Abstract
In this article, we introduce a new family of symmetric-asymmetric distributions based on skew distributions and on the family of order statistics with proportional hazards. This new family of distributions is able to fit both unimodal and bimodal asymmetric data. Furthermore, it contains, as special cases, the symmetric distribution and the “skew-symmetric” family, and therefore the skew-normal distribution. Another interesting feature of the family is that the parameter controlling the distributional shape in bimodal cases takes values in the interval (0, 1); this is an advantage for computing maximum likelihood estimates of model parameters, which is performed by numerical methods. The practical utility of the proposed distribution is illustrated in two real data applications.
1. Introduction
A seminal paper by [1] revealed the main properties of the “skew-normal” distribution whose probability density function (pdf) is given by
where and denote the cumulative and density functions of the standard normal distribution, respectively. Here, is a parameter that controls the asymmetry of the random variable Z. Generally this is denoted by SN. Since this work was published, numerous publications have been based on this model, primarily [2,3,4,5,6,7,8,9].
An important lemma demonstrated by [1] represents a fundamental result in the development of asymmetric and symmetric models for both unimodal and bimodal cases. This lemma is presented below.
Lemma 1.
Letbe a pdf symmetrical around zero and a distribution function G such thatexists and is a symmetric (around zero) density function; then
is a density function for any. This will be denoted by.
1.1. Asymmetric Models of Fractional Order Statistics
The study of asymmetric models based on order statistics goes back to [10], who introduced a model called the “Lehmann alternative”, which originated from the distribution of the maximum in the sample. It later became an alternative for distributions presenting a high degree of asymmetry and/or kurtosis. This family of distributions is represented by the distribution function
where F is a cumulative distribution function (cdf) and is a rational number. For , we have the distribution function of the maximum in the sample.
Subsequently, [11] introduced the distribution of fractional order statistics, which is defined by the pdf
where is a shape parameter and F is an absolutely continuous distribution function with pdf . This is called the power-symmetric (PS) model. Derivations and properties of the distributions of order statistics have been widely discussed by [12,13,14], among others. One important special case follows when : this is called the power-normal (PN) distribution (see [14]). Ref. [15] derived the expected (Fisher) information matrix for the PN distribution and showed that it is nonsingular at the vicinity of symmetry (), in contrast to the case of SN density, for which the Fisher formation matrix is singular at .
1.2. Asymmetric Bimodal Models
Several fields of science provide data that cannot be modeled or fitted with distributions such as skew-normal or fractional order statistics because the nature of these data leads to bimodal behaviors; these distributions have good performance only for unimodal cases. In many areas, such as health sciences, engineering, economics, among others, it is common to find data sets that present bimodal behaviors; thus, it is required other model alternatives that besides being able to capture a possible bimodality, do not present identifiability problems of the parameters, which are often proposals that come from mixtures of distributions. Consequently, this research is motivated with the interest of estimating, in a simple way, the parameters of the model that we propose and that has the faculty of fitting symmetric or asymmetric bimodal data, being thus a proposal that opens the possibility of new researches in these areas.
Models of this type have been studied by [16], who introduced the bimodal extension of the skew-normal model, called the “two-pieces skew-normal (TN) model”. This model is denoted by TN, whose pdf is represented by
where is a real number and is a normalizing constant. For , Kim demonstrates that model (1) is bimodal and symmetric around zero.
Ref. [17] developed the asymmetric bimodal model termed “the extended two-pieces skew-normal (ETN) model”, with a pdf given by
where and are real numbers and is a normalizing constant. The model is denoted by ETN and is an asymmetric extension of Kim’s model.
The proportional hazards model was introduced by [18] and is very important in survival analysis. Although [18] used this model to introduce covariables, it can also be used to introduce a shape parameter into the base distribution (see [19]). One example is the Burr XII distribution (see [20]), which can be obtained as a proportional hazards model from the base distribution function. The main object of this paper is to use this proportional hazards methodology to propose a new family of uni-/bimodal distributions, based on the power- symmetric family of distributions.
The paper is organized as follows. In Section 2, the extended skew model distribution with proportional hazards is derived, and its density function, special cases and moments are presented. In Section 3, parameter estimation is considered using maximum likelihood (ML). Observed and Fisher information matrices are derived, and it is shown that the Fisher information matrix is nonsingular. In Section 4, we perform a small-scale simulation study. In Section 5, two real data sets are analyzed using the proposed distribution and some other competing distributions to illustrate their applicability.
2. Extended Skew Model with Proportional Hazard
Following similar guidelines as in [10,11], we define the density function of the order statistics with proportional hazard.
Let F be a continuous cdf with pdf f, continuous and symmetric around zero, and hazard function . We say that Z has a distribution with proportional hazards, associated with the cdf F and pdf f, and parameter if its pdf is given by the expression
where is a positive real number and F is a continuous distribution function with density function continuous and symmetrical around zero. The PS distribution with proportional hazards is denoted by PSH. For , a pdf continuous and symmetric around zero, the density (3) matches the density of the variable where .
The cdf of the PSH model is given by
The expression proportional hazards model must be understood in the sense that the hazard function of this model concerning the function is
When , we get the PN distribution with proportional hazards, which is denoted by PNH. This model also represents an alternative for modeling data with skewness and kurtosis outside the permitted ranges for normal function.
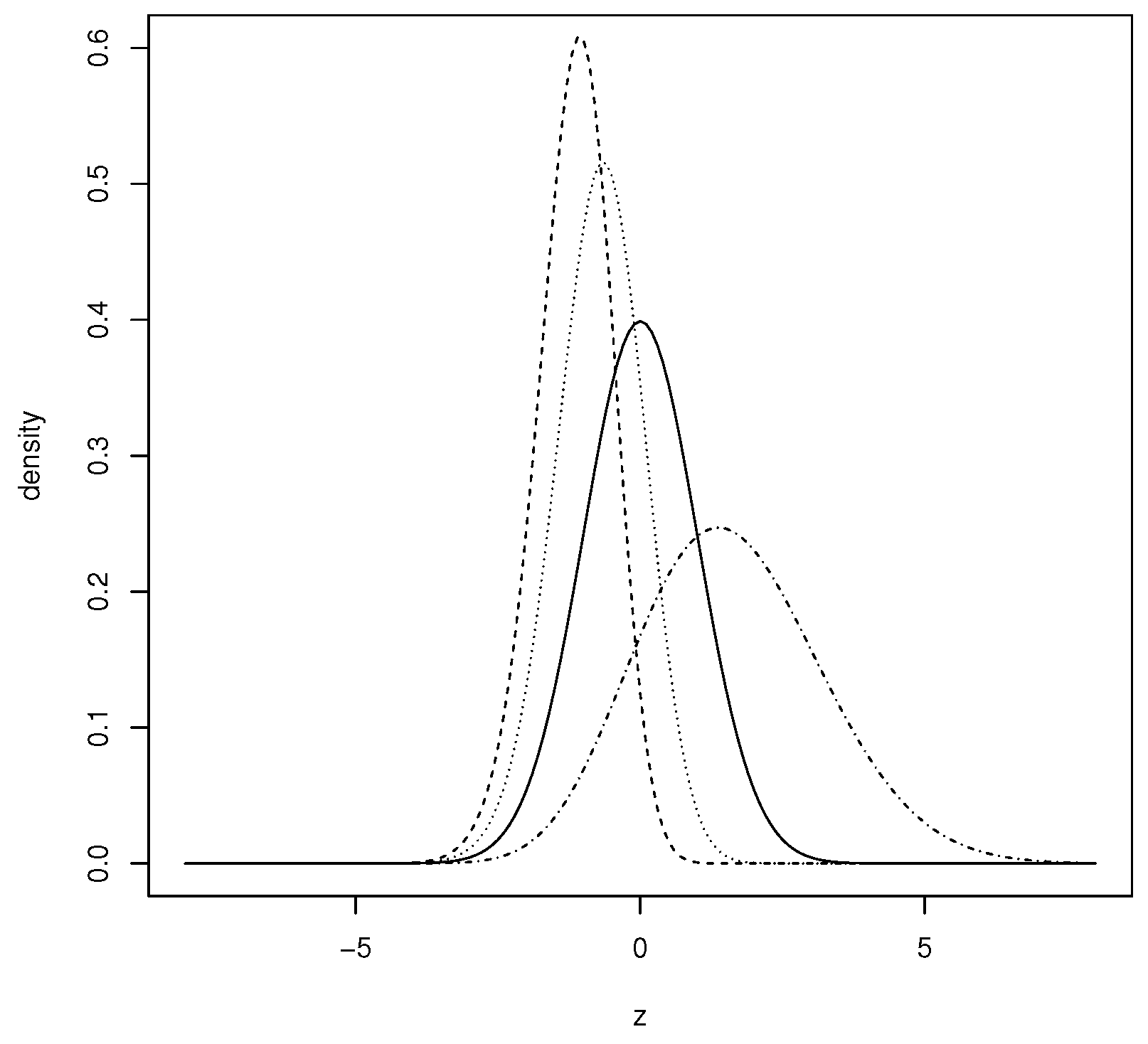
Figure 1 depicts how parameter controls the skewness and kurtosis of the PNH model.
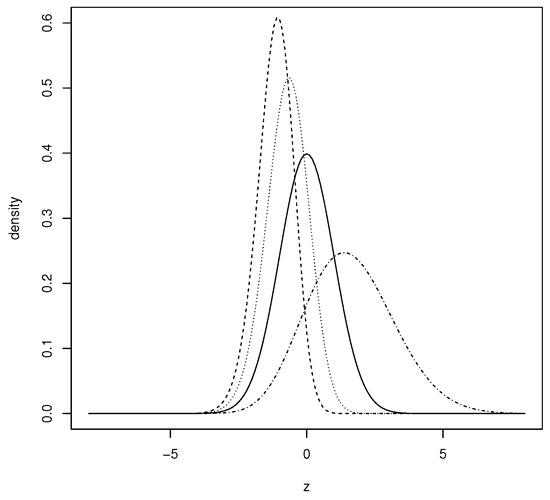
Figure 1.
Plots of the PNH distribution with 0.25 (dotted and dashed line), 1 (solid line), 2 (dashed line) and 3 (dotted line).
The PNH model is suitable for fitting asymmetric unimodal data. Although this model is more flexible than the normal model, it is unsuitable for fitting a bimodal data set. A more flexible model than the PNH is as defined below, which has the ability to fit unimodal and well as bimodal data. This model is obtained from the PNH model.
We define the extended proportional hazard model by the pdf
where , F is an absolutely continuous cdf with pdf , which is symmetrical around zero. We use the notation EPSH.
- Result 1.
- If , then the model (4) is symmetrical.
- Result 2.
- If then the cdf of Z is given by:
- Result 3.
- Let and . Then, using the inversion method, we can obtain a random variable with distribution . This variable can be obtained by the expressionwhere is the inverse function of F.
2.1. Skew-EPsH (SEPSH) Model
Although the EPSH model is adequate for fitting bimodal data sets, it is not suitable when the data set presents asymmetric bimodality. However, supported by the results given in [1], we can obtain a more general model that achieves asymmetric bimodality.
Based on models (4) and (2), we now introduce a new family of distributions with the special feature that for certain distributions (e.g., normal), it can fit asymmetrical uni and bimodal data sets. This new family of distributions has pdf
where F is a continuous distribution function with density which is symmetric around zero, and G is a continuous and symmetric cdf with pdf , symmetric around zero. This new family of distributions is called the asymmetric extended family with proportional hazards. Note that when we have the “skew-symmetric” distribution, i.e., this new model can be seen as a generalization of the “skew-symmetric” model and the models of order statistics for the case of proportional hazards.
The proof that function (6) is a density follows from Lemma 1 by taking which is symmetric around zero. Therefore, this new family of distributions belongs to the “skew-symmetric” family, and as belongs to the exponentiated family (see [13]) or family of order statistics [11], this model will be called “skew-power-symmetric (SPS)” and we will be denoted by SPS.
- Result 4.
- .
The proof of this result is immediate since is symmetric around zero. Therefore, the “skew-symmetric” distribution of Azzalini is a special case of the SPS distribution.
2.2. Skew-Power-Normal Model
Taking in (6) leads to the model
which will be called “skew-power-normal (SPN)” model, and will be denoted by SPN.
- Properties
The following properties are obtained directly from the model (7).
Property 1.
SPN(1, 0) = N(0, 1).
Property 2.
SPN(1, β) = SN(β).
Property 3.
SPN(α, 0) = PNH(α).
Property 4.
SPN(2, β) = a × SN(β) − b × ETN(β) with a and b positive constants.
Property 5.
SPN(2, 0) = a × N(0, 1) − b × TN(1) with a and b positive constants.
- Result 5.
- If , then for , its density function is unimodal asymmetric for and asymmetric bimodal for .
Proof of Result 5.
Differentiating with respect to z and equating to zero, we obtain that the points where the maxima and minima occur are the solutions of the equations
Then, is unimodal for and bimodal for . In addition, as is symmetric, then this density will be bimodal symmetric for . Therefore, we conclude that is asymmetric bimodal if and asymmetric unimodal otherwise. □
This feature makes the model attractive for fitting data presenting bimodality, since the parameter range is very short (between 0 and 1), making it advantageous for computational procedures taking into account that the starting point of the process maximizing the log-likelihood function is determined more accurately.
The Location-Scale Case
Consider a random variable , with and . The family of distributions with location-scale parameters for the SPN distribution is defined as the distribution of for and , and its density function is given by
where is the location parameter and is the scale parameter. We use the notation .
Figure 2 illustrates the behavior of the pdf (8) for different values of and . As can be seen from the figure, the shape of the bimodality depends on the parameters and .
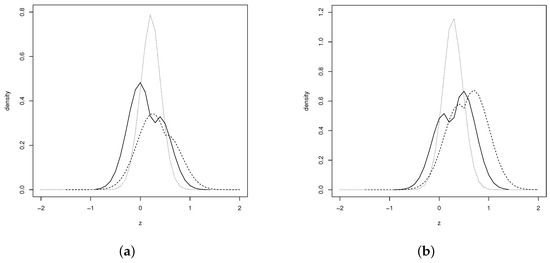
Figure 2.
Plots of the distributions: (a) SPN (solid line), SPN (dashed line) and SPN (dotted line) (b) SPN (solid line), SPN (dashed line) and SPN (dotted line).
2.3. Moments
The following expressions allow the calculation of the moments of a random variable with SPN distribution
where
The central moments for can be calculated from the expressions:
Consequently, the variance and the coefficients of asymmetry and kurtosis are given by , and .
3. Inference
We study next the ML estimators and the observed and expected information matrices for the parameters of the SPN model.
3.1. The Standard Case
For a random sample of the SPN distribution, we have the log-likelihood function
Therefore, the score function, defined as the derivatives with respect to the parameters and of the log-likelihood function, is given by
Equating the score function to zero leads to score equations
whose solution is obtained using iterative numerical methods.
Therefore, the elements of the observed information matrix, denoted by are given by
where and then, the parameters and are orthogonal, so the expected information matrix defined as times the expectation of the observed information matrix will be diagonal with elements
where and . Then for we have
which ensures the asymptotic convergence of the ML estimators for the parameters of the model.
3.2. The Location-Scale Case
For a random sample , with , the log-likelihood function of , given , is given by:
where . Thus, the score function is given by:
where “sgn” is the function. Equating these equations to zero, we obtain the corresponding score equations, the solution of which by iterative numerical methods leads to ML estimators.
3.3. Observed Information Matrix
The elements of the information matrix are defined similarly to the standard case and denoted by ; they are given by:
where …, and .
3.4. Expected Information Matrix
Similar to the standard case, the elements of the expected information matrix are times the expected value of the elements of the observed information matrix, namely:
with , , and . Taking , , and , the elements of the expected information matrix can be expressed as follows:
These expectations are calculated using numerical integration. When and , then which is the location-scale density of the normal distribution. Thus, the information matrix is reduced to
whose determinant is ; hence, we conclude for the special case of the normal distribution that the expected information matrix for the model is nonsingular. The upper submatrix is the information matrix of the normal distribution, and hence, for large n, we have that
so that is consistent and asymptotically normally distributed, where is the covariance matrix for large samples.
4. Simulation
We now carry out a simulation study to analyze the behavior of the ML estimator of the shape parameter . The samples were generated using the algorithm described in this document for different sample sizes 50, 100, 150, 300 and 1000. In each scenario, we performed 10,000 iterations and studied the mean and the root of the mean squared error (RMSE). The results are presented in Table 1, from which it is observed that for each scenario, the estimates were good for large and small sample sizes, and that when the sample size increases, the mean converges to the true value of the parameter and the RMSE decreases, which indicates that the estimator is consistent for .

Table 1.
ML estimator (mean) and RMSE for parameter , SPN model.
5. Applications
In this section we present two real data illustrations, the first associated with a bimodal data set and the second to a unimodal one.
5.1. Application 1
The first application includes 3848 observations of the variable , which measures a geometric feature of pollen grains. These data come from Pollen Data, available at http://lib.stat.cmu.edu/datasets/pollen.data (assessed on 12 August 2021). Table 2 shows the descriptive statistics of the variable .The quantities and indicate, respectively, the sample skewness and kurtosis coefficients.
Table 2.
Descriptive statistics for the variable (X).
Note that the skewness and kurtosis coefficients are different from the values expected for the normal distribution, which leads to considering the use of a more flexible model such as the SPN model discussed in this article.
Therefore, the hypothesis to be tested is
using the
statistic, this leads to
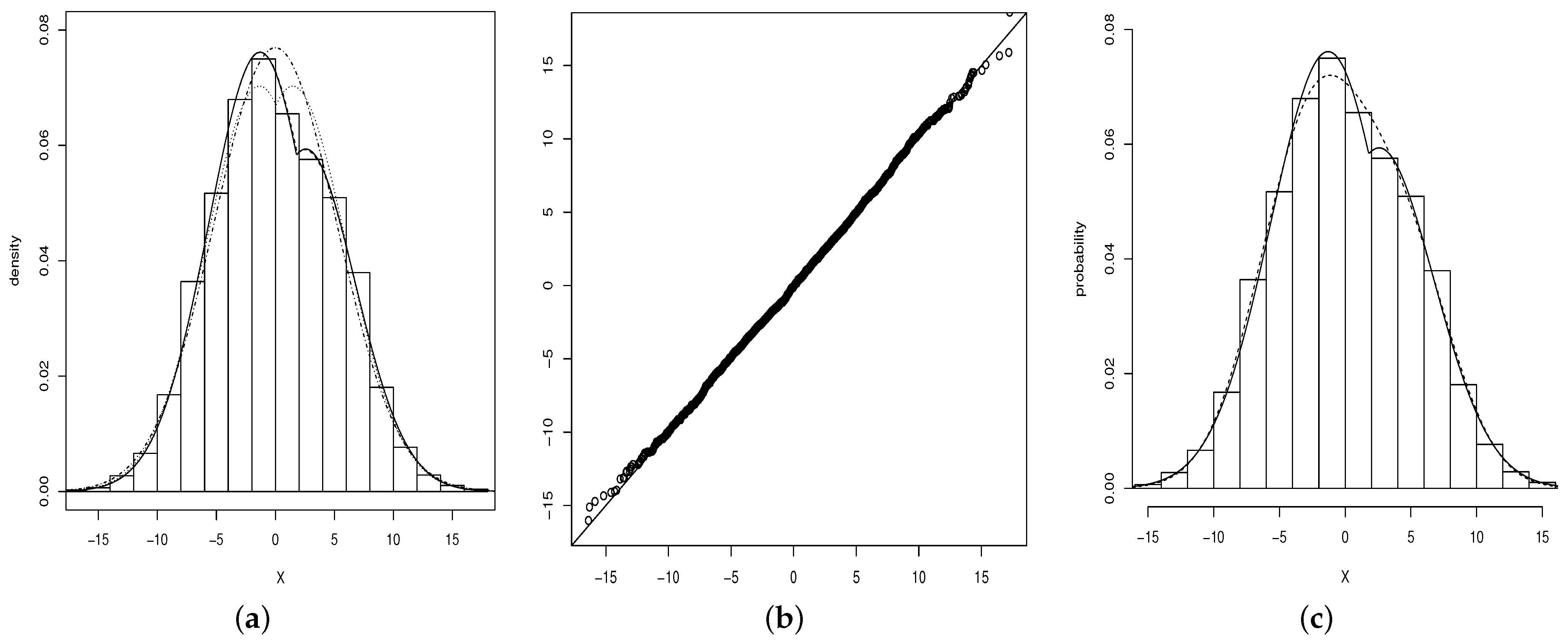
which is greater than the critical 5% chi-squared value, namely, Therefore, the SPN model seems to be a useful alternative for modeling the data. Table 3 shows the estimated standard errors ML estimates (in parentheses) for the SN, TN, ETN and SPN models. In Figure 3, we can see that the ETN and SPN models fit quite well.
Table 3.
Parameter estimates and standard errors for the SN, TN, ETN and SPN models.
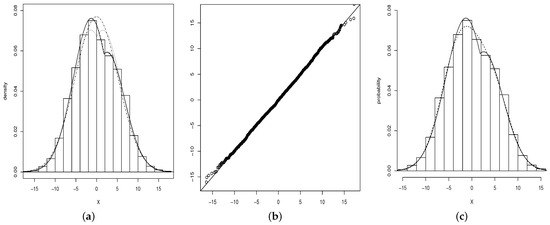
Figure 3.
(a) Histogram for the variable . Densities adjusted by ML: TN (dotted line), SN (dotted and dashed line), ETN (dashed line) and SPN (solid line). (b) qq-plot for the variable . (c) SPN (solid line) and MN (dashed line).
It is evident that the fitting of the normal and SN models in this example is inadequate due to the asymmetric behavior and bimodality of the data. Thus, the TN, ETN and SPN models are adequate for fitting the variable , so it is more reasonable to contrast the SPN model with models by [16,17]. To compare the models, which are not nested, we use the AIC criterion [21], namely
where k is the number of parameters of the model to consider. Furthermore, we consider the consistent AIC (CAIC) criterion, namely
where k is the number of parameters.
According to the AIC and CAIC criteria, the ETN and SPN models fit the variable well, and much better than the TN model. Moreover, no significant differences are noted between the ETN and SPN models. Figure 3a shows clearly that the ETN and SPN models have the same degree of fit; note that the graph of the SPN model is superimposed on the ETN model. This shows the SPN model as a second alternative for modeling bimodal data. Figure 3b shows the qq-plot of the variable for the SPN model.
Now we compare the SPN model with the mixture of the two normals model, which can be written as
where is the density of the standard normal distribution with parameters , and . We denote the two-normals mixture model as MN.
The estimated model is
with . This model presents BIC and CAIC greater than those for the SPN model, so the SPN model fits the data set better than the MN model. Figure 3c shows the estimated densities for the SPN and MN models.
5.2. Application 2
In this second application, we use the data available at http://lib.stat.cmu.edu/jasadata/laslett (accessed on 19 August 2021), which, according to their summary statistics (see Table 4), have appropriate characteristics to be modeled with distributions such as the one proposed in this research. A detailed description of these data can be found in the link above, where the roller surface roughness height is measured. In total, there are 1150 observations measured at 1-micron intervals along the roller drum.
Table 4.
Summary statistics for the variable roller.
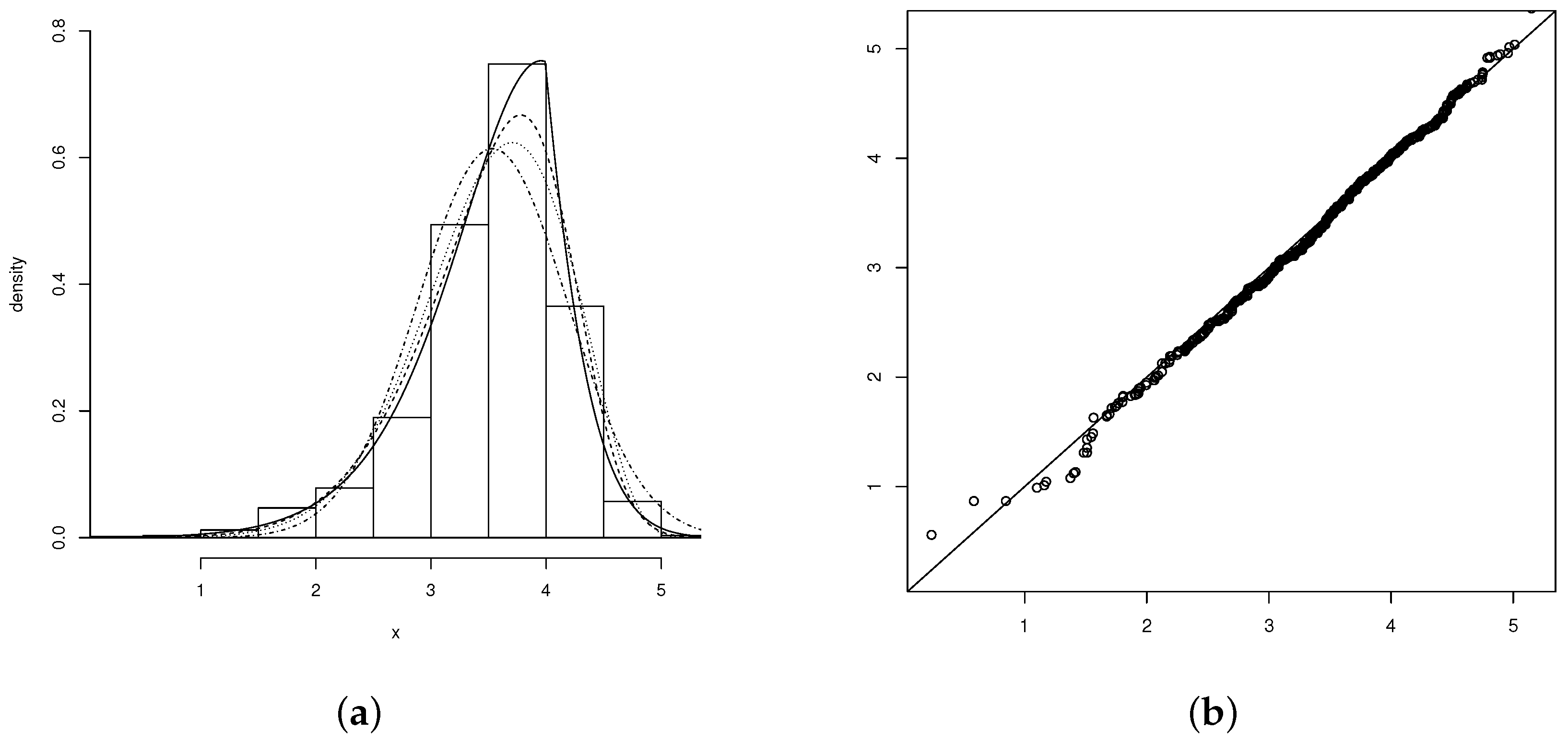
Hence, the PN, SN, and SPN models are fitted to the present data, and the MLE and standard errors (in parentheses) are calculated for each model studied (see Table 5). The results show the goodness of fit of the SPN model, which, compared to the other models, presents the best fit to the data. In addition, the plots of the fitted models are shown in Figure 4a, and the qq-plot for the SPN model is shown in Figure 4b.
Table 5.
Parameter estimates (standard error) for the PN, SN and PSN distributions.
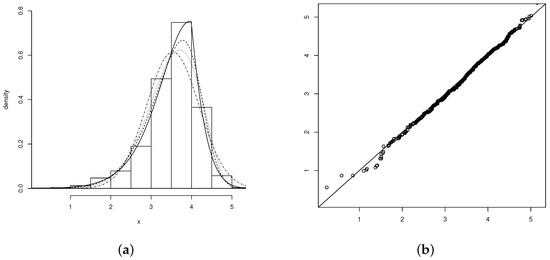
Figure 4.
(a) Histogram for the variable roller. Densities adjusted: PN (dashed line), SN (dotted line) and SPN (solid line). (b) qqplot for the variable roller.
In addition, a hypothesis test is performed to compare the normal model against the SPN model. Formally, we have the hypothesis
which can be tested using the statistic
After numerical evaluations, we obtain
which is greater than the 5% critical value of the Chi-squared distribution with one degree of freedom, namely .
According to the AIC criterion, the SPN model fits the roller data set better than the SN and PN models; i.e., the SPN model achieves satisfactory fitting of skewness and kurtosis, which are not adequately fitted by the previous models. A reason for the above situation can be explained because the skewness and kurtosis of the data analyzed are outside the permitted ranges for the SN ((−0.9953, 0.9953) and (3, 3.8692), respectively) and PN ((−0.6115, 0.9007) and (1.7170, 4.3556), respectively) models. This may be an indication that the SPN model has range of skewness and kurtosis greater than that of the SN and PN models.
6. Discussion
In this paper, we introduce a new family of continuous uni-/bimodal distributions. This family was generated based on power-symmetric and proportional hazards distributions. The SPN distribution, which is a particular case of this family, is studied in greater detail. The new family presented is a viable alternative for modeling asymmetric unimodal and bimodal data sets. Further specific conclusions are as follows, listed in order:
- The family of distributions presents flexibility in the modes of the base model, in both unimodal and bimodal cases;
- The parameters are estimated using the ML method; a simulation study for the maximum likelihood estimators indicates good parameter recovery;
- We show that the Fisher information matrix for the SPN distribution is nonsingular for the particular case of the normal distribution;
- In the first example, we contrasted the normal, SN and TN models. It is obvious that these models fail to capture the asymmetric bimodality of the data. In contrast, the ETN and SPN models are more suitable for fitting the distribution of the variable . In the second example we see that the normal, SN and PN models fail to adequately capture the high kurtosis of the variable roller. However, the SPN model appears to have more flexibility to fit this special feature.
Author Contributions
Conceptualization, G.M.-F. and C.B.-C.; methodology, H.W.G.; software, G.M.-F. and C.B.-C.; validation, G.M.-F., C.B.-C. and H.B.; formal analysis, O.V. and H.W.G.; investigation, G.M.-F. and C.B.-C.; writing—original draft preparation, H.B. and O.V.; writing—review and editing, O.V. and H.B.; funding acquisition, H.W.G. and O.V. All authors have read and agreed to the published version of the manuscript.
Funding
The research of Héctor W. Gómez was supported by SEMILLERO UA-2022 (Chile). The research of O. Venegas was supported by Vicerrectoría de Investigación y Postgrado of the Universidad Católica de Temuco, Projecto interno FEQUIP 2019-INRN-03.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in Application 1 is available at http://lib.stat.cmu.edu/datasets/pollen.data (accessed on 16 October 2021), and for Application 2 at http://lib.stat.cmu.edu/jasadata/laslett (accessed on 16 October 2021).
Acknowledgments
We thank the anonymous referees for their thorough reading and significant suggestions that undoubtedly improved the presentation of the manuscript. In particular, authors G.M-F. and C.B-C extend their sincere gratitude for their support to the Universidad de Córdoba- Colombia and Instituto Tecnológico Metropolitano (ITM)-Colombia, respectively.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Probability density function | |
| cdf | Cumulative distribution function |
| SN | Skew-normal |
| S | Skew-symmetric |
| PS | Power-symmetry |
| PN | Power-normal |
| TN | Two-pieces skew-normal |
| ETN | Extended two-pieces skew-normal |
| ML | Maximum likelihood |
| PSH | Power-symmetry distribution with proportional hazards |
| PNH | Power-normal distribution with proportional hazards |
| EPSH | Extended power-symmetry distribution with proportional hazards |
| SEPSH | Skew extended power-symmetry distribution with proportional hazards |
| SPS | Skew-power-symmetric |
| SPN | Skew-power-normal |
| AIC | Akaike information criterion |
| CAIC | Consistent AIC |
| MN | Two-normals mixture |
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Azzalini, A. Further results on a class of distributions which includes the normal ones. Statistica 1986, 46, 199–208. [Google Scholar]
- Henze, N. A probabilistic representation of the skew-normal distribution. Scand. J. Stat. 1986, 13, 271–275. [Google Scholar]
- Chiogna, M. Notes on Estimation Problems with Scalar Skew-Normal Distributions; Technical Report 15; Dept. Statistical Sciences, University of Padua: Padua, Italy, 1997. [Google Scholar]
- Pewsey, A. Problems of inference for Azzalini’s skew-normal distribution. J. Appl. Stat. 2000, 27, 859–870. [Google Scholar] [CrossRef]
- Venegas, O.; Sanhueza, A.I.; Gómez, H.W. An extension of the skew-generalized normal distribution and its derivation. Proyecc. J. Math. 2011, 30, 401–413. [Google Scholar] [CrossRef] [Green Version]
- Nadarajah, S.; Kotz, S. Skewed distributions generated by the normal kernel. Stat. Probab. Lett. 2003, 65, 269–277. [Google Scholar] [CrossRef]
- Gómez, H.W.; Venegas, O.; Bolfarine, H. Skew-symmetric distributions generated by the distribution function of the normal distribution. Environmetrics 2002, 18, 395–407. [Google Scholar] [CrossRef] [Green Version]
- Gómez-Déniz, E.; Arnold, B.C.; Sarabia, J.M.; Gómez, H.W. Properties and Applications of a New Family of Skew Distributions. Mathematics 2021, 9, 87. [Google Scholar] [CrossRef]
- Lehmann, E.L. The power of rank tests. Ann. Math. Stat. 1953, 24, 23–43. [Google Scholar] [CrossRef]
- Durrans, S.R. Distributions of fractional order statistics in hydrology. Water Resour. Res. 1992, 28, 1649–1655. [Google Scholar] [CrossRef]
- Eugene, N.; Lee, C.; Famoye, F. Beta-normal distribution and its applications. Commun. Stat. Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Gupta, R.C.; Gupta, R.D. Generalized skew normal model. Test 2004, 12, 501–524. [Google Scholar] [CrossRef]
- Gupta, R.D.; Gupta, R.C. Analyzing skewed data by power normal model. Test 2008, 17, 197–210. [Google Scholar] [CrossRef]
- Pewsey, A.; Gómez, H.W.; Bolfarine, H. Likelihood-based inference for power distributions. Test 2012, 21, 775–789. [Google Scholar] [CrossRef]
- Kim, H.J. On a class of two-piece skew-normal distribution. Statistics 2005, 39, 537–553. [Google Scholar] [CrossRef]
- Arnold, B.C.; Gómez, H.W.; Salinas, H.S. On multiple constraint skewed models. Statistics 2009, 43, 279–293. [Google Scholar] [CrossRef]
- Cox, D. Regression models and life tables. J. R. Stat. Soc. Ser. B 1972, 34, 187–220. [Google Scholar] [CrossRef]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data, 2nd ed.; John Wiley and Sons: New York, NY, USA, 2002. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; John Wiley and Sons: New York, NY, USA, 1994; pp. 53–54. [Google Scholar]
- Akaike, H. A new look at statistical model identification. IEEE Trans. Automat. Contr. 1974, 19, 716–723. [Google Scholar] [CrossRef]
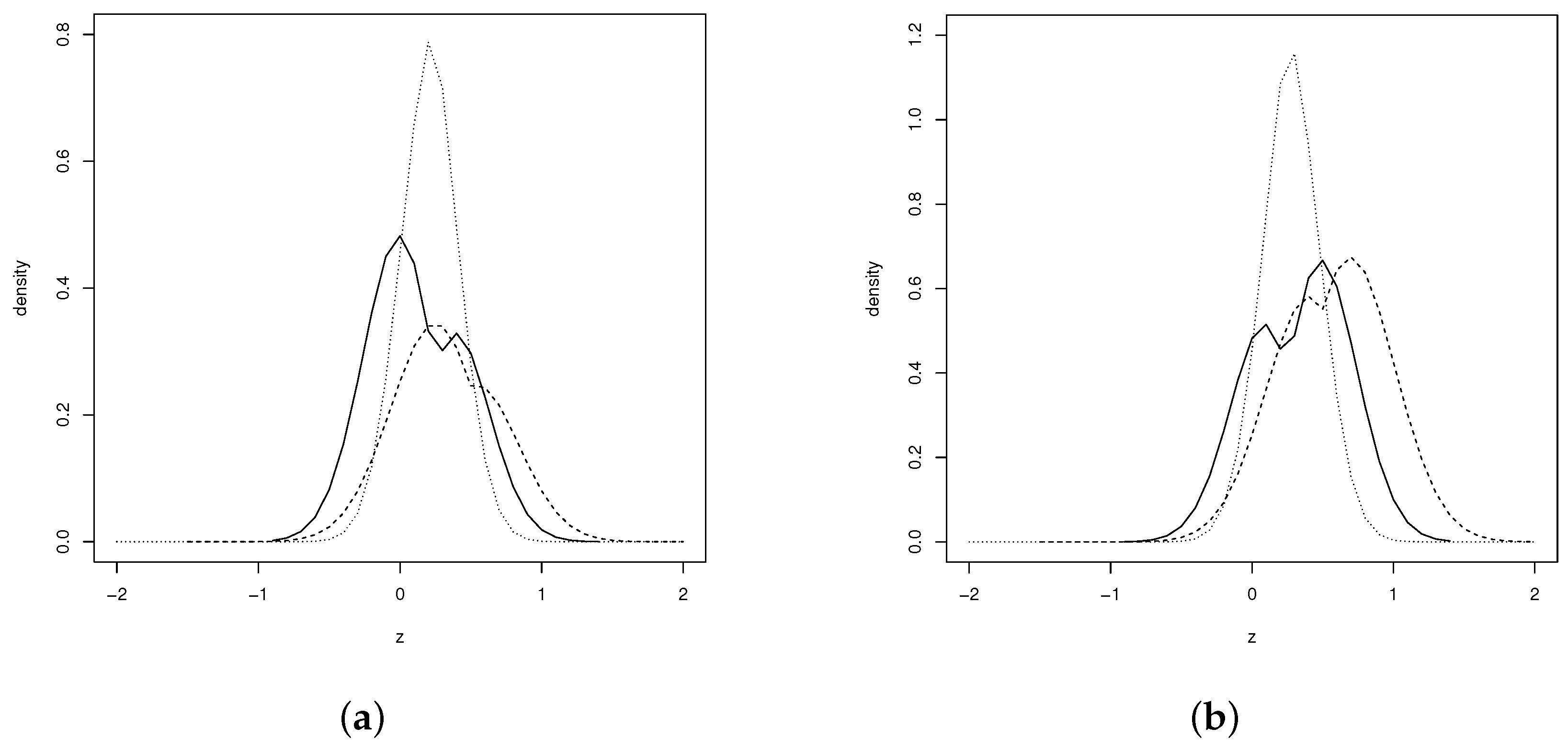
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).