Abstract
Grey models have attracted considerable attention as a time series forecasting tool in recent years. Nevertheless, the linear characteristics of the differential equations on which traditional grey models rely frequently result in inadequate predictive accuracy and applicability when addressing intricate nonlinear systems. This study introduces a conformable fractional order unbiased kernel-regularized nonhomogeneous grey model (CFUKRNGM) based on statistical learning theory to address these limitations. The proposed model initially uses a conformable fractional-order accumulation operator to derive distribution information from historical data. A novel regularization problem is then formulated, thereby eliminating the bias term from the kernel-regularized nonhomogeneous grey model (KRNGM). The parameter estimation of the CFUKRNGM model requires solving a linear equation with a lower order than the KRNGM model, and is automatically calibrated through the Bayesian optimization algorithm. Experimental results show that the CFUKRNGM model achieves superior prediction accuracy and greater generalization performance compared to both the KRNGM and traditional grey models.
1. Introduction
Numerous nations worldwide are presently seeing a transformation in their energy consumption frameworks. A multitude of scholars have exerted considerable effort to devise energy forecasting methodologies intended to precisely estimate national energy use. Lu et al. conducted a literature survey on building energy prediction using artificial neural networks (ANNs), highlighting their potential to improve prediction accuracy and efficiency in energy management systems [1]. Similarly, Wang et al. studied the application of Random Forest algorithms for hourly building energy prediction, revealing their higher precision compared to standard techniques [2]. Fan et al. proposed deep learning-based feature engineering methods to enhance building energy prediction models, leveraging neural networks to automatically extract features from large-scale data, resulting in significant improvements in forecasting accuracy [3]. Additionally, Cammarano et al. introduced the Pro-Energy model, combining solar and wind energy harvesting with wireless sensor networks and offering a promising solution for energy prediction in renewable energy systems [4]. Nevertheless, the swift acceleration of economic expansion renders several statistical models inadequate for managing the significant uncertainty in energy consumption predictions. Indeed, the economic frameworks of numerous nations worldwide have experienced substantial transformations in recent years, rendering only the most current data dependable for forecasting energy consumption. Consequently, numerous researchers have adopted forecasting models adept at managing limited sample sizes [5,6,7,8].
Grey system theory, initially introduced by Deng [9] in 1982, has gained substantial popularity in forecasting and decision-making research due to its strong performance under uncertain conditions and limited data scenarios. Among various grey models, the GM(1,1) model (or GM for short) is the most basic and widely adopted, recognized for delivering reliable forecasts even with minimal data (as few as four points) [10]. Owing to their effectiveness in handling small datasets, grey prediction models have found widespread applications in diverse fields, including traffic safety analysis [11], energy production prediction [12], energy economics forecasting [13], as well as environmental studies [14,15].
Nevertheless, traditional grey models rely on integer order accumulation, which can be inadequate for systems exhibiting strong memory effects or complex dynamics. To address this limitation, fractional calculus—capable of representing long-memory processes and refined dynamical details—has been gradually introduced into grey modeling. In 2013, Wu et al. [16] pioneered the integration of fractional order accumulation (abbreviated as FOA) into fractional grey models (abbreviated as FGM), thereby facilitating effective modeling of nonlinear sequences without additional nonlinear equations. This approach subsequently demonstrated robust performance in emission forecasting [17], clean energy production [18], space-floating target trajectories [19], and building settlement monitoring [20]. Concurrently, researchers have proposed a variety of fractional grey models for different application contexts. For example, Gao et al. [21] proposed a discrete fractional grey model aimed at forecasting China’s CO2 emissions. Ma et al. [22] employed conformable fractional derivatives and a brute-force approach for optimizing the order. Duan et al. [23] applied particle swarm optimization (abbreviated as PSO) to enhance fractional grey models for forecasting China’s crude oil consumption. Lin et al. [24] introduced fractional operators into a time-delay polynomial grey model, improving its flexibility. Wu et al. [25] adjusted the order of fractional accumulations in GMC(1,N) to forecast electric power consumption in Shandong province. These findings collectively underscore the pronounced advantages of fractional grey models in dealing with nonlinear and nonstationary sequences.
On the other hand, conventional grey models still encounter challenges when subjected to strong nonlinearities or external disturbances. In response, scholars have put forward the nonhomogeneous grey model (abbreviated as NGM) and its various extensions [26,27,28], incorporating time-dependent or other prior information into the whitening equation to capture more complex external drivers. However, adding linear terms alone may not thoroughly capture higher-order nonlinear structures in the data. To address this shortcoming, Ma et al. [29] introduced a kernel-based regularization scheme for nonhomogeneous grey models (abbreviated as KRNGM), which maps the linear model into a high-dimensional feature space, thereby flexibly representing nonlinear dynamics. This concept is grounded in Vapnik’s work on support vector machines (abbreviated as SVMs) [30], which has already gained widespread traction in machine learning [31], clustering [32], and principal component analysis [33]. Furthermore, the least squares support vector machine (abbreviated as LS-SVM) proposed by Suykens et al. [34] has simplified kernel-based methods, enabling successful applications in image classification [35], hydropower consumption forecasting [36], and natural disaster prediction [37].
Despite these developments, existing kernel-based regularized nonhomogeneous grey models still treat the bias term as a separately estimated parameter. This approach can not only complicate the model structure but also introduce biases in parameter estimation, thereby reducing its generalization capability. In order to enhance its practical utility, this study draws on the unbiased perspective proposed by Wang et al. [38] for LS-SVM, which jointly regularizes the bias term and kernel mapping parameters to effectively suppress uncertainties arising from the bias. This unbiased strategy has been extended to multiple applications in computer vision and machine learning. For instance, Jeon et al. [39] employed unbiased learning methods to mitigate convolutional neural networks’ (abbreviated as CNN) reliance on biased training data, while de Mello et al. [40] presented an innovative active learning strategy to curtail the detrimental effects of biased sampling on model performance.
This research advances current understanding by integrating conformable fractional order accumulation into the kernel-based regularized nonhomogeneous grey model. The outcome is the conformable fractional unbiased kernel-regularized nonhomogeneous grey model (CFUKRNGM). This methodology seeks to enhance predictive precision for intricate systems through the utilization of a tunable-order accumulation operator. This operator enables the modulation of historical data weighting. Furthermore, impartial regularization is employed to alleviate overfitting induced by the bias factor. Oil production projections serve as a case study for evaluating the model’s efficacy, illustrating its practical applicability.
2. Kernel-Regularized Nonhomogeneous Grey Model
2.1. Mathematical Basis of GM(1,1)
Grey system theory asserts that real observational data frequently encompass noise, random variations, and other uncertainties, complicating the direct formulation of a dynamic equation from the raw dataset. To resolve this, grey models utilize the accumulation generation operation (AGO), which converts the differential properties of the discrete series into a more uniform sequence, thus reducing significant oscillations that may exist in the raw data. Let the original sequence be specified as
and define its first-order accumulated operation (abbreviated as 1-AGO) sequence as
where
Through the 1-AGO operation, the original series is smoothed to some extent, providing a more stable data foundation for subsequent differential equation fitting.
Once the relatively smooth sequence is obtained, the core assumption in grey models is that this accumulated sequence can be described by a first-order linear differential equation, namely,
where a and b are constants to be estimated. This equation is referred to as the white equation of GM(1,1), which effectively maps a discrete, noise-perturbed sequence onto a relatively simple continuous dynamic system.
To relate Equation (4) to discrete observations, grey modeling introduces the concept of background values by setting
Here, approximately represents the average level of over the interval . Meanwhile, at discrete time , the differential equation is approximately satisfied by
which allows Equation (4) to be discretized at k as
This constitutes the GM(1,1) model in discrete form. Rearranging Equation (7) yields the matrix equation
where
By applying the least squares method, one obtains
thus determining the estimates of a and b. Consequently, the white equation of GM(1,1) captures, to a certain extent, the continuous evolution pattern of the sequence .
Once a and b are determined, one can analytically solve the continuous form of Equation (4):
For discrete time k, substituting and using yields
However, GM(1,1) makes forecasts for the accumulated sequence . To revert to the original scale , one must perform an inverse accumulation operation (abbreviated as IAGO):
This step yields the forecasted value of at time k, thereby completing the overall prediction procedure.
In GM(1,1), only the linear term and a constant term b are considered. To accommodate strong nonlinearities or external disturbances, an additional nonhomogeneous term is typically introduced, thus giving the whitening equation
which corresponds to the NGM(1,1,k,c) model. It allows the incorporation of more external drivers or nonlinear information under the grey model framework, thereby enhancing the depiction of complex systems. Similar to GM(1,1), discretizing and using background values and least squares (or regularization) enables the estimation of a, c, and the parameters of . When is unknown and strongly nonlinear, kernel methods (discussed in the following subsection) can be applied to approximate it.
2.2. Kernel-Regularized Nonhomogeneous Grey Model
As previously mentioned, the NGM(1,1,k,c) model maintains a fundamentally linear structure. To incorporate nonlinear modeling capability, this section proposes introducing kernel regularization into the nonhomogeneous grey model framework.
where represents a nonlinear transformation with respect to t. If is set as the identity function (), the model reduces to the NGM(1,1,k,c) form.
The whitening equation of KRNGM is
Here, represents a nonlinear transformation mapping inputs into a higher-dimensional feature space, while denotes the corresponding coefficient vector. After discretizing across the interval using the trapezoidal rule, the equation becomes:
where
To estimate the parameters of the KRNGM, the following optimization objective is defined:
where is a regularization coefficient that balances the model’s smoothness and fitting error. To solve this quadratic program with linear constraints, the Lagrangian is formulated as
According to the KKT conditions, one obtains
By eliminating a, w, and from the KKT conditions, one obtains the following linear system:
where
and is the -dimensional identity matrix whose diagonal elements are 1 and whose off-diagonal entries are 0.
By solving the above system, one obtains and c. Using the first relation in the KKT conditions provides the parameter a. If the kernel function satisfies , explicit construction of vectors can be avoided. Through this regularization process, one thereby determines the main parameters of the KRNGM model.
2.3. Time-Response Series of the KRNGM
Once the parameters of the KRNGM are determined, the forecasted sequences and can be calculated. The initial condition is set as , then
where . According to , one obtains
Applying the trapezoidal rule to the integral term in Equation (23) yields
Finally, to obtain the predicted original series , one applies the difference:
Through these steps, the KRNGM completes its overall prediction process.
3. Proposed Conformable Fractional Unbiased Kernel Regularized Nonhomogeneous Grey Model
This section introduces an unbiased kernel-regularized nonhomogeneous grey model with conformable fractional order (CFUKRNGM). The CFUKRNGM combines the advantages of the conformable fractional grey model (CFGM) and kernel-regularized models (KRNGM), utilizing an unbiased parameter estimation approach. The suggested CFUKRNGM improves conventional grey models in the analysis of intricate dynamic systems. It achieves this by integrating the flexible memory attributes of conformable fractional-order accumulation. Furthermore, it utilizes the nonlinear modeling potential afforded by kernel regularization.
3.1. The Definition of Conformable Fractional Accumulation and Difference
This subsection presents the definitions of conformable fractional accumulation and difference.
Definition 1.
Given a differential function f, the α order conformable fractional accumulation (abbreviated as α-CFA) [28] of f with α order is
where , and denotes the ceil function, which represents the smallest integer no larger than α.
Definition 2.
Given a differential function f, the α order conformable fractional difference (abbreviated as α-CFD) [28] of f with α order is
where .
The conformable fractional accumulation and the conformable fractional difference satisfy the following relationship:
Definition 1 is utilized to calculate the cumulative value of the original sequence, whereas Definition 2 determines the recovery value of the model’s fitted sequence. It is significant because, in comparison to conventional fractional order accumulation (FOA), both conformable fractional order accumulation and difference are more straightforward to execute.
3.2. The Conformable Fractional Unbiased Kernel Regularized Nonhomogeneous Grey Model
Based on the definitions of -CFA and -CFD, the CFUKRNGM model is formulated, and the corresponding implementation steps are described as follows.
For the given initial sequence , we first define its -CFA sequence as , with the following relationship:
Similar to the KRNGM model, the CFUKRNGM is expressed as
The differential Equation (31) is referred to as the whitening equation of the CFUKRNGM model. When , it reduces to the KRNGM model proposed by Ma et al. [22]. Specifically, if is defined as an identity map and , the CFUKRNGM model (31) simplifies to the NGM(1, 1, k, c) model.
3.3. Parameter Estimation for the CFUKRNGM Model
To determine the parameters of the KRNGM model, we begin by discretizing the differential Equation (31). By integrating (31) over the interval , the resulting expression is obtained as follows:
Noting that , and . To discretize the remaining integral terms involving and , we apply the two-point trapezoidal rule, which approximates the integral over as the average of the values at the endpoints of the interval.
where
and
The exact form of the nonlinear mapping being unknown necessitates a regularization method. The structural risk reduction technique in the KRNGM model notably omits the bias factor c, potentially leading to overfitting and diminishing the model’s generalization capability. This paper integrates the bias term c into the structural risk reduction framework, creating an innovative regularized optimization problem for parameter estimation of the CFUKRNGM model. The mathematical formulation of this optimization problem is expressed as follows:
Let and , then the optimization problem (36) can be rewritten as
where is a hyperparameter of the CFUKRNGM model. Notice that at this stage, , where . Clearly,
The problem (37) is essentially a quadratic programming problem with linear constraints, and therefore, we only need to find its extremum point. We first define the Lagrangian function as
The Karush–Kuhn–Tucker (abbreviated as KKT) conditions for problem (39) are given by the following:
Set . By eliminating a, , and , we obtain
The KKT conditions are equivalent to the following set of linear equations:
where
and represents an identity matrix of dimension with ones on the diagonal and zeros elsewhere. The parameter a is derived from the initial equation within these conditions (40).
Using the definition of in (38), we have
3.4. The Time Response Series of the CFUKRNGM
The differential equation, under the initial condition , can be solved by applying the method of variation of parameters from differential equations, leading to the following solution:
where
From the second equation in the KKT conditions (40), expressed as , the nonlinear function can be reformulated as
By substituting (44) into (47), we obtain
To discretize the integral in (45), we apply the two-point trapezoidal rule, resulting in the discrete-time equivalent:
Finally, the predicted values for are obtained as
4. Parameters Optimization of CFUKRNGM Model
This section focuses on the optimization of the hyperparameters for the CFUKRNGM model. The performance of the model is highly dependent on the selection of these hyperparameters, which control the trade-off between model complexity and fitting accuracy. To identify the optimal set of parameters, we employ the Bayesian optimization algorithm, an efficient global optimization algorithm that can effectively adjust hyperparameters in high-dimensional spaces.
4.1. Optimization Strategies for Hyperparameters
It is worth noting that, given the known kernel function parameter , regularization coefficient , unbiased coefficient , and accumulation order , the system parameters in the new model can be estimated. We select the parameters that minimize the mean absolute percentage error as the optimal parameters, with the mathematical expression given by
where represents the hyperparameter vector of each model.If the parameter optimization objective is the CFUKRNGM model, then . If the parameter optimization objective is the KRNGM model, then .
4.2. Bayesian Optimization Algorithm
As indicated by Equation (51), this function exhibits nonlinear properties, making it challenging to derive an analytical solution using conventional methods. In the field of parameter optimization, numerous strategies have been proposed by researchers to enhance model performance and accuracy. Traditional optimization methods, such as grid search [41] and random search [42], are widely applied in hyperparameter tuning. In addition, another class of optimization methods involves heuristic algorithms, such as genetic algorithms [43], PSO [44], and simulated annealing [45]. These methods do not rely on gradient information but instead simulate random behaviors observed in nature or physical processes to find the optimal solution. While these approaches can effectively handle complex optimization problems, they may suffer from early convergence and require longer computational times. With the rapid development of machine learning, the Bayesian optimization algorithm [46] has emerged as a global optimization method based on probabilistic models.
Bayesian optimization is a global optimization technique based on probability theory. It is especially efficacious for optimizing black-box functions. The fundamental concept is to develop a surrogate model that estimates the actual objective function. Gaussian processes are frequently employed for surrogate modeling. The optimization process is directed by an acquisition function that facilitates the efficient identification of the global optimum. Consider the input dataset and corresponding observed outputs , where each observed value includes a noise term , which is independently and identically distributed.
Assumes that the objective function is drawn from a gaussian process distribution:
where is the mean function, typically taken as , and is the covariance function or kernel, which defines the correlation between different input points.
Based on the Gaussian process model, the predicted value of the objective function at a new input point can be obtained. Considering the existing observed data points and their corresponding outputs , the joint distribution between the observed outputs and the prediction at can be expressed as follows:
where denotes the covariance matrix computed from the training samples, represents the variance of the noise, and , correspond to covariance values between training data points and the new data point .
The acquisition function serves as a crucial element within Bayesian optimization, guiding the choice of subsequent sampling points according to predictions from the surrogate model. Frequently used acquisition functions are listed as follows:
Expected Improvement (EI): The expected improvement measures the expected amount of improvement over the current best value. Its mathematical expression is
where denotes the optimal value obtained so far, and represents the estimated value at the new candidate point.
Probability of Improvement (PI): This acquisition function evaluates the likelihood that a new candidate point will yield better results compared to the current optimal value. Its mathematical definition is as follows:
where represents the predicted mean at the candidate point, and is its predicted standard deviation; additionally, denotes the cumulative distribution function of the standard normal distribution.
4.3. Optimization Steps of Parameters
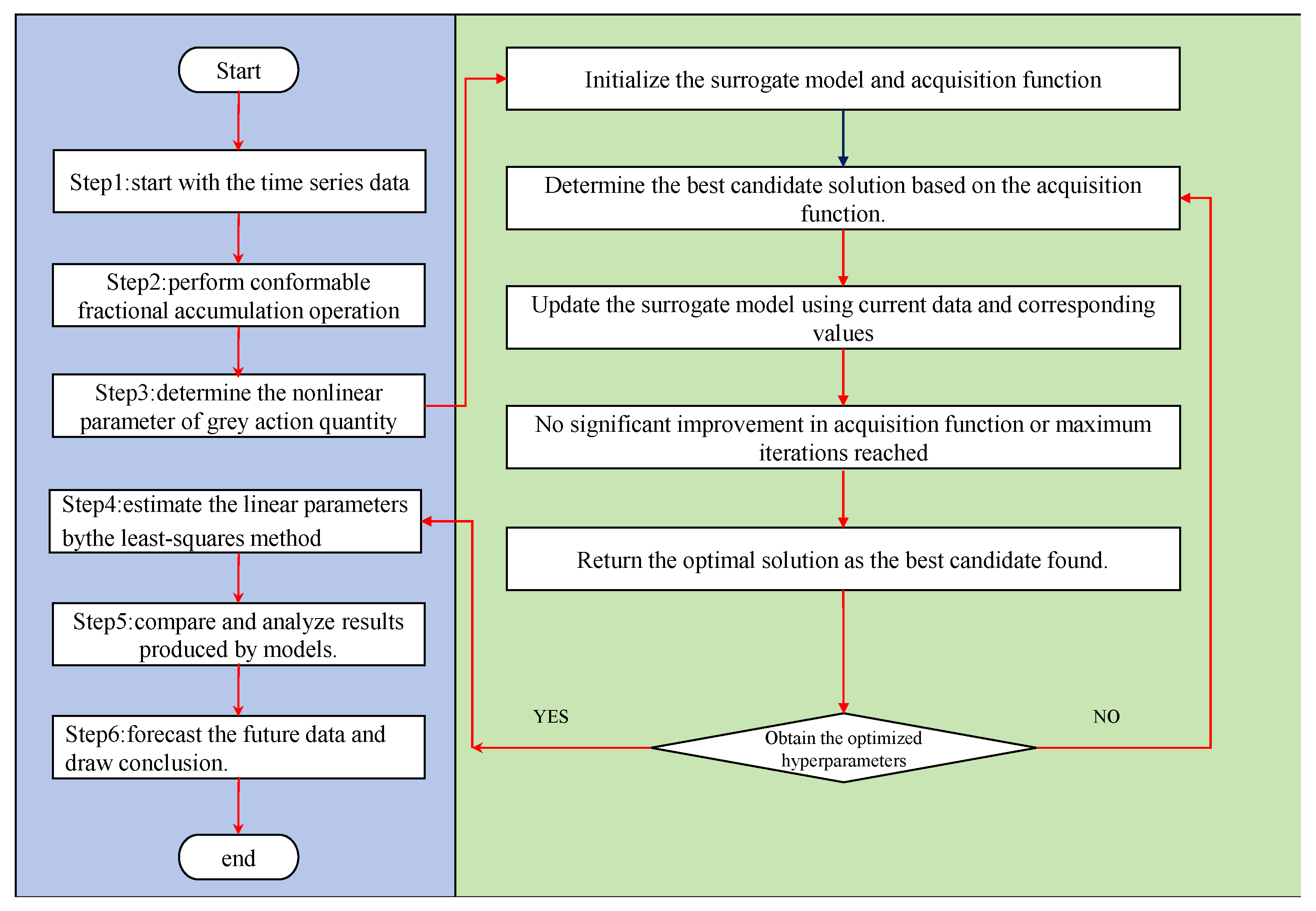
According to the preceding discussion, the algorithmic steps for optimizing the CFUKRNGM model using the Bayesian optimization algorithm are detailed in Algorithm 1. The entire optimization process consists of five steps. The input to Algorithm 1 is the training data, and the output is the optimal hyperparameters for the CFUKRNGM model. For a detailed procedure, refer to Algorithm 1.
| Algorithm 1: Bayesian Optimization for Hyperparameter Tuning |
| Input: Dataset , initial parameter . 1: while k < IterMax do 2: Step 1: Surrogate Model Update 3: Train the surrogate model using the current dataset = {, }. 4: Step 2: Acquisition Function Maximization 5: Find the by maximizing the acquisition function A(): = arg max A() 6: Use the predictive value update acquisition function of the surrogate model. 7: Step 3: Evaluate Objective Function f () 8: Step 4: Update Dataset 9: = ∪ {, f ()} 10: Step 5: Convergence Check 11: err = |f () − f ()| 12: if err ≤ then 13: Exit the loop. 14: end if 15: k ← k + 1 16: end while Output: The optimal hyperparameters |
The overall computational steps of CFUKRNGM with Bayesian optimization algorithm are depicted in the flowchart shown in Figure 1. The implementation of the proposed algorithm is publicly available as open-source on GitHub 1
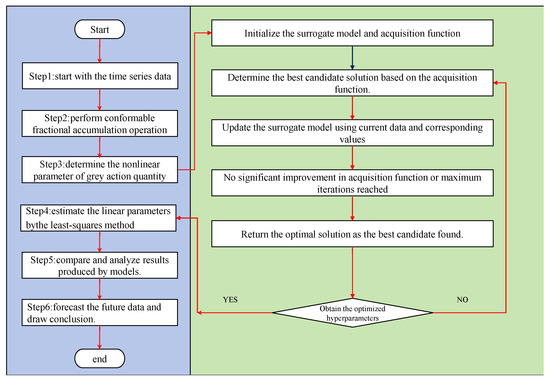
Figure 1.
The flowchart of the conformable fractional order unbiased kernel regularized nonhomogeneous grey model.
5. Numerical Experiment
This section employs four publicly available real-world datasets to verify the superiority of the CFUKRNGM model. The models used for comparison are conformable fractional grey system(abbreviated as CFGM) [22], fractional grey system (abbreviated as FGM) [47], kernel regularized nonhomogeneous grey model (abbreviated as KRNGM) [29], grey model (abbreviated as GM) [9], discrete grey forecasting model (abbreviated as DGM) [48], self-adaptive intelligence grey model(abbreviated as SAIGM) [49], time-delayed grey model(abbreviated as TDGM) [50], nonlinear grey model(abbreviated as NGM) [51], and autoregressive grey model(abbreviated as ARGM) [52]. For the grey models with hyperparameters, namely CFUKRNGM, KRNGM, FGM, and CFGM, the Bayesian optimization algorithm is uniformly applied to optimize the hyperparameters. Table 1 briefly summarizes the basic information of each dataset. The four datasets are all sourced from the Energy Institute Statistical Review of World Energy 2.

Table 1.
The information of the four datasets and the partitioning.
5.1. Evaluation Metrics
To evaluate and compare the effectiveness of various models, this study employs multiple performance indicators, including root mean squared error (RMSE), mean absolute error (MAE), normalized RMSE (NRMSE), mean absolute percentage error (MAPE), root mean squared percentage error (RMSPE), mean squared error (MSE), index of agreement (IA), and Theil’s U statistics (U1 and U2). These indicators comprehensively reflect both fitting and forecasting abilities of the CFUKRNGM model. The detailed mathematical definitions are provided in Table 2.
Table 2.
The nine evaluation metrics.
5.2. Case 1: Forecasting Oil Production in Block L
In this scenario, the CFUKRNGM model, along with other grey models for comparison, is utilized to simulate and predict oil production in Block L of the North China Oilfield (). Table 3 displays the oil production data spanning 20 months. Among these, the first 15 data points are used as the training set for model construction, while the remaining 5 are reserved for evaluating predictive performance. It is noteworthy that this dataset partitioning approach is consistent with the method adopted in [29].
Table 3.
Raw data of monthly oil production () of the block-L in North China oilfield.
Table 4 presents a comprehensive account of the predicted outcomes of the CFUKRNGM model alongside other grey models. The hyperparameters for the FGM, CFGM, KRNGM, and CFUKRNGM models were derived using the Bayesian optimization algorithm. In these models, hyperparameter adjustment is essential for improving model performance. The symbol in the table represents the penalty parameter, utilized to control the model’s complexity and degree of fit. In the CFUKRNGM model, is a constant intricately linked to its structural attributes. denotes the accumulation order of the FGM model, affecting the model’s fitting precision to the data. r denotes the accumulation order of the CFGM model, which dictates the model’s adaptability and fitting proficiency. is the bandwidth of the radial basis function (RBF) kernel, which regulates the model’s smoothness and generalization capacity. The optimized hyperparameters yield the most effective configurations for the models during fitting and prediction, hence guaranteeing their efficiency and accuracy in practical applications.
Table 4.
The oil production forecast results for the L block of the North China Oilfield.
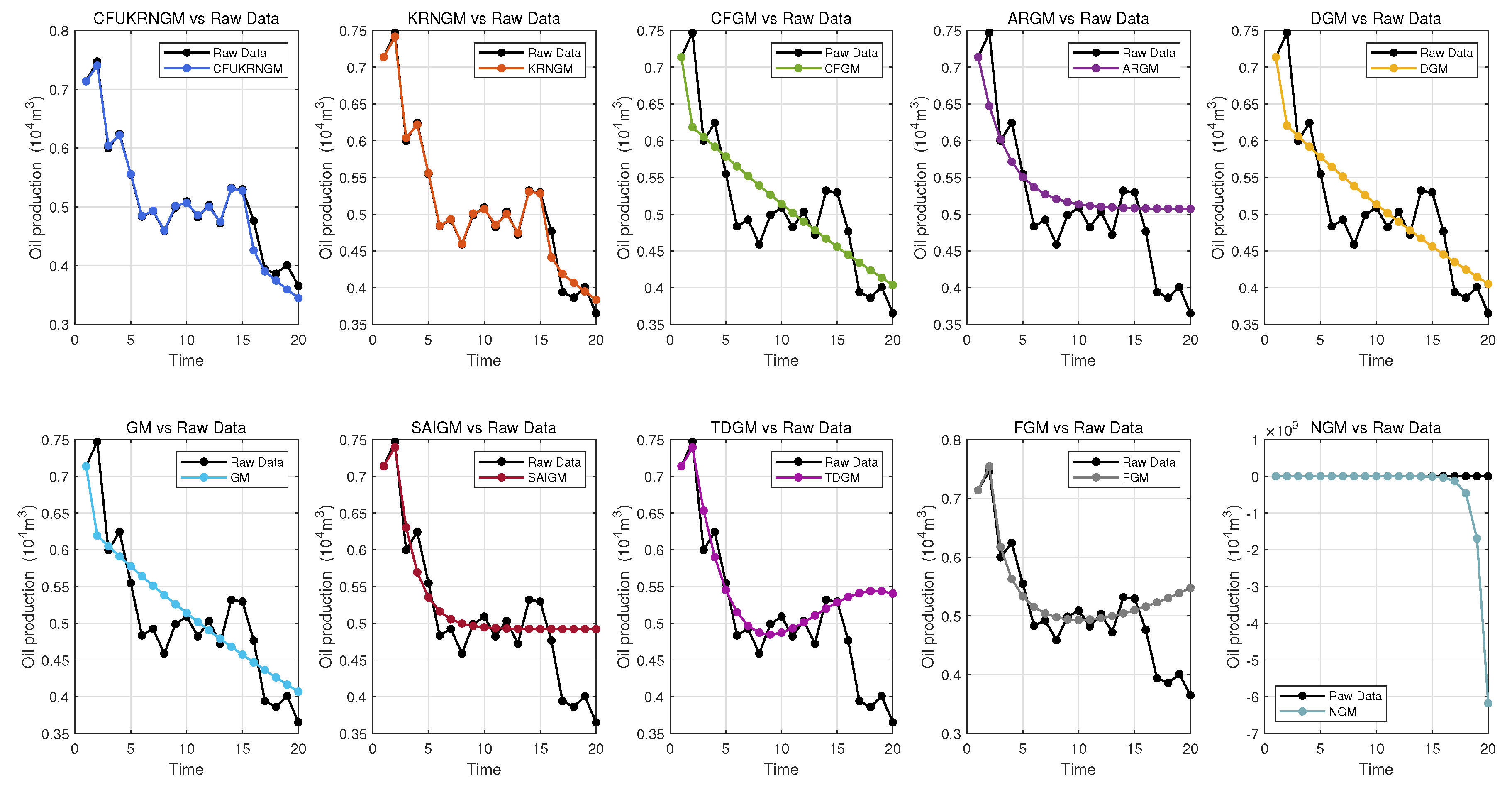
Figure 2 presents a comparative assessment of the CFUKRNGM model against nine alternative grey prediction models in the simulation and forecasting of oil production in Block L of the North China Oilfield. An exhaustive evaluation of the prediction results reveals that the CFUKRNGM model demonstrates much superior predictive accuracy relative to its counterparts.
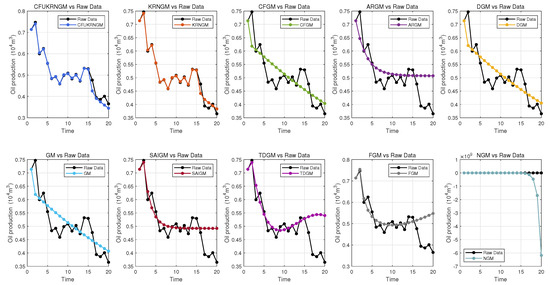
Figure 2.
The performance of 10 grey models’ predictions in Case 1.
For the oil production data of Block L in the North China Oilfield, Table 5 presents the evaluation metrics for both fitting and prediction performance across different models. Among these, the CFUKRNGM model consistently outperforms others, demonstrating superior accuracy across multiple metrics. In terms of fitting performance, CFUKRNGM achieves the lowest RMSE of 0.0026 and the smallest MAE of 0.0022, highlighting its strong capability in reducing prediction errors.
Table 5.
The computed evaluation metrics for the prediction results of 10 grey models in Case 1.
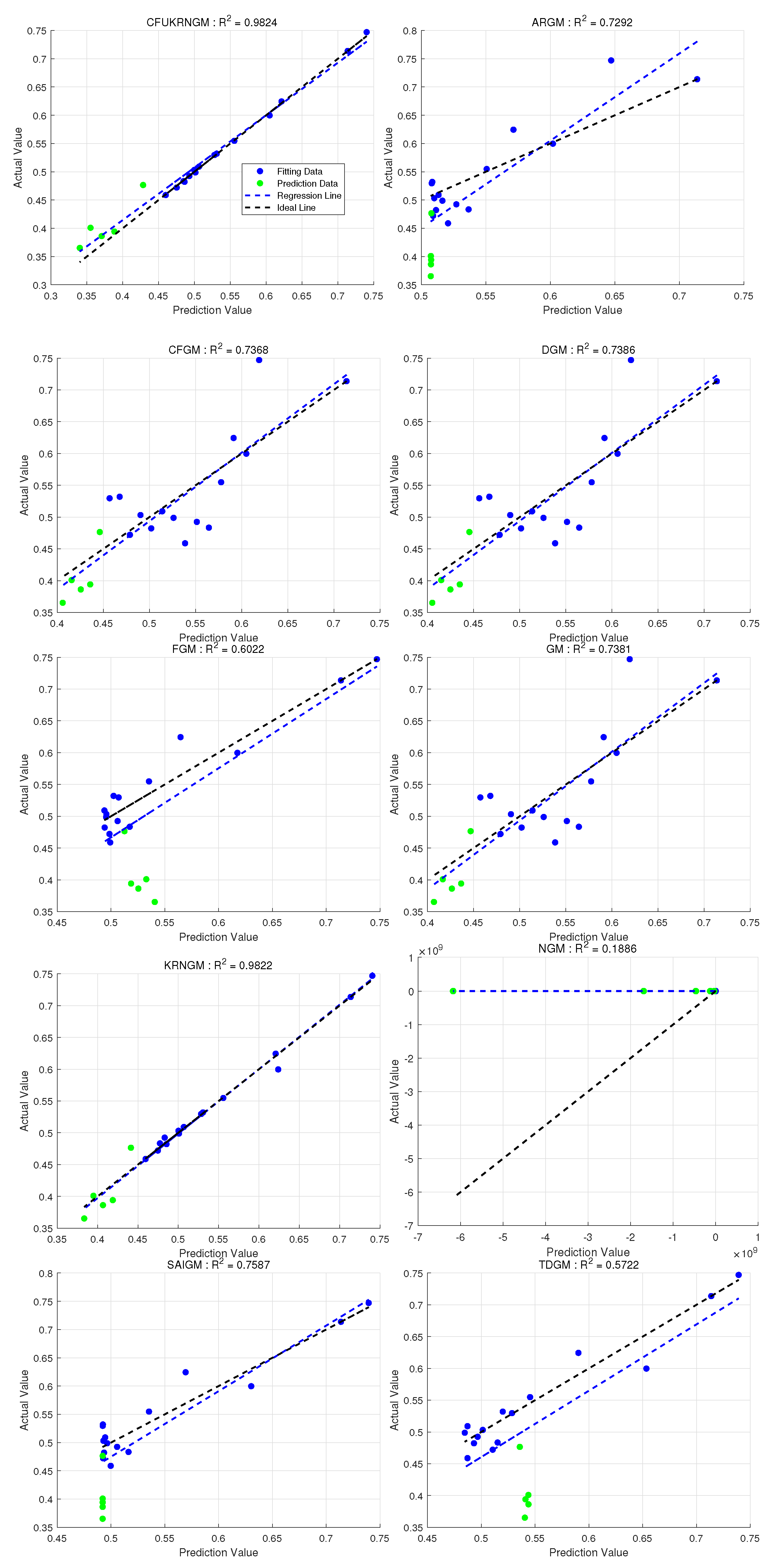
Figure 3 illustrates the detailed outcomes for all 10 models. The results clearly show that the majority of points predicted by CFUKRNGM closely align with the actual data, and the model achieves the highest overall R value. Therefore, in this validation case, CFUKRNGM proves to be the most effective model.
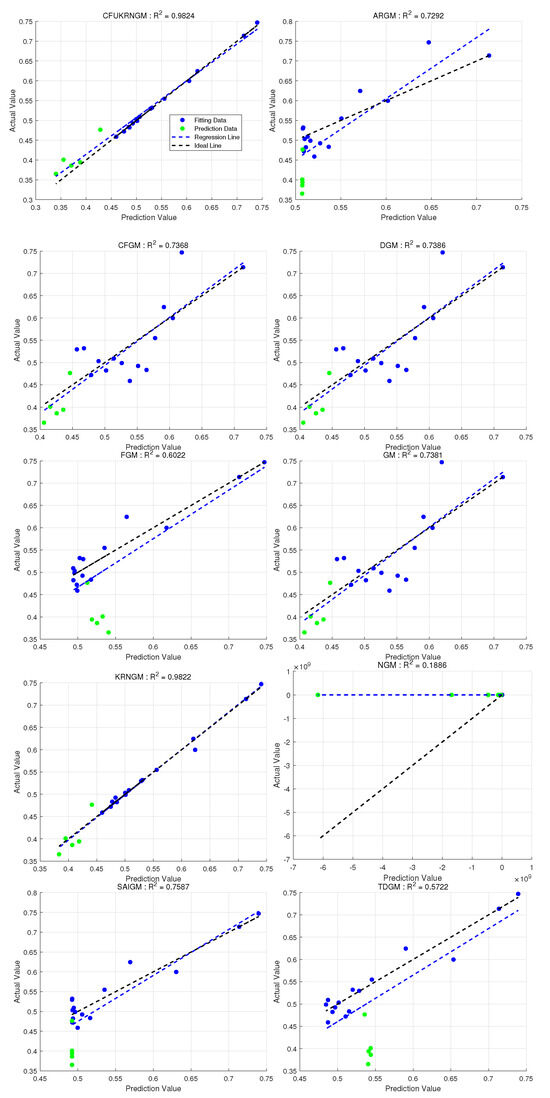
Figure 3.
The regression performance of ten grey models in Case 1. represents the coefficient of determination between the raw data and the predicted values of the models (Overall).
5.3. Case 2: Forecasting Carbon Dioxide Emissions in Turkey
Table 6 lists the carbon dioxide emission data for Turkey from 2004 to 2023. In this case, the hyperparameters of the FGM, CFGM, KRNGM, and CFUKRNGM models employed were meticulously tuned using the Bayesian optimization algorithm.
Table 6.
Carbon dioxide emissions in Turkey from 2004 to 2023 (unit: million metric tons).
Simulation forecasts were conducted for Turkey’s carbon dioxide emissions data spanning from 2004 to 2023, and the optimized hyperparameters are detailed in Table 7. Furthermore, metrics for assessing the fitting and predictive performance of each model are systematically presented in Table 8. A comprehensive analysis of the data in Table 7 and Table 8 reveals that the CFUKRNGM model not only demonstrates superior performance in fitting historical carbon dioxide emission data of Turkey but also outperforms other models in predicting data beyond the sample range, thereby confirming its significant advantages in terms of robustness and predictive accuracy.
Table 7.
The carbon dioxide emissions forecast results for Turkey from 2004 to 2023.
Table 8.
The computed evaluation metrics for the prediction results of 10 grey models in Case 2.
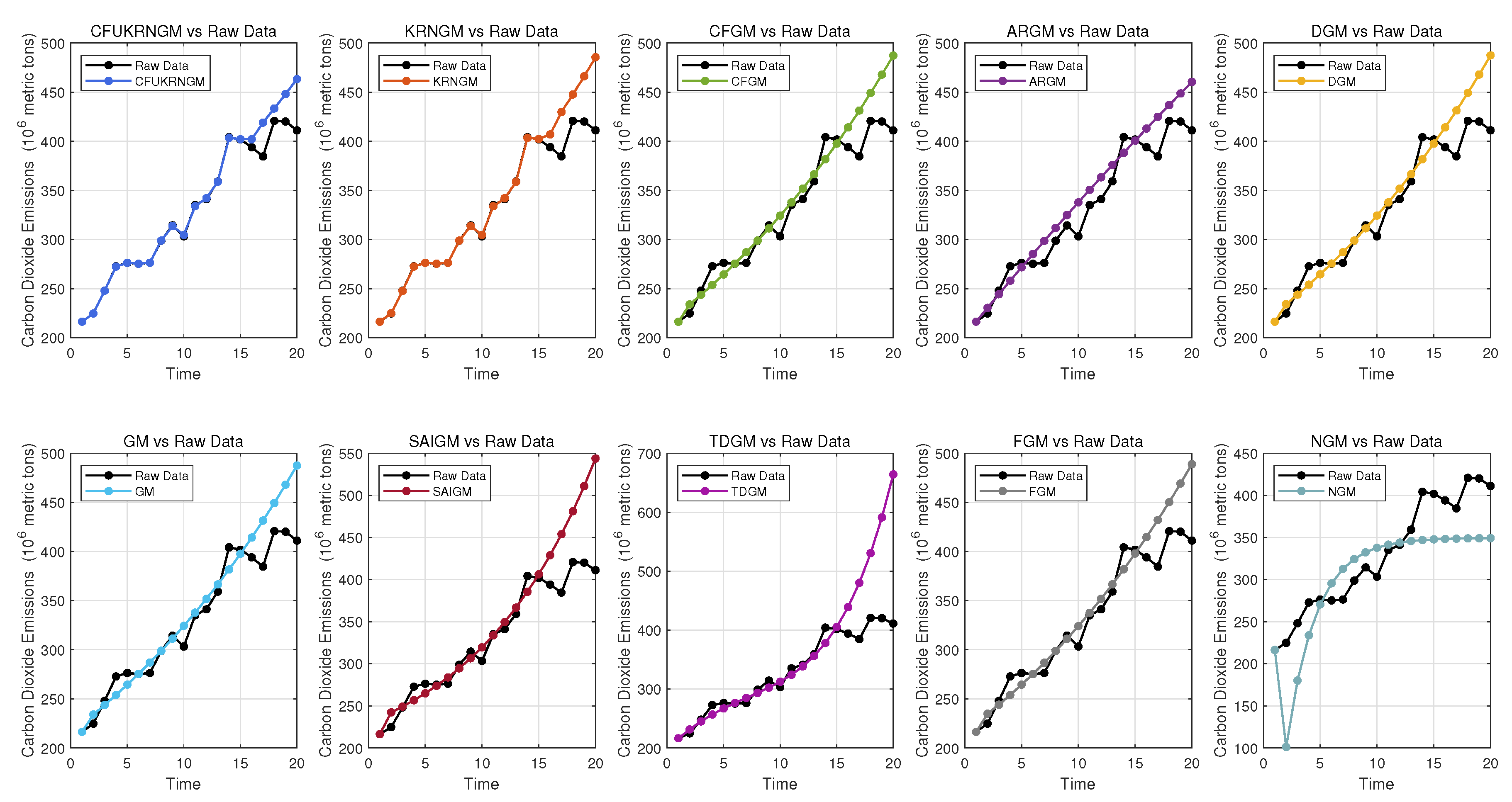
Figure 4 and Figure 5 respectively illustrate the forecasting outcomes of various grey prediction models. The analysis clearly indicates that the CFUKRNGM model outperforms the others in predictive accuracy. Notably, the coefficient of determination for CFUKRNGM reaches 0.982, exhibiting only a slight deviation from the theoretical optimal value of 1, which strongly validates its superior predictive performance and generalization ability.
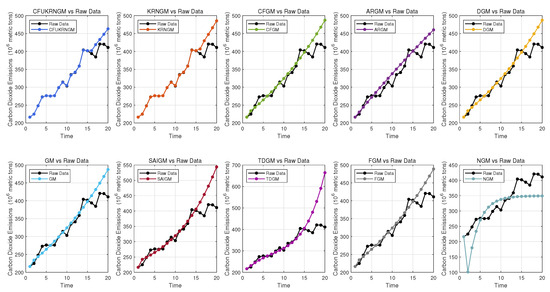
Figure 4.
The performance of 10 grey models’ predictions in Case 2.
5.4. Case 3: Forecasting Coal Production of Canada
In this case, grey models are used to simulate and predict coal production. The data in Table 9 represents Canada’s coal production from 2004 to 2023.
Table 9.
Coal production of Canada from 2004 to 2023 (unit: ).
The prediction results of the 10 grey models are summarized in Table 10. The hyperparameter optimization results for the FGM, CFGM, KRNGM, and CFUKRNGM models are also provided in Table 10. Clearly, the CFUKRNGM model exhibits the best predictive performance for out-of-sample data, demonstrating superior generalization ability and better capturing future trends.
Table 10.
The coal production forecast results for Canada from 2004 to 2023.
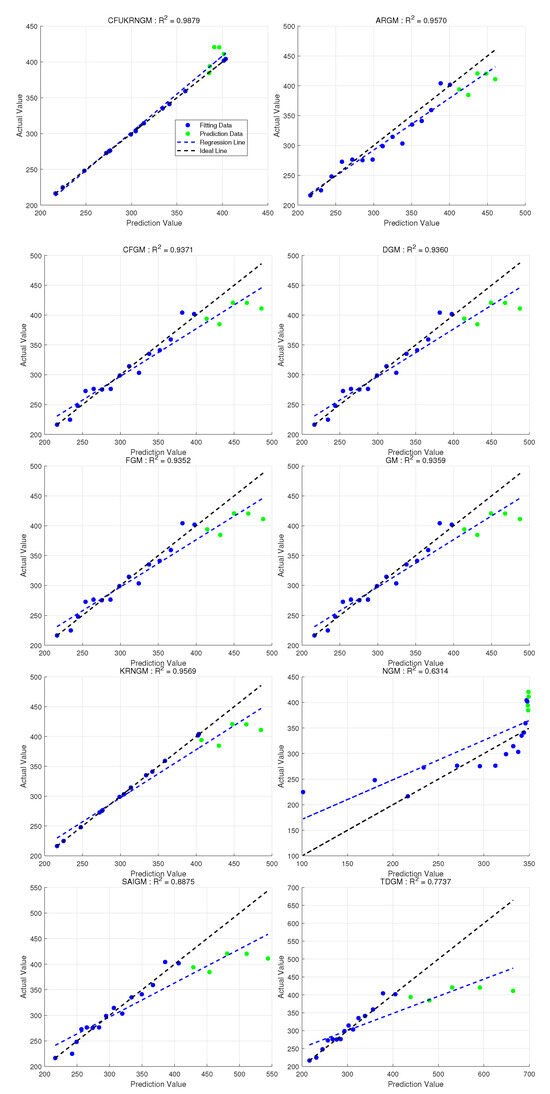
Figure 5.
The regression performance of ten grey models in Case 2. represents the coefficient of determination between the raw data and the predicted values of the models (Overall).
Figure 5.
The regression performance of ten grey models in Case 2. represents the coefficient of determination between the raw data and the predicted values of the models (Overall).
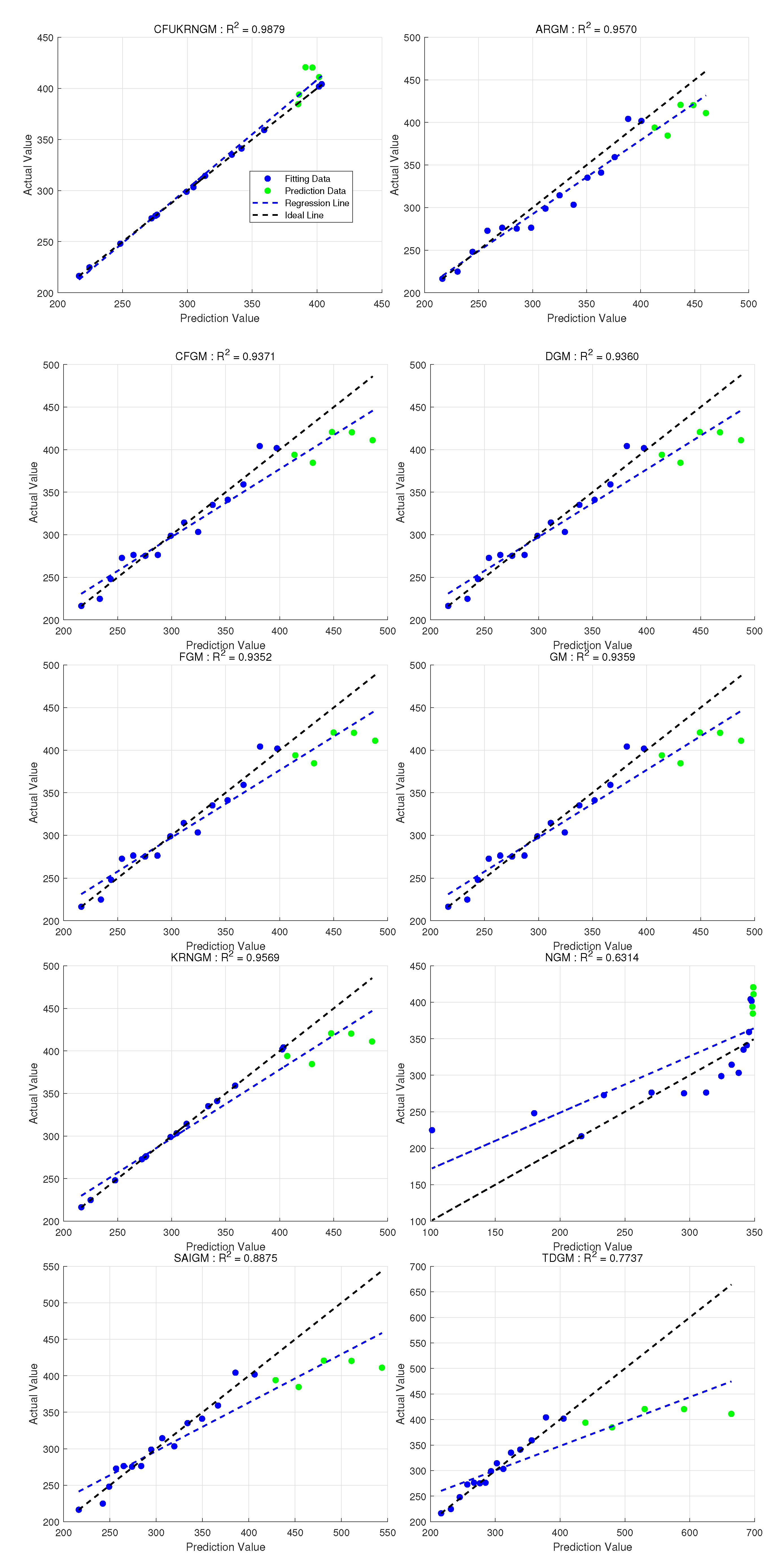
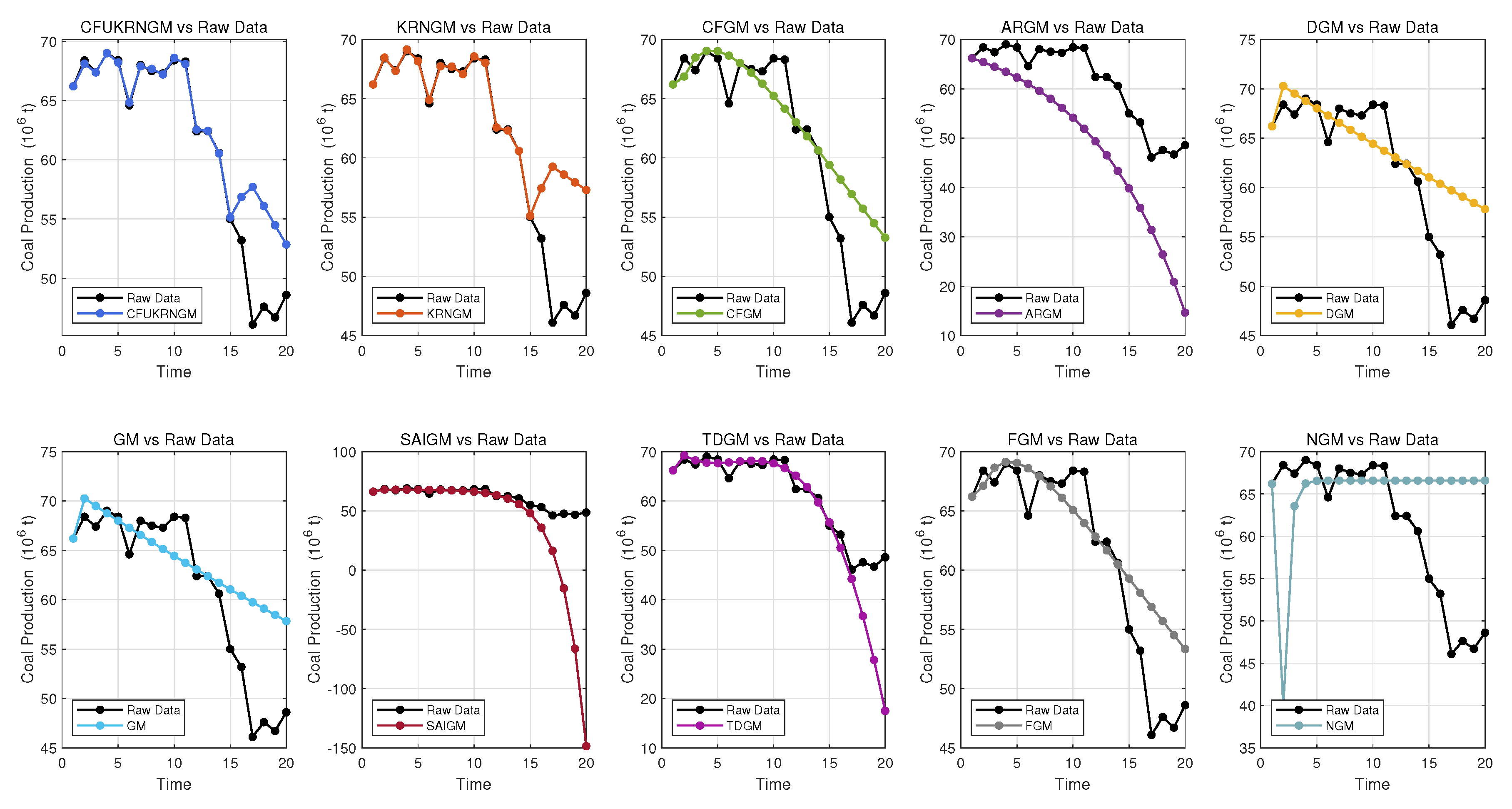
Figure 6 and Figure 7 present the prediction results of the 10 models. It is evident that most of the points generated by CFUKRNGM closely match the raw data, while the results from the other models are noticeably inferior, and CFUKRNGM achieves the highest overall value. Hence, in this validation case, CFUKRNGM outperforms all the other models.
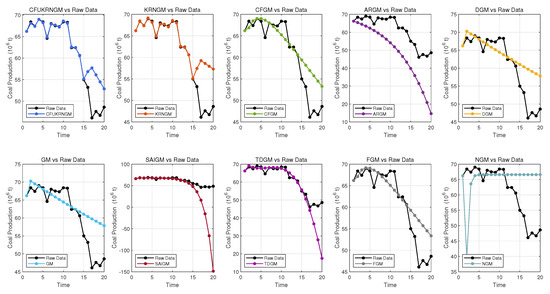
Figure 6.
The performance of 10 grey models’ predictions in Case 3.
Table 11 presents the evaluation of the prediction results of the 10 grey models for Canada’s coal production. Based on these metric values, the KRNGM and CFUKRNGM models exhibit smaller fitting errors, indicating a better ability to capture historical data trends. However, the CFUKRNGM model achieves lower prediction errors for future data, making it more accurate in forecasting future trends.
Table 11.
The computed evaluation metrics for the prediction results of 10 grey models in Case 3.
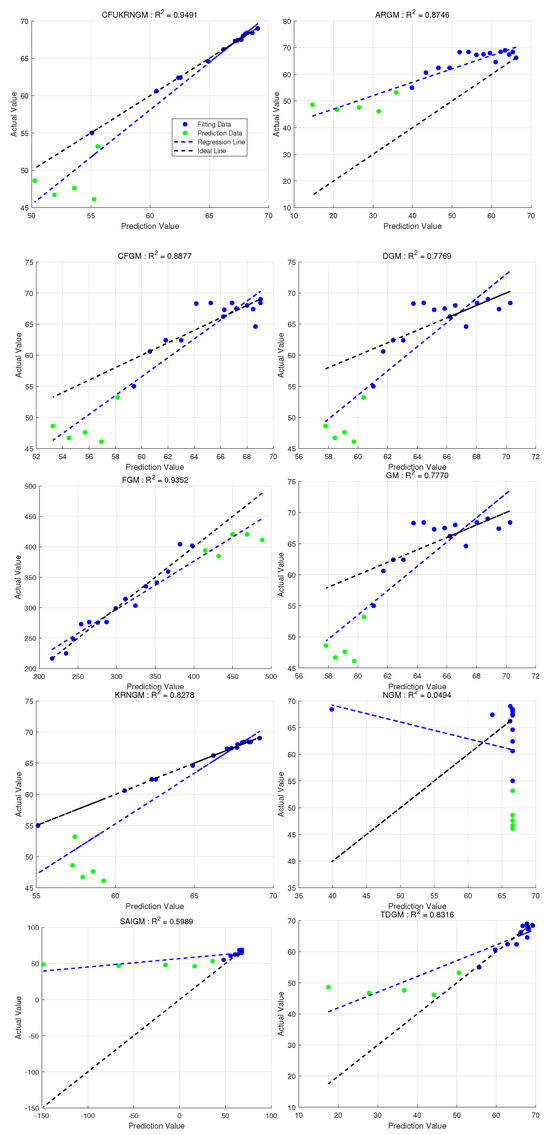
Figure 7.
The regression performance of ten grey models in Case 3. represents the coefficient of determination between the raw data and the predicted values of the models (Overall).
Figure 7.
The regression performance of ten grey models in Case 3. represents the coefficient of determination between the raw data and the predicted values of the models (Overall).
5.5. Case 4: Forecasting Natural Gas Electricity Generation in U.S.
This case study employs grey models to simulate and predict natural gas electricity generation in the United States. The original statistical data on U.S. natural gas electricity generation from 2003 to 2023 is provided in Table 12. Table 13 summarizes the simulation and forecasting results across ten grey models; the optimized hyperparameters for the FGM, CFGM, KRNGM, and CFUKRNGM models are also detailed in Table 13.
Table 12.
Natural gas electricity generation in the U.S from 2004 to 2023 (unit: Terawatt-hours).
Table 13.
The electricity generation from gas forecast results for United States from 2004 to 2023.
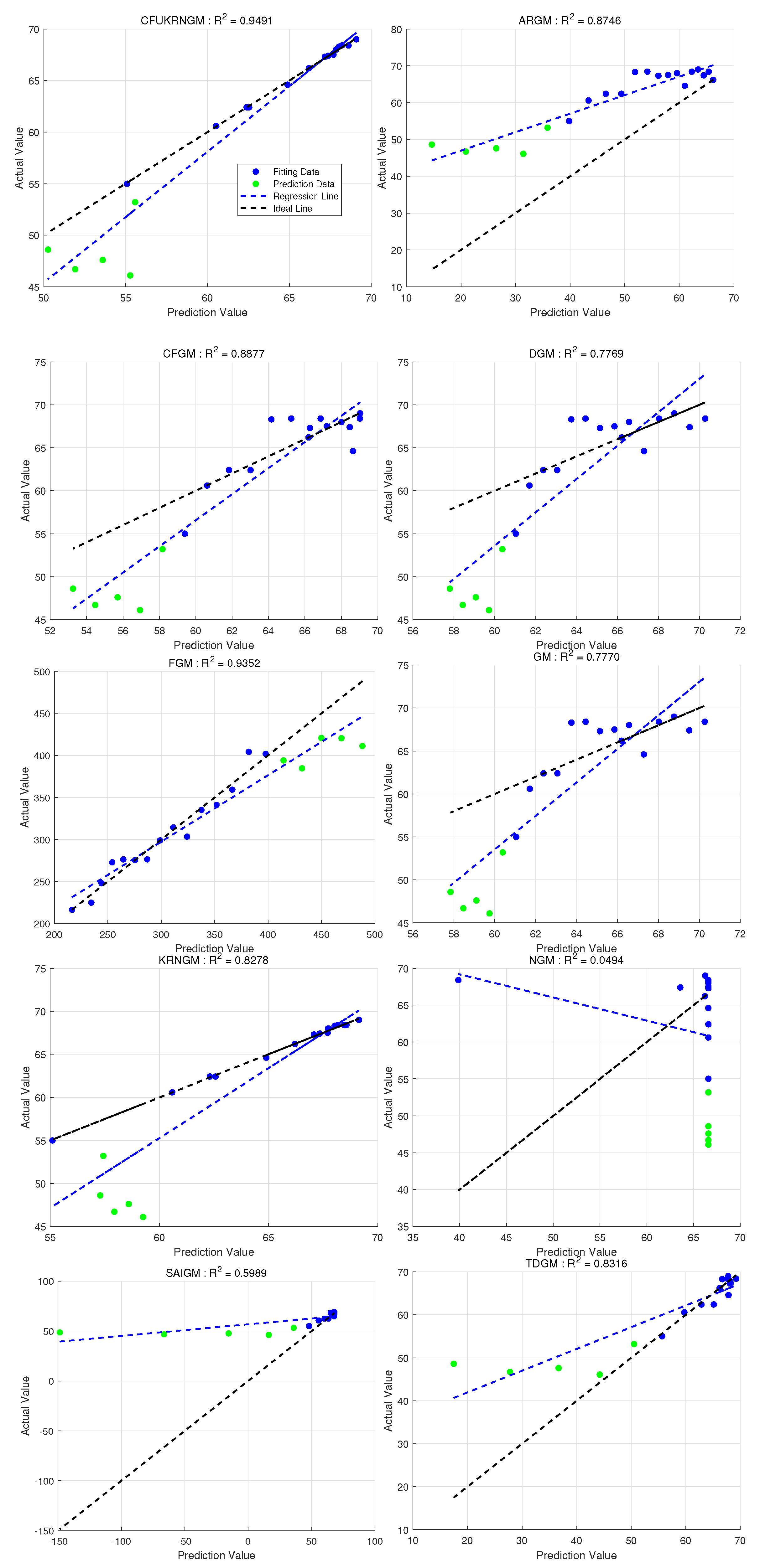
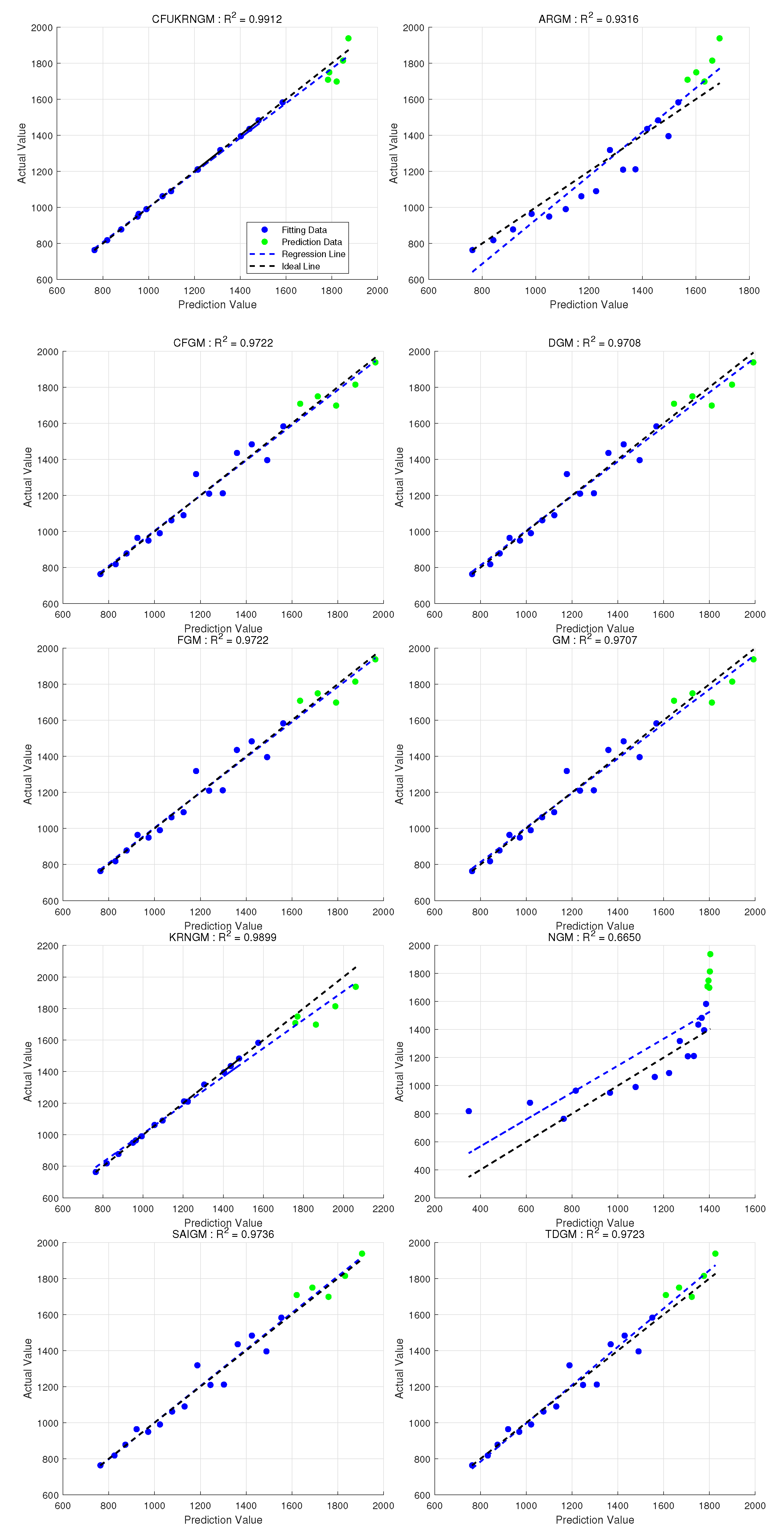
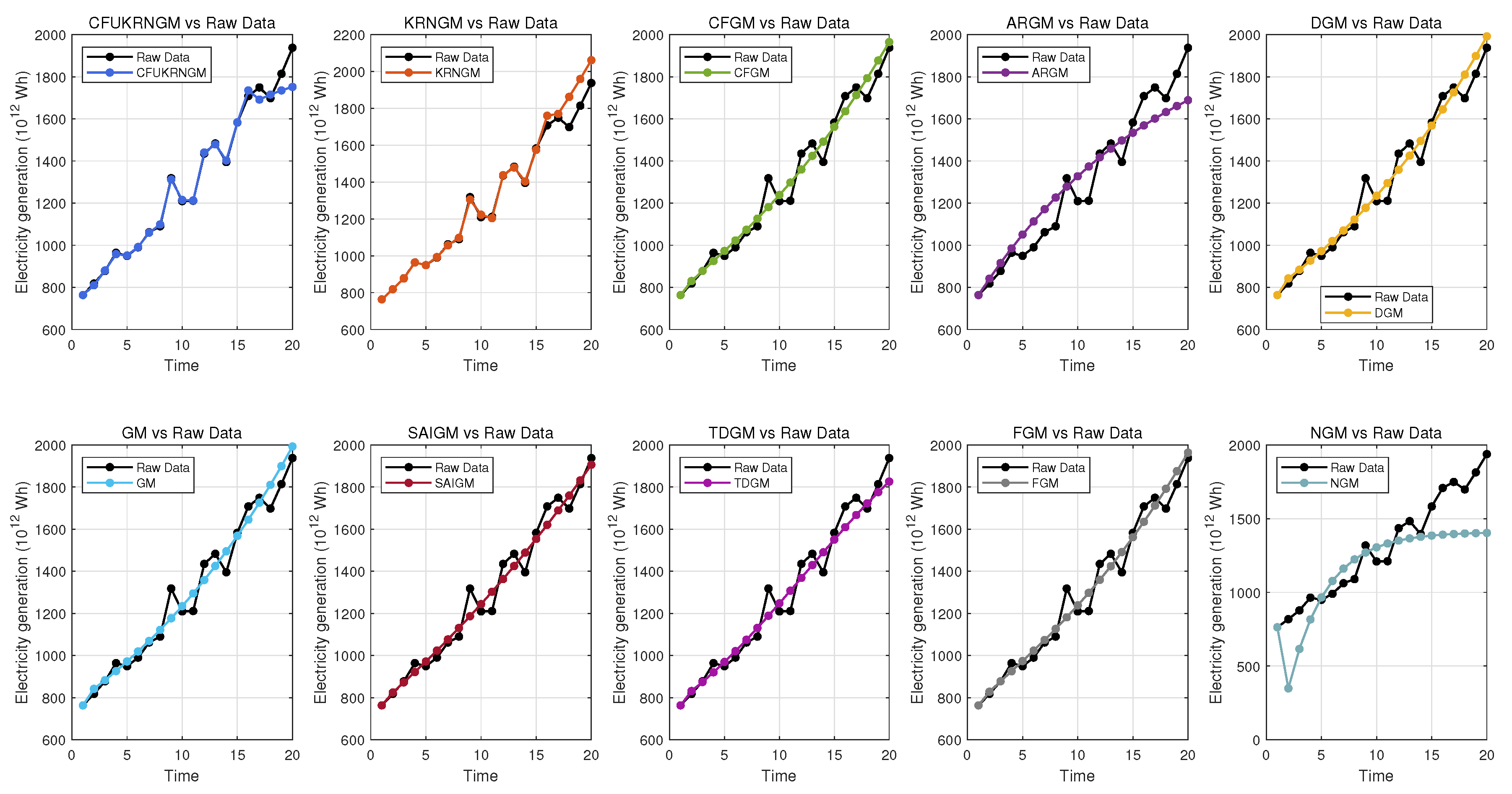
Figure 8 offers an exhaustive comparison of predictive accuracy across all ten models, distinctly demonstrating their individual fitting and forecasting capabilities. The visual comparisons indicate that the CFUKRNGM model’s predictions show an extraordinary level of alignment with the actual data points, as its associated linear regression line closely approximates the ideal reference line. This demonstrates that the CFUKRNGM model accurately reflects the fundamental dynamics and trends of the examined dataset. Thus, through both qualitative visual assessment and quantitative accuracy metrics, the CFUKRNGM model demonstrates the highest reliability and precision in this validation context. Moreover,The anticipated values produced by several grey models, in conjunction with the actual observed data, are depicted in Figure 9.
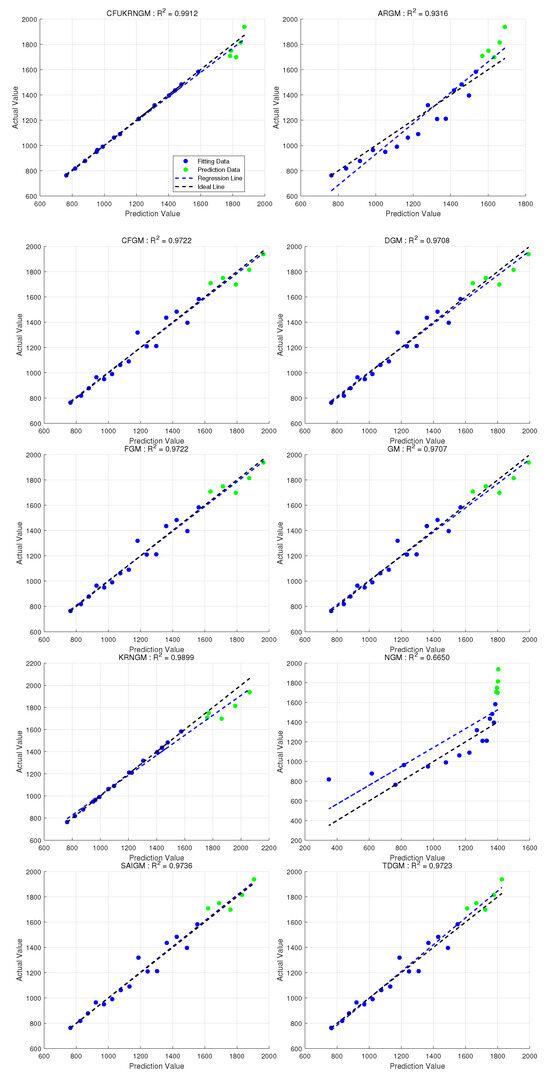
Figure 8.
The regression performance of ten grey models in Case 4. represents the coefficient of determination between the raw data and the predicted values of the models (Overall).
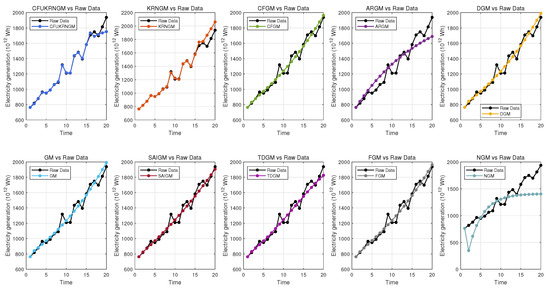
Figure 9.
The performance of 10 grey models’ predictions in Case 4.
Table 14 delineates the calculated evaluation metrics for each grey model in this instance. Table 14 demonstrates that the CFUKRNGM model surpasses the others in both fitting historical data and attaining superior predictive accuracy for future data. The CFUKRNGM model exhibits superior performance in both fitting and prediction.
Table 14.
The computed evaluation metrics for the prediction results of 10 grey models in Case 4.
6. Conclusions
In this work, a CFUKRNGM model was proposed to address the limitations of traditional grey models in handling complex nonlinear time series. By integrating CFA into the grey modeling process, the method extracts richer long-memory information from the data. Furthermore, a kernel function satisfying Mercer’s condition was introduced into the nonhomogeneous grey model framework, effectively embedding nonlinearity into the model and eliminating the bias term present in the original KRNGM, thus resulting in an unbiased modeling formulation. The parameter estimation for CFUKRNGM is achieved by solving only a single linear equation of reduced order (lower than that of the standard KRNGM), which simplifies the computational procedure. In addition, the key hyperparameters are automatically tuned using a Bayesian optimization algorithm. These innovations yield a model that preserves the efficiency of grey system models for small-sample forecasting while substantially enhancing their capacity to capture complex, nonlinear patterns in the data.
From a practical application perspective, the CFUKRNGM model has demonstrated strong predictive performance across various energy-related datasets, such as oil production, carbon dioxide emissions, and electricity generation. This not only validates the methodological advancement of the model but also highlights its broad real-world applicability. The model is capable of accurately forecasting energy production trends even with limited sample data, thereby providing quantitative support for energy scheduling, resource planning, and policy formulation. For instance, in oilfield production forecasting, accurately predicting output trends over a future time horizon can help enterprises optimize production plans and reduce resource waste. In the context of carbon emission prediction, the model’s outputs can inform the development of more scientifically grounded emission reduction strategies and energy transition policies. The results demonstrate that the removal of the bias factor and the incorporation of a nonlinear kernel function enhance the CFUKRNGM model’s alignment with the dynamic characteristics of complex data, therefore minimizing prediction errors and effectively mitigating overfitting across diverse settings. Nonetheless, it is important to acknowledge that the model’s effectiveness may still be limited by specific conditions. Excessive noise in the dataset, inadequate training samples, or the use of kernel functions ill-suited to the structural properties of a certain domain may result in diminished predictive accuracy. Furthermore, in situations characterized by significant non-stationarity or sudden alterations in data, the model may find it challenging to reliably identify underlying trends, which potentially leads to discrepancies in predictions. The limits of these models will be essential to our future research endeavors.
In summary, this work presents a unified and efficient grey modeling approach that bridges fractional order techniques with kernel regularization to overcome the linearity and bias limitations of previous models. The CFUKRNGM expands the methodological toolbox of grey system theory, offering a more flexible and accurate framework for time series forecasting under uncertainty. The results suggest that combining advanced mathematical tools (such as conformable fractional operators) with machine learning ideas (such as kernel methods and automatic hyperparameter tuning) can make grey models much better at modeling. Such an approach is not only effective for the cases examined in this study but also holds promise for a wide range of applications involving complex, nonlinear, and small-sample data. Future research can build upon the CFUKRNGM framework to explore other kernel functions or fractional operators and apply this model to diverse domains (e.g., energy consumption, economic indicators, or engineering systems), further extending the reach of grey system modeling in capturing real-world complexities.
Author Contributions
W.G.: Conceptualization, formal analysis, methodology, visualization, and writing—review and editing. Q.A.: Supervision and funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Social Science Fund of China [grant numbers: 24BTJ035].
Data Availability Statement
The data adopted in this study can be obtained from the website provided in the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
Notes
| 1 | https://github.com/gongwenkang/CFUKRNGM (accessed on 25 June 2025). |
| 2 | https://www.energyinst.org/statistical-review(accessed on 25 June 2025). |
References
- Lu, C.; Li, S.; Lu, Z. Building energy prediction using artificial neural networks: A literature survey. Energy Build. 2022, 262, 111718. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Y.; Zeng, R.; Srinivasan, R.S.; Ahrentzen, S. Random Forest based hourly building energy prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep learning-based feature engineering methods for improved building energy prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- Cammarano, A.; Petrioli, C.; Spenza, D. Pro-Energy: A novel energy prediction model for solar and wind energy-harvesting wireless sensor networks. In Proceedings of the 2012 IEEE 9th International Conference on Mobile Ad-Hoc and Sensor Systems (MASS 2012), Las Vegas, NV, USA, 8–11 October 2012; pp. 75–83. [Google Scholar]
- He, X.; Wang, Y.; Zhang, Y.; Ma, X.; Wu, W.; Zhang, L. A novel structure adaptive new information priority discrete grey prediction model and its application in renewable energy generation forecasting. Appl. Energy 2022, 325, 119854. [Google Scholar] [CrossRef]
- Feng, S.; Ma, Y.; Song, Z.; Ying, J. Forecasting the energy consumption of China by the grey prediction model. Energy Sources Part Econ. Planning Policy 2012, 7, 376–389. [Google Scholar] [CrossRef]
- Tsai, S.B. Using grey models for forecasting China’s growth trends in renewable energy consumption. Clean Technol. Environ. Policy 2016, 18, 563–571. [Google Scholar] [CrossRef]
- Duan, H.; Pang, X. A multivariate grey prediction model based on energy logistic equation and its application in energy prediction in China. Energy 2021, 229, 120716. [Google Scholar] [CrossRef]
- Ju-Long, D. Control problems of grey systems. Syst. Control Lett. 1982, 1, 288–294. [Google Scholar] [CrossRef]
- Julong, D. Essential Topics on Grey System: Theory and Application. In A Report on the Project of National Science Foundation of China; China Ocean Press: Beijing, China, 1988. [Google Scholar]
- Mao, M.; Chirwa, E.C. Application of grey model GM (1, 1) to vehicle fatality risk estimation. Technol. Forecast. Soc. Change 2006, 73, 588–605. [Google Scholar] [CrossRef]
- Wang, Y.; He, X.; Zhou, Y.; Luo, Y.; Tang, Y.; Narayanan, G. A novel structure adaptive grey seasonal model with data reorganization and its application in solar photovoltaic power generation prediction. Energy 2024, 302, 131833. [Google Scholar] [CrossRef]
- Li, X.; Li, N.; Ding, S.; Cao, Y.; Li, Y. A novel data-driven seasonal multivariable grey model for seasonal time series forecasting. Inf. Sci. 2023, 642, 119165. [Google Scholar] [CrossRef]
- Zhou, W.; Wu, X.; Ding, S.; Ji, X.; Pan, W. Predictions and mitigation strategies of PM2. 5 concentration in the Yangtze River Delta of China based on a novel nonlinear seasonal grey model. Environ. Pollut. 2021, 276, 116614. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Wu, X.; Ding, S.; Cheng, Y. Predictive analysis of the air quality indicators in the Yangtze River Delta in China: An application of a novel seasonal grey model. Sci. Total Environ. 2020, 748, 141428. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Liu, S.; Yao, L.; Yan, S.; Liu, D. Grey system model with the fractional order accumulation. Commun. Nonlinear Sci. Numer. Simul. 2013, 18, 1775–1785. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Chen, D.; Yao, L.; Cui, W. Using gray model with fractional order accumulation to predict gas emission. Nat. Hazards 2014, 71, 2231–2236. [Google Scholar] [CrossRef]
- Wang, Y.; Chi, P.; Nie, R.; Ma, X.; Wu, W.; Guo, B. Self-adaptive discrete grey model based on a novel fractional order reverse accumulation sequence and its application in forecasting clean energy power generation in China. Energy 2022, 253, 124093. [Google Scholar] [CrossRef]
- Wensong, J.; Zhongyu, W.; Mourelatos, Z.P. Application of Nonequidistant Fractional-Order Accumulation Model on Trajectory Prediction of Space Manipulator. IEEE/ASME Trans. Mechatronics 2016, 21, 1420–1427. [Google Scholar] [CrossRef]
- Zhang, J.; Qin, Y.; Zhang, X.; Che, G.; Sun, X.; Duo, H. Application of non-equidistant GM (1, 1) model based on the fractional-order accumulation in building settlement monitoring. J. Intell. Fuzzy Syst. 2022, 42, 1559–1573. [Google Scholar] [CrossRef]
- Gao, M.; Mao, S.; Yan, X.; Wen, J. Estimation of Chinese CO2 Emission Based on A Discrete Fractional Accumulation Grey Model. J. Grey Syst. 2015, 27, 114–130. [Google Scholar]
- Ma, X.; Wu, W.; Zeng, B.; Wang, Y.; Wu, X. The conformable fractional grey system model. ISA transactions 2020, 96, 255–271. [Google Scholar] [CrossRef]
- Duan, H.; Lei, G.R.; Shao, K. Forecasting Crude Oil Consumption in China Using a Grey Prediction Model with an Optimal Fractional-Order Accumulating Operator. Complexity 2018, 2018, 3869619. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Z.; Ma, N. Time-Delayed Polynomial Grey System Model with the Fractional Order Accumulation. Math. Probl. Eng. 2018, 2018, 3640625. [Google Scholar] [CrossRef]
- Wu, L.; Gao, X.; Xiao, Y.; Yang, Y.; Chen, X. Using a novel multi-variable grey model to forecast the electricity consumption of Shandong Province in China. Energy 2018, 157, 327–335. [Google Scholar] [CrossRef]
- Cai, M. Non-homogeneous Grey Model NGM (1, 1) with initial value modification and its application. In Proceedings of the 2010 2nd International Conference on Industrial and Information Systems, Dalian, China, 10–11 July 2010; Volume 1, pp. 102–104. [Google Scholar]
- Jiang, J.; Zhang, Y.; Liu, C.; Xie, W. An improved nonhomogeneous discrete grey model and its application. Math. Probl. Eng. 2020, 2020, 4638296. [Google Scholar] [CrossRef]
- Wu, W.; Ma, X.; Zeng, B.; Zhang, P. A Conformable Fractional Non-homogeneous Grey Forecasting Model with Adjustable Parameters CFNGMA (1, 1, k, c) and its Application. J. Grey Syst. 2024, 36, 1–12. [Google Scholar]
- Ma, X.; Hu, Y.s.; Liu, Z.b. A novel kernel regularized nonhomogeneous grey model and its applications. Commun. Nonlinear Sci. Numer. Simul. 2017, 48, 51–62. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory; John Wiley & Sons Google Schola: Hoboken, NJ, USA, 1998; Volume 2, pp. 831–842. [Google Scholar]
- Hofmann, T.; Schölkopf, B.; Smola, A.J. Kernel methods in machine learning. Ann. Stat. 2008, 36, 1171–1220. [Google Scholar] [CrossRef]
- Camastra, F.; Verri, A. A novel kernel method for clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 801–805. [Google Scholar] [CrossRef]
- Blanchard, G.; Bousquet, O.; Zwald, L. Statistical properties of kernel principal component analysis. Mach. Learn. 2007, 66, 259–294. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Chaos control using least-squares support vector machines. Int. J. Circuit Theory Appl. 1999, 27, 605–615. [Google Scholar] [CrossRef]
- Wang, H.; Fu, G.; Cai, Y.; Wang, S. Multiple feature fusion based image classification using a non-biased multi-scale kernel machine. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 700–704. [Google Scholar]
- Wang, S.; Tang, L.; Yu, L. SD-LSSVR-based decomposition-and-ensemble methodology with application to hydropower consumption forecasting. In Proceedings of the 2011 Fourth International Joint Conference on Computational Sciences and Optimization, Kunming and Lijiang City, China, 15–19 April 2011; pp. 603–607. [Google Scholar]
- Juyal, A.; Sharma, S. A Study of landslide susceptibility mapping using machine learning approach. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1523–1528. [Google Scholar]
- Wang, H.Q.; Sun, F.C.; Cai, Y.N.; Ding, L.G.; Chen, N. An unbiased LSSVM model for classification and regression. Soft Comput. 2010, 14, 171–180. [Google Scholar] [CrossRef]
- Jeon, M.; Kim, D.; Lee, W.; Kang, M.; Lee, J. A conservative approach for unbiased learning on unknown biases. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16752–16760. [Google Scholar]
- de Mello, C.E.R. Active Learning: An Unbiased Approach. Ph.D. Thesis, Ecole Centrale Paris. Universidade federal do Rio de Janeiro, Paris, France, 2013. [Google Scholar]
- Syarif, I.; Prugel-Bennett, A.; Wills, G. SVM parameter optimization using grid search and genetic algorithm to improve classification performance. TELKOMNIKA Telecommun. Comput. Electron. Control 2016, 14, 1502–1509. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Bertsimas, D.; Tsitsiklis, J. Simulated annealing. Stat. Sci. 1993, 8, 10–15. [Google Scholar] [CrossRef]
- Brochu, E.; Cora, V.M.; De Freitas, N. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Mao, S.; Gao, M.; Xiao, X.; Zhu, M. A novel fractional grey system model and its application. Appl. Math. Model. 2016, 40, 5063–5076. [Google Scholar] [CrossRef]
- Xie, N.m.; Liu, S.f. Discrete grey forecasting model and its optimization. Appl. Math. Model. 2009, 33, 1173–1186. [Google Scholar] [CrossRef]
- Zeng, B.; Meng, W.; Tong, M. A self-adaptive intelligence grey predictive model with alterable structure and its application. Eng. Appl. Artif. Intell. 2016, 50, 236–244. [Google Scholar] [CrossRef]
- Ma, X.; Mei, X.; Wu, W.; Wu, X.; Zeng, B. A novel fractional time delayed grey model with Grey Wolf Optimizer and its applications in forecasting the natural gas and coal consumption in Chongqing China. Energy 2019, 178, 487–507. [Google Scholar] [CrossRef]
- Shaikh, F.; Ji, Q.; Shaikh, P.H.; Mirjat, N.H.; Uqaili, M.A. Forecasting China’s natural gas demand based on optimised nonlinear grey models. Energy 2017, 140, 941–951. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Chen, H.; Zhang, N. Using a novel grey system model to forecast natural gas consumption in China. Math. Probl. Eng. 2015, 2015, 686501. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).