

Self-Supervised Learning for Online Anomaly Detection in High-Dimensional Data Streams

Abstract
1. Introduction
- Two variations of a data-driven, neighbor-based, and sequential anomaly detection method called NOMAD are proposed for both semi-supervised and supervised settings depending on the availability of the data;
- The computational complexity and asymptotic false alarm rate of NOMAD are analyzed, and a procedure for selecting a proper decision threshold to satisfy a desired false alarm rate is provided;
- A self-supervised online learning scheme that can effectively detect both known and unknown anomaly types by incorporating the newly detected anomalies into the training set is introduced;
- Finally, the performance of the proposed methods are evaluated in two real-world cybersecurity datasets.
2. Related Work
3. Problem Formulation
4. Proposed Methods
4.1. NOMAD Algorithm
| Algorithm 1 The proposed NOMAD procedure |
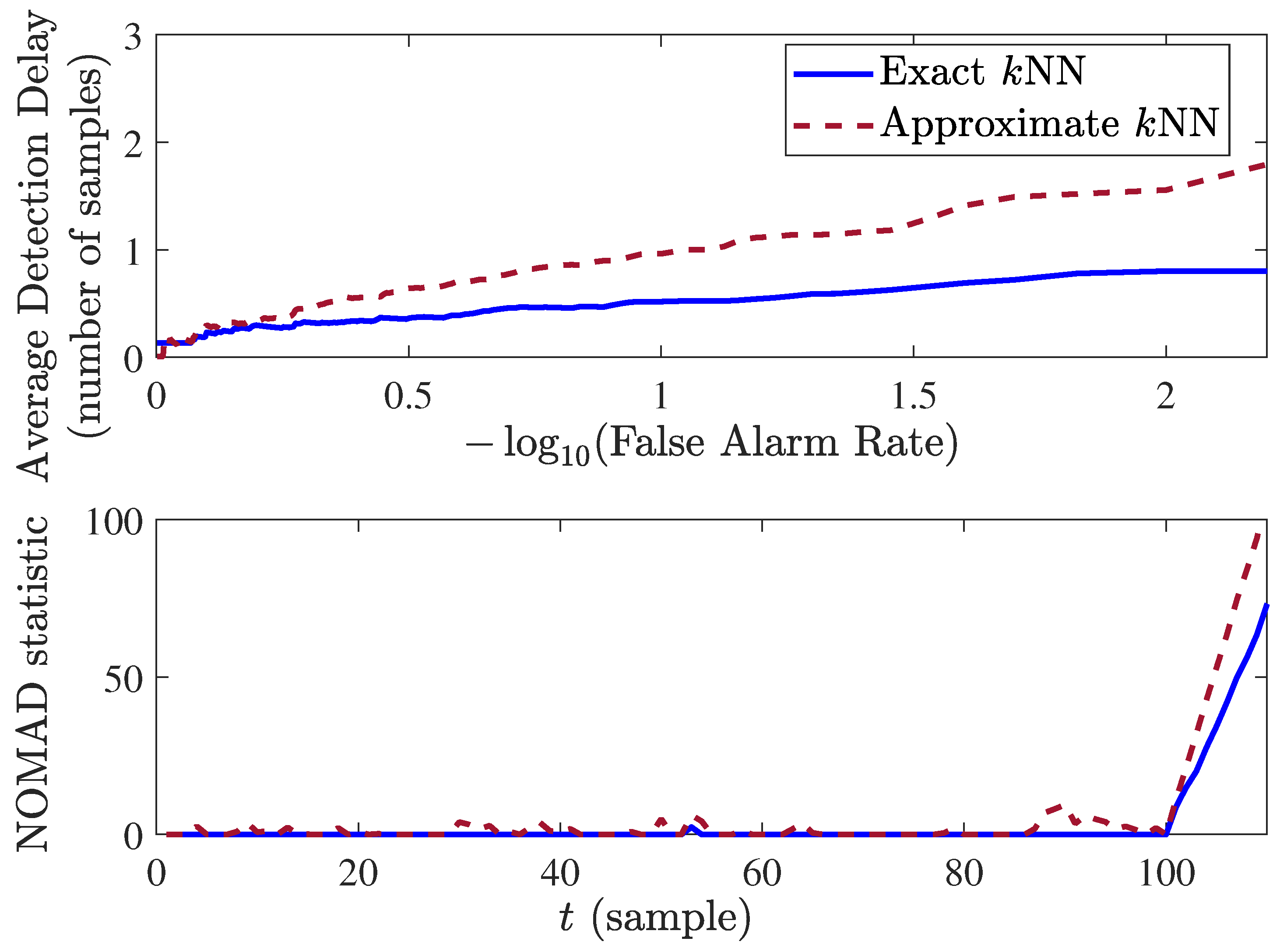
4.2. Analysis of NOMAD
4.3. An Extension: NOMADs
4.4. Unified Framework for Online Learning
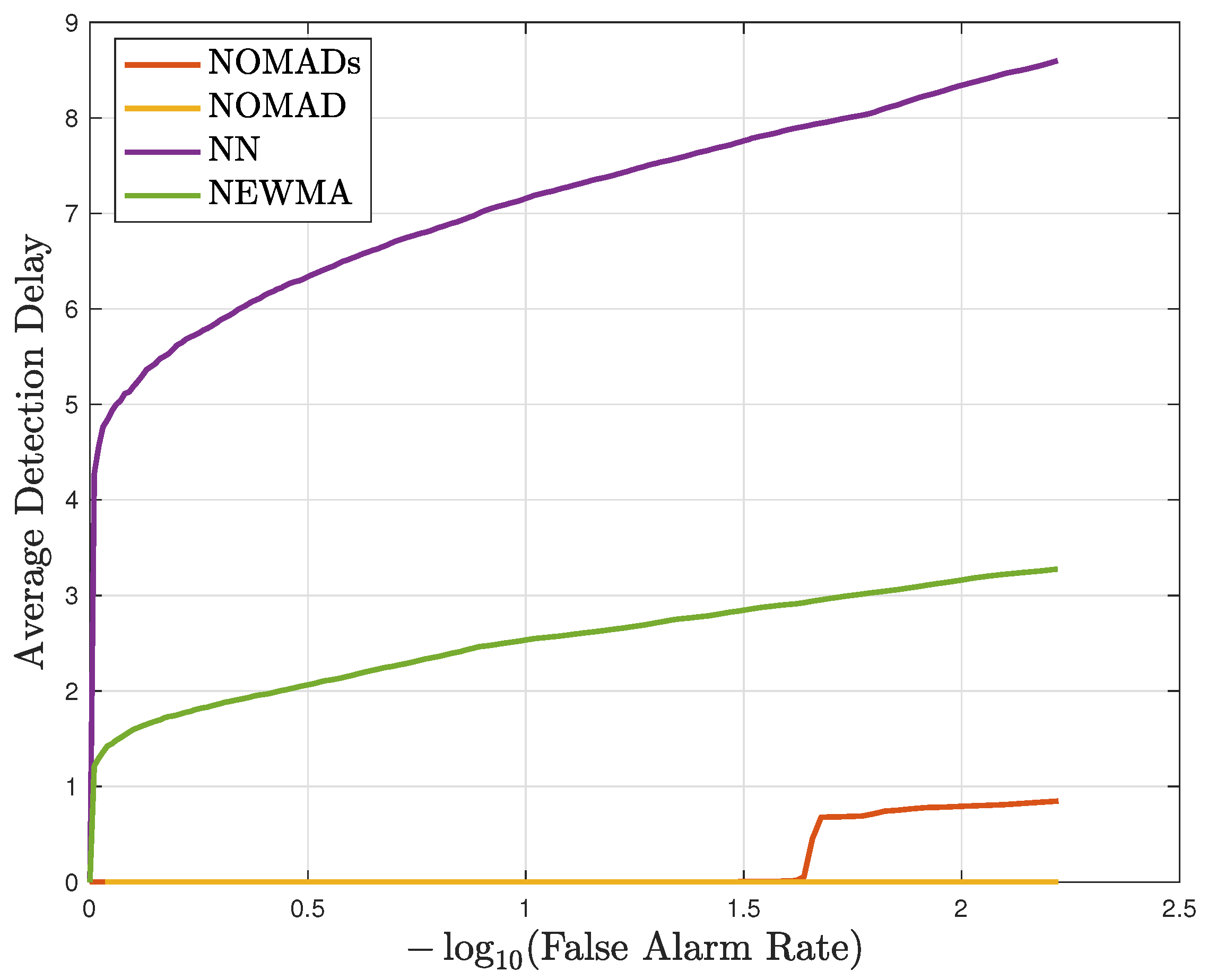
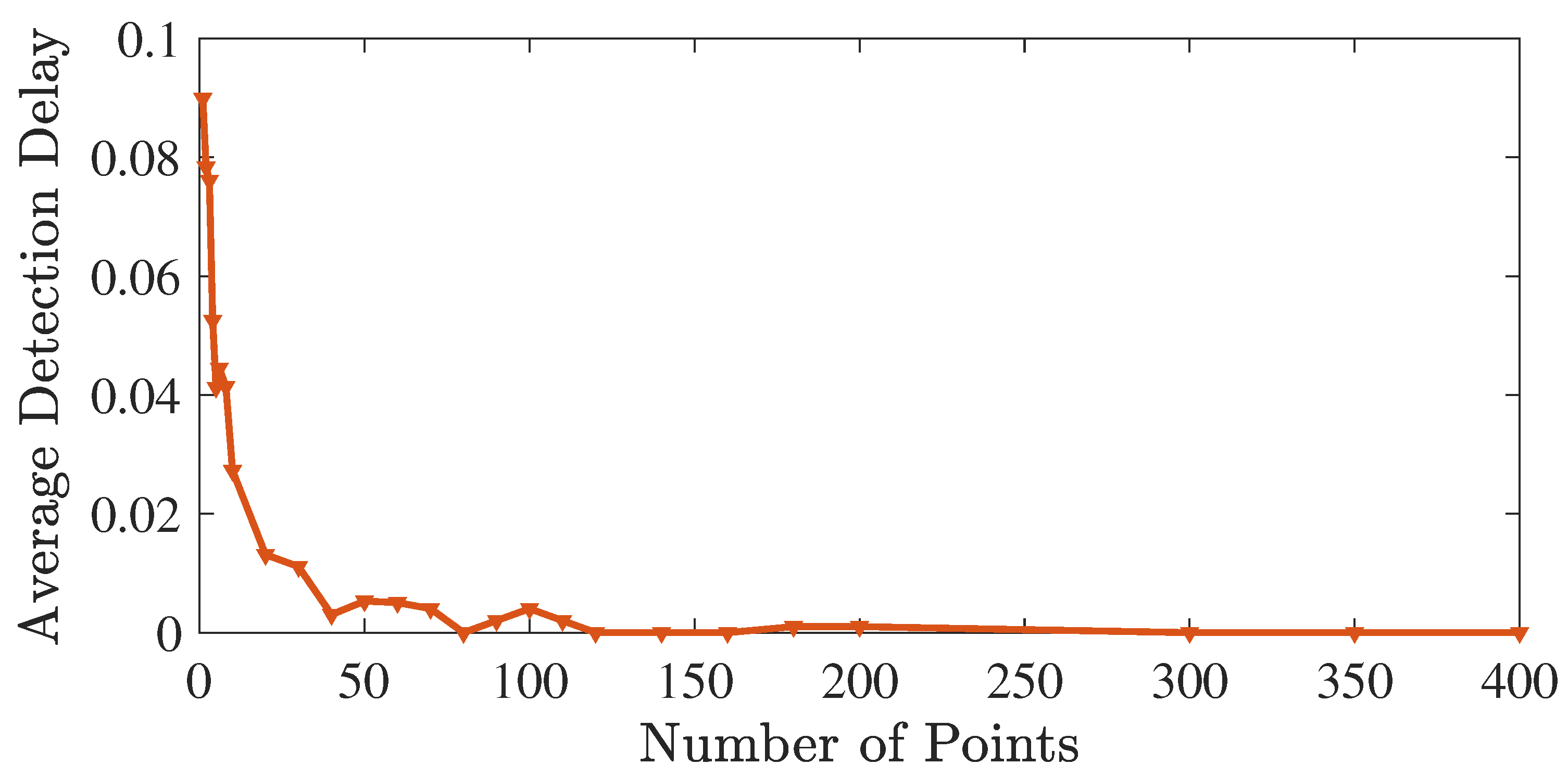
5. Experiments
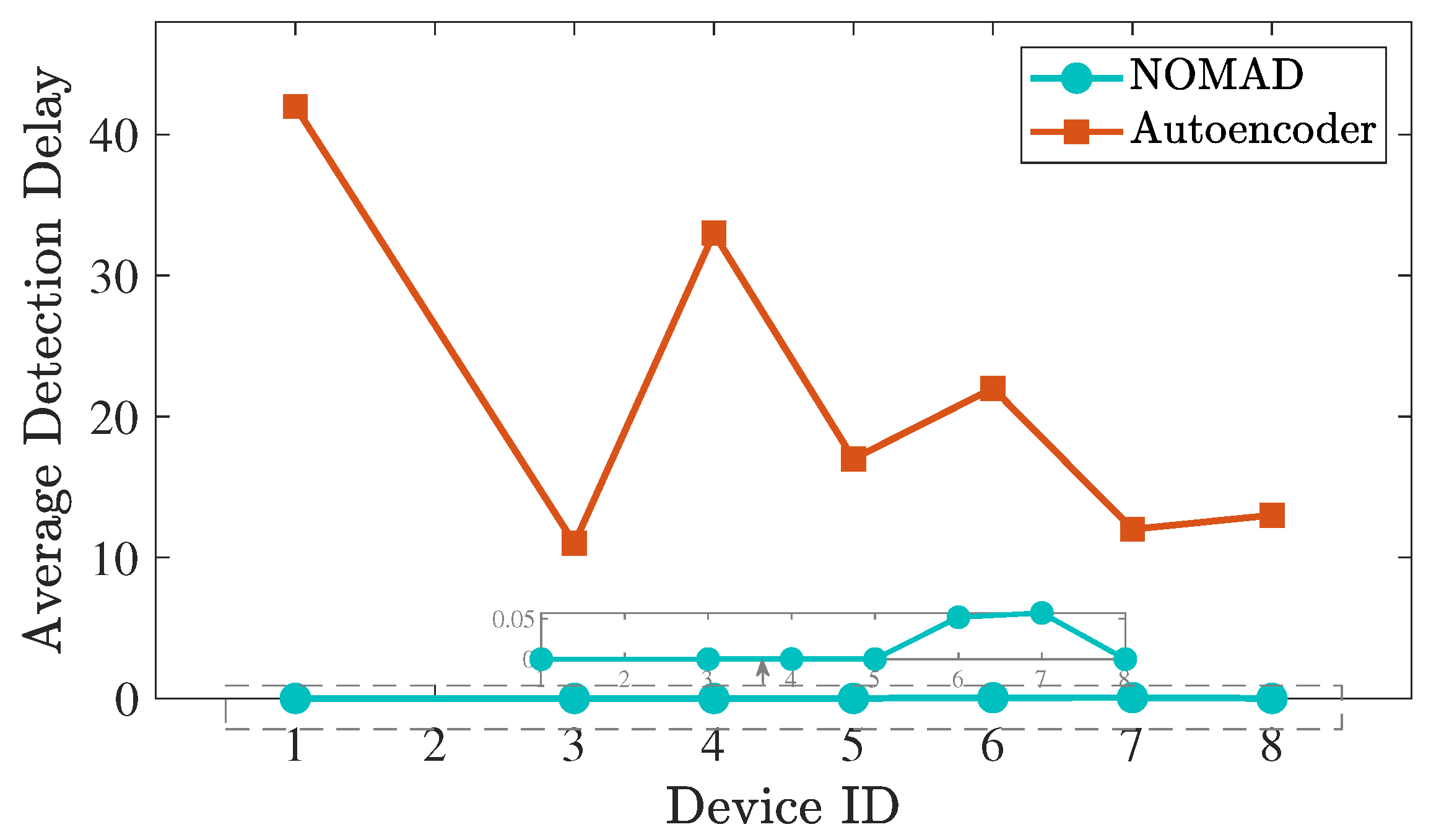
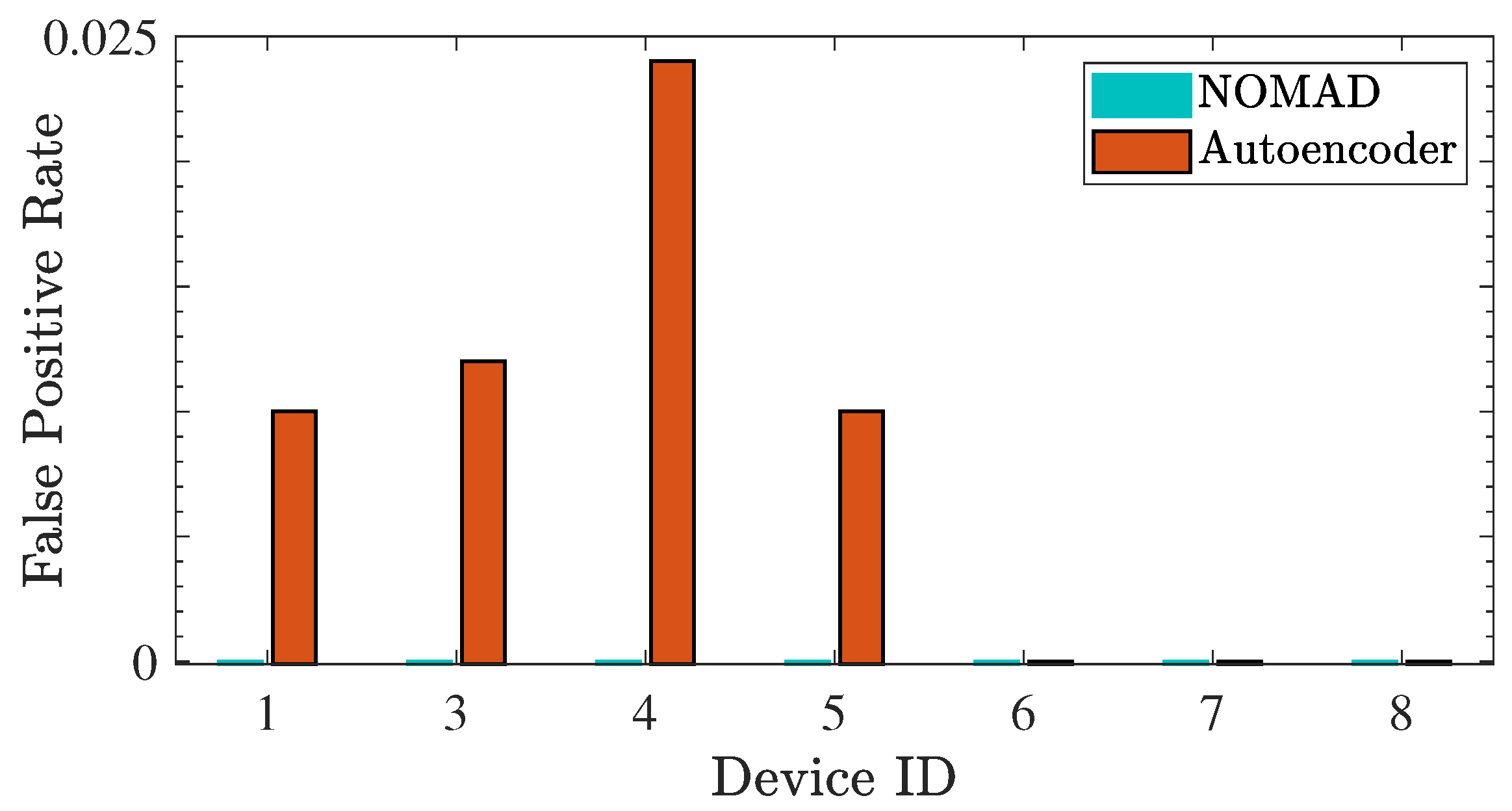
5.1. N-BaIoT Dataset
- (i)
- Device 3 (Ecobee Thermostat) is compromised (known anomaly type);
- (ii)
- Device 6 (Provision PT-838 security camera) is compromised (unknown anomaly type).
5.2. Cyber Physical System: SWaT Data Set
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 15. [Google Scholar] [CrossRef]
- Cui, M.; Wang, J.; Yue, M. Machine Learning-Based Anomaly Detection for Load Forecasting Under Cyberattacks. IEEE Trans. Smart Grid 2019, 10, 5724–5734. [Google Scholar] [CrossRef]
- Xiang, Y.; Li, K.; Zhou, W. Low-rate DDoS attacks detection and traceback by using new information metrics. IEEE Trans. Inf. Forensics Secur. 2011, 6, 426–437. [Google Scholar] [CrossRef]
- Doshi, K.; Yilmaz, Y.; Uludag, S. Timely detection and mitigation of stealthy DDoS attacks via IoT networks. IEEE Trans. Depend. Secur. Comput. 2021, 18, 2164–2176. [Google Scholar] [CrossRef]
- Elnaggar, R.; Chakrabarty, K.; Tahoori, M.B. Hardware trojan detection using changepoint-based anomaly detection techniques. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2706–2719. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, J.; Kato, N. Threshold tuning-based wearable sensor fault detection for reliable medical monitoring using Bayesian network model. IEEE Syst. J. 2018, 12, 1886–1896. [Google Scholar] [CrossRef]
- Doshi, K.; Yilmaz, Y. Online anomaly detection in surveillance videos with asymptotic bound on false alarm rate. Pattern Recognit. 2021, 114, 107865. [Google Scholar] [CrossRef]
- Matthews, B. Automatic Anomaly Detection with Machine Learning. 2019. Available online: https://ntrs.nasa.gov/citations/20190030491 (accessed on 23 April 2023).
- Haydari, A.; Yilmaz, Y. RSU-based online intrusion detection and mitigation for VANET. Sensors 2022, 22, 7612. [Google Scholar] [CrossRef]
- Mozaffari, M.; Doshi, K.; Yilmaz, Y. Real-Time Detection and Classification of Power Quality Disturbances. Sensors 2022, 22, 7958. [Google Scholar] [CrossRef]
- Doshi, K.; Abudalou, S.; Yilmaz, Y. Reward Once, Penalize Once: Rectifying Time Series Anomaly Detection. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting spacecraft anomalies using lstms and non-parametric dynamic thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Chatillon, P.; Ballester, C. History-based anomaly detector: An adversarial approach to anomaly detection. arXiv 2019, arXiv:1912.11843. [Google Scholar]
- Ravanbakhsh, M. Generative Models for Novelty Detection: Applications in abnormal event and situational change detection from data series. arXiv 2019, arXiv:1904.04741. [Google Scholar]
- Sabokrou, M.; Khalooei, M.; Fathy, M.; Adeli, E. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3379–3388. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Doshi, K.; Yilmaz, Y. Continual learning for anomaly detection in surveillance videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 254–255. [Google Scholar]
- Banerjee, T.; Firouzi, H.; Hero III, A.O. Quickest detection for changes in maximal knn coherence of random matrices. arXiv 2015, arXiv:1508.04720. [Google Scholar] [CrossRef]
- Soltan, S.; Mittal, P.; Poor, H.V. BlackIoT: IoT Botnet of high wattage devices can disrupt the power grid. In Proceedings of the 27th {USENIX} Security Symposium ({USENIX} Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 15–32. [Google Scholar]
- Steinwart, I.; Hush, D.; Scovel, C. A classification framework for anomaly detection. J. Mach. Learn. Res. 2005, 6, 211–232. [Google Scholar]
- Lee, W.; Xiang, D. Information-theoretic measures for anomaly detection. In Proceedings of the Security and Privacy, 2001, S&P 2001, 2001 IEEE Symposium, Oakland, CA, USA, 14–16 May 2000; pp. 130–143. [Google Scholar]
- Page, E.S. Continuous inspection schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Moustakides, G.V. Optimal stopping times for detecting changes in distributions. Ann. Stat. 1986, 14, 1379–1387. [Google Scholar] [CrossRef]
- Mei, Y. Efficient scalable schemes for monitoring a large number of data streams. Biometrika 2010, 97, 419–433. [Google Scholar] [CrossRef]
- Banerjee, T.; Hero, A.O. Quickest hub discovery in correlation graphs. In Proceedings of the Signals, Systems and Computers, 2016 50th Asilomar Conference, Pacific Grove, CA, USA, 6–9 November 2016; pp. 1248–1255. [Google Scholar]
- Hero, A.O. Geometric entropy minimization (GEM) for anomaly detection and localization. In Advances in Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2007; pp. 585–592. [Google Scholar]
- Sricharan, K.; Hero, A.O. Efficient anomaly detection using bipartite k-NN graphs. In Advances in Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2011; pp. 478–486. [Google Scholar]
- Scott, C.D.; Nowak, R.D. Learning minimum volume sets. J. Mach. Learn. Res. 2006, 7, 665–704. [Google Scholar]
- Zhao, M.; Saligrama, V. Anomaly detection with score functions based on nearest neighbor graphs. In Advances in Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2009; pp. 2250–2258. [Google Scholar]
- Chen, H. Sequential change-point detection based on nearest neighbors. Ann. Stat. 2019, 47, 1381–1407. [Google Scholar] [CrossRef]
- Zambon, D.; Alippi, C.; Livi, L. Concept drift and anomaly detection in graph streams. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5592–5605. [Google Scholar] [CrossRef]
- Zhao, Y.; Nasrullah, Z.; Li, Z. Pyod: A python toolbox for scalable outlier detection. arXiv 2019, arXiv:1901.01588. [Google Scholar]
- Angiulli, F.; Pizzuti, C. Fast outlier detection in high dimensional spaces. In European Conference on Principles of Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–27. [Google Scholar]
- Keriven, N.; Garreau, D.; Poli, I. NEWMA: A new method for scalable model-free online change-point detection. IEEE Trans. Signal Process. 2020, 68, 3515–3528. [Google Scholar] [CrossRef]
- Lazarevic, A.; Kumar, V. Feature bagging for outlier detection. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 157–166. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-BaIoT—Network-Based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, Australia, 2 December 2014; pp. 4–11. [Google Scholar]
- Zenati, H.; Foo, C.S.; Lecouat, B.; Manek, G.; Chandrasekhar, V.R. Efficient gan-based anomaly detection. arXiv 2018, arXiv:1802.06222. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. Mad-gan: Multivariate anomaly detection for time series data with generative adversarial networks. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2019; pp. 703–716. [Google Scholar]
- Lorden, G. Procedures for reacting to a change in distribution. Ann. Math. Stat. 1971, 42, 1897–1908. [Google Scholar] [CrossRef]
- Chen, G.H.; Shah, D. Explaining the success of nearest neighbor methods in prediction. Found. Trends Mach. Learn. 2018, 10, 337–588. [Google Scholar] [CrossRef]
- Gu, X.; Akoglu, L.; Rinaldo, A. Statistical Analysis of Nearest Neighbor Methods for Anomaly Detection. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 10921–10931. [Google Scholar]
- Muja, M.; Lowe, D.G. Scalable nearest neighbor algorithms for high dimensional data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2227–2240. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- Schilling, M.F. Multivariate two-sample tests based on nearest neighbors. J. Am. Stat. Assoc. 1986, 81, 799–806. [Google Scholar] [CrossRef]
- Henze, N. A multivariate two-sample test based on the number of nearest neighbor type coincidences. Ann. Stat. 1988, 772–783. [Google Scholar] [CrossRef]
- Zhou, B.; Liu, S.; Hooi, B.; Cheng, X.; Ye, J. BeatGAN: Anomalous Rhythm Detection using Adversarially Generated Time Series. Proc. IJCAI 2019, 2019, 4433–4439. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Stoyan, D.; Kendall, W.S.; Chiu, S.N.; Mecke, J. Stochastic Geometry and Its Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Basseville, M.; Nikiforov, I.V. Detection of Abrupt Changes: Theory and Application; Prentice Hall: Englewood Cliffs, NJ, USA, 1993; Volume 104. [Google Scholar]
- Scott, T.C.; Fee, G.; Grotendorst, J. Asymptotic series of generalized Lambert W function. ACM Commun. Comput. Algebra 2014, 47, 75–83. [Google Scholar] [CrossRef]
- Agresti, A. An Introduction to Categorical Data Analysis; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Execution Time (s) | |
|---|---|
| ExactkNN | FastkNN |
| 0.075 | 0.0054 |
| Algorithm | Pre | Rec | F1 |
|---|---|---|---|
| PCA | 24.92 | 21.63 | 0.23 |
| KNN | 7.83 | 7.83 | 0.08 |
| FB | 10.17 | 10.17 | 0.10 |
| AE | 72.63 | 52.63 | 0.61 |
| EGAN | 40.57 | 67.73 | 0.51 |
| MAD-GAN | 98.97 | 63.74 | 0.77 |
| BeatGAN | 64.01 | 87.46 | 73.92 |
| DAGMM | 89.92 | 57.84 | 70.40 |
| Ours | 99.76 | 64.7 | 0.783 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mozaffari, M.; Doshi, K.; Yilmaz, Y. Self-Supervised Learning for Online Anomaly Detection in High-Dimensional Data Streams. Electronics 2023, 12, 1971. https://doi.org/10.3390/electronics12091971
Mozaffari M, Doshi K, Yilmaz Y. Self-Supervised Learning for Online Anomaly Detection in High-Dimensional Data Streams. Electronics. 2023; 12(9):1971. https://doi.org/10.3390/electronics12091971
Chicago/Turabian StyleMozaffari, Mahsa, Keval Doshi, and Yasin Yilmaz. 2023. "Self-Supervised Learning for Online Anomaly Detection in High-Dimensional Data Streams" Electronics 12, no. 9: 1971. https://doi.org/10.3390/electronics12091971
APA StyleMozaffari, M., Doshi, K., & Yilmaz, Y. (2023). Self-Supervised Learning for Online Anomaly Detection in High-Dimensional Data Streams. Electronics, 12(9), 1971. https://doi.org/10.3390/electronics12091971