
Automated Generation of Urban Spatial Structures Based on Stable Diffusion and CoAtNet Models
Abstract
1. Introduction
2. Related Works
2.1. Floor Plan Generation Algorithms and Result Evaluation
2.2. Result Prediction Algorithm
2.3. Space-Syntax Evaluation Metrics
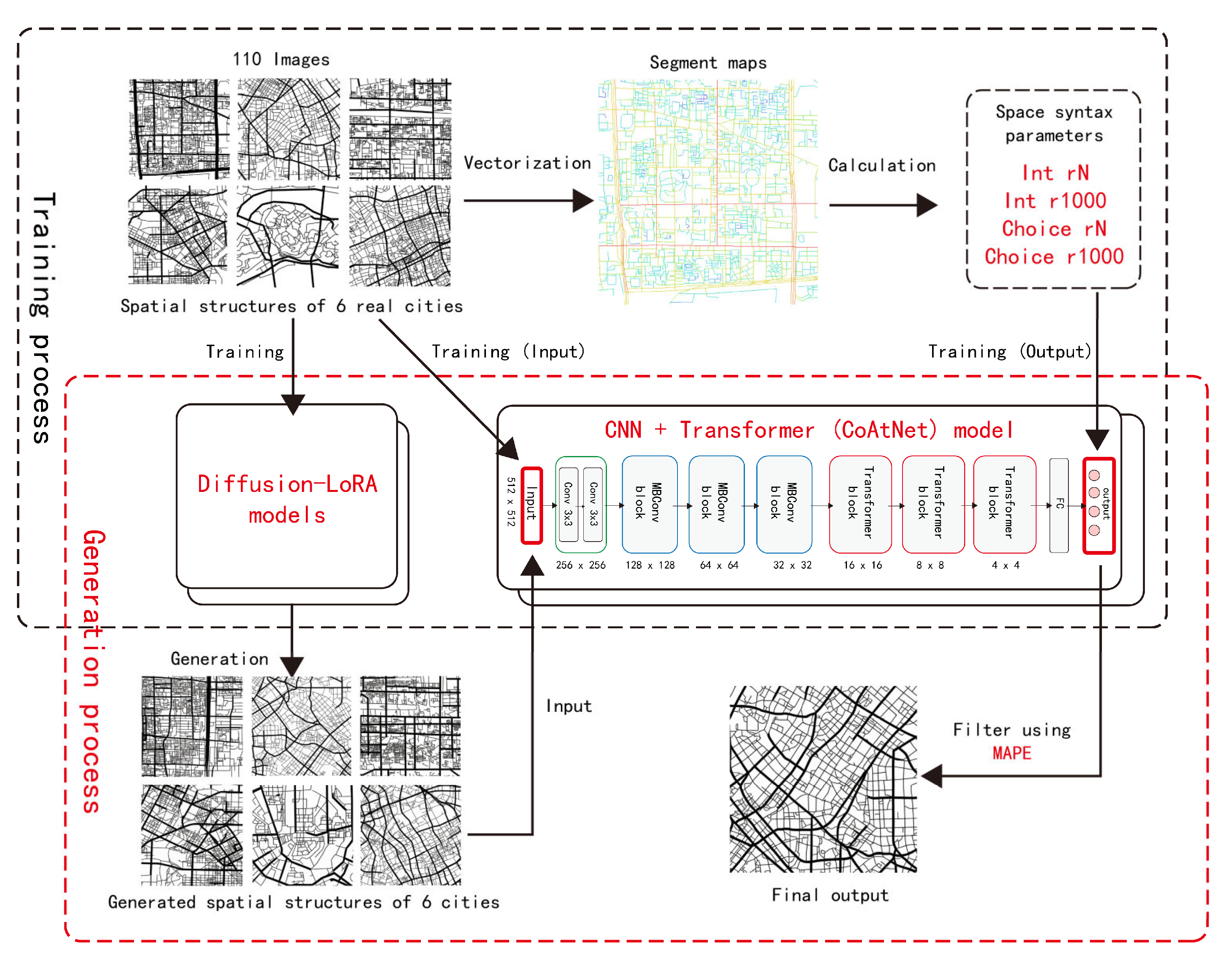
3. Research Framework
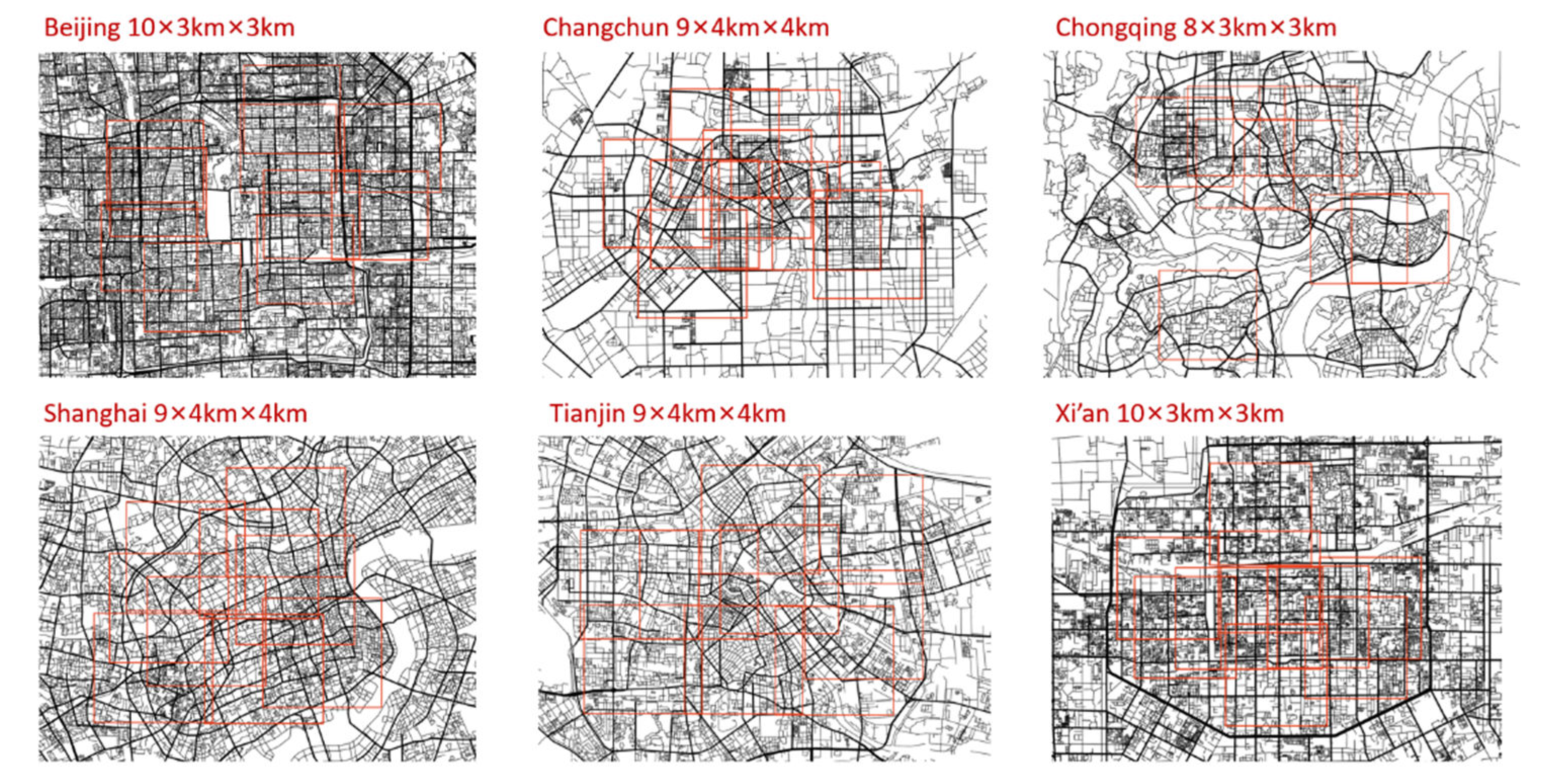
4. Calculation and Patterns of Space-Syntax Parameters in Real City Samples
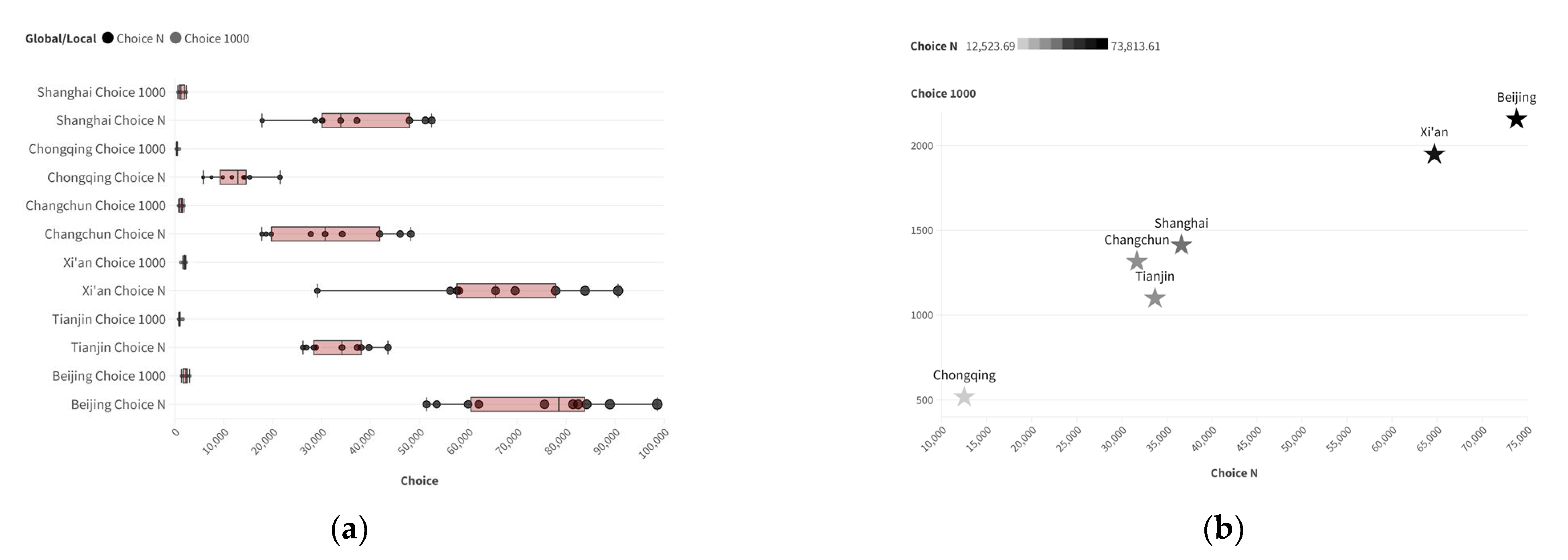
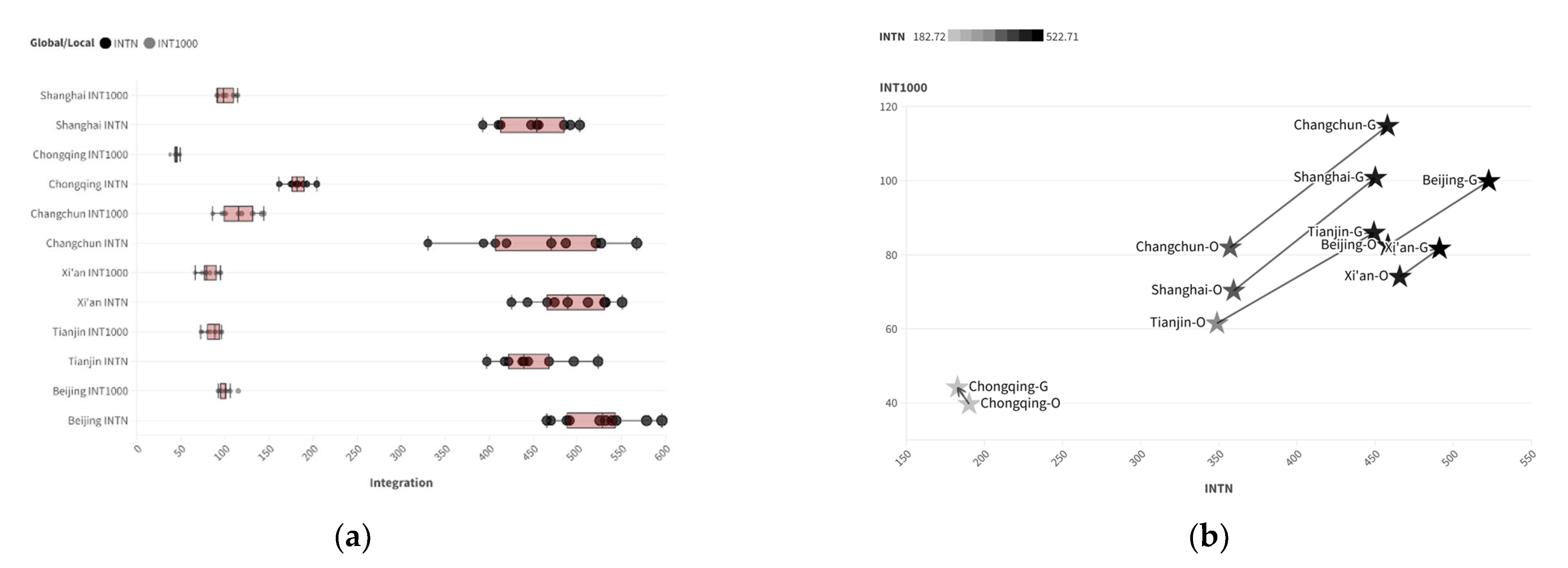
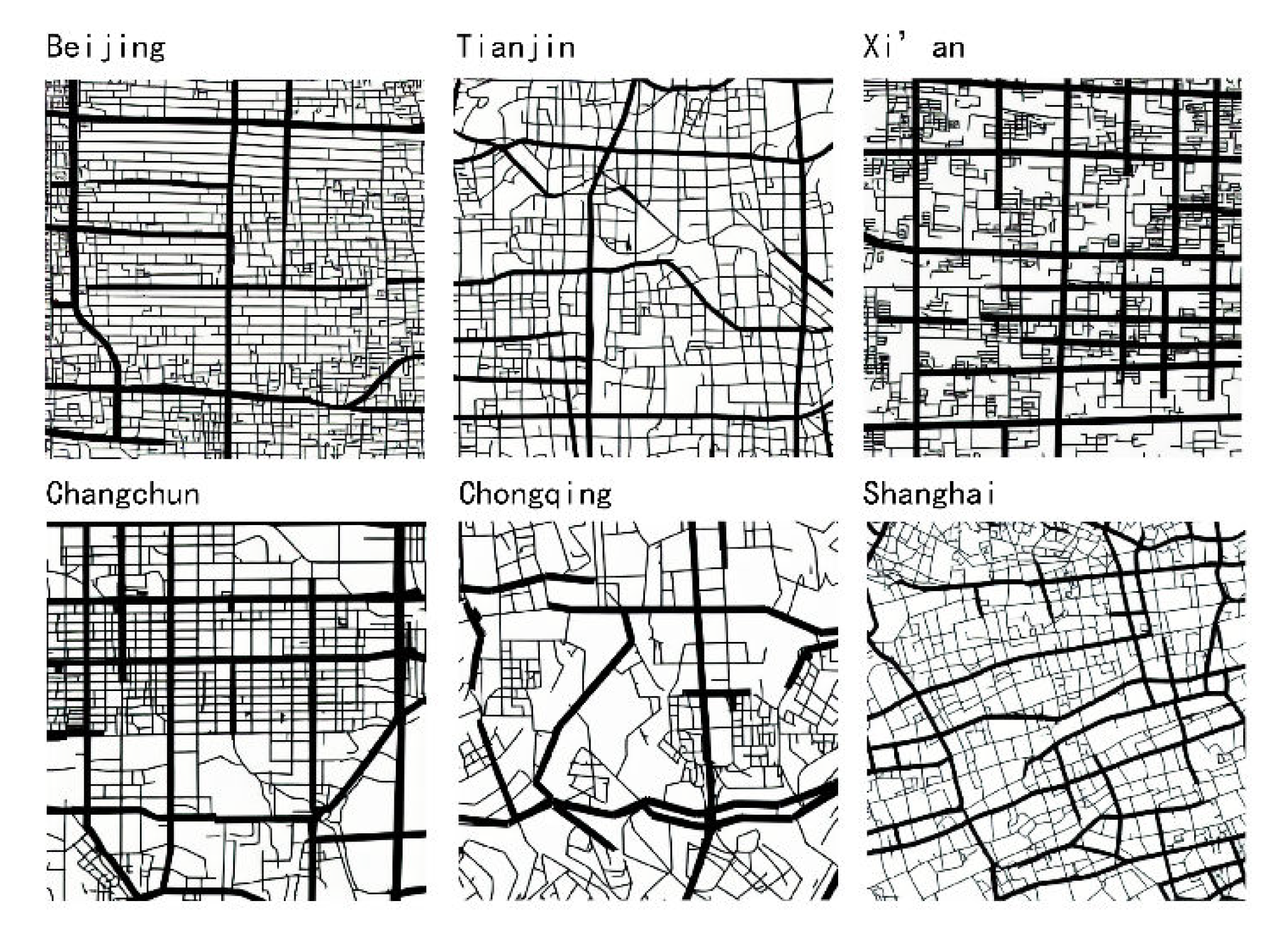
4.1. Calculation Results of Real Samples
4.2. Distribution Characteristics of Two-Scale Accessibility Data in Training Samples
5. Model Training, Road Network Generation, and Road Network Vectorization
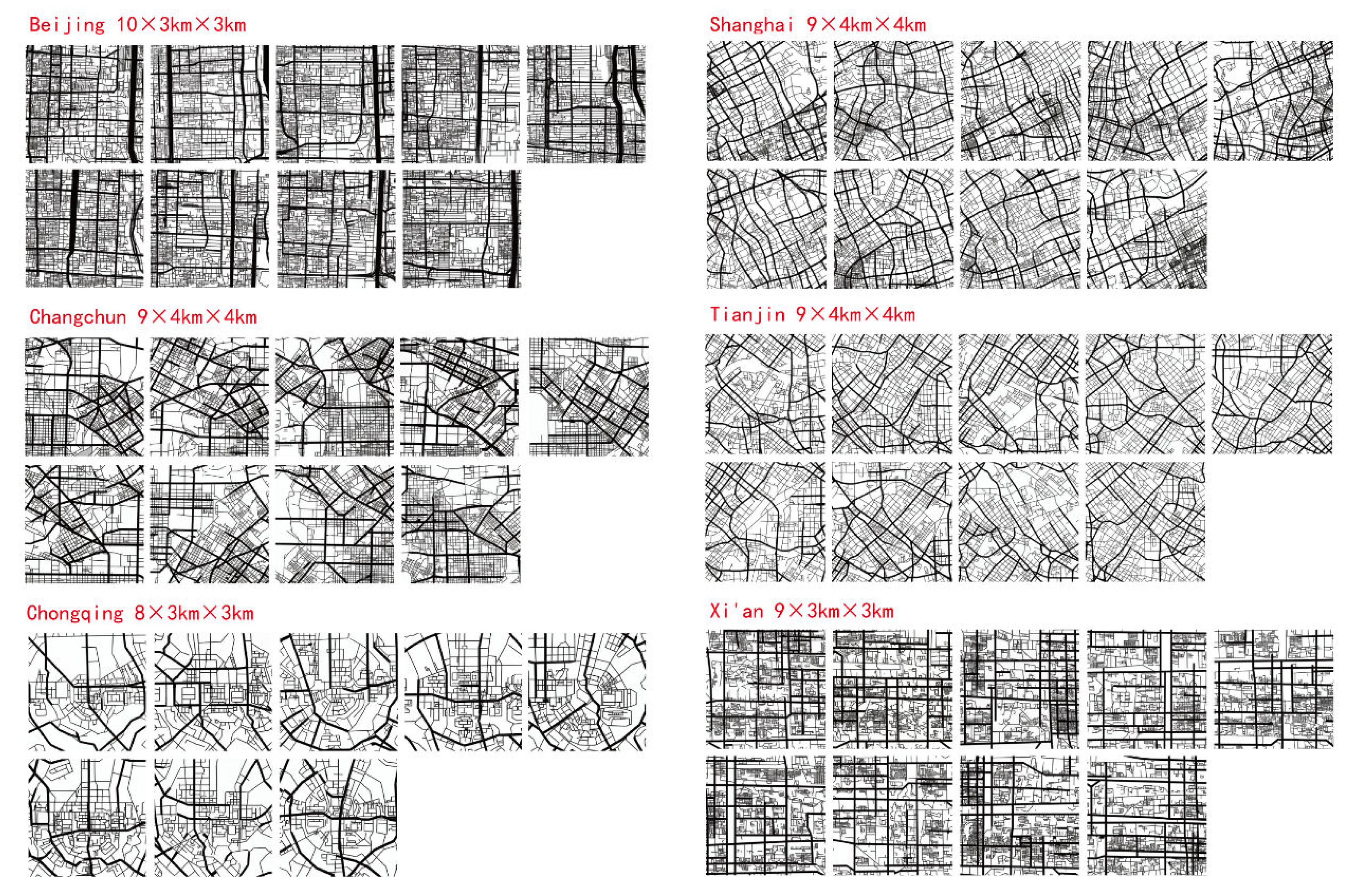
6. Calculation and Patterns of Accessibility for Samples Generated by Diffusion Models
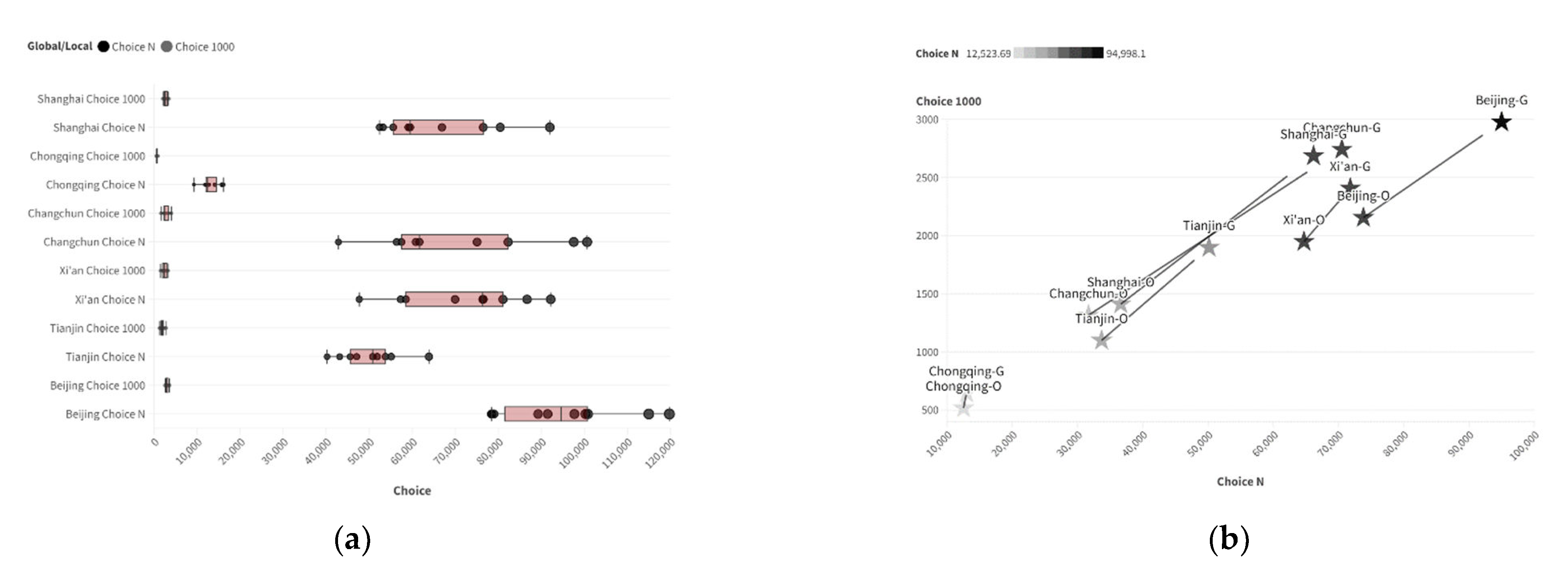
6.1. Calculation Results of Generated Samples
6.2. Distribution Characteristics of Two-Scale Accessibility Data in Generated Samples
7. Combining Convolution and Transformer Models to Predict Space-Syntax Indicators
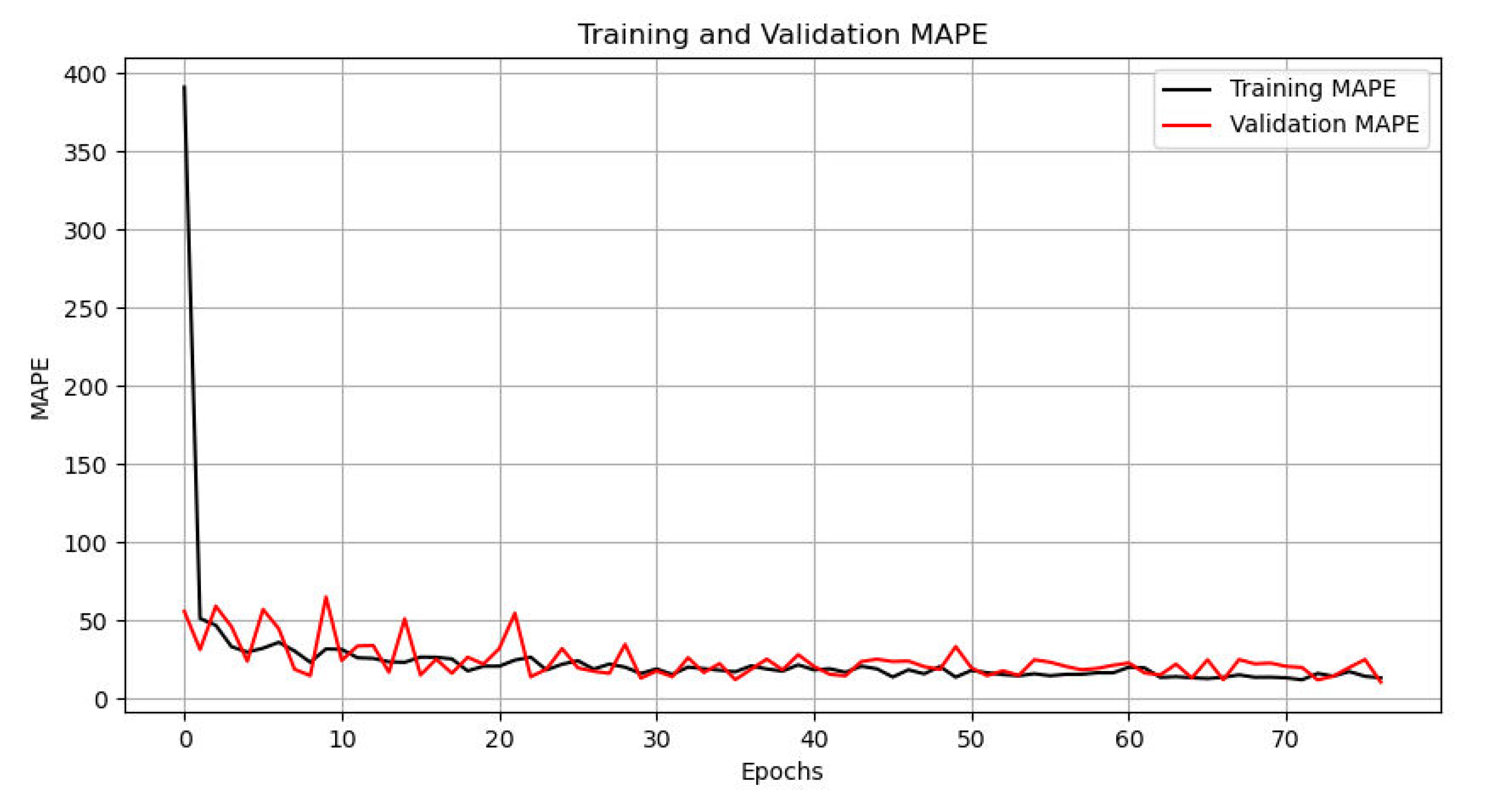
7.1. Training
7.2. Testing
8. Conclusions and Discussion
9. Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Zhang, T.; Du, X.; Zhang, Y.; Xie, H. Generative AI for Architectural Design: A Literature Review. arXiv 2024, arXiv:2404.01335. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Chen, J.; Shao, Z.; Hu, B. Generating Interior Design from Text: A New Diffusion Model-Based Method for Efficient Creative Design. Buildings 2023, 13, 1861. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. In Proceedings of the Advances in Neural Information Processing Systems; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: New York, NY, USA, 2022; Volume 35, pp. 36479–36494. [Google Scholar]
- Borji, A. Generated faces in the wild: Quantitative comparison of stable diffusion, midjourney and dall-e 2. arXiv 2022, arXiv:2210.00586. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: New York, NY, USA, 2021; Volume 139, pp. 8162–8171. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Gu, S.; Chen, D.; Bao, J.; Wen, F.; Zhang, B.; Chen, D.; Yuan, L.; Guo, B. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10696–10706. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; Mcgrew, B.; Sutskever, I.; Chen, M. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. In Proceedings of the International Conference on Machine Learning, Baltimore, MA, USA, 17–23 July 2022; pp. 16784–16804. [Google Scholar]
- Kawar, B.; Zada, S.; Lang, O.; Tov, O.; Chang, H.; Dekel, T.; Mosseri, I.; Irani, M. Imagic: Text-based real image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6007–6017. [Google Scholar]
- Avrahami, O.; Lischinski, D.; Fried, O. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18208–18218. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Shao, Y.; Zhang, W.; Cui, B.; Yang, M.H. Diffusion models: A comprehensive survey of methods and applications. arXiv 2022, arXiv:2209.00796. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef]
- Song, J.; Meng, C.; Ermon, S. Denoising Diffusion Implicit Models. In Proceedings of the International Conference on Learning Representations, Virtual Event, 26 April–1 May 2020. [Google Scholar]
- Chen, J.; Wang, D.; Shao, Z.; Zhang, X.; Ruan, M.; Li, H.; Li, J. Using artificial intelligence to generate master-quality architectural designs from text descriptions. Buildings 2023, 13, 2285. [Google Scholar] [CrossRef]
- Ko, J.; Ennemoser, B.; Yoo, W.; Yan, W.; Clayton, M.J. Architectural spatial layout planning using artificial intelligence. Autom. Constr. 2023, 154, 105019. [Google Scholar] [CrossRef]
- Hillier, B. Space Is the Machine; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Hillier, B.; Hanson, J. The Social Logic of Space; Cambridge University Press: Cambridge, UK, 1984. [Google Scholar]
- Duan, J.; Yang, T.; Sheng, Q.; Wang, H.; Dai, X. Space Syntax Tutorial; China Architecture & Building Press: Beijing, China, 2019; pp. 60–63. [Google Scholar]
- Wu, W.; Fu, X.-M.; Tang, R.; Qi, Y.-H.; Liu, L. Data-driven interior plan generation for residential buildings. AMC Trans. Gragh. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Huang, W.; Zheng, H. Architectural drawings recognition and generation through machine learning. In Proceedings of the 38th Annual Conference of the Association for Computer Aided Design in Architecture, Mexico City, Mexico, 18–20 October 2018; pp. 18–20. [Google Scholar]
- Chaillou, S. AI + Architecture|Towards a New Approach; Harvard University: Cambridge, MA, USA, 2022. [Google Scholar]
- Zeng, P.; Gao, W.; Yin, J.; Xu, P.; Lu, S. Residential floor plans: Multi-conditional automatic generation using diffusion models. Autom. Constr. 2024, 162, 105374. [Google Scholar] [CrossRef]
- Shabani, M.A.; Hosseini, S.; Furukawa, Y. Housediffusion: Vector floorplan generation via a diffusion model with discrete and continuous denoising. In Proceedings of the IEEE/CVF, Vancouver, BC, Canada, 18–22 June 2023; pp. 5466–5475. [Google Scholar]
- Wang, L.; Liu, J.; Cheng, G.; Liu, E.; Chen, W. Constructing a personalized AI assistant for shear wall layout using Stable Diffusion. arXiv 2023, arXiv:2305.10830. [Google Scholar]
- Park, K.; Ergan, S.; Feng, C. Quality assessment of residential layout designs generated by relational Generative Adversarial Networks (GANs). Autom. Constr. 2024, 158, 105243. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Alexey, D. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Khan, A.; Rauf, Z.; Sohail, A.; Khan, A.R.; Asif, H.; Asif, A.; Farooq, U. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 2023, 56 (Suppl. S3), 2917–2970. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Choudhary, P.; Adane, V. Spatial configurations of the urban cores in central India. In Proceedings of the Eighth International Space Syntax Symposium, Santiago de Chile, Chile, 3–6 January 2012; pp. 1–19. [Google Scholar]
- Can, I.; Heath, T. In-between spaces and social interaction: A morphological analysis of Izmir using space syntax. J. Hous. Built Environ. 2016, 31, 31–49. [Google Scholar] [CrossRef]
- Topçu, M. Morphological structures of historical Turkish cities. ICONARP Int. J. Archit. Plan. 2019, 7, 212–239. [Google Scholar] [CrossRef]
- Zhang, X.; Ren, A.; Chen, L.; Zheng, X. Measurement and spatial difference analysis on the accessibility of road networks in major cities of China. Sustainability 2019, 11, 4209. [Google Scholar] [CrossRef]
- Liao, P.; Gu, N.; Brisbin, C.; Rofe, M. Discovering the Spatial Properties of Chinese Historic Towns Through Mathematical Means. In Proceedings of the 12th Space Syntax Symposium, Beijing, China, 8–13 July 2019. [Google Scholar]
- Rejeb Bouzgarrou, A.; Claramunt, C.; Rejeb, H. Visualizing urban sprawl effects of a Tunisian city: A new urban spatial configuration of Monastir. Ann. GIS 2019, 25, 71–82. [Google Scholar] [CrossRef]
- El-Khouly, T.; Eldiasty, A.; Kamel, B. Monitoring the transformation in New Cairos urban vitality and the accompanying social and economic phenomena. Front. Archit. Res. 2023, 12, 867–891. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| INT N | INT 1000 m | Choice N | Choice 1000 m | |
|---|---|---|---|---|
| Beijing | 458.2306 | 82.50565 | 73,813.61 | 2155.474 |
| Tianjin | 348.8063 | 61.47971 | 33,689.06 | 1099.373 |
| Xi’an | 465.8156 | 74.01776 | 64,706.05 | 1949.081 |
| Changchun | 357.1978 | 81.92852 | 31,679.43 | 1315.592 |
| Chongqing | 190.1988 | 39.69585 | 12,523.69 | 517.466 |
| Shanghai | 359.4466 | 70.26574 | 36,621.01 | 1412.158 |
| INT N | INT 1000 m | Choice N | Choice 1000 m | |
|---|---|---|---|---|
| Beijing | 522.7124 | 99.86402 | 94,998.1 | 2977.679 |
| Tianjin | 449.2568 | 85.93206 | 50,151.41 | 1898.484 |
| Xi’an | 491.2224 | 81.65155 | 71,801.26 | 2408.57 |
| Changchun | 457.8964 | 114.7316 | 70,517.43 | 2742.022 |
| Chongqing | 182.7249 | 44.17633 | 12,985.31 | 646.1995 |
| Shanghai | 450.1251 | 100.7316 | 66,173.81 | 2686.066 |
| Stages | Size | Param |
|---|---|---|
| S0-Conv | 1/2 | L = 2 D = 32 |
| S1-MBConv | 1/4 | L = 2 D = 32 |
| S2-MBConv | 1/8 | L = 3 D = 64 |
| S3-MBConv | 1/16 | L = 6 D = 64 |
| S4-TFM | 1/32 | L = 8 D = 96 |
| S5-TFM | 1/64 | L = 14 D = 192 |
| S6-TFM | 1/128 | L = 2 D = 384 |
| MAPE | |
|---|---|
| INT N | 11.53% |
| INT 1000 m | 14.81% |
| Choice N | 18.77% |
| Choice 1000 m | 12.46% |
| Average | 14.39% |
| Before | After | |
|---|---|---|
| INT N | 14.35% | 8.84% |
| INT 1000 m | 20.69% | 9.60% |
| Choice N | 28.05% | 16.13% |
| Choice 1000 m | 34.69% | 12.43% |
| Average | 24.45% | 11.75% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Wan, B.; Sheng, Q. Automated Generation of Urban Spatial Structures Based on Stable Diffusion and CoAtNet Models. Buildings 2024, 14, 3720. https://doi.org/10.3390/buildings14123720
Yu D, Wan B, Sheng Q. Automated Generation of Urban Spatial Structures Based on Stable Diffusion and CoAtNet Models. Buildings. 2024; 14(12):3720. https://doi.org/10.3390/buildings14123720
Chicago/Turabian StyleYu, Dian, Bo Wan, and Qiang Sheng. 2024. "Automated Generation of Urban Spatial Structures Based on Stable Diffusion and CoAtNet Models" Buildings 14, no. 12: 3720. https://doi.org/10.3390/buildings14123720
APA StyleYu, D., Wan, B., & Sheng, Q. (2024). Automated Generation of Urban Spatial Structures Based on Stable Diffusion and CoAtNet Models. Buildings, 14(12), 3720. https://doi.org/10.3390/buildings14123720