Abstract
With rapid digital transformation, online information and reviews have become more consequential, which may lead to a public opinion crisis. How to predict the persuasion effect is an important research problem in the design of a crisis communication strategy. The method for solving this problem is to propose a predictive framework for digital persuasion, grounded in the elaboration likelihood model. Within this framework, a database is constructed, and a machine learning algorithm integrating Bayesian networks and decision trees, BNTree (Bayesian Network and Tree), is proposed. The results demonstrate that BNTree can predict persuasion effects more accurately. In addition, the prediction of BNTree also reflects the major cognitive route of netizens and the critical influence factors for persuasion effects. These findings imply that integrating psychological theory into algorithm design can enhance predictive performance and interpretability, providing practical support for crisis communication in the digital era.
1. Introduction
The Internet is driving a digital transformation in both personal life and organizational management. With the widespread adoption of social media platforms, information spread and sharing are facilitated [1]. People increasingly spend their leisure time scrolling through social media [2], where they receive information and create reviews. As a result, public opinion is increasingly formed and shaped online [3]. Understanding the online public opinion is critical for practitioners and policymakers alike. For example, word-of-mouth represents a special type of public opinion, and the sentiment it conveys is instrumental in building strong brands and sustaining a competitive advantage. Moreover, analyzing public opinion enables a deeper understanding of citizens’ attitudes toward issues with significant societal impact.
Sometimes, public opinion can be caused by some incidents, such as quality issues, product recalls, and accidents [4]. Netizens often use online social media to share information and discuss the incidents. Although public opinion can reflect key information about events and netizens’ reviews, such as application usability, user experience [5] and other comments, it may also contain irrational or fierce recognition about the events [6]. For instance, rumors or fake news on social media may mislead netizens into forming distorted perceptions of issues [7], which may result in a public opinion crisis [8].
At such times, persuasion is important in crisis communications. Persuasion refers to activities aimed at prompting the public to change their views, attitudes, and behaviors [9]. In management practices such as word-of-mouth management, brand marketing, and crisis management, relevant organizations often adopt certain persuasion strategies to protect their image, reputation, and brand and to mitigate the negative impact of emergencies.
In the actual evolution of public opinion, netizens often, under the influence of different public opinion persuasion scenarios, employ different cognitive routes and modes of thinking to analyze official responses, resulting in diverse interpretations. For example, some netizens focus on the authority of the persuader, the attitude of the persuader, or the emotions embedded in the response content, while others pay more attention to the factual truth reflected in the response. If the response is inappropriate, it may fail to achieve the desired effect and instead provoke widespread resistance among netizens, potentially causing further damage. Taking the case of BMW (Bayerische Motoren Werke) MINI’s differential treatment of domestic and foreign customers at the 2023 Shanghai Auto Show as an example, the firm’s public apology used inappropriate language, so this response failed to defuse public outrage and intensified anger toward the brand.
Cases such as these illustrate that, in an emergency, organizations must pay close attention to persuasive communication and adopt effective official responses to minimize the negative effects of public opinion. The prediction of public opinion trends has attracted significant attention, and machine learning algorithms play an important role in information management. Several scholars employ machine learning to predict public opinion trends or investigate public opinion as a predictor for other outcomes, such as predicting stock prices [10] or election results [11].
However, existing predictive frameworks rarely consider the heterogeneity of netizens’ cognitive characteristics or the factors that influence the effectiveness of public opinion persuasion under different cognitive routes, which are important in real-world cases.
This paper addresses the above limitation that existing predictive frameworks rarely account for the heterogeneity of netizens and for how distinct cognitive routes modulate persuasion effectiveness.
Drawing on the relevant psychology theory, this paper integrates Bayesian networks and decision trees to develop the BNTree (Bayesian Network and Tree) algorithm. The objectives are to capture diverse cognitive characteristics and map them to probable cognitive routes, to elucidate the mechanisms by which content and contextual features drive persuasion along those routes, and to improve the design of actionable communication strategies.
The contributions are as follows: BNTree is proposed as a hybrid machine learning model that integrates decision trees with Bayesian networks based on psychology theory; a formalized, ELM-based dataset is constructed to train the model and validate its performance; the BNTree prediction process not only takes into account the diverse cognitive characteristics of netizens, but also elucidates the specific mechanisms by which various influencing factors shape the effect of public opinion persuasion; and BNTree can be readily deployed in practice.
The remainder of this paper is organized as follows: The following section reviews related work. The Method and Data section introduces the research framework based on the elaboration likelihood model, describes the process of historical data collection, and proposes the algorithm procedure of BNTree. The Result section presents the experimental design and the empirical results. Finally, the last section summarizes the main conclusions, limitations, and directions for future research.
2. Related Works
2.1. Research on Factors Influencing the Persuasion Effect
Persuasion research is an important branch of management that investigates how persuaders change receivers’ views, attitudes, and behaviors through the transmission and exchange of information. The related works provide the theoretical foundation for scholars to understand and analyze the psychological mechanisms of public opinion persuasion.
Carl Hovland [12] points out that the effectiveness of persuasion depends on multiple factors, including the source, the message content, the persuasive techniques employed, and the audience’s characteristics. Richard E. Petty and John T. Cacioppo propose the elaboration likelihood model (ELM). The ELM indicates that when recipients possess both cognitive ability and cognitive motivation, they tend to activate the central route, forming their opinions and attitudes through careful thought and analysis of a message’s core content. In contrast, when cognitive ability or motivation is lacking, recipients tend to activate the peripheral route, forming their opinions and attitudes based on peripheral cues such as source credibility, others’ evaluations, and the attitudes displayed by the persuader [13].
The ELM is widely used in studies that analyze the factors influencing the public opinion persuasion effect. Song et al. [14] found that when the central route is activated, information matching has a significant positive impact on users’ attitudes toward health information, and when the peripheral route is activated, platform credibility exerts a significant positive impact on users’ attitudes toward health information. Syrdal et al. [15] employ ELM to analyze the relationship between the linguistic style of a persuasive post on Instagram and user engagement. Saini et al. [16] find that the spread of vaccination messages is mainly influenced by peripheral route factors, whereas the diffusion of anti-vaccination messages is shaped by both peripheral route and central route factors. In addition, anti-vaccination content that is emotionally contagious and objectively concrete more readily persuades netizens and is therefore propagated more widely. Yang et al. [17] examine users’ information-sharing behavior on social networking platforms and find that both central route and peripheral route factors influence users’ sharing decisions. Xu et al. [18] study how sender, signal, feedback, and environment factors are integrated with ELM mechanisms in affecting consumers’ information processing and decision making. Li et al. [19] propose that different types of comparative reviews can affect consumers’ perceived credibility of online reviews, thus impacting product sales. Zhang et al. [20] evaluate the impact of review text quality and the aesthetic quality of review photos on perceived usefulness.
Such research follows a similar methodological approach: scholars develop econometric quantitative models based on ELM to examine the factors influencing public opinion persuasion. Thus, the ELM offers useful insights into predicting public opinion persuasion. However, these studies primarily focus on the correlations between each individual factor and the effectiveness of public opinion persuasion. In real-world contexts, the persuasion effect is typically shaped by combinations of multiple variables. As a result, this line of research often fails to fully capture such complexity, making it difficult to provide precise predictions regarding the effectiveness of public opinion persuasion.
2.2. Research on Persuasion Effect Prediction
Compared with the econometric quantitative models, machine learning models can effectively capture the complex associations among multiple variables and are thus widely applied in research on the prediction of the effectiveness of public opinion persuasion. Two prominent research areas in this context are public opinion early warning and election prediction.
Public opinion early warning constitutes a critical step in evaluating the effect of public opinion persuasion. Analyzing latent crises within public opinion and their evolutionary trends provides a basis for inferring and predicting the effectiveness of public opinion persuasion strategies.
Some scholars develop models that learn features from the historical data to predict the level of popularity it may reach in the future. The grey prediction model [21,22] is a widely used method in prediction. Su et al. [23] use a novel seasonal grey decomposition and ensemble model to predict online public opinion.
Some scholars further consider the evolutionary dynamics and influencing factors of online public opinion, and they establish a concrete index system that dynamically grades and issues early warnings on public opinion risk. Chen et al. [24] determine the indicator-weight vector by applying the analytic hierarchy process, then construct a fuzzy evaluation matrix based on fuzzy set theory, and finally compute a comprehensive evaluation value for the public opinion level. Other scholars focus on analyzing social media data characteristics and, on that basis, issue early warnings of public opinion incidents. The resulting warnings, in turn, reflect the effectiveness of public opinion persuasion strategies. Ma et al. [25] propose event prediction with a feedback mechanism for public opinion events that incorporates a feedback mechanism. By using the feedback mechanism based on emerging event detection, the model enhances its event detection performance. Li et al. [26] propose Relational Prompt-based Pre-trained Language Models for Social Event Detection.
Election prediction is also popular within the field that investigates the effectiveness of public opinion persuasion. During an election, candidates typically adopt a variety of persuasion strategies to convince voters to embrace their advocated viewpoints, thereby influencing voting behavior. Consequently, election outcomes can be viewed as a direct manifestation of the effectiveness of public opinion persuasion.
Liu et al. [27] developed a hierarchical Bayesian forecasting model that analyzes the potential behavior of undecided voters by considering opinion polls and sentiment based on voter expectations. Quinlan et al. [28] focused on the vote share and seat shares in the Irish general election and proposed a structural model that surpasses opinion polls in predicting the government seat share. Kang et al. [29] propose a flexible Bayesian framework that incorporates abundant pre-election polls into historical data to forecast election outcomes at the provincial level in South Korea. Chin and Wang [30] developed four single forecasts and three combined forecasts by considering three types of data and examined the predictive performance of each forecast across the election period.
Predictions of public opinion persuasion effects based on machine learning models have yielded significant results. However, in the absence of guidance from psychology theory, simply generating prediction results without a clear understanding of the significance of influencing factors offers limited value for enhancing persuasion strategies. To achieve meaningful progress, it is essential to integrate persuasive theory into the design of these algorithms.
2.3. Research Gap and Novelty
Research on factors influencing the persuasion effect provides valuable variables for elucidating the psychological mechanisms, while machine learning approaches offer powerful tools for accurately predicting these effects. Therefore, the existing literature has advanced our understanding of persuasion, but important gaps remain that constrain the practical application in crisis communication. For example, the former research cannot fully reflect the complexity that the persuasion effect is typically influenced by combinations among multiple variables, making it difficult to provide precise predictions. As for machine learning research, in the absence of guidance from psychology theory, simply generating prediction results without a clear understanding of the significance of influencing factors offers limited value for enhancing persuasion strategies. To address these gaps, it is essential to integrate insights from both perspectives.
Therefore, this study aims to propose an interpretable, psychology theory-driven predictive framework grounded in the ELM. The framework not only improves the accuracy of persuasion effect prediction but also enhances the interpretability and practical guidance of the results for crisis communication. Moreover, integrating multiple methods to enhance prediction is a recent focus in advanced research [31]. Thus, BNTree is proposed as a new machine learning algorithm integrating Bayesian networks and decision trees.
3. Method and Data
In this study, our objective is not only to predict the persuasion effect, but also to provide transparent and theory-driven explanations consistent with the ELM. To achieve this, a real-world persuasive communication dataset is constructed to train the model and validate its performance. The data are obtained from social media platforms and third-party platforms, such as Weibo and “Zhiweidata”. Then, we propose the BNTree algorithm, which offers clear interpretability and theoretical mapping.
3.1. Research Framework Based on the ELM
Netizens, when confronted with different scenarios, often adopt various cognitive routes and modes of thinking to analyze official responses, leading to diverse interpretations of persuasive messages. It is essential for the analytical framework to take into account both these differences and the specific factors affecting persuasion effectiveness under different cognitive routes.
The elaboration likelihood model (ELM) provides a robust theoretical foundation for constructing such a framework. This study divides the cognitive process into two parts: the cognitive route selection process and the persuasive information attention process. The cognitive route selection process explains the reasons why netizens choose different routes, and the persuasive information attention process explains the reasons why netizens are persuaded. The following parts analyze each of these processes in detail.
The cognitive route selection process refers to the process by which netizens tend to choose a particular cognitive route under different public opinion persuasion scenarios. Specifically, when netizens possess both cognitive motivation and ability, they are more likely to activate the central route; conversely, when these are lacking, they tend to activate the peripheral route. Therefore, this study adopts four variables to measure public opinion persuasion scenarios, including the public opinion trigger, public opinion heat, recent response situation, and disclosure stage. These variables serve as the factors influencing the outcome of cognitive route selection.
The persuasive information attention process refers to the process in which netizens, under different cognitive routes, tend to focus on different aspects of persuasive information, thereby forming distinct views and attitudes. Specifically, netizens following the central route tend to focus on core information, while those following the peripheral route are more likely to focus on peripheral cues. Accordingly, this study adopts three kinds of variables: information quality (measured by incident investigation, incident handling, and analysis of responsibility), source credibility (measured by source authority and form of information release), and attitude of the response (measured by timeliness of response and response approach). These variables measure the persuasive information contained in official responses, aiming to explore the combinations of persuasive information that netizens on different cognitive routes pay attention to and the persuasive effects of these combinations on public opinion persuasion.
According to the above analysis, the data framework can be established. The database will be constructed according to the framework outlined in Table 1.

Table 1.
Data framework.
3.2. Data Collection and Database Construction
The database is important, contains a large number of public opinion persuasion cases, and serves as the foundation for analyzing the cognitive characteristics of netizens and studying the mechanisms by which various factors influence the effectiveness of public opinion persuasion. In this study, original data are collected from channels such as “Zhiweidata” and Weibo. Among them, “Zhiweidata” is the critical data resource, which is a well-known public opinion analysis platform, and integrates data from multiple social media platforms, including Weibo and WeChat [32]. The data from “Zhiweidata” are widely used in public opinion research [33].
In total, 133 samples from 2020 to 2024 are collected in this study, covering variables such as public opinion persuasion scenarios, official responses, and public feedback. The variables are observable from social media platforms and third-party platforms. Moreover, some of them are controllable and can be directly adjusted by the organizations.
The samples in the database encompass a variety of types, such as livelihood issues, emergencies, improper responses from management departments, and corporate or celebrity scandals, which increased the likelihood that the sample would reflect different persuasion scenarios. In addition, as for the size of the dataset, similarly sized datasets have also been used in other studies [34].
Based on the framework in Table 1, this study established formalization standards for the database. Through these standards, valuable information is extracted from the original data, leading to the final construction of the public opinion persuasion database. The following section will introduce the formalization standards.
- (1)
- Public Opinion Persuasion Scenario
Variable 1: Public opinion trigger refers to sudden events that draw widespread attention and discussion among netizens. These types of events influence netizens’ behaviors and attitudes. For example, when a public opinion trigger is closely related to the vital interests and actual needs of netizens, they are more likely to develop strong cognitive motivation and thus be willing to invest more effort into analyzing and considering the substantive content. On the contrary, if the trigger has little direct impact on their interests, netizens’ motivation to participate may decrease, and they will be more likely to focus on the peripheral cues [35]. The value criteria are shown in Table 2.
Table 2.
Value criteria related to public opinion trigger.
Variable 2: Public opinion heat refers to the level of discussion among netizens regarding topics related to sudden events. This variable provides a direct measure of the attention and participation of netizens. In this study, public opinion heat is reflected by the heat data collected from the “Zhiweidata” on the day before the official response is released by the persuader. If the heat data indicate 0, meaning no relevant public opinion heat was detected, it indicates that the event has not yet triggered any significant discussion among netizens, and thus, the public opinion heat is considered low. If the heat data are greater than 0 but not more than 1000, this suggests that the event has already attracted some discussion among netizens, so the public opinion heat is considered medium. If the heat data exceed 1000, it means that the event has already triggered widespread discussion among netizens, and the public opinion heat is considered high. The value criteria are shown in Table 3.
Table 3.
Value criteria related to public opinion heat.
Variable 3: Recent response situation refers to how persuaders have responded to sudden events before the official response is released. During the process of public opinion persuasion, netizens often raise questions and demands, hoping for clarification and answers from the persuaders. Therefore, the way persuaders respond can influence the cognitive ability and motivation of the netizen group. For example, when the recent response is inappropriate, it may stimulate netizens’ motivation to seek the truth. The value criteria are shown in Table 4.
Table 4.
Value criteria regarding recent response situation.
Variable 4: Disclosure stage refers to the stage at which information about the sudden incident is released on social media. Incident disclosure usually proceeds through three stages, including initial, updating, and finish stages. It can be observed that in different disclosure stages, the information about the incident varies and affects the cognitive ability and cognitive motivation of netizens. The value criteria are shown in Table 5.
Table 5.
Value criteria regarding disclosure stage.
- (2)
- Result of cognitive route selection
In the process of public opinion persuasion, netizens post comments and provide feedback on official responses. These comments often express the netizens’ attitudes toward the official response as well as the cognitive processes involved in forming these attitudes. Therefore, by analyzing and summarizing the semantic information contained in these comments, it is possible to extract the cognitive routes that netizens are inclined to choose. Taking the Chengdu No. 49 Middle School student’s fall as an example, in May 2021, a student in Chengdu, China, fell from a building and unfortunately died. Many netizens discussed the incident online, and one netizen commented, “This announcement is obviously unconvincing; it does not even include the timing of the incident.” It is evident that this netizen is concerned with the core information about the timing of the event in the response, indicating a tendency to activate the central route in the cognitive process. Through the analysis of a large number of comments, the criteria for determining the result of cognitive route selection are established. The value criteria are shown in Table 6.
Table 6.
Criteria used for determining the result of cognitive route selection.
Based on the criteria above, this study selects the top 50 most-liked comments under the response. The top 50 comments are identified as having the highest popularity and considered reflective of prevailing public opinion. This sampling strategy is employed to prioritize comments deemed most relevant for the study of persuasion in real-world conversational settings. Each comment is annotated according to the value criteria; comments that do not meet these criteria are excluded. Finally, the cognitive path with the highest frequency in the filtered results is determined as the one that netizens are most inclined to activate. The rationale for focusing on the most-liked comments is also based on the premise that large-scale public opinion crises impacting organizational reputation, brand image, and management decisions are typically shaped by majority or consensus-driven sentiment.
- (3)
- Persuasive Information
Variable 1: Information quality refers to the quality of persuasive information in terms of completeness, accuracy, and logicality [36]. Information quality has been extensively studied due to its persuasive effect [37,38]. This study adopts three variables as key indicators for measuring information quality, including incident investigation, incident handling, and analysis of responsibility. The value criteria are listed in Table 7.
Table 7.
Value criteria of the variables measuring information quality.
Variable 2: Source credibility refers to the level of competence and trustworthiness of the persuader as perceived by netizens [39,40]. According to existing research [41], the source authority is still a key factor influencing information communication. Moreover, Li et al. [42] use online voting as a representation of source credibility, suggesting that source credibility is important for patients when considering whether to adopt online consultation services. This study measures source credibility through two variables: source authority and form of information release. The value criteria are listed in Table 8.
Table 8.
Value criteria of the variables measuring source credibility.
Variable 3: Attitude of the response refers to the attitudes conveyed by the persuader to the netizens in official responses. Lee et al. [43] point out that the style and attitude of official responses are important factors when persuading netizens. According to the situational crisis communication theory proposed by Coombs [44], crisis response approaches can be divided into denial, diminish, and rebuild. Based on these findings, this study measures the attitude of the response in terms of the timeliness of response and the response approach. The value criteria are listed in Table 9.
Table 9.
Value criteria of the variables measuring attitude of the response.
- (4)
- Effectiveness of Public Opinion Persuasion
The effectiveness of public opinion persuasion refers to whether the persuader can effectively guide and persuade netizens to improve their views and attitudes toward the persuader. Comments embody the perspectives and attitudes of netizens. By analyzing the semantic features of these comments, it is possible to establish the value criteria in Table 10.
Table 10.
Value criteria regarding the effectiveness of public opinion persuasion.
To determine the effectiveness of public opinion persuasion, this study also selects the top 50 most-liked comments under the response. This sampling strategy mirrors the approach used in the process of annotating the cognitive route. Each comment is annotated according to the value criteria; comments that do not meet these criteria are excluded. Finally, the persuasion result with the highest frequency in the filtered results is determined to have the highest effectiveness in public opinion persuasion.
3.3. Development of BNTree
Based on the ELM, this study constructs an interpretable machine learning model to uncover the cognitive characteristics of netizens contained in the database. The model needs to analyze the mechanisms by which various factors influence the effectiveness of public opinion persuasion. These findings enable accurate predictions and provide persuasive decision support for persuaders to improve official responses in a targeted manner.
During the process of public opinion persuasion, netizens tend to choose different cognitive routes under various scenarios to process and analyze official responses, thereby forming corresponding views and attitudes. This process involves both cognitive route selection and persuasive information attention.
In the process of cognitive route selection, netizens do not make decisions based on hard rules but rather exhibit varying tendencies toward different routes. As a machine learning model based on probabilistic reasoning, a Bayesian Network is able to convert the uncertainty in the cognitive route selection process into probability values for uncertainty reasoning, thereby enabling the extraction of accurate and effective information from the database. Therefore, this study adopts the Bayesian Network to mine the characteristics of cognitive route selection.
In the process of persuasive information attention, netizens following different cognitive routes pay attention to different persuasive information, which may lead to the formation of distinct views and attitudes. For persuaders, a machine learning model needs not only to predict the persuasive effectiveness of responses, but also to identify the key factors influencing persuasion outcomes. Compared to machine learning algorithms such as neural networks and random forests, the decision tree offers strong interpretability, providing both predictive results and their corresponding rationales. Accordingly, this study employs the decision tree to mine the characteristics of persuasive information attention.
Based on the above analysis, this study integrates the Bayesian Network and the Decision Tree to construct the BNTree model. The framework of BNTree is shown in Figure 1.
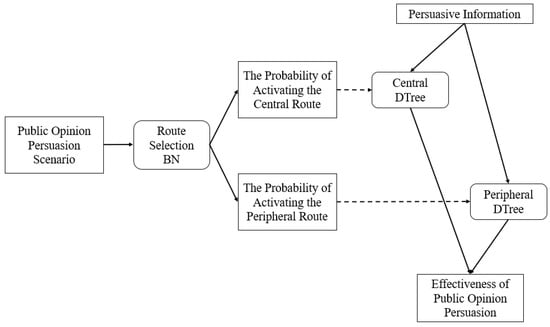
Figure 1.
Framework of BNTree.
The algorithm process of the BNTree is shown below.
Procedure 1: Calculate the conditional probability that netizens activate different cognitive routes. The input is a variable list for public opinion persuasion scenarios, denoted as , where r1 represents the value of the public opinion trigger, r2 represents the value of public opinion heat, r3 represents the recent response situation, and r4 represents the disclosure stage. By employing the Route Selection Bayesian Network, the probability of activating the central route and activating the peripheral route is calculated, denoted as and ;
Procedure 2: Calculate the persuasion effect on netizens under different cognitive routes. The input is a variable list of persuasive information, denoted as , where is composed of a variable list of information quality , a variable list of source credibility , and a variable list of the attitude of the response . By employing the Central Decision Tree, the persuasion effect on netizens who activate the central route is calculated, denoted as . By employing the Peripheral Decision Tree, the persuasion effect on netizens who activate the peripheral route is calculated, denoted as ;
Procedure 3: Calculate the persuasion effect. The formula is as follows:
Procedure 4: Determine whether the netizens are persuaded by the response. The criterion is as follows: when , the netizens are considered to be persuaded; when , the netizens are considered not to be persuaded.
Then, the following part presents the Route Selection BN, the Central DTree, and the Peripheral DTree included in the framework.
Constructing the Route Selection BN requires specifying the network structure. By analyzing the relationships between each factor and the result of cognitive route selection, the network structure is established, which is shown in Figure 2.
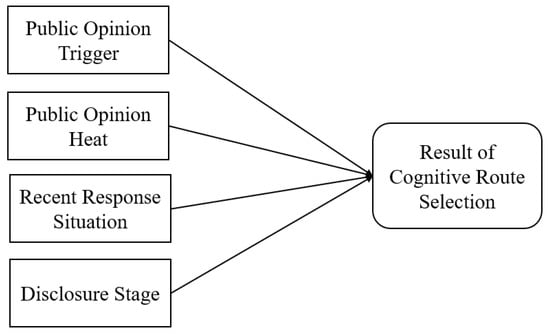
Figure 2.
Network structure of Route Selection BN.
Both the Central DTree and the Peripheral DTree utilize the ID3 decision tree, employing entropy as the criterion for node splitting. They are, respectively, trained on the database where netizens activate the central route and the peripheral route. Through this process, the persuasive information attention characteristics of netizens under different cognitive routes are summarized.
It is obvious that BNTree enables direct correspondence between ELM’s psychological constructs and algorithmic structure, allowing for clear tracing of cognitive routes and influential factors. This theoretical alignment and transparency are essential for both research explanation and practical decision support in public opinion management.
4. Results
4.1. Performance Comparison with Other Methods
In the Results section, this study firstly compares the BNTree with other traditional algorithms in terms of predictive performance. Then, the reason for the BNTree’s better performance than other algorithms is examined using SHAP values and impurity-based importance.
- (1)
- Predictive performances
Scikit-learn [45] is an open-source Python library that offers simple and efficient tools for data analysis and machine learning modeling, including Decision Tree, random forest, and Naive Bayes. Scikit-learn is widely used in research and is suitable for the baselines. Their predictive performances are evaluated using four metrics: accuracy, precision, recall, and F1 score. The model evaluation program is also developed by the Scikit-Learn library.
To rigorously assess model generalizability and minimize the risk of overfitting, we employ k-fold cross-validation for all algorithms. Specifically, the dataset is randomly divided into mutually exclusive subsets. For each of the rounds, one subset is reserved for testing, while the remaining subsets are used for training; the final performance metrics are averaged over all folds. This provides a more robust and reliable estimate of true model performance, as it ensures that the data point is probably used for training and validation in different rounds. In this study, five-fold cross-validation is employed, which means the model is evaluated five times in total. For each evaluation, 80% of the data is used for training, while the remaining 20% is used for testing.
The predictive performances are shown in Table 11.
Table 11.
Evaluation results.
Compared with other models, BNTree demonstrates outstanding predictive performance.
- (2)
- Feature importance
In machine learning, the variables can be divided into features and labels. Given the outstanding predictive performance of BNTree, the association between the features and label is subsequently analyzed to assess how practical significance is captured within the model. Because random forest shares structural similarities with BNTree, it is adopted as a baseline for comparison.
First, a theoretical comparison between BNTree and random forest is provided. Subsequently, SHAP (SHapley Additive exPlanations) values and impurity-based importance are employed to analyze their differences in greater depth.
From a theoretical perspective, BNTree bridges psychology, management, and machine learning. It integrates the Bayesian network and decision trees, in which a Bayesian network is used to estimate activation probabilities for distinct cognitive routes. Predictions from route-specific trees are subsequently aggregated using the corresponding posterior probabilities. Through this procedure, heterogeneous feature effects across routes are modeled explicitly, aligning with ELM. The prediction tends to rely on the major cognitive route and its corresponding critical features. In contrast, random forest is implemented as an ensemble of decision trees. Due to the lack of consideration for the psychological significance of each feature, random forest constructs trees primarily based on statistical criteria. As a result, it may fail to focus on features that play a critical role in the persuasion process and persuasion effectiveness among netizens.
SHAP is a framework for interpreting machine learning model predictions. Its core goal is to quantify the “importance” of each input feature in contributing to a specific model output by assigning a numerical SHAP value to every feature for every prediction [46,47]. Figure 3 depicts the SHAP summary plots corresponding to the BNTree and random forest, thereby illustrating each feature’s influence on model predictions and enabling a comparative assessment of feature effects between the two models.
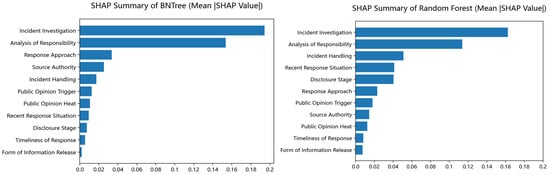
Figure 3.
The SHAP summary of the BNTree and random forest.
The top-ranked and lowest-ranked features are similar across the two models, indicating that the rank of features appears to be similar, and the two models capture the main patterns of the features. However, the within-model distributions of SHAP values differ markedly. In the BNTree, the first two features together account for the majority of the model’s prediction, followed by a pronounced drop to the following feature. In contrast, the random forest distributes importance more evenly across many features. These results illustrate that different models exhibit variations in their characterization of feature importance, which may influence the predictive performance.
Impurity-based importance is a metric used to quantify the usefulness of a feature in tree-based machine learning models. It measures how much a feature reduces the impurity of the target variable when splitting data into subsets during the tree-building process [48]. It is important to note that this metric is not applicable to the Bayesian component of the BNTree. Consequently, we do not perform a full-model impurity-based importance computation for the BNTree and instead restrict the analysis to the seven features within its tree component. In contrast, the random forest is composed entirely of decision trees, so impurity-based importance is computed for all features in that model. Figure 4 depicts the impurity-based importance plots corresponding to the BNTree and random forest.
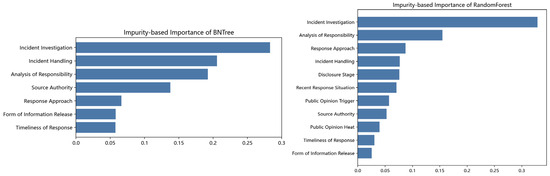
Figure 4.
The impurity-based importance of the BNTree and random forest.
After the Bayesian network estimates activation probabilities for distinct cognitive routes, the tree part of BNTree can concentrate the corresponding features under each cognitive route and yield larger impurity gains. Then, lots of features in the BNTree appear to show higher values of impurity-based importance compared with the random forest. Therefore, the plot of impurity-based importance reveals how the performance of BNTree is improved by bridging psychology, management, and machine learning.
The findings based on SHAP values and impurity-based importance are consistent with the theoretical analyses of the two models. Overall, the integration of psychology theory can enhance the machine learning algorithm design and support for digital-era crisis communication.
4.2. Visualization and Implication of the BNTree
By mining all data from the dataset, BNTree reveals the reasons why netizens choose different routes and the reasons why netizens are persuaded in a visualized form. From a managerial perspective, this approach provides actionable insights for organizational persuasive communication.
4.2.1. Reasons Why Netizens Choose Different Routes
The Route Selection BN reveals the characteristics of cognitive route selection among netizens. In Bayes Networks, the conditional probability table (CPT) reveals the reasons why netizens activate different routes. According to the CPT, this study sequentially analyzes the effects of each factor on the result of cognitive route selection. By comparing the conditional probability with the prior probability , it is possible to analyze the impact of the random variable on the random variable . This study adopts this method for analysis, where denotes the value influencing variables, and denotes the choice of cognitive routes.
- (1)
- Public Opinion Trigger
The effects of public opinion trigger are shown in Table 12.
Table 12.
The effects of public opinion trigger.
It can be observed that when the public opinion triggers are livelihood issues, netizens tend to activate the central route; when the public opinion triggers are corporate or celebrity scandals, netizens are inclined to activate the peripheral route.
Since livelihood issues encompass topics such as housing, healthcare, and education, which are closely related to the vital interests of netizens, netizens tend to carefully analyze the event investigation results and response measures provided by official sources, which means they are more likely to activate the central route.
In contrast, corporate or celebrity scandals are generally less relevant to what netizens care about, but they possess high levels of appeal. As a result, netizens often discuss such events with an entertainment mindset and do not analyze the detailed information in depth, which means they are more likely to activate the peripheral route.
- (2)
- Public Opinion Heat
The effects of public opinion heat are shown in Table 13.
Table 13.
The effects of public opinion heat.
It is evident that when public opinion heat is medium, netizens tend to activate the central route. Through case analysis, this study finds that when public opinion heat is low, online platforms are largely filled with fragmented information, which makes it difficult for netizens to engage in in-depth thinking. However, as public opinion heat rises and the volume of information increases sharply, netizens are prone to information overload and tiredness [49], making it difficult to activate the central route. In contrast, when public opinion heat is at a moderate level, netizens possess both sufficient information for analysis and the cognitive motivation to engage. At this stage, they tend to activate the central route.
- (3)
- Recent Response Situation
The effects of recent response situation are shown in Table 14.
Table 14.
The effects of recent response situation.
When the persuader adopts a passive response in recent responses, netizens tend to activate the central route. If the persuader fails to effectively respond to the main doubts and demands of netizens, or even exacerbates social conflicts due to improper responses, netizens often lack trust in the persuader. As a result, they tend to activate the central route and carefully analyze the content of the response.
- (4)
- Disclosure Stage
The effects of disclosure stage are shown in Table 15.
Table 15.
The effects of disclosure stage.
When an incident disclosure reaches the final stage, netizens tend to activate the central route. As the incident information becomes fully disclosed, driven by a strong motivation to understand the truth, netizens tend to activate the central route and conduct a detailed analysis of the event’s context and development.
4.2.2. Reasons Why Netizens Are Persuaded
The Central Route DTree and Peripheral Route DTree are established to inductively analyze the cognitive characteristics of netizens under different routes. Compared with other models, the tree-based results generated by the BNTree algorithm provide more interpretable insights. The hierarchical structure of decision trees enables clear visualization of decision-making pathways, revealing the specific combinations of persuasive information that netizens prioritize under different cognitive routes, as well as the corresponding persuasion effectiveness of these combinations.
The result of the Central Route DTree is shown in Figure 5.
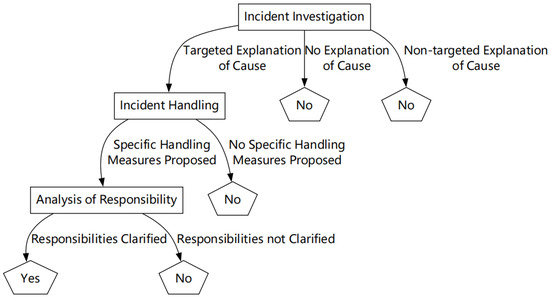
Figure 5.
Data mining result of the Central Route DTree.
According to the result, under the central route, netizens tend to focus on core information related to the incident. Furthermore, netizens choose to be persuaded only when the persuader provides clear and targeted explanations regarding the incident investigation, the incident handling, and the analysis of responsibility. The above analysis indicates that, under the central route, netizens display a more focused attention and place greater emphasis on the completeness and clarity of the information.
The data mining result of the Peripheral Route DTree is shown in Figure 6.
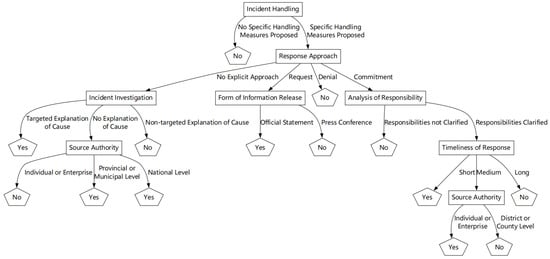
Figure 6.
Data mining result of the Peripheral Route DTree.
According to the result, under the peripheral route, the information that netizens focus on is relatively dispersed. Specifically, netizens pay attention not only to the core information related to the incident, but also to peripheral cues with lower relevance, such as the source credibility and the response approach.
Through top-down analysis of the result, regarding incident handling, if the persuader does not propose specific handling measures, netizens are often not effectively persuaded.
Regarding the response approach, when the persuader adopts a tone of denial, netizens tend to be difficult to persuade; when the persuader issues a request through the response, netizens tend to focus on the form of information release; When the persuader makes a commitment through the response, explicitly indicating that specific measures will be taken, netizens pay particular attention to the analysis of responsibility. If the analysis is not clear, netizens are difficult to persuade; when the persuader does not present a clear approach, netizens show more concern for the incident investigation. If the investigation is vague, netizens are often not effectively persuaded.
Regarding the timeliness of the response, the earlier the persuader issues an official response, the more effective the persuasion outcome is.
4.3. Application of the BNTree
This subsection clarifies the practical applications of the BNTree and its ease of deployment in real-world settings.
The main practical applications include the following: BNTree can infer the most likely cognitive routes of netizens from multiple observable features of an incident. Then, BNTree can identify the critical factors that influence the public opinion persuasion effect, empowering organizations to design more effective response methods. Moreover, BNTree is effective both before and after the strategy’s implementation. It can forecast a strategy’s impact in advance and later explain the drivers of the persuasion effect, thereby supporting the ongoing optimization of crisis communication.
As for its ease of deployment in real-world settings, the data used in BNTree can be obtained via social media platforms and third-party platforms, such as “Zhiweidata” and Weibo. In other words, the features required by the BNTree are observable. Moreover, some of them are controllable and can be directly adjusted by organizations, such as the timeliness of response and the response approach. BNTree’s architecture ensures traceability of each prediction. Thus, the prediction process and result are presented in a clear, non-technical format that decision makers without machine-learning expertise can readily understand.
4.4. Summary
In Section 4, the experimental results demonstrate the predictive performance, management implications, and applications of the BNTree. Finally, Table 16 is presented to summarize the results and to illustrate the strengths and weaknesses of BNTree and other algorithms, such as random forest.
Table 16.
Summary of results.
5. Conclusions and Discussions
In this study, a formalized database is constructed based on the ELM. In order to extract the cognitive characteristics of netizens from the database and analyze the influence of various factors on the public opinion persuasion effect, BNTree integrates Bayesian Network and Decision Tree algorithms. The predictive capability of BNTree is validated through comparisons with other machine learning algorithms. And from the management perspective, BNTree’s results reveal the reasons why netizens choose different routes and why they are persuaded.
Regarding cognitive route selection, it has been found that when an emergency is perceived as closely related to the interests of netizens, relevant information is given more serious attention, and the central route is more likely to be activated. Conversely, when the emergency is less relevant to their personal interests, a bystander mentality prevails, and the peripheral route is more likely to be chosen. Furthermore, variables such as public opinion heat, recent response situation, and incident stage are found to influence the choice of cognitive route.
Regarding the reasons why netizens are persuaded, the results of the decision tree component of the BNTree were analyzed. It was found that when the central route is activated, the information that netizens pay attention to is more focused, while under the peripheral route, the information that netizens pay attention to is more dispersed.
Turning to persuasion mechanisms, targeting the central or peripheral route represents a trade-off between rapid action and careful inquiry. Quick responses enable timely interventions and aid crisis containment. Careful investigation enhances accuracy, interpretability, and fairness, but it usually demands more time and resources. Different scenarios require tailored guidance strategies. Immediate action is required when confidence is high and the stakes are moderate. A deferred, comprehensive review should be applied to cases with high uncertainty or substantial consequences.
The BNTree can effectively predict the persuasion effectiveness of current official responses and can assist the persuader in adjusting strategies according to specific contexts. Thus, strong decision support is provided to enhance persuasiveness and improve public opinion management.
Overall, this study integrates psychological theory into a machine learning predictive framework that is both theoretically grounded and practically useful. Crucially, it demonstrates interdisciplinary value by bridging psychology, management, and machine learning, with implications that extend beyond the immediate application domain. In technology, a hybrid model is proposed that combines decision trees with Bayesian networks, together with a formalized, ELM-based dataset to train the model and validate its performance.
Nonetheless, several limitations remain. For example, some subjectivity is inherent in annotating cognitive routes and persuasion effects, which may introduce label noise. Moreover, the data are mainly obtained from Chinese social media platforms; thus, the cultural factors may limit the generalizability of our model to other contexts. Future work will address these issues by expanding the dataset, diversifying data sources, and adopting more robust validation to enhance stability and external validity. Additional directions include leveraging large language models to assist labeling, reduce annotation burden, and enable timely monitoring. Moreover, the quantified trade-off between quick responses and thorough investigation can be examined in the future.
Author Contributions
Conceptualization, W.L.; data curation, W.L. and H.Y.; methodology, W.L. and H.Y.; software, H.Y. and Z.H.; supervision, H.S.; validation, Z.H.; writing—original draft, W.L.; writing—review and editing, W.L. and H.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Social Science Fund of China (grant No. 20AZD059).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data and code presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kowal, J.; Klebaniuk, J.; Olejnik, K.; Weichbroth, P. Theoretical Model of the Interaction between Pandemic-Related Stressors and Social Media Use: A Systematic Literature Review and Meta-Analytical Synthesis. Int. J. Pedagog. Innov. New Technol. 2024, 11, 60–75. [Google Scholar] [CrossRef]
- Kowal, J.; Klebaniuk, J. Psychological Impact of Social Media Use on Quality of Life and Human Potentiality. In Proceedings of the AMCIS 2022—The Americas Conference on Information Systems 2022, Minneapolis, MN, USA, 10–14 August 2022. [Google Scholar]
- Geng, L.; Zheng, H.; Qiao, G.; Geng, L.; Wang, K. Online public opinion dissemination model and simulation under media intervention from different perspectives. Chaos Solitons Fractals 2023, 166, 112959. [Google Scholar] [CrossRef]
- Wu, D.; Qiu, Y.; Xue, M. Decision optimization of new energy vehicle supply chain considering information sharing for perceived quality under dual credit policy. J. Ind. Manag. Optim. 2025, 21, 4536–4559. [Google Scholar] [CrossRef]
- Weichbroth, P.; Baj-Rogowska, A. Do online reviews reveal mobile application usability and user experience? The case of WhatsApp. In Proceedings of the 2019 Federated Conference on Computer Science and Information Systems (FedCSIS), Leipzig, Germany, 1–4 September 2019; IEEE: New York, NY, USA, 2019; pp. 747–754. [Google Scholar]
- Zhang, L.; Dong, P.; Zhang, L.; Mu, B.; Yang, A. A systematic literature review of crisis management in online public opinion: Evolutionary path and implications for China. Kybernetes 2024. [Google Scholar] [CrossRef]
- Shen, C.; He, P.; Song, Z.; Zhang, Y. Cognitive disparity in online rumor perception: A group analysis during COVID-19. BMC Public Health 2024, 24, 3049. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, X.; Zhang, S. A new decision method for public opinion crisis with the intervention of risk perception of the public. Complexity 2019, 2019, 9527218. [Google Scholar] [CrossRef]
- Susmann, M.W.; Xu, M.; Clark, J.K.; Wallace, L.E.; Blankenship, K.L.; Philipp-Muller, A.Z.; Luttrell, A.; Wegene, D.T.; Petty, R.E. Persuasion amidst a pandemic: Insights from the Elaboration Likelihood Model. Eur. Rev. Soc. Psychol. 2022, 33, 323–359. [Google Scholar] [CrossRef]
- Grzonkowski, F.; Weichbroth, P. Exploring Cause-and-Effect Relationships Between Public Company Press Releases and Their Stock Prices. In Proceedings of the European Conference on Artificial Intelligence, Kraków, Poland, 30 September–5 October 2023; Springer Nature: Cham, Switzerland, 2023; pp. 74–82. [Google Scholar]
- Ali, H.; Farman, H.; Yar, H.; Khan, Z.; Habib, S.; Ammar, A. Deep learning-based election results prediction using Twitter activity. Soft Comput. 2022, 26, 7535–7543. [Google Scholar] [CrossRef]
- Hovland, C.I.; Janis, I.L.; Kelley, H.H. Communication and Persuasion; Yale University Press: New Haven, CT, USA, 1953. [Google Scholar]
- Petty, R.E.; Cacioppo, J.T. Source factors and the elaboration likelihood model of persuasion. Adv. Consum. Res. 1984, 11, 668–672. [Google Scholar]
- Song, J.; Li, Y.; Guo, X.; Shen, K.N.; Ju, X. Making mobile health information advice persuasive: An elaboration likelihood model perspective. J. Organ. End User Comput. (JOEUC) 2022, 34, 1–22. [Google Scholar] [CrossRef]
- Syrdal, H.A.; Myers, S.; Sen, S.; Woodroof, P.J.; McDowell, W.C. Influencer marketing and the growth of affiliates: The effects of language features on engagement behavior. J. Bus. Res. 2023, 163, 113875. [Google Scholar] [CrossRef]
- Saini, V.; Liang, L.L.; Yang, Y.C.; Le, H.M.; Wu, C.Y. The association between dissemination and characteristics of pro-/anti-COVID-19 vaccine messages on Twitter: Application of the elaboration likelihood model. JMIR Infodemiology 2022, 2, e37077. [Google Scholar] [CrossRef]
- Yang, B.; Liu, C.; Cheng, X.; Ma, X. Understanding users’ group behavioral decisions about sharing articles in social media: An elaboration likelihood model perspective. Group Decis. Negot. 2022, 31, 819–842. [Google Scholar] [CrossRef]
- Xu, X.Y.; Jia, Q.D. A new exploration of signaling theory in social commerce facilitated cross-border retailing: A four-stage approach. Inf. Manag. 2025, 62, 104154. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, M.; Wang, G.A.; Zhang, N. The effect of different types of comparative reviews on product sales. Decis. Support Syst. 2024, 184, 114287. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Yan, J. Exploring multimodal factors in online reviews: A machine learning approach to evaluating content effectiveness. J. Retail. Consum. Serv. 2025, 84, 104261. [Google Scholar] [CrossRef]
- Wang, X.; Qi, L.; Chen, C.; Tang, J.; Jiang, M. Grey System Theory based prediction for topic trend on Internet. Eng. Appl. Artif. Intell. 2014, 29, 191–200. [Google Scholar] [CrossRef]
- Yan, S.; Su, Q.; Gong, Z.; Zeng, X. Fractional order time-delay multivariable discrete grey model for short-term online public opinion prediction. Expert Syst. Appl. 2022, 197, 116691. [Google Scholar] [CrossRef]
- Su, Q.; Yan, S.; Wu, L.; Zeng, X. Online public opinion prediction based on a novel seasonal grey decomposition and ensemble model. Expert Syst. Appl. 2022, 210, 118341. [Google Scholar] [CrossRef]
- Chen, X.G.; Duan, S.; Wang, L.D. Research on trend prediction and evaluation of network public opinion. Concurr. Comput. Pract. Exp. 2017, 29, e4212. [Google Scholar] [CrossRef]
- Ma, W.; Hu, X.; Chen, C.; Wen, S.; Choo, K.R.; Xiang, Y. Social media event prediction using DNN with feedback mechanism. ACM Trans. Manag. Inf. Syst. (TMIS) 2022, 13, 33. [Google Scholar] [CrossRef]
- Li, P.; Yu, X.; Peng, H.; Xian, Y.; Wang, L.; Sun, L.; Zhang, J.; Yu, P.S. Relational prompt-based pre-trained language models for social event detection. ACM Trans. Inf. Syst. 2024, 43, 12. [Google Scholar] [CrossRef]
- Liu, Y.; Ye, C.; Sun, J.; Jiang, Y.; Wang, H. Modeling undecided voters to forecast elections: From bandwagon behavior and the spiral of silence perspective. Int. J. Forecast. 2021, 37, 461–483. [Google Scholar] [CrossRef]
- Quinlan, S.; Lewis-Beck, M.S. Forecasting government support in Irish general elections: Opinion polls and structural models. Int. J. Forecast. 2021, 37, 1654–1665. [Google Scholar] [CrossRef]
- Kang, S.; Oh, H.S. Forecasting South Korea’s presidential election via multiparty dynamic Bayesian modeling. Int. J. Forecast. 2024, 40, 124–141. [Google Scholar] [CrossRef]
- Chin, C.Y.; Wang, C.L. A new insight into combining forecasts for elections: The role of social media. J. Forecast. 2021, 40, 132–143. [Google Scholar] [CrossRef]
- Shi, D.; Gan, S.; Zurada, J.; Guan, J.; Wang, F.; Weichbroth, P. A multi-model approach to construction site safety: Fault trees, Bayesian networks, and ontology reasoning. Expert Syst. Appl. 2025, 288, 127817. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, F.; Gao, L. Echo chamber effects on short video platforms. Sci. Rep. 2023, 13, 6282. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Li, Z.; Zhang, K.; Bi, C. The formation pattern, causes, and governance of network public opinion on university emergencies. Front. Public Health 2024, 12, 1367805. [Google Scholar] [CrossRef] [PubMed]
- Xue, M.; Shen, H.; Zhao, J. Risk factors influencing environmental protest severity in China. Int. J. Confl. Manag. 2018, 29, 189–212. [Google Scholar] [CrossRef]
- Petty, R.E.; Cacioppo, J.T. Issue involvement can increase or decrease persuasion by enhancing message-relevant cognitive responses. J. Personal. Soc. Psychol. 1979, 37, 1915. [Google Scholar] [CrossRef]
- Petty, R.E.; Cacioppo, J.T.; Goldman, R. Personal involvement as a determinant of argument-based persuasion. J. Personal. Soc. Psychol. 1981, 41, 847. [Google Scholar] [CrossRef]
- Li, J. Promoting HPV vaccination: Effectiveness of mobile short videos for shaping attitudes and influencing behaviors. Humanit. Soc. Sci. Commun. 2024, 11, 1092. [Google Scholar] [CrossRef]
- Kitano, W. Information quality in sequential persuasion. Econ. Lett. 2025, 254, 112452. [Google Scholar] [CrossRef]
- Sussman, S.W.; Siegal, W.S. Informational influence in organizations: An integrated approach to knowledge adoption. Inf. Syst. Res. 2003, 14, 47–65. [Google Scholar] [CrossRef]
- Pornpitakpan, C. The persuasiveness of source credibility: A critical review of five decades’ evidence. J. Appl. Soc. Psychol. 2004, 34, 243–281. [Google Scholar] [CrossRef]
- Greškovičová, K.; Masaryk, R.; Synak, N.; Čavojová, V. Superlatives, clickbaits, appeals to authority, poor grammar, or boldface: Is editorial style related to the credibility of online health messages? Front. Psychol. 2022, 13, 940903. [Google Scholar] [CrossRef]
- Li, C.R.; Zhang, E.; Han, J.T. Adoption of online follow-up service by patients: An empirical study based on the elaboration likelihood model. Comput. Hum. Behav. 2021, 114, 106581. [Google Scholar] [CrossRef]
- Lee, M.T.; Theokary, C. The superstar social media influencer: Exploiting linguistic style and emotional contagion over content? J. Bus. Res. 2021, 132, 860–871. [Google Scholar] [CrossRef]
- Coombs, W.T. Protecting organization reputations during a crisis: The development and application of situational crisis communication theory. Corp. Reput. Rev. 2007, 10, 163–176. [Google Scholar] [CrossRef]
- Prodregosa, F. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lee, M.; Choi, I.; Kim, W.C. Predicting Mobile Payment Behavior Through Explainable Machine Learning and Application Usage Analysis. J. Theor. Appl. Electron. Commer. Res. 2025, 20, 117. [Google Scholar] [CrossRef]
- Nembrini, S.; König, I.R.; Wright, M.N. The revival of the Gini importance? Bioinformatics 2018, 34, 3711–3718. [Google Scholar] [CrossRef] [PubMed]
- Pang, H.; Ruan, Y. Determining influences of information irrelevance, information overload and communication overload on WeChat discontinuance intention: The moderating role of exhaustion. J. Retail. Consum. Serv. 2023, 72, 103289. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).