Abstract
High-precision 3D object detection is pivotal for autonomous driving. However, voxel-based two-stage detectors still struggle with small and non-rigid objects due to the misalignment between classification confidence and localization accuracy, and the loss of fine-grained spatial context during feature flattening. To address these issues, we propose the Varifocal Fine-grained Refinement Network (VFR-Net). We introduce Varifocal Loss (VFL) to learn IoU-aware scores for prioritizing high-quality proposals, and a Fine-Grained Refinement Attention (FGRA) Module to capture local geometric details via self-attention before flattening. Extensive experiments on the KITTI and ONCE datasets demonstrate that VFR-Net consistently outperforms the Voxel R-CNN baseline, improving the overall mAP by +1.12% on KITTI and +2.63% on ONCE. Specifically, it achieves AP gains of +1.81% and +1.28% for pedestrians and cyclists on KITTI (averaged over Easy/Moderate/Hard), and +6.53% and +1.50% on ONCE (Overall).
1. Introduction
In recent years, accompanying rapid socio-economic development, autonomous driving technology has revolutionized the transportation industry and has been widely adopted across various fields, including drones and robotics [1]. This technology is attracting increasing attention due to its potential not only to contribute to the advancement of vehicle intelligence and the optimization of traffic management but also to reduce driver burden and significantly enhance driving safety [2,3]. Generally, an autonomous driving system is composed of three primary subsystems: perception, decision, and control [1]. In particular, deep learning-based perception modules have become indispensable components of modern autonomous driving pipelines, as they process complex environmental data and provide reliable observations for downstream prediction and planning tasks [2,4]. While perception tasks include 2D object detection and semantic segmentation, 3D object detection remains one of the most critical and fundamental challenges in autonomous driving [1]. Unlike 2D detection, which is limited to planar image information, 3D object detection aims to capture the precise position, size, category, and orientation of objects in the real world [1,3], thereby playing a crucial role in the safe navigation of the ego vehicle.
For 3D object detection, LiDAR-based methods have become mainstream due to their superior ranging capabilities and robustness to illumination changes. Among various approaches, voxel-based two-stage detectors, represented by Voxel R-CNN [5], have become a dominant paradigm thanks to their favorable balance between accuracy and efficiency. However, despite their success, current voxel-based detectors still face significant hurdles in achieving robust performance on small and non-rigid objects (e.g., pedestrians and cyclists). In this work, we focus on two key accuracy-related issues in two-stage voxel-based 3D detectors, particularly those that degrade performance on small and non-rigid objects.
First, there exists a misalignment between classification confidence and localization accuracy, which can lead to the suppression of important proposals during Non-Maximum Suppression (NMS). Standard detectors typically use independent loss functions for classification and regression. As a result, the network may assign high classification scores to bounding boxes with low Intersection-over-Union (IoU), i.e., poorly localized boxes. During NMS, such high-score but poorly localized boxes may inadvertently suppress well-localized but lower-score boxes, degrading the final detection performance. This misalignment is particularly harmful for small objects, where even minor localization errors induce a large drop in IoU. To quantify this phenomenon, we measure the ratio of over-confident mislocalized proposals, defined as predictions with IoU below the class-specific IoU threshold and confidence score greater than or equal to the class-specific score threshold. As shown in Figure 1, VFR-Net significantly suppresses such proposals, reducing them by 38.5%, 74.0%, and 53.7% for Car, Pedestrian, and Cyclist on the KITTI validation set, respectively, clearly demonstrating the effectiveness of our IoU-aware confidence design.
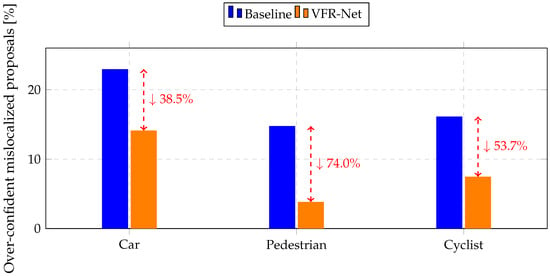
Figure 1.
Class-wise over-confident mislocalized ratio on the KITTI validation set. (score ≥ 0.7 and IoU < class threshold).
Second, we highlight a structural limitation of the feature aggregation process in the RoI head. Voxel R-CNN flattens high-dimensional sparse features obtained via RoI pooling into a single vector and then compresses them into a low-dimensional representation using fully connected (FC) layers. This simple flatten-then-FC paradigm has two drawbacks: (1) the flattening operation immediately destroys spatial adjacency within the RoI grid, and (2) FC layers aggregate features using fixed weights trained on general patterns. This rigidity makes it difficult to adapt to the diverse geometric deformations of non-rigid objects (e.g., pedestrians), often causing sparse foreground features to be overwhelmed by the dominant background noise (empty voxels) during compression. Consequently, simply stacking FC layers for dimensionality reduction is insufficient; it is desirable to refine RoI features with a mechanism that captures long-range dependencies and adaptively highlights informative locations before flattening.
To overcome the aforementioned challenges, we propose an enhanced 3D detection framework named Varifocal Fine-grained Refinement Network (VFR-Net) that effectively boosts the performance of Voxel R-CNN with modest architectural changes. Our method integrates two complementary components: Varifocal Loss (VFL) [6] and the Fine-Grained Refinement Attention (FGRA) Module.
First, we replace the conventional classification loss with VFL in both the Region Proposal Network (RPN) and the detection heads. VFL trains the network to predict IoU-aware classification scores, so that the confidence better correlates with localization quality. This alignment effectively rectifies the proposal ranking, ensuring that the NMS process correctly prioritizes high-quality predictions, thereby alleviating the suppression of valid detections caused by confidence–localization misalignment.
Second, we introduce the FGRA Module, a lightweight Multi-Head Self-Attention (MHSA) module, into the RoI head before the feature flattening stage. Unlike FC layers that rely on fixed templates, FGRA utilizes dynamic weights to model global context and long-range dependencies within each RoI grid. This mechanism functions as a content-adaptive filter that clusters semantically related foreground points and suppresses background noise, preserving fine-grained geometric details that are otherwise weakened during the drastic dimensionality reduction.
Importantly, VFL and the FGRA Module address different aspects of the bottleneck and work in a complementary manner: VFL improves the quality of confidence scores from the score side by aligning them with localization accuracy, while FGRA enhances RoI features from the feature side by mitigating information loss before flattening. Our ablation studies show that combining both components yields the largest performance gains, especially for pedestrians and cyclists.
Our main contributions are summarized as follows:
- We propose a cost-effective integration of Varifocal Loss (VFL) and the Fine-Grained Refinement Attention (FGRA) Module for voxel-based two-stage 3D detection. VFL learns IoU-aware confidence scores to mitigate confidence–localization misalignment, while FGRA refines RoI features before flattening to preserve fine-grained spatial context.
- Extensive experiments on the KITTI validation set show that VFR-Net consistently improves the overall mAP by +1.12% over the Voxel R-CNN baseline. Notably, the class-wise AP improves by +1.81% (Pedestrian) and +1.28% (Cyclist), averaged over Easy/Moderate/Hard.
- We further validate the generalization capability on the large-scale ONCE dataset, where VFR-Net improves the overall mAP by +2.63% (Overall). In particular, the Pedestrian and Cyclist AP gains are +6.53% and +1.50% (Overall), respectively.
The remainder of this paper is organized as follows. Section 2 reviews the related work in 3D object detection and attention mechanisms. Section 3 describes the proposed VFR-Net framework, including the Varifocal Loss and the FGRA module. Section 4 details the experimental setup, including the datasets and implementation details. Section 5 presents the experimental results and ablation studies. Finally, Section 6 concludes the paper.
2. Related Work
2.1. LiDAR-Based 3D Object Detection
LiDAR-based 3D object detection methods are broadly classified into point-based [7,8,9,10,11] and voxel-based [5,12,13,14,15] approaches. PointRCNN [7] is a two-stage framework that effectively utilizes the geometric structure of point clouds through bottom-up proposal generation based on foreground points and local feature refinement in canonical coordinates. VoteNet [8] is another 3D object detection method that directly processes raw point clouds. It combines PointNet++ [16]-based feature extraction with a voting mechanism inspired by Hough Voting [17]. This mechanism generates votes near object centers, which are subsequently clustered to form box proposals. While these point-based methods offer the advantage of preserving fine-grained geometric structures with high accuracy, their reliance on direct point-wise operations and neighborhood searches results in significant computational cost and memory usage. This, in turn, poses scalability challenges when dealing with dense point clouds or large-scale scenes.
On the other hand, grid-based methods, which discretize LiDAR point clouds into regular grids, have become the mainstream approach in real-time 3D object detection due to their high computational efficiency. VoxelNet [12] is a pioneering work that divides point clouds into voxels and aggregates information within each voxel into feature vectors using Voxel Feature Encoding (VFE) layers, thereby eliminating the need for handcrafted feature design. Subsequently, SECOND [14] introduced 3D sparse convolutions to significantly improve inference speed by omitting computations for empty voxels. PointPillars [13] adopted a pillar representation that compresses the vertical dimension, enabling high-speed processing via 2D convolutional neural networks. Voxel R-CNN [5] achieves high detection accuracy by balancing the preservation of detailed spatial information and computational cost through the direct utilization of voxel features for RoI pooling.
2.2. Attention Mechanisms in Point Clouds
Inspired by the remarkable success of attention mechanisms in 2D object detection networks, recent research has increasingly focused on incorporating these mechanisms into 3D object detection [18,19,20,21]. For instance, CasA [22] is designed to enhance the refinement stage of existing two-stage detectors by progressively refining proposals while integrating features from cascade stages via attention mechanisms. Furthermore, to handle features equivariant to rotation and reflection in 3D scenes, TED [23] extracts transformation-equivariant voxel features using sparse convolution, which are subsequently aligned and aggregated for detection. Moreover, Voxel R-CNN-HA [24] proposes Voxel RoI Self-Attention Pooling, which achieves significant improvements in feature aggregation for large objects, such as buses and trucks, by incorporating self-attention directly into the RoI pooling operation. However, due to the high computational complexity associated with attention mechanisms, the reduction in inference speed remains a significant challenge for these methods.
2.3. Loss Functions for Confidence Alignment
A critical challenge in 3D object detection is the misalignment between classification confidence and localization quality (IoU). Generally, classification and regression tasks are trained with independent loss functions, leading to the generation of bounding boxes with high classification scores but low localization accuracy. This often results in the suppression of higher-quality boxes during Non-Maximum Suppression (NMS).
To address this, methods such as CIA-SSD [15] have proposed IoU-aware confidence rectification and loss functions. Varifocal Loss (VFL) [6], originally proposed in the image recognition field, effectively resolves this misalignment by training positive samples with IoU values as targets. Its effectiveness has also been demonstrated in RangeDet [25], a range view-based detector. In this study, we introduce VFL into a sparse voxel-based two-stage detector. By employing VFL in both the RPN and RCNN heads, we enable the preferential preservation of high-quality proposals, which is particularly crucial for detecting small objects where localization errors are fatal.
3. VFR-Net
3.1. Overview
In this paper, we propose a novel 3D object detection framework named Varifocal Fine-grained Refinement Network (VFR-Net). The overall architecture of VFR-Net is illustrated in Figure 2. Our method is built upon the Voxel R-CNN [5] baseline, which is well known for its strong balance between accuracy and efficiency. While Voxel R-CNN achieves high performance for rigid and well-sampled objects such as cars, it still struggles with small or non-rigid objects—including pedestrians and cyclists—due to their extreme sparsity and weaker geometric cues in LiDAR data.

Figure 2.
The overall architecture of our proposed VFR-Net. The network takes raw point clouds as input, voxelizes them, and extracts features using a 3D backbone. The RPN then generates 3D proposals, which are refined by the RCNN head equipped with our proposed FGRA Module and trained with VFL. Red squares and black stars in the Voxel RoI pooling section represent the voxels (with center points) and the RoI grid points, respectively.
To overcome these limitations, we propose VFR-Net as a unified misalignment-aware refinement framework. Unlike conventional detectors that treat score prediction and feature aggregation as independent tasks, VFR-Net is designed to bridge the gap between confidence and localization accuracy from two synergistic dimensions:
- Supervision-level Alignment (Varifocal Loss): Instead of standard classification, we introduce VFL to learn IoU-aware confidence scores. This ensures that the ranking of proposals during NMS is directly aligned with their actual localization quality, resolving the score-localization misalignment at the supervision level.
- Representation-level Alignment (FGRA Module): To prevent the loss of fine-grained spatial context during feature flattening, the FGRA module captures long-range geometric dependencies within RoI features. This ensures that the refinement head has access to high-fidelity geometric information, addressing the information misalignment between sparse point clouds and rigid FC-based aggregation.
By integrating these components, VFR-Net provides a holistic solution where high-quality features and aligned confidence scores work in tandem to improve the detection of small and non-rigid objects.
The network takes raw LiDAR point clouds as input and first converts them into a voxel-based representation through a voxelization process, where the continuous 3D space is discretized into regularly spaced voxels and points falling into each voxel are aggregated into voxel-wise features. Here, BEV denotes the Bird’s-Eye View representation, in which the 3D voxel features are projected onto the ground plane (XY-plane) to form a 2D feature map. This BEV transformation is a standard operation widely adopted in voxel-based 3D object detectors, including Voxel R-CNN, to enable efficient region proposal generation using 2D convolutional backbones [5]. The voxel features are then processed by a 3D backbone for feature extraction. The RPN generates 3D proposals, which are refined by the RCNN head equipped with our proposed FGRA Module and trained with VFL.
3.2. Fine-Grained Refinement Attention (FGRA) Module
Standard Voxel R-CNN utilizes simple Fully Connected (FC) layers in the refinement head to regress the final bounding boxes. After Voxel RoI pooling, the grid features are flattened into a 1D vector and then passed through several FC layers. While computationally efficient, this flatten–then–FC paradigm has two inherent limitations: (1) the flattening operation immediately destroys the spatial structure inside the RoI grid, and (2) FC layers aggregate features using static weights determined during training. This rigidity limits the network’s ability to adapt to the diverse geometric variations in non-rigid objects (e.g., Pedestrian vs. Cyclist), often causing sparse foreground signals to be averaged out by the dominant background noise. These issues are particularly detrimental for small objects with sparse points, where subtle geometric cues and surrounding context are crucial for accurate recognition.
To alleviate this problem, we introduce a Fine-Grained Refinement Attention (FGRA) Module that operates after the initial RoI pooling stage and before the flattening step. As illustrated in Figure 3, the proposed FGRA Module refines high-level RoI features by explicitly modeling long-range dependencies within the RoI grid using a lightweight Multi-Head Self-Attention (MHSA) block, while remaining fully compatible with the original Voxel R-CNN architecture.

Figure 3.
Detailed structure of the Fine-Grained Refinement Attention (FGRA) Module. The module takes RoI features and coordinates as input. It utilizes a Pre-LayerNorm Transformer encoder architecture, where layer normalization is applied before both the Multi-Head Self-Attention and the Feed-Forward Network (Linear Block), to dynamically refine feature representations.
Formally, let denote the RoI features obtained from Voxel RoI pooling, where is the number of grid points and C is the channel dimension. Let denote the corresponding 3D coordinates of each RoI grid point (e.g., normalized in the RoI coordinate frame).These 3D coordinates are further used to construct a learned positional encoding. Specifically, is embedded into the feature space via a lightweight multi-layer perceptron (MLP) composed of two linear layers with a ReLU activation. The resulting positional embedding encodes the relative geometric location of each RoI grid point and is directly added to the corresponding RoI feature. The FGRA module follows a Pre-LayerNorm Transformer design, in which layer normalization is applied before both the self-attention and the feed-forward network to improve training stability, enabling the subsequent self-attention to be aware of spatial relationships. We first embed the coordinates and fuse them with the RoI features:
where is a lightweight MLP (or a linear layer) that maps 3D coordinates into the feature space. We then reshape the 3D grid into a sequence of tokens and linearly project them into query, key, and value embeddings:
where are learnable projection matrices. For each attention head, the self-attention is computed as
where is the dimensionality of the query/key vectors. Multi-head self-attention is then obtained by concatenating the outputs of all heads and applying a linear projection:
where each head is an instance of the above attention operation (computed on a split of the channel dimension into H heads) and is a learnable matrix.
The FGRA Module is implemented as a Transformer-style refinement module with residual connections and layer normalization:
where denotes layer normalization and is a lightweight feed-forward network with a bottleneck structure. The refined features are then flattened and fed into the subsequent FC layers in the RoI head, exactly as in the original Voxel R-CNN.
At operational level, unlike FC layers that apply a fixed template, FGRA computes dynamic attention weights based on the specific input content. This allows the model to function as a content-adaptive filter that (i) actively clusters spatially dispersed foreground points (e.g., relating the head and feet of a pedestrian); (ii) captures local geometric context to distinguish objects from clutter; and (iii) effectively suppresses isolated background noise. This denoising and aggregation capability is especially beneficial for pedestrians and cyclists, whose RoIs often contain only a few valid foreground voxels surrounded by empty space.
In practice, we use a single MHSA block with a small number of heads and a reduced hidden dimension, so that the refinement incurs only modest overhead while providing noticeably better RoI features. As shown in our ablation studies (Section 5.3), FGRA Module alone brings a moderate but consistent improvement, and when combined with the proposed Varifocal Loss, it yields additional gains by supplying more informative RoI representations to the IoU-aware classification head, further enhancing small-object detection performance.
The selection of an MHSA-based architecture for the FGRA module, as opposed to local window-based attention or standard sparse convolutions, is motivated by the inherent sparsity and non-rigid structure of LiDAR data. Unlike local convolutional kernels that are restricted by a fixed receptive field, MHSA provides a content-adaptive receptive field that can dynamically aggregate features across the entire RoI grid regardless of spatial distance. This capability is particularly critical for sparse objects such as pedestrians, where foreground voxels representing different semantic parts (e.g., head and feet) may be spatially isolated. By modeling long-range dependencies within each RoI, FGRA effectively clusters fragmented geometric cues into a holistic representation. Furthermore, while global Transformers applied to the entire point cloud suffer from quadratic computational complexity , our RoI-restricted MHSA focuses only on the grid points. This design achieves a superior balance between capturing complex geometric relationships and maintaining the real-time inference efficiency required for practical autonomous driving applications.
3.3. Varifocal Loss for Aligning Confidence
A critical bottleneck in two-stage 3D detectors is the misalignment between classification confidence and localization quality. In standard training, classification and regression are optimized independently. Consequently, a bounding box may receive a high classification score even if it has a low Intersection-over-Union (IoU) with the ground truth. This discrepancy is fatal during Non-Maximum Suppression (NMS): a poorly localized but high-score box can inadvertently suppress a well-localized but lower-score box. This issue is particularly detrimental for small objects like pedestrians and cyclists, where even minor localization errors result in significant IoU drops. As shown in Figure 1, the baseline Voxel R-CNN generates a large proportion of such over-confident yet mislocalized proposals (IoU , score ).
To address this issue, we replace the standard binary Cross-Entropy loss with Varifocal Loss (VFL) [6] in both the RPN and RCNN heads. Unlike standard classification which uses discrete labels , VFL trains the network to predict an IoU-Aware Classification Score (IACS).
Specifically, for each predicted box , we calculate its 3D IoU with the matched ground-truth box and use this float value as the classification target :
For negative samples (background), the target is set to . The computation of 3D IoU and the assignment of targets are conducted following the standard OpenPCDet implementation [26].
Formulation and Mechanism
Let p denote the predicted score and q be the target IoU score defined above. The Varifocal Loss is formulated as
where and are hyperparameters derived from Focal Loss [27] to handle class imbalance. Typical values used in practice are and , following the original VarifocalNet formulation [6].
This loss function provides two distinct supervision signals:
- For positive samples (): The loss is weighted by the target IoU q. This means that high-quality proposals (high IoU) generate larger gradients than low-quality ones, effectively encouraging the network to assign higher scores to well-localized boxes. This creates an explicit ranking rectification where classification confidence is positively correlated with localization accuracy.
- For negative samples (): The loss functions similarly to Focal Loss, down-weighting easy negatives to focus training on hard examples, thereby mitigating the severe foreground–background imbalance inherent in LiDAR point clouds.
By aligning the predicted score p with the actual localization quality q, VFR-Net ensures that the NMS procedure preserves the most accurate bounding boxes, directly improving detection performance.
3.4. Total Loss Function
VFR-Net is trained in an end-to-end manner using a multi-task loss function. The total loss is the sum of the losses from the RPN and the RCNN refinement head:
Each component is further decomposed into classification and regression terms:
We retain the standard box regression formulation (Smooth-L1 Loss) for terms as in the baseline Voxel R-CNN. The key modification lies in the classification terms , where we employ the proposed Varifocal Loss to enforce the IoU-aware supervision described above.
4. Experimental Setup
4.1. Datasets
To comprehensively evaluate the effectiveness of VFR-Net, we conducted experiments on two standard benchmarks: KITTI Dataset [28] and ONCE Dataset [29].
- KITTI Dataset: The KITTI Object Detection Benchmark [28] is widely recognized in the field of autonomous driving. It contains 7481 training samples and 7518 testing samples collected via a 64-beam LiDAR. Following the standard protocol widely adopted in previous works [5], we split the original training samples into a train set (3712 samples) and a val set (3769 samples). We report the evaluation results on the val set based on three difficulty levels: Easy, Moderate, and Hard. Specifically, the official KITTI evaluation protocol computes 3D Average Precision (AP) at 40 recall positions, using an IoU threshold of 0.7 for the Car class and 0.5 for the Pedestrian and Cyclist classes.
- ONCE Dataset: To verify the robustness of our method in large-scale and diverse scenarios, we also utilized the ONCE dataset [29]. This dataset features a full 360-degree field of view and includes various weather conditions. For our experiments, we used the standard split consisting of 4961 samples for training and 3321 samples for validation. During training, we adopt five fine-grained categories (Car, Bus, Truck, Pedestrian, and Cyclist), while following the official evaluation protocol we report the detection performance on three super-classes: Vehicle (Car + Bus + Truck), Pedestrian, and Cyclist.
4.2. Network Settings
The voxelization and point cloud range settings were configured specifically for each dataset to align with their respective spatial characteristics: These parameters are selected based on common practices in prior voxel-based 3D object detection methods [5], aiming to balance spatial resolution and computational efficiency.
- KITTI Dataset: The input point cloud range is clipped to m for the X-axis, m for the Y-axis, and m for the Z-axis, focusing on the forward-facing region where annotated objects are present. The voxel size is set to , which preserves fine-grained geometric details and is particularly important for detecting small objects such as pedestrians and cyclists.
- ONCE Dataset: Given the larger detection range, the point cloud is constrained within m for the X and Y axes, and m for the Z-axis, to cover a wider spatial area enabled by its full 360-degree LiDAR sensing. The voxel size is set to , which is adopted to reduce computational cost while maintaining sufficient spatial resolution over the extended range.
4.3. Training Configuration
The proposed VFR-Net was implemented using the PyTorch (v2.0.1) framework. All models were trained on a workstation equipped with an NVIDIA GeForce RTX 4070 Ti Super GPU running CUDA 11.8. We utilized the Adam optimizer [30] with a OneCycle learning rate schedule for end-to-end training.
- KITTI Dataset: The model was trained for 80 epochs with a batch size of 2.
- ONCE Dataset: The model was trained for 80 epochs with a batch size of 4.
For the KITTI dataset, the peak learning rate was set to 0.01, while for the ONCE dataset it was set to 0.003. In both cases, the learning rate followed the OneCycle policy with weight decay set to 0.01, and the Adam first-moment coefficient () was annealed from 0.95 to 0.85. We additionally applied gradient norm clipping with a maximum norm of 10. Regarding the proposed components, the hyperparameters for Varifocal Loss (VFL) were set to and , consistent with the original paper [6]. The Fine-Grained Refinement Attention (FGRA) Module uses 4 attention heads with a 128-dimensional feature embedding and a 256-dimensional hidden layer in the feed-forward network.
4.4. Evaluation Metrics
- KITTI dataset: We adopt the standard 3D Average Precision (AP) metric computed at 40 recall positions, following the official KITTI evaluation protocol [28]. The IoU thresholds are set to 0.7 for the Car class and 0.5 for the Pedestrian and Cyclist classes. These class-specific thresholds are defined by the official benchmark to account for the physical characteristics of different objects. While a 0.7 threshold is standard for rigid and well-sampled objects like cars, a lower threshold (0.5) is conventionally used for pedestrians and cyclists because these categories consist of smaller, non-rigid objects represented by significantly fewer LiDAR points. For such sparse objects, even a minor localization offset can lead to a dramatic drop in IoU, necessitating a more permissive threshold for stable and meaningful evaluation. We report AP on three difficulty levels (Easy, Moderate, Hard), and mainly focus on the Moderate setting for comparison.
- ONCE dataset: For ONCE, we follow the official evaluation protocol [29] and report orientation-aware 3D Average Precision (AP) with class-specific IoU thresholds (0.7 for Vehicle, 0.3 for Pedestrian, and 0.5 for Cyclist). The ONCE dataset employs a more permissive threshold of 0.3 for pedestrians (compared to 0.5 in KITTI) to reflect the challenges of its larger 360-degree sensing range (up to 140 m), where point density for small objects significantly decreases at a distance. By strictly adhering to these official protocols, we ensure a fair and consistent comparison with previous state-of-the-art methods. AP is computed from the precision–recall curve sampled at 50 recall positions. To analyze distance robustness, we report AP within three distance ranges: 0–30 m, 30–50 m, and 50 m–Inf.
5. Experiments
5.1. Main Results on KITTI
We compare the proposed VFR-Net with state-of-the-art 3D object detection methods on the KITTI validation set. The results are summarized in Table 1. We focus on the comparison with both LiDAR-only and LiDAR + RGB methods to provide a comprehensive assessment of the algorithmic improvements.

Table 1.
Performance comparison on the KITTI validation set for Car, Pedestrian, and Cyclist classes. The results are evaluated with AP calculated at 40 recall positions. The bold values indicate the best performance.
As shown in Table 1, VFR-Net achieves a mean Average Precision (mAP) of 77.14%, outperforming the strong baseline Voxel R-CNN (76.02%). Notably, our method achieves significant improvements in detecting small and non-rigid objects. Specifically, for the Pedestrian class (Moderate), VFR-Net attains 62.68% AP, representing a +2.08% improvement over the baseline (60.60%). Similarly, consistent performance gains are observed for the Cyclist class.
To address the concern that the results may depend on a single run, we additionally report mean ± standard deviation over three runs with different random seeds on KITTI Moderate in Table 2. The improvements are consistently observed across runs, with the largest gain on Pedestrian.
Table 2.
Reproducibility on KITTI Moderate (mean ± std over 3 runs). The bold values indicate the best performance.
In addition to accuracy improvements, Figure 4 illustrates that VFR-Net achieves a favorable accuracy–speed trade-off. Regarding inference speed, VFR-Net runs at 23.9 FPS, which is comparable to the baseline’s 24.6 FPS. This demonstrates that the proposed Fine-Grained Refinement Attention (FGRA) Module and Varifocal Loss introduce negligible computational overhead while effectively boosting detection accuracy. Consequently, our method maintains the real-time performance requirement (>20 Hz) necessary for autonomous driving applications. Notably, while some state-of-the-art methods such as TED-S [23] achieve higher mAP scores, they rely on complex architectures that result in significantly lower inference speeds (e.g., 11.15 FPS), failing to meet the 20 Hz real-time threshold required to synchronize with typical LiDAR scan rates. In contrast, VFR-Net maintains a high inference speed of 23.9 FPS while delivering substantial performance gains over the baseline. Furthermore, VFR-Net is more resource-efficient, consuming only 0.69 GB of VRAM compared to 1.00 GB for TED-S. This balance of high-level practicality, lower resource consumption, and improved accuracy—especially for small objects—makes VFR-Net a more deployable solution for real-world autonomous driving applications. This 20 Hz threshold is particularly significant as it matches the upper bound of typical LiDAR scan rates (10–20 Hz), ensuring that the system processes sensor data without latency or frame drops [36]. Furthermore, while KITTI annotations are limited to a 90-degree field of view, achieving higher frame rates is essential for scaling to full 360-degree surround perception in practical on-board deployments [37]. The efficiency of VFR-Net also provides a vital computational buffer for downstream tasks, such as path planning and tracking, thereby enhancing the overall system reliability.

Figure 4.
Accuracy vs. Speed trade-off comparison on the KITTI validation set. The accuracy is measured by the overall mAP calculated across all three classes (Car, Pedestrian, and Cyclist) and difficulty levels. Our proposed VFR-Net achieves a favorable balance between high detection accuracy and real-time inference speed compared to state-of-the-art methods.
From the qualitative comparison results shown in Figure 5, our proposed method demonstrates superior detection capabilities compared to the baseline Voxel R-CNN. In the representative examples, missed detections of small and occluded objects, which are commonly observed in the baseline, are effectively corrected by VFR-Net. This performance improvement is attributed to the enhanced feature refinement capabilities provided by the FGRA Module and the effective ranking by VFL, enabling more precise and robust object recognition. In the context of autonomous driving, missed detections of vulnerable road users (e.g., pedestrians) can lead to critical accidents; therefore, minimizing such errors is essential from a system safety perspective. These qualitative observations suggest that VFR-Net holds significant potential for enhancing the safety and reliability of practical autonomous driving applications.

Figure 5.
Visualization of detection results on the KITTI validation set. (a,d,g) represent the reference 2D images. (b,e,h) show the results of Voxel R-CNN, while (c,f,i) display the results of VFR-Net. Green boxes indicate the ground truth, while red, light blue, and yellow boxes represent the predicted cars, pedestrians, and cyclists, respectively. As highlighted by the circles, VFR-Net accurately detects small and occluded objects that the baseline failed to recognize, demonstrating its effectiveness.
5.2. Results on ONCE Dataset
To further validate the generalization capability and robustness of VFR-Net, we evaluated our method on the large-scale ONCE dataset [29]. While we have already provided a comprehensive comparison with various state-of-the-art methods in Table 1 for the KITTI dataset, for the ONCE dataset evaluation, we focus our comparison on Voxel R-CNN to ensure the fairest possible assessment. Since Voxel R-CNN is a highly optimized, industry-standard model that balances accuracy and efficiency, using it as the sole baseline within the same implementation framework and hardware environment allows us to eliminate external variables. This direct comparison enables us to isolate and demonstrate the pure performance gains specifically brought by our Varifocal Loss (VFL) and FGRA module. Table 3 reports the orientation-aware AP scores for the Vehicle, Pedestrian, and Cyclist classes across different distance ranges. Compared to the Voxel R-CNN baseline, VFR-Net improves the overall mAP from 52.09% to 54.72%. The gain is most pronounced for the Pedestrian class, where AP increases by +6.53% (from 21.49% to 28.02%). In addition, the Cyclist class also benefits from a consistent improvement of +1.50%, while the performance on the Vehicle class remains largely comparable to the baseline.
Table 3.
3D Average Precision (AP, %) on the ONCE validation set under different distance ranges. All metrics are orientation-aware AP with class-specific IoU thresholds (0.7 for Vehicle, 0.3 for Pedestrian, 0.5 for Cyclist), computed at 50 recall positions. The bold values indicate the best performance.
Furthermore, the distance-wise results indicate that our method effectively leverages fine-grained geometric details, especially at shorter ranges. In the 0–30 m range, the Pedestrian AP improves by +8.17% (from 23.39% to 31.56%). Figure 6 visualizes the distance-wise AP comparison for the Pedestrian class on the ONCE validation set, showing that VFR-Net achieves substantial accuracy gains in the near-range region and maintains competitive performance at longer distances. These results suggest that VFR-Net enhances feature representation for small objects by capturing rich local context.
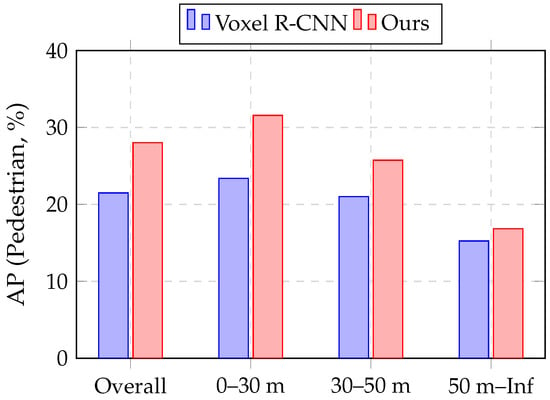
Figure 6.
AP comparison for Pedestrian under different distance ranges on the ONCE validation set.
5.3. Ablation Study
To analyze the effectiveness of each proposed component, we conducted extensive ablation studies on the KITTI validation set. The results are reported in Table 4.
Table 4.
Ablation studies of the proposed components on the KITTI validation set. (indicates that the network includes the corresponding module). The bold values indicate the best performance.
Effect of Varifocal Loss (VFL) and FGRA Module
Replacing the standard classification loss with VFL improves the overall mAP from 76.02% to 76.78%. This indicates that addressing the misalignment between classification confidence and localization quality effectively helps in ranking high-quality proposals, especially for categories with fewer points. Incorporating the Fine-Grained Refinement Attention (FGRA) Module alone also yields performance gains, improving the mAP to 76.11%. This confirms that capturing fine-grained geometric structure and local context via the FGRA Module in the RoI head is beneficial for refining sparse proposal features. By integrating both VFL and FGRA Module, VFR-Net achieves the best performance of 77.14% mAP. This suggests that the two components are complementary: VFL ensures better proposal ranking, while FGRA Module provides more discriminative feature representations for regression and classification.
5.4. Analysis of VFL Application Stages
We further investigated which stage of the two-stage detector benefits most from Varifocal Loss. Table 5 shows the comparison of applying VFL to the Region Proposal Network (RPN) only, the RCNN head only, and both.
Table 5.
Effect of applying VFL to different subnetworks on the KITTI validation set. (indicates that the corresponding subnetwork uses VFL). The bold values indicate the best performance.
The results indicate that applying VFL to both stages yields the highest accuracy. Although applying VFL only to the RCNN head significantly improves the Pedestrian AP (from 60.60% to 62.11%), applying it to both stages leads to further improvements in proposal quality, achieving the best overall mAP. In addition to AP, we analyze the ratio of over-confident yet mislocalized predictions under different VFL application stages. As shown in Figure 7, applying VFL to the RCNN head significantly reduces over-confident mislocalized predictions across all classes. When VFL is applied to both the RPN and RCNN, a comparable level of reduction is observed.
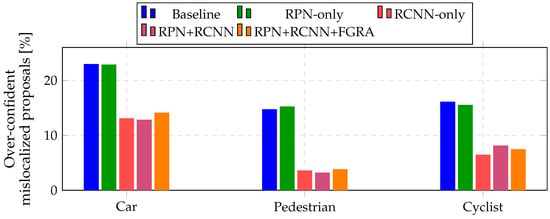
Figure 7.
Class-wise over-confident mislocalized ratio on the KITTI validation set (score and IoU < class threshold).
Interestingly, as shown in Table 5, applying VFL only to the RPN degrades the overall mAP. This phenomenon reveals a fundamental conflict between VFL’s characteristics and the established two-stage detection philosophy.
The primary objective of the RPN is to serve as a high-recall candidate generator, identifying as many potential objects as possible to ensure that no true positive is missed before the second stage. However, VFL introduces a strict IoU-aware weighting mechanism that penalizes predictions with low overlap. When applied to the RPN, VFL acts as a conservative filter that aggressively suppresses “imperfect” proposals—those with moderate IoU scores.
This leads to a “candidate starvation” effect: the RPN discards many proposals that, while not perfectly localized at the first stage, still contain sufficient foreground information to be successfully refined into high-quality boxes by the RCNN head. Since the second stage is specifically designed to perform fine-grained refinement, depriving it of these “potentially correctable” candidates limits the upper bound of the final detection accuracy. Therefore, VFL is most effective when applied to the precision-oriented RCNN stage, where its ability to align confidence with localization quality complements the final refinement process without compromising the necessary recall of the RPN.
5.5. Effect of the Number of Attention Heads
To further investigate the impact of the multi-head self-attention mechanism within the FGRA module, we conduct an ablation study by varying the number of attention heads . For this analysis, we evaluate the FGRA module in isolation (without VFL) to observe its direct effect on feature refinement. The results are summarized in Table 6.
Table 6.
Ablation study on the number of attention heads in the FGRA module (evaluated without VFL on the KITTI validation set). The bold values indicate the best performance.
The experimental results show a clear trend where the detection performance for the Pedestrian class consistently improves as the number of heads increases, reaching its peak at with an AP of 62.26% (a +1.66% gain over the baseline’s 60.60%). This confirms our design intuition that increasing attention heads allows the model to simultaneously capture diverse and fine-grained geometric dependencies, which is particularly beneficial for small, non-rigid objects.
However, we observe that an excessive number of heads can lead to a slight performance degradation in other categories, such as Cyclist, likely due to the dispersion of attention weights or increased model complexity relative to the available features. Among the tested configurations, achieves the best overall balance, yielding the highest mAP of 76.11% and outperforming the baseline across all metrics when integrated into the full VFR-Net framework. Consequently, we select as the default setting for the FGRA module to ensure optimal performance across diverse road participants.
6. Conclusions
In this paper, we proposed a novel 3D object detection framework named Varifocal Fine-grained Refinement Network (VFR-Net) to address the challenges of detecting small and non-rigid objects in LiDAR point clouds. Our approach enhances the widely used Voxel R-CNN baseline by synergistically integrating two key components: the Fine-Grained Refinement Attention (FGRA) Module and Varifocal Loss (VFL).
The FGRA Module utilizes a multi-head self-attention mechanism to capture fine-grained geometric details and global context dependencies from sparse proposal features. By refining the high-level semantic features prior to the flattening operation, this module effectively prevents the loss of spatial information critical for recognizing small objects. Concurrently, the introduction of VFL in both the RPN and RCNN heads resolves the misalignment between classification confidence and localization quality, ensuring that high-quality proposals are prioritized during inference.
Experimental results on the KITTI validation set demonstrate that VFR-Net significantly outperforms the baseline, achieving a +1.81% improvement in AP for the Pedestrian class and +1.28% for the Cyclist class, while maintaining a real-time inference speed of 23.9 FPS. Furthermore, evaluation on the large-scale ONCE dataset confirms the robustness of our method. Notably, our distance-based analysis revealed that VFR-Net maximizes the utilization of geometric details in the near-to-mid range (0–30 m), resulting in substantial accuracy gains, while maintaining superior robustness in distant, sparse regions compared to the baseline.
In future work, we plan to explore multi-modal fusion strategies by incorporating camera images to further enhance detection performance. Additionally, we aim to optimize the network architecture for deployment on embedded platforms, such as NVIDIA Jetson Orin, to achieve even higher efficiency for autonomous driving applications.
Author Contributions
Conceptualization, Y.S.; funding acquisition, X.K. and H.T.; investigation, Y.S.; methodology, Y.S.; software, Y.S.; supervision, T.S., X.K. and H.T.; validation, Y.S.; writing—original draft, Y.S.; writing—review and editing, T.S., X.K. and H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by Mazda Foundation.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
This work was partly supported by Mazda Foundation. During the preparation of this manuscript, the authors used ChatGPT (version 5.2, OpenAI) and Gemini (version 3, Google) for the purposes of text generation and manuscript refinement. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wen, L.H.; Jo, K.H. Deep Learning-Based Perception Systems for Autonomous Driving: A Comprehensive Survey. Neurocomputing 2022, 489, 255–270. [Google Scholar] [CrossRef]
- Zhao, J.; Wu, Y.; Deng, R.; Xu, S.; Gao, J.; Burke, A. A Survey of Autonomous Driving from a Deep Learning Perspective. ACM Comput. Surv. 2025, 57, 1–60. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D Object Detection for Autonomous Driving: A Comprehensive Survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Zhao, J.; Shi, J.; Zhuo, L. BEV Perception for Autonomous Driving: State of the Art and Future Perspectives. Expert Syst. Appl. 2024, 258, 125103. [Google Scholar] [CrossRef]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-Based 3D Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtual, 19–21 May 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep Hough Voting for 3D Object Detection in Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9277–9286. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. IPOD: Intensive Point-Based Object Detector for Point Cloud. arXiv 2018. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.W. CIA-SSD: Confident IoU-Aware Single-Stage Object Detector from Point Cloud. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Virtual, 19–21 May 2021; Volume 35, pp. 3555–3562. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Leibe, B.; Leonardis, A.; Schiele, B. Combined Object Categorization and Segmentation with an Implicit Shape Model. In Proceedings of the ECCV Workshop on Statistical Learning in Computer Vision, Prague, Czech Republic, 11–14 May 2004; p. 7. [Google Scholar]
- Sheng, H.; Cai, S.; Liu, Y.; Deng, B.; Huang, J.; Hua, X.S.; Zhao, M.J. Improving 3D Object Detection with Channel-Wise Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2743–2752. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel Transformer for 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3164–3173. [Google Scholar]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3D Object Detection with PointFormer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7463–7472. [Google Scholar]
- Hoang, H.A.; Bui, D.C.; Yoo, M. TSSTDet: Transformation-Based 3-D Object Detection via a Spatial Shape Transformer. IEEE Sens. J. 2024, 24, 7126–7139. [Google Scholar] [CrossRef]
- Wu, H.; Deng, J.; Wen, C.; Li, X.; Wang, C.; Li, J. CasA: A Cascade Attention Network for 3-D Object Detection from LiDAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Wu, H.; Wen, C.; Li, W.; Li, X.; Yang, R.; Wang, C. Transformation-Equivariant 3D Object Detection for Autonomous Driving. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2795–2802. [Google Scholar]
- Wang, H.; Tao, L.; Peng, Y.; Chen, Z.; Zhang, Y. Voxel RCNN-HA: A Point Cloud Multiobject Detection Algorithm with Hybrid Anchors for Autonomous Driving. IEEE Trans. Transp. Electrif. 2023, 10, 7286–7296. [Google Scholar] [CrossRef]
- Fan, L.; Xiong, X.; Wang, F.; Wang, N.; Zhang, Z. RangeDet: In Defense of Range View for LiDAR-Based 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2918–2927. [Google Scholar]
- Team, O.D. OpenPCDet: An Open-source Toolbox for 3D Object Detection from Point Clouds. 2020. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 11 January 2026).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Mao, J.; Niu, M.; Jiang, C.; Liang, H.; Chen, J.; Liang, X.; Li, Y.; Ye, C.; Zhang, W.; Li, Z.; et al. One Million Scenes for Autonomous Driving: ONCE Dataset. arXiv 2021. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Ye, W.; Xia, Q.; Wu, H.; Dong, Z.; Zhong, R.; Wang, C.; Wen, C. Fade3D: Fast and Deployable 3D Object Detection for Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2025, 26, 12934–12946. [Google Scholar] [CrossRef]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Liu, Z.; Huang, T.; Li, B.; Chen, X.; Wang, X.; Bai, X. EPNet++: Cascade Bi-Directional Fusion for Multi-Modal 3D Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 8324–8341. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, Q.; Hou, J.; Yuan, Y.; Xing, G. Unleash the Potential of Image Branch for Cross-Modal 3D Object Detection. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 51562–51583. [Google Scholar]
- Oleksiienko, I.; Nousi, P.; Passalis, N.; Tefas, A.; Iosifidis, A. Vpit: Real-time embedded single object 3D tracking using voxel pseudo images. Neural Comput. Appl. 2024, 36, 20341–20354. [Google Scholar] [CrossRef]
- Ye, M.; Xu, S.; Cao, T. Hvnet: Hybrid voxel network for lidar based 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1631–1640. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.