The current section includes the use of machine learning algorithms on different SBCs in order to measure the current of the SBC, the voltage of the SBC, the power consumption of the SBC, the CPU usage, the memory usage, the swap memory usage of the SBC, and the temperature of the SBC.
For the procedure of image classification in IoT devices, the python Pillow library was initially used to load the images one-by-one by saving RAM memory; however, this makes the process of inference more time consuming. The latter refers to the process of using a supervised trained algorithm of machine learning so that it can make predictions. The basic metrics that will be provided for supervisory comparison between all the devices are the CPU usage, percentage, and size in bytes of RAM memory usage (because Raspberry Pi 4B and Jetson Nano have 4 GB of RAM memory), the Swap memory, and, finally, a comparison in their internal temperature is made. The current consumption of each of the four devices that was used will be presented. The authors note at this point that all the measurements for the processing power (CPU usage), for the RAM memory, for the Swap memory, and for the internal temperature of the devices were implemented with the help of a simple python script that uses the python library psutil. The latter provides all these measurements and the data in an editable and storable format such as a .csv file. To measure the consumption of each device (power and current), a specialized measurement tool was used, constructed in authors’ laboratory (the Diffused Intelligence Laboratory), giving the ability to record voltage values, current values, and power consumption values every 10 s. This recording frequency can be easily modified to a desirable one. As a result, by recording these values, an overall picture of the power resources used is drawn, which seem to be of vital importance, taking into account the fact that IoT applications are based on low power consumption.
5.1. Analysis of the Individual Evaluation Metrics
From the diagram in
Figure 1, it can be seen that the more powerful a device is, the more it can utilize its power. It is interesting that Google Coral, which uses an ML accelerator, can achieve the same total time for inference as the Raspberry Pi 4B does, which seems to be the most powerful device among those analyzed here. For Jetson Nano, it is obvious that there is significant usage of its power in the beginning which decreases later; this seems to be expected because Jetson Nano dynamically loads the TensorFlow library in the beginning of the algorithm execution and thus demands a bit more time and more CPU resources. Another point is that the classification/prediction procedure was realized with the same dataset in all four devices, which was the outcome of using 20% of the initial amount in each category; obviously, the result of the outputting values was about the same among them.
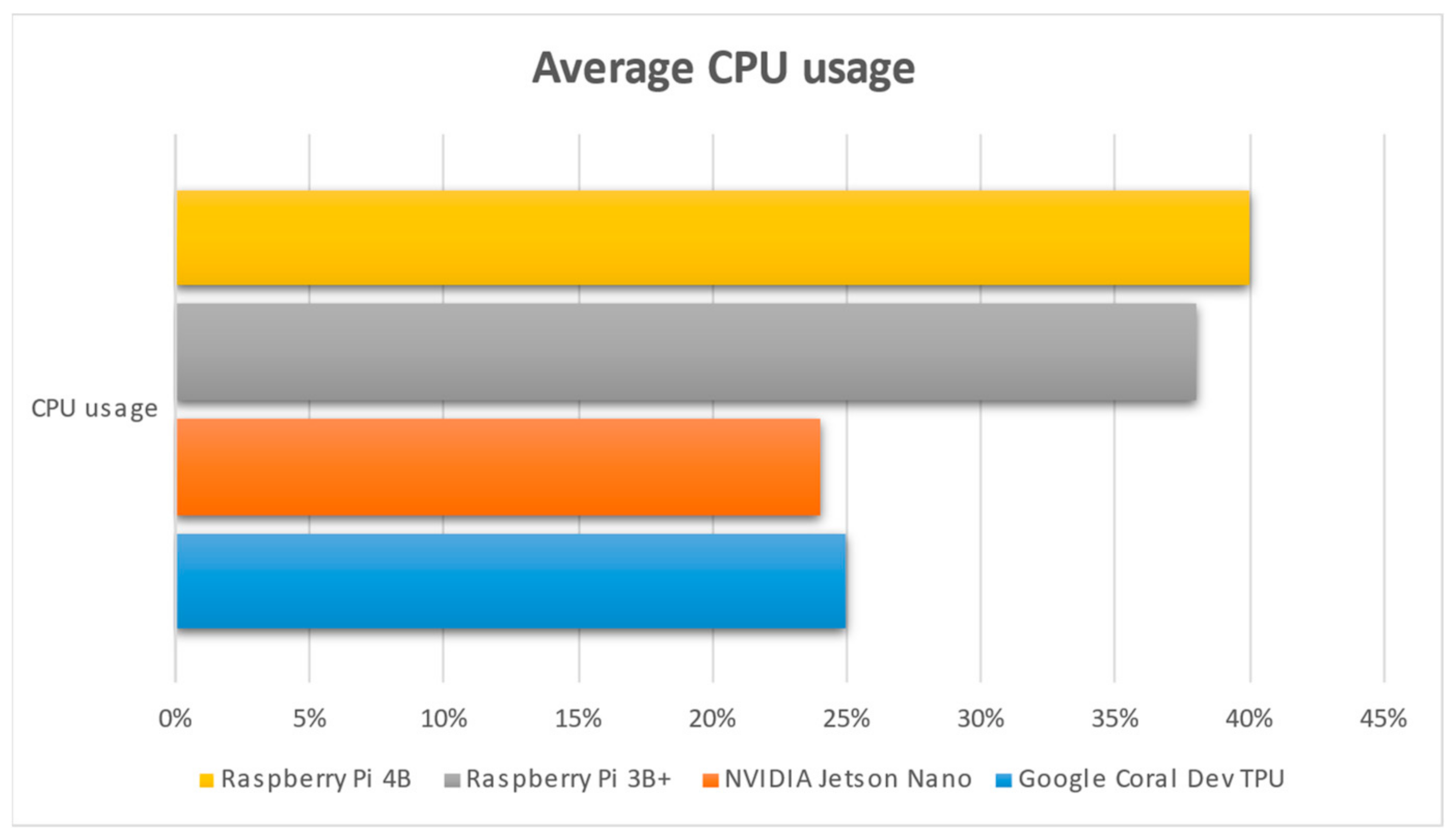
As can be observed in
Figure 1, NVIDIA Jetson Nano uses about half the CPU power (25%) that the 2 Raspberry Pi 3 (38%) and Raspberry Pi 4 (40%) use. This is an indication that NVIDIA Jetson Nano is based on its GPU to address the various commands given via the python script, with the related ML model. On the other hand, the two Raspberry devices are CPU-based, enabling them to execute the python code, which accounts for using more CPU resources in respect to the Jetson Nano. Another obvious aspect is the fact that the Google Coral TPU shows the same rationale as NVIDIA Jetson Nano, meaning that it uses fewer CPU resources. However, the fact that NVIDIA Jetson Nano and Google Coral Dev TPU use their CPUs less happens for a different reason. Google Coral TPU uses its ASIC module to execute the various python ML script’s commands related to tensors. The idea is that Google Coral can accelerate the parts of the code which are related to tensors, which are many, since the python code makes use of TensorFlow (Lite) package; thus, it does not need to use more of its CPU power. That is why it uses 25% of its CPU power instead of the 38% and 40% used by the Raspberry Pi 3 and 4.
In
Figure 1, it can be observed that Raspberry Pi 4B completed the job in about 244 s and Google Coral did so in 253 s; these times are very close to each other. Jetson Nano completed the job in 275 s and Raspberry Pi 3B+ completed the job in 473 s. It is noticeable that, although the authors’ model has a mean accuracy value in the prediction mode of about 90%, there are two classes (Tomato Septoria Leaf Spot and Tomato Late Blight) that achieved a score of 50%.
As highlighted in the Related Work Section, the authors of [
9] achieved a score of 93.33%. The authors of [
10] achieved the following scores: for the disease “Bacterial Blight”, they achieved 85.89%; for “Alternaria”, they achieved 84.61%; for “Cerespora”, they achieved 82.97%; for “Grey Mildew”, they achieved 83.78%; for “Fusarium Wilt”, they achieved 82.35%; for “Healthy leaf”, they achieved 80%. In [
11], the authors claim that they reached the following scores: (i) for ReLU, 7 × 7, they achieved a testing accuracy of 95.7% in 51 min; (ii) for L-ReU, 7 × 7, they achieved a testing accuracy of 97.3% in 53 min; (iii) for L-ReLU, 11 × 11, they achieved a testing accuracy of 98.0% in 54 min. Lastly, in [
12], the authors state that they hit 97% accuracy. Concluding based on the above scores, the average score is around 89.17%, which accounts for the current research results and the claim that “about 90%” is an accepted threshold.
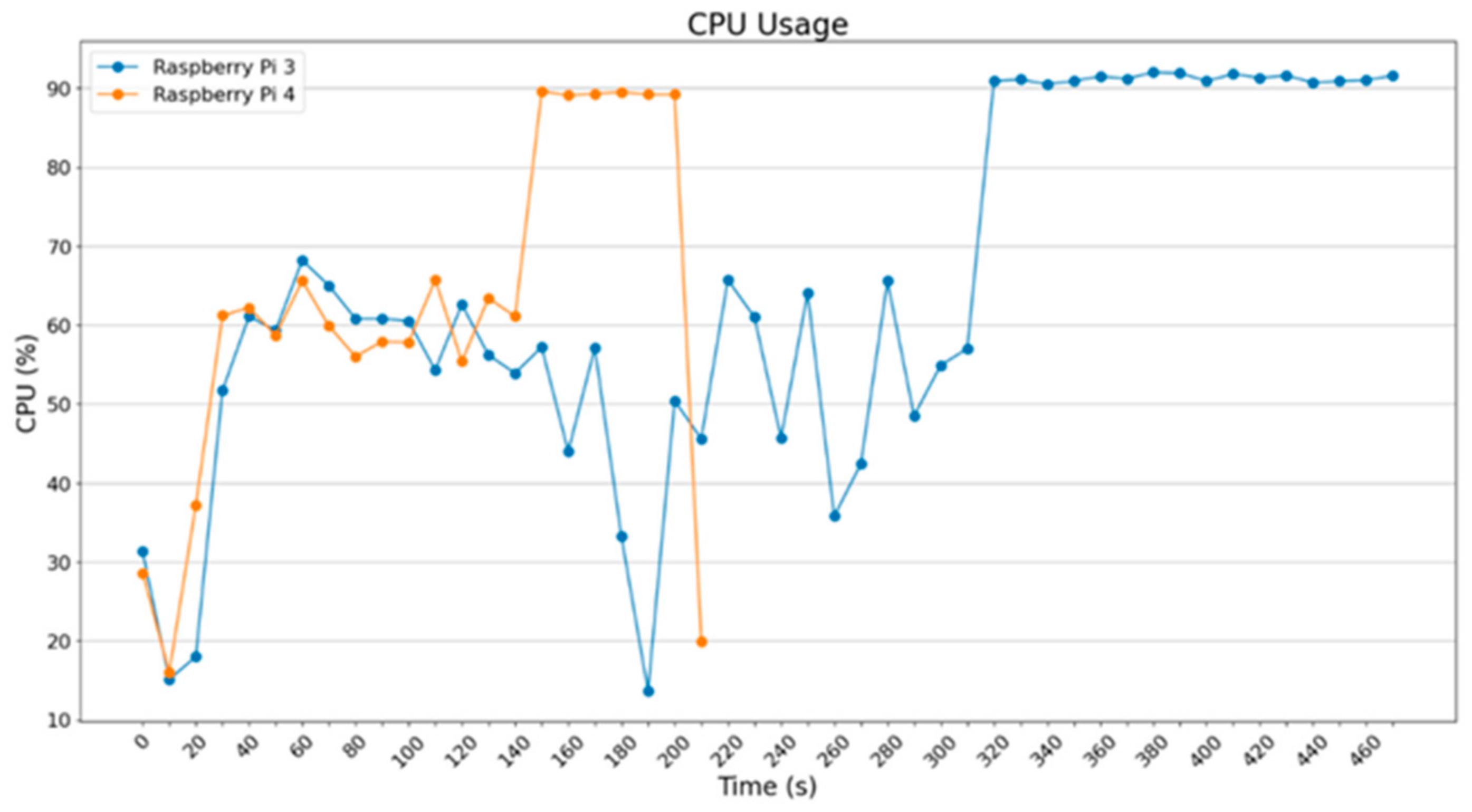
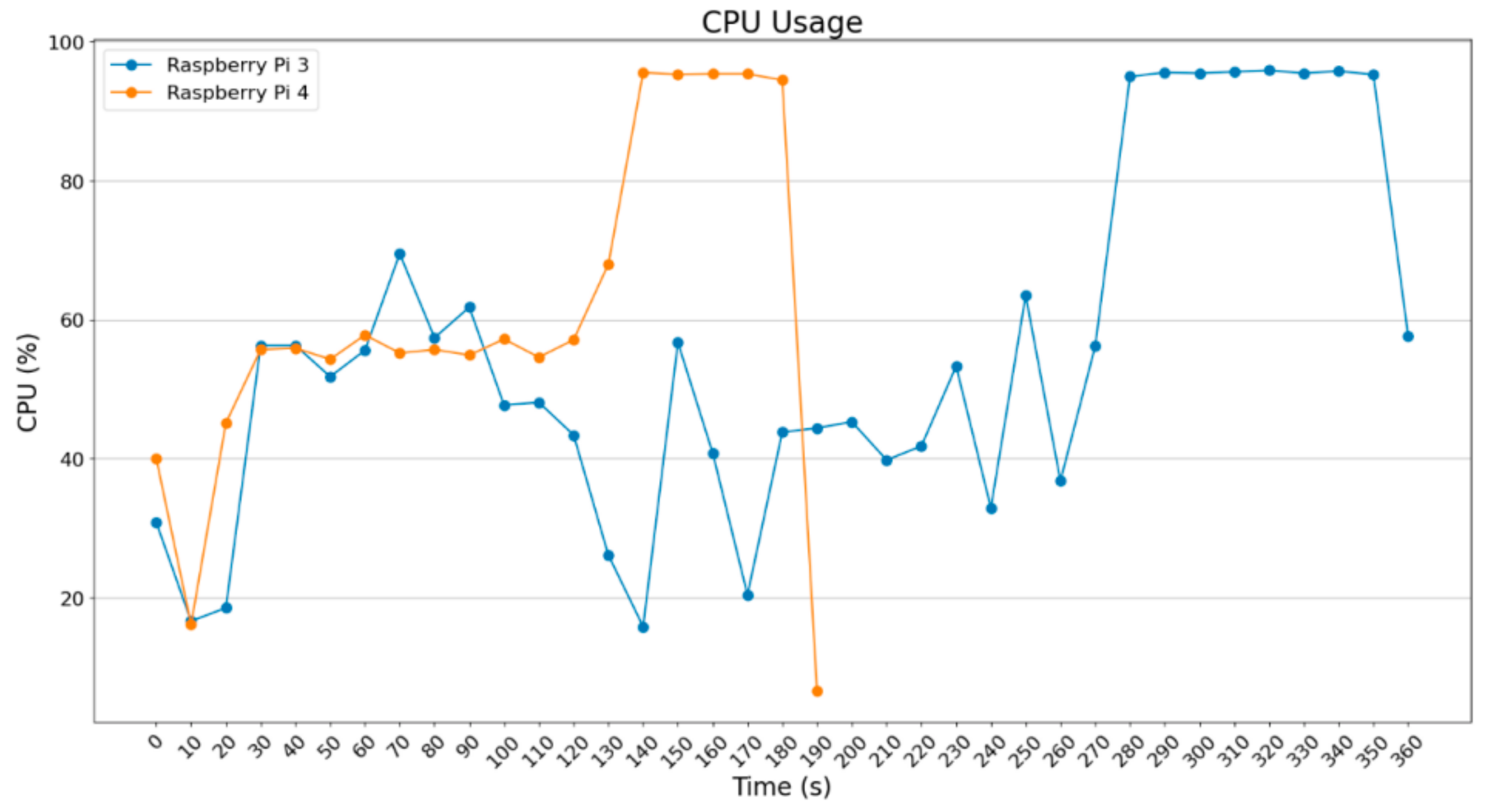
In
Figure 2, it can be observed that the 2 Raspberry Pi use more their CPU for the computations, whereas the NVIDIA Jetson Nano and the Google Coral Dev TPU used less CPU because the accelerators were used to a greater extent; CUDA cores were used for the Jetson and ASIC chip was used for the Google Coral.
Studying the images of these two categories more carefully, it is noted that errors took place because the images are identical and the extraction of different characteristics was quite difficult; for example, the class Tomato Early Blight had identical images and thus the accuracy was 79%, which is less than the mean accuracy of 90%. Unfortunately, although data augmentation was used and despite the authors’ efforts, such issues cannot be easily diminished when there is a small number of images available during the training procedure and given that the classification was performed among 33 labels without connecting identical categories. In
Figure 3, the differences among the accuracies accomplished per class can be observed.
Concerning the issue of identical images and the challenges they introduce, since the output of individual characteristics is difficult, an efficient solution can be the collection and usage of higher populations of images per class, which can allow for the efficient filtering of (near-) identical images. The research presented in this paper uses 33 classes, which is a significantly high number concerning the scale of the experiments carried out and the respective hardware used. Nevertheless, as the population of images per class was not that high, the problem of almost-identical images has occasionally been detected. For example, the Tomato Early Blight class included very similar images that led to an accuracy level of 79%, which is significantly lower than the accepted threshold of 90% in the current work.
The diagram in
Figure 4 depicts the processing time for each class with the use of Google Colab. The fully equivalent time is achieved with the use of various SBC devices; however, on Raspberry Pi 4, Jetson Nano, and Google Coral Dev Board, the equivalent time is five times higher, and on Raspberry Pi 3B+ it is ten times higher than the time achieved by Google Colab. What is worth mentioning is the total time for implementing the procedure; this is because, in real usage of the algorithm/application, a dataset of non-classified images is chosen. The small time differences per class are a result of the number of images, because the exact same number was not available for all classes, but there was a variance of only ±5 images per classes. The result is presented in order to compare Google Colab with the SBCs, where Google Colab is not an SBC, but is a powerful virtual machine provided by Google for research.
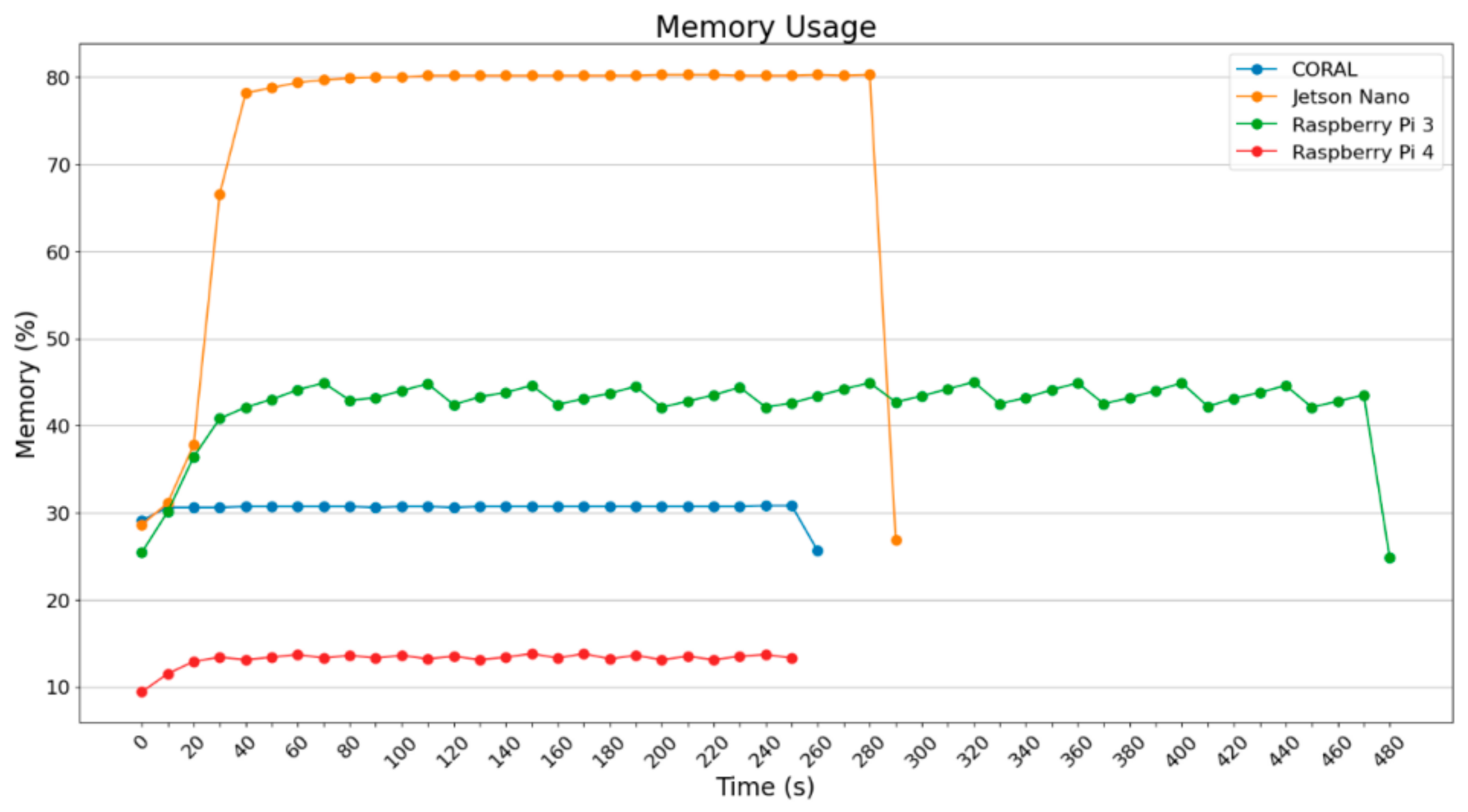
What is remarkable is the fact that Jetson Nano uses a lot of RAM memory, whereas the other devices operate using less than 500 MB. Raspberry Pi 3B+ does not exceed 50% of RAM, Google Coral does not exceed 30%, and Raspberry Pi 4B does not exceed 15%. The results in
Figure 5 and
Figure 6 are absolutely expected, meaning that Jetson Nano uses GPU most of the time to perform various operations which are energy-consuming.
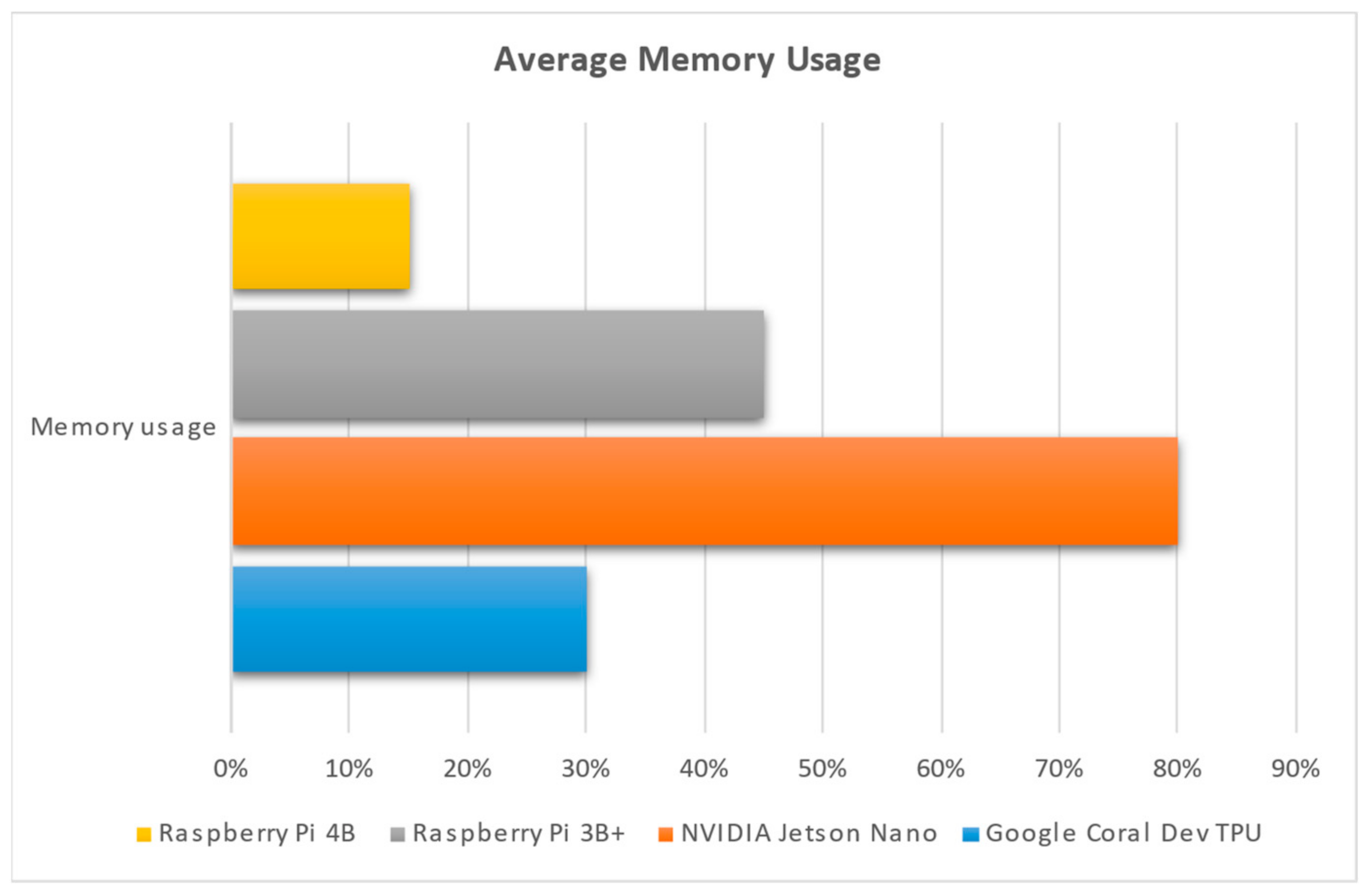
In
Figure 7, it can be observed that NVIDIA Jetson Nano uses more of its available RAM (4 GB); this is followed by Raspberry Pi 3B+, which contains 1 GB RAM; next comes Google Coral Dev TPU (1 GB RAM) and then Raspberry Pi 4B (4 GB RAM). In real numbers, NVIDIA Jetson Nano uses 3.2 GB RAM, Raspberry Pi 3B+ uses 450 MB RAM, Google Coral uses 300 MB RAM, and Raspberry Pi 4B uses 600 MB RAM.
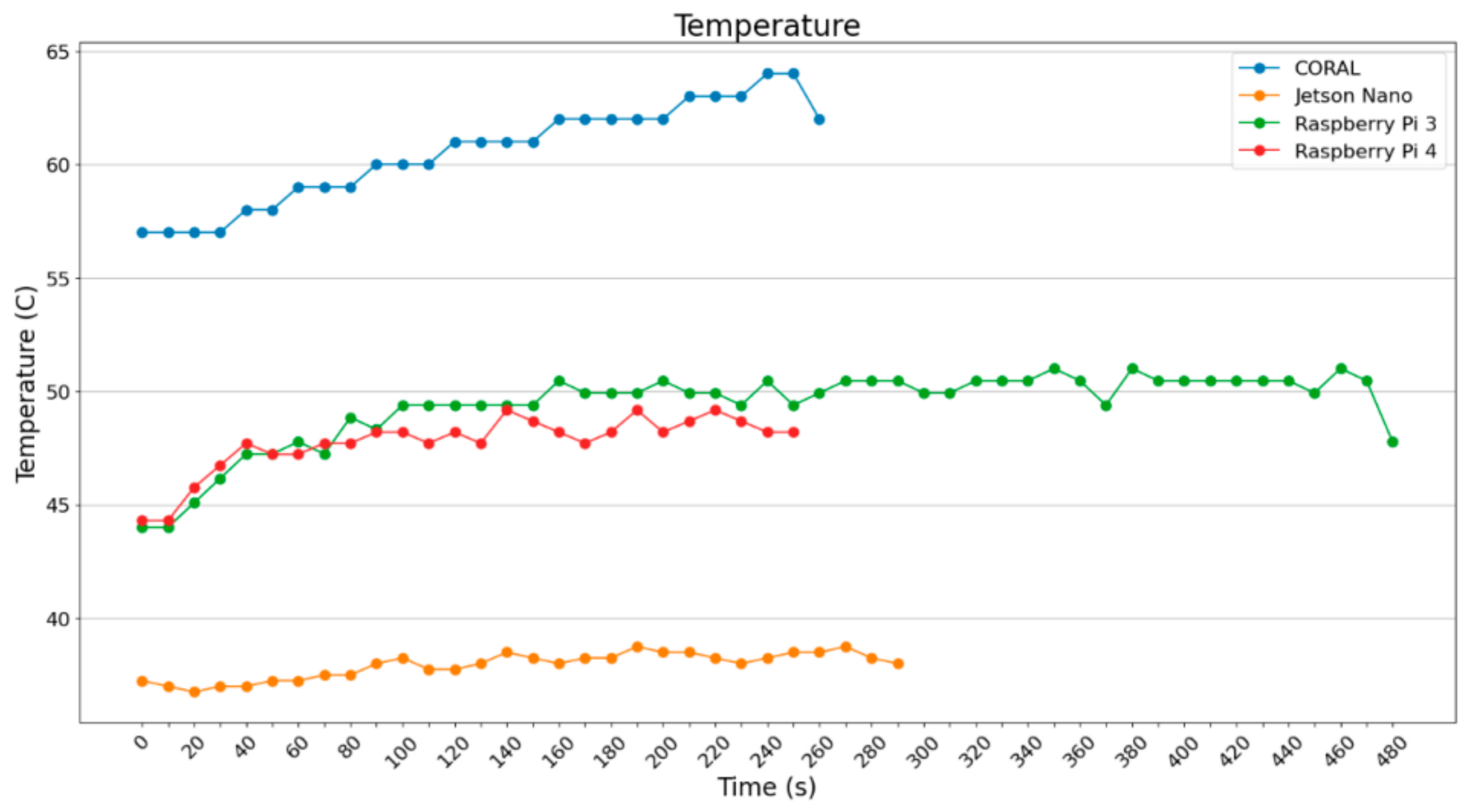
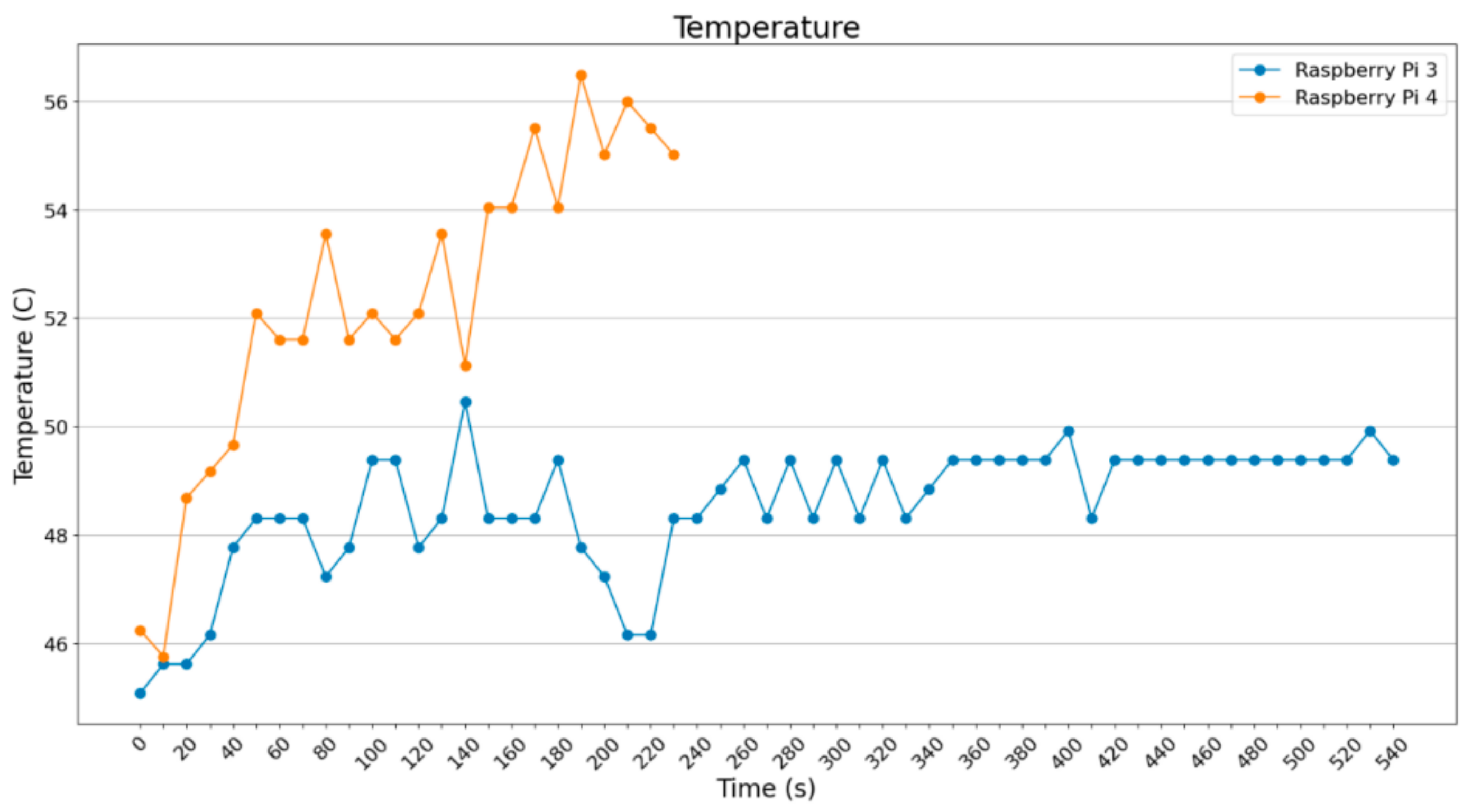
As far as temperature is concerned (
Figure 8), Jetson Nano shows very low temperatures when operating, due to its bigger fan and the large heat sink. Google Coral, on the other hand, shows high (but controlled) temperature; apart from the heat sink, the fan did not operate for a considerable amount of time. The fan was activated automatically a few times, when the heat could not be dissipated through the heat sink.
In
Figure 9, it can be observed that NVIDIA has the lowest temperature while operating four SBCs. This seems to be the result of a large heatsink and a big fan. Google Coral Dev’s TPU cannot handle the increased temperature of 60 °C, and hits the highest temperature of all four SBCs. The two Raspberry Pi devices hit temperatures between 48 °C and 50 °C, and although they both have heatsinks and fans working continuously, they do not seem to be so effective in dissipating the heat.
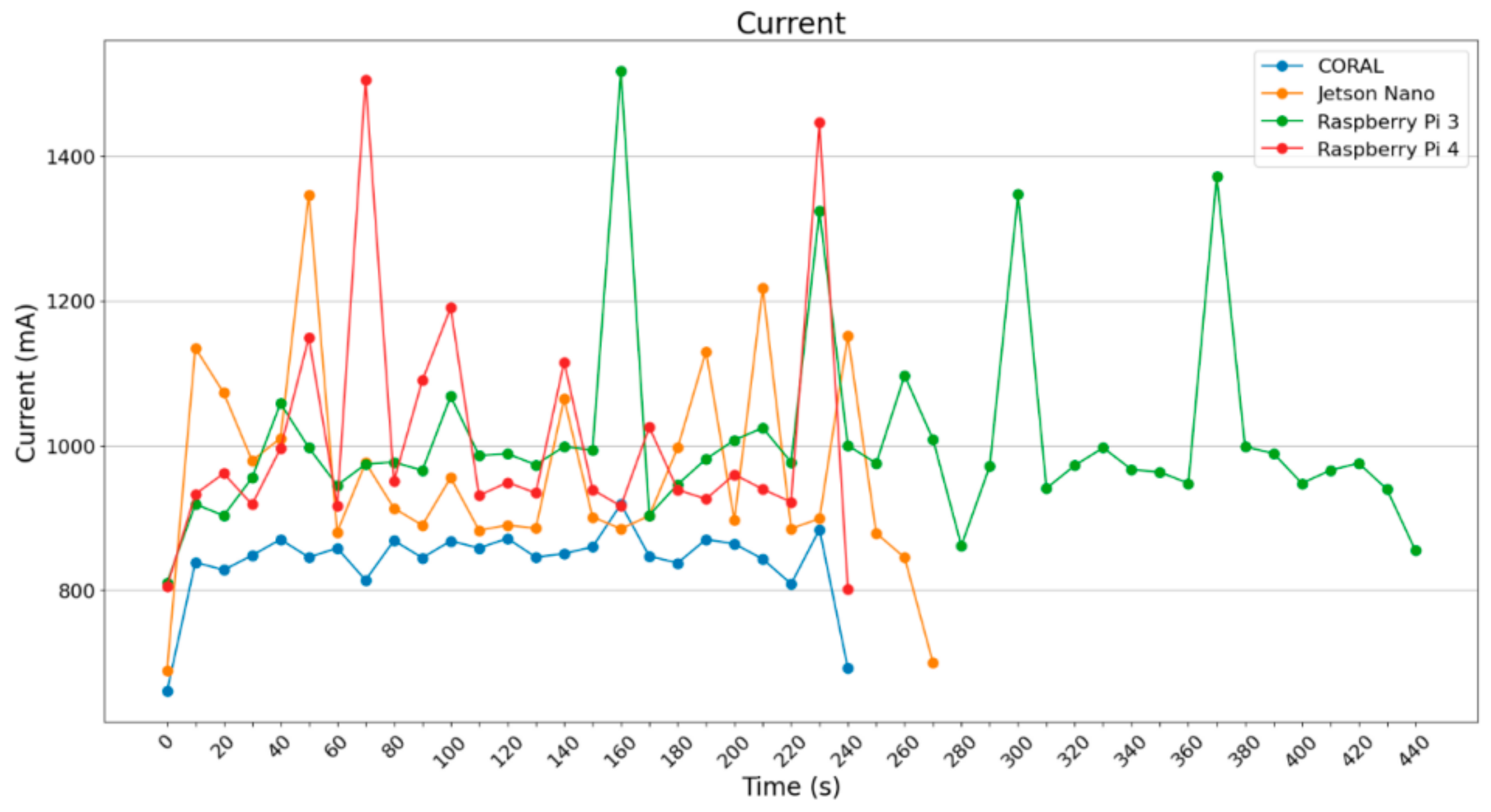
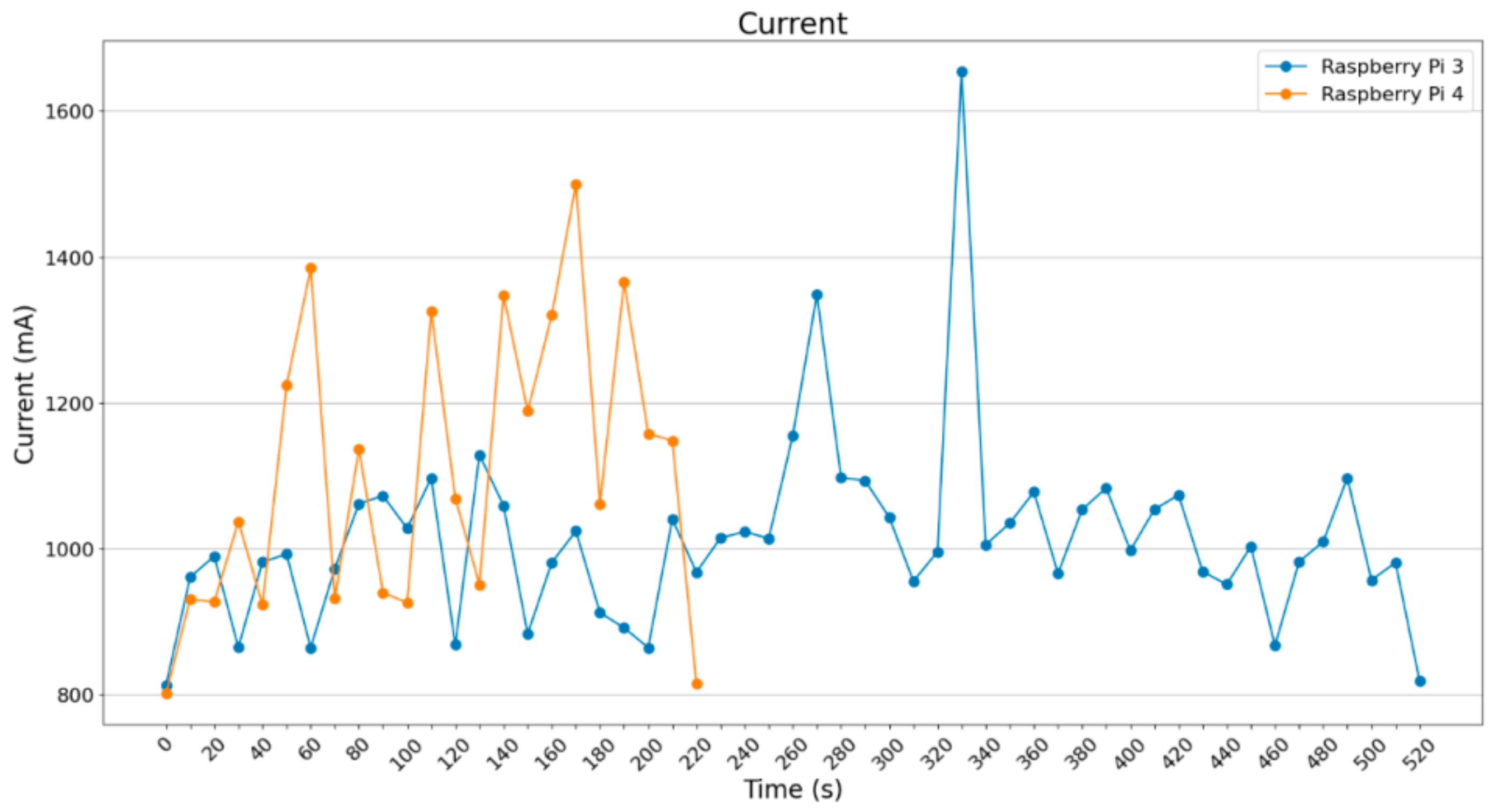
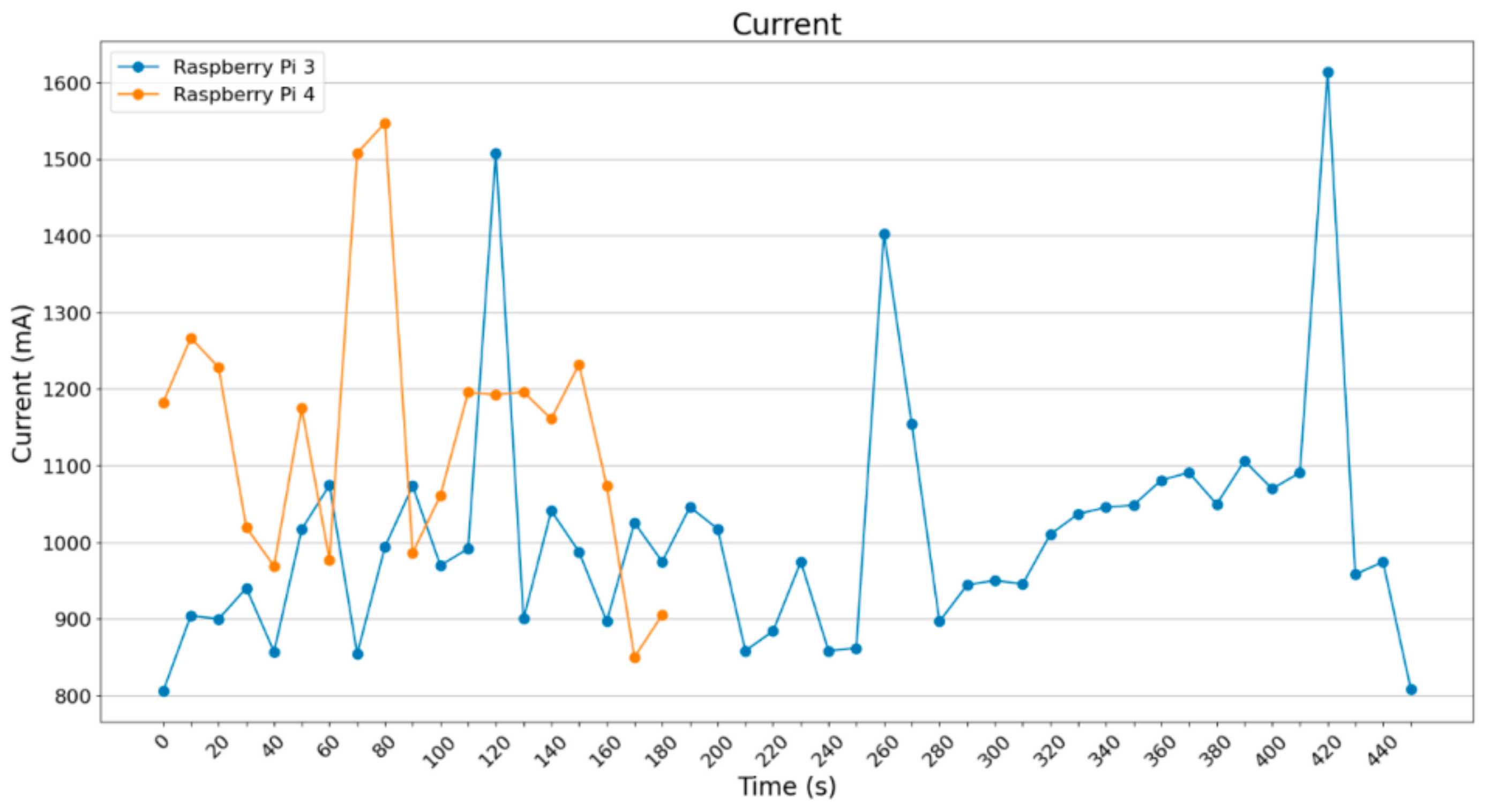
Concerning the current draw, the results are depicted in
Figure 10. All four SBCs were supplied with stable 5.1 Volt DC; however, the pictures depict only the current draw. The power can be easily estimated using the following equation:
All the devices except the Google Coral draw about 1000 mA of current with a few peak values over 1350 mA; the rest of the values are about 800 mA. Due to its architecture, Google Coral achieves very stable values of current draw and power consumption, which are clearly below the respective measurements of the other three devices.
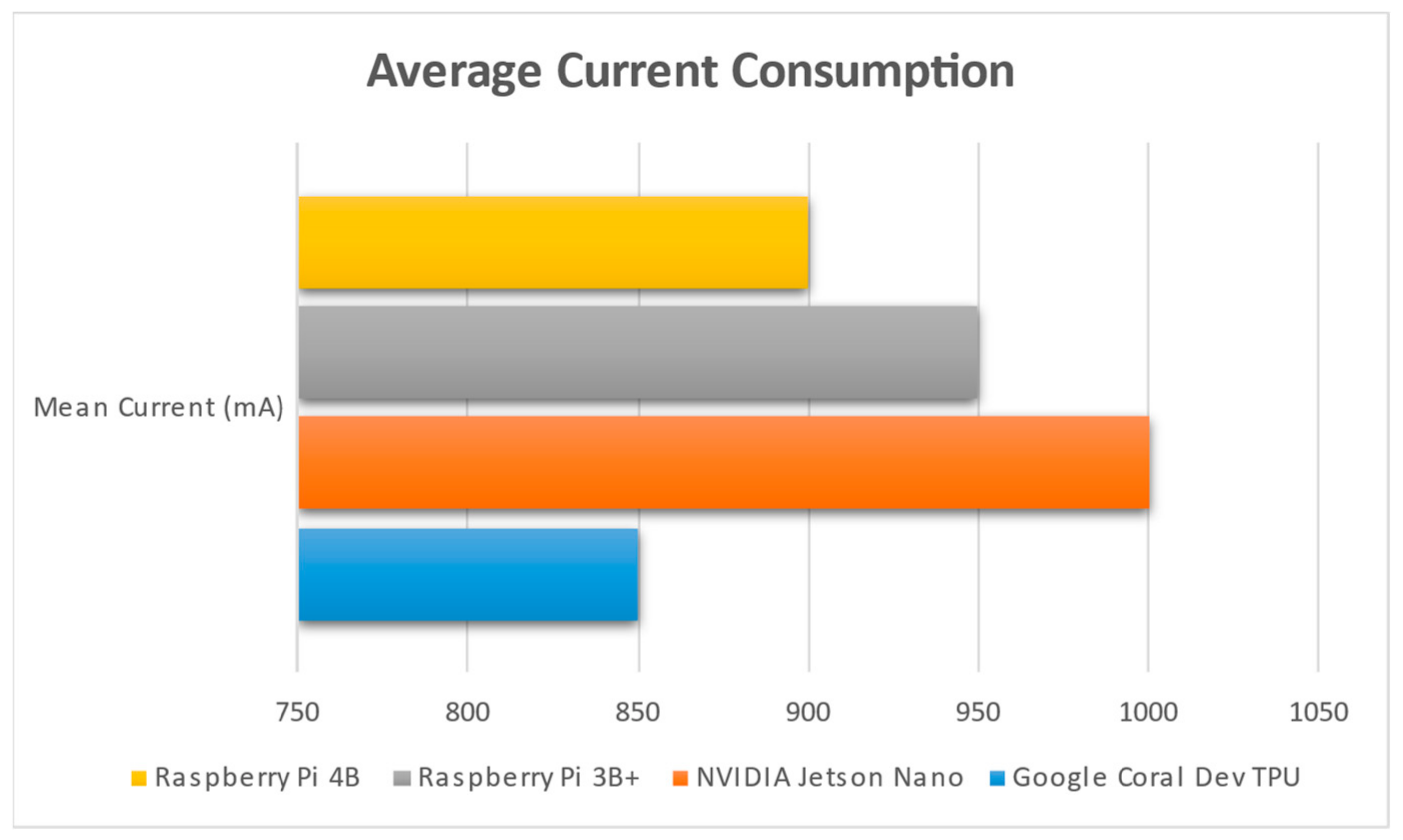
In
Figure 11, one can see that NVIDIA Jetson Nano is the most “energy-hungry” device of all four assessed; this is expected, since it is widely known that GPUs consume a lot of power, accounting for the tendency of the scientific community to also use devices such as ASIC or FPGA (field programmable gate arrays) (
https://inaccel.com/studio/ (accessed on 20 January 2024)), where the speedup is extreme with low power consumption.
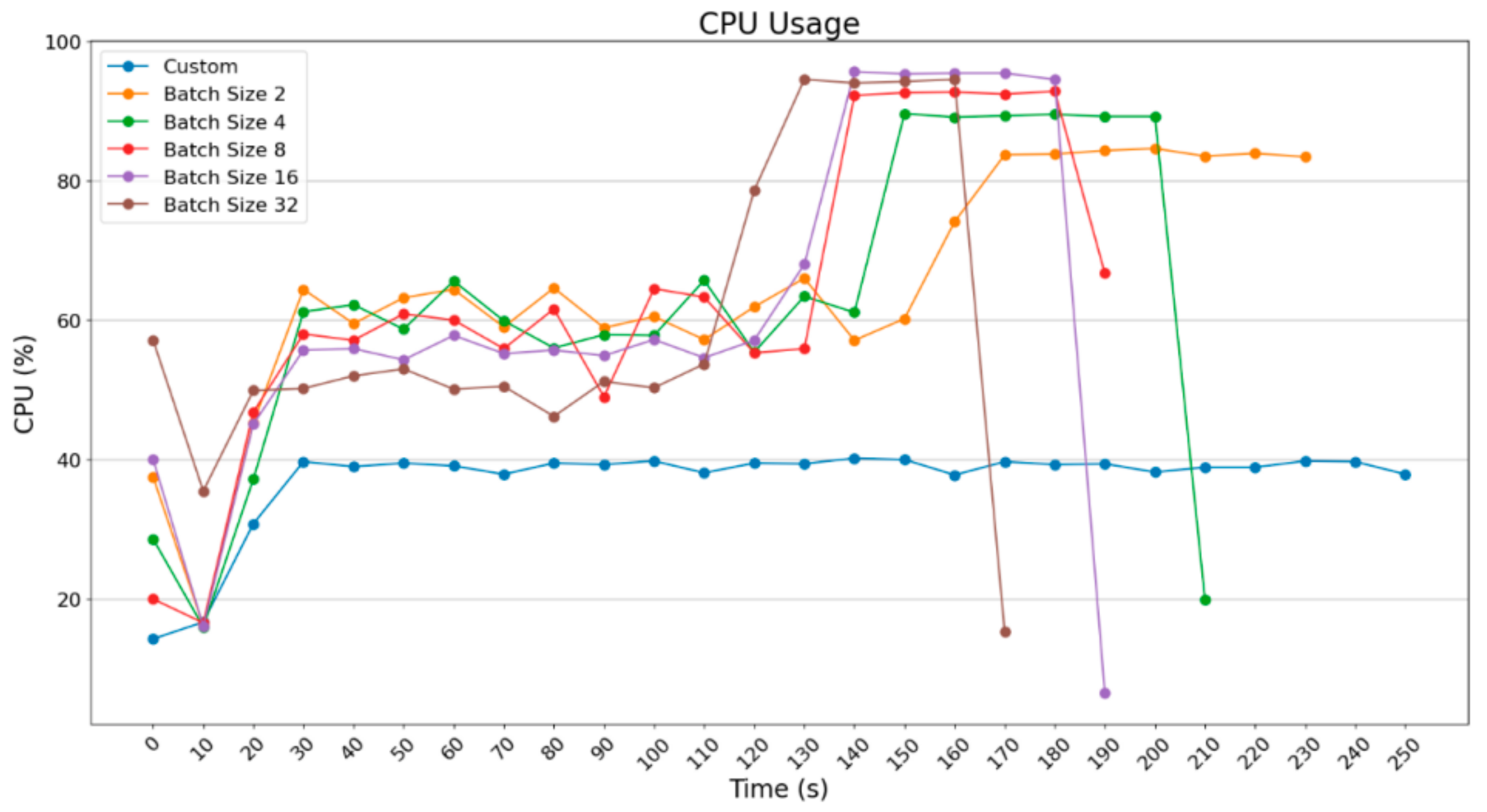
The use of generators apart from the training procedure affects the prediction part as well, where the images were loaded into the model per batch, with the help of generators. Moreover, images are processed in groups of 2, 4, 8, 16, and 32 in this case. For the realization of that experiment, Raspberry 3 and Raspberry 4 were chosen for use, but not Google Coral TPU, because it does not support the common TensorFlow and thus there was no chance of using ImageDataGenerator, which is part of Keras. Keras is an open-source library that provides a python interface for neural networks and it is an interface for TensorFlow library. In addition, neither of the NVIDIA Jetson Nanos were used because their OS did not support such a procedure.
The experiments that took place used batch_size = 2, 4, 8, and 16; only Raspberry Pi 4B+ was tested with batch_size = 32, improving the execution time. What is obvious in the following diagrams is that as the batch_size increases, the execution time decreases; meanwhile, there is a demand for more computational resources. In
Figure 12, a diagram for batch_size = 2 is depicted.
For the execution with batch_size = 2, nothing remarkable was noticed, only that Raspberry Pi 4 can implement its process faster. Below, the diagram for batch_size = 4 is depicted.
In
Figure 13, what is worth mentioning is that Raspberry Pi 3B+ improved the execution time a bit in comparison to the data in
Figure 12; also note that Raspberry Pi 4B improved the time for 80 s, which is significant in relation to the total time. Below, the diagrams for batch_size = 8 and batch_size = 16 are depicted.
In
Figure 14 (batch_size = 8), a small improvement is noted, but it remains similar to the previous (
Figure 13). In the diagram of
Figure 15, however, a significant improvement in execution time for the two Raspberry devices is noted due to the fact that a suitable increase in the images (batch_size) causes a decrease in recursions. That occurs because the algorithm needs to execute fewer iterations.
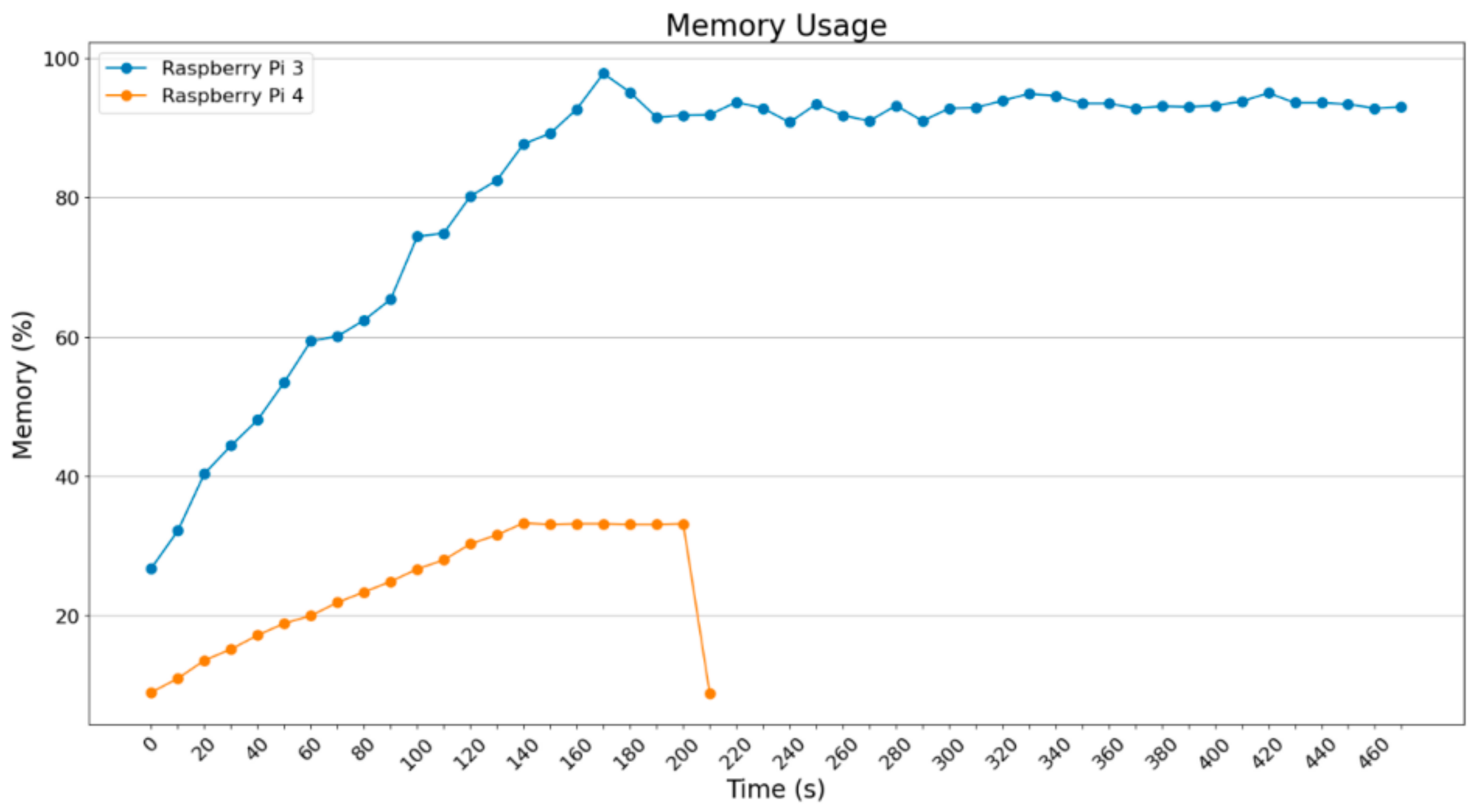
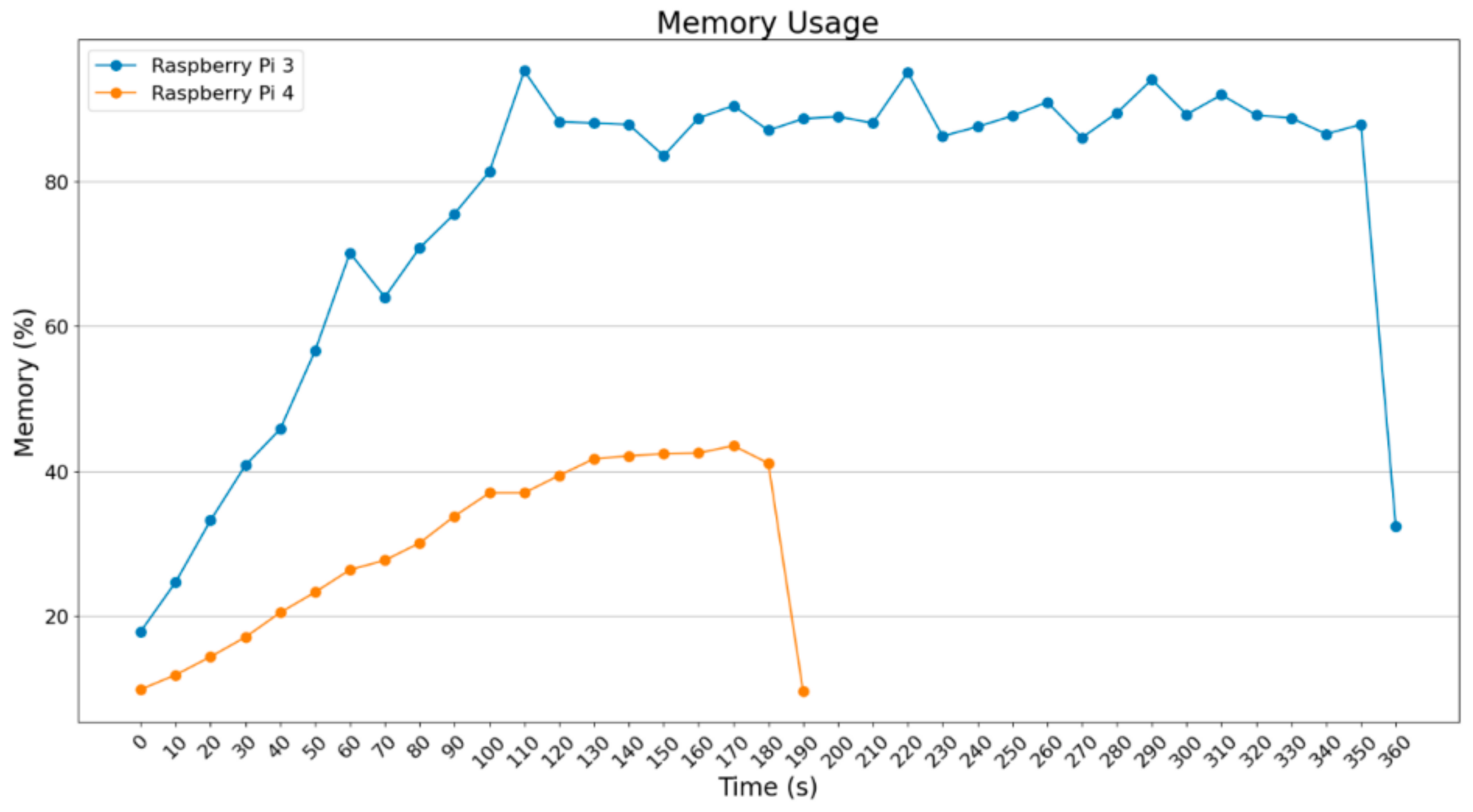
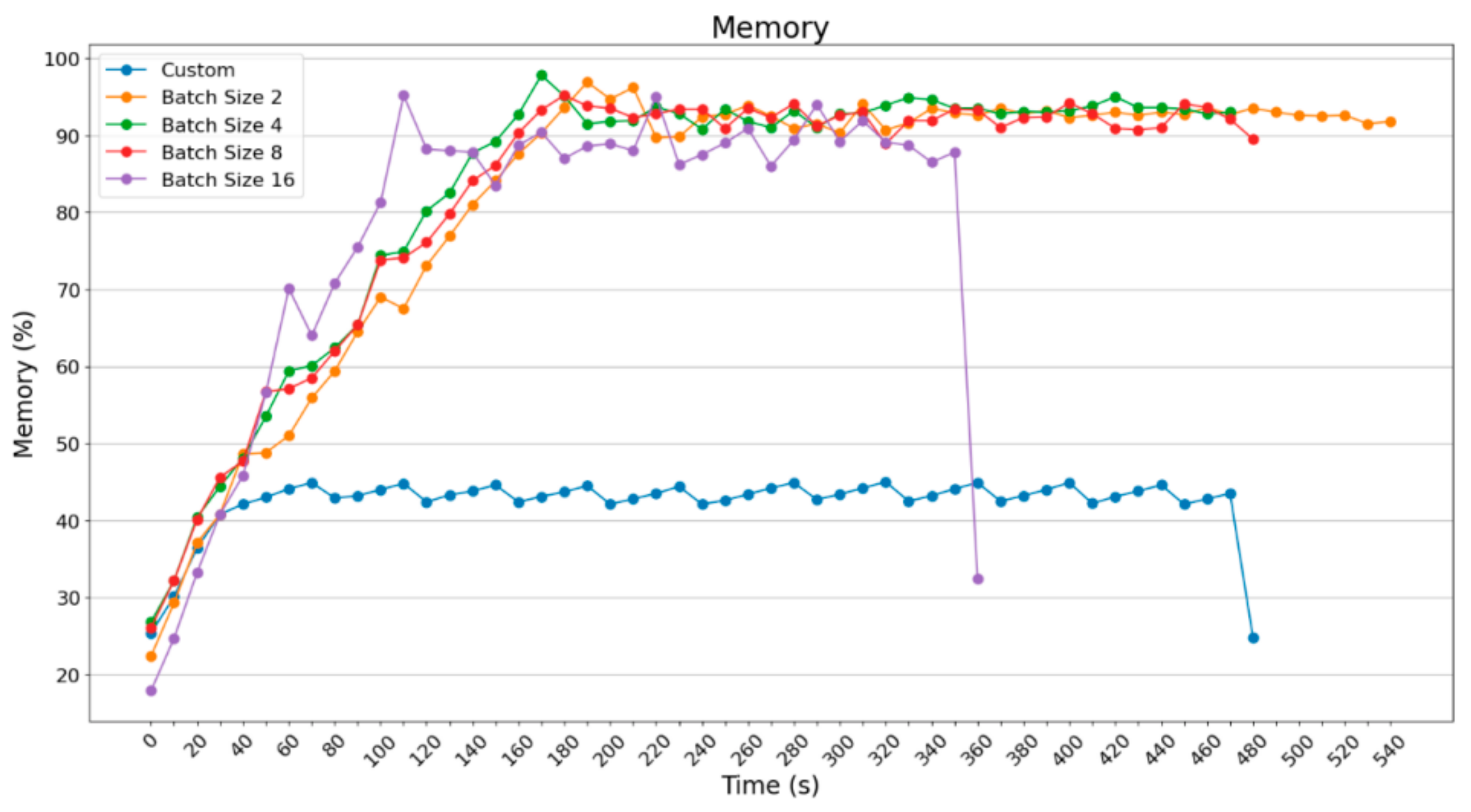
In
Figure 16,
Figure 17,
Figure 18 and
Figure 19, it is obvious that RAM usage for the Raspberry Pi 3B+ remains high at about 90%. Theoretically, it was expected that the Raspberry Pi 3B+ could not finalize those procedures given the extra load. However, as will be shown below, apart from the marginal usage of RAM, extra memory was enabled. Raspberry Pi 4B does not face any difficulty as the Raspberry Pi 3B+ does. It reached 30–40% RAM usage, so that it could process and accelerate the operations.
Below, diagrams related to RAM usage are examined, based on capacity this time.
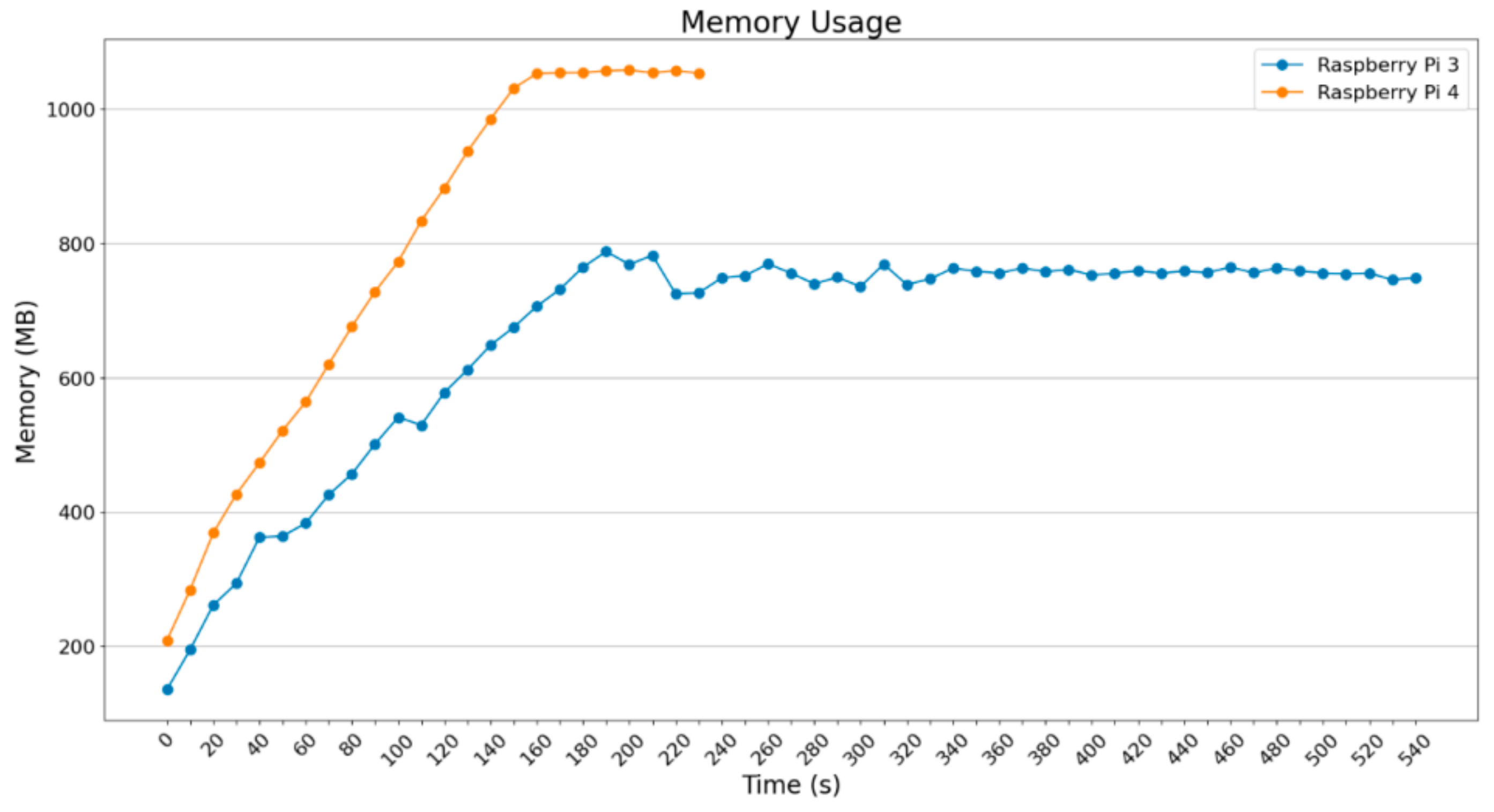
In
Figure 20 and
Figure 21, the RAM usage for batch_size = 2 and batch_size = 4 are depicted in MBytes. Raspberry Pi 3B+ uses around 800 MBytes, which is almost all of the available RAM (875 MB is the maximum available). Raspberry Pi 4B uses more MBytes because the maximum available is about 4 GB, something that makes it the most powerful IoT device, which is obvious from the execution time of the processes.
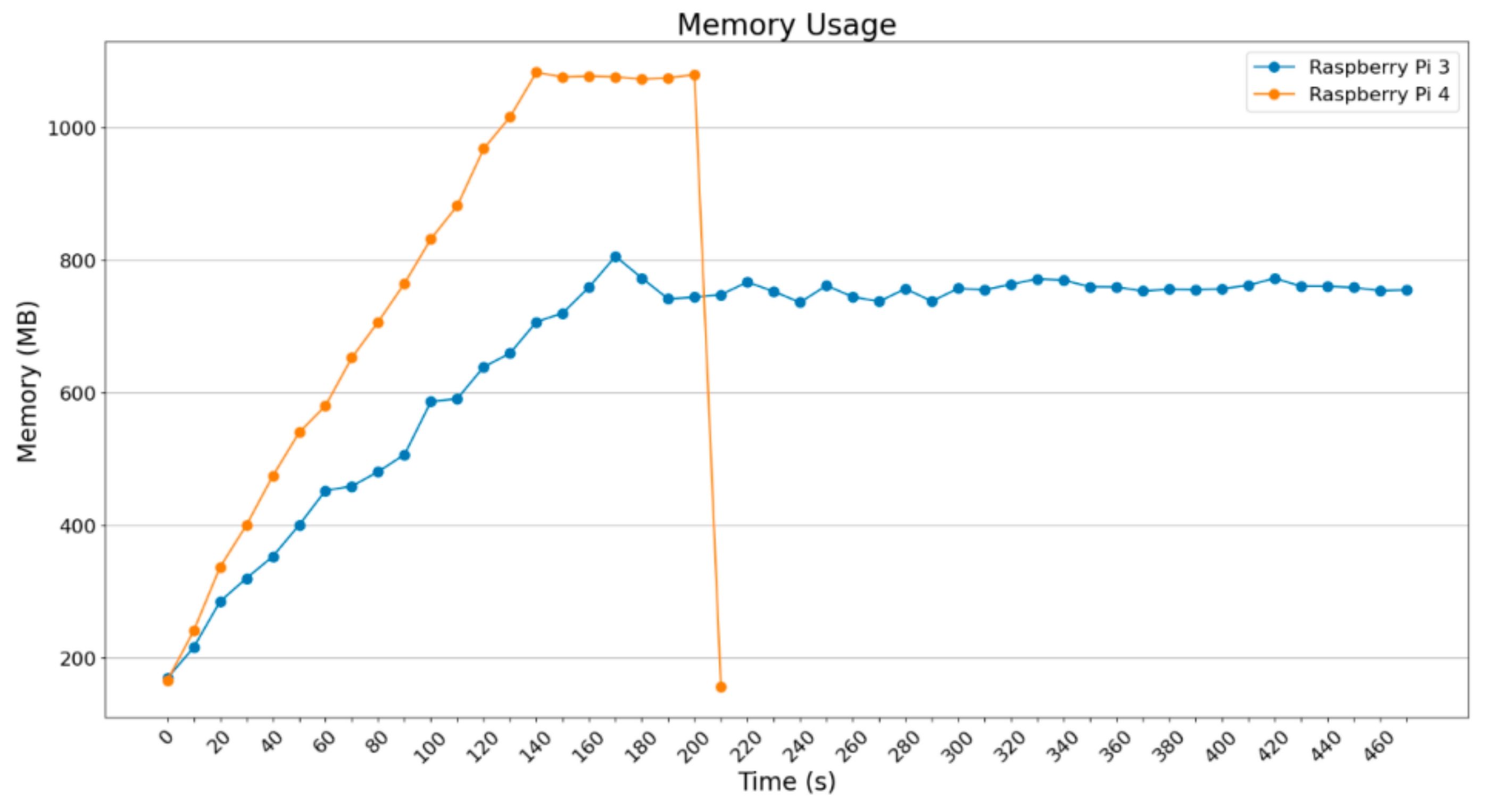
Figure 22 and
Figure 23 depict the usage of memory in MBytes in two of the heaviest situations that have been presented until this point; these are related to batch_size = 8 and batch_size = 16.
What is obvious in
Figure 22 and
Figure 23 is that the Raspberry Pi 4B starts being stressed in comparison to the previous situations since the memory demands increase, given that it loads and processes 8 and 16 images, reaching 1250 MBytes and 1500 MBytes RAM. Raspberry Pi 3B+ seems to be stressed under the load it was assigned to.
As far as temperature is concerned, nothing special was noticed; the variance was stable.
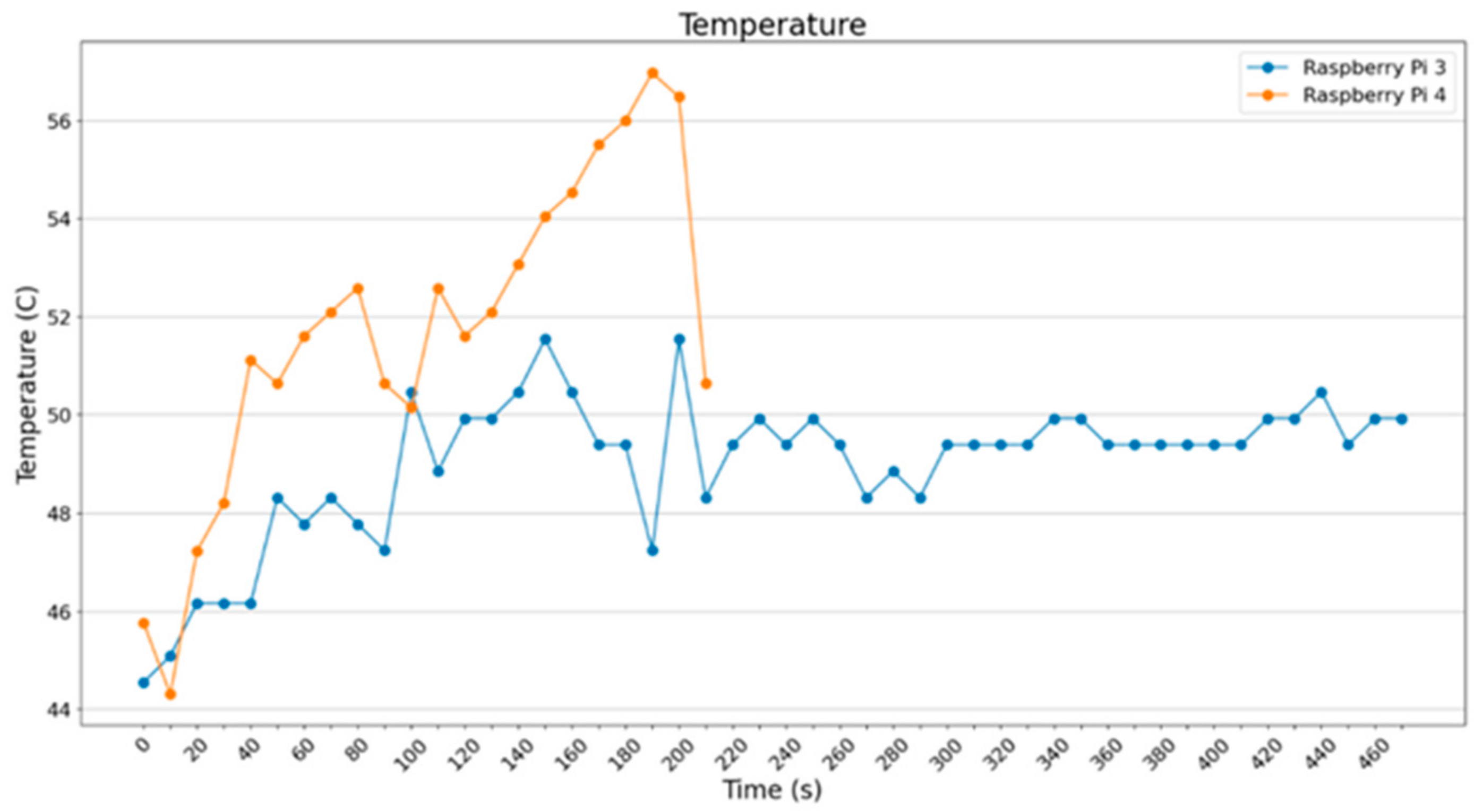
For batch_size = 2 (
Figure 24) and batch_size = 4 (
Figure 25), it is noted that Raspberry Pi 3B+ was operating steadily at about 49 °C, whereas the Raspberry Pi 4B showed an intense increase from 45 °C to 55 °C.
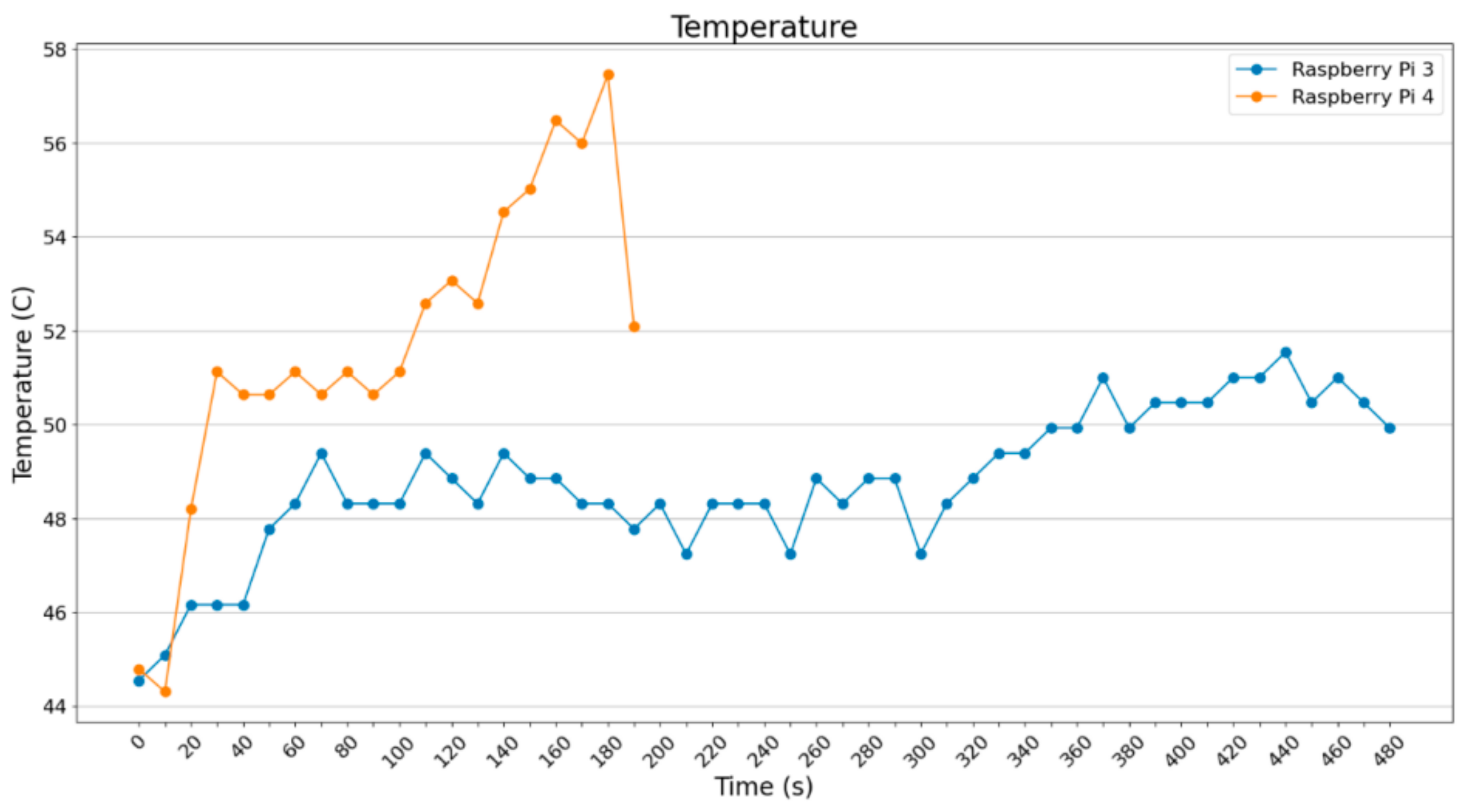
In
Figure 26 and
Figure 27, the cases for batch_size = 8 and batch_size = 16 are shown. It is noted that Raspberry Pi 3B+ remains at 49 °C with spike at the end, which is expected since it is quite loaded to operate smoothly, concerning both RAM and CPU usage. Regarding Raspberry Pi 4B, it is noted that it starts operating smoothly but it ends up stressed.
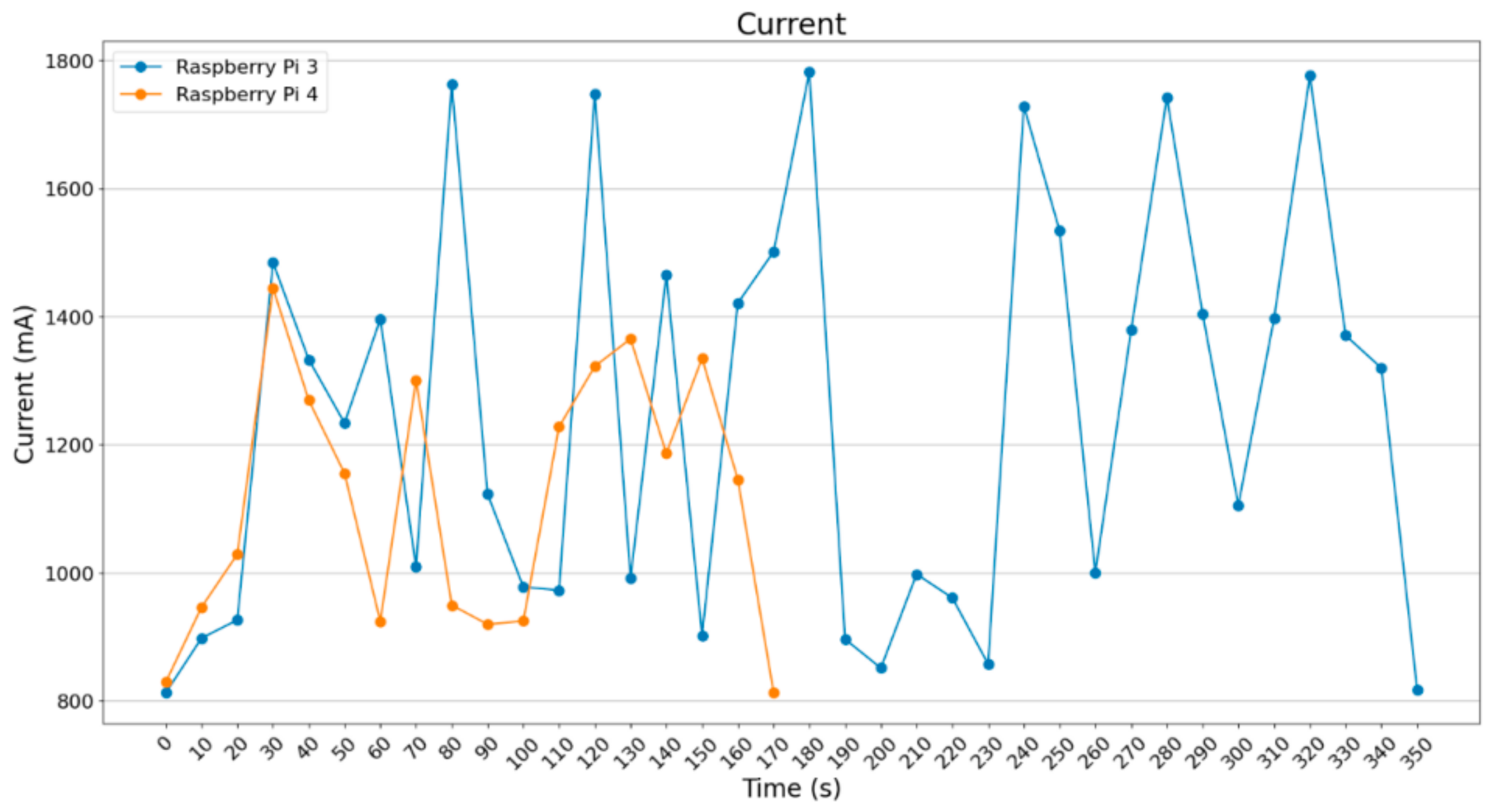
As far as the current draw per batch_size is concerned (i.e., the temperature graphs mentioned before), the same thing occurs in current draw as well, meaning that the more the batch_size increases, the more the SBCs are stressed. Consequently, power consumption is higher. Current draw mean value starts from around 1050 mA for batch_size = 2 to 1200 mA for batch_size = 16 in Raspberry Pi 4B. In Raspberry Pi 3B+, higher extreme values are observed.
In the below diagram (
Figure 28), many spikes are noted for Raspberry Pi 4B but not that many are noted for Raspberry Pi 3B+.
For batch_size = 4 (
Figure 29), a small increase in current draw can be noticed in the Raspberry Pi 4B around 1200 mA. Raspberry Pi 3B+ starts getting stressed, with spikes over 1500 mA. Below, the graph for batch_size = 8 (
Figure 30), showing a small current increase on both Raspberry Pi 3B+ and Raspberry Pi 4B.
In
Figure 31, a significant difference is depicted between the more powerful Raspberry Pi 4B and the Raspberry Pi 3B+. In the case of batch_size = 16, a small increase in current is noted in relation to batch_size = 8. However, Raspberry Pi 3B+ exceeded 1700 mA in more than half of the values sampled, whereas Raspberry Pi 4B was operating at around 1200 mA.
Next,
Figure 32 depicts how the Raspberry Pi 3B+ and Raspberry Pi 4B use the batch_size in different sizes and how each device is compared to itself given the executions including the Pillow technique. Starting with Raspberry Pi 3B+, the diagrams below were drawn; it is clear that, for the purpose of improving execution time, more resources were necessary, particularly for batch_size = 16.
Diagrams in
Figure 32 and
Figure 33 depict the following: the usage of RAM memory and CPU for Raspberry Pi 3B+ based on different executions. What is noticeable is that the usage of a custom solution on loading images one-by-one does not rewire the use of many computational resources, reaching the end result. However, with the use of ImageDataGenerator, good use of images per batch was possible; thus, there was a marginal decrease in the execution time of processing per group.
The next diagram (
Figure 34) shows the memory usage in MBytes; it is equivalent with the diagram of the percentage of memory RAM use.
The diagram that follows (
Figure 35) depicts the additional need as a result of the larger group on loading images, because a bigger memory is required. As is shown, Raspberry Pi 3B+ almost doubles the memory it uses by adding 750 MB Swap to complete the procedures in the more computationally difficult but faster situation.
The difference in execution time with batch_size = 16 is obvious, the difference in usage of computation resources is observable too. With regard to temperature (
Figure 36), there were no intense outputs, since time differs significantly with batch_size = 16. The batch_size = 32 For Raspberry Pi 4B was tried and, as will be shown in the following
Figure 37 and
Figure 38, output faster results, making good use of computational resources.
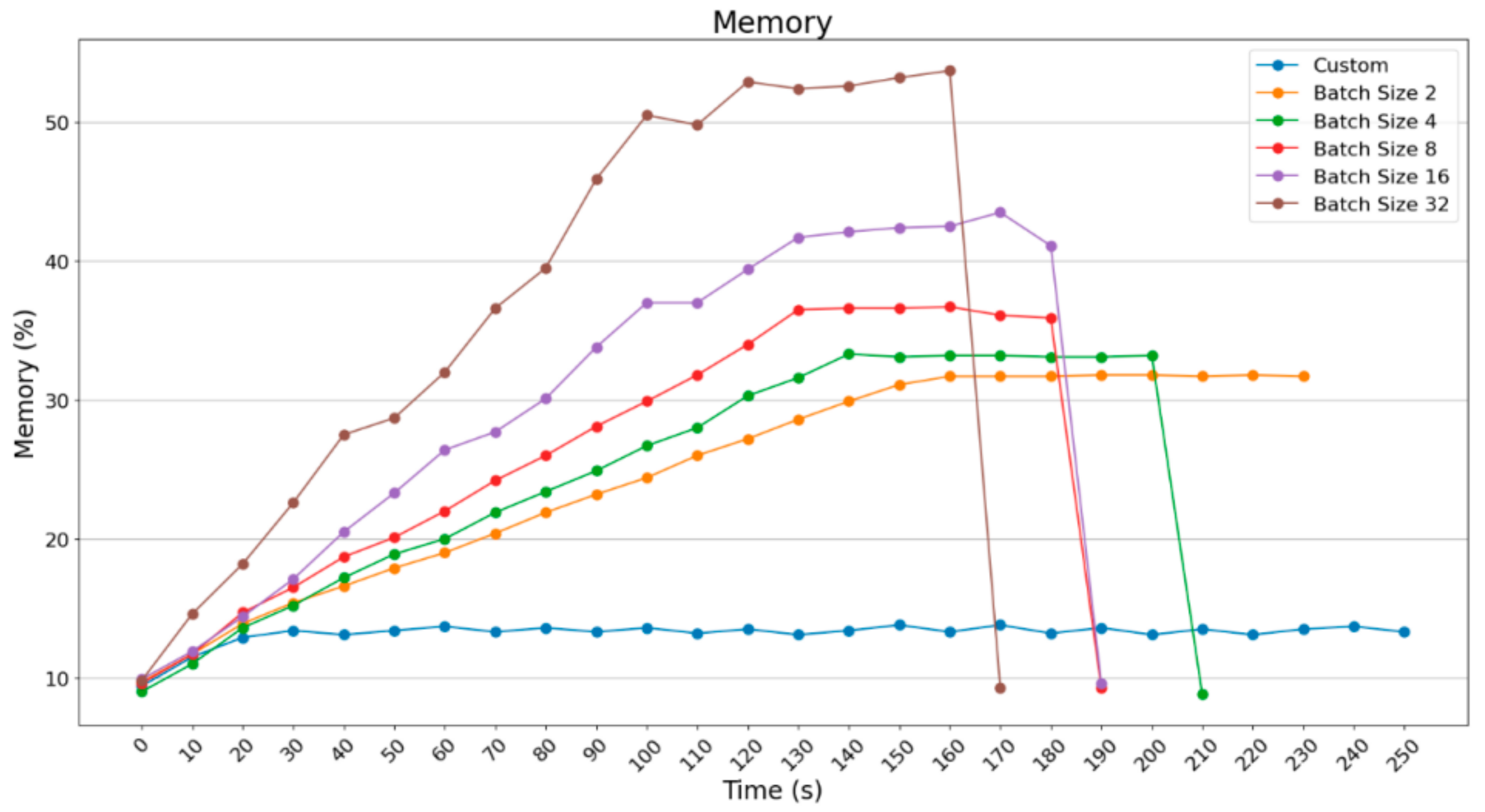
As far as the usage of computational power is concerned, there is not a significant difference between the experiments with the use of ImageDataGenerator. However, the usage of computational power is significant compared to the custom prediction.
In
Figure 39, an acceleration of about 20 s took place when batch_size = 3 was used. However, for acceleration concerning the execution time (by doubling the amount of the images per group), the percentage of memory exceeds 50%. Respectively, in
Figure 39, RAM in MBytes excels 1800 MBytes; in contrast, in the previous cases, it did not exceed 1500 MBytes.
In
Figure 40, it can be observed that the temperature readings do not show an essential difference between the cases, as the Raspberry Pi 4B maintains a temperature of around 52 °C in all scenarios.
Apart from the obvious improvement in execution time with batch_size = 32 and the necessary increase mainly in the memory resources, it is worth noticing that Raspberry Pi 4B can easily implement the process of prediction with Pillow, which stands for the custom way of loading images one-by-one with the use of ImageDataGenerator, although it requires 80 s more.
As can be observed from the graph, Raspberry Pi 4B is the fastest of all the four SBCs regarding the time completion of the task; as has been discussed in a previous section, it takes about 244 s to finish the task, i.e., the inference part of the ML model. The slowest hardware is that of the Raspberry Pi 3B+, taking about 453 s to complete the job. Raspberry Pi 4B uses 4 GB RAM and a more powerful processor: Broadcom BCM2711, quad-core Cortex-A72 (ARM v8) 64-bit SoC @ 1.5 GHz. This is in comparison to Raspberry’s Pi 3B+ CPU: Broadcom BCM2837B0, Cortex-A53 64-bit SoC @ 1.4 GHz. This is depicted in
Figure 41. The Raspberry Pi 3B+ also uses 1 GB RAM, which is significantly lower than the 4 GB RAM that Raspberry Pi 4B uses. Although it would be expected that NVIDIA Jetson Nano is the fastest of all four modules, it is evident that it is not. TPU and GPU, however, use less CPU power than the Raspberry Pi devices, which are CPU-centered.
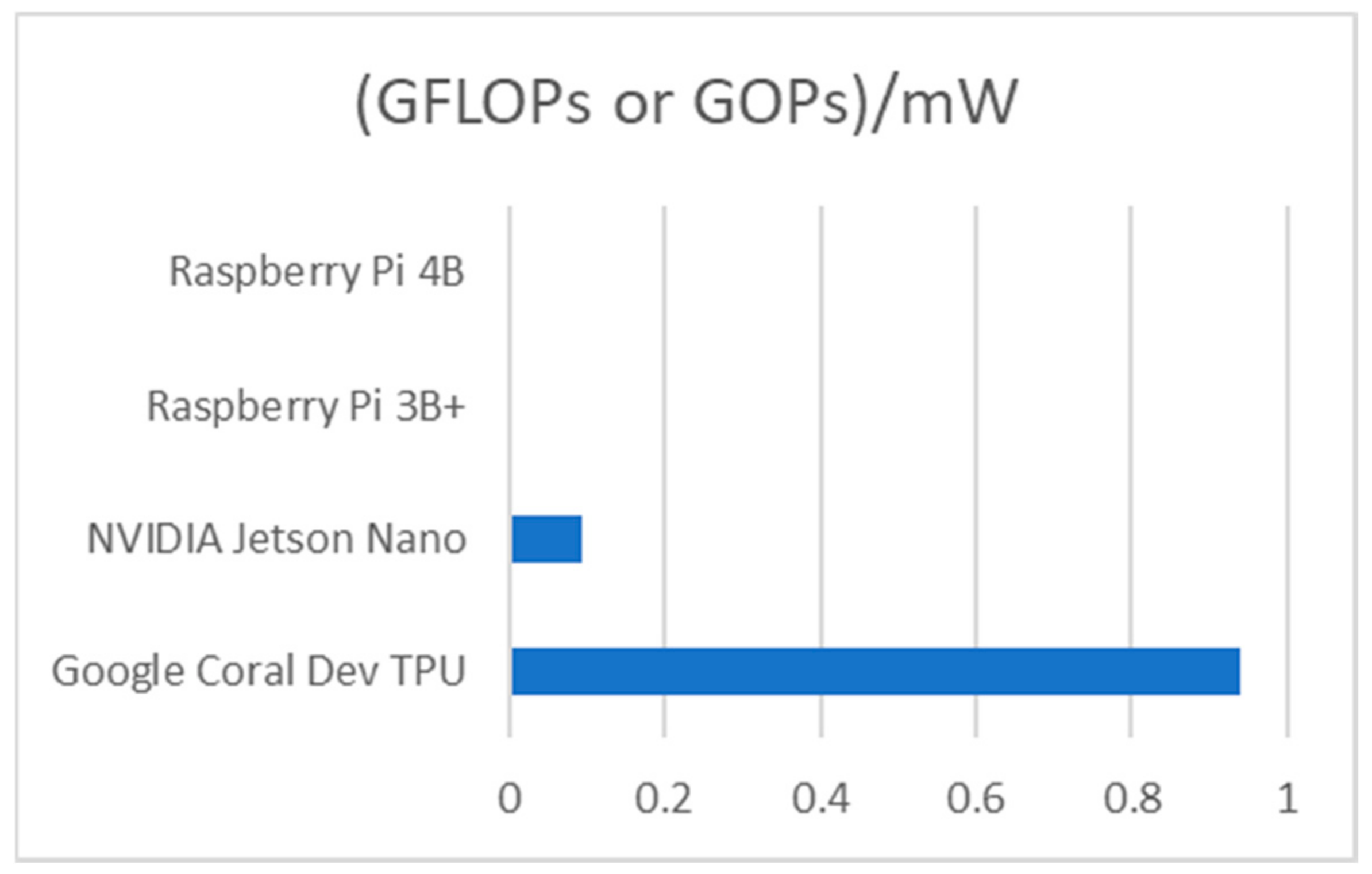
As is seen from
Table 2, concerning the inference part, the Google Coral Dev TPU is the most efficient, followed by NVIDIA Jetson Nano. Next comes the Raspberry Pi 3B+, and the last and least efficient module is the Raspberry Pi 4B. In
Figure 42, it is clear that Google Coral Dev TPU is by far the most efficient of all four SBCs.
5.3. Overall Experimental Evaluation Findings
Below, an analysis of the various constraints that were faced when working with dataset of the images, as well as possible solutions, is presented. There is also a discussion of the effect of temperature on the construction and the respective means to mitigate the effects. Lastly, we present the findings of our experience of how GPU and TPU accelerators behave in large-scale systems during the training phase, which unfortunately is not crystal clear in constrained-resource SBCs.
In the image processing part, the implementations that we studied until the time of writing the current subsection (2024) have been realized; they refer to one kind of leaf, that was divided into the basic leaf classes. In the current research, various leaves were used and were divided into more classes, rather than using one leaf, since there are different kinds of plants in an image depicting only one crop; thus, a generalized approach is needed. There was an effort to use real images and not perfected ones, which explains why there were light variations and other human-made conditions, making the model more efficient in real case prediction. The result from the metrics was as follows: GPUs are an “energy-hungry” solution. They may be good accelerators since they can implement extreme parallelization in their CUDA cores and decrease the completion time of a process, but they consume more energy in comparison to the other SBCs used in the current experiments. Raspberry Pi 4B is considered to be faster than the older Raspberry Pi 3B+ when completing a task; however, both are CPU-based, meaning that a lot of time is required in large ML models since they do not use accelerators. Google Coral Dev TPU is really “fast” in completing a task; this is because it mainly uses less CPU power and less energy in comparison with a GPU-based SBC, as it accelerates specific parts of the python code. However, changes in both the code and the models are necessary in order to progress, because the Google Coral Dev TPU does support the TensorFlow package.
Increased temperatures show that the SBC consumes a lot of power (current draw). This is very critical when there is a need to use an SBC far from wall plug electricity. To be more specific, when it is necessary to operate the SBC in a place where the power comes from a battery combined with a small solar panel or a small wind generator, there will be power supply constraints. Attention should be paid to use as little power as possible, because all the power will come from a battery that can be depleted too quickly. Another consequence of increased temperatures in an SBC is that there should be a configuration in the hardware in order to dissipate all the heat, meaning the use of a small fan, or two if the SBC is enclosed in a project box, becomes necessary. Moreover, the use of heatsinks on the CPU/GPU/TPU chip with specific glues dissipating the heat seems vital. The worst-case scenario appears when such SBC devices need to operate during the summer or hot months that add an extra burn due to the heat emitted by the chip. For this reason, bigger fans need to be used, adding an additional current load to the whole circuit device (fans consume more current); therefore, the battery depletes faster.
Experience with large-scale training ML models in Google Colab VM has shown that a GPU can offer acceleration in the training period of an ML model in comparison to a CPU. The idea is that a GPU is highly parallelizable, with thousands of threads working in parallel, whereas a CPU operates sequentially and consumes much more time than a GPU does. During the training phase, there is also the solution of a TPU, which accelerates the ML model in comparison to the CPU, depending on the number of tensors used.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}