

Artificial Intelligence/Machine Learning Applications in the Oil and Gas Industry
A special issue of Energies (ISSN 1996-1073). This special issue belongs to the section "H: Geo-Energy".
Deadline for manuscript submissions: closed (15 August 2023) | Viewed by 47172
Editors

Interests: reservoir modeling; enhanced oil recovery (EOR); CO2 EOR and storage; well test analysis

Special Issue Information
Dear Colleagues,
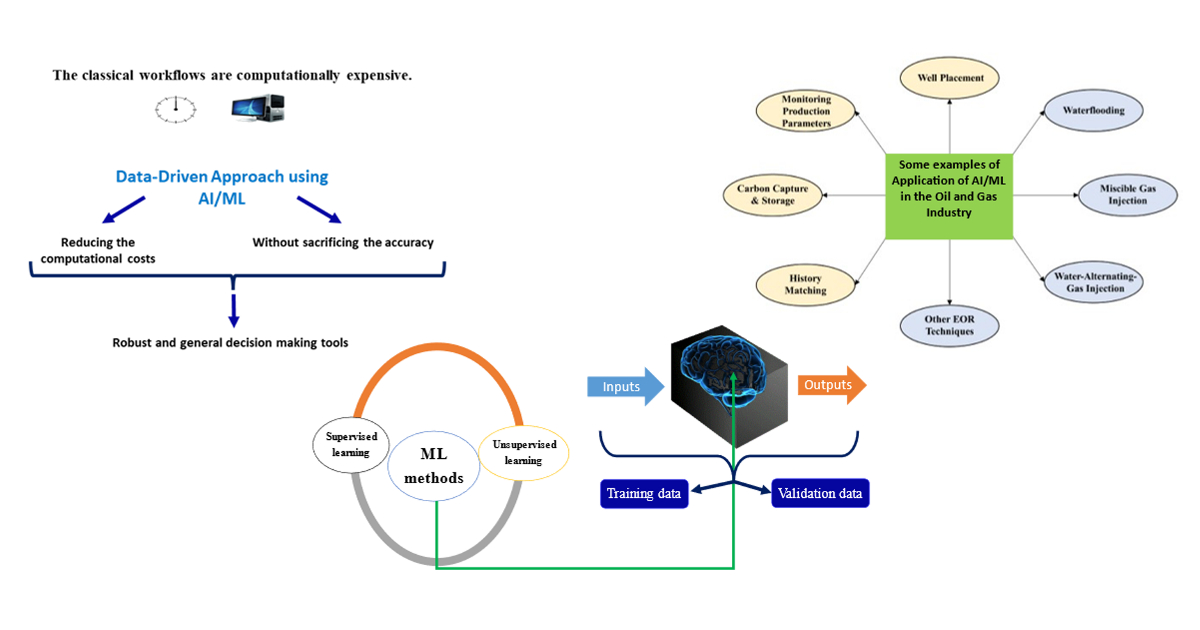
We have the pleasure of inviting submissions to a Special Issue of Energies on the subject area of “Artificial Intelligence/Machine Learning Applications in the Oil and Gas Industry”.
While more efficient algorithms and high-performance computers can enhance the speed and accuracy of numerical models, they are incapable of transforming these models to new levels of computational footprint. Artificial intelligence and machine learning (AI&ML) have been used in petroleum engineering applications, with the possibility of combining the advantages of both traditional and intelligent modeling approaches to develop more powerful and faster computational tools. AI&ML capabilities perceive the relationship among relevant data and develop models based on the available measurements or simulated data. This characteristic makes the data-driven approach a viable modeling technology specifically for cases with complex physics. Promising results have been obtained in the application of data-driven techniques for resolving a wide variety of modeling problems such as history matching, well placement, production forecasting, injection strategies, CO2 storage and optimization and many more.
Dr. Ashkan Jahanbani Ghahfarokhi
Dr. Alv-Arne Grimstad
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the special issue website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-anonymized peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Energies is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript. The Article Processing Charge (APC) for publication in this open access journal is 2600 CHF (Swiss Francs). Submitted papers should be well formatted and use good English. Authors may use MDPI's English editing service prior to publication or during author revisions.
Keywords
- artificial intelligence
- machine learning
- data analytics
- petroleum engineering
- oil and gas industry
- CO2 utilization and storage
- reservoir engineering
- optimization
- digitalization
- real-time reservoir management
Benefits of Publishing in a Special Issue
- Ease of navigation: Grouping papers by topic helps scholars navigate broad scope journals more efficiently.
- Greater discoverability: Special Issues support the reach and impact of scientific research. Articles in Special Issues are more discoverable and cited more frequently.
- Expansion of research network: Special Issues facilitate connections among authors, fostering scientific collaborations.
- External promotion: Articles in Special Issues are often promoted through the journal's social media, increasing their visibility.
- Reprint: MDPI Books provides the opportunity to republish successful Special Issues in book format, both online and in print.
Further information on MDPI's Special Issue policies can be found here.