Abstract
Multiple regression analysis has a wide range of applications. The analysis of error structures in regression model has also attracted much attention. This paper focuses on large-scale precision matrix of the error vector that only has lower polynomial moments. We mainly study upper bounds of the proposed estimator under different norms in term of the probability estimation. It is shown that our estimator achieves the same optimal convergence order as under Gaussian assumption on the data. Simulation experiments further validate that our method has advantages.
Keywords:
high-dimensional data analysis; non-Gaussian errors; lower polynomial moment; precision matrix estimation MSC:
62H12; 15A09; 62H10
1. Introduction
Multivariate regression methods are growing increasingly important in numerous fields, including chemometrics [1], neuroscience [2], genomics [3], and finance [4]. In genomics research, multivariate models connect gene expression to genetic variants and infer gene regulatory networks via Gaussian graphical models (GGMs)—a process that relies heavily on precision matrices. As emphasized by Liu and Yu [5], the error structure (closely linked to precision matrices) of the multivariate linear regression model for responses, , is critical for reliable inference but often overlooked in high dimensions settings. Compared with the covariance matrix, the precision matrix of the random error is more directly interpretable (e.g., it captures conditional dependence relationships in gene networks) and more relevant to practical applications, thus attracting considerable research attention.
Cai et al. [6] proposed CLIME (Constrained Minimization Estimation) method for precision matrix and obtained probability estimation under exponential and polynomial moment conditions, respectively. Cai et al. [7] further developed the ACLIME (Adaptive Constrained Minimization Estimation) method and established optimal convergence rate for precision matrix under Gaussian assumption on the data. By replacing the sample covariance matrix with a pilot estimator, Avella-Medina et al. [8] discussed optimal precision matrix estimation under finite 2 + moment condition. This robust estimation framework focuses on independent random vectors, meaning it cannot address the coupling between regression effects and error structures.
While these methods have achieved notable progress in precision matrix estimation, their frameworks primarily focus on single random vectors (e.g., univariate responses) and fail to account for regression relationships between multiple variables. Cai et al. [9] proposed a two-stage constrained minimization approach to estimate the coefficient matrix and the precision matrix of sub-Gaussian error , which means the data requires finite moments of any order. Chen et al. [10] used a scaled Lasso and pairwise regression strategy to estimate these two matrices, which considers Gaussian data and does not provide any convergence rate. Ten et al. [11] developed a bias-corrected method to estimate the covariance matrix of the error vector , but this method cannot infer the conditional independence between error variables. Additionally, its robustness is based on the Gaussian distribution framework, making it inadequate for in-depth analysis of error structures in non-Gaussian scenarios.
This paper adopts a two-stage constrained minimization method to investigate probability precision matrix estimation for error vectors that only possess order moment. Our theoretical results demonstrate that the proposed estimator not only achieves the same convergence rate as Cai et al.’s method but also exhibits superior numerical performance.
Throughout this paper, we use to denote for some positive constant C, and denotes . For a vector , we define and . For a matrix , , , , , and stands for the spectrum norm of a matrix .
The rest is organized as follows. Section 2 details the construction of the proposed estimator; Section 3 presents the theoretical properties of the estimator; Section 4 reports simulation studies and an analysis of human gut microbiome data; Section 5 provides discussions. All technical proofs are included in Appendix A.
2. Preliminaries
We begin with a genetical genomics dataset. Let be a p-dimensional random vector of gene expressions and be a q-dimensional random vector of genetic markers. We consider the following multiple regression model:
where is an unknown coefficient matrix. The random vector has a mean of , a covariance matrix , and a precision matrix . Assuming that and are independent, we observe n to be independent and identically distributed (i.i.d) random samples generated from the model (1). Accordingly, the samples of can be derived from the model (1).
In genomic studies, the coefficient matrix in the model (1) is sparse, as each gene is typically regulated by only a small number of genetic regulators. Similarly, the precision matrix is expected to be sparse, reflecting the fact that genetic interaction networks generally exhibit limited connectivity. Motivated by these sparsity properties and the need to establish rigorous convergence rates for estimators, we introduce the following conditions.
Condition 1.
For some constants , the dimensions satisfy , where . Additionally, there exist constants and such that
Condition 2.
The regression coefficient matrix with , where
Condition 3.
The precision matrix with , where
Condition 4.
There exists some such that , where is the covariance matrix of .
Remark 1.
Condition 1 imposes a polynomial moment constraint on , , and . This condition is weaker than the sub-Gaussian moment assumption adopted by Cai et al. [9], as sub-Gaussian random variables require finite moments of all orders. The dimension growth constraint implies that the growth rates of p and q are controlled by a polynomial function of the sample size n, with γ governing the maximum allowable growth rate of the dimensions relative to n.
Conditions 2 and 3 formalize the sparsity assumptions for Γ and Ω, respectively, where and represent the sparse measurements. Under the dimension growth constraint in Condition 1, it follows that . This ensures that the sparsity measures , and the convergence rates of the proposed estimators are all consistent with the polynomial growth of dimensions (see Theorems 2 and 3). Similar parameter spaces have been adopted in Bickel and Levina [12], Cai et al. [6] and Avella-Medina et al. [8]. However, our framework imposes no eigenvalue restrictions.
Note that corresponds to the precision matrix of , so the constraint in Condition 4 is analogous to the bounded norm assumption for Ω in Condition 3.
The following details the construction process of the proposed estimators.
Using the independent and identically distributed random samples , we define the sample means as , and . From the model (1), it follows that
Similar to the sample covariance matrix, we define the following sample matrix, , and . It is straightforward to verify that .
To estimate and , we first construct an estimator for via an optimization approach. Let , . For each ,
where is a tuning parameter with a positive constant . It follows that the above row-wise optimization problems are equivalent to the matrix-level optimization problem,
Secondly, we construct an estimator for . Substitute into the model (1), and let . We estimate by CLIME method proposed by Cai et al. [6]. Let and
where is the j-th standard basis vector in , and is a tuning parameter with a constant . We then symmetrize to obtain the final estimator , defined as
where denotes the indicator function.
Remark 2.
We obtain the proposed estimators via two key steps, corresponding to Equations (2) and (3). In the case where , estimation of Γ is unnecessary, and the precision matrix estimator can be directly derived via (3) (CLIME, Cai et al. [6]). When , several methods have been developed to estimate Γ, including those based on minimization (Tibshirani [13]) and the Dantzig selector (Candes and Tao [14]). In this paper, we consider the high-dimensional setting where both p and q may be large, but satisfy for some constant .
3. Main Result
In this section, we present our main results.
Theorem 1.
Under Condition 1, there exists a constant such that
and
Remark 3.
The following results establish error bounds for the coefficient matrix estimator under different matrix norms.
Theorem 2.
Suppose Conditions 1, 2 and 4 hold. Let with
Then, for some constant , the estimator defined in (2) satisfies
and
Remark 4.
Since is bounded and implies that as , the sparsity condition in Theorem 2 ensures that the upper bound of the above probability tends to zero. Moreover, since as , this sparsity requirement is mild.
Theorem 3.
Suppose Conditions 1–4 hold. Let and with . Then, for some constant , the estimator defined in (2) satisfies
and
Remark 5.
Since is a positive deterministic sequence, which may be bounded or slowly diverging as n and p grow, the condition
implies the corresponding condition in Theorem 2. Moreover, the convergence rate given in (11) matches that established by Cai et al. [9], confirming its optimality.
4. Numerical Results
4.1. Simulation Analysis
In this section, we evaluate the performance of the proposed method through simulation studies and compare it with two existing methods proposed by Cai et al. [6] and Friedman et al. [15].
For the coefficient matrix , the sparsity level is controlled by the parameter . Specifically, each element is generated independently from , where denotes the uniform distribution over , and denotes a Bernoulli random variable that takes 1 with probability and 0 with probability . This generation mechanism implies is non-zero with probability (and zero otherwise), so a smaller indicates a higher sparsity level for .
The sparsity of precision matrix is controlled by the parameter . To ensure is positive definite, we first construct a matrix with each element generated independently from (consistent with the sparsity mechanism of ). We then define , where ensures is positive definite.
We simulate covariate vectors and error vectors for , where stands for a multivariate Student-t distribution with 10 degrees of freedom and covariance matrix . The response vectors are then computed via the regression model .
In the following experiments, we control the sparsity of and using and , respectively, and consider three models with distinct dimensionality and sparsity settings:
Model 1: ;
Model 2: ;
Model 3: .
The three models correspond to three dimensions: low, medium, and high. Such differences allow us to examine how methods perform under varying degrees of dimensionality and sparsity.
The tuning parameters and are selected using five-fold cross-validation (CV) for our estimator. Specifically, we divide all the samples into five disjoint subgroups (also known as folds), and let denote the index set of samples in the v-th fold ().
Define the five fold CV score as
where is the number of samples in and
Here, and are estimates of and computed using the sample set .
We then determine the optimal tuning parameters as , and use this pair to compute the final estimates of and with the full sample set.
The proposed method is compared with two existing approaches, those of Cai et al. [6] and Friedman et al. [15], which do not account for covariate effects. We apply the same loss function to select the tuning parameters for those methods with .
Based on 50 independent replications, we compute the average errors (standard errors) under three norms for CLIME, GLASSO and our method.
Table 1 reports the numerical results. In Model 1, the standard errors of the three methods are comparable, but the proposed method still exhibits advantages due to its smaller average errors. As the model setting changes, with dimensionality increasing and sparsity becoming stricter (Models 2 and 3), the proposed method outperforms the compared methods across all three norms.

Table 1.
Average errors (standard errors) under three methods.
In summary, the results confirm that our method is particularly advantageous in medium-to-high-dimensional and highly sparse settings, where covariate adjustment plays a critical role in reducing estimation bias and improving stability. Its performance gains become more prominent as dimensionality increases, making it suitable for modern high-dimensional data analysis.
4.2. Application to Real Data
In this section, we apply our precision matrix estimator to analyze the human gut microbiome dataset from Wu et al. (Science, 2011) [16], which has also been studied by Cao et al. [17], He et al. [18], Li et al. [19], and Zhang et al. [20]. Our focus is on identifying differences in latent bacterial genus correlations between lean and obese individuals. The dataset includes 98 healthy subjects, with 63 classified as lean (BMI ) and 35 as obese (BMI ).
Data Preprocessing and Network Construction
- To ensure reliable signals, we retained bacterial genera present in at least 20% of samples within each group. This filtering step resulted in 30 retained bacterial genera, so the dimension .
- Zero counts in the filtered dataset were imputed with 0.5 and raw counts were normalized to relative abundances per sample to account for varying sequencing depths.
- For both groups, tuning parameters and were selected via five-fold cross-validation; see Section 4.1. To evaluate the stability of support recovery, we generated 63 bootstrap samples for the lean group and 35 for the obese group, repeated the analysis 100 times, and calculated the average occurrence frequency of each edge. Edges with a frequency ≥ 50% (appearing in at least 50 of 100 resamplings) were retained as “stable edges” for final network construction.
Quantitative Characteristics of Microbial Networks
Table 2 summarizes key quantitative features of the inferred networks, including structural complexity, association patterns, and stability.
Table 2.
Quantitative characteristics of gut microbial networks in lean and obese groups.
Network Visualization and Interpretation
Figure 1 and Figure 2 visualize the stable microbial networks for the lean and obese groups, respectively, to intuitively display differences in conditional associations between bacterial genera.
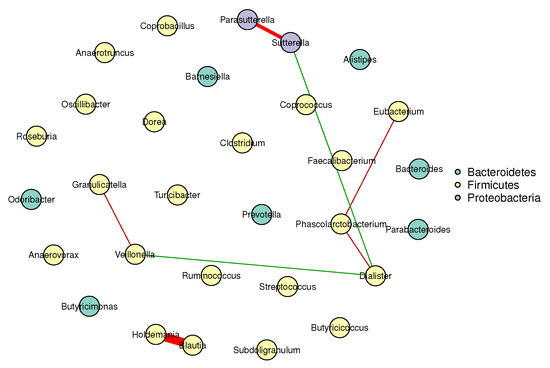
Figure 1.
Conditional correlation network of gut microbiota in the lean group (BMI ). Nodes represent 30 retained bacterial genera. Edges denote stable associations (bootstrap frequency ): green lines indicate positive correlations, red lines indicate negative correlations, and darker colors represent stronger associations.
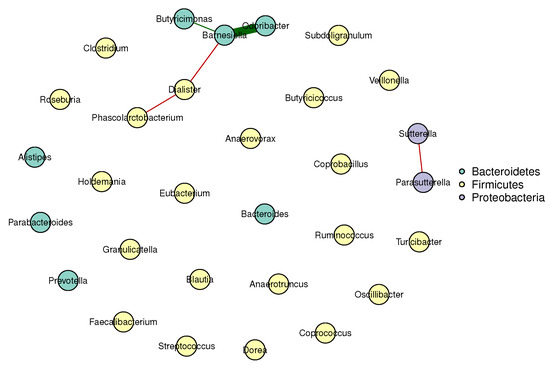
Figure 2.
Conditional correlation network of gut microbiota in the obese group (BMI ). Nodes represent 30 retained bacterial genera. Edges denote stable associations (bootstrap frequency ): green lines indicate positive correlations, red lines indicate negative correlations, and darker colors represent stronger associations.
Biological Implications of Network Differences
Our analysis reveals meaningful differences between the gut microbial networks of lean and obese individuals, which align with and extend prior findings in gut microbiome research:
- Predominant competitive conditional interactions: Both groups exhibit more negative than positive correlations between bacterial genera (lean group: 71.4% negative correlations; obese group: 60.0% negative correlations). This result is consistent with the findings of Cao et al. [17], Wang et al. [21], Zhang et al. [20] and Coyte et al. [22], and supports the notion that gut microbial interactions are primarily competitive.
- Reduced network complexity in obesity: The obese group had fewer stable edges (five, compared to seven in the lean group) and a lower mean edge strength (0.25, compared to 0.32 in the lean group). These observations indicate weakened conditional associations between bacterial genera in obese individuals, suggesting a decline in gut microbial network complexity.
- Network stability: The lean group’s network had a higher stability score (0.72, compared to 0.58 in the obese group), confirming more reproducible conditional associations and reflecting a robust gut microbial structure. In contrast, the lower stability of the obese group’s network suggested greater inter-individual variability in microbial interactions, a well-documented hallmark of obesity-related gut dysbiosis. This finding also aligned with prior reports of reduced modularity in obese gut microbial networks (Greenblum et al. [23]).
These results validate our multivariate method’s ability to capture biologically meaningful microbial interactions, highlighting competitive balance and core taxa preservation as key to gut health.
5. Conclusions
This paper proposes a two-stage procedure for covariate-adjusted precision matrix estimation in high dimensions. The error vector only requires a bounded lower polynomial moment condition, which is a weaker assumption than the sub-Gaussian conditions of existing methods. We establish non-asymptotic probabilistic upper bounds for the coefficient estimator and precision matrix estimator under multiple matrix norms. Despite relaxed assumptions, both estimators achieve optimal convergence rates matching those from stronger sub-Gaussian frameworks. Numerical simulations confirm the method outperforms covariate-unadjusted approaches (Cai et al. [6], Friedman et al. [15]). In a gut microbiome analysis, it successfully captures meaningful microbial network differences between lean and obese groups. Future work may extend this approach to other low moment condition pilot estimators (Avella-Medina et al. [8]).
Funding
This paper is supported by the National Natural Science Foundation of China (No. 12171016).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A
First, we use Bernstein inequality to prove a lemma.
Theorem A1
(Massart (2007) [24]). Assume that are i.i.d. random variables, and . Then, for ,
Lemma A1.
Assume Condition 1 holds. Then, for any fixed , there exists a constant such that
and
Proof.
We first prove inequality (A1). Since , it suffices to show
By the triangle inequality for probability, it follows that
To estimate , note that . Then,
and
due to Markov inequality and .
In order to estimate , define , then , and .
Apply Theorem A1 with and one obtains
By , one obtains . Therefore, and
with . This with (A6) and (A7) leads to (A1).
Since and are independent, . By Condition 1, . Replacing with and repeating the argument for (A1) yields (A2).
To prove (A3), let and define . Split into tail and truncated parts:
where corresponds to and to the truncated term.
Note that . Then,
Moreover,
This with , and Condition 1 give
To estimate , apply Bernstein’s inequality to the truncated (bounded by ), leading to . This gives , and (A3) holds
Lemma A2.
Assume Condition 1 holds. Then, for any fixed , there exists a constant such that
Consequently,
with the same probability bound.
Proof.
Let and split into truncated and tail parts,
Then,
Since and due to Condition 1, then Bernstein’s inequality (Theorem A1) yields, and for ,
Divide by n and use so that ; since and , we obtain
A union bound over preserves the rate.
By Condition 1, for some and constant ,
Similarly, so that uniformly in j. Hence
which is negligible compared to since under .
Proof of Theorem 1.
We first prove inequality (4). By the regression model , centering both sides by sample means gives . Multiplying both sides by and averaging over k yields
where . Thus, it suffices to show
where with the constant to be specified.
To prove (5), since , then
due to Lemma A1.
Lemma A3
(Cai et al. (2011) [6]). Supposing matrix satisfies , is any estimator of and . Then
Proof of Theorem 2.
Define two events and . Then, by (4) and (5), we have . It suffices to show that on ,
Since is the solution of (2), then and . This with event gives and
This with Condition 4 implies
Recall that Condition 2 hold and . Then, by Lemma A3, we have
If , then we have If , then by known condition , for large n,
Thus, we proved (A11) when happens and (7) holds. Substituting it into (A12), we can obtain that (8) holds. Finally, (9) follows from (7) and (8) and the inequality . The proof is done. □
Proof of Theorem 3.
Recall (3). We define event with . We first show that on A, the desired bounds for hold, and then verify .
By the definitions of and , it holds on A:
Hence, to estimate (11), one needs only to prove that when event A happens,
thanks to Lemma A3 and .
Note that the symmetrized estimator satisfies . Using , we have
This with matrix norm inequality yields
On event A, , and from (3). Moreover, it follows from (A13)
which concludes the expected estimate (A14) thanks to and .
Now, one needs only to prove .
Since , then by (6), we have and it suffices to show
due to , and .
Recall and . Substituting into and denote , and we have
and
Hence, we only need to prove
and
To estimate (A16), by and (7), we have
with probability at least . Thus, (A16) holds. It remains to show that (A17) holds, since
With Lemma A2, in the event of probability at least ,
where depends only on the moment bound in Condition 1. Substituting this into (A18) yields
using the bounds from Theorem 2 on , and , thereby establishing (A17). The proof is done. □
References
- Wold, S.; Sjostrom, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Harrison, L.; Penny, W.; Friston, K. Multivariate autoregressive modeling of fMRI time series. NeuroImage 2003, 19, 1477–1491. [Google Scholar] [CrossRef]
- Meng, C.; Kuster, B.; Culhane, A.C.; Gholami, A.M. A multivariate approach to the integration of multi-omics datasets. BMC Bioinform. 2014, 15, 162. [Google Scholar] [CrossRef]
- Lee, C.F.; Lee, A.C.; Lee, J. Handbook of Quantitative Finance and Risk Management; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Liu, R.; Yu, G. Estimation of the Error Structure in Multivariate Response Linear Regression Models. WIREs Comput. Stat. 2025, 17, e70021. [Google Scholar] [CrossRef]
- Cai, T.; Liu, W.; Luo, X. A Constrained l1 Minimization Approach to Sparse Precision Matrix Estimation. J. Am. Stat. Assoc. 2011, 106, 594–607. [Google Scholar] [CrossRef]
- Cai, T.T.; Liu, W.; Zhou, H.H. Estimating sparse precision matrix: Optimal rates of convergence and adaptive estimation. Ann. Stat. 2016, 44, 455–488. [Google Scholar] [CrossRef]
- Avella-Medina, M.; Battey, H.S.; Fan, J.; Li, Q. Robust estimation of high-dimensional covariance and precision matrices. Biometrika 2018, 105, 271–284. [Google Scholar] [CrossRef] [PubMed]
- Cai, T.T.; Li, H.; Liu, W.; Xie, J. Covariate-adjusted precision matrix estimation with an application in genetical genomics. Biometrika 2012, 100, 139–156. [Google Scholar] [CrossRef]
- Chen, M.; Ren, Z.; Zhao, H.; Zhou, H. Asymptotically Normal and Efficient Estimation of Covariate-Adjusted Gaussian Graphical Model. J. Am. Stat. Assoc. 2016, 111, 394–406. [Google Scholar] [CrossRef]
- Tan, K.; Romon, G.; Bellec, P.C. Noise covariance estimation in multi-task high-dimensional linear models. Bernoulli 2024, 30, 1695–1722. [Google Scholar] [CrossRef]
- Bickel, P.J.; Levina, E. Covariance regularization by thresholding. Ann. Stat. 2008, 36, 2577–2604. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression Shrinkage and Selection via The Lasso: A Retrospective. J. R. Stat. Soc. Ser. B Stat. Methodol. 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. The Dantzig selector: Statistical estimation when p is much larger than n. Ann. Stat. 2007, 35, 2313–2351. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse Inverse Covariance Estimation with the Graphical Lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef]
- Wu, G.D.; Chen, J.; Hoffmann, C.; Bittinger, K.; Chen, Y.Y.; Keilbaugh, S.A.; Bewtra, M.; Knights, D.; Walters, W.A.; Knight, R.; et al. Linking Long-Term Dietary Patterns with Gut Microbial Enterotypes. Science 2011, 334, 105–108. [Google Scholar] [CrossRef]
- Cao, Y.; Lin, W.; Li, H. Large Covariance Estimation for Compositional Data Via Composition-Adjusted Thresholding. J. Am. Stat. Assoc. 2019, 114, 759–772. [Google Scholar] [CrossRef]
- He, Y.; Liu, P.; Zhang, X.; Zhou, W. Robust covariance estimation for high-dimensional compositional data with application to microbial communities analysis. Stat. Med. 2021, 40, 3499–3515. [Google Scholar] [CrossRef]
- Li, D.; Srinivasan, A.; Chen, Q.; Xue, L. Robust Covariance Matrix Estimation for High-Dimensional Compositional Data with Application to Sales Data Analysis. J. Bus. Econ. Stat. 2023, 41, 1090–1100. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, H.; Lin, W. CARE: Large Precision Matrix Estimation for Compositional Data. J. Am. Stat. Assoc. 2025, 120, 305–317. [Google Scholar] [CrossRef]
- Wang, J.; Liang, W.; Li, L.; Wu, Y.; Ma, X. A new robust covariance matrix estimation for high-dimensional microbiome data. Aust. N. Z. J. Stat. 2024, 66, 281–295. [Google Scholar] [CrossRef]
- Coyte, K.Z.; Schluter, J.; Foster, K.R. The ecology of the microbiome: Networks, competition, and stability. Science 2015, 350, 663–666. [Google Scholar] [CrossRef]
- Greenblum, S.; Turnbaugh, P.J.; Borenstein, E. Metagenomic systems biology of the human gut microbiome reveals topological shifts associated with obesity and inflammatory bowel disease. Proc. Natl. Acad. Sci. USA 2012, 109, 594–599. [Google Scholar] [CrossRef]
- Massart, P. Concentration Inequalities and Model Selection; Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 2007; Volume 1896, pp. xiv+337. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).