
Enhanced Adaptive Wiener Filtering for Frequency-Varying Noise with Convolutional Neural Network-Based Feature Extraction †



Abstract
1. Introduction
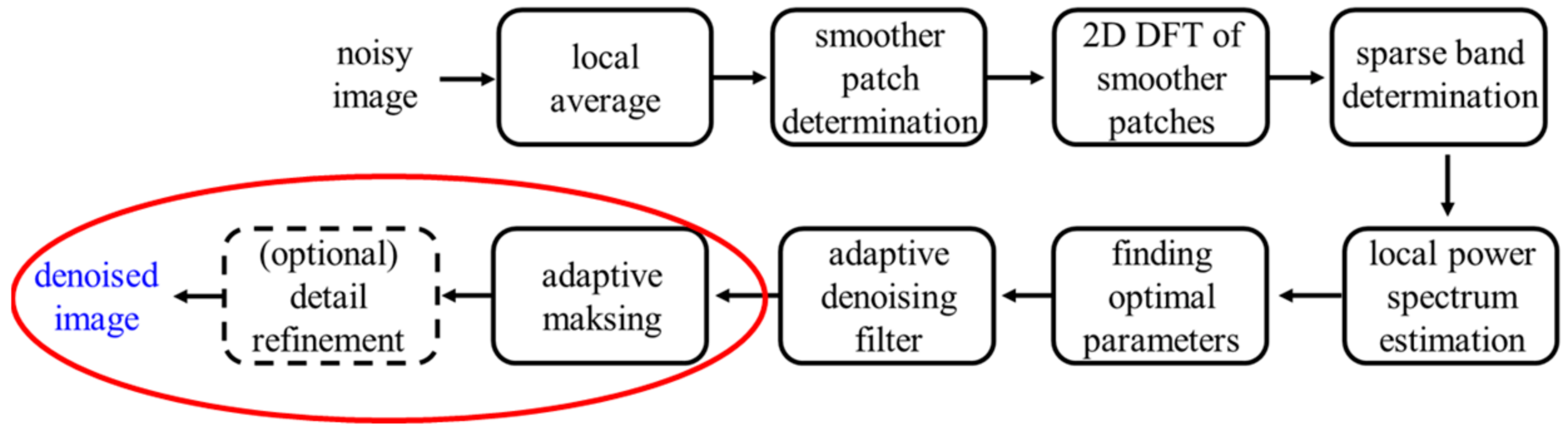
2. Proposed Algorithm
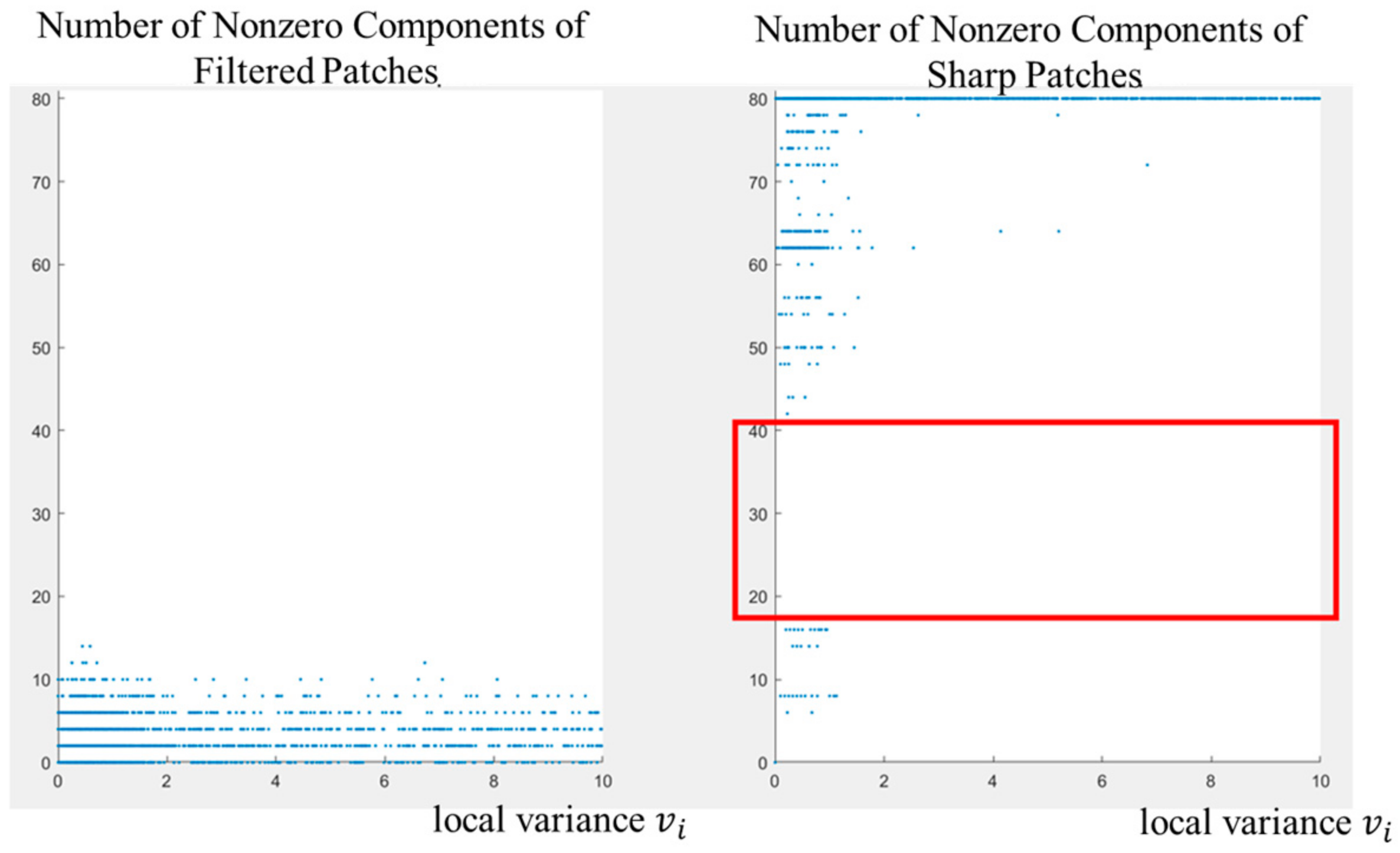
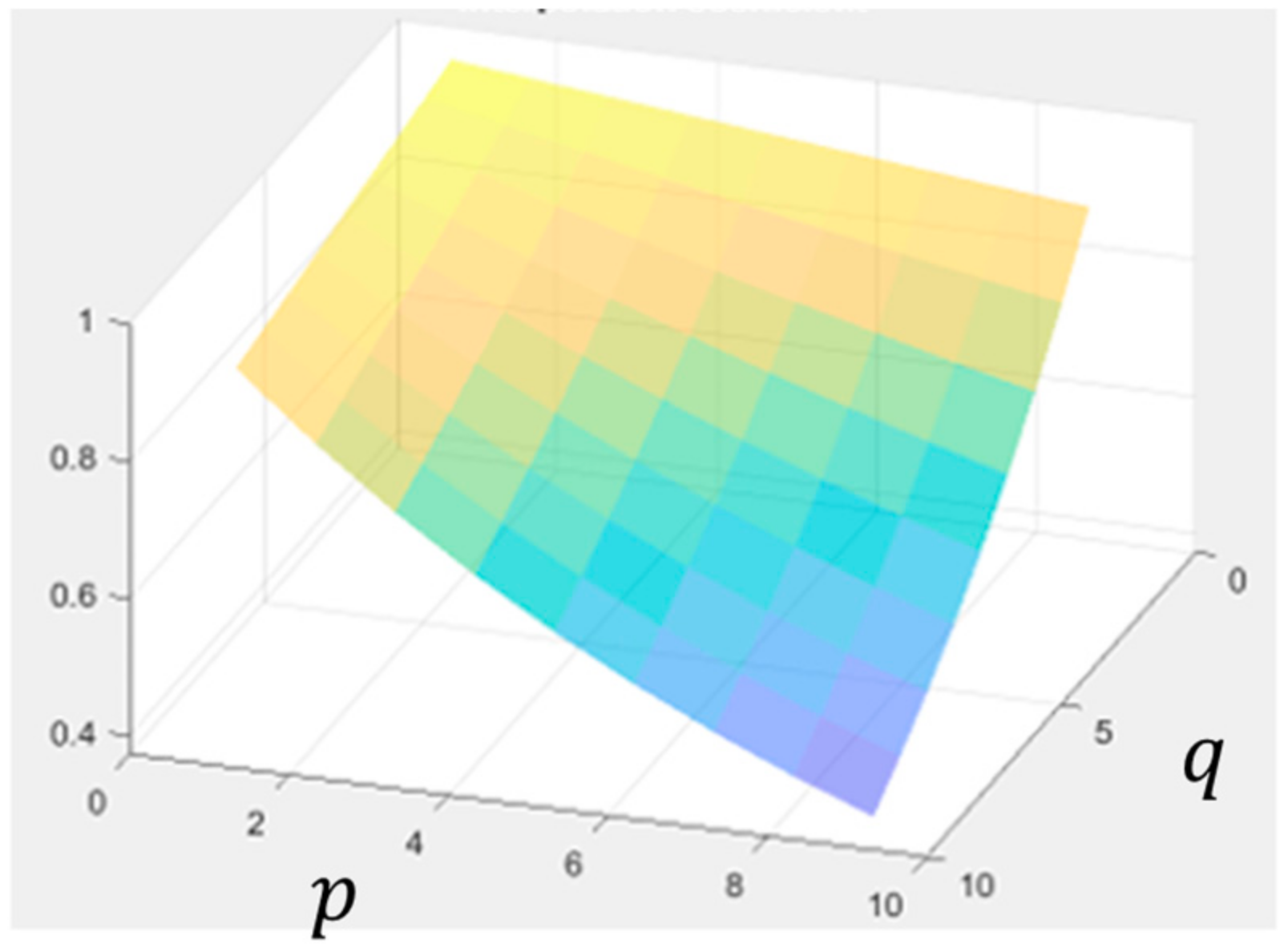
2.1. Adaptive Masking in Frequency Domain
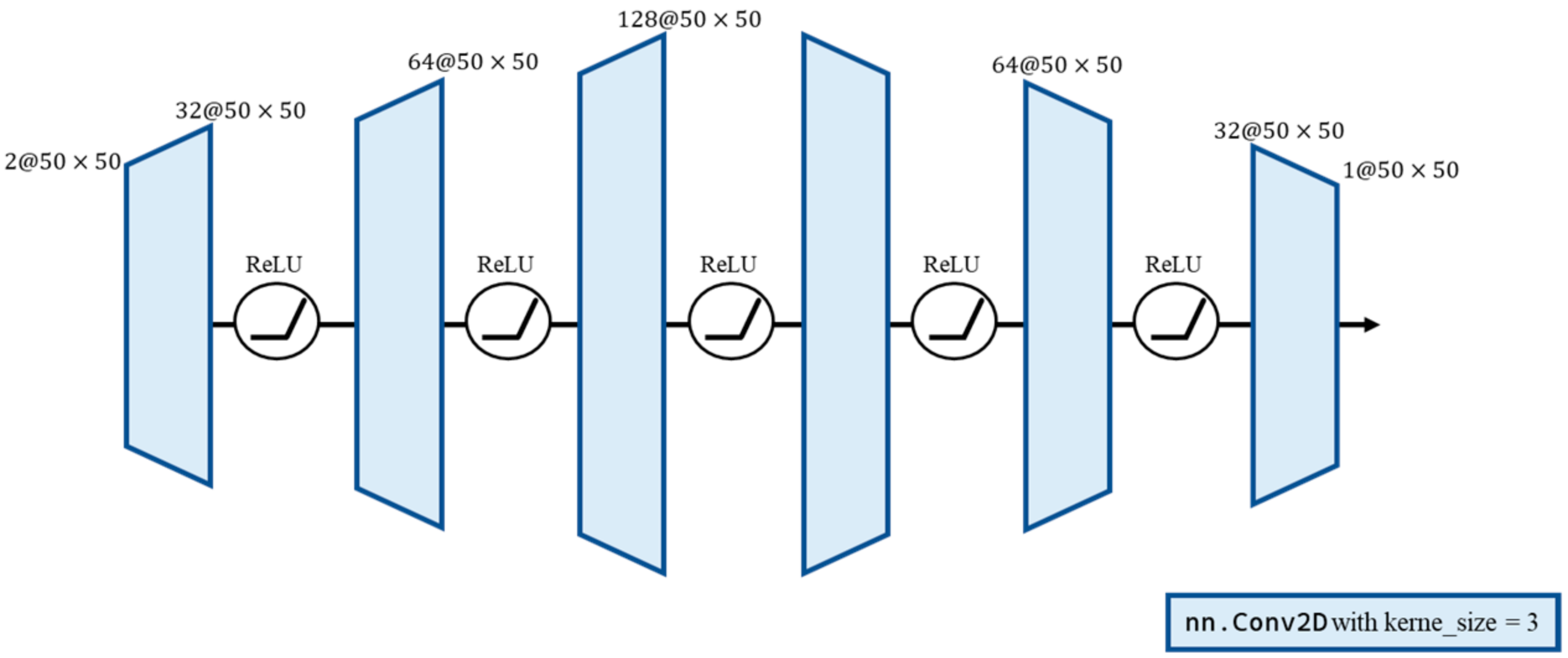
2.2. Detail Refinement
3. Results
3.1. AWGN
3.2. Poisson Noise
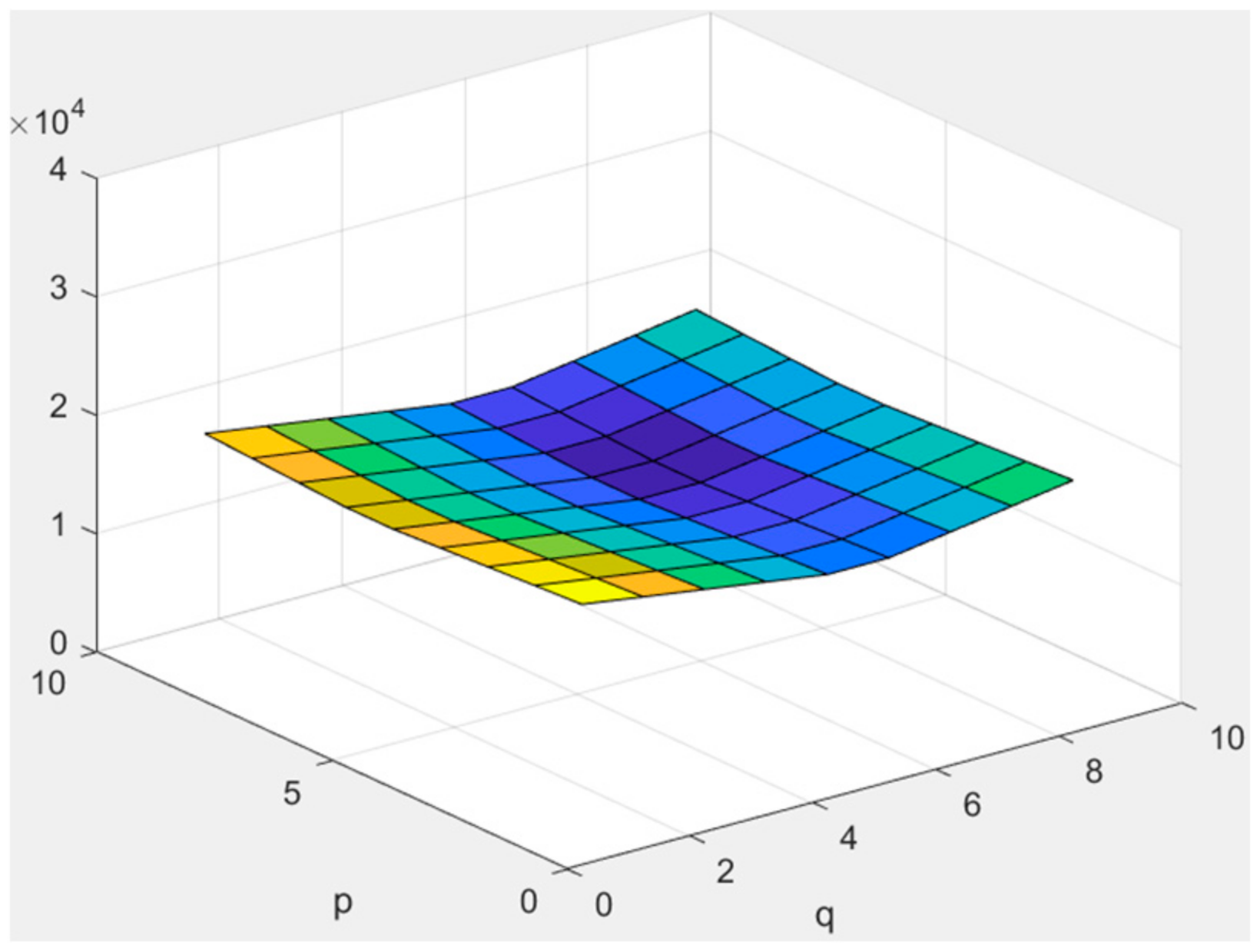
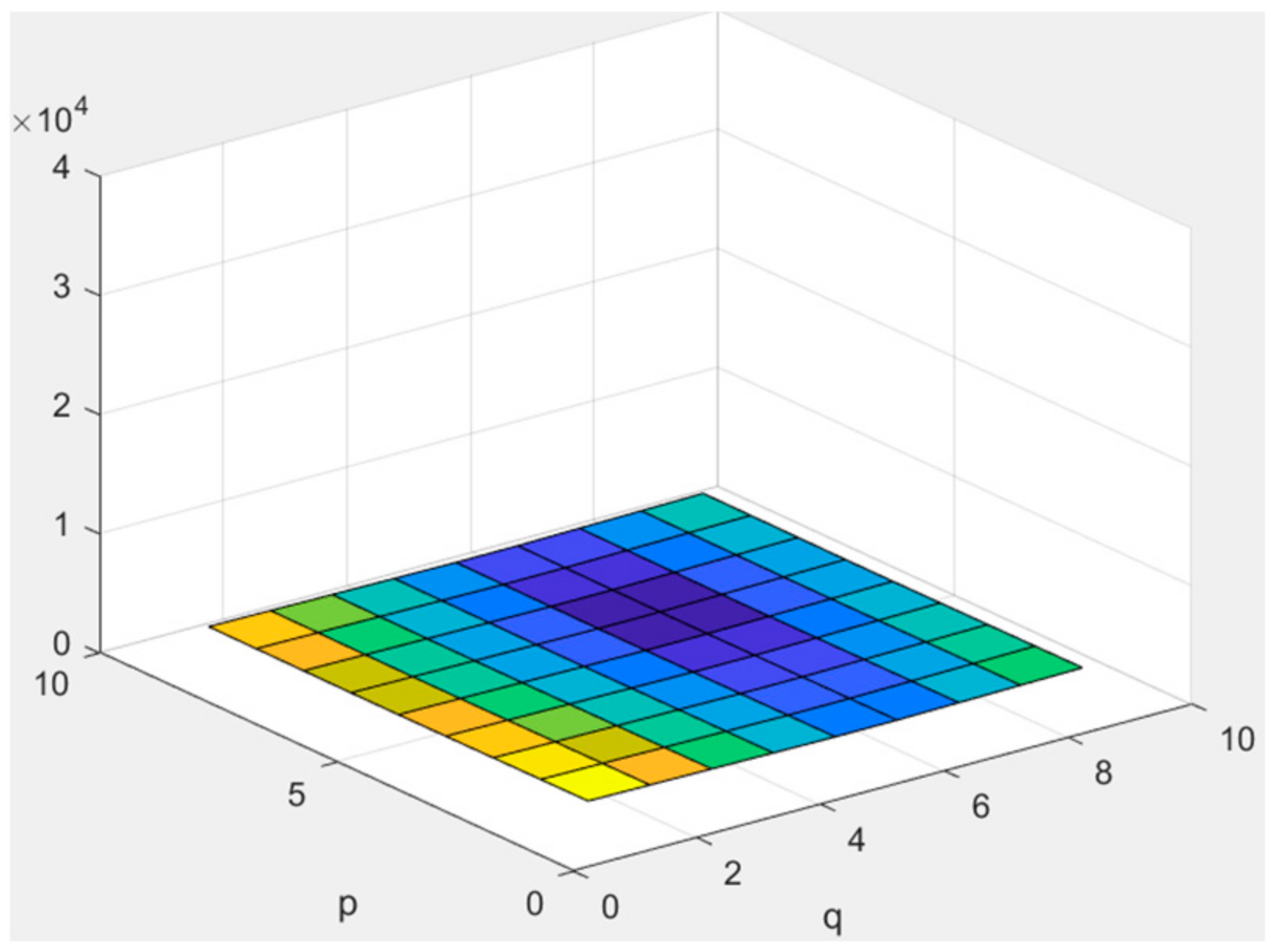
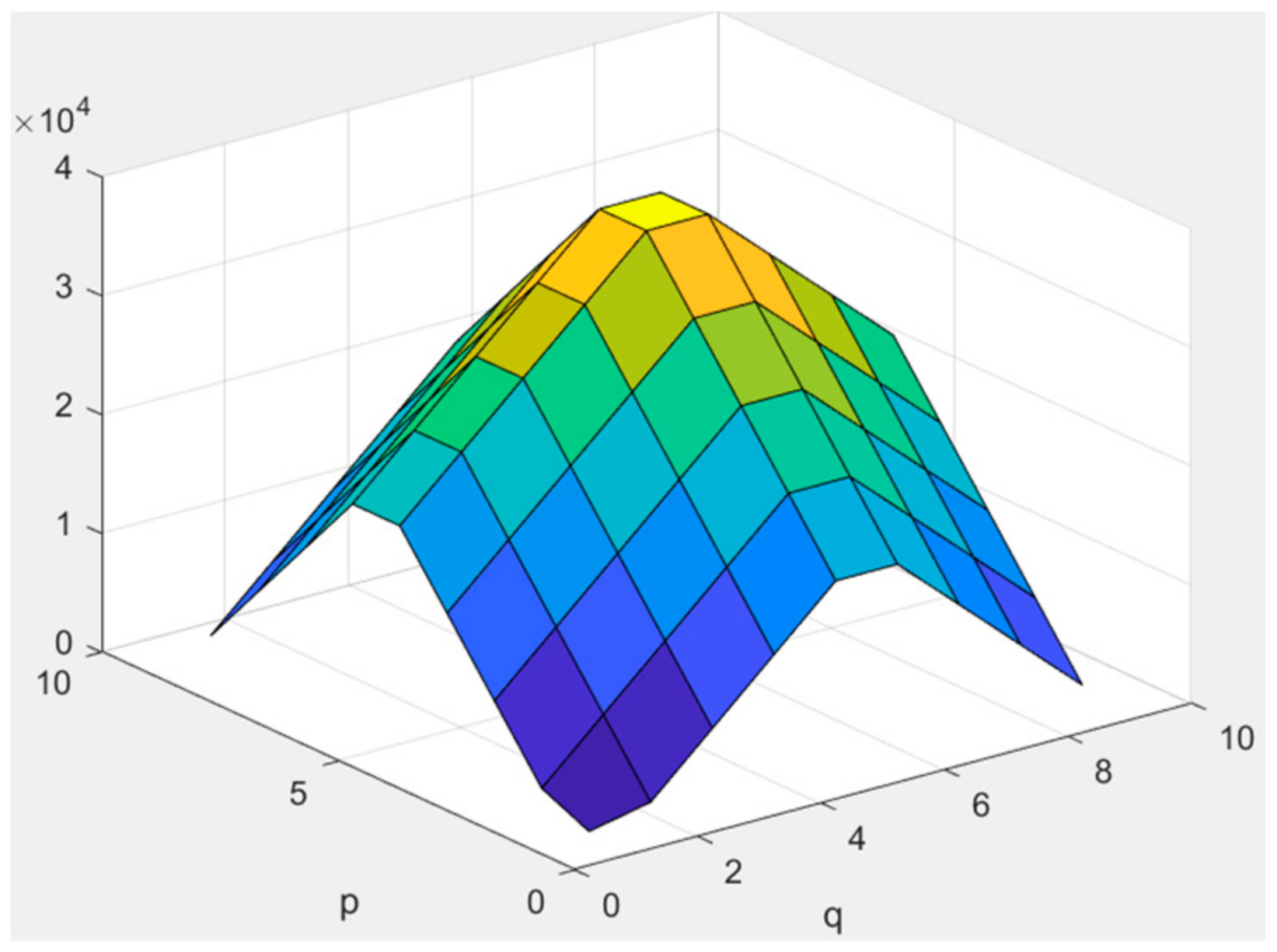
3.3. Frequency-Varying Noise (Peak-like)
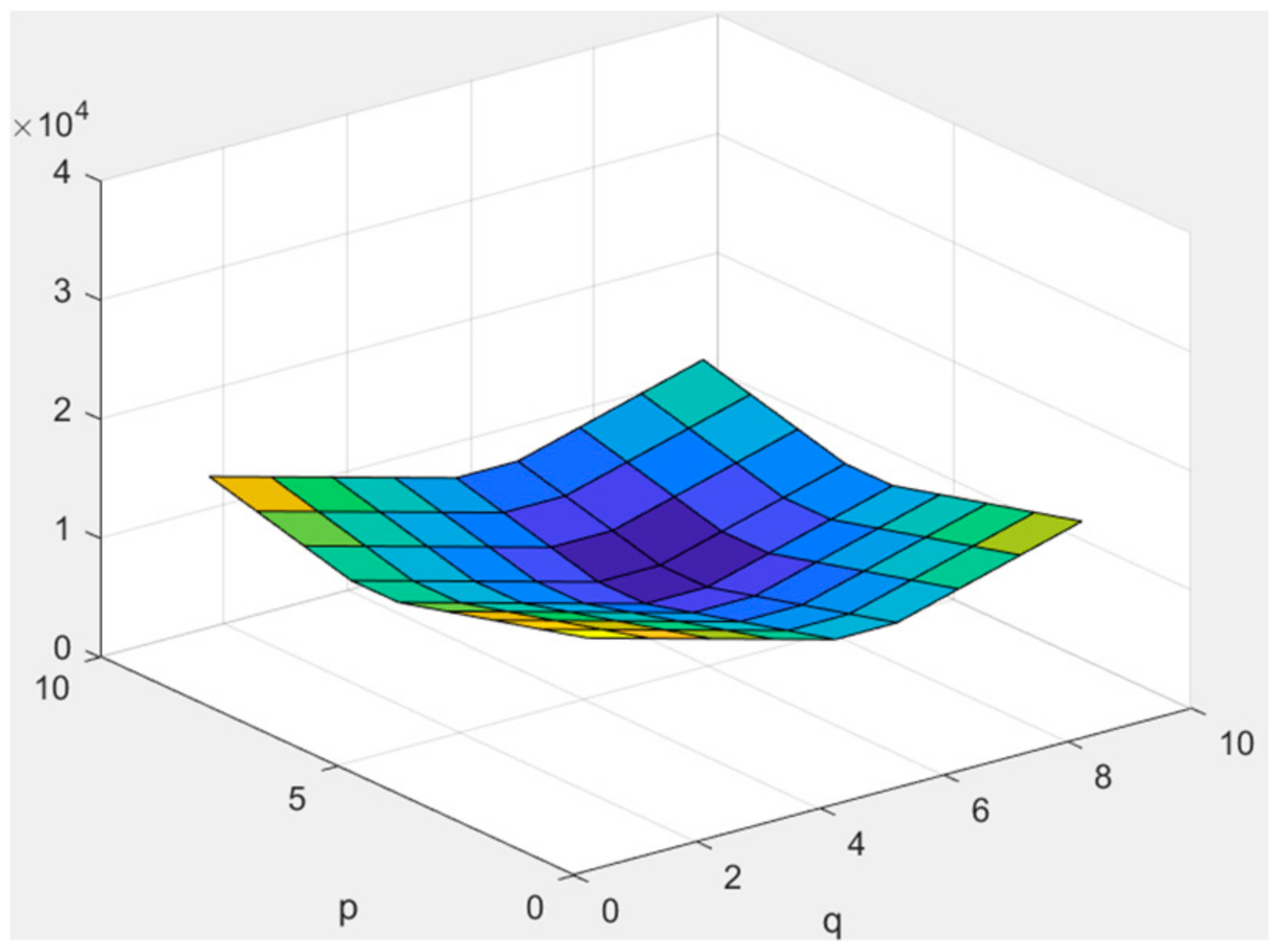
3.4. Frequency-Varying (Valley-like) Noise
3.5. Average Runtime per Image
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lebrun, M. An analysis and implementation of the BM3D image denoising method. Image Process. Line 2012, 2, 175–213. [Google Scholar] [CrossRef]
- Pyatykh, S.; Hesser, J.; Zheng, L. Image noise level estimation by principal component analysis. IEEE Trans. Image Process. 2012, 22, 687–699. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Tanaka, M.; Okutomi, M. Single-image noise level estimation for blind denoising. IEEE Trans. Image Process. 2013, 22, 5226–5237. [Google Scholar] [CrossRef]
- Ding, J.J.; Chang, J.Y.; Liao, C.L.; Tsai, Z.H. Image deblurring using local Gaussian models based on noise and edge distribution estimation. In Proceedings of the TENCON 2021—2021 IEEE Region 10 Conference, Auckland, New Zealand, 7–10 December 2021; pp. 714–719. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural adversarial examples. In Proceedings of the IEEE/CVT Conf. Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15262–15271. [Google Scholar]
- Zhang, X. Image denoising using local Wiener filter and its method noise. Optik 2016, 127, 6821–6828. [Google Scholar] [CrossRef]
- Ding, J.J.; Liao, C.L. Image denoising based on the noise prediction model using smooth patch and sparse domain priors. In Proceedings of the International Workshop on Advanced Imaging Technology (IWAIT), Jeju, Republic of Korea, 9–11 January 2023; Volume 12592, pp. 170–175. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSNR | Castle | Pillar | Bridge | Cottage | Snow Field | Average |
|---|---|---|---|---|---|---|
| Adaptive Wiener [9] | 29.273 | 31.703 | 29.886 | 30.639 | 28.766 | 29.273 |
| BM3D [5] | 27.010 | 28.704 | 27.200 | 27.714 | 27.003 | 27.010 |
| IRCNN [6] | 26.799 | 27.874 | 27.059 | 27.255 | 27.048 | 26.799 |
| Proposed | 30.310 | 31.965 | 30.640 | 30.981 | 29.381 | 30.310 |
| PSNR | Castle | Pillar | Bridge | Cottage | Snow Field | Average |
|---|---|---|---|---|---|---|
| Adaptive Wiener [9] | 32.889 | 34.548 | 32.658 | 32.286 | 31.662 | 32.809 |
| BM3D [5] | 32.665 | 35.108 | 32.709 | 32.684 | 32.142 | 33.062 |
| IRCNN [6] | 31.866 | 34.436 | 32.055 | 32.227 | 31.524 | 32.421 |
| Proposed | 33.095 | 35.095 | 33.154 | 32.910 | 32.099 | 33.271 |
| PSNR | Castle | Pillar | Bridge | Cottage | Snow Field | Average |
|---|---|---|---|---|---|---|
| Adaptive Wiener [9] | 27.778 | 29.176 | 28.491 | 28.415 | 27.278 | 28.227 |
| BM3D [5] | 21.519 | 22.807 | 21.839 | 21.965 | 21.990 | 22.024 |
| IRCNN [6] | 23.927 | 24.841 | 24.251 | 24.323 | 24.260 | 24.321 |
| Proposed | 28.637 | 28.900 | 28.816 | 28.181 | 26.888 | 28.285 |
| PSNR | Castle | Pillar | Bridge | Cottage | Snow Field | Average |
|---|---|---|---|---|---|---|
| Adaptive Wiener [9] | 31.338 | 33.561 | 31.488 | 32.293 | 30.644 | 31.865 |
| BM3D [5] | 31.865 | 33.612 | 31.961 | 32.594 | 31.104 | 32.227 |
| IRCNN [6] | 30.051 | 31.097 | 30.328 | 30.575 | 30.075 | 30.425 |
| Proposed | 32.032 | 33.513 | 32.068 | 32.498 | 31.215 | 32.265 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, C.-L.; Ding, J.-J.; Lu, D.-Y. Enhanced Adaptive Wiener Filtering for Frequency-Varying Noise with Convolutional Neural Network-Based Feature Extraction. Eng. Proc. 2025, 92, 47. https://doi.org/10.3390/engproc2025092047
Liao C-L, Ding J-J, Lu D-Y. Enhanced Adaptive Wiener Filtering for Frequency-Varying Noise with Convolutional Neural Network-Based Feature Extraction. Engineering Proceedings. 2025; 92(1):47. https://doi.org/10.3390/engproc2025092047
Chicago/Turabian StyleLiao, Chun-Lin, Jian-Jiun Ding, and De-Yan Lu. 2025. "Enhanced Adaptive Wiener Filtering for Frequency-Varying Noise with Convolutional Neural Network-Based Feature Extraction" Engineering Proceedings 92, no. 1: 47. https://doi.org/10.3390/engproc2025092047
APA StyleLiao, C.-L., Ding, J.-J., & Lu, D.-Y. (2025). Enhanced Adaptive Wiener Filtering for Frequency-Varying Noise with Convolutional Neural Network-Based Feature Extraction. Engineering Proceedings, 92(1), 47. https://doi.org/10.3390/engproc2025092047