Abstract
Electro-hydraulic servo systems are characterized by significant nonlinearities. Reinforcement learning (RL), known for its model-free nature and adaptive learning capabilities, presents a promising approach for handling uncertainties inherent in such systems. This paper proposes a predefined-time tracking control scheme based on RL, which achieves fast and accurate tracking performance. The proposed design employs an actor–critic neural network strategy to actively compensate for system uncertainties. Within a conventional backstepping framework, a command-filtering technique is integrated to construct a predefined-time control structure. This not only circumvents the issue of differential explosion but also guarantees system convergence within a predefined time, which can be specified independently by the designer. Simulation results and comparisons validate the enhanced control performance of the proposed controller.
1. Introduction
Electro-hydraulic servo systems are extensively utilized in defense and various critical industrial sectors owing to their prominent advantages, including high power density, strong load stiffness, and large output force/torque. These systems play a pivotal role in control and power transmission applications [1,2,3,4]. However, their complex dynamics and inherent uncertainties pose significant challenges to further enhancing controller performance. A well-established and powerful paradigm for handling such uncertainties is linear robust control. This approach typically seeks to derive a linear model representation of the system—either through physical model linearization or data-driven identification—and explicitly quantifies the discrepancies between this nominal model and the true nonlinear plant as bounded uncertainties. These uncertainties can be structured or unstructured and frequency-dependent, encompassing unmodeled dynamics, disturbances, and noise. Robust control theories, such as H∞ synthesis, are then employed to design controllers that guarantee stability and performance for all plants within the defined uncertainty set, yielding quantifiable robustness margins [5,6]. For instance, Fallahi et al. [5] modeled linearization errors in an electro-hydraulic servo system as a polytopic uncertainty and designed an H∞ controller via Linear Matrix Inequalities, achieving robust position control. Similarly, Lu et al. [6] addressed parameter uncertainties and load disturbances in a valve-controlled hydraulic motor by formulating them as structured norm-bounded uncertainties and developing a robust H∞ tracking controller. A key practical advantage of this paradigm is the direct synthesis of controllers amenable to stable digital implementation, often with favorable numerical properties. Nonetheless, the effectiveness of these linear robust methods can be constrained when applied to highly nonlinear systems. The conservatism introduced by covering all nonlinear behaviors with a linear uncertainty set may limit achievable performance, especially when strict transient performance is required.
To move beyond these limitations and more directly address or compensate for the system’s inherent nonlinearities, the field of advanced control has evolved toward a variety of nonlinear control strategies developed in recent decades, such as sliding mode control [7] and nonlinear robust control [8,9]. Despite their potential, sliding mode control employs high-gain switching feedback to achieve robustness, which introduces high-frequency chattering caused by discontinuous control signals. Similarly, robust control tends to rely on increased feedback gains to suppress disturbances, which may excite unmodeled high-frequency dynamics. Due to insufficient handling of uncertainties, these methods can result in deviations from the desired trajectory, system instability, and even compromised operational safety.
To overcome the limitations induced by high-gain strategies, it is essential to develop high-performance controllers capable of effectively suppressing or actively compensating for the influence of uncertainties on system performance. The robust integral of the sign of the error (RISE) controller [10,11] guarantees asymptotic tracking performance owing to the strong robustness of its integral robust control law against smooth time-varying disturbances. Nevertheless, the nonlinear robust gain in this controller depends critically on the upper bounds of the first and second time derivatives of the system uncertainties. Observer-based control methods, such as the Extended State Observer (ESO) [12,13] and the Disturbance Observer [14,15], circumvent high-gain feedback by estimating and proactively compensating for uncertainties. Additionally, leveraging the universal function approximation property of neural networks, researchers have successfully addressed a wide range of control problems involving unknown system dynamics [16,17]. It should be noted, however, that although these controllers demonstrate effective uncertainty handling, their performance remains inherently constrained by the accuracy of the system model due to their reliance on prior model knowledge.
Overcoming the limitations of traditional nonlinear control’s reliance on dynamic models, learning-based control strategies have emerged as viable alternatives, generating substantial interest in the research community. As a representative methodology, reinforcement learning (RL) eliminates the need for explicit mathematical models by autonomously learning optimal control policies through environmental interaction [18,19]. A prominent implementation of this approach is the actor–critic RL framework, where the actor network generates control decisions through environmental interaction, while the critic network evaluates these decisions and guides the actor’s updates via policy gradient feedback to enhance overall system performance. Nevertheless, it should be acknowledged that completely abandoning model-based structures presents significant challenges for controller adaptation in complex operational scenarios. In [20], an actor–critic RL-based optimal control scheme was developed to enhance tracking performance for unmanned surface vehicles exhibiting complex unknown nonlinearities. Another study [21] integrated reinforcement learning with a sliding mode observer design, achieving spacecraft attitude stabilization control within a conventional backstepping framework. Notably, these approaches effectively leverage nonlinear control theory to establish crucial guarantees for stability, safety, and convergence during the RL process. Similar integrations of intelligent decision-making with system dynamic stability have been successfully demonstrated in studies [22,23].
Another core challenge in electro-hydraulic servo systems involves achieving sufficiently fast response times. To address transient performance requirements, finite-time control methodologies have been developed to ensure system state stabilization within an estimable time frame. The authors of [24] developed an observer-based finite-time controller for hydraulic actuators with complex unknown dynamics, while [25] incorporated dynamic surface control to achieve high-precision finite-time control of hydraulic manipulators without complexity explosion. A notable limitation of these approaches, however, is their convergence time dependence on initial system conditions. To overcome this, ref. [26] proposed a fixed-time disturbance observer-based controller for electro-hydraulic systems under input saturation constraints. In an innovative extension, ref. [27] combined fixed-time control with reinforcement learning for spacecraft attitude consensus control, with a similar hybrid approach applied to manipulator control in [28]. Despite these advances, the convergence time upper bounds in such methods remain conservatively tuned through design parameters. To tackle these challenges, the predefined-time control concept introduced in [29] becomes the focus of this paper, as it allows arbitrary pre-specification of the system convergence time, independent of initial states or design parameters. Furthermore, the motivation of this work stems from effectively integrating the data-driven optimization capabilities of reinforcement learning with predefined-time control, thereby compensating for the limitations of predefined-time methods in handling complex uncertainties in electro-hydraulic servo systems.
Building upon the insights from the preceding discussion, this paper investigates the integration of reinforcement learning with predefined-time control to address trajectory tracking challenges in electro-hydraulic servo systems with complex nonlinearities. The proposed methodology employs an actor–critic neural network-based reinforcement learning strategy to actively identify and compensate for system uncertainties within the control design. Developed upon a command-filtered backstepping structure, the resulting predefined-time control framework ensures system convergence within a user-specified time. The main contributions of this work are summarized as follows:
- A predefined-time control framework is established for electro-hydraulic servo systems, guaranteeing predefined-time convergence of position tracking errors. The system convergence time is independent of initial states and requires no complex parameter computation.
- An intelligent integration of the actor–critic reinforcement learning framework effectively handles system uncertainties, thereby relaxing conventional assumptions regarding known uncertainty bounds or bounded derivatives.
- A novel nonsingular predefined-time command filter is utilized, which not only circumvents complexity explosion issues arising from repeated differentiation in backstepping design but also maintains continuity and non-singularity throughout the subsequent controller development.
The remainder of this paper is structured as follows. Section 2 presents the problem formulation and necessary preliminaries. The design of the RL-based predefined-time controller and its corresponding stability analysis are detailed in Section 3. Section 4 provides comprehensive simulation results and discussions. Finally, Section 5 concludes the paper with a summary of the main findings and contributions.
2. Problem Statement and Preliminaries
The configuration of the electro-hydraulic servo system considered in this study is shown in Figure 1, where a valve-controlled double-rod hydraulic cylinder directly drives an inertial load.
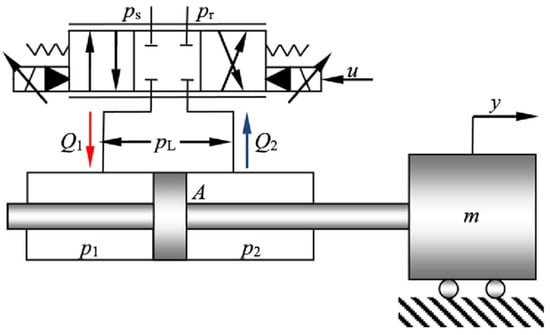
Figure 1.
Schematic diagram of the electro-hydraulic servomechanism.
The dynamic equation governing the inertial load is expressed as:
where is the mass of the inertial load, denotes the displacement of the inertial load, represents the pressure difference across the hydraulic cylinder, is the effective piston area, and signifies the unknown mechanical dynamics of the system.
The pressure dynamics of the hydraulic actuator are governed by the following equation:
where is the total control chamber volume, represents the effective bulk modulus of the hydraulic system, describing the combined deformability of the hydraulic oil and the hydraulic lines, represents the total leakage coefficient, is the load flow, and signifies the model uncertainties arising from complex internal leakage, parameter uncertainties, and unmodeled dynamic effects.
Remark 1.
In hydraulic systems, the compressibility of the fluid affects the system’s response speed, stiffness, and control accuracy. For high-dynamic-response systems, compressibility must be strictly controlled, making both pipeline rigidity and the bulk modulus of the hydraulic oil critically important. Here, we define the effective bulk modulus, , which describes the combined deformability of the hydraulic oil and the hydraulic lines. When the hydraulic lines are rigid, the deformation of the pipeline is negligible compared to that of the hydraulic oil itself. In such cases, it can be assumed that the bulk modulus describes only the susceptibility to deformation of the hydraulic oil. This simplification is a common assumption in engineering practice.
Neglecting spool dynamics, the load flow equation of the servo valve is given by:
where is the constant supply pressure, denotes the system control input, the flow gain is defined as , is the discharge coefficient, represents the spool valve area gradient, is the fluid density, and the sign function is given by:
For the controller design objective, the mathematical model of the electro-hydraulic system is expressed in state-space form. The state vector is defined as x = [x1, x2, x3]T = [, , /m]T. This formulation yields:
where , , , , and .
The control objective is to design a continuous control input that ensures accurate tracking of a prescribed smooth trajectory by the load position under the following assumptions, while guaranteeing predefined-time convergence performance for the hydraulic system subject to unknown dynamics and disturbances:
Assumption 1.
The desired motion trajectory for the system is twice continuously differentiable and bounded.
Assumption 2.
The system uncertainty is bounded, satisfying , where is an unknown positive constant.
3. Reinforcement Learning-Based Predefined-Time Controller Design
3.1. Preliminaries
The following preliminaries must be established prior to the controller design:
Lemma 1
([30]). Consider a continuously differentiable Lyapunov function candidate satisfying
where , , , and
are constants such that , , , and . Then, the closed-loop system achieves predefined-time practical stability. Specifically, the control system converges to a bounded region within a predefined time parameter that can be arbitrarily selected.
Lemma 2
([28]). Based on the universal approximation capability of neural networks, a continuous function can be represented in the form:
where represents the ideal weight vector, with indicating the number of neurons in the hidden layer, denotes the input vector; represents the approximation error, and the activation function employs the Gaussian function as specified in [28].
To mitigate the potential issue of “complexity explosion” in the third-order electro-hydraulic servo system, a nonsingular predefined-time differentiator is incorporated into the subsequent controller synthesis. Its structure is given as follows [31]:
where i = 1, 2; ζ is defined as a positive adjustable constant constrained by 0 < ζ < 1; (the virtual control law) acts as the filter input; constitutes the filter output; and serves as the adjustable parameter that determines the predefined convergence time.
3.2. Actor–Critic Network Design
This section designs actor–critic networks to cope with unknown nonlinear dynamics in the system. The critic network serves to assess control performance, and the actor network functions to approximate the unknown dynamics.
Critic Network: Through the evaluation of the current control policy’s execution cost, the estimated value is leveraged to provide feedback, thereby directing policy optimization. The long-term cost function is defined as follows:
where serves as the discount factor to guarantee the boundedness of the cost function, and represents the instantaneous cost function:
where denotes the error compensation signal, and represents the second-order virtual control signal (see Section 3.3 for detailed definitions).
Based on Equation (9), the Bellman equation is derived as:
Following Lemma 2, a neural network is employed to approximate the cost function, yielding the relations and the approximation , where denote the estimate of , obtained by minimizing the following objective function: , with .
The update rule for the critic network is designed in accordance with the gradient descent method:
where represents the adjustable gain, the intermediate variable , and denotes the gradient of .
Actor Network: According to Lemma 2, an actor neural network is employed to approximate the unknown dynamics , which, can be expressed in the following approximate form:
where denote the estimate of , obtained by minimizing the following objective function: , with , and represents the adjustable gain, .
The update rule for the actor network is designed in accordance with the gradient descent method:
where represents the adjustable gain.
The parameter projection approach guarantees bounded neural network weights, that is, and . The update algorithm can be configured as follows:
where the intermediate variable , and .
3.3. RL-Based Predefined-Time Controller Design
Based on the established system model, a predefined-time convergent control scheme is developed through a classical backstepping framework integrated with an actor–critic learning network. The design procedure is systematically carried out in the following three steps:
Step 1: Differentiating the error variable yields:
With the filtered error defined as the input, the filtered error compensator is constructed as follows:
where the filter compensation coefficients are denoted by , with parameters , and are constants such that , , and hold. determines the user-specified convergence time.
Differentiating the error compensation signal on both sides yields:
Accordingly, the virtual control is constructed as follows:
where the controller coefficients are denoted by , .
Step 2: Differentiating the error variable yields:
With the filtered error defined as the input, the filtered error compensator is constructed as follows:
where the filter compensation coefficients are denoted by , .
Differentiating the error compensation signal on both sides yields:
Accordingly, the virtual control is constructed as follows:
where the controller coefficients are denoted by , .
Step 3: Differentiating the error variable yields:
The filtered error compensator is constructed as follows:
where the filter compensation coefficients are denoted by , .
Differentiating the error compensation signal on both sides yields:
Accordingly, the actual control is constructed as follows:
where the controller coefficients are denoted by , .
The architecture of the algorithm proposed in this section is depicted in Figure 2.
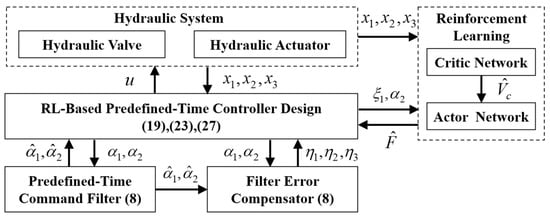
Figure 2.
Structure of the Proposed RL-Based Predefined-Time Control Strategy.
3.4. Main Result and Stability Analysis
Theorem 1.
Consider the electro-hydraulic servo system model described by (5), which contains unknown dynamics and disturbances. Under Assumptions 1 and 2, if the control law is implemented according to (27), then the system tracking error converges to a bounded set within a predefined time, and all internal signals remain bounded.
Proof of Theorem 1.
By incorporating the predefined-time filter, the proof of tracking error convergence is transformed into demonstrating the convergence of a composite signal comprising both the filtered error compensation signal and its compensator. To proceed with the analysis, a new Lyapunov function is constructed as follows:
The following inequality is established based on Lemma 3 in [31]:
where the variable i = 1, 2, and the constant satisfies .
Differentiating Equation (28) with respect to time yields:
where the constant . Then, according to Lemma 1, it is rigorously derived that the designed filter error compensator of the system achieves bounded convergence within a predefined time.
For the convergence proof of the filtered error compensation signal, the following Lyapunov function is constructed:
Differentiating Equation (31) with respect to time yields:
Given that is bounded above by , and is bounded above by . Furthermore, according to the mapping defined in Equation (18), the analytical result indicates that when conditions and are simultaneously satisfied, the additional constant S attains its maximum value. Therefore, stability verification under this maximal case directly ensures its general validity:
Since N is a bounded constant, Equation (32) can be further simplified to:
where the constant .
Recalling Lemma 1, it is derived that the filtered error compensation signal exhibits predefined-time boundedness. Since holds, the system tracking error is consequently guaranteed to achieve bounded stability after the predefined time, thereby completing the proof. □
Remark 2.
In practical implementations, raw sensor signals are commonly pre-filtered (e.g., second- or third-order filters) to attenuate high-frequency noise before being used by the control algorithm. Beyond this standard pre-processing, the proposed control architecture itself incorporates several inherent mechanisms that further suppress residual measurement noise: (i) the predefined-time backstepping core exhibits low-pass closed-loop dynamics, naturally attenuating high-frequency components in the feedback path; (ii) the non-singular predefined-time command filter smooths the error-signal sequence, adding a further barrier to noise propagation in the recursive design; and (iii) the Actor–Critic RL updates are intrinsically insensitive to zero-mean high-frequency noise, so that the resulting compensation signal remains smooth.
Remark 3.
Since the RL network has been proven to work without boundedness assumptions in the mechanical channel, a natural extension would be to design an RL network to learn and compensate for the uncertainties in the hydraulic dynamics. However, a core challenge in the current RL design scheme is the practical difficulty in reliably obtaining accurate differential signals of the pressure dynamics. Therefore, a promising future direction is to replace the model-based backstepping control with a reinforcement learning framework for controller design, so that it outputs the optimal control law directly—rather than just using RL to compensate for uncertainties.
4. Simulation Results
The simulations in this study were conducted with MATLAB R2018a.
To validate the efficacy of the proposed reinforcement learning-based predefined-time tracking controller, this section provides a comprehensive evaluation through comparative simulations of the electro-hydraulic servo system model under different control schemes. The system parameters are specified as follows: m = 30 kg, A = 904.8 mm2, Bv = 4000 N·s/m, Vt = 7.96 × 10−5 m3, ku = 1.197 × 10−8 m3/s/V/Pa1/2, Ps = 10 MPa, βe = 700 MPa, and Ct = 1 × 10−13 m3/s/Pa. The intermediate variable F is set as .
The desired trajectory for the system is specified as 0.01·cos(2·t) m. For comparative analysis, the following controllers are implemented:
(1) RLPDTC: The proposed RL-based predefined-time controller for electro-hydraulic servo systems. The basic parameters are configured as: r = 0.2, ζ = 1, η = 0.001, κ = 100, λ = 0.5, a1 = 50, a2 = 1, and Tf = 1 s.
(2) PDTC: A predefined-time controller without reinforcement learning-based dynamic compensation. All parameters remain identical to RLPDTC to specifically evaluate the contribution of the RL-based active compensation.
(3) VFPI: A velocity feed-forward PI controller with the structure , where denotes the tracking error. The parameters are set as: kp = 150 (proportional gain), ki = 30 (integral gain), and kF = 20 (velocity feed-forward coefficient).
Remark 4.
Based on the structure of the actor and critic neural networks given from Equation (9) to Equation (15), the key structural parameters of the proposed RLPDTC are designed as follows. The number of hidden-layer neurons for both the actor and critic networks is set to 5. This value was determined through simulation trial-and-error and existing control research experience, which helps avoid overfitting when approximating the unknown nonlinear dynamics F. The activation function is chosen as the Gaussian function, as shown in reference [28], to ensure numerical stability during the learning process. Weight initialization with small random values is a common practice in adaptive control, which prevents excessively large initial control signals and ensures a smooth start to the learning process. The selection of the learning rate among the weight update gain parameters is based on stability considerations of the gradient descent method—too large a value can cause oscillations, while too small a value leads to slow convergence. Through tuning, we chose and , which maintains system stability while ensuring a satisfactory convergence rate. The discount factor is set to 0.05 to balance the importance of immediate and future rewards. A smaller value promotes a faster system response, making it more suitable for short-term, highly dynamic tasks. The gain parameter was selected through simulation tuning, balancing convergence speed and approximation capability via a trial-and-error approach.
Figure 3 and Figure 4, respectively, show the comparative position tracking errors of the electro-hydraulic servo system under RLPDTC, PDTC, and VFPI control, along with the output tracking performance of RLPDTC following the desired command. As clearly demonstrated in Figure 3, RLPDTC exhibits enhanced compensation capability for unknown system dynamics compared to both PDTC and VFPI, leading to improved transient convergence performance. Moreover, the steady-state tracking error achieved by RLPDTC is significantly smaller, with the error amplitude ultimately stabilizing at 0.04 mm. By incorporating the reinforcement learning-based dynamic compensation mechanism into the predefined-time intelligent control design, RLPDTC ensures that the tracking error converges to a bounded range within the predefined time, thereby substantially enhancing tracking performance. The results confirm that RLPDTC achieves superior control effectiveness when compared with both PDTC and VFPI controllers. To quantitatively evaluate the performance of the RLPDTC and PDTC, the performance comparison for the last cycle is presented in the table below, where the maximum, average, and standard deviation of the tracking error are denoted as Me, μ, and σ, respectively. According to Table 1, RLPDTC reduces the maximum tracking error by approximately 81% and the mean square error by about 82%, demonstrating that the proposed method substantially improves tracking control accuracy and operational smoothness.
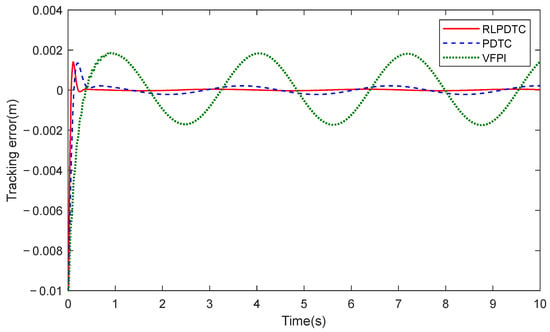
Figure 3.
Comparison of tracking errors.
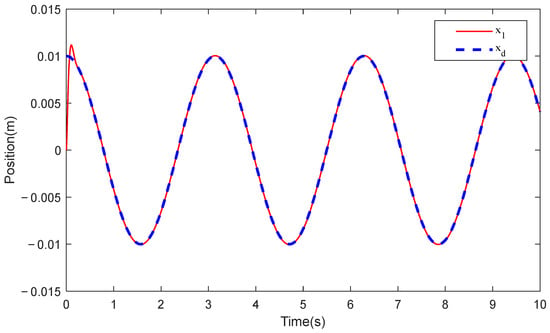
Figure 4.
Tracking performance of RLPDTC.

Table 1.
Performance indices of the last one cycle.
Furthermore, Figure 5 illustrates the approximation performance of RLPDTC for the system’s unknown dynamics, while Figure 6 and Figure 7 present the temporal evolution of the reinforcement learning network weights. The results demonstrate RLPDTC’s superior capability in accurately estimating unknown system dynamics, thereby verifying the efficacy of the integrated reinforcement learning-based compensation mechanism. Figure 8 displays the control input trajectory generated by the proposed RLPDTC framework. The obtained control signal exhibits smooth and continuous characteristics, confirming its practical applicability for real-world implementation.
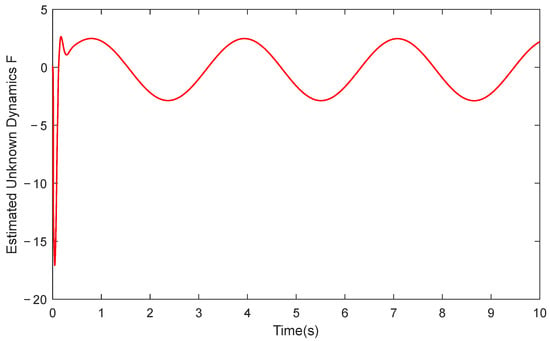
Figure 5.
Estimated Unknown Dynamics of RLPDTC.
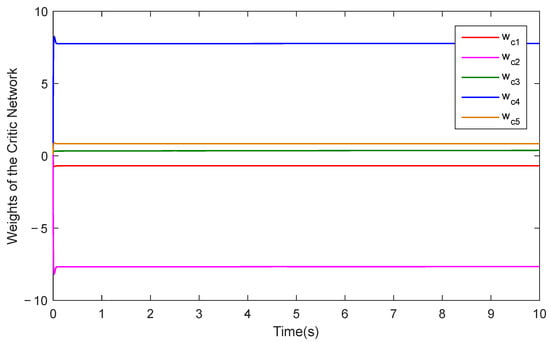
Figure 6.
Critic network weights of RLPDTC.
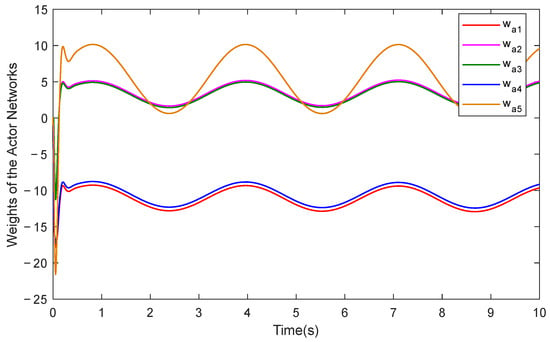
Figure 7.
Actor network weights of RLPDTC.
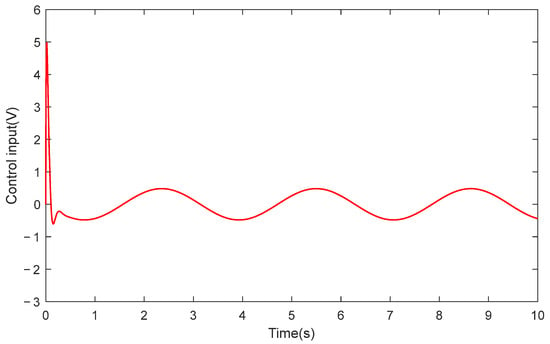
Figure 8.
Control input signal of RLPDTC.
An explicit high-frequency sinusoidal disturbance, sin(10t), whose frequency is significantly higher than the system’s main dynamic bandwidth, was superimposed on the original uncertainty F to simulate a type of high-frequency uncertainty. As shown in Figure 9, the Actor–Critic network demonstrates a considerable ability to approximate this high-frequency disturbance. This confirms that, within the simulation environment, our intelligent compensation mechanism also possesses adaptability to uncertainties that change relatively quickly. As shown in Figure 10, after introducing these high-frequency uncertainties, the tracking error exhibits the expected, minor high-frequency fluctuations, but their amplitude is strictly confined within an acceptable engineering range. Importantly, the predefined-time convergence property is not compromised, and the global stability of the system is maintained. This result verifies the robustness of the proposed framework against specific high-frequency uncertainties.
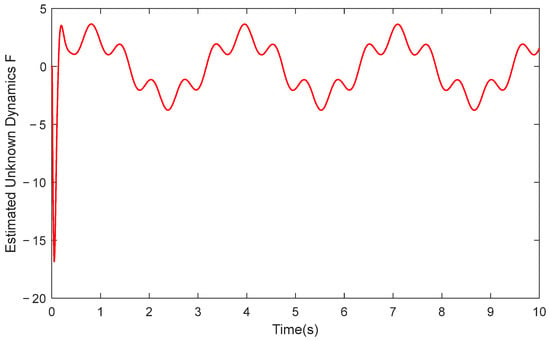
Figure 9.
High-frequency uncertainties: estimation of RLPDTC.
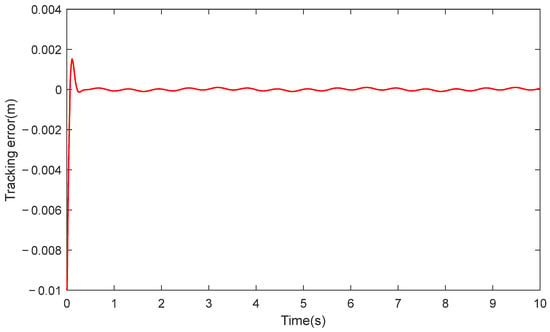
Figure 10.
Tracking Error of RLPDTC Under High-frequency Uncertainty.
5. Conclusions
This paper proposes a novel predefined-time intelligent control framework for electro-hydraulic servo systems. By integrating a reinforcement learning strategy into the predefined-time backstepping design, the controller is capable of approximating and actively feedforward-compensating for unmodeled system dynamics. Consequently, the system exhibits significant robustness without requiring prior knowledge of uncertainty bounds, and the key compensation effect is verified in comparative simulations. Within the novel predefined-time control framework, the system convergence time can be explicitly specified by the user and remains independent of the initial system conditions. This is rigorously supported by stability proofs and simulation validations. Simulation results demonstrate that the proposed method achieves superior tracking accuracy and convergence speed compared to existing representative control methods. This study also acknowledges its limitations, as the controller design still relies noticeably on key system parameter information. Therefore, future work will focus on enhancing the intelligence of hydraulic control systems, specifically in terms of self-tuning control parameters and optimizing the controller design.
Author Contributions
Conceptualization, T.H., X.N. and X.Y.; methodology, T.H., X.N. and J.L.; software, X.N.; validation, N.Q. and J.Y.; formal analysis, T.H. and X.Y.; investigation, J.L. and T.H.; resources, X.N. and J.Y.; data curation, T.H.; writing—original draft, T.H., X.N. and X.Y.; writing—review and editing, T.H., N.Q., J.Y. and X.Y.; visualization, N.Q.; supervision, J.L. and J.Y.; project administration, J.L. and N.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mattila, J.; Koivumaki, J.; Caldwell, D.G.; Semini, C. A survey on control of hydraulic robotic manipulators with projection to future trends. IEEE/ASME Trans. Mechatron. 2017, 22, 669–680. [Google Scholar] [CrossRef]
- Guo, Q.; Chen, Z. Neural adaptive control of single-rod electrohydraulic system with lumped uncertainty. Mech. Syst. Signal Process. 2021, 146, 106869. [Google Scholar] [CrossRef]
- Huang, Y.; Na, J.; Wu, X.; Gao, G. Approximation-free control for vehicle active suspensions with hydraulic actuator. IEEE Trans. Ind. Electron. 2018, 65, 7258–7267. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Zhou, C.; Huang, M. Probabilistic weighted support vector machine for robust modeling with application to hydraulic actuator. IEEE Trans. Ind. Inform. 2017, 13, 1723–1733. [Google Scholar] [CrossRef]
- Fallahi, M.; Zareinejad, M.; Baghestan, K.; Tivay, A.; Rezaei, S.M.; Abdullah, A. Precise position control of an electro-hydraulic servo system via robust linear approximation. ISA Trans. 2018, 80, 503–512. [Google Scholar] [CrossRef]
- Lu, K.; Feng, G.; Ding, B. Robust H-Infinity Tracking Control for a Valve-Controlled Hydraulic Motor System with Uncertain Parameters in the Complex Load Environment. Sensors 2023, 23, 9092. [Google Scholar] [CrossRef]
- Chen, C.-Y.; Li, T.-H.S.; Yeh, Y.-C.; Chang, C.-C. Design and implementation of an adaptive sliding-mode dynamic controller for wheeled mobile robots. Mechatronics 2009, 19, 156–166. [Google Scholar] [CrossRef]
- Yao, J.; Jiao, Z.; Yao, B. Robust control for static loading of electro-hydraulic load simulator with friction compensation. Chin. J. Aeronaut. 2012, 25, 954–962. [Google Scholar] [CrossRef]
- Zhou, J.; Hua, C.; Zhang, B.; Li, Y.; Zhang, Y. Performance Guaranteed Robust Tracking Control of Electro-Hydraulic Systems with Input Delays and Output Constraints. IEEE Trans. Ind. Electron. 2025, 72, 14469–14477. [Google Scholar] [CrossRef]
- Wang, S.; Na, J.; Ren, X. RISE-based asymptotic prescribed performance tracking control of nonlinear servo mechanisms. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 2359–2370. [Google Scholar] [CrossRef]
- Liu, L.; Yue, X.; Wen, H.; Dai, H. RISE-based adaptive tracking control for Euler-Lagrange mechanical systems with matched disturbances. ISA Trans. 2023, 135, 94–104. [Google Scholar] [CrossRef]
- Cao, H.; Li, Y.; Liu, C.; Zhao, S. ESO-based robust and high-precision tracking control for aerial manipulation. IEEE Trans. Autom. Sci. Eng. 2023, 21, 2139–2155. [Google Scholar] [CrossRef]
- Tang, G.; Xue, W.; Huang, X.; Song, K. On error-driven nonlinear ESO based control design with application to air-fuel ratio control of engines. Control Eng. Pract. 2024, 143, 105808. [Google Scholar] [CrossRef]
- Xu, B.; Zhang, L.; Ji, W. Improved non-singular fast terminal sliding mode control with disturbance observer for PMSM drives. IEEE Trans. Transp. Electrif. 2021, 7, 2753–2762. [Google Scholar] [CrossRef]
- Wei, X.; Song, X.; Zhang, H.; Hu, X.; Li, X. Disturbance-observer-based tracking trajectory control of under-actuated surface vessel with input and output constraints. Appl. Math. Model. 2026, 153, 116598. [Google Scholar] [CrossRef]
- Ma, J.; Yao, Z.; Deng, W.; Yao, J. Fixed-time adaptive neural network compensation control for uncertain nonlinear systems. Neural Netw. 2025, 189, 107563. [Google Scholar] [CrossRef]
- Kharrat, M. Neural networks-based adaptive fault-tolerant control for stochastic nonlinear systems with unknown backlash-like hysteresis and actuator faults. J. Appl. Math. Comput. 2024, 70, 1995–2018. [Google Scholar] [CrossRef]
- Ma, B.; Liu, Z.; Zhao, W.; Yuan, J.; Long, H.; Wang, X.; Yuan, Z. Target tracking control of UAV through deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5983–6000. [Google Scholar] [CrossRef]
- Bai, W.; Chen, D.; Zhao, B.; D’Ariano, A. Reinforcement learning control for a class of discrete-time non-strict feedback multi-agent systems and application to multi-marine vehicles. IEEE Trans. Intell. Veh. 2024, 10, 3613–3625. [Google Scholar] [CrossRef]
- Wang, N.; Gao, Y.; Zhao, H.; Ahn, C.K. Reinforcement learning-based optimal tracking control of an unknown unmanned surface vehicle. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3034–3045. [Google Scholar] [CrossRef] [PubMed]
- Zheng, M.; Wu, Y.; Li, C. Reinforcement learning strategy for spacecraft attitude hyperagile tracking control with uncertainties. Aerosp. Sci. Technol. 2021, 119, 107126. [Google Scholar] [CrossRef]
- Liang, X.; Yao, Z.; Ge, Y.; Yao, J. Disturbance observer based actor-critic learning control for uncertain nonlinear systems. Chin. J. Aeronaut. 2023, 36, 271–280. [Google Scholar] [CrossRef]
- Yao, Z.; Liang, X.; Jiang, G.-P.; Yao, J. Model-based reinforcement learning control of electrohydraulic position servo systems. IEEE/ASME Trans. Mechatron. 2022, 28, 1446–1455. [Google Scholar] [CrossRef]
- Chen, J.; Du, X.; Lyu, L.; Fei, Z.; Sun, X.-M. Accurate Finite-Time Motion Control of Hydraulic Actuators with Event-Triggered Input. IEEE Trans. Autom. Sci. Eng. 2024, 21, 5826–5836. [Google Scholar] [CrossRef]
- Liang, X.; Yao, Z.; Deng, W.; Yao, J. Adaptive neural network finite-time tracking control for uncertain hydraulic manipulators. IEEE/ASME Trans. Mechatron. 2024, 30, 645–656. [Google Scholar] [CrossRef]
- Wang, C.; Wang, J.; Guo, Q.; Liu, Z.; Chen, C.L.P. Disturbance Observer-Based Fixed-Time Event-Triggered Control for Networked Electro-Hydraulic Systems with Input Saturation. IEEE Trans. Ind. Electron. 2025, 72, 1784–1794. [Google Scholar] [CrossRef]
- Chen, R.-Z.; Li, Y.-X.; Ahn, C.K. Reinforcement-learning-based fixed-time attitude consensus control for multiple spacecraft systems with model uncertainties. Aerosp. Sci. Technol. 2023, 132, 108060. [Google Scholar] [CrossRef]
- Cao, S.; Sun, L.; Jiang, J.; Zuo, Z. Reinforcement learning-based fixed-time trajectory tracking control for uncertain robotic manipulators with input saturation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 4584–4595. [Google Scholar] [CrossRef]
- Sánchez-Torres, J.D.; Gómez-Gutiérrez, D.; López, E.; Loukianov, A.G. A class of predefined-time stable dynamical systems. IMA J. Math. Control Inf. 2018, 35, i1–i29. [Google Scholar] [CrossRef]
- Xie, S.; Chen, Q. Predefined-Time Disturbance Estimation and Attitude Control for Rigid Spacecraft. IEEE Trans. Circuits Syst. II Express Briefs 2024, 71, 2089–2093. [Google Scholar] [CrossRef]
- Que, N.; Sun, H.; Deng, W.; Yao, J.; Zhao, X.; Hu, J.; Luo, M. Command Filter-Based Adaptive Predefined-Time Tracking Control for Uncertain Systems with Disturbance Compensation. Int. J. Robust Nonlinear Control 2025, 35, 6604–6618. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.