
Surface Defect and Malformation Characteristics Detection for Fresh Sweet Cherries Based on YOLOv8-DCPF Method
 ,
,  , and
, and
Abstract
1. Introduction
2. Materials and Methods
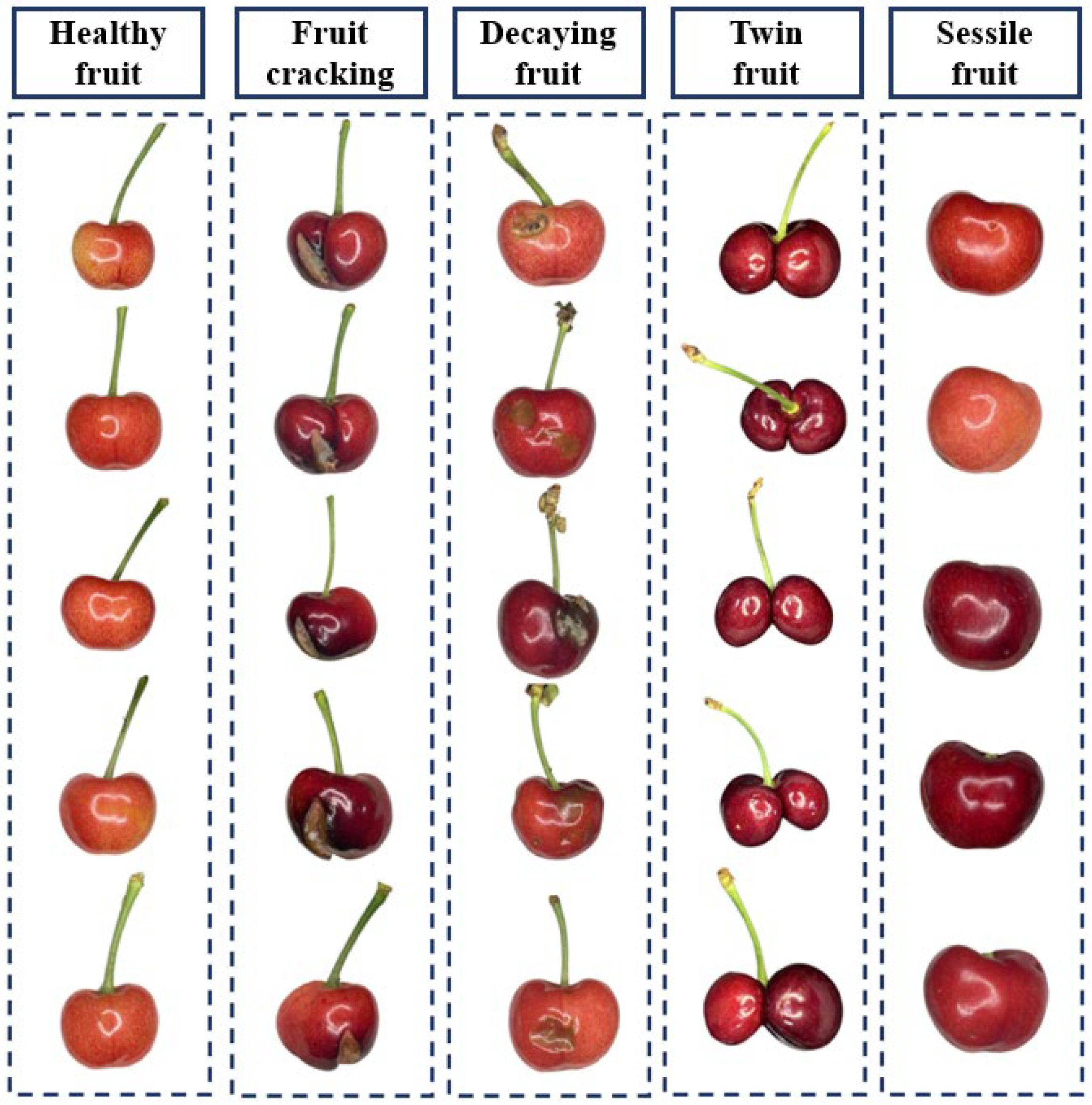
2.1. Image Data Acquisition and Preprocessing
2.1.1. Data Collection
2.1.2. Dataset Production
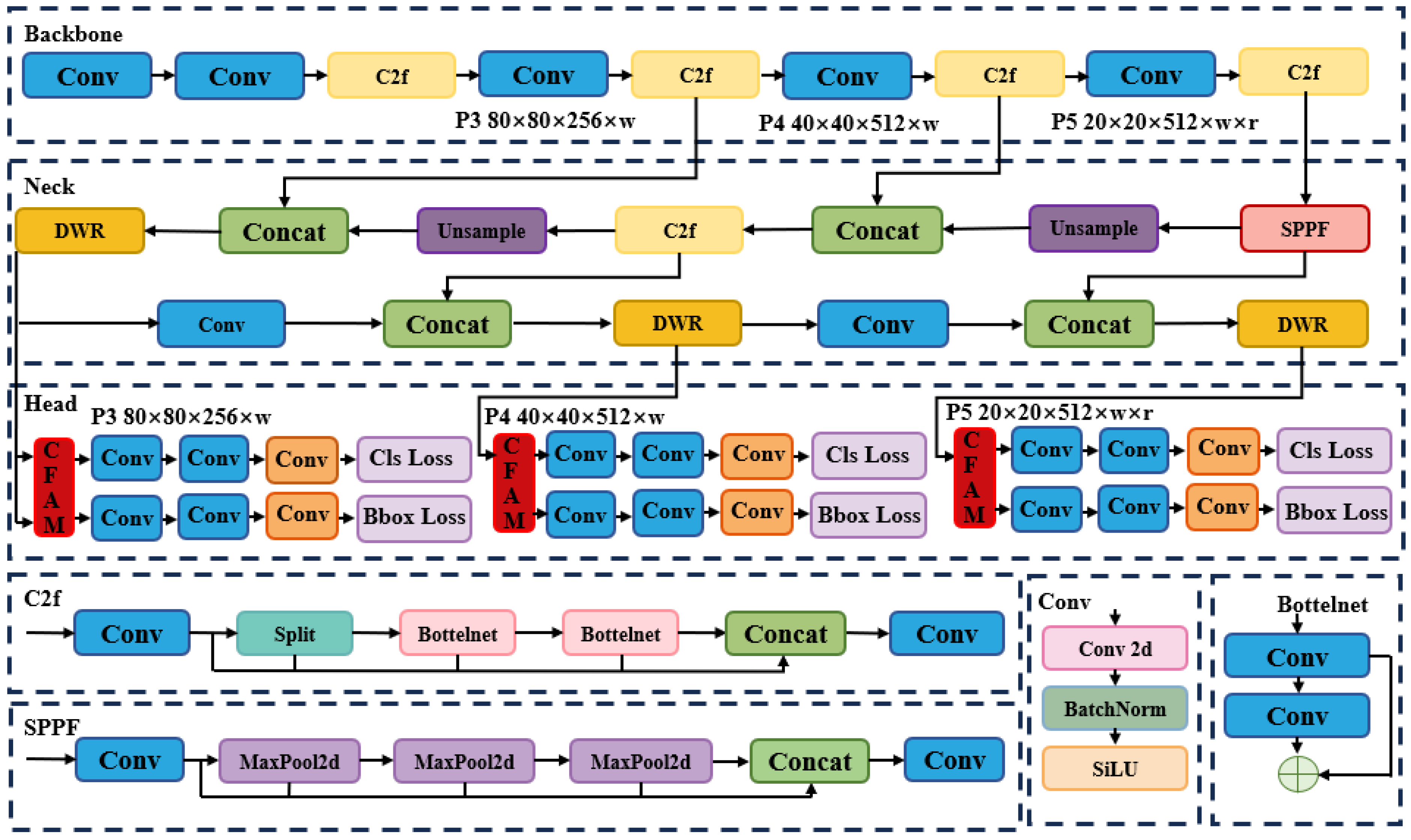
2.2. Construction of the YOLO-DCPF Model
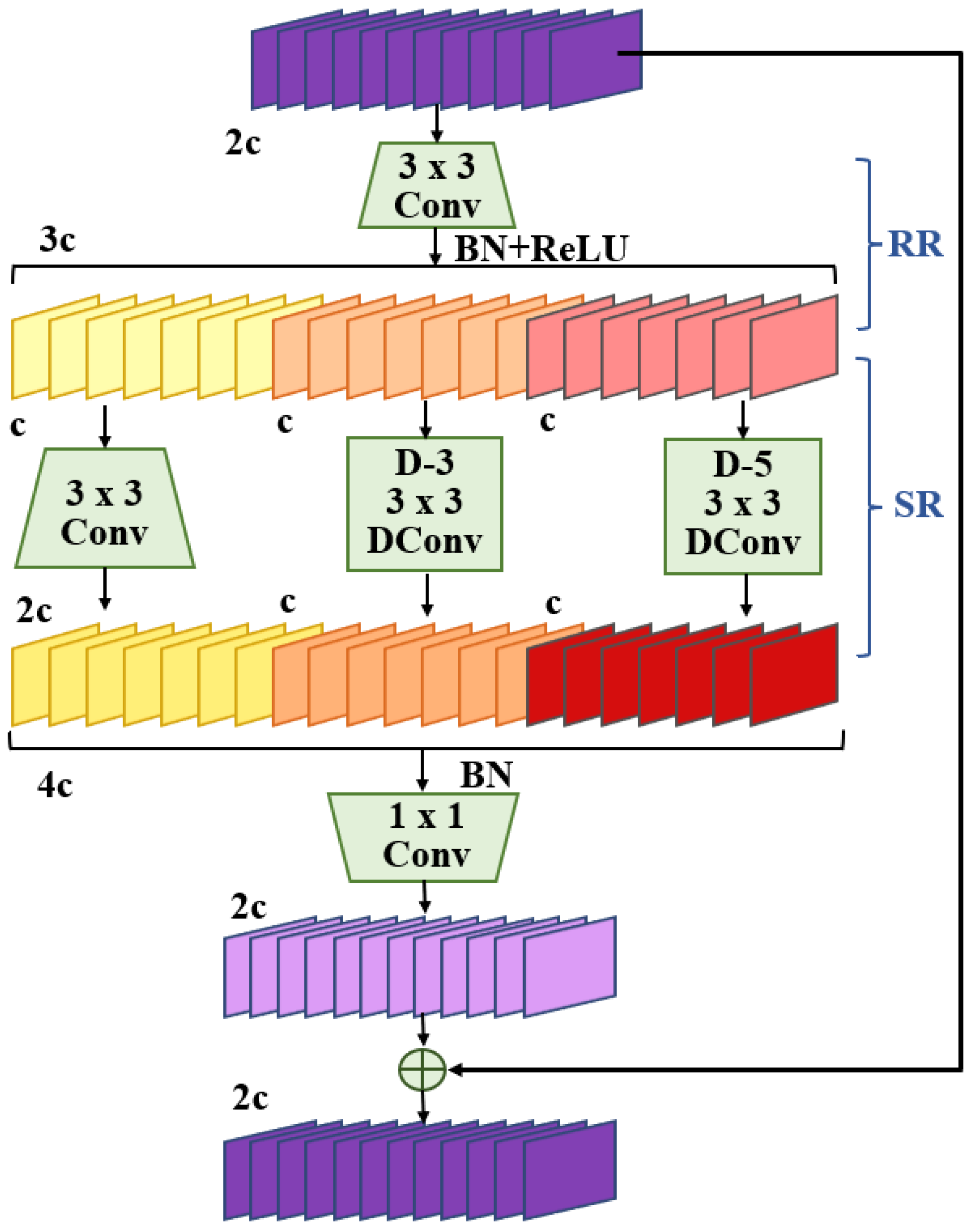
2.2.1. DWR Module
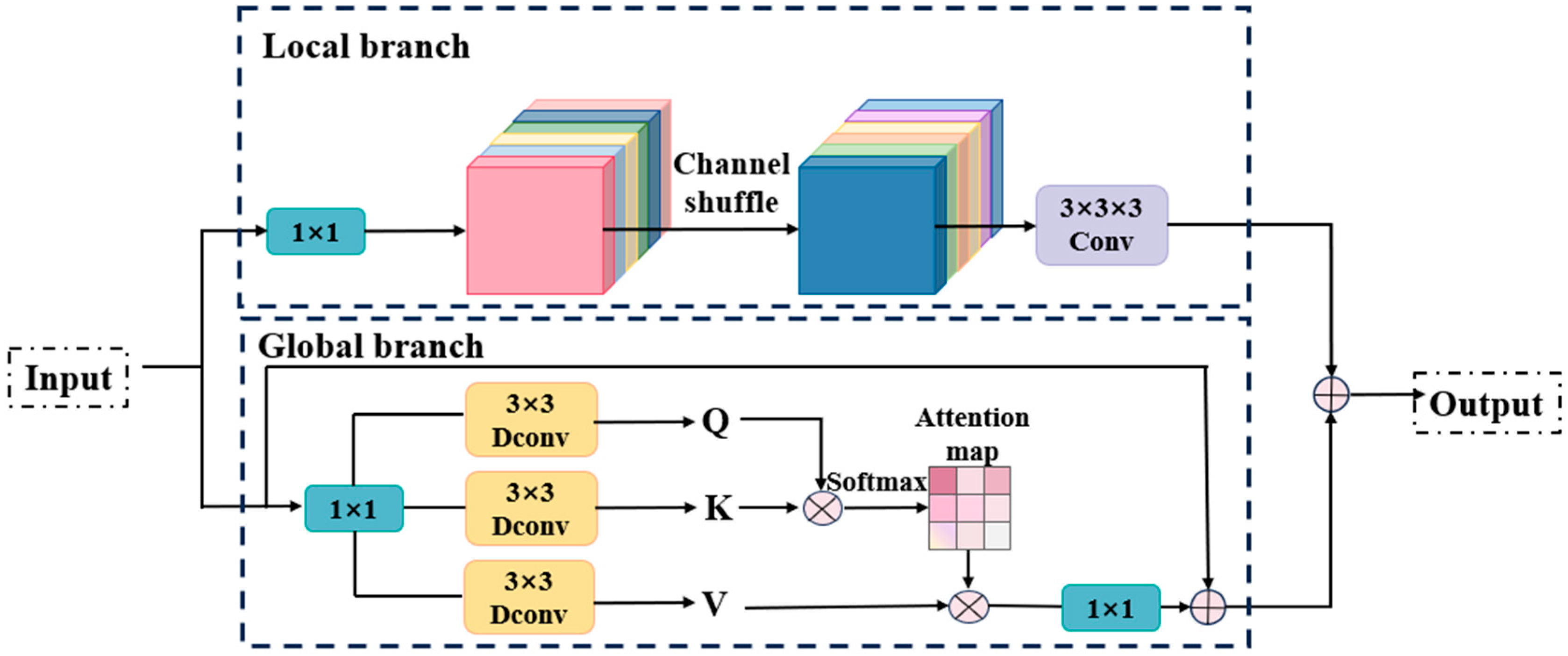
2.2.2. CAFM Attention Mechanisms
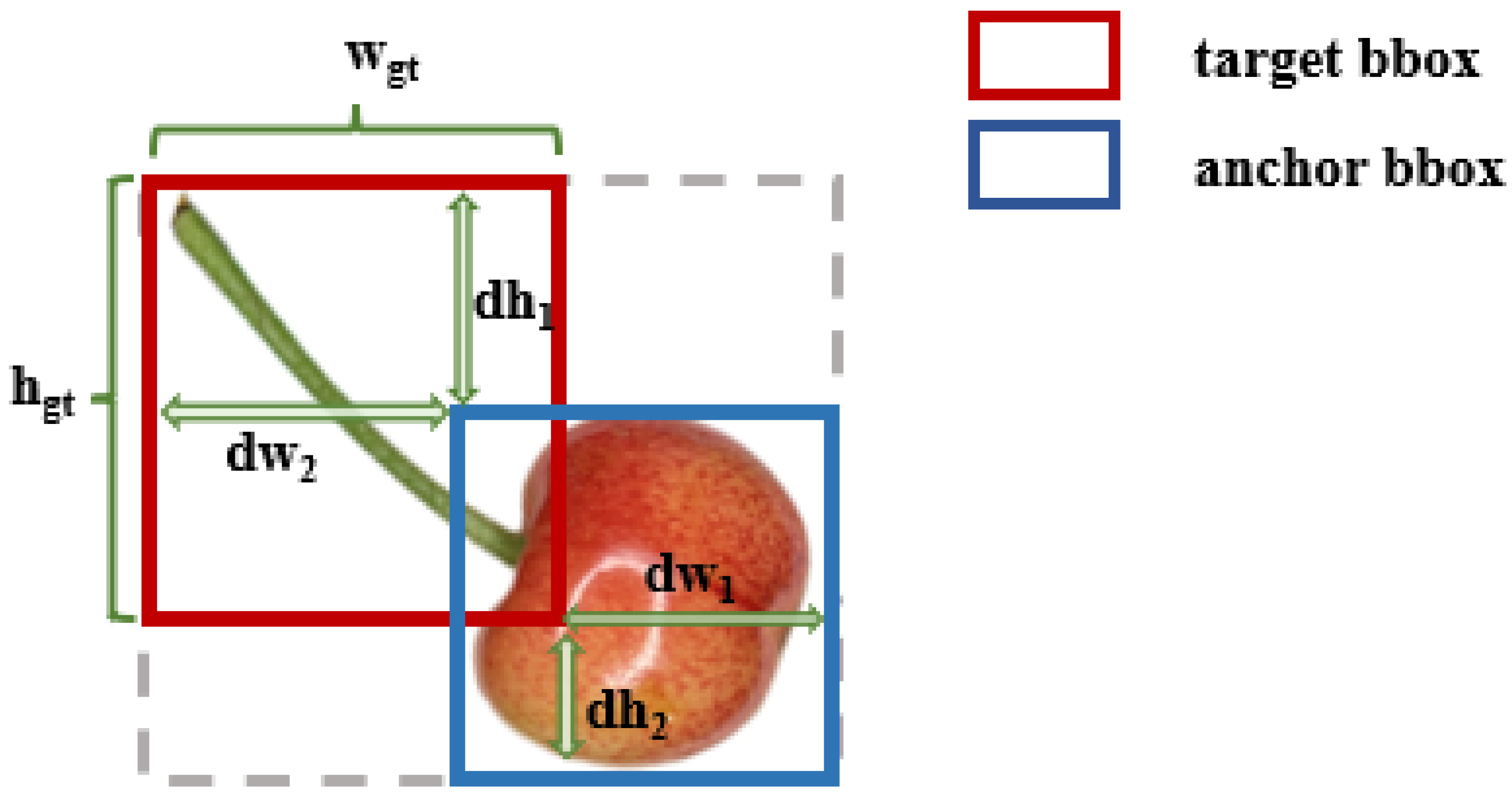
2.2.3. PIoU Loss Function
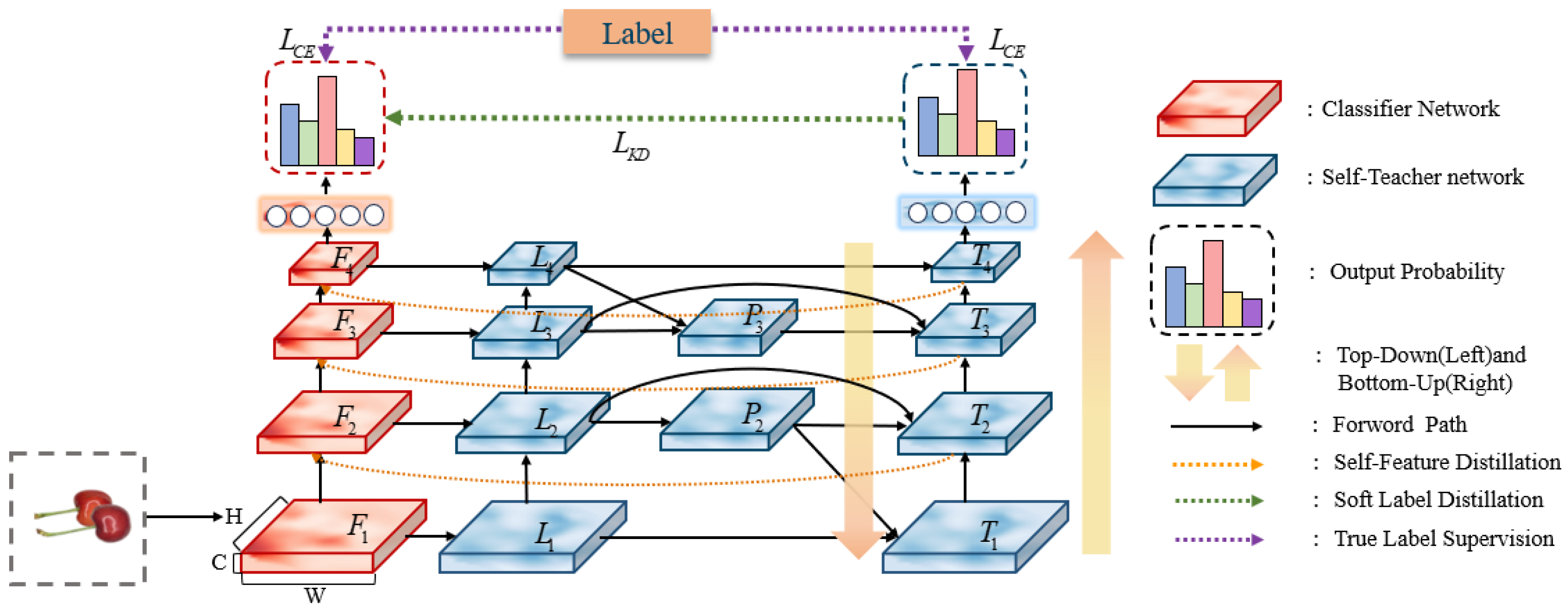
2.2.4. Self-Distillation
2.3. Test Environment
2.4. Evaluation Indicators
3. Results and Discussion
3.1. Ablation Experiments
3.2. Performance Analysis of Adding DWR Module at Different Locations
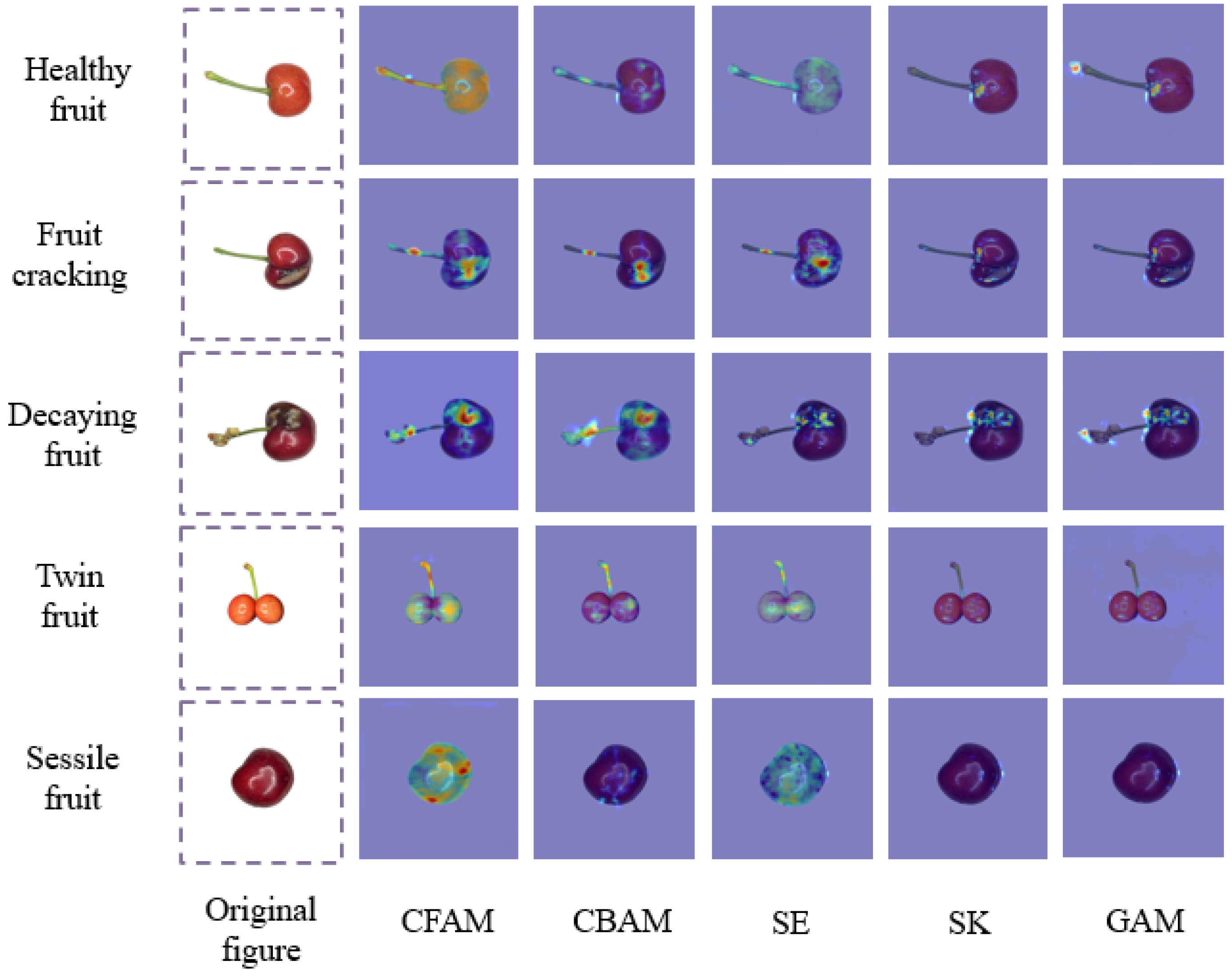
3.3. Comparison of Different Attention
3.4. Comparison of Different Loss Functions
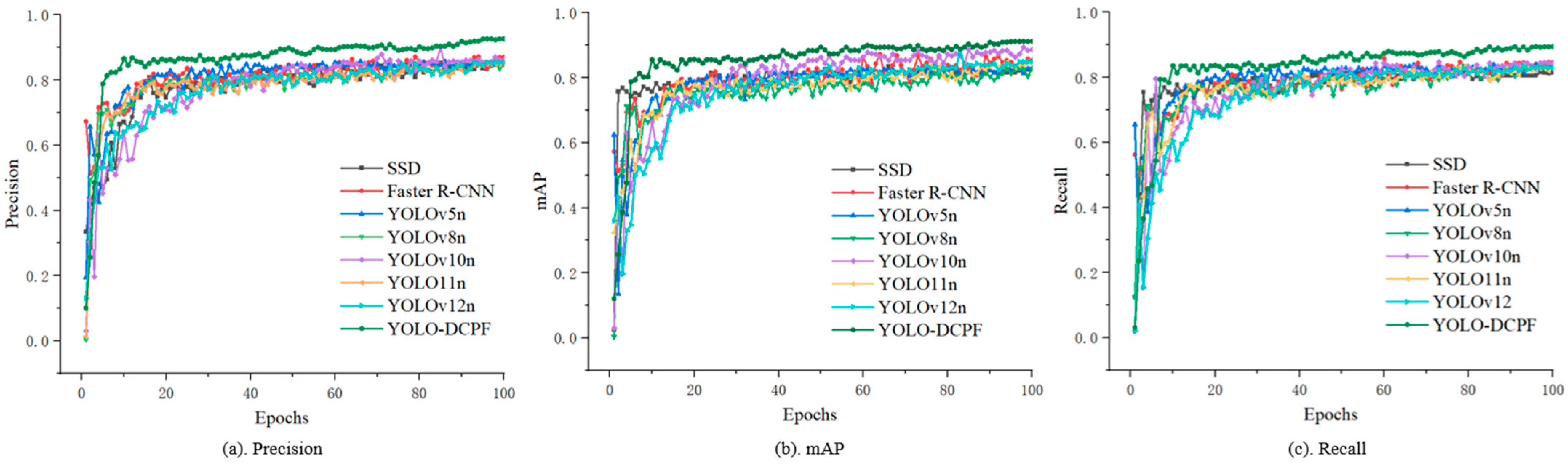
3.5. Comparison of Algorithms for the YOLO Series
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, J.; Wang, N.; Qin, L.; Wang, C.; Qian, C.; Zhao, Z.; Tian, J.; Sun, Y. Analysis on the Development of Facility Cherry Industry in Chifeng City. Analysis on the Development of Facility Cherry Industry in Chifeng City. North. Fruits 2024, 06, 59–62. [Google Scholar]
- Zou, Y.; Li, H.; Teng, F.; Jin, Z. The trade status, challenges and coping strategies of sweet cherry export trade in China. China Fruits 2024, 09, 134–140+150. [Google Scholar]
- Tang, Z. Research on the Problems and Countermeasures of Industrial Development of Cherry Industry in Shandong Province. China Fruit Veg. 2020, 40, 84–87. [Google Scholar]
- Wang, C.; Xiao, Z. Lychee Surface Defect Detection Based on Deep Convolutional Neural Networks with GAN-Based Data Augmentation. Agronomy 2021, 11, 1500. [Google Scholar] [CrossRef]
- Song, H.; Shang, Y.; He, D. Review on Deep Learning Technology for Fruit Target Recognition. Trans. Chin. Soc. Agric. Mach. 2023, 54, 1–19. [Google Scholar]
- Hou, J.; Che, Y.; Fang, Y.; Bai, H.; Sun, L. Early Bruise Detection in Apple Based on an Improved Faster RCNN Model. Horticulturae 2024, 10, 100. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Hu, G.; Zhou, J.; Chen, C.; Li, C.; Sun, L.; Chen, Y.; Zhang, S.; Chen, J. Fusion of the lightweight network and visual attention mechanism to detect apples in orchard environment. Trans. Chin. Soc. Agric. Eng. 2022, 38, 131–142. [Google Scholar]
- Sun, L.; Hu, G.; Chen, C.; Cai, H.; Li, C.; Zhang, S.; Chen, J. Lightweight apple detection in complex orchards using YOLOV5-PRE. Horticulturae 2022, 8, 1169. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Wei, R.; Pei, Y.; Jiang, Y.; Zhou, P.; Zhang, Y. Detection of cherry defects based on improved Faster R-CNN model. Food Mach. 2021, 37, 98–105+201. [Google Scholar]
- Zhang, Q.; Cao, H. Improved Faster R-CNN based on apple defective region target detection. J. Anhui Sci. Technol. Univ. 2023, 37, 96–101. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wu, H.; Zhu, R.; Wang, H.; Wang, X.; Huang, J.; Liu, S. Flaw-YOLOv5s: A Lightweight Potato Surface Defect Detection Algorithm Based on Multi-Scale Feature Fusion. Agronomy 2025, 15, 875. [Google Scholar] [CrossRef]
- Liu, J.; Pei, Y.; Chang, Z.; Chang, Z.; Chai, Z.; Cao, P. Cherry defect and classification detection based on improved YOLOX model. Food Mach. 2023, 39, 139–145. [Google Scholar]
- Feng, J.; Wang, Z.; Wang, S.; Tian, S.; Xu, H. MSDD-YOLOX: An enhanced YOLOX for real-time surface defect detection of oranges by type. Eur. J. Agron. 2023, 149, 126918. [Google Scholar] [CrossRef]
- Lu, J.; Chen, W.; Lan, Y.; Qiu, X.; Huang, J.; Luo, H. Design of citrus peel defect and fruit morphology detection method based on machine vision. Comput. Electron. Agric. 2024, 219, 108721. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Bu, Y.; David, C.C.; Chen, X. YOLOv8-Orah: An Improved Model for Postharvest Orah Mandarin (Citrus reticulata cv. Orah) Surface Defect Detection. Agronomy 2025, 15, 891. [Google Scholar] [CrossRef]
- Liang, X.; Jia, H.; Wang, H.; Zhang, L.; Li, D.; Wei, Z.; You, H.; Wan, X.; Li, R.; Li, W.; et al. ASE-YOLOv8n: A Method for Cherry Tomato Ripening Detection. Agronomy 2025, 15, 1088. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wei, H.; Liu, X.; Xu, S.; Dai, Z.; Dai, Y.; Xu, X. DWRSeg: Rethinking efficient acquisition of multi-scale contextual information for real-time semantic segmentation. arXiv 2022, arXiv:2212.01173. [Google Scholar]
- Hu, S.; Gao, F.; Zhou, X.; Dong, J.; Du, Q. Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Liu, C.; Wang, K.; Li, Q.; Zhao, F.; Zhao, K.; Ma, H. Powerful-IoU: More straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism. Neural Netw. 2024, 170, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Ji, M.; Shin, S.; Hwang, S.; Park, G.; Moon, I.C. Refine myself by teaching myself: Feature refinement via self-knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10664–10673. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision/% | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DWR | CFAM | PIoU | Self-Distilling | Healthy Fruit | Fruit Cracking | Decaying Fruit | Twin Fruit | Sessile Fruit | Precision/% | mAP0.5/% | Recall% | F1% |
| × | × | × | × | 95.4% | 76.0% | 72.0% | 92.3% | 92.7% | 85.7% | 85.6% | 83.3% | 84.0% |
| √ | × | × | × | 95.3% | 76.9% | 73.2% | 93% | 93.2% | 86.3% | 85.9% | 83.6% | 85.0% |
| √ | √ | × | × | 96.6% | 79.4% | 76.7% | 94.5% | 93.7% | 88.2% | 86.3% | 85.5% | 85.0% |
| √ | √ | √ | × | 97.3% | 83.1% | 79.2% | 95.1% | 94.3% | 90.0% | 88.2% | 87.9% | 86.0% |
| √ | √ | √ | √ | 97.8% | 88.4% | 83.1% | 96.5% | 97.0% | 92. 6% | 91.2% | 89.4% | 89.0% |
| Model | Precision/% | mAP0.5/% | Recall/% | F1/% |
|---|---|---|---|---|
| 15 floors | 82.2% | 82.5% | 80.0% | 85.0% |
| 18 floors | 82.7% | 83.9% | 81.2% | 85.0% |
| 21 floors | 83.8% | 84.4% | 81.8% | 85.0% |
| 15 + 18 floors | 85.1% | 84.5% | 82.9% | 84.0% |
| 15 + 18 + 21 floors | 86.2% | 85.9% | 83.6% | 85.0% |
| Moulde | Precision/% | mAP0.5/% | Recall/% | F1/% |
|---|---|---|---|---|
| C2f_DWR + CBAM | 85.7% | 82.5% | 79.4% | 81.0% |
| C2f_DWR + SE | 84.6% | 85.4% | 83.1% | 84.0% |
| C2f_DWR + SK | 85.9% | 85.5% | 82.3% | 84.0% |
| C2f_DWR + GAM | 86.5% | 85.8% | 82.4% | 84.0% |
| C2f_DWR + CAFM | 87.1% | 86.3% | 83.5% | 85.0% |
| Model | Precision/% | mAP0.5/% | Recall/% | F1/% |
|---|---|---|---|---|
| C2f_DWR + CAFM + CIoU | 87.1% | 86.3% | 83.5% | 85.0% |
| C2f_DWR + CAFM + SIoU | 87.6% | 84.8% | 82.3% | 83.0% |
| C2f_DWR + CAFM + WIoU | 86.8% | 86.1% | 83.1% | 84.0% |
| C2f_DWR + CAFM + EIoU | 84.0% | 85.3% | 81.0% | 83.0% |
| C2f_DWR + CAFM + PIoU | 89.8% | 88.2% | 87.9% | 86.0% |
| Model | Precision/% | mAP0.5/% | Recall% | F1/% | Weights/MB | Fps/fs−1 |
|---|---|---|---|---|---|---|
| SSD | 84.7% | 82.5% | 81.4% | 84.0% | 92.3 | 57.8 |
| Faster R-CNN | 87.1% | 85.3% | 84.6% | 87.0% | 112.8 | 21.5 |
| YOLOv5n | 85.1% | 82.8% | 83.2% | 88.0% | 3.9 | 75 |
| YOLOv8n | 85.7% | 85.6% | 83.3% | 84.0% | 5.8 | 98 |
| YOLOv10n | 86.1% | 88.7% | 84.3% | 87.0% | 6.3 | 90 |
| YOLO11n | 84.9% | 84.7% | 82.7% | 85.0% | 5.5 | 96 |
| YOLOv12n | 85.3% | 84.9% | 82.9% | 86.0% | 5.4 | 89 |
| YOLO-DCPF | 92.6% | 91.2% | 89.4% | 89.0% | 5.6 | 126 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Han, X.; Ren, L.; Ma, W.; Liu, B.; Sheng, C.; Song, Y.; Li, Q. Surface Defect and Malformation Characteristics Detection for Fresh Sweet Cherries Based on YOLOv8-DCPF Method. Agronomy 2025, 15, 1234. https://doi.org/10.3390/agronomy15051234
Liu Y, Han X, Ren L, Ma W, Liu B, Sheng C, Song Y, Li Q. Surface Defect and Malformation Characteristics Detection for Fresh Sweet Cherries Based on YOLOv8-DCPF Method. Agronomy. 2025; 15(5):1234. https://doi.org/10.3390/agronomy15051234
Chicago/Turabian StyleLiu, Yilin, Xiang Han, Longlong Ren, Wei Ma, Baoyou Liu, Changrong Sheng, Yuepeng Song, and Qingda Li. 2025. "Surface Defect and Malformation Characteristics Detection for Fresh Sweet Cherries Based on YOLOv8-DCPF Method" Agronomy 15, no. 5: 1234. https://doi.org/10.3390/agronomy15051234
APA StyleLiu, Y., Han, X., Ren, L., Ma, W., Liu, B., Sheng, C., Song, Y., & Li, Q. (2025). Surface Defect and Malformation Characteristics Detection for Fresh Sweet Cherries Based on YOLOv8-DCPF Method. Agronomy, 15(5), 1234. https://doi.org/10.3390/agronomy15051234