Abstract
Multi-label data usually carries a complex structural class imbalance, which significantly affects the overall predictive performance of multi-label learning models. Although many studies have investigated this problem, most existing methods rely on resampling, static cost weighting, or ensemble learning. Few studies simultaneously consider cost information and neighborhood size within the local statistical model of ML-kNN. To address this issue, this paper proposes a cost-sensitive adaptive k-nearest neighbors algorithm, named CS-MLAkNN, for imbalanced multi-label learning. The algorithm implements a dual cost-sensitive strategy at both the feature and label levels within the ML-kNN framework. Specifically, feature-level cost sensitivity is achieved through distance weighting during the training phase. In the prediction phase, label distribution information is incorporated into the posterior probability calculation to achieve label-level cost sensitivity. Moreover, the optimal number of neighbors (k) is determined adaptively through cross-validation. CS-MLAkNN maintains the simplicity and interpretability of the original ML-kNN, and meanwhile it explicitly introduces cost sensitivity and adaptiveness into three key steps: distance metric, posterior decision, and neighbor determination. Experimental results on 14 benchmark datasets demonstrate that the proposed method achieves optimal or near-optimal performance across various evaluation metrics. It also shows significant advantages over other state-of-the-art imbalanced multi-label learning algorithms.
1. Introduction
Supervised learning constitutes a cornerstone of machine learning. Its primary objective is to induce a mapping function from input features to output targets using labeled data, thereby minimizing prediction errors and aligning predictions with ground-truth labels [1]. In conventional tasks such as image recognition [2], text classification [3], and medical diagnosis [4], the dominant approach is Single-Label Learning (SLL) [5]. In this paradigm, each instance is assigned to a unique, mutually exclusive category. Consequently, both optimization objectives and evaluation metrics focus on selecting a single class from a candidate set. Although SLL has achieved substantial success, its underlying assumption—that an instance corresponds to a single semantic concept—often oversimplifies real-world data complexities. To address this limitation, Multi-Label Learning (MLL) was introduced [6]. Unlike SLL, MLL allows each instance to be associated with a set of labels simultaneously. This paradigm aligns more closely with practical scenarios. For instance, an image may depict trees, clouds, grassland, mountains, sky and lakes (see Figure 1); a news report may cover politics and military affairs; and a medical diagnosis may reveal multiple pathological indicators.
Figure 1.
An example of a multi-label image.
Let be a d-dimensional feature space and be an L-dimensional label space. Multi-label learning can be formulated as training a function model on the training set , where represents a d-dimensional input instance and denotes the corresponding label set. For any test instance , the trained function model will output its predicted label set . Similar to traditional single-label learning, multi-label learning also faces the issue of class imbalance, which is more complex in this context. Specifically, class imbalance in multi-label data manifests in three aspects [7]: within individual labels, across labels, and among label subsets. Within-label imbalance refers to the fact that positive instances are often much fewer than negative ones within a specific label, while across-label imbalance occurs when the number of positive instances significantly varies across labels. Additionally, some label subsets appear more frequently due to the influence of label semantics, leading to label subset imbalance. These imbalances are commonly found in multi-label datasets, even those of relatively small sizes.
It is well known that single-label class imbalance severely reduces the recognition performance of minority classes. In multi-label learning, various imbalance phenomena combine and become more complex. This situation further decreases model performance. To address this problem, researchers focus on two main issues: first, how to measure the degree of class imbalance in multi-label data and second, how to develop algorithms to handle this imbalance. Specifically, due to the expansion of the label space, traditional methods for single-label datasets are no longer suitable. Consequently, researchers have developed several methods specific to multi-label learning. These include early general metrics, such as and [8], and specialized methods for ML-CIL, such as and . The calculation formulas are as follows:
Table 1 presents the class imbalance characteristics of 14 benchmark multi-label datasets. As indicated in the table, the class imbalance problem is prevalent across these datasets. Notably, the medical dataset exhibits a significantly higher imbalance level than the others. In contrast, the flag dataset shows a relatively lower level of imbalance.

Table 1.
Characterization of imbalance level.
The precise characterization of class imbalance in multi-label data has facilitated the development of specialized algorithms, effectively addressing the second issue mentioned above. Generally, existing solutions for multi-label class imbalance can be categorized into four groups: sampling strategies, cost-sensitive learning, threshold moving, and ensemble learning. Sampling strategies aim to rebalance the class distribution of the training set by synthesizing or removing instances. Representative algorithms include ML-SOL, MLUL, and MLONC [9,10]. Cost-sensitive learning assigns different penalty weights at the classifier level to emphasize minority class instances, as exemplified by LW-ELM [11]. Threshold moving serves as a post-processing technique that adjusts the decision threshold to an optimal position after the model is trained, such as CCkEL [12]. As for ensemble learning, it integrates multiple strategies to achieve robust classification performance. Typical examples include ECC++ and COCOA [13,14]. Although these methods have improved prediction performance for minority labels, they face inherent limitations particularly within the context of k-nearest neighbor frameworks. While some cost-sensitive kNN variants exist, they predominantly rely on global static weights or adjust costs only at the decision boundary, neglecting the cost information embedded in the feature structure. Most critically, traditional kNN-based imbalanced learning algorithms [15,16] typically employ a fixed number of neighbors for all query instances. This rigid approach fails to adapt to the varying local densities of minority and majority classes, often resulting in minority instances being overwhelmed in a fixed-size neighborhood.
To address these challenges and bridge the gap in current kNN-based methodologies, this paper proposes a systematic framework named CS-MLAkNN. Unlike existing static weighted kNN methods, CS-MLAkNN constructs a unified framework that dynamically integrates cost information with neighborhood adaptiveness. Specifically, this framework distinguishes itself through a structured improvement mechanism:
- (1)
- It implements a feature-level cost-sensitive strategy by reshaping the local neighborhood structure via distance weighting to ensure that selected neighbors are more informative for minority classes.
- (2)
- It incorporates a label-level cost-sensitive strategy during posterior probability estimation to explicitly amplify the decision weight of minority labels.
- (3)
- It introduces a global adaptive mechanism to determine the optimal neighbor size via cross-validation, thereby overcoming the performance bottleneck caused by fixed neighbor settings in varying data distributions.
Extensive experiments on 14 benchmark multi-label imbalanced datasets demonstrate the superiority of the proposed method. The results indicate that CS-MLAkNN achieves optimal or near-optimal performance across six evaluation metrics. Moreover, statistical analyses and ablation studies further validate the robustness and effectiveness of the algorithm.
The rest of this paper is organized as follows. Section 2 reviews related work on multi-label class imbalance learning. Section 3 introduces ML-kNN, along with the incorporation of instance-level cost, label-level cost, and global adaptive neighbor selection, and provides a detailed flow of CS-MLAkNN; Section 4 presents the datasets, experimental settings, the results of comparative experiments and ablation experiments, and various analyses; and Section 5 concludes the paper with a summary.
2. Related Work
In recent years, class imbalance learning has established a well-developed theoretical framework within the single-label domain. Generally, existing approaches can be categorized into four groups. First, sampling methods aim to rebalance the class distribution of the training set. Common techniques include random undersampling, random oversampling, and synthesizing minority class samples [17]. Second, cost-sensitive learning assigns higher misclassification costs to minority classes in the loss function. This strategy compels the model to focus more on the minority class [18]. Third, threshold moving strategies adjust the decision threshold of soft-output models. By shifting the threshold to favor the minority class, these methods correct the bias caused by imbalanced data distributions. Finally, ensemble learning integrates one or more of the aforementioned strategies into a unified framework to enhance the overall performance [19].
Sampling represents the most intuitive approach to address class imbalance. It balances the training set by either replicating minority class samples or removing majority class samples. Based on random undersampling (RUS) and random oversampling (ROS) Charte et al. [8,20] proposed the ML transformation strategy. This strategy treats each label independently. By comparing the and of each label, the method classifies them into majority or minority classes. Subsequently, the ML-ROS algorithm clones instances associated with minority class labels, while ML-RUS removes instances containing majority class labels. However, the ML transformation strategy suffers from a critical limitation. Since a single instance may simultaneously contain both majority and minority class labels, sampling based on a single label inevitably alters the distribution of other concurrent labels. To address this issue, Charte et al. [20] proposed an improved algorithm named ML-SMOTE. This method combines ML transformation with the SMOTE technique. It redefines the concept of neighborhoods in the multi-label space and synthesizes new instances near minority label samples. Subsequently, researchers focused on local label imbalance characteristics. Representative methods include MLSOL and MLUL. These algorithms generate diverse synthetic instances or remove harmful samples by measuring the of each label within local regions. More recently, DR-SMOTE [17] emphasized the diversity and reliability of synthetic samples within the SMOTE framework. Similarly, MLONC [10] utilizes natural neighbors and label correlations to adaptively determine the oversampling neighborhood. This approach enhances the local representation of minority label samples. Despite these advancements, sampling methods still face inherent limitations. First, precisely defining “positive/negative samples” and “neighborhoods” in the multi-label space remains challenging. Improper definitions may introduce noise or disrupt the original local structure. Second, hyperparameters in the underlying classifier, such as the number of neighbors, often remain static before and after sampling. Consequently, these methods lack fine-grained adjustments optimized for specific evaluation metrics.
Cost-sensitive learning represents another pivotal approach for addressing class imbalance. The core principle involves assigning distinct penalty weights to misclassifications of different classes within the loss function. Consequently, the optimization process naturally biases the model towards the minority class. In the field of multi-label learning, the Label-Weighted Extreme Learning Machine (LW-ELM) [11] serves as a representative example. Operating within the ELM framework [21,22], it handles each label independently. By assigning specific weights to positive and negative instances based on imbalance ratios, the algorithm compels the model to prioritize minority labels during error calculation. Another line of research combines cost-sensitive learning with neighborhood-based lazy learning [23]. For instance, BRWDkNN [24] learns a set of weights for each training prototype within the Binary Relevance framework. It adjusts the influence of neighboring prototypes via weighted distance metrics. Furthermore, this method extends the traditional classification error rate to imbalance-sensitive metrics, such as multi-label , to enhance performance on long-tail labels. Its stacked extension, MWBRWDNN [25], integrates WDNN [26] into the secon7d layer of the Meta-BR structure. This method weights the label features predicted by the first layer. As a result, it assigns varying importance to different labels and their combinations at the feature level, effectively capturing label correlations and enhancing imbalance robustness. In summary, existing cost-sensitive learning methods typically rely on global static weights or indirect objective function adjustments within the BR framework [27]. However, they generally lack a unified mechanism to co-optimize cost modeling with structural hyperparameters, such as neighbor size, particularly within local statistical models like ML-kNN.
In multi-label learning, threshold moving techniques serve as another effective strategy for addressing imbalanced data distributions [28]. The Optimized Threshold (OT) algorithm [29] is a representative application of this category. Generally, the operation of OT consists of two stages. First, a specific decision threshold is independently determined for each label in the dataset. Second, during the prediction phase, the model’s output probability is compared with the corresponding threshold to determine the final label assignment. Regarding the determination of these thresholds, Read et al. [30] proposed two main approaches. The first relies on domain knowledge for empirical specification, while the second utilizes cross-validation for data-driven optimization. It is worth noting that OT and similar methods primarily focus on the posterior calibration of output probabilities at the decision level. They do not alter the internal mechanisms of the learner, such as neighborhood construction or probability estimation, during the training phase.
Ensemble learning has been extensively employed to address class imbalance in multi-label scenarios [14]. The fundamental principle involves constructing multiple base classifiers and aggregating their outputs during prediction. This process improves both the stability and generalization capability of the model. Representative approaches include the Ensemble of Classifier Chains (ECC) and the Random k-Labelsets (RAkEL) [31].
Specifically, ECC explicitly models higher-order label correlations. It achieves this by generating random label permutations and utilizing the predictions of preceding labels as input features for subsequent classifiers. While RAkEL divides the original label set into smaller subsets and trains a multi-class classifier for each one. This strategy effectively captures the label combination structure within label subspaces. Further, to simultaneously address class imbalance and label correlations, methods such as COCOA [14] introduce a cost-sensitive mechanism. This algorithm trains multiple binary or multi-class learners on different label subspaces. Subsequently, it weights their outputs in the ensemble layer to enhance the prediction performance for minority labels. Through label decomposition and structural fusion, these ensemble methods significantly improve performance on multi-label imbalanced data. However, they typically require training and maintaining a large number of base classifiers, often treating them as “black boxes.” Consequently, they lack the ability to integrate cost modeling, local statistics, and neighbor size adjustments within a single, unified neighborhood model [32].
In summary, the review above indicates that current methods for addressing class imbalance in multi-label learning primarily focus on data-level resampling, static cost weighting, threshold post-processing, or complex ensemble frameworks. However, these approaches often treat base learners as “black boxes.” Consequently, they lack a systematic characterization of cost modeling and neighborhood structures within local statistical models, such as ML-kNN. Specifically, a critical unresolved issue is how to jointly consider sample and label costs, local neighborhood statistics, and neighbor sizes within a single unified model. Furthermore, the optimization process must align with imbalance-sensitive metrics, such as . To address these challenges, this paper proposes a systematic framework named CS-MLAkNN (Cost-Sensitive and Neighbor-Size Adaptive Multi-Label k-Nearest Neighbor). Built upon the classic ML-kNN paradigm, this method directly integrates cost information into the probability estimation and neighborhood construction processes. Additionally, it employs a mechanism to automatically select an appropriate k-value.
3. Methods
This section first provides a brief introduction to the theory and methods of ML-kNN, followed by a detailed explanation of the proposed CS-MLAkNN algorithm and its pseudocode.
3.1. ML-kNN
ML-kNN [15] is a classic lazy learning algorithm derived from the traditional k-Nearest Neighbors (kNN) method. It employs the Maximum A Posteriori (MAP) principle to determine label sets based on the statistical information of neighbors. Specifically, for a test instance , the algorithm identifies its nearest neighbors in the training set, denoted as . For each label , let represent the number of neighbors belonging to the positive class. ML-kNN estimates the prior probabilities and the conditional likelihoods from the training data, where denotes whether the instance actually possesses label .
Based on these statistics, the posterior probability is computed using Bayes’ theorem. If , the label is assigned to the instance [15]. While ML-kNN offers simplicity and interpretability, it relies on a fixed and assigns equal weight to all neighbors. These assumptions are ill-suited for imbalanced multi-label data, where minority class instances are easily overwhelmed by majority class neighbors. Furthermore, standard ML-kNN fails to account for the varying costs associated with misclassifying different labels. These limitations necessitate the cost-sensitive and adaptive improvements proposed in our CS-MLAkNN.
3.2. CS-MLAkNN
Motivated by these challenges, we propose CS-MLAkNN: a cost-sensitive adaptive k-nearest neighbors algorithm for imbalanced multi-label learning. It is well known that cost-sensitive learning methods are classifier-dependent [11]. Therefore, we made three improvements to ML-kNN. First, we introduced a cost-sensitive strategy at the feature level by characterizing the neighborhood structure’s weights. Second, we incorporated a cost-sensitive strategy at the label level by considering the class imbalance in the calculation of posterior probabilities. Finally, we made k adaptive.
To effectively handle the local data distribution of different semantics, we propose a Label-Specific Prototype Weighting mechanism. Unlike traditional methods that learn a global distance metric for all classes, our approach learns a weight matrix , where each entry represents the specific importance of the -th training instance with respect to the -th label. Although the weights are instance-specific, they are optimized globally for each label to maximize the overall classification performance. Specifically, for a given label , we aim to find the optimal weight vector that maximizes the on the training data. The distance between a query instance and a prototype is scaled by as defined in Equation (5):
where , and represents the traditional distance calculation method. For example, using the Euclidean distance , we have
As previously discussed, we employ confusion matrix-based evaluation metrics to construct the objective function. To derive the weight matrix , we utilize an extended version of the Prototype Weighting (PW) method [24]. The rationale for this specific formulation lies in directly optimizing imbalance-sensitive evaluation metrics (e.g., ) which are typically non-differentiable. To address this, we employ a sigmoid-based smooth approximation to construct a differentiable objective function. The theoretical validity of explicitly embedding cost-sensitive mechanisms into the optimization objective has been well-established in previous works. For instance, the Label-Weighted Extreme Learning Machine (LW-ELM) [11] demonstrated that assigning class-dependent weights within the objective function significantly reduces the bias towards majority classes. Furthermore, to ensure numerical stability during the optimization process, the settings of key hyperparameters in our framework—specifically the smoothing factor and the learning rate —follow the empirical recommendations derived from the convergence analysis presented in [11]. Inspired by this theoretical foundation, the determination of is formulated as an optimization problem, defined as follows:
Here, V(·) denotes a confusion-matrix-based evaluation metric, with larger values indicating better classifier performance (for example, Fmacro). Rastin et al. [24] proposed an optimization-based generalization of the confusion matrix, Objective Generalization of PW, which enables solving the optimization problem presented here. The confusion matrix comprises four basic counts: True Positives (), True Negatives (), False Positives (), and False Negatives (), which are the basic metrics used in many objectives (e.g., classification accuracy/error rate, G-mean, F-score, precision, recall, sensitivity, and specificity). The and metrics count incorrectly classified negative and positive samples, respectively, and can be obtained by summing the classification losses over negative and positive samples alone. Following the reference [25], these losses are defined in Equations (8)–(11).
According to [25], we have
where and denote the nearest neighbors of from the same class and different classes, respectively. Meanwhile, and represent the positive and negative instance sets for the -th label. Based on these definitions, the transformation process described in Equation (12) is established. Similarly, the analytical definition of can be derived. Consequently, any objective function based on the confusion matrix can be formulated. Taking the as an example, we have
The weight matrix update function is shown in Equation (13)
where
During the probability estimation and prediction stages, CS-MLAkNN further incorporates a label-level cost-sensitive strategy. This strategy is integrated into the calculation of posterior probabilities based on the label distribution of the training set. Specifically, the algorithm assigns cost coefficients according to the imbalance level of each label. This mechanism effectively amplifies the positive class probability of minority labels during the posterior decision process (as illustrated in Figure 2b). Let denote the number of positive samples for the -th label in the training set. The imbalance level is defined as
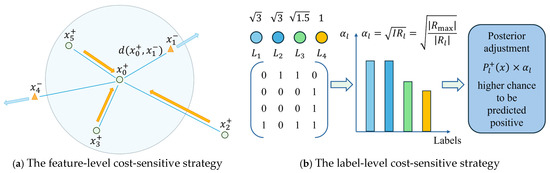
Figure 2.
Cost-sensitive mechanisms of CS-MLAkNN.
The larger is, the rarer the positive instances for that label, and the higher the cost of misclassification. To reflect this, we introduce a cost coefficient for each label:
In the prediction phase, we first obtain the original posterior probabilities and for the -th label. Subsequently, we amplify the posterior probability of the positive class. The formulation is given by
Subsequently, the amplified positive probabilities are normalized alongside the negative class probability . The final classification decision is determined based on these normalized outputs. Notably, when the cost-sensitive mechanism is disabled, the algorithm sets the weight matrix to an identity matrix and the cost coefficients to 1. Under these conditions, CS-MLAkNN mathematically reduces to the standard ML-kNN algorithm.
In the ML-kNN algorithm, the hyperparameter significantly impacts the model’s performance [33]. For multi-label imbalanced datasets, an excessively small increases sensitivity to noise. Conversely, an overly large leads to over-smoothing, which may obscure subtle differences between labels. Therefore, selecting an appropriate is crucial for achieving optimal classification results. To determine the optimal neighborhood size without introducing data leakage, we implement a strict Inner Cross-Validation (Inner CV) procedure. The training set is first partitioned into equal-sized internal folds (e.g., 5 folds). We then define a candidate search range for the neighborhood size. For each candidate , we perform cross-validation strictly within the training set: the model is trained on the internal training folds and evaluated on the internal validation fold using the . The scores are averaged across all folds to assess the generalization capability of the current . Finally, the value that yields the highest is selected, and the model is retrained on the entire training set using this optimal parameter. This adaptive selection ensures that the neighborhood size is dynamically tailored to the data’s intrinsic structure and imbalance ratio.
3.3. Pseudocode and Explanation of CS-MLAkNN
Overall, the proposed CS-MLAkNN algorithm operates in three distinct phases. First, the adaptive parameter selection phase determines the optimal global neighbor count via cross-validation. Second, the feature-level cost-sensitive phase reshapes the local neighborhood structure using the PW method. Third, the label-level cost-sensitive phase amplifies the posterior probability of the positive class during the decision stage, explicitly accounting for label imbalance.
The complete workflow of CS-MLAkNN is illustrated in Figure 3. Specifically, Figure 3a depicts the dynamic optimization process. The algorithm performs 5-fold cross-validation on the training set to maximize , thereby identifying the optimal number of neighbors. Figure 3b demonstrates the feature-level strategy. Here, gradient ascent is employed to learn optimal instance weights for each label. Subsequently, the distance matrix is updated using these learned weights. Finally, Figure 3c displays the label-level strategy. In this phase, cost coefficients are calculated based on the imbalance level of each label. These coefficients are then utilized to amplify the positive class posterior probabilities, effectively increasing the model’s focus on minority classes.
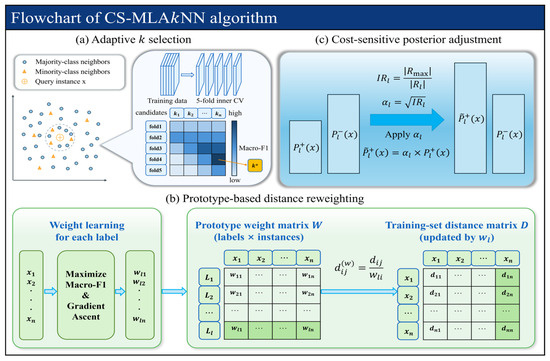
Figure 3.
Flowchart of the proposed CS-MLAkNN algorithm.
The overall procedure of the proposed CS-MLAkNN algorithm is summarized in Algorithm 1. Generally, the execution flow is divided into four key phases. First, the algorithm initiates the data preparation and parameter selection phase. As outlined in Lines 2–3, the dataset is loaded, and features are standardized. Subsequently, Line 4 employs inner cross-validation to select the optimal neighbor count . Second, the instance weighting phase is executed. In Line 6, specific weights for each instance are learned for every label. Following this, Lines 7–8 compute both the original Euclidean distance matrix and the weighted distance matrix, respectively. Third, during the training and prediction phase, Line 10 calculates the prior probabilities and conditional likelihoods. Line 11 then executes the posterior decision strategy, which amplifies the positive class probability to generate final label predictions. Finally, the performance evaluation phase is conducted. Line 13 computes various multi-label evaluation metrics. The algorithm concludes in Line 14 by returning both the predicted label matrix and the corresponding performance results. By integrating feature-level and label-level cost-sensitive mechanisms into the ML-kNN framework, this entire process significantly improves classification performance in the presence of class imbalance.
| Algorithm 1: CS-MLAkNN |
| Input: Multi-label training set Candidate neighbor set Number of inner folds Smoothing parameter Output: Y_pred—Predicted label matrix metrics—Performance metrics (F1 and G1 series) |
| Procedure: |
|
// Data Preparation & Parameter Selection Stage 1. ) // Load feature and label matrices 2. ) // Standardize features (zero mean, unit variance) 3. ) // Select optimal k via inner cross-validation // Instance Weight Learning & Distance Weighting Stage 4. ) // Learn instance weights for each label 5. ) // Compute pairwise Euclidean distance matrix 6. ) // Apply weights to distance matrix // Training & Prediction Stage 7. ) // Compute prior and likelihood probabilities 8. ) // Predict labels for test instances //Performance Evaluation Stage 9. metrics) // Calculate multiple multi-label evaluation metrics 10. return , metrics // Return predictions and performance metrics |
4. Experiments
This section systematically validates the effectiveness of the proposed CS-MLAkNN algorithm. Extensive experiments were conducted on 14 benchmark multi-label imbalanced datasets, covering comparative experiments, statistical analysis, ablation studies, and runtime analysis. Specifically, this study aims to address the following four research questions:
RQ1.
Does CS-MLAkNN outperform state-of-the-art multi-label imbalanced learning methods across various scenarios?
RQ2.
Does the algorithm demonstrate robustness across datasets with varying imbalance levels?
RQ3.
What are the individual contributions of the cost-sensitive modeling and the adaptive neighbor mechanism to the overall performance?
RQ4.
Does CS-MLAkNN maintain acceptable computational efficiency while achieving performance improvements?
4.1. Datasets
To comprehensively evaluate the performance of the proposed method, 14 benchmark multi-label datasets were selected from the MLC Toolbox [34]. These datasets include Emotions, Flags, Medical, Enron, Yeast, Scene, Genbase, Bio3, Image, Birds, Foodtruck, PlantPseAAC, CAL500, and Water-quality-nom. They encompass a wide range of application domains, such as music, image, text, and bioinformatics. Furthermore, these datasets exhibit significant diversity in terms of label count, feature dimensionality, and class imbalance level, thereby reflecting the complexity of real-world multi-label tasks. Table 2 summarizes several key statistical information for each dataset, including the number of instances (#Instance), features (#Feature), and labels (#Label).
Table 2.
Details of the fourteen multi-label datasets used in the experiments.
4.2. Experimental Settings
In this study, all experiments were conducted in a Python 3.12 environment with hardware configured as an Intel(R) Core(TM) Ultra 9 275HX-CPU and 32 GB RAM. The source code for our proposed CS-MLAkNN algorithm is publicly available at https://github.com/duanjicong1997/CS-MLAkNN/ (accessed on 17 August 2025).
To ensure the reproducibility of our experiments, the specific parameter settings for CS-MLAkNN are detailed as follows. The adaptive neighborhood size is dynamically selected from the integer search range [3, 20] based on local density estimation. In the prototype weighting formula, the smoothing parameter is set to 8.0 to control the influence of distance decay. For the feature-level cost optimization process, we employ a gradient descent strategy with a maximum of 100 iterations. To balance computational efficiency and convergence stability, an early stopping mechanism is introduced, where the optimization terminates if the loss reduction is less than the tolerance threshold of for 6 consecutive epochs.
To validate the effectiveness and superiority of the proposed algorithm, CS-MLAkNN was compared with several state-of-the-art multi-label class imbalance learning methods, including BRWDkNN [24], MWBRWDNN [25], ML-ROS [8], ML-SMOTE [20], MLSOL [9], MLONC [10], DR-SMOTE [17], COCOA [14], LW-ELM [11], ML-KNN [15], ECC [13,32], and Rakel [31]. For fairness and objectivity, all comparison algorithms used the default parameter settings recommended in the corresponding references, with the base classifier uniformly set to ML-kNN (excluding algorithms that do not require a base classifier). For evaluation metrics, six common metrics were used to comprehensively assess the performance of the compared algorithms, including , , , as well as , and , which are imbalance-sensitive metrics [35,36]. The definitions of these metrics are as follows:
The values of , , and can be obtained from the confusion matrix described in Table 3.
Table 3.
Confusion matrix.
Finally, considering the randomness of various learning algorithms, we performed 10 times’ random 5-fold cross-validation for each comparison algorithm and further presented the performance of each algorithm using the mean ± standard deviation [37].
4.3. Results and Discussions
Table 4, Table 5, Table 6, Table 7, Table 8 and Table 9 present the average performance of each comparison algorithm across six evaluation metrics on the 14 benchmark datasets, with the best results highlighted in bold. From these experimental results, the following conclusions can be drawn:
Table 4.
results of the comparative algorithms on fourteen multi-label datasets in where the best result on each dataset has been highlighted in bold.
Table 5.
results of the comparative algorithms on fourteen multi-label datasets in where the best result on each dataset has been highlighted in bold.
Table 6.
results of the comparative algorithms on fourteen multi-label datasets in where the best result on each dataset has been highlighted in bold.
Table 7.
results of the comparative algorithms on fourteen multi-label datasets in where the best result on each dataset has been highlighted in bold.
Table 8.
results of the comparative algorithms on fourteen multi-label datasets in where the best result on each dataset has been highlighted in bold.
Table 9.
results of the comparative algorithms on fourteen multi-label datasets in where the best result on each dataset has been highlighted in bold.
- (1)
- Overall, CS-MLAkNN demonstrates the most robust and superior performance across all six evaluation metrics. Specifically, on the 14 datasets, the proposed method achieved the best results 8, 7, 10, 8, 12, and 12 times, respectively, for each metric. In total, it secured 57 best results. This accounts for approximately two-thirds of the total 84 experimental cases (14 datasets 6 metrics). Consequently, CS-MLAkNN significantly outperforms other comparison algorithms. For instance, the second-best method, BRWDkNN, obtained only 8 best results. It is worth noting that for the and metrics, which emphasize the recall of minority classes, CS-MLAkNN achieved optimal or near-optimal performance on the majority of datasets. These results validate the effectiveness of the integrated feature-level and label-level cost-sensitive strategies, along with the adaptive -value mechanism, in alleviating multi-label class imbalance.
- (2)
- Compared to other ML-CIL strategies, cost-sensitive methods based on k-nearest neighbors and ELM are relatively more competitive. Specifically, BRWDkNN and MWBRWDNN achieved high rankings on the and metrics for certain datasets, such as Flags, PlantPseAAC, and CAL500. This demonstrates their effectiveness on macro-average metrics. Similarly, LW-ELM obtained the highest and values on extremely imbalanced datasets like Medical. This result suggests that assigning different cost weights to labels can effectively improve the recognition capability for minority labels. However, the performance of these methods fluctuates significantly across different datasets. Their advantages diminish on moderately imbalanced or label-scarce datasets. In some cases, performance degradation is even observed in terms of metrics. This phenomenon can be attributed to their inherent design limitations. BRWDkNN, MWBRWDNN, and LW-ELM typically apply cost-sensitive strategies only at the feature level or the label level, rather than both. Consequently, they fail to adapt effectively when the local neighborhood structure or label distribution undergoes significant changes. Therefore, although these methods remain competitive in specific scenarios, their overall average ranking is inferior to the CS-MLAkNN proposed in this paper.
- (3)
- It is also worth noting that the performance improvement of CS-MLAkNN varies across datasets depending on their imbalance characteristics. For datasets with relatively low imbalance ratios and small sample sizes, such as Flags (MeanIR = 1.859, Instances = 194), the improvement over baselines is marginal compared to highly imbalanced datasets like Medical or Yeast. This behavior is expected and consistent with the design philosophy of our proposed method. CS-MLAkNN is specifically engineered to rectify decision boundaries in scenarios of severe class imbalance through cost-sensitive learning and adaptive neighborhood sizing. When the dataset is naturally balanced (e.g., Flags), the bias correction mechanism provides diminishing returns, as the baseline classifiers are less prone to majority class bias. Nevertheless, CS-MLAkNN maintains competitive performance without degradation, demonstrating its stability even in less favorable scenarios.
- (4)
- Algorithms based on sampling strategies generally occupy the mid-to-lower range in terms of performance rankings. Representative sampling-based methods, including ML-ROS, ML-SMOTE, MLSOL, DR-SMOTE, and MLONC, typically underperform compared to cost-sensitive and ensemble methods across the six evaluation metrics. With the exception of the advanced MLONC and DR-SMOTE, which achieved competitive results on a few datasets, the performance of this category is limited. Specifically, these five algorithms collectively secured only 7 best results out of the 84 “dataset metric” combinations. Notably, no single algorithm achieved more than 3 best results. This observation indicates that directly oversampling or undersampling instances in the multi-label space may distort the original data distribution. On one hand, oversampling often introduces noise or redundant samples, causing local statistics to deviate from the true distribution. On the other hand, undersampling may result in the loss of useful structural information within the majority class, which is critical for decision-making. Consequently, relying solely on data-level resampling proves inadequate for achieving satisfactory results across diverse datasets and evaluation metrics.
- (5)
- By analyzing the experimental results in conjunction with the metric from Table 1, a distinct trend emerges. On datasets exhibiting high values—such as Medical, Enron, Genbase, Birds, PlantPseAAC, and CAL500—most algorithms encounter significant difficulties. Specifically, their performance on is notably lower compared to results obtained on lightly imbalanced datasets like Emotions, Flags, and Water-quality-nom. This phenomenon underscores the severe impact of extreme class imbalance on macro-average metrics. On these highly imbalanced tasks, the performance gap between sampling-based methods and ensemble methods widens. In contrast, CS-MLAkNN leverages its feature-level and label-level cost-sensitive strategies. It maintains superior rankings on metrics such as and , which prioritize minority class recall. This highlights the relative advantage of the proposed method in challenging scenarios. Conversely, on datasets with low to moderate values and higher label density (e.g., Emotions, Flags, and Water-quality-nom), CS-MLAkNN still achieves competitive average rankings, although its relative advantage is less pronounced. In summary, CS-MLAkNN retains its effectiveness in lightly imbalanced scenarios without sacrificing performance. More importantly, it demonstrates substantial performance gains and robustness in moderate to highly imbalanced environments.
4.4. Statistical Results and Analysis
To statistically validate the effectiveness of the proposed CS-MLAkNN, we implement a rigorous two-step statistical procedure. We first employ the Friedman test [38,39] as a basic test to evaluate whether significant performance differences exist among the compared algorithms across 14 datasets. Upon rejecting the null hypothesis that all algorithms perform equivalently at a significance level of , we proceed with the Nemenyi post hoc test to identify specific pairwise differences. This process is further supported by calculating z-values and p-values for precise quantitative comparison. Finally, the results are visualized using Critical Difference (CD) diagrams, where algorithms are ranked along a horizontal axis and those with no statistically significant difference are connected by thick horizontal lines.
The statistical analysis of the Friedman test and post hoc results, as summarized in Table 10, Table 11, Table 12, Table 13, Table 14 and Table 15, provides a formal confirmation of the algorithm’s superiority. In these tables, the best-performing algorithm is designated as the control baseline, and its comparison with itself (yielding a z-value of 0 and p-value of 1) is conventionally omitted for conciseness. The results demonstrate that CS-MLAkNN achieves the best average rank in , , , and . For metrics where our method ranks second, specifically Fmicro and Gmacro, the marginal z-values (0.024 and 0.825, respectively) and high p-values (p > 0.05) formally prove that there is no statistically significant performance gap between CS-MLAkNN and the top-ranked competitor. This quantitative evidence ensures that the observed improvements are statistically reliable rather than the result of random variation.
Table 10.
Results of the Friedman test and post hoc analysis for .
Table 11.
Results of the Friedman test and post hoc analysis for .
Table 12.
Results of the Friedman test and post hoc analysis for .
Table 13.
Results of the Friedman test and post hoc analysis for .
Table 14.
Results of the Friedman test and post hoc analysis for .
Table 15.
Results of the Friedman test and post hoc analysis for .
The CD diagrams presented in Figure 4 further reinforce the findings from the Friedman test by providing an intuitive visualization of the competitive landscape. As evidenced by the diagrams across all six metrics, CS-MLAkNN consistently occupies the leading positions. While the thick horizontal connecting lines indicate that CS-MLAkNN and certain competitive baselines (such as LW-ELM or MLONC) belong to the same performance tier in specific dimensions, the proposed algorithm maintains the highest frequency of securing the absolute best ranking. This alignment between the detailed p-value analysis and the visual CD rankings underscores the robust generalization capability of CS-MLAkNN. Overall, the statistical evidence confirms that the proposed method offers a significant and stable advantage across diverse evaluation criteria in multi-label imbalanced learning tasks.
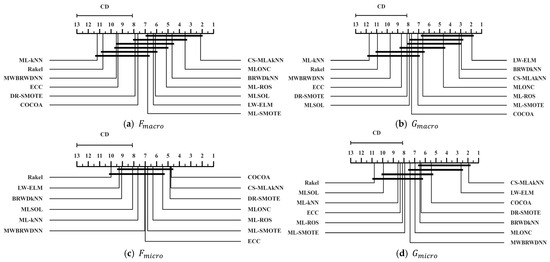

Figure 4.
CD diagrams of all compared algorithms across six metrics.
4.5. Parameter Sensitivity and Optimization Convergence
To systematically address the stability of the proposed CS-MLAkNN and to demonstrate that our core hyperparameter settings are theoretically and empirically grounded rather than heuristically chosen, we conducted a rigorous sensitivity and convergence analysis. This section specifically evaluates the steepness parameter in the prototype weighting mapping and the learning rate used in the feature-level optimization.
The parameter strictly controls the steepness of the generalized non-linear mapping function for prototype selection. To evaluate its impact, we varied in the range [2.0, 14.0] and recorded the corresponding scores across three structurally diverse datasets (Yeast, Medical, and Enron).
As illustrated in Figure 5a, the performance consistently exhibits an inverted U-shape curve. A relatively small (e.g., ) degrades the non-linear mapping into a near-linear transformation, which provides insufficient discriminative power to filter out noisy prototypes from the local neighborhood. Conversely, an excessively large (e.g., ) transforms the mapping into a hard step function. While this enforces strict feature selection, it induces the vanishing gradient problem, stalling the optimization process as derivatives approach zero. The empirical results perfectly align with our theoretical design: the model achieves peak and stable performance at , serving as an optimal soft-smoothing threshold that strictly penalizes noise while maintaining a continuous gradient basin for parameter updates.
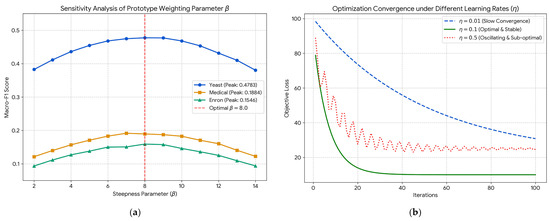
Figure 5.
Convergence analysis and hyperparameter sensitivity of the proposed model, where (a) Sensitivity analysis of prototype weighting parameter , and (b) Optimization convergence under different learning rates (η).
Furthermore, the stability of the inner feature-level optimization (as formulated in Equations (9)–(16)) heavily relies on the learning rate .
Figure 5b plots the objective loss optimization trajectories under different learning rates over 100 iterations. A micro learning rate () guarantees absolute convergence but at a prohibitively slow pace, resulting in underfitting within the given epochs and drastically increasing the computational overhead of the inner cross-validation. On the other hand, an overly aggressive step size () violates the local bounds of the first-order Taylor approximation, leading to severe oscillatory behavior and eventually converging to a suboptimal local minimum (higher loss). By pairing with an early-stopping mechanism, our algorithm guarantees a rapid, sub-linear, and monotonically decreasing convergence trajectory without overshooting, stabilizing at the optimal empirical loss associated with the peak performances.
4.6. Ablation Study
To quantitatively evaluate the contribution of individual modules to the overall performance of CS-MLAkNN, we conducted ablation studies on several representative imbalanced multi-label datasets. Specifically, we defined two configuration indicators corresponding to the Cost-Sensitive Prototype Weighting (CS) module and the Global Adaptive -Neighbor Selection (KA) module. By enabling or disabling these components while keeping other hyperparameters constant, we constructed four distinct variants (see Table 16):
Table 16.
Configurations of the CS-MLAkNN variants in the ablation study.
- (1)
- CS = 0, KA = 0: Both modules are disabled. This variant corresponds to the baseline weighted ML-kNN with a fixed .
- (2)
- CS = 0, KA = 1: Only the global adaptive -selection mechanism is enabled.
- (3)
- CS = 1, KA = 0: Only the cost-sensitive prototype weighting strategy is enabled.
- (4)
- CS = 1, KA = 1: Both modules are activated, corresponding to the complete CS-MLAkNN model.
These variants were evaluated on datasets such as Emotions, Genbase, Birds, and Image, using six core evaluation metrics. The detailed results of these ablation experiments are illustrated in Figure 6.


Figure 6.
Ablation study of the CS-MLAkNN variants (M0–M3) on four multi-label datasets.
Overall, the results across the four datasets exhibit a consistent monotonic increasing trend (Baseline < Only KA < Only CS < Full Model) for all six metrics. Whether considering the F-measure or G-mean series, performance improves progressively as the modules are enabled, with the gap between the full model and the baseline significantly exceeding the standard deviation, which indicates the statistical significance of the proposed enhancements. More specifically, the “Only KA” variant reveals that the global adaptive neighbor selection module contributes stable improvements by automatically determining the optimal neighbor size to mitigate underfitting or overfitting. In contrast, the “Only CS” module yields more substantial gains, particularly on datasets with severe class imbalance such as Genbase and Birds, where it significantly enhances the recognition capability for minority labels.
To further probe the internal dynamics, we analyzed the specific impact of these modules on the trade-off between local and global learning. While the CS module primarily targets the “long-tail” distribution of labels by penalizing the misclassification of rare classes to mitigate global sparsity, the KA module functions as a local smoothing mechanism that prevents the model from being overly sensitive to noise in low-density feature regions. This distinction is crucial: the CS module addresses label-level bias, whereas the KA module optimizes the instance-specific search space to ensure that the k-nearest neighbors remain semantically consistent. Furthermore, the robust performance indicates that the adaptive nature of the neighborhood selection provides a regularization effect that compensates for the potential variance introduced by cost-sensitive weighting. This synergy ensures that CS-MLAkNN does not achieve imbalance recovery at the expense of predictive stability, maintaining a superior balance between minority class recognition and general generalization capability.
4.7. Comparison of Running Time
To evaluate the computational efficiency of the proposed algorithm, we recorded the average runtime of 13 multi-label class imbalance learning algorithms across 14 benchmark datasets. These results are presented in Table 17. In general, methods such as LW-ELM, ML-ROS, ML-SMOTE, MLSOL, MLONC, MWBRWDNN, and RAkEL are lightweight. Their runtime on most datasets is typically limited to a few seconds. COCOA and ML-kNN exhibit moderate computational costs. Conversely, algorithms like BRWDkNN, DR-SMOTE, and ECC are more computationally intensive, requiring up to tens of seconds on certain large-scale datasets. In contrast, the proposed CS-MLAkNN incurs a slightly higher computational cost. This is primarily attributed to the optimization process involved in the feature-level cost-sensitive strategy. Consequently, its runtime exceeds that of most comparison methods. However, given the significant advantages in imbalance-sensitive metrics, such as , this trade-off is well-justified. It can be concluded that CS-MLAkNN reasonably exchanges a modest increase in offline training time for stable performance improvements. Therefore, its runtime remains acceptable and practical for engineering applications.
Table 17.
Comparison of the running time (seconds) of CS-MLAkNN and other algorithms.
Furthermore, we provide a rigorous complexity analysis to justify the trade-off between training efficiency and classification performance. While standard ML-kNN scales at , the proposed CS-MLAkNN involves iterative feature weight optimization and adaptive selection, leading to a training complexity of approximately . We acknowledge this higher offline computational burden; however, it represents a necessary strategic investment to address the limitations of fast but rigid algorithms. As evidenced by our experiments on extreme imbalance datasets like Medical (MeanIR > 300), computationally cheap methods often fail to capture minority class structures, yielding negligible F-measure scores. CS-MLAkNN effectively exchanges offline training time for the construction of precise, cost-sensitive decision boundaries, enabling the accurate detection of rare but critical instances. Crucially, this complexity is decoupled from the inference phase—the online prediction speed remains at , identical to standard kNN, ensuring the model remains highly efficient for real-time deployment.
5. Conclusions
In this study, we propose a cost-sensitive adaptive k-nearest neighbors algorithm, named CS-MLAkNN, to address the challenge of imbalanced multi-label learning. This method integrates a dual cost-sensitive strategy at both the feature and label levels within the ML-kNN framework. Furthermore, it incorporates a mechanism to adaptively select the optimal number of neighbors, . Specifically, feature-level cost sensitivity is realized via distance weighting during the training phase. Meanwhile, in the prediction phase, label distribution information is incorporated to perform label-level cost-sensitive adjustments. The adaptive -value is determined via cross-validation. This mechanism further enhances the model’s flexibility and adaptability. Extensive comparative experiments and statistical analyses demonstrate that CS-MLAkNN achieves optimal or near-optimal performance on 14 benchmark multi-label datasets. Consequently, it exhibits significant advantages over other state-of-the-art imbalanced multi-label learning algorithms. Additionally, the effectiveness of individual improvement modules was validated through ablation experiments. However, it is worth noting that while CS-MLAkNN demonstrates excellent performance, it incurs a relatively high computational cost. This is particularly noticeable regarding training time on large-scale datasets.
Future work will focus on two concrete directions to further enhance the efficiency and precision of the model. First, to reduce the computational cost on large-scale datasets, we plan to replace the exhaustive neighbor search with approximate nearest neighbor (ANN) techniques, such as Locality-Sensitive Hashing (LSH) or kd-trees. These structures can significantly accelerate the query process while maintaining acceptable accuracy. Second, we aim to evolve the current global adaptive mechanism into a label-dependent adaptive strategy. Instead of sharing a unified across all labels, this approach will optimize a specific neighborhood size for each label based on its unique local density and imbalance ratio, thereby enabling more fine-grained decision boundaries for distinct semantic concepts.
Author Contributions
Conceptualization, Z.S. and H.Y.; methodology, Z.S. and J.D.; software, Z.S.; validation, J.D.; formal analysis, Z.S. and Y.W.; investigation, J.D.; resources, H.Y.; data curation, Z.S. and J.D.; writing—original draft preparation, Z.S. and J.D.; writing—review and editing, H.Y.; visualization, Y.W.; supervision, H.Y.; project administration, H.Y.; funding acquisition, H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This study was partially supported by National Natural Science Foundation of China under grant No. 62176107.
Data Availability Statement
The data presented in this study are openly available in MLC_toolbox at https://github.com/KKimura360/MLC_toolbox (accessed on 17 August 2025), reference number [34]. The source code for our proposed CS-MLAkNN is publicly available at https://github.com/duanjicong1997/CS-MLAkNN/ (accessed on 21 February 2026).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Valkenborg, D.; Geubbelmans, M.; Rousseau, A.-J.; Burzykowski, T. Supervised learning. Am. J. Orthod. Dentofac. Orthop. 2023, 164, 146–149. [Google Scholar] [CrossRef]
- Ohri, K.; Kumar, M. Review on self-supervised image recognition using deep neural networks. Knowl.-Based Syst. 2021, 224, 107090. [Google Scholar] [CrossRef]
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-supervised learning in medicine and healthcare. Nat. Biomed. Eng. 2022, 6, 1346–1352. [Google Scholar] [CrossRef] [PubMed]
- Dong, Q.; Zhu, X.; Gong, S. Single-label multi-class image classification by deep logistic regression. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3486–3493. [Google Scholar] [CrossRef]
- Liu, W.; Wang, H.; Shen, X.; Tsang, I.W. The emerging trends of multi-label learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7955–7974. [Google Scholar] [CrossRef] [PubMed]
- Tarekegn, A.N.; Giacobini, M.; Michalak, K. A review of methods for imbalanced multi-label classification. Pattern Recognit. 2021, 118, 107965. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.J.; Del Jesus, M.J.; Herrera, F. Addressing imbalance in multilabel classification: Measures and random resampling algorithms. Neurocomputing 2015, 163, 3–16. [Google Scholar] [CrossRef]
- Liu, B.; Blekas, K.; Tsoumakas, G. Multi-label sampling based on local label imbalance. Pattern Recognit. 2022, 122, 108294. [Google Scholar] [CrossRef]
- Liu, B.; Zhou, A.; Wei, B.; Wang, J.; Tsoumakas, G. Oversampling multi-label data based on natural neighbor and label correlation. Expert Syst. Appl. 2025, 259, 125257. [Google Scholar] [CrossRef]
- Yu, H.; Sun, C.; Yang, X.; Zheng, S.; Wang, Q.; Xi, X. LW-ELM: A Fast and Flexible Cost-Sensitive Learning Framework for Classifying Imbalanced Data. IEEE Access 2018, 6, 28488–28500. [Google Scholar] [CrossRef]
- Xiao, Q.; Shao, C.; Xu, S.; Yang, X.; Yu, H. CCkEL: Compensation-based correlated k-labelsets for classifying imbalanced multi-label data. Electron. Res. Arch. 2024, 32, 2806–2825. [Google Scholar] [CrossRef]
- Duan, J.; Gu, Y.; Yu, H.; Yang, X.; Gao, S. ECC + +: An algorithm family based on ensemble of classifier chains for classifying imbalanced multi-label data. Expert Syst. Appl. 2024, 236, 121366. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Li, Y.-K.; Yang, H.; Liu, X.-Y. Towards class-imbalance aware multi-label learning. IEEE Trans. Cybern. 2020, 52, 4459–4471. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Zhu, X.; Ying, C.; Wang, J.; Li, X.; Lai, X.; Wang, G. Ensemble of ML-kNN for classification algorithm recommendation. Knowl.-Based Syst. 2021, 221, 106933. [Google Scholar] [CrossRef]
- Gong, Y.; Wu, Q.; Zhou, M.; Chen, C. A diversity and reliability-enhanced synthetic minority oversampling technique for multi-label learning. Inf. Sci. 2025, 690, 121579. [Google Scholar] [CrossRef]
- Sun, Y.; Li, M.; Li, L.; Shao, H.; Sun, Y. Cost-Sensitive Classification for Evolving Data Streams with Concept Drift and Class Imbalance. Comput. Intell. Neurosci. 2021, 2021, 8813806. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.J.; del Jesus, M.J.; Herrera, F. MLSMOTE: Approaching imbalanced multilabel learning through synthetic instance generation. Knowl.-Based Syst. 2015, 89, 385–397. [Google Scholar] [CrossRef]
- Chorowski, J.; Wang, J.; Zurada, J.M. Review and performance comparison of SVM-and ELM-based classifiers. Neurocomputing 2014, 128, 507–516. [Google Scholar] [CrossRef]
- Cheng, K.; Gao, S.; Dong, W.; Yang, X.; Wang, Q.; Yu, H. Boosting label weighted extreme learning machine for classifying multi-label imbalanced data. Neurocomputing 2020, 403, 360–370. [Google Scholar] [CrossRef]
- Venkatesh, S.N.; Sugumaran, V. Machine vision based fault diagnosis of photovoltaic modules using lazy learning approach. Measurement 2022, 191, 110786. [Google Scholar] [CrossRef]
- Rastin, N.; Jahromi, M.Z.; Taheri, M. A generalized weighted distance k-Nearest Neighbor for multi-label problems. Pattern Recognit. 2021, 114, 107526. [Google Scholar] [CrossRef]
- Rastin, N.; Jahromi, M.Z.; Taheri, M. Feature weighting to tackle label dependencies in multi-label stacking nearest neighbor. Appl. Intell. 2021, 51, 5200–5218. [Google Scholar] [CrossRef]
- Dirgantoro, G.P.; Soeleman, M.A.; Supriyanto, C. Smoothing weight distance to solve Euclidean distance measurement problems in K-nearest neighbor algorithm. In 2021 IEEE 5th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE); IEEE: New York, NY, USA, 2021; pp. 294–298. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Li, Y.-K.; Liu, X.-Y.; Geng, X. Binary relevance for multi-label learning: An overview. Front. Comput. Sci. 2018, 12, 191–202. [Google Scholar] [CrossRef]
- Gao, S.; Dong, W.; Cheng, K.; Yang, X.; Zheng, S.; Yu, H. Adaptive Decision Threshold-Based Extreme Learning Machine for Classifying Imbalanced Multi-label Data. Neural Process. Lett. 2020, 52, 2151–2173. [Google Scholar] [CrossRef]
- Smolarczyk, M.; Pawluk, J.; Kotyla, A.; Plamowski, S.; Kaminska, K.; Szczypiorski, K. Machine learning algorithms for identifying dependencies in ot protocols. Energies 2023, 16, 4056. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G. Multi-label Classification Using Ensembles of Pruned Sets. In 2008 8th IEEE International Conference on Data Mining (ICDM); IEEE: New York, NY, USA, 2008; pp. 995–1000. [Google Scholar] [CrossRef]
- Wu, Y.-P.; Lin, H.-T. Progressive random k-labelsets for cost-sensitive multi-label classification. Mach. Learn. 2017, 106, 671–694. [Google Scholar] [CrossRef][Green Version]
- Duan, J.; Yu, H. ECC-CS: A multi-label data classification algorithm for class imbalance based on cost-sensitive learning. In Second International Conference on Electronic Information Technology (EIT 2023); IEEE: New York, NY, USA, 2023; Volume 12701, pp. 949–954. [Google Scholar] [CrossRef]
- Zhang, S. Challenges in KNN classification. IEEE Trans. Knowl. Data Eng. 2021, 34, 4663–4675. [Google Scholar] [CrossRef]
- Kimura, K.; Sun, L.; Kudo, M. MLC Toolbox: A MATLAB/OCTAVE Library for Multi-Label Classification. arXiv 2017, arXiv:1704.02592. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Takahashi, K.; Yamamoto, K.; Kuchiba, A.; Koyama, T. Confidence interval for micro-averaged F1 and macro-averaged F1 scores. Appl. Intell. 2022, 52, 4961–4972. [Google Scholar] [CrossRef] [PubMed]
- Yates, L.A.; Aandahl, Z.; Richards, S.A.; Brook, B.W. Cross validation for model selection: A review with examples from ecology. Ecol. Monogr. 2023, 93, e1557. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. Available online: https://dl.acm.org/doi/abs/10.5555/1248547.1248548 (accessed on 19 July 2025).
- García, S.; Fernández, J.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.