Discrimination of Grape Seeds Using Laser-Induced Breakdown Spectroscopy in Combination with Region Selection and Supervised Classification Methods





Abstract
1. Introduction
2. Materials and Methods
2.1. Sample Preparation
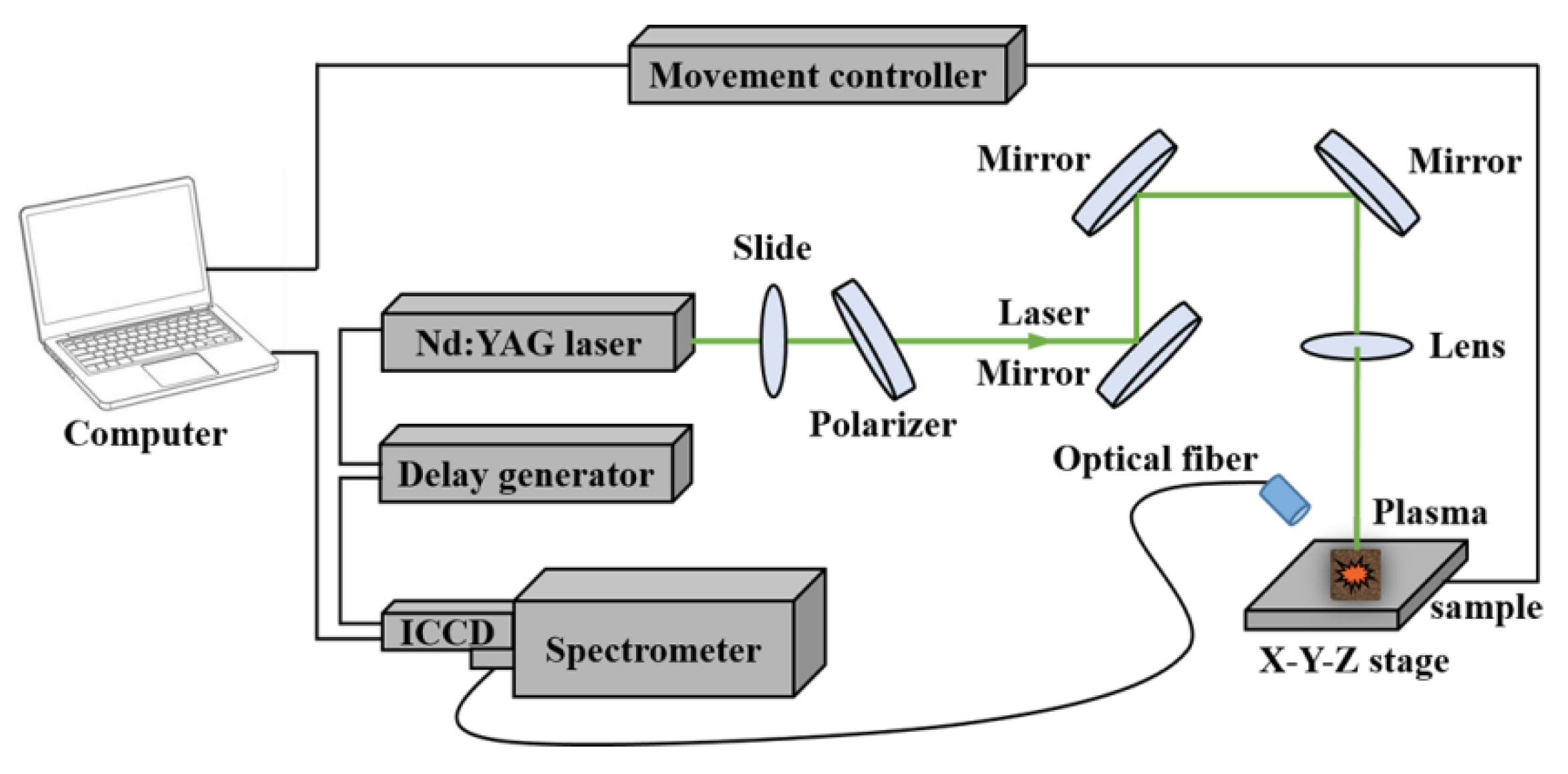
2.2. LIBS System
2.3. Chemometric Method
2.3.1. Principal Component Analysis
2.3.2. Region Selection Method
2.3.3. Classification Methods for Comparison
2.4. Model Evaluation and Software
3. Results
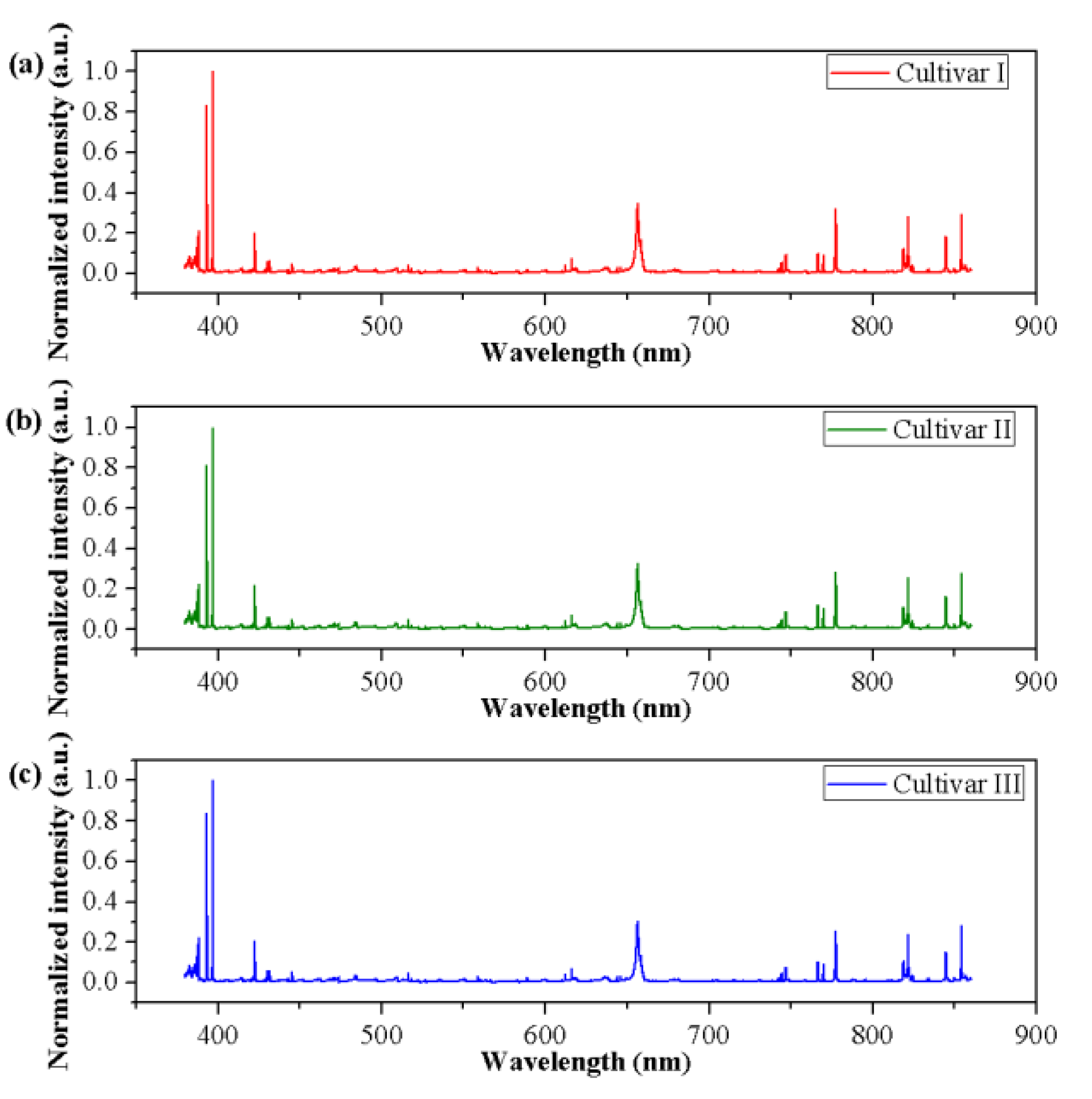
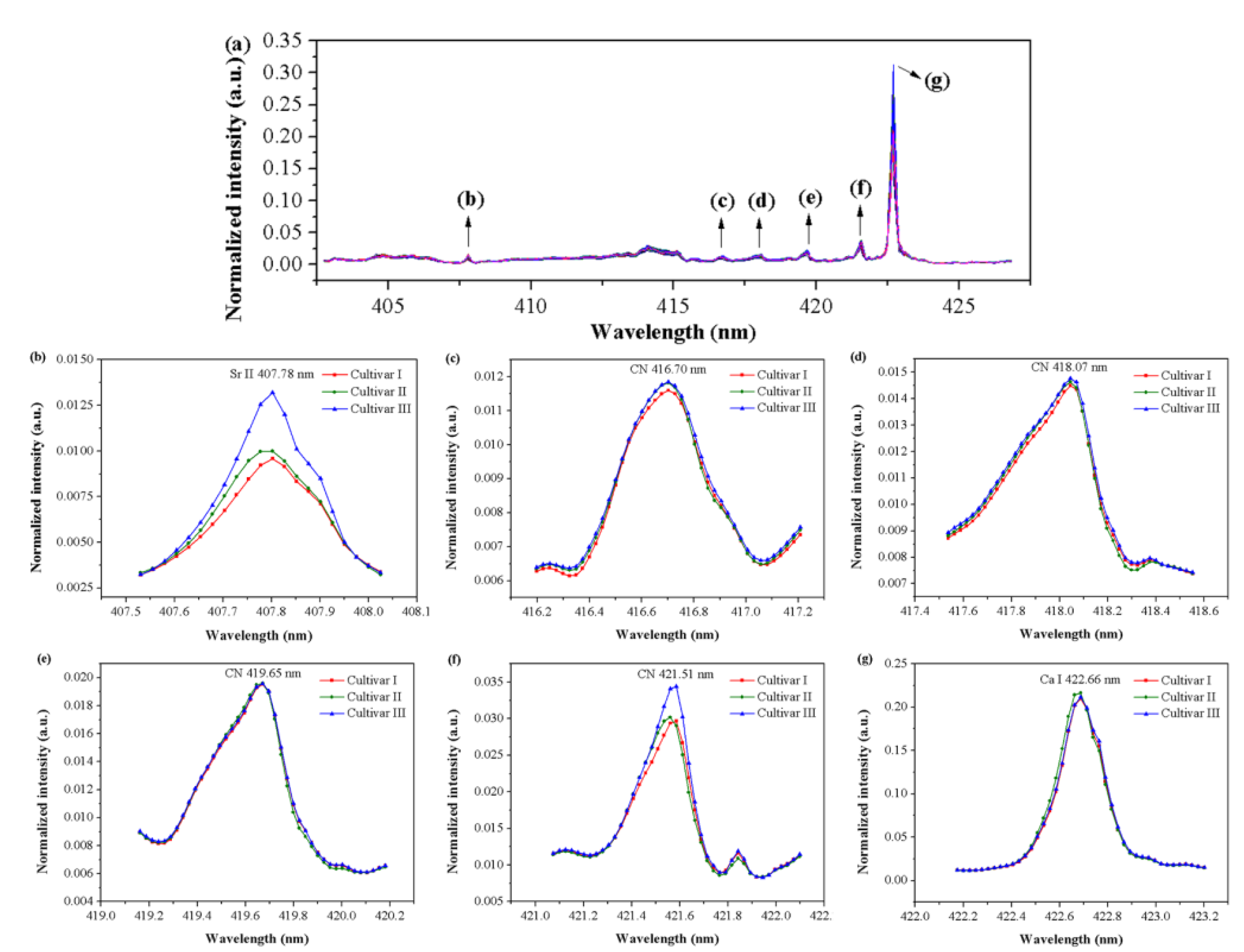
3.1. Preprocessing of Spectra Data
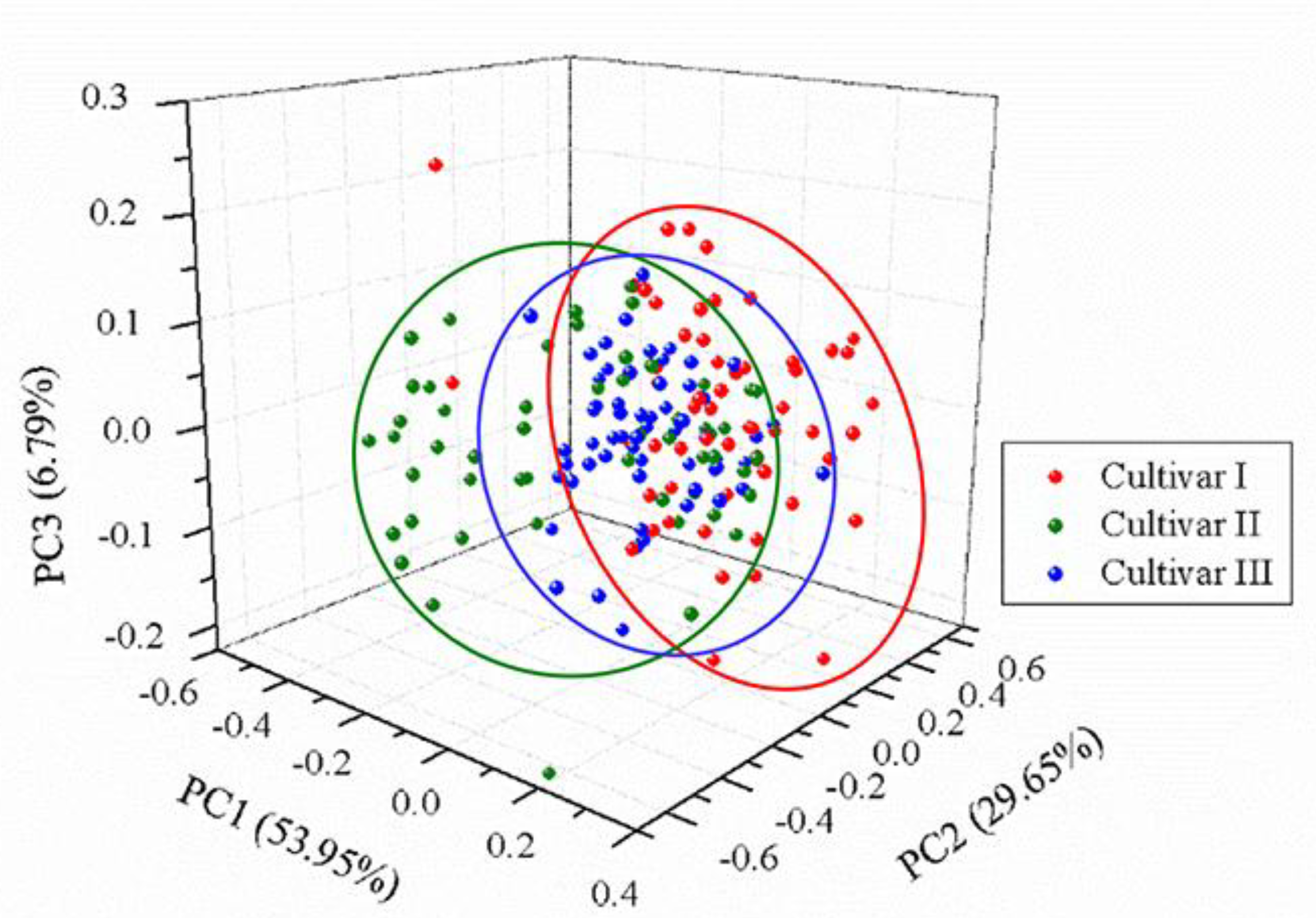
3.2. Principal Component Analysis
3.3. Discriminant Models on the Full Spectra
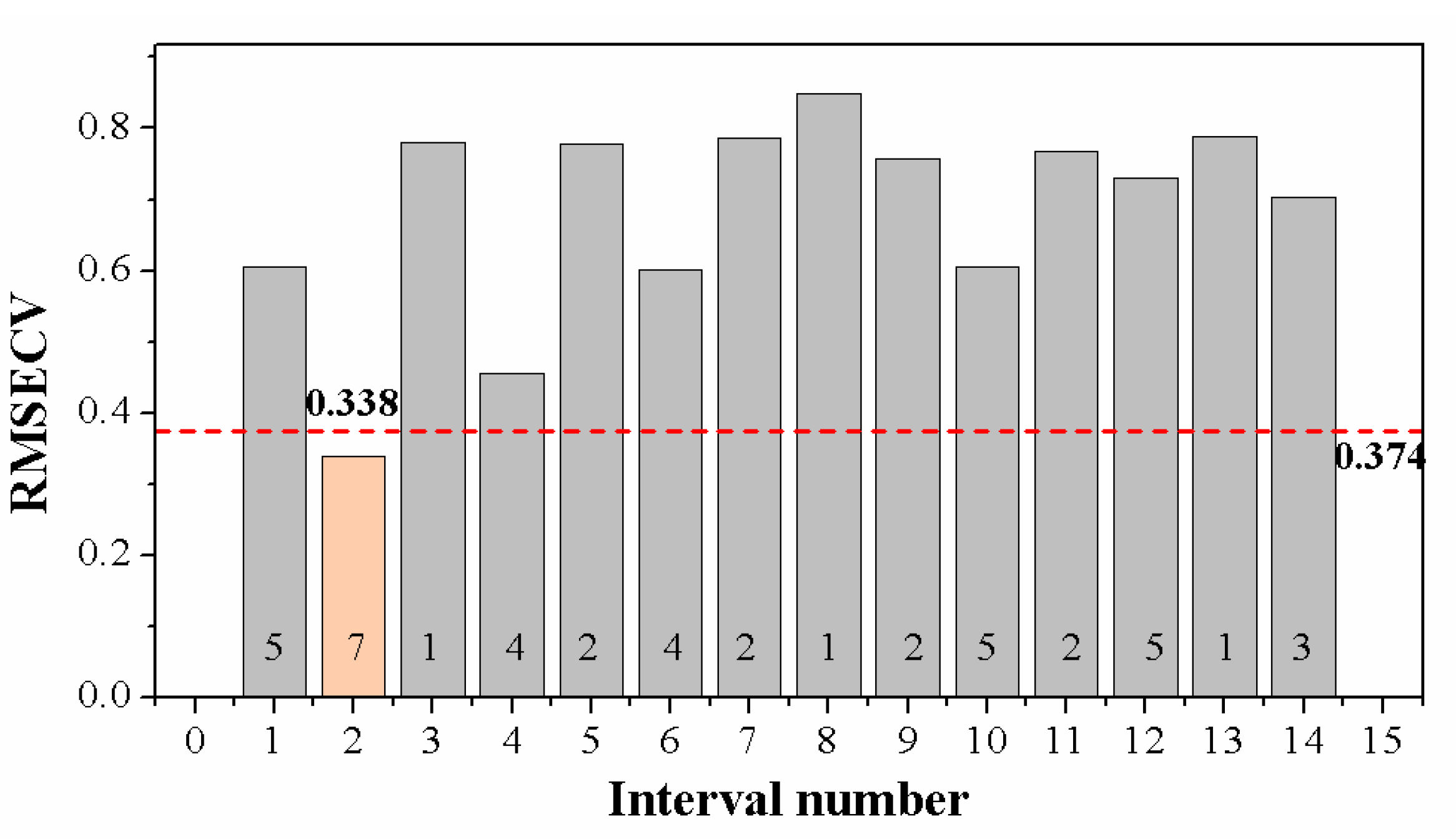
3.4. Spectral Region Selection by Interval Partial Least Squares
3.5. Discriminant Models on the Selected Spectral Region
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dranca, F.; Oroian, M. Kinetic improvement of bioactive compounds extraction from red grape (Vitis vinifera Moldova) pomace by ultrasonic treatment. Foods 2019, 8, 353. [Google Scholar] [CrossRef]
- Guaita, M.; Bosso, A. Polyphenolic characterization of grape skins and seeds of four Italian red cultivars at harvest and after fermentative maceration. Foods 2019, 8, 395. [Google Scholar] [CrossRef] [PubMed]
- Taseri, L.; Aktas, M.; Sevik, S.; Gulcu, M.; Seckin, G.U.; Aktekeli, B. Determination of drying kinetics and quality parameters of grape pomace dried with a heat pump dryer. Food Chem. 2018, 260, 152–159. [Google Scholar] [CrossRef] [PubMed]
- Lucarini, M.; Durazzo, A.; Kiefer, J.; Santini, A.; Lombardi-Boccia, G.; Souto, E.B.; Romani, A.; Lampe, A.; Ferrari Nicoli, S.; Gabrielli, P.; et al. Grape seeds: Chromatographic profile of fatty acids and phenolic compounds and qualitative analysis by FTIR-ATR spectroscopy. Foods 2019, 9, 10. [Google Scholar] [CrossRef] [PubMed]
- Montealegre, R.R.; Peces, R.R.; Vozmediano, J.L.C.; Gascuena, J.M.; Romero, E.G. Phenolic compounds in skins and seeds of ten grape Vitis vinifera varieties grown in a warm climate. J. Food Compos. Anal. 2006, 19, 687–693. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, C.; Zhu, S.; Gao, P.; Feng, L.; He, Y. Non-destructive and rapid variety discrimination and visualization of single grape seed using near-infrared hyperspectral imaging technique and multivariate analysis. Molecules 2018, 23, 1352. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Liu, F.; Zhou, F.; Song, K.; Zhang, C.; Ye, L.; He, Y. Challenging applications for multi-element analysis by laser-induced breakdown spectroscopy in agriculture: A review. Trac Trend Anal. Chem. 2016, 85, 260–272. [Google Scholar] [CrossRef]
- Maurya, G.S.; Jyotsana, A.; Kumar, R.; Kumar, A.; Rai, A.K. In situ analysis of impurities deposited on the tokamak flange using laser induced breakdown spectroscopy. J. Nucl. Mater. 2014, 444, 23–29. [Google Scholar] [CrossRef]
- Yu, K.; Zhao, Y.; Liu, F.; He, Y. Laser-induced breakdown spectroscopy coupled with multivariate chemometrics for variety discrimination of soil. Sci. Rep. UK 2016, 6, 27574. [Google Scholar] [CrossRef]
- Han, P.; Dong, D.; Du, X.; Jiao, L.; Zhao, X. Fast determination of calcium concentration in the internal tissues of a single seed using laser-induced breakdown spectroscopy. Anal. Methods UK 2016, 8, 6705–6710. [Google Scholar] [CrossRef]
- Atta, B.M.; Saleem, M.; Haq, S.U.; Ali, H.; Ali, Z.; Qamar, M. Determination of zinc and iron in wheat using laser-induced breakdown spectroscopy. Laser Phys. Lett. 2018, 15, 125603. [Google Scholar] [CrossRef]
- Luo, Z.; Zhang, L.; Chen, T.; Liu, M.; Chen, J.; Zhou, H.; Yao, M. Rapid identification of rice species by laser-induced breakdown spectroscopy combined with pattern recognition. Appl. Opt. 2019, 58, 1631–1638. [Google Scholar] [CrossRef] [PubMed]
- Prochazka, D.; Mazura, M.; Samek, O.; Rebrosova, K.; Porizka, P.; Klus, J.; Prochazkova, P.; Novotny, J.; Novotny, K.; Kaiser, J. Combination of laser-induced breakdown spectroscopy and Raman spectroscopy for multivariate classification of bacteria. Spectrochim. Acta B 2018, 139, 6–12. [Google Scholar] [CrossRef]
- Liu, F.; Shen, T.; Kong, W.; Peng, J.; Zhang, C.; Song, K.; Wang, W.; Zhang, C.; He, Y. Quantitative analysis of cadmium in tobacco roots using laser-induced breakdown spectroscopy with variable index and chemometrics. Front. Plant Sci. 2018, 9, 1316. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Guindo, M.L.; Xu, X.; Sun, M.; Peng, J.; Liu, F.; He, Y. Deep Learning associated with laser-induced breakdown spectroscopy (LIBS) for the prediction of lead in soil. Appl. Spectrosc. 2019, 73, 565–573. [Google Scholar] [CrossRef] [PubMed]
- Moncayo, S.; Manzoor, S.; Rosales, J.D.; Anzano, J.; Caceres, J.O. Qualitative and quantitative analysis of milk for the detection of adulteration by Laser Induced Breakdown Spectroscopy (LIBS). Food Chem. 2017, 232, 322–328. [Google Scholar] [CrossRef] [PubMed]
- Velioglu, H.M.; Sezer, B.; Bilge, G.; Baytur, S.E.; Boyaci, I.H. Identification of offal adulteration in beef by laser induced breakdown spectroscopy (LIBS). Meat Sci. 2018, 138, 28–33. [Google Scholar] [CrossRef]
- Zhu, S.; Feng, L.; Zhang, C.; Bao, Y.; He, Y. Identifying freshness of spinach leaves stored at different temperatures using hyperspectral imaging. Foods 2019, 8, 356. [Google Scholar] [CrossRef]
- Norgaard, L.; Saudland, A.; Wagner, J.; Nielsen, J.P.; Munck, L.; Engelsen, S.B. Interval partial least-squares regression (iPLS): A comparative chemometric study with an example from near-infrared spectroscopy. Appl. Spectrosc. 2000, 54, 413–419. [Google Scholar] [CrossRef]
- Rinnan, A.; Savorani, F.; Engelsen, S.B. Simultaneous classification of multiple classes in NMR metabolomics and vibrational spectroscopy using interval-based classification methods: iECVA vs. iPLS-DA. Anal. Chim. Acta 2018, 1021, 20–27. [Google Scholar] [CrossRef]
- Zhou, Y.; Xiang, B.; Wang, Z.; Chen, C. Determination of chlorpyrifos residue by near-infrared spectroscopy in white radish based on interval partial least square (iPLS) model. Anal. Lett. 2009, 42, 1518–1526. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Shang, L.; Zhu, X.; Nelson, S.O. Nondestructive detection of soluble solids content of apples from dielectric spectra with ANN and chemometric methods. Food Bioprocess Tech. 2015, 8, 1126–1138. [Google Scholar] [CrossRef]
- Gao, P.; Xu, W.; Yan, T.; Zhang, C.; Lv, X.; He, Y. Application of near-infrared hyperspectral imaging with machine learning methods to identify geographical origins of dry narrow-leaved oleaster (Elaeagnus angustifolia) fruits. Foods 2019, 8, 620. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Yang, X.; Han, S.; Fan, B.; Zhao, Z.; Wu, X.; Qian, J. Nondestructive prediction of tilapia fillet freshness during storage at different temperatures by integrating an electronic nose and tongue with radial basis function neural networks. Food Bioprocess Tech. 2018, 11, 1840–1852. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. B 2012, 42, 513–529. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology (NIST). Atomic Spectra Database (ASD). Available online: https://www.nist.gov/pml/atomic-spectra-database (accessed on 22 October 2019).
- Baudelet, M.; Guyon, L.; Yu, J.; Wolf, J.P.; Amodeo, T.; Frejafon, E.; Laloi, P. Spectral signature of native CN bonds for bacterium detection and identification using femtosecond laser-induced breakdown spectroscopy. Appl. Phys. Lett. 2006, 88, 063901. [Google Scholar] [CrossRef]
- Zhang, C.; Shen, T.; Liu, F.; He, Y. Identification of coffee varieties using laser-induced breakdown spectroscopy and chemometrics. Sensors 2018, 18, 95. [Google Scholar] [CrossRef]
- Liu, X.; Feng, X.; Liu, F.; Peng, J.; He, Y. Rapid identification of genetically modified maize using laser-induced breakdown spectroscopy. Food Bioprocess Tech. 2019, 12, 347–357. [Google Scholar] [CrossRef]
- Duan, F.; Fu, X.; Jiang, J.; Huang, T.; Ma, L.; Zhang, C. Automatic variable selection method and a comparison for quantitative analysis in laser-induced breakdown spectroscopy. Spectrochim. Acta B 2018, 143, 12–17. [Google Scholar] [CrossRef]
- Lin, P.; Li, X.L.; Chen, Y.M.; He, Y. A deep convolutional neural network architecture for boosting image discrimination accuracy of rice species. Food Bioprocess Tech. 2018, 11, 765–773. [Google Scholar] [CrossRef]
- Wu, N.; Zhang, C.; Bai, X.; Du, X.; He, Y. Discrimination of Chrysanthemum varieties using hyperspectral imaging combined with a deep convolutional neural network. Molecules 2018, 23, 2831. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Parameters | Activation | Additional Processing |
|---|---|---|---|
| Convolution-1D (1) | Kernel number = 32, Kernel size = 3, Strides = 1 | ReLU | Batch normalization |
| Max pooling | Size = 2, Strides = 2 | - | - |
| Convolution-1D (2) | Kernel number = 16, Kernel size = 3, Strides = 1 | - | Batch normalization |
| Dense (1) | Neurons = 512 | ReLU | Batch normalization, Dropout (0.5) |
| Dense (2) | Neurons = 32 | ReLU | Batch normalization, Dropout (0.2) |
| Dense (3) | Neurons = 3 | ReLU | - |
| SoftMax | - | - | - |
| Models | Parameter 1 | Calibration Set | Prediction Set | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| - | 1 | 2 | 3 | Accuracy | 1 | 2 | 3 | Accuracy | ||
| SVM | (9.1896, 9.1896) | 1 | 39 | 0 | 0 | 100% | 15 | 4 | 1 | 75.0% |
| 2 | 0 | 39 | 0 | 100% | 2 | 18 | 0 | 90.0% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 1 | 19 | 95.0% | ||
| Total | - | - | - | 100% | - | - | - | 86.7% | ||
| RBFNN | 2 | 1 | 39 | 0 | 0 | 100% | 20 | 0 | 0 | 100% |
| 2 | 0 | 39 | 0 | 100% | 3 | 17 | 0 | 85.0% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 0 | 20 | 100% | ||
| Total | - | - | - | 100% | - | - | - | 95.0% | ||
| ELM | 48 | 1 | 39 | 0 | 0 | 100% | 17 | 2 | 1 | 85.0% |
| 2 | 2 | 35 | 2 | 89.7% | 2 | 18 | 0 | 90.0% | ||
| 3 | 0 | 0 | 39 | 100% | 1 | 1 | 18 | 90.0% | ||
| Total | - | - | - | 96.6% | - | - | - | 88.3% | ||
| CNN | Seen in Table 1 | 1 | 39 | 0 | 0 | 100% | 20 | 0 | 0 | 100% |
| 2 | 0 | 39 | 0 | 100% | 2 | 18 | 0 | 90.0% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 0 | 20 | 100% | ||
| Total | - | - | - | 100% | - | - | - | 96.7% | ||
| - | p-Value 1 |
|---|---|
| SVM vs. RBFNN | 0.114 |
| SVM vs. ELM | 0.783 |
| SVM vs. CNN | 0.048 |
| RBFNN vs. ELM | 0.186 |
| RBFNN vs. CNN | 1.000 |
| ELM vs. CNN | 0.163 |
| Models | Parameter 1 | Calibration Set | Prediction Set | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| - | 1 | 2 | 3 | Accuracy | 1 | 2 | 3 | Accuracy | ||
| SVM | (147.0334, 27.8576) | 1 | 39 | 0 | 0 | 100% | 18 | 2 | 0 | 90.0% |
| 2 | 0 | 39 | 0 | 100% | 0 | 20 | 0 | 100% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 0 | 20 | 100% | ||
| Total | - | - | - | 100% | - | - | - | 96.7% | ||
| RBFNN | 3 | 1 | 39 | 0 | 0 | 100% | 14 | 6 | 0 | 70.0% |
| 2 | 0 | 39 | 0 | 100% | 4 | 16 | 0 | 80.0% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 3 | 17 | 85.0% | ||
| Total | - | - | - | 100% | - | - | - | 78.3% | ||
| ELM | 48 | 1 | 39 | 0 | 0 | 100% | 20 | 0 | 0 | 100% |
| 2 | 2 | 35 | 2 | 89.7% | 1 | 17 | 2 | 85.0% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 1 | 19 | 95.0% | ||
| Total | - | - | - | 96.6% | - | - | - | 93.3% | ||
| CNN | Seen in Table 1 | 1 | 39 | 0 | 0 | 100% | 18 | 2 | 0 | 90.0% |
| 2 | 0 | 39 | 0 | 100% | 1 | 19 | 0 | 95.0% | ||
| 3 | 0 | 0 | 39 | 100% | 0 | 0 | 20 | 100.0% | ||
| Total | - | - | - | 100% | - | - | - | 95.0% | ||
| - | p-Value 1 |
|---|---|
| SVM vs. RBFNN | 0.002 |
| SVM vs. ELM | 0.679 |
| SVM vs. CNN | 1.000 |
| RBFNN vs. ELM | 0.018 |
| RBFNN vs. CNN | 0.007 |
| ELM vs. CNN | 1.000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Zhao, Y.; Zhang, C.; Li, Y.; Bao, Y.; Liu, F. Discrimination of Grape Seeds Using Laser-Induced Breakdown Spectroscopy in Combination with Region Selection and Supervised Classification Methods. Foods 2020, 9, 199. https://doi.org/10.3390/foods9020199
He Y, Zhao Y, Zhang C, Li Y, Bao Y, Liu F. Discrimination of Grape Seeds Using Laser-Induced Breakdown Spectroscopy in Combination with Region Selection and Supervised Classification Methods. Foods. 2020; 9(2):199. https://doi.org/10.3390/foods9020199
Chicago/Turabian StyleHe, Yong, Yiying Zhao, Chu Zhang, Yijian Li, Yidan Bao, and Fei Liu. 2020. "Discrimination of Grape Seeds Using Laser-Induced Breakdown Spectroscopy in Combination with Region Selection and Supervised Classification Methods" Foods 9, no. 2: 199. https://doi.org/10.3390/foods9020199
APA StyleHe, Y., Zhao, Y., Zhang, C., Li, Y., Bao, Y., & Liu, F. (2020). Discrimination of Grape Seeds Using Laser-Induced Breakdown Spectroscopy in Combination with Region Selection and Supervised Classification Methods. Foods, 9(2), 199. https://doi.org/10.3390/foods9020199