Abstract
Face recognition in general scenarios has been saturated in recent years, but there is still room to enhance model performance in extreme scenarios and fairness situations. Inspired by the successful application of Transformer and ConvNet in computer vision, we propose a FIN-Block, which gives a more flexible composition paradigm for building a novel pure convolution model and provides a foundation for constructing a new framework for general face recognition in both extreme scenarios and fairness situations. FIN-Block-A uses a combination of stacked large-size convolution kernels and parallel convolution branches to ensure a large spatial receptive field while improving the module’s deep feature embedding and extraction capabilities. FIN-Block-B takes advantage of stacked orthogonal convolution kernels and parallel branches to balance model size and performance. By applying FIN-Block with an adapted convolution kernel size in different stages, we built a reasonable and novel framework Face-Inception-Net, and the performance of the model is highly competitive with ConvNeXt and InceptionNeXt. The models were trained on CASIA-WebFace and MS-wo-RFW databases and evaluated on 14 mainstream benchmarks, including LFW, extreme scene, and fairness test sets. The proposed Face-Inception-Net achieved the highest average TAR@FAR0.001 of 95.9% in all used benchmarks, fully demonstrating effectiveness and generality in various scenarios.
1. Introduction
In recent years, deep learning has made significant progress in the field of face recognition [1,2,3,4,5,6], with high-precision face recognition models trained on public face datasets now widely used in industrial fields, such as security, surveillance, and mobile applications. The tremendous success of face recognition is mainly attributed to three aspects: (1) large-scale training datasets, including CASIA Webface, VGGFace2, and MS-wo-RFW [5,6,7], have greatly improved the training accuracy of deep models [8]; (2) the network structure, such as GoogleNet [9] and ResNet [10] models, which form the backbone of face recognition models, help improve the performance of deep face recognition; (3) various loss functions are used as control signals during model training, introduced based on Euclidean distance [3] or angular/cosine margin [1,11] to enhance the distinctiveness of face features. These loss functions effectively guide the network to learn more discriminative features by emphasizing inter-class differences and intra-class consistency. However, the performance of DNNs in general scenarios, extreme conditions, and fairness still needs to be improved, making the design of new universal face recognition models a challenge. In IMAN [7], the impact of race-biased face datasets on model performance is demonstrated. In SFace [8], experiments show that the recognition rate of face recognition models in extreme conditions needs to be improved. Therefore, integrating existing achievements in face recognition with new technologies to design innovative universal face recognition models has significant scientific importance and potential application value.
Face recognition is a highly versatile task, facing challenges such as varying poses, lighting, obstructions, facial expressions, and age-related changes [12]. While current research often concentrates on specific aspects of face recognition, there is a pressing need for a universally applicable solution. Recent studies have made notable advancements. Zhang et al. [13] improved the Inception module, significantly enhancing performance on datasets featuring masked faces. LIAAD [14] developed a novel, lightweight attention-based method that, through knowledge distillation, improves accuracy and robustness against age variations in face recognition. Zhang et al. delved into face recognition and its applications, including expression recognition [15], generation [15], and face reconstruction [16,17]. The evolution of hardware and new technologies have spurred the development of more advanced model architectures. Taking inspiration from the successful incorporation of GELU, AdamW [18,19], and Dropout layers in Transformers, ConvNet led to ConvNext [20], a new convolutional model architecture that leverages the ResNet framework. ConvNext has surpassed Transformer models in performance, renewing interest in convolutional models in the computer vision field. InceptionNeXt [21] was introduced; it employs parallel branches, avoiding large convolutional kernels, which leads to superior performance and faster inference, offering new avenues for refining face recognition models. Despite these advancements, the quest for a universally applicable face recognition model has seen limited progress in recent years. The unique demands of face recognition tasks pose significant challenges in making precise adjustments to model structures to enhance versatility across various scenarios.
On the LFW dataset [22], face recognition technologies based on ResNet and Trans-former [23] have reached a performance saturation point. To thoroughly evaluate the effectiveness of our proposed improvements, we introduced verification datasets from multiple scenarios [7,22,24,25,26,27,28,29,30,31] and measured the models’ universality by calculating their average precision across these datasets. Much of the current research in face recognition focuses on Inception and its ResNet variants, demonstrating the possibility of achieving exceptional performance at lower computational costs by optimizing local network topology. Additionally, multilayer perceptrons (MLPs) [32] have been proven to achieve results comparable to complex attention mechanisms, providing theoretical support for enhancing the performance of pure convolutional network structures. Inspired by the parallel branches of InceptionNeXt [21] and the stacked convolutional kernels of Inception, we introduce two types of modules, FIN-Block-A/B. FIN-Block-A combines the design of stacked large convolutional kernels with parallel branches, aimed at expanding the model’s spatial receptive field and enhancing the efficiency of deep feature embedding and extraction. FIN-Block-B, on the other hand, optimizes the balance between model size and performance through stacking orthogonal convolutional kernels and parallel branches.
Based on these innovations, we constructed a novel Face-Inception-Net model, following the InceptionNeXt [21] stage structure design and adjusting the size of convolutional kernels at different stages to form a framework that is both rational and innovative. Compared to existing ConvNet [20] and InceptionNeXt [21] models, our model demonstrates strong competitive performance. The novelty of this study lies in the meticulous stage-wise improvements to the model structure: using large pure convolutional kernels for feature extraction in Stage 1; employing stacked large convolutional kernels for deeper feature mining in Stage 2; and using orthogonal square kernels of varying sizes in Stages 3/4 to optimize the balance between model performance and computational efficiency. We used the average TAR@FAR0.001 across different scenarios as a metric for model universality. Our experimental results not only proved that increasing model width is more effective than depth in large-scale face recognition tasks but also demonstrated the wide applicability of our method through evaluations on the extreme scene and fairness test sets [7].
The main contributions of our work are summarized as follows.
- We present an innovative FIN block that utilizes a hybrid of state-of-the-art convolution and Inception technologies. This architecture is designed to offer an expansive spatial receptive field alongside advanced capabilities for the extraction of deep feature embeddings.
- We use convolutional branches that combine different stages and dimensions to build the novel Face-Inception-Net. Evaluated on the extreme scene and fairness test set, experiments show that our model outperforms the compared models.
- By analyzing the experimental data, we found that our model can better balance the gap between the optimal solution and the average solution of the model. This means that our model is more powerful and stable.
Our model helps to accelerate the research of face recognition model architecture in complex cases.
2. Related Work
In this section, we commence with an overview of deep learning-based algorithms specifically tailored for deep face recognition. Subsequently, we delve into methodologies for integrating transformations with convolutions, exploring their synergistic potential. In conclusion, we highlight recent innovations in face recognition algorithms, tailored for a variety of scenarios, thereby presenting a comprehensive update on the state-of-the-art in the field.
2.1. Deep Face Recognition
Deep face recognition systems, underpinned by convolutional neural networks (CNNs) [33], have exhibited notable performance. These algorithms excel in extracting discriminative features from facial images, subsequently encoding them into an n-dimensional vector space. This space is distinguished by minimized intra-class distances and maximized inter-class distances, enabling precise identification and differentiation of individual faces.
During the training process of deep face recognition models, two key elements play a crucial role: (1) network architecture and (2) loss functions. For the network architecture, researchers have employed both traditional and novel network structures to design these models [6]. Well-known classical network structures, such as AlexNet [34], VGGNet [2], GoogleNet [9], ResNet [10], and SENet [35], are frequently utilized as backbone networks for face recognition models. For instance, Taigman et al. [36] pioneered the use of a nine-layer CNN with multiple locally connected layers for face recognition. In addition, novel architectures specifically designed for face recognition have been proposed to improve model performance [6]. For the latter role, researchers have proposed novel loss functions or modified existing ones to improve the discriminative capabilities of convolutional networks for distinguishing individuals. In early deep face recognition algorithms [37,38], cross-entropy loss is used for feature learning. Schroff et al. [39] introduced triplet loss as a means to directly optimize the embedded features, further improving the performance of the model. Recent research [1,3,11,40] has predominantly adopted angle/cosine margin loss, integrating an angle margin penalty to amplify the discriminative capabilities of features. By leveraging true labels as supervisory signals, these loss functions facilitate feature separability, fostering a pronounced differentiation among various categories.
Face recognition has realized remarkable achievements through years of development and technological advancement. Building on these accomplishments, we have undertaken our research. The optimization of the model and the application of loss functions are complex tasks, each requiring meticulous attention to detail and a deep understanding of underlying principles.
2.2. The Fusion of Transformer and Convolution
Transformer [23] is a widely used architecture in natural language processing (NLP) based on the self-attention architecture. The Transformer model has achieved top results in computer classification and segmentation tasks, but the model execution efficiency is far behind convolution. How to effectively combine Transformer and convolution has become a hot issue.
The application of Transformer [23] to various computer vision tasks has become a prominent trend. So far, research on models has branched out in several directions. (1) The fusion of two models has led to the development of hybrid architectures, such as Conformer (by the National University of Science and Technology) [41], Next-ViT [42], and CoTNet [43]. (2) The combination of the CNN module and the Transformer layer can be used to construct novel models, such as the module-parallel design scheme proposed by Mobile-Former [39] and CMT [38]. (3) Researchers have explored specialized approaches, including using the convolutional model as a guide to training tiny Transformers [44] and using the Transformer to improve the ConvNet convolutional training technique [20]. The Transformer model has gained prominence in computer vision, but CNNs have also made significant progress. More specifically, pure convolutional networks, such as ConvNeXt [20] and InceptionNeXt [21], exploit the inherent strengths of convolution in computer vision. By integrating “network modernization” techniques [41] with training techniques from Transformer [45,46] and other technologies, these models have achieved superior performance on Imagenet, surpassing that of the Transformer model.
The performance of convolutional network models in unconstrained face recognition has reached a plateau of accuracy. Nonetheless, with the relentless advancement of hardware and the continuous emergence of novel technologies, there is an ongoing trend toward designing new model structures that boast enhanced performance.
2.3. Face Recognition in Special Scenes
Conventional face recognition technology has matured to the point of fulfilling commercial deployment criteria, indicating a saturation in its development for standard applications. However, when it comes to extreme scenarios and fairness assessments, the model’s performance reveals room for improvement.
Face Transformer [47] proves that Transformer can be used for face recognition. Considering that the original Transformer may ignore the inter-patch information, Face Transformer modifies the patch generation process and makes the tokens with sliding patches that overlap each other. Inspired by the successful application of self-attention in computer vision, authors of [48] proposed a convolutional visual self-attention network (CVSAN), which uses self-attention to improve convolutional operators. A study conducted by [7] revealed the existence of racial bias in face recognition algorithms, resulting in significant performance degradation in real-world face recognition systems. To address racial bias, a novel IMAN method was proposed to bridge the domain gap, and its potential and effectiveness were validated through experiments. Authors of [14] proposed a novel lightweight attention angle distillation (LIAAD) method, which introduces a learning paradigm that can effectively distill the age-invariant attention and angle knowledge of these teachers into a lightweight student network, enabling it to be more robust with higher accuracy and robustness to the age factor.
The assessment of a model’s performance is fundamentally linked to the test set employed. In light of the saturation encountered in routine face recognition tasks, we incorporated test sets designed for fairness [7] and extreme scenarios [8]. This approach allowed for a thorough evaluation of our model’s capabilities, with the objective of showcasing its adaptability and versatility across a broad range of conditions.
3. Method
3.1. FIN-Block
Formulation of ConvNeXt Block. ConvNeXt [20] is a contemporary CNN model known for its streamlined architecture. In each ConvNeXt block, the input X undergoes an initial processing step with a depth convolution to propagate information across spatial dimensions. As shown in Figure 1, the token mixer is effectively established by using a depthwise convolution in ConvNeXt,
where denotes depthwise convolution with a kernel size of k × k. In ConvNeXt, k is set as 7 by default.
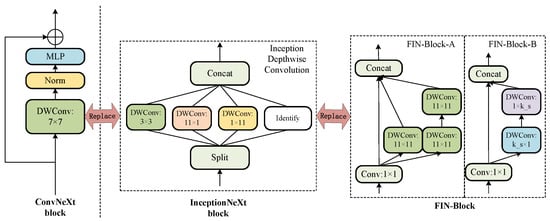
Figure 1.
Block illustration of ConvNeXt [20], InceptionNeXt [21], FIN-Block-A, and FIN-Block-B. ConvNeXt uses a large convolution kernel 7 × 7 instead of the original 3 × 3, uses the depth convolution layer to move up to replace the original convolution layer, and combines Norm and MLP [32,49,50] to form the ConvNeXt block. Compared to ConvNeXt, InceptionNeXt is efficient in that it decomposes the expensive large kernel depth convolution into four efficient parallel branches. FIN-Block-A and FIN-Block-B refer to the Inception structure, using 1 × 1 convolution and stacked depth convolution instead of large kernel depth convolution. The variable convolution kernel size allows for a more reasonable model structure.
Formulation of Inception depthwise convolution. As shown in Figure 1, conventional depthwise convolution with a large kernel size significantly hampers model speed. Therefore, InceptionNeXt [21] leaves partial channels unchanged and denotes them as a branch of identity mapping. For the processing channels, InceptionNeXt decomposes the depthwise operations with Inception style [9,49,51], using 3 × 3, 1 × , and × 1 kernels as branches. Specifically, for input X, we split it into four groups along the channel dimension,
where g is the channel numbers of convolution branches. Set ratio to determine the branch channel numbers by g = . The splitting inputs are fed into different parallel branches,
where denotes the small square kernel size set as 3 by default and represents the band kernel size set as 11 by default. Finally, the outputs from each branch are concatenated:
Formulation of FIN-Block. As shown in Figure 1, Inception [9] shows excellent performance with relatively low computational cost. MLPs [32,49,50] have also been shown to achieve comparable performance to attention mechanisms. Inception has shown that 1 × 1 convolutions are used to compute reductions before the expensive 3 × 3 and 5 × 5 convolutions. Besides being used as reductions, they include the use of rectified linear activation, which makes them dual-purpose. The ubiquitous use of dimension reduction allows for shielding a large number of input filters from the last stage to the next layer, reducing their dimension before convolving over them with a large patch size. Another practical and useful aspect of this design is that it aligns with the intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from different scales simultaneously. The design of the FIN-Block is inspired by Inception, which uses deep convolutional stacking and orthogonal bands kernel stacking to improve the performance of the model. The modified formula is shown below.
where and denote the small square kernel size set as 11 by default. Finally, the outputs from each are concatenated. The equation represents FIN-Block-A on the up and FIN-Block-B on the down. FIN-Block-A comprises a 1 × 1 small square kernel, large square kernel, and stack of two large square kernel. FIN-Block-B comprises a 1 × 1 small square kernel and stack of two orthogonal bands kernel.
3.2. Face-Inception-Net
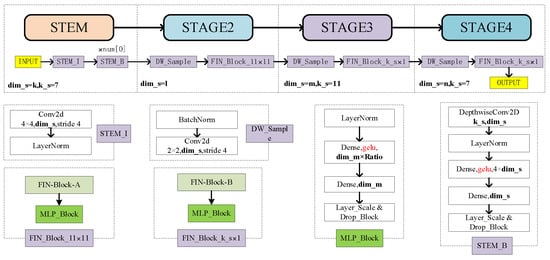
Based on FIN-Block-A and FIN-Block-B, we developed a set of models called Face-Inception-Net. Considering ConvNeXt [20] and InceptionNeXt as our primary baselines for comparison, we mainly followed their approach to construct models of different sizes. Similar to ResNet [10] and ConvNeXt, we adopted a 4-stage framework. For tiny models, the stage numbers are (3, 3, 9, 3), and for the base model, the stage numbers are (3, 3, 27, 3). Additionally, we experimented with stage numbers (5, 5, 10, 5) and dimensions (96, 192, 384, 786) for TV2 and stage numbers (5, 5, 10, 5) and dimensions (192, 384, 576, 786) for SV2. Our model uses BatchNorm instead of LayerNorm in the stem to prioritize speed. Detailed model configurations are shown in Table 1 and Figure 2. In terms of model structure, we mainly experimented with two popular stage-block combinations and explored the impact of block kernel size, model depth, and width on performance to find the optimal model that meets the requirements of face recognition.

Table 1.
Face-Inception-Net model configuration. It has a similar model configuration to Swin [45] and ConvNeXt [20].
3.3. Loss Function
In our experiments, after evaluating various loss functions [1,11], we selected ArcFace [1] as our definitive choice. ArcFace introduces a unified formula that blends the angular margin principles of both ArcFace and CosFace [11] with traditional softmax loss, providing a versatile framework for facial recognition. This adaptable formula, incorporating angular margin penalties from SphereFace [4], ArcFace [1], and CosFace [11], enhances the discriminative power of embeddings in face recognition models. The integration of these three penalty methods is succinctly captured in the following formula:
where represents the multiplicative angular margin used in SphereFace, denotes the additive angular margin found in ArcFace, and signifies the additive cosine margin from CosFace. The generalized loss expression is as follows:
where N is the number of samples; s denotes the scaling factor to control the logits’ magnitude; , and are parameters that adjust the margin effect, allowing the formula to adapt between Softmax , SphereFace , CosFace , and ArcFace ; m denotes the margin added to the angle between the feature vector of the i-th sample and the weight vector of its corresponding true class , which is central to the angular margin concept; and n represents the total number of classes.
4. Experiment
Following the Open Face Recognition pipeline [4], we trained Face-Inception-Net on a face database comprising images (X) and corresponding labels (y) in a supervised manner. We utilized a carefully designed loss function [1,3,11], which enhanced the discriminative capacity of the face image embedding. The LFW dataset served as the benchmark for evaluating face recognition performance. We introduced the dataset, including 2 training datasets and 14 test datasets, and assessed Face-Inception-Net’s effectiveness through various experiments. To ensure a fair comparison with established baselines, we maintained consistent hyperparameters during training. The experimental outcomes, achieved using learning rate decay and without model fine-tuning, are detailed further in Appendix A Table A1.
4.1. Dataset and Evaluate
For Training. We utilized CASIA-WebFace and MS-wo-RFW [5,6,7] as our training datasets. CASIA-WebFace comprises approximately 500,000 images of 1000 celebrities, featuring a wide variety of poses, lighting conditions, expressions, ages, and races. This diversity makes it an ideal dataset for developing robust face recognition systems. MS-wo-RFW, containing 3.5 million images from 7500 celebrities, includes specific test sets for African, Asian, Caucasian, and Indian demographics, facilitating region-specific evaluations. The CASIA-WebFace dataset is made available by InsightFace, while MS-wo-RFW is provided by IMAN [7].
For Testing. Given privacy concerns in face recognition, benchmarks typically encompass 5000 to 8000 face-matching tasks. We utilized 14 benchmarks for accuracy assessment. These include LFW [22], which tests face recognition algorithms under real-world conditions, AgeDB-30 [24] for age invariance, CFP-FF and CFP-FP [25] for pose variations, and VGG2-FP [26] for frontal to profile comparisons. For extreme scenarios, we used CALFW [27] to assess real-world variations, CPLFW [28] for cross-pose recognition, MLFW [29] for ethnic diversity, SLLFW [30] for low-light conditions, and TALFW [31] for temporal aging variations. Additionally, RFW [7] provided fairness metrics by evaluating racial fairness across diverse racial groups (Africa-test, Asian-test, Caucasian-test, and Indian-test). AgeDB-30, VGG2-FP, and CALFW were also pivotal in evaluating cross-age recognition performance.
For Evaluation. To thoroughly assess model performance, we utilized 14 test sets, categorizing them for detailed analysis. Our evaluation metrics include mean accuracy, ROC curve plots, and performance analysis across common, extreme, and fairness scenarios. For training, we adopted the ConvNeXt method. Unlike traditional approaches that focus solely on the optimal value, disregarding its correlation with fluctuating epoch results (where the optimum across different benchmarks rarely coincides in a single epoch), we averaged the accuracy across benchmarks for a more comprehensive performance and generalization assessment. Furthermore, we compared the optimal value and average TAR@FAR0.001 differences between our model and established models [34], like ConvNeXt and InceptionNeXt. Our model demonstrates exceptional performance in extreme scenarios and on racially balanced face datasets.
4.2. Implementation and Training Techniques
The effectiveness of ConvNeXt and InceptionNeXt shows that the final performance of the network is influenced by the training process as well as the architecture design. Transformers introduce different model designs for vision along with different training methods (such as the AdamW [18,19] optimizer) to the computer vision (CV) domain. Optimization strategies and related hyperparameter settings can help the model find better saddle points, but more hyperparameters also increase the difficulty of model training. Because of the variety of training tasks and loss functions, we experimented with different optimizers and learning rate decays. In our study, we first trained a baseline model using ResNet50 and Inception-ResNet-V1. After many rounds of pre-training, the number of rounds was set to approximately 120 epochs in the loop dataset. The optimizer adopts the Yogi optimizer proposed by Google [18,19,46,52]. By controlling the increase of the effective learning rate, better performance could be obtained under the similar convergence theory guarantee. Then, the EMA wrapper optimizer [37] was used to replace the training parameters with the moving average of the deep network training parameters. The learning rate decay uses learning rate warmup and cosine learning rate decay. The full set of hyperparameters we used can be found in Appendix A. In terms of the learning rate itself, this training method led to a 0.43% improvement in accuracy.
In addition, the improvement in training speed of technical teams, such as Mixed Precision [53], XLA [54], and TF32, is huge, reducing the time cost by more than half. This shows that training skills can affect performance in face recognition. We used a fixed training method with the same hyperparameters throughout the comparative training process, and each reported TAR@FAR0.001 is the average of all benchmarks obtained from training. The experiments were implemented in Tensorflow and performed on a Linux operating system using two Nvidia A100-40G GPUs.
4.3. Result
Training on CASIA-WebFace and MS-wo-RFW. Our initial learning rate was lr = 0.002, and the epoch was 120. There was a 1/10 × epoch linear warmup and then a cosine decay schedule; the learning rate decay multiple was 1/10. Batchsize = 256 for the CASIA-WebFace dataset, and Batchsize = 512 for the MS-wo-RFW dataset. We did not use data augmentation. For regularization, we used label smoothing [9], stochastic depth [55], and weight decay. Like ConvNeXt, we also used LayerScale [56] in the stem, a technique that helps train deep models. We used the exponential moving average (EMA) [57] because we find that it facilitates the overfitting of larger models. Our code is based on the TensorFlow [58,59,60] and TensorFlow Addons [60] libraries.
Figure 3 and Figure 4 below show our first experiments where the values in the MLFW, SLLFW, and TALFW test sets were not used. We compare the improved Face-Inception-Net model with the state-of-the-art ConvNeXt and InceptionNeXt models. As shown in Figure 3 and Figure 4, our proposed model shows strong competitiveness on both the CASIA-WebFace and MS-wo-RFW datasets. With similar model sizes and flops, Face-Inception-Net consistently outperforms ConvNeXt and InceptionNeXt in terms of accuracy. And, comparable experimental results were obtained on two different scale datasets, CASIA-WebFace and MS-wo-RFW.
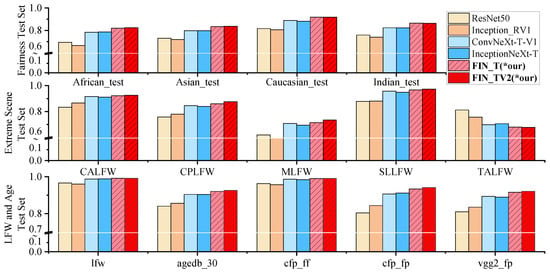
Figure 3.
The performance of the model using CASIA-WebFace training. The specific data can be seen in the Appendix A Table A2. We evaluated the model performance according to three aspects: LFW and age test set, extreme scene test set, and fairness test set. Except for the TALFW test set, our model achieves the best performance on all other benchmarks.
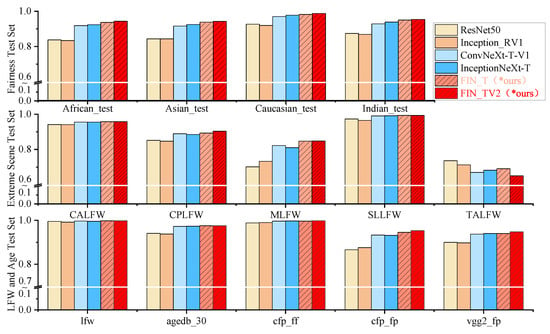
Figure 4.
The performance of the model using MS-wo-RFW training. The specific data can be seen in Appendix A Table A3. The model trained with MS-wo-RFW outperforms CASIA-WebFace in all aspects and is also largely consistent in distribution, demonstrating the validity of our experiments. We evaluated the model performance according to three aspects: LFW and age test set, extreme scene test set, and fairness test set. Except for the TALFW test set, our model achieved the best performance on all other benchmarks.
The training results of the CASIA-WebFace dataset are shown in Figure 3 and Figure 5. The accuracy Acc-mean(TAR@FAR0.001) obtained by the ResNet and Inception-ResNet models are 0.8263, 0.8137, 0.8157, and 0.8167, respectively. This is the result of using the old model training. Then, we reproduced ConvNeXt-Tiny and InceptionNeXt-Tiny, and the obtained accuracy was 0.8807 and 0.8833, respectively. So far, we conclude that using Inception to transform ConvNeXt is effective in the field of face recognition. We designed five models of Face-Inception-Net (FIN-T, FIN-S, FIN-B, FIN-TV2, and FIN-SV2), among which FIN-TV2 obtained the highest Acc-mean(TAR@FAR0.001) value of 0.9106. When we experimented with deeper networks, the performance of the model decreased, such as the small and basic models of ConvNeXt and InceptionNeXt. The FIN-S, FIN-B, and FIN-SV2 models we developed also showed a decrease in model performance. In this regard, we suggest that the size of the CASIA-WebFace dataset is too small and the complexity of the model is too high, resulting in overfitting. Furthermore, the performance of our model on the TALFW (Transferable Adversarial Labeled Faces in the Wild) dataset is worse, which is a bad sign that our model is not well-defended and vulnerable to attacks.

Figure 5.
ROC performance on CASIA-WebFace for related models. We divided the benchmark into five aspects to plot the ROC curve and analyze the model’s performance on various specific tasks, i.e., ALL Test Set ROC Curve, LFW and common Test Set ROC Curve, Extreme scene Test Set ROC Curve, Fairness Test Set ROC Curve, and Age Test Set ROC Curve. Our model achieves optimal performance on all ROC curves, as seen in the locally zoomed images. In one of the ROC curves for the extreme scene, the negative effect of TALFW is masked by the inclusion of five datasets.
The results of training on the MS-wo-RFW dataset are shown in Figure 4 and Figure 6. The accuracy Acc-mean(TAR@FAR0.001) obtained by the ResNet and Inception-ResNet models are 0.9040, 0.8878, 0.9059, and 0.8933, respectively. Training on the CASIA-WebFace dataset, we found that the use of a deep model resulted in performance degradation. The result of training with ConvNeXt is that the performance degradation of the model is suppressed but not completely eliminated. The results of the InceptionNeXt model improved compared to ConvNeXt, but the results were unstable. We propose that the model achieved an improvement in accuracy when the stage was (3,3,9,3) and (5,5,10,5). And, under the deeper small and base models, the accuracy of our model improved, which solved the problem of model performance degradation. In comparison, under the same parameters of our model, the accuracy of the FIN-T model is 0.9533, which is higher than the 0.9477 and 0.9494 of ConvNeXt-Tiny and InceptionNeXt-Tiny. The highest performance of FIN-SV2 is 0.9599, which is the best result in our experiments. Furthermore, the performance of our model on the TALFW (Transferable Adversarial Labeled Faces in the Wild) dataset leads to the same conclusion as on CASIA-WebFace.

Figure 6.
ROC performance on MS-wo-RFW for related models. The use of MS-wo-RFW training results in a better manipulative treatment than CASIA-WebFace, which can be seen to have a better effect on the Large-scale data sets. The distribution of other ROC curves is similar for the model trained on the two datasets.
On the fairness and extreme scene test sets. Our findings exceed those achieved by IMAN, based on comparative data sourced from their paper. The analysis shows our model, FIN-SV2, significantly surpasses previous models in accuracy while reducing racial bias. This improvement is particularly notable in test sets for African, Asian, and Indian demographics, where our model achieved accuracies over 0.94. These results, detailed in Table 2, suggest that using large datasets can mitigate racial bias in model performance effectively. Additionally, we assessed the model’s accuracy in various special scenarios, with results shown as ROC curves in Figure 5 and Figure 6. The experiments confirm that our improvements enhance facial recognition performance in complex scenarios. An analysis of the difference between optimal and average values further demonstrates the versatility and robustness of our approach.
Table 2.
Face fairness test set performance. The first three sets of data in the table come from the paper. The rest of the data are obtained from our experiments.
Optimal and mean analysis. In our experiments, we used several benchmarks and averaged all TAR@FAR0.001 results for consistent accuracy evaluation. The analysis showed a difference between the optimal and average values for models trained on various datasets, as shown in Table 3. Using a larger training set reduces this gap. Our FIN-Tiny and FIN-Tiny-V2 models outperformed others on the CASIA-WebFace dataset, whereas the InceptionNeXt series was more effective with the MS-wo-RFW dataset, highlighting our model’s improved performance. Further examination of the model structure revealed that a deeper stacked convolution structure boosts feature extraction, thus enhancing model performance. The gap between the optimal and average values reflects the model’s generalizability, with a smaller gap indicating stronger stability and generalizability across different datasets. However, this balance is not as optimal as with InceptionNeXt, indicating room for improvement.
Table 3.
The gap between the optimal and average performance reflects the model’s generality. The difference between the model’s optimal and average performance is presented in the table for the Casia and RFW datasets, indicating the disparity between the best and average values. This metric reflects the model’s generalizability; a smaller value signifies stronger generalizability.
Ablation studies. Table 4 highlights the three main improvements in our model training: the design of FIN-Block-A and FIN-Block-B, model structure enhancements, and training techniques. We conducted Face-Inception-Net ablation studies using FIN-Tiny as a baseline, focusing on the utilization of different FIN-Blocks at various stages. Specifically, ConvNeXt-proposed blocks are employed in the stem, while in the subsequent three stages, we systematically remove each block to assess our module’s effectiveness. Notably, removing the FIN-Block-B-11 model in stage 3 results in the most significant performance drop, from 90.48 to 89.96. These experiments underscore the importance of these blocks, as large convolution kernels increase the model’s receptive field, enabling deeper feature extraction and achieving an optimal balance between model parameters and performance.
Table 4.
Ablation for Face-Inception-Net on CASIA-WebFace face recognition benchmark. FIN-Tiny was utilized as the baseline for the ablation study. Acc-mean(TAR@FAR0.001) accuracy on the validation set is reported.
As shown in Table 4, the enhancement of our model training primarily encompasses three aspects. The first is changing the Inception stage configuration from (3,3,9,3) to (5,5,10,5), leading to the proposal of FIN-Tiny-V2. Furthermore, we adjusted the dimensions from (96,192,384,786) to (192,384,576,786), introducing FIN-Small-V2. This experiment validated our improvement direction, showing increased parameters and FLOPs for FIN-Tiny-V2 alongside enhanced model performance. Specifically, in the CASIA-WebFace database, FIN-Tiny-V2 outperformed both FIN-Small and FIN-Base, demonstrating the superiority of the (5,5,10,5) configuration for face recognition. FIN-Small-V2 also delivered remarkable results on the MS-wo-RFW dataset, with fewer parameters yet significant performance gains compared to FIN-Base. This confirms that, in face recognition, widening the model is more efficacious than deepening it, aligning with conclusions from the inception paper. Additionally, the adoption of a learning rate warmup and decay strategy, as opposed to a fixed learning rate, further improved our model accuracy by 0.43%.
5. Conclusions and Future Work
This study introduces Face-Inception-Net, utilizing advanced convolution techniques for improved performance. Unlike other architectures, FIN-Block-A and FIN-Block-B offer versatile composition, enabling swift adjustments in model width and depth for various tasks. FIN-Block-B’s extensive convolutional kernel stack provides a wide spatial receptive field and strong deep feature embedding, achieving an ideal balance between performance and model size. Our experiments showed that expanding the model and adjusting stage sizes significantly enhances face recognition performance. Moreover, results from the extreme scene and fairness test sets significantly demonstrate our method’s versatility and effectiveness.
Our findings indicate that incorporating fine-grained blocks at various stages enhances performance. These results were achieved in a single training session without subsequent fine-tuning, indicating the potential for further optimization and mean analysis improvement relative to InceptionNeXt. Future efforts will focus on simplifying the model structure and integrating pre-training with fine-tuning to maximize model performance.
Author Contributions
Conceptualization, Q.Z. and M.Z.; Methodology, Q.Z.; Software, X.W.; Validation, X.W.; Investigation, L.L.; Data curation, L.L.; Writing—original draft, Q.Z. and X.W.; Writing—review & editing, M.Z.; Visualization, P.L.; Supervision, M.Z.; Funding acquisition, Q.Z. and M.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the Key R&D Project of Henan Province (No. 231111222100), the Science and Technology Research Project of Henan Province (No. 222102320039), the Collaborative Innovation Project of Zhengzhou (No. 22ZZRDZX41) and the High-level Talent Fund Project of Henan University of Technology (No. BS2019027).
Data Availability Statement
We used two training sets CASIA-WebFace and MS-wo-RFW as well as LFW, AgeDB-30, CFP (CFP-FF, CFP-FP), MLFW, SLLFW, TALFW, RFW (Africa-test, Asian-test, Caucasian-test, and Indian-tests) 14 validation datasets. CASIA-WebFace train dataset and LFW, AgeDB-30, CFP (CFP-FF, CFP-FP), MLFW, SLLFW, TALFW, RFW test dataset analysed during the current study are available in the Github repository, https://github.com/deepinsight/insightface/wiki/Dataset-Zoo (accessed on 26 February 2024). MS-wo-RFW and RFW data that support the findings of this study are available from Pattern Recognition and Intelligent System Laboratory (PRIS Lab) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of Pattern Recognition and Intelligent System Laboratory (PRIS Lab). This data set can be obtained by contacting wangmei1@bupt.edu.cn. Details can be found at http://whdeng.cn/RFW/Trainingdataste.html (accessed on 26 February 2024).
Acknowledgments
We offer thanks to the public computing service platform of Henan University of Technology for providing computing power support. We also thank Pattern Recognition and Intelligent System Laboratory (PRIS Lab), Beijing University of Posts and Telecommunications, for providing the dataset.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In this appendix, we provide the experimental results in Table A2 and Table A3 and hyperparameters in Table A1.
Table A1.
Hyperparameters of Face-Inception-Net on CASIA-WebFace and MS-wo-RFW face recognition.
Table A1.
Hyperparameters of Face-Inception-Net on CASIA-WebFace and MS-wo-RFW face recognition.
| Face-Inception-Net | ||
|---|---|---|
| CASIA-WebFace | MS-wo-RFW | |
| Input resolution | 112 × 112 | 112 × 112 |
| Epochs | 120 | 120 |
| Batch size | 256 | 512 |
| Optimizer | Yogi | Yogi |
| Learning rate | 0.002 | 0.0025 |
| Learning rate decay | Cosine 0.1 | Cosine 0.1 |
| Warmup epochs | 0.1 × epochs | 0.1 × epochs |
| Weight decay | None | None |
| Dropout | 0.6 | 0.6 |
| LayerScale initialization | 1.00 × 10−6 | 1.00 × 10−6 |
| EMA decay rate | 0.99 | 0.99 |
Table A2.
Using the performance of the model trained by CASIA-WEBFACE, we recorded the accuracy of the model on each test set, including the optimal value and the optimal average value obtained in the round. * in the model brackets represents the Optim Value of the training process. Since the extreme scene face recognition dataset was not fully used during training, there are no optimal data for MLFW, SLLFW and TALFW in the table.
Table A2.
Using the performance of the model trained by CASIA-WEBFACE, we recorded the accuracy of the model on each test set, including the optimal value and the optimal average value obtained in the round. * in the model brackets represents the Optim Value of the training process. Since the extreme scene face recognition dataset was not fully used during training, there are no optimal data for MLFW, SLLFW and TALFW in the table.
| Average Value/Optim Value (*) | ResNet50 | ResNet101 | Incep-RV1 | Incep-RV2 | Convn Ext-T | Convn Ext-S | Convn Ext-B | Innext-T | Innext-S | Innext-B | FIN-T | FIN-S | FIN-B | FIN-TV2 | FIN-SV2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| lfw | 96.62 | 96.90 | 96.05 | 96.63 | 98.82 | 98.48 | 98.42 | 98.90 | 98.60 | 98.38 | 99.22 | 99.05 | 98.92 | 99.20 | 99.05 |
| agedb_30 | 84.05 | 83.60 | 85.62 | 83.27 | 90.43 | 89.60 | 88.98 | 90.38 | 89.88 | 89.60 | 92.07 | 91.48 | 91.85 | 92.65 | 92.43 |
| cfp_ff | 96.31 | 96.27 | 95.70 | 95.87 | 98.73 | 97.80 | 98.13 | 98.40 | 98.03 | 98.11 | 99.06 | 98.56 | 98.56 | 99.16 | 98.89 |
| cfp_fp | 80.37 | 77.89 | 84.37 | 79.27 | 90.67 | 89.97 | 89.79 | 91.19 | 88.50 | 88.76 | 93.39 | 91.67 | 91.49 | 94.14 | 94.06 |
| calfw | 83.35 | 84.88 | 86.57 | 86.62 | 91.55 | 90.22 | 89.13 | 91.10 | 89.87 | 90.15 | 92.13 | 91.85 | 91.83 | 92.48 | 92.23 |
| cplfw | 75.82 | 76.87 | 77.95 | 75.47 | 84.48 | 83.45 | 82.83 | 83.95 | 82.67 | 82.48 | 86.00 | 85.45 | 85.72 | 87.53 | 87.20 |
| vgg2_fp | 80.98 | 81.54 | 83.52 | 80.78 | 89.42 | 89.30 | 88.10 | 88.92 | 87.52 | 88.54 | 91.58 | 91.10 | 90.96 | 92.16 | 92.38 |
| African_test | 69.35 | 69.53 | 66.50 | 68.28 | 78.28 | 75.48 | 75.93 | 78.58 | 76.83 | 75.18 | 81.92 | 79.58 | 77.78 | 82.43 | 81.25 |
| Asian_test | 73.00 | 72.88 | 71.88 | 71.35 | 79.70 | 77.52 | 78.10 | 79.75 | 78.68 | 77.03 | 83.37 | 80.23 | 79.92 | 83.62 | 82.17 |
| Caucasian_test | 81.63 | 82.37 | 80.57 | 81.78 | 88.88 | 86.78 | 86.40 | 88.20 | 87.32 | 86.10 | 91.82 | 89.62 | 89.30 | 91.85 | 90.18 |
| Indian_test | 75.88 | 76.30 | 74.00 | 75.92 | 82.32 | 80.17 | 80.33 | 82.23 | 82.18 | 81.10 | 86.45 | 83.88 | 83.15 | 86.33 | 85.50 |
| MLFW | 61.88 | 58.95 | 59.83 | 58.00 | 70.75 | 66.13 | 67.20 | 69.43 | 66.75 | 67.62 | 71.42 | 70.18 | 70.48 | 73.48 | 71.57 |
| SLLFW | 87.78 | 87.98 | 88.03 | 88.15 | 95.77 | 93.95 | 93.98 | 94.85 | 94.82 | 93.57 | 96.72 | 96.02 | 95.83 | 97.25 | 96.85 |
| TALFW | 81.17 | 83.95 | 75.67 | 75.67 | 69.78 | 72.25 | 71.35 | 70.58 | 73.58 | 73.02 | 67.98 | 72.85 | 73.40 | 67.73 | 67.35 |
| lfw (*) | 96.92 | 97.10 | 96.95 | 97.07 | 98.87 | 98.48 | 98.45 | 98.95 | 98.65 | 98.38 | 99.27 | 99.07 | 99.10 | 99.37 | 99.27 |
| agedb_30 (*) | 86.50 | 84.25 | 84.53 | 83.50 | 90.75 | 90.07 | 89.82 | 91.45 | 90.52 | 90.50 | 93.48 | 92.23 | 91.93 | 93.42 | 93.02 |
| cfp_ff (*) | 96.87 | 96.01 | 96.34 | 96.27 | 98.39 | 98.00 | 98.13 | 98.56 | 98.19 | 98.07 | 98.96 | 98.59 | 98.60 | 99.00 | 98.97 |
| cfp_fp (*) | 84.39 | 81.91 | 83.47 | 80.20 | 92.67 | 90.61 | 90.10 | 91.60 | 90.29 | 89.59 | 93.37 | 92.37 | 91.77 | 95.00 | 94.36 |
| calfw (*) | 87.77 | 86.62 | 86.62 | 85.53 | 91.00 | 90.50 | 90.73 | 91.30 | 91.00 | 90.53 | 92.97 | 91.90 | 91.95 | 92.85 | 92.67 |
| cplfw (*) | 77.53 | 75.47 | 76.52 | 77.70 | 84.80 | 83.72 | 83.22 | 84.50 | 83.37 | 83.03 | 86.77 | 85.38 | 85.72 | 87.78 | 87.57 |
| vgg2_fp (*) | 83.78 | 82.24 | 82.66 | 81.42 | 90.36 | 89.30 | 88.78 | 89.34 | 88.80 | 88.76 | 91.90 | 91.10 | 90.96 | 92.76 | 92.68 |
| African_test (*) | 69.32 | 68.88 | 69.72 | 70.75 | 77.25 | 76.47 | 76.48 | 79.00 | 76.83 | 75.22 | 82.08 | 79.87 | 78.95 | 82.88 | 81.43 |
| Asian_test (*) | 73.18 | 72.97 | 74.50 | 72.77 | 79.70 | 78.17 | 78.07 | 79.78 | 78.90 | 78.87 | 83.18 | 80.95 | 81.05 | 83.25 | 82.17 |
| Caucasian_test (*) | 82.23 | 81.75 | 81.97 | 82.22 | 88.27 | 87.30 | 87.37 | 88.65 | 87.55 | 86.98 | 91.07 | 89.63 | 89.58 | 92.07 | 91.08 |
| Indian_test (*) | 76.78 | 75.82 | 76.82 | 76.87 | 82.30 | 81.95 | 81.72 | 83.12 | 82.45 | 81.87 | 85.78 | 84.70 | 83.80 | 86.38 | 86.12 |
| MLFW (*) | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
| SLLFW (*) | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
| TALFW (*) | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
Table A3.
Using the performance of the model trained by MS-wo-RFW, we recorded the accuracy of the model on each test set, including the optimal value and the optimal average value obtained in the round. * in the model brackets represents the Optim Value of the training process. Since the extreme scene face recognition dataset was not fully used during training, there are no optimal data for MLFW, SLLFW and TALFW in the table.
Table A3.
Using the performance of the model trained by MS-wo-RFW, we recorded the accuracy of the model on each test set, including the optimal value and the optimal average value obtained in the round. * in the model brackets represents the Optim Value of the training process. Since the extreme scene face recognition dataset was not fully used during training, there are no optimal data for MLFW, SLLFW and TALFW in the table.
| Average Value Optim Value (*) | Resnet 50 | Resnet 101 | Inception-RV1 | Inception-RV2 | Convn Ext-T | Convn Ext-S | Convn Ext-B | Innext-T | Innext-S | Innext-B | FIN-T | FIN-S | FIN-B | FIN-TV2 | FIN-SV2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| lfw | 99.47 | 99.12 | 99.15 | 98.83 | 99.65 | 99.60 | 99.70 | 99.55 | 99.72 | 99.58 | 99.63 | 99.70 | 99.73 | 99.73 | 99.75 |
| agedb_30 | 94.03 | 91.63 | 93.75 | 92.33 | 97.20 | 97.65 | 97.10 | 97.32 | 97.47 | 97.47 | 97.30 | 97.37 | 97.50 | 97.72 | 97.52 |
| cfp_ff | 98.80 | 98.24 | 98.93 | 98.31 | 99.60 | 99.61 | 99.59 | 99.71 | 99.73 | 99.73 | 99.73 | 99.69 | 99.61 | 99.77 | 99.81 |
| cfp_fp | 86.60 | 86.39 | 87.60 | 87.46 | 93.29 | 93.50 | 93.37 | 93.14 | 92.86 | 92.71 | 94.54 | 95.01 | 94.50 | 95.54 | 95.26 |
| calfw | 94.15 | 93.13 | 94.08 | 92.52 | 95.53 | 95.75 | 95.55 | 95.55 | 95.67 | 95.62 | 95.67 | 95.82 | 95.78 | 95.52 | 95.82 |
| cplfw | 85.20 | 84.38 | 84.65 | 83.02 | 88.93 | 89.47 | 88.97 | 88.50 | 89.02 | 88.40 | 89.17 | 89.77 | 89.30 | 90.03 | 90.38 |
| vgg2_fp | 89.98 | 89.74 | 89.74 | 89.28 | 93.70 | 93.50 | 92.82 | 93.92 | 93.48 | 93.56 | 93.90 | 94.12 | 94.02 | 94.40 | 94.74 |
| African_test | 83.78 | 81.68 | 83.42 | 80.23 | 91.88 | 91.75 | 91.72 | 92.35 | 92.35 | 93.22 | 93.10 | 94.07 | 93.72 | 93.52 | 94.33 |
| Asian_test | 84.38 | 81.78 | 84.38 | 80.27 | 91.60 | 91.33 | 90.70 | 92.52 | 92.72 | 92.47 | 93.30 | 93.53 | 93.80 | 93.65 | 94.27 |
| Caucasian_test | 92.70 | 91.32 | 91.92 | 90.22 | 97.02 | 97.42 | 97.03 | 97.77 | 98.00 | 97.73 | 98.02 | 98.27 | 98.22 | 98.53 | 98.73 |
| Indian_test | 87.40 | 84.25 | 86.88 | 83.48 | 92.88 | 92.98 | 92.62 | 93.92 | 93.93 | 94.23 | 94.63 | 94.88 | 95.02 | 94.85 | 95.33 |
| MLFW | 70.20 | 70.13 | 73.27 | 70.23 | 82.23 | 83.53 | 83.50 | 81.07 | 82.83 | 81.88 | 85.12 | 85.90 | 84.73 | 85.93 | 84.82 |
| SLLFW | 97.33 | 96.08 | 96.53 | 95.53 | 99.03 | 99.07 | 99.08 | 99.18 | 99.32 | 99.20 | 99.20 | 99.47 | 99.33 | 99.38 | 99.38 |
| TALFW | 73.58 | 77.38 | 71.27 | 78.02 | 66.98 | 69.33 | 67.68 | 68.18 | 69.42 | 67.18 | 64.72 | 69.65 | 69.12 | 66.28 | 65.02 |
| lfw (*) | 99.42 | 99.12 | 99.47 | 99.27 | 99.68 | None | 99.72 | 99.68 | 99.72 | 99.73 | 99.78 | None | 99.77 | 99.78 | 99.78 |
| agedb_30 (*) | 94.10 | 92.47 | 94.28 | 92.85 | 97.32 | None | 97.45 | 97.32 | 97.48 | 97.53 | 97.47 | None | 97.62 | 97.72 | 97.60 |
| cfp_ff (*) | 99.00 | 98.36 | 99.09 | 98.60 | 99.77 | None | 99.67 | 99.77 | 99.77 | 99.76 | 99.74 | None | 99.74 | 99.79 | 99.83 |
| cfp_fp (*) | 88.73 | 88.07 | 87.67 | 87.34 | 93.24 | None | 93.37 | 93.24 | 93.31 | 92.71 | 94.63 | None | 94.50 | 95.54 | 95.69 |
| calfw (*) | 94.12 | 92.97 | 94.17 | 93.55 | 95.77 | None | 95.68 | 95.77 | 95.72 | 95.78 | 95.72 | None | 95.87 | 95.75 | 95.88 |
| cplfw (*) | 84.97 | 83.87 | 85.37 | 84.38 | 88.82 | None | 89.15 | 88.82 | 89.35 | 88.60 | 89.63 | None | 89.82 | 90.22 | 90.47 |
| vgg2_fp (*) | 90.36 | 89.52 | 90.60 | 89.66 | 93.92 | None | 93.12 | 93.92 | 93.48 | 93.84 | 94.22 | None | 94.42 | 94.62 | 95.02 |
| African_test (*) | 83.35 | 80.25 | 84.13 | 81.70 | 92.78 | None | 91.72 | 92.78 | 92.67 | 93.22 | 93.28 | None | 93.95 | 94.32 | 95.05 |
| Asian_test (*) | 84.42 | 81.37 | 84.83 | 82.25 | 92.60 | None | 91.30 | 92.60 | 92.80 | 92.73 | 93.50 | None | 93.83 | 93.67 | 94.27 |
| Caucasian_test (*) | 92.93 | 90.13 | 93.17 | 91.43 | 97.95 | None | 97.03 | 97.95 | 98.17 | 97.92 | 98.25 | None | 98.43 | 98.53 | 98.78 |
| Indian_test (*) | 87.33 | 84.47 | 87.53 | 84.98 | 94.22 | None | 93.05 | 94.22 | 94.12 | 94.38 | 94.72 | None | 95.40 | 95.43 | 95.63 |
| MLFW (*) | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
| SLLFW (*) | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
| TALFW (*) | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
References
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Wang, M.; Deng, W. Mitigating bias in face recognition using skewness-aware reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9322–9331. [Google Scholar]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W.; Hu, J.; Tao, X.; Huang, Y. Racial faces in the wild: Reducing racial bias by information maximization adaptation network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 692–702. [Google Scholar]
- Zhong, Y.; Deng, W.; Hu, J.; Zhao, D.; Li, X.; Wen, D. SFace: Sigmoid-constrained hypersphere loss for robust face recognition. Proc. IEEE Trans. Image Process. 2021, 30, 2587–2598. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Wang, S.; Liu, P. A New Feature Extraction Method Based on the Information Fusion of Entropy Matrix and Covariance Matrix and Its Application in Face Recognition. Entropy 2015, 17, 4664–4683. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Zhang, Q. Attention-Mechanism-Based Models for Unconstrained Face Recognition with Mask Occlusion. Electronics 2023, 12, 3916. [Google Scholar] [CrossRef]
- Truong, T.D.; Duong, C.N.; Quach, K.G.; Le, N.; Bui, T.D.; Luu, K. LIAAD: Lightweight attentive angular distillation for large-scale age-invariant face recognition. Neurocomputing 2023, 543, 126198. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X.; Zhao, Y.; Wen, Y.; Tang, Z.; Liu, M. Facial prior guided micro-expression generation. IEEE Trans. Image Process. 2023, 33, 525–540. [Google Scholar] [CrossRef] [PubMed]
- Shahreza, H.O.; Marcel, S. Template inversion attack against face recognition systems using 3d face reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 19662–19672. [Google Scholar]
- Yang, H.; Zhu, H.; Wang, Y.; Huang, M.; Shen, Q.; Yang, R.; Cao, X. Facescape: A large-scale high quality 3d face dataset and detailed riggable 3d face prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 601–610. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. 2018. Available online: https://api.semanticscholar.org/CorpusID:3312944 (accessed on 26 February 2024).
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. arXiv 2023, arXiv:2303.16900. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in’Real-Life’Images: Detection, Alignment, and Recognition, Marseille, France, 12–18 October 2008. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. Agedb: The first manually collected, in-the-wild age database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 51–59. [Google Scholar]
- Sengupta, S.; Chen, J.C.; Castillo, C.; Patel, V.M.; Chellappa, R.; Jacobs, D.W. Frontal to profile face verification in the wild. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Zheng, T.; Deng, W.; Hu, J. Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments. arXiv 2017, arXiv:1708.08197. [Google Scholar]
- Zheng, T.; Deng, W. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments. Beijing Univ. Posts Telecommun. Tech. Rep. 2018, 5, 1–6. [Google Scholar]
- Wang, C.; Fang, H.; Zhong, Y.; Deng, W. Mlfw: A database for face recognition on masked faces. In Proceedings of the Chinese Conference on Biometric Recognition, Beijing, China, 11–13 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 180–188. [Google Scholar]
- Deng, W.; Hu, J.; Zhang, N.; Chen, B.; Guo, J. Fine-grained face verification: FGLFW database, baselines, and human-DCMN partnership. Pattern Recognit. 2017, 66, 63–73. [Google Scholar] [CrossRef]
- Zhong, Y.; Deng, W. Towards transferable adversarial attack against deep face recognition. Proc. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1452–1466. [Google Scholar] [CrossRef]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE conference on computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Zhang, M.; Lucas, J.; Ba, J.; Hinton, G.E. Lookahead optimizer: K steps forward, 1 step back. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5270–5279. [Google Scholar]
- Zhang, M.M.; Shang, K.; Wu, H. Learning deep discriminative face features by customized weighted constraint. Neurocomputing 2019, 332, 71–79. [Google Scholar] [CrossRef]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE international Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- Li, J.; Xia, X.; Li, W.; Li, H.; Wang, X.; Xiao, X.; Wang, R.; Zheng, M.; Pan, X. Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. arXiv 2022, arXiv:2207.05501. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Elliott, D.; Otero, C.E.; Wyatt, S.; Martino, E. Tiny transformers for environmental sound classification at the edge. arXiv 2021, arXiv:2103.12157. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zaheer, M.; Reddi, S.; Sachan, D.; Kale, S.; Kumar, S. Adaptive methods for nonconvex optimization. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Zhong, Y.; Deng, W. Face transformer for recognition. arXiv 2021, arXiv:2103.14803. [Google Scholar]
- Ge, Y.; Liu, H.; Du, J.; Li, Z.; Wei, Y. Masked face recognition with convolutional visual self-attention network. Neurocomputing 2023, 518, 496–506. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Benz, P.; Ham, S.; Zhang, C.; Karjauv, A.; Kweon, I. Adversarial robustness comparison of vision transformer and mlp-mixer to cnns. arXiv 2021, arXiv:2110.02797. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade: Second Edition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed precision training. arXiv 2017, arXiv:1710.03740. [Google Scholar]
- Abdelfattah, A.; Anzt, H.; Boman, E.G.; Carson, E.; Cojean, T.; Dongarra, J.; Fox, A.; Gates, M.; Higham, N.J.; Li, X.S.; et al. A survey of numerical linear algebra methods utilizing mixed-precision arithmetic. Int. J. High Perform. Comput. Appl. 2021, 35, 344–369. [Google Scholar] [CrossRef]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part IV 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 646–661. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with image transformers. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 32–42. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control. Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Abadi, M. TensorFlow: Learning functions at scale. In Proceedings of the 21st ACM SIGPLAN International Conference on Functional Programming, Nara, Japan, 18–22 September 2016; p. 1. [Google Scholar]
- Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, USENIX Association, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Silaparasetty, N. Machine Learning Concepts with Python and the Jupyter Notebook Environment: Using Tensorflow 2.0; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).