
Interoperability between Real and Virtual Environments Connected by a GAN for the Path-Planning Problem



Abstract
:1. Introduction
2. Related Works
3. Proposed Work
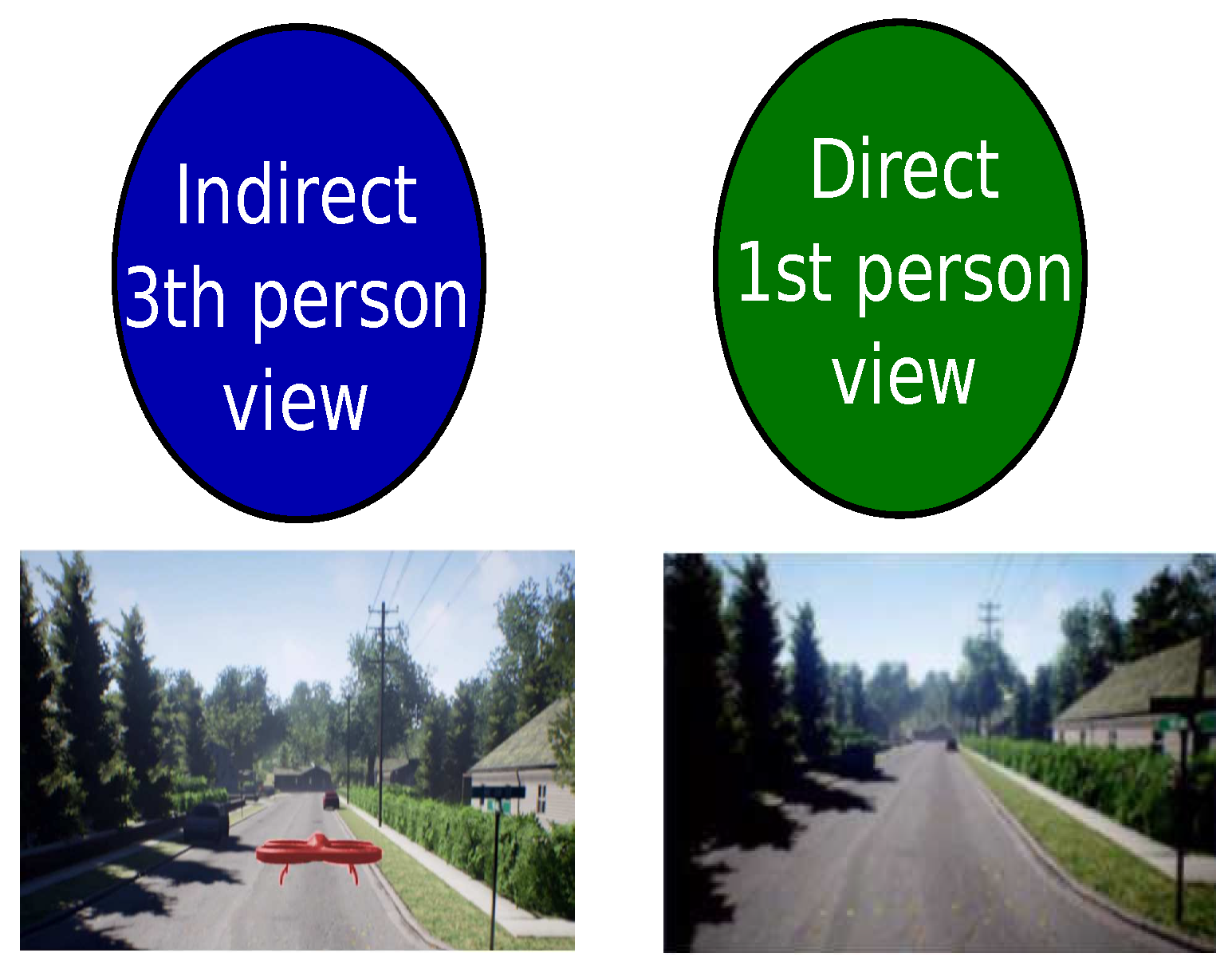
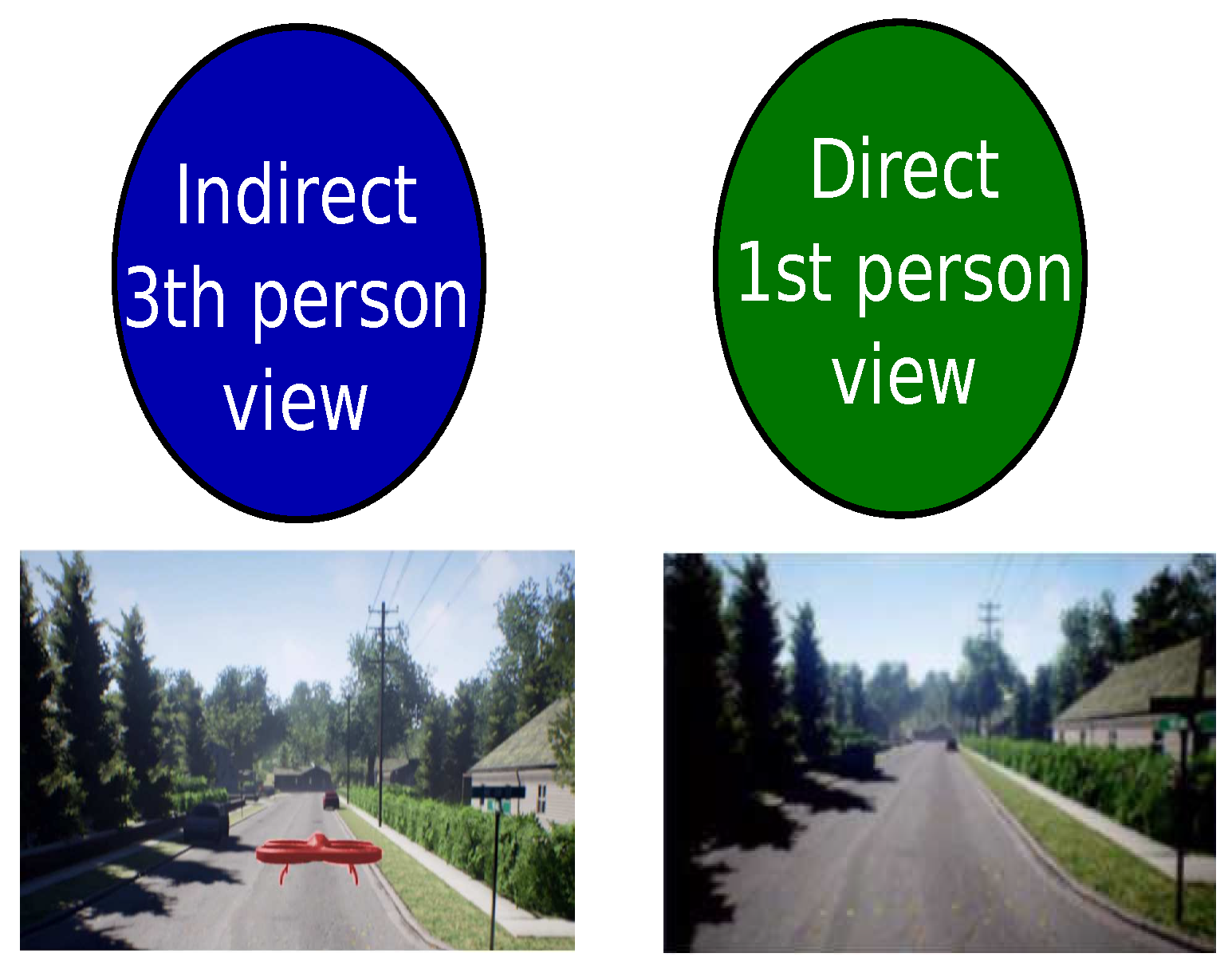
3.1. Interoperability Coefficient to Connect the Virtual and Real Environments
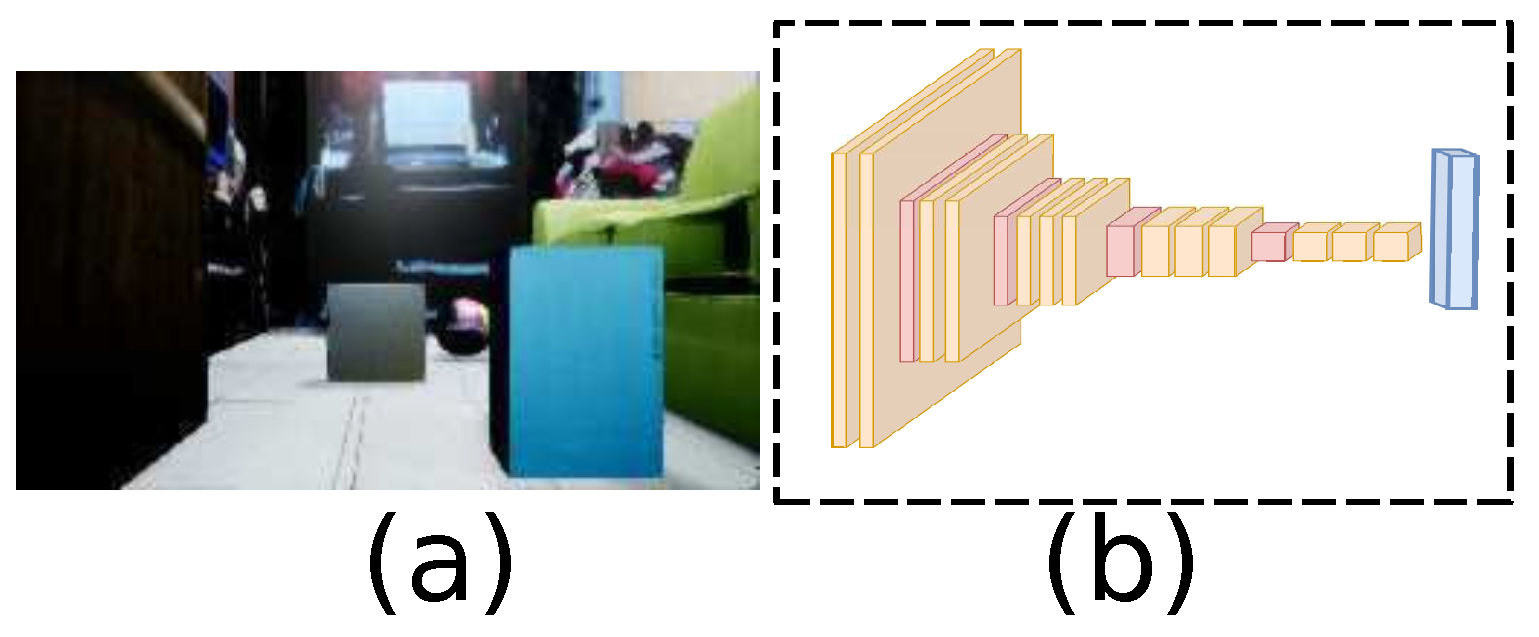
3.2. Virtual Dataset
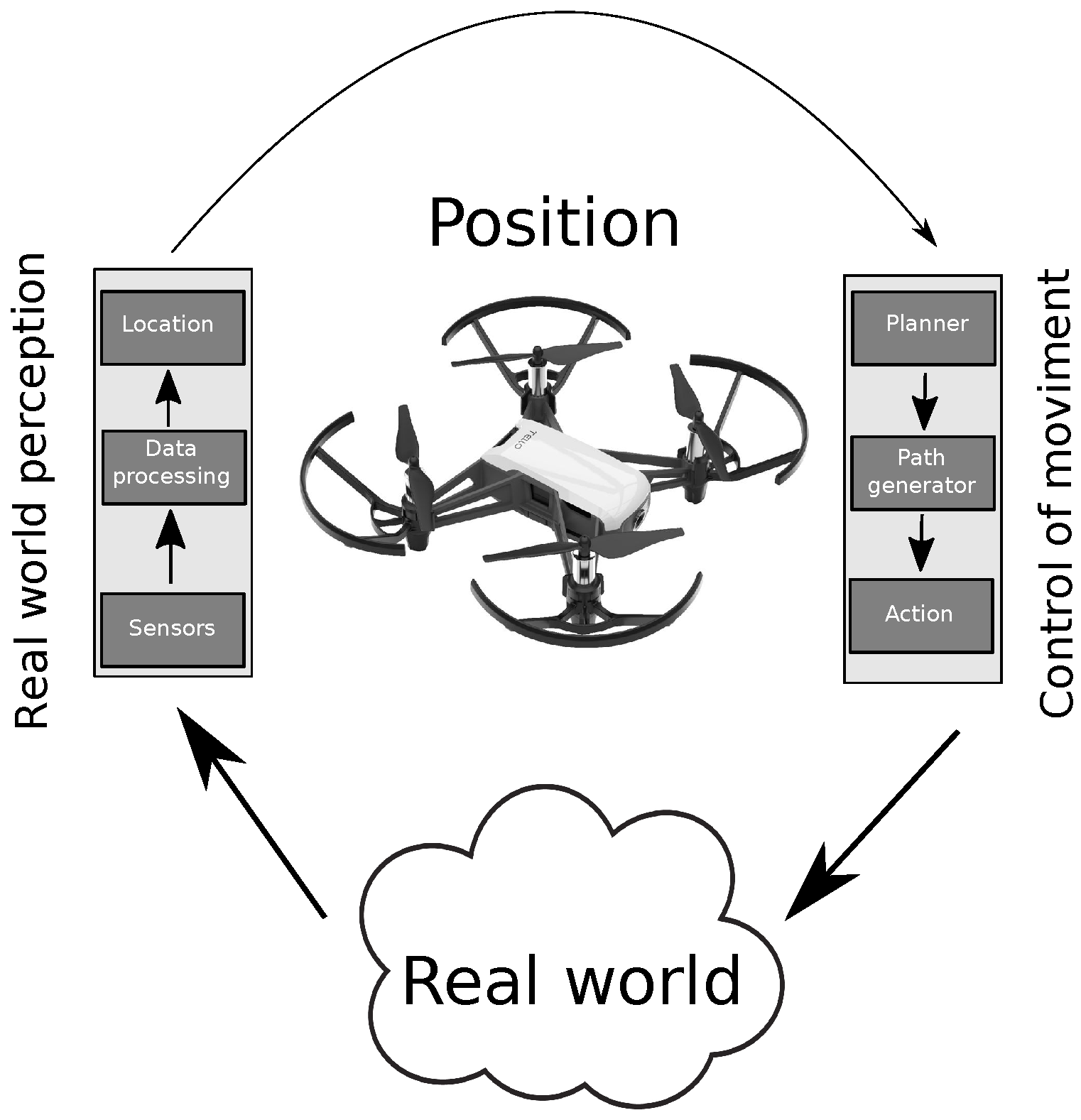
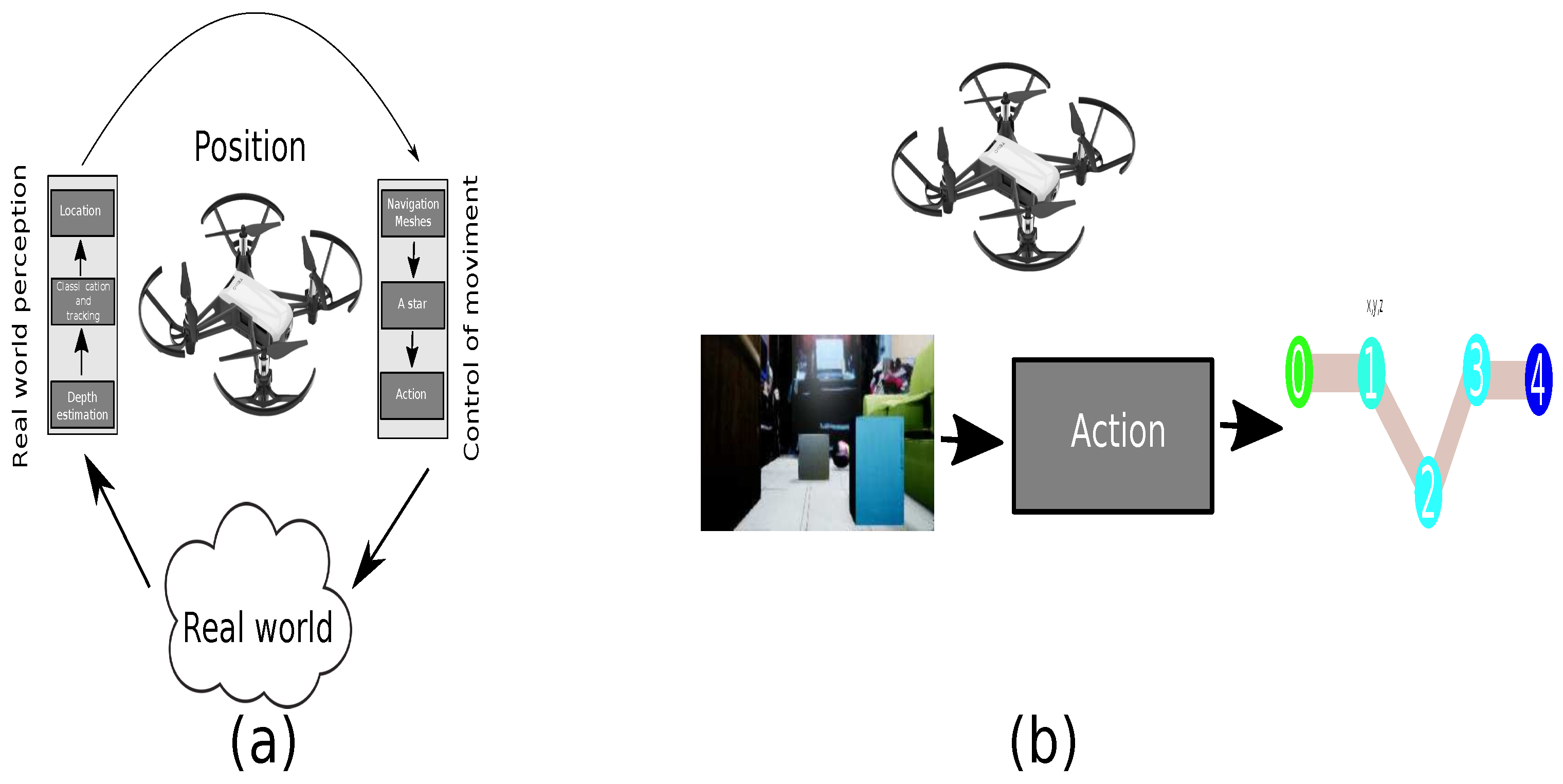
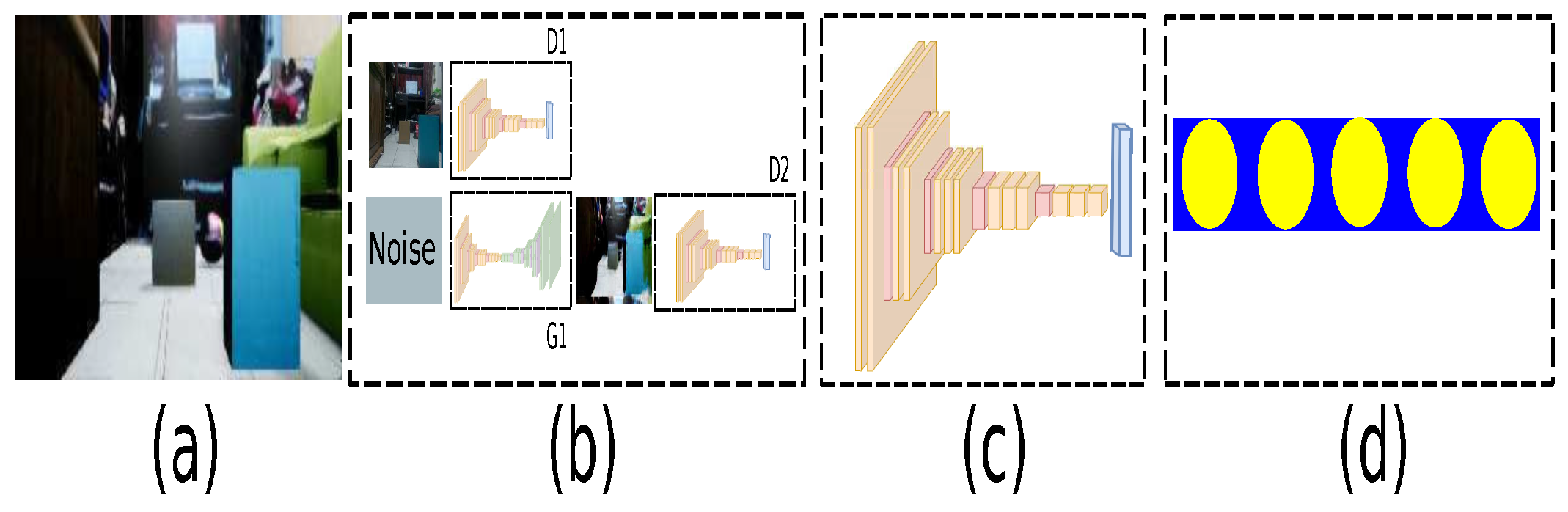
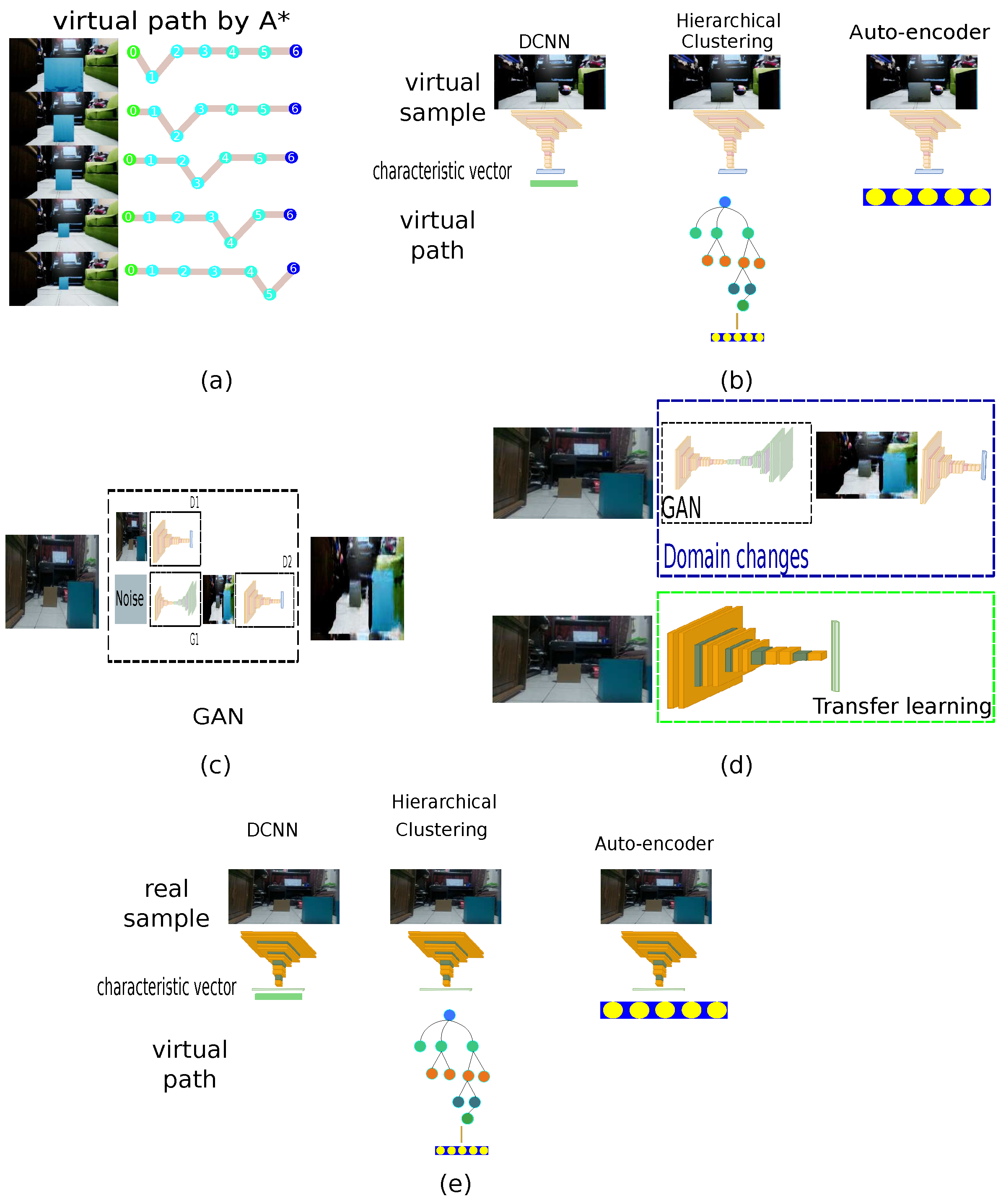
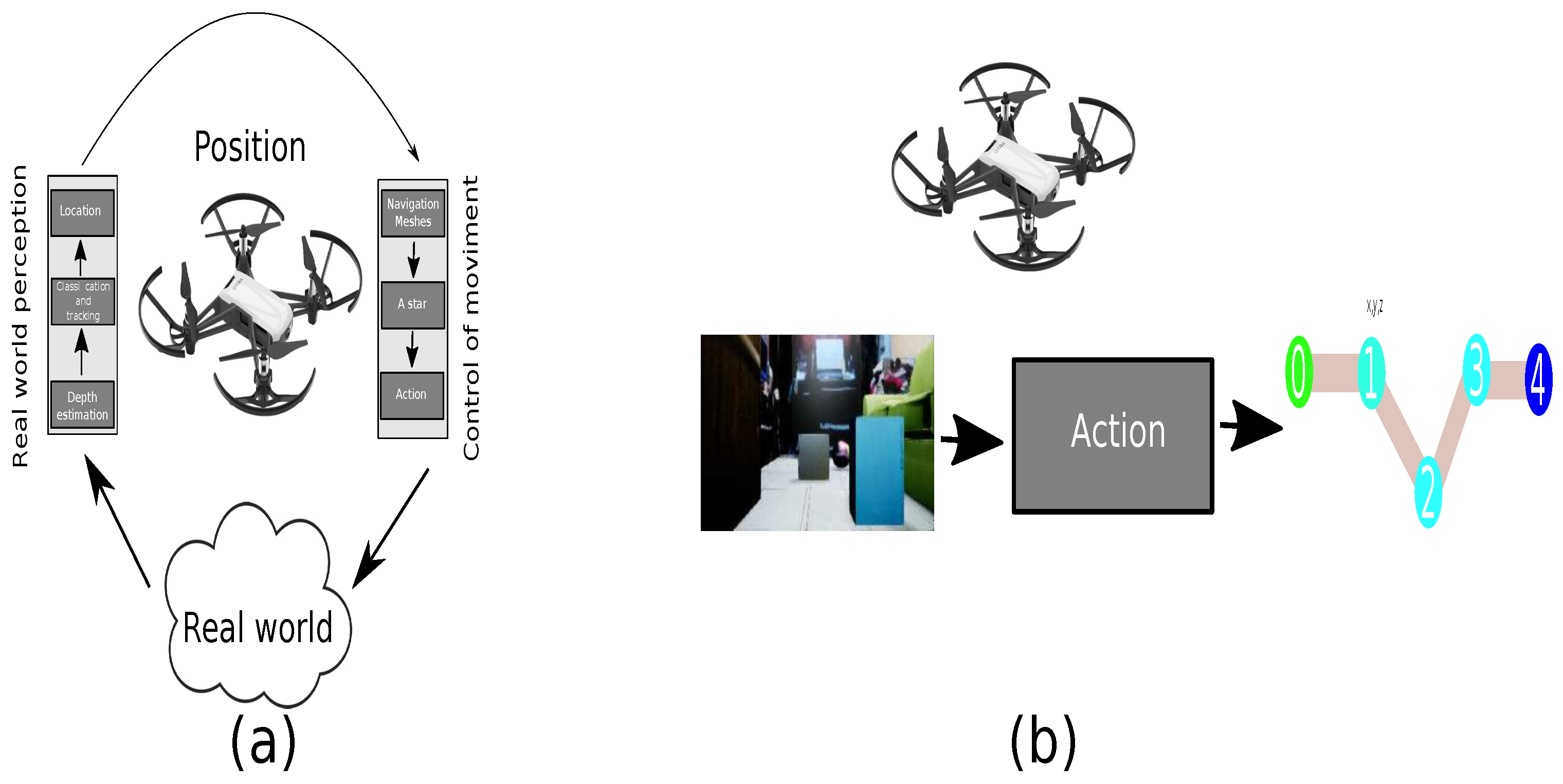
3.3. End-to-End Implementation
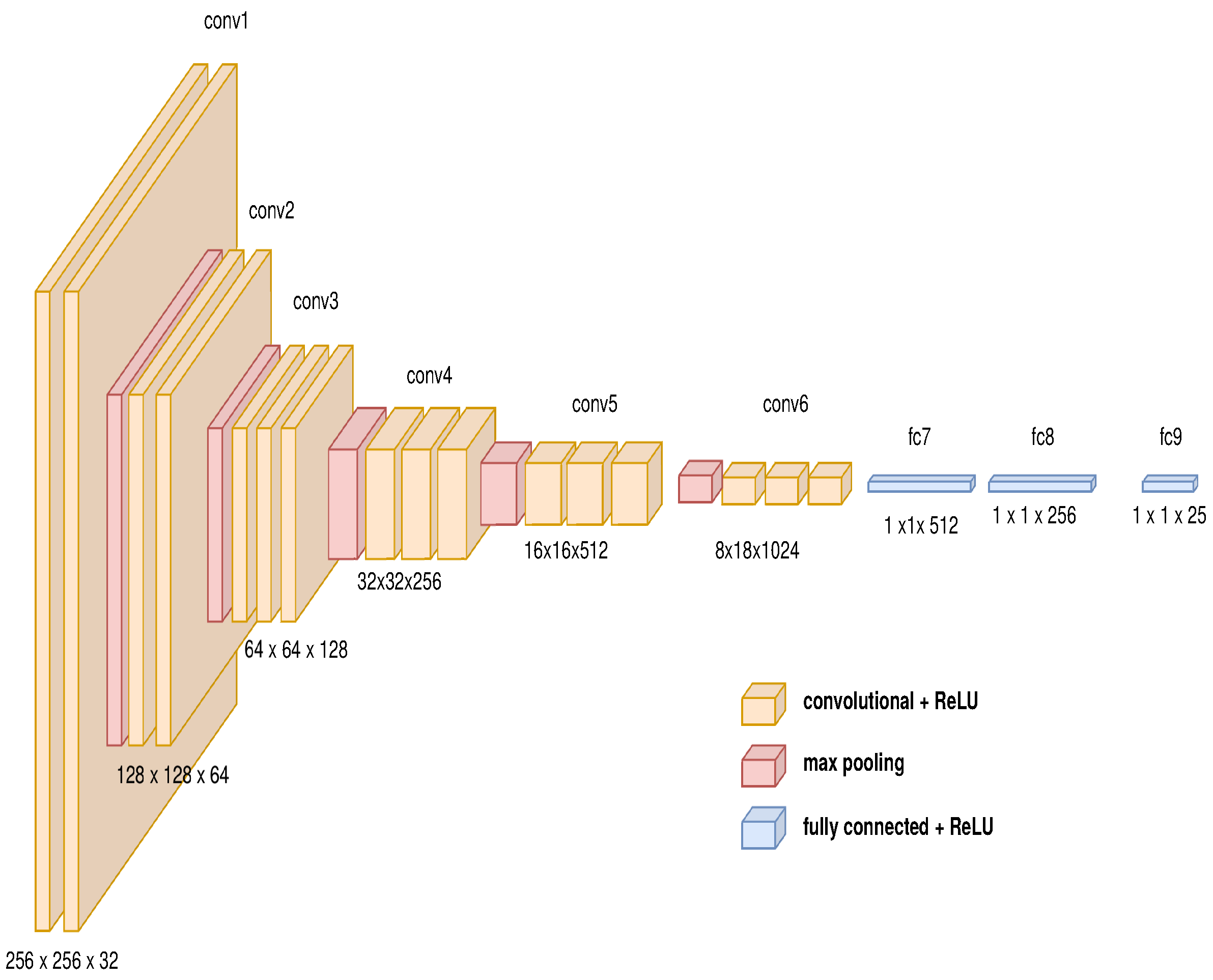
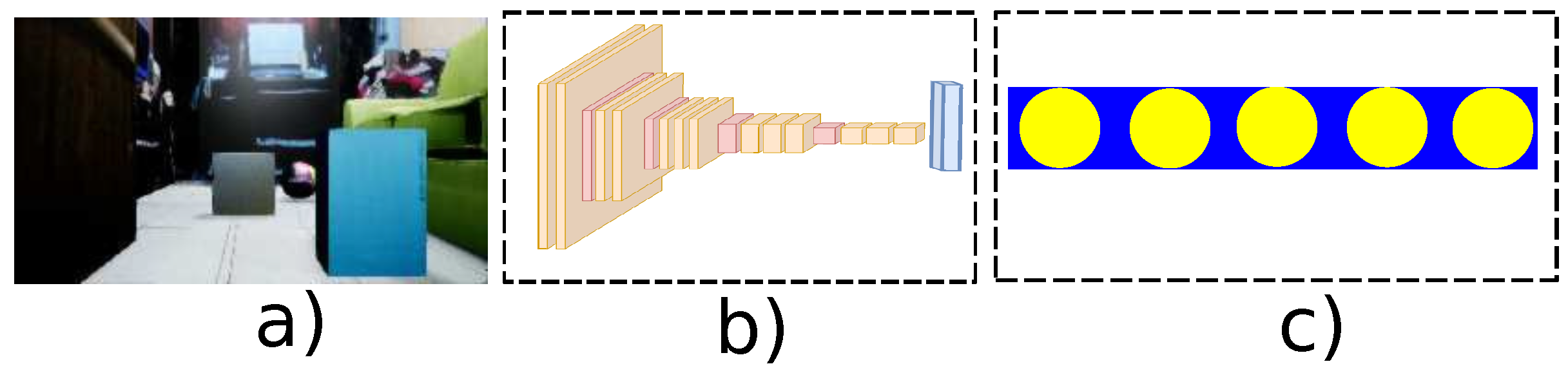
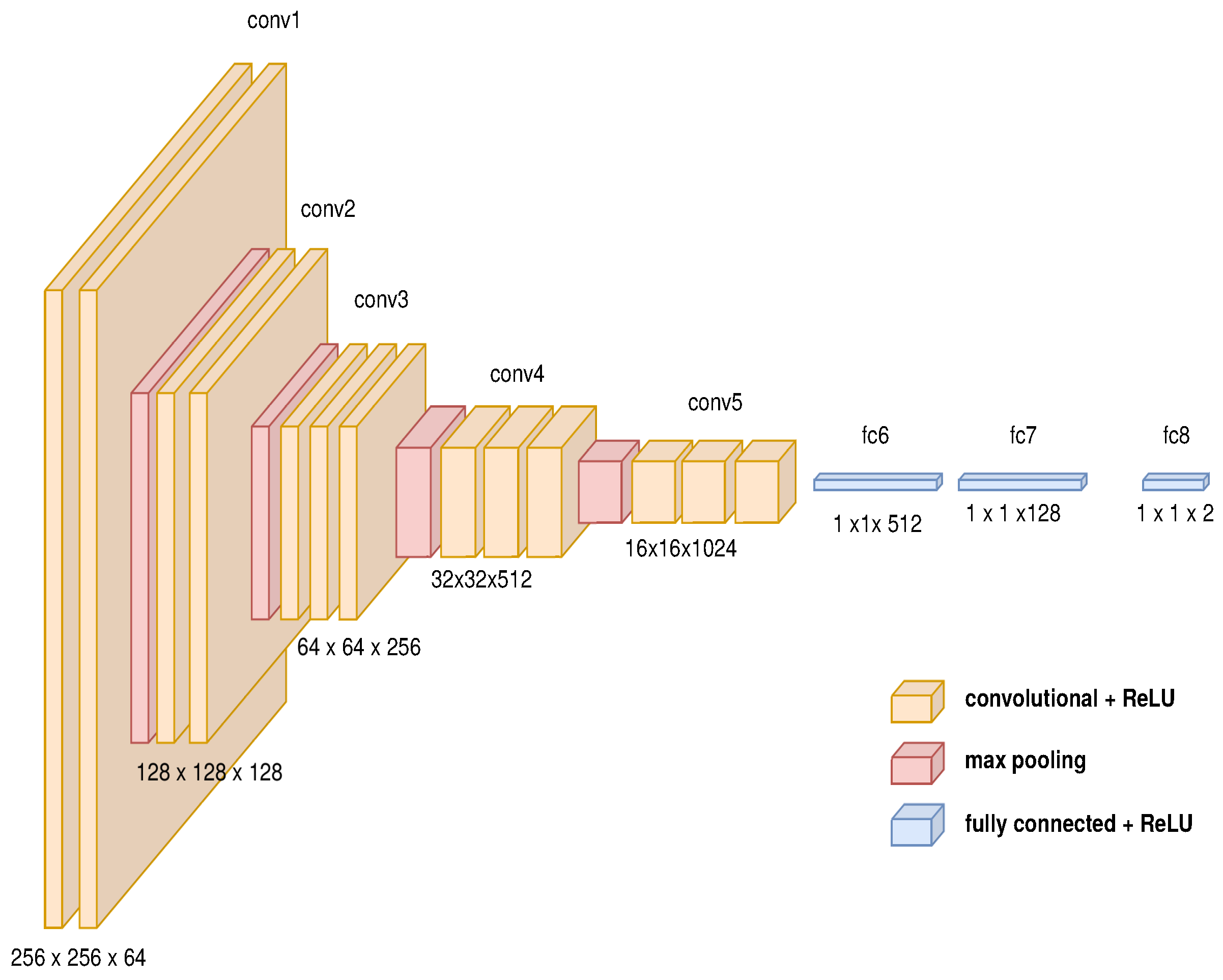
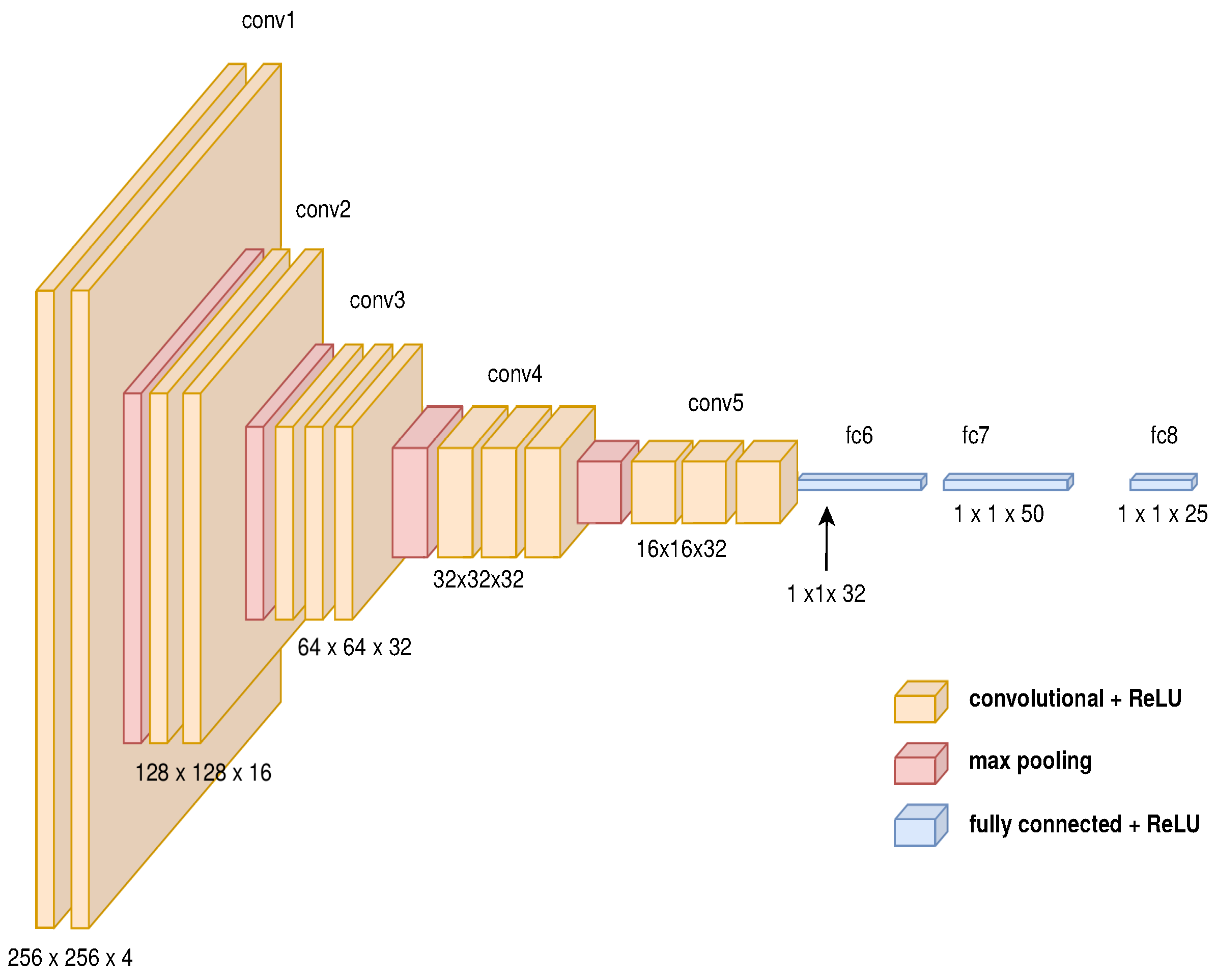
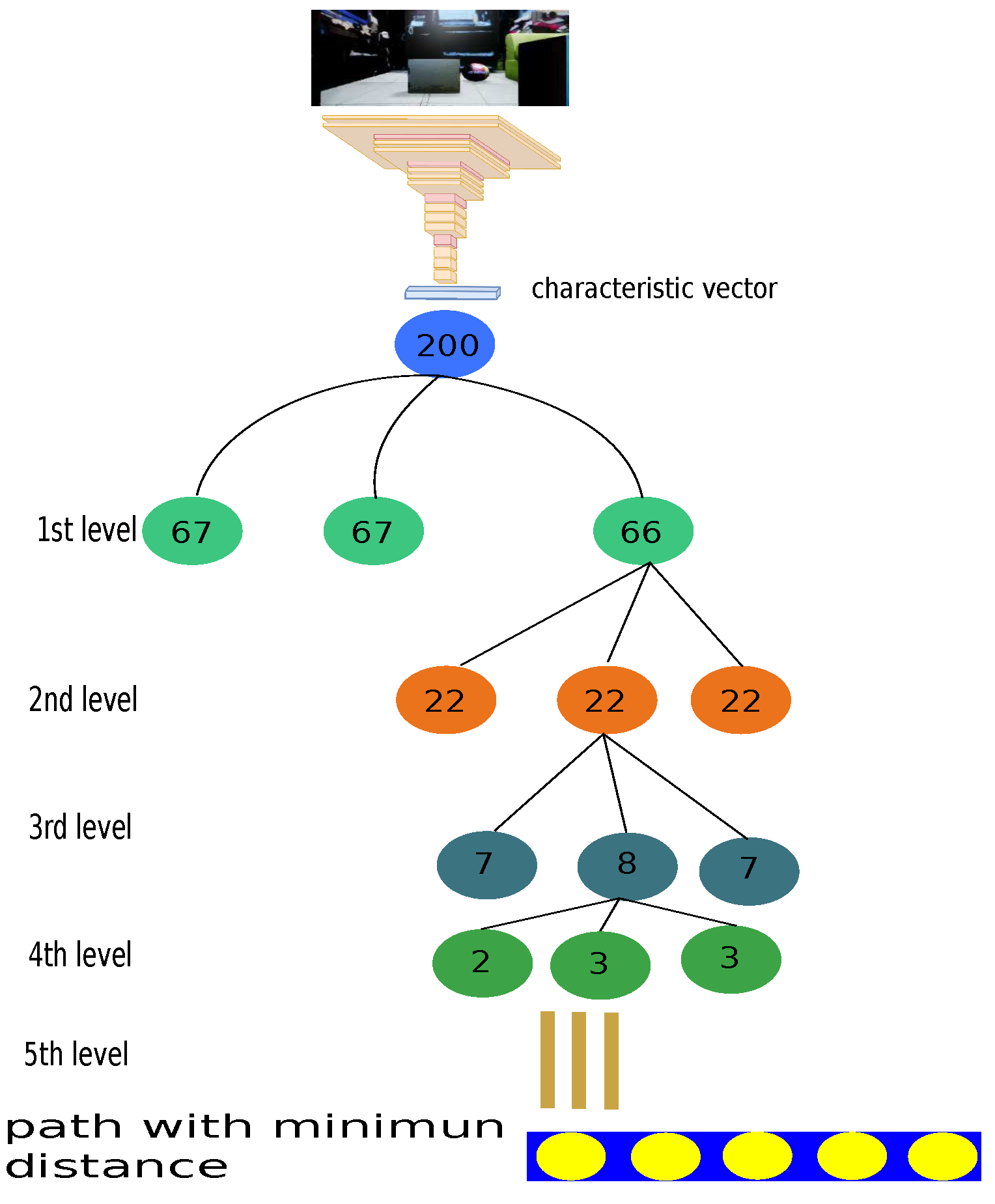
3.3.1. Image to Path: Deep Convolutional Neuronal Network
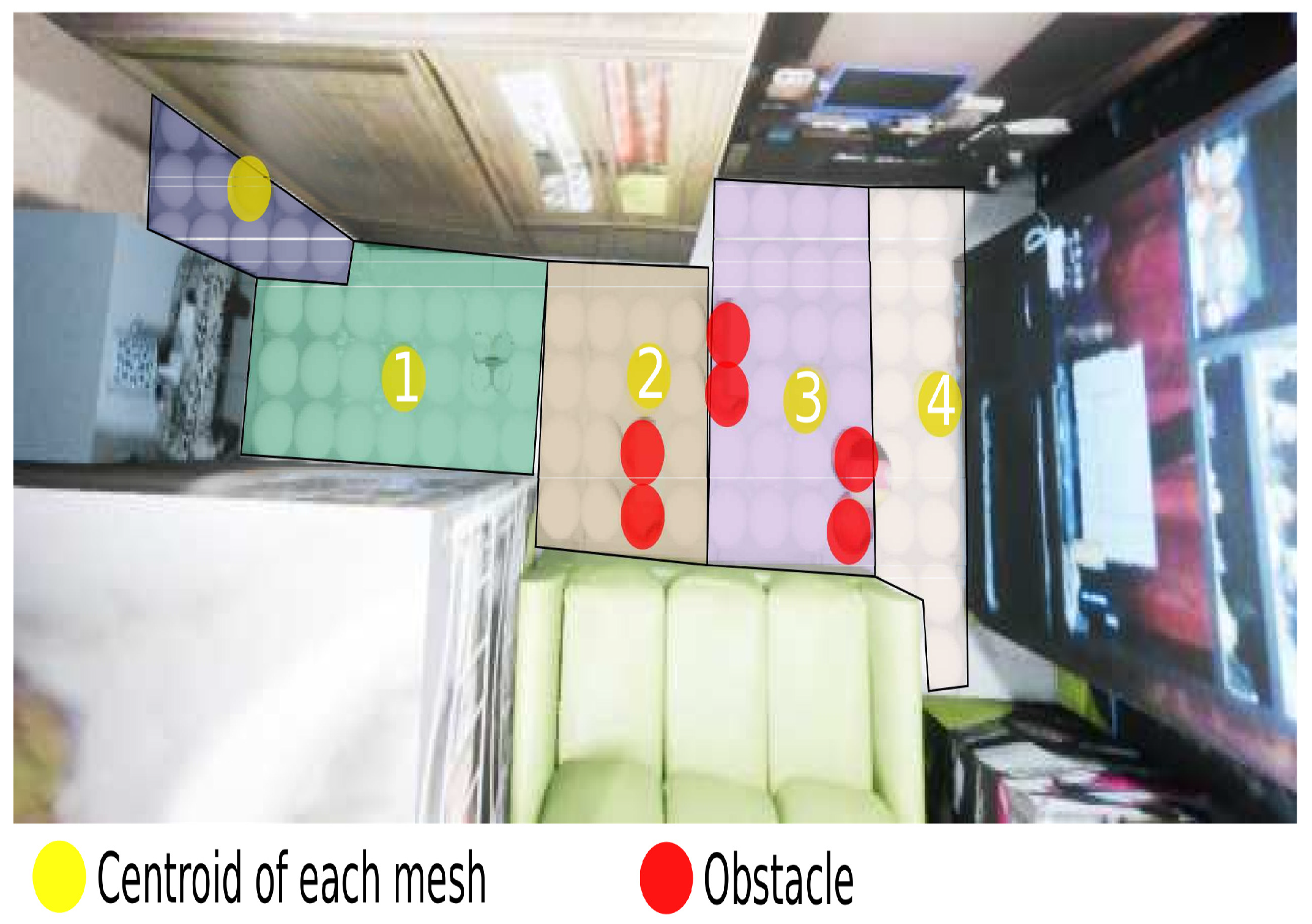
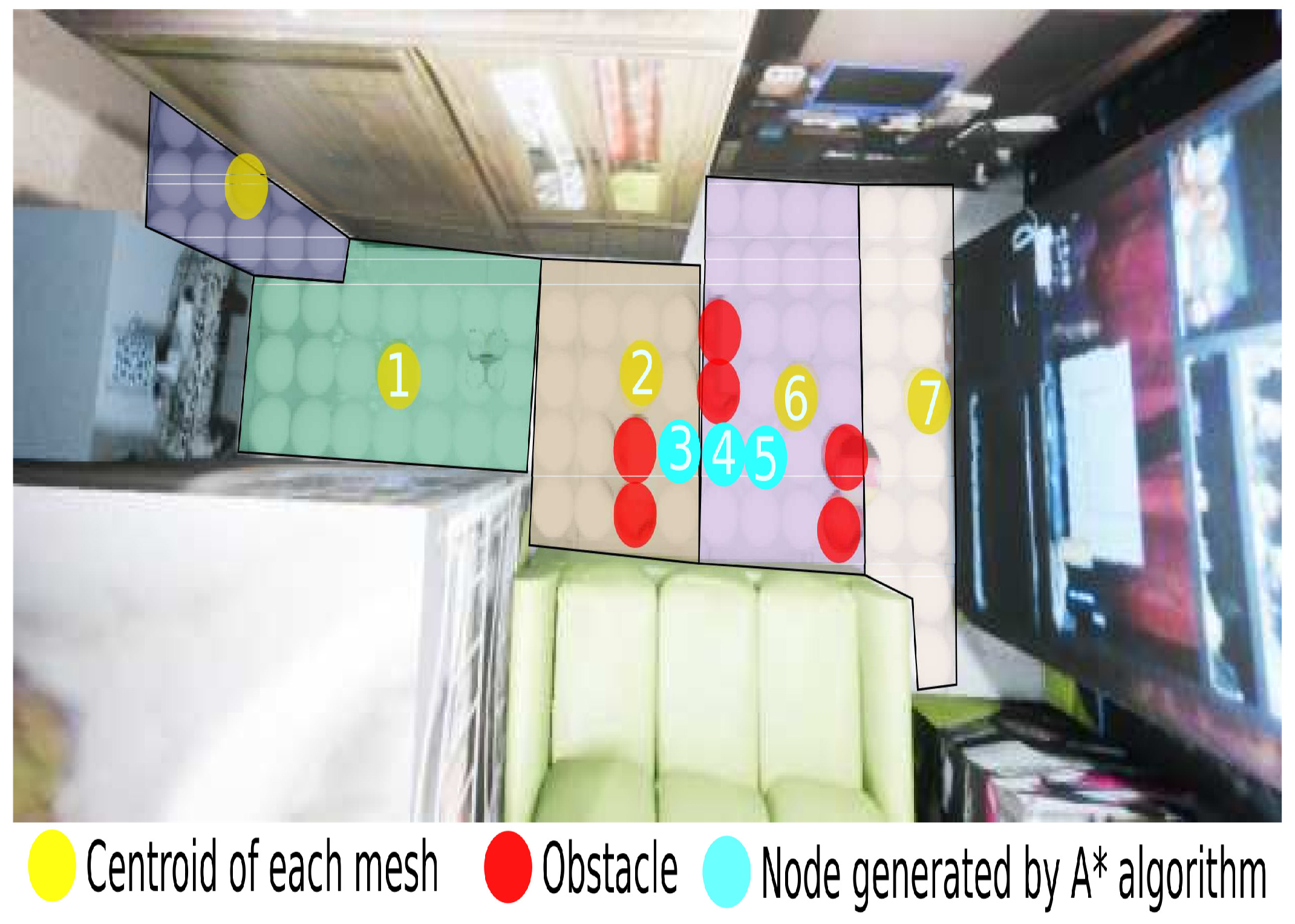
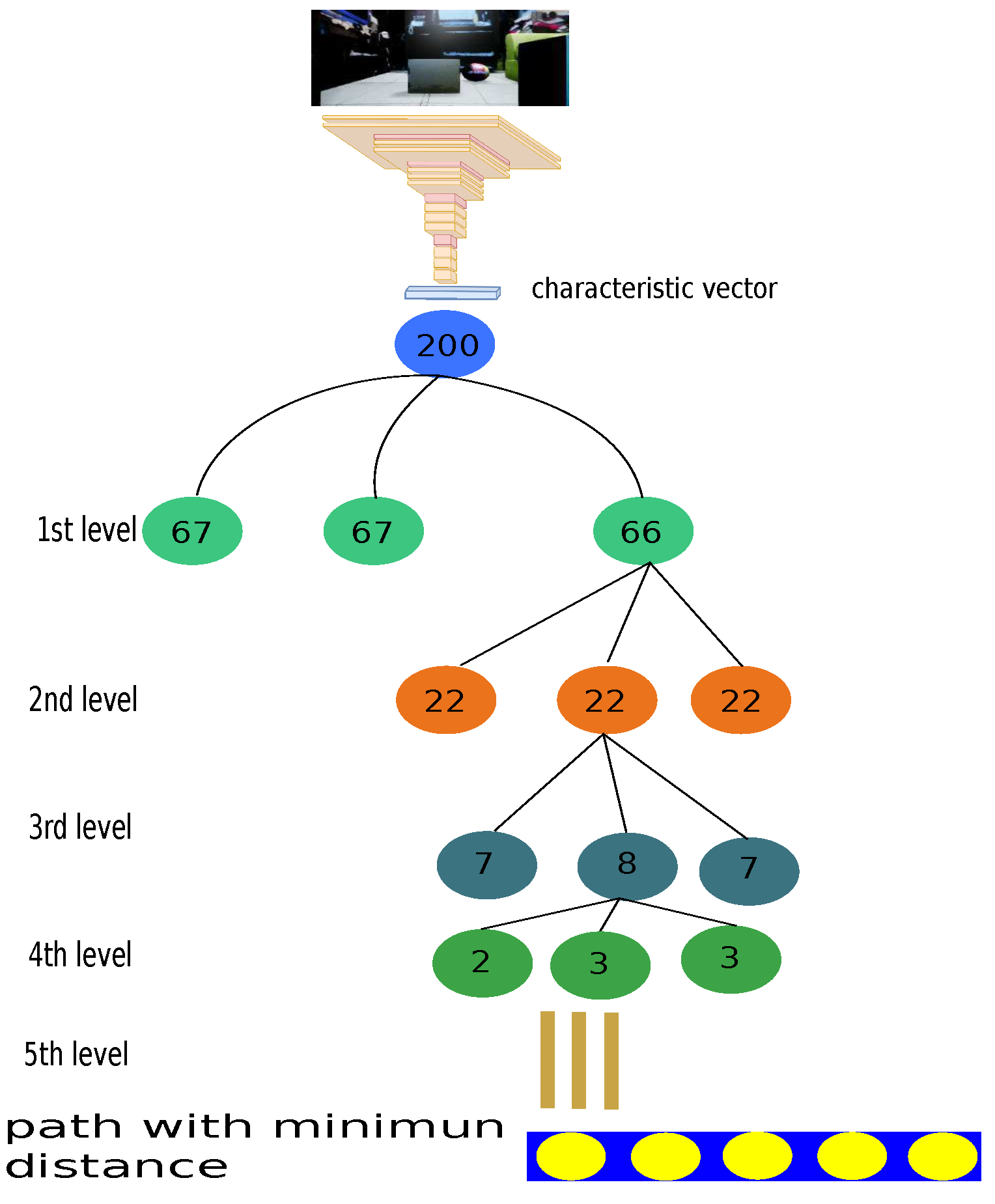
3.3.2. Image to Path: Hierarchical Clustering
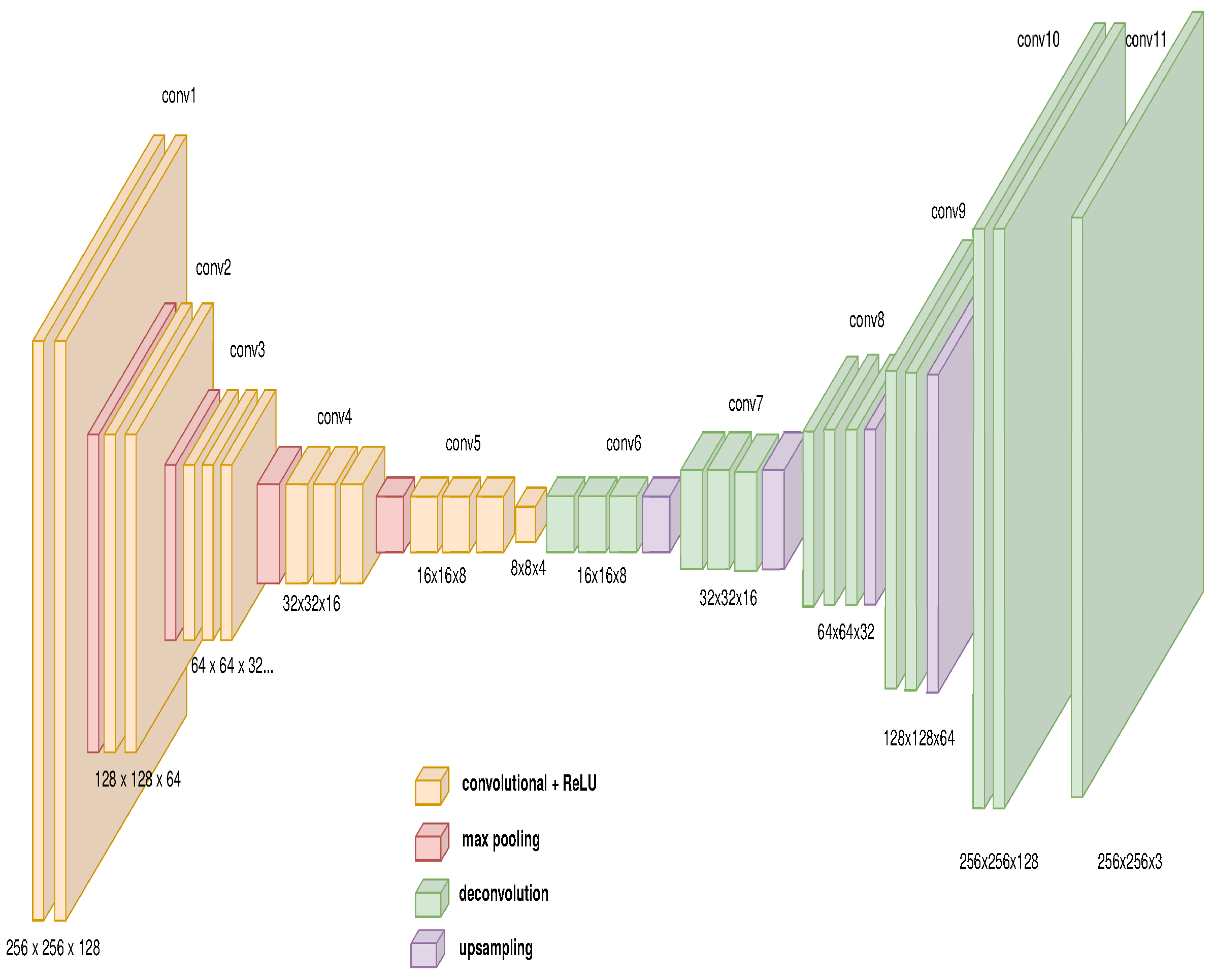
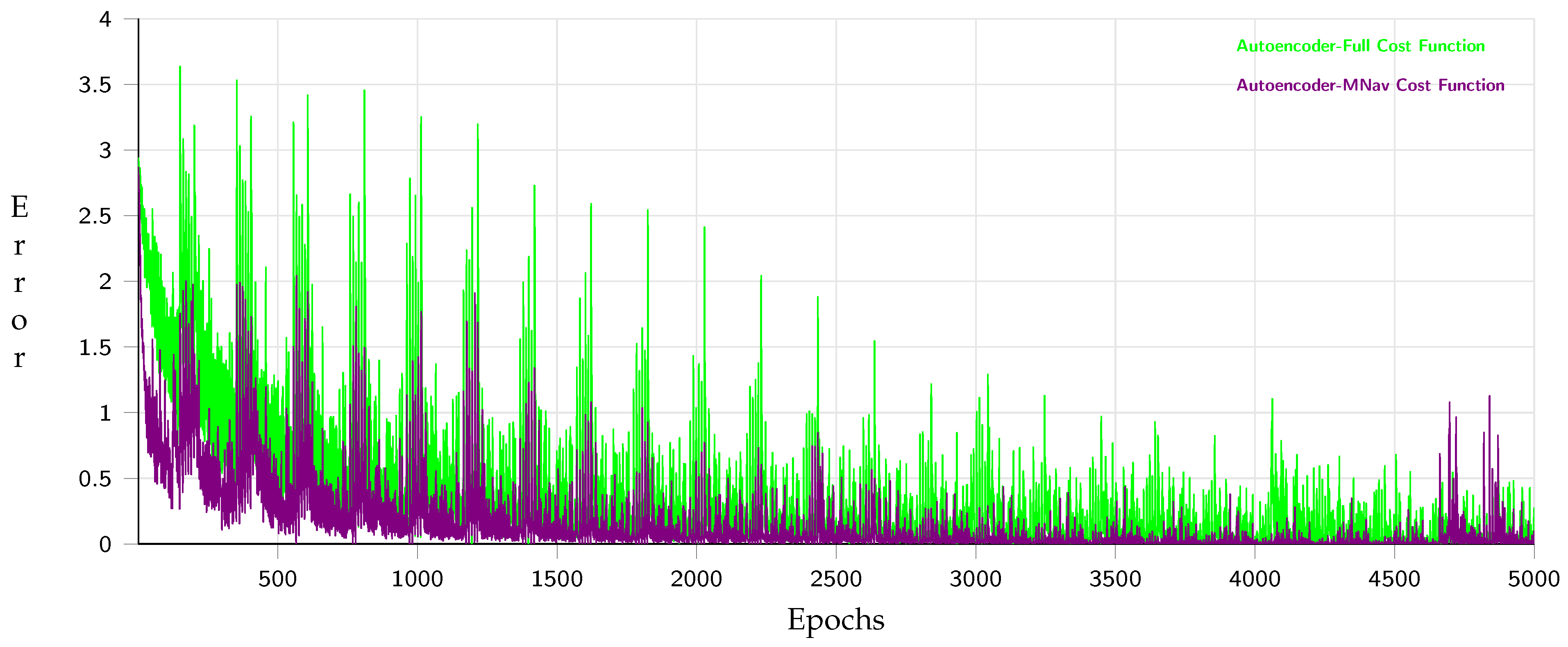
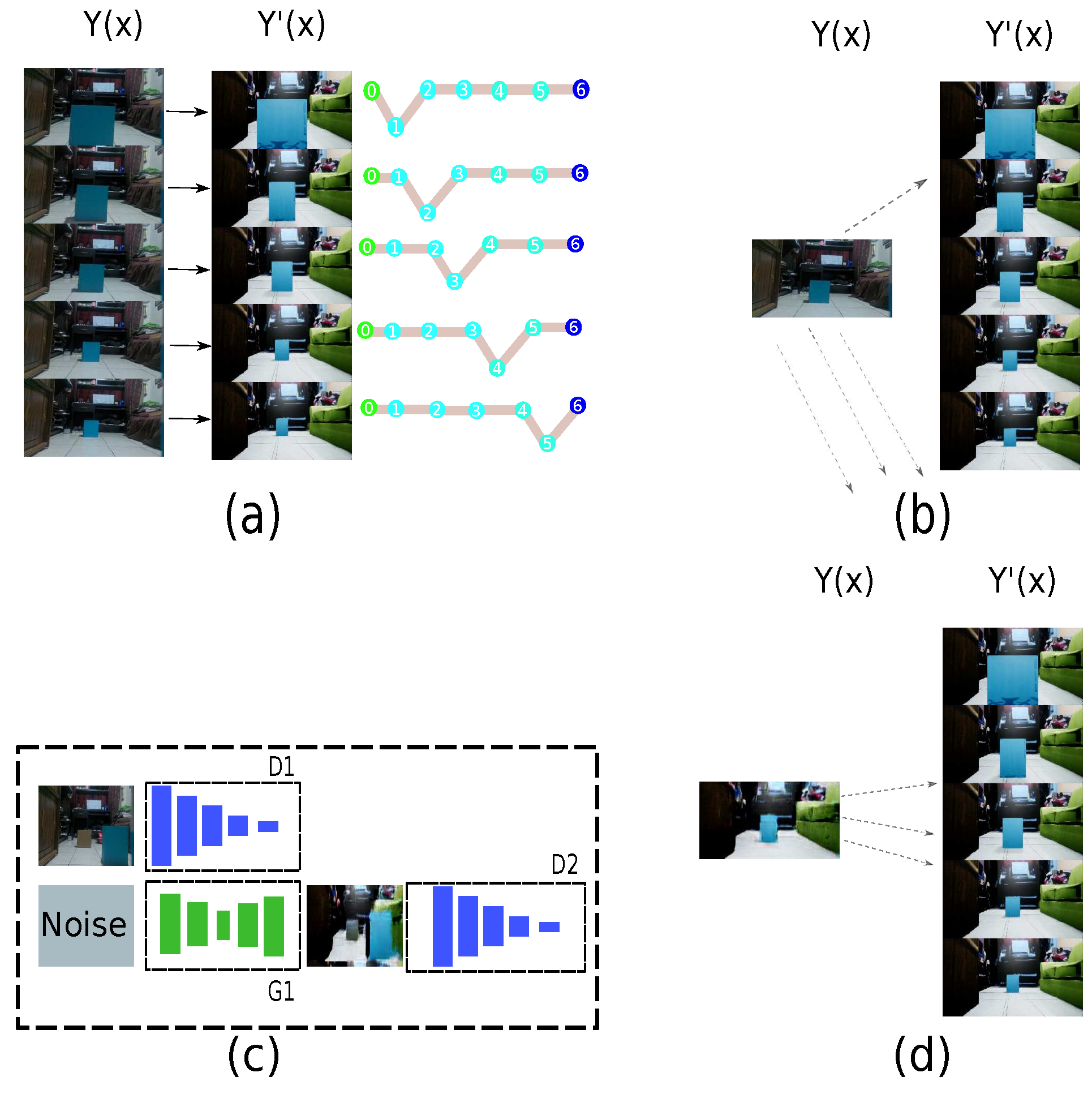
3.3.3. Image to Path: Auto-Encoder
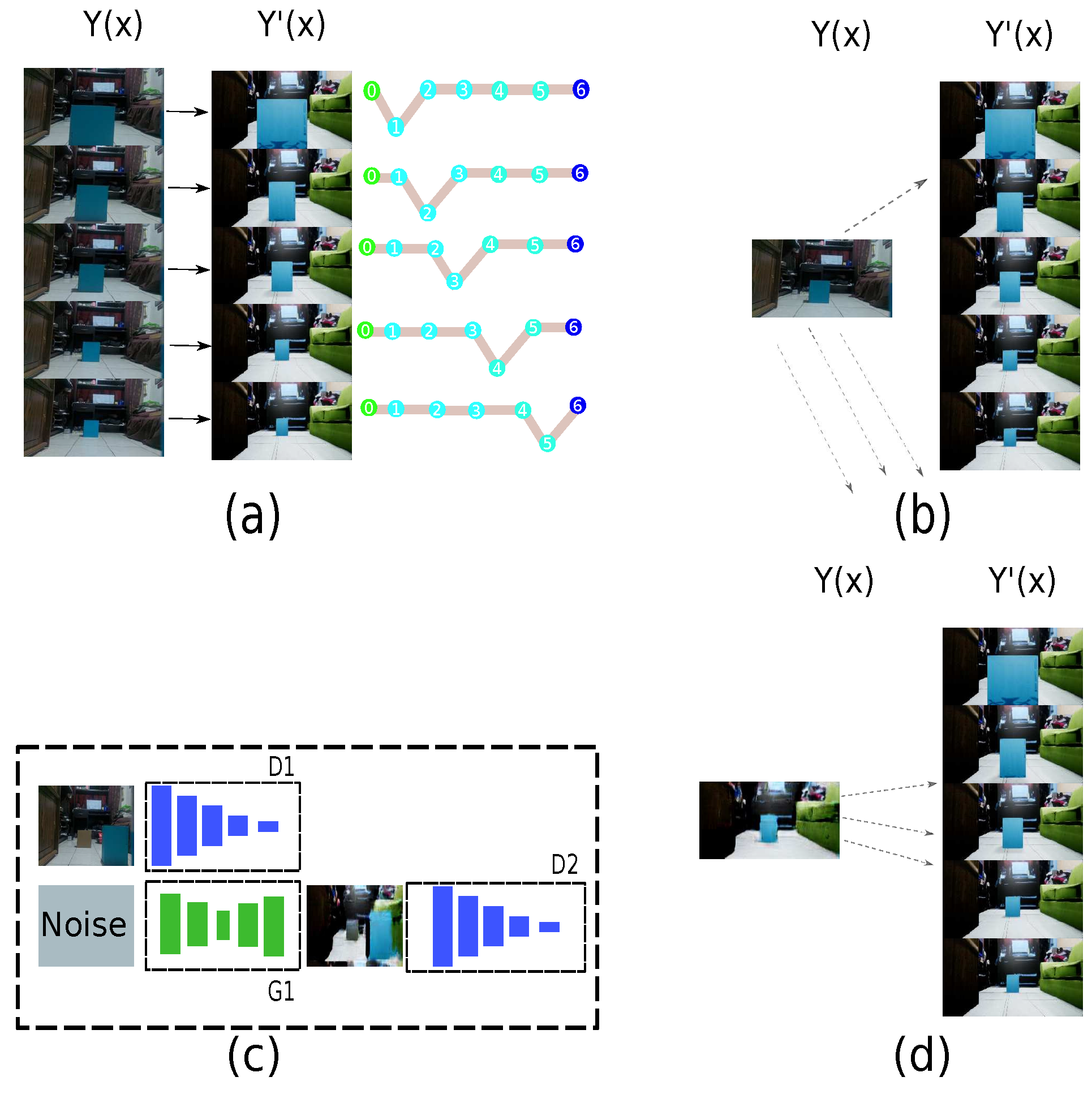
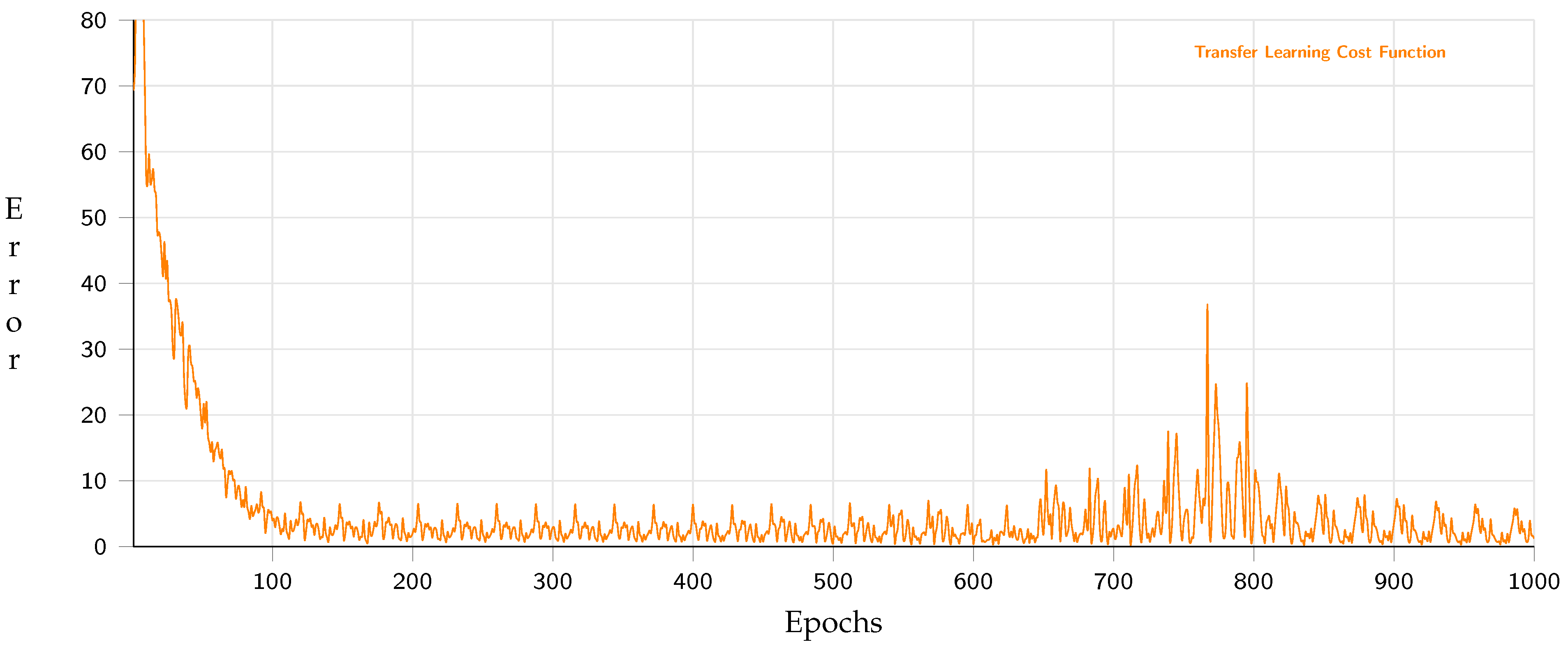
3.4. Strategy to Connect an Authentic Environment with Its Virtual Representation
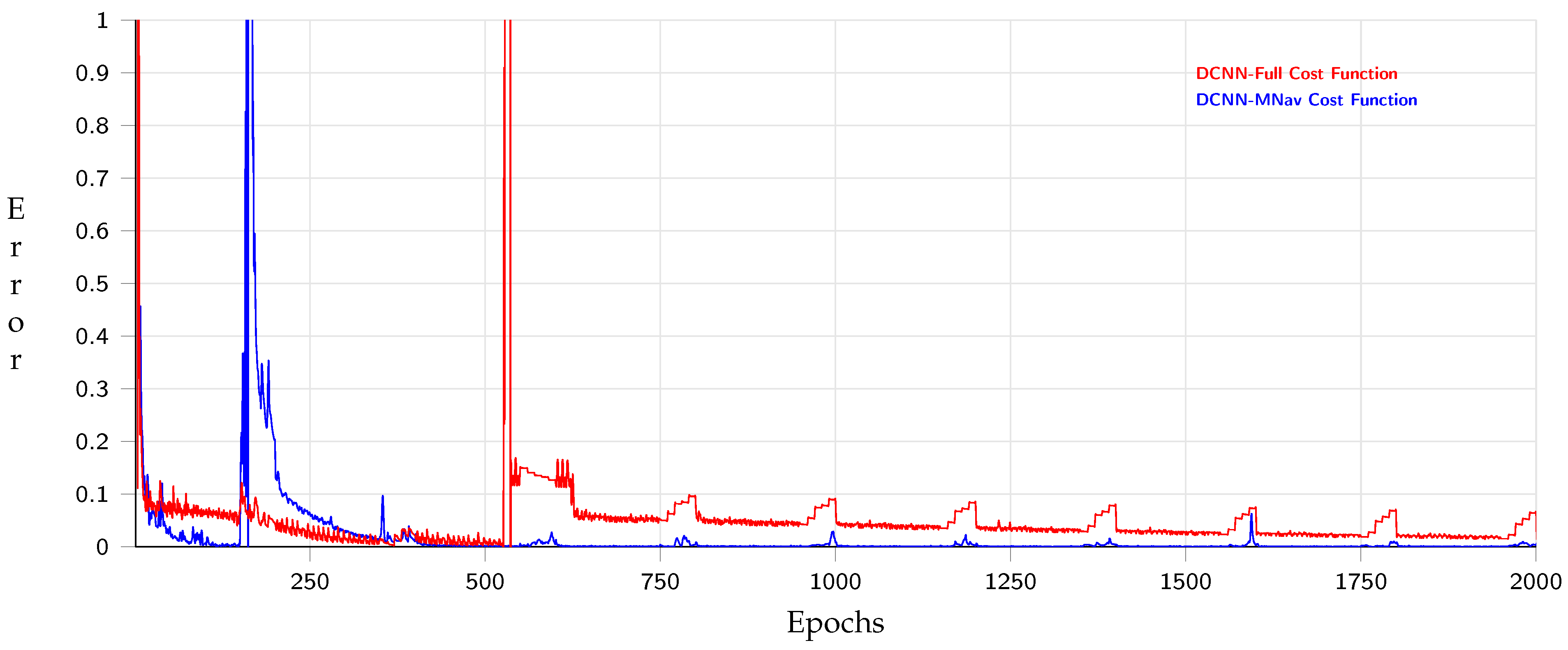
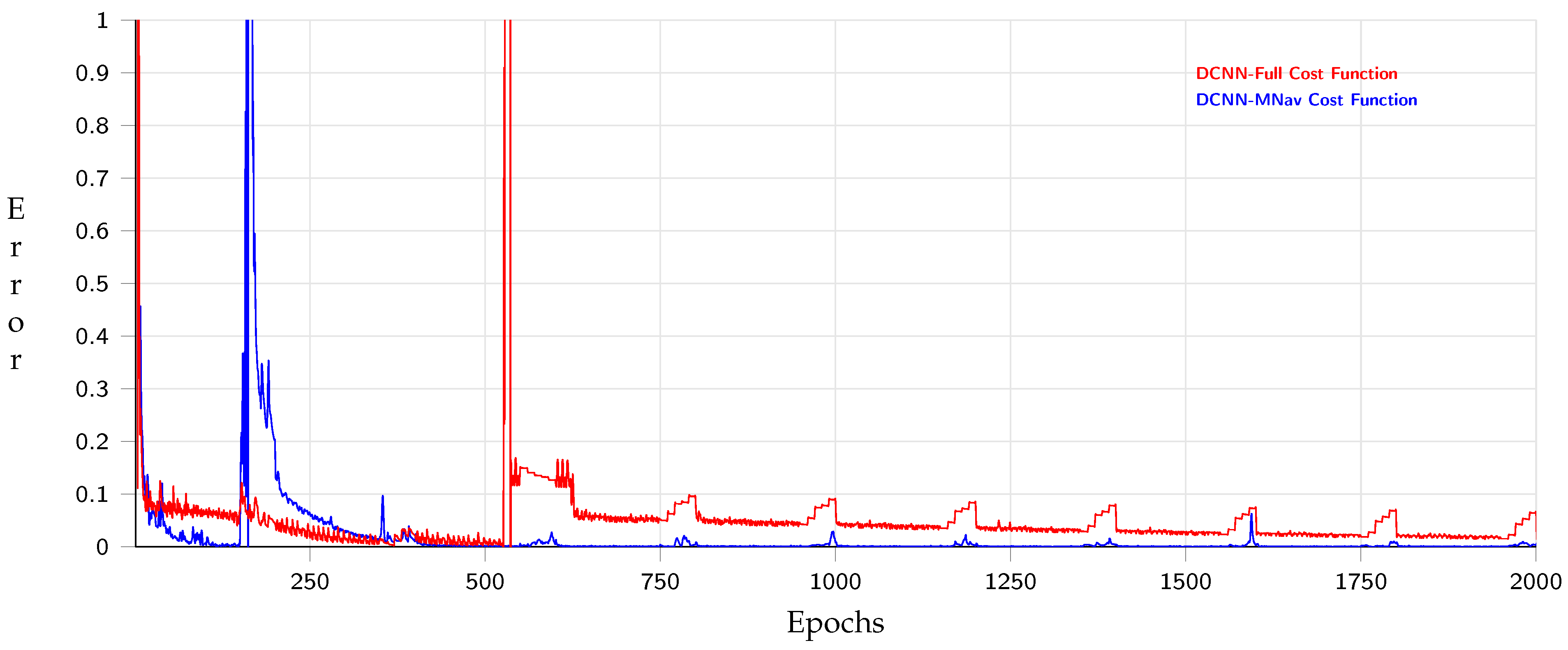
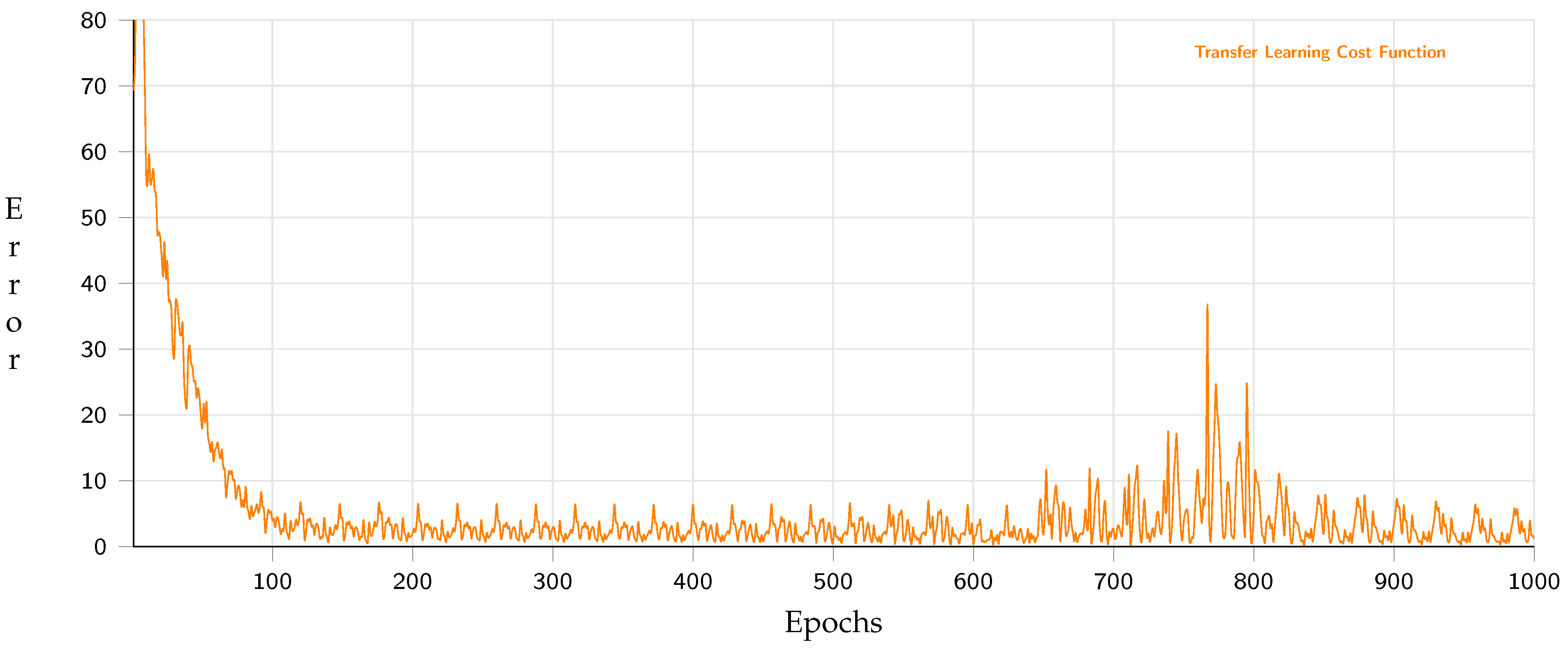
4. Experimental Phase and Analysis
- Average relative error (rel): ;
- Root mean-squared error (rms): ;
- Average () error: ;
- Threshold accuracy (): % of s.t. max() = thr for thr = ;
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Lighthill, I. Artificial Intelligence: A General Survey; Artificial Intelligence: A Paper Symposium; Science Research Council: London, UK, 1973. [Google Scholar]
- Althoefer, I.K.; Konstantinova, J.; Zhang, K. (Eds.) Towards Autonomous Robotic Systems; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, X.; Xiong, H.; Li, H.; Dai, L.; Chen, J.; Xing, J.; Chen, J.; Wu, X.; Hu, W.; et al. Towards human-like and transhuman perception in AI 2.0: A review. Front. Inf. Technol. Electron. Eng. 2017, 18, 58–67. [Google Scholar] [CrossRef]
- Alenazi, M.; Niu, N.; Wang, W.; Gupta, A. Traceability for Automated Production Systems: A Position Paper. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; pp. 51–55. [Google Scholar]
- Su, Y.-H.; Munawar, A.; Deguet, A.; Lewis, A.; Lindgren, K.; Li, Y.; Taylor, R.H.; Fischer, G.S.; Hannaford, B.; Kazanzides, P. Collaborative Robotics Toolkit (CRTK): Open Software Framework for Surgical Robotics Research. In Proceedings of the 2020 Fourth IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 9–11 November 2020; pp. 48–55. [Google Scholar] [CrossRef]
- Santos, J.; Gilmore, A.N.; Hempel, M.; Sharif, H. Behavior-based robotics programming for a mobile robotics ECE course using the CEENBoT mobile robotics platform. In Proceedings of the 2017 IEEE International Conference on Electro Information Technology (EIT), Lincoln, NE, USA, 14–17 May 2017; pp. 581–586. [Google Scholar] [CrossRef]
- Marko, B.; Prajish, S.; Dario, B.; Heike, V.; Marco, H. Rolling in the Deep–Hybrid Locomotion for Wheeled-Legged Robots Using Online Trajectory Optimization. IEEE Robot. Autom. Lett. 2020, 5, 3626–3633. [Google Scholar] [CrossRef] [Green Version]
- Luneckas, M.; Luneckas, T.; Kriaučiūnas, J.; Udris, D.; Plonis, D.; Damaševičius, R.; Maskeliūnas, R. Hexapod Robot Gait Switching for Energy Consumption and Cost of Transport Management Using Heuristic Algorithms. Appl. Sci. 2021, 11, 1339. [Google Scholar] [CrossRef]
- Luneckas, M.; Luneckas, T.; Udris, D.; Plonis, D.; Maskeliunas, R.; Damasevicius, R. A hybrid tactile sensor-based obstacle overcoming method for hexapod walking robots. Intell. Serv. Robot. 2021, 14, 9–24. [Google Scholar] [CrossRef]
- Zabarankin, M.; Uryasev, S.; Murphey, R. Aircraft routing under the risk of detection. Nav. Res. Logist. 2006, 53, 728–747. [Google Scholar] [CrossRef]
- Xue, Y.; Sun, J.-Q. Solving the Path Planning Problem in Mobile Robotics with the Multi-Objective Evolutionary Algorithm. Appl. Sci. 2018, 8, 1425. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, J.T.; Sharir, M. On the piano movers’ problem: II. General techniques for computing topological properties of real algebraic manifolds. Adv. Appl. Math. 1983, 4, 298351. [Google Scholar] [CrossRef] [Green Version]
- Chabot, D. Trends in drone research and applications as the Journal of Unmanned Vehicle Systems turns five. J. Unmanned Veh. Syst. 2018, 6, vi–xv. [Google Scholar] [CrossRef] [Green Version]
- Tanaka, M. Robust parameter estimation of road condition by Kinect sensor. In Proceedings of the SICE Annual Conference (SICE), Akita, Japan, 18–19 August 2012; pp. 197–202. [Google Scholar]
- Yue, H.; Chen, W.; Wu, X.; Zhang, J. Kinect based real time obstacle detection for legged robots in complex environments. In Proceedings of the 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA), Melbourne, VIC, Australia, 19–21 June 2013; pp. 205–210. [Google Scholar] [CrossRef]
- Chen, J.; Tian, S.; Xu, H.; Yue, R.; Sun, Y.; Cui, Y. Architecture of Vehicle Trajectories Extraction With Roadside LiDAR Serving Connected Vehicles. IEEE Access 2019, 7, 100406–100415. [Google Scholar] [CrossRef]
- Kristian, K.; Edouard, I.; Hrvoje, G. Computer Vision Systems in Road Vehicles: A Review. arXiv 2013, arXiv:1310.0315. [Google Scholar]
- Wang, T.; Wu, D.J.; Coates, A.; Ng, A.Y. End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3304–3308. [Google Scholar]
- Warakagoda, N.; Dirdal, J.; Faxvaag, E. Fusion of LiDAR and Camera Images in End-to-end Deep Learning for Steering an Off-road Unmanned Ground Vehicle. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Wu, T.; Luo, A.; Huang, R.; Cheng, H.; Zhao, Y. End-to-End Driving Model for Steering Control of Autonomous Vehicles with Future Spatiotemporal Features. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 950–955. [Google Scholar] [CrossRef]
- Wang, J.K.; Ding, X.Q.; Xia, H.; Wang, Y.; Tang, L.; Xiong, R. A LiDAR based end to end controller for robot navigation using deep neural network. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 614–619. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, J.; Tian, R.; Zhang, Y. End-to-End Autonomous Driving Decision Based on Deep Reinforcement Learning. In Proceedings of the 2019 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; pp. 658–662. [Google Scholar] [CrossRef]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Jung, T.; Dieck, M.C.T.; Rauschnabel, P.A. (Eds.) Augmented Reality and Virtual Reality. In Progress in IS; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Huang, J.Y.; Hughes, N.J.; Goodhill, G.J. Segmenting Neuronal Growth Cones Using Deep Convolutional Neural Networks. In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Wenchao, L.; Yong, Z.; Shixiong, X. A Novel Clustering Algorithm Based on Hierarchical and K-means Clustering. In Proceedings of the 2007 Chinese Control Conference, Wuhan, China, 26–31 July 2007; pp. 605–609. [Google Scholar] [CrossRef]
- Cui, Q.; Pu, P.; Chen, L.; Zhao, W.; Liu, Y. Deep Convolutional Encoder-Decoder Architecture for Neuronal Structure Segmentation. In Proceedings of the 2018 International Conference on Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO), Prague, Czech Republic, 19–21 May 2018; pp. 242–247. [Google Scholar] [CrossRef]
- Shao, L.; Zhu, F.; Li, X. Transfer Learning for Visual Categorization: A Survey. IEEE Trans. Neural Networks Learn. Syst. 2015, 26, 1019–1034. [Google Scholar] [CrossRef]
- Si, J.; Yang, L.; Lu, C.; Sun, J.; Mei, S. Approximate dynamic programming for continuous state and control problems. In Proceedings of the 2009 17th Mediterranean Conference on Control and Automation, Thessaloniki, Greece, 24–26 June 2009; pp. 1415–1420. [Google Scholar] [CrossRef]
- Jiao, J.; Liu, S.; Deng, H.; Lai, Y.; Li, F.; Mei, T.; Huang, H. Design and Fabrication of Long Soft-Robotic Elastomeric Actuator Inspired by Octopus Arm. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 2826–2832. [Google Scholar] [CrossRef]
- Spiteri, R.J.; Ascher, U.M.; Pai, D.K. Numerical solution of differential systems with algebraic inequalities arising in robot programming. In Proceedings of the 1995 IEEE International Conference on Robotics and Automation, Nagoya, Japan, 21–27 May 1995; Volume 3, pp. 2373–2380. [Google Scholar] [CrossRef]
- Karaman, S.; Frazzoli, E. Incremental sampling-based algorithms for optimal motion planning. arXiv 2021, arXiv:1005.0416. [Google Scholar]
- Musliman, I.A.; Rahman, A.A.; Coors, V. Implementing 3D network analysis in 3D-GIS. Int. Arch. ISPRS 2008, 37. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.640.7225&rep=rep1&type=pdf (accessed on 25 August 2021).
- Pehlivanoglu, Y.V.; Baysal, O.; Hacioglu, A. Path planning for autonomous UAV via vibrational genetic algorithm. Aircr. Eng. Aerosp. Technol. Int. J. 2007, 79, 352–359. [Google Scholar] [CrossRef]
- Ma, L.; Cheng, S.; Shi, Y. Enhancing Learning Efficiency of Brain Storm Optimization via Orthogonal Learning Design. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 6723–6742. [Google Scholar] [CrossRef]
- Chen, L.-W.; Liu, J.-X. Time-Efficient Indoor Navigation and Evacuation With Fastest Path Planning Based on Internet of Things Technologies. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 3125–3135. [Google Scholar] [CrossRef]
- Epstein, S.L.; Korpan, R. Metareasoning and Path Planning for Autonomous Indoor Navigation. In Proceedings of the ICAPS 2020 Workshop on Integrated Execution (IntEx)/Goal Reasoning (GR), Online, 19–30 October 2020. [Google Scholar]
- Shital, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. arXiv 2017, arXiv:1705.05065. [Google Scholar]
- Yan, F.; Liu, Y.S.; Xiao, J.Z. Path planning in complex 3D environments using a probabilistic roadmap method. Int. J. Autom. Comput. 2013, 10, 525–533. [Google Scholar] [CrossRef]
- Kajdocsi, L.; Kovács, J.; Pozna, C.R. A great potential for using mesh networks in indoor navigation. In Proceedings of the 2016 IEEE 14th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 29–31 August 2016; pp. 187–192. [Google Scholar] [CrossRef]
- Guo, X.; Du, W.; Qi, R.; Qian, F. Minimum time dynamic optimization using double-layer optimization algorithm. In Proceedings of the 10th World Congress on Intelligent Control and Automation, Beijing, China, 6–8 July 2012; pp. 84–88. [Google Scholar] [CrossRef]
- Wan, H. Deep Learning:Neural Network, Optimizing Method and Libraries Review. In Proceedings of the 2019 International Conference on Robots & Intelligent System (ICRIS), Haikou, China, 15–16 June 2019; pp. 497–500. [Google Scholar] [CrossRef]
- Ajit, A.; Acharya, K.; Samanta, A. A Review of Convolutional Neural Networks. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. RETRACTED ARTICLE: Feature selection for machine learning classification problems: A recent overview. Artif. Intell. Rev. 2011, 42, 157. [Google Scholar] [CrossRef] [Green Version]
- Veena, K.M.; Manjula Shenoy, K.; Ajitha Shenoy, K.B. Performance Comparison of Machine Learning Classification Algorithms. In Communications in Computer and Information Science; Springer: Singapore, 2018; pp. 489–497. [Google Scholar] [CrossRef]
- Wollsen, M.G.; Hallam, J.; Jorgensen, B.N. Novel Automatic Filter-Class Feature Selection for Machine Learning Regression. In Advances in Big Data; Springer: Berlin/Heidelberg, Germany, 2016; pp. 71–80. [Google Scholar] [CrossRef]
- Garcia-Gutierrez, J.; Martínez-Álvarez, F.; Troncoso, A.; Riquelme, J.C. A Comparative Study of Machine Learning Regression Methods on LiDAR Data: A Case Study. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 249–258. [Google Scholar] [CrossRef] [Green Version]
- Jebara, T. Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar] [CrossRef]
- Marinescu, D.C.; Marinescu, G.M. (Eds.) CHAPTER 3-Classical and Quantum Information Theory. In Classical and Quantum Information; Academic Press: Cambridge, MA, USA, 2012; pp. 221–344. ISBN 9780123838742. [Google Scholar] [CrossRef]
- El-Kaddoury, M.; Mahmoudi, A.; Himmi, M.M. Deep Generative Models for Image Generation: A Practical Comparison Between Variational Autoencoders and Generative Adversarial Networks. In Mobile, Secure, and Programmable Networking; MSPN 2019. Lecture Notes in Computer Science; Renault, É., Boumerdassi, S., Leghris, C., Bouzefrane, S., Eds.; Springer: Cham, Switzerland, 2019; Volume 11557. [Google Scholar] [CrossRef]
- Press, O.; Bar, A.; Bogin, B.; Berant, J.; Wolf, L. Language generation with recurrent generative adversarial networks without pre-training. arXiv 2017, arXiv:1706.01399. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. SeqGAN: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI 2017, San Francisco, CA, USA, 4–9 February 2017; pp. 2852–2858. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Weng, R.; Lu, J.; Tan, Y.; Zhou, J. Learning Cascaded Deep Auto-Encoder Networks for Face Alignment. IEEE Trans. Multimedia 2016, 18, 2066–2078. [Google Scholar] [CrossRef]
- Correction to A Review of the Autoencoder and Its Variants. IEEE Geosci. Remote. Sens. Mag. 2018, 6, 92. [CrossRef]
- Poghosyan, A.; Sarukhanyan, H. Short-term memory with read-only unit in neural image caption generator. In Proceedings of the 2017 Computer Science and Information Technologies (CSIT), Yerevan, Armenia, 25–29 September 2017; pp. 162–167. [Google Scholar] [CrossRef]
- Ibraheem, A.; Peter, W. High Quality Monocular Depth Estimation via Transfer Learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Handa, A. Real-Time Camera Tracking: When is High Frame-Rate Best? In Computer Vision-ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 222–235. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simple Environment Virtual vs. Real | Environment with Lights and Materials Virtual vs. Real | |
|---|---|---|
| Factor Correlation (mean) | 0.3708 | 0.5490 |
| Factor Correlation (std) | 0.0824 | 0.0755 |
| Number of Samples | Joint Entropy | Interoperability Coefficient |
|---|---|---|
| 10 | 0.5894 | 0.1985 |
| 20 | 0.2567 | 0.2935 |
| 30 | 0.1564 | 0.4465 |
| 43 | 0.0957 | 0.5047 |
| Model | rel-std ↓ | rms-std ↓ | -std ↓ | -std ↑ | -std ↑ | -std ↑ |
|---|---|---|---|---|---|---|
| GAN | 0.9481–0.5614 | 0.9418–0.2469 | 0.3479–0.0722 | 0.6767–0.0235 | 0.7925–0.0278 | 0.8491–0.0282 |
| GAN-Noise | 0.1693–0.2068 | 0.3862–0.1420 | 0.2392–0.0832 | 0.8538–0.0592 | 0.9334–0.0463 | 0.9624–0.0367 |
| Model | Accuracy Euclidean Distance (mean-std) ↓ | Accuracy Manhattan Distance (mean-std) ↓ | Accuracy Cosine Similarity (mean-std) ↓ | Coefficient Free Collision ↑ |
|---|---|---|---|---|
| DCNN-one2one | 53.8667 ± 3.9055 | 128.8 ± 14.5931 | 0.7069 ± 0.0586 | 0.02 |
| DCNN-Full | 22.6847 ± 3.5832 | 86.7401 ± 6.5722 | 0.8996 ± 0.03491 | 0.66 |
| DCNN-MNav | 8.4568 ± 1.5475 | 22.1415 ± 4.2568 | 0.91454 ± 0.0355 | 0.84 |
| HC-one2one | 15.1254 ± 2.4585 | 32.1346 ± 3.1354 | 0.8745 ± 0.02499 | 0.82 |
| HC-Full | 10.1411 ± 4.2164 | 24.2668 ± 3.1465 | 0.9224 ± 0.02587 | 0.92 |
| HC-MNav | 4.2145 ± 1.2441 | 9.2154 ± 1.8795 | 0.9952 ± 0.001256 | 0.96 |
| AED-one2one | 41.6589 ± 2.6425 | 130.0512 ± 2.9717 | 0.7496 ± 0.2654 | 0.04 |
| AED-Full | 19.6318 ± 2.1653 | 49.7123 ± 9.5722 | 0.9496 ± 0.0211 | 0.82 |
| AED-MNav | 4.7855 ± 2.1412 | 7.6569 ± 3.1336 | 0.98924 ± 0.01989 | 0.92 |
| Model | Size of Word | Accuracy Euclidean Distance (mean-std) ↓ | Accuracy Manhattan Distance (mean-std) ↓ | Accuracy Cosine Similarity (mean-std) ↓ | Coefficient Free Collision ↑ |
|---|---|---|---|---|---|
| DCNN-Full | Float16 | 27.9917 ± 2.1647 | 107.1066 ± 7.3813 | 0.9358 ± 0.2028 | 0.68 |
| Float32 | 27.9910 ± 2.1641 | 107.1053 ± 7.3780 | 0.9358 ± 0.2028 | 0.72 | |
| DCNN-MNav | Float16 | 10.1415 ± 1.5896 | 28.7415 ± 2.4785 | 0.9748 ± 0.01811 | 0.76 |
| Float32 | 10.1413 ± 1.5892 | 28.7408 ± 2.4779 | 0.9749 ± 0.01814 | 0.78 | |
| HC-Full | Float16 | 12.6325 ± 1.6896 | 19.1415 ± 3.1415 | 0.9813 ± 0.01258 | 0.92 |
| Float32 | 12.6319 ± 1.6888 | 19.1410 ± 3.1404 | 0.9814 ± 0.01256 | 0.92 | |
| HC-MNav | Float16 | 5.21227 ± 1.9859 | 10.0046 ± 1.0156 | 0.9916 ± 0.0009 | 0.94 |
| Float32 | 5.21223 ± 1.9853 | 10.0038 ± 1.0149 | 0.9916 ± 0.0011 | 0.94 | |
| AED-Full | Float16 | 17.1215 ± 2.4475 | 38.8528 ± 2.2332 | 0.9415 ± 0.0154 | 0.82 |
| Float32 | 17.1208 ± 2.4470 | 38.8520 ± 2.2325 | 0.9416 ± 0.0152 | 0.84 | |
| AED-MNav | Float16 | 4.7485 ± 0.9869 | 7.4415 ± 1.2023 | 0.9814 ± 0.0224 | 0.88 |
| Float32 | 4.7478 ± 0.9862 | 7.4409 ± 1.2018 | 0.9814 ± 0.0224 | 0.88 |
| Device | Float16 (FPS) | Flotat32 (FPS) |
|---|---|---|
| Jetson nano 2G Tensorflow-lite | 11 | 10 |
| Jetson nano 2G Tensor RT | 41 | 10 |
| Android device Moto X4 CPU-4 threads | 14 | 12 |
| Android device Moto X4 GPU | 20 | 16 |
| Android device Moto X4 NN-API | 6 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maldonado-Romo, J.; Aldape-Pérez, M. Interoperability between Real and Virtual Environments Connected by a GAN for the Path-Planning Problem. Appl. Sci. 2021, 11, 10445. https://doi.org/10.3390/app112110445
Maldonado-Romo J, Aldape-Pérez M. Interoperability between Real and Virtual Environments Connected by a GAN for the Path-Planning Problem. Applied Sciences. 2021; 11(21):10445. https://doi.org/10.3390/app112110445
Chicago/Turabian StyleMaldonado-Romo, Javier, and Mario Aldape-Pérez. 2021. "Interoperability between Real and Virtual Environments Connected by a GAN for the Path-Planning Problem" Applied Sciences 11, no. 21: 10445. https://doi.org/10.3390/app112110445
APA StyleMaldonado-Romo, J., & Aldape-Pérez, M. (2021). Interoperability between Real and Virtual Environments Connected by a GAN for the Path-Planning Problem. Applied Sciences, 11(21), 10445. https://doi.org/10.3390/app112110445