Abstract
Fire detection presents considerable challenges due to the destructive and unpredictable characteristics of fires. These difficulties are amplified by the small size and low-resolution nature of fire and smoke targets in images captured from a distance, making it hard for models to extract relevant features. To address this, we introduce a novel method for small-target fire and smoke detection named YOLOv7scb. This approach incorporates two key improvements to the YOLOv7 framework: the use of space-to-depth convolution (SPD-Conv) and C3 modules, enhancing the model’s ability to extract features from small targets effectively. Additionally, a weighted bidirectional feature pyramid network (BiFPN) is integrated into the feature-extraction network to merge features across scales efficiently without increasing the model’s complexity. We also replace the conventional complete intersection over union (CIoU) loss function with Focal-CIoU, which reduces the degrees of freedom in the loss function and improves the model’s robustness. Given the limited size of the initial fire and smoke dataset, a transfer-learning strategy is applied during training. Experimental results demonstrate that our proposed model surpasses others in metrics such as precision and recall. Notably, it achieves a precision of 98.8% for small-target flame detection and 90.6% for small-target smoke detection. These findings underscore the model’s effectiveness and its broad potential for fire detection and mitigation applications.
1. Introduction
Fires pose significant risks to human safety and result in substantial economic losses. According to data released by China’s National Fire and Rescue Administration in 2023, fire and rescue teams nationwide responded to a staggering 878,000 incidents, including urban and rural fires, forest and grassland fires, and other conflagrations, which resulted in substantial economic losses totaling 19.4 billion USD [1]. Fires typically escalate rapidly and prove challenging to contain, underscoring the critical importance of early intervention to mitigate the resulting damage and safeguard lives and property. Considering that fires frequently originate from small ignitions accompanied by smoke, the detection of fire and smoke in small targets assumes paramount significance.
Researchers have historically used various devices for fire detection, including sensors [2,3,4,5], spectrometers [6,7,8,9], and acoustic spectrum analyzers [10,11,12,13]. These methods depend on environmental conditions and equipment quality, typically involving the extraction of multi-dimensional features such as temperature, smoke concentration, gas composition, and light intensity. Sensors monitor variations in temperature, smoke concentrations, and hazardous gas levels (e.g., carbon monoxide); spectrometers analyze the spectral characteristics of flames or smoke to identify specific light intensities and wavelengths; and acoustic spectrum analyzers capture the sounds generated by fires, including combustion and explosions. While effective in certain contexts, these methods have notable limitations. They are often time-consuming and require significant effort, involving extensive data collection and processing. Additionally, detection efficiency and precision are frequently constrained by challenges such as high costs, sensitivity to environmental factors, inadequate real-time responsiveness, and limited application scope. For example, sensors may produce false alarms due to fluctuations in humidity or temperature, spectrometers may underperform in bright or smoky environments, and acoustic analyzers may be affected by background noise, reducing detection precision. Consequently, the practical application of these traditional methods faces numerous challenges.
In recent years, researchers have increasingly investigated computer vision models for fire detection, using classical machine learning methods [14,15,16,17,18]. Traditional methods extract features related to flames or smoke from images, which are then classified to determine fire presence. While classifiers enhance precision, they depend on manually selected features and do not specify the locations of flames or smoke. Recently, advanced fire detection algorithms using deep learning have emerged, categorized into two types: two-stage detection strategies based on region proposals [19,20], which offer high precision but slow speeds, and regression-based one-stage strategies [21,22,23,24,25,26], which balance precision and speed. However, many studies neglect that initial fire detection often involves small sizes and low pixel resolution, making it crucial to enhance detection precision for early-stage smoke and small fires.
In this study, we introduce a novel method called YOLOv7std for detecting fire and smoke in small targets based on an enhanced YOLOv7 model. Through modifications to the original YOLOv7 and employing transfer-learning techniques, we improve the precision of detecting small-target fires and smoke in fire images. Our model’s primary innovations comprise three key components:
- We refine the YOLOv7 architecture by replacing the PANet structure with the BiFPN structure and substituting the ELAN-W module with the C3 module, resulting in improved detection of small-target fires.
- We introduce the SPD-Conv module to reduce information loss and enhance feature-extraction precision, therefore improving the detection of small-target fires and smoke in images.
- To tackle the imbalance between positive and negative samples of fire and smoke, we introduce a weight factor of focal loss into the original bounding box loss function.
The rest of the paper is organized as follows. Section 2 reviews related work on fire detection. Section 3 presents the small-target fire and smoke detection method proposed in this study. Section 4 demonstrates the experimental results of the proposed method. Section 5 discusses the advantages and limitations of the method. Finally, Section 6 provides the conclusion of the research.
2. Related Work
2.1. Fire Detection
Fire detection methods can be broadly categorized into traditional device-based approaches and computer vision-based techniques.
2.1.1. Conventional Device-Based Fire Detection Methods
Several fire detection methods are currently in use, including sensor-based, infrared, acoustic spectrum, visible light, and computer vision detection. Sensor-based methods [2,3] collect data on humidity, temperature, carbon monoxide, and smoke, but it is susceptible to sensor and network failures. Infrared-based detection methods [6] use specialized equipment to gather thermal imaging data, which can effectively identify abnormal temperatures and provide high precision in fire detection. However, these methods are costly and only work when the fire generates heat. Zhang et al. [10] developed an IoT-based wildfire detection system utilizing acoustic spectral analysis. This system employs wireless acoustic detection and a tree-powered energy device to differentiate between canopy fires and surface fires. However, the system is dependent on specific acoustic characteristics and may be disturbed by background noise and complex environments. Seydi et al. [27] proposed a deep learning framework named Fire-Net, designed to detect small active forest fires by combining optical and thermal data from Landsat-8 images and employing residual and separable convolutional blocks. However, the method relies on satellite imagery, and real-time availability and resolution are limited by satellite transit frequency and cloud coverage. In contrast, the method of using ordinary cameras to collect fire images offers several advantages, including high precision, low cost, and ease of operation. It is particularly suitable for real-time monitoring of small-target fires and smoke over long distances and is, therefore, widely used in fire monitoring.
Although traditional fire detection methods have their own characteristics, they tend to exhibit slow response time, limited detection range, and susceptibility to interference when facing rapidly changing fire environments. Computer vision-based techniques, on the other hand, provide new ideas to solve these problems with their flexibility and adaptability.
2.1.2. A Computer Vision-Based Fire Detection Method
With advancements in computer vision, computational methods for fire detection are increasingly being employed to identify the presence or absence of fire in images. Thepade et al. [14] made significant advancements in lowering false alarm rates in fire detection using the LUV color space. Chowdhury et al. [15] improved the efficacy of fire detection by integrating visual sensors with smoke sensors. Mei et al. [16] combined machine learning with an enhanced ViBe algorithm, using a two-stage classifier based on random forest and support vector machine (SVM) for early detection. Zhao et al. [18] developed a backpropagation (BP) neural network with an SVM classifier, utilizing UAV images to improve fire image recognition by extracting features like roundness, sharpness, and flame area changes. Additionally, Ren et al. [28] proposed the region proposal network (RPN) for efficient region proposal generation by sharing full-image convolutional features with the detection network and merging it with faster region-based convolutional neural network (Fast R-CNN) into a unified network. Zhou et al. [29] proposed a center-based object detection network (CenterNet), a centroid-based object detection method that identifies the bounding box center of a target through keypoint estimation and predicts its additional attributes. Although these methods have made significant advancements in fire detection technology, they often provide classification results without accurately identifying the location of smoldering targets within the image.
Recently, You Only Look Once (YOLO) technology has demonstrated a wide range of applications in the field of fire detection. An adapted YOLOv3 algorithm has been developed for real-time, high-speed fire detection [21,22,23]. These approaches eliminate the need for manual feature extraction, reduce computational overhead, minimize parameter complexity, and significantly improve both detection accuracy and processing speed. Song et al. [30] proposed an improved flame and smoke detection algorithm based on YOLOv5s. The algorithm incorporates a dual cross-scale fusion module and an attention-enhanced inference layer, achieving a 3.2% mAP improvement, a detection speed of 243 FPS, and robust performance in complex scenarios. Titu et al. [31] optimized the YOLOv8n model with knowledge distillation for deployment on edge devices, achieving 89.23% accuracy in real-time fire detection using a Raspberry Pi-based drone system. Sun et al. [32] proposed YOLOv7-FIRE, which integrates a bidirectional transformer (BiFormer), normalized Wasserstein distance (NWD), and content-aware reassembly of features (CARAFE) to enhance small-target detection and feature preservation. Akhmedov et al. [26] proposed a method that integrates YOLOv10 with a de-fogging algorithm. The experimental results indicate that this approach surpasses other YOLO models in terms of precision, recall, and mean average precision at a threshold of 0.50 (mAP@0.50). Although the aforementioned methods have improved fire detection accuracy, they often neglect the critical aspect of early fire detection and lack specialized models for handling small-target fires and smoke. Tackling these challenges necessitates focusing on enhancing the model’s capability to capture the distinctive characteristics of early-stage fires and smoke, thereby minimizing the risks of missed detections and false alarms for small-scale targets.
At the same time, fire-specific databases have also been developed. For example, Shamsoshoara et al. [33] introduced the drone-collected fire image dataset “FLAME”, which includes annotated thermal heatmaps and video frames to facilitate fire detection and segmentation. Similarly, Bryce et al. [34] proposed the Flame2 dataset, comprising side-by-side infrared and visible spectrum video pairs captured by drones during a prescribed open-canopy fire in Northern Arizona in 2021.
2.2. YOLOv7
YOLOv7 is a one-stage target detection algorithm driven by convolutional neural networks. It utilizes techniques such as reparametrized convolution (REP) [35], efficient layer aggregation network (ELAN), and dynamic label assignment (DLA) to surpass the majority of established target detection algorithms in both precision and speed [36]. The YOLOv7 network model consists of four key components: input, backbone, neck, and head, as depicted in Figure 1.
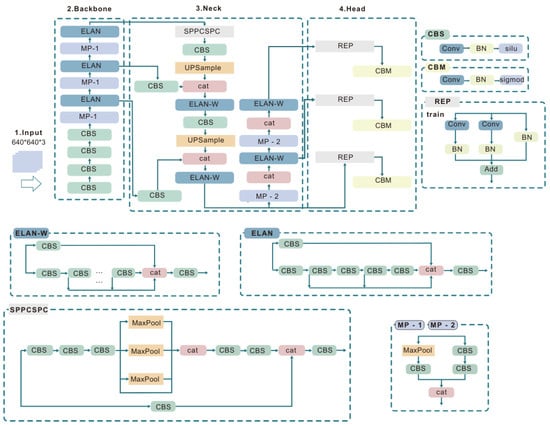
Figure 1.
YOLOv7 structural diagram. The YOLOv7 network structure diagram comprises four components: input, backbone, neck, and head. The backbone includes several CBS, ELAN, and MP-1. Neck consists of SPPCSPC, UPSample, ELAN-W, and CBS. The head consists of REP and CBM.
The input section undergoes fine-grained preprocessing, including scaling the image to a fixed size (e.g., 640 × 640 pixels), normalizing the pixel values to between 0 and 1, adjusting the channel order to (channels, height, width), and adding a batch dimension. These steps improve the quality and format, boosting the model’s accuracy and robustness in detecting small targets like fires and smoke.
In the backbone component, feature information is extracted from the preprocessed image tensor, with a notable enhancement being the incorporation of the extended-ELAN (E-ELAN) module alongside the max pooling convolutions (MPConv) module. The E-ELAN module employs several convolutions in multiple branches to augment precision by deepening the network. Its internal residual blocks utilize skip connections to mitigate gradient vanishing issues stemming from increased depth. The proposed E-ELAN improves cardinality using expand, shuffle, and merge operations, enhancing the network’s learning ability without interfering with the original gradient path. The MPConv module comprises MaxPool combined with a convolutional double branch of size 3 × 3. The MaxPool branch expands the receptive field of the feature layer before combining it with the convolutional branch, improving the network’s generalization ability.
The neck of YOLOv7 typically employs feature pyramid networks (FPN) [37] to aggregate features from different layers extracted by the backbone. This multiscale feature fusion method effectively captures targets of different sizes in fire scenes, from small flame tips to spreading smoke, thereby improving the model’s sensitivity and precision in detecting small targets. To further boost network performance, YOLOv7 incorporates the spatial pyramid pooling cross-stage partial channel (SPPCSPC) module [38] and ELAN-with expansion (ELAN-W) module [39] within the neck. The SPPCSPC module employs maximum pooling to obtain diverse receptive fields, enabling the network to adapt to images of varying resolutions. Meanwhile, the ELAN-W module improves feature learning and robustness by efficiently handling both the shortest and longest gradient paths [40]. The integrated features are subsequently forwarded to the detection head, which processes them to generate the final results.
The head component utilizes the REP module in conjunction with the YOLO detection head. The REP module achieves decoupling during both training and inference through structural reparameterization, thereby reducing network computation and enhancing processing speed. The output segment of the model incorporates three groups of REP modules, delivering feature information across three different scales. This design boosts the network’s ability to detect targets of different sizes.
During network training, the loss function of YOLOv7 is partitioned into three components: the classification loss function , the confidence loss function and the bounding box loss function , defined as follows:
The computes the probability of detecting an object’s category, while the determines whether an object is present within the predicted bounding box. Both employ binary cross-entropy as the loss function. If there are G categories, and for the i-th prediction frame, the classification loss can be expressed as:
where N is the number of prediction frames, the true category label is encoded using one-hot coding of the true category (i.e., 1 for the true category and 0 for the rest of the categories), and the predicted category probability is the predicted probability that the i-th prediction frame belongs to category g.
For the i-th prediction frame with confidence score and true confidence labeled , the confidence loss can be expressed as:
where is 1 to indicate that the i-th prediction frame contains the target and 0 to indicate that it does not contain the target.
The represents the error between the prediction box and the true value, employing CIoU as the loss function.
where denotes the intersection and merge ratio, i.e., the ratio of the area of overlap between the labeled box A and the predicted box B to the area of union between them, as shown in Figure 2. denotes the Euclidean distance between the centroids of both labeling box A and the predicted box B; C denotes the diagonal distance of the smallest closure region that can contain both labeling box A and the predicted box B; is a positive trade-off parameter table; is used to measure the degree of approximation of the width-to-height ratio of the labeled box and the predicted box, with a smaller value of indicates that the width-to-height ratio is closer to the labeled box; and are the widths of the labeled box A and the predicted box B, respectively, while and are their respective heights.
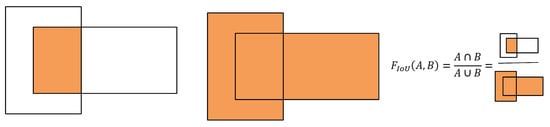
Figure 2.
Graphical representation of the The orange area represents the intersection region between detection boxes.
2.3. Transfer Learning
Transfer learning is a machine learning technique that leverages pre-trained models for new tasks. Currently, transfer learning finds widespread application in natural language processing, image, and speech recognition, as well as remote sensing and surveillance [41]. In transfer learning, two fundamental concepts are domain and task. The domain includes the set of all features X in the feature space and the distribution . The task consists of the decision function of the feature samples and the set of labels Y. Here is the conditional probability distribution and . Transfer learning is a method that applies knowledge from a source domain to enhance the performance of a classification model in a target domain. It leverages feature sample sets and along with category sets and from the respective domains. The spatial expressions for the source and target domains are defined as:
where is the number of source-domain label-feature samples, is the number of labeled samples in the target domain, and ≫. Transfer learning can be categorized across three dimensions: domain (data features), task (migration scenario), and data (migration object). Additionally, considering the specific migration object in transfer learning, methods are further categorized into four major types: instance-based, feature-based, model-based, and relationship-based [42].
Currently, transfer learning is widely employed in image speech recognition, remote sensing surveillance, and natural language processing [43]. This technique efficiently reduces computation and accelerates model training by leveraging pre-trained convolutional neural networks. These networks, initially trained on specific tasks, perform shallow network extraction to extract features that can be applied to other models. Subsequently, only the underlying layers of the network are trained [44]. Transfer learning proves invaluable in overcoming dataset limitations, such as those encountered in fire datasets.
3. Materials and Methods
3.1. Fire Image Collection
To meet the requirements for detecting small-scale targets, we selected the Roboflow (https://universe.roboflow.com/agostino-abbatecola-52ty4/veryfiresmokedetection, accessed on 30 November 2023) dataset [45] for training the model (referred to as Dataset A). This dataset comprises 7389 annotated images depicting various types of fires, including wilderness fires, residential habitat fires, factory fires, and roadway fires.
Additionally, we curated a custom dataset consisting of 493 images, referred to as Dataset B. Following the Microsoft COCO standard, targets smaller than 32 × 32 pixels were classified as “small targets”. High-resolution images of small-target fires were captured using a DJI Mini 3 Pro drone under various environmental conditions and viewing angles. To enhance the diversity and robustness of the dataset, we implemented comprehensive data preprocessing and augmentation techniques. These included transformations such as rotation, translation, scaling, cropping, and flipping to simulate different perspectives. Furthermore, adjustments to brightness, contrast, and saturation were applied to account for varying lighting conditions, while noise and blurring were introduced to replicate real-world imperfections, such as motion blur and atmospheric interference. As a result of these enhancements, Dataset B was expanded to include 826 unique fire and smoke images.
Combined with Dataset A, the complete dataset comprised 8215 images, categorized into four classes: wilderness fires, residential fires, factory fires, and roadway fires, as detailed in Table 1. We partitioned the datasets into training, validation, and testing sets following a 7:2:1 ratio. The specifics of Dataset A and Dataset B are presented in Table 2.

Table 1.
The number of images of different categories in our datasets.
Table 2.
Details of the datasets.
3.2. Fire Detection Model
To enhance the precision of YOLOv7 in handling small-sized and low-resolution targets, we refined the network architecture of YOLOv7, primarily focusing on the neck component. The enhancements involved replacing the original PANet structure and ELAN-W module with improved versions of the BiFPN and C3, respectively. Additionally, we introduced the SPD-Conv module [46] and used the Focal-CIoU loss function to replace the CIoU loss function in the original model. The modified network structure diagram is depicted in Figure 3.
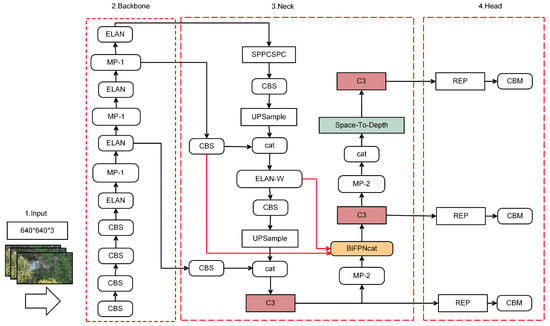
Figure 3.
Improving YOLOv7 network architecture. The red module section is the replacement of the ELAN-W section with C3, and the green is the new SPD-Conv module. The red line is the new parameter transmission route, and the orange is BiFPNcat after adjustment to the BiFPN structure.
3.2.1. BiFPN Replacement of PANet
In the neck of YOLOv7, the PANet architecture is refined into a BiFPN structure to better integrate information across various scales. BiFPN employs the principle of bidirectional fusion to reconstruct both top-down and bottom-up paths, integrating feature data across different scales. To address the issue of missing feature information, BiFPN utilizes upsampling and downsampling techniques to standardize feature resolution scales and establish bidirectional connections between feature maps at the same scale [47]. Figure 4 illustrates the structure of the BiFPN, which aims to improve target detection. Five feature maps at different scales (P3 to P7) are shown with bidirectional information transfer via top-down (red arrows) and bottom-up (blue arrows) paths, while lateral connections (mixed red and blue arrows) are used to enhance feature exchange among scales, ultimately producing enhanced multiscale feature maps as outputs.
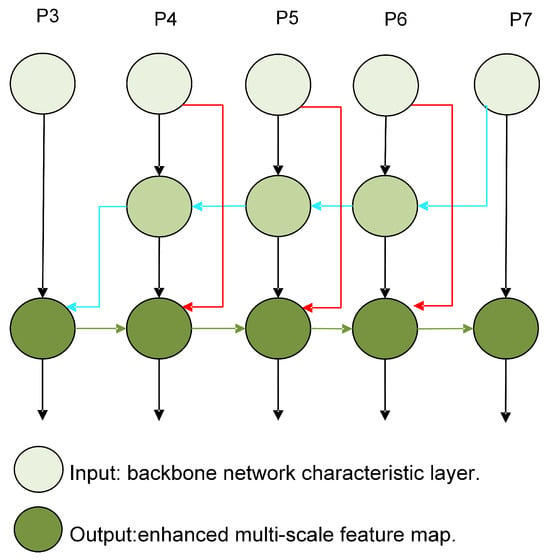
Figure 4.
The structure of BiFPN. The blue line represents a top-down pathway conveying high-level semantic information, while the green line denotes a bottom-up pathway conveying low-level positional information. Additionally, the red line signifies the same layer as the second point, with a new edge between the input nodes, The black line represents the direct connection between the backbone network characteristic layers and the enhanced multi-scale feature maps.
Unlike conventional feature fusion methods, BiFPN utilizes a weighted fusion mechanism to differentiate the integration of various input features. Given multiple features of differing scales , where represents the features of layer i, the objective is to determine a transformation f capable of efficiently aggregating features across different scales and producing multiple aggregated new features .
where the operation entails either upsampling or downsampling, while represents the convolutional operation.
In addition, BiFPN employs a rapid normalization method, which achieves comparable precision to SoftMax-based fusion but with faster computation. The fast normalization method is depicted as:
where represents the weight, which is ensured to be under the ReLU activation function, is utilized to mitigate unstable values and represents a very small constant, denotes the input features, and indicates the outcome of weighted feature fusion. The feature fusion at i-th level is articulated as follows:
where represents the intermediate feature of i-th level in the top-down path, and denotes the output feature of i-th level in the bottom-up path. The integration of BiFPN enhances the interrelation among feature scales, which helps to detect the shallow features of smaller fire and smoke targets, thus alleviating inaccuracies in recognition stemming from target overlap.
3.2.2. Substitution of ELAN-W with C3
The YOLOv7 network includes many ELAN-W modules, which add computational load and reduce inference speed. The C3 module, or Cross-Stage Partial Network (CSPNet), addresses this using three convolutions. The C3 module consists of three Conv modules, each incorporating a 1 × 1 convolution layer and multiple bottleneck modules. Each bottleneck module contains 1 × 1 and 3 × 3 convolution layers. The Conv module itself is composed of a 1 × 1 convolution layer, followed by a batch normalization layer and a SiLU activation function. As shown in Figure 5, the C3 module splits into two paths: one with convolutional and bottleneck modules and the other with a single convolutional module. Their outputs are concatenated and processed through an additional convolutional module. Each convolutional module in the C3 structure is designed for dimensionality reduction or expansion. The C3 module improves feature extraction and fusion using multiscale feature fusion and cross-channel information transfer, boosting model performance and significantly increasing inference speed, making it crucial to the network architecture.
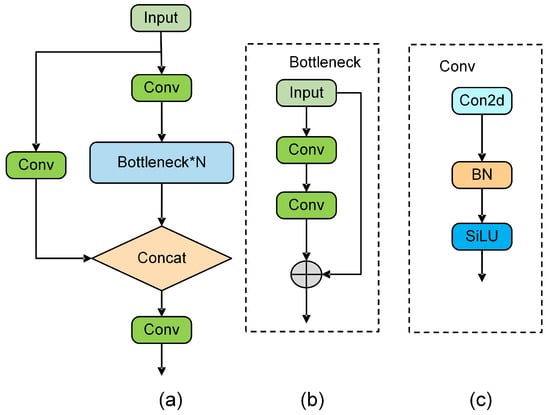
Figure 5.
Structure of C3 module. (a) The C3 module comprises three Conv modules, each consisting of 1 × 1 convolution and many bottleneck modules. (b) The bottleneck module includes 1 × 1 and 3 × 3 convolution layers, respectively. (c) The Conv module is composed of a 1 × 1 convolution layer, a batch normalization layer, and a SiLU activation function.
3.2.3. Incorporating SPD-Conv
In YOLOv7, much of the feature extraction and feature map reduction is achieved through 3 × 3 convolutions with maximum pooling at a step size of 2. Each operation effectively halves the feature map dimensions, reducing the computational load. However, this approach, due to its striding operation, often leads to the loss of valuable features, particularly when dealing with low-resolution images or targets with indistinct category boundaries. To mitigate this issue and maintain feature richness while reducing feature map size, we introduce the SPD-Conv module in the neck section. This module enhances small-target detection by expanding the feature map size, increasing channel depth, and preserving small-target features within the channels.
The SPD-Conv module consists of an SPD layer and a 1 × 1 convolution layer. It is segmented based on Equation (14), where an intermediate feature map of arbitrary size is substituted, using convolution with a scale step size.
where , , , and represent the four sub-mappings derived from the original feature map X. The parameter represents a scaling factor, and a series of sub-graphs f are obtained by downsampling the original feature map X according to . Each sub-graph consists of the elements obtained by dividing X by and . These sub-graphs are then spliced along the channel dimension to form a new feature map . This new feature map reduces the size in the spatial dimension by a multiple of while increasing the channel dimension by channels.
The operation procedure is illustrated in Figure 6. Four feature maps with dimensions W/2 × H/2 × C are acquired using the spaced sampling method. They are subsequently combined to produce a feature map with dimensions W/2 × H/2 × 4C. Dimensionality reduction is then carried out through 1 × 1 convolution, and correlations between feature maps are established to yield a feature map of size W/2 × H/2 × C. The SPD-Conv module exhibits higher information retention compared to traditional convolutional algorithms, thereby effectively enhancing feature-extraction capabilities for small-target fire and smoke images.
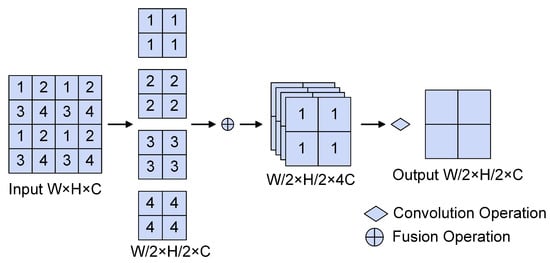
Figure 6.
SPD-Conv operation process diagram. The operation flow of SPD-Conv mainly consists of spaced sampling, splicing, and convolution operations.
3.2.4. Improvement of the Loss Function
In the YOLOv7 algorithm, the CIoU loss function represents bounding box regression loss, considering overlap area, center distance, and aspect ratios. However, it overlooks the imbalance between low-quality and high-quality samples. Low-quality samples with minimal overlap result in larger regression errors that hinder training. To enhance high-quality sample contributions, we use the Focal-CIoU loss function, which integrates CIoU and focal loss principles [48]. This introduces a weighting factor from focal loss into the original bounding box loss, addressing the category imbalance issue. The new bounding box loss function is defined in the following equation:
where is a parameter used to control the degree of outlier suppression. Given the necessity for high recall in fire target detection, we align with the weight coefficient of positive samples 0.5.
3.3. Transfer Learning in YOLOv7
Transfer learning involves using knowledge from a source-domain task to adjust a network model’s parameters for a target domain task, optimizing it for the target task’s specific needs. In this study, we employ transfer learning to train a compact fire detection model, as illustrated in Figure 7. Initially, the source domain is utilized for pre-training, using Dataset A to establish a fire detection model. Subsequently, the target domain, which consists of Dataset B, employs the weight file obtained from the pre-trained fire detection model. The new model’s weights are initialized using those from the pre-trained network instead of random initialization. By continuously optimizing the network parameters via the backpropagation algorithm, the predicted bounding box locations and categories are refined to align closely with the actual labels, resulting in an efficient fire detection model for the target domain.
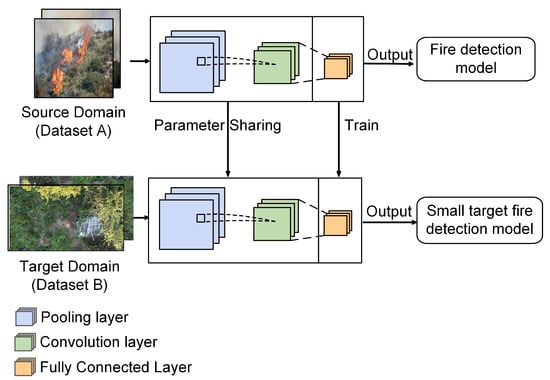
Figure 7.
Transfer-learning process training for small-target fire detection model.
3.4. Performance Comparisons
In this study, we primarily focus on precision and recall metrics. Precision measures the ratio of correctly identified fire and smoke predictions to all model predictions, while recall gauges the model’s ability to detect fire and smoke incidents. By evaluating both metrics, we provide a more comprehensive assessment of the models’ performance in real-world conditions.
We categorize samples into four types based on the combination of true and predicted labels. True Positive () represents the number of correctly identified fires and smoke; False Positive () indicates the number of non-fire and non-smoke instances misclassified as fire or smoke; True Negative () refers to the correctly identified non-fire and non-smoke instances; and False Negative () denotes the number of fires and smoke instances misidentified as non-fire and non-smoke. Hence, precision and recall are defined as follows:
In addition, another evaluation metric utilized for object detection is , which is defined as:
Furthermore, our model was benchmarked against six recent YOLO models—YOLOv3, YOLOv5, YOLOv7, YOLOv8, YOLOv10, and YOLOv11—all of which are designed for single-stage detection. A brief overview of each algorithm is provided below:
- YOLOv3: The third version of the YOLO algorithm for object detection employs multiscale prediction and feature pyramid networks to strike a balance between speed and precision [49].
- YOLOv5: Developed by ultralytics, YOLOv5 comprises lightweight target detection algorithms characterized by modular design, automated model optimization, and rapid training techniques, emphasizing simplicity and flexibility [50].
- YOLOv7: The seventh version of the YOLO series boasts a deeper network structure and enhanced performance optimization, resulting in improved precision and speed in target detection [51].
- YOLOv8: This version incorporates advanced techniques such as model compression and attention mechanisms to further improve both precision and efficiency [52].
- YOLOv10: Enhanced feature extraction, optimized network architecture, and improved training techniques in YOLOv10 result in higher precision and faster inference speeds for real-time object detection [53].
- YOLOv11: Demonstrates superior performance in computer vision tasks such as object detection, instance segmentation, pose estimation, and oriented object detection. It surpasses its predecessors in mean Average Precision () and computational efficiency while maintaining a balance between parameter count and accuracy [54].
4. Experiments and Results
4.1. Parameter Settings
For this experiment, all implementations and evaluations were performed on a computer with the Ubuntu 20.04 operating system. The software environment included PyTorch 1.12, CUDA 11.3, and Python 3.9, while the hardware setup featured 32 GB of RAM and an NVIDIA V100 GPU.
The key training parameter settings for the fire detection model are outlined in Table 3. The model has 33.39 M parameters and a size of 127.41 M. The training time per epoch for Dataset A is 2.8 min, so each training session lasts about 840 min, i.e., 14 h. The training time per epoch for Dataset B is 0.72 min, so each training lasts approximately 180 min or 3 h.
Table 3.
Training parameters of YOLOv7scb.
4.2. Performance Evaluation Against Different YOLO Models
To validate the advantages of the proposed YOLOv7scb model, we compared it with six other versions of YOLO, as shown in Table 4. On Dataset A, which contains non-small targets, YOLOv7scb outperforms the other models in most evaluation metrics. Specifically, YOLOv7scb achieves over 90% precision in the fire, smoke, and total categories. Compared to the earlier YOLOv3 model, YOLOv7scb shows improvements of 11%, 15%, and 15% in precision, recall, and mAP for the total categories, respectively. When compared to the latest YOLOv11, YOLOv7scb excels in precision for the fire, smoke, and overall categories. It also slightly outperforms YOLOv11 in overall recall metrics. However, YOLOv7scb slightly underperforms YOLOv11 in terms of mAP, suggesting that YOLOv7scb is still somewhat weaker in handling overlapping objects of fire and smoke in images.
Table 4.
Comparison with different YOLO models.
For Dataset B, YOLOv7scb also demonstrates commendable detection capabilities. In fire recognition, YOLOv7scb achieves excellent results across all evaluation metrics. Specifically, compared to the other models, YOLOv7scb improves precision by 2% to 10%, recall by 2% to 9%, and mAP by 2% to 15%. These notable improvements highlight the exceptional performance of YOLOv7scb in detecting small-target fires. Recognizing smoke poses various challenges due to its semi-transparent nature, irregular shapes, and blurry edges, which make it difficult to precisely define its boundaries. This confusion leads to an increase in false positives, adversely affecting both recall and precision. As a result, the evaluation metrics for smoke detection are consistently lower than those for fire detection in all experimental results. Despite these challenges, YOLOv7scb’s ability to detect smoke still outperforms that of other models. Furthermore, the model demonstrates superior performance on Dataset B compared to Dataset A. This can be attributed to the nature of the datasets: Dataset A comprises images with substantial interference and complex environments, whereas Dataset B is a custom-designed dataset specifically tailored for small-scale fire and smoke scenarios, featuring minimal environmental interference.
4.3. Performance Evaluation Against Different Methods
To validate the performance of our model, we compared it with three representative methods reviewed in the “Related Work” section, using the same dataset and training approach as our model. The experimental results are summarized in Table 5.
Table 5.
Comparison with different methods.
The results demonstrate that YOLOv7scb consistently outperforms existing methods across both datasets. For Dataset A, YOLOv7scb surpasses [30] by 1.8% and 1% in precision and recall, respectively, and achieves significant improvements over [28], outperforming it by 28%, 19.3%, and 8.3% in precision, recall, and mAP@0.5, respectively. Additionally, YOLOv7scb exceeds [29] by 22.5%, 15%, and 17% in precision, recall, and mAP@0.5, respectively. For Dataset B, YOLOv7scb demonstrates further advantages, achieving 7.9%, 5.4%, and 3% higher precision, recall, and mAP@0.5 compared to [30]. It also consistently outperforms [28,29] by similarly large margins in these metrics.
4.4. Ablation Experiments
To evaluate the effectiveness of each module of the YOLOv7scb model, we conducted experiments to assess the contribution of each module by systematically removing different components from the model.
4.4.1. Comprehensive Performance Analysis on Combinatorial Modules
We verify the effects of different combinatorial modules on YOLOv7, with the results presented in Table 6. For the public Dataset A, the YOLOv7scb model demonstrates significant improvements in detection precision compared to various combinations, including YOLOv7+C3, YOLOv7+BiFPN, YOLOv7+SPD-Conv, YOLOv7+BiFPN+C3, YOLOv7+SPD-Conv+C3, and YOLOv7+BiFPN+SPD-Conv. Specifically, the precision enhancements are 4.6%, 3.9%, 4.4%, 3.4%, 3.8% and 3.4%, respectively. In terms of fire detection, the improvements are 4.5%, 3.9%, 4.2%, 3.9%, 3.2% and 3.1%, while for smoke detection, they are 5.5%, 4.7%, 4.6%, 2.9% and 4.4%, respectively. Additionally, the recall rates have seen an overall increase of 2%, with specific improvements of 1.5% for fire and 2.2% for smoke. The outstanding performance of the YOLOv7scb model on the public Dataset A can be attributed to its advanced features, particularly the bidirectional feature transfer and multiscale feature fusion provided by the BiFPN. These capabilities enhance the model’s ability to capture both the core regions and the fine details of flames, resulting in higher precision and more reliable detection outcomes.
Table 6.
Results of ablation experiments.
In the small-target Dataset B, YOLOv7scb exhibits higher detection accuracies, with improvements of 3.8%, 12.5%, 6.1%, 6.4%, 6.1% and 10.5% over YOLOv7+C3, YOLOv7+BiFPN, YOLOv7+SPD-Conv, YOLOv7+BiFPN+C3, YOLOv7+SPD-Conv+C3 and YOLOv7+BiFPN+ SPD-Conv, respectively. Specifically, the fire detection precision is improved by 3.8%, 9.2%, 7.6%, 8.7%, 7.8% and 8.1%, while the smoke detection precision is improved by 3.7%, 3.7%, 4.6%, 4%, 4.4% and 13%, respectively. Additionally, YOLOv7scb outperforms other combinations in recall, with improvements of 3.8%, 4.1%, 4.5%, 4.2%, 6.1% and in mAP@.5, with improvements of 1.2%, 4.8%, 2.2%, 3.2%, 3.4% and 1.7%, respectively. These improvements are due to the enhanced capabilities of the C3 module, which improves the model’s ability to capture localized features, thereby enabling more precise detection of small-target fires and smoke. The incorporation of SPD-Conv, which utilizes convolution kernels with varying dilation rates to extract multiscale spatial information, further assists the model in precisely identifying targets within complex backgrounds.
4.4.2. Comprehensive Performance Analysis With vs. Without Transfer Learning
To enhance the detection of small-target fires and mitigate overfitting on small datasets, we applied transfer learning to Dataset B. Ablation experiments reveal that the model with transfer learning consistently outperforms the one without it across all evaluation metrics, as shown in Table 7. Specifically, transfer learning improved the precision, recall, and mAP for smoke detection on Dataset B by 10.4%, 4.4%, and 6.5%, respectively. For fire detection, precision, recall, and mAP increased by 0.1%, 11.7%, and 2.1%, respectively. These results demonstrate the effectiveness of transfer learning in enhancing model performance in complex scenarios, underscoring its critical role in fire and smoke detection tasks.
Table 7.
Performance metrics for transfer learning and non-transfer-learning models on Dataset B.
4.4.3. Comprehensive Performance Analysis with Focal-CIoU
To evaluate the model’s performance more precisely, we improved the Focal-CIoU loss function, as shown in Table 8. Experimental results reveal that the model using the enhanced Focal-CIoU loss function offers notable advantages in fire and smoke detection tasks. For Dataset A, Focal-CIoU improves precision and recall by 1.7% and 5.9%, respectively. The performance for mAP is almost equivalent. In Dataset B, the performance of Focal-CIoU is even more remarkable. Specifically, the precision for fire detection reaches 98.8%, with an improvement of 4.3%; the precision for smoke detection is 90.6%, with an improvement of 4.9%; and the overall precision improves by 4.6%. In terms of recall, the precision for fire detection is 96.8%, an increase of 4.2%; the precision for smoke detection is 82.2%, an increase of 2.5%; and the overall recall rate reaches 89.5%, an increase of 3.4%. Additionally, the mAP for smoke detection is 82.1%, and the overall mAP is 90.5%, with increases of 1.1% and 0.8%, respectively.
Table 8.
Contribution of the loss function.
Overall, the model using the Focal-CIoU loss function effectively tackles the issue of sample quality imbalance and delivers superior performance in detecting small and multiscale targets.
4.5. Practical Application Detection
To validate the practical performance of the proposed YOLOv7scb model, we selected fire images containing complex scenarios such as dense smoke, thin smoke, and small-scale fire targets for real-world fire detection applications. We compared YOLOv3, YOLOv5, YOLOv7, YOLOv8, YOLOv10, YOLOv11, and YOLOv7scb in a strictly controlled experimental environment, as shown in Figure 8.

Figure 8.
Comparison of YOLOv3, YOLOv5, YOLOv7, YOLOv8, YOLOv10, YOLOv11, and the proposed detection model: (a) Images featuring small-scale fires and small-scale smoke targets, (b) Images with dense smoke and small flames, (c) Images of small-scale fires accompanied by light smoke and low-light conditions.
We selected three images, each focusing on different scenarios: small-scale fire and smoke targets (Figure 8a), dense smoke and small flames (Figure 8b), and light smoke and weakly illuminated small-scale fires (Figure 8c). The red bounding boxes represent smoke, while the blue bounding boxes indicate fire in Figure 8. Each bounding box is labeled with the detected target and its corresponding detection precision. In Figure 8a, YOLOv7scb precisely identified both fire and smoke, with its bounding boxes closely aligned with the ground truth annotations. In contrast, other models displayed significant deviations, with some failing to detect small-scale targets altogether. In Figure 8b, YOLOv7scb precisely located both fire and smoke targets and successfully separated multiple targets without any overlap. This demonstrates the model’s exceptional non-maximum suppression (NMS) capabilities for multi-target detection. Other models, however, exhibited noticeable errors in smoke detection, with some missing certain fire targets entirely. In Figure 8c, YOLOv7scb effectively recognized smoke regions with faint features under low lighting conditions. Its detection boxes were clear and closely matched the ground truth annotations. These results underscore the model’s ability to handle challenging detection tasks, including small targets and complex fire scenes, with remarkable precision. In summary, YOLOv7scb excels in diverse and demanding environments, making it a reliable and practical solution for fire detection in real-world applications.
5. Discussion
In summary, we propose a novel method for detecting fire and smoke in low-resolution, small targets. Experimental results demonstrate that YOLOv7scb significantly outperforms existing approaches, offering a robust solution for small-target fire and smoke detection.
However, the model still had some shortcomings:
First, the small-target fire and smoke dataset (Dataset B) used in this study was manually labeled by the authors on a per-image basis, a process prone to subjective bias and potential errors. Future work will focus on developing more advanced and objective labeling techniques to enhance dataset reliability.
Second, although we introduced a weighted bidirectional feature pyramid network to effectively fuse multiscale features without increasing model complexity, the computational cost of the model remains a challenge for resource-constrained devices. Optimizing the model for low-power applications is a key direction for future research.
Lastly, the deployment of this proposed model relies heavily on camera sensors and is sensitive to environmental factors such as lighting conditions and occlusions. Despite our efforts to minimize the false alarm rate, this issue persists. Future research will aim to further reduce false alarms and enhance the overall performance and robustness of the recognition system.
6. Conclusions
Overall, this proposed model excels at detecting fire and smoke in scenes with small sizes and low pixel resolution. Specifically, YOLOv7scb is an extension of YOLOv7, incorporating SPD-Conv into the neck component to enhance focus on small targets, thereby augmenting recognition speed and precision. By integrating the BiFPN structure, YOLOv7scb achieves a more balanced information exchange across different scales. Additionally, the inclusion of C3, replacing the ELAN-W module, facilitates multiscale feature fusion and cross-channel information transfer mechanisms, thereby enhancing model representation. Moreover, the adoption of the improved loss function Focal-CIoU effectively addresses the issue of unbalanced training samples in bounding box regression. In long-distance shooting scenarios, YOLOv7scb achieves a commendable precision of 94.7% compared to alternative models, underscoring its efficacy in comprehensive fire and smoke detection. Swift and precise fire detection holds promise for mitigating economic losses, safeguarding forests and ecological environments, ensuring societal stability, and fostering sustainable resource development. In future research, we will look more closely at the practical applications of fire and smoke detection for small targets.
Author Contributions
Conceptualization, Y.L. and D.S.; methodology, Y.L.; software, G.L. (Guoxing Liu); validation, N.W., P.C. and J.Y.; formal analysis, G.L. (Guoxing Liu); investigation, G.L. (Guangmin Liang); resources, D.S.; data curation, Y.L.; writing—original draft preparation, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially supported by the Department of Science and Technology of Jilin Province, China, under Grant No. 20220203057SF.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Code that supports the reported results can be found at: https://github.com/Nightliuguoxing/YOLOv7scb, accessed on 18 June 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- China Central Television. National Fire and Rescue Administration: In 2023, More Than 2.13 Million Reports and Disposals of Various Types of Police Incidents Were Received and Handled; China Central Television: Beijing, China, 2024. Available online: https://www.119.gov.cn/qmxfxw/mtbd/spbd/2024/41284.shtml (accessed on 5 January 2024).
- Zhang, J.; Li, W.B.; Han, N.; Kan, J.M. Forest fire detection system based on a ZigBee wireless sensor network. Front. For. China 2008, 3, 369–374. [Google Scholar] [CrossRef]
- Aslan, Y.E.; Korpeoglu, I.; Ulusoy, Ö. A framework for use of wireless sensor networks in forest fire detection and monitoring. Comput. Environ. Urban Syst. 2012, 36, 614–625. [Google Scholar] [CrossRef]
- Wenning, B.L.; Pesch, D.; TimmGiel, A.; Görg, C. Environmental monitoring aware routing: Making environmental sensor networks more robust. Telecommun. Syst. 2010, 43, 3–11. [Google Scholar] [CrossRef]
- Zhu, Y.; Xie, L.; Yuan, T. Monitoring system for forest fire based on wireless sensor network. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 4245–4248. [Google Scholar]
- Goyal, S.; Shagill, M.; Kaur, A.; Vohra, H.; Singh, A. A yolo based technique for early forest fire detection. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 1357–1362. [Google Scholar] [CrossRef]
- Lu, Y.; Li, Y.; Song, F.; Zhang, Y.; Li, X.; Zheng, C.; Wang, Y. Development of a mid-infrared early fire detection system based on dual optical path nonresonant photoacoustic cell. Microw. Opt. Technol. Lett. 2024, 66, e33758. [Google Scholar] [CrossRef]
- Truong, C.T.; Nguyen, T.H.; Vu, V.Q.; Do, V.H.; Nguyen, D.T. Enhancing fire detection technology: A UV-based system utilizing fourier spectrum analysis for reliable and accurate fire detection. Appl. Sci. 2023, 13, 7845. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, X.; Zeng, Z.C.; Yung, Y.L. Fire monitoring and detection using brightness-temperature difference and water vapor emission from the atmospheric infrared sounder. J. Quant. Spectrosc. Radiat. Transf. 2024, 317, 108930. [Google Scholar] [CrossRef]
- Zhang, S.; Gao, D.M.; Lin, H.F.; Sun, Q. Wildfire detection using sound spectrum analysis based on the internet of things. Sensors 2019, 19, 5093. [Google Scholar] [CrossRef] [PubMed]
- Quinn, C.A.; Burns, P.; Jantz, P.; Salas, L.; Goetz, S.J.; Clark, M.L. Soundscape mapping: Understanding regional spatial and temporal patterns of soundscapes incorporating remotely-sensed predictors and wildfire disturbance. Environ. Res. 2024, 3, 025002. [Google Scholar] [CrossRef]
- Damasevicius, R.; Qurthobi, A.; Maskeliunas, R. A Hybrid Machine Learning Model for Forest Wildfire Detection using Sounds. In Proceedings of the 2024 19th Conference on Computer Science and Intelligence Systems, Belgrade, Serbia, 8–11 September 2024; pp. 99–106. [Google Scholar]
- Li, X.; Liu, Y.; Zheng, L.; Zhang, W. A Lightweight Convolutional Spiking Neural Network for Fires Detection Based on Acoustics. Electronics 2024, 13, 2948. [Google Scholar] [CrossRef]
- Thepade, S.D.; Dewan, J.H.; Pritam, D.; Chaturvedi, R. Fire detection system using color and flickering behaviour of fire with Kekre’s LUV color space. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation, Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Chowdhury, N.; Mushfiq, D.R.; Chowdhury, A.E.; Chaturvedi, R. Computer vision and smoke sensor based fire detection system. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar]
- Mei, J.J.; Zhang, W. Early Fire Detection Calculations Based on ViBe and Machine Learning. Acta Opt. Sin. 2018, 38, 0710001. [Google Scholar] [CrossRef]
- Lu, C.; Lu, M.Q.; Lu, X.B.; Cai, M.; Feng, X.Q. Forest fire smoke recognition based on multiple feature fusion. IOP Conf. Ser. Mater. Sci. Eng. 2018, 435, 012006. [Google Scholar] [CrossRef]
- Zhao, W.; Yu, F.F.; Fan, X.J.; Zhang, N.N. Fire Image Recognition Simulation of Unmanned Aerial Vehicle Forest Fire Protection System. Comput. Simul. 2018, 35, 459–464. [Google Scholar] [CrossRef]
- Wang, Y.; Dang, L.; Ren, J. Forest fire image recognition based on convolutional neural network. J. Algorithms Comput. Technol. 2019, 13. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Cheng, X.B.; Qiu, G.H.; Jiang, Y.; Zhu, Z.M. An improved small object detection method based on YoloV3. Pattern Anal. Appl. 2021, 24, 1347–1355. [Google Scholar]
- Qin, Y.Y.; Cao, J.T.; Ji, X.F. Fire detection method based on depthwise separable convolution and yolov3. Pattern Anal. Appl. 2021, 18, 300–310. [Google Scholar] [CrossRef]
- Wu, H.; Hu, Y.; Wang, W.; Mei, X. Ship fire detection based on an improved YOLO algorithm with a lightweight convolutional neural network model. Sensors 2022, 22, 7420. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Akhmedov, F.; Nasimov, R.; Abdusalomov, A. Dehazing Algorithm Integration with YOLO-v10 for Ship Fire Detection. Fire 2024, 7, 332. [Google Scholar] [CrossRef]
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; Halin, A.A. Fire-Net: A Deep Learning Framework for Active Forest Fire Detection. Sustainability 2022, 2022, 8044390. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection withvregion proposal networks. IEEE Trans. Pattern Anal. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.Y.; Wang, D.Q.; Krähenbühl, P. Objects as Points. arXiv 2021, arXiv:1904.07850. [Google Scholar]
- Song, H.; Qu, X.J.; Yang, X.; Wan, F.J. Flame and smoke detection based on the improved YOLOv5. Comput. Eng. 2023, 49, 1000–3428. [Google Scholar]
- Titu, M.F.S.; Pavel, M.A.; Michael, G.K.O.; Babar, H.; Aman, U.; Khan, R. Real-Time Fire Detection: Integrating Lightweight Deep Learning Models on Drones with Edge Computing. Drones 2024, 8, 483. [Google Scholar] [CrossRef]
- Sun, B.S.; Bi, K.Y.; Wang, Q.Y. YOLOv7-FIRE: A tiny-fire identification and detection method applied on UAV. AIMS Math. 2024, 9, 10775–10801. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L. Aerial Imagery Pile burn detection using Deep Learning: The FLAME dataset. arXiv 2020, arXiv:2012.14036. [Google Scholar] [CrossRef]
- Bryce, H.; Leo, O.; Fatemeh, A.; Abolfazl, R.; Eric, R.; Adam, W.; Peter, F.; Janice, C. FLAME 2: Fire detection and modeLing: Aerial Multi-spectral imagE dataset. IEEE Access 2022, 10, 121301–121317. [Google Scholar]
- Ding, X.H.; Zhang, X.Y.; Ma, N.N.; Han, J.G.; Ding, G.G.; Sun, J. RepVGG: Making VGG-style convNets great again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Dewi, C.; Chen, A.P.S.; Christanto, H.J. Deep learning for highly accurate hand recognition based on YOLOv7 model. Big Data Cogn. Comput. 2023, 7, 53. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, Y.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Hu, Y.Y.; Wu, X.J.; Zheng, G.D.; Liu, X.F. Object detection of UAV for anti-UAV based on improved YOLOv3. In Proceedings of the 2019 Chinese Control Conference, Guangzhou, China, 27–30 July 2019; pp. 8386–8390. [Google Scholar]
- Song, L.; Yasenjiang, M.S. Detection of X-ray prohibited items based on improved YOLOv7. In Proceedings of the 2023 8th International Conference on Intelligent Computing and Signal Processing, Xian, China, 21–23 April 2023; pp. 1874–1877. [Google Scholar]
- Fan, Y.X.; Tohti, G.; Geni, M.; Zhang, G.H.; Yang, J.Y. A marigold corolla detection model based on the improved YOLOv7 lightweight. Signal Image Video Process. 2024, 18, 4703–4712. [Google Scholar] [CrossRef]
- Guo, G.; Yuan, W. Short-term traffic speed forecasting based on graph attention temporal convolutional networks. Neurocomputing 2020, 410, 387–393. [Google Scholar] [CrossRef]
- Zhuang, F.Z.; Qi, Z.Y.; Duan, K.Y.; Xi, D.B.; Zhu, Y.C.; Zhu, H.S.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Azi, M.; Yanikoglu, B.; Aptoula, E. Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing 2021, 235, 228–235. [Google Scholar]
- Jiang, X.D. Feature extraction for image recognition and computer vision. In Proceedings of the 2009 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; pp. 1–15. [Google Scholar]
- Agostino, A. Veryfiresmokedetection Dataset. Roboflow Universe. Available online: https://universe.roboflow.com/agostino-abbatecola-52ty4/veryfiresmokedetection (accessed on 30 November 2023).
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. arXiv 2022, arXiv:2208.03641. [Google Scholar]
- Chen, J.; Mai, H.S.; Luo, L.B.; Chen, X.Q.; Wu, K. Effective feature fusion network in BIFPN for small object detection. In Proceedings of the 2021 IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 699–703. [Google Scholar]
- Zhang, Y.F.; Ren, W.Q.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lui, M.S.; Utaminingrum, F. A comparative study of YOLOv5 models on american sign language dataset. In Proceedings of the 7th International Conference on Sustainable Information Engineering and Technology, Malang, Indonesia, 22–23 November 2022; pp. 3–7. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, Y.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the International Conference on Advances in Data Engineering and Intelligent Computing Systems, Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).