Abstract
In order to enhance performance of robot systems in the manufacturing industry, it is essential to develop motion and task planning algorithms. Especially, it is important for the motion plan to be generated automatically in order to deal with various working environments. Although PRM (Probabilistic Roadmap) provides feasible paths when the starting and goal positions of a robot manipulator are given, the path might not be smooth enough, which can lead to inefficient performance of the robot system. This paper proposes a motion planning algorithm for robot manipulators using a twin delayed deep deterministic policy gradient (TD3) which is a reinforcement learning algorithm tailored to MDP with continuous action. Besides, hindsight experience replay (HER) is employed in the TD3 to enhance sample efficiency. Since path planning for a robot manipulator is an MDP (Markov Decision Process) with sparse reward and HER can deal with such a problem, this paper proposes a motion planning algorithm using TD3 with HER. The proposed algorithm is applied to 2-DOF and 3-DOF manipulators and it is shown that the designed paths are smoother and shorter than those designed by PRM.
1. Introduction
In the Industry 4.0 era, robots and related technologies are fundamental elements of assembley systems in manufacturing; for instance, efficient robot manipulators for various tasks in assembly lines, control of robots with high accuracy, and optimization methods for task scheduling [1,2].
When a task is given from a high level task scheduler, the manipulator has to move its end-effector from the starting point to the goal point without collision with any obstacles or other robots. For this, motion planning algorithms let robot manipulators know how to change their joint angles in order for the end-effector to reach the goal point without collision. Currently, in practice, human experts teach robot manipulators how to move in order to conduct various predefined tasks. Namely, a robot manipulator learns from human experts how to change its joint angles for a given task. However, when the tasks or the working environments change, such manual teaching (a robot manipulator’s learning) procedure has to be done again. The other downside of the current approach is optimality or efficiency. In other words, it is not clear if the robot manipulator moves optimally even though the robot manipulator can perform a given task successfully when a robot manipulator learns from human experts. Therefore, it is important to teach the robot manipulators an optimal path automatically when a task is given. Using policy search-based reinforcement learning, this paper presents a motion planning algorithm for robot manipulators, which makes it possible for the robot manipulator to generate an optimal path automatically; it is a smoother path compared with existing results [3,4,5].
For robot path planning, sampling-based algorithms find feasible paths for the robot manipulator using a graph consisting of randomly sampled nodes and connected edges in the given configuration space [6,7]. PRM (Probabilistic Roadmaps) and RRT (Rapid Exploring Random Trees) are two representatives of sampling-based planning algorithms. PRM consists of two phases. The learning phase samples nodes randomly from collision-free space in the configuration space and makes edges with direction by connecting the sampled nodes. Then, it constructs a graph using the nodes and edges. The query phase finds the optimal path connecting the starting node and goal node in the graph [8,9,10,11,12,13]. Note that the resulting path by PRM is made by connecting the sampled nodes in the configuration space; usually, it is not smooth and might be longer than the optimal path. RRT samples nodes from the neighbor of the starting point in the configuration space, constructs a tree by finding a feasible path from the starting node, and expands the graph until the goal point is reached. It works for various environments and can generate a path quickly, but its optimality is not guaranteed in general [14,15]. More recently, Fast Marching Methods (FMMs) using level sets have been proposed for path planning. The FMMs are mainly about efficiently solving the Eikonal equation whose solution provides the optimal path. It is shown that FMMs lead to an asymptotically optimal path and faster convergence than PRM and RRT [16]. Since FMMs, PRM, and RTT are sampling-based approaches, they need a high number of sampling points for high dimensional configuration space in order to obtain a smoother path, which means that they are computationally demanding in calculating the optimal path for given arbitrary starting and ending points. Also, they can suffer from memory deficiency in high dimensional space. However, in the proposed method, when a TD3 agent is trained, the optimal path can easily be computed (i.e., trained neural network computation).
Reinforcement learning is a deep learning approach which finds an optimal policy for an MDP (Markov Decision Process). The agent applies an action according to the policy to the environment and then the agent gets the next state and reward from the environment. The agent finds the optimal policy such that the sum of reward over the horizon is maximized [17,18]. In reinforcement learning, there are two typical approaches to find the optimal policy. Value-based approaches estimate the optimal (action) state value function and derive the corresponding policy from the estimate of the value function [19,20,21]. On the other hand, policy gradient approaches search the optimal policy directly from the set of state and reward data. It is known that policy gradient approaches show much better performance in general [22,23,24,25,26,27,28]. Recently, deep learning-based control and operation of robot manipulators have drawn much attention. In [29,30], robot path planning methods are proposed using a deep Q-network algorithm with emphasis on learning efficiency. For path training, a stereo image is used to train DDPG (Deep Deterministic Policy Gradient) in [31]. In [32], a real robot is trained using reinforcement learning for its path planning.
This paper presents a policy gradient-based path planning algorithm. To this end, RAMDP (Robot Arm Markov Decision Process) is defined first. In RAMDP, the state is the joint angle of the robot manipulator and the action is the variation of the joint angle. Then, DDPG (Deep Deterministic Policy Gradient) with HER (Hindsight Experience Replay) is employed for the purpose of searching the optimal policy [24,33]. DDPG is applied since the action in RAMDP is a continuous value and DDPG is devised for MDP with a continuous action. The twin delayed DDPG enhances performance of DDPG so that it shows good convergent property and avoids overestimation. In fact, HER is quite fit to robot path planning since RAMDP is an MDP with sparse reward. Sparse reward means that when an MDP has a finite length of an episode with a specific goal state and the episodes end at non-goal states (say, a failed episode) due to any reasons frequently, the agent can not get much reward. Since all reinforcement learning finds the optimal policy by maximizing the sum of reward, sparse reward is critical in reinforcement learning. However, as the episodes are saved in the memory, HER modifies the last state in a failed episode as a new goal. Then, the failed episode becomes a normal episode which ends at the goal state. Hence, HER enhances the sample efficiency and fits to the robot path planning. It is shown that such a procedure is quite helpful in a motion planning algorithm. In the proposed algorithm, when the state is computed after applying the action, the collision with obstacle or reaching the goal are checked. It turns out that many states end at non-goal states in the middle of learning. This is why conventional reinforcement learnings do not work well for robot path planning. However, using HER, those episodes can be changed to a normal episode which ends at goal states. Hence, the contribution of the paper is to present a path planning algorithm using DDPG with HER. The proposed method is applied to a 2-DOF and 3-DOF robot manipulators using simulation; experimental results are also shown for a 3-DOF manipulator. In both cases, it is quantitatively demonstrated that the resulting paths are shorter than those by PRM.
2. Preliminaries and Problem Setup
2.1. Configuration Space and Sampling-Based Path Planning
In sampling-based path planning, configuration space (also called joint space for robot manipulators) represents the space of possible joint angles and is a subset of n-dimensional Euclidean space where n denotes the number of the joints of the manipulator. The values of the joint angles of a robot manipulator are denoted as a point in [1,2,34]. The configuration space consists of two subsets: the collision-free space and in which the robot manipulator collides with other obstacles or itself. For motion planning, a discrete representation of the continuous is generated by random sampling. Then a connected graph (roadmap) is obtained. The nodes in the graph denote admissible configuration of the robot manipulators, and the edges connecting any two nodes mean feasible paths (trajectory) between the corresponding configurations. Finally, when the starting and goal configurations and are given, any graph search algorithm is employed to find the shortest path connecting and . There exists a shortest path between and since they are two nodes on the connected graph.
2.2. Reinforcement Learning
Reinforcement learning is an optimization-based method to solve an MDP (Markov Decision Process) [18]. An MDP is comprised of where S is a set of the state and A denotes a set of the action. Besides, P consists of which is the transition probability that the current state with the action becomes the next state . R stands for the reward function and is the discount factor. The agent’s policy implies the distribution of the action a for the given state s. In reinforcement learning, the agent takes action according to the policy at time t and state , and the environment returns the next state and reward by the transition P and reward function R. By repeating this, the agent updates its policy so as to maximize its expected return . The resulting optimal policy is denoted by . In order to find the optimal policy, value-based methods like DQN (Deep Q-Network) estimate the optimal value function (i.e., estimate the maximum return) and find the corresponding policy [19]. On the other hand, policy gradient methods compute the optimal policy directly from samples. For instance, REINFORCE, actor-critic method, DPG (Deterministic Policy Gradient), DDPG (Deep DPG), A3C (Asynchronous Advantage Actor-Critic), TRPO (Trust Region Policy Optimization) are representative methods of policy gradient methods [22,35,36]. Training performance of reinforcement learning is heavily dependent on samples which are several sets of the state, action, and next state. Hence, in addition to the various reinforcement learning algorithms, many research efforts have been directed to study on how to use episodes efficiently for the purpose of better agent learning, for example, replay memory [19] and HER (Hindsight Experience Replay) [33]. In this paper, for the sake of designing a motion planning algorithm, a policy gradient called TD3 (twin delayed Deep Deterministic Policy Gradient) is used for path planning.
3. TD3 Based Motion Planning for Smoother Paths
3.1. RAMDP (Robot Arm Markov Decision Process) for Path Planning
In order to develop a reinforcement learning (RL) based path planning, the robot arm MDP (RAMDP) needs to be defined properly first [17]. The state of the RAMDP is the angle value of each joint of the manipulator where the joint angle belongs to the configuration space . Hence, for collision-free operation of a robot manipulator, in the motion planning, the state belongs to only where n is the number of the joint in the manipulator. In the RAMDP, the action is joint angle variation. Unlike MDP with discrete state and action such as frozen-lake ([17]), the RAMDP under consideration has continuous state (i.e., joint angle) and continuous action (i.e., joint angle variation). Due to this, DDPG or its variants are fit to find the optimal policy for the agent in the RAMDP. In this paper, TD3 (twin delayed DDPG) is employed to find an optimal policy for the continuous action with deterministic policy in the RAMDP. Figure 1 describes how to generate the sample () in the RAMDP. Suppose that arbitrary initial state () and goal state () are given, and that the maximum length of the episode is T. At state , if the action is applied to the RAMDP, is produced from the RAMDP. Then, according to the reward function in (1), the next state and are determined. In view of (1), if does not belong to , then the next state is set as the current state. Furthermore, if the next state is the goal point, then the reward is 0, and otherwise the reward is −1. Then, the whole procedure is repeated until the episode ends. Note that this reward function leads to as short as possible path since TD3 tries to maximize the sum of reward and a longer path implies more −1 reward.
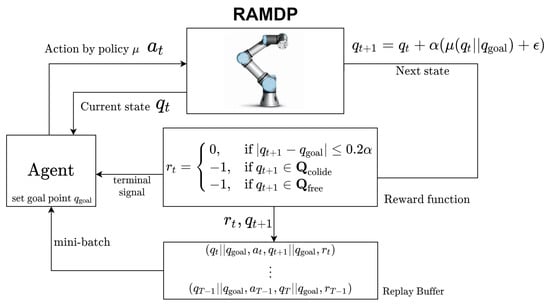
Figure 1.
Robot Arm Markov Decision Process (RAMDP).
There are two possibilities for the episode to end: (1) the next state becomes the goal state, i.e., , and (2) the length of the episode is T, i.e., and . For both cases, every sample in the form of () is saved in the memory. Note that when , the next state is set to the current state in order to avoid collision. In the worst case, if this happens repeatedly, the agent is trained such that the corresponding episode does not occur. Based on these samples in the memory, the optimal policy is determined in accordance with TD3, which is explained in the next subsection.
3.2. TD3 (Twin Delayed Deep Deterministic Policy Gradient)
In this section, TD3 is introduced [24], which is used to search the optimal policy in the proposed algorithm [17,22,35,36]. To this end, it is assumed that a sufficient number of samples () are stored in the memory.
Figure 2 describes the structure of TD3. The basic structure of TD3 is the actor-critic network. However, unlike the actor critic network, there are two critic deep neural networks (DNN), one actor DNN, and three target DNNs for each critic and actor DNNs. Hence, there are 6 DNNs (2 critic DNNs and their target DNNs, 1 actor DNN, and its target DNN) in TD3. As seen in Figure 3, the critic DNNs generate an optimal estimate of the state-action value function. The input of the critic DNN is a mini-batch from the memory and its output is . The mini-batch is a finite set of samples () from the memory. In TD3, it is important that the two critic DNNs are used in order to remove overestimation bias in function approximation. The overestimation bias can take place when bad states due to accumulated noises are overestimated. In order to cope with this, TD3 chooses the smaller value out of two critic DNN outputs critic DNN as the target value. In Figure 3, and are the parameters of the two critic DNNs, and and those of corresponding target DNNs. In order to train the critic DNN, as the cost function, the following quadratic function of temporal difference error is minimized,
where stands for the parameterized state-action value function Q with parameter ,
is the target value of the function , and the target action (i.e., the action used in the critic target DNN) is defined as,
where noise follows a clipped normal distribution . This implies that is a random variable with and belongs to the interval .
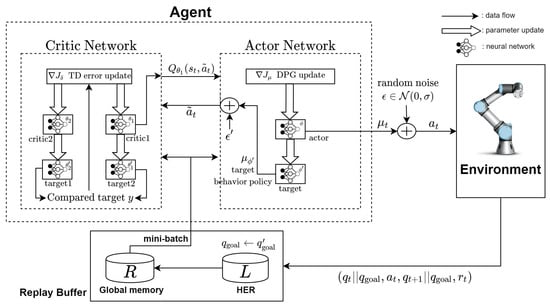
Figure 2.
Structure of TD3 (Twin Delayed Deep Deterministic Policy Gradient) with RAMDP.
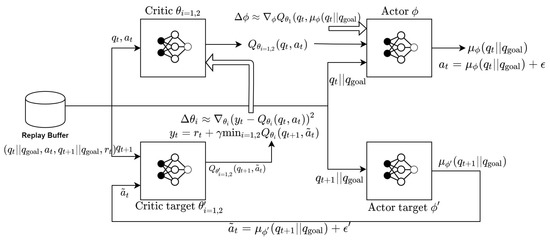
Figure 3.
Details of critic and actor deep neural network for RAMDP.
The inputs of the actor DNN are both from the critic DNN and the mini-batch from the memory, and the output is the action. Precisely, the action is given by where is the parameter of the actor DNN, is the output from the actor DNN, and a deterministic and continuous value. Noise follows the normal distribution , and is added for exploration. In order to tune the parameter , the following cost function is minimized.
where denotes the distribution of the state. Note that the gradient (equivalently ) is used to update the parameter . This is why the method is called the policy gradient.
Between the two outputs from the two critic target DNN, the common target value in (3) is used to update the two critic DNNs. Also, TD3 updates the actor DNN and all three target DNNs every d steps periodically in order to avoid too fast convergence. Note that the policy is updated proportionally to only [24]. The parameters for the critic target DNN and the actor target DNN are updated according to at every d steps, which not only maintain small temporal difference error, but also make the parameters in the target DNN updated slowly.
3.3. Hindsight Experience Replay
Since the agent in reinforcement learning is trained from samples, it is utmost important to have helpful samples which mean that the action state pair improve the action value function. On the other hand, many unhelpful samples are generated in RAMDP since many episodes end without reaching the goal. In other words, RAMDP is an MDP with sparse reward. For the purpose of enhancing sample efficiency, HER (Hindsight Experience Replay) is employed in this paper. For the episode in the memory where is not the goal state, HER resets as . This means that even though the episode does not end the goal state, the episode becomes a ended state at the goal after modification by HER. Then, the failed episodes can be use to train the agent since the modified episodes are a goal achieved episodes. Algorithm 1 summarizes the proposed algorithm introduced in this section.
| Algorithm 1 Training procedure for motion planning by TD3 with HER. The red part is for a robot manipulator, and the blue part is for HER. | |
| 1: Initialize critic networks and actor network with | |
| 2: Initialize target networks | |
| 3: Initialize replay buffer | |
| 4: for to M do | |
| 5: Initialize local buffer | ▹ memory for HER |
| 6: for to do | |
| 7: Randomly choose goal point | |
| 8: Select action with noise: | |
| 9: | ▹ denotes concatenation |
| 10: | |
| 11: | |
| 12: if then | |
| 13: | |
| 14: else if then | |
| 15: | |
| 16: else if then | |
| 17: Terminal by goal arrival | |
| 18: end if | |
| 19: | |
| 20: | |
| 21: Store the transition in | |
| 22: | |
| 23: Sample mini-batch of n transitions from | |
| 24: | |
| 25: | |
| 26: Update critics with temporal difference error: | |
| 27: | |
| 28: | |
| 29: if then | ▹ delayed update with d |
| 30: Update actor by the deterministic policy gradient: | |
| 31: | |
| 32: Update target networks: | |
| 33: | |
| 34: | |
| 35: end if | |
| 36: end for | |
| 37: if then | |
| 38: Set additional goal | |
| 39: for to do | |
| 40: Sample a transition from | |
| 41: | |
| 42: Store the transition in | |
| 43: end for | |
| 44: end if | |
| 45: end for | |
4. Case Study for 2-DOF and 3-DOF Manipulators
In order to show the effectiveness of the proposed method, it is applied to robot manipulators. Table 1 shows the information of the used 2-DOF and 3-DOF and manipulators.

Table 1.
Parameters of 2-DOF and 3-DOF manipulators.
For easy visualization, the proposed algorithm is applied to the 2-DOF manipulator first. Table 2 summarizes the tuning parameters for the designed TD3 with HER.
Table 2.
Tuning parameters for the designed TD3 with HER.
In order to train TD3 with HER for the 2-DOF manipulator, 8100 episodes are used. Figure 4 describes the success ratio of each episode with HER when the network is training. In other words, when the network is learning with arbitrary starting and goal points, sometimes the episodes end at the given goal point but sometimes the episodes end before reaching the given goal point. In Figure 4, the green lines denote the success ratio of every 10 episodes and the thick lines stand for the moving average of the gray lines. Figure 5 shows the reward as the number of the episode increases, i.e., the training is proceeding. The reward converges as the number of the episode increases. In view of the results in Figure 4 and Figure 5, we can see that learning is over successfully.
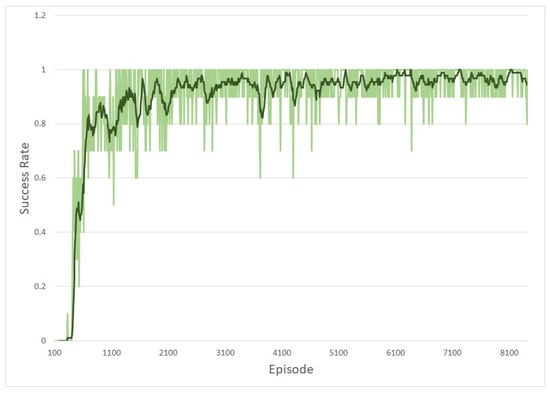
Figure 4.
2-DOF manipulator: success ration of reaching the goal point with HER.
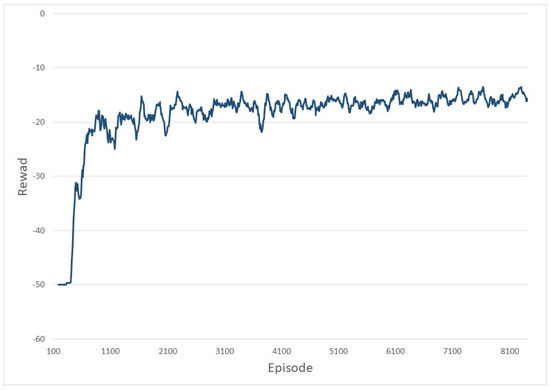
Figure 5.
2-DOF manipulator: reward from learning.
For the purpose of testing the trained TD3, it is verified if the optimal paths are generated when random starting and goal points are given to the trained TD3. For testing, only the actor DNN without its target DNN is used with the input being a starting and goal point repeatedly. The input to the trained actor DNN is , the output is , and then this is repeated with as depicted in Figure 6.
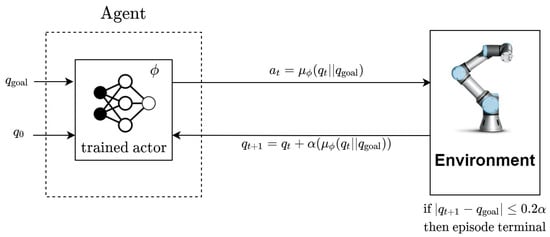
Figure 6.
Path generation using the trained actor DNN.
When this is applied to the 2-DOF manipulator, the resulting paths are shown in Figure 7. In Figure 7, the green areas represent obstacles in the configuration space, and the rhombus denote the starting point and the circles means the goal point. For comparison, PRM is also applied to generate the paths with the same starting and goal points. As shown in Figure 7, the proposed method generates smoother paths in general. This is confirmed from many other testing data as well. In Figure 7, the red lines are the resulting paths by PRM and the blue lines by the proposed method. In average, the resulting path by the proposed method is shortened by 3.45% compared with the path by PRM.
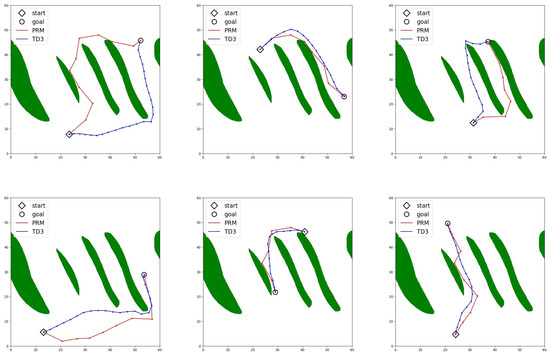
Figure 7.
DDPG based path generation for arbitrary starting and goal points in C-space.
In order to test the proposed method for a real robot manipulator, the 3-DOF open manipulator. For details, see http://en.robotis.com/model/page.php?co_id=prd_openmanipulator is considered. For easy understanding, Figure 8 shows the workspaces in Matlab and Gazebo in ROS (Robot Operating System) respectively, and configuration space of the open manipulator with four arbitrary obstacles.

Figure 8.
Workspace and configuration space. (a) Workspace in Matlab; (b) Workspace in Gazebo (in ROS); (c) Configuration space.
The tuning parameters for the TD3 with HER are also shown in Table 2.
For training, 140000 episodes are used. In view of the converged reward and success ratio in Figure 9 and Figure 10, we can see that the learning is also over successfully. With this result, random starting and goal points are given to the trained network in order to obtain a feasible path between them. Figure 11 shows several examples of generated paths by the trained actor DNN when arbitrary starting points and goal points are given. The red lines are resulting paths by PRM and the blue lines by the proposed method. As seen in the figure, the proposed method results in smoother and shorter paths in general. For the sake of between comparison, 100 arbitrary starting and gold points are used to generate paths using PRM and the proposed method. Figure 12 shows the lengths of the resulting 100 paths. In light of Figure 12, it is obvious that the proposed method generates smoother and shorter paths in general. Note that, in average, the resulting path by the proposed method is shortened by 2.69% compared with the path by PRM.
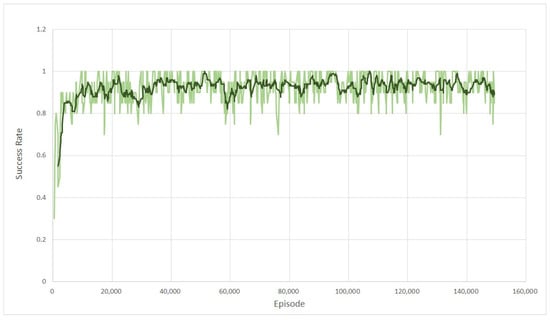
Figure 9.
3-DOF manipulator: success ration of reaching the goal point with HER.
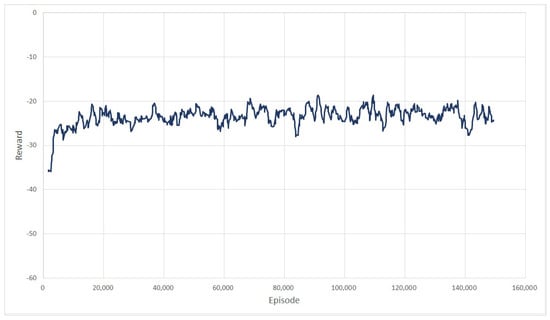
Figure 10.
3-DOF manipulator: reward from learning.
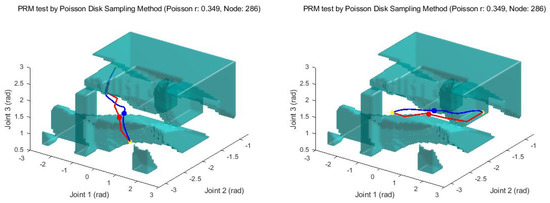
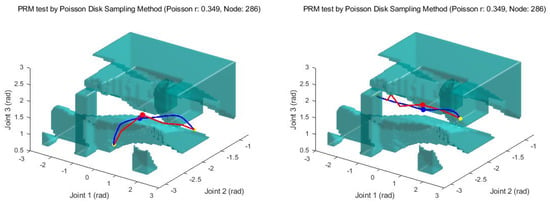
Figure 11.
Path generation using DDPG with HER.
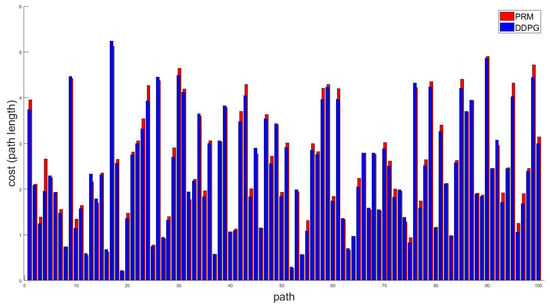
Figure 12.
Comparison of paths by PRM and the proposed method.
When the proposed method is also implemented to the open manipulator, the same experimental result as the simulation was obtained. The experimental result is presented in the https://sites.google.com/site/cdslweb/publication/td2-demo.
5. Conclusions
For the purpose of enhancing efficiency in manufacturing industry, it is important to improve performance of robot path planning and tasking scheduling. This paper presents a reinforcement learning-based motion planning method of robot manipulators with focus on smoother and shorter path generation, which means better operation efficiency. To this end, motion planning problem is reformulated as a MDP (Markov Decision Process), called RAMDP (Robot Arm MDP). Then, TD3 (twin delayed deep deterministic policy gradient, twin delayed DDPG) with HER (Hindsight Experience Replay) is designed. DDPG is used since the action in RAMDP is a continuous value and DDPG is a policy gradient tailored to an MDP with a continuous action. Moreover, since many failed episodes are generated in the RAMDP meaning that the episode ends at non-goal state due to mainly collision, HER is employed in order to enhance sample efficiency.
Future research topic includes how to solve motion planning problem for multi-robot arms whose common working space is non-empty. To solve this problem, configuration space augmentation might be a candidate solution. Since the augmented configuration space becomes high dimensional, it would be interesting to compare performance of the proposed reinforcement learning-based approach by that of sampling-based approaches such as FMMs, PRM, and RTT. Moreover, reinforcement learning-based motion planning for dynamic environment is also a challenge problem.
Author Contributions
M.K. and D.-K.H. surveyed the backgrounds of this research, designed the preprocessing data, designed the deep learning network, and performed the simulations and experiments to show the benefits of the proposed method. J.-S.K. and J.-H.P. supervised and supported this study. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
This work was supported by the Technology Innovation Program (or Industrial Strategic Technology Development Program) (10080636, Development of AI-based CPS technology for Industrial robot applications) funded By the Ministry of Trade, Industry & Energy(MOTIE, Korea), and by the Human Resources Development of the Korea Institute of Energy Technology Evaluation and Planning (KETEP) grant funded by the Ministry of Trade, Industry & Energy of the Korea government (No. 20154030200720).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MDP | Markov Decision Process |
| RAMDP | Robot Arm Markov Decision Process |
| DOF | Degrees Of Freedom |
| PRM | Probabilistic Roadmaps |
| RRT | Rapid Exploring Random Trees |
| FMMs | Fast Marching Methods |
| DNN | Deep Neural Networks |
| DQN | Deep Q-Network |
| (A3C) | Asynchronous Advantage Actor-Critic |
| (TRPO) | Trust Region Policy Optimization |
| (DPG) | Deterministic Policy Gradient |
| DDPG | Deep Deterministic Policy Gradient |
| TD3 | Twin Delayed Deep Deterministic Policy Gradient |
| HER | Hindsight Experience Replay |
| (ROS) | Robot Operating System |
References
- Laumond, J.P. Robot Motion Planning and Control; Springer: Berlin, Germany, 1998; Volume 229. [Google Scholar]
- Choset, H.M.; Hutchinson, S.; Lynch, K.M.; Kantor, G.; Burgard, W.; Kavraki, L.E.; Thrun, S. Principles of Robot Motion: Theory, Algorithms, and Implementation; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Cao, B.; Doods, G.; Irwin, G.W. Time-optimal and smooth constrained path planning for robot manipulators. In Proceedings of the 1994 IEEE International Conference on Robotics and Automation, San Diego, CA, USA, 8–13 May 1994; pp. 1853–1858. [Google Scholar]
- Kanayama, Y.J.; Hartman, B.I. Smooth local-path planning for autonomous vehicles1. Int. J. Robot. Res. 1997, 16, 263–284. [Google Scholar] [CrossRef]
- Rufli, M.; Ferguson, D.; Siegwart, R. Smooth path planning in constrained environments. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3780–3785. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Spong, M.W.; Hutchinson, S.A.; Vidyasagar, M. Robot modeling and control. IEEE Control Syst. 2006, 26, 113–115. [Google Scholar]
- Kavraki, L.E.; Kolountzakis, M.N.; Latombe, J.C. Analysis of probabilistic roadmaps for path planning. IEEE Trans. Robot. Autom. 1998, 14, 166–171. [Google Scholar] [CrossRef]
- Kavraki, L.E.; Svestka, P.; Latombe, J.C.; Overmars, M.H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Trans. Robot. Autom. 1996, 12, 566–580. [Google Scholar] [CrossRef]
- Kavraki, L.E. Random Networks in Configuration Space for Fast Path Planning. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 1995. [Google Scholar]
- Kavraki, L.E.; Latombe, J.C.; Motwani, R.; Raghavan, P. Randomized query processing in robot path planning. J. Comput. Syst. Sci. 1998, 57, 50–60. [Google Scholar] [CrossRef]
- Bohlin, R.; Kavraki, L.E. A Randomized Approach to Robot Path Planning Based on Lazy Evaluation. Comb. Optim. 2001, 9, 221–249. [Google Scholar]
- Hsu, D.; Latombe, J.C.; Kurniawati, H. On the probabilistic foundations of probabilistic roadmap planning. Int. J. Robot. Res. 2006, 25, 627–643. [Google Scholar] [CrossRef]
- Kuffner, J.J.; LaValle, S.M. RRT-connect: An efficient approach to single-query path planning. In Proceedings of the 2000 IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 995–1001. [Google Scholar]
- Lavalle, S.; Kuffner, J. Rapidly-exploring random trees: Progress and prospects. In Algorithmic and Computational Robotics: New Directions; CRC Press: Boca Ratol, FL, USA, 2000; pp. 293–308. [Google Scholar]
- Janson, L.; Schmerling, E.; Clark, A.; Pavone, M. Fast marching tree: A fast marching sampling-based method for optimal motion planning in many dimensions. Int. J. Robot. Res. 2015, 34, 883–921. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1994. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Langford, J. Efficient Exploration in Reinforcement Learning. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer US: Boston, MA, USA, 2017; pp. 389–392. [Google Scholar]
- Tokic, M. Adaptive ε-greedy exploration in reinforcement learning based on value differences. In Annual Conference on Artificial Intelligence; Springer: Berlin, Germany, 2010; pp. 203–210. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Hasselt, H.v.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Fujimoto, S.; van Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Degris, T.; Pilarski, P.M.; Sutton, R.S. Model-free reinforcement learning with continuous action in practice. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 2177–2182. [Google Scholar]
- Degris, T.; White, M.; Sutton, R.S. Off-policy actor-critic. arXiv 2012, arXiv:1205.4839. [Google Scholar]
- Bae, H.; Kim, G.; Kim, J.; Qian, D.; Lee, S. Multi-Robot Path Planning Method Using Reinforcement Learning. Appl. Sci. 2019, 9, 3057. [Google Scholar] [CrossRef]
- Lv, L.; Zhang, S.; Ding, D.; Wang, Y. Path Planning via an Improved DQN-Based Learning Policy. IEEE Access 2019, 7, 67319–67330. [Google Scholar] [CrossRef]
- Paul, S.; Vig, L. Deterministic policy gradient based robotic path planning with continuous action spaces. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 725–733. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Andrychowicz, M.; Wolski, F.; Ray, A.; Schneider, J.; Fong, R.; Welinder, P.; McGrew, B.; Tobin, J.; Abbeel, O.P.; Zaremba, W. Hindsight experience replay. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5048–5058. [Google Scholar]
- Lozano-Pérez, T. Spatial Planning: A Configuration Space Approach. In Autonomous Robot Vehicles; Cox, I.J., Wilfong, G.T., Eds.; Springer New York: New York, NY, USA, 1990; pp. 259–271. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Bejing, China, 22–24 June 2014; pp. I-387–I-395. [Google Scholar]
- Sutton, R.S.; Mcallester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Processing Systems 12; MIT Press: Cambridge, MA, USA, 2000; pp. 1057–1063. [Google Scholar]













© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).