Abstract
The capacity of a memoryless state-dependent channel is derived for a setting in which the encoder is provided with rate-limited assistance from a cribbing helper that observes the state sequence causally and the past channel inputs strictly causally. Said cribbing may increase capacity but not to the level achievable by a message-cognizant helper.
Keywords:
backward decoding; block Markov; causal; cribbing; helper; rate limited; state dependent channel 1. Introduction
An encoder for a state-dependent channel is said to have causal state information if the channel input it produces at time i may depend, not only on the message m it wishes to transmit, but also on the present and past channel states and (where stands for the states ). Its state information is noncausal if, in addition to depending on the message, its time i input may depend on all the channel states: past , present , and future (where n denotes the blocklength, and stands for ).
The former case was studied by Shannon [1], who showed that capacity can be achieved by what-we-now-call Shannon strategies. The latter was studied by Gel’fand and Pinsker [2], who showed that the capacity, in this case, can be achieved using binning [3].
As of late, there has been renewed interest in the causal case, but when the state information must be quantized before it is provided to the encoder [4]. While still causal, the encoder is not provided now with the state sequence directly, but rather with some “assistance sequence” describing it. Its time i output is now determined by the message m and by the present and past assistances . The assistance sequence is produced by a helper, which observes the state sequence causally and produces the time i assistance based on the present and past states subject to the additional constraint that take values in a given finite set whose cardinality is presumably smaller than that of the state alphabet . (If the cardinality of is one, the problem reduces to the case of no assistance; if it exceeds or equals the cardinality of , the problem reduces to Shannon’s original problem because, in this case, can describe unambiguously.) We refer to the base-2 logarithm of the cardinality of as the “help rate” and denote it :
Three observations in [4] inspired the present paper:
- Symbol-by-symbol quantizers are suboptimal: restricting to be a function of may reduce capacity.
- Allowing to depend not only on but also on the message m may increase capacity.
- If is allowed to depend on , as well as on the transmitted message, then message-cognizant symbol-by-symbol helpers achieve capacity: there is no loss in capacity in restricting to be a function of .
Sandwiched between the message-oblivious helper and the message-cognizant helper is the cribbing helper whose time-i assistance depends on and on the past symbols produced by the encoder
Such a helper is depicted in Figure 1.
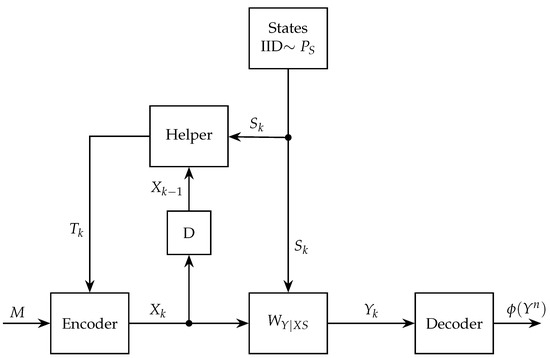
Figure 1.
Communication over a state-dependent channel with a rate-limited causal cribbing helper.
Since one can reproduce the channel inputs from the states and message, the cribbing helper cannot outperform the message-cognizant helper. And since the helper can ignore the past channel inputs, the cribbing capacity must be at least as high as that of the message-oblivious helper.
Here, we shall characterize the capacity with a cribbing helper and show that the above inequalities can be strict: the message-cognizant helper may outperform the cribbing helper, and the latter may outperform the message-oblivious helper (presumably because, thanks to the cribbing, it can learn something about the message). We further show that the capacity of the cribbing helper can be achieved using a block Markov coding scheme with backward decoding.
It is important to note that allowing the helper to crib does not render it a relay [5] because the helper does not communicate with the receiver. Therefore, our results do not have any bearing on the Relay problem.
It is also noteworthy that message-cognizant helpers are also advantageous in the noncausal case. For such helpers, capacity was recently computed in [6,7]. Cribbing, however, is somewhat less natural in this setting.
2. Problem Statement and Main Result
We are given a state-dependent discrete memoryless channel of finite input, output, and state alphabets , , and . When its input is and its state is , the probability of its output being is . The states are drawn IID , where is some given probability mass function (PMF) on the state alphabet . Also given is some finite set that we call the description alphabet. We shall assume throughout that its cardinality is at least 2
because otherwise the helper cannot provide any assistance.
Given some blocklength n, a rate-R message set is a set whose cardinality is (where we ignore the fact that the latter need not be an integer). A blocklength-n encoder for our channel comprises n mappings
with the understanding that if the message to be transmitted is , and if the assistance sequence produced by the helper is , then the time i channel input produced by the encoder is
which we also denote . Here, denotes the i-fold Cartesian product
and denotes . A blocklength-n cribbing helper comprises n mapping
with the understanding that—after observing the channel inputs and the states —the helper produces the time i assistance
which we also denote .
Communication proceeds as follows: the helper produces the time-1 assistance that is given by , and the encoder then produces the first channel input . The helper then produces the time-2 assistance that is given by , and the encoder then produces the second channel input , and so on.
The decoder is cognizant neither of the state sequence nor of the assistance sequence : it is thus a mapping of the form
with the understanding that, upon observing the output sequence , the decoder guesses that the transmitted message is .
Let denote the probability of a decoding error when the message M is drawn uniformly from . If , then we say that the coding scheme is of parameters or that it is a -scheme. A rate R is said to be achievable if, for every , there exist, for all sufficiently large n, schemes as above with . The capacity of the channel is defined as the supremum of all achievable rates R and is denoted C.
Define
where the maximum is over all finite sets and and over all joint distributions of the form
with T taking values in the assistance alphabet . (When writing Markov conditions and information theoretic quantities such as entropy and mutual information, we do not separate the variables with commas. We thus write , and not , for the joint entropy of X and Y. We do, however, introduce commas when this convention can lead to ambiguities; see, for example, (62).)
Our main result is stated next.
Theorem 1.
The capacity C of the memoryless state-dependent channel with rate-limited cribbing helper equals :
Moreover, the maximum in (10) can be achieved when:
- 1.
- and are both zero-one laws.
- 2.
- The alphabet sizes of U and V are restricted towhere .
- 3.
- The chainis a Markov chain.
(Henceforth, we use to indicate that A and C are conditionally independent given B and, more generally, to indicate that forms a Markov chain.)
The proof is given in Section 4.
Remark 1.
The assumption of (3) notwithstanding, the theorem also holds in case , which corresponds to no help.
Proof of Remark 1.
When T is deterministic, equals , and the data processing inequality implies that , thus establishing that, in this case, is upper bounded by the capacity without state information, i.e.,
Equality can be established by choosing V as null and U as X, a choice that results in being and in being . □
Remark 2.
As is to be expected, when , i.e., when T can describe S precisely, reduces to the Shannon strategies capacity of the channel with perfect causal state information at the transmitter:
where the maximization is over all the joint PMFs of the form (and where, without altering the result of the maximization, we can restrict to be zero–one valued).
Proof of Remark 2.
We first establish that is greater-equal . To that end, we set T to equal S and V to be null and then argue that, with this choice, the minimum of the two terms in (10) is the first, i.e., (which, because V is null, equals ). To that end, we calculate
where the first equality holds because V is null, the second because T equals S, the third because U is independent of S, and the final inequality follows from the Data Processing inequality.
It remains to prove that
which always holds. To simplify our analysis, we assume the Markov condition (13), and we then upper-bound (which is an upper bound on the minimum in the definition (10) of ). Under this Markov condition, the maximum of can be achieved with V null, which we proceed to assume. The joint PMF of the remaining variables is then of the form
We will show that—for every fixed —to any choice of and there corresponds a choice of , which is feasible for the maximization defining in (15) and that thus proves that .
3. Example
We next present an example where the message-cognizant helper outperforms the cribbing helper and the latter outperforms the plain-vanilla causal helper. It is trivial to find cases where the three perform identically, e.g., when the state does not affect the channel. The example is borrowed from ([4], Example 7) (from which we also lift the notation).
The channel inputs, states, and outputs are binary tuples
and are denoted , , and respectively. The two components of the state are IID, each taking on the values 0 and 1 equiprobably. Given the state and input, the channel output is deterministically given by
The assistance is one-bit assistance, so .
As shown in ([4], Claim 8), the capacity with a message-cognizant helper is 2 bits, and with a message-oblivious helper . Here, we show that the capacity with a cribbing helper is strictly smaller than 2 bits and strictly larger than . All logarithms in this section are base-2 logarithms, and all rates are in bits.
We begin by showing the former. Recall that if R is achievable, then it must satisfy the constraints
Recall also the form of the joint PMF
and that we may assume that is zero-one valued. Note that (29) implies
and consequently
We will show that the above constraints cannot be both satisfied if . To that end, we assume that
(it cannot be larger because ) and prove that
Since is of cardinality 4, it suffices to show that
In fact, it suffices to show that
i.e., that there exist of positive probability for which
This is what we proceed to do. We first show the existence of and for which . Once this is established, we proceed to pick .
Since , (32) implies that
Fix any (of positive probability). As we next argue, there must exist some for which is not zero–one valued. Indeed, by (29), , so and
so there must exist some for which
We next choose as follows. Conditional on , the chance variable U has some PMF (equal to by (29)) under which is uniform; see (37). It follows that there exist and (both of positive conditional probability) such that
where we introduced the notation
Returning to (43), we note that it implies that
In the former case, is positive, and in the latter, is positive. This establishes the existence of a triple for which (36) holds, and thus concludes the proof that the capacity with a cribbing encoder is smaller than 2. We next show that it exceeds .
To that end, we consider choosing
to be uniform over , and we let be a Bernoulli– random variable that is independent of U and of the channel, for some to be specified later. We further define
and
We choose the helper function —which can also be written as —to equal , so
and
Our encoder function ignores v and results in
where . That is,
Note that with the variables defined in (49)–(53), the Markov relations in item 3 of Theorem 1 hold.
We now proceed to calculate the rate bounds. For the RHS of (27), we have
where the last equality holds because if , then is null.
We next evaluate each of the terms on the RHS of (55) separately. When ,
so
and
where the second equality holds because is independent of U.
When ,
so
From (58), (60), and (55), we obtain that the RHS of (27) satisfies
4. Proof of Theorem 1
4.1. Direct Part
Pick a distribution as in (11), where and are 0–1 laws, so
for some deterministic functions f and h. Extend these functions to act on n-tuples componentwise so that if are n-tuples in and , then indicates that t is an n-tuple in whose i-th component equals , where and are the corresponding components of s and v. Likewise, we write .
To prove achievability, we propose a block Markov coding scheme with the receiver performing backward decoding. Although only the receiver is required to decode the message, in our scheme, the helper does too (but not with backward decoding, which would violate causality).
The transmission comprises Bn-length sub-blocks, for a total of channel uses. The transmitted message m is represented by sub-messages , with each of the sub-messages taking values in the set . The overall transmission rate is thus , which can be made arbitrarily close to R by choosing B very large. The sub-messages are transmitted in the first sub-blocks, with transmitted in sub-block b (for ). Hereafter, we use to denote the state n-tuple affecting the channel in sub-block b and use to denote its i-component (with ). Similar notation holds for , , etc.
We begin with an overview of the scheme, where we focus on the transmission in sub-blocks 2 through : the first and last sub-blocks must account for some edge effects that we shall discuss later. Let b be in this range. The coding we use in sub-block b is superposition coding with the cloud center determined by and the satellite by .
Unlike the receiver, the helper, which must be causal, cannot employ backward decoding: it decodes each sub-message at the end of the sub-block in which it is transmitted. Consequently, when sub-block b begins, it already has a reliable guess of (based on the previous channel inputs it cribbed). The encoder, of course, knows , so the two can agree on the cloud center indexed by . (We ignore for now the fact that may, with small probability, differ from .) The satellite is computed by the encoder as ; it is unknown to the helper. The helper produces the sub-block b assistance based on the state sequence and the cloud center
(Since acts componentwise, this help is causal with the i-th component of being a function of the corresponding component of the state sequence and ; it does not require knowledge of future states.)
For its part, the encoder produces the n-tuple
with causality preserved because and can be computed from and ahead of time, and because t is presented to the encoder causally and operates componentwise.
As to the first and last sub-blocks: In the first, we set as constant (e.g., ), so we have only one cloud center. In sub-block B, we send no fresh information, so each cloud center has only one satellite.
We now proceed to a more formal exposition. For this, we will need some notation. Given a joint distribution , we denote by the set of all jointly typical sequences , where the length n is understood from the context, and we adopt the -convention of [8]. Similarly, given a sequence z, stands for the set of all pairs that are jointly typical with the given sequence z.
To describe the first and last sub-blocks, we define and , respectively. The proof of the direct part is based on random coding and joint typicality decoding.
4.1.1. Code Construction
We construct B codebooks , , each of length n. Each codebook is generated randomly and independently of the other codebooks as follows:
- For every , generate length-n cloud centers , independently, each with IID components.
- For every and , generate length-n satellites , conditionally independently given , each according to
The codebook is the collection
Reveal the codebooks to the encoder, decoder, and helper.
4.1.2. Operation of the code
We first describe the operation of the helper and encoder in the first sub-block.
Helper. In the first sub-block, , the helper produces
where
Note that is causal in .
Encoder. Set and . The input to the channel is
where
Note that is causal in .
Helper at the end of the sub-block. Thanks to its cribbing, at the end of sub-block 1, the helper is cognizant of . In addition, it knows (since it is determined by , which was set a priori) and (since it was produced by itself). The helper now decodes the message by looking for an index such that
If such an index j exists and is unique, the helper sets . Otherwise, an error is declared. By standard results, the probability of error is vanishingly small provided that
Denote by the message decoded by the helper at the end of sub-block 1. We proceed to describe the operation of the helper and encoder in sub-block b, when .
Helper, . Denote by the message decoded by the helper at the end of sub-block . In sub-block b, the helper produces
where
Encoder, . Set and . The input to the channel is
where
Note that and are causal in and , respectively.
Helper at the end of the sub-block, . At the end of sub-block b the helper has at hand. In addition, it has (since was decoded at the end of the previous sub-block) and (since it was produced by itself). The helper now decodes the message . Assuming that was decoded correctly, this can be done with a low probability of error if (37) is satisfied.
We proceed to the last sub-block, where no fresh information is sent. Here , and the operations of the helper and encoder proceed exactly as in (77)–(80), with . Note that in sub-block B, the helper need not decode since it is set a priori and known to all.
4.1.3. Decoding
At the destination, we employ backward decoding. Starting at sub-block B with , the decoder looks for an index such that
If such an index exists and is unique, the decoder sets . Otherwise, an error is declared. By standard result, the decoding is correct with probability approaching 1 provided
In the next (backward) decoding sub-blocks, the decoding proceeds as in (81), with the exception that the estimate replaces the default value in (81). Thus, in sub-block , the decoder has at hand the estimate , and the channel output . It looks for an index j such that
Similarly, for , the decoder looks for an index j such that
If such an index j exists and is unique, the decoder sets . Otherwise, an error is declared. Assuming that was decoded correctly in the previous decoding stage, i.e., , the decoding of in sub-block b is correct with probability close to 1 provided that (82) holds. Note that is decoded in sub-block , that is, is not used at the destination. However, the transmission in sub-block 1 is not superfluous, as it is used by the helper to decode at the end of the first sub-block. Since (76) and (82) are the two terms in (10), this concludes the proof of the direct part.
4.2. Converse Part
Fix , and consider -codes with . For each n, feed a random message M that is drawn equiprobably from the set to the encoder. By the channel model,
Fano’s inequality and the fact that imply the existence of a sequence for which
where follows from (85); holds because is a function of (8); and holds because is a function of and hence of (so must be zero).
We proceed to derive the second bound. Starting again with Fano’s inequality,
Defining
we can rewrite (86) and (87) as
Moreover, with and defined as above, and are independent
and
where and are (blocklength dependent) deterministic functions. Indeed, can be determined from because determines the message M and determined , so determines from which can be computed using (5).
We next do away with the sums by conditioning on a time-sharing random variable. Let Q be a random variable uniformly distributed over independently of the channel and the state. Using Q, we can express the bounds (90), (91) as
where we define
and the auxiliaries
Note that the conditional law of Y given is that of the channel, namely, and that S is distributed like the channel state. Moreover,
Since U and V contain the time sharing random variable Q, (93) and (94) imply that,
for some deterministic functions h and f. Therefore, the joint distribution under which the RHS of (95) and the RHS of (96) are computed is of the form
where and are zero-one laws, or
where , , and are zero-one laws.
The form (105) and the inequalities (95), (96) establish the converse.
4.3. Cardinality Bounds
We next proceed to bound the alphabet sizes of in two steps. In the first, we do so while relaxing the zero-one-law requirements. In the second, we enlarge the alphabet to fulfill said requirements. Let
Fix a conditional distribution , and define the L functions of :
(with the functions corresponding to all by one of the tuples ). By the support lemma [5,8], there exists a random variable with alphabet , such that , , and are preserved. Denote by the resulting random variable U, i.e.,
We next bound the alphabet size of . For each , we define the L functions
Applying again the support lemma, for every there exists a random variable with alphabet such that (109)–(111) are preserved. If we multiply times we can, with proper labeling of the elements of , retain a Markov structure like (101). Now the alphabet sizes are fixed and independent of n. Thus, substituting in (95), (96) and taking the limit we have the upper bound
where
and the following Markov chain holds:
Note, however, that and are no longer zero-one laws. We remedy this using the Functional Representation lemma (FRL) [5] (at the cost of increasing the alphabet sizes): a standard convexity argument will not do because—although is a convex function of and also a convex function of and likewise —the minimum of two convex functions need not be convex.
The Functional Representation lemma implies that—without altering the conditional law of T given nor of X given —the random variables T and X can be represented as
where , are deterministic functions; and are independent random variables that are independent of ; and their alphabets satisfy
At the expense of increased alphabets sizes, we now append to and to to form the new auxiliary random variables
with alphabet sizes
We set
(irrespective of ) and
where equals 1 if the statement is true and equals 0 otherwise.
As we next argue, these auxiliary random variables and the above zero–one laws do not decrease the relevant mutual information expressions.
Beginning with , we note that because we have preserved the joint law of and because does not influence the mapping (54) to X. Since , this establishes that
Likewise, our new auxiliary random variables and zero–one laws do not alter , but , so
This completes the proof of Theorem 1.
Author Contributions
Writing—original draft preparation, A.L. and Y.S.; writing—review and editing, A.L. and Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Swiss National Science Foundation (SNSF) under Grant 200021-215090.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IID | Independent and Identically Distributed |
| FRL | Functional Representation Lemma |
| PMF | Probability Mass Function |
| RHS | Right-Hand Side |
References
- Shannon, C.E. Channels with side Information at the transmitter. IBM J. Res. Dev. 1958, 2, 289–293. [Google Scholar] [CrossRef]
- Gel’fand, S.I.; Pinsker, M.S. Coding for channel with random parameters. Probl. Control. Inform. Theory 1980, 9, 19–31. [Google Scholar]
- Keshet, G.; Steinberg, Y.; Merhav, N. Channel Coding in the Presence of Side Information. Found. Trends Commun. Inf. Theory 2008, 4, 1567–2190. [Google Scholar] [CrossRef]
- Lapidoth, A.; Wang, L. State-Dependent DMC with a Causal Helper. IEEE Trans. Inf. Theory 2024, 70, 3162–3174. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Lapidoth, A.; Wang, L.; Yan, Y. State-Dependent Channels with a Message-Cognizant Helper. arXiv 2023, arXiv:2311.082200. [Google Scholar] [CrossRef]
- Lapidoth, A.; Wang, L.; Yan, Y. Message-Cognizant Assistance and Feedback for the Gaussian Channel. arXiv 2023, arXiv:2310.15768. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems, 2nd ed.; Cambridge University Press: London, UK, 2011. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).