

Multi-Armed Bandit-Based User Network Node Selection

Abstract
1. Introduction
2. Related Work
3. System Model
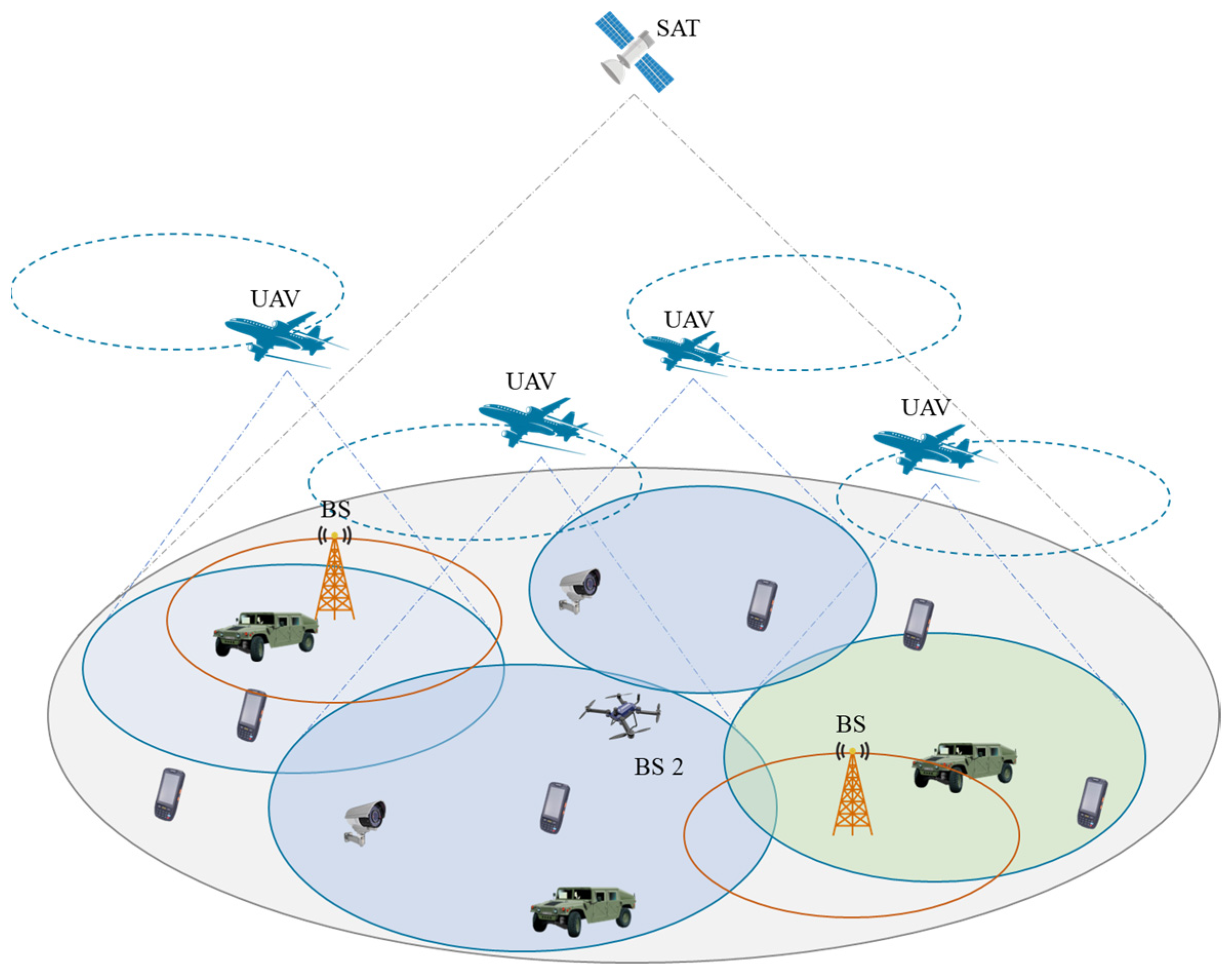
3.1. Network Architecture
3.2. Channel Model
3.3. Communication Model
3.4. Benefit Model
3.5. Objective Function
4. Network Selection Mechanism Based on the MAB Model
4.1. Dynamic Variance Sampling Algorithm
4.2. Theoretical Analysis and Proof
4.3. Algorithm Description and Procedure
| Algorithm 1. Dynamic variance sampling algorithm flow. |
| for do for each node , sample independently from the distribution select node: observe reward: update selected times: update mean benefit: end for |
5. Performance and Evaluation
5.1. Simulation Settings
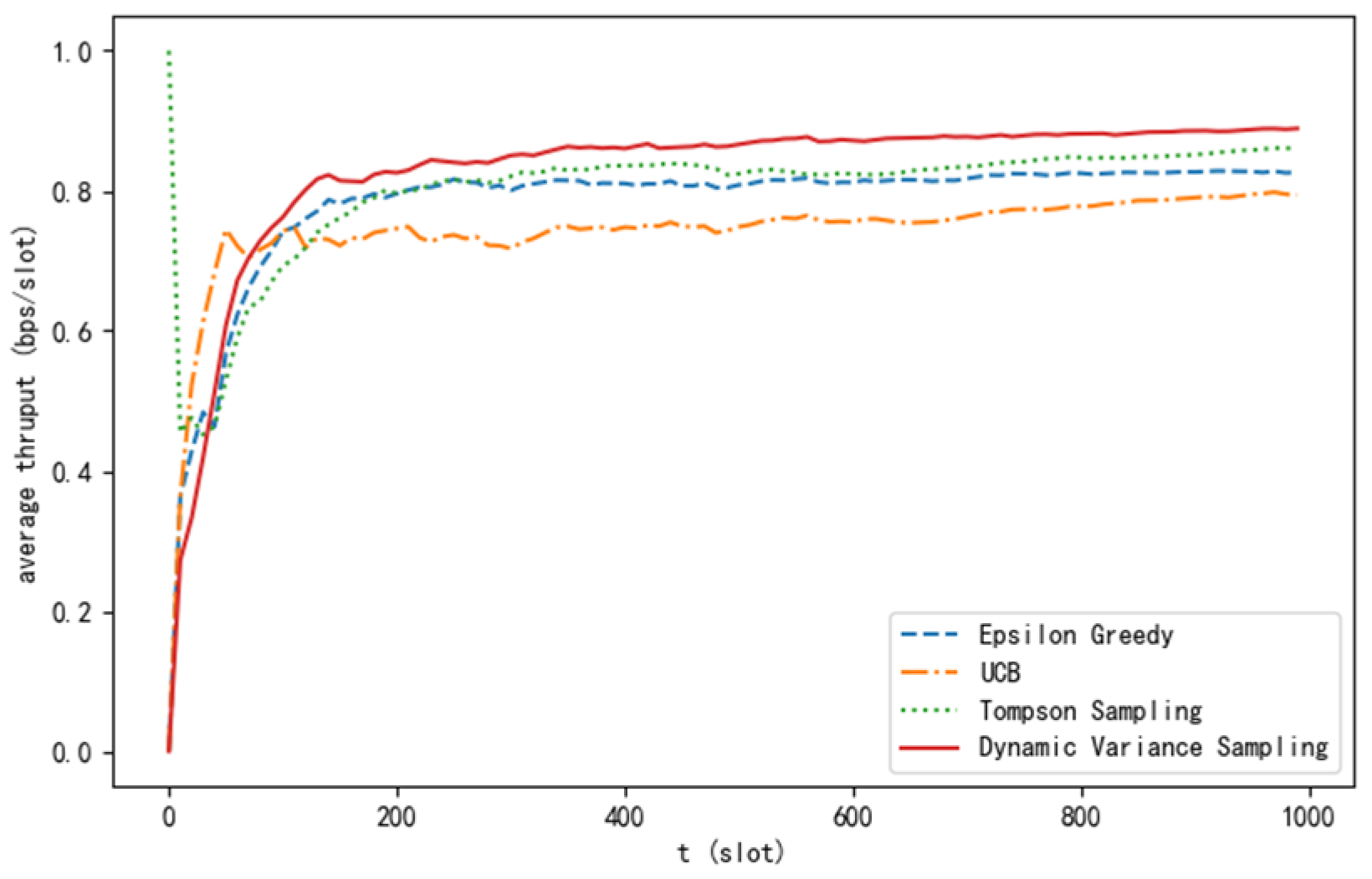
5.2. Results and Analysis
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meng, Y.; Qi, P.; Lei, Q.; Zhang, Z.; Ren, J.; Zhou, X. Electromagnetic Spectrum Allocation Method for Multi-Service Irregular Frequency-Using Devices in the Space-Air-Ground Integrated Network. Sensors 2022, 22, 9227. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Shi, Y.; Fadlullah, Z.M.; Kato, N. Space-Air-Ground Integrated Network: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2714–2741. [Google Scholar] [CrossRef]
- Geng, Y.; Cao, X.; Cui, H.; Xiao, Z. Network Element Placement for Space-Air-Ground Integrated Network: A Tutorial. Chin. J. Electron. 2022, 31, 1013–1024. [Google Scholar] [CrossRef]
- Yin, Z.; Cheng, N.; Luan, T.H.; Wang, P. Physical Layer Security in Cybertwin-Enabled Integrated Satellite-Terrestrial Vehicle Networks. IEEE Trans. Veh. Technol. 2022, 71, 4561–4572. [Google Scholar] [CrossRef]
- Anjum, M.J.; Anees, T.; Tariq, F.; Shaheen, M.; Amjad, S.; Iftikhar, F.; Ahmad, F. Space-Air-Ground Integrated Network for Disaster Management: Systematic Literature Review. Appl. Comput. Intell. Soft Comput. 2023, 2023, 6037882. [Google Scholar] [CrossRef]
- Cui, H.; Zhang, J.; Geng, Y.; Xiao, Z.; Sun, T.; Zhang, N.; Liu, J.; Wu, Q.; Cao, X. Space-Air-Ground Integrated Network (SAGIN) for 6G: Requirements, Architecture and Challenges. China Commun. 2022, 19, 90–108. [Google Scholar] [CrossRef]
- Sridharan, K.; Yoo, S.W.W. Online Learning with Unknown Constraints. arXiv 2024, arXiv:2403.04033. [Google Scholar]
- Xu, Y.; Anpalagan, A.; Wu, Q.; Shen, L.; Gao, Z.; Wang, J. Decision-Theoretic Distributed Channel Selection for Opportunistic Spectrum Access: Strategies, Challenges and Solutions. IEEE Commun. Surv. Tutor. 2013, 15, 1689–1713. [Google Scholar] [CrossRef]
- Dong, S.; Lee, J. Greedy confidence bound techniques for restless multi-armed bandit based Cognitive Radio. In Proceedings of the 2013 47th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 20–22 March 2013. [Google Scholar]
- Smallwood, R.D.; Sondik, E.J. The Optimal Control of Partially Observable Markov Processes Over a Finite Horizon. Oper. Res. 1973, 21, 1071–1088. [Google Scholar] [CrossRef]
- Agrawal, R. Sample mean based index policies by O(log n) regret for the multi-armed bandit problem. Adv. Appl. Probab. 1995, 27, 1054–1078. [Google Scholar] [CrossRef]
- Jiang, Z.; Hongcui, C.; Jiahao, X. Channel Selection Based on Multi-armed Bandit. Telecommun. Eng. 2015, 55, 1094–1100. [Google Scholar]
- Wang, Z.; Yin, Z.; Wang, X.; Cheng, N.; Zhang, Y.; Luan, T.H. Label-Free Deep Learning Driven Secure Access Selection in Space-Air-Ground Integrated Networks. In Proceedings of the GLOBECOM 2023–2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysi, 4–8 December 2023. [Google Scholar]
- Agrawal, S.; Goyal, N. Analysis of Thompson Sampling for the multi-armed bandit problem. Statistics 2011, 23, 39.1–39.26. [Google Scholar]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time Analysis of the Multiarmed Bandit Problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Agrawal, S.; Goyal, N. Thompson Sampling for Contextual Bandits with Linear Payoffs. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), Atlanta, GA, USA, 17–19 June 2013; pp. 513–521. [Google Scholar]
- Agrawal, S.; Goyal, N. Further Optimal Regret Bounds for Thompson Sampling. arXiv 2012, arXiv:1209.3353. [Google Scholar]
- Agrawal, S.; Goyal, N. Near-optimal regret bounds for Thompson sampling. J. ACM 2017, 64, 30. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning of Symbol |
|---|---|
| The number of times network node has been selected before moment | |
| The number of times network node has gained 1 after being selected before moment | |
| The number of times network node has gained 0 after being selected before moment | |
| Index of the selected network node at moment | |
| Benefit of network node after being selected at moment | |
| Expected benefit of network node | |
| Real numbers satisfying | |
| The KL dispersion between the Bernoulli distributions of and | |
| Total number of time slots | |
| Variables in the definition of Ft that depend on the value taken at time t | |
| Sample values sampled by the algorithm in the posterior distribution of network node i at moment t | |
| The mean value of the benefit of network node at time | |
| Event | |
| Event | |
| Sequence of historical strategy information up to moment | |
| Probability of an event | |
| Expectation calculus | |
| Indicator function | |
| Normal distribution | |
| Sampling the distribution |
| Symbol | Meaning of Symbol | Value |
|---|---|---|
| Satellite orbital altitude | ||
| Horizontal distance between satellite beam center and user | ||
| Satellite channel gain caused by rain attenuation | ||
| Maximum gain of satellite antenna | ||
| 3 dB angle of satellite beam | ||
| Satellite downlink power | ||
| Horizontal distance from UAV to user | ||
| The height of the drone | ||
| Rician coefficient of UAV small-scale fading | ||
| Downlink power of UAV | ||
| Channel power gain with a reference distance of 1 m | ||
| Distance between base station and user | ||
| Downlink power of base station | ||
| Small-scale fading of base station | ||
| Noise power received by users | ||
| Upper bound of communication rate |
| Parameter | Value |
|---|---|
| Scene radius | |
| Number of satellites | |
| Number of base stations | |
| Number of UAVs | |
| Angular velocity of UAV | |
| Flight radius of UAV | |
| User moving radius | |
| User angular velocity |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Q.; Xie, Z. Multi-Armed Bandit-Based User Network Node Selection. Sensors 2024, 24, 4104. https://doi.org/10.3390/s24134104
Gao Q, Xie Z. Multi-Armed Bandit-Based User Network Node Selection. Sensors. 2024; 24(13):4104. https://doi.org/10.3390/s24134104
Chicago/Turabian StyleGao, Qinyan, and Zhidong Xie. 2024. "Multi-Armed Bandit-Based User Network Node Selection" Sensors 24, no. 13: 4104. https://doi.org/10.3390/s24134104
APA StyleGao, Q., & Xie, Z. (2024). Multi-Armed Bandit-Based User Network Node Selection. Sensors, 24(13), 4104. https://doi.org/10.3390/s24134104