
FPGA Implementation of a Novel Multifunction Modulo (2n ± 1) Multiplier Using Radix-4 Booth Encoding Scheme

Abstract
1. Introduction
2. Related Work
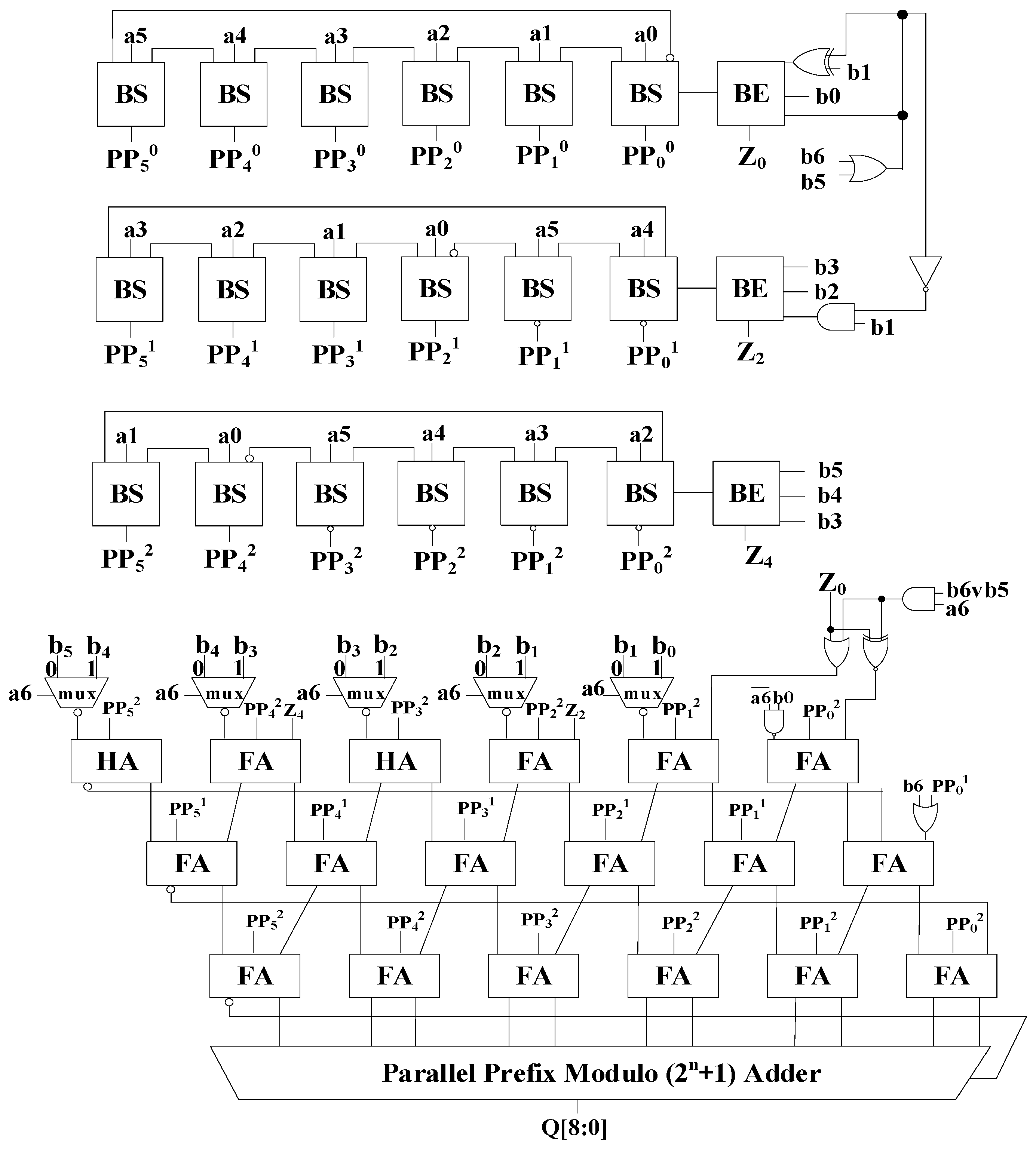
3. Proposed Modulo (2n ± 1) Multiplier Based on Radix-4 Booth Encoding
4. Experimental Results and Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vergos, H.T.; Efstathiou, C. Modified Booth 1’s Complement and Modulo 2n − 1 Multipliers. In Proceedings of the 7th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Jounieh, Lebanon, 17–20 December 2000; pp. 637–640. [Google Scholar]
- Efstathou, C.; Moshopoulos, N.; Axelos, N.; Pekmestzi, K. Efficient modulo 2n + 1 multiply and multiply-add units based on modified Booth encoding. Integration 2014, 47, 140–147. [Google Scholar] [CrossRef]
- Kaluri, K.; Leong, W.F.; Tan, K.H.; Johnson, L.; Soderstrand, M. FPGA hardware implementation of an RNS FIR digital filter. In Proceedings of the Conference Record of Thirty-Fifth Asilomar Conference on Signals, Systems and Computers (Cat.No.01CH37256), Pacific Grove, CA, USA, 4–7 November 2001; pp. 1340–1344. [Google Scholar]
- Schinianakis, D.M.; Fournaris, A.P.; Michail, H.E.; Kakarountas, A.P.; Stouraitis, T. An RNS implementation of an Fp elliptic curve point multiplier. IEEE Trans. Circuits Syst. I Regul. Pap. 2009, 56, 1202–1213. [Google Scholar] [CrossRef]
- Ma, S.; Hu, S.; Yang, Z.; Wang, X.; Liu, M.; Hu, J. High Precision Multiplier for RNS {2n − 1, 2n, 2n + 1}. Electronics 2021, 10, 1113. [Google Scholar] [CrossRef]
- Ramirez, J.; Garcia, A.; Lopez-Buedo, S.; Lloris, A. RNS-enabled Digital Signal Processor Design. Electron. Lett. 2002, 38, 266–268. [Google Scholar] [CrossRef]
- Nannarelli, A.; Re, M.; Cardarilli, G.C. Tradeoffs between residue number system and traditional FIR filter. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sydney, NSW, Australia, 6–9 May 2001; pp. 305–308. [Google Scholar]
- Juang, T.B.; Huang, J.H. Multifunction RNS modulo (2n ± 1) Multipliers Based on Modified Booth Encoding. In Proceedings of the 2012 IEEE Asia Pacific Conference on Circuits and Systems, Kaohsiung, Taiwan, 2–5 December 2012; pp. 515–518. [Google Scholar]
- Prediger, V.; Bairros, F.; Seman, L.O.; Bezerra, E.A.; Pettenghi, H. RNS processor using moduli sets of the form 2n ± 1. Int. J. Circuit Theory Appl. 2023, 51, 3432–3442. [Google Scholar] [CrossRef]
- Schoinianakis, D. Residue arithmetic systems in cryptography: A survey on modern security applications. J. Cryptogr. Eng. 2020, 10, 249–267. [Google Scholar] [CrossRef]
- Babenko, M.; Nazarov, A.; Deryabin, M.; Kucherov, N.; Tchernykh, A.; Hung, N.V.; Avetisyan, A.; Toporkov, V. Multiple Error Correction in Redundant Residue Number Systems: A Modified Modular Projection Method with Maximum Likelihood Decoding. Appl. Sci. 2022, 12, 463. [Google Scholar] [CrossRef]
- Sunder, S.; El-Guibaly, F.; Antoniou, A. Area-Efficient diminished-1 multiplier for fermat number-theoretic transform. IEE Proc. G 1993, 140, 211–215. [Google Scholar] [CrossRef]
- Palutla, K.; Gundabathina, P. Implementation of High Speed Modulo (2n + 1) Multiplier for IDEA Cipher. Procedia Comput. Sci. 2020, 171, 2016–2022. [Google Scholar] [CrossRef]
- Kalmykov, I.A.; Pashintsev, V.P.; Tyncherov, K.T.; Olenev, A.A.; Chistousov, N.K. Error-Correction Coding Using Polynomial Residue Number System. Appl. Sci. 2022, 12, 3365. [Google Scholar] [CrossRef]
- Singhal, S.K.; Mohanty, B.K.; Patel, S.K.; Saxena, G. Efficient Diminished-1 Modulo (2n + 1) Adder Using Parallel Prefix Adder. J. Circuits Syst. Comput. 2020, 29, 2050186. [Google Scholar] [CrossRef]
- Vergos, H.T.; Nikolos, D. Efficient Diminished-1 Modulo 2n + 1 Multipliers. IEEE Trans. Comput. 2005, 51, 491–496. [Google Scholar]
- Vergos, H.T.; Efstathiou, C. Design of efficient modulo 2n + 1 multipliers. IET Comput. Digit. Tech. 2007, 1, 49–57. [Google Scholar] [CrossRef]
- Chen, J.W.; Yao, R.H.; Wu, W.J. Efficient modulo 2n + 1 multipliers. IEEE Trans. VLSI Syst. 2011, 19, 2149–2157. [Google Scholar] [CrossRef]
- Juang, T.B.; Wu, G.L.; Chiu, C.C. Design of an area-efficient weighted modulo 2n + 1 multipliers. In Application and Innovation of Prototypes and Circuits; Ching Yun University: Taoyuan City, Taiwan, 2009; pp. 376–381. [Google Scholar]
- Sousa, L.; Chaves, R. A universal architecture for designing efficient modulo 2n + 1 multipliers. IEEE Trans. Circuits Syst. I 2005, 52, 1166–1178. [Google Scholar] [CrossRef]
- Juang, T.B.; Kuo, C.T.; Wu, G.L.; Huang, J.H. Multifuction RNS Modulo 2n ± 1 Multipliers. J. Circuits Syst. Comput. 2012, 21, 1250027. [Google Scholar] [CrossRef]
- Muralidharan, R.; Chang, C.H. Area-Power Efficient Modulo 2n − 1 and Modulo 2n + 1Multipliers for {2n − 1, 2n, 2n + 1} Based RNS. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 59, 2263–2274. [Google Scholar] [CrossRef]
- Kumar, R.; Jaiswal, R.K.; Mishra, R.A. Perspective and Opportunities of Modulo 2n − 1 Multipliers in Residue Number System: A Review. J. Circuits Syst. Comput. 2020, 29, 2030008. [Google Scholar] [CrossRef]
- Timarchi, S.; Akbarzadeh, N. Area-Time-Power Efficient Maximally Redundant Signed-Digit Modulo 2n − 1 Adder and Multiplier. Circ. Syst. Signal Pract. 2019, 38, 2138–2164. [Google Scholar] [CrossRef]
- Patel, B.K.; Kanungo, J. Efficient Tree Multiplexer Design by using Modulo 2n + 1 adder. In Proceedings of the 2021 Emerging Trends in Industry 4.0 (ETI 4.0), Raigarh, India, 19–21 May 2021. [Google Scholar] [CrossRef]
- Efstathiou, C.; Kouretas, I.; Kitsos, P. On the modulo 2n + 1 addition and subtraction for weighted operands. Microprocess Microsy 2023, 11, 2138–2164. [Google Scholar]
- Patel, B.K.; Kanungo, J. Diminished-1 multiplier using modulo 2n + 1 adder. Int. J. Eng. Technol. 2018, 7, 31–35. [Google Scholar] [CrossRef][Green Version]
- Lin, S.H.; Sheu, M.H. VLSI design of diminished-one modulo 2n + 1 adder using circular carry selection. IEEE Trans. Circuits Sys. II Express Briefs 2008, 55, 897–901. [Google Scholar]
- Juang, T.B.; Chiu, C.C.; Tsai, M.Y. Improved area-efficient weighted modulo 2n + 1 adders design with simple correction schemes. IEEE Trans. Circuits Sys. II Express Briefs 2010, 57, 198–202. [Google Scholar]
- Muralidharan, R.; Chang, C.H. Radix-4 and Radix-8 Booth Encoded Multi-Modulus Multipliers. IEEE Trans. Circuits Syst. I Regul. Pap. 2013, 60, 2940–2952. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
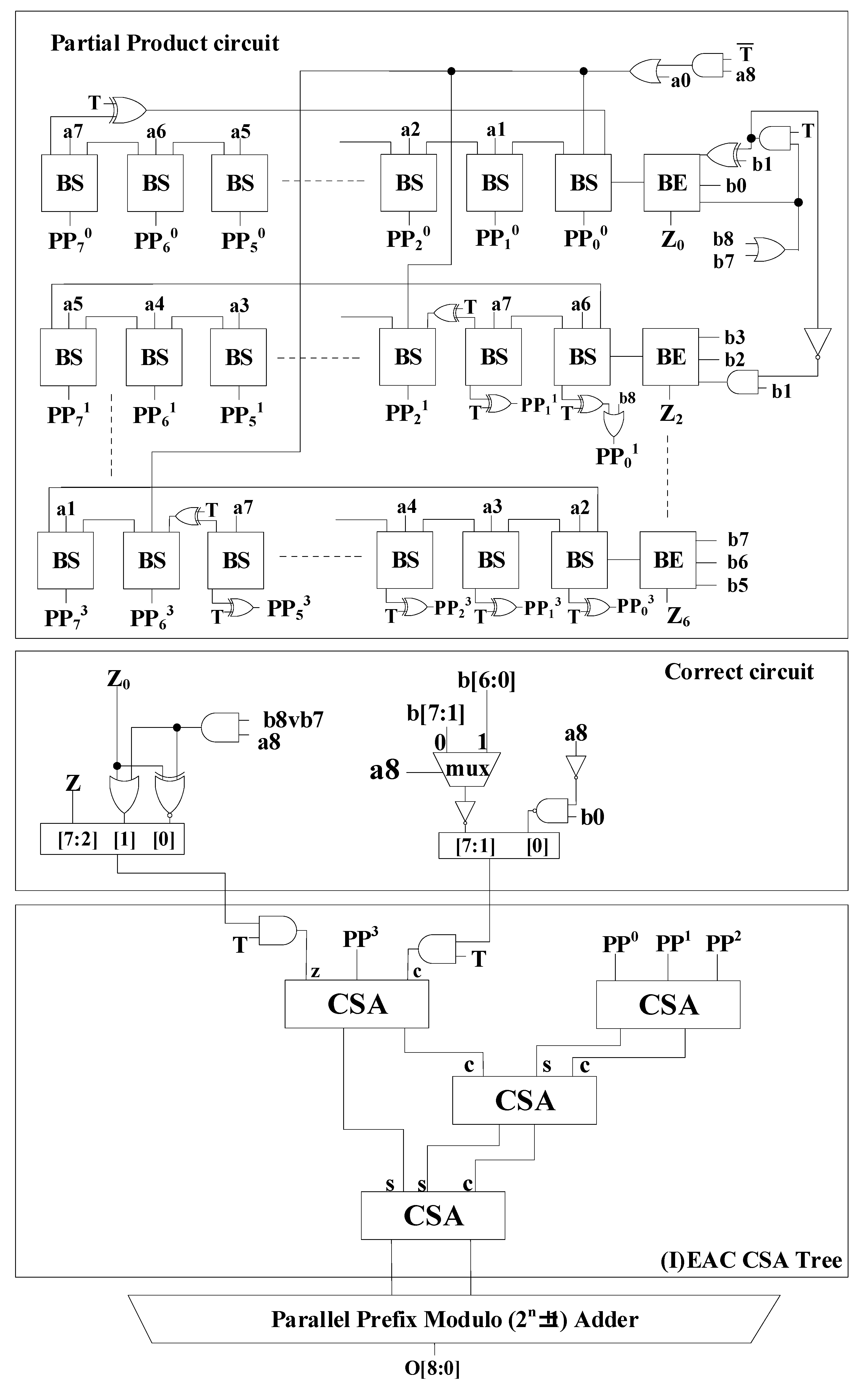{kind=link}
{kind=link}
{kind=link}
| Item | Merged Circuits [1,2] | Modulo (2n ± 1) [8] | Proposed Work | ||||
|---|---|---|---|---|---|---|---|
| Modulo (2n − 1) [1] | Modulo (2n + 1) [2] | Modulo (2n − 1) | Modulo (2n + 1) | Modulo (2n − 1) | Modulo (2n + 1) | ||
| Operation Range | Multiplicand | {0, 2n − 1} | {0, 2n + 1} | {0, 2n} | {1, 2n + 1} | {0, 2n} | {0, 2n + 1} |
| Multiplier | {0, 2n − 1} | {0, 2n + 1} | {0, 2n} | {0, 2n} | {0, 2n} | {0, 2n + 1} | |
| Item | Modulo (2n − 1) [1] | Modulo (2n + 1) [2] | Merged Circuits [1,2] | Modulo (2n ± 1) [8] | Proposed Work | |||
|---|---|---|---|---|---|---|---|---|
| n | Area (LUT) | Area (LUT) | Area (LUT) | Area Saving | Area (LUT) | Area Saving | Area (LUT) | Area Saving |
| 8 | 84 | 103 | 187 | 0 | 113 | +39.57% | 107 | +42.78% |
| 16 | 355 | 358 | 713 | 0 | 382 | +46.42% | 338 | +52.59% |
| 32 | 1406 | 1281 | 2687 | 0 | 1498 | +44.25% | 1284 | +52.21% |
| Item | Modulo (2n − 1) [1] | Modulo (2n + 1) [2] | Merged Circuits [1,2] | Modulo (2n ± 1) [8] | Proposed Work | |||
|---|---|---|---|---|---|---|---|---|
| n | Delay (ns) | Delay (ns) | Delay (ns) | Delay Saving | Delay (ns) | Delay Saving | Delay (ns) | Delay Saving |
| 8 | 13.203 | 15.332 | 15.332 * | 0 | 15.954 | +4.06% | 15.351 | −0.12% |
| 16 | 19.346 | 19.457 | 19.457 * | 0 | 21.219 | +9.06% | 20.729 | −6.54% |
| 32 | 30.532 | 28.565 | 30.532 * | 0 | 33.376 | +9.31% | 28.868 | +5.45% |
| Item | Modulo (2n − 1) [1] | Modulo (2n + 1) [2] | Merged Circuits [1,2] | Modulo (2n ± 1) [8] | Proposed Work | |||
|---|---|---|---|---|---|---|---|---|
| n | Power (W) | Power (W) | Power (W) | Power Saving | Power (W) | Power Saving | Power (W) | Power Saving |
| 8 | 0.042 | 0.044 | 0.086 | 0 | 0.048 | +44.19% | 0.048 | +44.19% |
| 16 | 0.105 | 0.105 | 0.21 | 0 | 0.114 | +45.71% | 0.107 | +49.05% |
| 32 | 0.282 | 0.283 | 0.565 | 0 | 0.309 | +45.31% | 0.289 | +48.85% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuo, C.-T.; Wu, Y.-C. FPGA Implementation of a Novel Multifunction Modulo (2n ± 1) Multiplier Using Radix-4 Booth Encoding Scheme. Appl. Sci. 2023, 13, 10407. https://doi.org/10.3390/app131810407
Kuo C-T, Wu Y-C. FPGA Implementation of a Novel Multifunction Modulo (2n ± 1) Multiplier Using Radix-4 Booth Encoding Scheme. Applied Sciences. 2023; 13(18):10407. https://doi.org/10.3390/app131810407
Chicago/Turabian StyleKuo, Chao-Tsung, and Yao-Cheng Wu. 2023. "FPGA Implementation of a Novel Multifunction Modulo (2n ± 1) Multiplier Using Radix-4 Booth Encoding Scheme" Applied Sciences 13, no. 18: 10407. https://doi.org/10.3390/app131810407
APA StyleKuo, C.-T., & Wu, Y.-C. (2023). FPGA Implementation of a Novel Multifunction Modulo (2n ± 1) Multiplier Using Radix-4 Booth Encoding Scheme. Applied Sciences, 13(18), 10407. https://doi.org/10.3390/app131810407