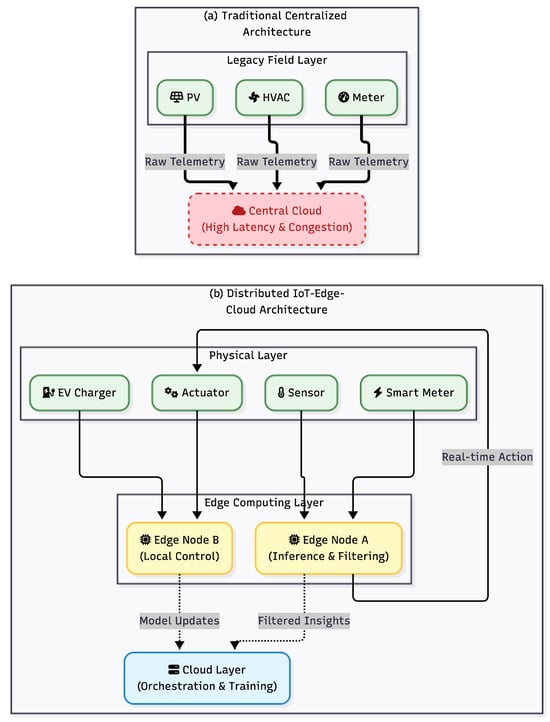
Figure 1.
Evolution of energy management architectures. (a) Traditional Centralized Architecture: Raw data travels to the cloud, causing potential latency and bottlenecks. (b) Distributed IoT-Edge-Cloud Architecture: The InTec approach [9] introduces an intermediate Edge layer for local inference and filtering, reducing bandwidth congestion and enabling real-time response [12].
2.2. Multi-Agent Systems for Energy Management
This subsection outlines the role of multi-agent systems (MAS) in distributed energy management and introduces key coordination mechanisms used to align local agent decisions with system-wide objectives.
Agent Coordination Mechanisms
Coordination among agents in distributed energy management systems requires balancing local objectives with global operational targets. Agents may represent diverse entities such as EV charging stations, microgrid controllers, shared storage operators, or building subsystems. The principal challenge arises from the need to adapt decisions under partial information, fluctuating environmental conditions, and heterogeneous device capabilities.
Multi-Agent Deep Reinforcement Learning (MADRL) has become a prominent approach to addressing this complexity, enabling agents to learn optimal behaviors without relying on explicit centralized environmental models. Model-free DRL is particularly relevant in non-linear and analytically intractable scenarios, where agents iteratively refine load-balancing or charge/discharge strategies through repeated interactions with their environment.
Effective coordination demands structured negotiation between agents whose goals may conflict. Pareto front optimization is frequently employed to scalarize multiple objectives using operator-defined weights, enabling solutions that balance individual agent preferences with global performance requirements [11]. This prevents disproportionate prioritization of a single objective, such as cost minimization, at the expense of user satisfaction or grid stability.
In EV charger-sharing networks, coordination can also be achieved through auction-based mechanisms embedded within MADRL frameworks. Agents adjust bids based on historical patterns and market forecasts, facilitating resource allocation that responds to real-time capacity constraints while maintaining economic efficiency. Predictive analytics reinforce these auction mechanisms by enabling the anticipation of demand spikes or supply shortages. Dynamic pricing integrated into agent policies further incentivizes behavior that aligns local actions with system-wide benefit under changing market conditions [19]. Coordination in this setting emerges from distributed interactions rather than from any single controlling node.
Shared storage assets introduce additional coordination challenges. Conflicts between Integrated Energy Station (IES) operators regarding access to common buffers can lead to inefficiencies unless cooperative scheduling mechanisms are implemented. Decentralized frameworks allow agents to negotiate usage based on mutually agreed priorities while retaining autonomy within their own operational zones. Traditional distributed algorithms often struggle to account for nuanced energy flow patterns across interconnected resources. MADRL approaches augmented with expert demonstrations address this by guiding learning toward strategies that satisfy hard constraints such as energy balance and user comfort. The Imitation–Augmented Actor–Critic (IAAC) method integrates expert trajectories with attention mechanisms, enabling the model to concentrate its learning on the most relevant state–action subspaces, mitigating overestimation issues common in algorithms such as MADDPG when state–action spaces are large [20].
Within smart building environments, coordination involves synchronizing multiple controllable loads—HVAC systems, lighting, and other actuators—through adaptive distributed control [21]. Multi-agent RL must reconcile disparate operational rhythms while responding to changes in occupancy and weather. DRL-driven scheduling can blend predictive models with real-time sensing to stabilize consumption without compromising occupant comfort.
Scalability remains a central obstacle for multi-agent coordination. As agent populations grow, communication overhead increases unless information exchange protocols are optimized. Cross-chain blockchain schemes have been proposed to coordinate local and global markets within EV charging infrastructures, distributing record-keeping to reduce bottlenecks while maintaining transparency and security. Such schemes support trusted sharing of load states among geographically dispersed nodes without relying on centralized intermediaries.
Policy complexity also affects scalability. Lightweight policy representations enable faster computation on resource-constrained edge devices while remaining compatible with global strategies learned at higher tiers. Balancing local autonomy with periodic synchronization—often through federated learning updates—helps maintain alignment across heterogeneous hardware environments. Nevertheless, pure decentralization risks strategic divergence if communication delays or failures occur. Incorporating fallback consensus protocols ensures coherent behavior under degraded network conditions.
The interaction between these autonomous entities requires a structured hierarchy to maintain system stability. Figure 2 illustrates the separation between the cyber layer (agents) and the physical layer, demonstrating how local bids are reconciled by a global coordination mechanism.
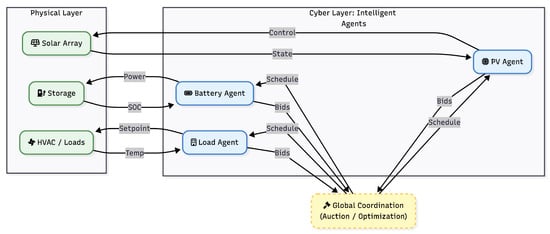
Figure 2.
Simplified hierarchical coordination loop in Multi-Agent Systems. The architecture decouples the Physical Layer (assets) from the Cyber Layer (agents). Local agents process state data (e.g., SOC, temperature) and submit bids to a global Coordinator. This mechanism resolves conflicts via auction or Pareto optimization before executing control actions [19,22,23].
2.3. Communication Protocols and Deployment
This subsection introduces the communication mechanisms that enable interoperability and efficient data exchange across IoT, edge, and cloud layers, focusing first on lightweight messaging protocols widely adopted in energy management systems.
2.3.1. MQTT for Lightweight Messaging
MQTT has emerged as a preferred communication protocol in many IoT-Edge-Cloud energy management deployments due to its suitability for resource-constrained environments and its publish–subscribe architecture, which minimizes unnecessary message traffic. Its inherently lightweight design reduces packet size, a critical advantage in scenarios where devices operate over low-bandwidth or wireless links such as Zigbee or LoRa [24]. In energy-optimization systems, this efficiency directly affects power consumption at both transmitting and receiving nodes, since reduced processing and shorter transmission times translate into lower energy expenditure. When combined with edge-based decision-making, MQTT provides a fast communication channel between distributed agents without introducing additional latency that could hinder real-time control loops [9].
The decoupling between publishers and subscribers enables flexible scaling as device populations grow, without restructuring communication patterns. For example, an edge node monitoring aggregated load data can publish updates simultaneously to multiple cloud analytics services while pushing alerts to local actuators. Message routing occurs through the broker, which can be located close to the edge tier, thereby reducing round-trip delays. This becomes essential when supporting high-frequency data streams from smart meters or photovoltaic inverters [25], where timely dissemination enables proactive adjustments to maintain grid stability.
In multi-agent reinforcement learning frameworks, MQTT enables asynchronous yet reliable inter-agent communication, preventing congestion that can arise in naïve peer-to-peer architectures. Its Quality of Service (QoS) levels allow for fine-grained tuning between delivery guarantees and bandwidth consumption. Low QoS levels can be applied to non-critical telemetry, while higher levels can be reserved for control directives where lost messages may violate operational constraints [26]. Such selective reliability is valuable in integrated energy stations or shared storage systems where hard constraints must be maintained. Although the broker’s central role introduces a potential single point of failure, redundancy through clustered brokers or distributed deployments can mitigate this risk. Local brokers within microgrids can also sustain internal coordination during WAN interruptions, with devices resynchronizing once external connectivity is restored.
MQTT integration across heterogeneous devices—from MCU-based smart plugs to Raspberry Pi gateways—is facilitated by its minimal implementation overhead, with many IoT SDKs supporting it natively. In building energy systems, MQTT-enabled sensors can coexist with mobile applications subscribed to the same topics, enabling edge nodes and AI-driven controllers to reconcile manual overrides with automated strategies in real time. Hierarchical topic structures further support segmentation by zone, device type, or operational state, allowing AI modules to selectively subscribe to relevant data rather than ingest full streams. This targeted subscription reduces the memory footprint at consuming agents, which is important when models must run on RAM-limited hardware.
Security considerations remain essential: MQTT does not enforce encryption or authentication by default. Deployments typically wrap payloads within TLS-secured channels and introduce token-based access control at the broker. For critical infrastructures such as smart grids or renewable energy communities [25], these layers are vital to prevent spoofing attacks or message tampering. Resource-constrained edge devices may require lightweight cryptographic routines to maintain responsiveness.
MQTT’s temporal characteristics align well with demand-response strategies. Short latencies between detecting grid frequency deviations and issuing actuation commands help stabilize the supply-demand balance before deviations accumulate. Adaptive publishing intervals support dynamic trade-offs between responsiveness and network load—higher frequencies during volatility, slower updates when conditions remain stable [27]. Predictive-maintenance routines likewise benefit from prompt anomaly reporting, as alerts regarding inverter inefficiencies or unusual appliance usage can reach diagnostic modules without delay.
From a deployment standpoint, MQTT supports bridging across diverse transport layers, acting as a mediator between wireless sensor networks (e.g., LoRaWAN) and IP-based cloud analytics platforms [24]. Gateways translate incoming frames into MQTT topics consumable by downstream decision engines, while preserving semantic labeling, which is important for explainable AI modules [6]. Ensuring alignment between messaging structures and interpretable model inputs maintains transparency and traceability across the pipeline.
In federated learning workflows for distributed optimization, MQTT enables efficient transmission of model updates rather than raw datasets [17]. This conserves bandwidth while preserving privacy in residential and industrial settings. Federated updates, being small in size, fit naturally within MQTT’s packet structure, and retained messages ensure that late-joining nodes receive the latest model parameters immediately. This highlights how the selection of communication protocols affects not only delivery speed but also the efficiency of collaborative learning across heterogeneous electrical subsystems coordinated via multi-agent principles [20].
2.3.2. BACnet and Building Automation Interoperability
BACnet, or Building Automation and Control Networks, was conceived to address longstanding interoperability limitations in early building automation systems. Before its development, many deployments relied on proprietary communication protocols, resulting in siloed infrastructures where controllers, sensors, and actuators from different vendors could not interoperate. Introduced in 1987, BACnet provided a standardized protocol defining common object types and services, enabling heterogeneous devices to exchange information without vendor-specific translation layers. This shared semantic model extends beyond HVAC to include lighting, access control, fire safety, and energy metering, supporting multi-vendor ecosystems and facilitating long-term scalability.
Unlike lightweight IoT messaging protocols such as MQTT, which focus primarily on efficient data transfer, BACnet incorporates richer semantic descriptions of device capabilities. This allows receiving systems to not only read data but also to interpret and act on it consistently. In modern IoT-Edge-Cloud environments, gateways often bridge BACnet’s object-oriented structure with topic-based or REST-style interfaces, ensuring compatibility with cloud analytics or edge-deployed AI modules.
Adopting BACnet in buildings with legacy proprietary systems often requires structured mapping between older control points and standardized BACnet objects. Although the protocol enforces interoperability, optional features and vendor-specific extensions still necessitate rigorous commissioning and occasional custom bindings. Nevertheless, its openness enables incremental upgrades: new devices can announce their capabilities via standardized descriptors, allowing AI-driven energy management modules to automatically incorporate them into optimization routines.
As BACnet implementations increasingly run over IP networks, cybersecurity becomes critical. The original protocol assumed physically isolated environments and lacked native cryptographic features. Contemporary deployments typically add TLS, VPN tunneling, or token-based authentication, especially when BACnet shares infrastructure with IoT protocols. Harmonizing security mechanisms across both ecosystems prevents cross-protocol vulnerabilities, an important consideration for smart grids and large commercial facilities.
Interoperability plays a key role in how energy management algorithms interact with physical assets. An edge-level predictive HVAC controller may issue setpoint commands through MQTT while relying on occupancy or temperature data retrieved from BACnet-only devices. Gateways translate between these models to ensure that multi-agent control strategies receive coherent and timely state information. Such coordination is particularly important when aligning actions across HVAC, lighting, and ventilation systems under stringent latency constraints.
From an operational perspective, BACnet’s unified communication layer mitigates vendor lock-in and reduces long-term system costs by allowing for component replacement or expansion without architectural overhauls. When combined with explainable AI models that leverage historical logs encoded in standardized BACnet objects, operators gain transparent, traceable insights into the reasoning behind automated control actions.
Maintaining consistent state representations across heterogeneous protocols is essential in hybrid IoT-Edge-Cloud deployments. When optimization engines rely on BACnet-derived measurements while issuing control commands through MQTT, misalignment between protocol layers can degrade performance. BACnet’s event-notification mechanisms help mitigate such mismatches by pushing state changes immediately rather than relying solely on fixed polling cycles [25]. In emerging environments such as IoT-rich smart grids and microgrids, middleware platforms increasingly reconcile syntactic and semantic differences across devices and communication schemes, ensuring that AI-driven and multi-agent control frameworks operate over a unified and coherent conceptual model [28].
Ensuring interoperability between these legacy protocols and modern cloud services is critical. Figure 3 depicts the data workflow through a Smart Gateway, which maps semantic BACnet objects to lightweight MQTT topics for upstream analytics.

Figure 3.
Interoperability workflow in hybrid environments. A Smart Gateway bridges the gap described in Section 2.3.2, translating semantic BACnet objects from legacy equipment into lightweight MQTT topics [24,29], enabling efficient integration of legacy OT domains with modern IT optimization engines.
2.3.3. Semantic Interoperability and Modeling
While protocols like MQTT and BACnet facilitate data transport, they function primarily at the syntactic level. A critical limitation in raw MQTT deployments is the lack of inherent context; a topic named building1/sensor/temp carries a payload, but without a semantic layer, consuming agents cannot distinguish whether this represents an indoor ambient temperature, a boiler return temperature, or a setpoint [30]. To achieve the “Interoperability” required for scalable Multi-Agent Systems, the framework must incorporate semantic modeling standards such as Brick Schema or Project Haystack.
Semantic layers provide a standardized ontology that maps low-level I/O points to high-level physical concepts and relationships (e.g., “Sensor A isPointOf VAV Box B feeds Room C”). This abstraction is essential for MAS scalability; it allows an agent trained on one building’s dataset to transfer its policy to another building by mapping inputs via the semantic graph rather than hard-coded tag names [31]. Furthermore, semantic standardization is a prerequisite for meaningful Explainable AI. As noted in Section 5.3, explaining a decision based on raw tags is opaque to facility managers; linking those tags to semantic definitions enables natural language explanations (e.g., “HVAC reduced because Zone North occupancy is zero”) [6,32].
2.4. Edge AI Platforms and Hardware
As energy management architectures shift toward distributed IoT-Edge-Cloud paradigms, the capabilities and constraints of edge hardware become central to system performance. This section examines the role of embedded platforms and specialized edge devices in supporting AI-driven optimization under strict power, latency, and memory limitations.
Low-Power Embedded Systems
Energy-aware AI deployments are shaped by hardware capabilities and constraints. In low-power embedded contexts, especially with microcontrollers, design constraints are explicit: operating at milliwatt power levels, kilobyte memory, and low clock speeds. These limits require algorithmic strategies distinct from those for edge servers or cloud platforms. Tiny Machine Learning (TinyML) enables ML inference directly on microcontrollers, without constant external computation. Model pruning, quantization, and compression enable local deployment of deep neural networks with only a few milliwatts of power. This is crucial for battery-powered IoT devices that must operate autonomously for long periods.
Quantization reduces numerical precision to 8-bit fixed-point formats, lowering storage requirements and speeding up multiply-accumulate operations. Similarly, pruning removes redundant parameters, which maintains accuracy while reducing inference cost. These methods work in tandem with hardware-specific optimizations in lightweight ML libraries that provide efficient kernels for convolutions, activations, and other operations tailored to microcontroller instruction sets. Consequently, portability may sometimes be sacrificed for optimal hardware efficiency.
Low-latency response is often as important as energy efficiency. In real-time control loops—such as adjusting HVAC output in response to occupancy—local inference avoids cloud-offload delays that would hinder responsiveness [33]. This advantage also reduces dependence on persistent connectivity; devices remain functional during network disruptions. Within IoT-Edge-Cloud hierarchies [9], low-power embedded systems naturally occupy the “thing” tier. They perform preliminary filtering or event detection before invoking local neural inference, minimizing upstream bandwidth usage and distributing computational load effectively across large device populations.
Integrating DRL or MARL at the microcontroller level remains challenging due to the high training time requirements [3]. While on-device training is generally infeasible, running compressed policies locally is achievable. Knowledge distillation enables small student models to inherit decision quality from large teacher networks. Periodic policy updates from edge or cloud servers can be distributed via lightweight protocols such as MQTT, enabling adaptive behavior without overwhelming constrained devices.
Hardware developments increasingly support embedded ML workloads. Modern MCUs include DSP extensions or AI accelerators designed for SIMD operations, enhancing throughput per watt for convolutional workloads. Memory architectures remain a limiting factor: constrained SRAM and slower flash storage require model designs that minimize intermediate activations. Techniques such as operator fusion reduce memory usage and lower instruction counts. Shallow but wide architectures often outperform deeper networks under strict latency and memory constraints.
Security concerns are similar to higher tiers but complicated by a few resources. Cryptographic routines use cycles and memory, so lightweight ciphers secure device-gateway communication without harming responsiveness. Thermal concerns arise in sealed enclosures; repeated short inference bursts can raise temperatures. Event-driven processing reduces this risk and extends battery life.
Low-power embedded systems broaden the reach of AI-driven energy optimization into remote or infrastructure-poor environments [12]. Examples include solar-powered agricultural pumps performing local anomaly detection (spotting unusual behavior), isolated microgrids fine-tuning inverter settings via occasional satellite-updated control signals, or campus lighting systems maintaining context-aware dimming during WAN (wide area network) outages. Interfacing these embedded nodes with upstream controllers requires careful tuning of synchronization frequency (how often data or models are updated). Infrequent updates risk model drift (loss of accuracy over time) as environmental patterns evolve, while excessive synchronization reduces the bandwidth savings gained by local inference. Federated learning (models trained across many devices without centralizing data) offers a compromise: devices transmit gradient updates (changes in the model) or compressed weight deltas (differences from previous model versions) rather than raw telemetry [16], aligning distributed models efficiently.
Ultimately, low-power embedded systems serve both as endpoint actuators (devices that take physical action) and as localized intelligence engines (processors that make decisions) within distributed AI infrastructures for energy management. Their importance will continue to grow as chip-level innovations and model compression techniques enable richer inference capabilities within strict power envelopes. By placing computation close to energy-relevant phenomena, these devices provide rapid responses under tight constraints while forwarding concise contextual information upstream, embodying architectural principles that link IoT “things” to edge nodes and cloud-level optimization engines.
Deploying complex models on such constrained hardware requires a specialized workflow. Figure 4 outlines the typical TinyML deployment pipeline, from cloud-based training to the optimization steps (pruning and quantization) necessary for efficient edge inference.

Figure 4.
The TinyML deployment pipeline for constrained hardware. To address power and memory limits, models undergo quantization and pruning [33] before deployment on microcontrollers. This flow enables low-latency local inference [34] without continuous cloud dependency.
3. State of the Art in AI for Energy Prediction and Optimization
Recent advances in Artificial Intelligence have significantly expanded the range of methodologies available for forecasting, optimization, and control within modern energy systems. Building on the architectural and technological foundations discussed in the previous section, current research spans statistical models, machine learning regression techniques, deep learning architectures, and reinforcement learning strategies operating across distributed IoT, Edge, and Cloud environments. These approaches differ markedly in terms of interpretability, computational demands, data requirements, and suitability for real-time deployment. This section reviews the principal families of methods used in energy prediction and optimization, highlighting their capabilities, limitations, and relevance within emerging distributed and explainable energy management frameworks.
3.1. Energy Prediction Models
Imagine the benefits of accurate energy forecasting—it is central to the optimization and control strategies throughout this work. Prediction models span a wide methodological spectrum, from classical statistical formulations to modern learning-based techniques. To clarify the progression, this section examines the main families of approaches. It begins with statistical time-series methods, which remain essential for interpretability and strong performance under well-characterized temporal structures.
3.1.1. Statistical Time Series Approaches
Statistical time series approaches in energy prediction continue to serve as foundational tools even in increasingly AI-driven contexts. Unlike neural network architectures or complex ensemble models, these methods build forecasts directly on identifiable temporal structures inherent in historical data. Techniques such as autoregressive integrated moving average (ARIMA), seasonal decomposition of time series (STL), and exponential smoothing focus on modeling trend, seasonality, and noise components, enabling explicit interpretation of patterns across different horizons. This emphasis on signal decomposition aligns with the broader pursuit of transparency, as operators can trace outputs to well-defined mathematical constructs rather than opaque learned representations.
An important refinement to classical frameworks involves mode decomposition, in which aggregated consumption data is partitioned into interpretable subsequences that capture distinct operational behaviors—daily cyclic variations, abrupt demand spikes, or room-level activity patterns. Such segmentation provides a granular view of how consumption evolves across spaces or microgrid assets. Each subsequence may correspond to a specific scenario, for instance, HVAC use during peak hours versus baseline nighttime loads, enabling more targeted forecasting while preserving interpretability.
This decomposition can be integrated with hybrid predictive pipelines in which deterministic components feed traditional statistical models, while residual or irregular patterns are passed to non-linear learners optimized for stochastic variability. In doing so, model complexity is managed effectively: interpretable components remain in mathematical form, while high-variance elements benefit from the flexibility of AI-based adaptation. Beyond prediction, feature decomposition supports behavior inference; systematic deviations from baseline sequences may reveal shifts in occupancy routines or equipment usage. This reinforces the diagnostic value of statistical approaches within broader optimization strategies, especially when communicating results to stakeholders who require comprehensible explanations instead of abstract algorithmic outputs.
Classical time series analysis also facilitates alignment between method capability and forecast horizon. Seasonal indices extracted via STL decomposition support medium-term planning—e.g., cooling demand in climates with strong summer peaks—while ARIMA models capture short-term autocorrelation patterns suited for hour-ahead dispatch scheduling [35]. Misalignment between forecast horizon and methodological assumptions often degrades accuracy more than parameter calibration issues. Seasonal adjustment, combined with trend estimation, also enables scenario testing under hypothetical modifications, such as energy retrofits or behavioral campaigns, that affect long-term trajectories.
Despite their advantages, statistical methods face challenges under non-stationarity induced by unpredictable events, abrupt equipment changes, or sudden occupancy shifts. Rolling-window estimation mitigates such issues by updating coefficients with recent data slices, though care must be taken to avoid overfitting transient anomalies. Recent advances integrate explainable artificial intelligence principles with traditional models—for instance, combining Shapley value attribution with residual analysis to reveal which exogenous variables (e.g., weather or schedules) drive forecast fluctuations during particular intervals.
Industrial forecasting settings often employ multivariate regression extensions with exogenous predictors such as weather metrics, calendar effects, and market prices. These structures capture interactions between internal system inertia and external influences while retaining transparency through interpretable regression coefficients. Interactive effects become evident when coefficients vary across seasons or economic cycles, offering insights into the contexts in which certain interventions exert greater leverage.
In smart building applications enriched by IoT sensing arrays (Section 2.4), rolling multivariate regressions leverage high-frequency data streams without losing periodic structure. Statistical baselines derived from historical datasets serve as reference modes to flag deviations significant enough to trigger adaptive control actions. Moreover, statistical decomposition is often used as a preprocessing step in hybrid AI pipelines for UBEM tasks [36], thereby improving the efficiency of downstream neural networks by isolating deterministic patterns from stochastic residuals. This resonates with explainable composite models where transparent statistical layers complement deeper but less interpretable learners.
Integration of statistical approaches into distributed management architectures also benefits from federated learning setups [17]. Lightweight seasonal decompositions executed at local nodes can propagate parameter updates upstream without sharing raw datasets, preserving privacy while improving collective accuracy across diverse environments.
In terms of system suitability, statistical models such as ARIMA and Exponential Smoothing offer distinct advantages for edge deployment due to their low computational footprint and high interpretability. Their mathematical transparency allows operators to easily validate baseline forecasts without complex post-hoc explainability tools [37]. However, their primary limitation lies in their inability to capture complex non-linear dependencies or rapidly incorporate high-dimensional exogenous variables (e.g., occupancy images or complex weather grids) as effectively as deep learning approaches [17]. Consequently, these methods are best suited for Level 1 (Edge) deployment in microcontrollers or gateways where memory is scarce, serving as reliable fallback mechanisms when cloud connectivity is lost.
3.1.2. Machine Learning Regression Models
Regression-based machine learning models play an essential role in energy prediction pipelines, particularly when continuous-valued outputs are required, such as load forecasts, temperature estimates, or consumption profiles. In contrast to the statistical time series methods discussed in Section 3.1.1, these algorithms learn predictive mappings from potentially high-dimensional input spaces without being bound to linear relationships or stationarity assumptions.
Before analyzing each regression family in detail, Table 1 summarises the main machine learning approaches used in energy prediction, highlighting their typical data requirements, computational demands, interpretability properties, and suitability for IoT-Edge-Cloud deployments.

Table 1.
Comparison of machine learning regression models for energy prediction in IoT-Edge-Cloud environments.
Support Vector Regression (SVR) exemplifies how kernelized approaches manage non-linear dependencies between predictors and target load values [21]. By transforming inputs into higher-dimensional feature spaces and optimizing a tolerance margin around the regression function, SVR accommodates irregular patterns common in real-world energy datasets, where operational schedules or environmental conditions shift unpredictably. Selecting appropriate kernels—radial basis functions for smooth, non-linear variation or polynomial kernels for power-law tendencies—remains a key modeling decision that influences accuracy and computational cost. However, SVR’s memory footprint scales quadratically with the number of support vectors, posing challenges when processing high-frequency sensor streams typical of IoT–Edge deployments.
Decision tree regression models partition input space via threshold-based splits that often align with interpretable operational conditions. For example, a division of outdoor temperatures can separate HVAC cooling-dominant from heating-dominant regimes, with subsequent splits refining predictions based on occupancy or appliance usage data. This hierarchical partitioning enhances interpretability because each path from root to leaf reflects a sequence of intuitive conditions leading to an energy forecast. Ensemble variants such as gradient boosting regression trees iteratively correct residual errors, improving accuracy compared to single-tree solutions at the expense of transparency unless complemented by XAI tools such as SHAP or LIME [5].
Artificial Neural Networks (ANNs), including multilayer perceptrons and deeper architectures, offer high expressivity by learning complex non-linear mappings end-to-end [41]. They integrate temporally lagged features with static building descriptors to represent intertwined temporal—spatial relationships in consumption data. With sufficiently large and heterogeneous training sets, ANNs can generalize across varied operational contexts. However, their opacity—especially in deep configurations—limits direct attribution without specialized interpretability layers. Methods such as partial dependence plots (PDPs) clarify how individual features influence predictions by holding other features constant [45], thereby supporting trust during deployment in sensitive infrastructure.
Hybrid modeling strategies frequently emerge in real-world smart building scenarios. Linear regression baselines serve as benchmarks against which more advanced ML regressors are evaluated [5]. Linear models remain valuable when relationships are predominantly additive and proportional; their coefficients provide straightforward sensitivity estimates for informing demand reduction policies. However, as many load datasets exhibit multimodal behavior beyond the linear scope—such as peak shifting due to tariffs or abrupt drops during equipment maintenance—the need arises to transition to more flexible learners. For example, k-Nearest Neighbors (KNN) regressors estimate outputs by averaging observations most similar to current input conditions [41]. This local adaptation is well-suited when similar operational states recur, although KNN performance can degrade if environmental conditions change rapidly.
Extreme Learning Machines (ELMs) expand the range of fast regression models for energy prediction. They randomly assign hidden-layer weights, then solve for output weights in closed form. This enables rapid training suited for edge deployments with limited resources. Such models must update often. Comparative studies benchmark ELMs against SVR and Generalized Regression Neural Networks (GRNN) for short-horizon indoor temperature estimation. These studies demonstrate ELM’s robustness to changing weather patterns. This stability is valuable where models must perform reliably within control loops despite outside volatility.
Explainability overlays are increasingly used alongside ML regressors in urban building energy modeling (UBEM). Stakeholders demand not only accuracy but also clarity about the causal pathways linking policy interventions—such as insulation retrofits—to predicted savings [36]. To meet these demands, XAI techniques quantify how critical factors influence regression outcomes, thereby reducing uncertainty and helping align optimization decisions with regulatory or sustainability goals. Among these methods, QLattice regressors combine transparent symbolic modeling with predictive performance beyond that of simple parametric forms. QLattice models yield compact analytical expressions for variable interactions that can be scrutinized directly.
In IoT–Edge–In IoT-Edge-Cloud contexts, the computational footprint becomes as decisive as predictive accuracy. Deploying resource-intensive gradient-boosting models on constrained edge hardware is often impractical without compression or distillation. Knowledge distillation transfers learned behavior from complex “teacher” models into lightweight “student” models capable of low-power inference, as required for embedded systems, noted in Section 2.4. Regression modeling also aligns naturally with federated learning paradigms, where local nodes train individualized regressors on site-specific consumption data and share model updates rather than raw measurements. This preserves privacy while combining insights from diverse environments to refine global parameter sets and distribute them back to each node. Maintaining this under non-stationary conditions—such as shifting occupancy habits or evolving tariff structures—remains critical. Online learning variants update parameters incrementally as new data arrives, maintaining relevance while reducing overhead compared to full retraining. Coupled with XAI dashboards that monitor feature importance drift, operators can detect early signals of behavioral shifts that affect prediction reliability.
From a deployment view in UBEM applications [36], regression algorithm selection balances expressivity, interpretability, scalability, and resistance to temporal drift. Options range from linear models to kernel-based SVR, ensemble trees, GRNNs, KNNs, ELMs, symbolic QLattices, and deep ANNs. This breadth allows practitioners to choose predictive cores suited for AI-driven optimization in IoT-Edge-Cloud systems that require explainable decision-making.
To illustrate the increasing complexity of modern forecasting pipelines, Figure 5 depicts a hybrid workflow. Here, raw IoT data is decomposed into deterministic components (handled by statistical methods) and stochastic residuals (processed by deep learning), enhancing overall accuracy as discussed in [35].
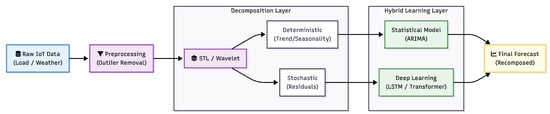
Figure 5.
A hybrid data-driven forecasting pipeline. By decomposing time series data into trend/seasonal and residual components, the system leverages the interpretability of statistical models for stable patterns while utilizing Deep Learning (e.g., LSTMs) to capture complex non-linear irregularities [17,35].
To consolidate the diverse modelling approaches discussed in this section, Table 2 provides a comparative overview of the principal families of prediction and optimization methods used in energy management. The table contrasts these approaches in terms of their underlying techniques, data requirements, computational characteristics, interpretability, and domain suitability. This synthesis helps clarify the practical trade-offs between statistical, machine learning, deep learning, hybrid, heuristic, and reinforcement learning paradigms, and serves as a reference point for selecting appropriate models in IoT-Edge-Cloud energy infrastructures.
Table 2.
Comparative summary of energy prediction and optimization approaches.
Regarding deployment suitability, traditional ML regressors like SVR and Random Forests present a balanced trade-off. SVR is highly effective for small-to-medium datasets often found in building-level metering, providing robust accuracy for non-linear loads [38]. However, its quadratic training complexity makes it unsuitable for continuous on-device retraining in resource-constrained IoT nodes. Deep Learning models (LSTMs, Transformers), while offering superior accuracy for multi-building forecasting [17,39], suffer from high computational opacity and resource demands. Therefore, a hybrid placement strategy is often required: heavy training and hyperparameter tuning are relegated to the Cloud layer, while optimized inference (via quantization or pruning) is deployed to Edge servers or advanced IoT controllers using TinyML frameworks [33,34].
3.2. Optimization and Control Methods
Before examining advanced control architectures, this section outlines the main classes of optimization techniques applied in energy management, emphasizing methods that balance computational feasibility with practical operational constraints.
To contextualize the diversity of available optimization techniques, Table 3 provides a comparative summary of the main control and optimization families used in energy management. The table contrasts their computational requirements, suitability for IoT-Edge-Cloud deployments, and typical application scenarios. This overview helps frame the detailed discussions that follow in subsequent subsections.
Table 3.
Comparison of optimization and control methods in energy management.
3.2.1. Mathematical Optimization Strategies
Before exploring heuristic and learning-based strategies, it is fundamental to acknowledge that mathematical optimization remains the cornerstone of energy management. Approaches such as Linear Programming (LP), Mixed-Integer Linear Programming (MILP), and Convex Optimization provide rigorous guarantees of global optimality and are the standard for Economic Dispatch and Optimal Power Flow (OPF).
Recent advancements have extended these methods to handle the complexities of modern microgrids. For instance, Liang et al. [48] demonstrated that steady-state convex models can enable high-efficiency economic dispatch in hybrid AC/DC networked microgrids. By employing least squares approximation to simplify non-convex bi-directional converter models, they achieved significant reductions in solution time while maintaining physical feasibility. However, as system complexity increases with distributed IoT assets and unknown non-linear dynamics, the reliance on explicit physical models often necessitates shifting toward the heuristic and data-driven methods discussed in the following subsections.
3.2.2. Heuristic and Metaheuristic Strategies
Heuristic and metaheuristic strategies occupy a distinct niche in energy prediction and optimization workflows, balancing exact optimality with computational tractability in complex, high-dimensional decision spaces. In many energy systems, particularly those incorporating distributed resources, storage units, and variable renewable generation, the search space for scheduling or dispatch decisions is too vast for deterministic algorithms to evaluate exhaustively under real-time constraints. Heuristic approaches simplify this problem using rule-based or approximate methods that converge efficiently toward acceptable solutions without incurring the heavy computational overhead of exact solvers. These rules may emerge from expert knowledge, simulation-informed patterns, or operational heuristics accumulated over long deployment periods, allowing for quick adaptation to fluctuating conditions with minimal computation.
Traditional heuristic scheduling in building energy management may prioritize appliance operations based on predefined weights, such as cost savings or user comfort. A simple priority queue can rank devices that may be deferred without degrading service and sequence their activation around tariff shifts. Although such schemes lack the ability to adjust dynamically to unforeseen changes—such as sudden peak periods or abrupt drops in renewable output—their simplicity makes them attractive when hardware limitations preclude more computationally intensive optimization [21]. Coupling heuristics with lightweight sensing platforms enables context-aware adjustments based on occupancy detection or temperature deviations while respecting battery constraints in embedded controllers.
Metaheuristic methods extend these ideas by embedding stochastic exploration into optimization searches, increasing the probability of escaping local optima at the expense of deterministic repeatability. Algorithms such as Genetic Algorithms (GA), Particle Swarm Optimization (PSO), Ant Colony Optimization (ACO), and Simulated Annealing introduce probabilistic operators that explore diverse regions of the solution space concurrently or iteratively refine candidate sets. In microgrid dispatch scenarios where integrated renewable sources create unstructured variability, these methods can outperform purely heuristic baselines because they tolerate noisy fitness landscapes and multi-modal payoff surfaces. For instance, PSO can simulate the collective behavior of agents by adjusting scheduling proposals based on both individual performance scores and the best-known global schedules, aligning decentralized behaviors without requiring full centralization.
Hybrid algorithms blending deterministic components with metaheuristics have been proposed to improve convergence speed while retaining flexibility under uncertain input conditions [46]. The imperialist competition algorithm, combined with sequential quadratic programming, illustrates this hybridity: an overarching metaheuristic explores promising regions of the solution space before a mathematical optimization routine fine-tunes the results locally. This symbiosis mitigates the risk that large-scale exploratory phases yield candidate solutions that are far from feasibility, an important safeguard when physical constraints such as load balance, thermal limits, or reserve margins must be satisfied.
Heuristic and metaheuristic strategies also adapt well to multi-agent contexts where coordination among distributed units is essential but global state information may be incomplete or delayed [22]. In such environments, metaheuristics serve as decentralized problem-solving tools, with each agent exploring its subset of possible actions in parallel while periodically exchanging performance summaries with peers. Pareto-based integration mechanisms can synthesize localized results into composite strategies that reflect trade-offs between economic efficiency and technical reliability, thereby avoiding brute-force enumeration across all agents’ joint action spaces.
One practical use case involves the dynamic scheduling of HVAC systems across multiple buildings interconnected through a district grid. Here, a GA can encode combinations of setpoints and operational sequences as chromosomes evaluated against objectives such as aggregate energy reduction and occupant comfort preservation [2]. Crossover operations recombine features from high-performing sequences found across different buildings, spreading effective control patterns throughout the network without imposing a strictly centralized architecture.
Within IoT-Edge-Cloud frameworks discussed in Section 2.4, applying metaheuristics requires sensitivity to latency constraints introduced by distributed computation. Lightweight variants such as Differential Evolution with reduced population sizes can execute directly on edge servers near data sources [16], reducing uplink communication delays by resolving feasible schedules locally before pushing summaries upstream. This layered optimization distributes computational load efficiently across tiers while preserving responsiveness at critical control points.
The uncertainty inherent in renewable generation outputs invites the use of metaheuristics capable of real-time adaptability through continuous re-optimization cycles [46]. Rolling horizon frameworks implement this concept by recalculating schedules periodically within overlapping prediction intervals. At each iteration, heuristic initialization seeds are drawn from previously successful configurations, providing informed starting points for subsequent exploration phases. Embedding forecast errors prevents overfitting to idealized inputs that rarely match live environmental conditions.
In multi-objective situations typical of smart grid operations—balancing cost minimization against carbon reduction—metaheuristics often incorporate objective scalarization techniques within their fitness evaluations [22]. Weight vectors applied within scalarization functions allow for the dynamic adjustment of priorities without retraining models or restructuring algorithm flow. This tunability is particularly valuable under shifting policy mandates or seasonal variations where economic incentives fluctuate relative to sustainability targets.
Explainability challenges are pronounced because stochastic search processes do not offer straightforward causal chains linking inputs to outputs. Interpretable surrogates can partially address this gap: post hoc regression models fitted to logged heuristic or metaheuristic decisions approximate decision boundaries in more transparent mathematical terms, enabling analysts to infer predominant drivers behind observed optimization patterns even when direct path tracing through probabilistic search history is infeasible.
Another layer appears when federated learning concepts intersect with metaheuristics deployed across heterogeneous nodes [17]. Instead of sharing raw datasets, nodes exchange tuned parameter sets—mutation rates, crossover probabilities—shown to perform well locally. Aggregating this “algorithm configuration intelligence” can accelerate global convergence faster than redistributing consumption data alone, while maintaining privacy and leveraging diverse experiential coverage.
Applications spanning distributed storage management highlight how metaheuristics accommodate discrete action sets alongside continuous control variables [3]. Scheduling charge/discharge cycles involves binary activation decisions paired with continuous rate settings driven by predicted demand; encoding both seamlessly within candidate representations enables joint optimization without artificial problem decomposition.
Integrating domain-specific heuristics into generic metaheuristic frameworks enhances the practicality of solutions. Constraint-handling mechanisms tailored to energy systems—such as penalty functions tied directly to violations of power-quality metrics—guide exploration toward deployable configurations rather than abstract optima misaligned with physical realities. This blend respects structural limitations while leveraging stochastic breadth to react effectively under operational pressure.
The execution flow of these heuristic strategies is visualized in Figure 6. Unlike analytical solvers, metaheuristics operate through an iterative search loop, evaluating candidate solutions against an objective function and physical constraints before issuing a control action.
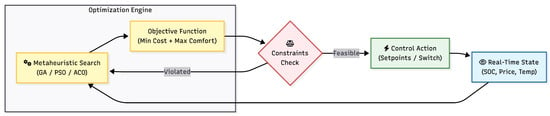
Figure 6.
The iterative optimization loop in heuristic-based energy management. The engine receives real-time state data and explores the solution space (e.g., via Genetic Algorithms or PSO) to find optimal setpoints that satisfy physical constraints [1,46].
The suitability of these optimization methods varies significantly across the architecture. Simple heuristic strategies (rule-based) are extremely lightweight and deterministic, making them ideal for the lowest IoT tier (e.g., smart plugs or thermostats) where immediate, fail-safe actuation is required [21]. In contrast, metaheuristics like GA or PSO offer the advantage of navigating non-convex solution spaces—typical in multi-source microgrid dispatch—without requiring gradient information. Their main limitation is the stochastic nature of the search, which does not guarantee global optimality and can be computationally expensive per iteration [46]. Thus, metaheuristics are best deployed at the Edge Server or Fog layer, where sufficient computing power exists to run population-based simulations within acceptable operational time windows.
Recent advancements in optimization have moved beyond standalone metaheuristics toward hybrid and hierarchical frameworks that address the limitations of traditional bio-inspired algorithms. While standard evolutionary methods effectively navigate non-convex spaces, modern approaches increasingly integrate them with learning-based components to handle dynamic constraints. For instance, hierarchical structures now allow for adjustable levels of control, where high-level agents determine strategic parameters while low-level optimizers manage device-specific constraints, significantly outperforming fixed-hierarchy baselines [46,50]. Furthermore, to address the multi-objective nature of microgrid scheduling (e.g., balancing cost vs. battery degradation), recent techniques have adopted Pareto optimization combined with Deep Reinforcement Learning (DRL) agents. This integration allows the system to dynamically select actions from a set of Pareto-dominant solutions based on operator preferences, rather than relying on static weightings common in older heuristic implementations [22]. Similarly, safety-constrained optimization has evolved to incorporate “safety filters” directly into the learning loop, ensuring that stochastic search actions do not violate physical grid limits [51].
3.3. Multi-Agent Approaches in Energy Systems
To frame how autonomous entities collaborate within modern energy infrastructures, this section reviews distributed coordination mechanisms that enable scalable, resilient, and interoperable multi-agent operation.
Distributed Coordination Strategies
Distributed coordination in multi-agent energy systems concerns how locally autonomous decision-makers align their actions to maintain overall operational objectives without relying on continuous centralized oversight. Strategies here must account for diverse factors: communication topology, computational distribution, heterogeneity in device capabilities, and fluctuating environmental conditions. One recurrent theme is negotiating the trade-off between decentralized autonomy and the need for global coherence in executing schedules or balancing loads. Purely decentralized algorithms offer advantages in latency and privacy by keeping decisions close to data sources, but risk suboptimality if agents lack sufficient situational awareness. Conversely, central optimization can, in theory, reach better global optima, yet often stalls under the computational and communication burdens of large-scale real-time control.
A common approach to distributed coordination is decomposition-based optimization, in which a large centralized problem is split into smaller local subproblems assigned to each agent. Coordination proceeds by iteratively exchanging aggregate variables or dual information that guide local solvers toward consistency. These methods scale well when the local subproblems remain convex [23], as in certain storage-scheduling or demand-response formulations. However, nonconvexities introduced by discrete decisions, such as binary ON/OFF states in diesel backup generators, may compromise convergence guarantees or necessitate heuristics to repair feasibility. In microgrid contexts, hybrid arrangements have been trialed: a centralized model predictive control (MPC) layer computes reference trajectories for distributed agents equipped with reinforcement learning policies that rapidly adjust to deviations [3]. Here, distributed reinforcement learners adapt to short-term anomalies while the centralized planner enforces long-term goals.
Multi-Agent Reinforcement Learning (MARL) frameworks form another pillar for coordination strategies under distribution. By modeling energy management interactions as partially observable Markov decision processes (POMDPs), MARL enables each agent to learn policies conditioned on local observations while embedding mechanisms—such as reward shaping and parameter sharing—that incentivize alignment with system-level performance metrics. Variants like Multi-Agent Proximal Policy Optimization (MAPPO) have demonstrated stable policy improvements in domains such as peer-to-peer (P2P) trading and EV charging management, where agents must balance self-interest with collective welfare over repeated interactions. Coordination emerges indirectly through learned value functions that internalize both individual and shared payoffs.
Auction-based protocols integrated into MARL settings leverage market analogies: agents submit bids reflecting their local utility for resources such as charging capacity or discharge opportunities from shared storage; allocation follows predefined rules that aim to maximize social welfare under constraints [19]. Such dynamic pricing exchanges enable flexible load shifting in response to forecasted congestion or scarcity, capitalizing on predictive features embedded in agent policies. The strategy’s strength lies in converting complex coupling constraints into price signals interpretable by heterogeneous devices—from advanced controllers to lighter embedded nodes—without revealing sensitive raw data about local states.
In bi-level optimization schemes suited for building-to-grid coordination, an upper strategic level determines parameters such as time-varying tariffs or demand response targets, while a lower operational level executes these directives inside each building energy management system [52]. This hierarchical distribution separates concerns: the upper tier addresses market integration and grid stability; the lower tier handles occupant comfort and device-specific constraints. Information flows upward via aggregated forecasts and downward via control setpoints or incentive parameters, thereby reducing bandwidth requirements relative to full-state broadcasting.
Peer-to-peer topologies present additional opportunities where no fixed hierarchy exists. Agents interact directly with neighbors to negotiate bilateral exchanges of energy or capacity commitments. Reputation systems or credit mechanisms can reinforce cooperative behavior amongst self-interested entities operating over unreliable communication links. When paired with fuzzy Q-learning adaptations [43], agents can navigate uncertain partner behaviors or incomplete operational data by adjusting policy confidence based on interaction outcomes.
Data-driven forecasting enhances these distributed strategies by equipping agents with anticipatory decision-making abilities [52]. Forecast-informed coordination enables preemptive measures—such as pre-charging storage before anticipated low-generation periods—without waiting for central commands. Yet integration of predictive modules requires synchronizing model updates across agents so that disparate forecasts do not misalign collective action timing. Distributed coordination also benefits from federated learning paradigms, where policy or predictor parameters are periodically aggregated without centralizing underlying datasets. This maintains privacy in residential settings while enabling knowledge sharing across regions experiencing different weather patterns or usage habits. Communication-efficient aggregation protocols tailored for low-bandwidth IoT networks are critical here; MQTT-based messaging patterns discussed earlier can serve as lightweight conduits for transmitting compact parameter deltas rather than high-volume telemetry.
A notable challenge lies in ensuring robustness when communication degrades or delays occur. Strategies inspired by consensus algorithms provide fallback pathways: even if fresh global updates stall, agents converge on safe default behaviors, such as limiting output swings, to prevent instabilities until synchronization resumes [23]. Redundant pathways for partial state sharing help mitigate partition effects in geographically sparse microgrids or urban grids segmented by security domains.
Explainability layers are becoming increasingly relevant within distributed coordination schemes. Since autonomous decisions propagate through interdependent subsystems, operators require transparency regarding why certain power flows were approved or deferred across the network. XAI tools applied post hoc on MARL-derived decisions can trace causal relationships between observed states (e.g., forecast deficits) and collective responses (e.g., ramp-up of reserve units), thereby validating alignment with operational rulesets [5]. Such explanations support accountability among interacting entities whose combined actions impact broader grid reliability.
The choice between strongly coupled coordination—requiring frequent information exchange—and loosely coupled strategies—where agents operate mostly independently with occasional synchronization—depends on both the physical system’s inertia and the capacity of the underlying ICT infrastructure. Fast-acting processes, such as frequency regulation, often demand near-continuous communication at millisecond scales, whereas slower thermal dynamics tolerate batched updates every few minutes or hours without compromising performance [52]. Aligning coordination frequency with process timescales ensures that distributed strategies remain both efficient and resilient, capturing the benefits of decentralization without undermining operational stability.
To conceptualize the learning process in decentralized systems, Figure 7 illustrates the Multi-Agent Reinforcement Learning (MARL) cycle. Agents interact with the physical environment, receiving state observations and rewards, which allows them to refine their policies autonomously over time.
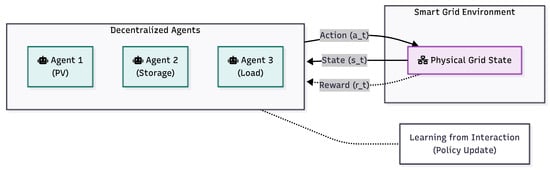
Figure 7.
Interaction diagram for Multi-Agent Reinforcement Learning (MARL). Agents (e.g., PV, Storage, Load controllers) perceive the grid state and execute actions. The environment returns a reward signal reflecting the quality of the action (e.g., cost savings, stability), driving the policy update process without requiring a predefined physical model [13,20].
From an operational perspective, Multi-Agent Deep Reinforcement Learning (MADRL) offers the significant advantage of scalability and adaptability, allowing the system to learn complex coordination strategies from experience without rigid pre-programming [20]. This approach is highly suitable for decentralized assets like EV charging networks or peer-to-peer trading markets, where keeping data local preserves privacy [19]. However, MADRL faces limitations regarding convergence stability and the difficulty of explaining policies derived from “black-box” neural networks [10]. Consequently, these agents are typically deployed as distributed software containers on Edge nodes (e.g., EV chargers, home gateways), while the training or coordination of global value functions is often synchronized via a federated Cloud aggregator to ensure system-wide stability [22].
3.4. Metrics and Datasets
A consistent evaluation framework is essential for comparing predictive models and ensuring their suitability for real-world deployment. This section outlines commonly used performance metrics and dataset considerations relevant to AI-driven energy forecasting.
3.4.1. Accuracy and Forecast Error Metrics
Evaluating predictive models in energy systems depends heavily on quantifying the difference between anticipated and actual outcomes using appropriate error metrics. These metrics do more than provide a numerical score; they inform model selection, guide hyperparameter tuning, and dictate operational trustworthiness in real-world applications. In contexts where IoT sensing streams are coupled with AI-based forecasting engines, accuracy metrics can also indirectly influence control decisions when automated systems adjust loads or schedules based on predicted conditions.
One of the most frequently applied measures is the Root Mean Square Error (RMSE), defined mathematically as
where are predicted values, are observed values, and n is the number of paired observations. RMSE’s squaring of residuals disproportionately amplifies larger errors, making it sensitive to extreme deviations, such as sudden spikes in demand caused by unexpected occupancy or equipment faults. This property can be beneficial when emphasizing the avoidance of rare but costly mispredictions. However, because RMSE is scale-dependent, it should only be used for comparisons involving forecasts of the same variable measured in identical units.
Mean Absolute Error (MAE) offers a more intuitive measure by averaging the absolute differences between predictions and actuals:
Changes in MAE are linear with respect to error magnitude, avoiding RMSE’s exaggerated penalization of outliers [53]. This characteristic makes MAE well-suited for operational monitoring where decision thresholds correspond directly to physical tolerances, for example, allowable deviation in HVAC setpoint predictions before occupant comfort is impacted.
Mean Squared Error (MSE), computed via
serves as both a standalone metric and as the precursor to RMSE. Within optimization frameworks combining multiple loss components, MSE often appears alongside MAE in weighted sums:
where controls relative emphasis between squared and absolute errors, is an L2 regularization coefficient, and denotes model parameters [17]. Such composite losses allow to tailor sensitivity to outliers versus uniform residual minimization while simultaneously managing overfitting through regularization.
To assess proportional accuracy rather than absolute magnitude differences, Mean Absolute Percentage Error (MAPE) is employed:
It expresses average deviations as a percentage of observed values, which aids interpretability for stakeholders less comfortable with unit-specific metrics [54]. However, MAPE’s reliance on division by observed values can distort assessments when approaches zero, an effect that should be carefully considered in low-load periods or when devices idle. An extension sometimes utilized in symmetrical evaluation contexts is Symmetric Mean Absolute Percentage Error (SMAPE), which normalises percentage errors by the average magnitude of forecasted and observed values rather than solely the latter.
For standardization across scales, especially when comparing performance across datasets with differing magnitudes, the Coefficient of Variation of RMSE (CV-RMSE) divides RMSE by the mean of observed values and typically expresses it as a percentage:
This form enables cross-variable comparisons provided both share consistent measurement granularity and time resolution [41]. CV-RMSE gains relevance in benchmarking across sectors, e.g., residential versus commercial datasets, where raw RMSE values may be misleading due to disparate consumption baselines.
Beyond direct error measures, R-squared () evaluates goodness-of-fit by representing the proportion of variance in observed data captured by the model:
A high indicates a strong correlation between predictions and actuals, but does not guarantee the absence of bias; models could track variation while systematically overshooting or undershooting actual values. In large-scale CNN-BiLSTM energy consumption forecasting studies, combined evaluation using RMSE, MAE, MAPE, and confirms alignment between predicted curves and real usage profiles under diverse temporal conditions [54].
Integrating these metrics into cross-validation schemes captures performance variability over temporal subgroups. For example, calculating monthly MAE or holiday-specific MAPE reveals where prediction models falter relative to routine operation days versus exceptional days such as public holidays [55]. Such stratified analysis allows for targeted model refinement, e.g., improving handling during irregular occupancy events without altering behavior under stable baseline conditions.
In multi-agent reinforcement learning environments from Section Distributed Coordination Strategies, forecast error metrics tie directly into reward structure design: higher penalties can be assigned for deviations measured via RMSE during critical grid states while lowering importance during surplus periods. When prediction outputs directly inform coordinated scheduling or dispatch actions across agents, accurate quantification ensures that behavior adapts appropriately to error magnitudes that truly matter operationally.
From a deployment perspective, under IoT-Edge-Cloud constraints, the compactness and computational simplicity of certain metrics (such as MAE) favor their use locally at edge nodes for quick assessment cycles without incurring heavy resource loads. Metrics that require aggregation over large datasets or more complex normalization steps can be reserved for periodic cloud-level evaluations, where broader comparative analytics help spot drift trends across distributed sites.
Applying explainable AI alongside error metrics provides transparency into why a given model’s score shifts across evaluation periods. Overlaying SHAP values with temporal distributions of MAE or MAPE identifies which predictors most strongly influence high-error intervals, guiding corrective retraining focused on problematic feature interactions rather than generic adjustments. In energy optimization systems that depend on accurate forecasts for proactive control decisions, this marriage between transparent attribution and quantitative evaluation forms an essential feedback loop that sustains both technical performance and stakeholder confidence over time [36].
3.4.2. Energy Savings and Economic Impact
Quantifying energy savings and their corresponding economic impact intertwines technical performance metrics with broader cost-benefit considerations. The influence of AI-driven optimization systems extends beyond reduced kWh consumption to include avoided operational expenses, deferred infrastructure investments, and lower environmental externalities. Various field studies have established empirical baselines for these effects, showing that reinforcement learning-based control frameworks can yield energy reductions averaging around 22% relative to standard automation strategies [16]. Translating such percentage savings into financial outcomes depends heavily on the contextual variables at play: local energy tariffs, demand charges, carbon tax policies, and maintenance costs driven by equipment usage patterns.
From an operational economics standpoint, a consistent reduction in peak load demand via predictive scheduling diminishes exposure to high tariff periods and lowers capacity charges levied by utilities. This price-avoidance effect becomes more pronounced in markets with dynamic pricing schemes that are sensitive to real-time grid constraints. In building-level scenarios integrating DERs (Distributed Energy Resources) such as photovoltaic arrays and battery storage, load shifting driven by AI forecasts enables greater self-consumption ratios; the monetary benefit here corresponds not only to displaced grid imports at retail rates but potential feed-in revenues where surplus generation is sold back into the network at preferential prices [52].
Economic calculations must include secondary savings beyond direct consumption reductions. Predictive maintenance, enabled by AI anomaly detection, reduces downtime and extends equipment life. For HVAC systems, improved scheduling cuts unnecessary compressor cycling, lowering wear-and-tear costs and the frequency of replacements [27]. To quantify this, project replacement timelines under different regimes and discount associated costs using net present value (NPV) analysis.
Aggregated across building portfolios, CO2 emission cuts derived from reduced electricity usage (often estimated at up to 25% alongside the noted 22% consumption decrease) can be monetized through carbon credit markets or internal sustainability valuations, depending on regulatory context. For commercial operators subject to ESG (Environmental, Social, Governance) reporting requirements, these reductions feed directly into shareholder value narratives and may qualify facilities for green financing instruments. Here, economic impact takes on a dual dimension: tangible cash flow from credits or tax breaks, plus intangible brand value enhancement.
When evaluating return on investment (ROI), payback periods offer a concise synthesis of cost-benefit dynamics. Evidence indicates that AI-driven optimizations often achieve favorable payback within short horizons, thanks to compounding financial gains from simultaneous reductions in electricity bills, demand charge mitigation, and operational efficiency improvements. Granular analyses partition these savings streams per category; for example, isolating savings from off-peak shifting versus outright efficiency improvement clarifies which strategies deserve prioritization within deployment roadmaps.
However, a nuanced examination exposes variability in economic outcomes. Tariff structures with low peak-to-off-peak differentials may yield modest load-shifting payouts compared to those with pronounced time-of-use pricing disparities. Similarly, facilities with already high baseline efficiency will see diminishing marginal returns from retrofitting advanced AI control unless targeting niche optimization such as thermal storage scheduling under renewable overgeneration conditions. This suggests optimal deployment strategies hinge on pre-assessment audits that model attainable savings against site-specific constraints.
Integrating multi-agent coordination elements into economic calculation frameworks allows for the modelling of collective efficiencies in networked infrastructures such as microgrids or district heating loops. Agents acting upon locally optimized objectives contribute indirectly to shared system benefits, e.g., smoother aggregate demand curves, which manifest financially as reduced balancing costs at the grid interface or eligibility for ancillary service markets compensating flexibility provision. These cooperative benefits must be allocated fairly among participants to maintain incentive alignment; mechanisms such as market-based auctions distribute remuneration proportionally to measured contributions to systemic stability [19].
At the strategic scale, deploying AI-enhanced GEBs (Grid-Interactive Efficient Buildings) reshapes utility capital planning by deferring capacity expansion investments [52]. For utilities, widespread responsive load management reduces the need for new peaker plants or substation upgrades that would be required by projected demand growth. Deferred capital expenditure becomes an avoided cost, benefiting not only building operators but also providing sector-level fiscal relief.
Economic modelling should also incorporate risk-adjusted valuation that reflects potential volatility in the achieved savings over time. Forecast-dependent optimization may underperform during atypical weather seasons or abnormal occupancy cycles; a sensitivity analysis using historical variance can bound the range of expected annualized savings figures. Combining deterministic savings components (derived from static schedule refinement) with stochastic ones (from forecast-contingent actions) yields a fuller distributional view relevant for investment appraisal.
A modern dimension involves adding explainability layers to economic assessments. Transparency about load manipulation decisions fosters stakeholder acceptance and is key to implementing costly strategies, such as curtailing non-essential loads during peak price intervals [56]. This acceptance is further supported by decision attribution, which clarifies links between predicted states (e.g., tariff spikes signaled by external price feeds) and avoided costs. Such documentation can be essential when seeking incentives tied to verifiable demand-response participation.
Projecting long-range impacts requires simulating how cumulative efficiency gains interact with evolving market conditions, such as declining solar feed-in tariffs due to policy shifts or increasing electrification loads from EV adoption. Scenario-based economic modelling then links these dynamics to potential futures: for example, one scenario may show stable ROI retention through diversified participation in flexible services, while another may reveal erosion of primary savings streams, offset only by emerging revenue channels.
Aligning technological metrics from Section 3.4.1 with expenditure and revenue models offers a clear view of the financial rationale for AI-enabled energy optimization. This pairing supports informed deployment, based not only on engineering feasibility but also on quantifiable economic benefit under varied conditions and regulations [3,16,52].
3.5. Critical Synthesis and Practitioner’s Guide
While the previous subsections detailed individual methodologies, selecting the appropriate architecture requires navigating trade-offs between accuracy, computational cost, and data availability. A critical synthesis of recent literature reveals that increased model complexity does not always translate to operational benefit.
3.5.1. Accuracy vs. Complexity Trade-Offs
Recent benchmarks challenge the assumption that deep learning is universally superior. For single-building forecasting with limited historical data, Huang and Kaewunruen [38] demonstrated that simpler Support Vector Regression (SVR) models () can outperform complex Transformer-based models () while consuming significantly fewer resources. The computational cost of Transformers outweighs their benefits when data is scarce or lacks high-dimensional cross-correlations. Conversely, for multi-building or urban-scale scenarios where capturing spatio-temporal dependencies between diverse assets is critical, Transformer architectures with attention mechanisms are indispensable, achieving up to 23.7% accuracy improvements over ARIMA/LSTM baselines by leveraging cross-series correlations [17].
3.5.2. Edge Feasibility and Latency
On edge devices, the decision boundary is dictated by hardware constraints. Standard Transformers are often prohibitive for microcontrollers due to memory bottlenecks. However, specialized “Attention-based TinyML” architectures now allow heterogeneous deployment, where critical attention mechanisms are accelerated on dedicated hardware while non-critical layers are pruned [34]. Practitioners should employ standard Deep Learning only when the inference latency budget exceeds 100 ms; for sub-millisecond control loops (e.g., frequency regulation), heuristic or lightweight decision trees remain the only viable option [33].
3.5.3. Decision Framework
To assist practitioners in selecting the optimal approach, Table 4 presents a decision matrix mapping common energy management constraints to the most suitable algorithmic families.
Table 4.
Practitioner’s selection guide for energy AI methods based on operational constraints.
4. Toward an Explainable and Distributed Framework
This section consolidates the insights obtained from the previous analysis of architectures, learning methods, and coordination schemes into a unified perspective oriented toward implementation. The goal is to outline how an explainable, distributed energy management framework can be structured so that predictive, optimization, and control components operate coherently across IoT, Edge, and Cloud layers while remaining interpretable for human stakeholders.
To operationalize these objectives, Figure 8 presents the conceptual architecture of the proposed Explainable and Distributed Energy Management Framework. The diagram illustrates the vertical integration from physical assets to cloud aggregators, highlighting the placement of Explainable AI modules at the Edge and the use of Federated Learning for privacy-preserving coordination.
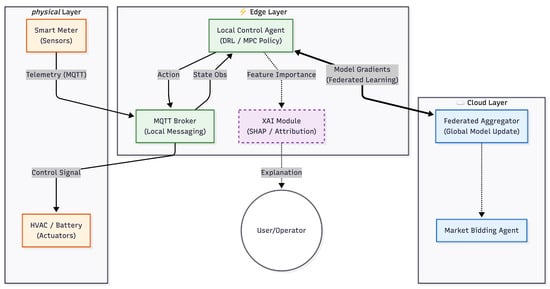
Figure 8.
The proposed Explainable and Distributed IoT-Edge-Cloud Framework. (1) Physical Layer: IoT sensors and actuators communicate via lightweight protocols (MQTT). (2) Edge Layer: Local agents perform real-time inference (TinyML) and generate local explanations (SHAP), ensuring low latency and autonomy. (3) Cloud Layer: Aggregates federated model updates and handles long-term strategic optimization, avoiding raw data transmission to preserve privacy.
4.1. Design Objectives
The first step in defining such a framework is to clarify the main design objectives that any practical implementation must satisfy. These objectives concern not only predictive performance, but also robustness, transparency, scalability, and suitability for deployment on heterogeneous hardware platforms. The following subsection focuses on accuracy and reliability as foundational requirements that influence all other architectural choices.
4.1.1. Accuracy and Model Reliability
Accuracy and reliability in AI models for distributed energy management fundamentally involve maintaining predictive and control performance across heterogeneous operating conditions without degradation due to temporal drift, incomplete data, or computational constraints. In contexts where outputs drive real-time optimization or dispatch, accuracy serves not merely as a forecast quality metric but as a linchpin for operational safety and economic viability. Reliability extends this by encompassing the consistency of outputs—whether forecasts or control directives—over time and across geographically or functionally diverse nodes.
The quantitative dimension of accuracy often begins with baseline error metrics such as RMSE, MAE, and MAPE [54], which provide numerical assessments of deviation between predicted and observed values. The choice among these is non-trivial; RMSE emphasizes penalizing large deviations, making it suitable in applications where rare but extreme mispredictions carry high cost implications, such as battery over-discharge events in storage scheduling. Conversely, MAE provides a more proportional measure of average deviation that aligns better with steady-state control, where incremental efficiency gains matter more than occasional extremes [53]. Incorporating CV-RMSE supports scaling comparisons across datasets from buildings or grids with disparate load baselines [41], while helps gauge how much variance the model captures without implying the absence of bias.
However, raw error statistics can be misleading if they neglect temporal stability. A model achieving low MAE during one season might exhibit volatility when weather patterns shift or occupancy behavior changes abruptly. Rolling evaluation windows address this by recalculating metrics periodically using recent data slices, revealing short-term trends in accuracy loss or gain. Detecting early-stage decline allows for intervention through model recalibration before operational consequences manifest.
Reliability also hinges on robustness against atypical inputs, sensor faults, incomplete datasets due to intermittent IoT connectivity, or abrupt contextual changes, such as sudden DER integration into a microgrid. Fault tolerance at the inference stage may involve imputation schemes for missing values combined with sensitivity analysis to ensure forecasts do not swing disproportionately under small perturbations. Models trained with noise injection techniques can exhibit improved stability because they learn distributions tolerant to imperfect data streams [59]. In distributed settings using federated learning, reliability additionally depends on managing uneven data quality across nodes; aggregation strategies must prevent outlier nodes from skewing global parameter updates while still incorporating valuable idiosyncratic patterns.
In multi-agent configurations that interact over shared objectives [22], accuracy has a cooperative dimension: one agent’s misprediction can cascade, distorting network-wide resource allocation decisions. Monitoring reliability at both individual and collective levels is necessary. Collective reliability refers to how well aggregated forecasts maintain coherence with actual system-state evolution, an aspect that is critical when agents act independently most of the time yet synchronize periodically (as in loosely coupled MARL systems). Integration with explainability tools such as SHAP [44] serves double duty here, tracing an unexpected spike in error to a specific input feature shift enables both correction in local models and coordination adjustments across peers.
Explicit consideration of model scalability impacts reliability under growing node populations typical of IoT–Edge deployments. Some regression frameworks [21] degrade in predictive performance when constrained hardware cannot support the required parameter volumes or update frequencies. Lightweight surrogate models distilled from heavier “teacher” architectures mitigate this problem while retaining acceptable levels of accuracy for local action execution [33]. Nonetheless, distillation processes require careful validation; over-compression risks eliminating subtleties essential for rare-event handling, lowering functional reliability under edge-case scenarios.
Hybridized forecasting approaches, statistical decomposition feeding residuals into ML regressors, enhance both accuracy and interpretability [36]. Deterministic components remain explainable and consistent unless structural changes occur in the underlying system; stochastic parts benefit from non-linear learning capacity to capture irregularities without replacing the statistically transparent backbone entirely. Such designs naturally create redundancy: if the ML layer encounters temporary drift during anomalous periods, the statistical layer can still anchor predictions within reasonable bounds until retraining restores performance.
Within optimization control loops informed by these forecasts [3], model reliability must extend into decision phase consequences; inaccurate predictions have operational latency effects that compound downstream. Validation protocols simulate sequences where forecast-induced actions play out under realistic sensor delays and actuation constraints to verify not only static prediction scores but also dynamic response fidelity. Reliability measures here might include tracking the stability of cumulative reward functions over simulated variability runs.
Operational explainability closely aligns with perceived reliability in stakeholder environments that require human oversight [6]. If an algorithm consistently recommends demand curtailment at certain intervals but occasionally fails without a clear cause, operator confidence erodes, even if mean accuracy remains statistically strong. Post-hoc interpretation layers connect observed behaviors with identifiable drivers, such as temperature thresholds crossing learned tipping points, thereby increasing trust by aligning decisions with defensible causal logic.
Environmental sustainability considerations underline why long-term model reliability matters beyond short-term metric wins. Continuous retraining cycles driven by unstable models consume additional compute power and energy; under large-scale UBEM contexts, this could materially offset gains from optimization itself. Designing models that maintain high accuracy without hyper-frequent retraining directly reduces net environmental impact and improves operational efficiency.
In sum, accuracy is a measurable outcome that shapes immediate optimization quality; reliability encompasses resilience, temporal stability, and trust-supportive transparency over extended operational horizons. Achieving both in distributed AI energy infrastructures means combining rigorous metric selection with resilience-focused design choices, from noise-tolerant training through hierarchical hybrid architectures, and embedding explainable diagnostics so that sustained performance aligns with both technical requirements and stakeholder assurance criteria [44,59].
4.1.2. Latency Constraints in Edge Environments
Latency in edge-based energy management environments plays a decisive role in determining how effectively AI-driven control loops can react to emerging conditions. The issue extends beyond raw computational speed to encompass the full end-to-end delay from sensor data generation to the execution of control actions on physical devices. This pathway includes sensing, local processing, communication (uplink or peer-to-peer), potential cloud-based computations, and downstream actuation. In distributed IoT-Edge-Cloud settings, each segment contributes to aggregate delay, making careful task allocation along the processing continuum essential [9]. When workloads demand near-instantaneous responses—such as frequency stabilization in microgrids or safety cutouts in industrial systems—milliseconds matter.
Deploying AI inference at the edge mitigates dependence on wide-area communication delays by enabling decisions close to data origin [33]. The resulting latency reduction is substantial compared with cloud-offloading models that transmit raw streams over bandwidth-constrained networks. For instance, thermal anomaly detection via smart cameras can run inference locally within 100 using optimized CNNs on embedded accelerators, whereas offloading the same workload upstream may yield multi-second delays due to fluctuating bandwidth, which directly affects the value of preventive interventions.
Message-oriented middleware introduces its own latency considerations. Lightweight protocols such as MQTT [24] reduce communication overhead, but broker placement and selected Quality of Service (QoS) levels influence timing. Higher QoS tiers, while increasing delivery guarantees, add confirmation overhead unsuited to ultra-low-latency control. Systems typically prioritize QoS for critical directives—e.g., load-shedding commands—and relax guarantees for non-critical telemetry. Co-locating brokers with edge nodes minimizes WAN hops but requires adequate provisioning to prevent the broker itself from becoming a bottleneck.
In multi-agent reinforcement learning settings [14], latency affects not only the timeliness of individual actions but also the stability of collective policy execution, because delayed information exchange causes agents to act on outdated data. Agents relying on outdated peer information risk misaligned behaviors, oscillations, or resource conflicts as a direct result of these delays. Asynchronous coordination addresses blocking due to delayed updates, but temporary inconsistencies are an expected consequence. Consensus-based fallbacks enable safe operation during communication lags, causing agents to adopt conservative setpoints until synchronization resumes.
Hardware constraints at the edge further influence achievable latencies. Microcontroller-based nodes cannot match the throughput of edge servers with GPUs or neural accelerators, yet they provide millisecond-scale responses for simpler workloads by avoiding network hops entirely. Model compression techniques—pruning and quantization—reduce computational demand without degrading inference quality. Because they reduce the number of required operations, these techniques directly translate into shorter execution times on constrained hardware.
Preprocessing steps prior to inference also contribute to delays when poorly optimized. Inefficient filtering, normalization, and feature extraction can add buffering overhead, which extends response time. Applying operator fusion and vectorized computation where possible minimizes such overhead, directly lowering latency. Event-driven architectures further reduce latency because processing is triggered only by significant changes, avoiding unnecessary workload from fixed polling intervals.
Latency constraints also interact with physical system inertia. Some processes—such as PV output fluctuations due to cloud movement—evolve over seconds; thus, forecasting delays of similar magnitude may remain acceptable for charge controller adjustments. Conversely, frequency dips following sudden load changes require sub-second corrective actions from storage assets, making any upstream delays detrimental [25]. Matching decision timing to process time constants ensures the right tasks remain localized, while slower dynamics can tolerate upstream routing.
Federated learning must also respect latency budgets during both parameter aggregation and model deployment. Wide-area aggregation introduces propagation delays that, if misaligned with operational cycles, can impede responsiveness. Scheduling federated updates during periods of reduced real-time sensitivity and compacting model updates before transmission helps reserve bandwidth for urgent control traffic.
Network heterogeneity complicates latency management. Low-power wireless mesh networks (e.g., Zigbee), common in building automation, offer energy efficiency but introduce hop-by-hop delays compared with wired Ethernet used in industrial microgrids [12]. Adaptive routing that shifts critical traffic onto lower-latency channels mitigates such disparities. Security layers also affect latency: encryption routines add processing overhead, and TLS handshakes or VPN tunnels impose setup delays [25]. Lightweight cryptographic primitives tuned for edge devices help balance security requirements with timing constraints important in protective relaying or fault isolation.
Architectural strategies often classify decisions by latency tolerance. Ultra-fast reactions execute fully on-device; moderately time-sensitive tasks—such as next-hour re-optimization—run at the edge; and long-horizon planning is delegated to the cloud. These divisions align naturally with hybrid control schemes that combine reactive local loops and predictive supervisory layers, ensuring that each decision tier operates within appropriate timing boundaries.
Ultimately, constraining latency in distributed energy management is not about maximizing absolute speed but about aligning computation with the temporal characteristics of the underlying physical processes while avoiding bottlenecks along the sensor—actuator chain. Deploying intelligence across multiple tiers offers redundancy against variable network conditions and ensures decisions are executed at the layer where their impact remains actionable. This reflects an engineering approach that is attentive not only to algorithmic efficiency but also to the physical constraints governing actionable time windows in cyber-physical energy systems [24].
4.1.3. Operational Workflow: The Teacher-Student Co-Evolution
To operationalize the proposed framework (Figure 8), we introduce a “Large and Small Model Co-evolution” mechanism. This workflow addresses the computational asymmetry between layers described in the Design Objectives. In this topology, the Cloud layer hosts a “Teacher” model—typically a complex Transformer or Deep Reinforcement Learning policy trained on aggregated historical data—capable of capturing high-order dependencies [9,17]. Conversely, Edge nodes run “Student” models: lightweight, quantized versions (e.g., TinyML) optimized for millisecond-latency inference on constrained hardware [33,34].
The coordination cycle functions as follows:
- 1.
- Global Training: The Cloud Teacher aggregates gradient updates from federated agents to refine a generalized global strategy without accessing raw local data [60].
- 2.
- Distillation and Deployment: The Teacher’s policy is compressed via knowledge distillation into a compact Student model that mimics the Teacher’s decision boundaries but with significantly fewer parameters. This Student model is transmitted downstream via MQTT to Edge Agents.
- 3.
- Local Inference and Adaptation: The Edge Agent executes the Student model for real-time control. If site-specific performance drifts (e.g., due to unique occupancy patterns), the Edge agent performs “personalized fine-tuning” and uploads only the weight deltas back to the Cloud to update the Teacher [60].
This bi-directional loop ensures that the Edge benefits from the “wisdom” of the Cloud without incurring latency penalties, fulfilling the requirement for scalable and responsive distributed intelligence.
4.2. Integration of MAS with Explainable AI
The integration of Multi-Agent Systems (MAS) with explainable AI requires a clear understanding of how individual agents contribute to global system behavior. Before analyzing specific coordination mechanisms or explainability techniques, it is essential to formalize the functional roles each agent type fulfils and how these responsibilities shape their interactions. Establishing this structure provides the foundation for embedding transparency, accountability, and interpretable decision-making within distributed energy management architectures.
Before detailing how individual agents operate within distributed decision-making architectures, Table 5 provides a comparative overview of common MAS configurations used in modern energy systems. The table summarizes the typical deployment environments (e.g., buildings, microgrids, electric mobility), the primary objectives each MAS configuration pursues, and the coordination or explainability requirements associated with them. This contextual framing helps situate the roles and responsibilities discussed in the following subsection.
Table 5.
MAS configurations across energy environments and primary objectives.
Agent Roles and Responsibilities
In distributed energy management systems, agents act as semi-autonomous decision-making entities whose responsibilities depend on their position within the system hierarchy, the information available to them, and their operational mandates. Their roles span from low-level data acquisition to high-level market participation, and clear functional delineation is essential to avoid redundancy, prevent conflicting actions, and enable the meaningful application of explainable AI across heterogeneous agent types.
In networked microgrids or regional integrated energy systems (RIES), aggregator agents typically serve as intermediaries between local controllers (e.g., building agents) and higher-order coordination actors such as distribution system operators (DSOs). They consolidate demand forecasts from multiple subordinate agents, compute reserve estimates, and relay flexibility offers to market mechanisms [61]. This virtual aggregation facilitates coordinated load-shaping strategies while preserving local privacy. Because aggregators influence the allocation of shared resources, they carry responsibility for ensuring fairness in distributing curtailment obligations or flexible capacity—an aspect closely tied to bias-mitigation challenges identified in modern MAS deployments [16].
At the asset tier, building agents control HVAC, lighting, onsite generation, and storage. They sense power demand profiles directly and reconcile internal needs with external directives from aggregators or supervisors [61]. This dual mandate needs priority schemes that balance global and local constraints. Explainability matters: agents must justify any deviations from upstream instructions, for example by citing occupant overrides, equipment safety, or regulatory rules.
RIES environments add horizontal interactions among peer hubs, where agents coordinate across electrical, thermal, and gas carriers [20]. In these multi-energy systems, the actions of one asset—for instance, increased heat pump load—affect downstream or laterally coupled devices. As a result, agent roles must incorporate real-time awareness of cross-carrier dependencies and participation in joint scheduling to maintain global efficiency.
Operational intelligence in each agent is modularized into four components: prediction, optimization, negotiation, and actuation. Prediction modules forecast variables within the agent’s scope. For example, building agents predict load profiles, and aggregators predict reserve availability. These forecasts often use machine learning with explainable outputs, such as SHAP feature attributions. Optimization modules turn forecasts into schedules or bids that meet both local objectives and system constraints. Negotiation modules handle exchanges of flexibility rights, using auction strategies [19] or Pareto front exploration for multi-objective coordination [22]. Actuation modules control physical hardware and monitor compliance.
Agents with dual consumer-producer roles additionally balance imports and exports to honor market commitments without compromising internal stability. In P2P trading contexts [21], this requires dynamic reprioritization based on real-time valuations of stored versus tradable energy. Explainability ensures transparency: if an agent declines to sell despite favorable prices due to anticipated reliability risks, the decision can be traced through interpretable policy logic.
In multi-agent reinforcement learning architectures [10], roles may map directly onto actor-critic distinctions. Some agents continuously gather state-action-reward trajectories for policy improvement, while others deploy trained policies on operational assets. Decentralized execution supports scalability and robustness in non-stationary environments where frequent global retraining is impractical [15]. Communication limitations impose additional responsibilities for selective state dissemination: transmitting only salient information reduces bandwidth usage, although it must be ensured that the shared features remain sufficient for coordinated action.
Agents responsible for shared storage resources must arbitrate conflicts when simultaneous charge or discharge requests exceed safe operational limits. Conflict resolution typically uses priority metrics—in which emergency support takes precedence over tariff-based arbitrage—or alternatively, algorithmic fairness indices. Integrating XAI facilitates post-event analyses explaining why some requests were granted while others were curtailed.
Cybersecurity responsibilities have become increasingly relevant. Because adversarial manipulation affecting one node can propagate through the MAS, sentinel agents may monitor transaction integrity using anomaly detection models trained on historical behavior. These watchdog agents periodically validate peers’ reported states against independent sensor observations to detect inconsistencies.
Adaptability is another cross-cutting responsibility. Agents incorporate federated learning updates delivered via lightweight protocols such as MQTT or execute scenario-based retraining when shifts in operational baselines are detected. This maintains model accuracy without centralizing sensitive data, aligning with privacy requirements typical of residential or multi-stakeholder commercial settings.
Assigning these interconnected responsibilities within a MAS framework enables functional modularity and establishes accountability patterns essential for explainability. Each role—aggregator, asset controller, forecaster, negotiator, trader, or security sentinel—links well-defined information flows with decision logic that can be audited. This structured mapping supports operator trust and stable automated collaboration under the volatile conditions characteristic of distributed energy systems [20,61].
4.3. Evaluation Guidelines
Evaluating distributed AI solutions in energy systems requires methodologies that remain valid under the practical constraints of real deployments. While algorithmic performance in controlled environments offers preliminary insight, meaningful assessment must consider how models behave when executed on heterogeneous, resource-limited edge devices embedded throughout IoT-Edge-Cloud architectures. To establish a realistic baseline for operational feasibility, it is necessary to benchmark models directly on representative hardware platforms under conditions that mirror real-world workloads.
4.3.1. Benchmarking on Edge Hardware
Benchmarking AI-driven energy management solutions on edge hardware involves assessing both computational feasibility and operational efficacy under the constraints typical of embedded and IoT environments. These devices often have limited processing power, minimal RAM, and stringent energy budgets, which means performance measurements cannot rely solely on metrics used in high-performance compute clusters. The benchmarking process should encompass inference speed, resource utilization (CPU cycles, memory footprint), thermal behavior, and the downstream impact on latency-sensitive control loops [33]. This aligns directly with the trade-offs discussed earlier in Section 4.1.2, where delays caused by slow inference or overloaded processors can compromise both individual agent actions and coordinated system performance.
A robust benchmarking regime distinguishes between static and dynamic workload profiles. Static profiling measures execution times and resource consumption for a fixed set of tasks—for example, predicting next-hour load using a regression model compressed through pruning and quantization. Dynamic profiling evaluates how these figures evolve when internal or external conditions change; fluctuating sensor streams, asynchronous message reception over MQTT [24], or federated learning updates injected into the model state all introduce variability that must be captured for realistic assessment. Measuring adaptability under dynamic loads is critical, as edge devices in energy systems must manage both routine prediction tasks and sporadic high-priority events, such as demand-response signals [25].
Hardware selection directly influences benchmark results. Microcontroller-based platforms such as ARM Cortex-M or RISC-V designs tolerate only lightweight models, making TinyML paradigms essential. For these targets, a primary benchmark metric is inference execution per milliwatt of power consumed. Embedding optimized kernels tuned for the architecture can drastically shorten execution paths: fused convolutions implemented within DSP extensions reduce clock cycles compared to general-purpose implementations. In contrast, single-board computers such as Raspberry Pi or NVIDIA Jetson Nano offer larger capacity but draw more power; benchmarks must weigh throughput gains against sustainability goals in long-term operation.
Benchmark methodologies should also include communication-related measurements, as IoT-Edge-Cloud architectures rely heavily on data exchange [9]. Execution speed loses practical value if output delivery to actuators or peer agents is delayed by queuing at network interfaces. Metrics such as end-to-end decision latency—from data acquisition through processing to actuation—capture this combined computational-communication performance. When using QoS levels from MQTT brokers to ensure delivery reliability, benchmarks should quantify how increased QoS tiers impact total latency relative to lower settings suitable for non-critical telemetry.
Resource saturation scenarios further illuminate real-world resilience. Running multiple inference instances concurrently while handling incoming federated learning parameters tests capacity isolation: ideally, updating local models with new weights should not starve active decision loops of CPU cycles. Benchmark runs can vary update size and frequency to identify thresholds beyond which degradation becomes unacceptable; this resonates with operational requirements for continuous availability in multi-agent coordination. Additionally, evaluating storage subsystem performance under read/write pressure is important, since temporary buffering of sensor data or intermediate activations can become bottlenecks if flash memory access speeds are low.
Thermal profiling complements computational benchmarks. Even modest MCUs housed in sealed industrial enclosures may face thermal accumulation during sustained workloads, especially when event bursts cause frequent neural inference spikes. Measurements should track temperature rise under prolonged synthetic stress alongside normal operational patterns; coupling these results with duty-cycle optimization strategies helps prevent heat-induced throttling.
Explainability targets reshape what constitutes acceptable benchmark outcomes [6]. If an agent’s role requires producing SHAP-value interpretations locally rather than offloading to cloud services, benchmark designs must include the time and resource costs of generating these attributions within tight latency budgets. Compression or approximation techniques applied to XAI outputs may also be evaluated: reduced-dimensional explanations can maintain transparency while fitting within hardware limits.
Comparative benchmarking between deployment modes offers insight into configuration trade-offs. Measuring identical workloads executed entirely on-device versus partitioned across edge nodes reveals shift points where network transport overhead outweighs computation savings from distribution. Hybrid setups may achieve optimal balances in which feature extraction occurs locally while inference runs on a nearby edge server equipped with moderate acceleration resources. Battery-powered deployments add another benchmark dimension: energy per inference cycle over extended periods informs viability for autonomous operation without maintenance intervention. A model producing predictions every 5 may operate comfortably within energy envelopes with aggressive quantization, whereas a less-optimized counterpart could halve its operational lifetime.
It is equally valuable to assess interoperability overhead in heterogeneous hardware fleets speaking mixed protocols, such as BACnet internally for building automation and MQTT externally for higher-level coordination [24]. Gateway translation delays must be incorporated into total action timing, as they affect cross-protocol responsiveness.
Finally, benchmarking should feed back into iterative design decisions rather than serve as a one-off validation step. Continuous monitoring during live deployment can track drift from baseline metrics due to environmental changes or firmware updates, an approach consistent with the sustained reliability goals discussed in Section 4.1.1. Real-time telemetry on inference latencies, memory allocations, packet turnaround times, and energy draw enables micro-adjustments before small inefficiencies accumulate into functional impairments across distributed MAS deployments.
When structured correctly, these benchmarking activities balance theoretical indicators with applied operational realities. They expose bottlenecks caused by device constraints, quantify communication impacts across realistic topologies, measure the local costs of explainability integration, and reveal endurance factors critical for unassisted field operation. This multidimensional view ensures that models validated in laboratory conditions can sustain their intended accuracy, responsiveness, and transparency within the unpredictability of edge-level energy management environments.
4.3.2. Key Performance Indicators for Energy AI
Key performance indicators (KPIs) for AI-driven energy systems provide quantifiable metrics for assessing how well deployed algorithms, architectures, and coordination mechanisms achieve their design objectives under operational constraints. In practice, these indicators span multiple dimensions: technical predictive accuracy, optimization efficiency, economic benefit, environmental impact, reliability of decision-making processes, and explainability compliance. Their selection is non-trivial because each indicator both reflects and influences deployment priorities. For instance, placing disproportionate emphasis on forecast accuracy may overlook latency limits that could delay the execution of optimal decisions despite near-perfect prediction scores [9].
Technical KPIs are most often grounded in statistical error metrics. Building on measures discussed previously, such as RMSE, MAE, and MAPE [54], operators may define thresholds for acceptable deviation based on equipment physical tolerances or contractual obligations with grid providers. A KPI might specify: “Maintain daily RMSE below 5% of average load” for core forecasting models linked to HVAC scheduling. This ensures fixed bounds on predictive deviations across varying load profiles. Complementing absolute error measures with correlation-based KPIs, such as , captures alignment between predicted and observed trends without discarding information about variance coverage [41]. The composite view prevents cases in which a model tracks variation while sustaining bias that erodes downstream control quality.
Optimization-centric KPIs focus on how effectively AI systems allocate resources or schedule loads in line with policy objectives. One example involves quantifying energy savings percentage against a rolling baseline prior to AI deployment. Savings must be paired with operational KPIs, such as “Peak demand reduction exceeding 15% during tariff-sensitive intervals,” ensuring that reductions occur during the periods with the highest financial returns. In multi-agent settings, fairness indices emerge as critical indicators of equitable resource distribution among agents participating in shared storage or demand response programs [22]. If some agents consistently receive preferential allocations due to model bias or communication latency effects, system-level stability could be compromised.
Economic KPIs integrate technical performance with direct monetary impact. Examples include average avoided cost per kWh shifted outside peak times or cumulative demand charge reductions over a billing cycle [52]. These provide transparency around ROI trajectories by connecting consumption changes directly to capital flow impacts. When DER integration is present, KPIs might track improvements in the self-consumption ratio—the percentage of generated renewable energy consumed onsite rather than exported at lower tariff rates—which is useful for gauging the optimization of local generation assets.
Environmental KPIs quantify sustainability contributions alongside economic results. Carbon-intensity reduction per unit of energy consumed offers a normalized measure, comparable across different facility sizes and fuel types [25]. Emission reductions can be aggregated into monetizable carbon credit equivalents to support strategic decisions in organizations pursuing ESG commitments. Reduced equipment cycling can extend asset lifetimes and decrease material waste. These secondary effects can be expressed as lifecycle-extension KPIs based on avoided wear metrics.
Reliability-related KPIs address the continuity and stability of AI outputs over time. Parameters such as “Mean time between forecast errors exceeding tolerance” reflect robustness to drift conditions or transient anomalies in input data streams. More granular reliability KPIs might monitor the rate of successful actuation events triggered by AI recommendations; any divergence between issued commands and executed actions may indicate coordination flaws or hardware incompatibilities that require remediation.
Latency-focused KPIs recognize that timeliness is itself a determinant of operational success in edge-based contexts. An indicative KPI could constrain “Median decision latency under 200 from sensor input to actuator signal” during peak loads. Distribution analysis (e.g., 95th percentile response times) further accounts for tail delays that may dominate worst-case risk scenarios such as frequency regulation events requiring sub-second intervention.
Explainability compliance emerges as a distinct KPI set, particularly relevant where regulatory approval requires traceable logic behind automated decisions. Metrics could include the proportion of actions accompanied by valid post-hoc attribution reports (e.g., SHAP explanations generated within prescribed latency) [36]. Another plausible target is an “Average stakeholder satisfaction score” derived from periodic surveys assessing clarity and usefulness of AI system reports; while qualitative, structured rubrics maintain consistency across evaluation cycles.
Federated learning deployments introduce new KPIs focused on improving models collaboratively, without centralized data aggregation. These KPIs include the bandwidth used per update round compared to the accuracy improvement after aggregation. A low ratio of data transferred to accuracy gained indicates efficient federated optimization. Privacy is measured by how well protocols comply with data governance rules, resulting in a KPI that blends ethical and technological objectives.
In multi-agent reinforcement learning for energy management, coordination efficiency is a key KPI. For example, the measure “percentage of synchronous action alignment within allowable tolerance windows” shows how often decentralized agents act together when necessary, for example during coordinated load shedding [20]. Auction-based strategies use settlement timeliness KPIs to track how quickly the process moves from bid request to final allocation, ensuring market mechanisms respond within required time constraints.
System scalability KPIs anticipate expansion needs by benchmarking incremental resource consumption per added device or agent against defined ceilings to ensure sustainable growth without degrading overall performance metrics. This can include modelling bandwidth load, latency shifts, and aggregated error propagation as node counts increase. Security-linked KPIs may quantify anomaly-detection rates reported by embedded monitoring agents relative to total transactions processed. Lower anomaly rates, combined with high detection accuracy, suggest that protective layers are effectively integrated within MAS architectures.
When deploying BACnet-MQTT hybrid environments in IoT-Edge-Cloud infrastructures, interoperability health becomes another relevant KPI set: the proportion of cross-protocol message translations completed successfully without loss or semantic distortion serves as a proxy for integration reliability across heterogeneous device fleets. Continuous monitoring guards against hidden degradation in communication pathways that may cascade into erroneous AI input states.
Ultimately, these KPIs form an interconnected landscape rather than isolated targets: gains in predictive accuracy may improve optimization efficiency; latency reductions can boost coordination alignment; explainability compliance supports stakeholder trust; and scalability oversight preserves performance during network growth. Structuring them cohesively ensures that assessment frameworks reflect the real-world interplay between diverse technical and organizational priorities that shape the long-term viability of distributed AI energy systems.
5. Discussion and Research Gaps
The previous sections have outlined architectures, learning paradigms, and deployment patterns for AI-driven energy management across IoT, Edge, and Cloud infrastructures. However, practical adoption hinges on understanding the trade-offs that arise when these techniques are instantiated in real systems, particularly between model complexity and latency, the tension between reinforcement learning performance and explainability, and the feasibility of federated learning under heterogeneous, privacy-constrained conditions. This section discusses these issues and identifies open research gaps that must be addressed before large-scale, trustworthy deployment becomes routine.
5.1. Trade-Offs in Model Complexity and Latency
Balancing model complexity with latency constraints in distributed energy management is a central design challenge. Deeper neural architectures, multi-objective DRL policies, and richer feature sets typically enhance predictive fidelity and control performance, but also raise computational and communication demands that may limit real-time responsiveness, particularly under the edge constraints described in Section 4.1.2.
Complex models are attractive because they capture non-linearities and heterogeneous signals [52]. In multi-agent DRL, specialized actor networks can improve decision quality, though maintaining multiple policies increases inference load [22]. Transformer-based forecasters scale more efficiently than earlier deep models, yet inference times can still exceed acceptable control windows in applications requiring fast demand response or frequency support.
A practical way to moderate these costs is through model compression. Pruning, quantization, and knowledge distillation shrink parameter counts and reduce runtime while preserving most predictive performance, though over-compression risks degrading behavior during rare or extreme events [33,34]. The communication overhead associated with high-capacity models is also non-negligible: richer representations imply larger update payloads in federated learning settings, which can delay local model refreshes in low-bandwidth environments.
Model selection must therefore reflect the temporal characteristics of the underlying process. Slowly varying dynamics, such as thermal inertia in buildings or storage systems, can tolerate more sophisticated pipelines, whereas sub-second grid-support tasks benefit from simple, deterministic policies that guarantee bounded latency even at some cost to optimality. Hybrid multi-agent approaches follow a similar logic: lightweight local policies ensure fast reaction, while periodic synchronization with a more expressive central model maintains global coherence [55].
Explainability requirements further influence architectural choices. Post-hoc attribution for complex models adds computational overhead, whereas inherently interpretable or compact architectures can provide timely explanations, which is valuable in regulated settings.
Overall, the balance between complexity and latency is context-dependent. Environments with strict real-time constraints favor conservative architectures augmented with selective compression, while systems with looser timing budgets can exploit deeper or multimodal models for incremental accuracy gains. Achieving this balance requires explicitly mapping each control task’s latency tolerance to the performance benefits achievable through additional model complexity, and adjusting these mappings as operating conditions evolve.
5.2. Challenges in Time Series Explainability
While XAI tools like SHAP and LIME are frequently applied to energy forecasting models, their direct transfer from tabular data to time series domains introduces fundamental validity challenges. A primary issue is the violation of feature independence assumptions. Standard perturbation-based methods (e.g., Kernel SHAP) treat input features as independent; however, in energy time series, a value at time t is highly autocorrelated with . Perturbing one time-step without adjusting its neighbors creates unrealistic input sequences (out-of-distribution samples) that the model never encountered during training, leading to unreliable attribution scores [5,7].
Furthermore, “raw” feature attribution is often semantically meaningless to non-expert stakeholders such as facility managers. Explaining a predicted load spike by highlighting that “lagged consumption at h had a high SHAP value” provides little actionable insight. To be useful, explanations must bridge the gap between low-level data points and high-level operational concepts. For instance, a meaningful explanation should aggregate temporal dependencies to identify that “the rate of temperature increase this morning mirrors historical heatwave patterns,” rather than isolating individual hourly inputs.
To address this, recent research is shifting toward attention-based architectures (e.g., Temporal Fusion Transformers) where interpretability is intrinsic rather than post-hoc. Attention weights can visualize which historical time-steps (e.g., yesterday’s peak vs. last week’s average) the model prioritized, preserving the temporal structure [17,35]. Additionally, context-aware XAI frameworks are emerging that select background datasets based on specific anomaly contexts (e.g., distinguishing between holidays and workdays) to stabilize explanations and reduce the variance often observed in standard SHAP implementations [5].
5.3. Challenges in Explainable Reinforcement Learning
Reinforcement learning frameworks applied to energy management face a distinctive set of challenges when explainability becomes a design requirement. These difficulties are not confined to post-hoc interpretation; they extend into how policies are learned, represented, and deployed in ways that must remain transparent across heterogeneous stakeholders. In contexts where multi-agent deep reinforcement learning coordinates distributed assets, decision pathways are often the outcome of high-dimensional state–action mappings optimized via iterative interaction rather than fixed analytical formulations. This opacity is compounded by the adaptive nature of policies, which evolve over time, meaning an explanation valid at one stage of training or under certain environmental conditions may no longer apply after further learning cycles.
One primary obstacle lies in the stochasticity inherent to most policy exploration strategies. Techniques such as -greedy action selection or entropy-regularized policies deliberately introduce randomness to promote exploration. From an interpretability standpoint, this creates tension: decisions taken under exploration may deviate from established optimal patterns not due to environmental changes but because of deliberate algorithmic noise. In safety-critical or compliance-driven energy settings, such as load-shedding for grid protection, operators require assurances that all automated actions adhere to known safe boundaries [6,36]. Explaining why an agent chose a suboptimal but exploratory action in such contexts is particularly problematic because standard XAI tools such as SHAP assume deterministic functional mappings between inputs and outputs.
The temporal credit assignment problem adds another layer of complexity. RL agents optimize long-term cumulative rewards, and an action’s ultimate impact may be mediated by sequences of future events and other agents’ behaviors. Explaining why a certain control decision was made thus cannot be reduced to attributing influence to immediate state variables; it demands tracing downstream effects through potentially long time horizons. Tools adapted from supervised learning attribution struggle here because they are not designed to capture chains of interdependent consequences across multiple steps or actors. Even when hierarchical DRL architectures break problems into shorter sub-tasks, cross-level dependencies persist, making causal reasoning about composite decisions non-trivial.
Partial observability in realistic energy systems compounds these issues [10]. Agents often operate with incomplete local information due to sensing limitations, privacy-preserving constraints in federated setups, or communication delays. As a result, decisions incorporate estimated states formed via recurrent networks or belief updates. This internal uncertainty is rarely surfaced in explanations presented to human operators, yet it significantly shapes policy execution. Conveying not only which factors were influential but also how confident the agent was about its state estimation could improve trustworthiness but requires enriched explanation formats that standard feature-attribution methods do not produce.
Multi-agent coordination introduces further complications. In distributed settings with flexible roles such as aggregators and asset controllers, one agent’s choices may reflect implicit predictions about peers’ future actions rather than immediate environmental cues. Standard XAI analyses conducted at the single-agent level risk misattributing importance if they ignore inter-agent influence channels, particularly when reward functions intertwine local and global terms. Capturing these relational dependencies demands explainability approaches that can parse joint policy spaces or model interactions as structured dependencies rather than independent decision rules.
The stability problem identified for interpretability tools such as Kernel SHAP is especially pertinent in RL contexts. Kernel SHAP’s variance across runs can undermine confidence if its attribution ordering changes simply from re-running on identical inputs. Since RL environments already embed variability through stochastic transitions and sampling noise, compounding this with unstable explanation outputs risks further eroding stakeholder trust. Achieving consistency might require integrating explanation generation into training loops so that models are jointly optimized for task performance and attribution stability, at the cost of additional complexity and possible trade-offs in raw control rewards.
Domain-specific semantics in energy use cases, such as mixed energy carrier systems or HVAC comfort–cost trade-offs [64], create additional barriers. Even if a DRL policy produces accurate control consequences, raw feature attributions may refer to low-level sensor channels without mapping them back to meaningful operational concepts for domain experts. Bridging this gap requires ontological layers translating technical variables into terms aligned with operator mental models, an extra design step that is rarely standardized across projects. Without such mapping, explanations may technically satisfy transparency metrics while remaining unintelligible for the intended user. Aligning explanations with regulatory compliance frameworks also entails quantifying not only what factors drove a decision, but also demonstrating that prohibited factors did not influence outcomes. For instance, in residential demand response programs that adhere to privacy guidelines, an agent must demonstrate that personal behavioral data did not materially sway load control decisions beyond allowable risk thresholds. Existing RL-focused XAI methods seldom provide negative relevancy reports certifying the absence of influence from particular variables, limiting adoption where auditability is critical.
Federated reinforcement learning implementations pose their own explainability concerns. Policy updates aggregated from heterogeneous nodes may blend idiosyncratic local biases into global models without explicit traceability of which regions’ experiences shaped particular behavioral shifts. Post-hoc analyses must then disentangle contributions from different participants without access to their full datasets, a technically open problem given the privacy constraints central to federated design. The computational overhead of generating explanations adds additional friction to edge-deployed RL controllers constrained by latency budgets, as discussed in Section 5.1. Many local agents lack the resources for exhaustive perturbation-based attribution over high-dimensional state spaces; approximations can speed up computation but risk oversimplification that strips away nuanced cause-and-effect linkages essential for operational clarity. Balancing fidelity of explanation with speed remains an unresolved engineering trade-off for embedded deployment. Finally, there remains a methodological gap between explaining static policy behavior post-training and explaining adaptive on-policy updates during continuous learning phases common in non-stationary environments, such as smart grids with increasing renewable penetration. Stakeholders may accept opaque adaptation if overall reward trends are upward, but rapid unexplained shifts, perhaps triggered by rare-event encounters, can provoke distrust or unsafe outcomes if left uninterpreted at deployment time. Streaming-compatible XAI capable of producing incremental updates that track changing policy logic could mitigate this risk, but it demands efficient temporal differencing methods absent from most current toolkits.
Addressing these intertwined challenges points to integrated research strands: stability-enhanced XAI algorithms co-trained with RL policies; relational explainers that capture multi-agent influence structures; semantic abstraction layers linked to domain ontologies; resource-aware approximation schemes for embedded contexts; and streaming-capable attribution tracking across continual adaptation cycles. Advancing along these vectors would improve both functional transparency and operational trust without forfeiting the adaptability advantages that make reinforcement learning attractive for complex distributed energy systems.
5.4. Federated Learning for Edge-Based Energy AI
Federated learning (FL) frameworks offer a promising approach for training AI models for energy management without violating data privacy regulations or overburdening network capacity by transmitting raw measurements from edge devices. The premise is particularly appealing given the heterogeneity of data sources in distributed IoT–Edge environments: residential smart meters, industrial load controllers, photovoltaic inverters, and occupancy sensors all generate patterns that differ in scale, resolution, and statistical distribution. Traditional centralized training not only risks exposing sensitive operational data but also struggles to aggregate meaningful models under non-IID distributions typical of geographically and functionally diverse energy assets. Personalized federated learning aims to address this by adapting global parameter updates to each client node’s local peculiarities. This adaptation can markedly improve performance when standard global models underfit or misalign with site-specific conditions, a limitation visible when forecasting building-level consumption using models trained on regionally aggregated datasets. Choosing the appropriate personalization strategy is critical. Clustering-based approaches group clients with similar data patterns before aggregating within these subsets, but this adds complexity and may introduce privacy vulnerabilities if cluster membership reveals sensitive attributes. Optimization-based personalization avoids some of these shortcomings by adjusting objective functions or applying regularization at each client, enabling alignment with the global model while respecting local deviations [65]. Moreover, ensuring data privacy in these distributed interactions remains paramount for user acceptance [57,58]. This aligns well with constrained edge computing, where heavy reconfiguration overhead is undesirable.
Architectural choices for the global model have substantial downstream implications. Many existing energy prediction implementations rely on baseline LSTM or CNN models; expanding to advanced architectures, such as sparsity-constrained transformers embedded within mixture-of-experts configurations, promises improved adaptability across heterogeneous conditions while avoiding unnecessary compute bloat at nodes that do not require all experts’ capacities. Sparse gating in mixture-of-experts ensures that only relevant sub-models are activated locally, keeping inference latency low and reducing RAM usage on microcontroller-class devices. This design dovetails with the latency concerns discussed earlier: complex yet modular networks can deliver high predictive fidelity without imposing uniform resource demands across all FL participants.
Multi-task learning integrated into federated schemes adds another dimension. Related objectives, such as load forecasting, renewable generation estimation, and anomaly detection, can share model components while retaining task-specific heads. Cross-task sharing improves sample efficiency per device but complicates aggregation logic because weight updates from different tasks have asymmetric value depending on node specialization. Implementations for building energy forecasting have shown that weighting mechanisms that control the influence of inter-task parameters can fill knowledge gaps between underrepresented and overrepresented tasks while suppressing noise propagation from poorly performing nodes.
From a communication perspective, FL’s key advantage lies in reducing upstream bandwidth demand by transmitting compact gradient updates or weight deltas rather than high-frequency raw telemetry [26]. Leveraging lightweight protocols such as MQTT as the transport layer for FL updates minimizes additional messaging burden atop existing control traffic, though ensuring message sequencing and version integrity becomes essential to avoid stale model deployments corrupting local policies. Edge–cloud orchestration can reduce round-trip delay by performing aggregations on intermediate edge servers rather than distant cloud instances. Periodically retained “last valid” model parameters help reboot nodes gracefully after connection interruptions without forcing full retraining cycles upon reconnection.
Security considerations extend beyond transport encryption. Poisoning attacks, in which adversarial clients submit malicious gradients to the federation, could destabilize or bias shared policies in ways that are damaging to grid safety or economic fairness [6]. To mitigate this, Robust Aggregation algorithms, such as Krum or Coordinate-wise Median, serve as essential defense layers. Unlike simple averaging, these methods employ statistical selection processes to filter out malicious updates based on their spatial distance from the majority consensus. Incorporating such outlier detection routines into the aggregation process helps isolate adversarial contributions that deviate significantly from peer consensus without prior justification. In energy market participation agents, for example, surrogate validation against known price–load dynamics can act as a sanity check before accepting updates influencing bidding strategies.
Heterogeneous hardware tiers introduce further complexity in scheduling aggregation rounds and deciding model architecture baselines. Low-power embedded clients may only support compressed student networks distilled from richer teacher models maintained at more capable nodes; conversely, industrial controllers might handle full-scale models and contribute more exhaustive updates. Weighting client contributions by both dataset quality/volume and processing capability prevents skew in which weaker-device noise dominates aggregated parameters solely because of numeric prevalence in participant counts. Adaptive participation rules allow under-resourced nodes to skip certain rounds during high-load intervals without forfeiting long-term inclusion in federation gains.
Privacy-preserving extensions, such as secure aggregation, ensure that even partial gradient information cannot be reverse-engineered into raw consumption traces. Combining these cryptographic methods with compression algorithms supports both confidentiality and communication efficiency, though tuning compression ratios is delicate: overly aggressive quantization may erode convergence rates for time series models sensitive to small parameter perturbations. Experiments show that maintaining modest precision (e.g., 8-bit quantization) strikes an effective balance between transfer size reduction and final accuracy retention for LSTM-based federated predictors deployed across smart building fleets.
The interplay between FL cycles and continual learning requirements introduces temporal coordination challenges. Energy usage patterns evolve due to seasonal shifts, retrofits, or tariff changes; if FL round frequency is too low relative to the rate of drift, outdated policies persist locally beyond their useful life. Conversely, overly frequent rounds strain bandwidth budgets and may render marginal gains negligible compared to the cost of synchronization. Adaptive triggering mechanisms based on monitored forecast error spikes at the client level offer one compromise: initiate an off-cycle FL update only when local MAE exceeds a time-adjusted threshold for sustained periods, aligning computational effort with practical need while improving relevance of distributed learning progression.
Integrating FL directly into multi-agent architectures can enhance collaborative optimization without sacrificing the autonomy inherent to agent-based control schemes described earlier in Section 4.2. Each agent trains its own local model segment, such as a forecast submodule or bidding policy network, and contributes selectively through federations scoped by task similarity rather than sheer geographic proximity. This preserves diversity where beneficial (e.g., diverse bidding tactics) while harmonizing shared competencies, such as net demand prediction, which is critical for joint actions, such as coordinated load curtailment during grid stress events. In such hybrids, explainable AI layers operate both locally (per-agent decision transparency) and globally (post-aggregation attribution), closing feedback loops between distributed autonomy and overarching strategic coherence while staying within privacy-compliant operational boundaries enabled by federated design principles.
6. Conclusions
Advancements in artificial intelligence for energy management have demonstrated substantial potential when combined with distributed architectures, multi-agent systems, and explainable frameworks. The transition from centralized EMS/BMS models to IoT-Edge-Cloud paradigms mitigates scalability bottlenecks, latency issues, and vulnerability to single points of failure. By relocating computational tasks closer to data sources and granting greater local autonomy, these architectures enhance responsiveness and resilience in environments characterized by heterogeneous assets and fluctuating operating conditions.
Multi-agent reinforcement learning approaches provide adaptive coordination mechanisms that reconcile local objectives with global system goals through negotiation, auction-based resource allocation, and Pareto-based optimization. Embedding explainable AI techniques within these frameworks is essential for transparency, operator trust, and regulatory compliance. Feature attribution methods and model-agnostic explanations help reveal decision causality, narrowing the gap between complex model outputs and the expectations of system operators and other stakeholders.
The deployment of AI models on low-power embedded systems underscores the importance of model compression, pruning, and quantization to satisfy strict energy and latency constraints without unacceptable losses in predictive performance. Federated learning has emerged as a promising strategy for training models collaboratively across distributed nodes while preserving data privacy and minimizing communication overhead. This paradigm aligns with the inherent heterogeneity of energy systems by enabling local personalization that reflects site-specific conditions while still leveraging shared global knowledge.
Evaluation metrics that jointly consider forecast accuracy, latency, economic impact, and explainability provide a comprehensive basis for assessing AI-driven energy solutions. Benchmarking on edge hardware highlights concrete trade-offs between computational complexity and real-time responsiveness, supporting hybrid architectures that allocate tasks according to latency sensitivity and available resources. At the same time, integrating multi-agent systems with explainable AI requires clearly defined agent roles, robust communication protocols, and auditable decision trails to maintain coordination integrity and support post-hoc analysis.
Significant challenges remain, particularly in providing stable, meaningful explanations for reinforcement learning policies in multi-agent, partially observable settings, where stochastic exploration and long-term credit assignment shape decision pathways. Addressing these challenges requires new XAI methods that capture temporal dependencies, inter-agent influences, and uncertainty, alongside architectural and compression techniques that balance model complexity with strict latency and reliability requirements. Overall, the synthesis of distributed AI architectures, multi-agent coordination, explainability frameworks, and privacy-preserving learning paradigms outlines a promising trajectory for sustainable, efficient, and trustworthy energy management systems, while also defining a clear agenda for future research and large-scale deployment.
Author Contributions
C.Á.-L. led the conceptualization of the study, designed the methodological structure, conducted the formal analysis, and carried out the investigation and data curation, including the compilation, organization, and evaluation of the reviewed literature. He was also responsible for developing the initial manuscript draft, preparing all figures and tables, and generating the visualization components associated with the framework and comparative analyses. A.G.-B. contributed to the conceptual refinement of the research scope, supported the methodological validation, provided technical and analytical resources, and participated actively in manuscript review and editing. He additionally supervised the research process, ensured coherence across sections, and oversaw project administration throughout the preparation of the work. T.L. contributed to the investigation through specialized domain insights in distributed optimization and multi-agent systems, provided essential academic resources and validation feedback, participated in the critical revision of the manuscript, and supported the supervision of the study. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Secretary of State for Digitalization and Artificial Intelligence and by the European Union (Next Generation) within the framework of the Recovery, Transformation and Resilience Plan (International Chair Project on Trustworthy AI), grant number TSI-100933-2023-0001. Additionally, this work was supported in part by the National Natural Science Foundation of China under Grant numbers 62422117 and U2541215.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| BACnet | Building Automation and Control Networks |
| BEMS | Building Energy Management System |
| DER | Distributed Energy Resources |
| DL | Deep Learning |
| DRL | Deep Reinforcement Learning |
| EMS | Energy Management System |
| FL | Federated Learning |
| IoT | Internet of Things |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| MARL | Multi-Agent Reinforcement Learning |
| MAS | Multi-Agent System |
| MILP | Mixed-Integer Linear Programming |
| MPC | Model Predictive Control |
| MQTT | Message Queuing Telemetry Transport |
| RMSE | Root Mean Square Error |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| XAI | Explainable Artificial Intelligence |
References
- González-Briones, A.; De La Prieta, F.; Mohamad, M.S.; Omatu, S.; Corchado, J.M. Multi-Agent Systems Applications in Energy Optimization Problems: A State-of-the-Art Review. Energies 2018, 11, 1928. [Google Scholar] [CrossRef]
- Al Sayed, K.; Boodi, A.; Sadeghian Broujeny, R.; Beddiar, K. Reinforcement learning for HVAC control in intelligent buildings: A technical and conceptual review. J. Build. Eng. 2024, 95, 110085. [Google Scholar] [CrossRef]
- Ramesh, S.; Sukanth, B.N.; Sathyavarapu, S.J.; Sharma, V.; Nippun Kumaar, A.A.; Khanna, M. Comparative analysis of Q-learning, SARSA, and deep Q-network for microgrid energy management. Sci. Rep. 2025, 15, 694. [Google Scholar] [CrossRef]
- Alhasnawi, B.N.; Jasim, B.H.; Esteban, M.D.; Guerrero, J.M. A Novel Smart Energy Management as a Service over a Cloud Computing Platform for Nanogrid Appliances. Sustainability 2020, 12, 9686. [Google Scholar] [CrossRef]
- Noorchenarboo, M.; Grolinger, K. Explaining deep learning-based anomaly detection in energy consumption data by focusing on contextually relevant data. Energy Build. 2025, 328, 115177. [Google Scholar] [CrossRef]
- Alsaigh, R.; Mehmood, R.; Katib, I. AI explainability and governance in smart energy systems: A review. Front. Energy Res. 2023, 11, 1071291. [Google Scholar] [CrossRef]
- Salih, A.M.; Raisi-Estabragh, Z.; Galazzo, I.B.; Radeva, P.; Petersen, S.E.; Lekadir, K.; Menegaz, G. A Perspective on Explainable Artificial Intelligence Methods: SHAP and LIME. Adv. Intell. Syst. 2025, 7, 2400304. [Google Scholar] [CrossRef]
- Moraliyage, H.; Dahanayake, S.; De Silva, D.; Mills, N.; Rathnayaka, P.; Nguyen, S.; Alahakoon, D.; Jennings, A. A Robust Artificial Intelligence Approach with Explainability for Measurement and Verification of Energy Efficient Infrastructure for Net Zero Carbon Emissions. Sensors 2022, 22, 9503. [Google Scholar] [CrossRef]
- Larian, H.; Safi-Esfahani, F. InTec: Integrated things-edge computing: A framework for distributing machine learning pipelines in edge AI systems. Computing 2024, 107, 41. [Google Scholar] [CrossRef]
- Zhu, D.; Yang, B.; Liu, Y.; Wang, Z.; Ma, K.; Guan, X. Energy management based on multi-agent deep reinforcement learning for a multi-energy industrial park. Appl. Energy 2022, 311, 118636. [Google Scholar] [CrossRef]
- Wilk, P.; Wang, N.; Li, J. A multi-agent deep reinforcement learning based energy management for behind-the-meter resources. Electr. J. 2022, 35, 107129. [Google Scholar] [CrossRef]
- Sittón-Candanedo, I.; Alonso, R.S.; García, O.T.; Muñoz, L.; Rodríguez-González, S. Edge Computing, IoT and Social Computing in Smart Energy Scenarios. Sensors 2019, 19, 3353. [Google Scholar] [CrossRef] [PubMed]
- Wilk, P.; Wang, N.; Li, J. Multi-Agent Reinforcement Learning for Smart Community Energy Management. Energies 2024, 17, 5211. [Google Scholar] [CrossRef]
- Jamjuntr, P.; Techawatcharapaikul, C.; Suanpang, P. Adaptive Multi-Agent Reinforcement Learning for Optimizing Dynamic Electric Vehicle Charging Networks in Thailand. World Electr. Veh. J. 2024, 15, 453. [Google Scholar] [CrossRef]
- Ajagekar, A.; Decardi-Nelson, B.; You, F. Energy management for demand response in networked greenhouses with multi-agent deep reinforcement learning. Appl. Energy 2024, 355, 122349. [Google Scholar] [CrossRef]
- Ekanayaka Gunasinghalge, L.U.G.; Alazab, A.; Talukder, M.A. Artificial intelligence for energy optimization in smart buildings: A systematic review and meta-analysis. Energy Inform. 2025, 8, 135. [Google Scholar] [CrossRef]
- Moveh, S.; Merchán-Cruz, E.A.; Abuhussain, M.; Dodo, Y.A.; Alhumaid, S.; Alhamami, A.H. Deep Learning Framework Using Transformer Networks for Multi Building Energy Consumption Prediction in Smart Cities. Energies 2025, 18, 1468. [Google Scholar] [CrossRef]
- Charbonnier, F.; Morstyn, T.; McCulloch, M.D. Scalable multi-agent reinforcement learning for distributed control of residential energy flexibility. Appl. Energy 2022, 314, 118825. [Google Scholar] [CrossRef]
- Han, Y.; Meng, J.; Luo, Z. Multi-Agent Deep Reinforcement Learning for Blockchain-Based Energy Trading in Decentralized Electric Vehicle Charger-Sharing Networks. Electronics 2024, 13, 4235. [Google Scholar] [CrossRef]
- Liu, J.; Ma, Y.; Chen, Y.; Zhao, C.; Meng, X.; Wu, J. Multi-agent deep reinforcement learning-based cooperative energy management for regional integrated energy system incorporating active demand-side management. Energy 2025, 319, 135056. [Google Scholar] [CrossRef]
- Aguilar, J.; Garces-Jimenez, A.; R-Moreno, M.D.; García, R. A systematic literature review on the use of artificial intelligence in energy self-management in smart buildings. Renew. Sustain. Energy Rev. 2021, 151, 111530. [Google Scholar] [CrossRef]
- Jung, S.W.; An, Y.Y.; Suh, B.; Park, Y.; Kim, J.; Kim, K.I. Multi-Agent Deep Reinforcement Learning for Scheduling of Energy Storage System in Microgrids. Mathematics 2025, 13, 1999. [Google Scholar] [CrossRef]
- Jendoubi, I.; Bouffard, F. Multi-agent hierarchical reinforcement learning for energy management. Appl. Energy 2023, 332, 120500. [Google Scholar] [CrossRef]
- Condon, F.; Martínez, J.M.; Eltamaly, A.M.; Kim, Y.C.; Ahmed, M.A. Design and Implementation of a Cloud-IoT-Based Home Energy Management System. Sensors 2023, 23, 176. [Google Scholar] [CrossRef] [PubMed]
- Cicceri, G.; Tricomi, G.; D’Agati, L.; Longo, F.; Merlino, G.; Puliafito, A. A Deep Learning-Driven Self-Conscious Distributed Cyber-Physical System for Renewable Energy Communities. Sensors 2023, 23, 4549. [Google Scholar] [CrossRef] [PubMed]
- Kaewdornhan, N.; Chatthaworn, R. Predictive Energy Management for Microgrid Using Multi-Agent Deep Deterministic Policy Gradient With Random Sampling. IEEE Access 2024, 12, 95071–95090. [Google Scholar] [CrossRef]
- Yaïci, W.; Krishnamurthy, K.; Entchev, E.; Longo, M. Recent Advances in Internet of Things (IoT) Infrastructures for Building Energy Systems: A Review. Sensors 2021, 21, 2152. [Google Scholar] [CrossRef] [PubMed]
- González-Briones, A.; Prieto, J.; De La Prieta, F.; Herrera-Viedma, E.; Corchado, J.M. Energy Optimization Using a Case-Based Reasoning Strategy. Sensors 2018, 18, 865. [Google Scholar] [CrossRef]
- Gaitan, N.C.; Ungurean, I. BACnet Application Layer over Bluetooth—Implementation and Validation. Sensors 2021, 21, 538. [Google Scholar] [CrossRef]
- Bonino, D.; Corno, F.; De Russis, L. A Semantics-Rich Information Technology Architecture for Smart Buildings. Buildings 2014, 4, 880–910. [Google Scholar] [CrossRef]
- Hernández, J.L.; García, R.; Schonowski, J.; Atlan, D.; Chanson, G.; Ruohomäki, T. Interoperable Open Specifications Framework for the Implementation of Standardized Urban Platforms. Sensors 2020, 20, 2402. [Google Scholar] [CrossRef] [PubMed]
- Teixeira, B.; Pinto, T.; Silva, F.; Santos, G.; Praça, I.; Vale, Z. Multi-Agent Decision Support Tool to Enable Interoperability among Heterogeneous Energy Systems. Appl. Sci. 2018, 8, 328. [Google Scholar] [CrossRef]
- Soro, S. TinyML for Ubiquitous Edge AI. arXiv 2021, arXiv:2102.01255. [Google Scholar] [CrossRef]
- Wiese, P.; İslamoğlu, G.; Scherer, M.; Macan, L.; Jung, V.J.B.; Burrello, A.; Conti, F.; Benini, L. Toward Attention-Based TinyML: A Heterogeneous Accelerated Architecture and Automated Deployment Flow. IEEE Des. Test 2025, 42, 63–72. [Google Scholar] [CrossRef]
- Zheng, P.; Zhou, H.; Liu, J.; Nakanishi, Y. Interpretable building energy consumption forecasting using spectral clustering algorithm and temporal fusion transformers architecture. Appl. Energy 2023, 349, 121607. [Google Scholar] [CrossRef]
- Darvishvand, L.; Kamkari, B.; Huang, M.J.; Hewitt, N.J. A systematic review of explainable artificial intelligence in urban building energy modeling: Methods, applications, and future directions. Sustain. Cities Soc. 2025, 128, 106492. [Google Scholar] [CrossRef]
- Shariff, S.M. Autoregressive Integrated Moving Average (ARIMA) and Long Short-Term Memory (LSTM) Network Models for Forecasting Energy Consumptions. Eur. J. Electr. Eng. Comput. Sci. 2022, 6, 7–10. [Google Scholar] [CrossRef]
- Huang, J.; Kaewunruen, S. Forecasting Energy Consumption of a Public Building Using Transformer and Support Vector Regression. Energies 2023, 16, 966. [Google Scholar] [CrossRef]
- Mishra, A.; Lone, H.R.; Mishra, A. DECODE: Data-driven energy consumption prediction leveraging historical data and environmental factors in buildings. Energy Build. 2024, 307, 113950. [Google Scholar] [CrossRef]
- Zharova, A.; Boer, A.; Knoblauch, J.; Schewina, K.I.; Vihs, J. An explainable multi-agent recommendation system for energy-efficient decision support in smart homes. Environ. Data Sci. 2024, 3, e7. [Google Scholar] [CrossRef]
- Bui, V.; Le, N.T.; Nguyen, V.H.; Kim, J.; Jang, Y.M. Multi-Behavior with Bottleneck Features LSTM for Load Forecasting in Building Energy Management System. Electronics 2021, 10, 1026. [Google Scholar] [CrossRef]
- Mahjoub, S.; Chrifi-Alaoui, L.; Marhic, B.; Delahoche, L. Predicting Energy Consumption Using LSTM, Multi-Layer GRU and Drop-GRU Neural Networks. Sensors 2022, 22, 4062. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Jia, Y.; Xu, Y.; Xu, Z.; Chai, S.; Lai, C.S. A Multi-Agent Reinforcement Learning-Based Data-Driven Method for Home Energy Management. IEEE Trans. Smart Grid 2020, 11, 3201–3211. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z. Large language model-based interpretable machine learning control in building energy systems. Energy Build. 2024, 313, 114278. [Google Scholar] [CrossRef]
- Mouakher, A.; Inoubli, W.; Ounoughi, C.; Ko, A. Expect: EXplainable Prediction Model for Energy ConsumpTion. Mathematics 2022, 10, 248. [Google Scholar] [CrossRef]
- Cui, F.; An, D.; Xi, H. Integrated energy hub dispatch with a multi-mode CAES-BESS hybrid system: An option-based hierarchical reinforcement learning approach. Appl. Energy 2024, 374, 123950. [Google Scholar] [CrossRef]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-Line Building Energy Optimization Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2019, 10, 3698–3708. [Google Scholar] [CrossRef]
- Liang, Z.; Chung, C.Y.; Zhang, W.; Wang, Q.; Lin, W.; Wang, C. Enabling High-Efficiency Economic Dispatch of Hybrid AC/DC Networked Microgrids: Steady-State Convex Bi-Directional Converter Models. IEEE Trans. Smart Grid 2025, 16, 45–61. [Google Scholar] [CrossRef]
- Gao, G.; Li, J.; Wen, Y. DeepComfort: Energy-Efficient Thermal Comfort Control in Buildings Via Reinforcement Learning. IEEE Internet Things J. 2020, 7, 8472–8484. [Google Scholar] [CrossRef]
- Yao, L.; Liu, P.Y.; Teo, J. Hierarchical multi-agent deep reinforcement learning with adjustable hierarchy for home energy management systems. Energy Build. 2025, 331, 115391. [Google Scholar] [CrossRef]
- Deng, J.; Wang, X.; Meng, F. A novel safe multi-agent deep reinforcement learning-based method for smart building energy management. Energy Build. 2025, 347, 116256. [Google Scholar] [CrossRef]
- Bayasgalan, A.; Park, Y.S.; Koh, S.B.; Son, S.Y. Comprehensive Review of Building Energy Management Models: Grid-Interactive Efficient Building Perspective. Energies 2024, 17, 4794. [Google Scholar] [CrossRef]
- Maarif, M.R.; Saleh, A.R.; Habibi, M.; Fitriyani, N.L.; Syafrudin, M. Energy Usage Forecasting Model Based on Long Short-Term Memory (LSTM) and eXplainable Artificial Intelligence (XAI). Information 2023, 14, 265. [Google Scholar] [CrossRef]
- Natarajan, Y.; Sri Preethaa, K.R.; Wadhwa, G.; Choi, Y.; Chen, Z.; Lee, D.E.; Mi, Y. Enhancing Building Energy Efficiency with IoT-Driven Hybrid Deep Learning Models for Accurate Energy Consumption Prediction. Sustainability 2024, 16, 1925. [Google Scholar] [CrossRef]
- Pinheiro, M.G.; Madeira, S.C.; Francisco, A.P. Short-term electricity load forecasting—A systematic approach from system level to secondary substations. Appl. Energy 2023, 332, 120493. [Google Scholar] [CrossRef]
- Oulefki, A.; Amira, A.; Kurugollu, F.; Soudan, B. Dataset of IoT-based energy and environmental parameters in a smart building infrastructure. Data Brief 2024, 56, 110769. [Google Scholar] [CrossRef]
- Tan, M.; Zhao, J.; Liu, X.; Su, Y.; Wang, L.; Wang, R.; Dai, Z. Federated Reinforcement Learning for smart and privacy-preserving energy management of residential microgrids clusters. Eng. Appl. Artif. Intell. 2025, 139, 109579. [Google Scholar] [CrossRef]
- Li, Y.; He, S.; Li, Y.; Shi, Y.; Zeng, Z. Federated Multiagent Deep Reinforcement Learning Approach via Physics-Informed Reward for Multimicrogrid Energy Management. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 5902–5914. [Google Scholar] [CrossRef]
- Ji, W.; Cao, Z.; Li, X. Small Sample Building Energy Consumption Prediction Using Contrastive Transformer Networks. Sensors 2023, 23, 9270. [Google Scholar] [CrossRef]
- Chen, Z.; He, J.; Yu, L.; Zhao, Q. Personalized Federated Deep Reinforcement Learning for Smart Home Energy Management. IFAC-PapersOnLine 2025, 59, 193–198. [Google Scholar] [CrossRef]
- Rando Mazzarino, P.; Macii, A.; Bottaccioli, L.; Patti, E. A Multi-Agent Framework for Smart Grid Simulations: Strategies for power-to-heat flexibility management in residential context. Sustain. Energy Grids Netw. 2023, 34, 101072. [Google Scholar] [CrossRef]
- Afrasiabi, M.; Mohammadi, M.; Rastegar, M.; Kargarian, A. Multi-agent microgrid energy management based on deep learning forecaster. Energy 2019, 186, 115873. [Google Scholar] [CrossRef]
- Maguluri, L.P.; Umasankar, A.; Vijendra Babu, D.; Anselin Nisha, A.S.; Prabhu, M.R.; Tilwani, S.A. Coordinating electric vehicle charging with multiagent deep Q-networks for smart grid load balancing. Sustain. Comput. Inform. Syst. 2024, 43, 100993. [Google Scholar] [CrossRef]
- Das, H.P.; Lin, Y.W.; Agwan, U.; Spangher, L.; Devonport, A.; Yang, Y.; Drgoňa, J.; Chong, A.; Schiavon, S.; Spanos, C.J. Machine Learning for Smart and Energy-Efficient Buildings. Environ. Data Sci. 2024, 3, e1. [Google Scholar] [CrossRef]
- Wang, R.; Bai, L.; Rayhana, R.; Liu, Z. Personalized federated learning for buildings energy consumption forecasting. Energy Build. 2024, 323, 114762. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.