Abstract
The increasing interest in automated code conversion and transcompilation—driven by the need to support multiple platforms efficiently—has raised new challenges in verifying that translated codes preserve the intended behaviors of the originals. Although it has not yet been widely adopted, transcompilation offers promising applications in software reuse and cross-platform migration. With the growing use of Large Language Models (LLMs) in code translation, where internal reasoning remains inaccessible, verifying the equivalence of their generated outputs has become increasingly essential. However, existing evaluation metrics—such as BLEU and CodeBLEU, which are commonly used as baselines in transcompiler evaluation—primarily measure syntactic similarity, even though this does not guarantee semantic correctness. This syntactic bias often leads to misleading evaluations where structurally different but semantically equivalent code is penalized. This syntactic bias often leads to misleading evaluations, where structurally different but semantically equivalent code is penalized. To address this limitation, we propose a formal verification framework based on equivalence checking using First-Order Logic (FOL). The approach models core programming constructs—such as loops, conditionals, and function calls—that function as logical axioms, enabling equivalence to be assessed at the behavioral level rather than simply by their textual similarity. We initially used the Z3 solver to manually encode Swift and Java code into FOL. To improve scalability and automation, we later integrated ANTLR to parse and translate both the source and transcompiled codes into logical representations. Although the framework is language-agnostic, we demonstrate its effectiveness through a case study of Swift-to-Java transcompilation. The experimental results demonstrated that our method effectively identifies semantic equivalence, even when syntax differs significantly. Our method achieves an average semantic accuracy of 86.1%, compared to BLEU’s syntactic accuracy of 64.45%. This framework bridges the gap between code translation and formal semantic verification. These results highlight the potential for formal equivalence checking to serve as a more reliable validation method in code translation tasks, enabling more trustworthy cross-language code conversion.
1. Introduction
Modern software development increasingly relies on cross-platform development to port code across programming languages and platforms. From legacy system migration to cross-platform mobile applications, translating code from one high-level language to another has become a critical practice in the industry [1]. The transcompilation approach has emerged as a potential method to accelerate cross-platform development by translating code between high-level programming languages [2]. Although this approach has not yet been widely adopted across the industry, it is gaining traction in academic research, particularly in domains that require portability across platforms, such as mobile systems [3]. The increasing heterogeneity of software ecosystems combined with the need to reduce redundant development efforts has led researchers to explore transcompilers [2,4,5,6,7,8,9,10] as they are seen to be a promising complement to frameworks such as Xamarin, React Native, and Flutter.
However, ensuring that a transcompiled program behaves identically to the original is difficult. Traditional validation methods, such as unit tests or code reviews, often fail to catch subtle bugs; in turn, code conversion errors can have severe consequences in safety-critical and enterprise systems [11]. This issue necessitates other methods to validate the semantic correctness of transcompiled codes beyond the level conventional testing can guarantee. The transcompilation tools currently use the Bilingual Evaluation Understudy (BLEU) metric [12] and CodeBLEU metric [13]. BLEU is an evaluation metric used to compare machine translation with human translations. The higher the number of matches between the machine and human code, the more accurate the translation’s efficiency is deemed. Unfortunately, a high n-gram overlap with a reference does not ensure functional equivalence. As Qi et al. [14] observed, metrics such as BLEU and CodeBLEU often fail to expose critical translation errors, especially when the target language lacks certain constructs that are present in the source language. In other words, a transcompiler can produce code that seems correct lexically yet diverges in runtime behavior or edge-case semantics [15]. Empirical studies have confirmed that such metrics correlate poorly with true semantic correctness. Thus, using a purely syntactic evaluation is inadequate for validating cross-language code translation. Accordingly, our study adopts BLEU as a reference benchmark to represent the current practice; subsequently, we introduce a formal logic-based equivalence metric that captures behavioral preservation beyond textual similarity.
Verifying semantic equivalence across diverse programming languages poses significant challenges. Each language has its own syntax, type system, and runtime semantics, making one-to-one correspondence non-trivial [16]. For example, differences between static and dynamic typing or memory management in Swift and Java mean that a direct translation must carefully preserve logic despite their divergent language features. Existing formal verification tools fail to fully address this problem. Model checkers like CBMC [17] and JBMC [18] are able to check safety properties or assertions within a single program [19]. However, they cannot inherently prove that a program in language X is semantically equivalent to a program in language Y. Even specialized efforts to validate code generation—for instance, using CBMC to check the equivalence between an auto-generated C program and its Stateflow model [20]—require a custom setup and remain language-specific. In general, there is a notable gap in applying formal methods to translate high-level code. Recent surveys report that few prior studies have aimed to formally verify translations between high-level languages; instead, transcompilers are typically evaluated only by testing or examining their BLEU-style scores [11]. This lack of tool support and research highlights the challenges of cross-language equivalence checking using current techniques. Moreover, the absence of a cross-language verification category in the annual benchmark for software verification, the SV-COMP competition, is further evidence of this paucity [21]. Clearly, new approaches are needed to determine whether a transcompiled code faithfully preserves the original program’s semantics.
While traditional compiler verification methods such as CompCert [22] aim to prove that a compiler preserves semantics, such approaches require full access to the compiler’s internal translation rules and formal specifications. Notably, such conditions are rarely met in real-world transcompilers. Frameworks such as TC-Verifier [23] aim to verify the transcompiler through model checking. However, this study reveals that current transcompilers remain incomplete and cannot fully capture all translation behaviors. Many existing frameworks are also closed-source, heuristic, or based on Large Language Models (LLMs); thus, their internal reasoning and decision processes are inaccessible for trying to determine formal proof [11,14].
Therefore, it is essential to have a post hoc semantic equivalence checking layer. Instead of verifying the compiler, we verified the output code using equivalence checking. This enabled external validation independent of the source and target languages. This distinction provides a practical and future-proof approach to ensuring reliability in LLM-driven and traditional transcompilation workflows.
In this paper, we propose a formal verification framework for transcompiled code that addresses the above challenges using a logic-based approach. First, we model the semantics of both the source program and its transcompiled output by FOL, capturing the program’s behavior (e.g., flow of values, conditions, and effects) as logical axioms. By expressing both versions in a common logical representation, we reduce the equivalence problem to a logical satisfiability check. Subsequently, we leverage a Satisfiable Modulo Theories (SMT) solver called Z3 to automatically determine whether the two sets of FOL axioms are equivalent or if any semantic discrepancies exist. Z3 is a state-of-the-art solver that can efficiently develop logical formulas over various theories, making it well-suited for checking our conditions for translation correctness [24]. Initially, we crafted the logical specifications manually to perform a pilot equivalence checking using Z3. Building on this, we developed an automated pipeline using ANTLR [25] to parse the source and target codes while automatically generating the FOL semantic representations. Integrating a parser generator (for syntax) with logical modeling (for semantics) allows our framework to scale to real-world programming languages by handling their grammar and producing corresponding logical constraints. Moreover, to quantify the degree of semantic preservation, we introduce a novel metric we have termed the percentage of shared axioms, which measures how many logical semantic parts of the source code are identical in both the original and transcompiled programs. This metric provides a continuous gauge of semantic overlap, complementing the all-or-nothing result of a traditional equivalence check.
We demonstrate our framework on a case study involving a Swift-to-Java transcompiler. These languages were chosen due to their distinctly different features (Swift is a modern, strongly typed language for iOS, and Java is a classic, static language for Android), as defined by an existing transcompiler tool described by [6]. Using this approach, we formally encode several sample Swift programs and their corresponding Java translations, utilizing the solver-backed analysis to verify where the semantics align or diverge. While FOL is well-suited for capturing static code features, such as variable declarations, control flow, and function calls, it is limited in handling certain dynamic features, including unbounded loops and dynamic memory allocation. Nevertheless, it is sufficiently expressive for checking the equivalence of two static program structures. This work showcases the feasibility of using logic-based formal verification to validate code conversion equivalence. Our work:
- Introduces a new framework that translates high-level transcompiled source and target codes as FOL representation, which ensures logical representation of the code.
- Applies Z3-based equivalence checking using manually encoded FOL representations of Swift and Java code.
- Automates the FOL generation process using ANTLR to enable scalable semantic verification.
- Defines an interpretable metric based on shared axioms to assess semantic preservation across translations.
- Validates the approach through a Swift-to-Java case study, showing improved semantic accuracy over BLEU-style metrics.
The remaining sections of this paper are organized as follows: Section 2 reviews the related work on formal verification and equivalence checking. Section 3 outlines our formal verification approach, which implements equivalence checking. This approach begins by applying a Z3-based manual method and extends to using an automated pipeline using ANTLR. This section also describes our experimental setup, including evaluating the metrics used. Section 4 presents the results and features a discussion. Finally, Section 5 concludes the paper and suggests directions for future work.
2. Related Works
It is crucial to ensure that a program’s semantics are preserved across programming languages, as purely syntactic checks or testing can omit some behavioral differences. This issue has motivated research into formal methods used to verify semantic equivalence between a source code and its translated counterpart. Some approaches rely on symbolic execution, demonstrating their effectiveness by systematically exploring possible execution paths to verify program equivalence. Notably, Ramos and Engler [26] developed UC-KLEE, which leverages under-constrained symbolic execution to validate the functional equivalence of two C programs. Their approach systematically generates symbolic inputs to identify the semantic differences in programs, also uncovering subtle compiler-induced discrepancies. However, UC-KLEE is limited to verifying equivalence within programs using the same language and is constrained by the path-explosion challenges common to symbolic execution methods.
Another symbolic equivalence framework is CIVL [27], which combines symbolic execution with SMT solving to validate the functional equivalence of programs written in different languages, such as C and Fortran. CIVL translates both programs into a shared intermediate representation (CIVL-IR), then symbolically executes them in lockstep using Z3 to ensure that their states match across all inputs. While CIVL has proven effective in verifying code transformations such as loop parallelization, it requires input-output correspondences to be specified manually. Moreover, it depends on aligning both programs under their control-flow levels. In contrast, our approach abstracts their program behavior into FOL axioms and checks their semantic equivalence at a higher logical level. Although both methods use an intermediate representation (CIVL-IR in their case, FOL in ours), our framework avoids the need for path-level synchronization and manual annotation. It is more flexible across modern high-level languages because it leverages grammar-based automation via ANTLR.
Addressing some limitations of purely symbolic techniques, Gupta et al. [28] introduced strategies such as invariant sketching and query decomposition within SMT-based equivalence checking. Their method efficiently manages complexity by decomposing equivalence checking tasks into smaller, more manageable queries and automatically inferring invariants, thereby significantly improving scalability. However, like many SMT-driven methods, this approach is typically applied within the same language or intermediate representation, while cross-language scenarios are left largely unexplored.
In the domain of translation validation, PEQcheck [29] is a recent equivalence checker designed to verify that a program’s behavior is unchanged by the source-code refactorings. Instead of trying to prove that two whole programs are equivalent monolithically, PEQcheck breaks the problem down by identifying the modified code segments in the refactored version. It constructs separate verification tasks for each segment. The original program provides the specification for the refactored one, and only the parts of the state that are modified and live in the changed segment need to be proven equivalent, while read-only and unaffected states can be shared freely. By being localized and context-aware, PEQcheck avoids the state-space explosion associated with full program equivalence and has demonstrated improved performance in checking non-trivial refactorings. Similarly, PEQtest [30] takes a testing-based approach to equivalence checking, using differential test generation to identify behavioral differences when devising formal proof is too challenging to accomplish. Nevertheless, this tool’s scope is also restricted to code modifications within the same language and is unable to address translations between distinct programming languages.
General software model checkers have also been applied to try to solve equivalence problems. The bounded model checker CBMC (for C/C++ programs) and its Java counterpart JBMC can be employed to try to determine whether two implementations are equivalent by constructing a product program or joint verification condition. For example, Sampath et al. [17] utilized CBMC to verify the equivalence of Simulink models and auto-generated C code by translating both into a unified state-based representation. Likewise, JBMC [18] can verify Java bytecode against specifications or against another Java program by exploring its execution up to a bound and checking assertions. While such model checkers are powerful, they are not built for cross-language equivalence.
From a compiler verification perspective, formal methods such as CompCert and Alive2 provide strong translation correctness within single-language contexts or intermediate representations. Employing Coq-based formal proofs, CompCert ensures the semantic preservation of C-to-assembly compilation, but the method’s high manual overhead limits its adaptability [11]. Utilizing SMT-based validation, Alive2 verifies LLVM optimizations automatically, but it is confined to LLVM’s intermediate representation [31]. Both methods demonstrate robust semantic equivalence verification but cannot verify translations across distinct high-level programming languages.
Software verification competitions, such as SV-COMP [21], have made significant strides in verifying program correctness but have rarely veered from single-language boundaries. SV-COMP provides a rigorous evaluation for verifiers on tasks in C, Java, and some other languages. However, each verification task is defined for a single input program in one specific language and has a corresponding safety property. SV-COMP cannot verify that two programs in different languages are equivalent—in fact, its rules stipulate that each task’s program must be written in a given language and accompanied by a specification property with that same context. This highlights the current lack of benchmarking and tool support for formally verifying the correctness of transcompilation across languages.
Building on this gap, our initial methodology was inspired by the work of Fangzhen Lin [32], who demonstrated how to translate object-oriented programs to FOL for verification. His method converts classes and their members into logical functions and uses Z3 to verify whether a given assertion is a theorem of the translated axioms. While Lin’s approach deftly abstracts program semantics as logic and avoids loop invariants, it targets only the correctness of a single program in one language. It does not address the matter of equivalence between two programs or support cross-language reasoning. Thus, we extended this concept by applying FOL modeling to both the source and transcompiled codes, enabling semantic equivalence checking between languages. Initially, we encoded Swift and Java programs into FOL and used Z3 to validate their equivalence. To improve scalability and reduce human effort, we integrated ANTLR to automate the logic extraction process based on the grammars of languages.
In summary, while previous studies have made progress in equivalence checking and program verification, none have explicitly targeted semantic equivalence across different programming languages. The framework proposed in this paper addresses this gap by introducing automated logic extraction through ANTLR and verifying semantic equivalence via FOL, thereby enabling rigorous cross-language verification.
3. Methodology
3.1. Framework Overview
This framework introduces a logic-based approach to formally verifying the semantic equivalence between the source and transcompiled code across different programming languages. Instead of relying on syntactic similarity metrics, this framework abstracts both code versions into one formal representation using FOL and evaluates their functional equivalence at the logical level. As illustrated in Figure 1, the framework evolves through two main phases. In the initial phase, the code is translated into FOL using Z3 syntax, and equivalence is verified by executing the Z3 solver. This framework serves as the proof of concept to establish the soundness of logic-based semantic verification.

Figure 1.
Overview of the verification framework.
To overcome the limitations of the encoding involved with Z3, the second phase of the framework fully automates the logic generation using Another Tool for Language Recognition (ANTLR). Swift and Java code are then parsed into structured syntax trees and mapped into logical predicates through predefined transformation rules. Subsequently, equivalence is checked by directly comparing the generated logic representations. This automated process produces a semantic equivalence score based on the proportion of common axioms that exist between the source and transcompiled codes. This forms the core of the deployed verification workflow. Thus, the framework transitions from a solver-based prototype to an automated, grammar-driven verification pipeline, enabling the scalable and interpretable semantic validation of the transcompiled code.
3.2. Equivalence Checking Using Z3
As shown in Figure 2, we initially used the Z3 solver to verify the equivalence of the programming language codes using FOL. In the first step, we convert the source and target codes into a logical expression known as FOL. In the second step, we write these logical expressions using the Z3 solver. In our final step, we check the equivalence between the source and target languages of the transcompiled code using the Z3 SMT solver.
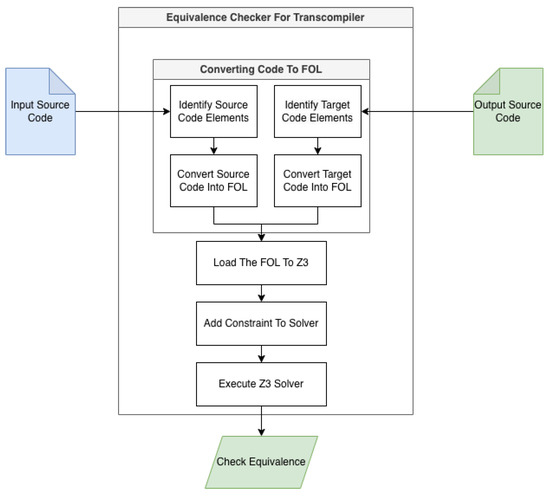
Figure 2.
Formal verification of transcompiler using Z3 SMT solver.
3.2.1. Expressiveness of FOL in Code Verification
A critical aspect of this framework is to ensure that the FOL representation is sufficiently expressive to capture the full semantics of both the source and target codes. The level of expressiveness of the FOL representation directly impacts the accuracy of the equivalence checking process because it determines the extent to which various programming constructs can be formalized.
FOL is particularly effective in capturing static and deterministic constructs within programming languages. These include:
- Static Code Structures: Variables, methods, classes, loops with fixed bounds, and simple conditional statements.
- Deterministic Control Flow: Constructs such as if-else statements, for-loops, and bounded while-loops can be accurately captured within FOL expressions.
- Function and Method Calls: Provided that functions or methods have well-defined inputs and outputs, FOL can effectively model their behavior.
For example, a loop that iterates over a range of values can be represented by a bounded quantifier in FOL
for i in 0..<10 {
print(i)
}
Z3 FOL representation of this for loop is:
This representation encompasses all the essential components of the loop structure.
3.2.2. Code Conversion to First-Order Logic (FOL)
The first practical step in the proposed methodology is to manually convert the functioning line of the source and target codes into FOL representations. This conversion is crucial because it provides a similar code structure for both the source and target codes, making them more suitable for logical analysis. The process of translating code to FOL involves multiple steps:
- Identification of Code Elements: The very first step in translating the source and target codes into predicate logic or FOL is to recognize the various elements inside the code, including the classes, methods, attributes, and control structures. For example, the Swift code in Table 1 contains a single class, two attributes (“x and y”), and a constructor that begins with the keyword “init” to initialize the attributes. Additionally, the class contains a method called myFunction, which has a condition that checks whether “x is greater than y,” or vice versa. This condition prints from zero to the more minor attribute minus one if the attribute is true.
 Table 1. Swift and Java implementations of MyClass using variables x and y.
Table 1. Swift and Java implementations of MyClass using variables x and y. - Defining Logical Statements: The next step is to convert the identified code elements into first-order logic. All statements are converted into predicates using logical statements that represent the code’s conditions and transformations. FOL expressions are used to describe every class, method, loop, and condition. Consider a class named MyClass, for instance, which contains a method, attributes, and both Java and Swift code. This class can be translated into first-order logic as follows:Class Instantiation and Attributes:Method Definition:Method Behavior:Since we have converted the code into first-order logic, we can use the Z3 tool to determine whether the source and target codes are equivalent.This detailed conversion process ensures that the logical representations are precise and accurately reflect the original code’s behavior.
3.2.3. Equivalence Checking Using Z3 Solver
Once the code is converted to first-order logic, the next step is to configure the Z3 SMT solver to manage the logical expressions. A SMT solver is a computational tool that determines the level of satisfaction of logical formulas within first-order theories, such as equality, arithmetic, and bit vectors. Z3 [24] is an SMT solver from Microsoft Research, aimed at solving problems that arise in software verification and analysis. Consequently, it integrates support for many theories. This step involves defining the logical expressions for both the source and transcompiled target codes. The Z3 solver is configured to verify the equivalence of these expressions.
For instance, the equivalent Swift code for the Java example above is formulated in a similar manner using first-order logic. The Z3 solver can now be configured to verify the equivalence of the logical expressions.
Note that the Z3 example in Figure 3 is intentionally schematic. The Java and Swift logical groups were written to be structurally identical to demonstrate how Z3 handles equivalence constraints. Because the predicates mirror each other line-by-line, adding a constraint such as s.add(A == B) will naturally evaluate that the translations are satisfiable. Therefore, this example is pedagogical rather than analytical—it illustrates how the solver processes logical expressions, not how semantic differences are detected. All meaningful semantic comparisons in our framework are performed in the automated ANTLR phase, where the generated FOL representations differ structurally and allow for real equivalence checking.

Figure 3.
Equivalence checking of MyClass using Z3.
The Z3 solver evaluates whether the logical statements for the source and target codes are equivalent. This process involves:
- Adding FOL to the Z3 solver: Both the source code (Swift) and the target code (Java) FOL expressions are loaded into the solver.
- Adding the Constraints: The constraints are added using the add function, which specifies the items that need to be checked.
- Solver Execution: The solver checks whether the added constraints have been satisfied. If the solver finds that the constraints have been satisfied, it confirms the equivalence of the source and target codes; if the constraints have not been satisfied, it identifies that the two codes are not equivalent.
3.2.4. Observed Challenges and Limitations of Using Z3
During our experimentation with the solver-based phase, several limitations became evident:
- A Lack of Semantic Completeness: The simplified Z3 example shown in Figure 3 does not encode certain essential semantic aspects such as program state evolutions, next-state transitions, control-flow behaviors, or variable-store updates. The example does not represent the full program semantics; therefore, it is used only as an illustration of solver interaction.
- Manual and Solver-Dependent Workflow: Both the source and target programs had to be manually rewritten as logical formulas and submitted into the solver. This process is time-consuming, difficult, and prone to human error, as each new program requires that the logical formulas be reconstructed from scratch.
- No Direct Link to Programming Languages: Although Z3 can check for satisfiability, it cannot parse or interpret Swift or Java syntax. All language constructs must be expressed manually in FOL, preventing the automatic extraction of semantics and hindering the scalability of this approach.
- Limited Support for Cross-Language Mapping: Z3 provides no built-in mechanism for aligning the structural components of programs that are written in different languages. Establishing a correspondence between constructs (e.g., loops, conditionals, and method bodies) is difficult without an automated parsing layer.
After several experiments, it became evident that these limitations were not in the logical framework but in the practical integration of the Z3 solver. Since this aimed to compare the abstract FOL representations of programs rather than prove theorems within an SMT environment, we shifted toward a parsing-based approach. This refinement preserved the same equivalence-checking concept while replacing the solver with an automated mechanism for code translation and logical comparison. Consequently, the next phase of the framework employs ANTLR to automatically generate and align the logical structures of the two programs for equivalence verification.
3.3. Formal Semantics Mapping of Swift and Java Constructs
A crucial step toward ensuring semantic rigor is to define how language constructs in Swift and Java are represented as logical axioms. Our mapping adopts an axiomatic-semantics perspective, where each construct contributes a predicate that expresses its state of transformation or logical constraint. This mapping allows equivalence checking to be performed independently of syntax, focusing on the logical relationships between program states rather than their textual structures.
Formally, we define a mapping function
assigning each syntactic construct from either language to its logical representation , capturing its syntax in First-Order Logic. Examples of these mappings for the core programming constructs in Swift and Java are provided in Appendix A.
Illustrative Mapping Example
To illustrate the process more concretely, consider the following Swift and Java code fragments, which implement identical behaviors using different loop structures.
As shown in Table 2, both two-code lines print the digits 0 through 9 functionally exactly. Due to their syntactic differences—distinct loop structures (for vs. while) and output statements (print(i) vs. System.out.println(i))—BLEU would likely provide a low similarity score because it ignores semantic similarity and focuses solely on comparing texts token by token and line by line.
Table 2.
Syntactically Different but Semantically Equivalent Loops.
FOL Representation of the Example
i = 0
i(0) = i
(i(n) < 10 → Print(i(n)) ∧ i(n+1) = i(n) + 1)
Here is how each component of the FOL corresponds to the program logic:
- i = 0This initializes the loop counter i to zero, just like int i = 0 in Java or the implicit counter in Swift’s for i in 0..<10.
- (0) = iThis states that the value of i at the initial step (n = 0) is i. This serves as the base case scenario for the logical sequence.
- (...)This universal quantifier means that the following logical expression must hold for all the steps n in the Loop. It also abstracts the repetition aspect of the Loop.
- i(n) < 10This condition checks whether the current value of i at step n is less than 10, similar to the loop condition in both Swift (0..<10) and Java (while(i < 10)).
- → (Implication)This symbol, read as “implies,” means that if the loop condition i(n) < 10 holds at step n, then the following two actions must occur.
- Print(i(n))This indicates that the current value of i is printed at step n. It abstracts the output command from both languages (print(i) in Swift and System.out.println(i) in Java).
- ∧ (Logical AND)This symbol connects multiple logical statements. In this case, it ensures that both the print operation and the increment step happen together whenever the condition is true.
- i(n + 1) = i(n) + 1This equation represents the increment logic. It states that the value of i at the next step (n+1) is one more than its value at the current step n, mimicking the i++ behavior in Java SE 22 version and the implicit increment in Swift’s 5.1 for loop.
This example demonstrates how evaluation metrics like BLEU are limited in trying to verify code equivalence. In contrast, FOL reveals the equivalence between the two codes by modeling all the code’s components. This insight further indicates the need for formal verification techniques in our transcompilation framework because it provides a degree of rigor and correctness that is not possible with BLEU or CodeBLEU.
Additional mappings for other constructs—including variable declarations, arrays, conditionals, functions, classes, and method invocations—are described in Appendix A.
3.4. Automated Equivalence Checking Using ANTLR
Building on the limitations identified in the Z3, this phase retains the same formal logic approach but replaces the solver with an automated parsing mechanism by using ANTLR. The ANTLR-based framework directly generates FOL representations from both the source and target codes, eliminating the need to depend on manual formula constructions and external solvers. This automation ensures faster processing, consistent logical translation, and full integration within the verification workflow of the tool.
The enhanced framework focuses on the formal verification of the transcompiled code through equivalence checking using ANTLR. As shown in Figure 4, the framework begins by taking the input code (e.g., Swift) and the output code (e.g., Java) generated by ANTLR, which produces parsers for both the source and target languages, providing a structured representation of the code in the form of a parser tree. The next step is to identify key code elements from the source and output codes, such as the function signatures, loops, conditionals, and variables. Identifying these elements is crucial for ensuring that the transcompiled code retains the same functionality as the source code. The next phase involves converting the input and output codes into First-Order Logic (FOL) representations. FOL abstracts the functional behaviors of the code into predicate formats, which allows for a rigorous comparison between the input and output codes. Finally, the equivalence checker compares the FOL representations of both codes. If the two representations match, the transcompiled code is deemed functionally equivalent to the source code. If discrepancies are found, the equivalence checker identifies the areas where the transcompiled code deviates from the original, allowing corrections to be made.

Figure 4.
Architecture of the formal verification with ANTLR.
3.5. Experimental Setup
We conducted experiments to answer the two research questions and assess the effectiveness of our proposed equivalence-checking approach.
- RQ1: How accurate is ANTLR-based automated formal verification in ensuring semantic equivalence between original Swift and trans-compiled Java code?
- RQ2: What efficiency advantages does ANTLR-based verification have over the earlier Z3-based manual verification approach?
3.5.1. Evaluation Metric
The following evaluation metrics are used in our experiments.
Equivalence Accuracy: To evaluate the effectiveness of our formal verification framework, we used Equivalence Accuracy to measure the degree of logical consistency between the source and transcompiled programs. This metric is calculated using Equation (1)
Here, “Total Common Axioms” denotes the total number of axioms that are logically equivalent in both the source code (Swift) and the target code (Java) while “Total Source Axioms” denotes the number of axioms extracted from the source code. This metric provides a measurable assessment of the conformity of the transcompiled code to the original, focusing on its logical structure and behavior.
BLEU Metric: To assess the accuracy of our proposed approach compared to the other transcompiler-based approaches mentioned in [4,6], we used the BLEU metric. This metric calculates the number of n-gram overlaps between a machine-generated output and a reference translation. In this experiment, two files were provided to the BLEU tool: the first was the desired target-language output (a human translation reference), while the second was the transcompiled output produced by the baseline system described in [6].
The equation that BLEU uses is as follows:
where is the modified precision for n-grams, is the weight between 0 and 1 for , and .
The BLEU calculation considers the brevity penalty (BP); thus, it penalizes short machine translations. BP is calculated as follows:
Here, c is the length of the candidate translation, and r is the effective reference length (best match).
3.5.2. Efficiency and Automation Comparison
To assess the practical efficiency gains of our automated equivalence checking phase, we conducted a qualitative comparison to analyze the initial Z3-based manual method and the enhanced ANTLR-based automated framework.
The evaluation focused on the following five key aspects:
- FOL conversion effort: The amount of manual effort required to represent program logic in FOL.
- Time required per application: The average duration needed to verify each sample program.
- Error-proneness due to manual input: The likelihood of initiating mistakes when encoding the logic manually using the Z3-based approach.
- Ability to handle complex loop constructs: The system’s capability of managing nested loops and control flow variations.
- Ease of integration with the transcompiler: How seamlessly the verification method can be integrated into the overall transcompilation pipeline.
3.5.3. Code Samples
- Bubble Sort Algorithm: A basic sorting algorithm is used to sort an array of integers.
- Linked List Implementation: A data structure consisting of nodes, where each node contains data and references the next node.
- Stack: A data structure that follows the Last In, First Out (LIFO) principle.
- A Simple Banking Application: A basic application with account management features.
- Binary Search Tree: A tree data structure, where each node has at most two children, referred to as the left and right children.
These samples were selected to evaluate how the verification system handles:
- Static and dynamic control flow.
- Function and method calls.
- Recursive and iterative patterns.
- Simple to moderately complex applications.
Tools Used:
- Z3 SMT Solver: Used for equivalence checking by analyzing the logical expressions derived from the source and target codes.
- ANTLR: Used for parsing the source and target codes and generating structured syntax trees for equivalence checking.
- Languages: The source code was written in Swift, while the target code was transcompiled to Java.
4. Experiments and Results
4.1. Syntactic vs. Semantic Evaluation—BLEU vs. Equivalence Accuracy
To answer this question, we compared the BLEU baseline scores with the proposed Equivalence Accuracy metric across ten different Swift-to-Java transcompiled code samples. These included both mobile application components and standalone algorithmic examples. Table 3 compares the BLEU scores—representing syntactic similarity—with the Z3-based Equivalence Accuracy, which evaluates the semantic consistency between the source and translated codes. The BLEU score indicates the degree to which the translated Java code aligns with a reference translation at a syntactic level. Meanwhile, using FOL, the Z3 Solver Accuracy assesses whether the functional behavior of the source and translated codes is semantically equivalent.
Table 3.
Comparison of BLEU (syntactic) and Equivalence Accuracy (semantic) scores across different code samples.
Our first observation was that the BLEU scores vary significantly, depending on how closely the structure of the translated code matches the reference. Applications with conventional and straightforward translations, such as “Make a Call” and “Smart Calculator,” achieved near-perfect BLEU scores, ranging from 93% to 100%. However, when examining programs that involve algorithmic or structural transformations—such as “Stack” and “Binary Search Tree”—the BLEU scores dropped sharply, even though the underlying logic had been correctly preserved. This reveals BLEU’s sensitivity to abiding by syntactic form rather than actual behavior.
Additionally, Table 3 shows the Z3-based Equivalence Accuracy. remains consistently high across all code samples, even for structurally complex programs. While the BLEU scores fluctuate dramatically, the Z3-based verification maintains an average accuracy of 86.1%. This confirms that the translated code preserves the intended functional behavior even when the syntax differs.
These results reinforce the limitations of using BLEU as the sole evaluation metric in transcompiler research. While BLEU captures syntax-level translation, it fails to detect the deeper semantic equivalence in cases when different syntactic structures represent the same logic, which is a common occurrence in real-world cross-platform development. For instance, a Swift for Loop and a Java while loop may implement identical behavior, but BLEU penalizes this variation and suggests the two lack equivalence. In contrast, Z3-based FOL checking identifies logical equivalence, offering a more robust evaluation of the functional correctness between two programs. The consistently high Z3 Equivalence accuracy—particularly in structurally complex programs, such as linked lists, trees, and algorithms—positions this type of formal verification as a superior alternative or complement to traditional BLEU-based assessments in evaluating the quality of transcompiled codes.
4.2. Efficiency Comparison—Z3 vs. ANTLR
To evaluate the efficiency of formal verification, we compared the original Z3-based manual equivalence checking method with the enhanced ANTLR-based automated approach. The comparison focuses on effort, runtime, accuracy, integration, and scalability.
Table 4 summarizes the key efficiency differences between the two methods.
Table 4.
Efficiency Comparison: Z3-Based vs. ANTLR-Based Verification.
As Table 4 shows, while the two approaches achieve comparable semantic accuracy, their efficiency characteristics differ significantly. In the Z3-based phase, each FOL must be manually encoded before you can solve. The solver runtime is stochastic because Z3 explores the satisfiability search space: simple programs terminate within seconds, but complex ones—especially those with nested loops or inter-dependent constraints—require several hours or even up to a full day of computation to complete. This program complexity effect limits scalability and makes it impractical to verify large samples.
In contrast, the ANTLR-based phase performs deterministic verification. Both the source and transcompiled code are automatically translated into FOL strings, which are then compared. Since this comparison involves only structural matching and not theorem solving, its runtime remains stable (1–2 s) regardless of the code size or complexity. This consistency, together with the full automation and integration within the transcompiler, demonstrates that the ANTLR-based method has a clear efficiency and scalability advantage, even though it sacrifices the solver-level reasoning depth of Z3.
5. Conclusions and Future Work
This paper presented a novel formal verification framework for evaluating the semantic correctness of transcompiled mobile application code using First-Order Logic (FOL). The study addressed the limitations of syntactic evaluation metrics such as BLEU and CodeBLEU—which often penalize valid translations by failing to identify surface-level differences—by introducing a two-phase equivalence-checking pipeline that operates at the logical level of program behavior.
In Phase 1, Swift and Java programs are manually translated into FOL axioms and verified for equivalence using the Z3 SMT solver. This stage demonstrates the feasibility of logic-based semantic verification, achieving an average semantic accuracy of 86.1%, substantially higher than BLEU’s baseline syntactic accuracy of 64.45%. However, this phase was constrained by the lengthy manual effort required to encode FOL and the limited scalability of solver-based verification.
To overcome these limitations, Phase 2 introduces automation through ANTLR, enabling the direct extraction of logical representations from source codes and transcompiled codes via grammar-based parsing rules. This enhancement reduced the verification time from hours to seconds, improving scalability without compromising accuracy. Although the experiments focused on Swift-to-Java translation, the proposed framework is language-agnostic; thus, it can be extended to other language pairs by providing suitable grammar definitions.
5.1. Scope and Limitations
The current framework serves to verify the semantic equivalence of structural and deterministic constructs—including variables, loops, conditionals, and function definitions—across diverse programming languages. These constructs were selected because their behaviors can be expressed as static, state-based relations within the boundaries of First-Order Logic (FOL). Within this scope, FOL provides a precise and tractable means of reasoning to determine equivalence, capturing control flow, value propagation, and the logical relationships between program components.
However, the expressiveness of FOL is inherently limited as it cannot directly represent higher-order functions, dynamic memory allocation, asynchronous execution, runtime polymorphism, or side effects that depend on a mutable state over time. Thus, features such as reflection, concurrency, and reactive event handling require either higher-order logic or temporal extensions to express dependencies between changing states. Even with such extensions, some categories of behavior—such as non-deterministic scheduling, external I/O effects, and dynamic linking—remain difficult to reason about formally.
Therefore, the current study deliberately confines its verification to statically analyzable components in which logical equivalence can be unambiguously established. Although this restriction limits completeness, it ensures rigor and interpretability within a large and well-defined boundary. Within this boundary, the method remains valuable for evaluating the semantic consistency of transcompiled artifacts and exposing the translation mismatches that syntactic metrics alone cannot reveal.
5.2. Future Work
Building on the current foundation, future work should focus on the following:
- Expanding Beyond FOL: In an upcoming study, we aim to explore higher-order and temporal logics to model dynamic constructs and richer language features that extend beyond the figures expressible in FOL.
- Cross-Language Generalization: Applying the framework to additional language pairs (e.g., Python –Swift and Kotlin–JavaScript) will help validate its extensibility and reveal new grammar-mapping challenges in heterogeneous programming environments.
- Runtime Semantics Integration: Combining static, logic-based verification with runtime behavior analysis may provide a comprehensive view of semantic correctness across different execution contexts.
By addressing these directions, the proposed framework could evolve into a key component of next-generation transcompilation workflows, delivering automation alongside a formal assurance of semantic equivalence.
Author Contributions
Conceptualization, A.H.Y. and N.E.; methodology, A.A.M.; software, A.A.M., M.A. and S.A.E.; validation, A.A.M., W.M., A.H.Y. and A.J.; formal analysis, A.A.M.; investigation, A.A.M., M.A. and S.A.E.; resources, N.E.; data curation, M.A. and S.A.E.; writing—original draft preparation, A.A.M.; writing—review and editing, W.M., S.S., H.Z., A.H.Y., A.J. and N.E.; visualization, W.M. and S.S.; supervision, S.S., H.Z. and A.H.Y.; project administration, W.M. and S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
This work was supported in part by the OEAD organization project No. P017-2022. The authors of this paper express their gratitude Jens Knoop, Head of Research Unit Compilers and Languages at TU Wien, for his valuable review of this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Formal Semantics Mapping of Swift and Java Constructs
Table A1.
Representative mapping of Swift and Java constructs to their FOL representations and captured semantics.
Table A1.
Representative mapping of Swift and Java constructs to their FOL representations and captured semantics.
| Construct | Swift Example | Java Example | FOL Representation | Semantics Captured |
|---|---|---|---|---|
| Variable Declaration/Assignment | var x: Int = 5 | int x = 5; | Int(x) value(x) = 5 | Type assertion and initial value binding. |
| Array Declaration | var a = [1,2,3] | int[] a = {1,2,3}; | Array(Int(a)) = {1,2,3} | Element type and initialization. |
| Conditional (if/else) | if x > y { print(x) } else { print(y) } | if(x > y) System.out.println(x); else System.out.println(y); | (x > y → Print(x)) (¬(x > y) → Print(y)) | Branch behavior and output action. |
| Loop (for/while) | for i in 0..<n { sum += i } | while(i<n) { sum+=i; i++; } | k < n ( i(k) < n → sum(k+1) = sum(k) + i(k) ) | Iterative state transition under loop condition. |
| Function Definition | func add(a: Int, b: Int) -> Int { return a+b } | int add(int a,int b){return a+b;} | add(a,b) = a + b | Input–output behavior abstraction. |
| Class Definition | class MyClass { var x: Int } | class MyClass { int x; } | Class(MyClass) obj ( x(obj):Int ) | Object instantiation and type membership. |
| Method Invocation | obj.myFunc() | obj.myFunc(); | Call(obj,myFunc) → Effect(obj) | Object-bound behavior. |
| State Update | x += 1 | x = x + 1; | x’ = x + 1 | Next-state semantics for mutation. |
References
- Biørn-Hansen, A.; Grønli, T.M.; Majchrzak, T.A.; Kaindl, H.; Ghinea, G. The Use of Cross-Platform Frameworks for Google Play Store Apps. In Proceedings of the 55th Hawaii International Conference on System Sciences, Virtual, 4–7 January 2022. [Google Scholar] [CrossRef]
- Mahmoud, A.T.; Radwan, M.B.; Soliman, A.M.; Yousef, A.H.; Zayed, H.H.; Medhat, W. Trans-Compiler-Based Conversion from Cross-Platform Applications to Native Applications. Ann. Emerg. Technol. Comput. 2024, 8, 1. [Google Scholar] [CrossRef]
- Mahmoud, A.T.; Muhammad, A.A.; Yousef, A.H.; Zayed, H.H.; Medhat, W.; Selim, S. Industrial Practitioner Perspective of Mobile Applications Programming Languages and Systems. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 275–285. [Google Scholar] [CrossRef]
- Muhammad, A.A.; Soliman, A.; Zayed, H.; Yousef, A.H.; Selim, S. Automated library mapping approach based on cross-platform for mobile development programming languages. Softw. Pract. Exp. 2024, 54, 683–703. [Google Scholar] [CrossRef]
- Barakat, R.; Radwan, M.B.A.; Medhat, W.M.; Yousef, A.H. Trans-Compiler-Based Database Code Conversion Model for Native Platforms and Languages. In Proceedings od the 11th International Conference, MEDI 2022, Cairo, Egypt, 21–24 November, 2022; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2023; Volume 13761, pp. 162–175. [Google Scholar] [CrossRef]
- Muhammad, A.A.; Mahmoud, A.T.; Elkalyouby, S.S.; Hamza, R.B.; Yousef, A.H. Trans-Compiler based Mobile Applications code converter: Swift to java. In Proceedings of the 2020 2nd Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 24–26 October 2020; pp. 247–252. [Google Scholar]
- Muhammad, A.A.; Soliman, A.M.; Selim, S.; Yousef, A.H. Generic Library Mapping Approach for Trans-Compilation. In Proceedings of the 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference, MIUCC 2021, Cairo, Egypt, 26–27 May 2021; pp. 62–68. [Google Scholar] [CrossRef]
- El-Kaliouby, S.S.; Selim, S.; Yousef, A.H. Native Mobile Applications UI Code Conversion. In Proceedings of the 2021 16th International Conference on Computer Engineering and Systems, ICCES 2021, Cairo, Egypt, 15–16 December 2021. [Google Scholar] [CrossRef]
- Salama, D.; Hamza, R.; Kamel, M.; Muhammad, A.; Yousef, A. TCAIOSC: Trans-Compiler Based Android to iOS Converter. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 26–28 October, 2020; 1058. [Google Scholar] [CrossRef]
- Hamza, R.B.; Salama, D.I.; Kamel, M.I.; Yousef, A.H. TCAIOSC: Application Code Conversion. In Proceedings of the NILES 2019—Novel Intelligent and Leading Emerging Sciences Conference, Giza, Egypt, 28–30 October 2019; pp. 230–234. [Google Scholar] [CrossRef]
- Mahmoud, A.T.; Mohammed, A.A.; Ayman, M.; Medhat, W.; Selim, S.; Zayed, H.; Yousef, A.H.; Elaraby, N. Formal Verification of Code Conversion: A Comprehensive Survey. Technologies 2024, 12, 244. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Toulouse, France, 6–11 July 2001; pp. 311–318. [Google Scholar] [CrossRef]
- Ren, S.; Guo, D.; Lu, S.; Zhou, L.; Liu, S.; Tang, D.; Sundaresan, N.; Zhou, M.; Blanco, A.; Ma, S. CodeBLEU: A Method for Automatic Evaluation of Code Synthesis. arXiv 2020, arXiv:cs.SE/2009.10297. [Google Scholar] [CrossRef]
- Qi, M.; Huang, Y.; Wang, M.; Yao, Y.; Liu, Z.; Gu, B.; Clement, C.; Sundaresan, N. SUT: Active Defects Probing for Transcompiler Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Singapore, 2023; pp. 14024–14034. [Google Scholar] [CrossRef]
- Evtikhiev, M.; Bogomolov, E.; Sokolov, Y.; Bryksin, T. Out of the BLEU: How should we assess quality of the Code Generation models? J. Syst. Softw. 2023, 203, 111741. [Google Scholar] [CrossRef]
- Ou, G.; Liu, M.; Chen, Y.; Du, X.; Wang, S.; Zhang, Z.; Peng, X.; Zheng, Z. Enhancing LLM-based Code Translation in Repository Context via Triple Knowledge-Augmented. arXiv 2025, arXiv:cs.SE/2503.18305. [Google Scholar] [CrossRef]
- Kroening, D.; Tautschnig, M. CBMC: The C Bounded Model Checker. 2020. Available online: https://github.com/diffblue/cbmc (accessed on 30 April 2025).
- Cordeiro, L.C.; Kesseli, P.; Kroening, D.; Schrammel, P.; Trtík, M. JBMC: A Bounded Model Checking Tool for Verifying Java Bytecode. In *International Conference on Computer Aided Verification* (CAV 2018); Springer: Cham, Switzerland, 2018; pp. 58–67. Available online: https://link.springer.com/chapter/10.1007/978-3-319-96145-3_3 (accessed on 30 April 2025).
- Cordeiro, L.; Kroening, D.; Schrammel, P. JBMC: Bounded Model Checking for Java Bytecode. In Proceedings of the Tools and Algorithms for the Construction and Analysis of Systems, Prague, Czech Republic, 6–11 April 2019; Beyer, D., Huisman, M., Kordon, F., Steffen, B., Eds.; Springer: Cham, Switzerland, 2019; pp. 219–223. [Google Scholar]
- Sampath, P.; Rajeev, A.; Ramesh, S. Translation Validation for Stateflow to C. In Proceedings of the 51st Annual Design Automation Conference, San Francisco, CA, USA, 1–5 June 2014. [Google Scholar] [CrossRef]
- Beyer, D.; Strejček, J. Improvements in Software Verification and Witness Validation: SV-COMP 2025. In Proceedings of the Tools and Algorithms for the Construction and Analysis of Systems (TACAS 2025), Hamilton, ON, Canada, 3–8 May 2025; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2025; Volume 15698. [Google Scholar]
- Leroy, X. Formal verification of a realistic compiler. Commun. ACM 2009, 52, 107–115. [Google Scholar] [CrossRef]
- Mahmoud, A.T.; Medhat, W.; Selim, S.; Zayed, H.; Yousef, A.H.; Elaraby, N. TC-Verifier: Trans-Compiler-Based Code Translator Verifier with Model-Checking. Appl. Syst. Innov. 2025, 8, 60. [Google Scholar] [CrossRef]
- De Moura, L.; Bjørner, N. Z3: An efficient SMT solver. In Proceedings of the 2008 Tools and Algorithms for Construction and Analysis of Systems, Budapest, Hungary, 29 March–6 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 337–340. [Google Scholar]
- Terence, P. The Definitive ANTLR 4 Reference, 1st ed.; The Pragmatic Bookshelf: Flower Mound, TX, USA, 2013; pp. 1–328. [Google Scholar]
- Ramos, D.A.; Engler, D.R. Practical, low-effort equivalence verification of real code. In Proceedings of the International Conference on Computer Aided Verification, Snowbird, UT, USA, 14–20 July 2011; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6806, pp. 669–685. [Google Scholar] [CrossRef]
- Wu, W.; Siegel, S. F Verifying Functional Equivalence of Programs with CIVL. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC17), Denver, CO, USA, 12–17 November 2017. [Google Scholar]
- Gupta, S.; Saxena, A.; Mahajan, A.; Bansal, S. Effective Use of SMT Solvers for Program Equivalence Checking Through Invariant-Sketching and Query-Decomposition. In Proceedings of the Theory and Applications of Satisfiability Testing—SAT 2018, Oxford, UK, 9–12 July 2018; Beyersdorff, O., Wintersteiger, C.M., Eds.; Springer: Cham, Switzerland, 2018; pp. 365–382. [Google Scholar]
- Jakobs, M. PEQcheck: Localized and Context-aware Checking of Functional Equivalence (Technical Report). arXiv 2021, arXiv:2101.09042. [Google Scholar] [CrossRef]
- Jakobs, M.C.; Wiesner, M. PEQtest: Testing Functional Equivalence. In Proceedings of the Fundamental Approaches to Software Engineering, Munich, Germany, 2–7 April 2022; Johnsen, E.B., Wimmer, M., Eds.; Spinger: Cham, Switzerland, 2022; pp. 184–204. [Google Scholar]
- Lopes, N.P.; Lee, J.; Hur, C.K.; Liu, Z.; Regehr, J. Alive2: Bounded translation validation for LLVM. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual, 20–25 June 2021; pp. 65–79. [Google Scholar] [CrossRef]
- Lin, F. Translating classes to first-order logic: An example. In Proceedings of the 21st Workshop on Formal Techniques for Java-Like Programs, FTfJP 2019—Co-located with ECOOP 2019, London, UK, 15 July 2019; pp. 1–3. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).