Abstract
The categories for call center conversation data are valuably used for reporting business results and marketing analysis. However, they typically lack clear patterns and suffer from severe imbalance in the number of instances across categories. The call center conversation categories used in this study are Payment, Exchange, Return, Delivery, Service, and After-sales service (AS), with a significant imbalance where Service accounts for 26% of the total data and AS only 2%. To address these challenges, this study proposes a model that ensembles meta-information generated through Named Entity Recognition (NER) with machine learning inference results. Utilizing KoBERT (Korean Bidirectional Encoder Representations from Transformers) as our base model, we employed Easy Data Augmentation (EDA) to augment data in categories with insufficient instances. Through the training of nine models, encompassing KoBERT category probability weights and a CatBoost (Categorical Boosting) model that ensembles meta-information derived from named entities, we ultimately improved the F1 score from the baseline of 0.9117 to 0.9331, demonstrating a solution that circumvents the need for expensive LLMs (Large Language Models) or high-performance GPUs (Graphic Process Units). This improvement is particularly significant considering that, when focusing solely on the category with a 2% data proportion, our model achieved an F1 score of 0.9509, representing a 4.6% increase over the baseline.
Keywords:
machine learning; NLP; classification; data augmentation; metadata; data cleansing; BERT; EDA; NER 1. Introduction
In call centers, the analysis of conversation data exchanged between customers and agents is routinely conducted to facilitate customer request analysis, complaint detection, purchase behavior prediction, and the assessment of customer sentiment and opinions. Consequently, these data, which will be referred to as ‘call center conversation data’ throughout this paper, represent a critical asset within call center operations. The task of classifying these data is particularly vital for the effective execution of the analyses mentioned above. In call center environments, agents manually assign a category to a call center conversation data at the end of conversations to classify the call center conversation data. However, inaccurate classifications or bulk assignments to an ‘other’ category frequently occur due to factors such as overwork, fatigue, lack of experience, or carelessness. This consequently diminishes the reliability of analyses for call center operations [1]. As a result, automated conversation classification has remained a long-standing challenge. With the advancement of Speech-to-Text (STT) technology and the subsequent accumulation of call center conversation records, this task has become increasingly important across various research domains, including Natural Language Processing (NLP) [2].
Also, the Korean call center industry has witnessed an increasing trend in both in-house and outsourced operations over the last five years [3]. Not only general corporations but also local autonomous entities are establishing call centers to improve citizen convenience. Nevertheless, due to limitations in operational expertise and budget, outsourcing is favored. As of 2024, among organizations utilizing call centers, 660 are outsourcing, 385 operate in-house, and 84 employ a hybrid model of both outsourcing and in-house management. The outsourced call center market is characterized by intense competition, resulting in widespread low-price contract acquisitions and a significant sensitivity to cost. Given this environment, investment in call center IT infrastructure presents a considerable challenge. Consequently, there is a pressing need to develop a lightweight and cost-effective classification system for call center conversation data.
Call center conversation data exhibit several distinctions compared to general text data [4]. First, the informality of spoken language is prominent, characterized by frequent grammatical errors, conversational interruptions, exclamations, and abbreviations. Second, domain-specific vocabulary, technical terminology, and brand names from industries such as finance, telecommunications, healthcare, and retail are interspersed throughout the data. Third, linguistic diversity exists, encompassing the morphological complexity of Korean along with the occurrence of dialects and multilingual expressions.
A considerably more significant technical challenge lies in the severe imbalance in data distribution. The call center conversation data used in this study also showed extreme disparities in data volume across conversation categories. While some categories contained substantial amounts of data, others possessed extremely limited samples. This imbalance leads to models becoming biased toward data-rich categories during training, thereby degrading overall classification performance [5,6].
Previous studies on call center conversation data classification primarily sought to automate this process using traditional Natural Language Processing (NLP) techniques such as rule-based regular expressions or TF-IDF (Term Frequency-Inverse Document Frequency) calculations. However, these approaches proved insufficient in effectively addressing the unique characteristics of call center conversation data, particularly the data imbalance problem. Furthermore, while some foundational work applied a Convolutional Neural Network (CNN) model to classify these data, this model also exhibited a limitation where the automated classification results were not fully trusted by management, largely attributable to the inherent characteristics of call center data [2,4].
To overcome these technical challenges, this study proposes the following innovative approaches: First, after selecting validated models, data augmentation techniques, including Easy Data Augmentation (EDA), will be applied to mitigate the imbalance between categories [7]. Building upon this, we aim to overcome the limitations of existing language model-based classification performance by ensembling meta-information derived from Named Entity Recognition (NER) results [8]. Through these multifaceted approaches, this study aims to extract the unique characteristics of call center conversations and develop classification models optimized for them, thereby achieving a superior classification performance even in imbalanced and unstructured data environments.
To this end, we conduct nine experiments across three stages: first, establishing baseline models using LSTM and BERT; second, fine-tuning these baseline models with performance enhancements achieved through various data augmentation techniques; and third, ensembling meta-information. Through this process, we ultimately aim to achieve an improved performance compared to previous models, while ensuring efficient operation on a cheap and lightweight computing infrastructure.
The remainder of this paper is organized as follows. Section 2 surveys pertinent literature on call centers, automated call analysis, and text classification methodologies, encompassing foundational techniques such as LSTM, Transformer, BERT, EDA, and NER. Section 3 defines the challenge of classifying imbalanced Korean conversational data from call centers. It further presents the overarching three-stage framework adopted in this research and elaborates on the nine distinct models specifically engineered to enhance classification efficacy. Section 4 provides a detailed exposition of the proposed methodology and models. This includes the data preprocessing pipeline, the architectural configurations of the baseline LSTM and BERT models, the applied data augmentation strategies (i.e., under-sampling, over-sampling, and EDA), and the architecture of the ensemble model, which integrates NER-derived meta-information via CatBoost. Section 5 showcases the empirical results obtained from all nine developed models, featuring a thorough performance analysis based on key metrics such as precision, recall, and F1 score. The discussion further investigates the influence of data augmentation and meta-information on classification accuracy, with a specific focus on bolstering performance for minority classes. Finally, Section 6 offers concluding remarks, summarizing the principal findings and their implications. It underscores the efficacy of the proposed ensemble methodology in alleviating data imbalance issues, acknowledges this study’s inherent limitations, and proposes avenues for future research aimed at further advancing Korean text classification within call center applications.
2. Previous Studies
2.1. Call Center-Related Research
Research related to call centers has explored various aspects, including the analysis, monitoring, and classification of calls. Previous studies on call center data analysis often utilized traditional Natural Language Processing (NLP) techniques [9]. However, these approaches have faced limitations in reflecting the unique characteristics of call center data [5]. Specifically, traditional methods like rule-based regular expressions or TF-IDF calculations have reportedly failed to adequately address challenges such as data imbalance inherent in call center data.
Regarding automated call center analysis and monitoring systems, research has presented a method for estimating the domain-specific importance of conversation fragments based on the difference in corpus statistics (i.e., word frequency distribution) [2]. For example, the principle was that in call data dealing with software and hardware-related issues, “important” fragments tend to show common words such as “error” or “password” appearing with a higher frequency compared to other domains. The authors aimed to use this by estimating domain-specific word importance, and further, domain-specific fragment importance, to retrieve possible solutions to problems presented in the conversation.
There has also been research on designing a machine learning model to detect call center agent negligence. This research extracted 17 features related to the voice itself from the audio recording of a given phone conversation, such as average silence duration, call duration, percentage of longest silence, position of longest silence, maximum sound level, etc. [10]. It is observed that this research achieved its purpose by generating meta-information solely from the recorded audio, without using the agent’s conversation text.
Research has also shown that lightly supervised training, utilizing output from an automatic speech recognizer in conjunction with supervised labeling of calls by call type, can substantially reduce classification error rates and development efforts, especially when only limited training data are available [11].
Since the period when conversation texts were insufficient and language models were not yet fully developed, there has been a consistent demand for call center dialogue analysis and automation. Even after the advancement of Speech-to-Text (STT) technology facilitated the sufficient generation of consultation dialogue texts, these needs have still not been clearly addressed. This persistent challenge stems from the requirement for text classification technologies specifically designed to resolve the unique constraints characteristic of call center conversations.
2.2. Text Data Classification Research
With the advancement of STT technology, the classification of conversation conversations has begun to actively utilize text data categorization techniques. Text data classification has seen significant advancements beyond traditional techniques, particularly with the rise of deep learning and specialized data handling methods.
Traditional methods for text classification, such as extraction summary-based approaches relying mainly on word frequency counts, TF-IDF, sentence similarity, topic sentence-based removal, and graph-based ranking, have been shown to have limitations [5]. These methods reportedly do not properly reflect features like syntactic patterns or positions and do not work effectively with new documents.
To address the limitations of traditional methods, researchers have experimented with deep learning techniques such as Convolutional Neural Networks (CNNs) [12], Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM), and Gated Recurrent Units (GRUs) for various classification tasks [5]. LSTM, for instance, is a recurrent neural network designed to solve the long-term dependency problem inherent in standard RNNs and has shown prominence in text classification.
More recently, models leveraging advanced pre-trained Transformer-based architectures, such as the BERT model, have showcased promising capabilities across diverse classification tasks [6]. The Transformer architecture has been noted for outperforming recurrent neural networks in tasks like translation by processing sequences in parallel.
A significant challenge in text classification, particularly with imbalanced datasets, is addressed through text data augmentation [1]. Resampling methods like under-sampling and random over-sampling are primary techniques in this area. Random over-sampling is generally considered an accessible and common approach, although under-sampling carries inherent risks.
The Easy Data Augmentation (EDA) technique has received significant attention and continues to be relevant, especially considering challenges associated with augmenting Korean text [13]. Furthermore, BERT-based data augmentation has demonstrated effectiveness in improving model performance. For example, the BERT model can effectively fill in appropriate vocabulary in place of deleted existing words, showcasing its capability in practical text augmentation applications using examples like newspaper articles.
Researchers have also extensively explored the utilization of meta-information in document classification. This represents a growing trend in natural language processing to enhance machine learning model performance by integrating additional contextual information. Promising techniques include directly incorporating information like project names and research objectives into the body of technical documents to expand the informational context available to models. Alternatively, researchers have achieved notable performance improvements by selectively integrating meta-information such as project names and keywords into CNN models. By leveraging these supplementary metadata, researchers aim to create more nuanced and accurate classification systems that can better capture the underlying meaning and intent [12].
2.3. Underlying Technologies
2.3.1. Long Short-Term Memory (LSTM)
LSTM is an artificial neural network that addresses the long-term dependency problem (forgetting past time point data) of RNNs [14]. It is configured and trained to remember and forget information and demonstrates its prominence in text classification as a recurrent neural network that incorporates a time-series concept with a recurrent structure to preserve internal information.
2.3.2. Transformer
The Transformer architecture, leveraging the attention mechanism, outperformed recurrent neural networks in translation by processing sequences in parallel, overcoming their limitations with long sequences [5]. It converts words and sentences into vectors, generates relationship information through self-attention layers (allowing each word to consider others in the input), and uses multiple such layers (multi-head attention) within its encoder and decoder structure.
2.3.3. BERT (Bidirectional Encoder Representations from Transformers)
The BERT model is composed by stacking multiple encoders, which are components of the Transformer, and is trained to output specific word embedding vectors according to the given context. Unlike the Word2Vec model, often used as a word embedding method, BERT has the advantage of taking context into account [5].
2.3.4. Easy Data Augmentation (EDA)
Data augmentation addresses learning limitations caused by data imbalance by increasing the training dataset size through various means [13]. EDA is a text classification-focused technique that diversifies text data using simple operations: synonym replacement (SR), random insertion (RI), random swap (RS), and random deletion (RD). SR replaces words with synonyms. RI adds random words to test model robustness and expand the data. RS swaps word positions to evaluate sensitivity to word order. RD removes random words to enhance robustness and data diversity.
2.3.5. Named Entity Recognition (NER)
Named Entity Recognition is a technique that recognizes and extracts words corresponding to people, organizations, companies, places, times, dates, units, etc., from the text and classifies them [15]. Korean NER presents greater challenges than English NER due to its unique linguistic features. The agglutinative nature and complex morphology of Korean necessitate crucial preprocessing steps like morphological analysis. Handling issues like typos, spacing errors, ambiguity, neologisms, and especially compound noun decomposition significantly impacts accuracy. Unlike English, where spaces clearly delineate words, Korean requires specific processing for combined words, creating new meanings. While Transformer-based models have shown promise in Korean NER, achieving performance levels comparable to English remains an ongoing challenge [16].
Modern NER leverages deep learning to consider context, leading to improved reliability and broader application across NLP tasks. The adoption of Transformer architectures has significantly advanced NER technology, enabling more effective contextual understanding and higher accuracy.
The types of tags addressed in NER are not uniform but rather adjusted according to their intended application [17]. This research focused on the tag categories listed in Table 1, which are commonly addressed in most NER systems.

Table 1.
NER tag list.
3. Problem and Overall Approach
3.1. Problem Description
Call centers have become increasingly important customer touchpoints in the internet era. The analysis and classification of conversations are considered increasingly crucial, encompassing various aspects such as conversation analysis, monitoring, and classification. Call centers report performance metrics to client companies or upper departments based on these data, while marketing departments establish and execute budgets through various analyses. Therefore, conversation category information can be considered the most fundamental analytical material. This study aims to develop an AI model capable of automatically classifying categories based on call center conversation data. For model development, we utilized question-and-answer data from public institution and shopping mall call centers provided by the National Information Society Agency (NIA) in Korea.
Each conversation in the dataset is provided in text format along with corresponding classification metadata [18]. These data were officially released in 2021 with the participation of KT, one of Korea’s leading telecommunications companies. Among the available datasets, we selected distribution company call center data for this study. In distribution industry call centers, customer interaction content is classified into the following six standard categories: Payment Inquiries (0), Exchange Requests (1), Return Requests (2), Delivery Inquiries (3), Service Requests (4), and After-Sales Service Inquiries (5). This classification reflects the primary types of inquiries commonly occurring in distribution-related customer services.
As shown in Table 2, the data exhibit significant imbalance across the six categories. Categories 0 and 4 contain more than twice the number of entries compared to the middle group, while the smallest category (5) represents less than one-tenth of the volume of the largest categories. To achieve accurate classification despite this data imbalance, it is necessary to employ appropriate data augmentation methods. Additionally, call center conversation data possess distinct Korean language characteristics that must be addressed in the model development process.
Table 2.
Number of training data instances by category.
Korean, as an agglutinative language with complex morphological structures, presents unique challenges for text data augmentation techniques [16]. Furthermore, Named Entity Recognition (NER) in Korean is more difficult than in English, requiring extensive preprocessing including morphological analysis, correction of spacing errors, and handling of compound nouns. Consequently, traditional Natural Language Processing (NLP) techniques have shown limitations in this context. Conventional approaches such as rule-based regular expressions or TF-IDF calculations are inadequate for reflecting the unique characteristics of call center data. These approaches fail to address the data imbalance problem and do not properly account for features such as grammatical patterns or positional characteristics, resulting in reduced effectiveness when applied to new documents.
Therefore, the primary objective of this study is to develop an AI model capable of accurately classifying call center conversation data into six standard categories while effectively addressing the challenges of data imbalance and the linguistic characteristics of Korean. Furthermore, this research aims for the developed model to be cost-effective and capable of CPU-based inference during the inference stage after training.
3.2. Overall Approach
To enhance the performance of conversation category classification, we first selected high-performing text classification models and devised a data augmentation strategy to address data imbalance. Prior studies have shown the effectiveness of such approaches; however, this study aimed to go one step further beyond existing methodologies. Among previous works on text categorization, several have demonstrated success by incorporating meta-information. For instance, some frameworks utilized document length, category labels, titles, abstracts, and authors as additional inputs for training [19]. Other studies improved classification performance by prepending task names, research goals, and content summaries to the text [5]. Remarkably, some even extracted silence durations and audio intensity from conversational speech to generate meta-features for classification [10].
Given these precedents, we hypothesized that meta-information could also be beneficial for call center conversation classification. Since patterns of entities—such as person names, locations, quantities, and temporal expressions—may vary by conversation topic (category), we expected that Named Entity Recognition (NER) could be employed to extract such information as learnable meta-features. We proposed an ensemble model that combines class probability outputs (weights) from a machine learning model with entity count data obtained from a named entity recognizer. We anticipated that this approach would extend prior research and lead to more accurate classification models, as shown in Figure 1.
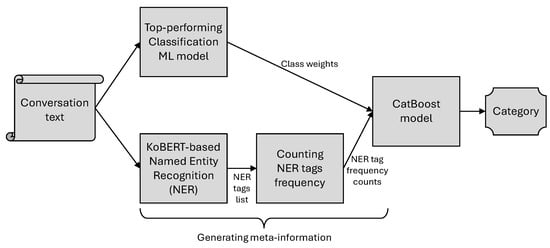
Figure 1.
Process of classifying call center conversation data by ensemble of machine learning model inference results and named entity frequency counts.
To implement this approach, we followed a three-stage process: (1) base model selection, (2) data augmentation, and (3) meta-information integration. The procedure is summarized in Figure 2.
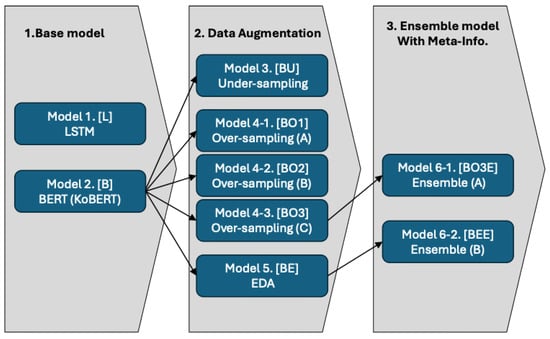
Figure 2.
Improving model performance: Data augmentation and ensemble model with meta-info.
In the first stage, we selected base models for category classification of text data. Long Short-Term Memory (LSTM) and Bidirectional Encoder Representations from Transformers (BERT) were chosen as the primary machine learning models. Compared to traditional methods such as Support Vector Machines (SVMs) or embedding-based models, LSTM and BERT have demonstrated superior performance and are supported by extensive research on hyperparameter tuning [20]. Moreover, few previous studies have applied Convolutional Neural Networks (CNNs) to classify Korean call center conversations, which further justified our model choices.
In the second stage, we performed data augmentation to address the considerable imbalance in the number of samples across categories, which hindered classification performance. Three techniques were applied: resampling (under-sampling and over-sampling) and Easy Data Augmentation (EDA). These methods are widely used in English and other languages due to their ease of implementation, computational efficiency, and proven effectiveness. Unlike embedding-based methods such as SMOTE, resampling and EDA tend to produce less distortion in Korean text data, making them particularly suitable. Although semantic-level augmentation approaches have recently gained attention [21], the lack of resources such as an Abstract Meaning Representation (AMR) parser for Korean makes them difficult to implement in this context.
In the third stage, we addressed the limitations of improving classification performance solely through base model tuning by generating meta-information from conversation texts via named entity recognition. Specifically, we extracted entity tags from the text and incorporated them into the model. The final ensemble model combined the prediction probabilities from the base text classification model with the distribution of named entities, using the CatBoost algorithm. Through this process, we developed a total of nine models, as detailed in Figure 2, which show progressively improved performance across the three stages.
The training procedures for each model at each stage are described as follows:
- The first stage: Models 1 [L] and 2 [B] are basic models trained with LSTM and BERT, respectively. As will be explained later, Model 1 showed insufficient classification performance, so subsequent experiments were conducted based only on BERT.
- The second stage: Model 3 [BU] is a BERT model trained on data processed through under-sampling, a resampling technique that reduced the number of instances in categories with high counts to a medium group level. In this experiment, the maximum number of instances per category was set to 2500, and any excess was randomly deleted. Models 4-1 [BO1] through 4-3 [BO3] are BERT models trained on data that underwent over-sampling, a resampling technique that simply augments data by randomly replicating them. Model 4-1 [BO1] adjusted all categories to a maximum of 50,000 instances, while Model 4-2 [BO2] doubled the number of instances in the medium groups and increased the number of instances in the lower groups by a factor of five. Model 4-3 [BO3] doubled the number of instances in both the medium and lower groups. Model 5 [BE] is a BERT model trained on data applying Easy Data Augmentation (EDA), which comprehensively utilizes text data augmentation techniques such as synonym replacement using Korean WordNet and random vocabulary deletion. The over-sampling method that had shown the best performance—doubling the number of instances in the medium and lower groups—was also applied to EDA.
- The third stage: Model 6-1 [BO3E] is an ensemble model that combines the conversation category weight information calculated from the best-performing model trained on resampling-augmented data with tag subtotal information derived from NER, using the CatBoost algorithm. Model 6-2 [BEE] is an ensemble model that combines the conversation category weight information calculated from the best-performing model trained on EDA-augmented data with tag subtotal information derived from NER, using the CatBoost algorithm. This design ensures efficient computation, enabling the model to operate effectively even in lower-specification computing environments.
4. Methodology
4.1. Data Preprocessing
Call center conversation data undergo a multi-step preprocessing procedure to ensure data quality and analytical relevance. First, records from the Speech-To-Text (STT) output with excessively short call durations are excluded. Calls lasting less than one minute are removed because the category labels entered by agents in such cases often do not reflect the actual conversation content and are frequently substituted by default clicks, resulting in low data reliability. Similarly, when working with transcribed text datasets, records with fewer than a certain number of tokens (e.g., less than 20) are filtered out to eliminate insufficiently informative data.
Second, portions of the conversation that are not pertinent to the analysis are removed. In call center conversations, fixed expressions such as greetings and automated guidance scripts frequently occur and are considered noise. These are eliminated by discarding the initial segment of each STT transcript, typically of a predetermined length.
Finally, a curated list of removable strings is maintained and applied in batch processing. Utterances that indicate active listening—such as backchanneling responses—are largely removed, as they contribute little to accurate category classification. However, expressions tied to specific customer issues, such as complaints, are retained for their potential informative value. For example, phrases like “I understand” or “Yes, yes” are excluded, whereas expressions such as “I’m sorry” or “My apologies,” which are indicative of customer dissatisfaction, are preserved.
4.2. Base Model
4.2.1. Model 1. [L] Long Short-Term Memory (LSTM) Model
In Model 1. [L], a fundamental LSTM-based model was used. The activation function employed is Softmax, and the loss function utilized is the CrossEntropyLoss function. The batch size was set to 64, as shown in Table 3.
Table 3.
Model 1. [L] LSTM model basic hyperparameters.
CrossEntropyLoss was selected as the loss function due to its well-established capability to deliver high accuracy in multi-class classification tasks and its prevalence as a default choice in numerous deep learning models. It exhibits stable performance across diverse datasets and models, frequently yielding favorable outcomes without requiring specific hyperparameter optimization [22]. It is acknowledged that CrossEntropyLoss can exhibit diminished performance on minority classes when addressing imbalanced datasets. While alternative loss functions such as Weighted Cross-Entropy Loss and Focal Loss can enhance classification performance by assigning weights to imbalanced data, they were excluded to mitigate potential confounding factors in this research. The present study aims to enhance performance through data augmentation and ensembles leveraging meta-information. To minimize the introduction of additional variable factors, the category-neutral CrossEntropyLoss was retained.
4.2.2. Model 2. [B] Bidirectional Encoder Representations from Transformers (BERT) Model
In Model 2. [B], a fundamental BERT-based model was used. For the BERT model, KoBERT provided by SK T-Brain [23] served as the pre-trained model, and hyperparameters such as the learning rate, optimization algorithm, Warmup ratio (a setting that keeps the learning rate low until a specified proportion of the total training steps), and drop-out were fine-tuned. Training took approximately six hours, which limited the exploration of extensive configuration variations. The training was initiated with a maximum sequence length of 128 and a batch size of 32, as detailed in Table 4.
Table 4.
Model 2. [B] BERT model basic hyperparameters.
The KoBERT model employs a tokenizer trained on Korean Wiki and news datasets [23]. The pooled output vector from the BERT architecture feeds into a classifier, which consists of a drop-out layer and a fully connected layer, to output the probability of belonging to each category [5]. Although more advanced lightweight BERT models like ALBERT and RoBERTa are available, a model pre-trained on Korean is crucial for processing Korean call center conversation, as multilingual models have not yet demonstrated sufficient performance for practical application in this context.
Similar to our use of KoBERT, we also evaluated KoGPT2, distributed by SK Telecom (https://github.com/SKT-AI/KoGPT2 (accessed on 15 May 2025)). However, its unidirectional decoder architecture inherent to the GPT model resulted in lower performance, leading to its exclusion from this study.
4.3. Data Augmentation
Call center conversation data characteristically exhibit significant differences in the number of instances between categories. This data imbalance generally has a negative impact on category classification performance. We utilized under-sampling and over-sampling, which are applicable to text data, along with Easy Data Augmentation (EDA), a collection of text augmentation techniques.
4.3.1. Model 3. [BU] Under-Sampling
Model 3. [BU] is a BERT model trained on under-sampled data. Category 4 (Service request), which accounts for 25% of the total data, has 5388 records, while the mid-size groups, categories 1 through 3, range from 1500 to 2500 records. During under-sampling, an attempt was made to randomly delete records from categories 0 and 4 down to the mid-group size of 2500 records. The results are shown in Table 5.
Table 5.
Model 3—Under-sampling results.
4.3.2. Model 4-1. [BO1] to 4-3. [BO3]—Over-Sampling (A~C)
Models 4-1. [BO1] to 4-3. [BO3] are BERT models trained on over-sampled data. For data augmentation, an over-sampling method involving random sampling and simple replication of data was employed. To increase the data volume, we implemented the following approach:
- Model 4-1. [BO1]: All categories were balanced by standardizing their total number of records to 5000 each (Table 6).
Table 6. Model 4-1. [BO1] Over-sampling (A) results.
- Model 4-2. [BO2]: For categories 1 through 3, which represent mid-size groups, the number of samples was doubled. The number of records in the smallest category (category 5) was increased by a factor of five (Table 7).
Table 7. Model 4-2 [BO2] Over-sampling (B) results.
- Model 4-3. [BO3]: The number of records in categories 1 through 3 and category 5 was doubled (Table 8).
Table 8. Model 4-3. [BO3] Over-sampling (C) results.
4.3.3. Model 5. [BE] Easy Data Augmentation (EDA)
Model 5. [BE] is a BERT model trained on data augmented using EDA. EDA provides four distinct methods for text augmentation. Synonym Replacement (SR) substitutes specific words with others of similar meaning. Random Insertion (RI) adds arbitrary words to sentences to test model robustness or expand datasets. Random Swap (RS) exchanges the positions of two words within a sentence to evaluate sensitivity to word order. Random Deletion (RD) removes random words from sentences to verify model robustness and increase data diversity [7]. In this study, the four methods were applied with random frequencies and in random quantities, as shown in Table 9.
Table 9.
Model 5. [BE] Easy Data Augmentation (EDA) results.
The implementation of EDA for Korean texts, known as KorEDA, utilizes the Korean WordNet developed by KAIST Semantic Web Research Center [24]. Initially, KorEDA recommended using only Random Deletion (RD) and Random Swap (RS) due to the limitations of the WordNet approach, which cannot account for contextual nuances. This recommendation aimed to ensure safety during the augmentation process. However, due to insufficient diversity in the augmented data, Synonym Replacement (SR) and Random Insertion (RI) were subsequently included as well. These four techniques from KorEDA were applied to call center conversations with random weights.
The performance of EDA stems from WordNet; therefore, we augmented it with vocabulary relevant to the call center domain. We employed Google’s gemma3:4b model via ollama (https://ollama.com (accessed on 15 May 2025)), a solution for running large language models in a local environment. Based on six categories of call center conversation data, we generated 5374 call center-related vocabulary items as keys for the Korean WordNet. For each vocabulary item (key), we added up to 20 similar or related words.
4.4. Ensemble of BERT Inference Results and NER Results
Prior research has explored the integration of meta-information for text classification. These studies concatenated the main text of technical documents with Korean project titles, research objective summaries, research content summaries, and Korean keywords into a single input sequence for training [5]. However, call center conversations often lack such readily available meta-information.
This study proposes a novel method to enhance the performance of call center conversation category classification by ensembling the classification predictions from a machine learning model with named entities extracted from the conversation sentences, effectively utilizing these extracted entities as meta-information. This approach aims to improve classification accuracy without relying on the computationally expensive inference of LLMs, offering a more practical and cost-effective solution for real-world call center applications.
Google’s BERT model leverages bidirectional Transformer modules, effectively capturing contextual information from both preceding and succeeding tokens, which has been shown to improve the accuracy of Named Entity Recognition (NER) and demonstrates high reliability across various NER tasks [25]. Conversely, OpenAI’s GPT employs a unidirectional approach, interpreting sentences based solely on prior tokens. While capable of handling complex contexts and lengthy texts, GPT may exhibit lower reliability in Korean language processing compared to BERT, which simultaneously considers both forward and backward contextual cues.
4.4.1. Meta-Information Generation
The Named Entity Recognition (NER) system [8] was developed based on the pre-trained KoBERT model provided by SK T-Brain [23]. The entity counts for each tag as shown in Table 1 were calculated for each conversation. It was expected that tag distributions would vary by category, with tags like DT (date), PS (person), OG (organization), and LC (location) being more frequent in categories such as delivery or reservation inquiries.
A composite dataset was created by integrating the BERT model inference results with the NER summary statistics, using the conversation index as the joining key. Columns 0–5 contained the probability scores predicted by the BERT model, columns 6–19 comprised the NER tag frequency counts, and column 20 stored the ground truth category labels, as illustrated in Table 10. This enriched dataset was subsequently used to train the CatBoost model, enabling it to leverage both semantic features from BERT and named entity information for improved classification performance.
Table 10.
Dataset layout based on BERT model weight results integrated with NER tag counts.
4.4.2. Models 6-1. [BO3E] Ensemble (A) and 6-2. [BEE] Ensemble (B)
Models 6-1. [BO3E] and 6-2. [BEE] are ensemble classifiers designed to combine category weight information derived from BERT-based conversation classifiers with tag subtotal features obtained through Named Entity Recognition (NER), utilizing the CatBoost algorithm for final classification. Both models integrate two types of meta-information: (1) the category probability distributions inferred from the best-performing BERT models and (2) the frequency counts of named entity tags per conversation. Specifically, Model 6-1 employs the BERT model (Model 4-3. [BO3]) trained on resampling-augmented data, whereas Model 6-2 utilizes the BERT model (Model 5. [BE]) trained on data augmented using Easy Data Augmentation (EDA).
CatBoost was chosen as the ensemble classifier due to its strong performance in multi-class classification tasks and its ability to handle both numerical and categorical features effectively. Unlike traditional Gradient Boosting Machine (GBM)-based algorithms, CatBoost mitigates issues such as target leakage and the complexity of processing categorical variables by introducing an innovative ordering principle and a novel technique for encoding categorical features [26]. These capabilities enable CatBoost to process categorical values automatically without requiring extensive preprocessing, resulting in consistently robust performance compared to other Gradient Boosted Decision Tree (GBDT) implementations. Leveraging these strengths, our ensemble models achieved substantial performance gains over the baseline BERT models within a relatively short development time.
5. Experimental Results
5.1. Model 1. [L] Long Short-Term Memory (LSTM)
The final hyperparameter tuning results are presented in Table 11. For Model 1. [L], an LSTM-based model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.5065 (Table 12).
Table 11.
The final LSTM model hyperparameter tuning results.
Table 12.
Classification report—Model 1. [L] LSTM.
As shown in Table 12, Model 1. [L] exhibits low overall accuracy. The model demonstrates a highly imbalanced performance across different classes, with notably lower precision for classes other than class 0. While the recall is generally high, this suggests a tendency of the model to predict positive instances frequently, potentially leading to a high number of false positives. Data imbalance likely has a significant impact on the model’s performance; the majority class (Class 0—Payment Inquiry) shows a relatively reasonable performance, whereas the minority classes perform poorly.
The LSTM model demonstrated insufficient classification performance; therefore, only the BERT model was utilized in subsequent experiments. While there remains potential for further tuning, this approach was deemed adequate given the paper’s primary focus on data augmentation and ensemble methods with metadata rather than exhaustive model optimization.
5.2. Model 2. [B] Bidirectional Encoder Representations from Transformers (BERT)
The final hyperparameter tuning results are shown in Table 13. For Model 2. [B], a BERT-based model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9117 (Table 14).
Table 13.
The final BERT model hyperparameter tuning results.
Table 14.
Classification report—Model 2. [B] BERT model (base).
Overall, the model demonstrates high accuracy and performs well in the text classification task. All classes show decent performance with an F1 score of 0.8 or higher. However, the F1 scores for Return Request (2) and After-Sales Service Inquiry (5) are slightly lower than those of other classes, so it might be worth considering improving the model’s performance for these two classes. In particular, the low recall for After-Sales Service Inquiry may be related to data imbalance, and it might be worth considering acquiring more data or improving learning methods for minority classes.
5.3. Model 3. [BU] Under-Sampling
For Model 3. [BU], an under-sampling model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9067 (Table 15). Starting with Model 3. [BU], the under-sampling model, the hyperparameter settings of Model 2. [B], the BERT model, are used without any changes.
Table 15.
Classification report—Model 3. [BU] Under-sampling.
Overall, all classes exhibit decent performance, with F1 scores above 0.85. Under-sampling resulted in a slight increase in the F1 score for the categories with fewer instances. However, the overall performance decreased somewhat compared to the base model (F1 score decreased by 0.0050). It is necessary to explore methods to improve the classification performance across all classes.
5.4. Over-Sampling
5.4.1. Model 4-1. [BO1] Over-Sampling (A)
The first over-sampling method aimed to balance all categories by setting their total number of records to 5000, increasing the smaller categories through duplication to reach a total of 5000 records per category. For Model 4-1. [BO1], an over-sampling (A) model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9100 (Table 16). This performance was lower than that of the base model.
Table 16.
Classification report—Model 4-1. [BO1] Over-sampling (A) each category to 5000 instances.
Overall, the model exhibits high accuracy (0.9112) and demonstrates a decent performance across most classes, with F1 scores exceeding 0.8. The low Precision for After-Sales Service Inquiry (5) indicates that it cannot be resolved by simple replication-based over-sampling.
5.4.2. Model 4-2. [BO2] Over-Sampling (B)
To balance the number of instances across categories, the second over-sampling method doubled the number of instances for categories 1 through 3 (mid-size groups) and increased the number of instances in the smallest category (category 5) by a factor of five. For Model 4-2. [BO2], an over-sampling (B) model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9200 (Table 17).
Table 17.
Classification report—Model 4-2. [BO2] Over-sampling (B): Doubled records in categories 1–3 (mid-size) and fivefold increased records in category 5.
Up to this point, this model demonstrated the highest overall accuracy (Accuracy: 0.9263); however, this increase was primarily driven by improvements in classes with a large number of instances, and the Precision for the AS inquiry class (5) dropped significantly. This indicates that the model frequently misclassifies inquiries that are not AS inquiries as AS inquiries. Even augmenting the AS inquiry class (which has the fewest instances) by five times its original size was ineffective. This low Precision suggests that simply replicating instances, even extensively, does not lead to a proper understanding of the characteristics of that class.
5.4.3. Model 4-3. [BO3] Over-Sampling (C)
For the third over-sampling method, the data for categories 1-3 and the data for category 5 (which had a very small number of instances) were doubled through duplication. For Model 4-3. [BO3], an over-sampling (C) model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9220 (Table 18).
Table 18.
Classification report—Model 4-3. [BO3] Over-sampling (C): Doubled records in categories 1–3 and 5.
Overall, the model demonstrates a very high accuracy and exhibits a decent to high performance across all classes. Notably, the Precision for the AS inquiry class (5), which was a major issue in previous models, significantly improved, enhancing the model’s reliability. Despite the data imbalance issue, the performance for each class appeared to be consistently maintained. It seems that with simple replication-based over-sampling, augmenting the data by more than twofold does not prevent confusion during model training.
5.5. Model 5. [BE] Easy Augmentation Data
The most successful over-sampling configuration (C), which involved doubling the number of instances in the underrepresented categories, was also applied to EDA. For Model 5. [BE], an EDA model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9250 (Table 19).
Table 19.
Classification report—Model 5. [BE] EDA: Doubled records in categories 1–3 and 5.
The F1 score and Accuracy generally increased. Although the AS inquiry (5)’s F1 score slightly decreased compared to Model 4-3. [BO3], it maintained its performance, seemingly resolving the issues of previous models. Despite the data imbalance problem, the performance across different classes remained relatively balanced. However, the Recall value for Delivery inquiry (3) continued to show less improvement compared to other major classes, even when compared to the AS inquiry class.
5.6. Ensemble Model
Simply augmenting the key fields of the Korean WordNet by 5734 entries led to a diversification of vocabulary sufficient to improve performance compared to previous attempts that showed no significant difference from common over-sampling. Consequently, the diversity of NER tags also increased, resulting in an improvement when ensembled. This outcome can also be attributed to the adoption of the CatBoost algorithm, which is known to perform better in multi-class classification tasks compared to traditional Gradient Boosting Machine (GBM)-based algorithms.
5.6.1. Model 6-1 [BO3E] Ensemble Model (A) Trained on Over-Sampled (C) Data
The level of text diversity appears to significantly impact the diversity of NER tags. When a model trained by doubling the augmentation of categories 1 through 3 and 5, which showed a good performance with over-sampling, was utilized in the ensemble, the performance actually declined.
For Model 6-1. [BO3E], an ensemble (A) model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.8969 (Table 20).
Table 20.
Classification report—Model 6-1. [BO3E] Ensemble model (A) on over-sampled (C) data.
Overall, the model’s accuracy slightly decreased, and in particular, the Precision and F1 score for AS inquiry (class 5) significantly dropped, leading to a serious issue with the model’s reliability. This indicates that the model struggles to correctly identify instances of AS inquiry (class 5) and frequently misclassifies other inquiries as AS inquiries. The performance for delivery inquiry (class 3) also still requires improvement. Further investigation is needed to determine if simple replication-based over-sampling is incompatible with CatBoost.
5.6.2. Model 6-2 [BEE] Ensemble Model (B) Trained on Data Augmented with EDA
For Model 6-2. [BEE], an ensemble (B) model, as referenced in Figure 2, these tuned parameters led to a weighted F1 score of 0.9331 (Table 21).
Table 21.
Classification report—6-2. [BEE] Ensemble model (B) trained on data augmented with EDA.
Despite the significantly smaller support for AS inquiry (5) compared to other classes, the high Precision, Recall, and F1 score indicate that the model learned the limited AS inquiry data effectively. The weighted avg. value does not show a substantial difference from the macro avg. value, suggesting that data imbalance did not significantly impact the overall performance of the model. However, due to the small number of AS inquiry data points, acquiring more data to train the model could potentially lead to further performance improvements. In conclusion, the model demonstrates an overall high performance and exhibits respectable predictive capabilities across all classes.
According to the feature importance shown in Figure 3, the category predictions inferred by the BERT model were the most significant features. Among the NER tags, DT (date), PS (person), OG (organization), LC (location), and QT (quantity) were the most important in that order.
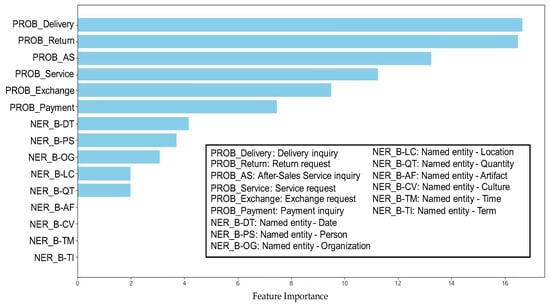
Figure 3.
Feature importance—BERT model/over-sampling + NER ensemble.
These results align with the retail industry call center domain, demonstrating the usefulness of NER tag information in category classification. Furthermore, we enhanced NER performance by expanding the Korean lexicon with keywords derived from the current conversation categories. We could further diversify the Korean WordNet by extracting keywords and contexts from existing conversations using LLMs. There is potential to further improve the performance of the ensemble model, and if we focus on a specific business domain rather than a general-purpose one, we could expand the WordNet more cost-effectively to enhance classification performance.
5.7. Summary of Experimental Results
The results of the nine experiments outlined in Figure 2 are summarized in Table 22. The experiment with the best performance was the ensemble model using the CatBoost algorithm, which utilized the subtotal of NER tags as meta-information for the BERT model trained on data augmented with EDA.
Table 22.
Comparison of best performance: Machine learning models with data augmentation and ensemble using NER meta-information.
6. Conclusions
Call center consultation conversation data exhibit an imbalanced distribution across classification categories, presenting challenges in developing accurate classification models. Additionally, Korean, as an agglutinative language with complex morphological structures, poses unique difficulties in text data augmentation, further complicating the development of classification models. In this study, we developed methods for accurate classification of call center consultation conversation data with these characteristics.
Previous research on text category classification has demonstrated an improved performance of classification algorithms through the utilization of meta-information. In this study, we introduced the concept of utilizing Named Entity Recognition (NER) tag information as meta-information for call center consultation conversations. Based on this approach, we selected appropriately tuned baseline models, augmented the data, and proposed two novel ensemble models that additionally incorporate meta-information utilizing NER tag information according to the augmentation method.
To evaluate their effectiveness, we compared our models with seven existing models. Comparative results revealed that our proposed method achieved an F1 score of 0.9331, representing a 2.3% improvement over the baseline model, while accuracy similarly improved by 2% to 0.9337. Although the final performance might appear marginally incremental at the first glance, it is noteworthy when considering the data imbalance. The model trained on EDA-augmented data achieved only 0.8837 Precision, 0.8246 Recall, and an 0.8531 F1 score for the AS Service (5) category, which constitutes merely 2% of the entire dataset. In the ensemble model incorporating NER tag meta-information, the classification performance for the AS Service (5) category improved significantly to 0.9245 Precision (+4.6%), 0.9800 Recall (+4.6%), and a 0.9509 F1 score (+4.6%). The final ensemble model effectively mitigated the data imbalance problem, thereby enhancing the accuracy of the classification model.
While this research has reached a conclusion for now, there remains significant room for improvement. In Korean, simple data duplication for over-sampling is unlikely to yield significant results, and Korean language models for EDA and NER are not yet sufficient. Given Korean WordNet limitations, using LLMs can offer a quick alternative. The available Korean WordNet lacks sufficient vocabulary, EDA-based augmentation lacks diversity, and extracted NER entities do not perfectly align with the call center domain. However, recent Korean WordNet enhancements using LLMs significantly improved EDA-based augmentation diversity, leading to richer NER tags. Consequently, ensembling the BERT model with enhanced NER tag information substantially improved target model performance. Building upon these findings, future advancements in Korean text classification should prioritize developing high-quality, domain-specific Korean lexical resources using LLMs; creating NER models leveraging LLMs for more accurate entity extraction; researching efficient model lightweighting for CPU-based inference in call center environments; and exploring various ensemble techniques and meta-information strategies optimized for call center classification. In conclusion, leveraging LLMs to enhance Korean lexical resources and improve the performance of EDA and NER, based on this enhancement, shows significant potential for drastically improving the performance of call center conversation classification models. We anticipate that continuous research and development will contribute to providing more effective and cost-efficient AI-based conversation services in real-world operational environments. As each technological component utilized in this study continues to advance, cost-effective and high-performance text classification can be achieved by selectively incorporating the most rapidly evolving components, much like assembling Lego blocks.
Author Contributions
Conceptualization, W.K.; methodology, S.J.; validation, S.J.; formal analysis, S.J.; data curation, S.J.; writing original draft preparation, S.J.; writing review and editing, W.K.; supervision, W.K.; funding acquisition, W.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Research Program funded by SeoulTech: U2023-0277 (Seoul National University of Science and Technology: U2023-0227).
Data Availability Statement
The datasets presented in this article are not readily available because the data have some personal information. Requests to access the datasets should be directed to authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Mishne, G.; Carmel, D.; Hoory, R.; Roytman, A.; Soffer, A. Automatic analysis of call-center conversations. In Proceedings of the International Conference on Information and Knowledge Management, New York, NY, USA, 31 October–5 November 2005; pp. 453–459. [Google Scholar]
- Kim, W. [Deep Dive] Industries Using Contact Centers, with 113,595 Employees, Down 6.78% Year Over Year. Available online: https://www.newsprime.co.kr/news/article/?no=679131 (accessed on 15 May 2025).
- Ryu, K.-D. A Study on Artificial Intelligence Based Contact Center System. Ph.D. Thesis, Seoul University of Science and Technology, Seoul, Republic of Korea, 2019. [Google Scholar]
- Hwang, S.; Kim, D. BERT-based classification model for Korean documents. J. Soc. E-Bus. Stud. 2020, 25. [Google Scholar] [CrossRef]
- Afzal, M.; Hussain, J.; Abbas, A.; Hussain, M.; Attique, M.; Lee, S. Transformer-based active learning for multi-class text annotation and classification. Digit. Health 2024, 10, 20552076241287357. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Park, J. KoBERT-NER. Available online: https://github.com/monologg/KoBERT-NER (accessed on 15 May 2025).
- Khasanova, E.; Hiranandani, P.; Gardiner, S.; Chen, C.; Fu, X.-Y.; Corston-Oliver, S. Developing a production system for Purpose of Call detection in business phone conversations. arXiv 2022, arXiv:2205.06904. [Google Scholar] [CrossRef]
- Iheme, L.O.; Ozan, S. Feature Selection for Anomaly Detection in Call Center Data. In Proceedings of the 2019 11th International Conference on Electrical and Electronics Engineering (ELECO), Bursa, Turkey, 28–30 November 2019; pp. 926–929. [Google Scholar] [CrossRef]
- Tang, M.; Pellom, B.L.; Hacioglu, K. Call-type classification and unsupervised training for the call center domain. In Proceedings of the 2003 IEEE Workshop on Automatic Speech Recognition and Understanding (IEEE Cat. No.03EX721), St Thomas, VI, USA, 30 November–4 December 2003; pp. 204–208. [Google Scholar] [CrossRef]
- Choi, J.-Y.; Hahn, H.; Jung, Y. Research on text classification of research reports using Korea national science and technology standards classification codes. J. Korea Acad.-Ind. Coop. Soc. 2020, 21, 169–177. [Google Scholar] [CrossRef]
- Bae, J.; Lee, C.; Lim, J.; Kim, H. BERT-based Data Augmentation Techniques for Korean Semantic Role Labeling. In Proceedings of the Korean Computer Science and Technology Conference, Jeju, Republic of Korea, 2–4 July 2020; pp. 335–337. [Google Scholar]
- Noh, Y.-D.; Cho, K.-C. A text content classification using LSTM for objective category classification. J. Korea Soc. Comput. Inf. 2021, 26, 39–46. [Google Scholar] [CrossRef]
- Association, K.T.T. Named Entity Recognition. In IT Terminology Dictionary; Telecommunications Technology Association (TTA): Seongnam-city, Gyeonggi-do, Korea, 2016. [Google Scholar]
- Chen, Y.; Lim, K.; Park, J. Korean named entity recognition based on language-specific features. Nat. Lang. Eng. 2024, 30, 625–649. [Google Scholar] [CrossRef]
- Keraghel, I.; Morbieu, S.; Nadif, M. Recent Advances in Named Entity Recognition: A Comprehensive Survey and Comparative Study. arXiv 2024, arXiv:2401.10825. [Google Scholar] [CrossRef]
- 42Maru. Customer (Call Center) Question-and-Answer Data. Available online: https://aihub.or.kr/aidata/30716 (accessed on 15 May 2025).
- Zhang, Y.; Garg, S.; Meng, Y.; Chen, X.; Han, J. Motifclass: Weakly supervised text classification with higher-order metadata information. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1357–1367. [Google Scholar]
- Reusens, M.; Stevens, A.; Tonglet, J.; De Smedt, J.; Verbeke, W.; Vanden Broucke, S.; Baesens, B. Evaluating text classification: A benchmark study. Expert Syst. Appl. 2024, 254, 124302. [Google Scholar] [CrossRef]
- Shou, Z.; Jiang, Y.; Lin, F. AMR-DA: Data Augmentation by Abstract Meaning Representation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Spratling, M.W.; Schütt, H.H. A margin-based replacement for cross-entropy loss. ArXiv 2025, arXiv:2501.12191. [Google Scholar] [CrossRef]
- SKTBrain. KoBERT. Available online: https://github.com/SKTBrain/KoBERT (accessed on 15 May 2025).
- Kim, T. KorEDA. Available online: https://github.com/catSirup/KorEDA (accessed on 15 May 2025).
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).