Abstract
In this investigation, the potential of M5P, Random Tree (RT), Reduced Error Pruning Tree (REP Tree), Random Forest (RF), and Support Vector Regression (SVR) techniques have been evaluated and compared with the multiple linear regression-based model (MLR) to be used for prediction of the compressive strength of bacterial concrete. For this purpose, 128 experimental observations have been collected. The total data set has been divided into two segments such as training (87 observations) and testing (41 observations). The process of data set separation was arbitrary. Cement, Aggregate, Sand, Water to Cement Ratio, Curing time, Percentage of Bacteria, and type of sand were the input variables, whereas the compressive strength of bacterial concrete has been considered as the final target. Seven performance evaluation indices such as Correlation Coefficient (CC), Coefficient of determination (R2), Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Bias, Nash-Sutcliffe Efficiency (NSE), and Scatter Index (SI) have been used to evaluate the performance of the developed models. Outcomes of performance evaluation indices recommend that the Polynomial kernel function based SVR model works better than other developed models with CC values as 0.9919, 0.9901, R2 values as 0.9839, 0.9803, NSE values as 0.9832, 0.9800, and lower values of RMSE are 1.5680, 1.9384, MAE is 0.7854, 1.5155, Bias are 0.2353, 0.1350 and SI are 0.0347, 0.0414 for training and testing stages, respectively. The sensitivity investigation shows that the curing time (T) is the vital input variable affecting the prediction of the compressive strength of bacterial concrete, using this data set.
1. Introduction
Concrete is located in the second place (after water) as the most consumed material. Like most construction materials, it is prone to microcracking and has air voids in the structure. Microcracks and micropores in concrete are very undesirable because they provide an open path for the ingress of water and other harmful substances. They can also cause corrosion of steel bars and deterioration of concrete.
Rapid development of buildings, especially in developing countries causes high energy consumption, environmental pollution and exploitation of resources. These behaviors directly affect the comfort and health of building residents [1,2]. Considering the construction development, concrete strength, concrete durability, and eco-friendliness with industrial materials (fly ash, blast furnace slag, metakaolin, silica fume, etc.), continuous research in the field of concrete technology has led to the growth of unique concrete.
High-strength concrete (HSC) is a type of concrete containing special additives in mixtures [3,4] and it represents a crucial step in the development of concrete technology [5]. The durability also plays an important role in concrete structures based on HSC. Since new building materials are not needed, its durable structure with a long service life helps to save resources. It also reduces the generation of construction waste, thereby reducing the environmental pollution. According to the economic view, it decreases repair and maintenance costs [6,7,8].
Usually occurring defects are cracks caused by the following reactions, action, shrinkage, freeze-thaw, the low tensile strength of concrete, hardening of concrete, etc. [9].
This bacterial self-healing method is superior to other methods because it is biologically based, environment-friendly, cost-effective and sustainable. It has been found that urease-positive bacteria can affect the precipitation of calcium carbonate (calcite) by producing urease. The enzyme catalyzes the hydrolysis of urea into CO2 and ammonia, leading to pH precipitation and an increase in calcite in the bacterial environment. To avoid leaching in the channel, this innovative environmental protection technology had been first used to repair cracks. It has been found that the precipitation of calcite induced by Bacillus Pasteur and Bacillus sphaericus can effectively repair concrete cracks and improve the compressive strength [10,11,12].
The durability of concrete samples in alkaline, sulfate, and freeze-thaw environments treated by Bacillus Pasteur is improved, comparing with untreated conventional concrete samples.
The durability of concrete samples is of particular importance for aqueous environments that determine the performance of concrete structures. As reflected in the study [13,14], Ghassemi et al. conducted a study of the long-term fatigue performance of PC (polymer concrete), EPC (epoxy polymer concrete) and OCC (ordinary cement concrete) in various environments. The samples were exposed to four different environments for 6 and 12 months. It was the impact of sea water and fresh water as well as of acidic and alkaline solutions. The research has shown that the aqueous environment has a destructive effect on the properties of PC and EPC, significantly reducing fatigue life and fatigue strength compared to other environments. On the other hand, the solutions of fresh and sea water improved the fatigue strength of OCC samples after six months of exposure. In the case of sea water, the improvement of properties lasted only up to the first 6 months. The alkaline and acid solutions caused a deterioration of the fatigue resistance of OCC samples to a greater extent than of PC and EPC samples. Scientists have shown the destructive effect of the aqueous environment, especially on modified concretes. It is an important aspect for a future analysis, in the case of the bacterial concretes considered in this paper.
As per the literature reviewed, materials viz. bentonite and magnesium oxide could aid in attaining high sealing proficiency for the cracks having initial width of around 0.18 mm and act as effective sealing for cracks [15]. As reflected from the study [16], Huang et al. characterized self-healing behaviors of microcracks. C-S-H and calcium carbonate [17] have been utilized as two products for self-healing of the concrete cracks as a formation of water as well as carbon monoxide dihydrate. Utilization of organic compounds, bacteria as well as volcanic ash-coated materials proves to be another effective technique for resolving cracks issue. This method includes differentiation of biological (e.g., bacteria) factors from the chemical factors (e.g., calcium lactate) and conjoining them yields in sophisticated outcomes.
Bacteria can be used to manufacture CaCO3 in Biological Concrete and Self-Repair or Microbial-Induced Calcite Precipitation (MICP). It fills in any gaps that occur in the concrete. Bacillus pseudo bacillus, Bacillus sphaericus, Bacillus pasteurella, Escherichia coli, Bacillus balodurans, Bacillus sphaericus, Bacillus subtilis, Bacillus halodurans, and other bacteria can be used in concrete. These bacteria can live in an alkali-rich environment, by using the metabolic process including sulfate reduction, urea hydrolysis, and photosynthesis.
The technology can be a method of bio-mineralization used on the surface or inside of concrete. The internal method involves depositing calcite (calcium carbonate) into concrete at a specific concentration. One of the bio-mineralization processes is the Microbial-Induced Calcite Precipitation (MICP). Microbial urea hydrolyzes urea to create ammonia and carbon dioxide, which is the most important concept in this process. The pH would then rise as a result of releasing the ammonia into the atmosphere. The released carbon dioxide reacts with calcium carbonate, which accumulates in the concrete pores [18]. Kalra et al. [19] and Irigaray et al. [20] show that the relationship between concrete strength is a highly nonlinear function. Therefore, a comprehensive mathematical model is used to establish a nonlinear analysis function, which can better understand the performance of concrete, compared to the concrete composition of conventional concrete without cementing materials. Therefore, it is necessary to use its mixture composition and proportion to explore high performance computing (HPC) model.
Regression approaches and machine learning techniques have been used in recent studies to measure and forecast Compressive Concrete Strength (CCS) [21,22]. Researchers may now use modeling techniques to further infer realistic solutions, due to the growing use of modeling techniques in the engineering field [23,24,25].
In CSS estimation problems, linear and nonlinear regression (LR and NLR) approaches are commonly used. In 2002, Bhanja and Sengupta [22] conducted a report on CCS, estimating the strength of 28-day concrete using a 5 percent to 30% silica fume substitute as a cementitious material. The role of concrete dimensionless variables in CCS prediction has been expressed in the success of their nonlinear model. In a subsequent study [26], the role of multilinear regression in predicting 28-day CCS was emphasized. To measure the CCS of construction sites more rapidly and reliably, many cementing materials must be analysed.
NLR can solve a wider range of classification. Regression trees and regression problems (CART) have been commonly used to predict the relationship between variables, according to their graphical representation and simplicity [21,27]. In CART, the same predictor variable could be used at different levels, and compared to other modeling techniques, what is considered multiple times in classification trees and regression trees (RT).
Artificial neural networks (ANN) have been used in a variety of studies to model the relationship between concrete properties and their components [21,28,29], to predict CCS, Water, cement, super plasticizer, silica fume, coarse aggregate, and fine aggregate composition, as well as 25 different artificial neural network architectures. In 28 days without slump CCS, Sobhani et al. compared the prediction results of NLR, ANN, and the inference method model based on the adaptive network [30]. They tested multiple structures of each model and found that the adaptive network-based reasoning method and ANN produced acceptable CCS prediction results, when compared to the NLR-based model.
In 2007 Gupta took the lead in using support vector machines (SVM) to forecast CCS, owing to the widespread popularity of machine learning techniques for basic output prediction [31]. The potential of SVM as an efficient technique for modeling CCS using a limited number of samples is demonstrated in this analysis. The research was also conducted by Yan and Shi to demonstrate the effectiveness of SVM in predicting concrete results [32]. According to their findings, SVM performed well, in comparison to other models. However, the experimental data used in the analysis, like most others, seldom had a minimal compressive strength boundary.
Support vector regression, M5P, Random Forest (RF), Random Tree (RT), and Reduced Error Pruning Tree (REP Tree) techniques have all enhanced their efficiency in various fields. The capacity of these soft computing techniques for the estimation of the compressive strength for bacterial concrete is evaluated in this analysis and compared to a multiple linear regression-based equation. According to the authors’ best knowledge, the efficiency of these techniques for the prediction of the compressive strength for bacterial concrete has not been compared yet. This manuscript employs five statistical indices and one graphical tool (the Taylor diagram) to evaluate the performance of developed models.
2. Research Significance
Regression approaches and advanced machine learning techniques allow the realistic prediction of concrete properties. The present research permits to verify which of the tested computational models enables the best prediction of the compressive concrete strength (CCS) for bacterial concrete. Correct prediction of concrete properties will enable the efficient and economical design of durable structures, minimizing the time of selecting the appropriate material, as well as the time and resources committed for repairs. The proposed forecasting techniques also allow civil engineering scholars of the smart design new materials.
3. Review of Regression and Soft Computing Techniques
3.1. Multiple Linear Regression
Using observed data, multiple linear regression is utilized to discover the link between input and output variables. For nonlinear and difficult issues, MLR is frequently used [33,34]. MLRs are a multivariate statistical approach that fits a linear equation to observed data to represent the linear correlations between the dependent variable and two or more independent variables. Each response of independent variables is related with the value of the dependent variable . The equation for y’s regression can be written as follows:
where y is the dependent variable, , … are the independent variables, , … are the regression coefficients, and is constant.
MLR models were the usual method for estimating responses between a dependent variable and various independent factors where the dependent variable and independent variables had a linear connection [35].
3.2. Random Forest
Breiman was the first to suggest the random forest algorithm (1996) [36]. It is a highly adaptable algorithm that is used successfully to a variety of engineering problems.
Random Forest (RF) is a tree-structured classifier that consists of a group of classifiers. Bagging and random feature selections are two important machine learning techniques features used by RF.
The target class is the target pattern of each tree as the target class in this machine learning classifier, which includes several decision trees.
RF is a step away from bagging. When growing a tree, RF will randomly pick a subset of features to break at each node rather than using all of them. RF uses Out-of-Bag (OOB) samples to perform cross-validation in parallel with the training phase in order to test the random forest algorithm’s prediction accuracy.
Depending to (Breiman 2001) [37] the random forest algorithm is easy to use, has a low learning curve, and has higher prediction accuracy. Two user-defined parameters must be tuned for the best solution. The number of trees increases and the number of input parameters are user-defined parameters. For model development, the trial-and-error method is used.
3.3. M5P Model
M5P is a straightforward algorithm for predicting complex and nonlinear problems. Quinlan (1992) [38] introduced the M5 tree as a new tree algorithm for predicting complex problems with several data sets and input variables. The algorithm also includes pruning to reduce the chance of overfitting. Instead, each node is divided to gain more information, and the variance of the class value in the subset up to each branch is smaller. A division norm is used to create the basic tree model, which provides the standard deviation of the class value extended to the node. At each node, a linear relationship is formed using this approach. The algorithm created a good tree structure with high prediction accuracy [39,40,41,42,43,44]. It has been proven many times that computational procedures based on uncertainty modelling and probabilistic structural analysis are used in the analysis of engineering structures [45].
By classifying or splitting the entire data space into many subspaces, the tree algorithm allocates a linear regression function at the terminal node and fits a multiple linear regression model to each subspace. The M5 tree method can handle very high dimensionality and deals with continuous problems rather than discrete ones. It shows the piecewise details of each linear model that was built to approximate the data set’s nonlinear relationship. Information about the partition norm of the M5 model tree has been obtained based on the error calculations of each node. Calculate the standard deviation of the class value that reaches the node to determine the error. To break at this node, choose the attribute that maximizes the reduction of expected errors caused by the test of each attribute. The following formula is used to measure the standard deviation reduction (SDR):
where,
- K—set of instances that attain the node.
- Ki—the subset of illustrations that have the product of the possible set.
- and —the standard deviation
3.4. Random Tree Model
The multi-strategy feature of RT allows users to obtain a very diverse set of regression models. Nonetheless, these models are tree-based, which means that training cases would be divided by tree-based models or constructed for all training cases.
For tree-based models, RT has the following main features: learning trees to minimize the square error (least squares (LS) regression tree), learning trees to minimize the absolute deviation (least absolute deviation (LAD) regression tree), selecting the probability between different models to be used in the leaves during the prediction task is pruned based on the sequence-based regression tree. RT generated a set of alternate tree models and selected one of them based on some criteria. Different methods have been used to estimate the best pruning tree from a series of alternate trees.
3.5. Reduced Error Pruning Tree (REP Tree)
Rep Tree generates several trees in various iterations using regression tree logic. After that, it selects the best tree from among all the trees that have been created. A representative is someone who represents another individual. When pruning a tree, the mean square error of the tree’s prediction is used as a metric. The (“REPT”) is a quick decision tree learning method that constructs a decision tree using knowledge gain or reduced variance.
3.6. Support Vector Regression (SVR)
The support vector machine SVM is an advanced machine learning technique for data classification that is based on statistical theory. To differentiate the two forms of samples, SVM looks for the best hyper plane. It maps the original data to higher-dimensional feature space and finds the best separation hyperplane there using a kernel function.
Support vector regression (SVR) uses sparse, kernels, and VC control of the number and number of support vectors, much like classification. SVR is proved to be an operative tool for real-valued function estimation, despite not being as common as SVM.
The (SVM) is based on statistical learning or the Vapnik-Chervonenkis (VC) theory, and it is capable of locating previously unseen data.
Kernels, sparse solutions, and VC regulation of the number and edges of support vectors are all features of support vector regression (SVR). SVR is proved to be an efficient tool for real-valued function estimation, despite not being as common as SVM. SVR is a supervised learning system that employs asymmetric loss function for instruction that penalizes both high and low miscalculations. A flexible tube with a minimum radius is shaped symmetrically around the estimation function using Vapnik’s insensitive process so that absolute values of errors less than a certain threshold are ignored above and below the estimation value. Points outside the tube were penalized in this way, but points inside the tube were not penalized. One of the key benefits of SVR is that its computational complexity is independent of the input space’s dimensionality. It also has a high prediction accuracy and excellent generalization ability.
3.7. Performance Evaluation Indices
Correlation coefficient (CC):
The correlation coefficient measures the intensity of a linear relationship between two variables. The correlation coefficient is always having a range between −1 and 1 in value, where 1 or −1 means complete correlation (in this case, all points are on a straight line). A positive correlation means the positive correlation between variables (the increase in one variable corresponds to the increase in another variable), while negative correlation means the negative correlation between variables (the increase in value is that one variable resembles the decrease in another variable). A correlation value comes close to 0 means that there is no correlation among variables.
Correlation coefficient:
Coefficient of determination (R2):
Root mean square error (RMSE):
The root mean square deviation (RMSD) or root mean square error (RMSE) is a widely used measure of the difference between a model’s or estimator’s expected value and the observed value (sample or population value). The root mean squared deviation (RMSD) is the square root of the root mean squared average.
Root mean square error:
Mean absolute error:
The mean absolute error (MAE) is a statistic that measures the difference in error between pairs of observations that describe the same phenomenon. The calculation formula of MAE is represented by the Equation (6);
Mean absolute error:
Nash Sutcliffe model efficiency:
The formula for calculating the efficiency of Nash-Sutcliffe is: divide the ratio of the observed time series variance by the error variance of the modeled time series. The Nash-Sutcliffe efficiency is equal to 1 (NSE = 1) in the case of an ideal model with an expected error variance equal to zero.
Nash-Sutcliffe efficiency
- values of the actual observations in a sample
- mean of the values of the actual observations
- values of the predicted observations in a sample
- mean of the values of the predicted observations
4. Materials and Methodology
Materials
The materials have been used in this experimental for define the effect of bacteria on the mechanical properties of concrete. In this study, Bascillus subtilis bacteria with calcite lactate were used in different percentage such as 5%, 10%, and 15% of cement weight for M20 and M40 grade concrete.
Ordinary Portland cement of 53 grade was used and tested for various properties as per IS: 4031-1996 [46] and the physical properties shown in Table 1. Local available river sand and crushed stone sand were used as fine aggregates. Crushed granite broken stone of 20 mm nominal size was used as coarse aggregate. Properties of coarse aggregate were shown in Table 2. Fresh water was used in the manufacturing of concrete. The mixing and curing of concrete was done as per IS: 456-2000 [47].

Table 1.
Physical properties of Portland cement.
Table 2.
Properties of coarse aggregate.
In this research Bacillus subtilis microscopic organisms utilized which are refined at DVS Bio life Pvt Ltd. Laboratory, Hyderabad, India. Calcium lactate utilized for this examination alongside Bacillus subtilis microbes and nutrient broth. It is accessible in powder shape having white shading. The nutrient broth was set up by including 2.5 g of peptone, 2.5 g of NaCl, 1.5 g beef extract concentrate to 500 mL refined water in a cone shaped flask. This flask was secured with cotton plug and encased with silver thwart. From that point forward, the arrangement was untainted in autoclave over 20 min at 121 °C temperature. After this disinfection, the arrangement was in orange shading and polluting influence free. From that point forward, the cup opened in laminar wind current chamber and the bacillus subtilis microorganisms added to this arrangement. From that point onward, the arrangement hatched in orbital shaker at a speed of 125 rpm at 37 °C. Following one day, this arrangement was changed into whitish yellow hue. Calcium lactate (C6H10CaO6) were used for this work along with bacillus subtilis bacteria as nutrient broth. This material has the form of powder having white colour.
4.1. Design Proportions
The mix proportions for M40 and M20 grades concrete are designed using IS: 10262-2009 [48]. Materials required per one cubic meter of concrete are shown in Table 3 and Table 4.
Table 3.
The proportion of ingredients per one cubic meter of M20 grade concrete.
Table 4.
Proportion of ingredients per one cubic meter of M40 grade concrete.
4.2. Data Set
Data set: overall 128 observations have been collected from laboratory experiments. Out of 128, randomly separated 87 observations were chosen as training data set, and the rest 41 observations were taken for model validation and testing. Total data set consider 7 input variables namely Cement (C) in kg, Sand (S) in kg, Aggregate (A) in kg, Water to Cement Ratio (W/C), Curing Period (T) in days, and compressive strength of bacterial concrete is considered as output. Features of the overall data set, training, and testing data sets are listed in Table 5. Table 5 indicates that the range of cement is 340–390 kg, sand 642–736 kg, aggregate 1214–1261 kg, water-cement ratio 0.42–0.48, and curing period 7–365 days. There are two types of sand: natural sand (1) and crushed aggregate sand (2).
Table 5.
Features of data set used the model development and validation.
5. Results and Discussion
5.1. Results of Multiple Linear Regression
A Linear regression-based model is used to develop a linear relationship among independent variables and dependent variables. In this study XLSTAT software (Addinsoft, Paris, France) is used to develop the MLR model. It relies on the least square technique. The LR model is developed using training data set and its final equation is as follow:
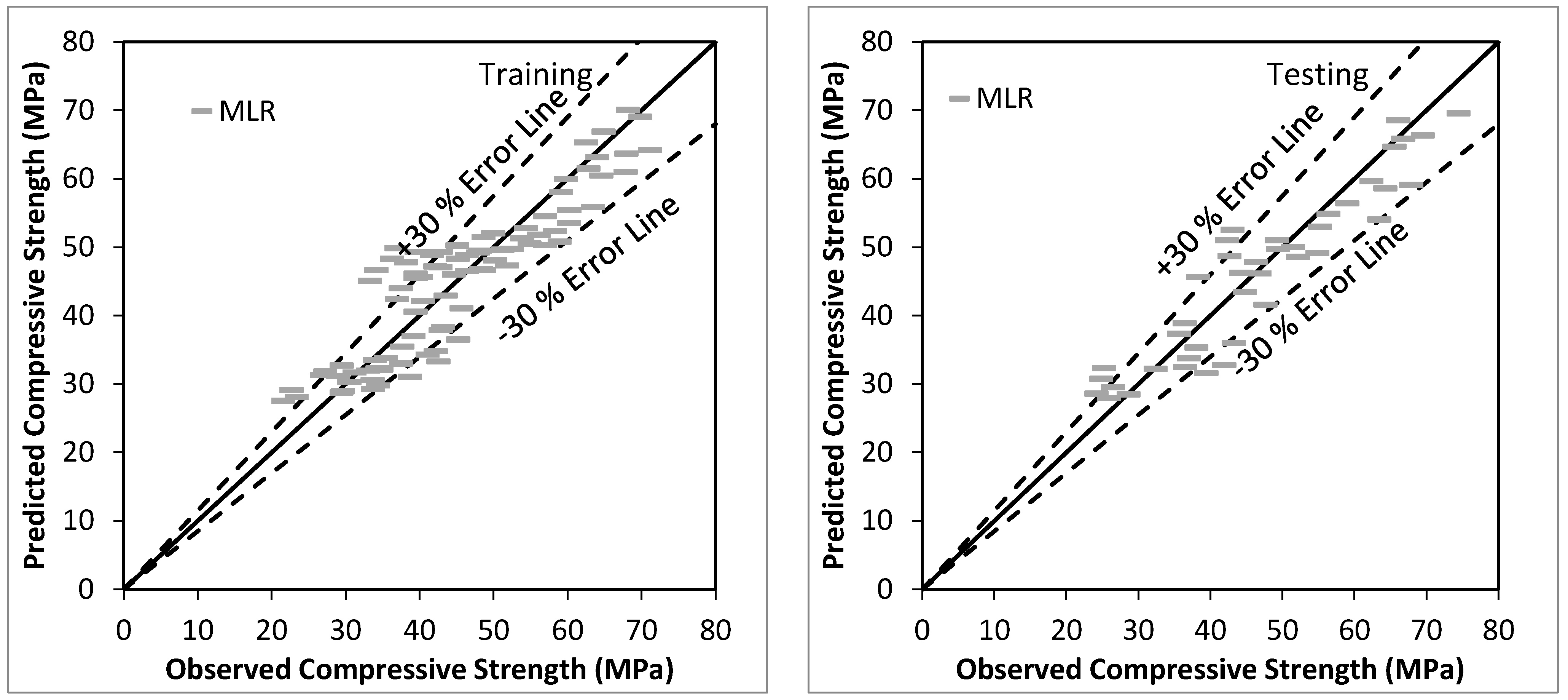
Figure 1 shows the agreement plot among observed and predicted values, using MLR based model for the training and testing stage respectively. The predicted values are among ±30% Error band. Overall performance of MLR based model is satisfactory for the prediction of the compressive strength of bacterial concrete with CC (0.9373), R2 (0.8786), RMSE (4.8727), MAE (3.9642), Bias (−0.7300), SI (0.1041), and NSE (0.8735) using testing data.
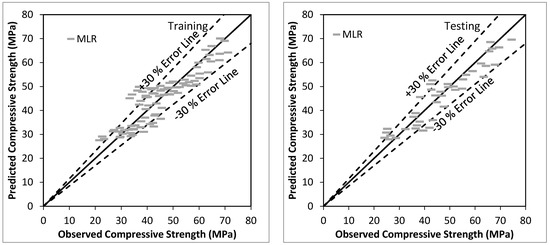
Figure 1.
Observed vs. Predicted values using MLR based model using training and testing stage.
5.2. Results of the Tree and Forest-Based Models
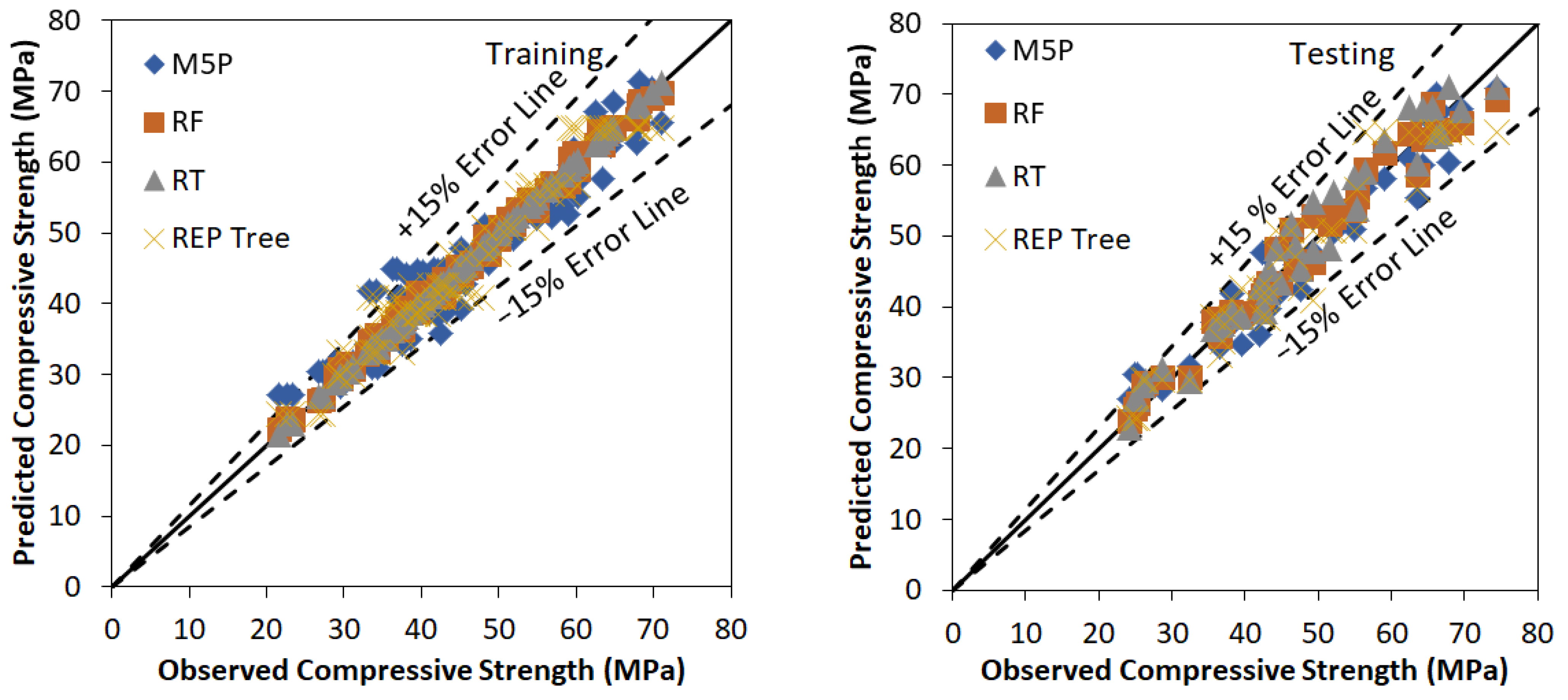
In this investigation M5P, RF, RT, and REP based models have been developed using WEKA software to predict the values of the compressive strength of bacterial concrete. The model development is a trial-and-error process. Many trials have been carried out to find the optimum value of user-defined parameters of various tree and forest-based models. Figure 2 represents the agreement plot between observed and predicted values using RF, M5P, RT, and REP Tree based models for the training and testing stage respectively. Most of the predicted values using M5P, RF, RT, and REP tree-based models are within ±15% error band. Performance assessment indices values for various tree and forest-based models using training and testing data set are listed in Table 6. Outcomes of Table 6 conclude that the RF based model is performing better than M5P, RT and REP based models for training and testing stages with higher values of CC (0.9973, 0.9868), R2 (0.9947, 0.9739), NSE (0.9944, 0.9722) and lower values of RMSE (0.9010, 2.2853), MAE (0.7387, 1.8161), Bias (0.0890, 0.2327) and SI (0.0199, 0.0488) respectively. Other major outcome from this analysis is the fact that RT based model is found to be performing better than M5P and REP Tree based models with values of CC (0.9999, 0.9808), R2 (0.9999, 0.9620), NSE (0.9999, 0.9576) and lower values of RMSE (0.1316, 2.8224), MAE (0.0589, 2.4918), Bias (0.0000, 0.8627) and SI (0.0029, 0.0603) respectively. It has been shown that there is a difference among observed and predicted values using M5P, RF, RT, and REP Tree based models. All the tree and forest based applied models are useful to predict the values of the compressive strength of bacterial concrete.
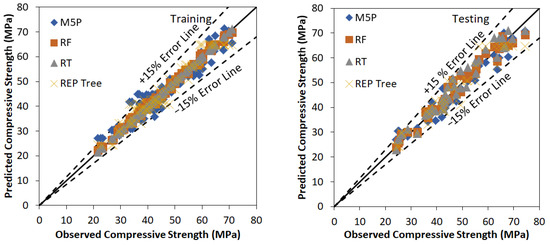
Figure 2.
Observed vs. Predicted values using M5P, RF, RT and REP tree based model using training and testing stage.
Table 6.
Performance evaluation parameters M5P, RF, RT, REP Tree, SVR_Poly (Polynomial kernel), SVR_NPoly (Normalized Poly Kernel), SVR_PUK, SVR_RBF (RBF Kernel), MLR.
5.3. Results of SVR Based Models
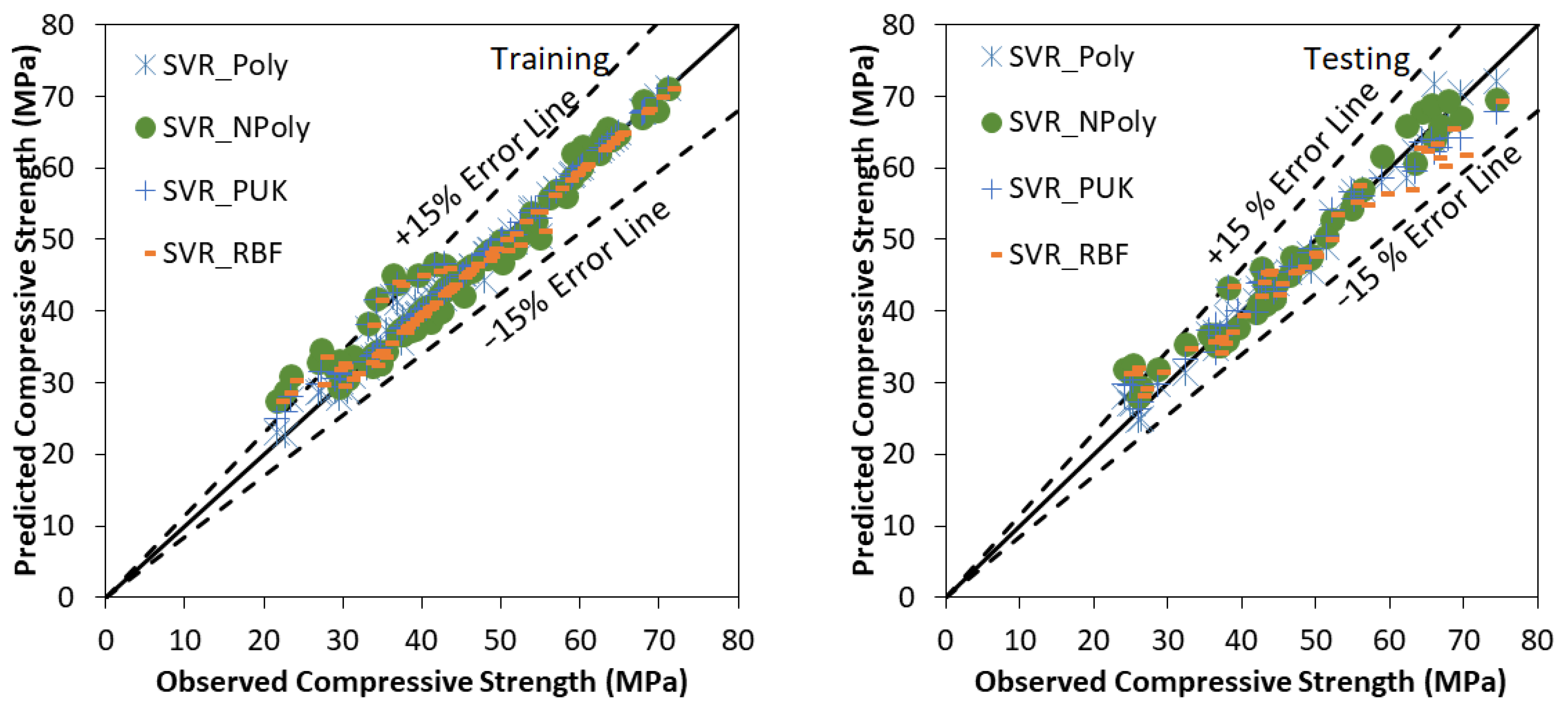
SVR based model development is similar to a tree or forest-based model development. Many trials have been carried out to find the optimum value of users defined parameters of various tree and forest-based models. Figure 3 presents the agreement plot among observed and predicted values using SVR based models for the training and testing stage respectively. Most of the predicted values using SVR based models are within ±15% Error band. Performance assessment indices values for various tree and forest-based models using training and testing data set are listed in Table 6. Outcomes of Table 6 conclude that the polynomial kernel function based support vector regression based model is performing better than normalized Poly kernel, Pearson VII, and radial basis kernel function based models with CC (0.9919, 0.9901), R2 (0.9839, 0.9803) NSE (0.9832, 0.9800) and lower values of RMSE (1.5680, 1.9384), MAE (0.7854, 1.5155), Bias (0.2353, 0.1350) and SI (0.0347, 0.0414) for training and testing stages, respectively. In Figure 3 SVR_Poly denotes the Polynomial kernel function based support vector Regression based model, SVR_NPoly denotes the Normalized Poly kernel function based support vector Regression based model, SVR_PUK denotes the Pearson VII kernel function based support vector Regression based model and SVR_RBF denotes the Radial basis kernel function based support vector Regression based model.
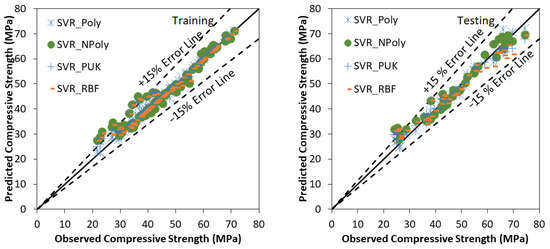
Figure 3.
Observed vs. Predicted values using SVR based models using training and testing stage.
5.4. Comparison among Regression and Soft Computing-Based Models
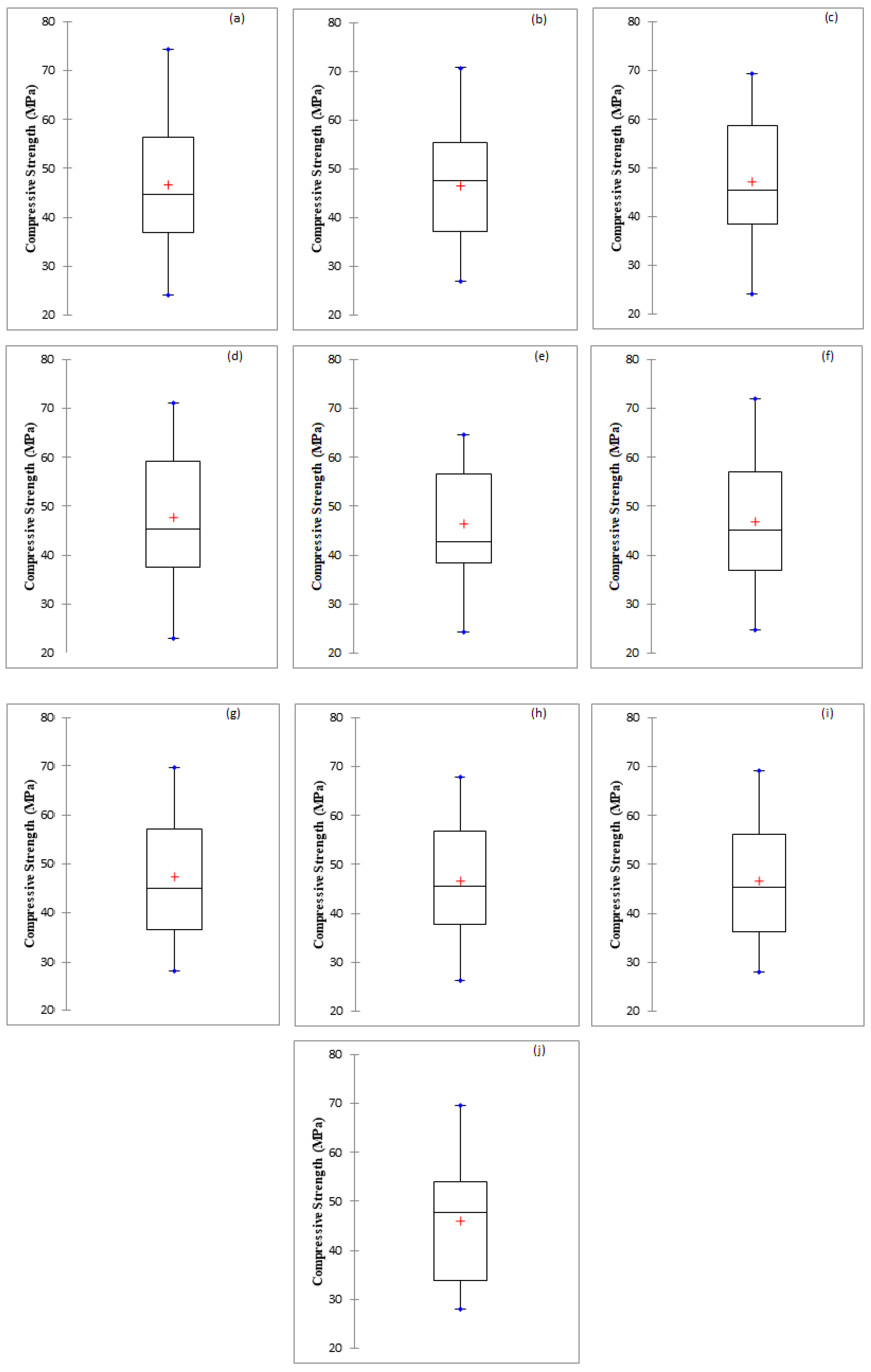
In this investigation predictive accuracy of M5P, RF, RT, REP, and SVR based models have been assessed for the prediction of the compressive strength of bacterial concrete. The results have been compared with the multiple linear regression-based model (Table 6). For this purpose, seven statistical performance indices are selected namely CC, R2, RMSE, MAE, Bias, SI, and NSE. The results of performance evaluation indices recommend that polynomial kernel function-based support vector regression-based model performed better than other soft computing and regression-based models with CC (0.9919, 0.9901), R2 (0.9839, 0.9803), NSE (0.9832, 0.9800), RMSE (1.5680, 1.9384), MAE (0.7854, 1.5155), Bias (0.2353, 0.1350) and SI (0.0347, 0.0414) for training and testing stages, respectively. Overall SVR based models work better than a tree and MLR-based models except for SVR_NPoly based model. In tree-based models, RF based model is performing better than other tree based applied models. Overall MLR-based model performance is the least among all applied models with CC (0.9373), R2 (0.8786), RMSE (4.8727), MAE (3.9642), Bias (−0.7300), SI (0.1041), and NSE (0.8735) using testing data. Box plot diagram for all used techniques have been shown in Figure 4. Descriptive statistics results of actual and predictive values of compressive strength of concrete have been presented in Table 7.
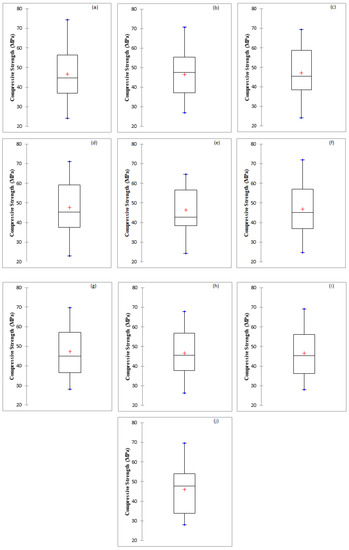
Figure 4.
Box plot diagram (a) Actual, (b) M5P, (c) RF, (d) RT, (e) REP Tree, (f) SVR_Poly, (g) SVR_NPoly, (h) SVR_PUK, (i) SVR_RBF and (j) MLR.
Table 7.
Descriptive statistics results of actual and predictive values of compressive strength of concrete [MPa].
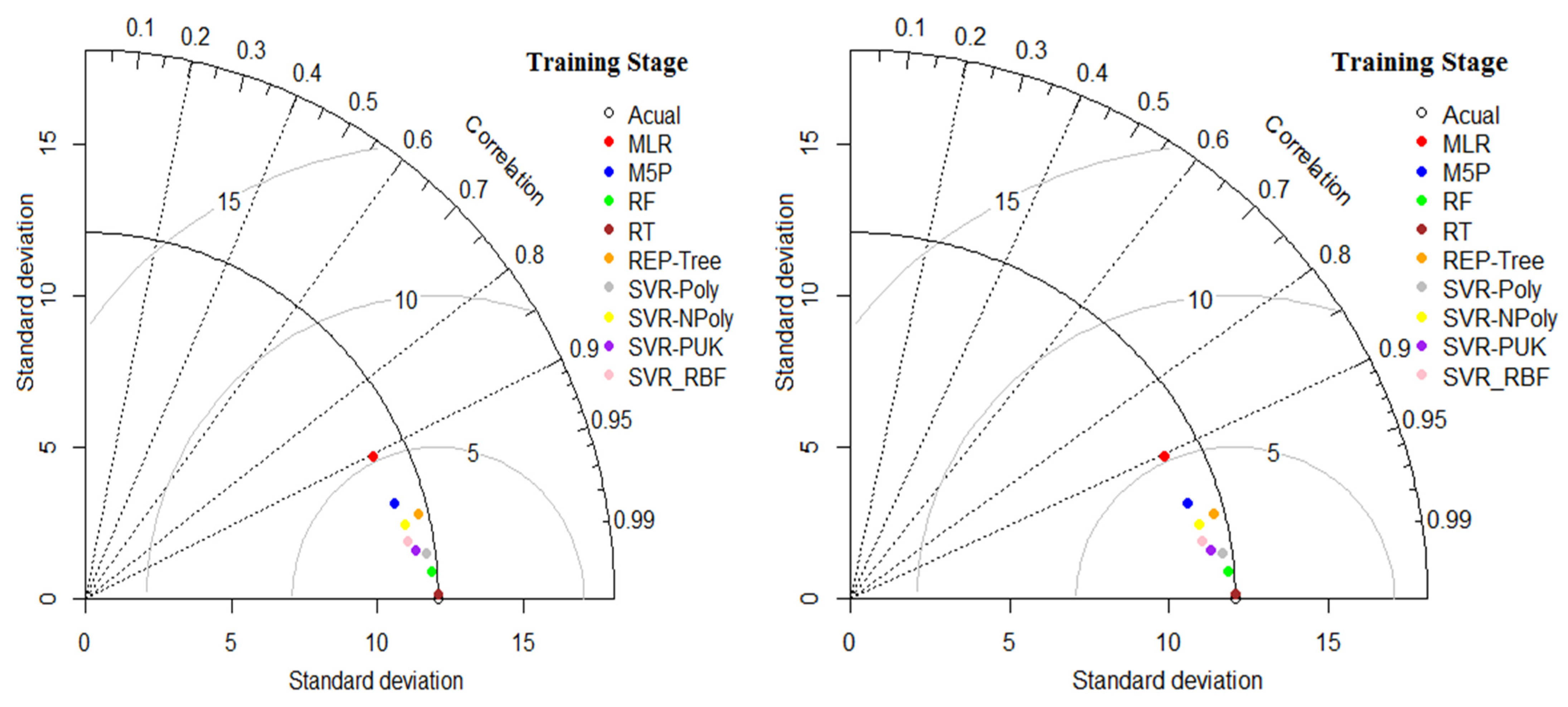
The Taylor chart shows the performance of the developed model in terms of correlation, RMSE and stand deviation, as shown in Figure 5. This figure indicates that SVR_Poly is the best performing model. Whereas, the MLR model has the worst performance, when using this data set to predict the compressive strength of concrete.
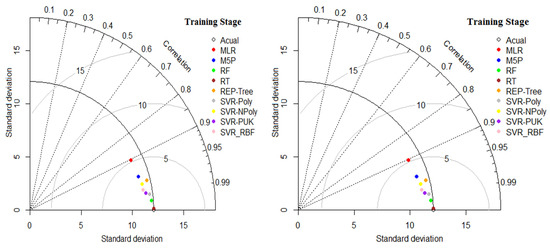
Figure 5.
Taylor diagram for all applied models.
5.5. Sensitivity Analysis
The SVR_Poly model has been used for sensitivity testing to determine the important input variables in compressive strength. A set of different test data was created by deleting one input parameter at a time, as shown in Table 8. According to CC, MAE, and RMSE report, the impact of each input variable on the compressive strength was observed. The results in Table 8 show that, compared with other input parameters using this data set, curing time plays an important role in predicting the compressive strength of concrete.
Table 8.
Sensitivity results using SVR_Poly based model.
6. Conclusions
In this investigation, Random Forest (RF), M5P, REP tree Random Tree and support vector regression have been developed to predict the compressive strength of concrete and compared with Multiple Linear Regression (MLR). For that purpose, the experiments have been performed with the variation of percentage of bacterial concrete 0%, 5%, 10%, and 15%, and two kinds of sand: natural sand and crushed aggregate.
The comparison analysis using performance evaluation indices concludes that developed RF approach outperformed rest of the tree based models and MLR (M5P, RT, REP tree and MLR) using given data set with CC (0.9973, 0.9868), R2 (0.9947, 0.9739), NSE (0.9944, 0.9722) and lower values of RMSE (0.9010, 2.2853), MAE (0.7387, 1.8161), Bias (0.0890, 0.2327) and SI (0.0199, 0.0488) respective for model development and validation period, correspondingly. Other major outcome from this investigation is the fact that RT based model performs better than M5P, REP Tree and MLR based models.
The comparison analysis using performance evaluation indices concludes that developed SVR_Poly approach outperformed rest of the models (SVR_Poly, SVR_NPoly, SVR_PUK, SVR_RBF and MLR) using given data set with CC (0.9919, 0.9901), R2 (0.9839, 0.9803) NSE (0.9832, 9800) and lower values of RMSE (1.5680, 1.9384), MAE (0.7854, 1.5155), Bias (0.2353, 0.1350) and SI (0.0347, 0.0414) for training and testing stages, respectively for model development and validation period, correspondingly. Other major outcome from this investigation is the fact that SVR_Poly based model performs better than SVR_NPoly, SVR_PUK, SVR_RBF, and MLR model. The results of the sensitivity study conclude that the curing time plays an important role in predicting the compressive strength of bacterial concrete using this data set with SVR_Poly model.
Author Contributions
All authors participated in investigation, writing—original draft preparation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the University of Diyala and Cracow University of Technology.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this article are available within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Franzoni, E. Materials selection for green buildings: Which tools for engineers and architects? Procedia Eng. 2011, 21, 883–890. [Google Scholar] [CrossRef] [Green Version]
- Melchert, L. The Dutch sustainable building policy: A model for developing countries? Build. Environ. 2007, 42, 893–901. [Google Scholar] [CrossRef]
- Mindeguia, J.-C.; Hager, I.; Pimienta, P.; Borderie, C.L.; Carré, H. Parametrical study of transient thermal strain of high performance concrete. Cem. Concr. Res. 2013, 48, 40–52. [Google Scholar] [CrossRef]
- Ostrowski, K.; Sadowski, Ł.; Stefaniuk, D.; Wałach, D.; Gawenda, T.; Oleksik, K.; Usydus, I. The effect of the shape of coarse aggregate on the 2 properties of self-compacting high-performance 3 fibre-reinforced concrete. Materials 2018, 11, 1372. [Google Scholar] [CrossRef] [Green Version]
- Ostrowski, K. The influence of coarse aggregate shape on the properties of high-performance, self-compacting concrete. Tech. Trans. Civ. Eng. 2017, 5, 25–33. [Google Scholar] [CrossRef] [Green Version]
- Häkkinen, T.; Belloni, K. Barriers and drivers for sustainable building. Build. Res. Inf. 2011, 39, 239–255. [Google Scholar] [CrossRef]
- Chen, Z.S.; Martinez, L.; Chang, J.P.; Wang, X.J.; Xionge, S.H.; Chin, K.S. Sustainable building material selection: A QFD-and ELECTRE III-embedded hybrid MCGDM approach with consensus building. Eng. Appl. Artif. Intell. 2019, 85, 783–807. [Google Scholar] [CrossRef]
- Invidiata, A.; Lavagna, M.; Ghisi, E. Selecting design strategies using multi-criteria decision making to improve the sustainability of buildings. Build. Environ. 2018, 139, 58–68. [Google Scholar] [CrossRef]
- Roodman, D.M.; Lenssen, N.K.; Peterson, J.A. A Building Revolution: How Ecology and Health Concerns Are Transforming Construction; Worldwatch Institute: Washington, DC, USA, 1995; p. 11. [Google Scholar] [CrossRef]
- Wang, J.; Jonkers, H.M.; Boon, N.; De Belie, N. Bacillus sphaericus LMG 22257 is physiologically suitable for self-healing concrete. Appl. Microbiol. Biotechnol. 2017, 101, 5101–5114. [Google Scholar] [CrossRef]
- Stanaszek-Tomal, E. Bacterial Concrete as a Sustainable Building Material? Sustainability 2020, 12, 696. [Google Scholar] [CrossRef] [Green Version]
- Achal, V.; Mukherjee, A. A review of microbial precipitation for sustainable construction. Constr. Build. Mater. 2015, 93, 1224–1235. [Google Scholar] [CrossRef]
- Ghassemi, P.; Rajabi, H.; Toufigh, V. Fatigue performance of polymer ond ordinary cement concrete under corrosive conditions: A comparative study. Eng. Fail. Anal. 2020, 111, 104493. [Google Scholar] [CrossRef]
- Ghassemi, P.; Toufigh, V. Durability of epoxy polymer and ordinary cement concrete in aggressive environments. Constr. Build. Mater. 2020, 234, 117887. [Google Scholar] [CrossRef]
- Qureshi, T.; Kanellopoulos, A.; Al-Tabbaa, A. Autogenous self-healing of cement with expansive minerals-I: Impact in early age crack healing. Constr. Build. Mater. 2018, 192, 768–784. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Ye, G.; Damidot, D. Characterization and quantification of self-healing behaviors of microcracks due to further hydration in cement paste. Cem. Concr. Res. 2013, 52, 71–81. [Google Scholar] [CrossRef]
- Sisomphon, K.; Copuroglu, O.; Koenders, E.A.B. Self-healing of surface cracks in mortars with expansive additive and crystalline additive. Cem. Concr. Compos. 2012, 34, 566–574. [Google Scholar] [CrossRef]
- Akadiri, P.O.; Chinyio, E.A.; Olomolaiye, P.O. Design of a sustainable building: A conceptual framework for implementing sustainability in the building sector. Buildings 2012, 2, 126–152. [Google Scholar] [CrossRef] [Green Version]
- Kalra, M.; Mehmood, G. A Review paper on the Effect of different types of coarse aggregate on Concrete. In IOP Conference Series: Materials Science and Engineering, October 2018; IOP Publishing: Bristol, UK, 2018; Volume 431, p. 082001. [Google Scholar] [CrossRef]
- Irrigaray, M.A.P.; Pinto, R.D.A.; Padaratz, I.J. A new approach to estimate compressive strength of concrete by the UPV method. Rev. IBRACON Estrut. Mater. 2016, 9, 395–402. [Google Scholar] [CrossRef]
- Anyaoha, U.; Peng, X.; Liu, Z. Concrete performance prediction using boosting smooth transition regression trees (BooST). In Nondestructive Characterization and Monitoring of Advanced Materials, Aerospace, Civil Infrastructure, and Transportation; XIII; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10971, p. 109710I. [Google Scholar] [CrossRef]
- Bhanja, S.; Sengupta, B. Investigations on the compressive strength of silica fume concrete using statistical methods. Cem. Concr. Res. 2002, 32, 1391–1394. [Google Scholar] [CrossRef]
- Lee, S.C. Prediction of concrete strength using artificial neural networks. Eng. Struct. 2003, 25, 849–857. [Google Scholar] [CrossRef]
- Khalaj, G.; Pouraliakbar, H. Computer-aided modeling for predicting layer thickness of a duplex treated ceramic coating on tool steels. Ceram. Int. 2014, 40, 5515–5522. [Google Scholar] [CrossRef]
- Khalaj, G.; Nazari, A.; Khoie, S.M.M.; Khalaj, M.J. Pouraliakbar, H. Chromium carbonitride coating produced on DIN 1.2210 steel by thermo-reactive deposition technique: Thermodynamics, kinetics and modeling. Surf. Coat. Technol. 2013, 225, 1–10. [Google Scholar] [CrossRef]
- Zain, M.F.M.; Abd, S.M. Multiple regression model for compressive strength prediction of high performance concrete. J. Appl. Sci. 2009, 9, 155–160. [Google Scholar] [CrossRef]
- Hayes, T.; Usami, S.; Jacobucci, R.; McArdle, J.J. Using Classification and Regression Trees (CART) and random forests to analyze attrition: Results from two simulations. Psychol. Aging 2015, 30, 911. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yeh, I.C. Modeling of strength of high-performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Chopra, P.; Sharma, R.K.; Kumar, M. Prediction of compressive strength of concrete using artificial neural network and genetic programming. Adv. Mater. Sci. Eng. 2016, 2016, 7648467. [Google Scholar] [CrossRef] [Green Version]
- Sobhani, J.; Najimi, M.; Pourkhorshidi, A.R.; Parhizkar, T. Prediction of the compressive strength of no-slump concrete: A comparative study of regression, neural network and ANFIS models. Constr. Build. Mater. 2010, 24, 709–718. [Google Scholar] [CrossRef]
- Gupta, S.M. Support vector machines based modelling of concrete strength. World Acad. Sci. Eng. Technol. 2007, 36, 305–311. [Google Scholar]
- Yan, K.; Shi, C. Prediction of elastic modulus of normal and high strength concrete by support vector machine. Constr. Build. Mater. 2010, 24, 1479–1485. [Google Scholar] [CrossRef]
- Thakur, M.S.; Pandhiani, S.M.; Kashyap, V.; Upadhya, A.; Sihag, P. Predicting Bond Strength of FRP Bars in Concrete Using Soft Computing Techniques. Arab. J. Sci. Eng. 2021, 46, 4951–4969. [Google Scholar] [CrossRef]
- Dayev, Z.; Kairakbaev, A.; Yetilmezsoy, K.; Bahramian, M.; Sihag, P.; Kıyan, E. Approximation of the discharge coefficient of differential pressure flowmeters using different soft computing strategies. Flow Meas. Instrum. 2021, 79, 101913. [Google Scholar] [CrossRef]
- Singh, A.; Singh, R.M.; Kumar, A.S.; Kumar, A.; Hanwat, S.; Tripathi, V.K. Evaluation of soft computing and regression-based techniques for the estimation of evaporation. J. Water Clim. Chang. 2021, 12, 32–43. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 16–18 November 1992; Volume 92, pp. 343–348. [Google Scholar]
- Yetilmezsoy, K.; Sihag, P.; Kıyan, E.; Doran, B. A benchmark comparison and optimization of Gaussian process regression, support vector machines, and M5P tree model in approximation of the lateral confinement coefficient for CFRP-wrapped rectangular/square RC columns. Eng. Struct. 2021, 246, 113106. [Google Scholar] [CrossRef]
- Upadhya, A.; Thakur, M.S.; Sharma, N.; Sihag, P. Assessment of Soft Computing-Based Techniques for the Prediction of Marshall Stability of Asphalt Concrete Reinforced with Glass Fiber. Int. J. Pavement Res. Technol. 2021, 1–20. [Google Scholar] [CrossRef]
- Kumar, V.; Sihag, P.; Keshavarzi, A.; Pandita, S.; Rodríguez-Seijo, A. Soft Computing Techniques for Appraisal of Potentially Toxic Elements from Jalandhar (Punjab), India. Appl. Sci. 2021, 11, 8362. [Google Scholar] [CrossRef]
- Salmasi, F.; Nouri, M.; Sihag, P.; Abraham, J. Application of SVM, ANN, GRNN, RF, GP and RT models for predicting discharge coefficients of oblique sluice gates using experimental data. Water Supply 2021, 21, 232–248. [Google Scholar] [CrossRef]
- Sangeeta; Haji Seyed Asadollah, S.B.; Sharafati, A.; Sihag, P.; Al-Ansari, N.; Chau, K.W. Machine learning model development for predicting aeration efficiency through Parshall flume. Eng. Appl. Comput. Fluid Mech. 2021, 15, 889–901. [Google Scholar] [CrossRef]
- Sihag, P.; Al-Janabi, A.M.S.; Alomari, N.K.; Ab Ghani, A.; Nain, S.S. Evaluation of tree regression analysis for estimation of river basin discharge. Modeling Earth Syst. Environ. 2021, 1–13. [Google Scholar] [CrossRef]
- Miluccio, G.; Losanno, D.; Parisi, F.; Cosenza, E. Traffic-load fragility models for prestressed concrete girder decks of existing Italian highway bridges. Eng. Struct. 2021, 249, 113367. [Google Scholar] [CrossRef]
- Indian Standard 4031-1996. Methods of Physical Tests for Hydraulic Cement; Bureau of Indian Standards: New Delhi, India, 1996.
- Indian Standard 456-2000. Indian Standard Code of Practice for General Structural Use of Plain and Reinforced Concrete; Bureau of Indian Standards: New Delhi, India, 2000.
- Indian Standard 10262-2009. Indian Standards in Concrete Mix Design; Bureau of Indian Standards: New Delhi, India, 2009.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).