
Forecasting Half-Hourly Electricity Prices Using a Mixed-Frequency Structural VAR Framework


Abstract
1. Introduction
2. Models and Methods
2.1. Mixed-Frequency VAR
2.2. Parameter Estimation
2.2.1. Gibbs Sampler for VAR
- Step 1:
- Set initial values for the prior hyperparameters and . The initial value for can be chosen as the least squares estimate.
- Step 2:
- Draw VAR coefficients in matrix from the multivariate normal distribution and using (3).
- Step 3:
- Use the result from Step 2 to draw values for the covariance matrix from the inverse Wishart distribution and using (4).
2.2.2. Mean Field Variational Bayes for VAR
2.3. RU-MIDAS Model
2.4. Variable Selection Techniques
2.4.1. LASSO
2.4.2. Adaptive LASSO
2.4.3. Random Subspace Methods
Random Subset Regression
Random Projection Regression
3. Data and Results
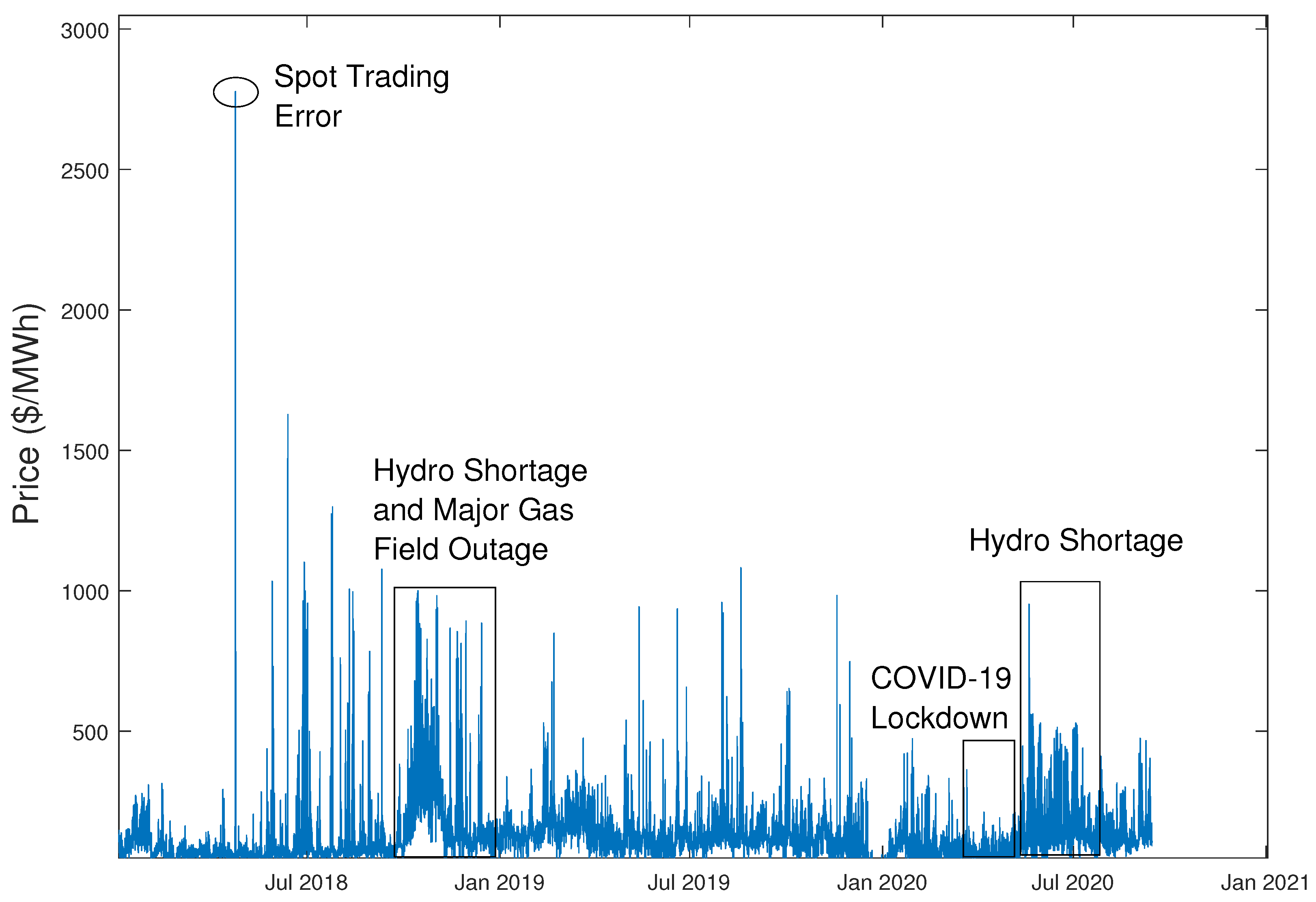
3.1. Description and Key Features
3.2. Forecast Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bańbura, M., Giannone, D., & Reichlin, L. (2010). Large bayesian vector auto regressions. Journal of Applied Econometrics, 25(1), 71–92. [Google Scholar] [CrossRef]
- Bishop, C. M., & Nasrabadi, M. (2006). Pattern recognition and machine learning (Vol. 4). Springer. [Google Scholar]
- Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. (2017). Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518), 859–877. [Google Scholar] [CrossRef]
- Boot, T., & Nibbering, D. (2019). Forecasting using random subspace methods. Journal of Econometrics, 209(2), 391–406. [Google Scholar] [CrossRef]
- Carvalho, C. M., Polson, N. G., & Scott, J. G. (2010). The horseshoe estimator for sparse signals. Biometrika, 97(2), 465–480. [Google Scholar] [CrossRef]
- Cavalcante, L., Bessa, R. J., Reis, M., & Browell, J. (2017). Lasso vector autoregression structures for very short-term wind power forecasting. Wind Energy, 20(4), 657–675. [Google Scholar] [CrossRef]
- Cross, J. L., Hou, C., & Poon, A. (2020). Macroeconomic forecasting with large bayesian vars: Global-local priors and the illusion of sparsity. International Journal of Forecasting, 36(3), 899–915. [Google Scholar] [CrossRef]
- Diebold, F. X. (2015). Comparing predictive accuracy, twenty years later: A personal perspective on the use and abuse of diebold–mariano tests. Journal of Business & Economic Statistics, 33(1), 1. [Google Scholar]
- Eraker, B., Chiu, C. W., Foerster, A. T., Kim, T. B., & Seoane, H. D. (2014). Bayesian mixed frequency vars. Journal of Financial Econometrics, 13(3), 698–721. [Google Scholar] [CrossRef]
- Foroni, C., Ravazzolo, F., & Rossini, L. (2023). Are low frequency macroeconomic variables important for high frequency electricity prices? Economic Modelling, 120, 106160. [Google Scholar] [CrossRef]
- Gefang, D. (2014). Bayesian doubly adaptive elastic-net lasso for var shrinkage. International Journal of Forecasting, 30(1), 1–11. [Google Scholar] [CrossRef]
- Gefang, D., Koop, G., & Poon, A. (2020). Computationally efficient inference in large bayesian mixed frequency vars. Economics Letters, 191, 109120. [Google Scholar] [CrossRef]
- Gefang, D., Koop, G., & Poon, A. (2023). Forecasting using variational bayesian inference in large vector autoregressions with hierarchical shrinkage. International Journal of Forecasting, 39(1), 346–363. [Google Scholar] [CrossRef]
- Ghysels, E. (2016). Macroeconomics and the reality of mixed frequency data. Journal of Econometrics, 193(2), 294–314. [Google Scholar] [CrossRef]
- Ghysels, E., Santa-Clara, P., & Valkanov, R. (2004). The midas touch: Mixed data sampling regression models. UCLA: Finance. Available online: https://escholarship.org/uc/item/9mf223rs (accessed on 15 July 2022).
- Götz, T. B., & Hauzenberger, K. (2021). Large mixed-frequency vars with a parsimonious time-varying parameter structure. The Econometrics Journal, 24(3), 442–461. [Google Scholar] [CrossRef]
- Hansen, P. R., Lunde, A., & Nason, J. M. (2011). The model confidence set. Econometrica, 79(2), 453–497. [Google Scholar] [CrossRef]
- Hsu, N., Hung, H., & Chang, Y. (2008). Subset selection for vector autoregressive processes using lasso. Computational Statistics & Data Analysis, 52(7), 3645–3657. [Google Scholar]
- Huurman, C., Ravazzolo, F., & Zhou, C. (2012). The power of weather. Computational Statistics & Data Analysis, 56(11), 3793–3807. [Google Scholar]
- Jedrzejewski, A., Marcjasz, G., & Weron, R. (2021). Importance of the long-term seasonal component in day-ahead electricity price forecasting revisited: Parameter-rich models estimated via the lasso. Energies, 14(11), 3249. [Google Scholar] [CrossRef]
- Kapoor, G., & Wichitaksorn, N. (2023). Electricity price forecasting in New Zealand: A comparative analysis of statistical and machine learning models with feature selection. Applied Energy, 347, 121446. [Google Scholar] [CrossRef]
- Koop, G., & Korobilis, D. (2010). Bayesian multivariate time series methods for empirical macroeconomics. Foundations and Trends in Econometrics, 3(4), 267–358. [Google Scholar] [CrossRef]
- Koop, G., & Korobilis, D. (2018). Variational bayes inference in high-dimensional time-varying parameter models. Available online: https://mpra.ub.uni-muenchen.de/id/eprint/87972 (accessed on 1 August 2022).
- Litterman, R. B. (1986). Forecasting with bayesian vector autoregressions—Five years of experience. Journal of Business & Economic Statistics, 4(1), 25–38. [Google Scholar]
- Ludwig, N., Feuerriegel, S., & Neumann, D. (2015). Putting big data analytics to work: Feature selection for forecasting electricity prices using the lasso and random forests. Journal of Decision Systems, 24(1), 19–36. [Google Scholar] [CrossRef]
- Marcjasz, G., Uniejewski, B., & Weron, R. (2020). Beating the naïve—Combining lasso with naïve intraday electricity price forecasts. Energies, 13(7), 1667. [Google Scholar] [CrossRef]
- Messner, J. W., & Pinson, P. (2019). Online adaptive lasso estimation in vector autoregressive models for high dimensional wind power forecasting. International Journal of Forecasting, 35(4), 1485–1498. [Google Scholar] [CrossRef]
- Mosquera-López, S., Uribe, J. M., & Manotas-Duque, D. F. (2017). Nonlinear empirical pricing in electricity markets using fundamental weather factors. Energy, 139, 594–605. [Google Scholar] [CrossRef]
- Ormerod, J. T., & Wand, M. P. (2010). Explaining variational approximations. The American Statistician, 64(2), 140–153. [Google Scholar] [CrossRef]
- Schorfheide, F., & Song, D. (2015). Real-time forecasting with a mixed-frequency var. Journal of Business & Economic Statistics, 33(3), 366–380. [Google Scholar]
- Sheppard, K. (2009). Mfe matlab function reference financial econometrics. Available online: https://www.kevinsheppard.com/files/code/matlab/mfe-toolbox-documentation.pdf (accessed on 22 March 2022).
- Sims, C. A. (1980). Macroeconomics and reality. Econometrica: Journal of the Econometric Society, 48, 1–48. [Google Scholar] [CrossRef]
- Son, H., & Kim, C. (2017). Short-term forecasting of electricity demand for the residential sector using weather and social variables. Resources, Conservation and Recycling, 123, 200–207. [Google Scholar] [CrossRef]
- Suomalainen, K., Pritchard, G., Sharp, B., Yuan, Z., & Zakeri, G. (2015). Correlation analysis on wind and hydro resources with electricity demand and prices in new zealand. Applied Energy, 137, 445–462. [Google Scholar] [CrossRef]
- Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267–288. [Google Scholar] [CrossRef]
- Uniejewski, B., Marcjasz, G., & Weron, R. (2019). Understanding intraday electricity markets: Variable selection and very short-term price forecasting using lasso. International Journal of Forecasting, 35(4), 1533–1547. [Google Scholar] [CrossRef]
- Uniejewski, B., & Weron, B. (2018). Efficient forecasting of electricity spot prices with expert and lasso models. Energies, 11(8), 2039. [Google Scholar] [CrossRef]
- Wand, M. P., Ormerod, J. T., Padoan, S. A., & Frühwirth, R. (2011). Mean field variational bayes for elaborate distributions. Bayesian Analysis, 6(4), 847–900. [Google Scholar] [CrossRef]
- Weron, R. (2014). Electricity price forecasting: A review of the state-of-the-art with a look into the future. International Journal of Forecasting, 30(4), 1030–1081. [Google Scholar] [CrossRef]
- You, C., Ormerod, J. T., & Mueller, S. (2014). On variational bayes estimation and variational information criteria for linear regression models. Australian & New Zealand Journal of Statistics, 56(1), 73–87. [Google Scholar]
- Ziel, F. (2016). Forecasting electricity spot prices using lasso: On capturing the autoregressive intraday structure. IEEE Transactions on Power Systems, 31(6), 4977–4987. [Google Scholar] [CrossRef]
- Zou, H. (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101(476), 1418–1429. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Median | Variance | Skewness | Kurtosis | |
|---|---|---|---|---|---|
| Price (NZ$/MWh) | 117.67 | 98.90 | 8331.90 | 4.32 | 52.20 |
| Demand (MWh) | 1437.73 | 1463.03 | 92,283.67 | 0.03 | 2.18 |
| Temperature (Celsius) | 15.71 | 15.50 | 18.64 | 0.11 | 2.63 |
| Rainfall (mm) | 0.13 | 0.00 | 0.55 | 17.97 | 701.54 |
| Solar Radiation (mJ/m2) | 172.45 | 1.00 | 6938.61 | 1.58 | 4.60 |
| Air Pressure (hPa) | 1015.80 | 1016.50 | 62.59 | −0.37 | 3.29 |
| Humidity (%) | 80.47 | 82.00 | 146.51 | −0.45 | 2.45 |
| Wind Speed (km/h) | 15.88 | 15.00 | 95.67 | 0.77 | 3.38 |
| Wind Direction (degrees) | 180.59 | 210 | 10,022.77 | −0.22 | 2.01 |
| Price | Demand | Temp | Rain | Solar | Pressure | Humidity | Wind Speed | Wind Direction | |
|---|---|---|---|---|---|---|---|---|---|
| Price | 1 | 0.344 | −0.0479 | 0.022 | 0.108 | 0.0986 | −0.084 | 0.033 | −0.056 |
| Demand | 0.344 | 1 | −0.076 | 0.026 | 0.246 | −0.022 | −0.212 | 0.154 | 0.061 |
| Temp | −0.0479 | −0.076 | 1 | −0.029 | 0.493 | −0.083 | −0.464 | 0.254 | −0.021 |
| Rain | 0.022 | 0.026 | −0.029 | 1 | −0.073 | −0.177 | 0.166 | 0.080 | 0.027 |
| Solar | 0.108 | 0.246 | 0.493 | −0.073 | 1 | 0.033 | −0.627 | 0.273 | 0.093 |
| Pressure | 0.0986 | −0.022 | −0.083 | −0.177 | 0.033 | 1 | −0.084 | −0.378 | −0.197 |
| Humidity | −0.084 | −0.212 | −0.464 | 0.166 | −0.627 | −0.084 | 1 | −0.412 | −0.150 |
| Wind Speed | 0.033 | 0.154 | 0.254 | 0.080 | 0.273 | −0.378 | −0.412 | 1 | 0.166 |
| Wind Direction | −0.056 | 0.061 | −0.021 | 0.027 | 0.093 | −0.197 | −0.150 | 0.166 | 1 |
| Model | AR(1) Coef. | Half-Life |
|---|---|---|
| Actual | −0.9707 | 0.7140 |
| MF-VAR | −0.9745 | 0.7113 |
| RU-MIDAS-VAR | −0.9899 | 0.7002 |
| Lag p | Lag p | ||||||
|---|---|---|---|---|---|---|---|
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 45.9472 | 72.2045 | 34.6090 | MF-VAR MLS | 58.9771 | 87.7004 | 38.2073 |
| MF-VAR MFVB | 46.9001 | 73.4641 | 35.2611 | MF-VAR MFVB | 58.3423 | 86.4735 | 37.7803 |
| MF-VAR GS | 47.7419 | 75.9605 | 30.4006 | MF-VAR GS | 58.4798 | 87.5852 | 35.5844 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 42.7937 | 72.6223 | 38.3311 | 44.9211 | 73.1058 | 39.1370 | ||
| 45.9872 | 72.4249 | 36.1998 | 57.3355 | 88.9184 | 18.5820 | ||
| Adaptive LASSO | 43.1545 | 70.4230 | 41.2096 | Adaptive LASSO | 46.0301 | 76.0408 | 29.9470 |
| Subset Regression | 54.6850 | 83.2752 | 56.9606 | Subset Regression | 57.2314 | 86.9146 | 40.8667 |
| Projection Regression | 51.4763 | 80.8129 | 53.9186 | Projection Regression | 55.5147 | 85.4771 | 38.6816 |
| RU-MIDAS-VAR MLS | 46.0136 | 72.2729 | 34.5711 | RU-MIDAS-VAR MLS | 59.0786 | 87.8343 | 38.3589 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 42.6590 | 72.3683 | 37.9954 | 45.3994 | 75.5241 | 36.6278 | ||
| 46.0803 | 72.5578 | 35.9015 | 58.7990 | 90.1122 | 17.6100 | ||
| Adaptive LASSO | 43.5719 | 71.8944 | 38.4876 | Adaptive LASSO | 45.5970 | 75.8669 | 38.7187 |
| Subset Regression | 52.4915 | 81.7978 | 56.3428 | Subset Regression | 57.7477 | 87.2958 | 42.0268 |
| Projection Regression | 51.2251 | 80.8534 | 53.9446 | Projection Regression | 55.9291 | 85.9688 | 39.3641 |
| Morning Peak | Midday Off-Peak | ||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 54.6073 | 82.1370 | 14.8220 | MF-VAR MLS | 47.5784 | 73.1042 | 3.7002 |
| MF-VAR MFVB | 55.3793 | 83.5628 | 15.7624 | MF-VAR MFVB | 48.8180 | 74.6297 | 3.9611 |
| MF-VAR GS | 55.2612 | 86.3424 | 13.2280 | MF-VAR GS | 48.3737 | 76.4844 | 3.2597 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 54.6468 | 82.5341 | 15.6724 | 44.0121 | 73.1371 | 3.9950 | ||
| 55.0219 | 89.1511 | 13.1186 | 44.2649 | 72.8327 | 3.7915 | ||
| Adaptive LASSO | 53.8210 | 83.2561 | 15.5626 | Adaptive LASSO | 45.3429 | 72.9665 | 3.9627 |
| Subset Regression | 68.3809 | 101.3910 | 20.0747 | Subset Regression | 57.0204 | 85.4541 | 5.8694 |
| Projection Regression | 65.5759 | 98.7949 | 19.5033 | Projection Regression | 53.1245 | 82.0871 | 5.6827 |
| RU-MIDAS-VAR MLS | 54.7064 | 82.2539 | 14.7734 | RU-MIDAS-VAR MLS | 47.6310 | 73.1516 | 3.6902 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 55.0073 | 82.9469 | 15.7267 | 47.6601 | 73.6399 | 3.9032 | ||
| 55.0474 | 82.9350 | 15.5213 | 47.6984 | 75.8949 | 3.9001 | ||
| Adaptive LASSO | 53.5300 | 83.7917 | 14.9882 | Adaptive LASSO | 44.1214 | 72.9532 | 3.8927 |
| Subset Regression | 66.7269 | 100.1605 | 19.4789 | Subset Regression | 54.4827 | 83.5487 | 5.7332 |
| Projection Regression | 65.5392 | 99.1871 | 19.1159 | Projection Regression | 52.6773 | 81.7077 | 5.7334 |
| Evening Peak | Night Off-Peak | ||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 61.1290 | 104.7811 | 0.8279 | MF-VAR MLS | 39.6659 | 59.4733 | 66.3977 |
| MF-VAR MFVB | 62.2437 | 106.5511 | 0.8689 | MF-VAR MFVB | 40.4225 | 60.3357 | 67.3719 |
| MF-VAR GS | 64.7439 | 110.7438 | 0.7590 | MF-VAR GS | 41.9589 | 62.7301 | 58.2653 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 60.7020 | 104.8512 | 0.7521 | 35.2874 | 57.2525 | 76.4216 | ||
| 60.7203 | 107.1022 | 0.7467 | 39.5438 | 59.4261 | 68.3569 | ||
| Adaptive LASSO | 56.8763 | 98.7281 | 0.8817 | Adaptive LASSO | 35.4375 | 59.0505 | 79.9593 |
| Subset Regression | 72.7502 | 116.9132 | 1.1265 | Subset Regression | 46.7055 | 68.4308 | 115.0509 |
| Projection Regression | 71.8114 | 116.6687 | 1.0519 | Projection Regression | 44.1571 | 65.8535 | 105.5108 |
| RU-MIDAS-VAR MLS | 61.1883 | 104.8416 | 0.8257 | RU-MIDAS-VAR MLS | 39.7358 | 59.5502 | 66.3361 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 61.1077 | 105.2518 | 0.8456 | 39.2643 | 59.4555 | 74.0237 | ||
| 61.1593 | 105.4274 | 0.8437 | 39.5477 | 59.4938 | 68.7988 | ||
| Adaptive LASSO | 56.4591 | 99.9185 | 0.8355 | Adaptive LASSO | 35.2920 | 59.9381 | 74.6538 |
| Subset Regression | 71.3481 | 115.9424 | 1.0911 | Subset Regression | 43.9589 | 65.5341 | 109.3512 |
| Projection Regression | 70.8592 | 116.2536 | 1.0469 | Projection Regression | 42.8587 | 64.8399 | 104.4356 |
| Morning Peak | Midday Off-Peak | ||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 67.9381 | 97.6032 | 23.2370 | MF-VAR MLS | 66.3473 | 95.4826 | 8.7707 |
| MF-VAR MFVB | 67.2869 | 96.2480 | 22.8303 | MF-VAR MFVB | 65.6230 | 94.0924 | 8.5966 |
| MF-VAR GS | 67.6195 | 97.9506 | 20.3349 | MF-VAR GS | 65.0256 | 95.9446 | 8.1388 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 55.6432 | 80.1613 | 20.3435 | 47.2202 | 77.4684 | 4.0638 | ||
| 68.8604 | 105.0660 | 8.8490 | 61.6604 | 93.4404 | 2.6254 | ||
| Adaptive LASSO | 57.1686 | 86.5855 | 14.0758 | Adaptive LASSO | 49.0756 | 79.2626 | 3.4859 |
| Subset Regression | 73.6302 | 106.0827 | 15.5964 | Subset Regression | 63.9974 | 93.0562 | 5.9785 |
| Projection Regression | 72.9490 | 105.5436 | 16.2854 | Projection Regression | 59.8845 | 89.7752 | 5.1609 |
| RU-MIDAS-VAR MLS | 68.0862 | 97.7560 | 23.3134 | RU-MIDAS-VAR MLS | 66.5073 | 95.6890 | 8.7869 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 63.9649 | 94.3260 | 27.8201 | 65.9945 | 97.8141 | 9.3677 | ||
| 66.5887 | 95.8687 | 25.8593 | 67.1229 | 98.2629 | 9.3552 | ||
| Adaptive LASSO | 60.7567 | 96.0937 | 13.0557 | Adaptive LASSO | 48.1070 | 78.5502 | 4.0298 |
| Subset Regression | 75.2452 | 107.3810 | 17.4752 | Subset Regression | 63.0006 | 92.2766 | 5.5519 |
| Projection Regression | 72.7223 | 105.2908 | 16.3465 | Projection Regression | 59.7987 | 89.6835 | 5.2760 |
| Evening Peak | Night Off-Peak | ||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 78.9431 | 118.5856 | 2.0710 | MF-VAR MLS | 47.8377 | 70.5075 | 68.4979 |
| MF-VAR MFVB | 78.0582 | 116.9086 | 2.0301 | MF-VAR MFVB | 47.3563 | 69.5981 | 67.8214 |
| MF-VAR GS | 79.1230 | 117.0852 | 1.9854 | MF-VAR GS | 47.7414 | 70.3040 | 63.3899 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 61.3004 | 98.0360 | 0.8575 | 36.5449 | 57.2421 | 75.9995 | ||
| 70.9618 | 114.9250 | 0.7219 | 46.5724 | 69.6286 | 34.7978 | ||
| Adaptive LASSO | 59.4086 | 97.0294 | 0.9291 | Adaptive LASSO | 37.2777 | 58.7348 | 57.6482 |
| Subset Regression | 80.9618 | 122.4441 | 1.1081 | Subset Regression | 45.2735 | 67.4052 | 78.2747 |
| Projection Regression | 80.9158 | 123.0694 | 1.0370 | Projection Regression | 44.2874 | 66.7439 | 75.8000 |
| RU-MIDAS-VAR MLS | 79.0620 | 118.7199 | 2.0788 | RU-MIDAS-VAR MLS | 47.8871 | 70.5774 | 68.7853 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 75.1225 | 114.8347 | 2.1224 | 43.1750 | 65.0516 | 68.3824 | ||
| 75.2718 | 114.9091 | 2.1174 | 45.0147 | 67.2977 | 39.9329 | ||
| Adaptive LASSO | 62.8122 | 108.2875 | 0.8411 | Adaptive LASSO | 36.8866 | 58.5351 | 75.1392 |
| Subset Regression | 80.9481 | 122.6194 | 1.1255 | Subset Regression | 45.4298 | 67.5162 | 80.0261 |
| Projection Regression | 80.9835 | 123.1973 | 1.0391 | Projection Regression | 44.2645 | 66.7739 | 74.9143 |
| MF-VAR | RU-MIDAS-VAR | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MLS | MFVB | GS | LASSO |
Adaptive LASSO |
Subset Regression |
Projection Regression | MLS | LASSO |
Adaptive LASSO |
Subset Regression |
Projection Regression | ||
| MF- VAR | MLS | 1 | 2.906 | 3.053 | 2.947 | 3.012 | 2.244 | 2.060 | 0.746 | 2.894 | 2.964 | 2.448 | 2.289 |
| MFVB | 2.906 | 1 | −1.960 | −0.401 | −0.433 | 3.134 | 3.959 | −3.400 | 0.142 | 0.358 | −2.506 | −2.964 | |
| GS | 3.053 | −1.960 | 1 | 0.413 | 0.561 | 3.299 | 3.969 | −3.546 | −1.808 | −2.546 | −2.851 | −3.110 | |
| LASSO | 2.947 | −0.401 | 0.413 | 1 | 0.138 | 4.039 | 3.776 | −3.326 | −0.381 | −0.391 | −4.081 | −3.612 | |
| Adaptive LASSO | 3.012 | −0.433 | 0.561 | 0.138 | 1 | 4.039 | 3.665 | −3.566 | −0.543 | −0.278 | −3.595 | −3.426 | |
| Subset Regression | 2.244 | 3.134 | 3.299 | 4.039 | 4.039 | 1 | −1.893 | −2.341 | 3.277 | 3.619 | 0.767 | 3.565 | |
| Projection Regression | 2.060 | 3.959 | 3.969 | 3.776 | 3.665 | −1.893 | 1 | −2.060 | 3.957 | 4.287 | 2.755 | 2.229 | |
| RU- MIDAS- VAR | MLS | 0.746 | −3.400 | −3.546 | −3.326 | −3.566 | −2.341 | −2.060 | 1 | 3.396 | 3.762 | 2.627 | 2.403 |
| LASSO | 2.894 | 0.142 | −1.808 | −0.381 | −0.543 | 3.277 | 3.957 | 3.396 | 1 | −0.394 | 2.743 | 2.990 | |
| Adaptive LASSO | 2.964 | 0.358 | −2.546 | −0.391 | −0.278 | 3.619 | 4.287 | 3.762 | −0.394 | 1 | 2.493 | 3.118 | |
| Subset Regression | 2.448 | −2.506 | −2.851 | −4.081 | −3.595 | 0.767 | 2.755 | 2.627 | 2.743 | 2.493 | 1 | −1.912 | |
| Projection Regression | 2.289 | −2.964 | −3.110 | −3.612 | −3.426 | 3.565 | 2.229 | 2.403 | 2.990 | 3.118 | −1.912 | 1 | |
| Lag p = 24 | Lag p = 240 | ||||||
|---|---|---|---|---|---|---|---|
| Overall Cross-Validation | |||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 39.0213 | 54.2849 | 25.9527 | MF-VAR MLS | 43.9939 | 59.8975 | 20.7390 |
| MF-VAR MFVB | 39.0588 | 54.4013 | 26.0758 | MF-VAR MFVB | 43.9310 | 59.9331 | 20.9073 |
| MF-VAR GS | 39.0699 | 54.3874 | 25.7957 | MF-VAR GS | 44.4511 | 60.4291 | 20.4364 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 39.3532 | 54.6452 | 26.5770 | 39.1645 | 55.5124 | 19.0060 | ||
| 39.4099 | 54.6039 | 26.0981 | 40.1439 | 55.9094 | 18.3995 | ||
| Adaptive LASSO | 39.5322 | 55.4278 | 26.5786 | Adaptive LASSO | 39.5543 | 55.9071 | 19.6482 |
| Subset Regression | 45.1129 | 64.4887 | 48.1684 | Subset Regression | 43.3860 | 61.8194 | 20.8003 |
| Projection Regression | 43.9946 | 63.5313 | 46.1500 | Projection Regression | 43.1366 | 61.7508 | 20.5415 |
| RU-MIDAS-VAR MLS | 39.0448 | 54.2908 | 25.9188 | RU-MIDAS-VAR MLS | 43.9905 | 59.8949 | 20.6971 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 39.0548 | 54.4545 | 27.0251 | 39.7438 | 56.0688 | 19.8824 | ||
| - | - | - | - | 40.8673 | 56.5273 | 19.2821 | |
| Adaptive LASSO | 39.5127 | 55.5343 | 26.6036 | Adaptive LASSO | 40.0017 | 55.9823 | 19.6184 |
| Subset Regression | 44.5340 | 63.9418 | 47.6400 | Subset Regression | 43.2785 | 61.8100 | 20.7348 |
| Projection Regression | 44.1214 | 63.5890 | 46.2788 | Projection Regression | 43.2121 | 61.7507 | 20.8290 |
| Morning Peak Cross-Validation | |||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 43.8639 | 58.2397 | 10.0080 | MF-VAR MLS | 51.0876 | 65.7240 | 8.1383 |
| MF-VAR MFVB | 43.9907 | 58.2995 | 10.3847 | MF-VAR MFVB | 50.7665 | 65.5618 | 8.4403 |
| MF-VAR GS | 44.0088 | 58.5488 | 9.8737 | MF-VAR GS | 51.5391 | 66.3977 | 7.2382 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 44.7242 | 59.1166 | 10.4724 | 46.2319 | 60.9060 | 7.5837 | ||
| - | - | - | - | 52.3180 | 68.4850 | 5.4996 | |
| Adaptive LASSO | 43.8443 | 59.0427 | 10.0107 | Adaptive LASSO | 47.0004 | 60.5723 | 6.2794 |
| Subset Regression | 57.2532 | 73.8674 | 13.1330 | Subset Regression | 55.0560 | 71.3817 | 11.0370 |
| Projection Regression | 57.8610 | 74.6463 | 12.5676 | Projection Regression | 55.4509 | 71.7095 | 11.2152 |
| RU-MIDAS-VAR MLS | 43.8844 | 58.2552 | 9.9796 | RU-MIDAS-VAR MLS | 51.0863 | 65.7137 | 8.0282 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 44.3937 | 58.9833 | 10.3828 | 46.9679 | 61.5296 | 8.2155 | ||
| - | - | - | - | 53.0959 | 69.4049 | 5.1654 | |
| Adaptive LASSO | 44.0027 | 59.4278 | 11.8893 | Adaptive LASSO | 47.4248 | 61.1734 | 6.2672 |
| Subset Regression | 56.6396 | 73.3442 | 12.7472 | Subset Regression | 55.5680 | 71.8681 | 11.5234 |
| Projection Regression | 56.1396 | 72.9728 | 13.0419 | Projection Regression | 55.4070 | 71.6640 | 11.7774 |
| Evening Peak Cross-Validation | |||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 52.7036 | 69.5604 | 0.6461 | MF-VAR MLS | 55.7896 | 73.6556 | 0.8524 |
| MF-VAR MFVB | 52.6321 | 69.4464 | 0.6617 | MF-VAR MFVB | 55.9292 | 73.8143 | 0.8721 |
| MF-VAR GS | 52.7788 | 69.7454 | 0.6286 | MF-VAR GS | 56.5841 | 74.1283 | 0.8266 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 52.5444 | 69.6440 | 0.6617 | 49.8996 | 68.4681 | 0.6113 | ||
| 52.6011 | 69.6018 | 0.6581 | 53.1975 | 72.7117 | 0.5464 | ||
| Adaptive LASSO | 52.6772 | 69.7427 | 0.6613 | Adaptive LASSO | 49.8631 | 68.3418 | 0.5994 |
| Subset Regression | 61.8930 | 81.6559 | 0.8904 | Subset Regression | 53.5917 | 73.3821 | 0.9414 |
| Projection Regression | 61.0245 | 80.6504 | 0.8715 | Projection Regression | 54.4470 | 74.4293 | 0.9545 |
| RU-MIDAS-VAR MLS | 52.7315 | 69.5781 | 0.6460 | RU-MIDAS-VAR MLS | 55.7557 | 73.6337 | 0.8530 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 52.5322 | 69.7340 | 0.6729 | 51.0066 | 68.5294 | 0.7254 | ||
| 52.6387 | 69.7206 | 0.6629 | 53.2158 | 72.8385 | 0.5546 | ||
| Adaptive LASSO | 52.5016 | 69.5445 | 0.6602 | Adaptive LASSO | 51.0101 | 68.5017 | 0.6478 |
| Subset Regression | 61.1652 | 81.0363 | 0.8681 | Subset Regression | 54.1344 | 73.7514 | 0.9815 |
| Projection Regression | 61.6345 | 81.4736 | 0.8602 | Projection Regression | 54.1406 | 73.7965 | 0.9665 |
| Afternoon Off-Peak Cross-Validation | |||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 39.8537 | 54.4063 | 2.9195 | MF-VAR MLS | 47.5721 | 62.9285 | 2.9189 |
| MF-VAR MFVB | 39.7880 | 54.4804 | 3.0612 | MF-VAR MFVB | 47.4596 | 63.0013 | 3.0012 |
| MF-VAR GS | 39.9843 | 54.6214 | 2.8014 | MF-VAR GS | 48.3398 | 64.0571 | 2.7732 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 40.7583 | 54.9285 | 3.0502 | 42.2081 | 60.2456 | 2.4681 | ||
| - | - | - | - | 43.9839 | 60.0132 | 1.9250 | |
| Adaptive LASSO | 40.8676 | 56.0234 | 2.9358 | Adaptive LASSO | 43.0138 | 60.3792 | 2.3438 |
| Subset Regression | 45.7822 | 63.7576 | 4.2465 | Subset Regression | 45.8491 | 63.8941 | 3.5062 |
| Projection Regression | 44.6630 | 62.6429 | 4.3299 | Projection Regression | 45.7327 | 63.5678 | 3.5471 |
| RU-MIDAS-VAR MLS | 39.8304 | 54.3609 | 2.9204 | RU-MIDAS-VAR MLS | 47.5807 | 62.9313 | 2.9191 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 40.2548 | 54.7857 | 3.0817 | 42.6140 | 61.0330 | 2.5166 | ||
| - | - | - | - | 42.7366 | 58.9088 | 2.0225 | |
| Adaptive LASSO | 40.5783 | 54.3715 | 3.0957 | Adaptive LASSO | 42.5791 | 61.5725 | 2.4816 |
| Subset Regression | 45.0336 | 63.1032 | 4.2150 | Subset Regression | 45.7977 | 63.8068 | 3.5176 |
| Projection Regression | 44.3662 | 62.3619 | 4.3749 | Projection Regression | 45.6615 | 63.6501 | 3.4872 |
| Night Off-Peak Cross-Validation | |||||||
| Model | MAD | RMSE | MAPE | Model | MAD | RMSE | MAPE |
| MF-VAR MLS | 33.3966 | 44.9116 | 49.5500 | MF-VAR MLS | 36.3687 | 48.4260 | 39.1064 |
| MF-VAR MFVB | 33.5049 | 45.0345 | 49.6254 | MF-VAR MFVB | 36.3521 | 48.4165 | 39.3302 |
| MF-VAR GS | 33.3630 | 44.8812 | 49.3355 | MF-VAR GS | 36.5378 | 48.5702 | 38.7799 |
| MF-VAR LASSO | MF-VAR LASSO | ||||||
| 32.3393 | 46.0774 | 68.6164 | 32.0412 | 44.2983 | 36.0362 | ||
| 33.1203 | 44.8136 | 51.7147 | 32.5423 | 44.5084 | 34.5579 | ||
| Adaptive LASSO | 33.1236 | 45.9539 | 52.0444 | Adaptive LASSO | 32.2955 | 44.6052 | 35.7815 |
| Subset Regression | 37.1682 | 51.9024 | 94.5028 | Subset Regression | 35.6758 | 49.3582 | 36.3426 |
| Projection Regression | 37.4977 | 52.3368 | 95.8479 | Projection Regression | 35.5013 | 49.1460 | 38.0939 |
| RU-MIDAS-VAR MLS | 33.4498 | 44.9400 | 49.4855 | RU-MIDAS-VAR MLS | 36.3638 | 48.4273 | 39.0438 |
| RU-MIDAS-VAR LASSO | RU-MIDAS-VAR LASSO | ||||||
| 32.2032 | 45.9315 | 69.5419 | 32.1665 | 45.8040 | 55.9070 | ||
| 32.9623 | 44.6521 | 52.6003 | 33.5490 | 45.3027 | 36.1274 | ||
| Adaptive LASSO | 33.0932 | 46.0954 | 53.1199 | Adaptive LASSO | 32.3220 | 45.3433 | 39.8832 |
| Subset Regression | 36.7217 | 51.4238 | 93.0253 | Subset Regression | 35.4182 | 49.1436 | 37.9251 |
| Projection Regression | 36.3093 | 51.1871 | 90.0338 | Projection Regression | 35.4040 | 49.1487 | 38.0873 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kapoor, G.; Wichitaksorn, N.; Li, M.; Zhang, W. Forecasting Half-Hourly Electricity Prices Using a Mixed-Frequency Structural VAR Framework. Econometrics 2025, 13, 2. https://doi.org/10.3390/econometrics13010002
Kapoor G, Wichitaksorn N, Li M, Zhang W. Forecasting Half-Hourly Electricity Prices Using a Mixed-Frequency Structural VAR Framework. Econometrics. 2025; 13(1):2. https://doi.org/10.3390/econometrics13010002
Chicago/Turabian StyleKapoor, Gaurav, Nuttanan Wichitaksorn, Mengheng Li, and Wenjun Zhang. 2025. "Forecasting Half-Hourly Electricity Prices Using a Mixed-Frequency Structural VAR Framework" Econometrics 13, no. 1: 2. https://doi.org/10.3390/econometrics13010002
APA StyleKapoor, G., Wichitaksorn, N., Li, M., & Zhang, W. (2025). Forecasting Half-Hourly Electricity Prices Using a Mixed-Frequency Structural VAR Framework. Econometrics, 13(1), 2. https://doi.org/10.3390/econometrics13010002