Abstract
The problem of identifying non-stationary communication channels with a sparseness property using the local basis function approach is considered. This sparseness refers to scenarios where a few impulse response coefficients significantly differ from zero. The sparsity-aware estimation algorithms are usually obtained using regularization. Unfortunately, the minimization problem lacks a sometimes closed-form solution; one must rely on numerical search, which is a serious drawback. We propose the fast regularized local basis functions (fRLBF) algorithm based on appropriately reweighted regularizers, which can be regarded as a first-order approximation of the approach. The proposed solution incorporates two regularizers, enhancing sparseness in both the time/lag and frequency domains. The choice of regularization gains is an important part of regularized estimation. To address this, three approaches are proposed and compared to solve this problem: empirical Bayes, decentralized, and cross-validation approaches. The performance of the proposed algorithm is demonstrated in a numerical experiment simulating underwater acoustics communication scenarios. It is shown that the new approach can outperform the classical one and is computationally attractive.
1. Introduction
In modern wireless systems, distortion in transmitted signals is primarily caused by multi-path effects, where the signal reaches the receiver along different paths with varying time delays. When these multi-path effects are dominated by a few strong reflectors (scatterers), the impulse response coefficients significantly differ from zero [1,2,3]. The time variation of these coefficients is due to the movement of the transmitter/receiver and/or changes in the pattern of scatterers. Depending on how fast the channel coefficients vary with time, different estimation approaches may be required. For slowly varying coefficients, the time-localized versions of the least squares or maximum likelihood approach may be used [4,5,6]. Fast parameter changes can be tracked by algorithms relying on an explicit model of parameter variation, either stochastic [7,8,9] or deterministic [10,11,12,13,14]. Further improvements in parameter estimation accuracy are achieved through regularization [15]. While regularization is commonly used in system identification, most research in the field focuses on time-invariant systems [16,17]. The papers [18,19] started a new trend in the identification of time-varying systems. In both studies, estimation is conducted using the local basis functions (LBF) or fast local basis functions (fLBF) approach for time-varying finite impulse response (FIR) systems, with regularization applied to penalize excess values of the squared norm of hyperparameters [18] or the squared norm of trajectory parameters [19]. While useful for general-purpose identification, such regularization does not effectively address the specific sparsity property of mobile telecommunication channels.
Sparsity-aware estimation algorithms typically utilize regularization and belong to the LASSO (Least Absolute Shrinkage and Selection Operator) family [20]. Mainstream sparse identification techniques, such as sparse Bayesian learning [21], the Iterative Shrinkage-Thresholding Algorithm (ISTA) [22], its accelerated variant Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) [23], Orthogonal Matching Pursuit (OMP) [24], and its extension Compressive Sampling Matching Pursuit (CoSaMP) [25], perform sparse channel estimation in an iterative manner. The ISTA algorithm and its fast version FISTA are designed to handle only a single regularization term; when two or more regularization terms are present, both algorithms must be modified to approximate the solution. A common extension to ISTA/FISTA in this context is the use of the Alternating Direction Method of Multipliers (ADMM) algorithm [26], which can efficiently handle multiple regularization terms. On the other hand, OMP and CoSaMP are greedy algorithms that iteratively construct a sparse solution by selecting the most relevant components at each step. For all of these algorithms, the processing time increases with the number of iterations, making the choice of appropriate stopping criteria crucial for practical applications. Moreover, since the underlying minimization problem does not admit a closed-form solution, these methods rely on numerical optimization, which can be computationally demanding—especially when channel parameter estimation, adaptive hyperparameter selection, and regularization gain optimization must all be performed within a sliding window fashion.
In this paper, the fast regularized local basis functions (fRLBF) algorithm is proposed to address these challenges. In this approach, regularization is replaced with appropriately reweighted regularizers. This solution differs from the one described in [27] as it incorporates two regularizers. The first regularizer penalizes a large number of basis functions used to approximate the time evolution of channel parameters, while the second one penalizes a large number of non-zero components of the parameter vector. Finally, three approaches to adaptively choose regularization gains are proposed: the empirical Bayes approach, the decentralized approach, and the cross-validation approach. The core advantages of the proposed multi-stage solution are its computational efficiency in the sliding window approach and its flexibility, which allows each system parameter trajectory to be identified independently. Furthermore, regularization can be performed either jointly or separately for all parameters. Thanks to its multi-stage structure and adaptive hyperparameter selection, the proposed method is well-suited for sparse problems, achieving very high accuracy in time-varying channel estimation.
2. Material and Methods
Many non-stationary communication channels, both terrestrial and underwater, can be well approximated by a time-varying FIR model of the form [1,2]
where denotes discrete (normalized) time, is the complex-valued output signal, is the regression vector composed of past samples of the complex-valued input signal , is the vector of time-varying system coefficients, and denotes measurement noise. The symbol ∗ stands for complex conjugate, and H denotes the Hermitian (complex conjugate) transpose.
The following assumptions are made:
- (1)
- is a zero-mean circular white noise with variance .
- (2)
- , independent of , is a zero-mean circular white noise with variance .
- (3)
- is a sequence independent of and .
Circular white noise is a sequence of independent and identically distributed (i.i.d.) random variables with independent real and imaginary parts. The FIR model structure is a direct consequence of multi-path signal propagation, while the time-varying nature of stems from Doppler shifts caused by transmitter/receiver movement and/or changes in the surrounding environment. These assumptions (1)–(3) are typical in wireless communication systems.
The self-interference channel model of a full-duplex underwater acoustic (UWA) system is an example of non-stationary communication channel with sparseness. In these systems, the transmit and receive antennas operate concurrently within the same frequency bandwidth [28], nearly doubling the limited capacity of the acoustic link. The goal is to isolate the signal from in (1), which includes both the far-end signal and measurement noise, by removing the self-interference component . This self-interference is caused by reflections from surrounding objects like the sea surface, sea bottom, fish, and vessels. Since the near-end signal , generated by the transmit antenna, is always known, the problem reduces to tracking the impulse response coefficients of the self-interference channel.
2.1. Local Basis Functions Estimators
The local basis function (LBF) identification technique assumes that within the local analysis interval of length , centered at t, system parameters can be expressed as linear combinations of a certain number of linearly independent real or complex-valued time functions , referred to as basis functions, namely
where .
Following the local estimation paradigm, parameter trajectories based on the hypermodel (2) are estimated independently for each position of the analysis interval , using a sliding window approach. Thus, while system hyperparameters are assumed constant within each interval , their values are allowed to change along with the position of the analysis window, and are therefore expressed as functions of t.
The hypermodel (2) can be represented more compactly
where , , and ⊗ denote the Kronecker product of the corresponding vectors/matrices. Using (3), the system Equation (1) can be reformulated as
where denotes the generalized regression vector.
The most common choices for basis functions before normalization, which enable recursive computability, include powers of time (Taylor series approximation), cosine functions (Fourier series approximations), and the complex exponential basis set [1]. Figure 1 shows the first three basis functions before normalization in the range : on the left, powers of time; on the right, cosine functions. In this paper, we will adopt real-valued powers of time as basis functions (for generality, we will retain the complex conjugate transpose). For convenience, and without loss of generality, we will assume that the adopted basis functions are orthonormal, namely
where denotes the identity matrix.
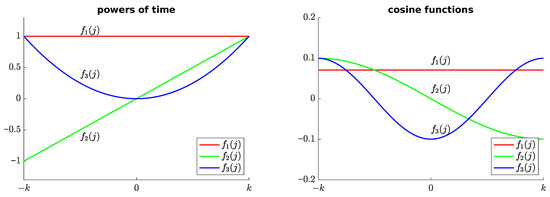
Figure 1.
The first three basis functions before normalization in the range : on the left, powers of time; on the right, cosine functions.
The LBF estimator has the form [14]
where .
An essential property of LBF is that it performs non-causal identification, reducing estimation delay but introducing decision delay. The number of estimated hyperparameters determines the minimum window length K, which must be substantially greater than to prevent numerical issues. Unfortunately, the LBF technique requires inverting an matrix at every instant t, posing a significant computational drawback.
To help readers understand the concept of the LBF approach, it is illustrated here using results obtained for a non-stationary one-tap FIR system described by
where the input is a zero-mean, unit-variance, white binary sequence (). The coefficient is modeled as a sinusoidal linear chirp, and the variance of the measurement white Gaussian noise is set to ensure an average signal-to-noise ratio of . Unlike classical parameter estimation methods, the LBF approach does not require restrictive assumptions such as local stationarity or slow parameter variations. Instead, the local evolution of the parameter is directly represented as a linear combination of basis functions. Figure 2, Figure 3 and Figure 4 demonstrate the estimation capabilities of the LBF approach and emphasize the importance of proper selection of the design parameters k and m.
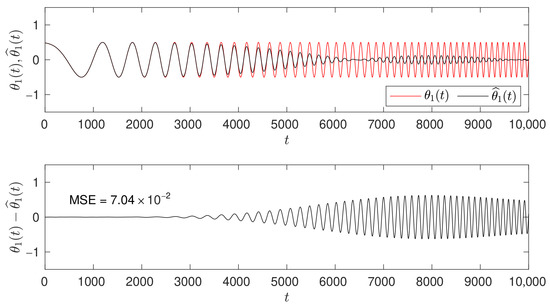
Figure 2.
From top to bottom: the true parameter trajectory (red) with the LBF parameter estimate superimposed (black) for and ; and, at the bottom, the corresponding estimation error along with the mean square estimation error (MSE).
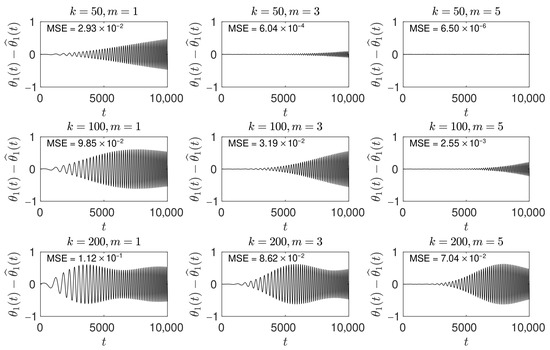
Figure 3.
This figure shows grid of plots of the estimation error for different LBF settings, obtained for all combinations of and . In each plot, the parameter mean square estimation error (MSE) is displayed in the top-left corner.
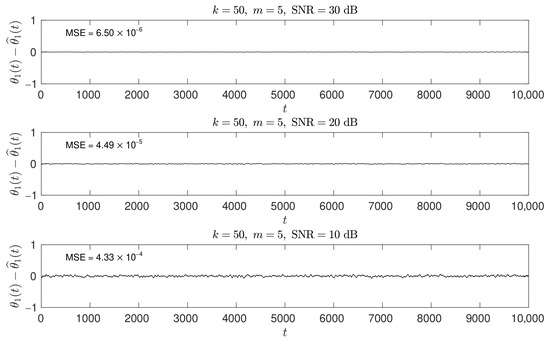
Figure 4.
The parameter estimation error for different SNR levels dB for the setting and . In each plot, the parameter mean square estimation error (MSE) is shown in the top-left corner.
Figure 2 presents, from top to bottom, the true parameter trajectory (red) with the LBF parameter estimate superimposed (black) for and , followed by the estimation error, . The LBF estimation was initialized before and continued beyond 10,000. The chosen values of and yield a small parameter estimation error as long as the parameter variations are moderate. However, when the parameter begins to vary faster, a better choice of k and m is necessary to maintain satisfactory tracking performance.
Figure 3 presents a grid of plots showing the estimation error for different LBF settings, obtained for all combinations of and . The selection of these design parameters depends on the rate at which the system parameters vary. For constant parameters, one would typically choose a relatively large window size K and set . Note that for , the basis function approach reduces to the classical least squares method. For slowly time-varying parameters, a smaller value of k and a larger number of basis functions m becomes beneficial. In the case of faster changing parameters, m should be increased further, and an appropriate window size K must be selected to achieve a favorable mean squared estimation error, shown in the top left corner of each plot. The improvement over the classical least squares method (case ) is substantial when additional basis functions are used (case )—compare, for example, the plots for , and .
Figure 4 presents how different SNR levels dB impact the parameter estimation error. In this simulated experiment, for and , the MSE increased by approximately a factor of 10 each time the SNR dropped by 10 dB.
2.2. fLBF Estimators
As shown in [29,30], under assumptions (1)–(3), the LBF estimates and can be approximated by the following computationally fast formulas:
where
denotes the impulse response of the FIR filter associated with the LBF estimator, and denotes the vector of pre-estimated trajectories. These pre-estimates can be obtained through “inverse filtering” of the estimates yielded by the exponentially weighted least squares (EWLS) algorithm
where , denotes the forgetting constant. The short-memory EWLS estimates can be computed using the well-known recursive algorithm [4]:
with initial conditions and , where c denotes a large positive constant. Alternatively, to reduce the computational cost, one can use the iterative dichotomous coordinate descent (DCD) algorithm described in [31].
The inverse filtering formula has the form
where , denotes the effective width of the exponential window. For large values of t, when the effective window width reaches its steady state value , the Formula (17) can be replaced with
The recommended choice of the forgetting factor [29], which performs well in practice, is
For , the effective window length is approximately equal to half the number of estimated coefficients, i.e., . As increases, the mean square deviation of from becomes increasingly dominated by the bias error, which arises primarily because the estimated parameter trajectory lags behind the true trajectory. Therefore, to achieve a favorable bias–variance trade-off, should remain relatively small.
According to [29], under assumptions (1)–(3), the pre-estimate is approximately unbiased, i.e., as follows:
where denotes approximately zero-mean white noise with large covariance matrix . The unbiasedness property comes at the cost of significant variability. The fLBF estimate can thus be interpreted as a denoised version of obtained via the basis function approach.
The fLBF approach is illustrated using the same one-tap FIR example as the LBF method—see (8). Figure 5 presents the pre-estimates (A, black) obtained by inverse filtering of the EWLS estimates using Formula (18), with at an SNR level of 10 dB. These pre-estimates were then denoised using the FIR filter impulse response defined in (11) for and , resulting in the final fLBF estimates shown in (B, black). In this simple case, the estimation error for the fLBF results shown in (C) closely matches that of the LBF approach.
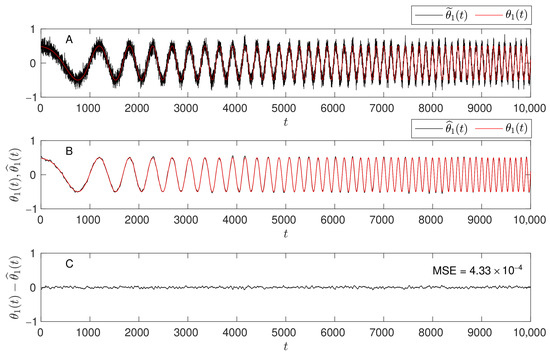
Figure 5.
From top to bottom: (A) the true parameter trajectory (red) with pre-estimates superimposed (black) at an SNR level of 10 dB; (B) the true parameter trajectory (red) with fLBF estimates superimposed (black) for and ; (C) the estimation error, , with the mean square estimation error (MSE) indicated in the top-right corner.
2.3. Regularized fLBF Estimators
Denote by the norm of a complex-valued vector , and by its norm. Finally, let , where denotes a positive definite Hermitian matrix.
The LASSO-type regularized fLBF estimator, defined as
where denote regularization constants, which incorporates two regularizers. When both regularization constants are set to zero, the solution reduces to the standard fLBF approach. These constants allow for fine-tuning the degree of shrinkage applied to the estimates as they approach zero. Setting higher regularization constants increases shrinkage but does not eliminate parameters entirely, unlike LASSO, which can set coefficients to zero. The first regularizer, , promotes sparseness in the frequency domain by penalizing the excessive number of basis functions used to approximate the time evolution of channel parameters . The second regularizer, , promotes sparseness in the time/lag domain by penalizing non-zero components of the vector . With the inclusion of the second regularizer, schemes (21) and (22) serve as a group LASSO solution, enhancing model sparsity at both individual (hyperparameter) and group (parameter) component levels [32].
Due to the lack of a closed-form solution to the minimization problem in (21) and (22), numerical search is necessary, posing a drawback for sliding window estimation. Similarly, selecting optimal regularization gains and presents a similar challenge. To mitigate these issues, we propose replacing the regularization terms in (21) with appropriately reweighted regularizers. Reweighting is a known optimization technique [33,34]. Note that the norm of the vector can be expressed as
where is the weight matrix. In order to apply the reweighting technique directly to the vector
one would need to know the true trajectories of the system hyperparameters , which are assumed to be unknown. Therefore, the weight matrix is initialized based on the estimated values obtained from the fLBF algorithm. Using the reweighting technique together with the fLBF approach, one arrives at the approximations
and
This leads to the following approximate version of (21) and (22), further referred to as the fast regularized LBF (fRLBF) estimator
where
The last transition in (34) follows from the identity
which holds true for Kronecker products, provided that all dimensions match.
Utilizing the fact that the matrix is block diagonal
the relationship (32) and (33) can be rewritten in a simpler, decomposed form
where
LASSO estimators discard insignificant components by shrinking them to zero. The proposed fRLBF scheme approximates this behavior. When the estimates and are very small in magnitude, the weights and in (38) and (39) become very large, effectively shrinking the corresponding fLBF estimates towards zero.
Remark 1.
Communication channels typically exhibit a decaying power profile due to spreading and absorption loss, which can be modeled by assuming that
where , represents the decay rate of the exponential power envelope. Incorporating this prior knowledge into the estimation scheme is straightforward by setting
This corresponds to replacing the second regularizer in (21) with the weighted norm given by
Hence, adjusting ξ according to the decaying power profile leads to improved estimation results.
2.4. Computational Complexity of fRLBF Estimators
First of all, we note that for the selected basis set, powers of time, the fLBF estimates are recursively computable [14]. This is a direct consequence of the recursive computability of . It is easy to check that
where
denotes the transition matrix, and denotes binomial coefficient, leading to the following recursive formula:
All n fLBF estimates can be obtained at the cost of complex flops (complex multiply-add operations) per time updated. Importantly, this cost remains independent of the analysis window width K.
To estimate the computational burden of the second estimation stage, consider the matrix inversion lemma [4]
where
Exploiting the diagonal nature of the matrix and the fact that , the cost of updating the estimates , is approximately complex flops, after neglecting terms of order and . Additional complex additions are required to update .
Finally, computation of , requires complex flops, square root operations, and real divisions. Hence, the cost of running the two-stage procedure is roughly complex flops, complex additions, square root operations, and real divisions per time update.
Remark 2.
Since all eigenvalues of the matrix are located on the unit circle in the complex plane, the recursive algorithm (44) is not exponentially stable but only marginally stable. This means that it has the tendency to diverge at a slow (linear) rate when the number of time steps becomes very large. To prevent numerical problems caused by the unbounded accumulation of round-off errors, the algorithm (44) should be periodically reset by directly computing using (40). In the absence of an automated mechanism for detecting numerical issues and initiating timely resets, a practical strategy was employed. To balance the computational efficiency of the recursive formulation with numerical stability, algorithm (44) was reset every 1000 steps, with the fLBF estimates re-initialized directly from the local estimation window at these intervals [35].
2.5. Multi-Step Procedure of fRLBF Estimators
The fRLBF scheme described above is a two-step procedure. For improved performance, one can consider a multi-step procedure, similar to those described in [33,34], at the expense of increased computational complexity, as follows:
where
and , . To avoid numerical issues, the magnitudes of and should be replaced by a fixed number before inversion if they are too close to zero. This iterative procedure can be implemented efficiently without requiring inversion of an matrix, as demonstrated in the previous section (see (45)–(47)).
It is important to emphasize that the proposed fRLBF approach is not iterative in the same sense as algorithms like ISTA, where a stopping criterion is required to prevent excessive computational cost once convergence is achieved, or OMP, where limiting the number of selected atoms is essential not only to control computational cost but also to avoid increased estimation error due to over-parameterization. In the fRLBF approach, estimation convergence is determined by how the pre-estimates are obtained and by the careful selection of fLBF hyperparameters. The multi-step procedure is intended solely for fine-tuning the results, with each iteration involving complex flops, square root operations, and real divisions. While increasing the number of iterations can yield incremental improvements in estimation accuracy, typical criteria—such as absolute or relative changes in parameter values—require selecting an appropriate convergence threshold. If not properly chosen, this can lead to unnecessary iterations and reduced computational efficiency. In the case of the time-varying FIR model, the optimal number of iterations is application-dependent and should be selected to balance estimation accuracy with computational efficiency. Based on empirical observations, the best trade-off was achieved by stopping the procedure after the second iteration.
2.6. Selection of Regularization Gains
The choice of regularization gains is an important part of regularized estimation—if the values of and are not chosen appropriately, the accuracy of fRLBF estimates can be worse than the accuracy of their not regularized versions. In this section, we will present three approaches to solve this problem.
2.6.1. Empirical Bayes Approach
Bayesian redefinition of the optimization problem (32) and (33) is based on the observation that minimization of the quadratic cost function
is equivalent to the maximization of the expression
which can be given a probabilistic interpretation. Assuming that the pre-estimation noise is Gaussian, the first term in (54) represents the conditional data distribution (likelihood)
where and . The second term corresponds to a prior distribution of
where denotes the determinant of the matrix . The likelihood for the unknown parameters and can be obtained from (see Appendix A)
where
denotes the residual sum of squares. Good [36] referred to the maximization of (57) as a type II maximum likelihood method, but recently it has been more frequently referred to as the empirical Bayes approach [15,36].
Since the maximum likelihood estimate of the variance can be obtained in the form , the optimal value of the regularization matrix can be obtained by maximizing the concentrated likelihood function , or equivalently by minimizing the quantity
In the case of structured matrix of the form , the optimization is restricted to regularization gains and . This leads to the following optimization formula (see Appendix B):
where
As a practical way of solving the optimization problem, one can consider parallel estimation. In this case, not one but p fRLBF algorithms equipped with different regularization gains , yielding the estimates and , are run simultaneously and compared using the empirical Bayes measure of fit (61). At each time instant t, the best fitting values of and are chosen using the grid search
and the final estimates for empirical Bayes approach have the form
The cost of evaluating (63) is of order per time update. Note that in this case, the following computational shortcut can be used to evaluate the residual sum of squares:
Note also that the first term on the right-hand side of (64) can be updated recursively.
2.6.2. Decentralized Approach
Alternatively, following the decomposed form in (38) and (39), we propose to optimize the regularization gains and independently for each , which enhances the flexibility of the approach. Since some of the parameters may be static while others time-varying, different regularization gains are necessary. This leads to the decomposed optimization formula
where
and
Similar to the centralized approach, at each time instant t, the best fitting values of and are chosen using the grid search
and the final estimates for the decentralized approach have the form
2.6.3. Cross-Validation Approach
Denote by and the “holey” estimates of and , obtained by excluding from the estimation process the central “measurement”
The proposed leave-one-out cross-validation approach is based on minimization of the local sum of squared deleted residuals
where N determines the size of the local decision window.
It is straightforward to check that
where . Using the matrix inversion lemma, one obtains
Combining (74) with (75) and taking into account the fact that , one arrives at
where (cf. (45))
This means that deleted residuals can be determined without evaluating of the corresponding holey estimates of .
Remark 3.
The optimization formula can be further extended by the adaptive selection of the power decay coefficient ξ
where .
2.7. Debiasing
One of the crucial observations about the fLBF approach is that the estimated parameter trajectory lags behind the true one. The length of this delay depends on the forgetting factor used in the pre-estimation stage (18) and may vary with time. Since fLBF estimates are used to obtain fRLBF estimates, the estimation lag is inherited.
In [37] authors proposed a simple adaptive scheme to obtain time-shifted fLBF estimates
where the time-shift is estimated for every time instant t
and , where is an initial approximation obtained by rounding . The proposed debiasing procedure can reduce the bias of fLBF estimates without affecting the variance component of the mean square parameter estimation error. The time-shifted fLBF estimates can be used to obtain the time-shifted fRLBF estimates (dfRLBF).
Another solution to the problem relies on replacing unidirectional pre-estimates (18) with bidirectional pre-estimates obtained with non-causal double exponentially weighted least squares estimates [38].
2.8. The Number of Basis Functions and the Analysis Window Size
To balance the bias and variance in the mean squared parameter estimation error, it is crucial to choose appropriate values for the design parameters m and k. Increasing m or decreasing k reduces estimation bias but raises variance, while decreasing m or increasing k does the opposite [29]. Therefore, adjusting m and k according to the rate and mode of parameter variation ensures satisfactory estimation results. This can be achieved using parallel estimation techniques, where multiple identification algorithms with different settings are run simultaneously, providing estimates , for various and . At each time instant, only one algorithm is selected, yielding parameter estimates in the form
where
and denotes the local decision statistic such as the cross-validation selection rule [29] or the modified Akaike’s final prediction error criterion [39]. One can use the proposed regularization scheme only for the best-fitting fLFB algorithm or apply the decision rules to the fRLBF estimates .
3. Results and Discussion
To demonstrate the identification performance of a non-stationary communication channel with sparseness using the proposed regularization approach, we analyzed a channel loosely inspired by the self-interference channel model of a full-duplex UWA system [28].
3.1. Channel Model
Following the methodology described in [28], first we generated a channel model with an exponential envelope. The channel was characterized as a 50-tap FIR filter with complex-valued coefficients that varied independently with the decreasing variance chosen according to
where was set to 0.69. Next, variations were introduced to the channel coefficients to better reflect real-world conditions. First, 30% of these coefficients were randomly set to zero, mimicking signal obstruction or absorption, similar to physical barriers underwater. Subsequently, 50% of the coefficients were assigned fixed values, representing stable transmission paths or reflections from static features like the sea floor. Finally, 20% of the coefficients were left unchanged to simulate time-varying effects. These fluctuations are often introduced by moving objects, such as marine life or waves, or by changes in surface reflections.
The input signal was generated as a circular white binary sequence , while the measurement noise followed a circular white Gaussian distribution with variance settings corresponded to input signal-to-noise ratios (SNR) of 30 dB, 20 dB, and 10 dB, respectively. Typical trajectories of the time-varying channel coefficient are shown in Figure 6.
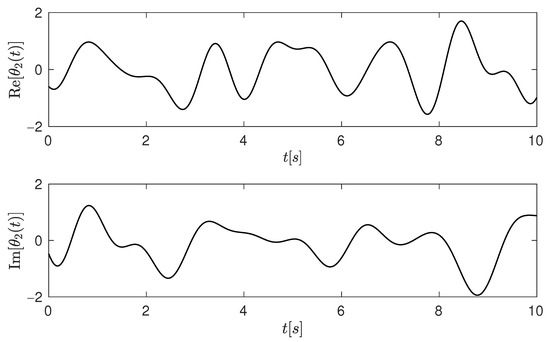
Figure 6.
The true time-varying channel coefficient trajectory (a typical example) was used in the system Equation (1) to generate the system output at different SNR levels.
3.2. Metrics
To assess the performance of the compared approaches, we utilized two metrics. The first metric is the self-interference cancellation factor (SICF) [28], defined as
The second metric, introduced in [15], measures the normalized root mean squared error of fit, denoted as FIT(t)
where . A FIT value of 100 indicates a perfect match between the true and estimated impulse response. In the simulation experiment, all results were averaged over 20 independent realizations of channel coefficients and 10,000 time instants. Each realization had a different variation pattern. Additionally, each data realization included an additional 1000 time instants at the beginning and the end to mitigate boundary problems.
3.3. Simulation Experiment Settings
In the numerical experiment, three algorithms were compared: LBF, fLBF, and fRLBF (after debiasing dfLBF and dfRLBF). These comparisons were conducted across various combinations of k and m and at three SNR levels: 10 dB, 20 dB, and 30 dB. The combinations considered include and , excluding the combination for LBF. This exclusion was necessary because without regularization, it is impossible to estimate 250 hyperparameters based on only 201 data points. For the dfRLBF algorithm, three approaches were proposed and compared for selecting the regularization parameters: the empirical Bayes (dfRLBF [A]), the decentralized (dfRLBF [B]), and the cross-validation approach (dfRLBF [C]). The regularization parameter combinations included , , and . These values were selected based on pre-experimental experience and are intended to cover typical ranges of regularization intensity. The case where the regularization gains are set to zero yields results identical to those obtained with the fLBF approach (without regularization). An improvement in estimation accuracy was observed as the regularization gains increased. However, for values above 1, a degradation in the estimation results occurred. One may obtain even better estimation accuracy by introducing a finer grid in the range of regularization gains between 0.1 and 1, but this comes at the cost of increased computational load.
The size of the local decision window for the cross-validation rule was set to , while for the debiasing technique, it was set to .
3.4. Results
Table 1 compares the averaged FIT [%] and SICF [dB] scores for three algorithms, LBF, fLBF, and dfLBF, across various k, m, and SNR settings. The choice of k and m significantly influences the identification results for all methods, as shown in the table. When , LBF’s performance is inferior compared to the fLBF and dfLBF methods. The most notable discrepancy between LBF and dfLBF is observed at and with a 30 dB SNR, where the differences are FIT = 2.4% and SICF = 7.2 dB. As m increases, so does the number of estimated hyperparameters. LBF’s reliance on matrix inversion makes it sensitive to the number of hyperparameters, affecting the minimum window length required. Consequently, some table entries are marked with ‘x’ where there are insufficient data points to estimate the hyperparameters. Despite its non-causal nature (it uses both past and future data) causing decision delays that grow with larger k, LBF’s estimated parameter trajectory does not lag behind the true one. At high SNR (30 dB), LBF achieves its best results with , showing FIT = 99.2% and SICF = 45.4 dB, outperforming the other methods. The fLBF method, despite being non-causal, requires time-shift correction to mitigate bias arising from using causal pre-estimates. It utilizes causal pre-estimates and inherits the estimation delay. Once debiasing is applied, dfLBF mostly shows improvement, especially at higher SNRs (≥20 dB). For instance, at and , the improvements at 10 dB SNR are FIT = and SICF = dB, while at 30 dB SNR, they are FIT = 1.1% and SICF = dB. This suggests that time-shift estimates are less precise in low SNR scenarios. In the table, the best results for each unique parameter combination of k, m, and SNR are highlighted in bold, demonstrating that no single method is superior across all settings.

Table 1.
Average FIT [%] and SICF [dB] values for the LBF, fLBF, and dfLBF algorithms. Results are presented across varying design parameters: local estimation window size (, for ) and number of basis functions (), and at signal-to-noise ratio (SNR) levels of 10 dB, 20 dB, and 30 dB. Best performance values among the compared methods are highlighted in bold for each unique parameter combination and SNR level; a method with a greater number of highlighted results signifies its superior overall performance under identical experimental conditions. Cases with insufficient data for the LBF algorithm are denoted by ‘x’.
In the experiment, the fRLBF approach improved FIT [%] and SICF [dB] scores compared to fLBF, with only a few instances of minor degradation. Table 2 presents results for the dfRLBF (after debiasing) with three gain selection algorithms: dfRLBF , dfRLBF , and dfRLBF . The table highlights the best results for each unique parameter combination k, m, and SNR, showing that dfRLBF [B] performs best at 10 and 20 dB SNR, while both dfRLBF and dfRLBF achieve the highest FIT [%] and SICF [dB] scores at 30 dB SNR.
Table 2.
Average FIT [%] and SICF [dB] values for the dfRLBF algorithm, comparing various gains selection approaches: [A] empirical Bayes approach, [B] decentralized approach, and [C] cross-validation approach. Performance is evaluated across design parameters and , and at SNR levels of 10 dB, 20 dB, and 30 dB. Best performance values for each unique parameter combination k, m, and SNR are highlighted in bold. An adaptive approach, dynamically selecting m and k at each time instant, is denoted by ‘A’.
At a high SNR level of 30 dB, dfRLBF performs slightly worse than dfRLBF and dfRLBF , primarily because its decentralized regularization gain selection mechanism is more sensitive to local variations, resulting in frequent adjustments of the regularization gains. This makes it less stable than approaches that select regularization gains jointly. However, in low and medium SNR scenarios, this gain selection mechanism can enhance channel estimation performance. As expected, the proposed regularization yields the highest improvements at SNR 10 dB; for instance, dfRLBF compared to dfLBF at 10 dB SNR with results in FIT = 5.6% and SICF = 3.6 dB. As SNR increases, the score improvements diminish, such as dfRLBF versus dfLBF at 30 dB SNR with , resulting in FIT = 1% and SICF = 1.1 dB. In the adaptive approach, labeled as ‘A’ in the table, regularization is applied to the best-fitting dfLBF algorithm. At lower SNR levels (10 and 20 dB), adaptive dfRLBF outperforms both adaptive dfRLBF and dfRLBF , with results approaching those from the best settings. However, at 30 dB SNR, the adaptive dfRLBF approach is superior to the others, showing results that are equal to or better than those from the best settings.
Table 3 shows the average FIT [%] and SICF [dB] values for the multi-step dfRLBF approach with varying iterations: across design parameters and , and at SNR level of 10 dB. The multi-step procedure described in (48)–(50) notably improves performance at low SNR (10 dB), with the most improvement seen from dfRLBF to dfRLBF . Additional iterations yield only slight accuracy gains, as illustrated in Figure 7 for 20 iterations. A practical rule of thumb is to stop after the second iteration, since each additional iteration increases the computational cost by complex flops, square root operations, and real divisions. This pattern is similar for the dfRLBF and dfRLBF methods.
Table 3.
Average FIT [%] and SICF [dB] values for the dfRLBF [B] algorithm with varying numbers of iterations in the multi-step procedure. Performance is evaluated across design parameters and , and at an SNR level of 10 dB. Best performance values for each unique parameter combination k, m, and SNR are highlighted in bold.
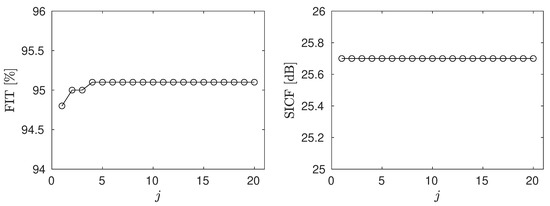
Figure 7.
Convergence of the average FIT [%] and SICF [dB] values for the multi-step dfRLBF algorithm, evaluated for and at an SNR level of 10 dB over twenty iterations in the multi-step procedure (). The presented results were averaged over time for a single realization of the channel model (a typical example).
Figure 8 compares LBF, fLBF, and dfRLBF for and at an SNR level of 10 dB, focusing on parameter channel errors. The dfRLBF approach yields both quantitative and qualitative improvements over the LBF and fLBF algorithms. The improvement is noticeable for taps , where the channel parameter errors are smaller than in the other compared methods.
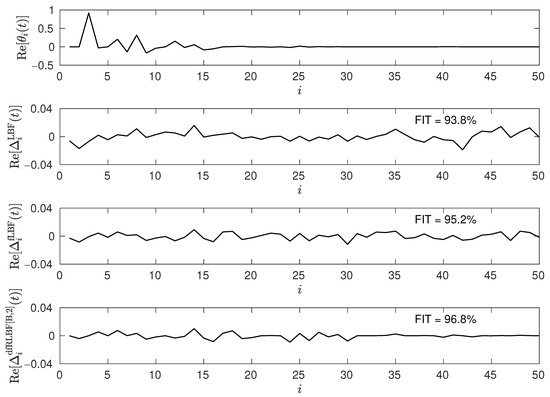
Figure 8.
A snapshot of the true impulse response of the identified system (top figure) and three corresponding parameter channel errors obtained using the LBF, fLBF, and dfRLBF , respectively, for and settings at an SNR level of 10 dB.
3.5. Impact of Measurement Noise
So far, it has been assumed that the measurement noise follows a Gaussian distribution. To provide a more comprehensive evaluation, three additional noise models are considered using the same experimental setup: Laplacian noise, non-stationary noise, and pulse noise. All noises meet the assumption (2).
The Laplacian noise is generated with the same variance as the Gaussian noise used in previous experiments [40]. This model is commonly employed to represent measurement noise that occasionally includes small outliers, as the heavier tails of the Laplace distribution make such deviations more likely compared to the Gaussian case.
To simulate non-stationary measurement noise, the noise variance was modulated over time according to the function
where T is the total number of samples. At each time instant, the noise sample was drawn from a zero-mean Gaussian distribution with the corresponding time-varying standard deviation .
Pulse noise is introduced using a Gaussian mixture model with -contamination [41]. Such a model is often used to describe measurement noise that is mostly Gaussian, but occasionally includes outliers or impulsive disturbances modeled by the high-variance Gaussian component. In this model, the noise distribution is a weighted sum (mixture) of two zero-mean Gaussian distributions with different variances
where denotes the probability that a sample is drawn from the contaminating distribution, determining the frequency of outliers, while the coefficient controls the severity of these outliers by substantially increasing the variance of the contaminated component.
Three realizations of measurement noise sequences with different distributions are presented in Figure 9. From to top to bottom: (A) Laplace noise, (B) non-stationary noise, and (C) pulse noise generated for parameters . Table 4 presents the average FIT [%] and SICF [dB] values for the dfLBF and dfRLBF algorithms under various types of measurement noise and at SNR levels of 10 dB, 20 dB, and 30 dB. Both approaches achieve high values for these metrics when applied to Gaussian, Laplacian, and non-stationary noise. However, performance drops significantly in the presence of pulse noise, primarily because the fLBF approach relies on -norm minimization, which is not robust to impulsive disturbances. Nevertheless, under these challenging conditions, the dfRLBF algorithm demonstrates a marked improvement over the dfLBF method. Similar results were also observed for the dfRLBF and dfRLBF approaches.
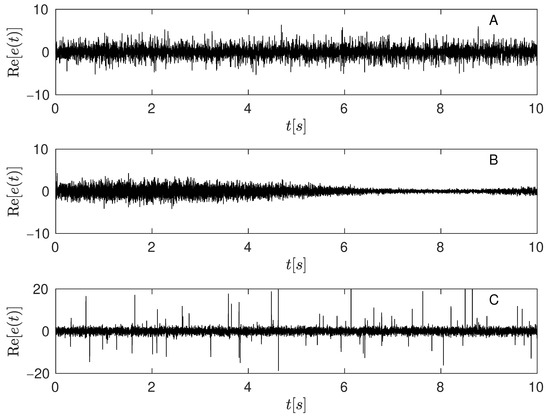
Figure 9.
Three measurement noise sequences with different distributions. From top to bottom: (A) Laplacian noise, (B) non-stationary noise with time-varying variance, and (C) mixture noise—Gaussian noise contaminated by occasional impulsive (pulse) noise modeled for parameters .
One practical solution is to incorporate a pulse detection algorithm that identifies pulses within the estimation window. With this enhancement, a robust LBF and fLBF approach would estimate channel parameters using only the outlier-free observations , as proposed in [42]. However, a limitation of this approach is that the estimation window will contain fewer data points, which, in cases of a high percentage of contamination, may lead to a drop in estimation performance or even numerical issues. An alternative solution, described in [43], combines pulse detection with the reconstruction of corrupted signal samples based on a signal model. This recursive algorithm is computationally efficient, preserves the original number of data points in the estimation window after reconstruction, and can effectively handle bursts of outliers affecting multiple consecutive samples. The results obtained by combining the pulse removal algorithm [43] with the proposed approaches are denoted as ‘Pulse*’ in Table 4. The pulse removal algorithm [43] based on semi-causal detection was configured with the following settings: an estimation window size of 201, a fifth-order AR model, a prediction-based detection threshold of 3.5, an interpolation-based detection threshold of 4.0, and a maximum detection burst length of 5.
Table 4.
Average FIT [%] and SICF [dB] values for the dfLBF and dfRLBF [B] algorithms under various types of measurement noise—Gaussian noise, Laplacian noise, non-stationary noise, pulse noise, and data preprocessed with the pulse removal algorithm [43] (denoted as Pulse*). Performance was evaluated for parameters and , across SNR levels of 10 dB, 20 dB, and 30 dB.
Table 4.
Average FIT [%] and SICF [dB] values for the dfLBF and dfRLBF [B] algorithms under various types of measurement noise—Gaussian noise, Laplacian noise, non-stationary noise, pulse noise, and data preprocessed with the pulse removal algorithm [43] (denoted as Pulse*). Performance was evaluated for parameters and , across SNR levels of 10 dB, 20 dB, and 30 dB.
| FIT [%] | SICF [dB] | ||||||
|---|---|---|---|---|---|---|---|
| Method | Noise | 10 dB | 20 dB | 30 dB | 10 dB | 20 dB | 30 dB |
| dfLBF | Gaussian | 93.3 | 97.7 | 98.8 | 26.4 | 35.6 | 41.5 |
| Laplace | 92.5 | 97.4 | 97.4 | 25.8 | 35 | 33.3 | |
| Non-stationary | 91.8 | 97 | 97 | 23.8 | 33 | 34.4 | |
| Pulse | 65 | 66.3 | 66.4 | 10.3 | 10.5 | 10.6 | |
| Pulse* | 87 | 90.7 | 91.2 | 18.9 | 21.2 | 21.6 | |
| dfRLBF [B] | Gaussian | 95.3 | 98.3 | 98.9 | 29.2 | 37.7 | 41 |
| Laplace | 95.1 | 98.1 | 97.4 | 28.8 | 37 | 33.3 | |
| Non-stationary | 94.7 | 97.8 | 97.5 | 27.1 | 35.1 | 34.4 | |
| Pulse | 79.2 | 80 | 80.1 | 14.5 | 14.8 | 14.8 | |
| Pulse* | 91.8 | 93.9 | 94.3 | 22.5 | 24.6 | 24.9 | |
3.6. Comparison with the Orthogonal Matching Pursuit
The Orthogonal Matching Pursuit (OMP) algorithm [24] was employed to obtain a sub-optimal least squares estimate of the hyperparameter vector , as defined in (9). This estimation was achieved by selecting most significant atoms. The atom dictionary, an matrix , was constructed from basis functions and explicitly defined as . The corresponding observation vector, with dimensions , was formed by concatenating all pre-estimate vectors, specifically .
A significant reduction in computational cost during the atom selection step is attributed to the sparse nature of matrix , characterized by its relatively small number of non-zero elements—only 2%. Furthermore, the block diagonal structure of provides crucial optimization for the OMP algorithm. This structure ensures that only a single coefficient needs to be determined per iteration, thereby avoiding the computationally intensive process of recomputing all previously identified coefficients, which is characteristic of standard OMP. This optimized implementation, while preserving the accuracy of the results, effectively lowers the computational cost of the OMP algorithm roughly by a factor of 12 compared to conventional OMP implementation. Additionally, once the atom dictionary is constructed with the chosen design parameters n, k, and m, it remains fixed throughout the simulation.
The atom dictionary for OMP algorithm was constructed with design parameters , , and to investigate the impact of the number of selected atoms on processing time. Table 5 summarizes the average FIT [%], SICF [dB], and processing time ( in seconds) achieved by OMP. This table illustrates how (selected from dictionary elements) influences performance under different SNR conditions (10 dB, 20 dB, 30 dB). The reported is for a single realization of 12,000-sample channel coefficients. In comparison, the dRLBF [B ] algorithm requires about 5 s for coefficient shrinking on the same CPU, after its regularization gains (, ) are chosen, with their optimization taking roughly 68 s.
Table 5.
Average FIT [%], SICF [dB] values, and processing time () in seconds for the Orthogonal Matching Pursuit (OMP) algorithm. The table demonstrates the impact of the number of selected atoms (, chosen from possible atoms in the dictionary) on performance across various SNR levels (10 dB, 20 dB, 30 dB). Processing time is measured per one realization of channel coefficients of length 12,000 samples. The best results per SNR level are indicated in bold.
It is important to note that an increasing number of selected atoms leads to a substantial increase in processing time, making the OMP algorithm less usable compared to the dfRLBF [B] approach for sliding window estimation. Furthermore, an increased number of atoms leads to a noticeable degradation in the OMP algorithm’s performance across both metrics, particularly evident at a low SNR of 10 dB—see Figure 10. At higher SNR levels (20 dB and 30 dB), this degradation remains observable but is smaller.
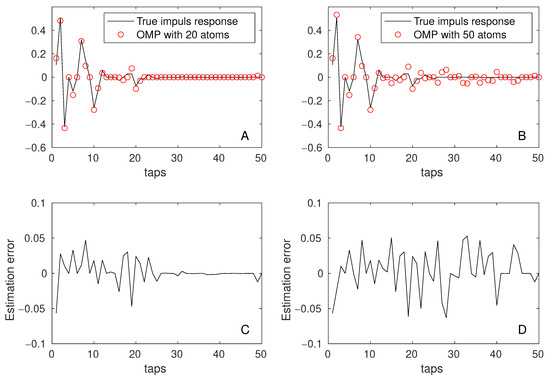
Figure 10.
A snapshot of the true impulse response (solid line) and superimposed OMP estimates (circles) for and atoms are shown in Plots (A) and (B), respectively. OMP results were generated under parameters and at an SNR of 10 dB. Plots (C,D), directly below, illustrate the parameter estimation errors corresponding to the OMP results presented in Plots (A,B).
Table 6 presents the average FIT [%] and SICF [dB] values achieved by the OMP algorithm at different SNR levels (10 dB, 20 dB, and 30 dB), using a fixed selection of atoms. For each experimental condition, atom dictionaries were constructed from matrices , utilizing a fixed and exploring all combinations of and . At a low SNR of 10 dB, the OMP algorithm achieved the best results among the evaluated methods (LBF, fLBF, dfLBF). Only the dfRLBF [B] approach yielded performance comparable to OMP at this SNR level. Conversely, for SNR values of 20 dB and 30 dB, dfRLBF [B] demonstrated superior performance over OMP, with this advantage becoming more pronounced as the SNR increased. Table 7 shows average FIT [%] and SICF [dB] values, showing the difference in scores between the dfRLBF [B] and OMP algorithms. Positive values indicate dfRLBF [B]’s superior performance, whereas negative values suggest OMP’s better performance.
Table 6.
Average FIT [%] and SICF [dB] values for the Orthogonal Matching Pursuit (OMP) algorithm, using selected atoms. For these experiments, atom dictionaries were constructed from matrices for each combination of design parameters: fixed , , and . The best results per SNR level are indicated in bold.
Table 7.
Average FIT [%] and SICF [dB] values, quantifying the performance difference between the dfRLBF [B] and OMP ( atoms) algorithms. The table illustrates the impact of varying design parameters: local estimation window size (, for ) and number of basis functions (), across SNR levels of 10 dB, 20 dB, and 30 dB. Positive values indicate dfRLBF [B]’s superior performance, whereas negative values suggest OMP’s better performance.
3.7. Discussion
Once the communication channel can be approximated by the time-varying FIR model shown in (1), the main goal is to identify the unknown time-varying system coefficients. The assumption regarding the speed of parameter changes is very important, as it determines the choice of the identification algorithm. Classical identification algorithms are typically limited to tracking slowly time-varying parameters [4,5,6]. In contrast, the time-varying channel identification algorithm proposed in this paper is designed to effectively track parameter variations at various speeds, including slow, medium, and fast changes. This enhanced capability is achieved through the use of a hypermodel based on local basis functions. By employing a linear combination of an appropriate number of basis functions (m) and selecting a suitable analysis window size (K), the algorithm can accurately capture even rapid parameter changes. Therefore, the design parameters m and K play a crucial role in the performance of the identification process, as demonstrated in all tables presented.
Previous research has proposed two local statistics for parameter selection: the cross-validation selection rule [29] and the modified Akaike’s final prediction error criterion [39]. In this paper, we show that the cross-validation selection rule is also effective for the proposed regularized estimators. As shown in Table 2, results obtained using this rule closely approach the best results across all tested combinations of m and k. Recent works [44,45] show that if there is prior knowledge of parameter changes, it can improve the selection and/or type of basis functions used in the local basis function approach.
Another important aspect examined in this work is the compensation of estimation bias introduced by the causal EWLS algorithm used to obtain pre-estimates at the first stage. This bias can be mitigated by replacing unidirectional pre-estimates with bidirectional pre-estimates. Alternatively, as detailed in Equations (79)–(82), the parameter estimates can also be refined by applying a time-shift correction at each time instant. As shown in Table 1, the time-shift correction leads to improved estimation results across all SNR cases, with greater benefits observed at higher SNR levels. However, accurately estimating the time-shift in low SNR scenarios remains challenging and may require further investigation in future research.
Next, it was demonstrated that the proposed regularization technique is suitable for channel identification with sparse characteristics. As shown in Figure 8, the channel parameter errors are reduced and are closer to zero in the impulse response tail compared to the LBF or fLBF methods. This behavior is the expected outcome of the proposed method. To achieve the best results, it is necessary to select the regularization gains adaptively. In this paper, three gain selection approaches were derived and compared. The best results were obtained when the gain selection was performed independently for each system coefficient.
The proposed method was validated using various noise models, including Gaussian noise, Laplace noise, non-stationary noise, and pulse noise, achieving high estimation accuracy for all cases except the challenging pulse noise scenario (see Table 4). Since both the LBF and fLBF approaches are based on -norm minimization, they are inherently not robust to severe impulsive (pulse) noise. Even a small proportion of contamination, such as 1%, can significantly degrade the accuracy of channel parameter estimation. To address this challenge, an additional preprocessing step can be implemented to detect and exclude, trim, or replace corrupted samples before applying the proposed method, as discussed in [42]. Alternatively, the strategy proposed in [43] allows for detecting corrupted samples and replacing them with interpolated values based on a signal model.
Finally, the proposed approach was compared with the Orthogonal Matching Pursuit (OMP) algorithm [24]. The atom dictionary, constructed from basis functions, exhibited inherent sparsity and a block diagonal structure, which reduced the computational cost of the OMP algorithm by a factor of 12 without affecting its results. Nevertheless, the computational burden of OMP remained significantly higher than that of the dfRLBF [B] approach, and was strongly dependent on the number of selected atoms. While OMP achieved comparable results to dfRLBF [B] with 20 atoms at a low SNR of 10 dB, its performance in both metrics declined at higher SNR levels (20 dB and 30 dB).
A brief summary of the key aspects of the proposed multistage method for non-stationary sparse channel identification is provided in Table 8.
Table 8.
Summary of proposed multistage approach for identification of non-stationary sparse communication channels.
4. Conclusions
The proposed regularization technique, using local basis functions with reweighted regularizers in both the time and frequency domains, effectively enhances the identification of non-stationary communication channels, especially those with sparse characteristics and exponential envelope profiles, as commonly observed in full-duplex underwater acoustic channels. Three adaptive gain selection approaches, the empirical Bayes, decentralized, and cross-validation, were investigated, showing additional improvements with debiasing and multi-step procedures. The proposed fRLBF approach presents a superior alternative to LBF for lower SNR levels (10 and 20 dB), providing lower complexity and greater flexibility. In simulation experiments, the proposed fRLBF approach achieved results that were competitive with, or even superior to, those obtained using the Orthogonal Matching Pursuit algorithm, while also delivering significant computational savings. Additionally, the proposed method demonstrated robustness to various types of measurement noise—including Gaussian, Laplacian, and non-stationary noise—but its performance deteriorated in the presence of pulse noise. This suggests that a preprocessing step for pulse noise removal should be considered in such scenarios.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The MATLAB R2022b code used to generate input data, the final results, and the processing code are attached to the paper under the link https://doi.org/10.5281/zenodo.17507866.
Acknowledgments
Computer simulations were carried out at the Academic Computer Center in Gdańsk.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Derivation of (57)
Derivation of (57) is based on the identity
valid for any positive definite Hermitian matrix , which stems from properties of the multivariate Gaussian distribution and the following “completing the squares” identity
Combining (55) with (56), one obtains , and which, when substituted to (A1), leads to (57).
References
- Tsatsanis, M.K.; Giannakis, G.B. Modeling and equalization of rapidly fading channels. Int. J. Adapt. Contr. Signal Process. 1996, 10, 159–176. [Google Scholar] [CrossRef]
- Stojanovic, M.; Preisig, J. Underwater acoustic communication channels: Propagation models and statistical characterization. IEEE Commun. Mag. 2009, 47, 84–89. [Google Scholar] [CrossRef]
- Songzuo, L.; Iqbal, B.; Khan, I.U.; Ahmed, N.; Qiao, G.; Zhou, F. Full Duplex Physical and MAC Layer-Based Underwater Wireless Communication Systems and Protocols: Opportunities, Challenges, and Future Directions. J. Mar. Sci. Eng. 2021, 9, 468. [Google Scholar] [CrossRef]
- Söderström, T.; Stoica, P. System Identification; Prentice-Hall: Hoboken, NJ, USA, 1988; ISBN 978-0-13-881236-2. [Google Scholar]
- Haykin, S. Adaptive Filter Theory; Prentice-Hall: Hoboken, NJ, USA, 1996; ISBN 978-0-13-322760-4. [Google Scholar]
- Niedźwiecki, M. Identification of Time-Varying Processes; Wiley: Hoboken, NJ, USA, 2000; ISBN 978-0-471-98629-4. [Google Scholar]
- Kitagawa, G.; Gersch, W. A smoothness priors time-varying AR coefficient modeling of nonstationary covariance time series. IEEE Trans. Autom. Control 1985, 30, 48–56. [Google Scholar] [CrossRef]
- Kitagawa, G.; Gersch, W. Smoothness Priors Analysis of Time Series; Springer: Berlin/Heidelberg, Germany, 1996; ISBN 978-0-387-94819-5. [Google Scholar]
- Niedźwiecki, M. Locally adaptive cooperative Kalman smoothing and its application to identification of nonstationary stochastic systems. IEEE Trans. Signal Process. 2012, 60, 48–59. [Google Scholar] [CrossRef]
- Niedźwiecki, M. Functional series modeling approach to identification of nonstationary stochastic systems. IEEE Trans. Autom. Control 1988, 33, 955–961. [Google Scholar] [CrossRef]
- Tsatsanis, M.K.; Giannaki, G.B. Time-varying system identification and model validation using wavelets. IEEE Trans. Signal Process. 1993, 41, 3512–3523. [Google Scholar] [CrossRef]
- Borah, D.K.; Hart, B.D. Frequency-selective fading channel estimation with a polynomial time-varying channel model. IEEE Trans. Commun. 1999, 47, 862–873. [Google Scholar] [CrossRef]
- Wei, H.L.; Liu, J.J.; Billings, S.A. Identification of time-varying systems using multi-resolution wavelet models. Int. J. Syst. Sci. 2002, 33, 1217–1228. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Ciołek, M. Generalized Savitzky-Golay filters for identification of nonstationary systems. Automatica 2020, 108, 108477. [Google Scholar] [CrossRef]
- Ljung, L.; Chen, T. What can regularization offer for estimation of dynamic systems? In Proceedings of the 11th IFAC Workshop on Adaptation and Learning in Control and Signal Processing, Caen, France, 3–5 July 2013; pp. 1–8. [Google Scholar]
- Chen, T.; Ohlsson, H.; Ljung, L. On the estimation of transfer functions, regularizations and Gaussian process—Revisited. Automatica 2012, 48, 1525–1535. [Google Scholar] [CrossRef]
- Pillonetto, G.; Dinuzzo, F.; Chen, T.; De Nicolao, G.; Ljung, L. Kernel methods in system identification, machine learning and function estimation: A survey. Automatica 2014, 50, 657–682. [Google Scholar] [CrossRef]
- Gańcza, A.; Niedźwiecki, M.; Ciołek, M. Regularized local basis function approach to identification of nonstationary processes. IEEE Trans. Signal Process. 2021, 69, 1665–1680. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Gańcza, A.; Kaczmarek, P. Identification of fast time-varying communication channels using the preestimation technique. In Proceedings of the 19th Symposium on System Identification, SYSID, Padova, Italy, 13–16 July 2021; Volume 54, pp. 351–356. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the LASSO. J. R. Statist. Soc. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Daubechies, I.; Defrise, M.; De Mol, C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 2004, 57, 1413–1457. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Davis, G.; Mallat, S.; Avellaneda, M. Adaptive greedy approximations. Constr. Approx. 1997, 13, 57–98. [Google Scholar] [CrossRef]
- Needell, D.; Tropp, J.A. Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Gańcza, A.; Niedźwiecki, M. Regularized identification of fast time-varying systems—Comparison of two regularization strategies. In Proceedings of the 60th IEEE Conference on Decision and Control, Austin, TX, USA, 14–17 December 2021; pp. 864–871. [Google Scholar]
- Shen, L.; Zakharov, Y.; Henson, B.; Morozs, N.; Mitchell, P. Adaptive filtering for full-duplex UWA systems with time-varying self-interference channel. IEEE Access 2020, 8, 187590–187604. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Ciołek, M.; Gańcza, A. A new look at the statistical identification of nonstationary systems. Automatica 2020, 118, 109037. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Gańcza, A.; Ciołek, M. On the preestimation technique and its application to identification of nonstationary systems. In Proceedings of the 59th Conference on Decision and Control CDC 2020, Jeju Island, Republic of Korea, 14–18 December 2020; pp. 286–293. [Google Scholar]
- Zakharov, Y.V.; White, G.P.; Liu, J. Low-complexity RLS algorithms using dichotomous coordinate descent iterations. IEEE Trans. Signal Process. 2008, 56, 3150–3161. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. A note on the group lasso and sparse group lasso. arXiv 2010, arXiv:1001.0736. [Google Scholar] [CrossRef]
- Bani, M.S.; Chalmers, B.L. Best approximation in Linf via iterative Hilbert space procedures. J. Approx. Theory 1984, 42, 173–180. [Google Scholar] [CrossRef]
- Burrus, C.S.; Barreto, J.A.; Selesnick, I.W. Iterative reweighted least squares design of FIR filters. IEEE Trans. Signal Process. 1994, 42, 2926–2936. [Google Scholar] [CrossRef]
- Gańcza, A. Local Basis Function Method for Identification of Nonstationary Systems. Ph.D. Thesis, The Gdańsk University of Technology, Gdańsk, Poland, 2024. [Google Scholar]
- Good, I.J. The Estimation of Probabilities; MIT Press: Cambridge, MA, USA, 1965; ISBN 978-0-262-57015-2. [Google Scholar]
- Niedźwiecki, M.; Gańcza, A.; Shen, L.; Zakharov, Y. Adaptive identification of linear systems with mixed static and time-varying parameters. Signal Process. 2020, 200, 108664. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Gańcza, A.; Shen, L.; Zakharov, Y. On Bidirectional preestimates and their application to identification of fast time-varying systems. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Niedźwiecki, M.; Ciołek, M. Fully adaptive Savitzky-Golay type smoothers. In Proceedings of the 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Miller, S.L.; Childers, D.G.S. Probability and Random Processes: With Applications to Signal Processing and Communications, 2nd ed.; Academic Press: Cambridge, MA, USA, 2012; ISBN 978-0-12-386981-4. [Google Scholar]
- Huber, P.J. Robust Estimation of a Location Parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Gańcza, A.; Żuławiński, W.; Wyłomańska, A. Robust local basis function algorithms for identification of time-varying FIR systems in impulsive noise environments. In Proceedings of the 63rd Conference on Decision and Control (CDC), Milan, Italy, 16–19 December 2024; pp. 3463–3470. [Google Scholar]
- Ciołek, M.; Niedźwiecki, M. Detection of impulsive disturbances in archive audio signals. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 671–675. [Google Scholar]
- Niedźwiecki, M.; Gańcza, A. Karhunen-Loeve-based approach to tracking of rapidly fading wireless communication channels. Signal Process. 2023, 209, 109043. [Google Scholar] [CrossRef]
- Niedźwiecki, M.; Gańcza, A. On Optimal Tracking of Rapidly Varying Telecommunication Channels. IEEE Trans. Signal Process. 2024, 72, 2726–2738. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).