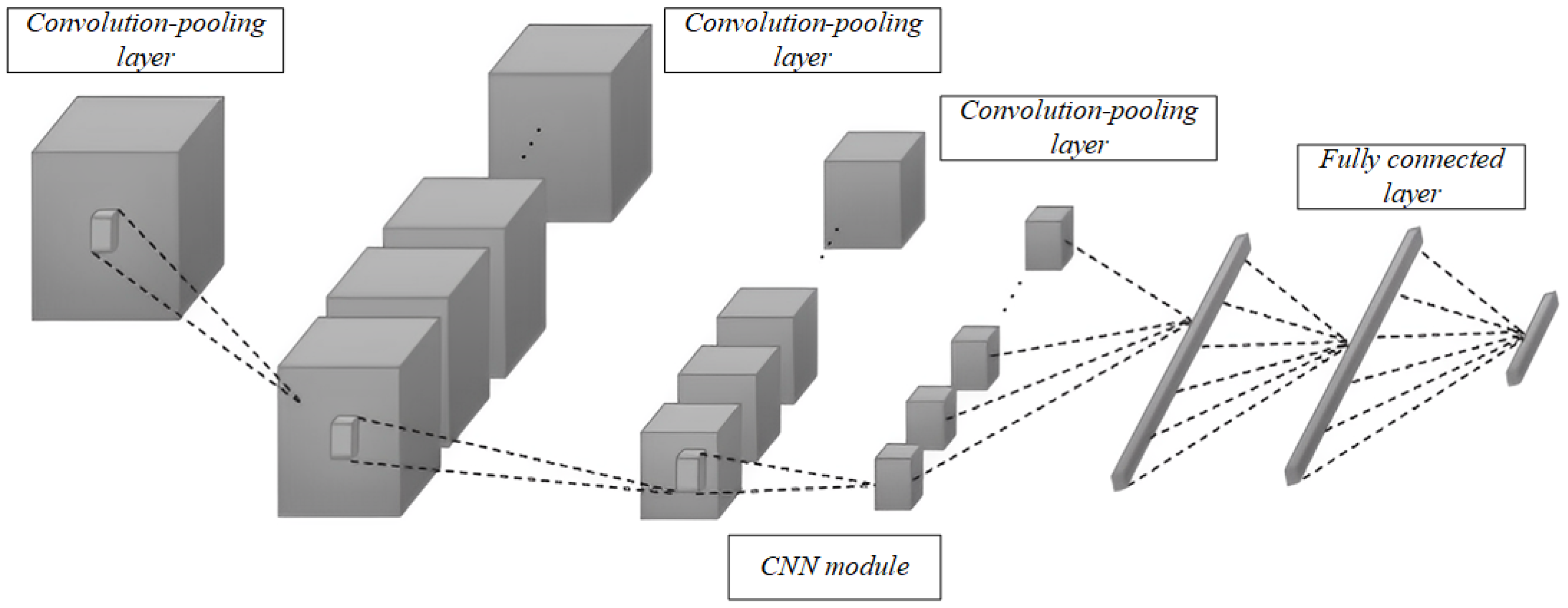
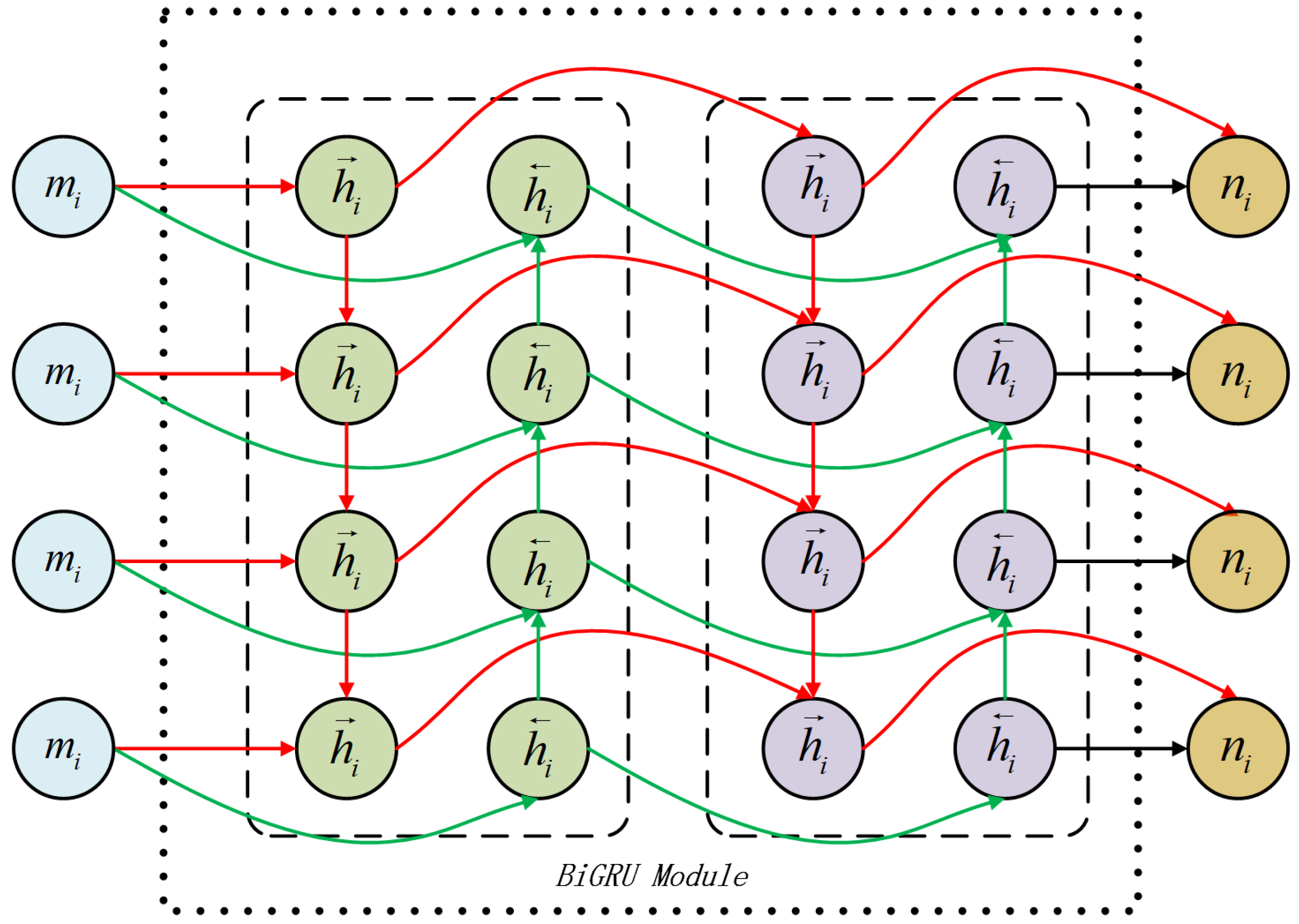
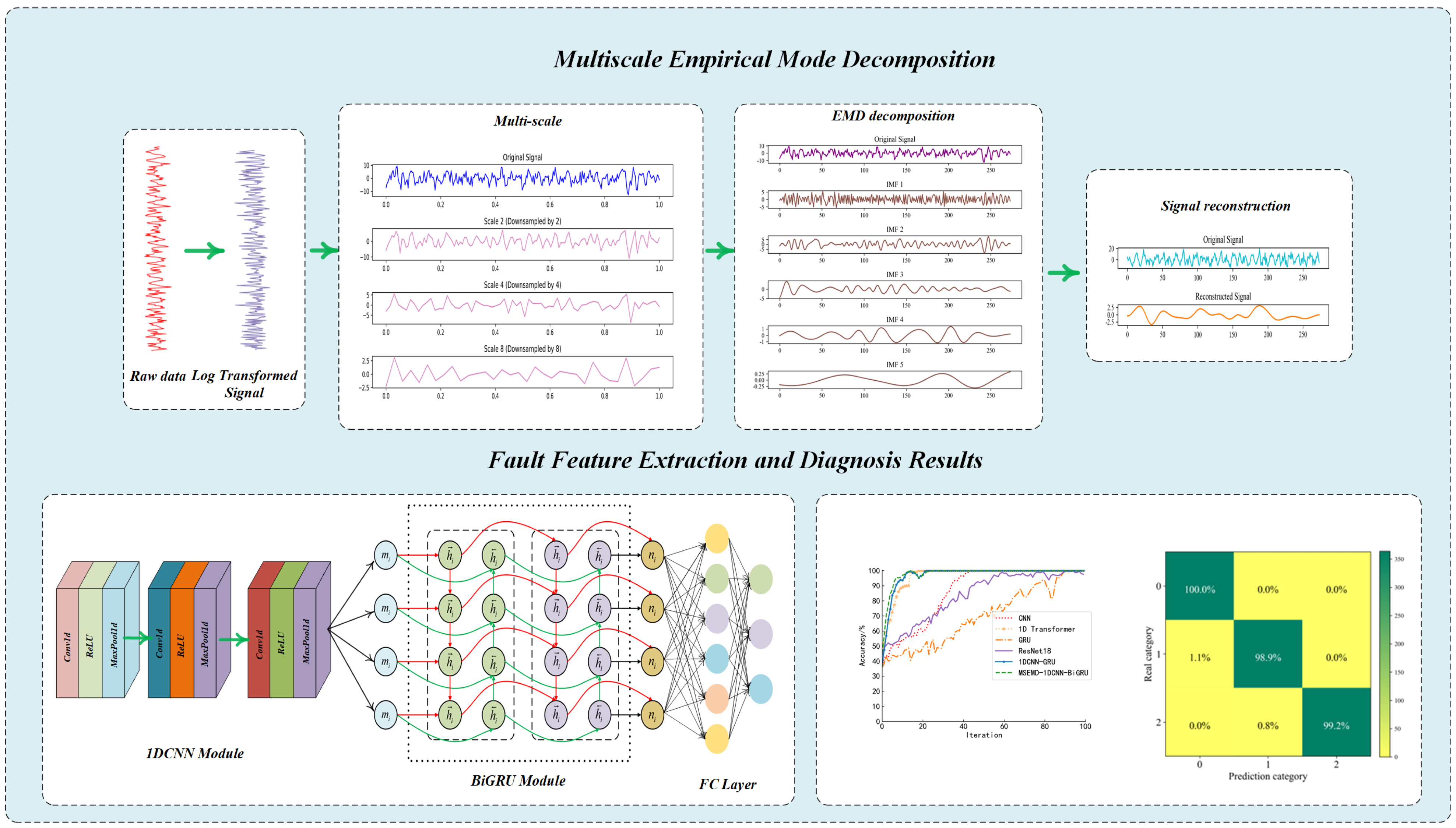
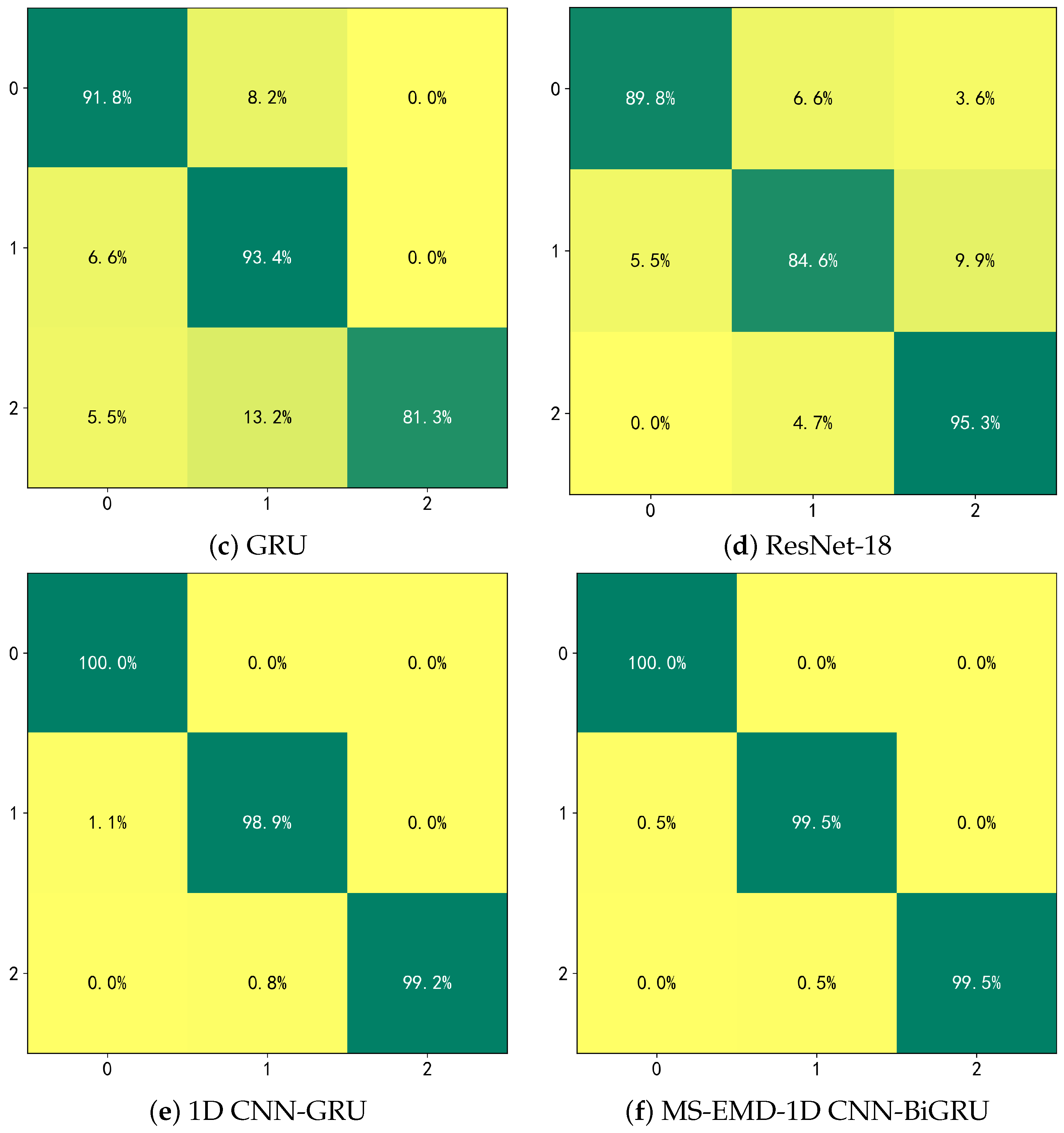
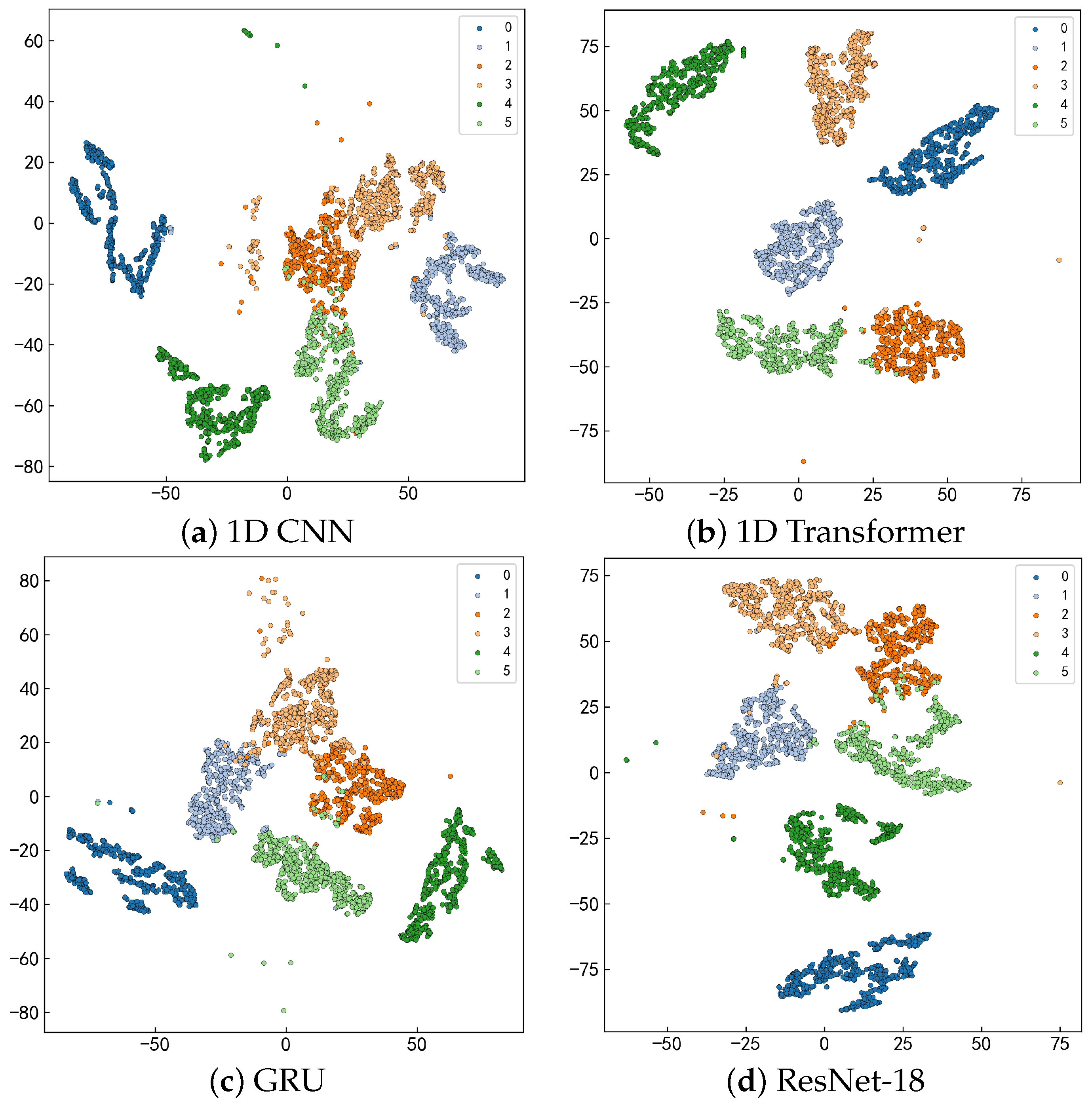
This section provides a detailed analysis of the experimental procedure, aiming to fully evaluate the performance and practical value of the proposed MS-EMD and 1D CNN-BiGRU model for industrial robot gearbox fault detection. First, we describe the dataset used in the experiments, including its origin, how the data were collected, and the overall experimental setup. To tackle noise and non-stationary behavior in the raw vibration signals, we applied preprocessing steps such as multi-scale decomposition via MS-EMD, which effectively removes noise and pulls out fault features from different frequency bands. In practice, MS-EMD adaptively breaks the signal into intrinsic mode functions, capturing local vibration patterns and providing high-quality inputs for the fault detection model. We also applied nonlinear transforms and signal reconstruction to boost signal stability and sharpen feature representation.
3.3.1. Experimental Data
Considering that obtaining real data from industrial robot gearboxes is challenging, we used a publicly available dataset from reference [
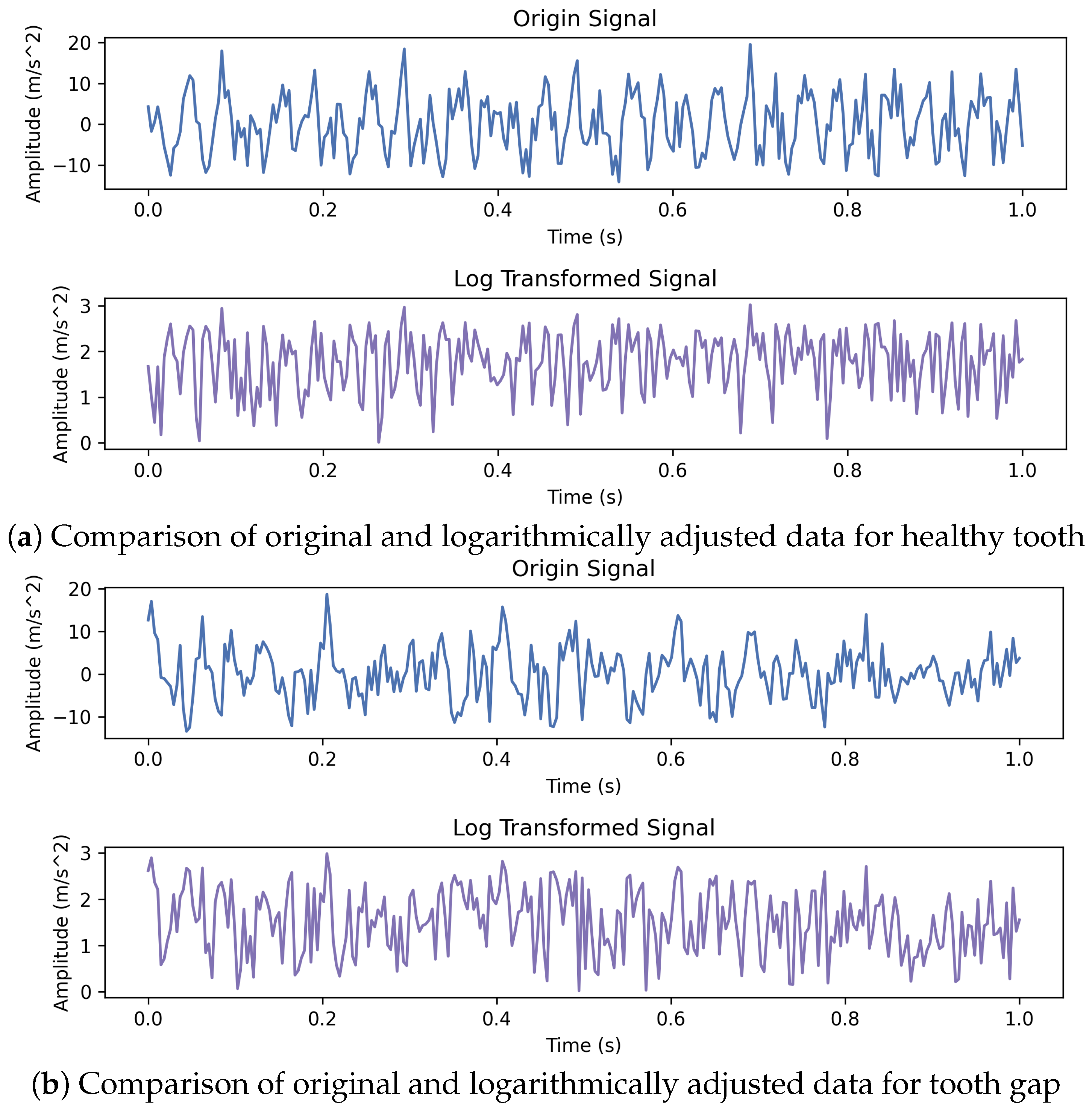
28] for this study. The dataset was collected from an experimental setup of a real industrial gearbox, simulating the working conditions of the gearbox, and records vibration signals under various typical operating conditions. It comprehensively captures the vibration characteristics induced by gear faults. The data include radial vibration signals from three different gear conditions in the gearbox setup: healthy teeth of helical gears, a single tooth gap, and three worn teeth, as shown in
Figure 4 and
Figure 5. Because the fault types and vibration characteristics of this dataset closely resemble common fault modes in industrial robot gearboxes, it holds significant research reference value. The data acquisition system has a sampling frequency of 10 kHz, with each collection lasting 10 s, providing high-resolution dynamic signals that help capture transient vibration features during fault occurrences. The test gearbox operates at a speed of 1420 rpm, with the small gear having 15 teeth and the large gear having 110 teeth, and a meshing frequency of 355 Hz, which accurately reflects the vibration characteristics during the gear meshing process.
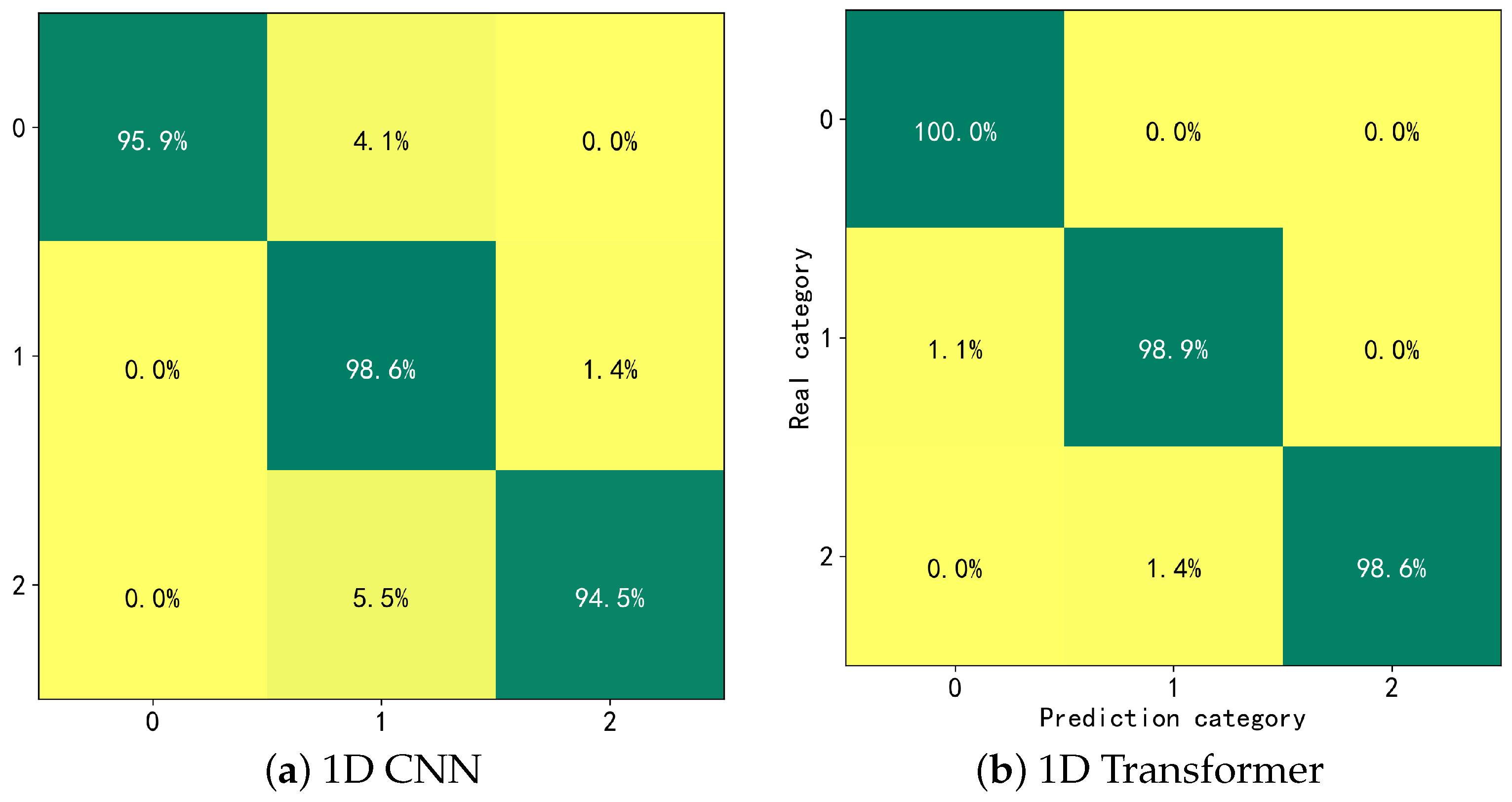
In this study, we conducted fault diagnosis analysis on an industrial gearbox under three conditions: healthy teeth, chipped teeth, and worn teeth. The dataset consists of 1092 triaxial vibration signal samples, evenly distributed across the three conditions with 364 samples per category, ensuring class balance and facilitating fair learning of each fault mode by the model. Each sample contains 274 data points, representing a segment of vibration signals collected from an industrial gearbox operating at 1420 RPM, covering part of a 10 s sampling period. This ensures that the dynamic characteristics of faults are captured. The signals were acquired using industrial-grade accelerometers (Analog Devices ADXL210JQC, sensitivity 100 mV/g) and a high-precision ADC (Advantech PCI-1710, 12-bit resolution, sampling rate 100 kS/s). The signals were stored in MATLAB 2016 as voltage data after preprocessing to remove baseline drift. The theoretical gear meshing frequency (GMF) of the gearbox is 355 Hz, while the actual peak frequency obtained through FFT analysis is 365 Hz. The dataset was split into training, validation, and testing sets at a 6:2:2 ratio, with each category—including healthy teeth, chipped teeth, and worn teeth—represented in each subset, ensuring high industrial relevance. Unlike synthetic datasets, this dataset is derived from real-world industrial experiments, reflecting the nonlinear and complex nature of vibration signals. It provides researchers with reliable data for fault feature extraction and the training and validation of machine learning models. The specific data distribution and sample details are shown in
Table 2.
3.3.3. MS-EMD Decomposition and Feature Selection
Compared with traditional signal decomposition techniques such as wavelet transform, empirical wavelet transform (EWT), and variational mode decomposition (VMD), MS-EMD offers significant advantages. While wavelet transform is widely used in time–frequency analysis, it requires the predefinition of a mother wavelet function, limiting its flexibility, and its performance deteriorates when dealing with high-noise signals [
29]. EWT and VMD improve decomposition efficiency and noise resistance but are sensitive to parameter initialization and exhibit higher computational complexity [
30,
31,
32]. MS-EMD, on the other hand, achieves adaptive processing of non-stationary signals through multi-scale decomposition without requiring predefined basis functions or complex parameter tuning. This makes it particularly well suited for industrial signal analysis under complex operating conditions.
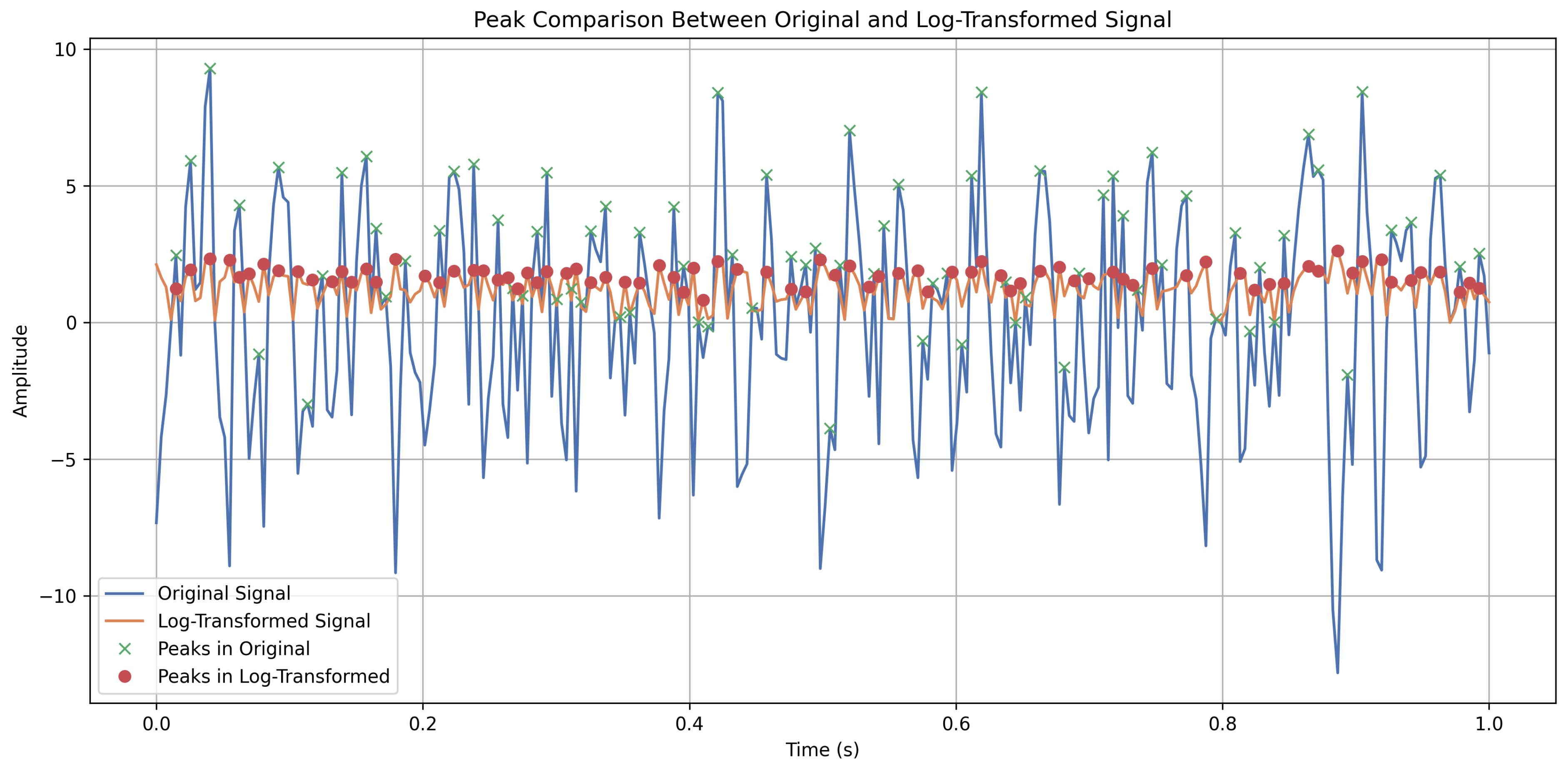
In this subsection, we show how the tooth gap fault data are handled in the MS-EMD decomposition and feature filtering steps. First, the log-transformed tooth gap signal is preprocessed using a low-pass filter, whose cutoff and order are adjusted dynamically based on the sampling rate and chosen down-sampling factors. This filter not only suppresses aliasing but also keeps the low-frequency content intact, providing a clean input for the multi-scale decomposition.
Next, the signal is down-sampled with factors of two, four, and eight to create multiple sequences at different time resolutions; the down-sampling factors of two, four, and eight were chosen because they follow a multiplicative relationship, allowing for a gradual reduction in temporal resolution to extract different signal characteristics sequentially. These factors are simple and efficient as they align with the binary nature of data processing. They are widely applied in fields such as signal processing and wavelet analysis, where their incremental pattern has been proven to effectively balance precision and efficiency. When changing the down-sampling factor reveals features in the high-, mid-, and low-frequency bands, larger factors yield lower time resolution and capture global trends, while smaller factors retain finer details for local analysis. The down-sampling process not only alters the time resolution of the signal but also reduces its amplitude to some extent. By applying down-sampling, local details of the signal are smoothed out, and the fluctuation amplitude gradually decreases. As a result, the signal exhibits a smoother variation trend at lower time resolutions. This process helps EMD to better identify low-frequency components of the signal and reduces the impact of noise on the decomposition results. The core of EMD lies in decomposing the signal into multiple intrinsic mode functions (IMFs), with each IMF representing a specific frequency component of the signal. Smaller amplitude fluctuations mitigate the interference of high-frequency noise during the EMD decomposition process. This ensures that the extracted IMFs better capture the essential characteristics of the signal rather than being overly influenced by transient peaks and local noise. The resulting signals after down-sampling by two, four, and eight are shown in
Figure 8, illustrating how the tooth gap fault signature evolves across scales. These scaled signals enrich the information available for the subsequent EMD decomposition.
These multi-scale signals offer detailed input for the subsequent EMD process, enabling thorough analysis across various frequency ranges and temporal scales. This enables more precise extraction of key features of the tooth gap fault. After generating the multi-scale signals, we applied empirical mode decomposition to each scale separately. EMD works by iteratively peeling off the signal’s own oscillation patterns, so you do not need to define any wave shapes in advance. This flexibility makes it easier to uncover how the signal’s behavior changes over time. By performing EMD decomposition on signals at different scales, we can capture detailed information from various frequency bands. At higher time resolution, EMD extracts subtle changes and local vibration patterns, while at a lower time resolution, EMD is more effective at capturing the global trends and low-frequency components of the signal, offering a macro perspective on fault evolution.
Figure 9 shows the EMD decomposition results of the tooth gap fault data at different down-sampling factors. The differences in frequency and time resolution of signals at various scales can be clearly observed, further validating the effectiveness of the MS-EMD method in multi-scale signal analysis.
Down-sampling factors of two, four, and eight reveal different characteristics of the signal at various time scales. Considering the signal’s frequency distribution, a down-sampling of two retains more high-frequency components, making it suitable for analyzing rapid variations and subtle fluctuations in the signal. In contrast, a down-sampling of four focuses on extracting mid-frequency features, while a down-sampling of eight emphasizes low-frequency components and long-term trends. This layered approach provides a comprehensive view of the signal across high-, mid-, and low-frequency bands. Larger down-sampling factors, such as four and eight, effectively suppress the high-frequency components of the signal, reducing amplitude fluctuations and enhancing the extraction of low-frequency information. This aids EMD in decomposing the signal by isolating stable and representative low-frequency components while mitigating the interference of high-frequency noise. As the down-sampling factor increases, the time resolution of the signal decreases, details are smoothed out, and the overall signal becomes more uniform. For fault signals like those associated with gear tooth defects, such down-sampling emphasizes the long-term trends and low-frequency variations in the signal. This results in clearer decomposition outcomes for EMD, facilitating the identification of fault characteristics. By selecting appropriate down-sampling factors, such as four or eight, unnecessary details can be minimized, allowing EMD to focus on the signal’s primary trends and extract more representative features, thereby providing more reliable information for fault diagnosis.
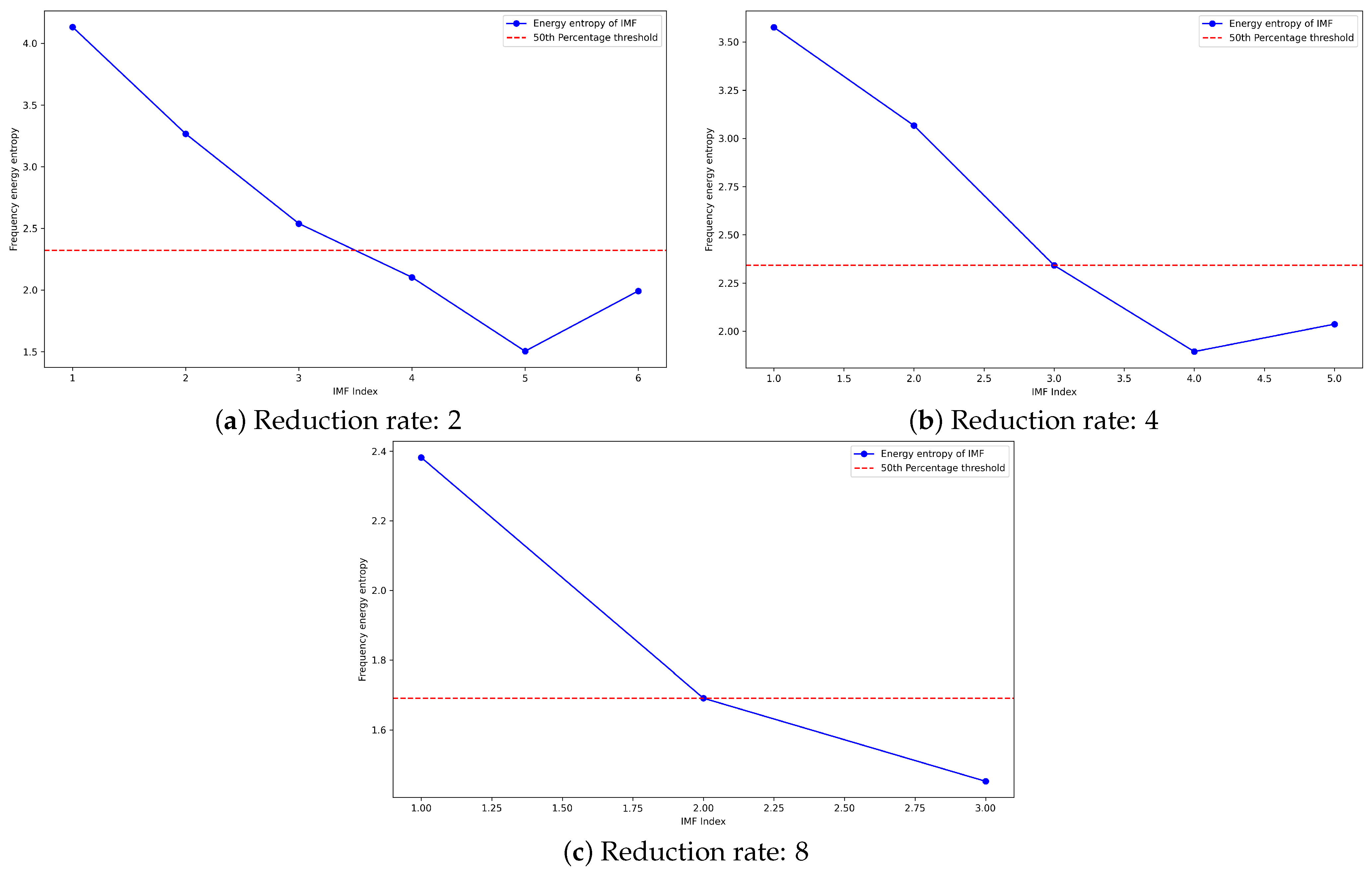
To select the key IMFs containing fault information, we use the frequency energy entropy method to evaluate the energy distribution of each IMF (the specific calculation is given in Formula (11)). By setting a 50% energy threshold, only the IMFs with energy entropy below this threshold are retained, thus removing noise and irrelevant high-frequency information while highlighting low-frequency fault features.
To filter the IMFs, in this study, a 50% frequency energy entropy threshold was empirically set as the criterion for determining key intrinsic mode functions (IMFs) [
29]. The 50% energy threshold serves as a balancing strategy that retains most of the useful information in the signal while effectively filtering out secondary modes, thus preventing the model from becoming overly complex due to redundant features. Only IMFs with energy entropy below this threshold are kept, as these components are typically concentrated in the low-frequency range and contain the primary fault characteristics. In contrast, IMFs with higher energy entropy are generally random noise or high-frequency irrelevant information. The selection of the 50% energy entropy threshold is not arbitrary but rather a balanced strategy supported by theoretical analysis and experimental validation. Energy entropy, as an indicator of signal complexity and randomness, reflects the energy distribution of the signal across different frequency bands. By choosing an appropriate threshold, it is possible to retain the main features of the signal while effectively filtering out high-frequency noise. The threshold setting must strike a balance between retaining meaningful features and eliminating noise, avoiding excessive information loss or noise interference. The 50% energy entropy threshold can be explained from several perspectives. First, it is a commonly used empirical choice that aims to retain most of the useful information while efficiently filtering out noise. Low-frequency components usually contain the signal’s main features, while high-frequency parts tend to include noise or irrelevant components. By selecting a 50% threshold, key low-frequency information in the signal is preserved, while high-frequency noise is suppressed, reducing interference in signal analysis. Additionally, experimental results indicate that the 50% energy entropy threshold provides good decomposition performance for most signals. When compared with other thresholds (e.g., 30%, 40%, 60%), the IMFs selected with the 50% threshold typically highlight the fault characteristics of the signal and reduce irrelevant information, improving the accuracy of subsequent fault diagnosis models. A threshold that is too low (e.g., 30%) may retain too many IMFs, including significant high-frequency noise, which increases computational complexity and affects subsequent analysis. A threshold that is too high (e.g., 70%) may better suppress noise but could also lose important details of the signal. The 50% threshold effectively balances information retention and the removal of redundant information, preventing overcomplication while preserving essential details. Moreover, the 50% energy entropy threshold significantly improves the signal reconstruction quality. The filtered IMFs are smooth, with noticeable noise suppression. Compared with other thresholds, the IMFs obtained with the 50% threshold retain the low-frequency information of the signal better while reducing high-frequency noise interference, providing clearer and more reliable input data for subsequent feature extraction and fault diagnosis.
In
Table 3, we present the signal reconstruction errors under different energy entropy thresholds (30%, 40%, 50%, 60%), including mean squared error (MSE) and root mean square error (RMSE). By comparing the results for different thresholds, it is evident that the 50% energy entropy threshold performs the best in signal reconstruction, exhibiting the lowest MSE and RMSE values. This indicates that the 50% threshold can effectively retain the key signal features while suppressing high-frequency noise, ensuring the accurate extraction of the main characteristics of the signal. On the other hand, lower thresholds (such as 30% and 40%) retain too much high-frequency noise, leading to higher reconstruction errors. Higher thresholds (like 60%) may remove more noise but also result in the loss of important low-frequency information, causing a decline in reconstruction performance. Therefore, the 50% energy entropy threshold strikes a good balance between noise suppression and feature retention, providing the optimal signal reconstruction performance. This makes it a reliable data source for subsequent fault diagnosis and feature extraction.
During the filtering process, the frequency energy entropy distribution under different down-sampling factors is shown in
Figure 10. From the figure, it can be seen that as the down-sampling factor increases, the frequency energy entropy distribution of the IMFs exhibits a certain regularity. For instance, larger down-sampling factors correspond to IMFs in lower frequency ranges, which usually have lower energy entropy, indicating that the signal energy is more concentrated. On the other hand, smaller down-sampling factors retain more high-frequency components, with their corresponding IMF energy entropy distribution being more dispersed. Finally, the selected IMFs are re-constructed into a new signal, a process that not only effectively reduces irrelevant noise in the data but also enhances the clarity of the fault feature signals, providing more reliable and clear input data for the subsequent 1D CNN-BiGRU fault diagnosis model.
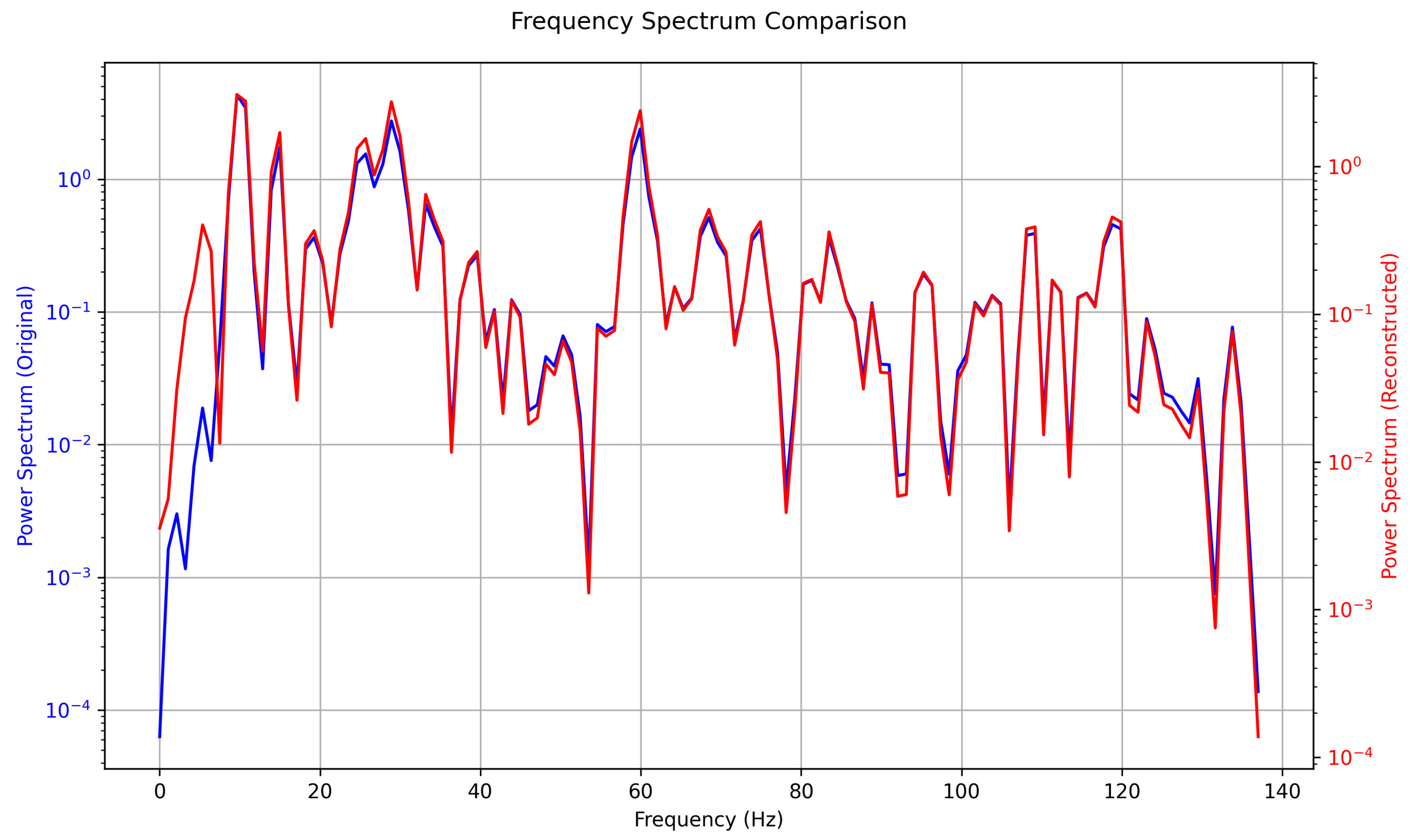
From the spectral comparison in
Figure 11, several key features can be observed. The frequency spectra of the original signal and the reconstructed signal show significant differences in the 0–10 Hz range. This could be because the low-frequency energy is primarily contributed by noise or other non-characteristic components in the original signal. The MS-EMD decomposition process exhibits good noise suppression capabilities in the low-frequency band, effectively removing irrelevant low-frequency noise in the reconstructed signal. In the 10–140 Hz frequency range, the spectra of the original and reconstructed signals are almost identical, indicating that the MS-EMD method can accurately extract frequency features related to the fault, with no significant loss of key information during the reconstruction process. This result demonstrates that MS-EMD not only extracts fault characteristic signals but also preserves the high fidelity of the signal, ensuring that the reconstructed signal retains the primary dynamic features of the original signal in its spectrum.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}