Abstract
In this paper, an event-triggered optimal control strategy is proposed for three-phase grid-connected voltage source inverters (VSIs) based on the voltage-modulated direct power control (VM-DPC) principle. The optimization control problem of VSIs is addressed in the framework of nonzero sum (NZS) games to ensure mutual cooperation between active power and reactive power. To achieve optimal performance, the power components are driven to track their desired references while minimizing the individual performance index function. Accurate tracking of active and reactive powers not only stabilizes the grid but also guarantees compliant renewable integration. An adaptive dynamic programming (ADP) approach is adopted, where the critic neural network (NN) approximates the value function and provides optimal control policies. Moreover, an event-triggered mechanism with a dead-zone operation is incorporated to reduce redundant updates, thereby saving computational and communication resources. The stability of the closed-loop system and a strictly positive minimum inter-event interval are guaranteed. Simulation results verify that the proposed method achieves accurate power tracking, improved dynamic performance, and efficient implementation.
1. Introduction
With the rapid development of renewable energy, such as photovoltaic generation, wind power, and battery energy storage, power electronic converters have become indispensable in modern power systems. Unlike traditional synchronous generators, renewable sources cannot be directly interfaced with the grid and therefore rely on converters to regulate power exchange and ensure stable operation. Among various topologies, the grid-connected voltage source inverter (VSI) has emerged as a core interface, enabling the conversion of DC energy into controllable AC power and supporting a wide range of applications including distributed generation [1,2], microgrids [3], and energy storage systems [4].
The dynamic behavior of grid-connected VSIs is principally governed by their control, making their impedance characteristics highly dependent on the chosen control strategy. Common strategies include vector current control (VCC) and direct power control (DPC). In VCC, the inverter output currents are regulated in the synchronous -frame by means of proportional–integral (PI) controllers and a phase-locked loop (PLL) to synchronize with the grid voltage [5]. This approach offers accurate steady-state performance and is widely adopted in grid-connected converters. However, VCC requires a well-tuned PLL, which may deteriorate performance in weak or distorted grids, and its cascaded structure involving inner current loops and outer voltage loops limits dynamic response.
To overcome these limitations, direct power control (DPC) was proposed to directly regulate instantaneous active and reactive powers, thereby eliminating the need for multiple cascaded loops and enhancing transient dynamics [6,7]. This technique operates without the phase-locked loop (PLL) and achieves low steady-state harmonic distortion through pulse-width modulation (PWM) with a fixed switching frequency. Among various DPC methods, voltage-modulated direct power control (VM-DPC) in the -frame, initially developed for converters, has gained significant attention [8,9,10]. The VM-DPC transforms the original nonlinear time-varying system in a stationary -frame to a linear time-invariant (LTI) system in asynchronous rotating -frame without PLL and dynamic information loss.
Building on the aforementioned research, this work formulates the VM-DPC model of the grid-connected VSI as a two-input nonlinear dynamic system, where active and reactive powers are treated as the state variables. Since the two control inputs simultaneously influence the system dynamics rather than exhibiting a strictly antagonistic relationship, the problem is naturally modeled as a nonzero-sum game (NZS). For NZS game methods, investigating the Nash equilibrium among multiple agents enables them to coordinate their strategies toward a global optimal outcome. This formulation enables the application of optimal control strategies to achieve cooperative optimization of active and reactive power control, leading to enhanced dynamic performance and adaptability.
In summary, VM-DPC has emerged as a representative benchmark for advanced power control strategies in grid-connected converters. Numerous studies have further extended VM-DPC by integrating various auxiliary control techniques, thereby offering diverse perspectives for performance enhancement. Among these techniques, the proportional–integral scheme is extensively used because of its straightforward structure and reliable performance. Nevertheless, the conventional PI control inherently relies on fixed gains and linear error correction, which limits its ability to achieve optimal performance across different operating conditions and restricts the dynamic enhancement potential of VM-DPC. Moreover, model predictive control (MPC) has also been proposed to enhance the performance of VM-DPC [11,12]. Nonetheless, MPC operates in the discrete domain and requires online linearization and optimization each cycle, which increases computational load and complicates embedded implementation. To further enhance optimization performance, linear quadratic regulator (LQR) has been applied to the VM-DPC framework with finite or infinite horizon optimization [8]. However, the above optimal control approaches typically rely on accurate models, which may reduce their effectiveness in dealing with nonlinear dynamics and time-varying disturbances.
As one of the most effective algorithms to address optimization problems, adaptive dynamic programming (ADP) has found prosperous applications in many systems theoretically and practically, such as grid-connected inverters [13,14], switched systems [15,16] and microgrids [17,18]. By integrating dynamic programming, NNs and reinforcement learning (RL), ADP methods are dedicated to seeking the approximate optimal solution directly, and can get out of the “curse of dimensionality” [19,20]. As for the grid-connected VSIs subject to changing environments and complex system dynamics, the introduction of ADP-based control methods can circumvent the difficulty in obtaining the analytical optimal solution.
Accounting for the bandwidth limitation, frequent control updates and data transmission can bring extra challenges to the optimal control of grid-connected VSIs under the conventional time-triggered mechanism. By employing event-triggered control, the control signal is updated only when necessary or when significant events occur according to a predefined triggering condition. This not only guarantees the stable operation of the VSI system, but also reduces computational complexity and communication burden [20,21]. Therefore, it is of great value to design reliable event-triggered control schemes for grid-connected VSIs.
Inspired by the above, this work combines ADP technologies with event-triggered control to address the optimal control problem of grid-connected VSIs, which is further formulated as a nonzero-sum game. The objective is to ensure that both active and reactive powers accurately track their desired values. Furthermore, such regulation contributes to maintaining grid stability and enables compliant integration of DC sources such as renewable energy units. The main contributions of this article are summarized as follows.
- To the best of our knowledge, this work is the first time an ADP-based algorithm is applied to address the NZS game problem of grid-connected voltage source inverters. By analyzing the Nash equilibrium of active and reactive power interactions, the proposed method enables these power components to collaborate effectively, achieving a globally optimized performance.
- In order to release communication and calculation burdens, a novel group of event-triggered control schemes is devised; meanwhile, the stability of the controlled system is guaranteed.
- The theoretical analysis determines the minimum triggering interval of the proposed mechanism, theoretically ensuring the exclusion of Zeno behavior. Moreover, the introduction of the dead-zone operation leads to the reduction in trigger frequency and the alleviation of communication and calculation burdens.
2. System Model Description and Problem Formulation
In this section, the structure of VSI is briefly introduced, and then the VSI system is formulated by VM-DPC method.
2.1. Modeling of Grid-Connected VSIs
Figure 1 illustrates the topology of a three-phase VSI, where a DC source—representing renewable generation units or energy storage systems—is connected to the grid through an R–L output filter. By applying the Clark transformation, the system dynamics can be formulated in the -frame as a second-order model.
where , , and represent the output currents and voltages of VSI, and the grid voltages in -frame, respectively. L and R are the inductance and resistance of the filter.
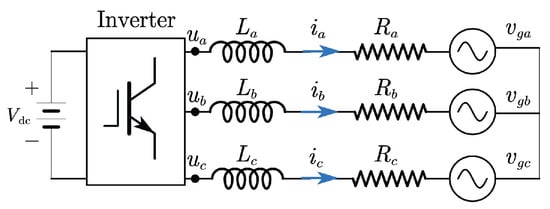
Figure 1.
Three-phase voltage source inverter connected to a grid.
The output instantaneous active and reactive power could be described as:
where P and Q are the instantaneous active power and reactive power, respectively. The time derivative of (2) is:
Assumption 1.
The grid is considered ideal with balanced and sinusoidal voltages of constant amplitude and angular frequency ω.
In -frame, grid voltages are modeled as
where and denote the grid voltage magnitude and angular frequency. Accordingly, one obtains the following equations:
At this stage, the dynamics of the real and reactive powers for grid-connected VSIs have been derived. In the following section, these equations are reformulated into a linear time-invariant form based on the VM-DPC principle.
2.2. State-Space Formulation via VM-DPC
It should be noted that due to the time-varying nature of and , system (6) is a nonlinear time-varying model. The complexity of this structure makes controller design challenging. By employing the VM principle, however, system (6) can be reformulated as a linear time invariant (LTI) model through the introduction of the following two new VM inputs [9].
Therefore, the model (6) can be transformed as:
This study investigates power tracking control for grid-connected VSIs, where the active and reactive powers are regulated to their references and , thereby maintaining grid frequency and voltage stability while ensuring compliant interconnection. Based on the VM-DPC formulation, the steady-state relations between the power dynamics and the control inputs can be obtained by enforcing the equilibrium conditions and . Consequently, the inputs and strive to reach their corresponding steady-state references and , which can be explicitly derived from and as
At the same time, the overall system is reformulated into a state-space form that provides the basis for subsequent optimal control design.
Since the active and reactive power loops pursue different performance objectives and impose mutually coupled effects through the converter dynamics, their regulation naturally forms a two-player nonzero-sum interaction. Modeling the control as an NZS game enables deriving equilibrium control policies that balance both channels in an optimal and coordinated manner.
Design the error state as and the corresponding control input as , . Then, the model of the grid-connected VSIs is deduced as follows:
with , and .
Remark 1.
Compared to traditional decoupled control or centralized optimal control [8,11,12], the proposed game-theoretic framework explicitly captures the coupling between the P–Q dynamics and the mutual influence between their individual regulation objectives. This enables the two control input to independently adjust their strategies based on their own performance index while still achieving cooperative optimization through the Nash equilibrium.
3. Event-Triggered Adaptive Critic Design
This part introduces an ET-driven ADP framework designed to solve the NZS game problem of the grid-connected VSI system (10). The proposed approach ensures efficient power regulation while reducing computational load. Furthermore, the stability of the closed-loop system is rigorously analyzed.
Figure 2 block diagram of the proposed event-triggered ADP control scheme. The system states are sampled and sent to the ET-ADP controller, where the critic neural network and weight-update law approximate the Hamilton function and compute the optimal control policy. An event-triggering mechanism determines control updates, and the resulting input is applied to the actuator to close the loop.
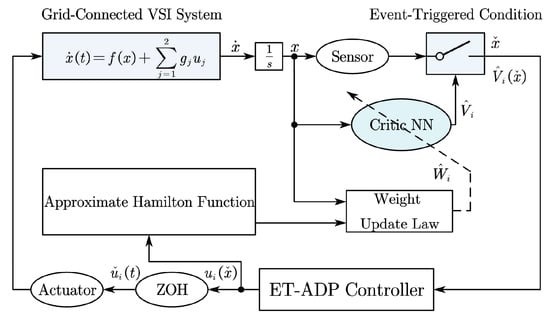
Figure 2.
Structure diagram of the proposed control scheme.
3.1. Triggering Adaptive Controller Design
First of all, to capture the interactions between the active and reactive power regulation objectives in the grid-connected VSI system, the control problem is formulated as an NZS differential game. The performance index corresponding to the ith decision maker is written as
where and are symmetric and positive definite. Following the formulation in [22], the input-related cost components and are given by
where denote the corresponding weighting matrices. Accordingly, the value function associated with the ith player is represented as
Definition 1
([19,23]). A pair of control strategies is regarded as a Nash equilibrium if
hold for every admissible and . That is, neither player can improve its own performance index through unilateral deviation from .
The Hamiltonian corresponding to the ith player under the admissible control policies can be written as
where , and denotes the gradient of with respect to the state vector x.
Thus, the optimal value function
satisfies the HJ equation
From the stationarity property of the HJ equation, the optimal control inputs for the two players are obtained as
Owing to the difficulty and complexity of directly solving the HJ equation, the optimal value function is approximated through a critic neural network as
where denotes the ideal weight vector, is the selected activation basis, L represents the number of neurons in the hidden layer, and stands for the residual approximation term.
Since the ideal critic-network weight is unavailable in practice, (22) cannot be directly utilized. Let denote the adaptive estimate of . Accordingly, the critic NN output is taken as
Furthermore, differentiating with respect to x yields
Similarly, we have
Let denote the sequence of event-triggering instants, where is the k-th sampling time. The state is held constant between two consecutive sampling times, i.e., for . Using a zero-order holder, the control inputs become
Define the measurement error as , . Replacing with its adaptive estimate and evaluating the controller at the sampled state , the implementable control laws are given by
Based on the above controller representation, the Hamiltonian residual for the ith player is written as
We introduced an auxiliary term as
To reduce the Hamiltonian residual , the critic weights are adjusted to minimize the performance index
Applying the gradient descent method [24], the weight update law for the ith critic network is obtained as
where is the weight estimation error, and denotes the learning rate. Since is constant, it follows that
3.2. Event-Based Adaptive Critic Design and Stability Analysis
For the subsequent stability analysis, we adopt the following assumptions as in [22,25].
Assumption 2.
The control law satisfies a Lipschitz condition, i.e.,
where .
Assumption 3.
For any , the optimal critic NN weight , the input coefficient matrix , the partial derivative of the NN activation function , the partial derivative of the NN estimation error and the additional term are norm bounded, that is where , , , and are all positive constants.
Assumption 4.
Under the persistence of excitation (PE) condition, the signal of each player remains persistently excited, which guarantees the following inequality:
where , and , are positive constants. The inequality implies that .
Lemma 1.
Suppose that the above assumptions all hold. For the grid-connected VSI model (10), using the event-triggered control strategy (29), (30) and the adaptive law of the critic NN weight (34), there exists , such that when , the weight estimation error of the critic NN, i.e., , is uniformly ultimately bounded (UUB).
Proof.
To analyze the stability of the weight estimation error , consider the Lyapunov function as
Since the dynamics of evolve according to a continuous flow and is continuous in time over the interval , it follows that the first-order difference of at the triggering instant satisfies
Therefore, it is sufficient to analyze the behavior of the system during the flow period.
For , we obtain
Based on Equation (39), this implies that when
we have
In other words, there exists a constant such that, for all , the weight estimation error is uniformly ultimately bounded (UUB) by the upper bound . □
Theorem 1.
For the NZS games formulated in system (10), assume that the approximate optimal control inputs in (29), (30) together with the weight adaptation law in (34) are implemented. Under the following triggering condition:
holds, with the dead-zone operation
Here, parameter and the given positive constant ϱ is the triggering termination condition. We define and it is assumed to be bounded as . Then the weight estimation errors and the system state x are UUB.
Proof.
Let Lyapunov function candidate be given by .
Case 1.
When , the time derivative of is
Due to Equation (19), the following equation holds:
By using Young’s inequality, we further obtain
Through the derivation procedure, the subsequent equations can be obtained:
Next, we proceed with the Lyapunov analysis. The derivative of with respect to time is computed as
where .
As the function remains unchanged during Case 1, the time derivation equals zero.
Combining the results from each term of the above Lyapunov equation leads to the following expression:
Furthermore, we have
where
Therefore, under condition (41), if either
or
the derivative of the Lyapunov function satisfies , implying that both the weight estimation errors and the system state x remain uniformly ultimately bounded (UUB).
Case 2.
At the sampling instant , the change in can be expressed as
From the discussion in Case 1, it follows that the combined function does not increase over the interval . Therefore, when the conditions (41), (55), (56) holds, . As , are all time-continuous functions, .
Theorem 1 has been proven. □
This UUB property ensures that the tracking errors converge to a sufficiently small neighborhood of zero, and the size of this neighborhood can be systematically reduced by tuning the learning rate, the critic basis functions, and the event-triggered threshold. It already ensures a rigorous and practically sufficient stability guarantee for the closed-loop system, which is consistent with the standard theoretical results commonly established in ADP-based control frameworks [19,23].
3.3. Exclusion of Zeno Behavior
Herein, Theorem 2 is presented which establishes the existence of a lower bound for the event-triggering interval, thereby confirming that Zeno behavior does not occur.
Theorem 2.
Proof.
Under the proposed event-triggered control policy (29) and (30), the dynamics of the system are given by
It is evident that, based on Assumption 2, is also Lipschitz continuous. This implies that
where is a positive constant.
Moreover, since remains constant over the interval , it follows that
To facilitate the following analysis, we define
With this definition, (61) can be further derived as
where .
Utilizing the comparison lemma with the initial condition , the solution to inequality (63) is bounded by
In the context of event-triggered control systems, we analyze the inter-event time , which satisfies
Subsequently, it can be deduced that
Since serves as the triggering termination criterion for the system, upon execution of the triggering, we obtain that . This implies that for all , possesses a positive lower bound given by , where .
Thus, Theorem 2 is proved. □
Theorem 2 demonstrates that the triggering condition in (41) guarantees a strictly positive lower bound on the triggering interval, thereby eliminating the possibility of Zeno behavior in the proposed event-triggered adaptive control scheme. In addition, the introduction of the dead-zone mechanism helps suppress redundant triggering when the system state approaches the equilibrium region. This assertion will be comprehensively verified and elucidated in Section 4.
4. Simulation
This section presents three cases that illustrate the practicality and resilience of the event-triggered adaptive critic method applied to grid-connected VSI systems.
Case 1.
Considering the parameters in [9], the parameters of the VSI are chosen as follows: filter inductance , filter resistance , and nominal grid frequency .
The activation functions of the NNs for the active power control and reactive power control are given as , with basis functions. Considering Assumption 3, the chosen activation functions provide smooth and bounded approximations over the operating range of the P-Q dynamics, which facilitates the calculation of required in the ADP-based control law and contributes to stable and efficient critic weight adaptation. Uniform learning rates and are adopted for the studied system. The performance index functions for the NZS game of the system, as described in Equation (11), were defined with parameters , , , , , and , where denotes the identity matrix. The dead-zone boundary is set to , with a sampling interval of 1 ms. The critic NN completes parameter convergence within a 500 ms adaptation period.
The triggering condition (41) is implemented with , . In order to fulfill the PE condition described in Assumption 4, excitation signals are introduced into the system during the first 250 ms. The resulting simulation results are presented in Figure 3 and Figure 4.
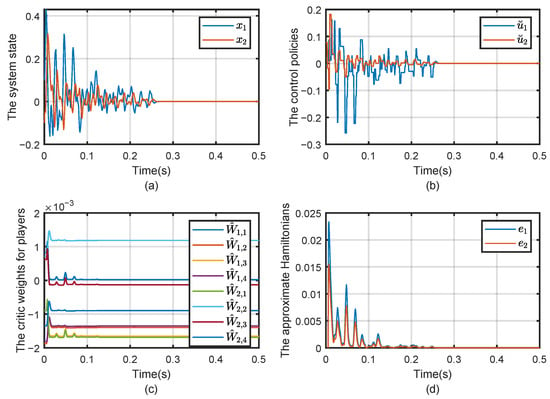
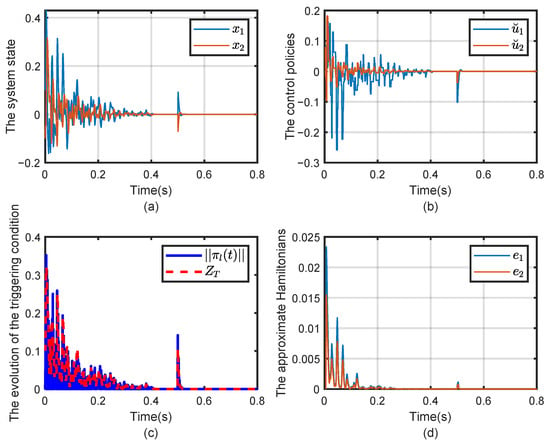
Figure 3.
Evolution of (a) the state x, (b) the control strategy , (c) evolution of the critic weigh and (d) the approximate Hamiltonian .
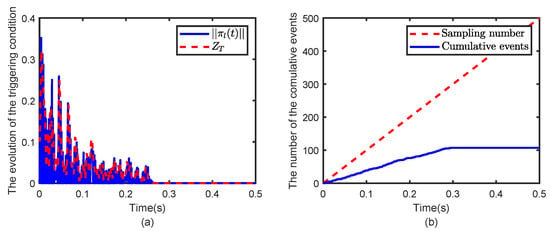
Figure 4.
Evolution of (a) the triggering condition and evolution of (b) the cumulative number of triggers.
The state trajectories of the grid-connected VSIs are illustrated in Figure 3a. As observed, the state vectors rapidly converge to zero, demonstrating that both active and reactive power successfully track their respective reference values. This confirms the effectiveness of the proposed adaptive approach in regulating the PQ dynamics, thereby further improving the DC source’s capability to maintain stable synchronization with the interconnected power network, ensuring seamless power exchange and grid stability. Figure 3b illustrates that the control input of each subsystem is updated only when the corresponding event-triggering condition is satisfied, and it eventually converges to zero. This indicates that the proposed strategy achieves aperiodic yet effective control. Moreover, the Hamiltonian functions of all subsystems gradually converge to zero, as shown in Figure 3d, further validating the stability and effectiveness of the proposed method.
The changing trajectories of the critic NN weights are presented in Figure 3c. After the whole system operates for 500 ms, all the weights converged to the following values, where , , respectively.
In Figure 4, once the norm of the event-triggered error exceeds the triggering threshold and the condition is satisfied, an event is triggered for the studied system. Under the designed event-triggered condition, the cumulative number of triggers and the corresponding triggering instants are illustrated in Figure 4. Unlike the time-triggered scheme, which requires 500 samples for the system, the event-triggered scheme significantly reduces the sampling burden, requiring only 107 samples for the system. It can be observed that when the system state enters a small neighborhood around the origin, i.e., , the cumulative number of triggers remains unchanged due to the triggering termination condition . This condition effectively reduces unnecessary computations by preventing further triggers once the state stabilizes, thus significantly conserving computational resources.
To further evaluate the grid-current quality of the proposed ADP-based control method, a switching-level single-phase VSI model was reconstructed and driven by the learned control signal. The control signal was mapped to a sinusoidal PWM modulation depth and applied to an L–R grid filter to obtain the actual inductor/grid current waveform. Figure 5 shows the full-horizon inductor current and the extracted steady-state current used for harmonic analysis. The corresponding THD is found to be 2.79% which satisfies the typical <5% grid-code requirement.
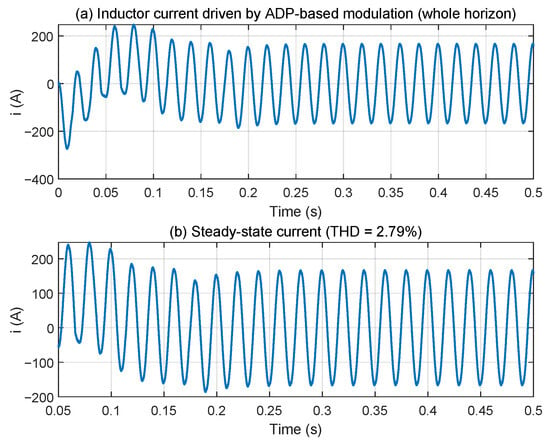
Figure 5.
Grid current under the proposed control method.
Case 2.
To evaluate the robustness of the proposed adaptive control strategy, an additional simulation is conducted in which the initial values of the system’s active and reactive powers are changed after the system has already stabilized and reached its reference power values. This experiment simulates the scenario where, after the system is running stably, changes in initial power values occur at due to load variations or external disturbances, testing how the system recovers stability and continues to track the target power. The resulting simulation results are presented in Figure 6.
Figure 6.
Evolution of (a) the state x, (b) the control strategy , evolution of (c) the triggering condition and (d) the approximate Hamiltonian .
As shown in Figure 6, the system state, input control signals, and the approximate Hamiltonian change rapidly at . These signals then converge to zero, indicating that the power tracking and grid synchronization objectives are successfully achieved.
Case 3.
In this case, a further simulation is conducted to evaluate the performance of the proposed adaptive control strategy when key electrical parameters are varied. The filter inductance , filter resistance , and nominal grid frequency . The resulting simulation results are presented in Figure 7 and Figure 8.
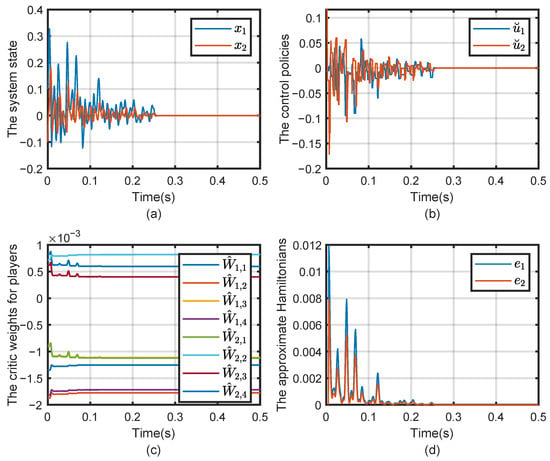
Figure 7.
Evolution of (a) the state x, (b) the control strategy , (c) evolution of the critic weigh and (d) the approximate Hamiltonian .
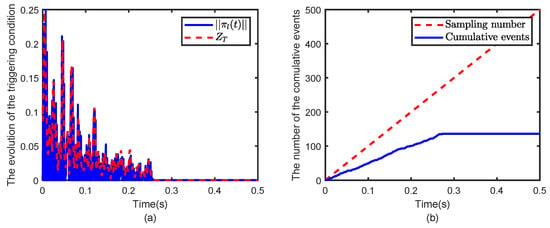
Figure 8.
Evolution of (a) the triggering condition and evolution of (b) the cumulative number of triggers.
The state trajectories shown in Figure 7a rapidly converge to zero, indicating that the active and reactive powers successfully track their respective reference values under the new parameter configuration. As in the first experiment, the control inputs are updated only when the event-triggering condition is satisfied, as illustrated in Figure 7b, and the Hamiltonian functions converge to zero, as shown in Figure 7d, further validating the stability and effectiveness of the method. The changing trajectories of the critic NN weights are presented in Figure 7c. After the whole system operates for 500 ms, all the weights converged to the following values, where , , respectively.
In Figure 8, the event-triggered condition again demonstrates significant savings in computational resources, with the number of triggers reduced compared to the time-triggered scheme. The system continues to maintain efficient operation with only 136 samples required, confirming that the adaptive control strategy remains effective and computationally efficient even under modified system parameters.
The simulation validates that, despite the changes in electrical parameters, the system continues to demonstrate stable power tracking and grid synchronization. This further confirms the robustness and adaptability of the proposed adaptive control approach, ensuring that the system can maintain performance under varying operational conditions.
Reconfirm the relevant parameters to prove that the proposed algorithm meets the grid connection standards. The control signal was mapped to a sinusoidal PWM modulation depth and applied to an L–R grid filter to obtain the actual inductor/grid current waveform. Figure 9 shows the full-horizon inductor current and the extracted steady-state current used for harmonic analysis. The corresponding THD is found to be 2.35% which satisfies the typical <5% grid-code requirement.
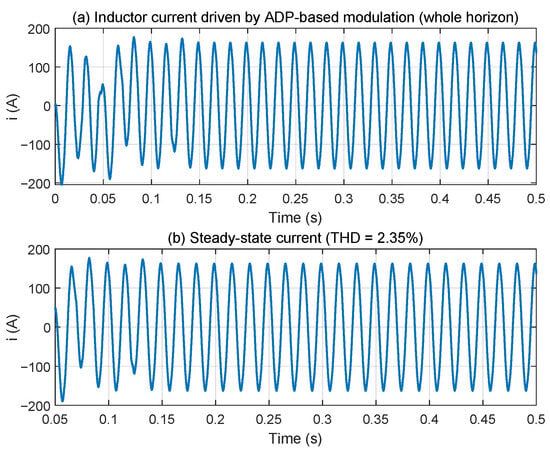
Figure 9.
Grid current under the proposed control method.
Case 4.
To further evaluate the advantages of the proposed ADP-based event-triggered control strategy, a comparative study with a conventional proportional–integral (PI) controller is carried out. In this case, the ADP controller is trained during the interval 0–0.3 s, where the critic neural networks learn the optimal value function under persistently excited system dynamics. After the training stage, the obtained convergent optimal control policy is fixed and directly applied to the VSI power regulation system for the remaining time.
For comparison, a baseline PI controller is designed using proportional gains and integral gains , ensuring a reasonable transient behavior in nominal conditions. Unlike the ADP controller, the PI scheme updates its control action at every sampling instant and does not incorporate any learning or optimization mechanism. To test the robustness of the two controllers, three disturbances of different magnitudes and directions are injected into the power error states at 0.35 s, 0.40 s, and 0.45 s, respectively. These disturbances emulate sudden variations in the operating conditions of the inverter.
The simulation results in Figure 10 demonstrate that although both controllers achieve convergence under normal operating conditions, the ADP-ET controller exhibits noticeably faster decay, smaller fluctuation amplitudes, and significantly quicker recovery after disturbances, highlighting its superior transient performance and robustness compared to the conventional PI strategy.
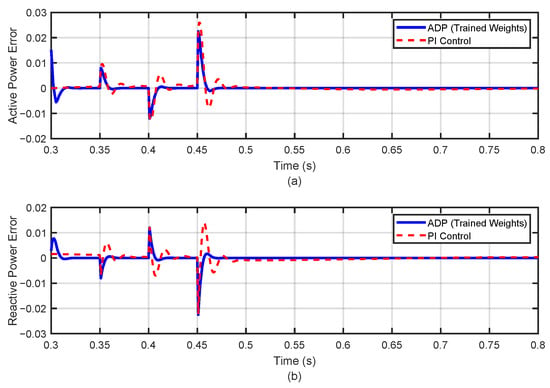
Figure 10.
Comparison of ADP and PI control under multiple disturbances: (a) active power error; (b) reactive power error.
5. Conclusions
This paper proposed an optimal control scheme for three-phase grid-connected VSIs. By applying VM-DPC, the nonlinear dynamics were simplified into an LTI form, enabling a tractable design framework. The power regulation problem was modeled as a nonzero-sum game and solved using an ADP approach with a critic NN. An event-triggered mechanism was further incorporated to reduce redundant computation while preserving stability. The overall scheme combines model simplification, online learning, and event-driven updating in a unified framework, providing improved dynamic performance, reduced computational load, and strong adaptability to model uncertainties. Simulation results confirmed accurate power tracking, enhanced dynamics, and efficient implementation.
Future work will focus on implementing the proposed control scheme on a Hardware-in-the-Loop(HIL) or laboratory hardware platform, extending the method to multi-phase and multi-converter systems, and incorporating grid disturbances and stability constraints into the learning framework.
Author Contributions
Conceptualization, Z.M.; Methodology, J.W.; Software, H.S.; Validation, D.Z.; Formal analysis, W.Y.; Writing—original draft, Y.B. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by National Natural Science Foundation of China (No. 62373091, 62103087, 62203311, 62473319 & U22A2055), China Postdoctoral Science Foundation (No. GZC20240227, 2024T170112, 2024M750373, 2023M740542 & 2021M690567), National Key R&D Program of China under grant 2018YFA0702200, the Fundamental Research Funds for the Central Universities (No. N25LPY031), Natural Science Foundation of Liaoning Province (No. 2023-MSBA-082), Natural Science Foundation of Shandong Province (No. ZR2024QF276), Natural Science Foundation of Guangdong Province (No. 2025A1515011504), Guangdong Basic and Applied Basic Research Foundation (No. 2023A1515110335).
Data Availability Statement
The original contributions presented in this study are included in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chang, G.W.; Nguyen, K.T. A New Adaptive Inertia-Based Virtual Synchronous Generator with Even Inverter Output Power Sharing in Islanded Microgrid. IEEE Trans. Ind. Electron. 2024, 71, 10693–10703. [Google Scholar] [CrossRef]
- Chandan, B.; Kumar Pal, P.; Chandra Jana, K.; Siwakoti, Y.P. Performance Evaluation of a New Transformerless Grid-Connected Six-Level Inverter With Integrated Voltage Boosting. IEEE J. Emerg. Sel. Top. Power Electron. 2024, 12, 4361–4376. [Google Scholar] [CrossRef]
- Muraleedharan, N.; Mishra, M.K. Voltage Ride-Through Strategy for Grid-Connected Dual Voltage Source Inverter Under Unsymmetrical Fault Conditions. IEEE Trans. Power Electron. 2025, 40, 17438–17450. [Google Scholar] [CrossRef]
- Ebrahimi, J.; Eren, S. A Multi-Source DC/AC Converter for Integrated Hybrid Energy Storage Systems. IEEE Trans. Energy Convers. 2022, 37, 2298–2309. [Google Scholar] [CrossRef]
- Schweizer, M.; Almér, S.; Pettersson, S.; Merkert, A.; Bergemann, V.; Harnefors, L. Grid-Forming Vector Current Control. IEEE Trans. Power Electron. 2022, 37, 13091–13106. [Google Scholar] [CrossRef]
- Lunardi, A.; Conde, E.; Rocha, N.; Sguarezi Filho, A. Direct power control for DFIG systems under distorted voltage using predictive repetitive control. Int. J. Electr. Power Energy Syst. 2025, 165, 110465. [Google Scholar] [CrossRef]
- Rath, A.; Pratap Behera, B.; Kumar Sethi, B. Improved Shunt Active Filter for Non-Ideal Grid Using Model Predictive and Sliding Mode Control. IEEE Trans. Consum. Electron. 2024, 70, 6600–6608. [Google Scholar] [CrossRef]
- Shen, H.; Xu, J.; Zhang, Q.; Park, J.H.; Peng, C. An Optimal Control Scheme for Grid-Connected Voltage Source Inverter via Grid Voltage Modulated-Direct Power Control. IEEE Trans. Autom. Sci. Eng. 2025, 22, 7216–7225. [Google Scholar] [CrossRef]
- Gui, Y.; Blaabjerg, F.; Wang, X.; Bendtsen, J.D.; Yang, D.; Stoustrup, J. Improved DC-Link Voltage Regulation Strategy for Grid-Connected Converters. IEEE Trans. Ind. Electron. 2021, 68, 4977–4987. [Google Scholar] [CrossRef]
- Gong, Z.; Liu, C.; Shang, L.; Lai, Q.; Terriche, Y. Power Decoupling Strategy for Voltage Modulated Direct Power Control of Voltage Source Inverters Connected to Weak Grids. IEEE Trans. Sustain. Energy 2023, 14, 152–167. [Google Scholar] [CrossRef]
- Aragon, C.A.; Guzman, R.; de Vicuña, L.G.; Miret, J.; Castilla, M. Constrained Predictive Control Based on a Large-Signal Model for a Three-Phase Inverter Connected to a Microgrid. IEEE Trans. Ind. Electron. 2022, 69, 6497–6507. [Google Scholar] [CrossRef]
- Zheng, C.; Dragičević, T.; Majmunović, B.; Blaabjerg, F. Constrained Modulated Model-Predictive Control of an LC-Filtered Voltage-Source Converter. IEEE Trans. Power Electron. 2020, 35, 1967–1977. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, Y.; Gao, W.; Davari, M.; Deng, C. Adaptive, Optimal, Virtual Synchronous Generator Control of Three-Phase Grid-Connected Inverters Under Different Grid Conditions—An Adaptive Dynamic Programming Approach. IEEE Trans. Ind. Inform. 2022, 18, 7388–7399. [Google Scholar] [CrossRef]
- Davari, M.; Gao, W.; Aghazadeh, A.; Blaabjerg, F.; Lewis, F.L. An Optimal Synchronization Control Method of PLL Utilizing Adaptive Dynamic Programming to Synchronize Inverter-Based Resources With Unbalanced, Low-Inertia, and Very Weak Grids. IEEE Trans. Autom. Sci. Eng. 2025, 22, 24–42. [Google Scholar] [CrossRef]
- Liu, D.; Baldi, S.; Yu, W.; Chen, G. On Distributed Implementation of Switch-Based Adaptive Dynamic Programming. IEEE Trans. Cybern. 2022, 52, 7218–7224. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Yu, W.; Baldi, S.; Cao, J.; Huang, W. A Switching-Based Adaptive Dynamic Programming Method to Optimal Traffic Signaling. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 4160–4170. [Google Scholar] [CrossRef]
- Mi, Z.; Su, H.; Sun, Q.; Cai, Y.; Ming, Z. Dynamic event-triggered-based adaptive frequency control of microgrids under cyber-attacks via adaptive dynamic programming. IET Renew. Power Gener. 2025, 19, e13187. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Q.; Zhou, J.; Guerrero, J.M.; Wang, R.; Lashab, A. Optimal Frequency Control for Virtual Synchronous Generator Based AC Microgrids via Adaptive Dynamic Programming. IEEE Trans. Smart Grid 2023, 14, 4–16. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.X.; Xie, X.P.; Rubio, J.d.J. An Unknown Multiplayer Nonzero-Sum Game: Prescribed-Time Dynamic Event-Triggered Control via Adaptive Dynamic Programming. IEEE Trans. Autom. Sci. Eng. 2025, 22, 8317–8328. [Google Scholar] [CrossRef]
- Su, H.; Zhang, H.; Liang, X.; Liu, C. Decentralized Event-Triggered Online Adaptive Control of Unknown Large-Scale Systems Over Wireless Communication Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4907–4919. [Google Scholar] [CrossRef]
- Xue, S.; Liu, Z.; Wang, L.; Zhang, W.; Ren, K.; Yang, X. Adaptive dynamic programming based event-triggered multi-H∞ control. Neurocomputing 2025, 638, 130157. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, B.; Liu, D.; Zhang, S. Adaptive Dynamic Programming-Based Event-Triggered Robust Control for Multiplayer Nonzero-Sum Games With Unknown Dynamics. IEEE Trans. Cybern. 2023, 53, 5151–5164. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wei, Q.; Liu, D. Event-triggered adaptive dynamic programming for discrete-time multi-player games. Inf. Sci. 2020, 506, 457–470. [Google Scholar] [CrossRef]
- Su, H.; Zhang, H.; Gao, D.W.; Luo, Y. Adaptive Dynamics Programming for H∞ Control of Continuous-Time Unknown Nonlinear Systems via Generalized Fuzzy Hyperbolic Models. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 3996–4008. [Google Scholar] [CrossRef]
- Yang, X.; He, H. Event-Driven H∞-Constrained Control Using Adaptive Critic Learning. IEEE Trans. Cybern. 2021, 51, 4860–4872. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).