Abstract
Early detection of morbidities that complicate pregnancy improves health outcomes in low- and middle-income countries. Automatic revision of electronic health records (EHRs) can help identify such morbidity risks. There is a lack of corpora to train models in Spanish in specific domains, and there are no models specialized in maternal EHRs. This study aims to develop a fine-tuned model that detects clinical concepts using a built database with text extracted from maternal EHRs in Spanish. We created a corpus with 13.998 annotations from 200 clinical notes in Spanish associated with EHRs obtained from a reference institution of high obstetric risk in Colombia. Using the Beginning–Inside–Outside tagging scheme, we fine-tuned five different transformer-based models to classify between 16 classes associated with eight entities. The best model achieved a macro F1 score of 0.55 ± 0.03. The entities with the best performance were signs, symptoms, and negations, with exact F1 scores of 0.714 and 0.726, respectively. The lower scores were associated with those classes with fewer observations. Even though our dataset is shorter in size and more diverse in entity types than other datasets in Spanish, our results are comparable to other state-of-the-art named entity recognition models fine-tuned in Spanish and the biomedical domain. This work introduces the first fine-tuning of a model for named entity recognition specifically designed for maternal EHRs. Our results can be used as a base to develop new models to extract concepts in the maternal–fetal domains and help healthcare providers detect morbidities that complicate pregnancy early.
1. Introduction
Following the achievement of the United Nations’ Millennium Development Goals (MDGs), the Sustainable Development Goals (SDGs) were established to mobilize action across all nations and address a wide spectrum of social requirements. Among these goals, enhancing maternal health and reducing maternal mortality continue to be a significant priority for the global community.
Maternal mortality is a sentinel event and refers to the death of a woman during pregnancy, childbirth, or within 42 days of the end of the pregnancy [1]. Maternal Mortality Ratio (MMR) has been identified as an important indicator of the quality of medical care and an indicator of progress in the international development goals. Despite a decrease in global maternal mortality during the last decade, rates remain unacceptable. According to the World Health Organization (WHO), the estimated global MMR in 2020 was 220 deaths per 100,000 live births, which is an issue of global concern [2].
However, beyond maternal mortality, it is important to act on the conditions that increase maternal morbidity as a precursor to mortality. Despite the lack of an agreed-upon definition for maternal morbidity [3], the WHO has defined it as “any health condition attributed to and/or complicating pregnancy, and childbirth that has a negative impact on the woman’s well-being and/or functioning” and estimates that for each maternal death, 20 or 30 women suffer from maternal morbidity.
Maternal near-miss (MNM) is an indicator that includes women who survived after presenting a potentially fatal complication during pregnancy, childbirth, or the puerperium as a case of extremely severe maternal morbidity, a severity that brings women very close to death [4]. More than 18.67/1000 live births of the general population of the world suffered from MNM. However, due to a lack of agreement on the definition of an MNM, comparing the prevalence in different countries or regions is relatively difficult [5]. However, equally important as mortality, this problem affects most middle- and low-income countries, such as those in Africa or Latin America. Authors report an incidence of MMN between 5.9 and 12.3 per 1000 live births in the Latin American and Caribbean region [6].
To address this problem, healthcare systems increasingly turn to technological solutions. One notable advancement is the growing adoption of electronic health records (EHRs). EHRs offer real-time access to a patient’s medical history, enabling informed clinical decision-making, improved communication between healthcare providers, and reduced likelihood of medical errors. Using the benefits of EHRs, maternal healthcare can become more efficient and effective, resulting in improved maternal and newborn outcomes [7].
A critical challenge derived from the adoption of EHRs consists in the extraction of relevant information stored in the unstructured clinical text, which has given rise to a task of natural language processing (NLP) known as Named Entity Recognition (NER), becoming an essential task when analyzing and extracting useful information. In this respect, various strategies have emerged, including the use of rule-based approaches, machine learning models, and deep learning.
In the fields of natural language processing (NLP), deep learning models have taken on great relevance in recent years, especially those that include the mechanism of self-attention, given the various success cases [8]. These models, which are also known as transformers, have been adapted in specific domains and tasks, as is the case in the clinical domain [9], where transfer learning is very common in adjusting a model with clinical data. However, despite the significant progress made in biomedical NER in the last years, there are limited annotated corpora available for languages other than English and Chinese, which are the most common languages used in biomedical NER.
The rise in the popularity of deep learning (DL) models can be attributed to the vast volume of patient data extracted from EHR. One of the advantages of DL is its ability to minimize the tasks of preprocessing and feature engineering [10,11]. This is particularly valuable in the context of clinical text, which exhibits high variability, a prevalence of grammatical errors, and a multitude of acronyms and other challenges. Therefore, leveraging DL models becomes a practical and effective solution.
Instead of using a Convolutional Neural Network (CNN) or Recurrent Neural Network (RNN), transformer models can efficiently process variable-length sequences of data, allowing for the capture of long-range dependency relationships in text and other types of sequential data. A transformer-based model is a deep network that seeks to numerically represent each word according to its context based on self-attention [12]. To obtain an adequate numerical representation of each word, the models are trained in an initial phase to solve masked language model (MLM) tasks on a large number of texts [13]. These models have been widely used in NLP tasks, including text generation, machine translation, text summarization, etc. In particular, transformer-based models have had a significant impact in biomedical NER, where they are used to identify relevant entities in the healthcare domain, such as genes, proteins, diseases, and treatments, which can have a major impact on medical research and medical decision-making [14].
A large number of parameters that need to be adjusted in transformer-based models involve using systems with high hardware requirements over several days, which are time-consuming, leading to high costs when training these models [15]. The use of transformers has promoted the development of linguistic models, in addition to the creation of platforms, such as Hugging Face, that allow for hosting and sharing these models, which has facilitated a rapid adaptation to new domains on specific tasks [16]. Therefore, the generation of new models for the particularities of the Spanish clinical domain, in most cases, has focused on adding and adjusting one or more layers on existing models, a process known as fine-tuning [17]. In the end, we will have as a result models that are adjusted to specific tasks, such as NER, in which the learning of the original models is transferred. Other studies have explored the use of general-purpose large language models (LLMs) such as GPT, LLaMA [18], Gemini [19], and Claude, applying prompt engineering techniques to perform NER tasks [20]. Nevertheless, several works have shown that this approach is often ineffective when applied to domain-specific tasks such as clinical NER [21,22]. While some efforts have focused on prompt tuning to achieve acceptable performance, these methods typically require extensive and meticulous prompt design, which may not generalize well across clinical settings [23].
Despite the potential advantages of NLP in enhancing maternal morbidity, there remains a scarcity of research and knowledge regarding its application in this field, particularly in low-resource settings and Spanish-speaking countries. Particularly, there is a lack of corpora in Spanish associated with specific medical fields to train or fine-tune deep learning models. To the best of the authors’ knowledge, there are no models adjusted to named entity recognition associated with maternal EHR, neither in English nor in Spanish.
To address this gap, we have constructed a new dataset comprising sentences in Spanish extracted from maternal EHRs. This study aims to explore the use of pre-trained transformer-based models, which are fine-tuned using our dataset, to extract clinical concepts related to maternal electronic health records. Our hypothesis is that NLP has the capability to enhance maternal health outcomes by assisting healthcare providers in making well-informed decisions, identifying high-risk patients, and improving the overall quality of maternal care.
The main contributions of this work are as follows: (1) The present study introduces the first application of NER using transformer-based models tailored explicitly to Spanish maternal EHRs, addressing a gap in the biomedical NLP tools for this subdomain. (2) We fine-tuned and evaluated five transformer-based models, including domain-specific variants, on a corpus of 200 maternal clinical notes annotated with 13,998 entities across 14 classes, which was compiled and annotated specifically for this work. (3) We present a model tuned for our specific domain and linguistic realities that achieves results comparable to state-of-the-art models trained on larger biomedical datasets.
2. Materials and Methods
2.1. Dataset and Annotations
The corpus is a collection of 200 de-identified Spanish EHR notes, with an average number of sentences per note of 9.74, that were provided by a reference institution of high obstetric risk, which has highly complex Gynecology and Obstetrics services. The EHRs correspond to those women who gave birth between 2015 and 2019. A total of 25% of the EHR notes were labeled by two clinical professionals in an annotation software called INCEpTION [24]. The remaining 75% were annotated by a single clinical professional. Figure 1 shows an example of an annotated note. The selected entities are related to risk factors and outcomes in pregnancy and childbirth. The entities were annotated according with the Unified Medical Language System (UMLS) and its semantic network. The corpus had a total of 8 entities, corresponding to five categories (Idea or Concept was itemized into negation, quantitative, qualitative, and temporal concepts):

Figure 1.
EHR note sample with annotation using INCEpTION.
- Anatomy (T023): Body part, organ, or organ component.
- Disease or Syndrome (T047): Observations made by patients or clinicians about the body or mind that are considered abnormal or caused by disease.
- Healthcare activity (T058): Descriptions of diagnostics and laboratory procedures.
- Idea or Concept:
- (a)
- Negation (C1518422): Those concepts that indicated something does not exist or that it lacks veracity.
- (b)
- Quantitative concepts (T081): Those concepts that refer to the numerical nature of data, such as measurements obtained in a laboratory test.
- (c)
- Qualitative concepts (T080): Concepts that are used to name what is linked to the quality, such as the way of being or the properties of something.
- (d)
- Temporal concepts (T079): These refer to a point in time that can be a time, but they exclude the concepts that refer to duration (duration is an amount).
- Sign or Symptom (T184): An observable manifestation of a disease or condition based on clinical judgment, even if a disease or condition experienced by the patient and is reported as a subjective observation.
At the end of the process, the corpus contained 1842 sentences and 13,998 labeled entities belonging to 7 classes, as shown in Table 1. We obtained a value of = 0.636 from the 50 clinical notes annotated by two physicians, which is considered a substantial level, in accordance with [25]. This result is a very competitive outcome in the clinical context, where the interpretation of medical entities may vary slightly between experts. To mitigate potential discrepancies, joint discussions were held regarding annotation differences, thus improving consistency in the rest of the documents labeled by a single annotator.

Table 1.
Entity distribution in the train and test datasets.
2.2. Preprocessing
The clinical notes’ text and corresponding labels were extracted and processed in Python. We implemented a code to transform all labels in their respective Beginning–Inside–Outside (BIO) format [26]. Figure 2 shows an example with the BIO tagging format where the letter “B” stands for the beginning of an entity or a named entity, while the letter “I” denotes the interior of the entity. The letter “O” is used to indicate the exterior of the entity and represents the tokens that are considered as non-entities or not part of any named entity.
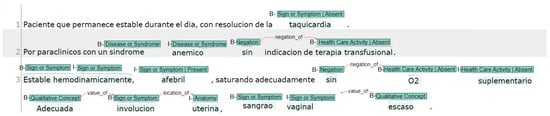
Figure 2.
EHR note sample annotated using INCEpTION with BIO tagging.
In addition, the clinical notes were divided into sentences to sum a total of 1947 clinical sentences; the sentence segmentation was performed according to the default rules of the INCEpTION software [24]. We deleted the sentences with a single token as a unique value, resulting in 1842 sentences. The sentences were randomly split into a training set (1473 sentences), a test set (185 sentences), and a validation set (184 sentences).
2.3. Deep Learning Models
In this study, we carefully chose five transformer-based models to tackle the clinical NER task in Spanish. In this work, we considered five transformer-based models, which are available at Hugging Face under the names bert-base-cased (bert), bsc-bio-es (bio-es), bsc-bio-ehr-es (bio-ehr-es), roberta-base-bne (roberta), and gpt2-finetuned-comp2 (gpt-2). We used various models in our study, each with different pre-training tasks. Some models, such as BERT, were pre-trained on the masked language modeling (MLM) task, where the model learns to predict masked words within a sentence. Similarly, RoBERTa, which is based on BERT, also follows this pre-training approach, but with improvements in data efficiency and model performance. We also utilized bio-es and bio-ehr-es, BERT-based models explicitly fine-tuned for the NER task, making it particularly suitable for extracting entities in clinical texts. We also incorporated GPT-2, which differs from BERT-based models as it was pre-trained using causal language modeling that involves predicting the next word in a sequence. With this combination of models, we aim to compare the accuracy and precision in identifying biomedical entities from our clinical data in Spanish with the proposed models.
The selected models are described as follows:
- bert: Bidirectional Encoder Representations from Transformers [27] is a pre-trained deep learning model developed by Google for natural language processing tasks such as question answering and language inference. It is based on the transformer architecture and is trained on a large corpus of text data using unsupervised learning. BERT can be fine-tuned for a wide range of natural language understanding tasks and has achieved state-of-the-art results on a number of benchmarks, including the GLUE benchmark and SQuAD.
- roberta: It is an optimized bert model [28], which has been pre-trained by Text Mining Unit (TeMU) at the Barcelona Supercomputing Center, using the most extensive Spanish corpus known to date, with a total of 201,080,084 documents, compiled from the web crawlings performed by the National Library of Spain (Biblioteca Nacional de España) from 2009 to 2019.
- gpt-2: Generative Pre-trained Transformer is a language generation model developed by OpenAI. GPT-2 is trained on a massive dataset of over 40 GB of text data and can generate human-like text in various languages and styles. It can be used for various natural language processing tasks such as language translation, text summarization, and question answering. We used a fine-tuned version of GPT-2 available in Hugging Face (https://huggingface.co/brad1141/gpt2-finetuned-comp2, accessed on 2 October 2024). This version was fine-tuned on the token classification task. This supervised fine-tuning allowed the model to adapt its generative capabilities toward the specific task of entity recognition and categorization. This aligns with recent trends in NLP in which generative models are used for information extraction [29].
- bio-es: A model produced by the Barcelona Supercomputing Center based on the roberta model using a large biomedical corpora from a variety of sources in Spanish with a total of 1.1 B tokens across 2.5 M documents, allowing us to acquire specialized knowledge and language patterns relevant to the field of biomedicine in Spanish. Additionally, this model was fine-tuned on three NER tasks: PharmaCoNER, CANTEMIST, and ICTUSnet [30].
- bio-ehr-es: Like the bio-es model, bio-ehr-es is based on the roberta model and was fine-tuned in the same NER tasks as bio-es. The key difference is that bio-ehr-es incorporates electronic health record (EHR) information drawn from a corpus with more than 514k clinical documents containing 95 million tokens [30].
2.4. Fine-Tuning
Since our main goal is to extract clinical concepts from EHRs, we applied a fine-tuning strategy to test and evaluate our dataset using the NER task. We used the NER task as a benchmark to measure the performance of five models based on publicly available transformers on Hugging Face. We initialized the models by loading a pre-trained, fine-tuned base model. We added a dropout layer after the base model output to enhance generalization and mitigate overfitting. We incorporated a linear classification layer to map the model feature representation to the desired output classes. Since the task is token classification, the model predicts a label for each input token, making it suitable for NER. All models were configured identically.
We follow the methodology described in [30], where we limit the fine-tuning to 20 epochs and search for a learning rate value using an exponential growth sequence 1 × , 2 × , 3 × , 5 × , 8 × , taking close values to those reported in databases with similar domains in Spanish (e.g., CANTEMIST [31], PharmaCoNER [32], ICTUSnet).
The models were performed in Python 3.12. All experiments were performed using an Nvidia Quadro RTX 5000 GPU with 16 GB (Nvidia, Santa Clara, CA, USA).
2.5. Evaluation Metrics
Our fine-tuning models were evaluated through macro and micro F1 scores. The macro F1 score is reported to be a good metric when there is an imbalanced dataset where all classes are equally important [33]. For our case, we found that most token-level annotations, using the BIO tagging scheme, were labeled as “O” (outside), resulting in a class imbalance where non-entity tokens are overrepresented in the dataset.
The micro F1 score was particularly useful for comparing the performance of our fine-tuned models with other related works in the literature [30,34].
Furthermore, we computed the exact and partial boundaries for precision and recall using nervaluate (https://github.com/MantisAI/nervaluate accessed on 7 November 2024), which is a Python library for NER tasks based on the metrics from [35]. The exact and partial boundaries give information on the performance of the model where the predictions given to an entity are only a part (partial) or all the boundaries of the given entity [36].
where TP means true positives, FP false positives, and FN false negatives.
3. Results and Discussion
In Table 2, we present the best scores achieved on the test set, along with their respective standard deviations (mean ± std). These scores are calculated based on all seeds used for a given configuration. Furthermore, we provide the best learning rates (LRs) and number of epochs for each model. Since averaging the epochs or the learning rate would not be meaningful, the reported LR represents the best result obtained by averaging the performances of the five repetitions.
Table 2.
Performances of different models (mean ± std) for NER task in our dataset constructed from maternal EHRs, where P, R, and F1 represent precision, recall, and F1 score measures, while LR, TC, and MLM indicate learning rate, token classification, and mask language models. Bold values identify the highest results per column.
To determine the best performances, we rank them using the macro F1 score. In most cases, the best macro F1 score results align with the other evaluation measures. The highest performers for each measure are highlighted in bold.
Table 2 illustrates that the bio-ehr-es model achieves the highest micro F1 score, while the bio-es model performs best regarding macro F1 score. To delve deeper into the comparison of these models, Table 3 and Table 4 present the recall (R), precision (P), and F1 score (F1) measures for each class, considering both exact and partial boundaries. Similarly to Table 2, the reported values represent the mean and standard deviation obtained from five repetitions using five different seeds.
Table 3.
Performances of bsc-bio-es models for a learning rate of 8.0 × mean ± std for the NER task in our dataset constructed from maternal EHRs. Bold values identify the highest results per column.
Table 4.
Performances of bsc-bio-ehr-es models for a learning rate of 5.0 × mean ± std for the NER task in our dataset constructed from maternal EHRs. Bold values identify the highest results per column.
When comparing the bio-ehr-es and bio-es models, we observe that bio-es demonstrates higher sensitivity, while bio-ehr-es exhibits greater precision overall. For instance, regarding recall with partial boundaries, bio-es outperforms bio-ehr-es in seven out of eight classes, with the only exception being class T081, corresponding to quantitative concepts. Conversely, for precision with partial boundaries, bio-ehr-es surpasses bio-es in seven out of eight classes, with the exception of class T079, representing temporal concepts. Moreover, bio-es performs better in six out of eight classes in terms of F1 score. It should be noted that the class-level comparisons for partial and exact boundaries are consistent, meaning that the classes with the best performance for partial boundaries align with those for exact boundaries.
In general, Table 3 and Table 4 demonstrate that classes T184 (signs and symptoms) and C151844 (negations) exhibit superior performance in both the bsc-bio-ehr-es and bsc-bio-es models; the top performers for each measure are highlighted in bold type. Overall, the bsc-bio-es model achieves higher performance scores in both exact and partial schemes. However, it is worth noting that the bsc-bio-ehr-es model stands out particularly in class T023 (Anatomy), which could be attributed to its pre-training on electronic health records. Based on these results, we select the bsc-bio-es model.
Figure 3 displays the confusion matrix for the bsc-bio-es model. The matrix reveals that classes with larger samples generally detect more true positives than false positives. Notably, classes with the prefix “B” perform better than those with the prefix “I”. For instance, class I-T023, with only five samples in the test set, does not have any true positives. On the other hand, class T184 detects 466 true positives while producing 201 false positives. It is important to mention that the majority of false positives belong to the non-entity class (“O” in the BIO tagging scheme).
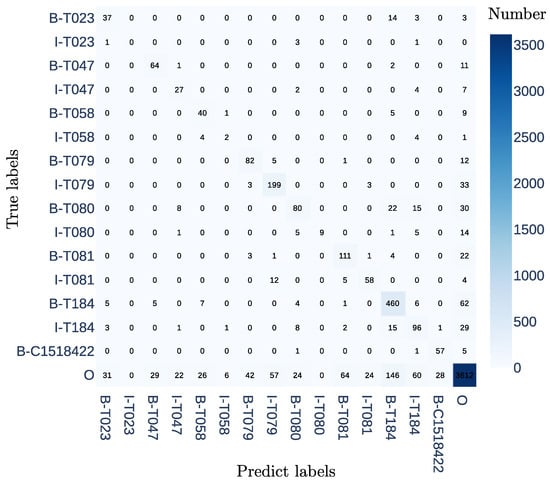
Figure 3.
The confusion matrix for the NER task in our dataset constructed from maternal EHRs using the bsc-bio-es model with a learning rate of 8.0 × .
This work introduces the first fine-tuning of an NER model designed explicitly for maternal electronic health records (EHRs). We conducted fine-tuning on five models using our dataset, and the best-performing model achieved an F1 micro score of 0.83 and an F1 macro score of 0.55%. These results are comparable to other state-of-the-art NER models fine-tuned in Spanish and the biomedical domain [30]. For example, the bio-ehr-es model achieved an F1 micro score of 0.834 on the CANTEMIST dataset [30]. It is worth noting that the best model reported in the CANTEMIST challenge achieved an F1 micro score of 0.89. The CANTEMIST corpus includes 1301 annotated clinical documents, with 63,016 sentences and 16,030 mentions of entities related to tumor morphologies. In comparison, our database consists of 200 discharge notes containing 1842 sentences and 13,998 labeled entities belonging to 14 classes, making it shorter in size but more diverse in entity types and with a higher density of labeled entities per sentence than the CANTEMIST dataset, which focuses solely on a single entity.
Based on our findings, the top-performing models were bio-ehr-es and bio-es, surpassing the performance of GPT-2, BERT, and Roberta. This outcome is in line with our expectations since bio-ehr-es and bio-es are built upon the foundation of Roberta and fine-tuned using Spanish biomedical resources in an NER task. However, it was unexpected that bio-ehr-es would yield lower performance than bio-es. We initially hypothesized that bio-ehr-es would outperform bio-es due to its additional pre-training on electronic health records (EHRs). Although the F1 scores are very close between the two models, suggesting comparable performance across models, bio-es slightly outperformed bio-ehr-es (0.565 ± 0.07 vs. 0.631 ± 0.048). Bio-es was trained on general biomedical data, which may have made it more versatile for various clinical tasks, including less frequent or more descriptive entities. In contrast, if bio-ehr-es was primarily pre-trained in structured or specific records, it may have acquired a narrower or more rigid vocabulary, which is less useful in the context of our discharge notes.
Regarding the performance achieved by each entity, the highest scores were obtained by signs and symptoms (with a partial F1 score of 0.749) and negation entities (with a partial F1 score of 0.726). This finding is particularly significant because identifying negation is crucial for determining the presence or absence of signs and symptoms, serving as a prerequisite for future projects aimed at maternal risk electronic phenotyping. Furthermore, other entities such as disease and syndrome, which are important for electronic phenotyping, achieved a partial F1 score of 0.695. On the other hand, the entities associated with the prefix “I” exhibited the poorest performance, likely due to their limited number of samples. This suggests the need for future work involving additional note annotations and dataset expansion.
It is worth noting that certain entities can be prone to confusion or misclassification, even by trained human annotators. We constructed an annotation guide based on the Unified Medical Language System (UMLS) Semantic Network. At the end of the annotation process, we identified some discrepancies between the interpretation of entities T080 (qualitative concept) and T184 (symptom). Specifically, in some cases, one annotator interpreted a descriptive attribute as part of the symptom, while the other considered it a separate qualitative concept. For instance, in the expression “red breasts”, one annotator labeled “red” as a qualitative concept (T080), while the other labeled it as part of the symptom (T184). This variation reflects the inherent challenge of using UMLS in clinical NER tasks, as qualitative attributes may be contextually linked to symptoms. This observation aligns with the confusion matrix, where several qualitative concepts (T080) are detected by the model as signs or symptoms (T184).
In the confusion matrix, it is evident that the majority of false-positive samples correspond to words that do not belong to the entity class (“O”). However, it is possible that during the annotation process, certain entities were overlooked, leading to false positives where the model detected entities that were not marked by the annotator.
Limitations observed include that not all clinical notes were annotated by all evaluators; we observed a variability in the granularity of the concepts’ (qualitative, quantitative, and temporal) annotation; sometimes, annotators included one word and on other occasions included two or more in the same entity; this variability was associated with fatigue or inconsistent use of the annotation guide. In the future, we suggest shorter annotation sessions and a series of retraining exercises before each session. Once the database increases in size, we anticipate that we will need to increase the number of annotators, which could increase variability. Therefore, establishing robust annotation protocols and ongoing training will be critical to maintaining high-quality annotations.
When working with sensitive and private information, such as medical records, it is essential to ensure data security and privacy. Using local language models, such as BERT installed on a local machine, provides several key advantages in this regard. By processing data locally, we eliminate the need to transmit sensitive information over the Internet, significantly reducing the risk of data breaches or unauthorized access. Additionally, local installations allow for greater control over the data processing environment, enabling the implementation of stringent security measures and compliance with data protection regulations. This approach ensures that all processing occurs within a controlled and secure environment, safeguarding the confidentiality and integrity of private information.
4. Conclusions
This work introduces the first fine-tuning of an NER model designed explicitly for maternal EHRs. Our results show that the model tuned for our specific domain and healthcare system’s linguistic, clinical, and infrastructural realities achieves results comparable to state-of-the-art models trained on larger biomedical datasets. Future works involving a dataset expansion can help to improve the results for the best manager of maternal risk. Our results can be used to develop new models to extract concepts in the maternal–fetal domains and help healthcare providers detect early morbidity that complicates pregnancy.
Author Contributions
A.F.G.-F.: Conceptualization, Formal analysis, Supervision, Methodology, Writing—original draft, Writing—review and editing; M.C.D.: Conceptualization, Formal analysis, Methodology, Software, Writing—original draft; S.R.: Conceptualization, Methodology, Software, Writing—original draft; E.A.T.-S.: Conceptualization, Methodology, Resources, Writing—original draft; S.A.-V.: Data curation, Investigation, Resources, Writing—review and editing; J.F.F.-A.: Data curation, Methodology, Supervision, Writing—review and editing; A.O.-D.: Conceptualization, Funding acquisition, Supervision, Formal analysis, Writing—original draft, Writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Instituto Tecnológico Metropolitano through the project P20242. Also, this project received funds from the Agencia de Educación Superior de Medellín (Sapiencia) and Universidad Nacional Abierta y a Distancia. This work was also supported by the Clinica Universitaria Bolivariana, Medellín, Colombia, by granting access to anonymized data for this project.
Institutional Review Board Statement
This study was conducted according to the guidelines of the Declaration of Helsinki and approved by the Ethics Committee of Universidad Pontificia Bolivariana (Act 02, 10 February 2020).
Informed Consent Statement
Patient consent was waived because the hospital where the data were collected is a university hospital. All admissions to the hospital imply the signature of the acceptance of data capture through the clinical history based on Colombian regulations and the law of habeas data. In this case, users authorize the processing of data for research purposes.
Data Availability Statement
The data that support the findings of this study are available from the authors, but restrictions apply to the availability of these data due to reasons of sensitivity. Data were used under license from the Clínica Universitaría Bolivariana (Medellín) for the current study and so are not publicly available. Data are, however, available from the authors upon reasonable request and with permission from the Clínica Universitaria Bolivariana. Requests for access to these data should be made to the corresponding author.
Acknowledgments
We thank the Clinica Universitaria Bolivariana for allowing access to EHRs.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Centers for Disease Control and Prevention: CDC. Pregnancy Mortality Surveillance System; CDC: Atlanta, GA, USA, 2022. [Google Scholar]
- World Health Organization: WHO. Maternal Mortality; WHO: Geneva, Switzerland, 2023. [Google Scholar]
- Vanderkruik, R.C.; Tunçalp, Ö.; Chou, D.; Say, L. Framing maternal morbidity: WHO scoping exercise. BMC Pregnancy Childbirth 2013, 13, 213. [Google Scholar] [CrossRef] [PubMed]
- Pan American Health Organization. Recommendations for Establishing a National Maternal Near-Miss Surveillance System in Latin America and the Caribbean; Pan American Health Organization: Washington, DC, USA, 2022. [Google Scholar]
- Abdollahpour, S.; Miri, H.H.; Khadivzadeh, T. The global prevalence of maternal near miss: A systematic review and meta-analysis. Health Promot. Perspect. 2019, 9, 255. [Google Scholar] [CrossRef]
- Aleman, A.; Colomar, M.; Colistro, V.; Tomaso, G.; Sosa, C.; Serruya, S.; de Francisco, L.A.; Ciganda, A.; De Mucio, B. Predicting severe maternal outcomes in a network of sentinel sites in Latin-American countries. Int. J. Gynecol. Obstet. 2023, 160, 939–946. [Google Scholar] [CrossRef]
- Kasthurirathne, S.N.; Mamlin, B.W.; Purkayastha, S.; Cullen, T. Overcoming the maternal care crisis: How can lessons learnt in global health informatics address US maternal health outcomes? In Proceedings of the AMIA Annual Symposium, Washington, DC, USA, 4–8 November 2017; American Medical Informatics Association: Washington, DC, USA, 2017; Volume 2017, p. 1034. [Google Scholar]
- Chen, P.; Zhang, M.; Yu, X.; Li, S. Named entity recognition of Chinese electronic medical records based on a hybrid neural network and medical MC-BERT. BMC Med. Inform. Decis. Mak. 2022, 22, 315. [Google Scholar] [CrossRef]
- López-García, G.; Jerez, J.M.; Ribelles, N.; Alba, E.; Veredas, F.J. Explainable clinical coding with in-domain adapted transformers. J. Biomed. Inform. 2023, 139, 104323. [Google Scholar] [CrossRef] [PubMed]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE J. Biomed. Health Inform. 2017, 22, 1589–1604. [Google Scholar] [CrossRef]
- Torres-Silva, E.A.; Rúa, S.; Giraldo-Forero, A.F.; Durango, M.C.; Flórez-Arango, J.F.; Orozco-Duque, A. Classification of Severe Maternal Morbidity from Electronic Health Records Written in Spanish Using Natural Language Processing. Appl. Sci. 2023, 13, 10725. [Google Scholar] [CrossRef]
- Wu, Y.; Jiang, M.; Xu, J.; Zhi, D.; Xu, H. Clinical named entity recognition using deep learning models. In Proceedings of the AMIA Annual Symposium, Washington, DC, USA, 4–8 November 2017; American Medical Informatics Association: Washington, DC, USA, 2017; Volume 2017, p. 1812. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Harnoune, A.; Rhanoui, M.; Mikram, M.; Yousfi, S.; Elkaimbillah, Z.; El Asri, B. BERT based clinical knowledge extraction for biomedical knowledge graph construction and analysis. Comput. Methods Programs Biomed. Update 2021, 1, 100042. [Google Scholar] [CrossRef]
- Scaboro, S.; Portelli, B.; Chersoni, E.; Santus, E.; Serra, G. Extensive evaluation of transformer-based architectures for adverse drug events extraction. Knowl.-Based Syst. 2023, 275, 110675. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Huggingface’s transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. Ammus: A survey of transformer-based pretrained models in natural language processing. arXiv 2021, arXiv:2108.05542. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Montoya-Lora, D.; Giraldo-Forero, A.F.; Torres-Silva, E.A.; Rua, S.; Arango-Valencia, S.; Barrientos-Gómez, J.G.; Florez-Arango, J.F.; Orozco-Duque, A. Prompt Engineering of GPT-3.5 for Extracting Signs and Symptoms and Their Assertions in Maternal Electronic Health Records: A Pilot Study. In Proceedings of the Latin American Conference on Biomedical Engineering, Panama City, Panama, 2–5 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 53–62. [Google Scholar]
- Yuan, K.; Yoon, C.H.; Gu, Q.; Munby, H.; Walker, A.S.; Zhu, T.; Eyre, D.W. Transformers and large language models are efficient feature extractors for electronic health record studies. Commun. Med. 2025, 5, 83. [Google Scholar] [CrossRef] [PubMed]
- Jahan, I.; Laskar, M.T.R.; Peng, C.; Huang, J.X. A comprehensive evaluation of large language models on benchmark biomedical text processing tasks. Comput. Biol. Med. 2024, 171, 108189. [Google Scholar] [CrossRef]
- Rohanian, O.; Nouriborji, M.; Kouchaki, S.; Nooralahzadeh, F.; Clifton, L.; Clifton, D.A. Exploring the effectiveness of instruction tuning in biomedical language processing. Artif. Intell. Med. 2024, 158, 103007. [Google Scholar] [CrossRef]
- Klie, J.C.; Bugert, M.; Boullosa, B.; De Castilho, R.E.; Gurevych, I. The inception platform: Machine-assisted and knowledge-oriented interactive annotation. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations, Santa Fe, NM, USA, 21–25 August 2018; pp. 5–9. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Uronen, L.; Salanterä, S.; Hakala, K.; Hartiala, J.; Moen, H. Combining supervised and unsupervised named entity recognition to detect psychosocial risk factors in occupational health checks. Int. J. Med. Inform. 2022, 160, 104695. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Rezapour, M.; Ali, E. GPT-2 Based Named Entity Recognition, with back-translation data augmentation. ESS Open Arch. Eprints 2024, 172, 17284645. [Google Scholar]
- Carrino, C.P.; Llop, J.; Pàmies, M.; Gutiérrez-Fandiño, A.; Armengol-Estapé, J.; Silveira-Ocampo, J.; Valencia, A.; Gonzalez-Agirre, A.; Villegas, M. Pretrained Biomedical Language Models for Clinical NLP in Spanish. In Proceedings of the 21st Workshop on Biomedical Language Processing, Dublin, Ireland, 26 May 2022; pp. 193–199. [Google Scholar] [CrossRef]
- Miranda-Escalada, A.; Farré, E.; Krallinger, M. Named Entity Recognition, Concept Normalization and Clinical Coding: Overview of the Cantemist Track for Cancer Text Mining in Spanish, Corpus, Guidelines, Methods and Results. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020), Online, 23 September 2020; pp. 303–323. [Google Scholar]
- Gonzalez-Agirre, A.; Marimon, M.; Intxaurrondo, A.; Rabal, O.; Villegas, M.; Krallinger, M. Pharmaconer: Pharmacological substances, compounds and proteins named entity recognition track. In Proceedings of the 5th Workshop on BioNLP Open Shared Tasks, Hong Kong, China, 4 November 2019; pp. 1–10. [Google Scholar]
- Takahashi, K.; Yamamoto, K.; Kuchiba, A.; Koyama, T. Confidence interval for micro-averaged F 1 and macro-averaged F 1 scores. Appl. Intell. 2022, 52, 4961–4972. [Google Scholar] [CrossRef] [PubMed]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Segura-Bedmar, I.; Martínez, P.; Herrero-Zazo, M. Semeval-2013 task 9: Extraction of drug-drug interactions from biomedical texts (ddiextraction 2013). In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, Georgia, 14–15 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 341–350. [Google Scholar]
- Tsai, R.T.H.; Wu, S.H.; Chou, W.C.; Lin, Y.C.; He, D.; Hsiang, J.; Sung, T.Y.; Hsu, W.L. Various criteria in the evaluation of biomedical named entity recognition. BMC Bioinform. 2006, 7, 92. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).