
An Efficient Method for Generating Adversarial Malware Samples

Abstract
:1. Introduction
2. Related Work
3. Methodology for Generating Adversarial Malware Examples
3.1. Motivations
3.2. Finding Data Area Important for Classification
3.3. Generating Adversarial Examples
| Algorithm 1: Extracting feature byte sequences of a benign sample. |
| Input: |
| Output: |
3.4. Strategies for Injecting Feature Sequences
4. Experiments
4.1. Dataset Description
4.2. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Prior Knowledge | Descriptions & Advantages | Disadvantages |
|---|---|---|---|
| Generating image adversarial samples | |||
| Szegedy et al. [5] | White-box | Distortion rate of the generated adversarial sample is low. | Calculation process is complex and time-consuming. |
| Goodfellow et al. [9] | White-box | It can generate a large number of adversarial samples effectively and can be used in deep learning models. | Ease of optimization has come at the cost of models that are easily misled. |
| Moosavi-Dezfooli et al. [11] | Black-box | The modification to the original input is small, and the generated adversarial sample has good attack effect. | Calculation process is complex and time-consuming, and it is difficult to apply to large datasets. |
| Papernot et al. [12] | White-box | The original input is less modified and the process of generating adversarial samples is simple. | The method needs to be trained with large, labeled datasets. |
| Xiao et al. [13] | White-box | An optimization framework for the adversary to find the near-optimal label flips that maximally degrades the classifier’s performance. | It can only be suitable for Support Vector Machines. Adversarial label noise is inevitable due to the limitation of quality control mechanisms. |
| Papernot et al. [14] | Black-box | An approach based on a novel substitute training algorithm using synthetic data generation to craft adversarial examples misclassified by black-box DNNs. | Construction process of the approach is complex and time-consuming. So, it is difficult to apply to large datasets. |
| Liu et al. [15] | Black-box | An ensemble-based approach can generate transferable adversarial examples which can successfully attack Clarifai.com. | Performance of generating targeted transferable adversarial examples of the model is poor, compared to other previous models. |
| Generating malware adversarial samples | |||
| Suciu et al. [7] | White-box | The one-shot FGSM append attack uses the gradient value of the classification loss, with respect to the target label to update the appended byte values. | The success rate of append attacks is relatively low. |
| Kolosnjaji et al. [16] | White-box | Adversarial malware samples are generated by injecting padding bytes at the end of file, which can preserve the intrusive functionality of an executable. | Applicable for the deep learning-based detector MalConv. |
| Kreuk et al. [17] | White-box | The same payload can be injected into different locations and can be effective when applied to different malware files. | Applicable for CNN-based malware detector. |
| Hu et al. [18] | Black-box | An approach can decrease the detection rate to nearly zero and make the retraining based defensive method against adversarial examples hard to work. | Suitable for machine learning-based malware detector. |
| Hu et al. [20] | Black-box | The generated adversarial examples can attack a RNN-based malware detector. | Not applicable for attacking other systems except RNN-based malware detectors. |
| Chen et al. [21] | White-box | A method based on Jacobian matrix to generate adversarial samples. | It is not applicable for generating a large number of samples. |
| Kreuk et al. [22] | White-box | The method generates adversarial examples by appending to the binary file a small section and has high attack success rates. | The method heavily relies on the learned embeddings of the model, which can hinder the transferability of adversarial examples with different byte embeddings. |
| Peng et al. [23] | Black-box | It outruns other GAN based schemes in performance and has a lower overhead of API call inserting. | The generation process is complex and time-consuming, and it is applicable for CNN-based detectors. |
| Chen et al. [24] | White-box, Black-box | Attack success rate of the method is high, and it can be readily extended to other similar adversarial machine learning tasks. | Not applicable for generating a large number of samples. |
| Chen et al. [25] | Black-box | It uses reinforcement learning to generate malware adversarial samples which has high success rate of attack. | Not applicable for generating a large number of samples. |
References
- Alzaylaee, M.K.; Yerima, S.Y.; Sezer, S. DL-Droid: Deep learning based android malware detection using real devices. Comput. Secur. 2020, 89, 101663. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. HYDRA: A multimodal deep learning framework for malware classification. Comput. Secur. 2020, 95, 101873. [Google Scholar] [CrossRef]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C.K. Malware detection by eating a whole exe. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 268–276. [Google Scholar]
- Wang, W.; Zhao, M.; Wang, J. Effective android malware detection with a hybrid model based on deep autoencoder and convolutional neural network. J. Ambient Intell. Humaniz. Comput. 2019, 10, 3035–3043. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Support Vector Machines Under Adversarial Label Noise. J. Mach. Learn. Res. 2011, 20, 97–112. [Google Scholar]
- Suciu, O.; Coull, S.E.; Johns, J. Exploring adversarial examples in malware detection. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 20–22 May 2019; pp. 8–14. [Google Scholar]
- Maiorca, D.; Demontis, A.; Biggio, B.; Roli, F.; Giacinto, G. Adversarial detection of flash malware: Limitations and open issues. Comput. Secur. 2020, 96, 101901. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Goodfellow, I. New CleverHans Feature: Better Adversarial Robustness Evaluations with Attack Bundling. arXiv 2018, arXiv:1811.03685. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Xiao, H.; Xiao, H.; Eckert, C. Adversarial label flips attack on support vector machines. In Proceedings of the 20th European Conference on Artificial Intelligence (ECAI 2012), Montpellier, France, 27–31 August 2012; pp. 870–875. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into transferable adversarial examples and black-box attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Kolosnjaji, B.; Demontis, A.; Biggio, B.; Maiorca, D.; Giacinto, G.; Eckert, C.; Roli, F. Adversarial malware binaries: Evading deep learning for malware detection in executables. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 533–537. [Google Scholar]
- Kreuk, F.; Barak, A.; Aviv-Reuven, S.; Baruch, M.; Pinkas, B.; Keshet, J. Deceiving end-to-end deep learning malware detectors using adversarial examples. arXiv 2018, arXiv:1802.04528v3. Available online: http://arxiv.org/abs/1802.04528v3 (accessed on 1 December 2021).
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv 2017, arXiv:1702.05983. [Google Scholar]
- Al-Dujaili, A.; Huang, A.; Hemberg, E.; O’Reilly, U.M. Adversarial deep learning for robust detection of binary encoded malware. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 21–23 May 2018; pp. 76–82. [Google Scholar]
- Hu, W.; Tan, Y. Black-box attacks against RNN based malware detection algorithms. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 245–251. [Google Scholar]
- Chen, S.; Xue, M.; Fan, L.; Hao, S.; Xu, L.; Zhu, H.; Li, B. Automated poisoning attacks and defenses in malware detection systems: An adversarial machine learning approach. Comput. Secur. 2018, 73, 326–344. [Google Scholar] [CrossRef] [Green Version]
- Kreuk, F.; Barak, A.; Aviv-Reuven, S.; Baruch, M.; Keshet, J. Adversarial examples on discrete sequences for beating whole-binary malware detection. arXiv 2018, arXiv:1802.04528v1. Available online: http://arxiv.org/abs/1802.04528v1 (accessed on 1 December 2021).
- Peng, X.; Xian, H.; Lu, Q.; Lu, X. Semantics aware adversarial malware examples generation for black-box attacks. Appl. Soft. Comput. 2021, 109, 107506. [Google Scholar] [CrossRef]
- Chen, B.; Ren, Z.; Yu, C.; Hussain, I. Adversarial examples for cnn-based malware detectors. IEEE Access 2019, 7, 54360–54371. [Google Scholar] [CrossRef]
- Chen, J.; Jiang, J.; Li, R.; Dou, Y. Generating adversarial examples for static PE malware detector based on deep reinforcement learning. In Proceedings of the 5th Annual International Conference on Information System and Artificial Intelligence (ISAI2020), Hangzhou, China, 22–23 May 2020. [Google Scholar]
- Krčál, M.; Švec, O.; Bálek, M.; Jašek, O. Deep convolutional malware classifiers can learn from raw executables and labels only. In Proceedings of the 6th International Conference on Learning Representation (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]

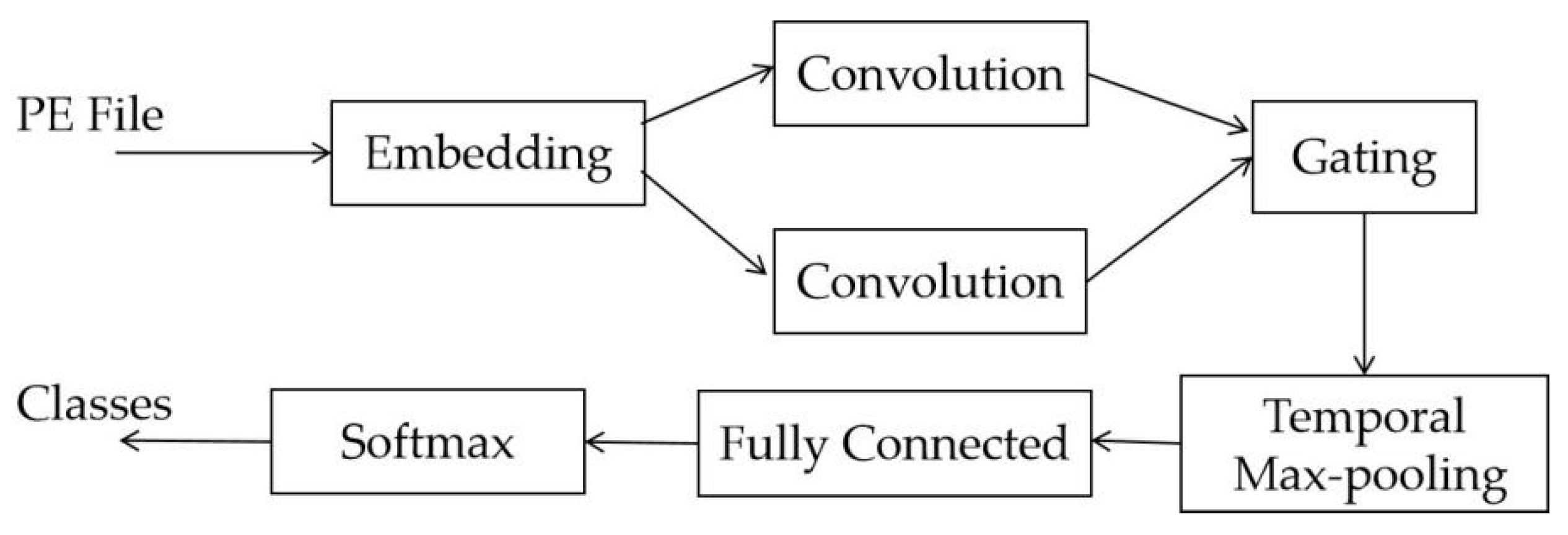




| Detector | Kernel Length | Moving Stride | Kernel Number | Training Samples | Accuracy |
|---|---|---|---|---|---|
| MalConv1 | 200 | 200 | 200 | 20,000 | 92.5% |
| MalConv2 | 400 | 400 | 150 | 20,000 | 92.6% |
| MalConv3 | 500 | 500 | 128 | 20,000 | 94.1% |
| MalConv4 | 800 | 800 | 100 | 20,000 | 91.8% |
| No. of Injected Bytes | 1000 | 2000 | 5000 | 10,000 |
|---|---|---|---|---|
| SR of Experiment 1 | 0.42 | 0.55 | 0.78 | 0.88 |
| SR of Experiment 2 | 0.46 | 0.57 | 0.77 | 0.86 |
| SR of Experiment 3 | 0.45 | 0.59 | 0.78 | 0.90 |
| SR of Experiment 4 | 0.41 | 0.61 | 0.76 | 0.89 |
| Average SR | 0.44 | 0.58 | 0.77 | 0.88 |
| Avg Time Cost Per Sample(min) | 0.2 | 0.5 | 1.1 | 2.1 |
| No. of Injected Bytes | 1000 | 2000 | 5000 | 10,000 | 20,000 |
|---|---|---|---|---|---|
| SR of Experiment 1 | 0.34 | 0.41 | 0.60 | 0.77 | 0.88 |
| SR of Experiment 2 | 0.37 | 0.44 | 0.61 | 0.73 | 0.90 |
| SR of Experiment 3 | 0.32 | 0.40 | 0.64 | 0.74 | 0.91 |
| SR of Experiment 4 | 0.33 | 0.43 | 0.63 | 0.76 | 0.87 |
| Average SR | 0.34 | 0.42 | 0.62 | 0.75 | 0.89 |
| Avg Time Cost Per Sample(min) | 0.2 | 0.2 | 0.4 | 0.9 | 1.9 |
| No. of Injected Bytes | 1000 | 2000 | 5000 | 10,000 |
|---|---|---|---|---|
| SR of Experiment 1 | 0.09 | 0.11 | 0.18 | 0.21 |
| SR of Experiment 2 | 0.09 | 0.11 | 0.17 | 0.20 |
| SR of Experiment 3 | 0.06 | 0.13 | 0.15 | 0.24 |
| SR of Experiment 4 | 0.08 | 0.13 | 0.14 | 0.23 |
| Average SR | 0.08 | 0.12 | 0.16 | 0.22 |
| No. of Injected Bytes | 1000 | 2000 | 5000 | 10,000 | 20,000 |
|---|---|---|---|---|---|
| SR of Experiment 1 | 0.03 | 0.07 | 0.07 | 0.10 | 0.18 |
| SR of Experiment 2 | 0.05 | 0.05 | 0.09 | 0.12 | 0.15 |
| SR of Experiment 3 | 0.03 | 0.06 | 0.09 | 0.11 | 0.16 |
| SR of Experiment 4 | 0.05 | 0.06 | 0.07 | 0.11 | 0.19 |
| Average SR | 0.04 | 0.06 | 0.08 | 0.11 | 0.17 |
| Softmax Classification Loss | Mean Squared Error | |||||||
|---|---|---|---|---|---|---|---|---|
| Byte seq. len. | 1000 | 2000 | 5000 | 10,000 | 1000 | 2000 | 5000 | 10,000 |
| Experiment 1 | 0.23 | 0.33 | 0.52 | 0.70 | 0.15 | 0.25 | 0.36 | 0.51 |
| Experiment 2 | 0.26 | 0.39 | 0.55 | 0.66 | 0.21 | 0.27 | 0.40 | 0.49 |
| Experiment 3 | 0.25 | 0.30 | 0.56 | 0.69 | 0.19 | 0.29 | 0.42 | 0.52 |
| Experiment 4 | 0.22 | 0.32 | 0.53 | 0.71 | 0.22 | 0.30 | 0.41 | 0.54 |
| Average SR | 0.24 | 0.31 | 0.54 | 0.69 | 0.19 | 0.28 | 0.40 | 0.52 |
| Avg Time Cost Per Sample(min) | 25 | 51 | 99 | 239 | 23 | 47 | 100 | 240 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Shao, M.; Nie, C.; Fu, K. An Efficient Method for Generating Adversarial Malware Samples. Electronics 2022, 11, 154. https://doi.org/10.3390/electronics11010154
Ding Y, Shao M, Nie C, Fu K. An Efficient Method for Generating Adversarial Malware Samples. Electronics. 2022; 11(1):154. https://doi.org/10.3390/electronics11010154
Chicago/Turabian StyleDing, Yuxin, Miaomiao Shao, Cai Nie, and Kunyang Fu. 2022. "An Efficient Method for Generating Adversarial Malware Samples" Electronics 11, no. 1: 154. https://doi.org/10.3390/electronics11010154
APA StyleDing, Y., Shao, M., Nie, C., & Fu, K. (2022). An Efficient Method for Generating Adversarial Malware Samples. Electronics, 11(1), 154. https://doi.org/10.3390/electronics11010154