
A Deep Learning Framework for Traffic Accident Detection Based on Improved YOLO11


Abstract
1. Introduction
- A dataset was constructed, covering a diverse range of accident types and environmental conditions. This dataset facilitates robust feature learning and significantly improves the model’s generalization capability in real-world traffic scenarios.
- MLLA (Mamba-Like Linear Attention) Module: A lightweight linear attention mechanism was integrated into the network architecture, enhancing feature representation and improving detection accuracy while incurring minimal computational overheads.
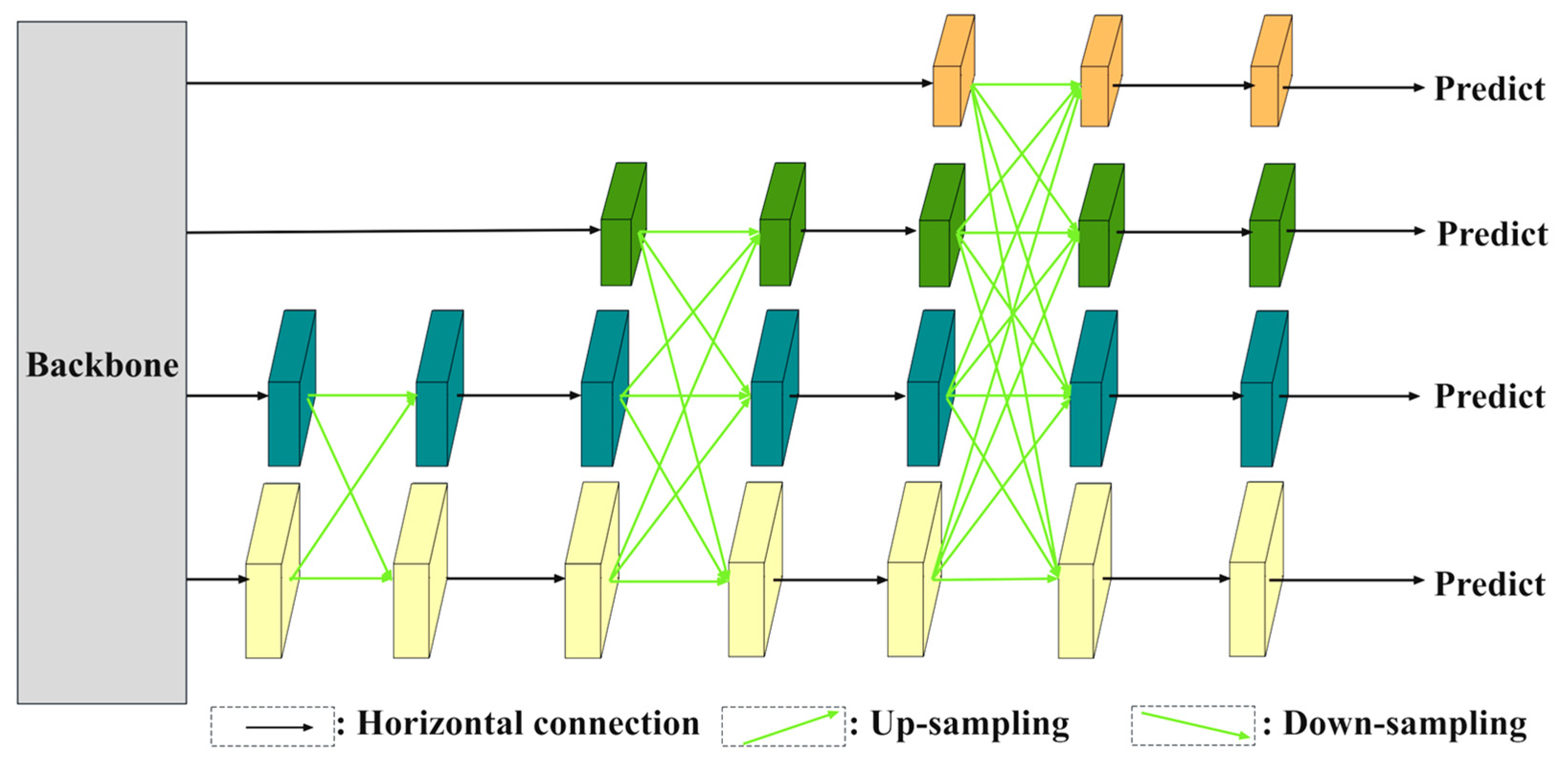
- AFPN (Asymptotic Feature Pyramid Network): An optimized detection head structure was implemented and an asymptotic feature fusion strategy was employed to progressively integrate low-level, high-level, and top-level features. This design enhances detection performance, particularly for small and overlapping objects.
- Focaler-IoU Loss Function: The Focaler-IoU loss function was employed to improve localization accuracy and enhance the model’s robustness in complex and challenging detection scenarios.
2. Related Works
3. Materials and Methods
3.1. Dataset Construction
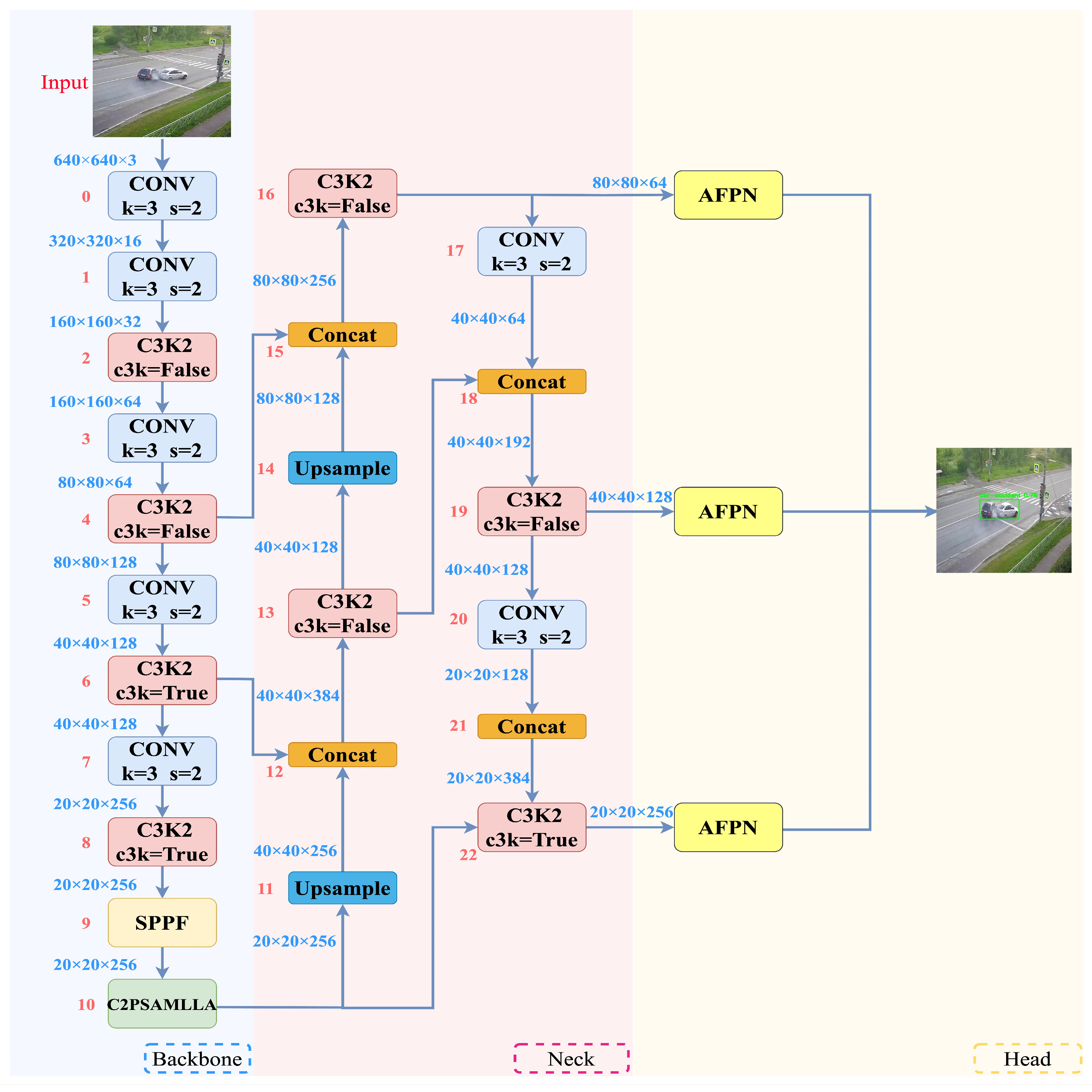
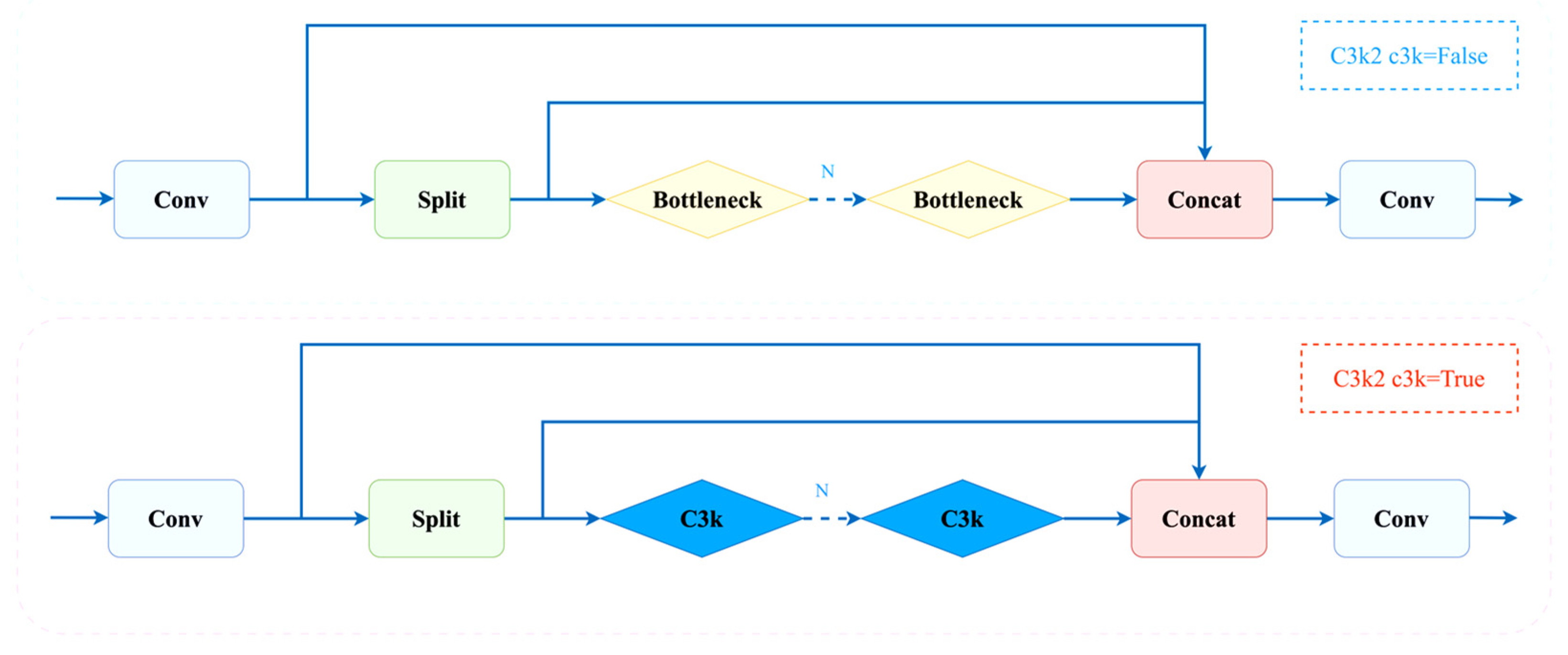
3.2. YOLO11-AMF
3.2.1. MLLA
3.2.2. AFPN
3.2.3. Focaler-IoU
3.2.4. Evaluation Indicators
3.3. Experimental Environment and Parameter Settings
4. Results
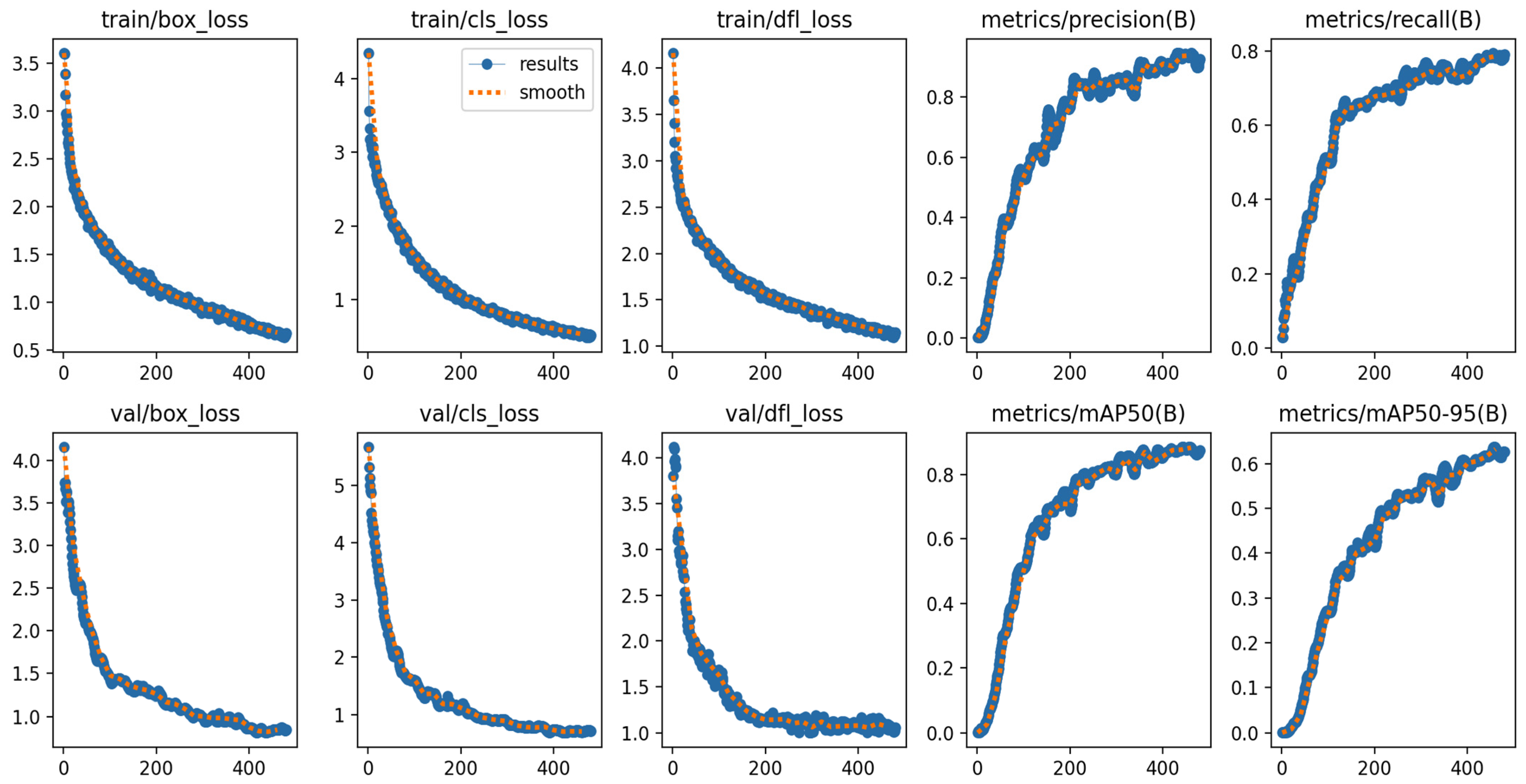
4.1. Experimental Results of the Improved YOLO11 Model
4.2. Comparison of Different Models Experiment
4.3. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Li, Y.; Wei, L.; Nie, G. High-Precision Traffic Sign Detection and Recognition Using an Enhanced YOLOv5. J. Circuits Syst. Comput. 2025, 34, 2550118. [Google Scholar] [CrossRef]
- Zhang, J.; Yi, Y.; Wang, Z.; Alqahtani, F.; Wang, J. Learning multi-layer interactive residual feature fusion network for real-time traffic sign detection with stage routing attention. J. Real-Time Image Process 2024, 21, 176. [Google Scholar] [CrossRef]
- Liu, L.; Wang, L.; Ma, Z. Improved lightweight YOLOv5 based on ShuffleNet and its application on traffic signs detection. PLoS ONE 2024, 19, e0310269. [Google Scholar] [CrossRef]
- Wang, Q.; Li, X.; Lu, M. An Improved Traffic Sign Detection and Recognition Deep Model Based on YOLOv5. IEEE Access 2023, 11, 54679–54691. [Google Scholar] [CrossRef]
- Yan, H.; Pan, S.; Zhang, S.; Wu, F.; Hao, M. Sustainable utilization of road assets concerning obscured traffic signs recognition. Proc. Inst. Civ. Eng.-Eng. Sustain. 2024, 178, 124–134. [Google Scholar] [CrossRef]
- Zhao, S.; Gong, Z.; Zhao, D. Traffic signs and markings recognition based on lightweight convolutional neural network. Vis. Comput. 2024, 40, 559–570. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2023, 35, 7853–7865. [Google Scholar] [CrossRef]
- Qu, S.; Yang, X.; Zhou, H.; Xie, Y. Improved YOLOv5-based for small traffic sign detection under complex weather. Sci. Rep. 2023, 13, 16219. [Google Scholar] [CrossRef] [PubMed]
- Elassy, M.; Al-Hattab, M.; Takruri, M.; Badawi, S. Intelligent transportation systems for sustainable smart cities. Transp. Eng. 2024, 16, 100252. [Google Scholar] [CrossRef]
- Suganuma, N.; Yoneda, K. Current status and issues of traffic light recognition technology in Autonomous Driving System. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2022, 105, 763–769. [Google Scholar] [CrossRef]
- Yang, L.; He, Z.; Zhao, X.; Fang, S.; Yuan, J.; He, Y.; Li, S.; Liu, S. A Deep Learning Method for Traffic Light Status Recognition. J. Intell. Connect. Veh. 2023, 6, 173–182. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, W.; Yang, X. An Enhanced Deep Learning Model for Obstacle and Traffic Light Detection Based on YOLOv5. Electronics 2023, 12, 2228. [Google Scholar] [CrossRef]
- Zhou, Q.; Zhang, D.; Liu, H.; He, Y. KCS-YOLO: An Improved Algorithm for Traffic Light Detection under Low Visibility Conditions. Machines 2024, 12, 557. [Google Scholar] [CrossRef]
- Li, K.; Wang, Y.; Hu, Z. Improved YOLOv7 for Small Object Detection Algorithm Based on Attention and Dynamic Convolution. Appl. Sci. 2023, 13, 9316. [Google Scholar] [CrossRef]
- Kamble, S.J.; Kounte, M.R. Machine Learning Approach on Traffic Congestion Monitoring System in Internet of Vehicles. Procedia Comput. Sci. 2020, 171, 2235–2241. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Kim, G.; Park, Y. Analyzing Performance of YOLOx for Detecting Vehicles in Bad Weather Conditions. Sensors 2024, 24, 522. [Google Scholar] [CrossRef] [PubMed]
- Kumeda, B.; Fengli, Z.; Oluwasanmi, A.; Owusu, F.; Assefa, M.; Amenu, T. Vehicle Accident and Traffic Classification Using Deep Convolutional Neural Networks. In Proceedings of the 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, Chengdu, China, 14–15 December 2019; pp. 276–280. [Google Scholar]
- Tamagusko, T.; Correia, M.G.; Huynh, M.A.; Ferreira, A. Deep Learning applied to Road Accident Detection with Transfer Learning and Synthetic Images. Transp. Res. Procedia 2022, 64, 90–97. [Google Scholar] [CrossRef]
- Ghahremannezhad, H.; Shi, H.; Liu, C. Real-Time Accident Detection in Traffic Surveillance Using Deep Learning. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 15–17 October 2022; pp. 1–6. [Google Scholar]
- Lin, C.; Hu, X.; Zhan, Y.; Hao, X. MobileNetV2 with Spatial Attention module for traffic congestion recognition in surveillance images. Expert Syst. Appl. 2024, 255, 14. [Google Scholar] [CrossRef]
- Fang, J.; Qiao, J.; Xue, J.; Li, Z. Vision-Based Traffic Accident Detection and Anticipation: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1983–1999. [Google Scholar] [CrossRef]
- Fu, Y. Combining Mamba and Attention-Based Neural Network for Electric Ground-Handling Vehicles Scheduling. Systems 2025, 13, 155. [Google Scholar]
- Li, Z. Mamba with split-based pyramidal convolution and Kolmogorov-Arnold network-channel-spatial attention for electroencephalogram classification. Front. Sens. 2025, 6, 2673–5067. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Tian, H.; Feng, Z. Asymptotic Feature Pyramid Network for Labeling Pixels and Regions. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7820–7829. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12595–12604. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Dollar, Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, T.; Meidani, H. End-to-end heterogeneous graph neural networks for traffic assignment. Transp. Res. Part C Emerg. Technol. 2024, 165, 104695. [Google Scholar] [CrossRef]
- Drliciak, M.; Cingel, M.; Celko, J.; Panikova, Z. Research on Vehicle Congestion Group Identification for Evaluation of Traffic Flow Parameters. Sustainability 2024, 16, 1861. [Google Scholar] [CrossRef]
- Zhao, Y.; Ju, Z.; Sun, T.; Dong, F.; Li, J.; Yang, R.; Fu, Q.; Lian, C.; Shan, P. TGC-YOLOv5: An Enhanced YOLOv5 Drone Detection Model Based on Transformer, GAM & CA Attention Mechanism. Drones 2023, 7, 446. [Google Scholar] [CrossRef]
- Huang, Z.; Li, L.; Krizek, G.C.; Sun, L. Research on Traffic Sign Detection Based on Improved YOLOv8. J. Comput. Commun. 2023, 11, 226–232. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, D.; Wu, B.; An, D. NST-YOLO11: ViT Merged Model with Neuron Attention for Arbitrary-Oriented Ship Detection in SAR Images. Remote Sens. 2024, 16, 4760. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment Configuration | Parameter |
|---|---|
| Operating system | Ubuntu 20.04 (Google Colab Environment) |
| CPU | Intel Xeon @ 2.20 GHz |
| GPU | NVIDIA Tesla T4 (12 GB GDDR5) |
| RAM | 13 GB |
| Development environment | Google Colab |
| Programming language | Python 3.9 |
| Hyperparameter | Value |
|---|---|
| Epochs | 500 |
| Batch size | 16 |
| Num workers | 2 |
| Initial learning rate | 0.01 |
| Optimizer | Adam |
| Input image size | 640 × 640 |
| Algorithm | Batch Size | Precision/% | mAP50–95/% | Parameters/m | GFlops |
|---|---|---|---|---|---|
| DETR | 16 | 91.4 | 63.4 | 36.7 | 36.81 |
| Faster R-CNN | 16 | 82.9 | 66.1 | 28.2 | 37.52 |
| YOLOV5n | 16 | 94.9 | 58.6 | 2.5 | 7.2 |
| YOLOV8n | 16 | 87.2 | 59.4 | 3.0 | 8.2 |
| YOLO11 | 16 | 90.0 | 59.7 | 2.6 | 6.4 |
| YOLO-AMF | 16 | 96.5 | 66 | 2.7 | 6.8 |
| Algorithm | Batch Size | Precision/% | Recall/% | mAP50/% | mAP50–95/% | F1-Score/% |
|---|---|---|---|---|---|---|
| YOLOV5n | 16 | 94.9 | 71.4 | 82.4 | 58.6 | 81.5 |
| 32 | 84.1 | 80.0 | 83.8 | 63.6 | 82.0 | |
| 64 | 91.9 | 71.4 | 78.8 | 56.9 | 80.4 | |
| YOLOV8n | 16 | 87.2 | 78.2 | 86.4 | 59.4 | 82.5 |
| 32 | 99.1 | 68.6 | 86.7 | 64.1 | 81.0 | |
| 64 | 96.0 | 68.6 | 79.3 | 56.2 | 80.0 | |
| YOLO11 | 16 | 90.0 | 76.9 | 83.7 | 59.7 | 82.9 |
| 32 | 92.5 | 74.6 | 89.1 | 61.8 | 82.6 | |
| 64 | 92.4 | 77.1 | 82.0 | 60.1 | 84.1 | |
| YOLO11-AMF | 16 | 96.5 | 82.9 | 90.0 | 66.0 | 89.2 |
| 32 | 90.6 | 77.1 | 89.0 | 60.8 | 83.3 | |
| 64 | 83.6 | 87.7 | 86.9 | 63.8 | 85.6 |
| MLLA | AFPN | Focaler-Iou | Precision/% | Recall/% | mAP50/% | mAP50–95/% | F1-Score/% |
|---|---|---|---|---|---|---|---|
| - | - | - | 89.9 | 76.9 | 83.6 | 59.7 | 82.9 |
| √ | - | - | 87.9 | 77.1 | 83.1 | 58.4 | 82.2 |
| - | √ | - | 76.7 | 80.0 | 82.2 | 56.6 | 78.3 |
| - | - | √ | 91.0 | 71.4 | 83.4 | 57.8 | 80 |
| √ | √ | - | 68.9 | 76.1 | 79.5 | 52.5 | 72.4 |
| √ | - | √ | 92.7 | 74.3 | 84.1 | 55.0 | 82.5 |
| - | √ | √ | 97.0 | 68.6 | 83.1 | 60.9 | 80.3 |
| √ | √ | √ | 96.5 | 82.9 | 90.0 | 66.0 | 89.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Huang, L.; Lai, X. A Deep Learning Framework for Traffic Accident Detection Based on Improved YOLO11. Vehicles 2025, 7, 81. https://doi.org/10.3390/vehicles7030081
Li W, Huang L, Lai X. A Deep Learning Framework for Traffic Accident Detection Based on Improved YOLO11. Vehicles. 2025; 7(3):81. https://doi.org/10.3390/vehicles7030081
Chicago/Turabian StyleLi, Weijun, Liyan Huang, and Xiaofeng Lai. 2025. "A Deep Learning Framework for Traffic Accident Detection Based on Improved YOLO11" Vehicles 7, no. 3: 81. https://doi.org/10.3390/vehicles7030081
APA StyleLi, W., Huang, L., & Lai, X. (2025). A Deep Learning Framework for Traffic Accident Detection Based on Improved YOLO11. Vehicles, 7(3), 81. https://doi.org/10.3390/vehicles7030081