Abstract
Effective detection of wood defects is essential for maximizing wood use in a sustainable industry. However, traditional methods often struggle with complex textures and irregular shapes. This work introduces MSFE-YOLOv11-OBB, an advanced framework for oriented object detection. To tackle localization and scale challenges, we propose several key innovations: (1) a Recalibration Feature Pyramid Network (FPN) with attention modules to enhance contour accuracy, (2) a CSP-PTB module that integrates CNN-based local features with transformer-based global reasoning to create a more robust pattern representation, and (3) an LSRFAConv module designed to capture subtle structural cues, improving the detection of tiny cracks. Experimental results on an industrial dataset show that our model achieves an mAP@50 of 76.2%, improving over the baseline by 4.7% while maintaining a real-time speed of 86.99 FPS. Comparative analyses confirm superior boundary fitting and multiscale recognition capabilities. By effectively characterizing defect orientation and geometry, this framework offers an intelligent, high-precision solution for automated wood detection, significantly enhancing industrial processing efficiency and resource sustainability.
1. Introduction
The growing demand for renewable materials has made wood essential in construction, furniture manufacturing, and paper production [1]. However, wood’s natural biological characteristics and storage conditions often lead to defects such as knots and cracks, reducing the effective utilization rate to 50%–70% [2,3,4]. Currently, many wood processing companies still depend on manual grading, which is labor-intensive and susceptible to subjective errors. This reliance creates significant bottlenecks, failing to meet the high-throughput and precision requirements of modern industrial workflows [5].
Wood defect detection has progressed from manual inspections to the application of various non-destructive testing (NDT) techniques [6]. These include ultrasonic testing, near-infrared analysis, laser scanning, acoustic emission monitoring, X-ray computed tomography (CT), and resistance drilling [7,8,9,10,11]. More recently, automated optical scanning systems have been developed. Although NDT methods provide a solid foundation for quality assessment, their effectiveness in industrial settings is often limited due to low detection efficiency and the need for specialized expertise. Optical scanning systems, which use texture and color analysis to identify defects, present a more automated alternative. However, existing methods still face challenges, such as insufficient feature robustness and limited adaptability, particularly given the high morphological diversity of wood defects and the strict real-time requirements of high-speed production lines.
To address these challenges, deep learning has supplanted traditional handcrafted feature-based methods in optical scanning defect detection. By learning multi-level representations end-to-end, deep learning models offer superior robustness against complex textures, irregular defects, and environmental noise [12,13,14]. Specifically, CNNs [15] leverage hierarchical extraction to fuse local and global information, enabling high-precision, real-time detection of intricate surface defects. Currently, most detection algorithms are broadly categorized into two types: one-stage and two-stage. The two-stage approach includes representative methods such as R-CNN [16], Fast R-CNN [17], and Faster R-CNN [18]. However, they consume higher computational resources due to their complex computations and high learning costs. A major turning point came in 2016 when Redmon et al. introduced the You Only Look Once (YOLO) framework, an end-to-end detector that replaced the traditional sliding-window paradigm with a one-stage regression pipeline. By processing the entire image in a single forward pass, YOLO significantly reduced computational overhead while ensuring high detection precision, changing the face of object detection [19]. Since then, the YOLO family has been continually developed from YOLOv1 to YOLOv12 [20,21,22,23,24,25,26,27], with each version optimizing the trade-off between precision, inference efficiency, and model complexity. Building on these advancements, Zhang et al. [28] developed WLSD-YOLO by integrating a GVC neck into YOLOv8 to reduce the number of parameters. This model achieved a Mean Average Precision of 76.5%, surpassing the original YOLOv8 by 2.9% while increasing throughput by 3.8 FPS. Cui et al. [29] enhanced the YOLOv3 framework by adding a spatial pyramid pooling (SPP) module to the feature pyramid network (FPN). Evaluated on an augmented set of data, their approach achieved a detection accuracy of 93.23%. Sun et al. [30] proposed AMAF-YOLO, which is a lightweight detector based on YOLOv12, and incorporates a simplified global context network to lower the complexity. Therefore, axis-aligned bounding boxes (AABB) are a basic selection in many YOLO-based models. But these boxes are unable to adapt to the irregular contours of the wood defects; they often contain unnecessary background regions or overlap with neighbouring targets.
Axis-aligned bounding boxes often enclose excessive background areas, which can be problematic. Additionally, closely spaced or overlapping defects may result in significant overlap or coincidence of these bounding boxes. This overlap hinders the non-maximum suppression algorithm’s ability to effectively distinguish between individual objects, leading to frequent missed or false detections. To address this challenge, one-stage detection algorithms that utilise oriented bounding boxes (OBB), such as the YOLO-OBB series, have been integrated into industrial scanning workflows. Chaurasia et al. [31] introduced YOLO-CSL, a lightweight rotated detector that employs cyclic smoothing labels (CSL) for robust orientation classification, achieving a mAP of 57.86 on the DOTA v1.5 dataset. In the context of wood defect detection, wood knots and cracks exhibit various orientations, extremely high aspect ratios, and a dense spatial distribution. To address the research gap in modelling orientations for wood defects, this study introduces OBB into surface defect detection. This approach provides a unified representation of the defect’s principal-axis orientation and spatial structure.
To address the above limitations, this paper proposes MSFE-YOLOv11-OBB, a wood defect-oriented bounding box detection model based on multiscale feature optimisation. The proposed architecture combines three enhanced modules to enhance feature representation, improve localisation accuracy, and increase robustness to complex wood textures. First, Recalibrated FPN is proposed to replace the basic FPN in YOLOv11-OBB by selectively fusing boundary cues and semantic information to better capture fine-grained contours and achieve better spatial localization. Second, CSP-PTB module, a combination of CNNs and transformer-based global modeling, replaces the deeper C3k2 layers in the backbone. This hybrid design combines local and global feature patterns, thereby enhancing the overall representational capacity. Third, the proposed large-small receptive-field attention convolution (LSRFAConv) is adapted to elongated defects such as cracks, enabling efficient dual-path feature fusion that retains detailed structural information. Collectively, these three modules work synergistically through hybrid feature extraction, adaptive multiscale learning, and fine-detail perception to significantly boost the precision of wood defect detection.
2. Materials and Methods
2.1. Baseline Model
YOLOv11 [32] is an object detection framework released by Ultralytics in 2024, which provides notable enhancements in accuracy and inference efficiency compared to previous versions of the YOLO family. The model architecture comprises three basic parts: the backbone, neck, and detection head. Among its main innovations are the improved C3k2 module [23] and cross-channel parallel spatial attention (C2PSA) mechanism [32] and the addition of depthwise convolution (DWConv) in the detection head to lower computational cost without hurting detection quality. For feature extraction, YOLOv11 uses an enhanced CSPDarknet backbone, in which the original C2f module is replaced with the more efficient C3k2. In addition, following the SPP structure applied in YOLOv8 [33], the model incorporates C2PSA to fuse convolutional operations and attention-based refinement to enhance feature expressiveness in complex industrial environments. YOLOv11-OBB is an extension of YOLOv11 that is designed for oriented object detection. By swapping the usual detection head with a special head that can predict angle parameters, YOLOv11-OBB can predict the rotation direction and magnitude of each bounding box. This orientation information allows the detector to better localize objects of arbitrary poses, especially when directionality is an important attribute. Given these advantages, YOLOv11-OBB is utilized as the baseline model in this research. The general architecture is indicated in Figure 1.
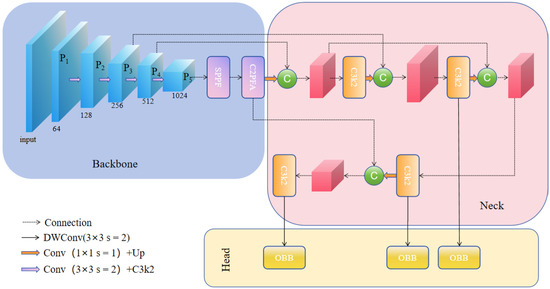
Figure 1.
The overall architecture of YOLOv11-OBB.
2.2. MSFE-YOLOv11-OBB
2.2.1. Overall Architecture
Although the YOLOv11-OBB baseline model achieves good object detection performance, it degrades when used for wood-defect inspection. Wood defects have large variations in size, shape, and morphology, and the natural grain patterns of wood are often similar to actual defects, so it is very difficult to automatically detect them. Crack detection is especially challenging: the baseline model is difficult to adapt to the unique structural properties of cracks. Tiny cracks are often missed because of insufficiently discriminative feature representations, while elongated cracks are often detected in fragmented segments, which causes the continuity of the crack to be disrupted and the overall structure of the crack to be incomplete. Moreover, the feature extraction backbone, mostly based on CNNs, is limited by a limited receptive field. This limits the network to only learning localized, low-level characteristics, such as partial crack textures or parts of knot edges. As a result, the model struggles with incorporating larger contextual information, such as relationships between defective and non-defective regions, global configuration of defects, and long-range feature dependencies. In environments with complex defect morphologies and dense background textures, these limitations are more pronounced, eventually reducing the localization accuracy and the reliability of the classification. Additionally, shallow feature maps tend to encode fine-grained textures and initial contour information, while deeper layers are focused on high-level semantic attributes associated with the underlying material structure. Directly fusing these heterogeneous feature types runs the risk of introducing redundant details and semantic misalignment between low-level and high-level representations. Such inconsistencies may cause feature conflict, which may reduce precision and robustness of wood-defect detection models.
To overcome these challenges, we improved the YOLOv11-OBB framework to boost the detection robustness and accuracy for the complex wood defects. We introduce MSFE-YOLOv11-OBB, the architecture of which can be seen in Figure 2. First, the FPN is upgraded by the proposed Recalibration FPN, which replaces the original FPN while at the same time restructuring the neck by incorporating the SBA module [34]. This modification helps to strengthen the multiscale feature representation and improves the object localization. Next, the CSP-PTB module is introduced in place of C3k2 blocks. By integrating the complementary power of transformers and CNNs, CSP-PTB enables the efficient extraction of both local and global features while minimizing computational overhead. Finally, in order to deal with the large differences in the scale of cracks that are typical of wood defects, we propose the LSRFAConv. This module uses a dual-branch design, in which a large-kernel branch is used to capture long-range dependencies and a small-kernel branch is used to preserve fine-grained local details. LSRFAConv improves structural continuity and edge fidelity at minimal additional computational cost, resulting in improved detection performance across both precision and morphological integrity, especially for slender or elongated defects such as cracks.
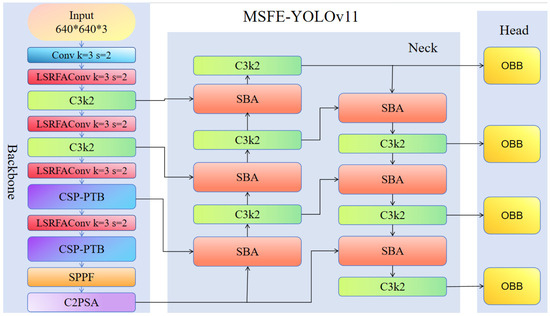
Figure 2.
Proposed framework of the MSFE-YOLOv11-OBB.
2.2.2. Recalibrated Feature Pyramid Network
The YOLOv11-OBB baseline model uses a bidirectional FPN with weighted feature fusion to fuse information across scales. However, such a fusion approach may not suffice when dealing with the large-scale variations found in the detection of wood defects. As reported in studies [35,36], shallow feature maps have low-level semantic content, but preserve fine-grained information, showing sharper boundaries of objects and less spatial distortion. In contrast, deep feature maps contain rich high-level semantic information of material properties. Direct fusion of these heterogeneous features can cause redundancy and semantic mismatch. To overcome this limitation, we propose the Recalibration FPN. By integrating the SBA module into the neck of YOLOv11-OBB, this design selectively preserves the boundary-preserving details with contextual semantic information, which helps to enhance the representation of fine-grained object contours and improve localization accuracy. Unlike conventional fusion techniques, the recalibration attention unit (RAU) adaptively extracts mutually correlated feature representations from two different input streams prior to fusion. Two RAU modules process shallow and deep features that address the lack of spatial boundary information in high-level features and the limited semantic context in low-level characteristics. The outputs of both RAU modules are then fed into a 3 × 3 convolutional layer and concatenated, as shown in Figure 3. This strategy allows for the strong integration of heterogeneous features and the refinement of coarse-grained representations. The working of the RAU block is formally expressed as follows:
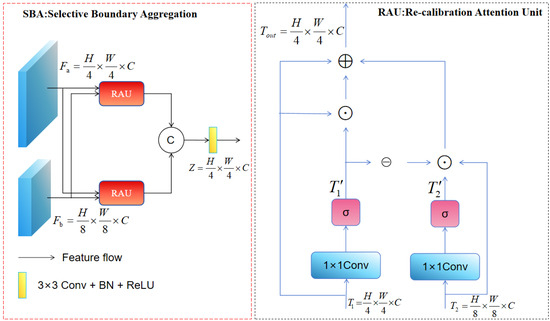
Figure 3.
Framework of the selective boundary aggregation.
Here, and represent the input feature maps. Both inputs are first processed in linear mapping and sigmoid activation to decrease the channel dimension to 32, and the intermediate feature maps and . The symbol denotes element-wise multiplication, while ⊖ is a reverse subtraction operation applied to . This operation is used to convert the initial coarse and imprecise estimates of features to a refined and complete prediction map.
A linear mapping operation (1 × 1 convolution) was used to perform the mapping operation. Accordingly, the general workflow of the SBA module can be expressed as follows:
Here, means 3 × 3 convolution + batch normalization + ReLU activation. and are shallow and deep semantic features, respectively, with rich boundary and contextual information. Concat indicates channel-wise concatenation, and corresponds to the final output of the SBA module.
2.2.3. Cross Stage Partial-Partially Transformer Block (CSP-PTB)
In computer vision, transformers have received a lot of attention because of their high ability to capture global feature dependencies. However, direct application of them over all channels is computationally expensive. To obtain efficient feature representation while mitigating this overhead, we propose a hybrid module named CSP-PTB, as shown in Figure 4. In this design, the input feature map is split into two parallel branches that combine the concepts of CNNs and transformers [37]. This setup combines the complementary strengths of both: CNNs are well-suited for extracting local features, and the transformer model models long-range dependencies and global context. By proportionally allocating input channels between the two branches, CSP-PTB achieves an effective balance between detection precision and computational efficiency.
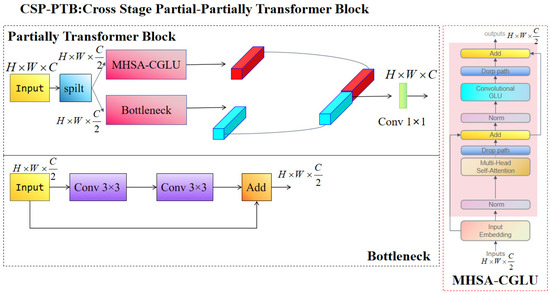
Figure 4.
Framework of the cross stage partial-partially transformer block.
To leverage transformers’ global feature extraction capabilities without significantly increasing computational cost, we propose the partially transformer block (PTB), in which transformer operations are applied to only a subset of input channels. This approach allows efficient feature representation while minimizing the overhead. The input channels are split into two parallel branches: one feeds the features to multi-head self-attention (MHSA)-CGLU and the other to a conventional CNN block. The output from both branches is then concatenated and fused with a 1 × 1 convolution. The whole operation of the PTB module is formalized in Equation (4).
Here, is the input feature map, is the features processed through the CNN branch, and is the features from the transformer branch. The symbol denotes channel-wise concatenation, and is the 1 × 1 convolution used to reconcile the output channel dimension.
We further propose the MHSA-CGLU module that combines MHSA and Convolutional GLU [38]. The MHSA part captures the global contextual dependencies, while the Convolutional GLU improves the representation of the nonlinear feature characteristics, which improves the overall expressive capacity of the module.
2.2.4. Large-Small Receptive-Field Attention Convolution
Crack detection in wood is especially difficult because of its visual similarity to natural wood grain, diverse morphologies, discontinuous structures, low contrast with the background, and susceptibility to aliasing (caused by downsampling). To solve these problems, we propose an improved version of traditional RFA convolution, which is named as LSRFAConv. This dual-path, fine-tuning convolutional module is especially designed to enhance the feature representation and robustness to detect fine cracks. LSRFAConv combines a large-kernel perception branch and a small-kernel aggregation branch, which can effectively capture the long-range spatial connectivity and maintain the fine-grained local edge details, while also having minimal computational overhead. The module also includes lightweight channel gating and position-aware weighting mechanisms to enable adaptive selection and weighted reconstruction of k2 local sampling positions. This design improves the detection precision as well as the structural integrity of elongated defects such as cracks. The whole architecture is divided into four parallel branches: the position-weight generation and scale-alignment branch, the small-kernel aggregation branch, the large-kernel perception branch, and the channel-gating fusion branch, as shown in Figure 5.
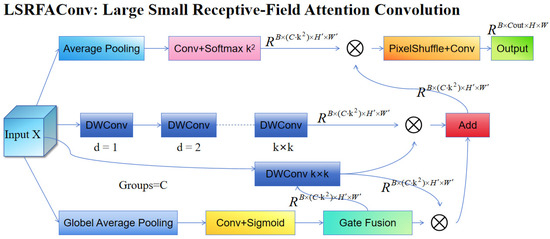
Figure 5.
Framework of the large-small receptive-field attention convolution.
First, position-weight generation and scale-alignment branch: The input feature map is smoothed and scale-aligned with average pooling with a given kernel size and stride to get an intermediate feature map . Then, a grouped 1 × 1 convolution is applied to with a given number of groups to generate an output tensor , which is normalized along the channel dimension with a softmax function to generate the position-aware normalized weight . Second, the small-kernel aggregation branch is designed to retain crack-edge information and short-range texture information. The input is mapped to channels using a grouped transformation with groups, resulting in an output tensor . This approach is equivalent to learning multiple light local prototype kernels for each input channel, which allows fine-grained response to various sampling offsets while keeping the computational complexity low. As a result, crack boundaries and endpoint structures are well preserved. Third, the large-kernel perception branch makes the long-range connectivity and contextual consistency for slender cracks better. The input is sequentially processed by two 3 × 3 DWConvs: the first one with = 1 and the second one with = 2. Each convolution is followed by normalization and a nonlinear activation, giving an intermediate feature map with an expanded receptive field. Finally, a grouped depthwise separable convolution projects into channels to produce branch output feature .
Finally, the channel-gating fusion branch adaptively balances the contributions of the large-kernel perception and small-kernel aggregation branches under different scenarios. The input feature map is first processed by global average pooling, followed by 1 × 1 convolution and sigmoid activation to get the channel-wise gating coefficient . This coefficient G is then repeated times in the channel dimension to form the expanded weight tensor . The features from the large and small kernel branches are linearly fused using as the weighting factor , as formalized in Equation (5). Next, the position-weighted feature generated by the position-weight generation and scale-alignment branch is applied using element-wise multiplication to the fused feature map along the channel dimension to obtain the weighted expanded features U, expressed in Equation (6). This intermediate feature U is then rearranged to a higher resolution plane based on the pixel-rearrangement rule to produce the upsampled feature . Finally, E’ is fed into the output mapping unit, which applies a single convolution with a given kernel size and stride to recover spatial scale and reshape channels. Specifically, the spatial resolution is restored from to , which is the same as the backbone resolution, while the number of channels are transformed from to the target output dimension . The resultant tensor forms the final output feature of the LSRFAConv module.
2.3. Dataset
In the experimental phase, a wood restoration and image acquisition platform was utilized, as shown in Figure 6a. The system basically consists of an image acquisition unit, a robotic arm, and a conveyor assembly. The image acquisition unit is based on a Hikvision MV-CS200-10UC industrial camera, which has been chosen for its good color fidelity and the ability to obtain good quality images, compatible with the industrial standards. The robotic arm is equipped with a patch-dispensing nozzle, a pneumatic drive system, and a corresponding control module. The conveyor assembly includes a worktable, guide wires, and a transport belt, allowing for automated and consistent movement of samples. The imaging system was mounted above an industrial conveyor belt. The camera was positioned 600 mm from the wood surface to provide a field of view (FOV) covering the entire width of the plank. Line-scan LED lighting was used to minimize shadows and highlight subtle texture-related defects. The wood used was high-quality oak, a species widely used in the flooring and furniture industries for its distinctive grain patterns and structural integrity. Each specimen measured 1900 mm in length and 190 mm in width. The detailed data acquisition parameters are provided in Table 1. The dataset collected for this study is focused on defects that decrease the economic value of timber and is divided into four different types depending on the morphological characteristics [39], as shown in Table 2. In addition, the complexity of wood grain patterns and variations in color and shading make the detection and recognition of defects even more difficult, as shown in Figure 7.

Figure 6.
Image acquisition platform.

Table 1.
Data acquisition parameters.
Table 2.
Defect annotation standards.

Figure 7.
Visualization of wood defect samples.
For the construction of the defect dataset in this study, images were taken through a Hikvision camera with its official MVS (version V3.4.1) software platform. To simulate real-world industrial detection scenarios, the conveyor belt was set to a fixed speed of 80 mm/s, while the camera was set to continuous acquisition mode at a fixed frame rate of 19.21 fps with zero trigger delay to ensure continuous image acquisition. The exposure time was carefully set to 5000 µS. Moreover, to minimize the effects of illumination variations, motion blur, and industrial noise, the image acquisition system was enclosed, thereby ensuring that all images in the dataset were collected under identical environmental conditions, as shown in Figure 6b. This acquisition procedure produced a total of 5007 raw images with a resolution of 5472 × 3648, all saved in Bayer GB 8 pixel format. To support later rotated object detection, each image was carefully annotated with rotated bounding boxes using the X-AnyLabeling (version 2.4.3) tool. For model development and evaluation, the dataset was divided into training, validation, and test datasets with a ratio of 8:1:1. The training data was used for learning model parameters, the validation data was used for hyperparameter tuning and intermediate evaluation during training, and the test data was used for evaluating the final model performance and generalization capability. The specific dataset construction information is shown in Table 3.
Table 3.
Distribution of defects within the dataset.
2.4. Experimental Config
The experimental environment and the parameter settings are summarized in Table 4 and Table 5, respectively. All other configurations not specifically mentioned are the default settings of the YOLOv11n-OBB baseline model.
Table 4.
Experimental environment.
Table 5.
Experimental parameters.
2.5. Evaluation Metrics
In order to assess the performance of the proposed method, precision (P), recall (R), and mAP are used as the main evaluation metrics, which are widely used to evaluate object detection performance. More precisely, precision measures how well the model can accurately identify instances of defects and recall measures how well the model can identify all actual defects. The formula for calculating P and R is as follows:
where represents false positive, indicates true positive, and presents false negative.
Average Precision (AP) is the area under the precision-recall curve for a single class. Mean Average Precision (mAP) is the average of all AP values across all classes. The mathematical formulation is expressed as follows:
Here, K denotes the total number of object classes in the dataset, i is the image index or sample number, P is the precision, R is the recall, and AP is the Average Precision for a single class.
The params define the complexity of the detector network, and the GFLOPs is the number of floating-point arithmetic operations. Speed is measured in frames per second (FPS).
Here, is the input size, is the size of the convolution kernel, is the output size, and is the size of the output feature map. is the image preprocessing time (ms), is the algorithm inference time (ms), and is the postprocessing time (ms).
The angle between the predicted and actual angles is taken as the angle prediction error. Here, is predicted angle; is actual angle.
2.6. Models of Ablation Study
To test the individual contributions of Recalibration FPN, CSP-PTB, and LSRFAConv to the overall performance of MSFE-YOLOv11-OBB, we performed eight sets of ablation experiments using all possible permutations and combinations of the three modules and the baseline model, with constant experimental conditions. The results are summarized in Table 6, where each check mark indicates whether the corresponding module was included in a given experiment.
Table 6.
Configuration of modules for the ablation study.
3. Experimental Results and Comparative Analysis
3.1. Ablation Study
As shown in Table 7, Model No. 1 is the YOLOv11-OBB baseline. Model No. 2, which adds the CSP-PTB only, gives a 0.8% improvement in mAP@50 over the baseline and decreases the number of parameters by 4.7%. This shows that CSP-PTB is not only able to effectively combine the feature-extraction capabilities of CNNs and transformers, but also enhances the computational efficiency. Model No. 3 is a combination of LSRFAConv alone. By taking advantage of adaptive sampling position selection and weighted feature reconstruction, mAP@50 is improved by 1.2% without a substantial rise of computational cost. The detection precision for cracks and knots with cracks reaches 64.1% and 84.7%, respectively, which shows the ability of the module to boost the performance of crack detection. Model No. 4 is the modified FPN with SBA, which shows the significant performance improvement: mAP@50 is improved by 3.4%, and the performance of individual defect detection is improved to 64.7%, 81.5%, 70%, and 83.3% in the corresponding defect categories.
Table 7.
Results of the ablation experiments.
In the ablation studies, Model No. 5 is a combination of LSRFAConv and Model No. 2. Although there is a small drop in crack detection, the overall mAP@50 still outperforms the baseline and Model No. 2. This result is due to the fact that CSP-PTB focuses on global semantic associations, while LSRFAConv focuses on local spatial details. A simple convolutional fusion strategy is not enough to completely overcome the difference of feature distribution and semantic hierarchy between the two modules, resulting in minor conflicts, which makes each module less effective individually. Model No. 6, which incorporates feature pyramid restructuring, is able to improve detection precision for all types of defects. Notably, crack detection outperforms the other eight models with the highest performance at 66.4%, and mAP@50 increases by 4.1%. Model No. 7 achieves mAP@50 of 75.8%, which is a balanced trade-off between precision and robustness. In this configuration, the dual dynamic regulation mechanism of SBA and LSRFAConv enables the model to adaptively adjust processing strategies to the feature characteristics of different regions, thereby significantly improving detection precision in complex wood defect scenarios.
Ultimately, the MSFE-YOLOv11-OBB model gets a 4.7% improvement in mAP@50, which is 76.2%. Compared to the baseline, the detection precision of dead knots and knots with cracks improves by 11.3% and 3.3%, respectively, which demonstrates the synergistic effect of the three proposed modules in multiscale feature fusion. These results show that the model is a high-precision and cost-effective solution for oriented object detection of defects in the industrial wood inspection.
3.2. Module Analysis
3.2.1. LSRFAConv Module Experiment
To further assess the effectiveness of incorporating the small-kernel aggregation branch, large-kernel perception branch, and gating mechanism into RFAConv, we performed ablation studies between RFAConv and LSRFAConv on the YOLOv11-OBB baseline model. As indicated in Table 8, the use of the standard RFAConv results in a significant drop in mAP@50 and other performance metrics. As opposed, by incorporating the improved LSRFAConv, the overall mAP@50 is increased by 0.7%, and the crack detection precision is improved by 1.1%. These results show that the proposed module, which integrates the multiscale receptive fields with a dynamic gating mechanism, is highly effective in enhancing the detection performance of wood defects.
Table 8.
Comparison of LSRFAConv and the RFAConv.
3.2.2. Recalibrated FPN Experiment
To evaluate the impact of fusing high- and low-resolution features on the performance of Recalibration FPN, we performed comparative experiments with the YOLOv11-OBB baseline and the proposed Recalibration FPN. Detection head fusion configurations P345, P3456, and P2345. The results of the experiments are summarized in Table 9. The results show that high-resolution features can be incorporated to achieve the highest mAP@50 of 74.9% in the model. This improvement is due to the synergistic effect between the P2 layer and the recalibration mechanism. Specifically, the P2 layer is used to keep fine-grained details such as edges and textures that are associated with tiny wood defects, while the recalibration mechanism is used to dynamically adjust the weight of feature fusion to promote the representation of defect regions and suppress background interference. Performance differences between the different models and types of defects can be used to determine information about feature pyramid adaptability: the high-resolution P2 layer is very helpful for the detection of small defects (e.g., dead knots and cracks), while the low-resolution P6 layer is beneficial for the detection of large defects (e.g., knots with cracks). In contrast, medium-sized defects (e.g., live knots) have relatively low sensitivity to additional feature levels. Notably, the recalibration mechanism offers synergistic benefits when used primarily in combination with other feature levels; when used only within conventional layer configurations, it may suppress salient features, which may degrade performance.
Table 9.
Comparison of high-resolution and low-resolution feature fusion.
3.3. Comparative Experiment
The performance of several oriented object detection models on the wood defect dataset is summarized in Table 10. The proposed MSFE-YOLOv11-OBB model achieves an mAP@50 of 76.2%, fully satisfying the detection requirements of industrial assembly lines. Its performance is significantly better than other YOLO-based models such as YOLOv8-OBB with a score of 71.2%, YOLOv10 with a score of 71.3%, YOLOv11 with a score of 71.5%, and YOLOv12 with a score of 70.8%. Compared with mainstream oriented object detection models, S2ANet 47.1%, Rotate Faster R-CNN 41.3%, and LSKNet 41.3% have significantly lower detection precision. In particular, MSFE-YOLOv11-OBB achieves the highest detection precision for all four defect categories among all the evaluated models. These results illustrate the robustness of the suggested method and its great potential for practical application in the industrial wood defect detection.
Table 10.
Experimental comparison findings on the dataset.
3.4. Visualization Analysis
3.4.1. Statistics of Results
To give a visual comparison of the proposed MSFE-YOLOv11-OBB model with the YOLOv11-OBB baseline, one representative image per defect category was chosen from the wood defect dataset, and the findings are indicated in Figure 8. In all four categories of defects, MSFE-YOLOv11-OBB outperforms the baseline model. While YOLOv11-OBB sometimes misclassifies or misses some of the defects, MSFE-YOLOv11-OBB correctly identifies and localizes previously missed instances. The proposed model exhibits obvious advantages in adverse conditions, such as tiny defects, complex backgrounds, and low contrast. For example, in the case of detecting small defects, e.g., dead knots and live knots, on complex backgrounds, the YOLOv11-OBB baseline has severe missed detections, while MSFE-YOLOv11-OBB is able to detect and classify all instances of defects. In the case of low-contrast cracks, the baseline model is affected by the performance degradation, whereas MSFE-YOLOv11-OBB achieves high detection precision with no omissions. Moreover, for large defects such as nodular cracks with associated fissures, YOLOv11-OBB sometimes fails to detect all instances, while MSFE-YOLOv11-OBB achieves complete and precise detection.

Figure 8.
Results of MSFE-YOLOv11-OBB.
3.4.2. Gradient-Weighted Class Activation Mapping (Grad-CAM) Visualization
To further evaluate the detection performance of MSFE-YOLOv11-OBB, Grad-CAM was adopted to compare the attention responses of the proposed model and YOLOv11-OBB as the baseline model. The resulting heat maps, which are based on feature maps, are useful for visualizing the regions each model is most sensitive to. Four representative images corresponding to four different categories of defects were selected for analysis, in which the comparative findings are represented in Figure 9. The first row gives the original images, the second row gives the Grad-CAM activation maps of the baseline model, and the third row gives the activation maps of the MSFE-YOLOv11-OBB model.
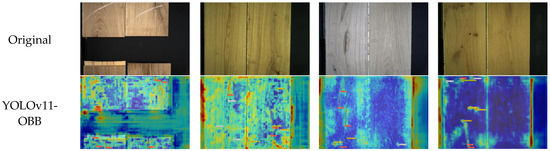

Figure 9.
Grad-CAM comparison.
The comparison shows that MSFE-YOLOv11-OBB generates more focused and concentrated attention responses for all the defect categories. High-activation areas are very close to the actual defect locations, while with the baseline model, activation patterns are scattered with a lot of background noise. These results suggest that the proposed model is able to cover the entire defect region while suppressing activations in irrelevant areas. Overall, the visual analysis shows that MSFE-YOLOv11-OBB performs better than the baseline in terms of coverage and localization precision. The better correspondence between predicted and ground truth regions demonstrates the model’s ability to properly focus on important areas of defects, which improves the interpretability of the model and gives good evidence for the efficacy of the model for wood defect detection.
3.4.3. Angular Error Analysis
To rigorously evaluate the improvements in contour fitting and crack continuity achieved by MSFE-YOLOv11-OBB, this study defines the angular prediction error (APE) as the deviation between the predicted and ground-truth angles, utilising this as a quantitative metric. Table 11 illustrates the average APE for the four defect categories in the test set. Comparative results show a substantial reduction in APE for three defect types, except for dead knots. Notably, the APE for cracks decreased substantially from 9.82° to 3.27°, demonstrating that the proposed method significantly improves the continuity of crack orientation in complex scenarios. Regarding small targets with weak directionality, such as dead knots, the APE increased marginally from 0.62° to 0.99°. However, as the absolute error remains below 1°, this slight fluctuation has a negligible impact on practical detection performance. In conclusion, the reduction in APE confirms the superior performance of MSFE-YOLOv11-OBB in strengthening crack continuity and improving bounding box alignment, thereby enhancing overall detection precision.
Table 11.
Mean angular prediction error.
4. Discussion
This study presents the development of the MSFE-YOLOv11-OBB model, which integrates Recalibration FPN, CSP-PTB, and LSRFAConv into the YOLOv11n-OBB framework. The resulting model exhibited excellent performance in detecting wood defects in real-world industrial production settings. This chapter examines the mechanisms that led to these successes, compares the model with existing research, and assesses the limitations of this work.
4.1. Analysis of Key Findings
The superior performance of MSFE-YOLOv11-OBB in detecting wood defects is mainly due to the synergistic effects of its integrated modules. Specifically, the Recalibration FPN enhances feature fusion within the neck network, while the CSP-PTB strengthens the backbone’s feature extraction capabilities. Additionally, the LSRFAConv improves the representation of local features that are specific to various wood crack patterns. By incorporating the OBB head, the model significantly enhances its ability to represent directional defects. These architectural advancements resulted in a notable 11.3% increase in Mean Average Precision at 50 (mAP@50) for detecting dead knots, along with a 4.7% improvement in overall mAP@50. This demonstrates the model’s high precision across different defect orientations and types. Unlike the weighted feature fusion approach proposed by Wang et al. [2], our study improves the representation of complex defects through Recalibration FPN and CSP-PTB. Furthermore, while Zhou et al. [40] concentrated on dual-level attention mechanisms and dynamic gradient gains to adapt to wood cracks, our approach addresses highly directional crack defects explicitly by utilizing LSRFAConv in combination with an OBB head. This strategy enables more effective identification of irregular defects with random orientations, which are commonly encountered in real-world industrial applications.
4.2. Comparative Analysis and Research Gaps
Wang et al. [14] achieved high-precision wood defect detection using YOLOv7. However, their reliance on HBB presents significant challenges when adapting to the complex geometric shapes found in natural timber defects. As noted in [41], HBB-based frameworks often include excessive background noise and can suffer from severe overlap or even complete coincidence when defects are closely spaced or intersecting. In contrast, our study addresses the inherent geometric complexity of wood defects by implementing the OBB strategy. This approach effectively isolates multidirectional cracks and irregular dead knots, reducing the feature misalignment commonly seen in HBB models and ensuring high detection precision in industrial scenarios.
Despite achieving positive results, this study still has several limitations.
- (1)
- Although the dataset was categorized into four defect types in strict alignment with the actual requirements of industrial wood defect detection, the wood defect types are much broader than this. Consequently, future research will prioritize expanding the repository to encompass a broader spectrum of defect morphologies and tree species, thereby enhancing the model’s robustness in a variety of industrial contexts.
- (2)
- MSFE-YOLOv11-OBB maintains real-time efficiency; however, integrating the Recalibration FPN and CSP-PTB modules adds significant computational overhead. This presents challenges for deployment on resource-constrained edge devices. Future work will focus on implementing lightweight architectures and model pruning techniques to reduce computational costs while preserving detection effectiveness.
4.3. Industrial Deployment
The MSFE-YOLOv11-OBB model demonstrates impressive real-time performance during inference, fulfilling the deployment needs for industrial applications. It has also been successfully implemented in practical industrial scenarios. Experimental results show that the model achieves an inference speed of 86.99 FPS while maintaining a mAP@50 of 76.2%. This indicates a favourable balance between detection reliability and computational efficiency. From a practical application standpoint, the inference speed of 86.99 FPS is crucial for modern timber production lines, especially within latency-sensitive industrial wood repair platforms. The high efficiency of our model enables real-time defect identification, allowing precise coordinates to be sent to robotic arms for targeted glue injection and patching. As noted by [42], OBBs offer better localization accuracy than traditional methods. This precision minimizes unnecessary wood glue waste by restricting the repair area to the exact shape of the defect, thereby optimizing raw material use and reducing operational costs in large-scale industrial manufacturing.
5. Conclusions
This paper introduces MSFE-YOLOv11-OBB, a model for the detection of wood defects in industrial environments, which pays attention to the multiscale feature extraction and the improved detection of elongated cracks. The important findings are summarized as follows:
- (1)
- Recalibration FPN: This module allows the adaptive aggregation of boundary and semantic information to generate finer-grained object contours and better recalibrate object positions. It greatly improves the multiscale feature fusion, and the mAP@50 is higher than the YOLOv11-OBB baseline.
- (2)
- CSP-PTB: The dual-branch hybrid structure uses the efficient feature extraction ability of CNNs and the good global context modeling ability of transformers to enhance the overall detection accuracy.
- (3)
- LSRFAConv: On the basis of RFAConv, this four-branch module solves the problems of crack detection. The small-kernel aggregation branch helps to preserve fine-grained crack edges and short-range texture patterns, while the large-kernel perception branch helps to improve modeling of long-range crack connectivity and contextual consistency. A channel-gating unit adaptively fuses and balances the contributions from both branches to achieve better detection performance without significant increase in model parameters.
Experiments performed on a self-constructed dataset of wood defects show that MSFE-YOLOv11-OBB achieves a 4.7% improvement in mAP@50 compared to the baseline with real-time performance appropriate for industrial applications. The results demonstrate the effectiveness of the proposed approach in achieving a balance between high detection precision and practical deployment requirements. This advancement enables automated, intelligent monitoring of oriented wood defect detection in industrial settings. Notably, the model has been successfully implemented on an industrial production line, where it is seamlessly integrated with conveyor systems, robotic manipulators, and adhesive spraying units. This configuration enables real-time defect identification and automated glue-based repair of wooden boards, demonstrating the model’s practical applicability across comprehensive industrial workflows.
Author Contributions
Supervision, funding acquisition, writing—review and editing, F.X.; Software, methodology, investigation, data curation, visualization, writing—original draft, H.Y.; Conceptualization, validation, supervision, funding acquisition, methodology, data curation, writing-review and editing, X.C.; Supervision, W.W.; Validation, data curation, H.W.; Supervision, D.K. All authors have read and agreed to the published version of the manuscript.
Funding
The research was supported by the National University Student Innovation Program of China (grant NO. 202410674017S).
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare that they have no known competing interests.
References
- Wang, R.; Chen, Y.; Zhang, G.; Liang, F.; Mou, X.; Jin, H. DRR-YOLO: A Multiscale Wood Surface Defect Detection Method Based on Improved YOLOv8. IEEE Sens. J. 2025, 25, 16702–16719. [Google Scholar] [CrossRef]
- Wang, B.; Wang, R.; Chen, Y.; Yang, C.; Teng, X.; Sun, P. FDD-YOLO: A Novel Detection Model for Detecting Surface Defects in Wood. Forests 2025, 16, 308. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, C.; Ren, Z.; Na, B. Review of the Current State of Application of Wood Defect Recognition Technology. Bioresources 2022, 18, 2288. [Google Scholar] [CrossRef]
- Pramreiter, M.; Nenning, T.; Huber, C.; Müller, U.; Kromoser, B.; Mayencourt, P.; Konnerth, J. A Review of the Resource Efficiency and Mechanical Performance of Commercial Wood-Based Building Materials. Sustain. Mater. Technol. 2023, 38, e00728. [Google Scholar] [CrossRef]
- Kryl, M.; Danys, L.; Jaros, R.; Martinek, R.; Kodytek, P.; Bilik, P. Wood Recognition and Quality Imaging Inspection Systems. J. Sens. 2020, 2020, 3217126. [Google Scholar] [CrossRef]
- Wang, R.; Liang, F.; Wang, B.; Zhang, G.; Chen, Y.; Mou, X. An Efficient and Accurate Surface Defect Detection Method for Wood Based on Improved YOLOv8. Forests 2024, 15, 1176. [Google Scholar] [CrossRef]
- Lin, C.-J.; Huang, Y.-H.; Huang, G.-S.; Wu, M.-L. Detection of Decay Damage in Iron-Wood Living Trees by Nondestructive Techniques. J. Wood Sci. 2016, 62, 42–51. [Google Scholar] [CrossRef]
- Hu, C.; Afzal, M.T. A Wavelet Analysis-Based Approach for Damage Localization in Wood Beams. J. Wood Sci. 2006, 52, 456–460. [Google Scholar] [CrossRef]
- Longuetaud, F.; Mothe, F.; Kerautret, B.; Krähenbühl, A.; Hory, L.; Leban, J.M.; Debled-Rennesson, I. Automatic Knot Detection and Measurements from X-Ray CT Images of Wood: A Review and Validation of an Improved Algorithm on Softwood Samples. Comput. Electron. Agric. 2012, 85, 77–89. [Google Scholar] [CrossRef]
- Tomczak, K.; Tomczak, A.; Jelonek, T. Measuring Radial Variation in Basic Density of Pendulate Oak: Comparing Increment Core Samples with the IML Power Drill. Forests 2022, 13, 589. [Google Scholar] [CrossRef]
- Downes, G.M.; Harrington, J.J.; Drew, D.M.; Lausberg, M.; Muyambo, P.; Watt, D.; Lee, D.J. A Comparison of Radial Wood Property Variation on Pinus Radiata between an IML PD-400 ‘Resi’ Instrument and Increment Cores Analysed by SilviScan. Forests 2022, 13, 751. [Google Scholar] [CrossRef]
- Yang, J.; Luo, L.; Chen, M.; Su, S.; Yan, J. Improved YOLOv8-Based Defect Detection for Furniture Artificial Panels under Complex Texture Backgrounds. Nondestruct. Test. Eval. 2025, 1–29. [Google Scholar] [CrossRef]
- Xie, X. A Review of Recent Advances in Surface Defect Detection Using Texture Analysis Techniques. ELCVIA Electron. Lett. Comput. Vis. Image Anal. 2008, 7, 1–22. [Google Scholar] [CrossRef]
- Wang, R.; Liang, F.; Wang, B.; Mou, X. ODCA-YOLO: An Omni-Dynamic Convolution Coordinate Attention-Based YOLO for Wood Defect Detection. Forests 2023, 14, 1885. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lee, H.; Eum, S.; Kwon, H. ME R-CNN: Multi-Expert R-CNN for Object Detection. IEEE Trans. Image Process. 2020, 29, 1030–1044. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: New York, NY, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- An, Y.; Chen, X.; He, X.; Xiong, X.; Kong, D.; Song, P. FSU-YOLO: Aero-Engine Blade Defect Detection Based on Improved YOLOv8. Meas. Sci. Technol. 2025, 36, 105417. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: New York, NY, USA, 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y. M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. In Neural Information Processing Systems; Neural Information Processing Systems Foundation: San Diego, CA, USA, 2024. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, L.; Yang, Z.; Yin, J.; Jing, Z. WLSD-YOLO: A Model for Detecting Surface Defects in Wood Lumber. IEEE Access 2024, 12, 65088–65098. [Google Scholar] [CrossRef]
- Cui, Y.; Lu, S.; Liu, S. Real-Time Detection of Wood Defects Based on SPP-Improved YOLO Algorithm. Multimed. Tools Appl. 2023, 82, 21031–21044. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, J.; Zeng, S.; Hu, J.; Li, K. AMAF-YOLO: Dynamic Cross-Region Attention and Multi-Scale Fusion for Small Object Detection. Nondestruct. Test. Eval. 2025, 1–31. [Google Scholar] [CrossRef]
- Chaurasia, D.; Patro, B.D.K. Detection of Objects in Satellite and Aerial Imagery Using Channel and Spatially Attentive YOLO-CSL for Surveillance. Image Vis. Comput. 2024, 147, 105070. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024, Chennai, India, 18–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- Tang, F.; Huang, Q.; Wang, J.; Hou, X.; Su, J.; Liu, J. DuAT: Dual-Aggregation Transformer Network for Medical Image Segmentation. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV); Springer Nature: Singapore, 2023. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving Semantic Segmentation via Decoupled Body and Edge Supervision. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Cheng, D.; Sun, J. ExFuse: Enhancing Feature Fusion for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Vaswani, A.; Brain, G.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2024. [Google Scholar]
- Hwang, S.-W.; Lee, T.; Kim, H.; Chung, H.; Choi, J.G.; Yeo, H. Classification of Wood Knots Using Artificial Neural Networks with Texture and Local Feature-Based Image Descriptors. Holzforschung 2022, 76, 1–13. [Google Scholar] [CrossRef]
- Zhou, J.; Ning, J.; Xiang, Z.; Yin, P. ICDW-YOLO: An Efficient Timber Construction Crack Detection Algorithm. Sensors 2024, 24, 4333. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 2844–2853. [Google Scholar]
- Yu, Y.; Yang, X.; Li, Y.; Han, Z.; Da, F.; Yan, J. Wholly-WOOD: Wholly Leveraging Diversified-Quality Labels for Weakly-Supervised Oriented Object Detection. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2025. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.